Handwritten Devanagari Character Recognition Using Layer-Wise Training of Deep Convolutional Neural Networks and Adaptive Gradient Methods


Abstract
:1. Introduction
- This work is the first to apply the deep learning approach on the database created by ISI, Kolkata. The main contribution is a rigorous evaluation of various DCNN models.
- Deep learning is a rapidly developing field, which is bringing new techniques that can significantly ameliorate the performance of DCNNs. Since these techniques have been published in the last few years, there is even a validation process for establishing their cross-domain utility. We explored the role of adaptive gradient methods in deep convolutional neural network models, and we showed the variation in recognition accuracy.
- The proposed handwritten Devanagari character recognition system achieves a high classification accuracy, surpassing existing approaches in literature mainly regarding recognition accuracy.
- A layer-wise technique of DCNN technique is proposed to achieve the highest recognition accuracy and also get a faster convergence rate.
2. Previous Work
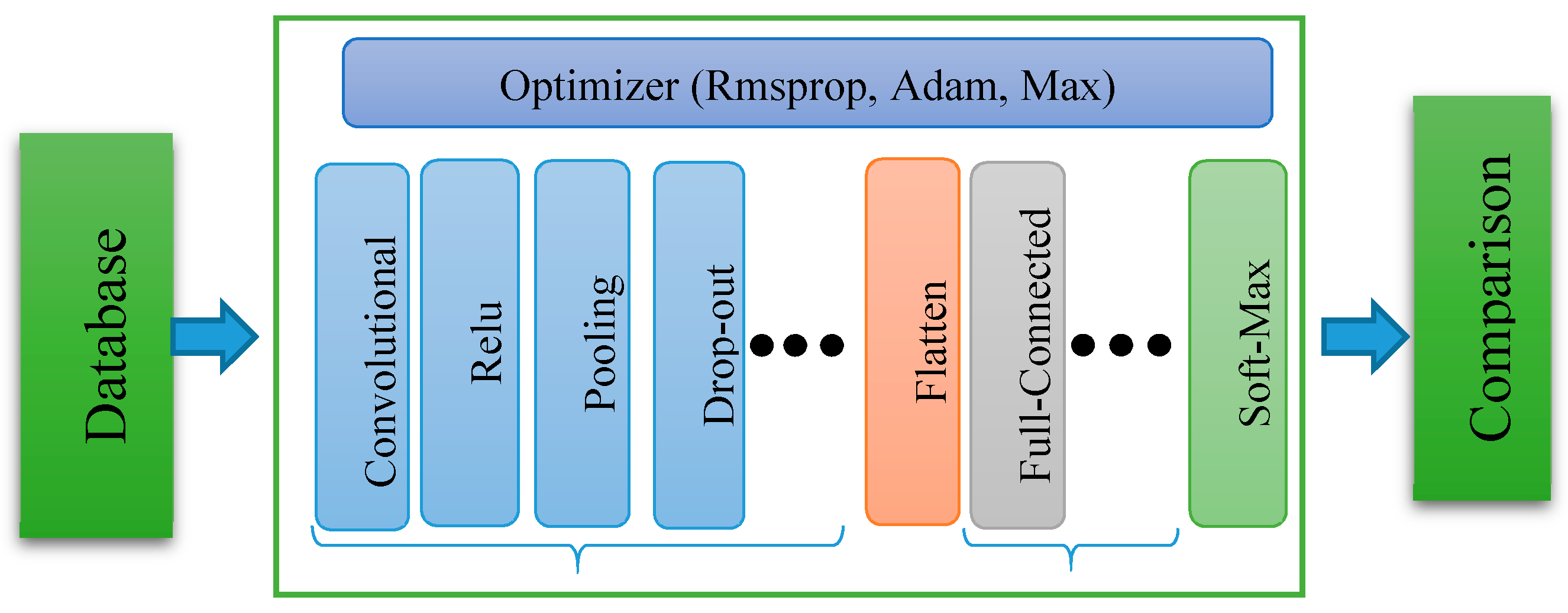
3. Deep Convolutional Neural Networks (DCNN)
3.1. DCNN Notation
- xINy: An input layer where x represents the width and height of the image and y represent the number of channels.
- xCy: A convolutional layer where x represents a number of kernels and y represents the size of kernel y*y.
- xPy: A pooling layer where x represents pooling size x*x, and y represents pooling stride.
- Relu: Represents rectified layer unit.
- xDrop: A dropout layer where x represents the probability value.
- xFC: A fully connected or dense layer where x represents a number of neurons.
- xOU: A output layer where x represents classes or labels.
3.2. Different Adaptive Gradient Methods
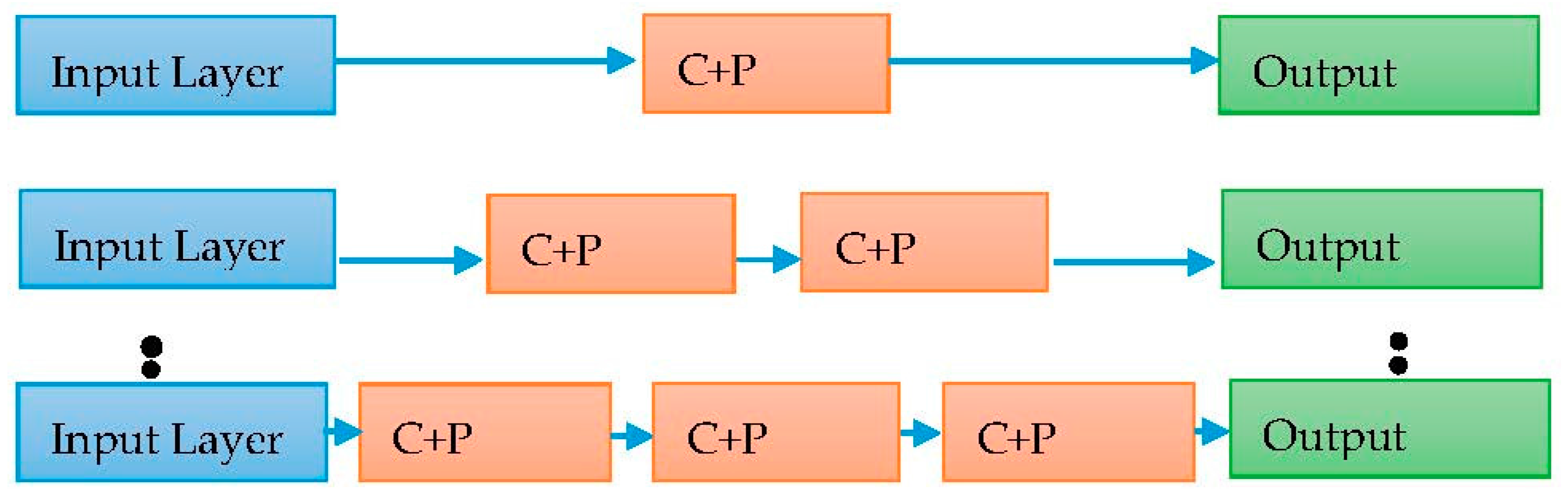
3.3. Layerwise Training DCNN Model
| Algorithm 1. Layer wise training of deep convolutional neural network |
| INPUT: Model, Ƭ, ȶ, α1, α2, ȵ \\ Ƭ = (TrainData), ȶ = (TestData), |
| OUTPUT: TM \\ TrainedModel |
| Begin \\ Add first layer of convolutional layer and pooling layer |
| Model.add (xCy, Ƭ, Relu) |
| Model.add (xPy) |
| Model.add (xFC) |
| Model.add (xOU) |
| Model.compile (optimizer) |
| Model.fit (Ƭ, ȶ, α1) |
| for all I := 1: ȵ-1 step 1 do |
| \\ Remove the last two layers (FC & OU) of existing model to add next layer of convolutional and pooling |
| Model.layer.pop() |
| Model.layer.pop() |
| Model.add (xCy, Ƭ, Relu) |
| Model.add (xPy) |
| \\ Again added fully connected and output layer |
| Model.add (xFC) |
| Model.add (xOU) |
| Model.compile (optimizer) |
| Model.fit (Ƭ, ȶ, α1) \\ Trained the model with high learning rate |
| end for |
| Model.fit (Ƭ, ȶ, α2) \\ Perform fine tuning with low learning rate |
| end |
4. Experiments and Discussions
4.1. Experimental Setup
4.2. Results
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Jürgen, S. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar]
- Ciregan, D.; Meier, U.; Schmidhuber, J. Multi-column deep neural networks for image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–8 December 2012. [Google Scholar]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Navneet, D.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the CVPR 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005; Volume 1. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Surinta, O.; Karaaba, M.F.; Schomaker, L.R.B.; Wiering, M.A. Recognition of handwritten characters using local gradient feature descriptors. Eng. Appl. Artif. Intell. 2015, 45, 405–414. [Google Scholar] [CrossRef]
- Ojala, T.; Pietikäinen, M.; Harwood, D. A comparative study of texture measures with classification based on featured distributions. Pattern Recognit. 1996, 29, 51–59. [Google Scholar] [CrossRef]
- Bay, H.; Tuytelaars, T.; van Gool, L. Surf: Speeded up robust features. In Proceedings of the 9th European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; pp. 404–417. [Google Scholar]
- Wang, X.; Paliwal, K.K. Feature extraction and dimensionality reduction algorithms and their applications in vowel recognition. Pattern Recognit. 2003, 36, 2429–2439. [Google Scholar] [CrossRef]
- Zeiler, M.D.; Rob, F. Visualizing and understanding convolutional networks. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014. [Google Scholar]
- Simonyan, K.; Andrew, Z. Very deep convolutional networks for large-scale image recognition. arXiv, 2004; arXiv:1409.1556. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Zisserman, A. Spatial transformer networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 11–12 December 2015. [Google Scholar]
- Cireşan, D.; Ueli, M. Multi-column deep neural networks for offline handwritten Chinese character classification. In Proceedings of the 2015 International Joint Conference on Neural Networks (IJCNN), Killarney, Ireland, 12–17 July 2015. [Google Scholar]
- Sarkhel, R.; Das, N.; Das, A.; Kundu, M.; Nasipuri, M. A Multi-scale Deep Quad Tree Based Feature Extraction Method for the Recognition of Isolated Handwritten Characters of popular Indic Scripts. Pattern Recognit. 2017, 71, 78–93. [Google Scholar] [CrossRef]
- Ahranjany, S.S.; Razzazi, F.; Ghassemian, M.H. A very high accuracy handwritten character recognition system for Farsi/Arabic digits using Convolutional Neural Networks. In Proceedings of the 2010 IEEE Fifth International Conference on Bio-Inspired Computing: Theories and Applications (BIC-TA), Changsha, China, 23–26 September 2010. [Google Scholar]
- Sethi, I.K.; Chatterjee, B. Machine Recognition of Hand-printed Devnagri Numerals. IETE J. Res. 1976, 22, 532–535. [Google Scholar] [CrossRef]
- Sharma, N.; Pal, U.; Kimura, F.; Pal, S. Recognition of off-line handwritten devnagari characters using quadratic classifier. In Computer Vision, Graphics and Image Processing; Springer: Berlin/Heidelberg, Germany, 2006; pp. 805–816. [Google Scholar]
- Deshpande, P.S.; Malik, L.; Arora, S. Fine Classification & Recognition of Hand Written Devnagari Characters with Regular Expressions & Minimum Edit Distance Method. JCP 2008, 3, 11–17. [Google Scholar]
- Arora, S.; Bhatcharjee, D.; Nasipuri, M.; Malik, L. A two stage classification approach for handwritten Devnagari characters. In Proceedings of the International Conference on Computational Intelligence and Multimedia Applications, Sivakasi, Tamil Nadu, India, 13–15 December 2007; Volume 2, pp. 399–403. [Google Scholar]
- Arora, S.; Bhattacharjee, D.; Nasipuri, M.; Basu, D.K.; Kundu, M.; Malik, L. Study of different features on handwritten Devnagari character. In Proceedings of the 2009 2nd International Conference on Emerging Trends in Engineering and Technology (ICETET), Nagpur, India, 16–18 December 2009; pp. 929–933. [Google Scholar]
- Hanmandlu, M.; Murthy, O.V.R.; Madasu, V.K. Fuzzy Model based recognition of handwritten Hindi characters. In Proceedings of the 9th Biennial Conference of the Australian Pattern Recognition Society on Digital Image Computing Techniques and Applications, Glenelg, Australia, 3–5 December 2007; pp. 454–461. [Google Scholar]
- Arora, S.; Bhattacharjee, D.; Nasipuri, M.; Basu, D.K.; Kundu, M. Recognition of non-compound handwritten devnagari characters using a combination of mlp and minimum edit distance. arXiv, 2010; arXiv:1006.5908. [Google Scholar]
- Kumar, S. Performance comparison of features on Devanagari handprinted dataset. Int. J. Recent Trends 2009, 1, 33–37. [Google Scholar]
- Pal, U.; Sharma, N.; Wakabayashi, T.; Kimura, F. Off-line handwritten character recognition of devnagari script. In Proceedings of the Ninth International Conference on Document Analysis and Recognition, Curitiba, Parana, Brazil, 23–26 September 2007; Volume 1, pp. 496–500. [Google Scholar]
- Pal, U.; Wakabayashi, T.; Kimura, F. Comparative study of Devnagari handwritten character recognition using different feature and classifiers. In Proceedings of the 10th International Conference on Document Analysis and Recognition, Catalonia, Spain, 26–29 July 2009; pp. 1111–1115. [Google Scholar]
- Duchi, J.; Hazan, E.; Singer, Y. Adaptive subgradient methods for online learning and stochastic optimization. J. Mach. Learn. Res. 2011, 12, 2121–2159. [Google Scholar]
- Zeiler, M.D. ADADELTA: an adaptive learning rate method. arXiv, 2012; arXiv:1212.5701. [Google Scholar]
- Hinton, G. Slide 6, Lecture Slide 6 of Geoffrey Hinton’s Course. Available online: http://www.cs.toronto.edu/∼tijmen/csc321/slides/lecture_slides_lec6.pdf (accessed on 19 July 2017).
- Kingma, D.; Jimmy, B. Adam: A method for stochastic optimization. arXiv, 2014; arXiv:1412.6980. [Google Scholar]
- Dongre, V.J.; Vijay, H.M. Devnagari handwritten numeral recognition using geometric features and statistical combination classifier. arXiv, 2013; arXiv:1310.5619. [Google Scholar]
- Jangid, M.; Sumit, S. Gradient local auto-correlation for handwritten Devanagari character recognition. In Proceedings of the 2014 International Conference on High Performance Computing and Applications (ICHPCA), Bhubaneswar, India, 22–24 December 2014. [Google Scholar]
- Jangid, M.; Sumit, S. Similar handwritten Devanagari character recognition by critical region estimation. In Proceedings of the 2016 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Jaipur, India, 21–24 September 2016. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
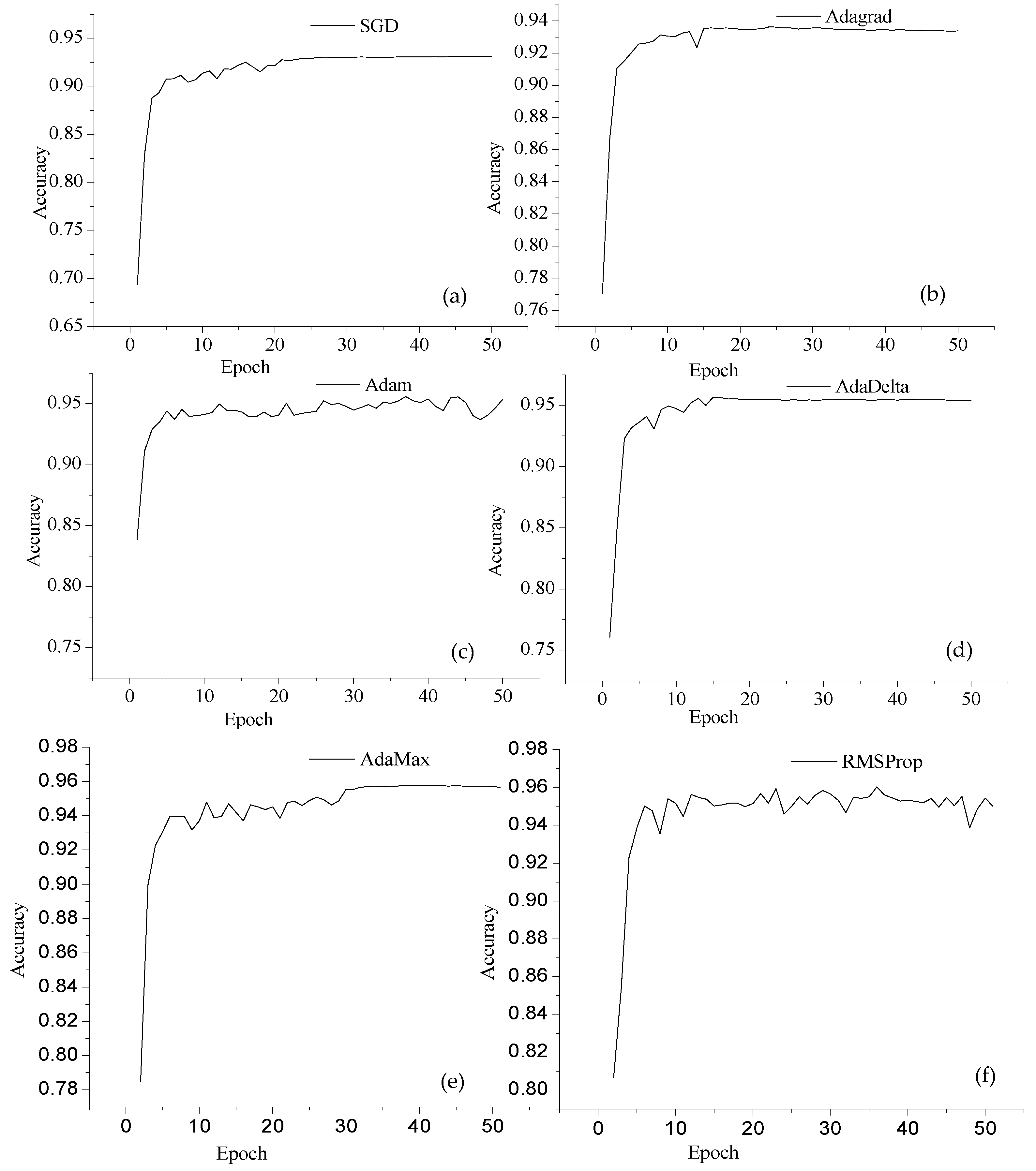{kind=link}
| Network | Model Architectures |
|---|---|
| NA-1 | 64IN64-64C2-Relu-4P2-500FC-47OU |
| NA-2 | 64IN64-64C2-Relu-4P2-1000FC-47OU |
| NA-3 | 64IN64-32C2-Relu-4P2-32C2-Relu-4P2-1000FC-47OU |
| NA-4 | 64IN64-64C2-Relu-4P2-64C2-Relu-4P2-1000FC-47OU |
| NA-5 | 64IN64-32C2-Relu-4P2-32C2-Relu-4P2-32C2-Relu-4P2-1000FC-47OU |
| NA-6 | 64IN64-64C2-Relu-4P2-64C2-Relu-4P2-64C2-Relu-4P2-1000FC-47OU |
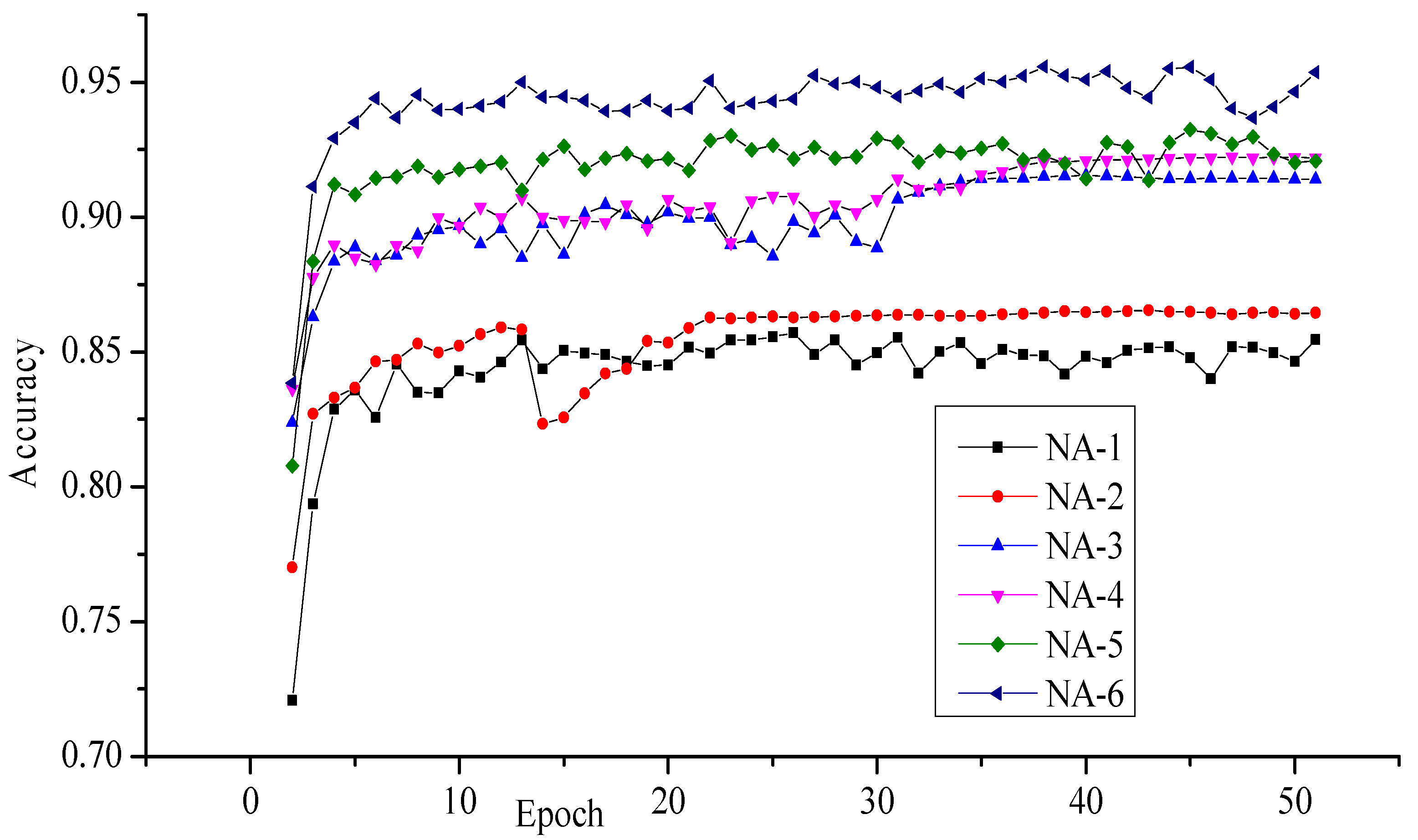
| Recognition Accuracy | Different Network Architectures | |||||
|---|---|---|---|---|---|---|
| NA-1 | NA-2 | NA-3 | NA-4 | NA-5 | NA-6 | |
| Maximum | 0.8571 | 0.8654 | 0.9153 | 0.9224 | 0.9324 | 0.9558 |
| Minimum | 0.7208 | 0.7701 | 0.8237 | 0.8363 | 0.8077 | 0.8385 |
| Average | 0.8436 | 0.8549 | 0.9000 | 0.9058 | 0.9190 | 0.9427 |
| Std. Deviation | 0.0204 | 0.0169 | 0.0165 | 0.0158 | 0.0178 | 0.0168 |
| Network Architectures | Layer Type | Layer Size | Trainable Parameters | Total Parameters |
|---|---|---|---|---|
| NA-1 | Conv1 layer | 64 × 64 × 64 | 1088 | 34,873,135 |
| Dense layer | 500 | 34,848,500 | ||
| Output layer | 47 | 23,547 | ||
| NA-2 | Conv1 layer | 64 × 64 × 64 | 1088 | 61,553,135 |
| Dense layer | 1000 | 61,505,000 | ||
| Output layer | 47 | 47,047 | ||
| NA-3 | Conv1 layer | 32 × 64 × 64 | 544 | 7,265,007 |
| Conv2 layer | 32 × 33 × 33 | 16,416 | ||
| Dense layer | 1000 | 7,201,000 | ||
| Output layer | 47 | 47,047 | ||
| NA-4 | Conv1 layer | 64 × 64 × 64 | 1088 | 14,514,735 |
| Conv2 layer | 64 × 33 × 33 | 65,600 | ||
| Dense layer | 1000 | 14,401,000 | ||
| Output layer | 47 | 47,047 | ||
| NA-5 | Conv1 layer | 32 × 64 × 64 | 544 | 1,649,423 |
| Conv2 layer | 32 × 33 × 33 | 16,416 | ||
| Conv3 layer | 32 × 17 × 17 | 16,416 | ||
| Dense layer | 1000 | 1,569,000 | ||
| Output layer | 47 | 47,047 | ||
| NA-6 | Conv1 layer | 64 × 64 × 64 | 1088 | 3,316,335 |
| Conv2 layer | 64 × 33 × 33 | 65,600 | ||
| Conv3 layer | 64 × 17 × 17 | 65,600 | ||
| Dense layer | 1000 | 3,137,000 | ||
| Output layer | 47 | 47,047 |
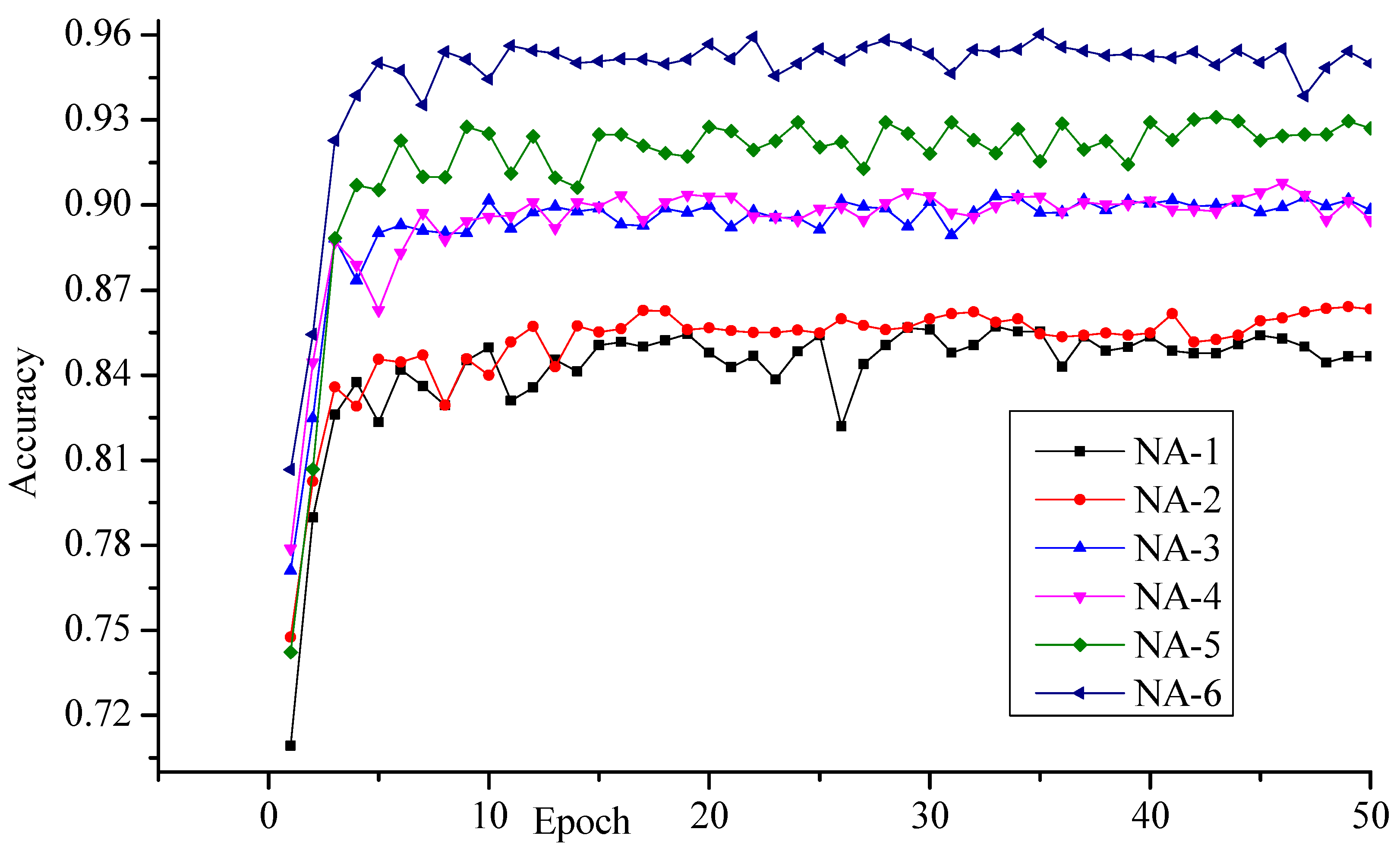
| Recognition Accuracy | Different Network Architectures | |||||
|---|---|---|---|---|---|---|
| NA-1 | NA-2 | NA-3 | NA-4 | NA-5 | NA-6 | |
| Maximum | 0.8572 | 0.8641 | 0.903 | 0.9079 | 0.9311 | 0.9602 |
| Minimum | 0.7093 | 0.7475 | 0.7711 | 0.7788 | 0.7422 | 0.8067 |
| Average | 0.8383 | 0.8501 | 0.8927 | 0.8941 | 0.9150 | 0.9463 |
| Std. Deviation | 0.0321 | 0.0232 | 0.0210 | 0.0197 | 0.0308 | 0.0252 |
| Recognition Accuracy | Different Optimizers | |||||
|---|---|---|---|---|---|---|
| SGD | Adagrad | Adam | AdaDelta | AdaMax | RMSProp | |
| Maximum | 0.931 | 0.9364 | 0.9558 | 0.9565 | 0.9579 | 0.9602 |
| Minimum | 0.6933 | 0.7703 | 0.7585 | 0.7605 | 0.7851 | 0.8067 |
| Mean | 0.9168 | 0.9280 | 0.9411 | 0.9457 | 0.9448 | 0.9463 |
| Std. Deviation | 0.0365 | 0.0252 | 0.0274 | 0.0311 | 0.0256 | 0.0252 |
| Database | No. of Samples | Recognition Accuracy | |
|---|---|---|---|
| DCNN | Layer-Wise DCNN | ||
| ISIDCHAR | 36,172 | 96.02% | 97.30% |
| V2DMDCHAR | 20,305 | 96.45% | 97.65% |
| ISIDCHAR+V2DMDCHAR | 56,477 | 96.53% | 98.00% |
| S. No. | Accuracy Obtained | Feature; Classifier | Method Proposed by | Data Size |
|---|---|---|---|---|
| 1 | 95.19 | Gradient; MIL | U. Pal [26] | 36,172 |
| 2 | 95.24 | GLAC; SVM | M. Jangid [32] | 36,172 |
| 3 | 96.58 | Masking, SVM | M. Jangid [33] | 36,172 |
| 4 | 96.45 | DCNN | Proposed work | 36,172 |
| 5 | 97.65 | SL-DCNN | Proposed work | 36,172 |
| 6 | 98 | SL-DCNN | Proposed work | 56,477 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jangid, M.; Srivastava, S. Handwritten Devanagari Character Recognition Using Layer-Wise Training of Deep Convolutional Neural Networks and Adaptive Gradient Methods. J. Imaging 2018, 4, 41. https://doi.org/10.3390/jimaging4020041
Jangid M, Srivastava S. Handwritten Devanagari Character Recognition Using Layer-Wise Training of Deep Convolutional Neural Networks and Adaptive Gradient Methods. Journal of Imaging. 2018; 4(2):41. https://doi.org/10.3390/jimaging4020041
Chicago/Turabian StyleJangid, Mahesh, and Sumit Srivastava. 2018. "Handwritten Devanagari Character Recognition Using Layer-Wise Training of Deep Convolutional Neural Networks and Adaptive Gradient Methods" Journal of Imaging 4, no. 2: 41. https://doi.org/10.3390/jimaging4020041
APA StyleJangid, M., & Srivastava, S. (2018). Handwritten Devanagari Character Recognition Using Layer-Wise Training of Deep Convolutional Neural Networks and Adaptive Gradient Methods. Journal of Imaging, 4(2), 41. https://doi.org/10.3390/jimaging4020041