Learning Descriptors Invariance through Equivalence Relations within Manifold: A New Approach to Expression Invariant 3D Face Recognition


Abstract
:1. Introduction
2. The Literature Review
3. The Proposed Approach
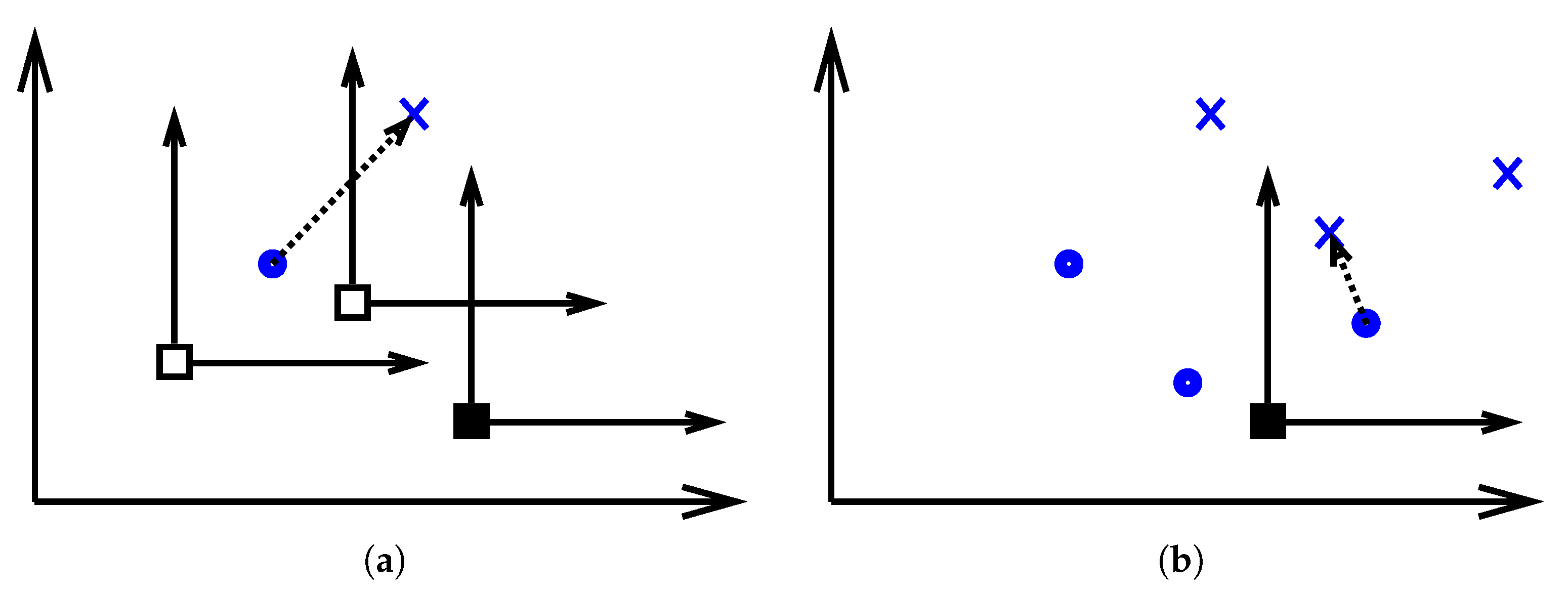
3.1. Conceptual Analysis
3.2. The Correspondence of the Descriptors
3.3. The Construction of the Embedded Graph
3.4. The Heuristic Graph Search
3.5. The Dissimilarity Measure between Ensembles
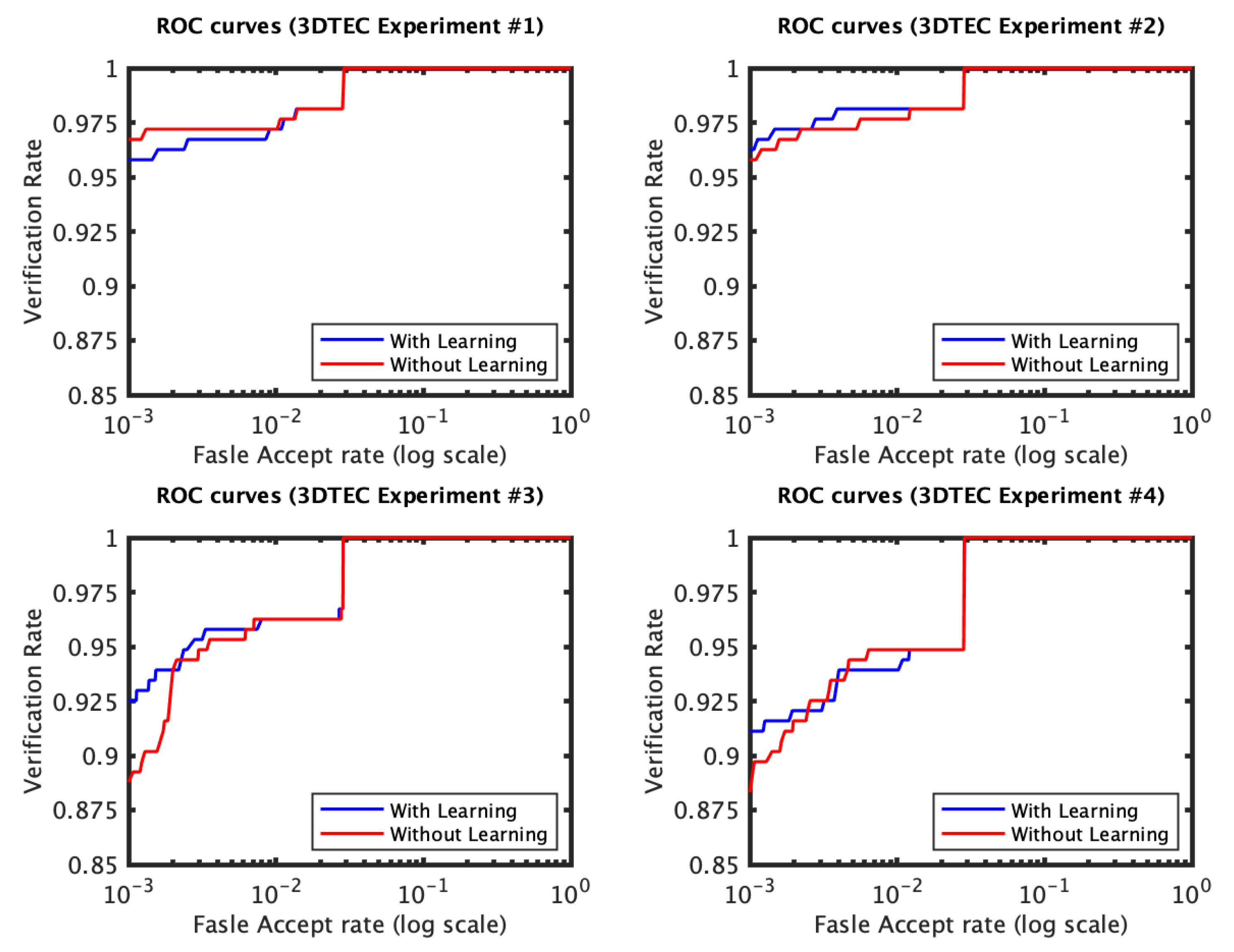
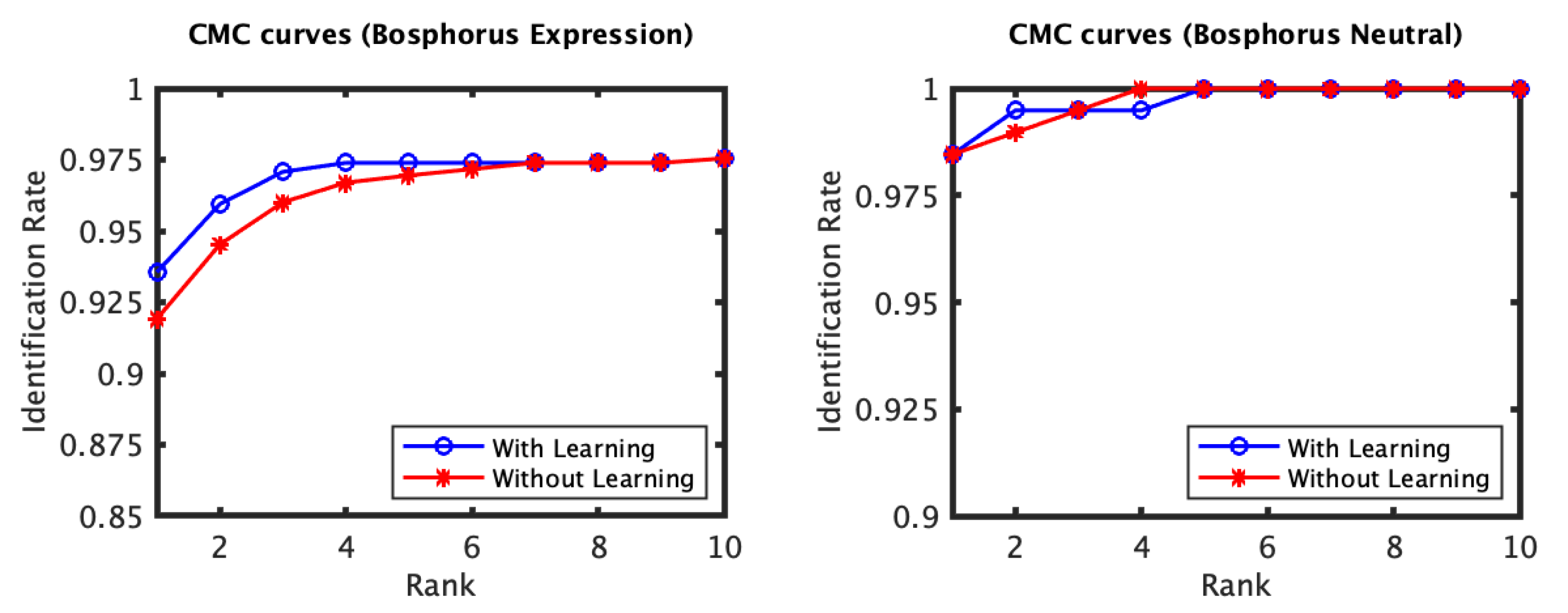
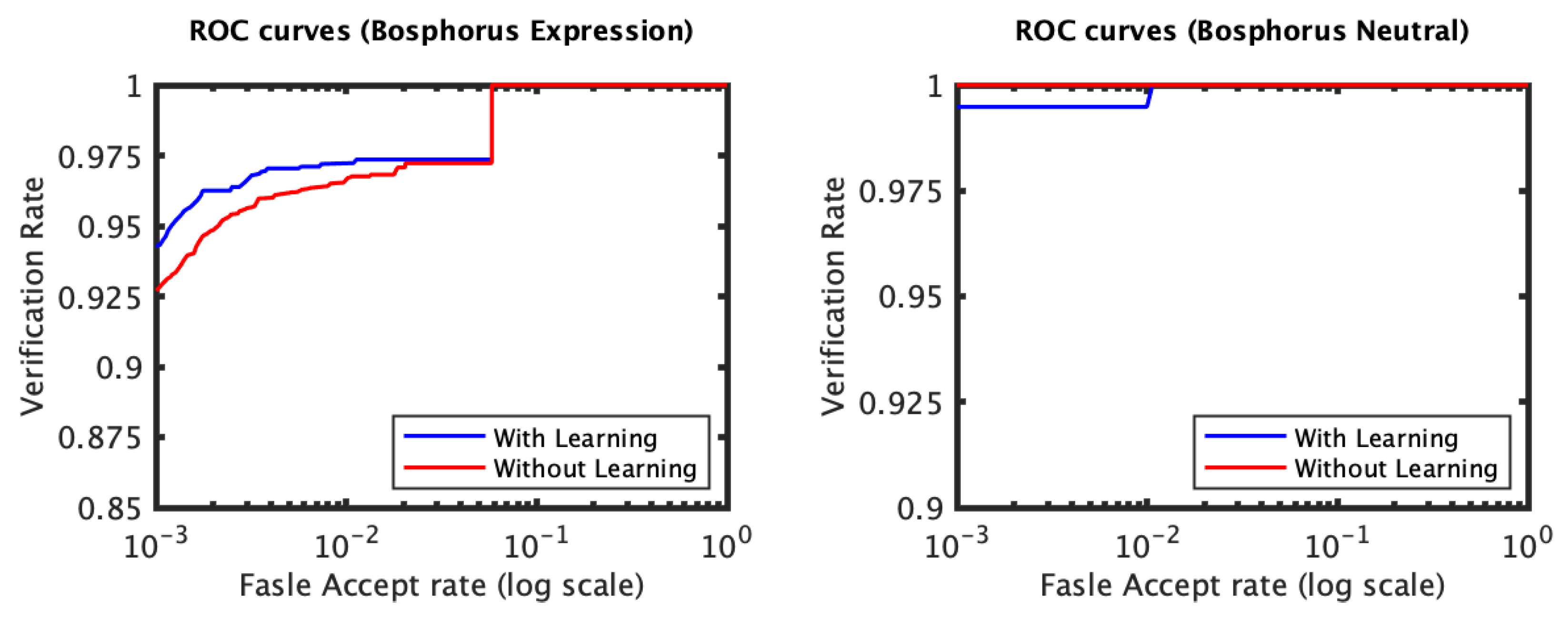
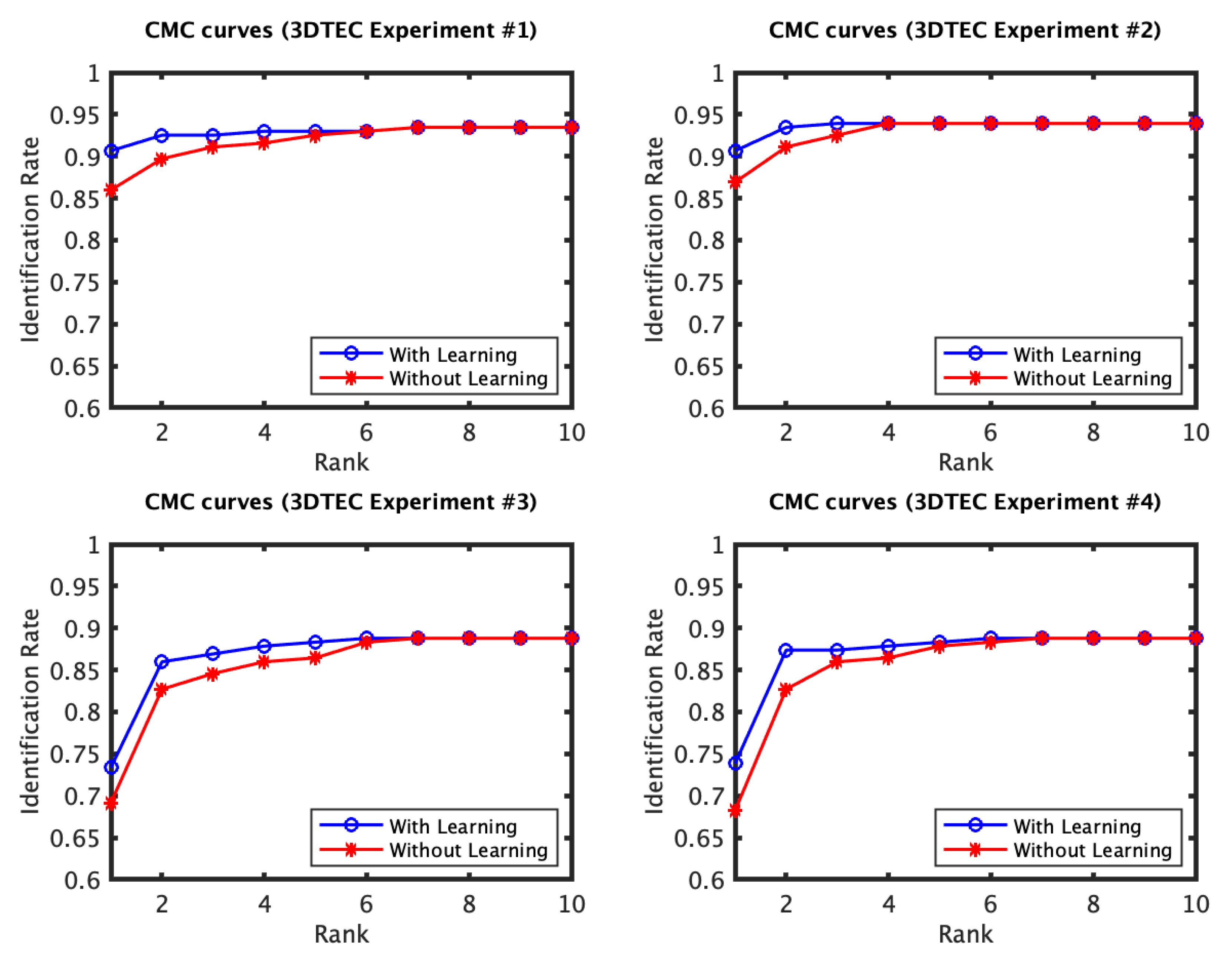
4. Experiments
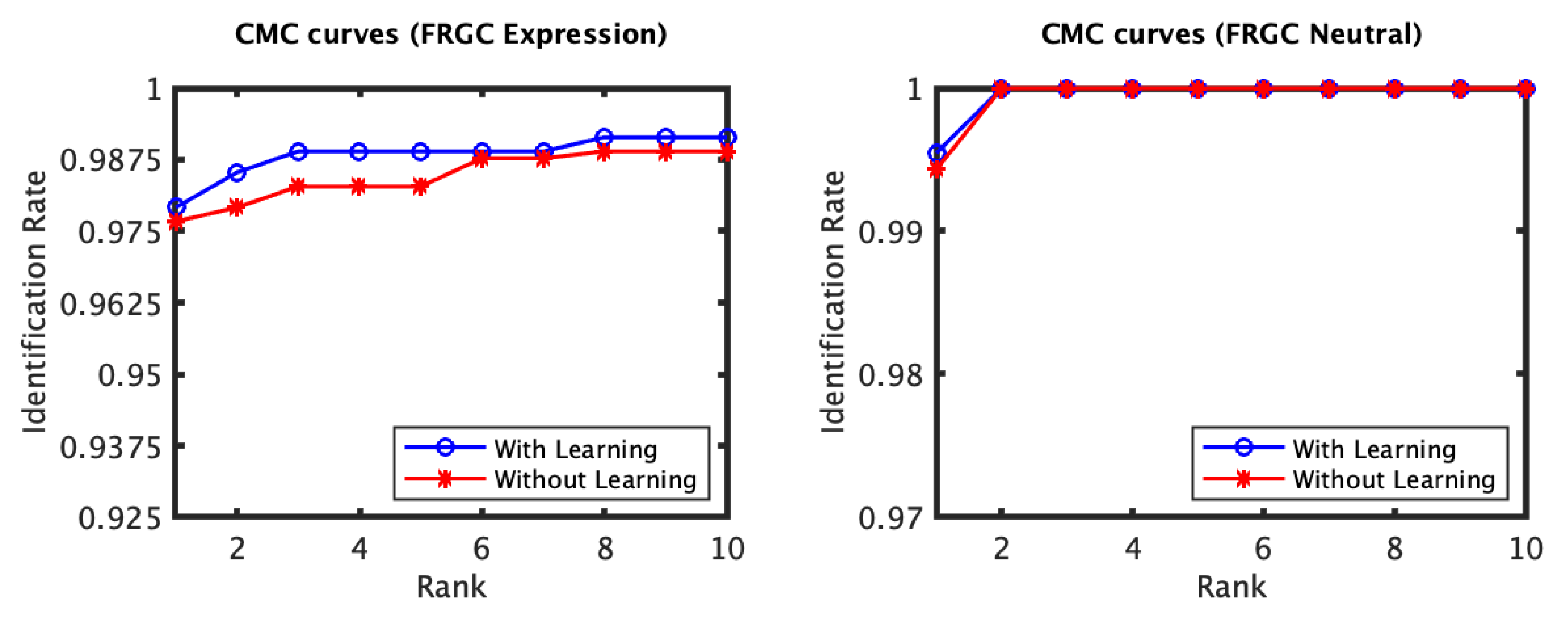
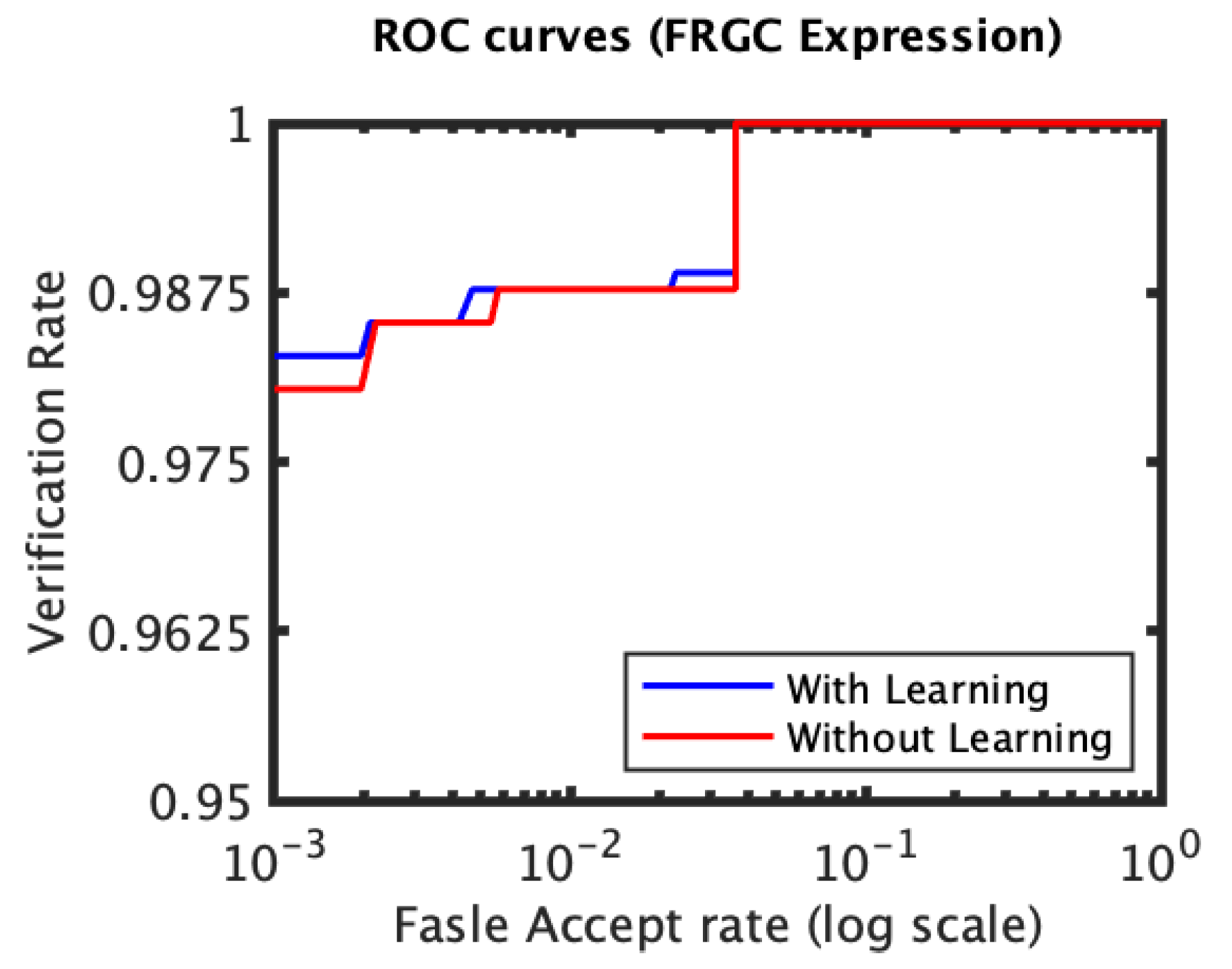
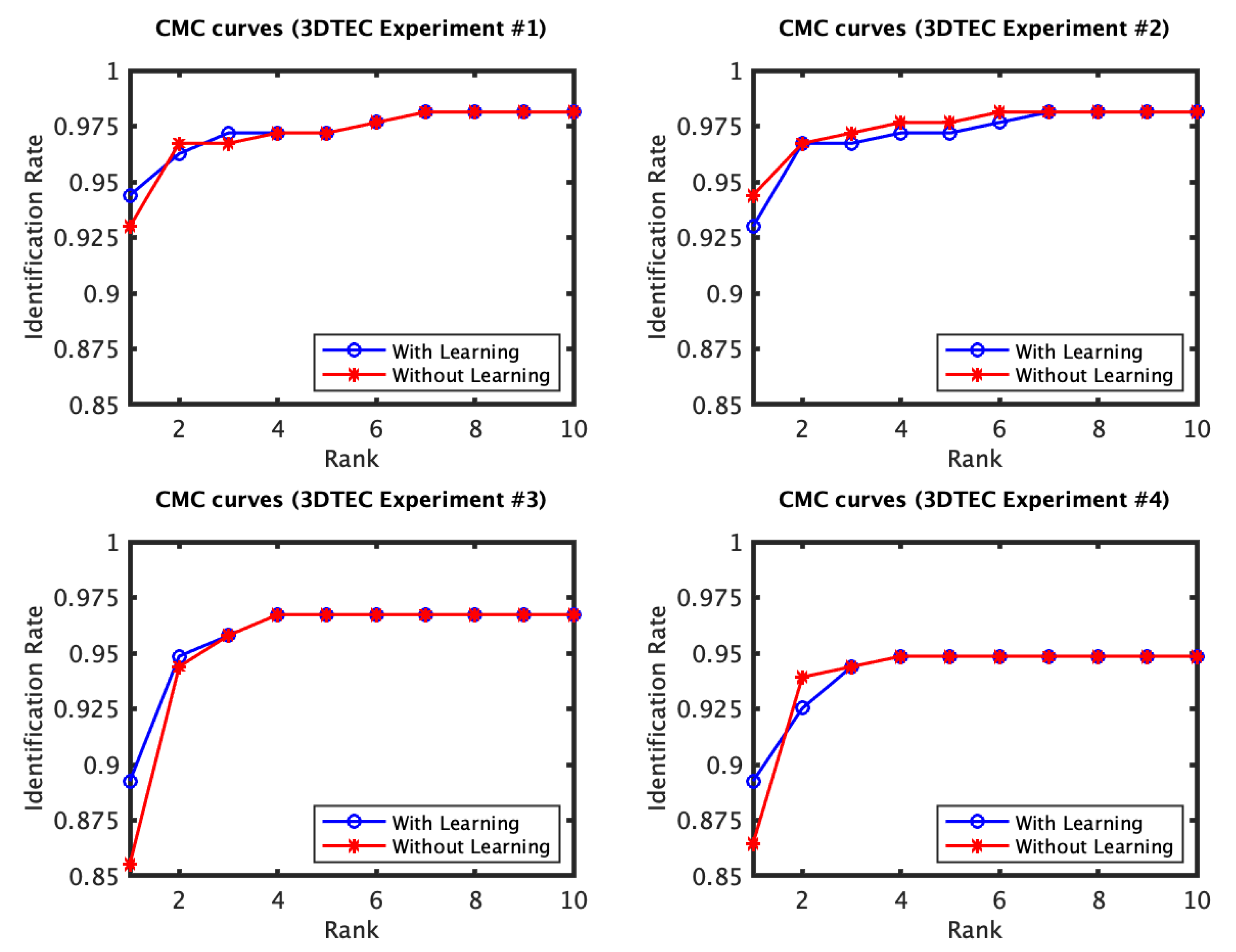
4.1. RAIK Descriptor Based Experiments
4.2. Local 3D PCA Descriptor Based Experiments
5. Conclusions
Funding
Conflicts of Interest
References
- Lowe, D.G. Object recognition from local scale-invariant features. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–27 September 1999; IEEE: New York, NY, USA, 1999; Volume 2, pp. 1150–1157. [Google Scholar]
- Belongie, S.; Malik, J.; Puzicha, J. Shape matching and object recognition using shape contexts. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 509–522. [Google Scholar] [CrossRef] [Green Version]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the 2011 IEEE International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011; pp. 2564–2571. [Google Scholar]
- Mian, A.S.; Bennamoun, M.; Owens, R. Keypoint detection and local feature matching for textured 3D face recognition. Int. J. Comput. Vis. 2008, 79, 1–12. [Google Scholar] [CrossRef]
- Al-Osaimi, F.; Bennamoun, M.; Mian, A. Interest-point based face recognition from range images. In Proceedings of the British Machine Vision Conference, Warwick, UK, 10–13 September 2007. [Google Scholar]
- Al-Osaimi, F.R. A novel multi-purpose matching representation of local 3D surfaces: A rotationally invariant, efficient, and highly discriminative approach with an adjustable sensitivity. IEEE Trans. Image Process. 2015, 25, 658–672. [Google Scholar] [CrossRef] [PubMed]
- Mian, A.S.; Bennamoun, M.; Owens, R. An efficient multimodal 2D-3D hybrid approach to automatic face recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 1927–1943. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chang, K.J.; Bowyer, K.W.; Flynn, P.J. Effects on facial expression in 3D face recognition. In Proceedings of the Defense and Security, International Society for Optics and Photonics, Orlando, FL, USA, 29–30 March 2005; pp. 132–143. [Google Scholar]
- Chang, K.I.; Bowyer, W.; Flynn, P.J. Multiple nose region matching for 3D face recognition under varying facial expression. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 1695–1700. [Google Scholar] [CrossRef] [PubMed]
- Faltemier, T.C.; Bowyer, K.W.; Flynn, P.J. A region ensemble for 3-D face recognition. IEEE Trans. Inf. Forensics Secur. 2008, 3, 62–73. [Google Scholar] [CrossRef]
- Bronstein, A.M.; Bronstein, M.M.; Kimmel, R. Expression-invariant 3D face recognition. In Proceedings of the Audio-and Video-Based Biometric Person Authentication, Guildford, UK, 9–11 June 2003; Springer: Berlin/Heidelberg, Germany, 2003; pp. 62–70. [Google Scholar]
- Drira, H.; Ben Amor, B.; Srivastava, A.; Daoudi, M.; Slama, R. 3D face recognition under expressions, occlusions, and pose variations. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 2270–2283. [Google Scholar] [CrossRef] [Green Version]
- Smeets, D.; Hermans, J.; Vandermeulen, D.; Suetens, P. Isometric deformation invariant 3D shape recognition. Pattern Recognit. 2012, 45, 2817–2831. [Google Scholar] [CrossRef]
- Berretti, S.; Del Bimbo, A.; Pala, P. 3D face recognition using isogeodesic stripes. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 2162–2177. [Google Scholar] [CrossRef] [Green Version]
- Metaxas, D.N.; Kakadiaris, I.A. Elastically adaptive deformable models. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 1310–1321. [Google Scholar] [CrossRef]
- Murtuza, M.N.; Lu, Y.; Karampatziakis, N.; Theoharis, T. Three-Dimensional Face Recognition in the Presence of Facial Expressions: An Annotated Deformable Model Approach. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 640–649. [Google Scholar]
- Al-Osaimi, F.; Bennamoun, M.; Mian, A. An expression deformation approach to non-rigid 3D face recognition. Int. J. Comput. Vis. 2009, 81, 302–316. [Google Scholar] [CrossRef] [Green Version]
- Maalej, A.; Amor, B.B.; Daoudi, M.; Srivastava, A.; Berretti, S. Shape analysis of local facial patches for 3D facial expression recognition. Pattern Recognit. 2011, 44, 1581–1589. [Google Scholar] [CrossRef] [Green Version]
- Gökberk, B.; İrfanoğlu, M.O.; Akarun, L. 3D shape-based face representation and feature extraction for face recognition. Image Vis. Comput. 2006, 24, 857–869. [Google Scholar] [CrossRef]
- Lu, X.; Jain, A.K. Multimodal Facial Feature Extraction for Automatic 3D Face Recognition; Tech. Rep. MSU-CSE-05-22; Department of Computer Science, Michigan State University: East Lansing, MI, USA, 2005. [Google Scholar]
- Xu, C.; Li, S.; Tan, T.; Quan, L. Automatic 3D face recognition from depth and intensity Gabor features. Pattern Recognit. 2009, 42, 1895–1905. [Google Scholar] [CrossRef]
- Tan, X.; Triggs, B. Fusing Gabor and LBP feature sets for kernel-based face recognition. In Analysis and Modeling of Faces and Gestures; Springer: Berlin/Heidelberg, Germany, 2007; pp. 235–249. [Google Scholar]
- Wang, Y.; Liu, J.; Tang, X. Robust 3D face recognition by local shape difference boosting. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1858–1870. [Google Scholar] [CrossRef] [Green Version]
- Singh, C.; Mittal, N.; Walia, E. Face recognition using Zernike and complex Zernike moment features. Pattern Recognit. Image Anal. 2011, 21, 71–81. [Google Scholar] [CrossRef]
- Turk, M.; Pentland, A. Eigenfaces for recognition. J. Cogn. Neurosci. 1991, 3, 71–86. [Google Scholar] [CrossRef]
- Belhumeur, P.N.; Hespanha, J.P.; Kriegman, D. Eigenfaces vs. fisherfaces: Recognition using class specific linear projection. IEEE Trans. Pattern Anal. Mach. Intell. 1997, 19, 711–720. [Google Scholar] [CrossRef] [Green Version]
- Blanz, V.; Vetter, T. Face recognition based on fitting a 3D morphable model. IEEE Trans. Pattern Anal. Mach. Intell. 2003, 25, 1063–1074. [Google Scholar] [CrossRef] [Green Version]
- Wang, X.; Tang, X. A unified framework for subspace face recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2004, 26, 1222–1228. [Google Scholar] [CrossRef] [PubMed]
- Russ, T.; Boehnen, C.; Peters, T. 3d face recognition using 3d alignment for pca. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, New York, NY, USA, 17–22 June 2006; Volume 2, pp. 1391–1398. [Google Scholar]
- Draper, B.A.; Baek, K.; Bartlett, M.S.; Beveridge, J.R. Recognizing faces with PCA and ICA. Comput. Vis. Image Underst. 2003, 91, 115–137. [Google Scholar] [CrossRef]
- Harguess, J.; Aggarwal, J. A case for the average-half-face in 2D and 3D for face recognition. In Proceedings of the 2009 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Miami, FL, USA, 20–25 June 2009; pp. 7–12. [Google Scholar]
- Liu, C.; Wechsler, H. Independent component analysis of Gabor features for face recognition. IEEE Trans. Neural Netw. 2003, 14, 919–928. [Google Scholar] [PubMed] [Green Version]
- Verleysen, M.; François, D. The curse of dimensionality in data mining and time series prediction. In Computational Intelligence and Bioinspired Systems; Springer: Berlin/Heidelberg, Germany, 2005; pp. 758–770. [Google Scholar]
- Jain, A.; Zongker, D. Feature selection: Evaluation, application, and small sample performance. IEEE Trans. Pattern Anal. Mach. Intell. 1997, 19, 153–158. [Google Scholar] [CrossRef] [Green Version]
- Paalanen, P.; Kamarainen, J.K.; Ilonen, J.; Kälviäinen, H. Feature representation and discrimination based on Gaussian mixture model probability densities—Practices and algorithms. Pattern Recognit. 2006, 39, 1346–1358. [Google Scholar] [CrossRef]
- Raudys, S.J.; Jain, A.K. Small sample size effects in statistical pattern recognition: Recommendations for practitioners. IEEE Trans. Pattern Anal. Mach. Intell. 1991, 13, 252–264. [Google Scholar] [CrossRef]
- Schölkopf, B.; Smola, A.; Müller, K.R. Nonlinear component analysis as a kernel eigenvalue problem. Neural Comput. 1998, 10, 1299–1319. [Google Scholar] [CrossRef] [Green Version]
- Hotta, K. Robust face recognition under partial occlusion based on support vector machine with local Gaussian summation kernel. Image Vis. Comput. 2008, 26, 1490–1498. [Google Scholar] [CrossRef]
- Ksantini, R.; Boufama, B.S.; Ahmad, I.S. A new KSVM+ KFD model for improved classification and face recognition. J. Multimed. 2011, 6, 39–47. [Google Scholar]
- Yang, M.H. Kernel eigenfaces vs. kernel fisherfaces: Face recognition using kernel methods. In Proceedings of the 2013 10th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG), Shanghai, China, 22–26 April 2013; p. 0215. [Google Scholar]
- Balasubramanian, V.N.; Ye, J.; Panchanathan, S. Biased manifold embedding: A framework for person-independent head pose estimation. In Proceedings of the 2007 CVPR’07 IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–7. [Google Scholar]
- Chang, Y.; Hu, C.; Feris, R.; Turk, M. Manifold based analysis of facial expression. Image Vis. Comput. 2006, 24, 605–614. [Google Scholar] [CrossRef]
- Zhang, T.; Yang, J.; Zhao, D.; Ge, X. Linear local tangent space alignment and application to face recognition. Neurocomputing 2007, 70, 1547–1553. [Google Scholar] [CrossRef]
- Lin, T.; Zha, H.; Lee, S.U. Riemannian manifold learning for nonlinear dimensionality reduction. In Computer Vision—ECCV 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 44–55. [Google Scholar]
- Pan, Y.; Ge, S.S.; Al Mamun, A. Weighted locally linear embedding for dimension reduction. Pattern Recognit. 2009, 42, 798–811. [Google Scholar] [CrossRef]
- Samir, C.; Srivastava, A.; Daoudi, M. Three-dimensional face recognition using shapes of facial curves. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 1858–1863. [Google Scholar] [CrossRef] [PubMed]
- Raytchev, B.; Yoda, I.; Sakaue, K. Head pose estimation by nonlinear manifold learning. In Proceedings of the ICPR 2004 17th International Conference on Pattern Recognition, Cambridge, UK, 26 August 2004; Volume 4, pp. 462–466. [Google Scholar]
- Fischler, M.A.; Bolles, R.C. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Fiedler, M. Algebraic connectivity of graphs. Czechoslov. Math. J. 1973, 23, 298–305. [Google Scholar] [CrossRef]
- Donath, W.E.; Hoffman, A.J. Lower bounds for the partitioning of graphs. IBM J. Res. Dev. 1973, 17, 420–425. [Google Scholar] [CrossRef]
- Phillips, P.J.; Flynn, P.J.; Scruggs, T.; Bowyer, K.W.; Chang, J.; Hoffman, K.; Marques, J.; Min, J.; Worek, W. Overview of the face recognition grand challenge. In Proceedings of the CVPR 2005. IEEE Computer Society Conference on Computer Vision and pattern Recognition, San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 947–954. [Google Scholar]
- Vijayan, V.; Bowyer, K.; Flynn, P. 3D twins and expression challenge. In Proceedings of the 2011 IEEE International Conference on Computer Vision Workshops (ICCV Workshops), Barcelona, Spain, 6–13 November 2011; pp. 2100–2105. [Google Scholar]
- Savran, A.; Alyüz, N.; Dibeklioğlu, H.; Çeliktutan, O.; Gökberk, B.; Sankur, B.; Akarun, L. Bosphorus database for 3D face analysis. In Proceedings of the European Workshop on Biometrics and Identity Management; Springer: Berlin/Heidelberg, Germany, 2008; pp. 47–56. [Google Scholar]
- Ouamane, A.; Chouchane, A.; Boutellaa, E.; Belahcene, M.; Bourennane, S.; Hadid, A. Efficient tensor-based 2d+ 3d face verification. IEEE Trans. Inf. Forensics Secur. 2017, 12, 2751–2762. [Google Scholar] [CrossRef]
- Kim, D.; Hernandez, M.; Choi, J.; Medioni, G. Deep 3D face identification. In Proceedings of the 2017 IEEE International Joint Conference on Biometrics (IJCB) IEEE, Denver, CO, USA, 1–4 October 2017; pp. 133–142. [Google Scholar]
- Tuan Tran, A.; Hassner, T.; Masi, I.; Medioni, G. Regressing robust and discriminative 3D morphable models with a very deep neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5163–5172. [Google Scholar]
- Li, H.; Huang, D.; Morvan, J.M.; Wang, Y.; Chen, L. Towards 3D face recognition in the real: A registration-free approach using fine-grained matching of 3D keypoint descriptors. Int. J. Comput. Vis. 2015, 113, 128–142. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Approach | FRGC V2.0 | Bosphorus | 3D TEC | ||||
|---|---|---|---|---|---|---|---|
| Expression | Neutral | (Expression) | Exp. I | Exp. II | Exp. III | Exp. IV | |
| Li et al. [57] | 96.3% (combined) | 98.82% | NA | NA | NA | NA | |
| Kim et al. [55] | NA | NA | 99.2% | 94.8% | 94.8% | 81.3% | 79.9% |
| This paper | 97.90% | 99.55% | 93.55% | 94.39% | 92.99% | 89.25% | 89.25% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Al-Osaimi, F.R. Learning Descriptors Invariance through Equivalence Relations within Manifold: A New Approach to Expression Invariant 3D Face Recognition. J. Imaging 2020, 6, 112. https://doi.org/10.3390/jimaging6110112
Al-Osaimi FR. Learning Descriptors Invariance through Equivalence Relations within Manifold: A New Approach to Expression Invariant 3D Face Recognition. Journal of Imaging. 2020; 6(11):112. https://doi.org/10.3390/jimaging6110112
Chicago/Turabian StyleAl-Osaimi, Faisal R. 2020. "Learning Descriptors Invariance through Equivalence Relations within Manifold: A New Approach to Expression Invariant 3D Face Recognition" Journal of Imaging 6, no. 11: 112. https://doi.org/10.3390/jimaging6110112
APA StyleAl-Osaimi, F. R. (2020). Learning Descriptors Invariance through Equivalence Relations within Manifold: A New Approach to Expression Invariant 3D Face Recognition. Journal of Imaging, 6(11), 112. https://doi.org/10.3390/jimaging6110112