No-Reference Quality Assessment of In-Capture Distorted Videos




Abstract
:1. Introduction
- A no-reference video quality assessment method for in-capture distortions using two CNNs for encoding video frames in terms of both semantics and quality attributes, and a temporal modeling block including a Recurrent Neural Network (RNN) and a Temporal Hysteresis Pooling layer.
- An evaluation of the proposed method with previous VQA methods on four benchmark databases containing in-capture distortions also in cross-database setup.
- An ablation study measuring the advantages of combining semantics and quality features and the impact of using alternative approaches to RNN for temporal modeling.
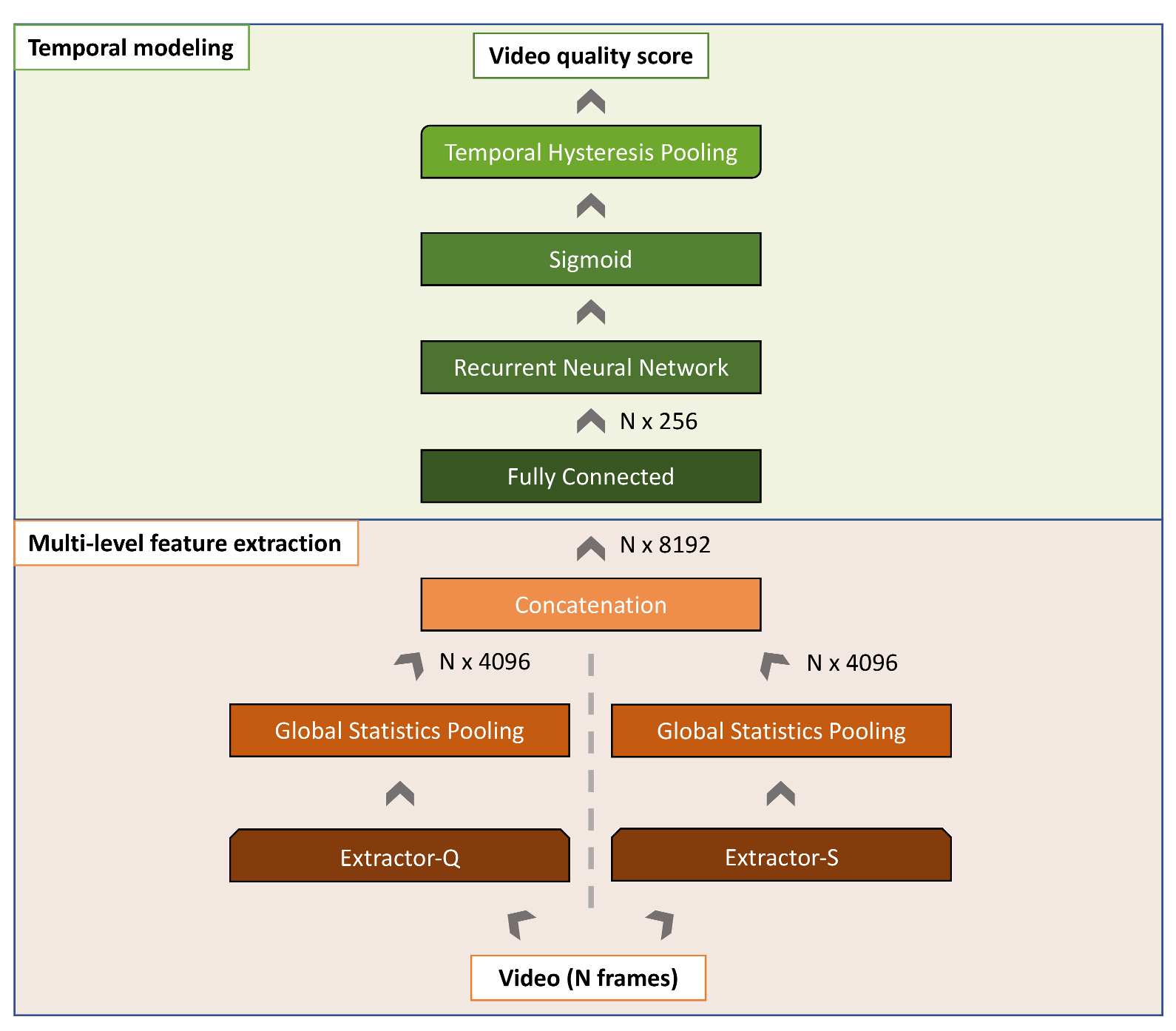
2. The Quality and Semantics Aware Video Quality Method
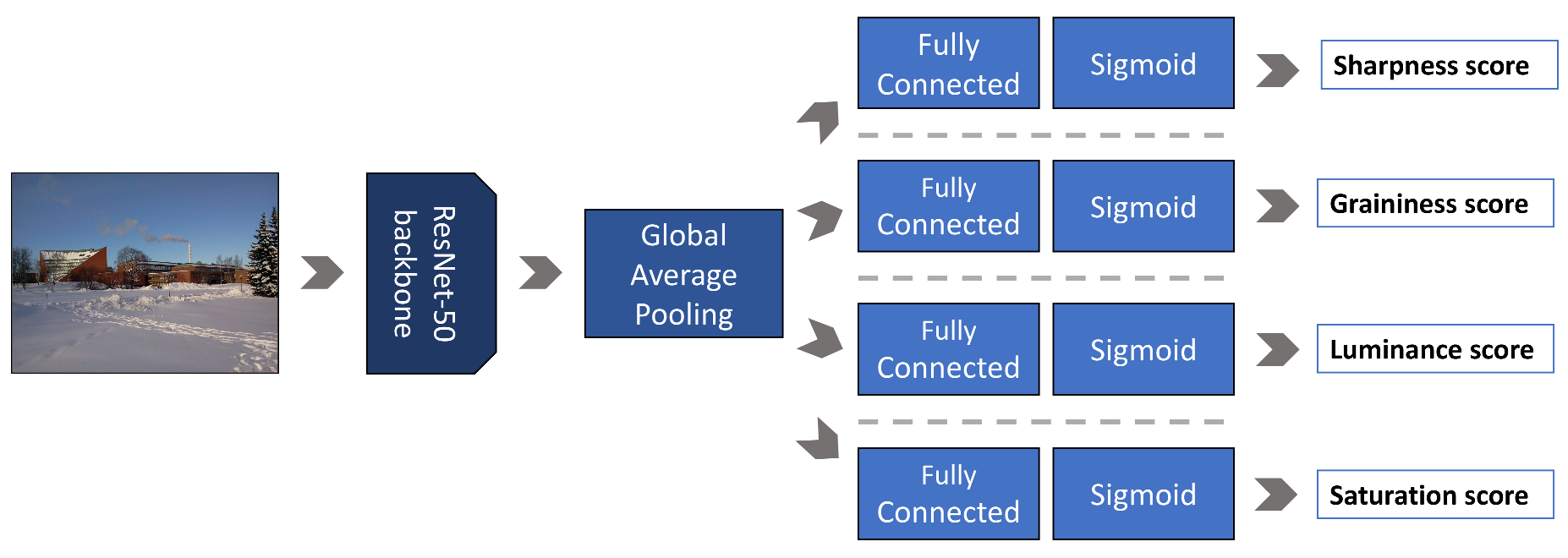
2.1. Multi-Level Feature Extraction
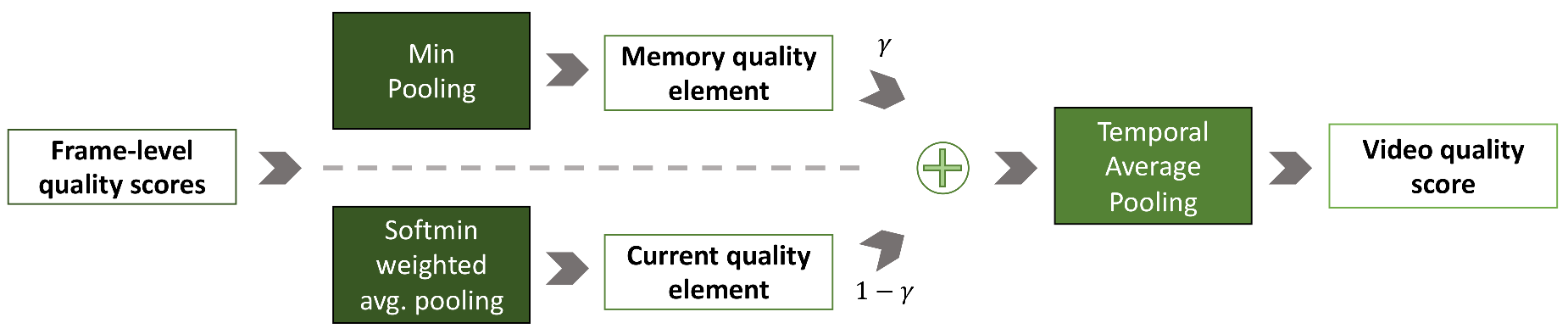
2.2. Temporal Modeling
2.3. Implementation Details
3. Experiments
3.1. Database with In-Capture Video Distortions
3.2. Experimental Setup
4. Results
4.1. Performance on Single Databases
4.2. Performance Across Databases
4.3. Computation Time
4.4. Ablation Study
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Ahmed, D.E.M.; Jama, A.M.; Khalifa, O.O. Video Transmission Over Wireless Networks Review and Recent Advances. Int. J. Comput. Appl. Technol. Res. 2015, 4, 444–448. [Google Scholar] [CrossRef]
- Ahmed, I.; Ismail, M.H.; Hassan, M.S. Video Transmission using Device-to-Device Communications: A Survey. IEEE Access 2019, 7, 131019–131038. [Google Scholar] [CrossRef]
- Wang, Z.; Lu, L.; Bovik, A. Video Quality Assessment Based on Structural Distortion Measurement. Signal Process. Image Commun. 2004, 19, 121–132. [Google Scholar] [CrossRef] [Green Version]
- Bampis, C.; Li, Z.; Bovik, A. Spatiotemporal Feature Integration and Model Fusion for Full Reference Video Quality Assessment. IEEE Trans. Circuits Syst. Video Technol. 2018, 29, 2256–2270. [Google Scholar] [CrossRef]
- Bampis, C.G.; Li, Z.; Katsavounidis, I.; Bovik, A.C. Recurrent and Dynamic Models for Predicting Streaming Video Quality of Experience. IEEE Trans. Image Process. 2018, 27, 3316–3331. [Google Scholar] [CrossRef]
- Manasa, K.; Channappayya, S.S. An Optical Flow-Based Full Reference Video Quality Assessment Algorithm. IEEE Trans. Image Process. 2016, 25, 2480–2492. [Google Scholar] [CrossRef]
- Soundararajan, R.; Bovik, A.C. Video Quality Assessment by Reduced Reference Spatio-Temporal Entropic Differencing. IEEE Trans. Circuits Syst. Video Technol. 2013, 23, 684–694. [Google Scholar] [CrossRef]
- Zeng, K.; Wang, Z. Temporal motion smoothness measurement for reduced-reference video quality assessment. In Proceedings of the International Conference on Acoustics, Speech and Signal Processing (ICASSP), Dallas, TX, USA, 14–19 March 2010; pp. 1010–1013. [Google Scholar]
- Mittal, A.; Soundararajan, R.; Bovik, A. Making a “Completely Blind” Image Quality Analyzer. IEEE Signal Process. Lett. 2013, 20, 209–212. [Google Scholar] [CrossRef]
- Mittal, A.; Saad, M.; Bovik, A. A ‘Completely Blind’ Video Integrity Oracle. IEEE Trans. Image Process. 2015, 25, 289–300. [Google Scholar] [CrossRef]
- Li, D.; Jiang, T.; Jiang, M. Quality Assessment of In-the-Wild Videos. In Proceedings of the International Conference on Multimedia, Nice, France, 21–25 October 2019; ACM: New York, NY, USA, 2019; pp. 2351–2359. [Google Scholar] [CrossRef] [Green Version]
- Saad, M.; Bovik, A. Blind quality assessment of videos using a model of natural scene statistics and motion coherency. In Proceedings of the Asilomar Conference on Signals, Systems and Computers (ASILOMAR), Pacific Grove, CA, USA, 4–7 November 2012; pp. 332–336. [Google Scholar] [CrossRef] [Green Version]
- Mittal, A.; Moorthy, A.K.; Bovik, A.C. No-Reference Image Quality Assessment in the Spatial Domain. IEEE Trans. Image Process. 2012, 21, 4695–4708. [Google Scholar] [CrossRef]
- Xu, J.; Ye, P.; Liu, Y.; Doermann, D. No-reference video quality assessment via feature learning. In Proceedings of the International Conference on Image Processing (ICIP), Paris, France, 27–30 October 2014; pp. 491–495. [Google Scholar] [CrossRef] [Green Version]
- Kundu, D.; Ghadiyaram, D.; Bovik, A.C.; Evans, B.L. No-Reference Quality Assessment of Tone-Mapped HDR Pictures. IEEE Trans. Image Process. 2017, 26, 2957–2971. [Google Scholar] [CrossRef]
- Li, Y.; Po, L.; Cheung, C.; Xu, X.; Feng, L.; Yuan, F.; Cheung, K. No-Reference Video Quality Assessment With 3D Shearlet Transform and Convolutional Neural Networks. IEEE Trans. Circuits Syst. Video Technol. 2016, 26, 1044–1057. [Google Scholar] [CrossRef]
- Wang, C.; Su, L.; Zhang, W. COME for No-Reference Video Quality Assessment. In Proceedings of the Conference on Multimedia Information Processing and Retrieval (MIPR), Miami, FL, USA, 10–12 April 2018; pp. 232–237. [Google Scholar]
- Larson, E.C.; Chandler, D.M. Most apparent distortion: Full-reference image quality assessment and the role of strategy. J. Electron. Imaging 2010, 19, 011006. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Cho, K.; van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1724–1734. [Google Scholar]
- Hosu, V.; Hahn, F.; Jenadeleh, M.; Lin, H.; Men, H.; Szirányi, T.; Li, S.; Saupe, D. The Konstanz natural video database (KoNViD-1k). In Proceedings of the International Conference on Quality of Multimedia Experience (QoMEX), Erfurt, Germany, 31 May–2 June 2017; pp. 1–6. [Google Scholar]
- Nuutinen, M.; Virtanen, T.; Vaahteranoksa, M.; Vuori, T.; Oittinen, P.; Häkkinen, J. CVD2014—A database for evaluating no-reference video quality assessment algorithms. IEEE Trans. Image Process. 2016, 25, 3073–3086. [Google Scholar] [CrossRef]
- Ghadiyaram, D.; Pan, J.; Bovik, A.C.; Moorthy, A.K.; Panda, P.; Yang, K.C. In-capture mobile video distortions: A study of subjective behavior and objective algorithms. IEEE Trans. Circuits Syst. Video Technol. 2017, 28, 2061–2077. [Google Scholar] [CrossRef]
- Korhonen, J. Two-Level Approach for No-Reference Consumer Video Quality Assessment. IEEE Trans. Image Process. 2019, 28, 5923–5938. [Google Scholar] [CrossRef]
- Siahaan, E.; Hanjalic, A.; Redi, J.A. Semantic-aware blind image quality assessment. Signal Process. Image Commun. 2018, 60, 237–252. [Google Scholar] [CrossRef] [Green Version]
- Ji, W.; Wu, J.; Shi, G.; Wan, W.; Xie, X. Blind image quality assessment with semantic information. J. Vis. Commun. Image Represent. 2019, 58, 195–204. [Google Scholar] [CrossRef]
- Gao, X.; Lu, W.; Tao, D.; Li, X. Image quality assessment and human visual system. In Proceedings of the Visual Communications and Image Processing 2010, Huangshan, China, 11–14 July 2010; International Society for Optics and Photonics: Bellingham, WA, USA, 2010; Volume 7744, p. 77440Z. [Google Scholar]
- Michelson, A.A. Studies in Optics; Courier Corporation: Chelmsford, MA, USA, 1995. [Google Scholar]
- Young, G.M.; Goldstein, R.B.; Peli, E.; Arend, L.E. Contrast sensitivity to patch stimuli: Effects of spatial bandwidth and temporal presentation. Spat. Vis. 1993, 7, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Seshadrinathan, K.; Bovik, A.C. Temporal hysteresis model of time varying subjective video quality. In Proceedings of the International Conference on Acoustics, Speech and Signal Processing (ICASSP), Prague, Czech Republic, 22–27 May 2011; pp. 1153–1156. [Google Scholar]
- Williams, R.J.; Zipser, D. A learning algorithm for continually running fully recurrent neural networks. Neural Comput. 1989, 1, 270–280. [Google Scholar] [CrossRef]
- Elman, J.L. Finding structure in time. Cogn. Sci. 1990, 14, 179–211. [Google Scholar] [CrossRef]
- Dodge, S.; Karam, L. Understanding how image quality affects deep neural networks. In Proceedings of the 2016 eighth international conference on quality of multimedia experience (QoMEX), Lisbon, Portugal, 6–8 June 2016; pp. 1–6. [Google Scholar]
- Bianco, S.; Celona, L.; Napoletano, P.; Schettini, R. On the use of deep learning for blind image quality assessment. Signal Image Video Process. 2017, 12, 355–362. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Bianco, S.; Cadene, R.; Celona, L.; Napoletano, P. Benchmark Analysis of Representative Deep Neural Network Architectures. IEEE Access 2018, 6, 64270–64277. [Google Scholar] [CrossRef]
- Virtanen, T.; Nuutinen, M.; Vaahteranoksa, M.; Oittinen, P.; Häkkinen, J. CID2013: A Database for Evaluating No-Reference Image Quality Assessment Algorithms. IEEE Trans. Image Process. 2014, 24, 390–402. [Google Scholar] [CrossRef] [PubMed]
- Snyder, D.; Garcia-Romero, D.; Povey, D.; Khudanpur, S. Deep Neural Network Embeddings for Text-Independent Speaker Verification. In Proceedings of the Interspeech 2017, Stockholm, Sweden, 20–24 August 2017; pp. 999–1003. [Google Scholar]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic Differentiation in Pytorch. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Sinno, Z.; Bovik, A.C. Large-scale study of perceptual video quality. IEEE Trans. Image Process. 2018, 28, 612–627. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Thomee, B.; Shamma, D.A.; Friedland, G.; Elizalde, B.; Ni, K.; Poland, D.; Borth, D.; Li, L.J. YFCC100M: The new data in multimedia research. Commun. Acm 2016, 59, 64–73. [Google Scholar] [CrossRef]
- Ye, P.; Kumar, J.; Kang, L.; Doermann, D. Unsupervised feature learning framework for no-reference image quality assessment. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 1098–1105. [Google Scholar]
- Hosu, V.; Lin, H.; Sziranyi, T.; Saupe, D. KonIQ-10k: An Ecologically Valid Database for Deep Learning of Blind Image Quality Assessment. IEEE Trans. Image Process. 2020, 29, 4041–4056. [Google Scholar] [CrossRef] [Green Version]
- Ghadiyaram, D.; Bovik, A.C. Massive Online Crowdsourced Study of Subjective and Objective Picture Quality. IEEE Trans. Image Process. 2016, 25, 372–387. [Google Scholar] [CrossRef] [Green Version]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. In Proceedings of the International Conference Learning Representations (ICLR) Workshop, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
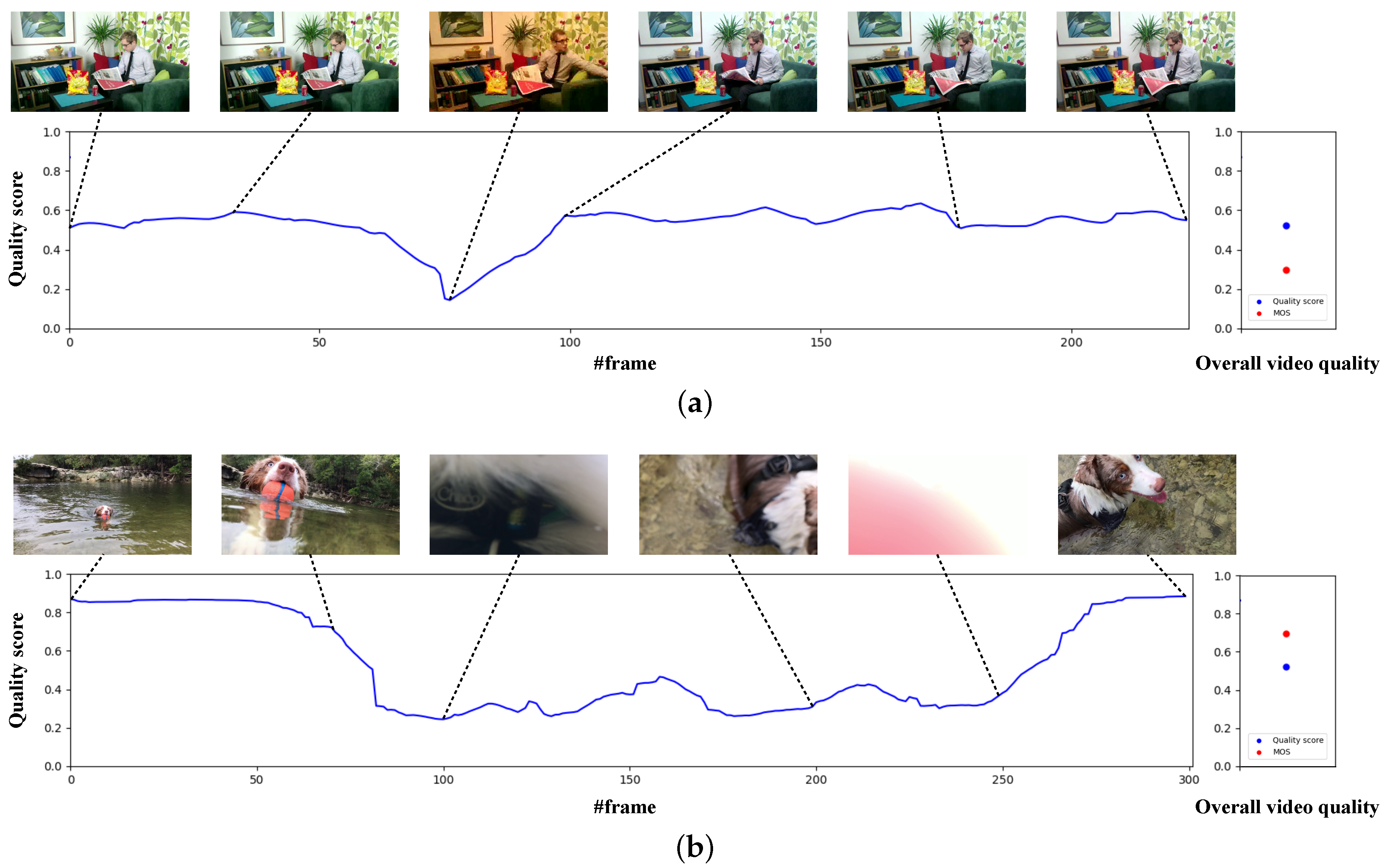{kind=link}
{kind=link}
| Name | No. of Video Sequence | No. of Scenes | No. of Devices | Device Types | Distortion Type | Video Length (s) | Resolution | MOS Range |
|---|---|---|---|---|---|---|---|---|
| CVD2014 (2014) [22] | 234 | 5 | 78 | smartphone and DSLR | generic | 10–25 | –93.38 | |
| KoNViD-1k (2017) [21] | 1200 | 1200 | N/A | DSLR | generic | 8 | 1.22–4.64 | |
| LIVE-Qualcomm (2017) [23] | 208 | 54 | 8 | smartphones | specific | 15 | 16.56–73.64 | |
| LIVE-VQC (2018) [41] | 585 | 585 | 101 | smartphones | generic | 10 | 0–100 |
| CVD2014 | KonViD-1k | |||||
|---|---|---|---|---|---|---|
| PLCC ↑ | SROCC ↑ | RMSE ↓ | PLCC ↑ | SROCC ↑ | RMSE ↓ | |
| NIQE [9] | ||||||
| BRISQUE [13] | ||||||
| V-CORNIA [14] | ||||||
| V-BLIINDS [12] | ||||||
| HIGRADE [15] | ||||||
| TLVQM [24] | ||||||
| VSFA [11] | ||||||
| QSA-VQM (only quality) | ||||||
| QSA-VQM | ||||||
| LIVE-Qualcomm | LIVE-VQC | |||||
| PLCC↑ | SROCC↑ | RMSE↓ | PLCC↑ | SROCC↑ | RMSE↓ | |
| NIQE [9] | ||||||
| BRISQUE [13] | ||||||
| V-CORNIA [14] | ||||||
| V-BLIINDS [12] | ||||||
| HIGRADE [15] | ||||||
| TLVQM [24] | ||||||
| VSFA [11] | ||||||
| QSA-VQM (only quality) | ||||||
| QSA-VQM | ||||||
| Training | CVD2014 | KoNViD-1k | ||||
|---|---|---|---|---|---|---|
| Testing | LIVE-Qualcomm | KoNViD-1k | LIVE-VQC | CVD2014 | LIVE-Qualcomm | LIVE-VQC |
| TLVQM [24] | ||||||
| VSFA [11] | ||||||
| QSA-VQM (proposed) | ||||||
| Training | LIVE-Qualcomm | LIVE-VQC | ||||
| Testing | CVD2014 | KoNViD-1k | LIVE-VQC | CVD2014 | LIVE-Qualcomm | KoNViD-1k |
| TLVQM [24] | ||||||
| VSFA [11] | ||||||
| QSA-VQM (proposed) | ||||||
| Mode | Method | 240frs@540p | 364frs@480p | 467frs@720p | 450frs@1080p |
|---|---|---|---|---|---|
| CPU | BRISQUE [13] | 12.69 | 12.34 | 41.22 | 79.81 |
| NIQE [9] | 45.65 | 41.97 | 155.90 | 351.83 | |
| TLVQM [24] | 50.73 | 46.32 | 136.89 | 401.44 | |
| V-CORNIA [14] | 225.22 | 325.57 | 494.24 | 616.48 | |
| VSFA [11] | 269.84 | 249.21 | 936.84 | 2081.84 | |
| V-BLIINDS [12] | 382.06 | 361.39 | 1391.00 | 3037.30 | |
| QSA-VQM (proposed) | 281.21 | 265.13 | 900.72 | 2012.61 | |
| GPU | VSFA [11] | 8.85 | 7.55 | 27.63 | 58.48 |
| QSA-VQM (proposed) | 9.70 | 9.15 | 25.79 | 55.27 |
| CVD2014 | KonViD-1k | |||||
|---|---|---|---|---|---|---|
| PLCC ↑ | SROCC ↑ | RMSE ↓ | PLCC ↑ | SROCC ↑ | RMSE ↓ | |
| FC | ||||||
| GRU | ||||||
| RNN | ||||||
| LIVE-Qualcomm | LIVE-VQC | |||||
| PLCC↑ | SROCC↑ | RMSE↓ | PLCC↑ | SROCC↑ | RMSE↓ | |
| FC | ||||||
| GRU | ||||||
| RNN | ||||||
| PLCC ↑ | SROCC ↑ | RMSE ↓ | |
|---|---|---|---|
| CVD2014 | |||
| KonVid-1k | |||
| LIVE-VQC |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Agarla, M.; Celona, L.; Schettini, R. No-Reference Quality Assessment of In-Capture Distorted Videos. J. Imaging 2020, 6, 74. https://doi.org/10.3390/jimaging6080074
Agarla M, Celona L, Schettini R. No-Reference Quality Assessment of In-Capture Distorted Videos. Journal of Imaging. 2020; 6(8):74. https://doi.org/10.3390/jimaging6080074
Chicago/Turabian StyleAgarla, Mirko, Luigi Celona, and Raimondo Schettini. 2020. "No-Reference Quality Assessment of In-Capture Distorted Videos" Journal of Imaging 6, no. 8: 74. https://doi.org/10.3390/jimaging6080074
APA StyleAgarla, M., Celona, L., & Schettini, R. (2020). No-Reference Quality Assessment of In-Capture Distorted Videos. Journal of Imaging, 6(8), 74. https://doi.org/10.3390/jimaging6080074