

SVD-Based Mind-Wandering Prediction from Facial Videos in Online Learning

 , and
, and
Abstract
:1. Introduction
- We implemented an SVD-based 1D temporal eye-signal extraction for attentional state prediction in webcam-based online learning, requiring only eye landmark detection, without gaze tracking or any specialized hardware support.
- We designed a thorough set of experiments pipeline for evaluation of our proposal with other baseline models in the context of analyzing and predicting attentional state.
- Our SVD-based 1D temporal signal can capture subtle or major movements of both eye boundary and eye pupil, whereas EAR-based 1D temporal signal can only reflect eye boundary variations, requiring additional gaze tracking to capture eye pupil variations.
- Our proposed SVD-based attentional state prediction model outperformed the combination of EAR-based and gaze-based models in state-of-the-art webcam-based mind-wandering prediction study [6] by 7% for F1-score in predicting ‘not-focus’, and 2% in the AUROC metric, indicating the degree of separability between “Focus” and “non-Focus” states for the prediction model.
2. Related Work
2.1. Specialized Hardware-Based MW Detection
2.2. Facial Video-Based Mind-Wandering Detection
2.3. Feature Extraction
3. Problem Statement
4. Proposed Methodology
5. Experiments
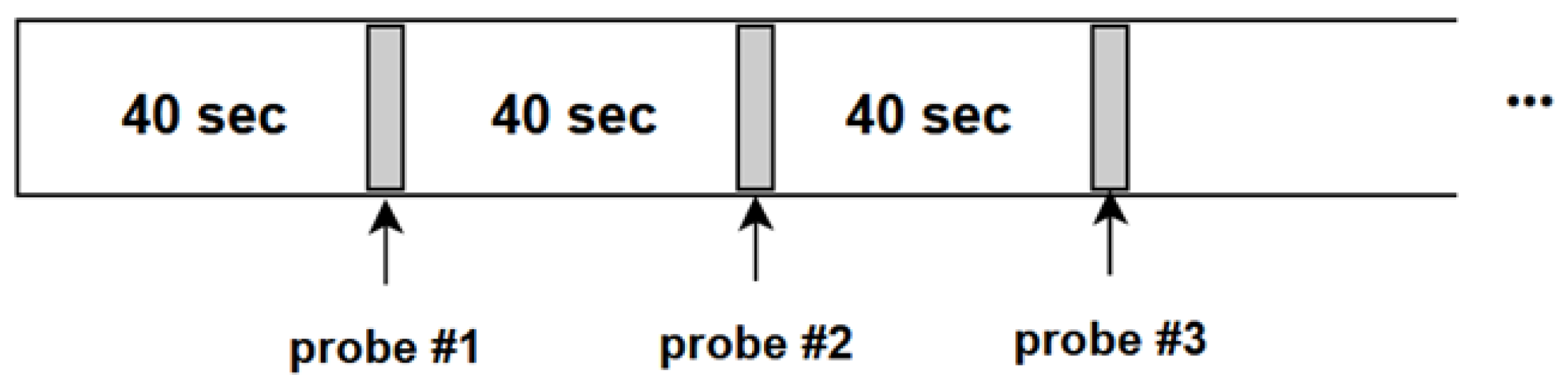
5.1. Overview Experiment
5.2. Dataset

5.3. Implementation Details
5.4. Features Extraction
5.4.1. Proposed SVD-Based Approach
5.4.2. Baseline Methods
- (a)
- EAR-based approach
- (b)
- Gaze-based approach
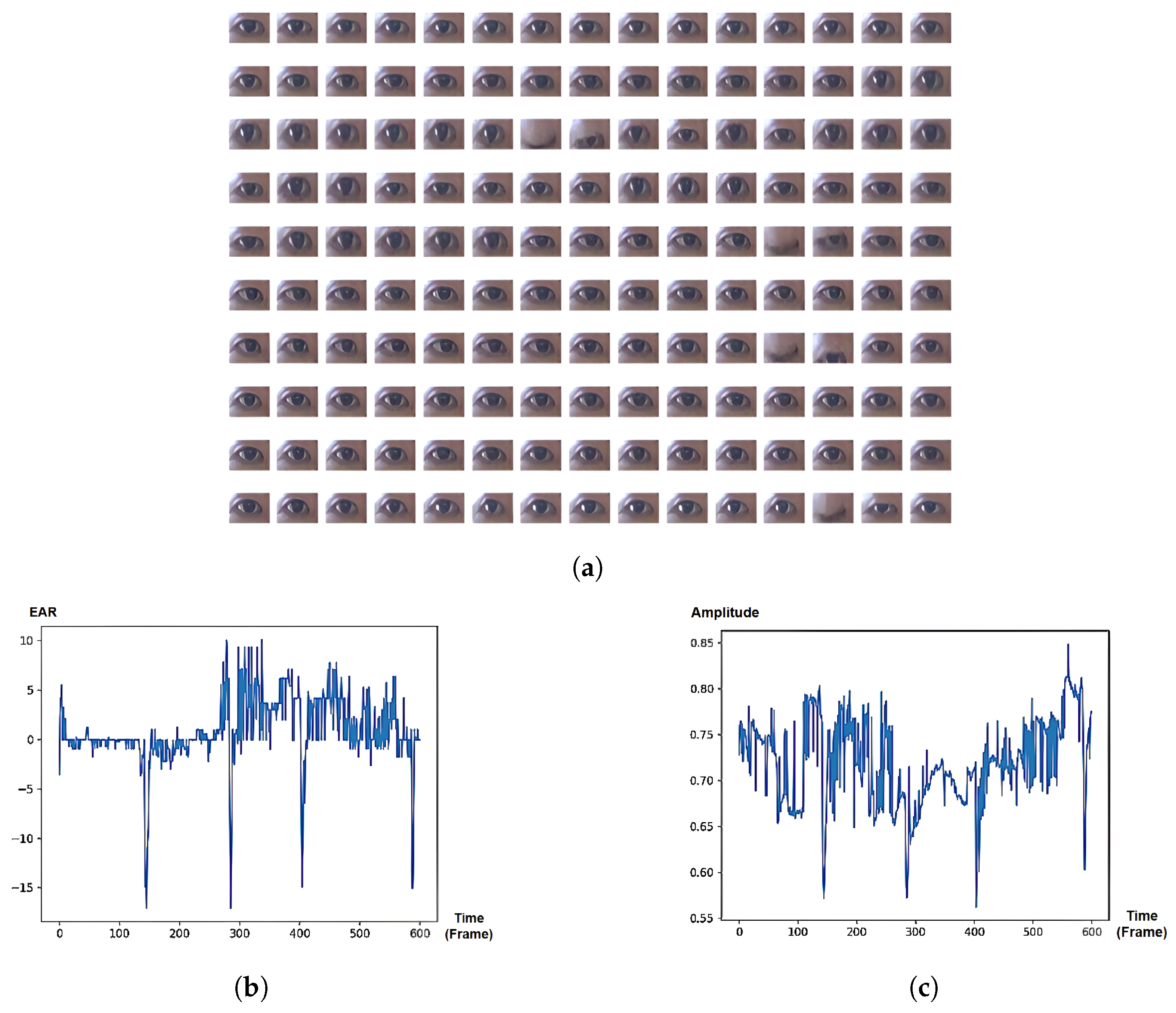
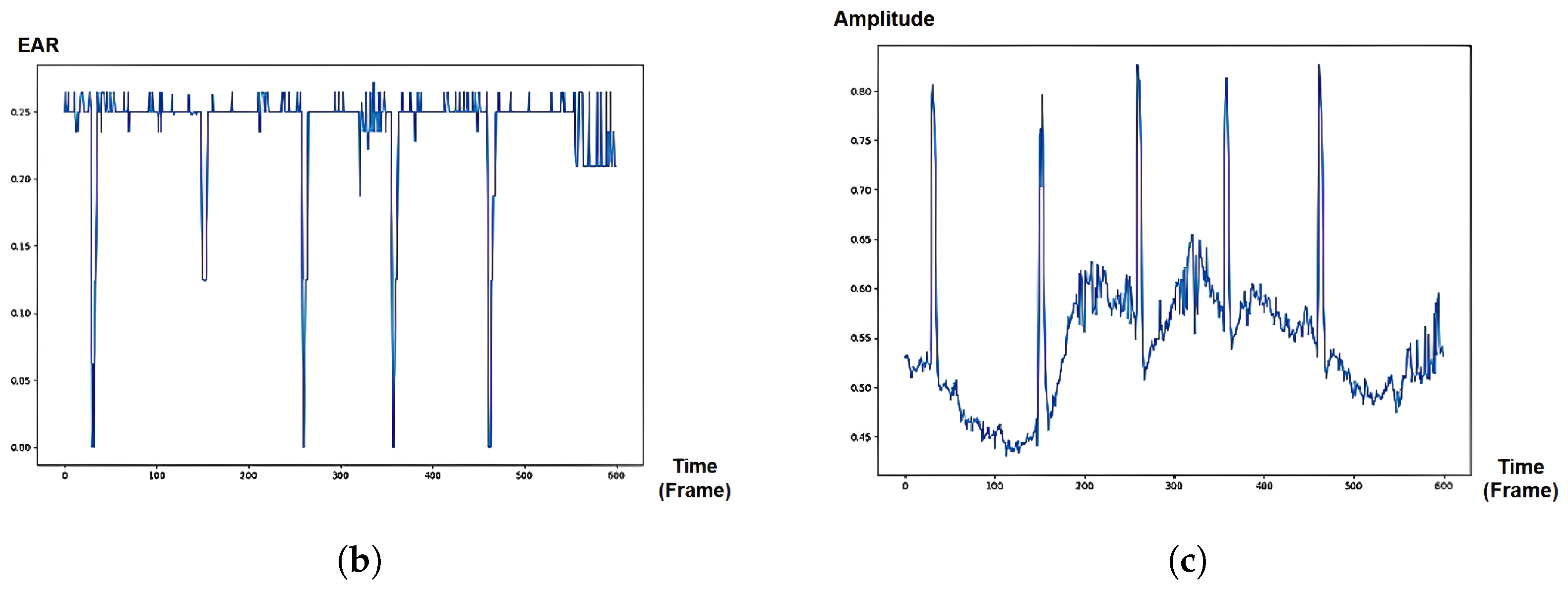
5.5. Analysis of Temporal Eye Signals on Eye Activities
5.6. Features Selection and Generated Datasets
5.7. Evaluation Metrics
5.8. Prediction Model Results and Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Giambra, L.M. Task-unrelated thought frequency as a function of age: A laboratory study. Psychol. Aging 1989, 4, 136. [Google Scholar] [CrossRef] [PubMed]
- Antrobus, J.S.; Singer, J.L.; Greenberg, S. Studies in the stream of consciousness: Experimental enhancement and suppression of spontaneous cognitive processes. Percept. Mot. Skills 1966, 23, 399–417. [Google Scholar] [CrossRef]
- Cherry, J.; McCormack, T.; Graham, A.J. The link between mind wandering and learning in children. J. Exp. Child Psychol. 2022, 217, 105367. [Google Scholar] [CrossRef] [PubMed]
- Szpunar, K.K.; Moulton, S.T.; Schacter, D.L. Mind wandering and education: From the classroom to online learning. Front. Psychol. 2013, 4, 495. [Google Scholar] [CrossRef] [PubMed]
- Barrot, J.S.; Llenares, I.I.; Del Rosario, L.S. Students’ online learning challenges during the pandemic and how they cope with them: The case of the Philippines. Educ. Inf. Technol. 2021, 26, 7321–7338. [Google Scholar] [CrossRef] [PubMed]
- Lee, T.; Kim, D.; Park, S.; Kim, D.; Lee, S.J. Predicting mind-wandering with facial videos in online lectures. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 2104–2113. [Google Scholar]
- D’Mello, S.; Olney, A.; Williams, C.; Hays, P. Gaze tutor: A gaze-reactive intelligent tutoring system. Int. J. Hum.-Comput. Stud. 2012, 70, 377–398. [Google Scholar] [CrossRef]
- Hutt, S.; Krasich, K.; Brockmole, J.R.; K. D’Mello, S. Breaking out of the lab: Mitigating mind wandering with gaze-based attention-aware technology in classrooms. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems, Online, 8–13 May 2021; pp. 1–14. [Google Scholar]
- Aslan, S.; Mete, S.E.; Okur, E.; Oktay, E.; Alyuz, N.; Genc, U.E.; Stanhill, D.; Esme, A.A. Human expert labeling process (HELP): Towards a reliable higher-order user state labeling process and tool to assess student engagement. Educ. Technol. 2017, 57, 53–59. [Google Scholar]
- Kajo, I.; Kamel, N.; Ruichek, Y.; Malik, A.S. SVD-based tensor-completion technique for background initialization. IEEE Trans. Image Process. 2018, 27, 3114–3126. [Google Scholar] [CrossRef] [PubMed]
- Bekhouche, S.E.; Kajo, I.; Ruichek, Y.; Dornaika, F. Spatiotemporal CNN with Pyramid Bottleneck Blocks: Application to eye blinking detection. Neural Netw. 2022, 152, 150–159. [Google Scholar] [CrossRef]
- Taruffi, L.; Pehrs, C.; Skouras, S.; Koelsch, S. Effects of sad and happy music on mind-wandering and the default mode network. Sci. Rep. 2017, 7, 14396. [Google Scholar] [CrossRef]
- Jang, D.; Yang, I.; Kim, S. Detecting Mind-Wandering from Eye Movement and Oculomotor Data during Learning Video Lecture. Educ. Sci. 2020, 10, 51. [Google Scholar] [CrossRef]
- Barron, E.; Riby, L.M.; Greer, J.; Smallwood, J. Absorbed in thought: The effect of mind wandering on the processing of relevant and irrelevant events. Psychol. Sci. 2011, 22, 596–601. [Google Scholar] [CrossRef]
- Blanchard, N.; Bixler, R.; Joyce, T.; D’Mello, S. Automated physiological-based detection of mind wandering during learning. In Proceedings of the Intelligent Tutoring Systems: 12th International Conference, ITS 2014, Honolulu, HI, USA, 5–9 June 2014; Proceedings 12. Springer: Berlin/Heidelberg, Germany, 2014; pp. 55–60. [Google Scholar]
- Smallwood, J.; Davies, J.B.; Heim, D.; Finnigan, F.; Sudberry, M.; O’Connor, R.; Obonsawin, M. Subjective experience and the attentional lapse: Task engagement and disengagement during sustained attention. Conscious. Cogn. 2004, 13, 657–690. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Sugano, Y.; Bulling, A. Evaluation of appearance-based methods and implications for gaze-based applications. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems, Glasgow, UK, 4–9 May 2019; pp. 1–13. [Google Scholar]
- Bates, A.T. Technology, e-Learning and Distance Education; Routledge: Oxfordshire, UK, 2005. [Google Scholar]
- Stewart, A.; Bosch, N.; Chen, H.; Donnelly, P.; D’Mello, S. Face forward: Detecting mind wandering from video during narrative film comprehension. In Proceedings of the International Conference on Artificial Intelligence in Education, Wuhan, China, 28 June–1 July 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 359–370. [Google Scholar]
- Stewart, A.; Bosch, N.; D’Mello, S.K. Generalizability of Face-Based Mind Wandering Detection across Task Contexts. In Proceedings of the 10th International Conference on Educational Data Mining (EDM 2017), Wuhan, China, 25–28 June 2017; pp. 88–95. [Google Scholar]
- Zhao, Y.; Lofi, C.; Hauff, C. Scalable mind-wandering detection for MOOCs: A webcam-based approach. In Proceedings of the Data Driven Approaches in Digital Education: 12th European Conference on Technology Enhanced Learning, EC-TEL 2017, Tallinn, Estonia, 12–15 September 2017; Proceedings 12. Springer: Berlin/Heidelberg, Germany, 2017; pp. 330–344. [Google Scholar]
- Andrillon, T.; Burns, A.; Mackay, T.; Windt, J.; Tsuchiya, N. Predicting lapses of attention with sleep-like slow waves. Nat. Commun. 2021, 12, 3657. [Google Scholar] [CrossRef]
- Baldwin, C.L.; Roberts, D.M.; Barragan, D.; Lee, J.D.; Lerner, N.; Higgins, J.S. Detecting and quantifying mind wandering during simulated driving. Front. Hum. Neurosci. 2017, 11, 406. [Google Scholar] [CrossRef]
- Neon—Eye Tracking Glasses, Developed by PupilLabs, Technical Specifications. Available online: https://pupil-labs.com/products/invisible/tech-specs (accessed on 1 April 2024).
- Wisiecka, K.; Krejtz, K.; Krejtz, I.; Sromek, D.; Cellary, A.; Lewandowska, B.; Duchowski, A. Comparison of Webcam and Remote Eye Tracking. In Proceedings of the 2022 Symposium on Eye Tracking Research and Applications, ETRA ’22, New York, NY, USA, 8–11 June 2022. [Google Scholar] [CrossRef]
- Hutt, S.; Krasich, K.; Mills, C.; Bosch, N.; White, S.; Brockmole, J.R.; D’Mello, S.K. Automated gaze-based mind wandering detection during computerized learning in classrooms. User Model. User-Adapt. Interact. 2019, 29, 821–867. [Google Scholar] [CrossRef]
- Li, B.; Sano, A. Extraction and Interpretation of Deep Autoencoder-based Temporal Features from Wearables for Forecasting Personalized Mood, Health, and Stress. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2020, 4, 1–26. [Google Scholar] [CrossRef]
- Jia, Y.; Zhou, C.; Motani, M. Spatio-temporal autoencoder for feature learning in patient data with missing observations. In Proceedings of the 2017 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Kansas City, MO, USA, 13–16 November 2017; pp. 886–890. [Google Scholar] [CrossRef]
- Bixler, R.; D’Mello, S. Automatic gaze-based user-independent detection of mind wandering during computerized reading. User Model. User-Adapt. Interact. 2016, 26, 33–68. [Google Scholar] [CrossRef]
- Brishtel, I.; Khan, A.A.; Schmidt, T.; Dingler, T.; Ishimaru, S.; Dengel, A. Mind wandering in a multimodal reading setting: Behavior analysis & automatic detection using eye-tracking and an eda sensor. Sensors 2020, 20, 2546. [Google Scholar] [CrossRef]
- Steindorf, L.; Rummel, J. Do your eyes give you away? A validation study of eye-movement measures used as indicators for mindless reading. Behav. Res. Methods 2020, 52, 162–176. [Google Scholar] [CrossRef]
- Brigham, E.O.; Morrow, R. The fast Fourier transform. IEEE Spectr. 1967, 4, 63–70. [Google Scholar] [CrossRef]
- Klinger, E. Modes of normal conscious flow. In The Stream of Consciousness: Scientific Investigations into the Flow of Human Experience; Springer: Berlin/Heidelberg, Germany, 1978; pp. 225–258. [Google Scholar]
- Soukupova, T.; Cech, J. Eye blink detection using facial landmarks. In Proceedings of the 21st Computer Vision Winter Workshop, Rimske Toplice, Slovenia, 3–5 February 2016; p. 2. [Google Scholar]
- MediaPipe Face Mesh [Online]. 2020. Available online: https://github.com/google/mediapipe/wiki/MediaPipe-Face-Mesh (accessed on 1 April 2024).
- Barandas, M.; Folgado, D.; Fernandes, L.; Santos, S.; Abreu, M.; Bota, P.; Liu, H.; Schultz, T.; Gamboa, H. TSFEL: Time series feature extraction library. SoftwareX 2020, 11, 100456. [Google Scholar] [CrossRef]
- Fontana, E.; Rungger, I.; Duncan, R.; Cîrstoiu, C. Spectral analysis for noise diagnostics and filter-based digital error mitigation. arXiv 2022, arXiv:2206.08811. [Google Scholar]
- Cho, Y. Rethinking eye-blink: Assessing task difficulty through physiological representation of spontaneous blinking. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems, Online, 8–13 May 2021; pp. 1–12. [Google Scholar]
- Ghoddoosian, R.; Galib, M.; Athitsos, V. A realistic dataset and baseline temporal model for early drowsiness detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019; pp. 178–187. [Google Scholar]
- Rayner, K.; Chace, K.H.; Slattery, T.J.; Ashby, J. Eye movements as reflections of comprehension processes in reading. Sci. Stud. Read. 2006, 10, 241–255. [Google Scholar] [CrossRef]
- Chaudhary, A.K.; Pelz, J.B. Motion tracking of iris features to detect small eye movements. J. Eye Mov. Res. 2019, 12. [Google Scholar] [CrossRef]
- Park, S.; Mello, S.D.; Molchanov, P.; Iqbal, U.; Hilliges, O.; Kautz, J. Few-shot adaptive gaze estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9368–9377. [Google Scholar]
- FAZE: Few-Shot Adaptive Gaze Estimation Source Code. 2020. Available online: https://github.com/NVlabs/few_shot_gaze (accessed on 1 April 2024).
- FAZE: Few-Shot Adaptive Gaze Estimation Issue. 2020. Available online: https://github.com/NVlabs/few_shot_gaze/issues/6 (accessed on 1 April 2024).
- Statsmodel (Python library)—Ordinary Least Squares. Available online: https://www.statsmodels.org/dev/generated/statsmodels.regression.linear_model.OLS.html (accessed on 1 April 2024).
- ROC Curve. Available online: https://www.evidentlyai.com/classification-metrics/explain-roc-curve (accessed on 1 April 2024).
- F1, Accuracy, ROC AUC, PR AUC Metrics. Available online: https://deepchecks.com/f1-score-accuracy-roc-auc-and-pr-auc-metrics-for-models/ (accessed on 1 April 2024).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Features | Description | |
|---|---|---|
| Statistical | Absolute energy | Computes the absolute energy of the signal |
| Entropy | Computes the entropy of the signal using the Shannon Entropy | |
| Interquartile range | Computes interquartile range (Q3-Q1) of the signal | |
| Max | Computes the maximum value of the signal | |
| Min | Computes the minimum value of the signal | |
| Mean | Computes the mean value of the signal | |
| Mean absolute deviation | Computes mean absolute deviation of the signal | |
| Median | Computes median value of the signal | |
| Median absolute deviation | Computes median absolute deviation of the signal | |
| Standard deviation | Computes standard deviation of the signal | |
| Variance | Computes variance of the signal | |
| Peak to peak distance | Computes peak to peak distance of the signal | |
| Root mean square | Computes root mean square of the signal | |
| Kurtosis | Computes kurtosis of the signal | |
| Skewness | Computes skewness of the signal | |
| Spectral | Max power spectrum | Computes maximum power spectrum density of the signal after Fast Fourier Transform (FFT) |
| Maximum frequency | Returns the frequency with 95% of the Cumulative sum of the magnitude after FFT | |
| Median frequency | Returns the frequency with 50% of the Cumulative sum of the magnitude after FFT | |
| Power bandwidth | Computes power spectrum density bandwidth of the signal after FFT | |
| Fundamental frequency | Finds the lowest frequency of the signal after FFT | |
| Spectral centroid | Computes the barycenter of the spectrum after FFT | |
| Spectral decrease | Computes the amount of decreasing of the spectra amplitude after FFT | |
| Spectral distance | Compute spectral distance between Cumulative sum of the magnitude after FFT and its linear regression | |
| Spectral entropy | Compute Spectral entropy of the spectrum after FFT | |
| Spectral kurtosis | Computes the flatness of a distribution around its mean value in the spectrum after FFT | |
| Statistical | Spectral skewness | Computes the asymmetry of a distribution around its mean value in the spectrum after FFT |
| Spectral slope | Computes the spectral slope, obtained by linear regression of the spectral amplitude after FFT | |
| Spectral spread | Computes the spread of the spectrum around its mean value after FFT | |
| Spectral variation | Computes the amount of variation of the spectrum along time after FFT | |
| Wavelet energy | Computes Continuous Wavelet Transform (CWT) energy of each wavelet scale | |
| Wavelet entropy | Computes CWT entropy of the signal | |
| Wavelet variance | Computes CWT variance value of each wavelet scale. | |
| Method | Domain | Features | Focused | Not-Focused | p-Value | ||
|---|---|---|---|---|---|---|---|
| Mean | SD | Mean | SD | ||||
| EAR | statistical | Absolute energy | 2027.00 | 920.69 | 2302.74 | 930.27 | <0.001 *** |
| Entropy | 0.50 | 0.18 | 0.44 | 0.16 | <0.001 *** | ||
| Kurtosis | 5.08 | 21.76 | 6.37 | 30.10 | 0.050 * | ||
| Mean absolute deviation | 0.23 | 0.47 | 0.25 | 0.47 | 0.001 ** | ||
| Root mean square | 0.89 | 1.60 | 1.01 | 1.68 | <0.001 *** | ||
| Skewness | −0.88 | 1.70 | −0.52 | 2.15 | 0.006 ** | ||
| Standard deviation | 0.29 | 0.59 | 0.35 | 0.64 | <0.001 *** | ||
| spectral | Maximum frequency | 42.64 | 1.72 | 43.11 | 1.72 | 0.007 ** | |
| Wavelet energy (scale = 5) | 0.55 | 1.08 | 0.63 | 1.11 | 0.020 * | ||
| Wavelet energy (scale = 8) | 0.65 | 1.27 | 2.27 | 1.32 | 0.020 * | ||
| Wavelet entropy | 2.11 | 0.02 | 2.11 | 0.02 | <0.001 *** | ||
| Wavelet variance (scale = 5) | 1.47 | 3.81 | 1.61 | 3.59 | 0.020 * | ||
| Wavelet variance (scale = 8) | 2.03 | 5.20 | 2.27 | 5.16 | 0.030 * | ||
| Gaze | horizontal saccade percentage | 0.39 | 0.13 | 0.36 | 0.14 | 0.007 ** | |
| SVD | statistical | Entropy | 0.71 | 0.12 | 0.78 | 0.07 | <0.001 *** |
| Kurtosis | 0.91 | 2.43 | 0.52 | 1.51 | 0.003 ** | ||
| Max | 0.71 | 0.09 | 0.72 | 0.08 | 0.007 ** | ||
| Standard deviation | 0.07 | 0.01 | 0.07 | 0.01 | 0.001 ** | ||
| spectral | Max power spectrum | 1.18 | 0.72 | 1.01 | 0.56 | <0.001 *** | |
| Maximum frequency | 41.29 | 3.86 | 42.35 | 3.00 | <0.001 *** | ||
| Spectral decrease | −5.71 | 2.12 | −5.98 | 1.96 | <0.001 *** | ||
| Spectral kurtosis | 4.31 | 2.25 | 4.16 | 1.59 | 0.003 ** | ||
| Datasets | Description |
|---|---|
| EAR-spectral | Dataset consisting of EAR-based spectral features |
| Gaze | Dataset consisting of Gaze-based features |
| EAR-stats + Gaze | Dataset consisting of EAR-based statistical and Gaze-based features |
| EAR-spectral + Gaze | Dataset consisting of EAR-based spectral and Gaze-based features |
| SVD-stats | Dataset consisting of SVD-based statistical features |
| SVD-spectral | Dataset consisting of SVD-based spectral features |
| Features | Model | Focused | Not-Focused | AUROC | ||
|---|---|---|---|---|---|---|
| Accuracy | F1 | Accuracy | F1 | |||
| EAR-stats * | XGBoost | 0.84 ± 0.03 | 0.79 ± 0.02 | 0.17 ± 0.04 | 0.21 ± 0.04 | 0.53 ± 0.03 |
| DNN | 0.81 ± 0.02 | 0.77 ± 0.01 | 0.12 ± 0.03 | 0.19 ± 0.02 | 0.49 ± 0.01 | |
| EAR-spectral | XGBoost | 0.80 ± 0.04 | 0.77 ± 0.02 | 0.16 ± 0.07 | 0.18 ± 0.07 | 0.53 ± 0.02 |
| DNN | 0.76 ± 0.03 | 0.75 ± 0.02 | 0.14 ± 0.04 | 0.16 ± 0.02 | 0.45 ± 0.01 | |
| Gaze * | XGBoost | 0.79 ± 0.03 | 0.76 ± 0.03 | 0.18 ± 0.08 | 0.19 ± 0.08 | 0.54 ± 0.03 |
| DNN | 0.68 ± 0.02 | 0.61 ± 0.02 | 0.12 ±0.03 | 0.15 ± 0.04 | 0.50 ± 0.02 | |
| EAR-stats + Gaze * | XGBoost | 0.83 ± 0.05 | 0.78 ± 0.04 | 0.20 ± 0.05 | 0.23 ± 0.08 | 0.55 ± 0.01 |
| DNN | 0.77 ± 0.03 | 0.69 ± 0.02 | 0.22 ± 0.03 | 0.24 ± 0.03 | 0.51 ± 0.02 | |
| EAR-spectral + Gaze | XGBoost | 0.85 ± 0.04 | 0.80 ± 0.02 | 0.19 ± 0.07 | 0.24 ± 0.08 | 0.56 ± 0.03 |
| DNN | 0.71 ± 0.02 | 0.69 ± 0.04 | 0.28 ± 0.05 | 0.27 ± 0.03 | 0.53 ± 0.02 | |
| SVD-stats | XGBoost | 0.81 ± 0.04 | 0.78 ± 0.03 | 0.22 ± 0.08 | 0.25 ± 0.06 | 0.52 ± 0.03 |
| DNN | 0.76 ± 0.03 | 0.76 ± 0.05 | 0.26 ± 0.04 | 0.24 ± 0.02 | 0.49 ± 0.03 | |
| SVD-spectral | XGBoost | 0.84 ± 0.04 | 0.80 ± 0.03 | 0.27 ± 0.09 | 0.30 ± 0.09 | 0.57 ± 0.04 |
| DNN | 0.79 ± 0.05 | 0.78 ± 0.02 | 0.28 ± 0.03 | 0.26 ± 0.07 | 0.51 ± 0.02 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Anh, N.T.L.; Bach, N.G.; Tu, N.T.T.; Kamioka, E.; Tan, P.X. SVD-Based Mind-Wandering Prediction from Facial Videos in Online Learning. J. Imaging 2024, 10, 97. https://doi.org/10.3390/jimaging10050097
Anh NTL, Bach NG, Tu NTT, Kamioka E, Tan PX. SVD-Based Mind-Wandering Prediction from Facial Videos in Online Learning. Journal of Imaging. 2024; 10(5):97. https://doi.org/10.3390/jimaging10050097
Chicago/Turabian StyleAnh, Nguy Thi Lan, Nguyen Gia Bach, Nguyen Thi Thanh Tu, Eiji Kamioka, and Phan Xuan Tan. 2024. "SVD-Based Mind-Wandering Prediction from Facial Videos in Online Learning" Journal of Imaging 10, no. 5: 97. https://doi.org/10.3390/jimaging10050097
APA StyleAnh, N. T. L., Bach, N. G., Tu, N. T. T., Kamioka, E., & Tan, P. X. (2024). SVD-Based Mind-Wandering Prediction from Facial Videos in Online Learning. Journal of Imaging, 10(5), 97. https://doi.org/10.3390/jimaging10050097