
Derivative-Free Iterative One-Step Reconstruction for Multispectral CT



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
1.1. Multispectral CT
1.2. Two-Step and One-Step Algorithms
1.3. Our Contributions
- We present a novel derivative-free algorithm designed to combine the advantages of one-step and two-step approaches. To achieve this, we introduce a simple and computationally efficient iterative update that incorporates appropriate preconditioning.
- Image reconstruction is performed in the image domain, which naturally allows for the inclusion of an image smoothness prior. Our method can be combined with additional regularization. However, in order to show the method in its pure form, we will not include such a modification.
- Our methods integrate benefits of two-step approaches by separating iterative updates into two parts. Moreover, the main ingredient that makes the algorithm efficient is the use of the full nonlinear forward model but linearization around zero for the adjoint problem. In addition to avoiding computation and evaluation of the derivative of the forward map, this also allows for including simple but efficient channel preconditioning.
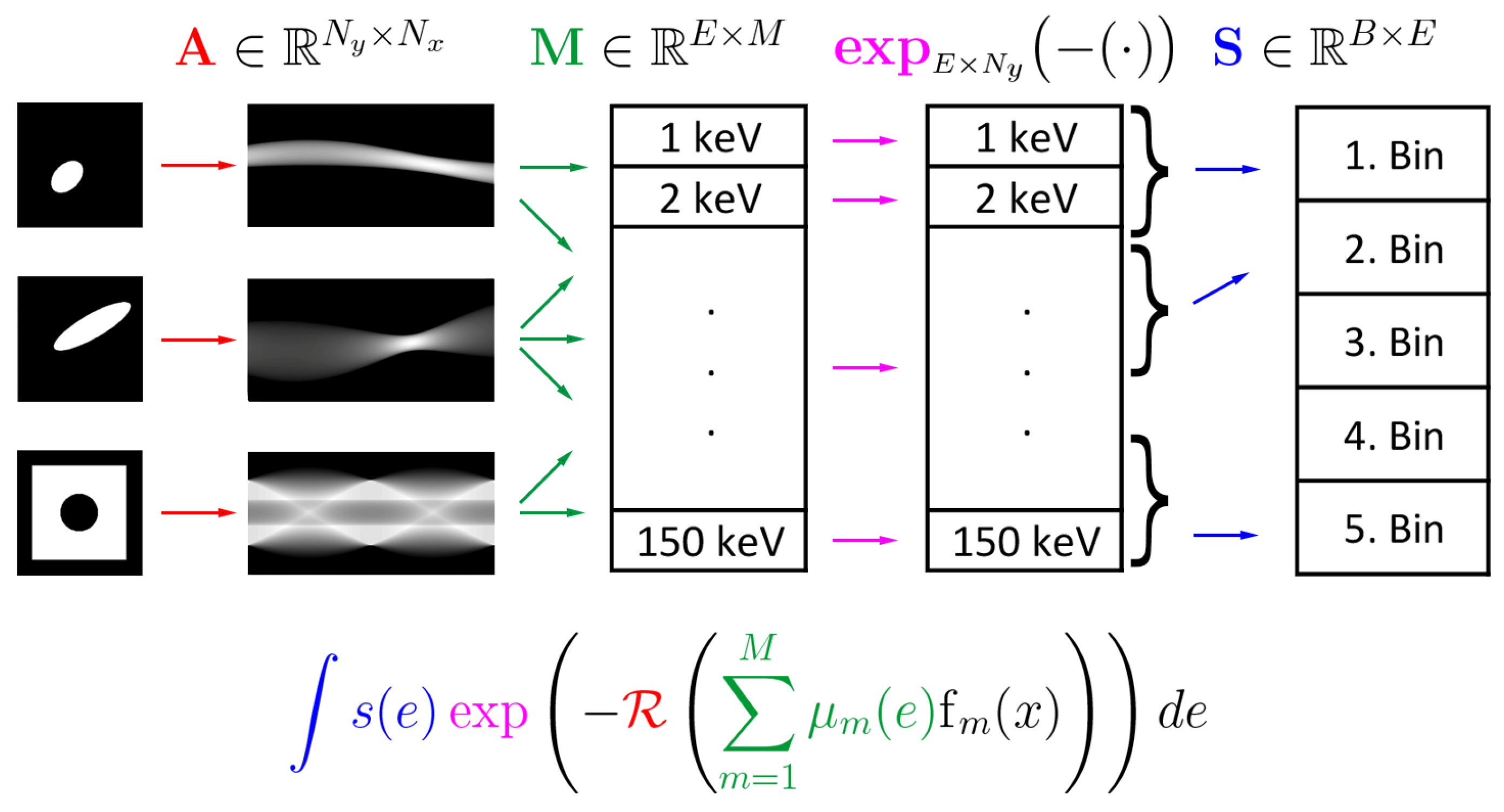
2. Mathematical Modelling of MSCT
2.1. Continuous Model
2.2. Discretization
- The columns of are the discrete material images;
- is the discretized Radon transform;
- The columns of are the discretized material attenuations;
- The columns of the discretized effective spectra;
- The columns of are the observed spectral data.
3. Algorithm Development
3.1. Derivatives Computation
3.2. Gradient and Newton—One-Step Algorithms
- Landweber method:
- In the context of inverse problems, the standard gradient method with a constant step size is known as the (nonlinear) Landweber iteration , which is (24) for the case where is the identity and . Landweber’s iteration is stable, robust, and easy to implement. It is even applicable in ill-posed cases, where, with an appropriate stopping criterion, it serves as a regularization method [32]. On the other hand, it is also known to be slow in the sense that many iterative steps are required. In our case, this is due to the ill-conditioning of the forward operator.
- Gauss–Newton method:
- Several potential accelerations of Landweber’s method exist, and preconditioning seems one of the most natural ones. In the context of nonlinear least squares, the Gauss–Newton method and its variants are well-established and effective. In this case, one chooses the preconditioner in (24), which results in:The Gauss–Newton method (25) has the potential to significantly reduce the required number of iterations. On the other hand, each one of these iterations is numerically costly, as it requires inversion of the nonstationary normal operator . Moreover, due to ill conditioning, the inversion needs to be regularized [28,33,34]. The algorithms proposed in this paper use simplifications that do not need to be regularized and avoid the costly inversion of the normal operator.
3.3. Proposed Algorithms
- CP-full:
- The first proposed algorithm is an instance of (24). Instead of no preconditioning, as in Landweber’s method, or the costly preconditioning , as in the Gauss–Newton method, we propose preconditioning with the channel mixing term only. That is, we exploit the factorization and propose the choice for the preconditioner. This results in the following CP-full iteration:While efficiently addressing the nonlinearity via a Gauss–Newton-type preconditioner in the channel dimension, it is computationally much less costly than the full Gauss–Newton update. Instead of inverting , which in matrix form has size in the Gauss–Newton method, it requires inversion of the smaller matrices only, which can be done separately for each pixel in the projection domain. Assuming and , this dramatically reduces the cost of preconditioning from to per iterative update.
- CP-fast:
- In the derivative-free version, we go one step further and completely avoid the derivative . For that purpose, we replace the derivative in (26) by the derivative at zero. According to Remark 6, we have with . Now, with denoting the pseudoinverse of , we arrive at the iterative update:We refer to (27) as the derivative-free fast channel-preconditioned (cp-fast) iteration. It only involves the derivative at zero, which can be computed once before the actual iteration. In this sense, it is actually derivative-free and fast. It can be interpreted as using the full nonlinear model for the forward problem, the linearization at zero for the adjoint problem, and including channel preconditioning.
4. Numerical Simulations
4.1. Comparison Methods
- Ref. [19] derives a nonlinear CG method for a weighted LSQ term;
4.2. Numerical Implementation
- for the base materials;
- for the effective energy spectra;
- for the Radon transform.
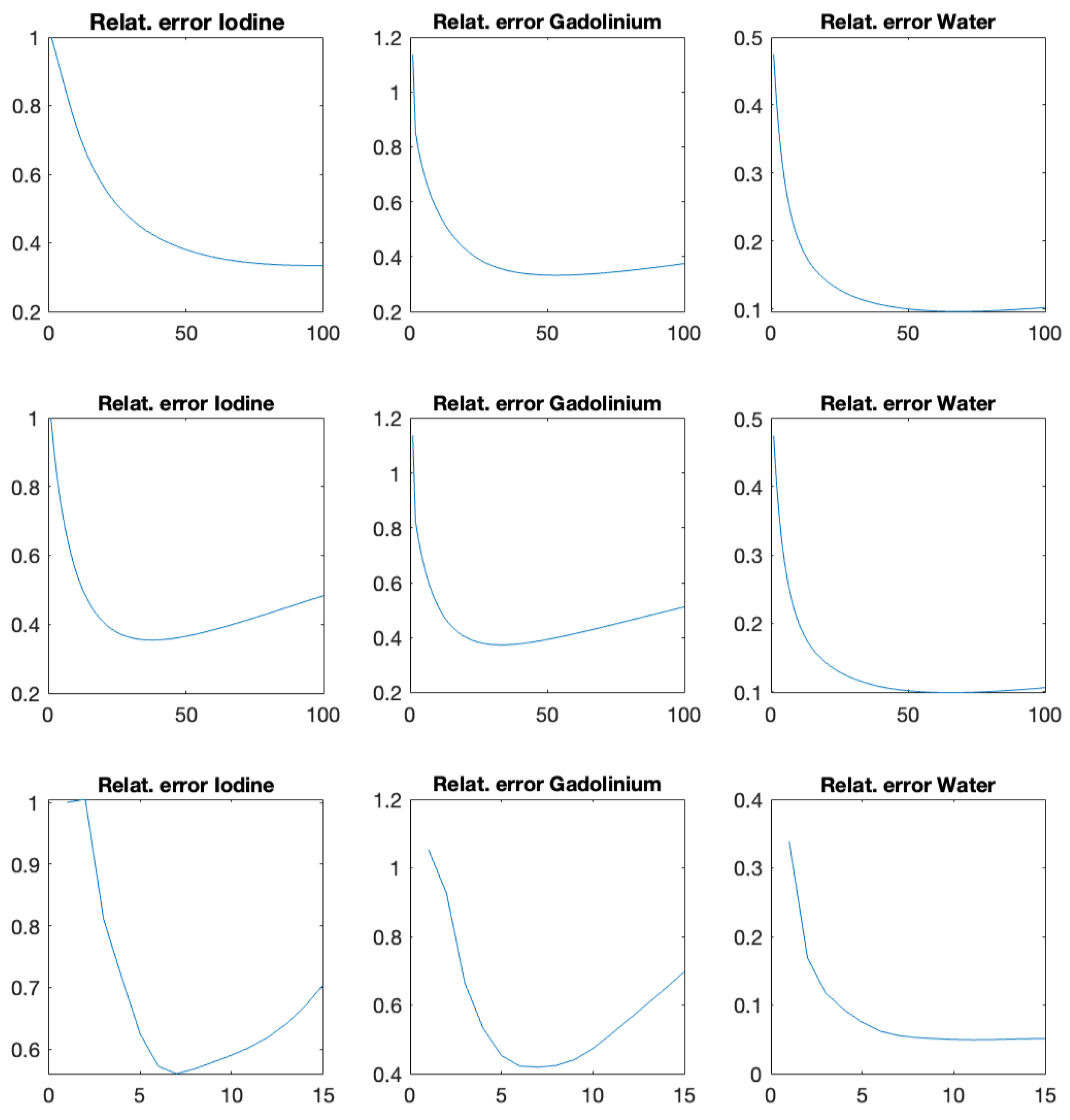
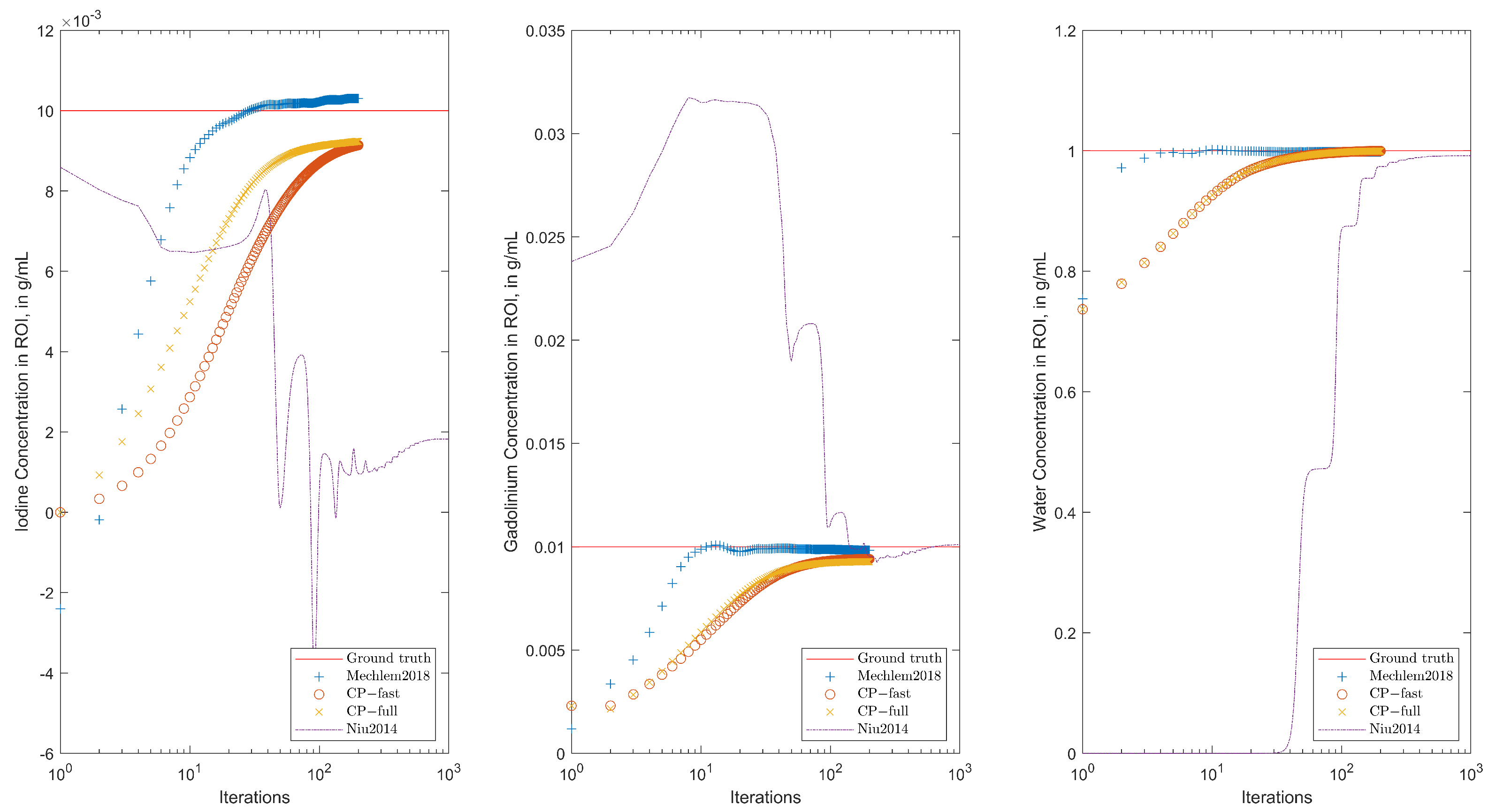
4.3. Results
5. Conclusions and Outlook
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. Proof of Theorem 1
References
- McDavid, W.D.; Waggener, R.G.; Payne, W.H.; Dennis, M.J. Spectral effects on three-dimensional reconstruction from X rays. Med. Phys. 1975, 2, 321–324. [Google Scholar] [CrossRef]
- Kiss, M.B.; Bossema, F.G.; van Laar, P.J.; Meijer, S.; Lucka, F.; van Leeuwen, T.; Batenburg, K.J. Beam filtration for object-tailored X-ray CT of multi-material cultural heritage objects. Herit. Sci. 2023, 11, 130. [Google Scholar] [CrossRef]
- Pan, X.; Siewerdsen, J.; La Riviere, P.J.; Kalender, W.A. Anniversary Paper: Development of X-ray computed tomography: The role of Medical Physics and AAPM from the 1970s to present. Med. Phys. 2008, 35, 3728–3739. [Google Scholar] [CrossRef] [PubMed]
- Herman, G.T. Correction for beam hardening in computed tomography. Phys. Med. Biol. 1979, 24, 81. [Google Scholar] [CrossRef]
- Van Gompel, G.; Van Slambrouck, K.; Defrise, M.; Batenburg, K.J.; De Mey, J.; Sijbers, J.; Nuyts, J. Iterative correction of beam hardening artifacts in CT. Med. Phys. 2011, 38, S36–S49. [Google Scholar] [CrossRef] [PubMed]
- Rigaud, G. On analytical solutions to beam-hardening. Sens. Imaging 2017, 18, 5. [Google Scholar] [CrossRef]
- Kazantsev, D.; Jørgensen, J.S.; Andersen, M.S.; Lionheart, W.R.; Lee, P.D.; Withers, P.J. Joint image reconstruction method with correlative multi-channel prior for X-ray spectral computed tomography. Inverse Probl. 2018, 34, 064001. [Google Scholar] [CrossRef]
- Rigie, D.S.; La Riviere, P.J. Joint reconstruction of multi-channel, spectral CT data via constrained total nuclear variation minimization. Phys. Med. Biol. 2015, 60, 1741. [Google Scholar] [CrossRef] [PubMed]
- Hu, Y.; Nagy, J.G.; Zhang, J.; Andersen, M.S. Nonlinear optimization for mixed attenuation polyenergetic image reconstruction. Inverse Probl. 2019, 35, 064004. [Google Scholar] [CrossRef]
- Arridge, S.R.; Ehrhardt, M.J.; Thielemans, K. (An overview of) Synergistic reconstruction for multimodality/multichannel imaging methods. Philos. Trans. R. Soc. A 2021, 379, 20200205. [Google Scholar] [CrossRef]
- Mory, C.; Sixou, B.; Si-Mohamed, S.; Boussel, L.; Rit, S. Comparison of five one-step reconstruction algorithms for spectral CT. Phys. Med. Biol. 2018, 63, 235001. [Google Scholar] [CrossRef] [PubMed]
- Heismann, B.; Balda, M. Quantitative image-based spectral reconstruction for computed tomography. Med. Phys. 2009, 36, 4471–4485. [Google Scholar] [CrossRef] [PubMed]
- Maaß, C.; Baer, M.; Kachelrieß, M. Image-based dual energy CT using optimized precorrection functions: A practical new approach of material decomposition in image domain. Med. Phys. 2009, 36, 3818–3829. [Google Scholar] [CrossRef]
- Willemink, M.J.; Persson, M.; Pourmorteza, A.; Pelc, N.J.; Fleischmann, D. Photon-counting CT: Technical principles and clinical prospects. Radiology 2018, 289, 293–312. [Google Scholar] [CrossRef] [PubMed]
- Kreisler, B. Photon counting Detectors: Concept, technical Challenges, and clinical outlook. Eur. J. Radiol. 2022, 149, 110229. [Google Scholar] [CrossRef] [PubMed]
- Schmidt, T.G. Optimal “image-based” weighting for energy-resolved CT. Med. Phys. 2009, 36, 3018–3027. [Google Scholar] [CrossRef]
- Niu, T.; Dong, X.; Petrongolo, M.; Zhu, L. Iterative image-domain decomposition for dual-energy CT. Med. Phys. 2014, 41, 041901. [Google Scholar] [CrossRef] [PubMed]
- Schirra, C.O.; Roessl, E.; Koehler, T.; Brendel, B.; Thran, A.; Pan, D.; Anastasio, M.A.; Proksa, R. Statistical reconstruction of material decomposed data in spectral CT. IEEE Trans. Med. Imaging 2013, 32, 1249–1257. [Google Scholar] [CrossRef]
- Cai, C.; Rodet, T.; Legoupil, S.; Mohammad-Djafari, A. A full-spectral Bayesian reconstruction approach based on the material decomposition model applied in dual-energy computed tomography. Med. Phys. 2013, 40, 111916. [Google Scholar] [CrossRef]
- Long, Y.; Fessler, J.A. Multi-material decomposition using statistical image reconstruction for spectral CT. IEEE Trans. Med. Imaging 2014, 33, 1614–1626. [Google Scholar] [CrossRef]
- Mechlem, K.; Ehn, S.; Sellerer, T.; Braig, E.; Münzel, D.; Pfeiffer, F.; Noël, P.B. Joint statistical iterative material image reconstruction for spectral computed tomography using a semi-empirical forward model. IEEE Trans. Med. Imaging 2017, 37, 68–80. [Google Scholar] [CrossRef]
- Weidinger, T.; Buzug, T.M.; Flohr, T.; Kappler, S.; Stierstorfer, K. Polychromatic iterative statistical material image reconstruction for photon-counting computed tomography. Int. J. Biomed. Imaging 2016, 2016, 5871604. [Google Scholar] [CrossRef]
- Barber, R.F.; Sidky, E.Y.; Schmidt, T.G.; Pan, X. An algorithm for constrained one-step inversion of spectral CT data. Phys. Med. Biol. 2016, 61, 3784. [Google Scholar]
- Chen, B.; Zhang, Z.; Xia, D.; Sidky, E.Y.; Pan, X. Non-convex primal-dual algorithm for image reconstruction in spectral CT. Comput. Med. Imaging Graph. 2021, 87, 101821. [Google Scholar] [CrossRef]
- Scherzer, O.; Grasmair, M.; Grossauer, H.; Haltmeier, M.; Lenzen, F. Variational Methods in Imaging; Springer: New York, NY, USA, 2009; Volume 167. [Google Scholar]
- Benning, M.; Burger, M. Modern regularization methods for inverse problems. Acta Numer. 2018, 27, 1–111. [Google Scholar] [CrossRef]
- Ebner, A.; Haltmeier, M. Plug-and-Play image reconstruction is a convergent regularization method. arXiv 2022, arXiv:2212.06881. [Google Scholar] [CrossRef]
- Kaltenbacher, B.; Neubauer, A.; Scherzer, O. Iterative Regularization Methods for Nonlinear Ill-Posed Problems; Walter de Gruyter: Berlin, Germany, 2008. [Google Scholar]
- Fessler, J.A. Method for Statistically Reconstructing Images from a Plurality of Transmission Measurements Having Energy Diversity and Image Reconstructor Apparatus Utilizing the Method. U.S. Patent 6,754,298, 22 June 2004. [Google Scholar]
- Du, K.; Ruan, C.C.; Sun, X.H. On the convergence of a randomized block coordinate descent algorithm for a matrix least squares problem. Appl. Math. Lett. 2022, 124, 107689. [Google Scholar] [CrossRef]
- Rabanser, S.; Neumann, L.; Haltmeier, M. Analysis of the block coordinate descent method for linear ill-posed problems. SIAM J. Imaging Sci. 2019, 12, 1808–1832. [Google Scholar] [CrossRef]
- Hanke, M.; Neubauer, A.; Scherzer, O. A convergence analysis of the Landweber iteration for nonlinear ill-posed problems. Numer. Math. 1995, 72, 21–37. [Google Scholar] [CrossRef]
- Hanke, M. A regularizing Levenberg–Marquardt scheme, with applications to inverse groundwater filtration problems. Inverse Probl. 1997, 13, 79. [Google Scholar] [CrossRef]
- Rieder, A. On the regularization of nonlinear ill-posed problems via inexact Newton iterations. Inverse Probl. 1999, 15, 309. [Google Scholar] [CrossRef]
- Chambolle, A.; Pock, T. A first-order primal-dual algorithm for convex problems with applications to imaging. J. Math. Imaging Vis. 2011, 40, 120–145. [Google Scholar] [CrossRef]
- Bousse, A.; Kandarpa, V.S.S.; Rit, S.; Perelli, A.; Li, M.; Wang, G.; Zhou, J.; Wang, G. Systematic Review on Learning-based Spectral CT. arXiv 2023, arXiv:2304.07588. [Google Scholar] [CrossRef] [PubMed]







Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Prohaszka, T.; Neumann, L.; Haltmeier, M. Derivative-Free Iterative One-Step Reconstruction for Multispectral CT. J. Imaging 2024, 10, 98. https://doi.org/10.3390/jimaging10050098
Prohaszka T, Neumann L, Haltmeier M. Derivative-Free Iterative One-Step Reconstruction for Multispectral CT. Journal of Imaging. 2024; 10(5):98. https://doi.org/10.3390/jimaging10050098
Chicago/Turabian StyleProhaszka, Thomas, Lukas Neumann, and Markus Haltmeier. 2024. "Derivative-Free Iterative One-Step Reconstruction for Multispectral CT" Journal of Imaging 10, no. 5: 98. https://doi.org/10.3390/jimaging10050098
APA StyleProhaszka, T., Neumann, L., & Haltmeier, M. (2024). Derivative-Free Iterative One-Step Reconstruction for Multispectral CT. Journal of Imaging, 10(5), 98. https://doi.org/10.3390/jimaging10050098