No-Reference Image Quality Assessment Based on the Fusion of Statistical and Perceptual Features

Abstract
:1. Introduction
1.1. Related Work
1.2. Contributions
1.3. Structure
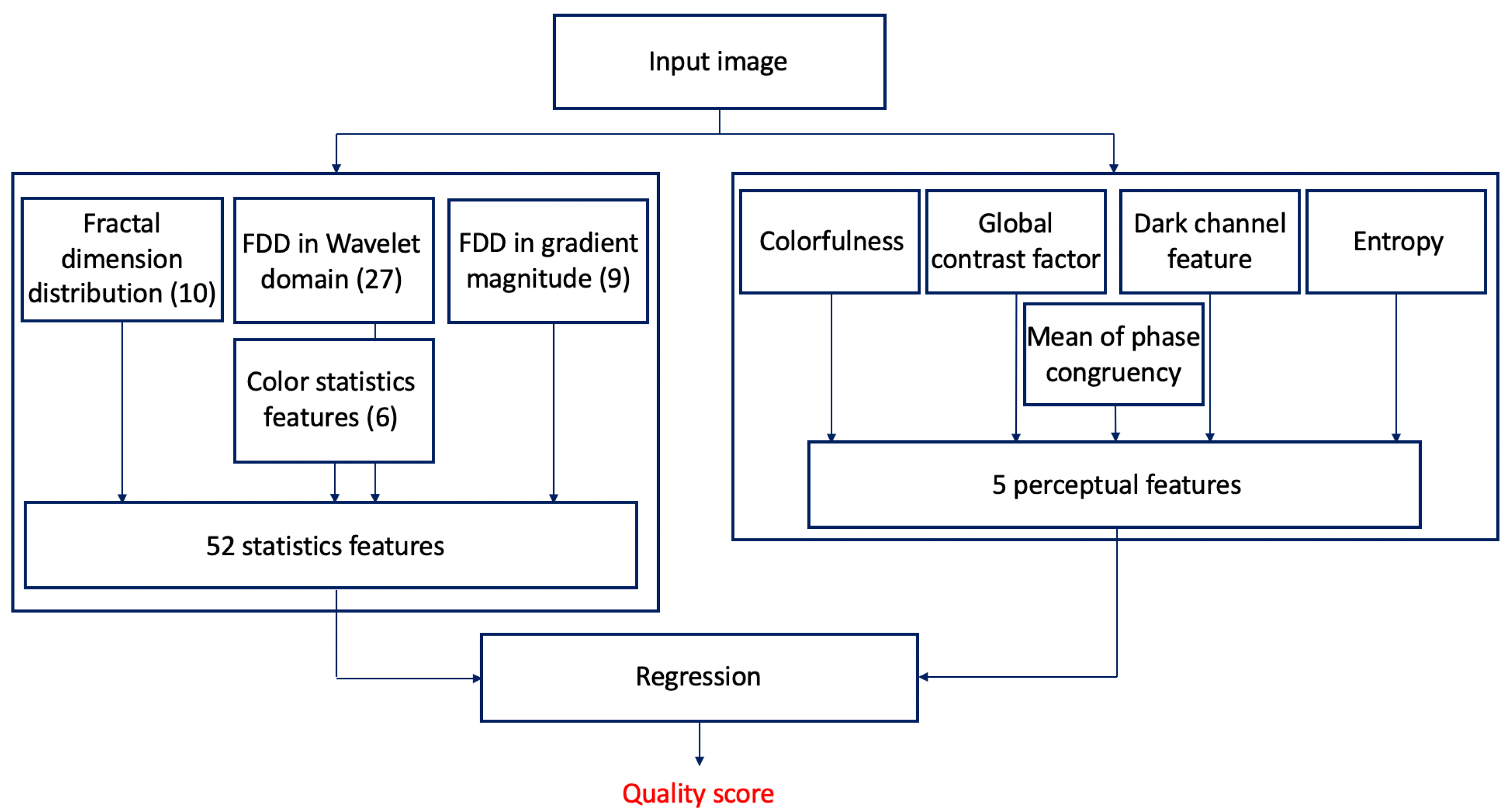
2. Methodology
2.1. Statistical Features
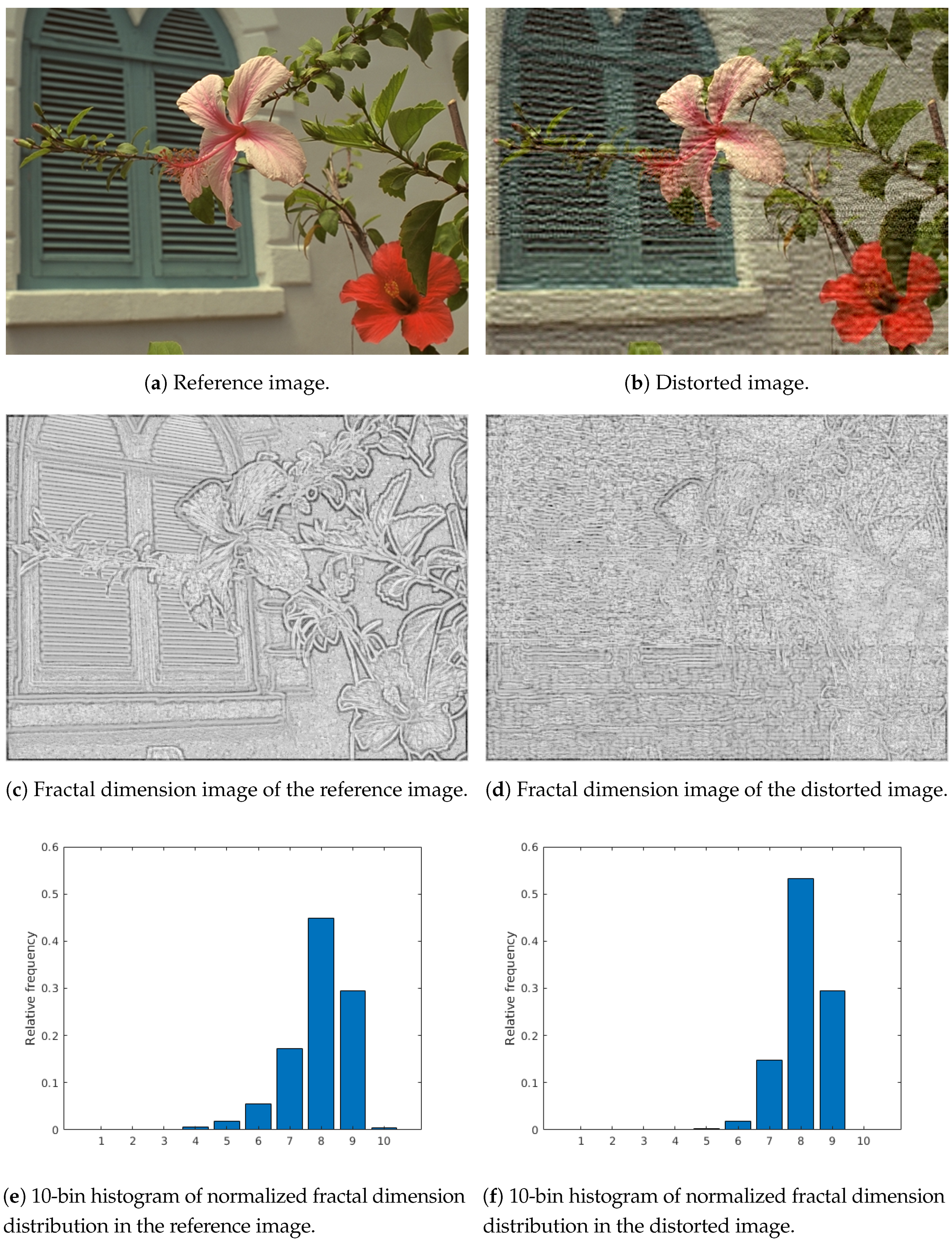
- Local fractal dimension distribution: Fractal analysis was first proposed by Mandelbrot [34] and it deals with the study of irregular and self-similar objects. By definition, fractal dimenstion characterizes patterns or sets “by quantifying their complexity as a ratio of the change in detail to the change in scale” [34]. The fractal dimension image is produced by considering each pixel in the original image as a center of a 7-by-7 rectangular neighborhood and the fractal dimension is calculated from this neighborhood. To determine the fractal dimension of a grayscale image patch, the box counting technique developed by Al-Kadi and Watson [35] was applied. From the fractal dimension image, a 10-bin normalized histogram was calculated considering the values between −2 and 3. Figure 2 illustrates the local fractal dimension images of a reference and a distorted image. It can be observed that the fractal dimension of an image patch is extremely sensitive to image distortions.
- First digit distribution in wavelet domain: Benford’s law, also called the first digit law, states leading digit in many real-world datasets occurs with probabilityMore specifically, Benford’s law [36] works on a distribution of numbers if that distribution spans quite a few order of magnitudes. As pointed out in [37], the first digit distribution in the transform domain of a pristine natural image harmonizes better with the Benford’s law than those of a distorted image. In this study, the normalized first digit distribution is utilized in the wavelet domain and in the image gradient domain to extract feature vectors. Specifically, an Fejér-Korovkin wavelet [38] was used to transform the image into wavelet domain. Next, the normalized first digit distribution was measured in horizontal detail coefficients, vertical detail coefficients, and diagonal detail coefficients. Finally, a 27-dimensional feature vector was obtained in the wavelet domain by concatenating the normalized first digit distributions in the horizontal, vertical, and diagonal detail coefficients, respectively.
- First digit distribution in gradient magnitude: The gradient of the image was determined with the help of 3-by-3 Sobel operator. The normalized first digit distribution of the gradient magnitude image was measured and a 9-dimensional feature vector was compiled.Table 1 illustrates the average and median Euclidean distances between first digit distributions of TID2013 [39] images in the wavelet and gradient magnitude domain and Benford’s law prediction. It can be observed that the first digit distributions in the wavelet domain is almost the same as Benford’s law prediction. Moreover, it can be clearly seen that the distorted images distance from Benford’s law is significantly larger than those of the reference images. One can further observe that the most distorted images’ first digit distribution Euclidean distance from the Benford’s law is the largest, since the standard deviation of the distance values for the distorted images is three times larger than those of the reference images. In the gradient magnitude domain, the above mentioned observations are less significant. Furthermore, the standard deviations are almost the same.
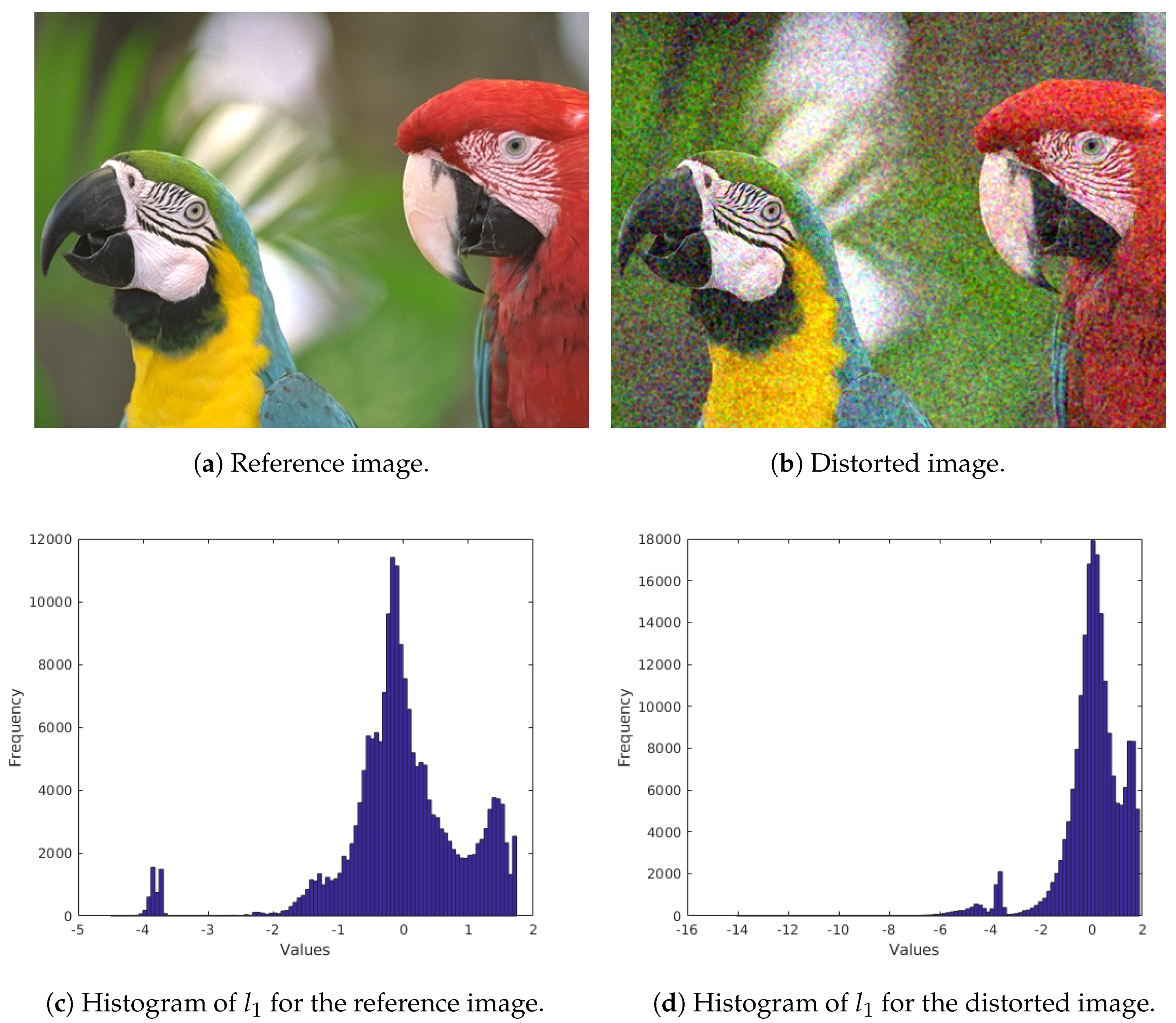
- Color statistics features: To extract the statistical properties of the color, the model of Ruderman et al. [40] was applied. Specifically, an RGB image was first transformed into a mean-subtracted logarithmic signal:where , , and are the mean values of the logarithms of the R, G, and B image channels, respectively. From these signals, the following , , and signals are derived:As pointed out by Ruderman et al. [40], the distributions of the coefficients in , , and approximately fit to Gaussian distributions for natural images (see Figure 3 for an example). As a consequence, a Gaussian distribution was fit to the coefficients of , , and . Moreover, the mean and the variance were taken as quality-aware features. As a result, the color statistics feature vector contains six elements (mean and variance for , , and ). Figure 3 illustrates the distribution of values in a reference image and in its distorted counterpart from TID2013 [39] database.
2.2. Perceptual Features
- Colorfulness: As pointed out in [41], humans prefer slightly more colorful images and colorfulness influence perceptual quality judgements. It was calculated using the following formula [42]:where and stand for the standard deviation and mean of the matrices given in the subscripts. Furthermore, and , where R, G, and B denote the red, green, and blue channels of the input image, respectively.
- Global contrast factor: Humans’ ability to recognize or distinguish objects in the image strongly depends on the contrast. As a consequence, contrast may influence the perceptual quality and is incorporated into the proposed model. In this study, Matkovic et al.’s [43] model was applied which is limited to grayscale contrast. Global contrast factor is computed as follows:where is defined as , . Furthermore, isandwhere L stands for the intensity pixel value of the image after applying gamma correction (). Assuming that the image’s width is w and its height is w, and the image is reshaped into a row-wise one dimensional array.
- Dark channel feature: He et al. [44] called dark pixels those pixels whose intensities in at least one color channel are very low. Specifically, a dark channel was defined as:where denotes the intensity value for a color channel and stands for the image patch centered around pixel x. In this study, the dark channel feature of an image is defined as:where denotes the intensity value for a color channel and stands for an image patch centered around pixel x. Moreover, S denotes the area of the input image.
- Entropy: It has many different interpretations, such as “measure of order” or “measure of randomness”. In other words, it describes how much information is provided by the image. Therefore, it can be applied to characterize the texture of an image. Furthermore, image entropy changes with the type and level of image distortions. Entropy of a grayscale image I is defined as:where is the empirical distribution of the grayscale values.
- Mean of phase congruency image: The main idea behind phase congruency is that perceptually significant image features can be observed at those spatial coordinates where the Fourier series components are maximally in phase [45]. The formal definition of phase congruency (PC) is the following [46],where is the energy of signal x and stands for the nth Fourier amplitude. Equation (15) was developed further by Kovesi [45] by incorporating noise compensation,where weights for frequency spread, and denotes the floor function, T is an estimation for the noise level, and is a small constant for avoiding the division by 0. Furthermore,where is the phase of the nth Fourier component at x and is the average phase at x. Phase congruency was used to detect boundary, texture direction, and image segmentation [47]. In Figure 4, it is illustrated that perceptual quality degradations severely modify the phase congruency image. That is why, the mean of the phase congruency image was used as a perceptual metric in this study.
3. Experimental Results
3.1. Evaluation Protocol
3.2. Experimental Setup
3.3. Parameter Study
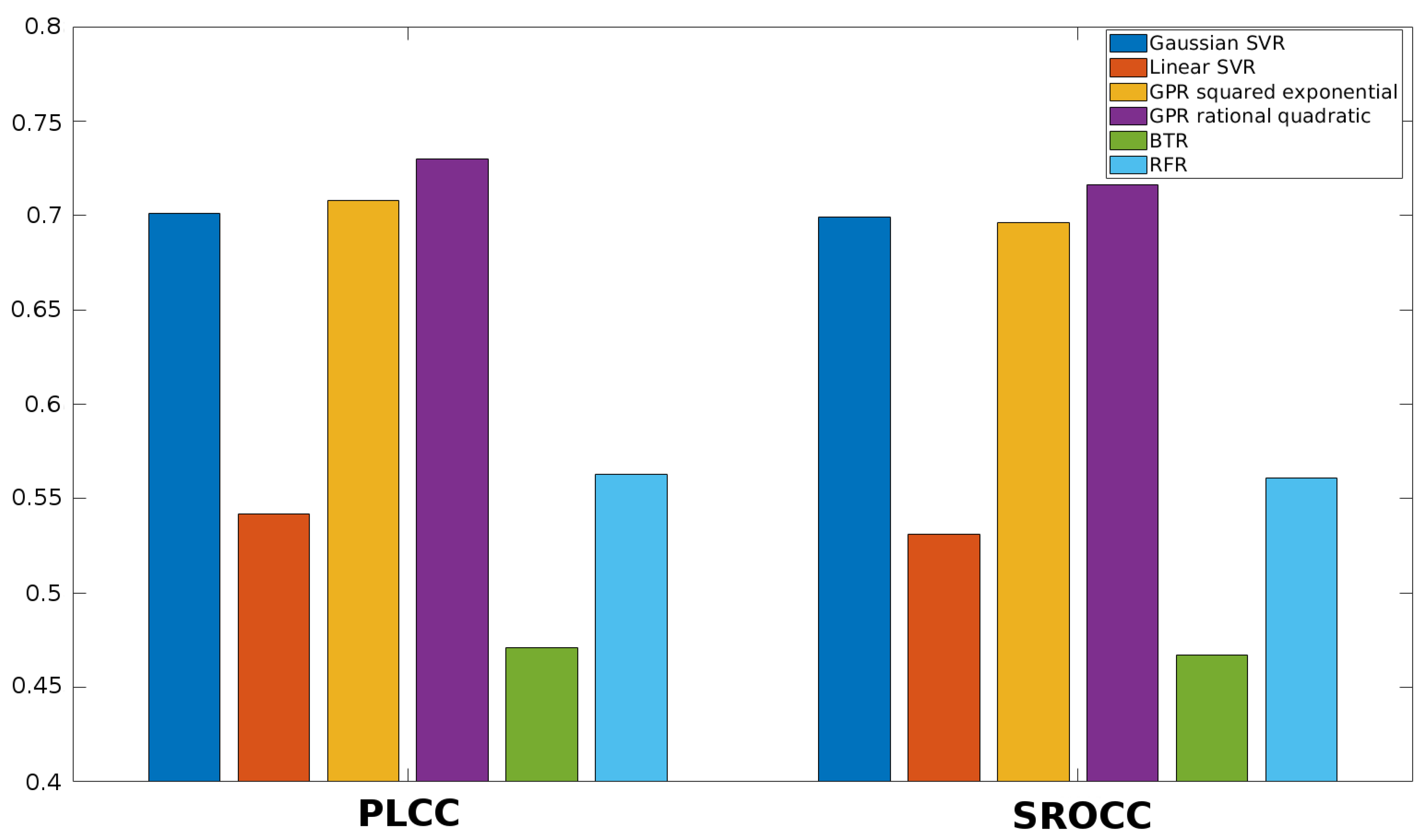
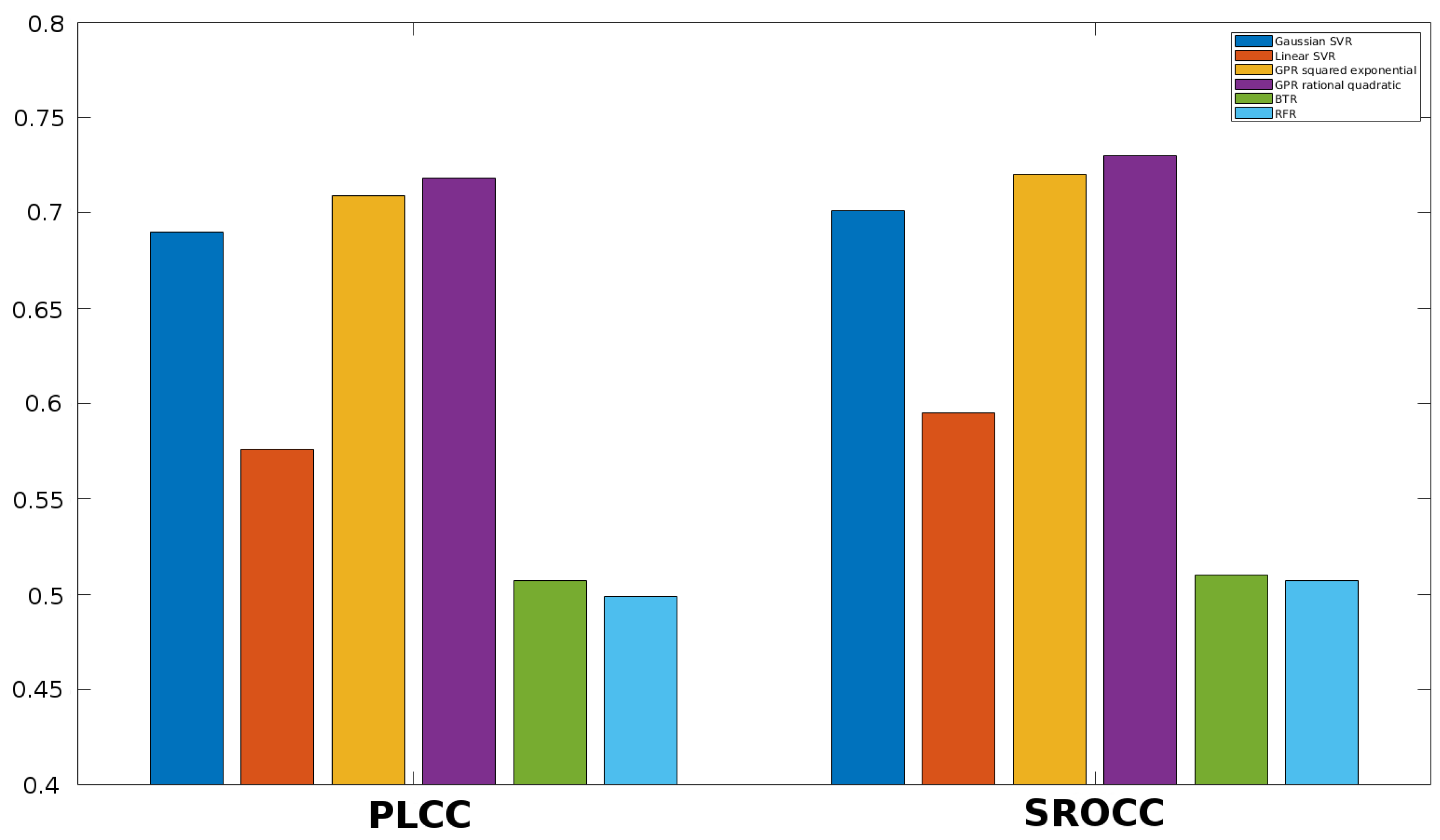
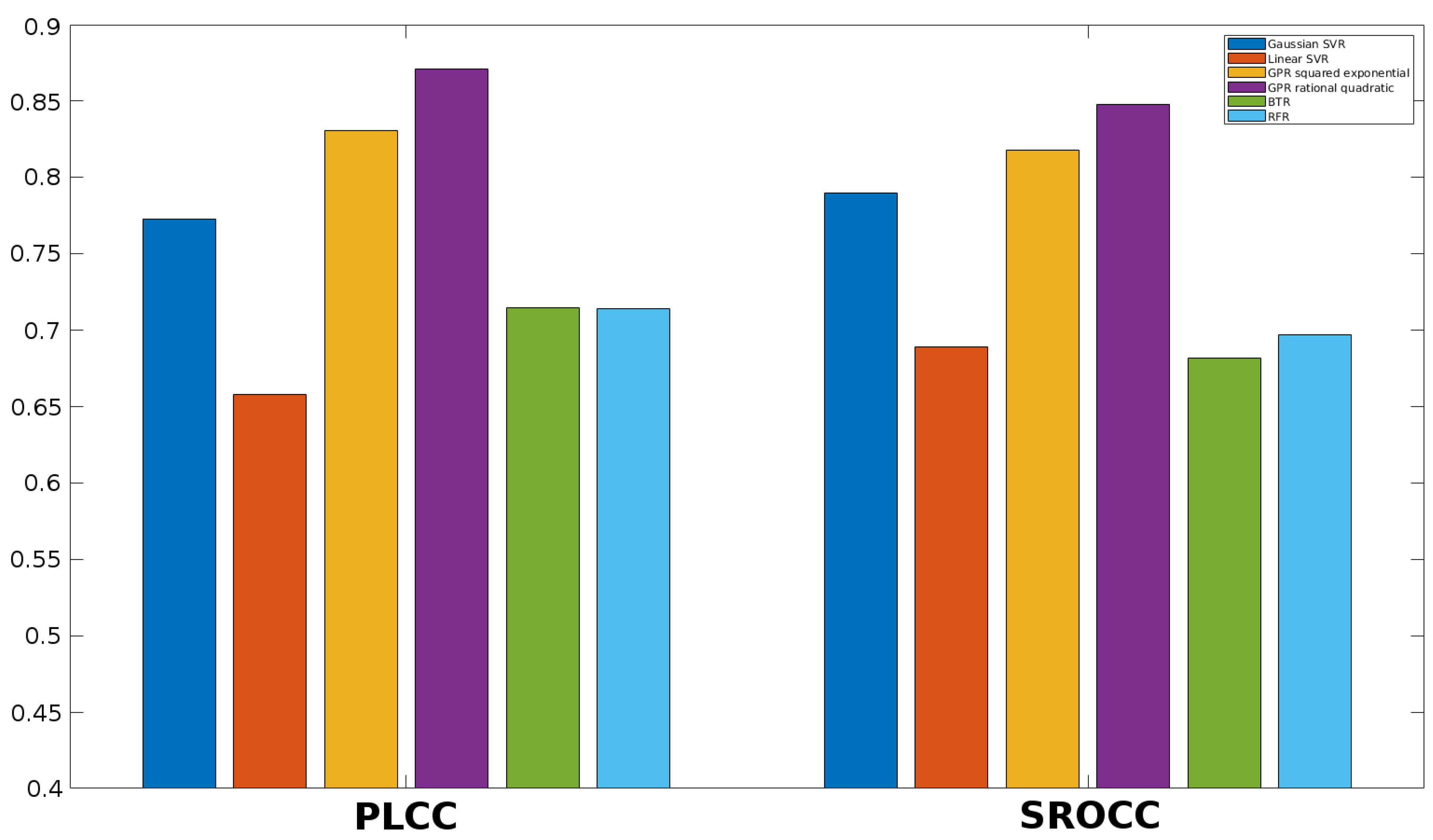
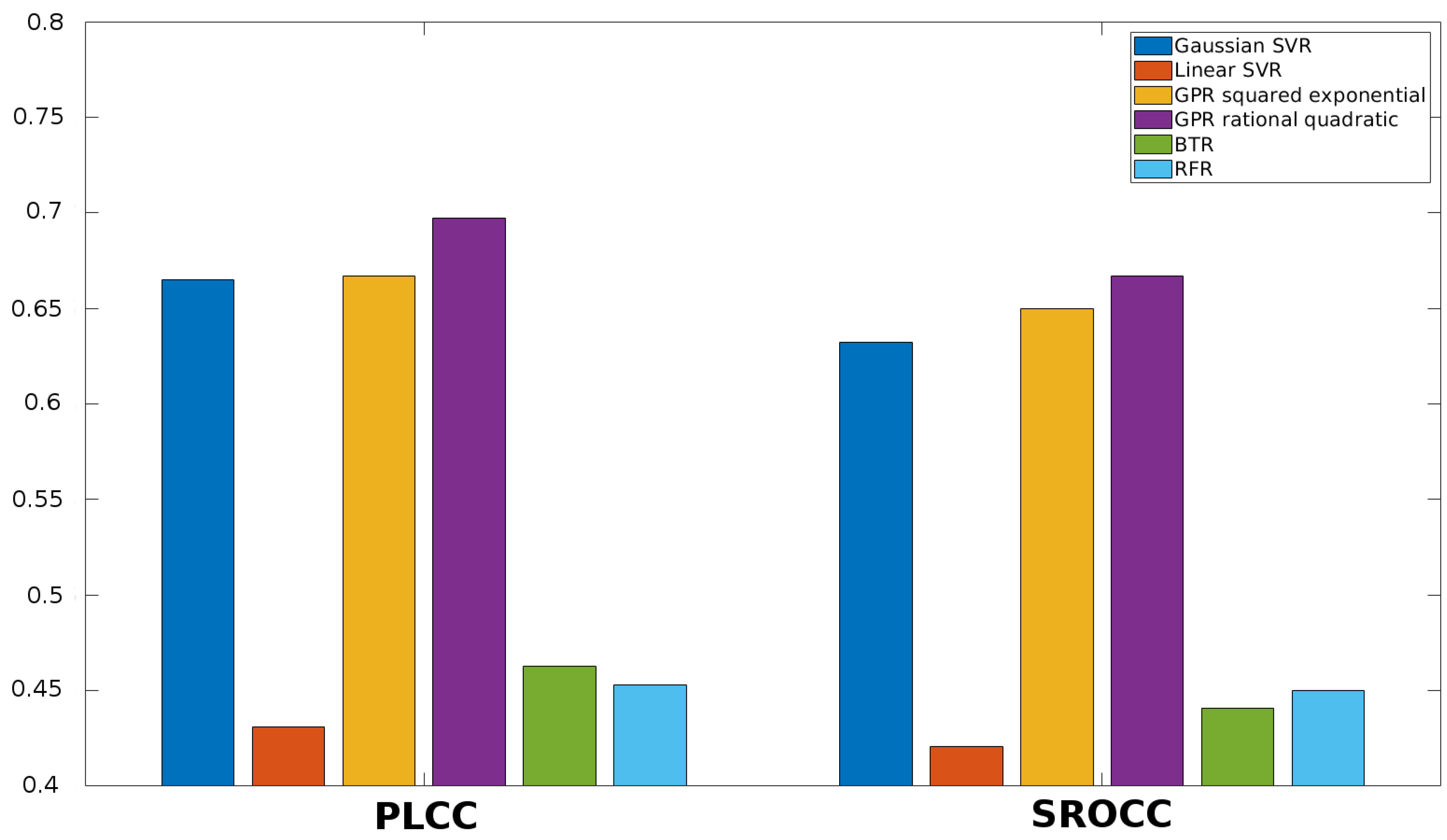
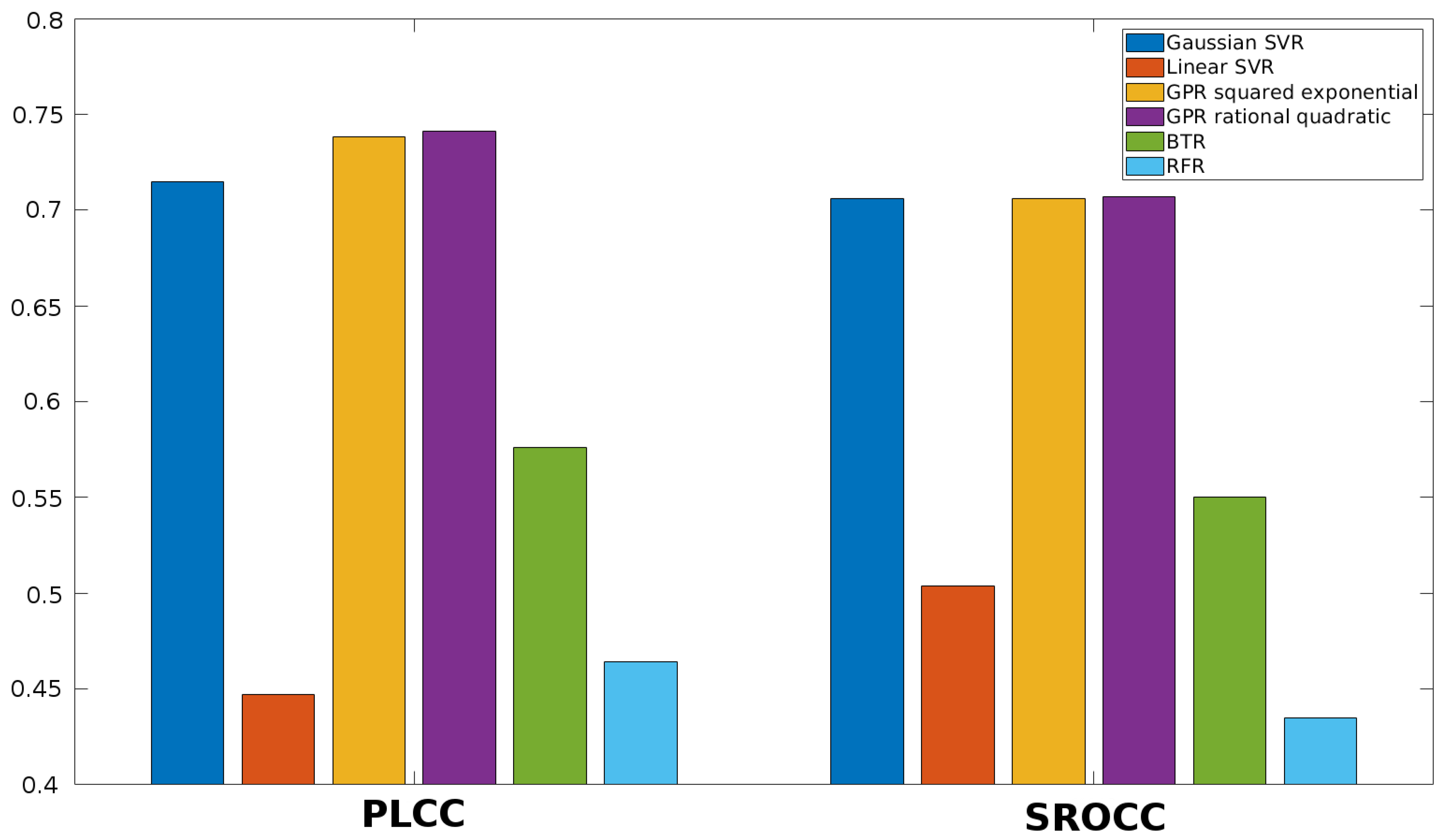
3.4. Comparison to the State-of-the-Art
4. Conclusions
Funding
Acknowledgments
Conflicts of Interest
References
- Dugonik, B.; Dugonik, A.; Marovt, M.; Golob, M. Image Quality Assessment of Digital Image Capturing Devices for Melanoma Detection. Appl. Sci. 2020, 10, 2876. [Google Scholar] [CrossRef] [Green Version]
- Kwon, H.J.; Lee, S.H. Contrast Sensitivity Based Multiscale Base–Detail Separation for Enhanced HDR Imaging. Appl. Sci. 2020, 10, 2513. [Google Scholar] [CrossRef] [Green Version]
- Korhonen, J. Two-level approach for no-reference consumer video quality assessment. IEEE Trans. Image Process. 2019, 28, 5923–5938. [Google Scholar] [CrossRef] [PubMed]
- Lee, C.; Cho, S.; Choe, J.; Jeong, T.; Ahn, W.; Lee, E. Objective video quality assessment. Opt. Eng. 2006, 45, 017004. [Google Scholar] [CrossRef]
- Wang, Z. Applications of objective image quality assessment methods [applications corner]. IEEE Signal Process. Mag. 2011, 28, 137–142. [Google Scholar] [CrossRef]
- Dodge, S.; Karam, L. Understanding how image quality affects deep neural networks. In Proceedings of the 2016 eighth international conference on quality of multimedia experience (QoMEX), Lisbon, Portugal, 6–8 June 2016; pp. 1–6. [Google Scholar]
- Aqqa, M.; Mantini, P.; Shah, S.K. Understanding How Video Quality Affects Object Detection Algorithms. In Proceedings of the 14th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2019) (5: VISAPP), Prague, Czech Republic, 25–27 February 2019; pp. 96–104. [Google Scholar]
- Hertel, D.W.; Chang, E. Image quality standards in automotive vision applications. In Proceedings of the 2007 IEEE Intelligent Vehicles Symposium, Istanbul, Turkey, 13–15 June 2007; pp. 404–409. [Google Scholar]
- BT, R.I.R. Methodology for the Subjective Assessment of the Quality of Television Pictures; International Telecommunication Union: Bern, Switzerland, 2002; Volume 1, pp. 1–48. [Google Scholar]
- ITU-T RECOMMENDATION, P. Subjective Video Quality Assessment Methods for Multimedia Applications; International Telecommunication Union: Bern, Switzerland, 1999; Volume 1, pp. 1–42. [Google Scholar]
- Guan, J.; Zhang, W.; Gu, J.; Ren, H. No-reference blur assessment based on edge modeling. J. Vis. Commun. Image Represent. 2015, 29, 1–7. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Evan, B.L. Blind measurement of blocking artifacts in images. In Proceedings of the 2000 International Conference on Image Processing (Cat. No. 00CH37101), Vancouver, BC, Canada, 10–13 September 2000; Volume 3, pp. 981–984. [Google Scholar]
- Liu, H.; Klomp, N.; Heynderickx, I. A no-reference metric for perceived ringing artifacts in images. IEEE Trans. Circuits Syst. Video Technol. 2009, 20, 529–539. [Google Scholar] [CrossRef] [Green Version]
- Sazzad, Z.P.; Kawayoke, Y.; Horita, Y. No reference image quality assessment for JPEG2000 based on spatial features. Signal Process. Image Commun. 2008, 23, 257–268. [Google Scholar] [CrossRef]
- Moorthy, A.K.; Bovik, A.C. A two-step framework for constructing blind image quality indices. IEEE Signal Process. Lett. 2010, 17, 513–516. [Google Scholar] [CrossRef]
- Suykens, J.A.; Vandewalle, J. Least squares support vector machine classifiers. Neural Process. Lett. 1999, 9, 293–300. [Google Scholar] [CrossRef]
- Saad, M.A.; Bovik, A.C.; Charrier, C. Blind image quality assessment: A natural scene statistics approach in the DCT domain. IEEE Trans. Image Process. 2012, 21, 3339–3352. [Google Scholar] [CrossRef] [PubMed]
- Lu, P.; Li, Y.; Jin, L.; Han, S. Blind image quality assessment based on wavelet power spectrum in perceptual domain. Trans. Tianjin Univ. 2016, 22, 596–602. [Google Scholar] [CrossRef]
- Lu, W.; Zeng, K.; Tao, D.; Yuan, Y.; Gao, X. No-reference image quality assessment in contourlet domain. Neurocomputing 2010, 73, 784–794. [Google Scholar] [CrossRef]
- Mittal, A.; Moorthy, A.K.; Bovik, A.C. No-reference image quality assessment in the spatial domain. IEEE Trans. Image Process. 2012, 21, 4695–4708. [Google Scholar] [CrossRef] [PubMed]
- Drucker, H.; Burges, C.J.; Kaufman, L.; Smola, A.J.; Vapnik, V. Support vector regression machines. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 1997; pp. 155–161. [Google Scholar]
- Kim, D.O.; Han, H.S.; Park, R.H. Gradient information-based image quality metric. IEEE Trans. Consum. Electron. 2010, 56, 930–936. [Google Scholar] [CrossRef]
- Xue, W.; Mou, X.; Zhang, L.; Bovik, A.C.; Feng, X. Blind image quality assessment using joint statistics of gradient magnitude and Laplacian features. IEEE Trans. Image Process. 2014, 23, 4850–4862. [Google Scholar] [CrossRef]
- Liu, L.; Hua, Y.; Zhao, Q.; Huang, H.; Bovik, A.C. Blind image quality assessment by relative gradient statistics and adaboosting neural network. Signal Process. Image Commun. 2016, 40, 1–15. [Google Scholar] [CrossRef]
- Ghadiyaram, D.; Bovik, A.C. Perceptual quality prediction on authentically distorted images using a bag of features approach. J. Vis. 2017, 17, 32. [Google Scholar] [CrossRef]
- Liu, L.; Dong, H.; Huang, H.; Bovik, A.C. No-reference image quality assessment in curvelet domain. Signal Process. Image Commun. 2014, 29, 494–505. [Google Scholar] [CrossRef]
- Li, Y.; Po, L.M.; Xu, X.; Feng, L.; Yuan, F.; Cheung, C.H.; Cheung, K.W. No-reference image quality assessment with shearlet transform and deep neural networks. Neurocomputing 2015, 154, 94–109. [Google Scholar] [CrossRef]
- Ou, F.Z.; Wang, Y.G.; Zhu, G. A Novel Blind Image Quality Assessment Method Based on Refined Natural Scene Statistics. In Proceedings of the IEEE International Conference on Image Processing, Taipei, Taiwan, 22–25 September 2019; pp. 1004–1008. [Google Scholar]
- Freitas, P.G.; Akamine, W.Y.; Farias, M.C. Referenceless image quality assessment by saliency, color-texture energy, and gradient boosting machines. J. Braz. Comput. Soc. 2018, 24, 9. [Google Scholar] [CrossRef] [Green Version]
- Garcia Freitas, P.; Da Eira, L.P.; Santos, S.S.; Farias, M.C.Q.d. On the Application LBP Texture Descriptors and Its Variants for No-Reference Image Quality Assessment. J. Imaging 2018, 4, 114. [Google Scholar] [CrossRef] [Green Version]
- Mittal, A.; Soundararajan, R.; Bovik, A.C. Making a “completely blind” image quality analyzer. IEEE Signal Process. Lett. 2012, 20, 209–212. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, L.; Bovik, A.C. A feature-enriched completely blind image quality evaluator. IEEE Trans. Image Process. 2015, 24, 2579–2591. [Google Scholar] [CrossRef] [Green Version]
- Xue, W.; Zhang, L.; Mou, X. Learning without human scores for blind image quality assessment. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 995–1002. [Google Scholar]
- Mandelbrot, B.B. The Fractal Geometry of nature/Revised and Enlarged Edition; WH Freeman and Co.: New York, NY, USA, 1983; 495p. [Google Scholar]
- Al-Kadi, O.S.; Watson, D. Texture analysis of aggressive and nonaggressive lung tumor CE CT images. IEEE Trans. Biomed. Eng. 2008, 55, 1822–1830. [Google Scholar] [CrossRef]
- Fewster, R.M. A simple explanation of Benford’s Law. Am. Stat. 2009, 63, 26–32. [Google Scholar] [CrossRef] [Green Version]
- Al-Bandawi, H.; Deng, G. Classification of image distortion based on the generalized Benford’s law. Multimed. Tools Appl. 2019, 78, 25611–25628. [Google Scholar] [CrossRef]
- Nielsen, M. On the construction and frequency localization of finite orthogonal quadrature filters. J. Approx. Theory 2001, 108, 36–52. [Google Scholar] [CrossRef] [Green Version]
- Ponomarenko, N.; Jin, L.; Ieremeiev, O.; Lukin, V.; Egiazarian, K.; Astola, J.; Vozel, B.; Chehdi, K.; Carli, M.; Battisti, F.; et al. Image database TID2013: Peculiarities, results and perspectives. Signal Process. Image Commun. 2015, 30, 57–77. [Google Scholar] [CrossRef] [Green Version]
- Ruderman, D.L.; Cronin, T.W.; Chiao, C.C. Statistics of cone responses to natural images: Implications for visual coding. JOSA A 1998, 15, 2036–2045. [Google Scholar] [CrossRef] [Green Version]
- Yendrikhovskij, S.; Blommaert, F.J.; de Ridder, H. Optimizing color reproduction of natural images. In Proceedings of the Color and Imaging Conference, Scottsdale, AZ, USA, 17–20 November 1998; Society for Imaging Science and Technology: Springfield, VA, USA, 1998; Volume 1998, pp. 140–145. [Google Scholar]
- Hasler, D.; Suesstrunk, S.E. Measuring colorfulness in natural images. In Human Vision and Electronic Imaging VIII; International Society for Optics and Photonics: Bellingham, WA, USA, 2003; Volume 5007, pp. 87–95. [Google Scholar]
- Matkovic, K.; Neumann, L.; Neumann, A.; Psik, T.; Purgathofer, W. Global contrast factor—A new approach to image contrast. Comput. Aesthet. 2005, 2005, 159–168. [Google Scholar]
- He, K.; Sun, J.; Tang, X. Single image haze removal using dark channel prior. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 2341–2353. [Google Scholar] [PubMed]
- Kovesi, P. Phase congruency detects corners and edges. In Proceedings of the Australian Pattern Recognition Society Conference, DICTA, Sydney, Australia, 10–12 December 2003; Volume 2003. [Google Scholar]
- Morrone, M.C.; Ross, J.; Burr, D.C.; Owens, R. Mach bands are phase dependent. Nature 1986, 324, 250–253. [Google Scholar] [CrossRef]
- Qiu, W.; Chen, Y.; Kishimoto, J.; de Ribaupierre, S.; Chiu, B.; Fenster, A.; Yuan, J. Automatic segmentation approach to extracting neonatal cerebral ventricles from 3D ultrasound images. Med Image Anal. 2017, 35, 181–191. [Google Scholar] [CrossRef] [PubMed]
- Kundu, D.; Ghadiyaram, D.; Bovik, A.; Evans, B. Large-scale crowdsourced study for high dynamic range images. IEEE Trans. Image Process. 2017, 26, 4725–4740. [Google Scholar] [CrossRef]
- Lin, H.; Hosu, V.; Saupe, D. KADID-10k: A large-scale artificially distorted IQA database. In Proceedings of the 2019 Eleventh International Conference on Quality of Multimedia Experience (QoMEX), Berlin, Germany, 5–7 June 2019; pp. 1–3. [Google Scholar]
- Larson, E.C.; Chandler, D.M. Most apparent distortion: Full-reference image quality assessment and the role of strategy. J. Electron. Imaging 2010, 19, 011006. [Google Scholar]
- Ponomarenko, N.; Battisti, F.; Egiazarian, K.; Astola, J.; Lukin, V. Metrics performance comparison for color image database. In Proceedings of the Fourth International Workshop on Video Processing and Quality Metrics for Consumer Electronics, Scottsdale, AZ, USA, 14–16 January 2009; Volume 27, pp. 1–6. [Google Scholar]
- Ye, P.; Kumar, J.; Kang, L.; Doermann, D. Unsupervised feature learning framework for no-reference image quality assessment. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 1098–1105. [Google Scholar]
- Moorthy, A.K.; Bovik, A.C. Blind image quality assessment: From natural scene statistics to perceptual quality. IEEE Trans. Image Process. 2011, 20, 3350–3364. [Google Scholar] [CrossRef]
- Xu, J.; Ye, P.; Li, Q.; Du, H.; Liu, Y.; Doermann, D. Blind image quality assessment based on high order statistics aggregation. IEEE Trans. Image Process. 2016, 25, 4444–4457. [Google Scholar] [CrossRef]
- Gu, Z.; Zhang, L.; Li, H. Learning a blind image quality index based on visual saliency guided sampling and Gabor filtering. In Proceedings of the 2013 IEEE International Conference on Image Processing, Melbourne, Australia, 15–18 September 2013; pp. 186–190. [Google Scholar]
- Venkatanath, N.; Praneeth, D.; Bh, M.C.; Channappayya, S.S.; Medasani, S.S. Blind image quality evaluation using perception based features. In Proceedings of the 2015 Twenty First National Conference on Communications (NCC), Mumbai, India, 27 February–1 March 2015; pp. 1–6. [Google Scholar]
- Liu, L.; Liu, B.; Huang, H.; Bovik, A.C. No-reference image quality assessment based on spatial and spectral entropies. Signal Process. Image Commun. 2014, 29, 856–863. [Google Scholar] [CrossRef]
- Fieller, E.C.; Hartley, H.O.; Pearson, E.S. Tests for rank correlation coefficients. I. Biometrika 1957, 44, 470–481. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Mean | Median | Standard Deviation | |
|---|---|---|---|
| Horizontal detail coefficients—Reference images | 0.026 | 0.020 | |
| Horizontal detail coefficients—Distorted images | 0.043 | 0.029 | |
| Vertical detail coefficients—Reference images | 0.024 | 0.018 | |
| Vertical detail coefficients—Distorted images | 0.042 | 0.027 | |
| Diagonal detail coefficients—Reference images | 0.029 | 0.026 | |
| Diagonal detail coefficients—Distorted images | 0.049 | 0.036 | |
| Gradient magnitudes—Reference images | 0.069 | 0.053 | |
| Gradient magnitudes—Distorted images | 0.073 | 0.058 |
| Database | Ref. Images | Test Images | Resolution | Distortion Levels | Number of Distortions |
|---|---|---|---|---|---|
| TID2008 [51] | 25 | 1700 | 4 | 17 | |
| TID2013 [39] | 25 | 3000 | 5 | 24 | |
| CSIQ [50] | 30 | 866 | 4–5 | 6 | |
| ESPL-LIVE HDR [48] | - | 1811 | - | - | |
| KADID-10k [49] | 81 | 10,125 | 5 | 25 |
| Distortion Level | TID2013 [39] | TID2008 [51] | ||
|---|---|---|---|---|
| PLCC | SROCC | PLCC | SROCC | |
| Level 1 | 0.383 | 0.448 | 0.478 | 0.484 |
| Level 2 | 0.355 | 0.423 | 0.452 | 0.494 |
| Level 3 | 0.288 | 0.307 | 0.719 | 0.675 |
| Level 4 | 0.592 | 0.560 | 0.791 | 0.758 |
| Level 5 | 0.746 | 0.739 | - | - |
| All | 0.697 | 0.667 | 0.741 | 0.707 |
| Distortion Type | TID2013 [39] | TID2008 [51] | ||
|---|---|---|---|---|
| PLCC | SROCC | PLCC | SROCC | |
| Additive Gaussian noise | 0.763 | 0.798 | 0.849 | 0.836 |
| Additive noise in color components | 0.572 | 0.813 | 0.599 | 0.699 |
| Spatially correlated noise | 0.963 | 0.969 | 0.899 | 0.914 |
| Masked noise | 0.425 | 0.532 | 0.385 | 0.495 |
| High frequency noise | 0.929 | 0.930 | 0.925 | 0.922 |
| Impulse noise | 0.586 | 0.619 | 0.745 | 0.761 |
| Quantization noise | 0.673 | 0.707 | 0.593 | 0.687 |
| Gaussian blur | 0.699 | 0.707 | 0.681 | 0.693 |
| Image denoising | 0.594 | 0.520 | 0.672 | 0.654 |
| JPEG compression | 0.877 | 0.972 | 0.835 | 0.866 |
| JPEG2000 compression | 0.913 | 0.872 | 0.848 | 0.817 |
| JPEG transmission errors | 0.003 | 0.080 | 0.031 | 0.108 |
| JPEG2000 transmission errors | 0.481 | 0.513 | 0.342 | 0.571 |
| Non eccentricity pattern noise | 0.007 | 0.044 | 0.001 | 0.009 |
| Local block-wise distortions | 0.600 | 0.673 | 0.784 | 0.847 |
| Mean shift | 0.038 | 0.001 | 0.258 | 0.012 |
| Contrast change | 0.409 | 0.416 | 0.361 | 0.444 |
| Change of color saturation | 0.771 | 0.757 | - | - |
| Multiplicative Gaussian noise | 0.931 | 0.990 | - | - |
| Comfort noise | 0.240 | 0.302 | - | - |
| Lossy compression of noisy images | 0.915 | 0.931 | - | - |
| Image color quantization with dither | 0.822 | 0.879 | - | - |
| Chromatic aberrations | 0.362 | 0.352 | - | - |
| Sparse sampling and reconstruction | 0.890 | 0.792 | - | - |
| All | 0.697 | 0.667 | 0.741 | 0.707 |
| ESPL-LIVE HDR [48] | KADID-10k [49] | CSIQ [50] | TID2013 [39] | TID2008 [51] | Weighted Average | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Method | PLCC | SROCC | PLCC | SROCC | PLCC | SROCC | PLCC | SROCC | PLCC | SROCC | PLCC | SROCC |
| BIQI [15] | 0.476 | 0.405 | 0.463 | 0.418 | 0.560 | 0.524 | 0.521 | 0.392 | 0.537 | 0.396 | 0.486 | 0.415 |
| BLIINDS-II [17] | 0.459 | 0.448 | 0.567 | 0.521 | 0.816 | 0.774 | 0.554 | 0.560 | 0.562 | 0.570 | 0.565 | 0.537 |
| BRISQUE [20] | 0.446 | 0.423 | 0.531 | 0.528 | 0.763 | 0.704 | 0.477 | 0.418 | 0.492 | 0.423 | 0.521 | 0.497 |
| CORNIA [52] | 0.684 | 0.624 | 0.588 | 0.551 | 0.809 | 0.711 | 0.710 | 0.612 | 0.699 | 0.608 | 0.641 | 0.582 |
| CurveletQA [26] | 0.547 | 0.544 | 0.501 | 0.467 | 0.631 | 0.584 | 0.554 | 0.503 | 0.598 | 0.562 | 0.531 | 0.496 |
| DIIVINE [53] | 0.483 | 0.489 | 0.529 | 0.470 | 0.793 | 0.768 | 0.689 | 0.599 | 0.698 | 0.610 | 0.581 | 0.522 |
| HOSA [54] | 0.691 | 0.683 | 0.625 | 0.620 | 0.821 | 0.797 | 0.760 | 0.675 | 0.725 | 0.701 | 0.674 | 0.653 |
| FRIQUEE [25] | 0.657 | 0.623 | 0.657 | 0.643 | 0.818 | 0.770 | 0.773 | 0.706 | 0.728 | 0.699 | 0.692 | 0.663 |
| GRAD-LOG-CP [23] | 0.540 | 0.540 | 0.501 | 0.467 | 0.834 | 0.821 | 0.669 | 0.635 | 0.713 | 0.716 | 0.571 | 0.545 |
| IQVG [55] | 0.408 | 0.416 | 0.552 | 0.534 | 0.796 | 0.753 | 0.596 | 0.524 | 0.631 | 0.591 | 0.564 | 0.536 |
| PIQE [56] | 0.025 | 0.033 | 0.289 | 0.237 | 0.644 | 0.522 | 0.462 | 0.364 | 0.427 | 0.327 | 0.322 | 0.261 |
| SSEQ [57] | 0.482 | 0.505 | 0.381 | 0.401 | 0.783 | 0.707 | 0.659 | 0.574 | 0.664 | 0.563 | 0.486 | 0.472 |
| NBIQA [28] | 0.655 | 0.658 | 0.632 | 0.625 | 0.834 | 0.799 | 0.720 | 0.674 | 0.724 | 0.697 | 0.668 | 0.652 |
| SPF-IQA (proposed) | 0.718 | 0.730 | 0.715 | 0.707 | 0.871 | 0.848 | 0.697 | 0.667 | 0.741 | 0.707 | 0.722 | 0.710 |
| Method | Length of the Feature Vector | Time Cost (seconds) |
|---|---|---|
| BIQI [15] | 18 | 0.011 |
| BLIINDS-II [17] | 24 | 20.200 |
| BRISQUE [20] | 36 | 0.020 |
| CORNIA [52] | 100 | 0.075 |
| CurveletQA [26] | 12 | 0.542 |
| DIIVINE [53] | 88 | 5.845 |
| FRIQUEE [25] | 560 | 7.807 |
| GRAD-LOG-CP [23] | 40 | 0.014 |
| HOSA [54] | 14,700 | 0.141 |
| IQVG [55] | 8000 | 12.970 |
| SSEQ [57] | 12 | 0.486 |
| NBIQA [28] | 51 | 7.775 |
| SPF-IQA (proposed) | 57 | 2.783 |
© 2020 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Varga, D. No-Reference Image Quality Assessment Based on the Fusion of Statistical and Perceptual Features. J. Imaging 2020, 6, 75. https://doi.org/10.3390/jimaging6080075
Varga D. No-Reference Image Quality Assessment Based on the Fusion of Statistical and Perceptual Features. Journal of Imaging. 2020; 6(8):75. https://doi.org/10.3390/jimaging6080075
Chicago/Turabian StyleVarga, Domonkos. 2020. "No-Reference Image Quality Assessment Based on the Fusion of Statistical and Perceptual Features" Journal of Imaging 6, no. 8: 75. https://doi.org/10.3390/jimaging6080075
APA StyleVarga, D. (2020). No-Reference Image Quality Assessment Based on the Fusion of Statistical and Perceptual Features. Journal of Imaging, 6(8), 75. https://doi.org/10.3390/jimaging6080075