1. Introduction
The appearance of a material can be a signature of quality and a criterion for object choice. Terms such as glossiness, matteness, transparency, metallic feel, and roughness are commonly used to describe the perceptual attributes of material appearance. This information not only helps in appreciating the beauty in life but also guides us in determining value. In recent years, the appearance of materials has become a crucial research topic in academia and industry [
1]. The acquisition, modeling, and reproduction of material appearances are primarily based on two-dimensional images obtained by digital cameras.
Digital cameras can only capture a limited range of luminance levels in real-world scenes because of sensor constraints. High-quality cameras for high dynamic range (HDR) imaging are sometimes unaffordable. However, most existing image content has a low dynamic range (LDR), and most legacy content predominantly comprises 8-bit LDR images. Objects in real scenes do not always have matte surfaces and often have surfaces with strong gloss or specular highlights. In such cases, the pixel values in the captured images are saturated and clipped because of the limited dynamic range of image sensors, leading to missing physical information in saturated image regions.
Metals are typical object materials that saturate easily, and the luminance of the reflected light from a metal object covers an extensive dynamic range, all the way from matte surface reflection to specular reflection.
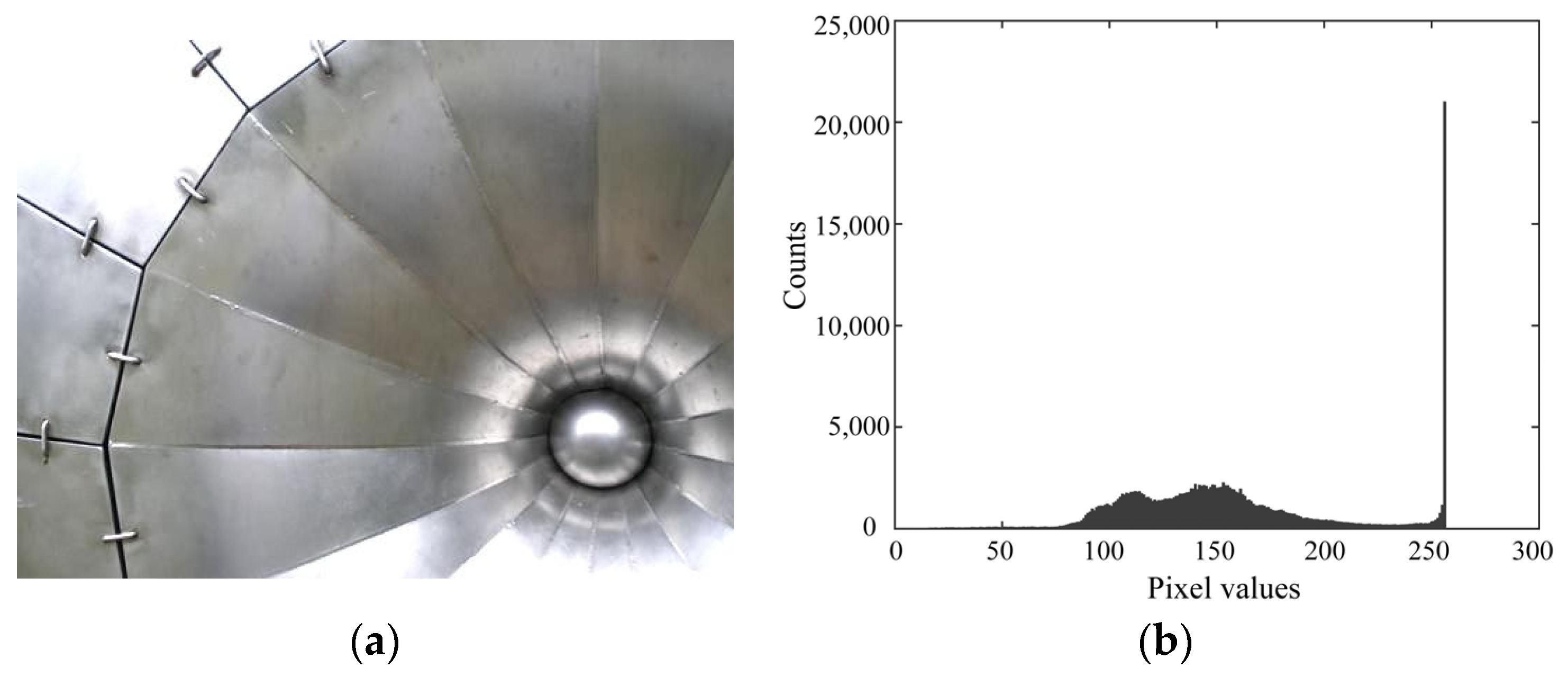
Figure 1 shows an example from the Flickr material database ([
2,
3]), where the database is divided into 10 material categories: metal, plastic, fabric, foliage, and so on. All of these categories consist of 8-bit images.
Figure 1a shows the color image named metal_moderate_005_new.
Figure 1b shows the corresponding luminance histogram in the 8-bit range. A wide area of the metal object surface is saturated. The color and shading information in the saturated image area are entirely incorrect, and physical details are missing. Consequently, appearance modeling methods that attempt to reproduce appearance, such as gloss perception, fail for this object.
Therefore, a method is required to infer the original HDR image from a single LDR image suffering from saturation, often referred to as the inverse tone-mapping problem [
4]. This is an ill-posed problem because a missing signal that does not appear in a given LDR image must be restored [
5]. To date, this problem has been mainly addressed in the field of computer graphics [
6,
7,
8,
9,
10,
11] and partly in computer vision [
5,
12]. The target images are natural scenes and not material objects. Therefore, in addition to objects, the captured images contain the sky and various light sources.
This study targets the reconstruction of saturated gloss on an object surface. The HDR reconstruction of saturated gloss is important not only from a physical perspective, but also from a human psychology evaluation perspective. Studies on gloss perception are also underway [
13,
14,
15], involving a complex interaction of variables, including illumination, surface properties, and observer. In recent years, neural networks have been applied to elucidate gloss perception [
16,
17], and the reconstruction of saturated gloss on object surfaces is a challenging research problem.
In this study, we consider a method for reconstructing the original HDR image from a single LDR image suffering from the saturation of metallic objects. A deep neural network approach is adopted to directly map the 8-bit LDR image to an HDR image. Note that there is no publicly available HDR image dataset; however, a few LDR datasets such as the Flickr material database are widely used. A small HDR image dataset in the preliminary work is shown in [
18]. Therefore, we first construct an HDR image database specializing in metallic objects. A large number of various metallic objects with different shapes are collected for this purpose. These objects are photographed in a general lighting environment so that a strong gloss or specular reflection will be observed. Each captured HDR image is clipped to create a set of 8-bit LDR images. The pairs of created LDR images and original HDR images in the database are used to train and test the network.
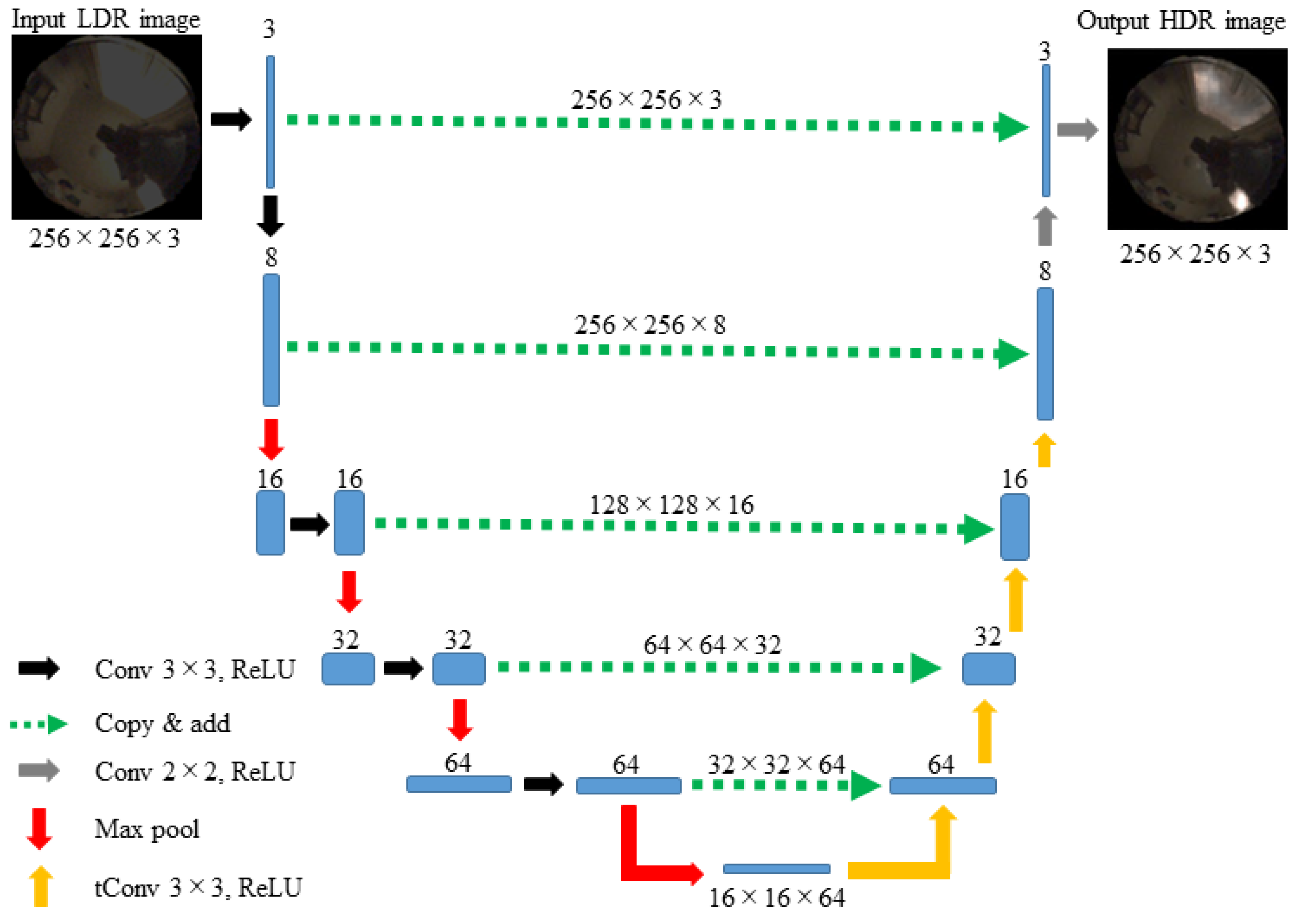
We propose an LDR-to-HDR mapping method to predict the information that has been lost in saturated areas of LDR images. A convolutional neural network (CNN) was designed in the form of a deep U-Net-like architecture. The network consisted of an encoder, a decoder, and a skip connection to maintain high image resolution. Although the CNN approach with skip connections is known in machine learning, the effectiveness of such an approach was not shown for HDR image reconstruction from LDR images in the field of material appearance. Here is the first attempt for metallic objects.
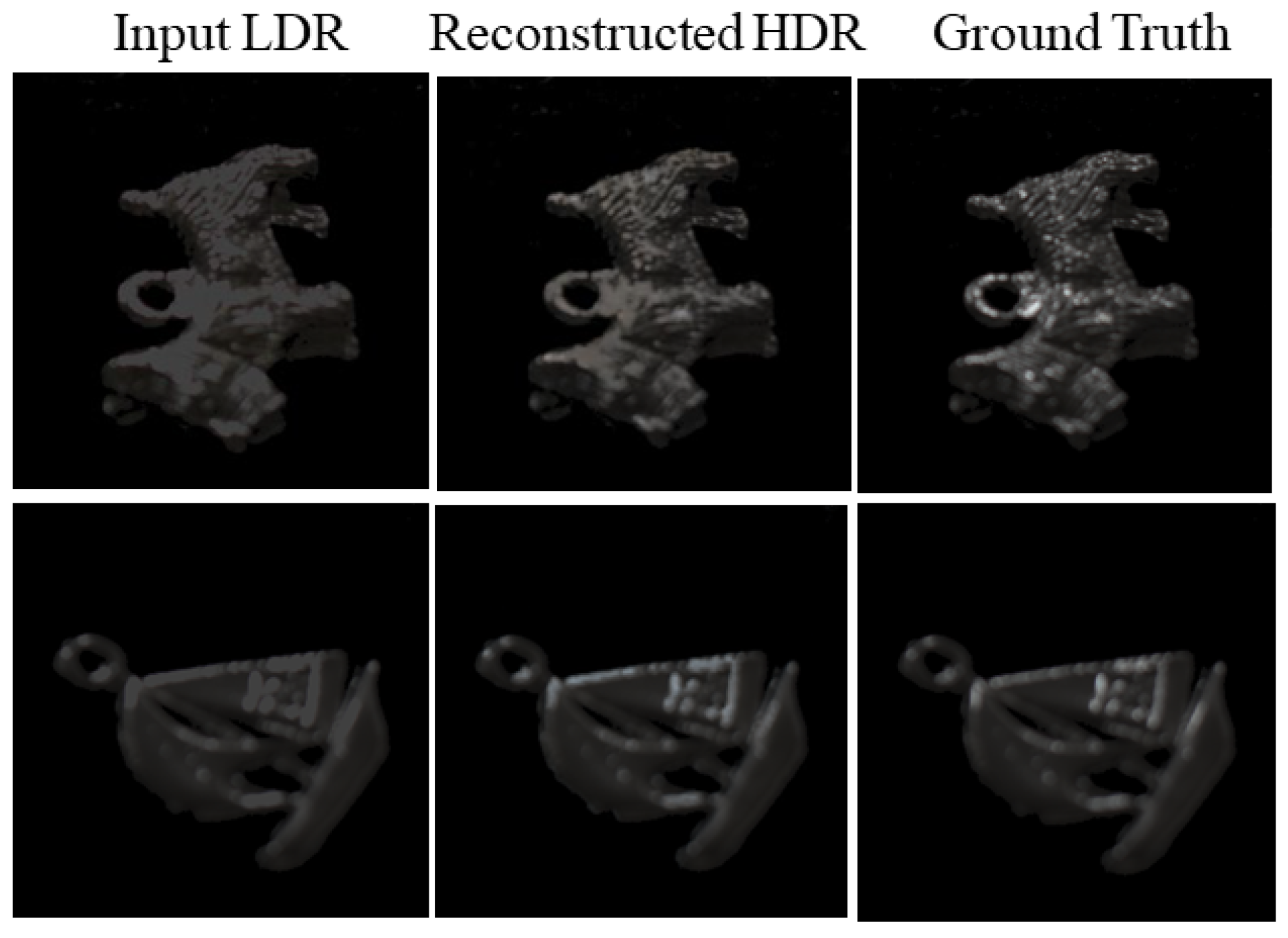
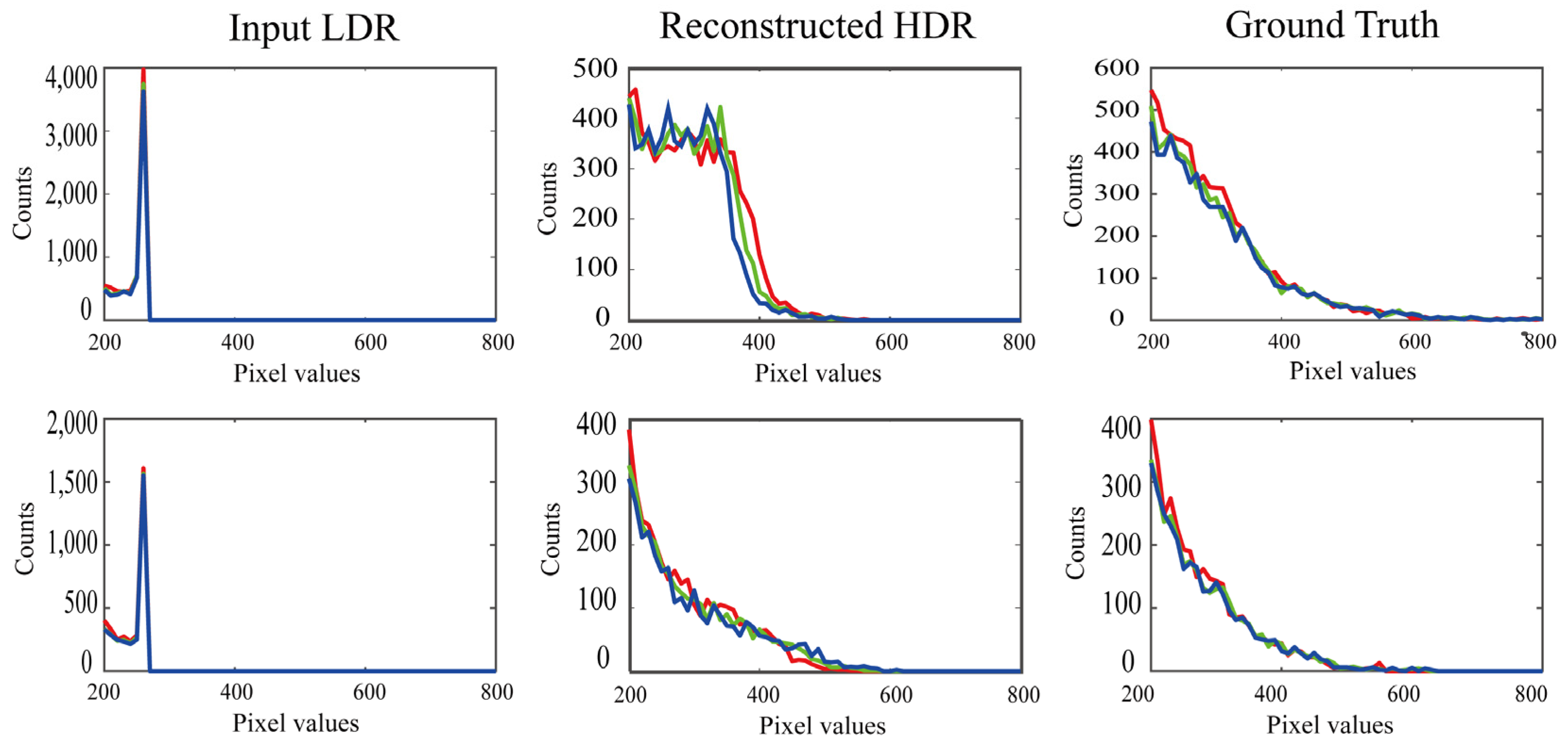
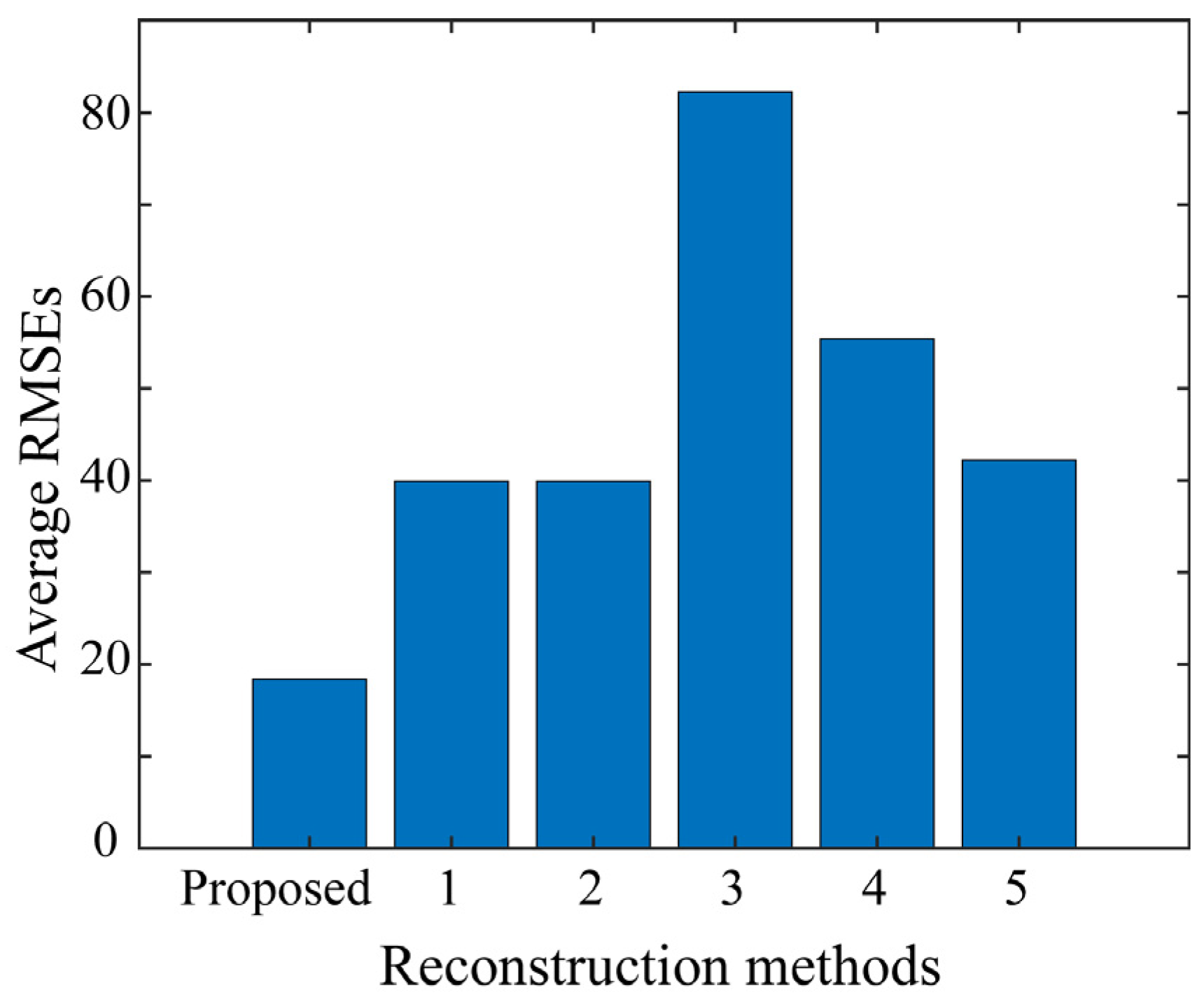
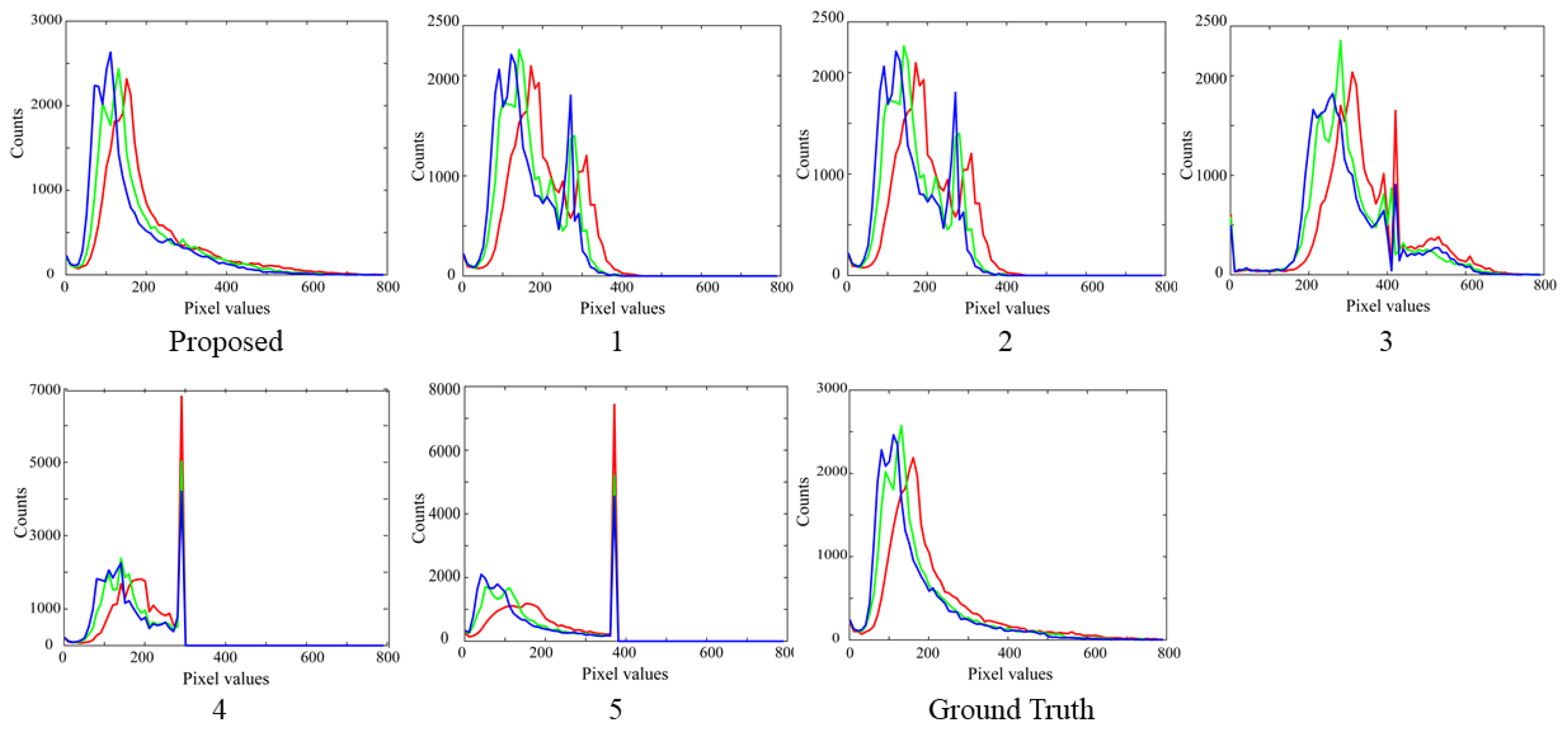
In experiments, the performance of the proposed method is compared with those of other methods, examining in detail the accuracy of the reconstructed HDR images, which demonstrate the superiority of the proposed method in numerical error and histogram reconstruction validations. In addition to physical accuracy, perceptual faithfulness is also demonstrated through human psychological experiments.
2. HDR Image Database for Metallic Objects
A large number of objects with different shapes made from different materials were collected. The collected material set consisted of a wide range of metallic materials, such as iron, copper, zinc, nickel, brass, aluminum, stainless steel, gold, silver, and metal plating. Painted metal objects were excluded from the analysis. The object shapes included not only flat plates but also various complicated curved surfaces.
Figure 2 shows 267 metal objects collected in this manner. Light reflection from a metallic object consists of mostly specular reflection, rather than diffuse reflection [
19]. The color appearing on the surface of an object is a metal color, coincident with a gloss/highlight color. We note that the color of the gloss/highlighted areas is not white. The metal colors are shown in
Figure 2.
The metal objects were photographed using two types of cameras: an Apple iPhone 8 mobile phone camera with a depth of 12 bits and digital single lens reflex (DSLR) camera. For the details, including the spectral sensitivity functions, the reader is referred to [
20]. The camera images were captured in the lossless Adobe digital negative (DNG) raw image format. A white reference standard was used for calibration. The DSLR camera was a Canon EOS 5D Mark IV, with a camera depth of 14 bits. Raw image data in CR2 format were converted into a 16-bit tiff to obtain images similar to the mobile phone camera format.
The lighting environment at the time of capture was based on a combination of three light sources: two fluorescent ceiling lamps and natural daylight through a window. During image capture, the surface of the metal object included glosses or highlights. Many images were captured by changing the shutter speed and lighting conditions for each metallic object in one-shot mode. Among the captured images, the image without saturation and with the highest dynamic range was used as the HDR image of the target object.
In place of a fixed lighting setup, a varying one was employed during the capture. Images were captured using the iPhone 8 camera under light from a fluorescent ceiling lamp and/or natural daylight from a window in a room, while the Canon EOS camera was used with a different type of fluorescent ceiling lamp in another room. These settings were not in laboratories but in actual rooms. The geometry and spectral power distributions of the three light sources varied, mitigating the risk of the learning process overfitting to a specific lighting environment.
Shading in a captured image is highly dependent on the positions of the object and camera. Therefore, by shifting the positions, multiple objects were photographed under different shading conditions. Thus, a set of 267 original images of metal objects was constructed, thereby erasing the backgrounds of target objects.
The original image was resampled to a size of 256 × 256 pixels. For data augmentation, each original image was geometrically varied by (1) image horizontal flipping, (2) zoom using the three factors of 1.0, 1.3, and 1.5, and (3) rotations using 13 angles of −90, −75, −60, −45, −30, −15, 0, 15, 30, 45, 60, 75, and 90 degrees. Accordingly, each original image had 78 modifications.
The processes for creating HDR and LDR are summarized as follows:
(1) HDR creation: The RGB pixel values of the acquired image were divided by the RGB values of the white reference, that is, the original image was normalized such that the RGB values of the white reference standard were set to 1 (8 bits). Subsequently, inverse gamma transformation was applied to compress the normalized images.
(2) LDR creation: The LDR images were created after clipping the HDR images and adjusting the final format to 8 bits following inverse gamma transformation.
The captured images had relative values based on the white reference standard. The white standard object of Minolta CR-A43 was placed near the target object and photographed along with the target object, and the camera values of the metallic object were normalized using the camera values of this white reference. If the luminance level of the object was the same as that of the white reference, the pixel value of x = 1.0.
To compress the dynamic range for convenient data processing, the nonlinear transformation of inverse gamma correction was applied to pixel values
x:
where
γ was set to 2.0. Furthermore, the pixel values were converted using 255 ×
y to map the 8-bit LDR range to [0, 255]. Pixel values above this range were saturated in HDR. When the number of saturated pixels was small, we regarded this as noise. The saturated areas were assumed not to cover the entire object because in such a case, the saturated pixels cannot be recovered from a single LDR image. Based on these considerations, the ratio
R of the saturated area to the total object area was calculated for each image. Subsequently, the saturated HDR image set satisfying the condition of
was adopted as being effective for the present study. The total number of HDR and LDR pairs in the image database created in this way was 14,535.
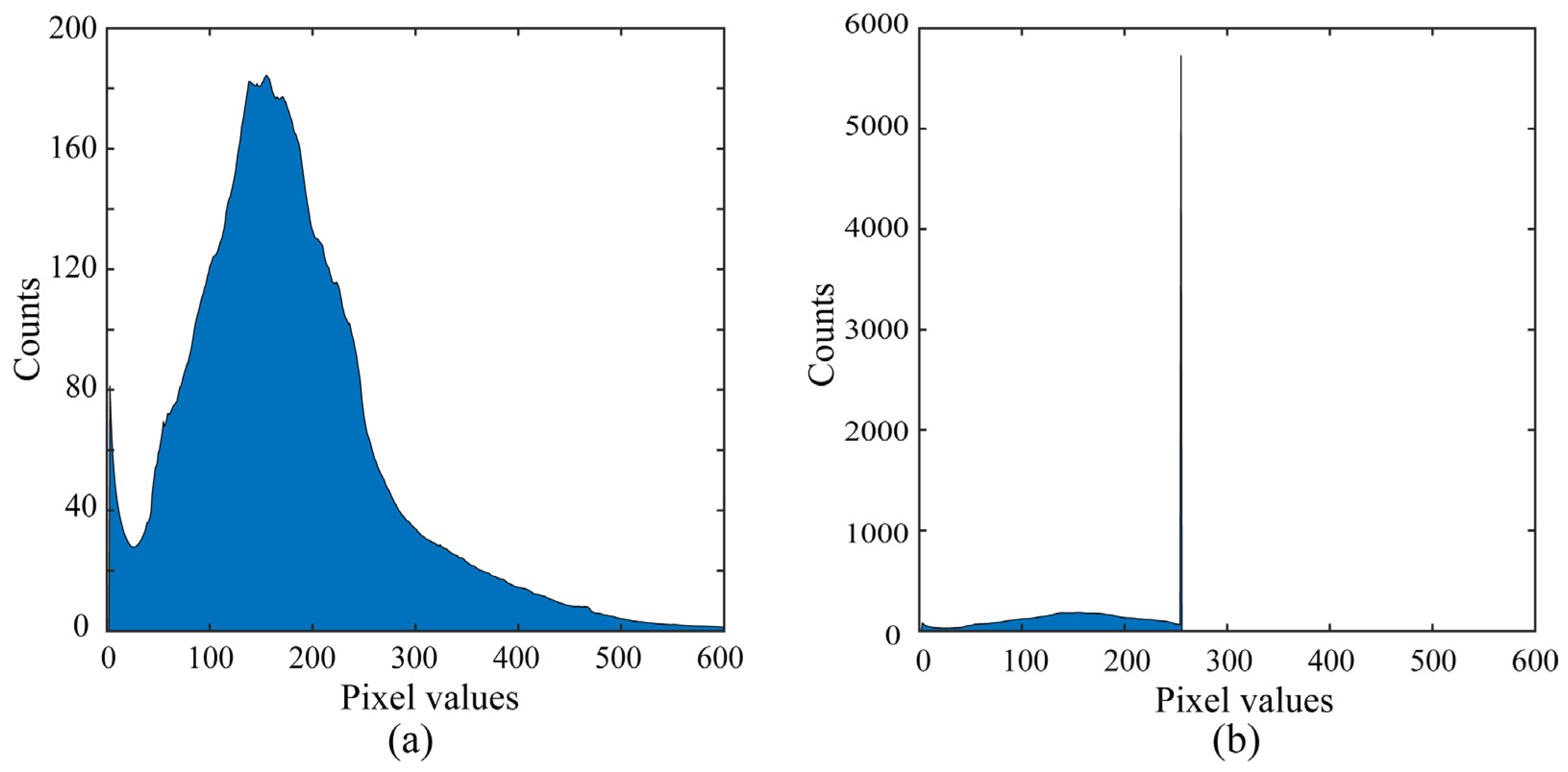
Figure 3a displays the average luminance histogram for the HDR image database. The RGB pixel values covered a very wide range [0, 2010].
Figure 3b shows the average luminance histogram of the corresponding LDR image database suffering from saturation, with images clipped into the 8-bit range with a maximum of 255.
5. Conclusions
The reconstruction of saturated gloss on object surfaces is crucial for the acquisition, modeling, and reproduction of the appearance of a material. In this study, the proposed method reconstructs the original HDR image from a single saturated LDR image of metallic objects. First, an HDR image database was constructed from a large number of metallic objects with different shapes and of various materials. These objects were photographed using two different cameras in a general lighting environment to observe strong gloss or specular reflection. Each of the captured HDR images was clipped to create a set of 8-bit LDR images. The HDR and LDR images were represented by 256 × 256 pixels in each RGB channel. The total number of HDR and LDR pairs in the created image database was 14,535, split into training and testing sets.
Next, a method for reconstructing an HDR image from a single LDR image was proposed to predict the information lost in the saturated areas of the LDR images. A CNN approach was adopted to map the 8-bit LDR image directly to an HDR image. A deep CNN with a U-Net-like architecture was designed. The LDR input image was first transformed to produce a compact feature representation of the image, and then the HDR image was reconstructed. The network was equipped with skip connections to maintain a high image resolution. A network algorithm was constructed using MATLAB machine learning functions. The entire network consisted of 32 layers, and a total 85,900 of learnable parameters.
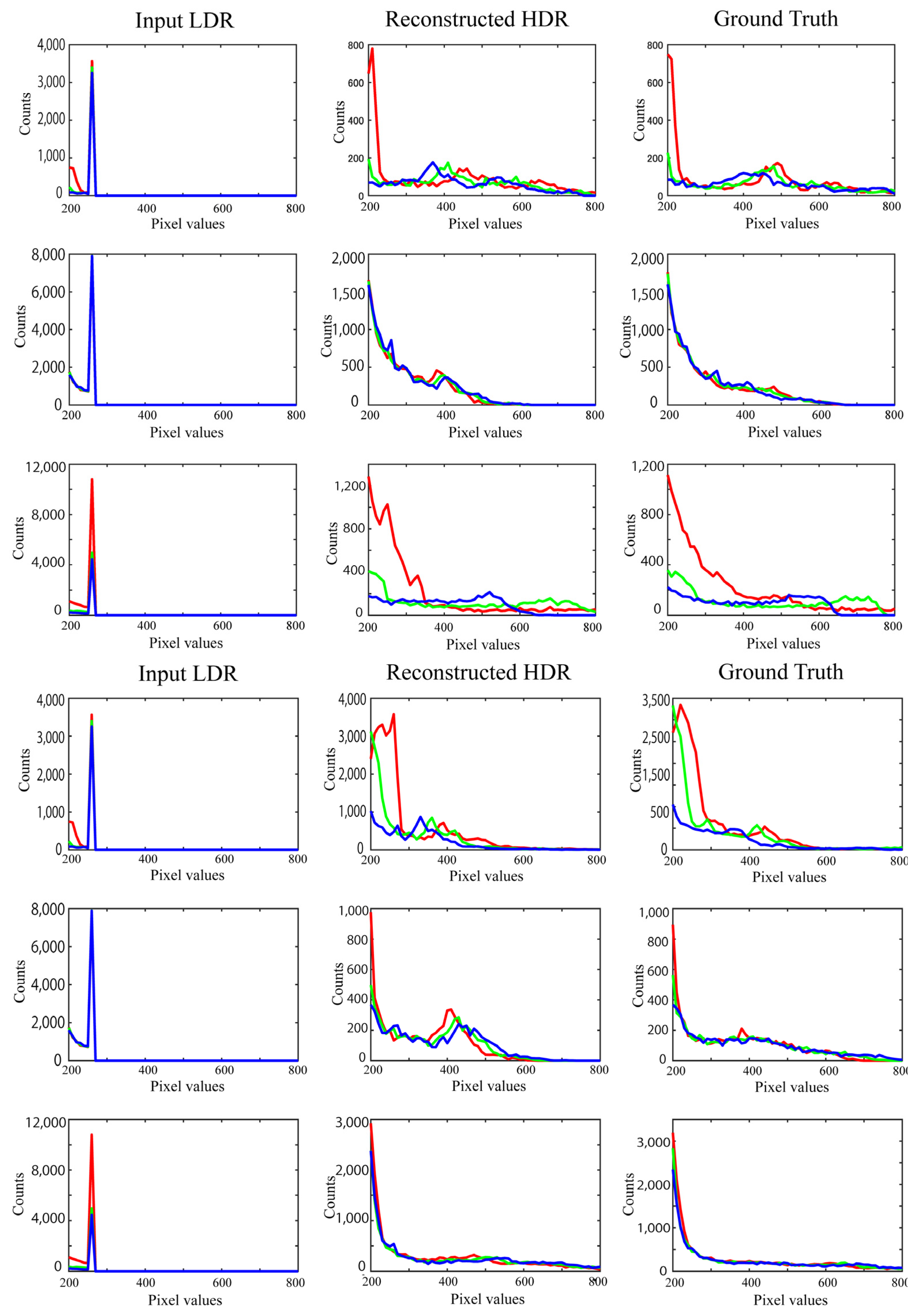
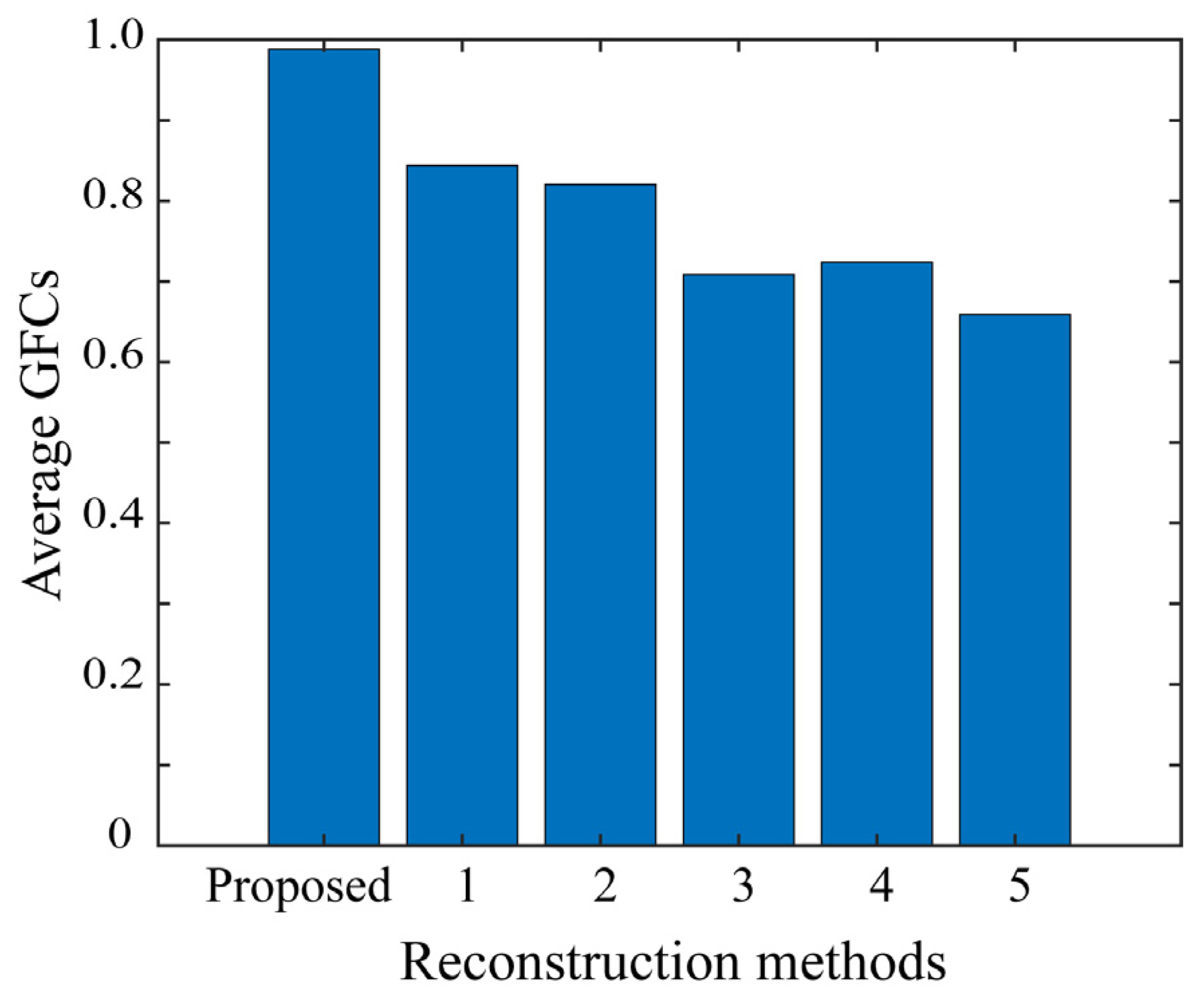
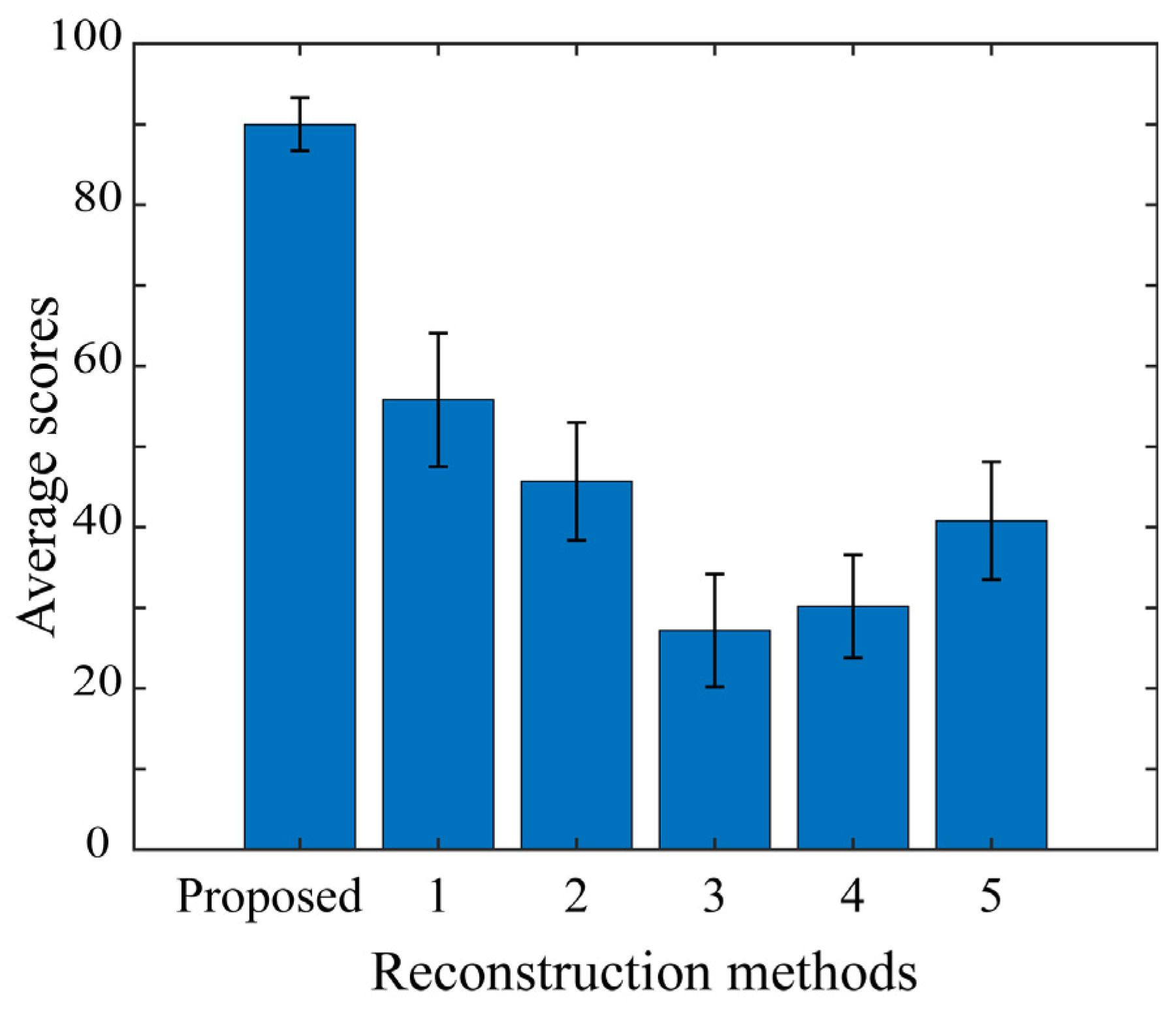
In experiments, we examined the performance of the proposed method using a set of test images for validation. The HDR images reconstructed from the LDR images were close to the target HDR images. The performance of the proposed method was validated based on RMSE values and RGB histogram distributions. The proposed method was also compared with other algorithms open to the public. The superiority of the proposed method was demonstrated not only in terms of quantitative accuracy based on RMSE and GFC, but also based on perceptual faithfulness in human psychological experiments.
The technical novelty of this paper lies in the combination of three aspects: the construction of an HDR image database for metallic objects, the development of a reconstruction method of HDR images from LDR images, and the evaluation of the performance for the HDR image reconstruction. Furthermore, our experimental findings indicate that the efficacy of converting LDR images to HDR images is unaffected by the material composition of metal objects but may be influenced by the objects’ shapes. For example, for a flat metal plate, depending on the lighting environment, the entire surface may have a strong specular reflection or the surface may become considerably dark. In other words, the reflections may change drastically depending on the lighting environment. In such cases, the performance of reconstructing the HDR image declines.
The proposed reconstruction method of the original HDR image from a single saturated LDR image is specialized to metallic objects. Among the numerous types of materials available, materials with strong gloss or specular reflection are limited to metals and dielectric materials such as plastic. The reflection of the metal was based only on specular reflection, whereas the reflection of the dielectric material was decomposed into two components: diffuse reflection and specular reflection. Therefore, saturated areas on dielectric objects often have the same color as the illumination. Addressing the challenge of reconstructing HDR images from saturated LDR images of dielectric objects remains a task for future research.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}














