
Design of Flexible Hardware Accelerators for Image Convolutions and Transposed Convolutions




Abstract
:1. Introduction
- A comprehensive evaluation of the state-of-the-art TCONV algorithms suitable for implementation in hardware is provided.
- An original TCONV approach, thought to avoid complex remapping of filter coefficients and suitable for exploitation also in CONV operations, is presented.
- A flexible reconfigurable hardware accelerator is proposed. It was purposely designed to adapt itself at run-time to two operating modes and to different kernel sizes, as required to support all operations employed in both CONV and TCONV layers.
- For evaluation purposes, the novel method was exploited in the context of SR imaging, and the proposed reconfigurable hardware architecture was used to accelerate the popular fast super resolution CNN (FSRCNN) [10]. The experiments, performed on the Xilinx XC7K410T field programmable gate array (FPGA) chip, demonstrated the benefits of the proposed approach in terms of area occupancy and energy saving over several state-of-the-art counterparts. In fact, the new accelerator exhibited a logic resource requirement and a power consumption up to ~63% and ~48% lower, respectively, than previous designs [11,13,14,15,16,17]. The adopted parallelism and the achieved 227 MHz running frequency allow the above advantages to be obtained without compromising the competitiveness of the proposed design in terms of speed performance.
2. Background and Related Works
3. The Hardware-Oriented Algorithm Proposed to Convert TCONVs into CONVs
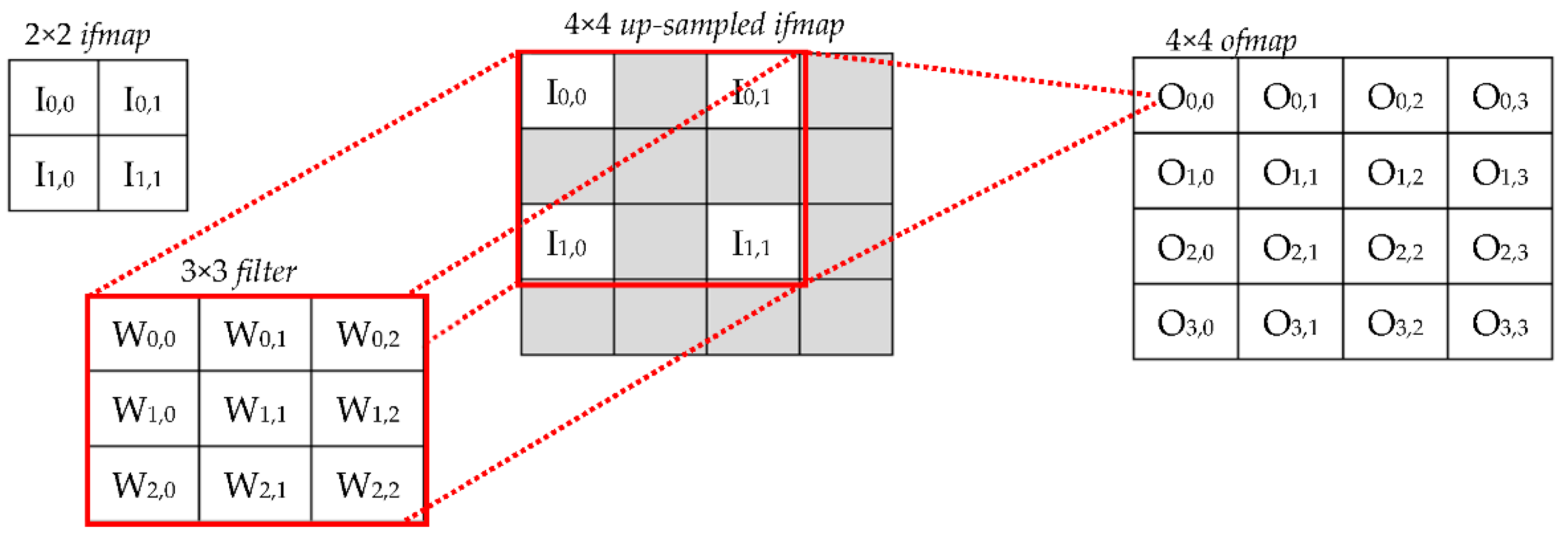
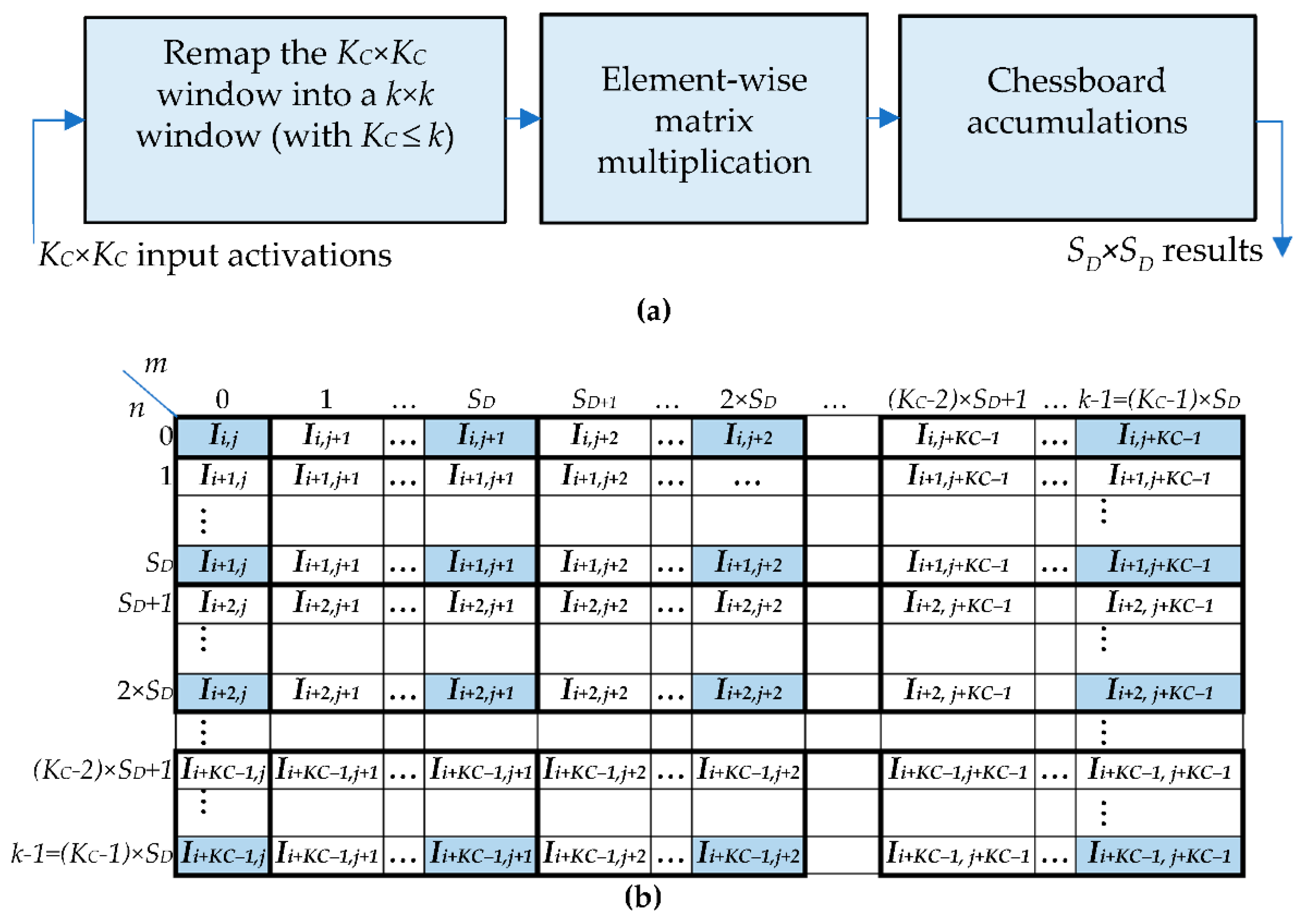
- The first activation Ii,j is assigned to the local position (0,0) within the up-sampled window RI and replicated no more;
- The activations with a row index equal to i are replicated SD times horizontally;
- The activations with a column index equal to j are replicated SD times vertically;
- The activations with row and column indices varying, respectively, from i + 1 to i + KC − 2 and from j + 1 to j + KC − 2, are replicated SD times vertically and SD times horizontally, thus forming SD × SD sub-windows, as illustrated in Figure 2b;
- If , the activations with a row index equal to KC − 1 are replicated SD times horizontally (this is the case illustrated in Figure 2b); otherwise, they are replicated times;
- If , the activations with a column index equal to KC − 1 are replicated SD times vertically (this is the case illustrated in Figure 2b); otherwise, they are replicated times.
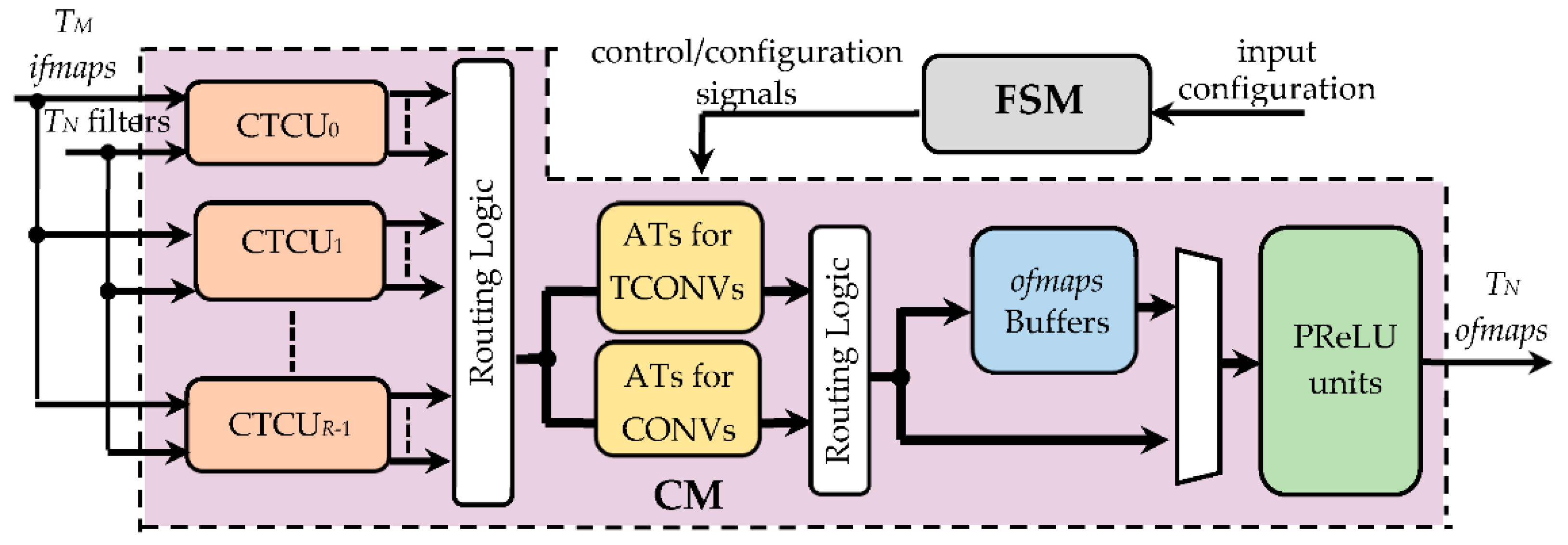
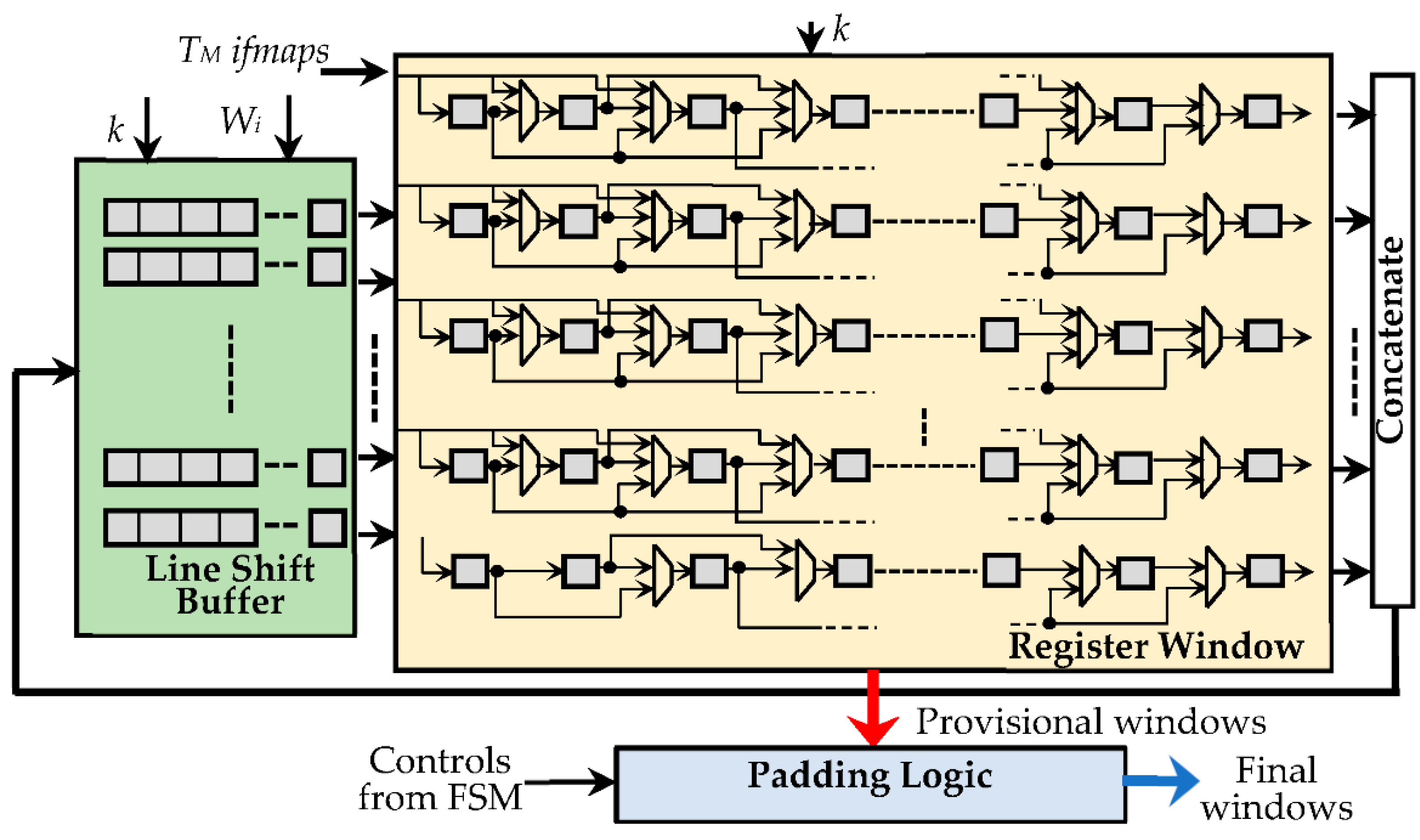
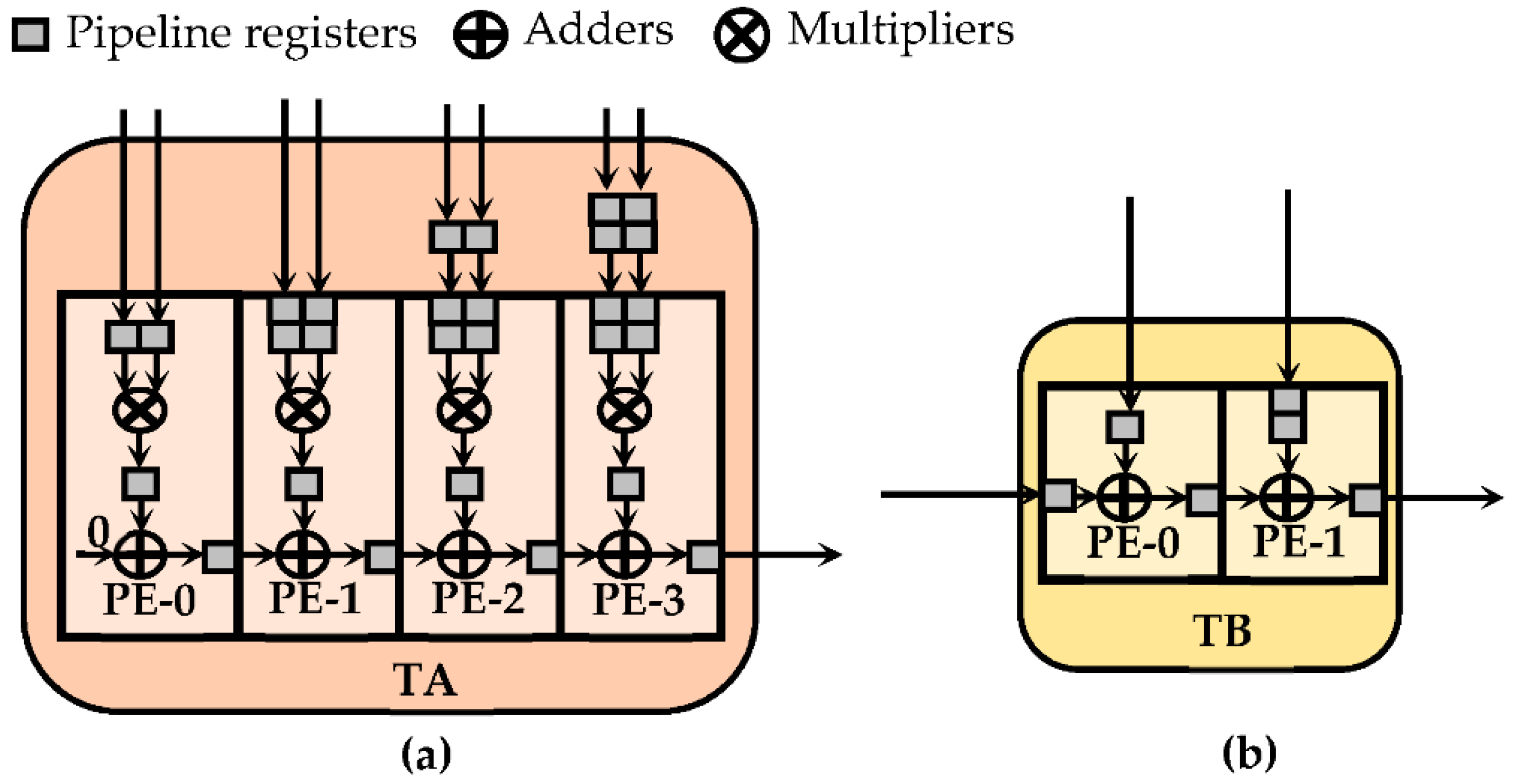
4. The Proposed Run-Time Reconfigurable Hardware Accelerator
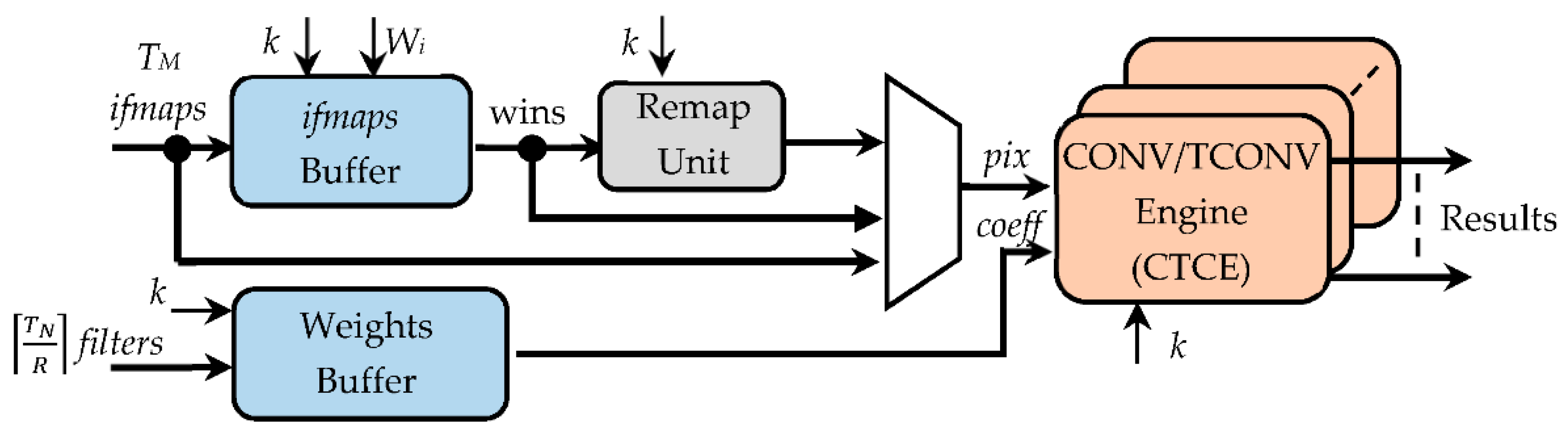
- The register window (RW), composed of KM × KM NA-bit registers, with KM being set to TM × k × k, thus ensuring that up to TM k × k sliding windows can be accommodated at a time. The sparse multiplexing logic visible in Figure 7 guarantees that the used registers are properly cascaded according to the current value of k.
- The line shift buffer, used to locally store Wi − k pixels of k − 1 rows of each received ifmap, and to perform shift operations, as conventionally required to properly accommodate the sliding windows during the overall computation.
- The padding logic, used to establish if the current sliding windows must be zero-padded, which occurs when the current anchor points are associated with the bordering pixels of the processed ifmaps.
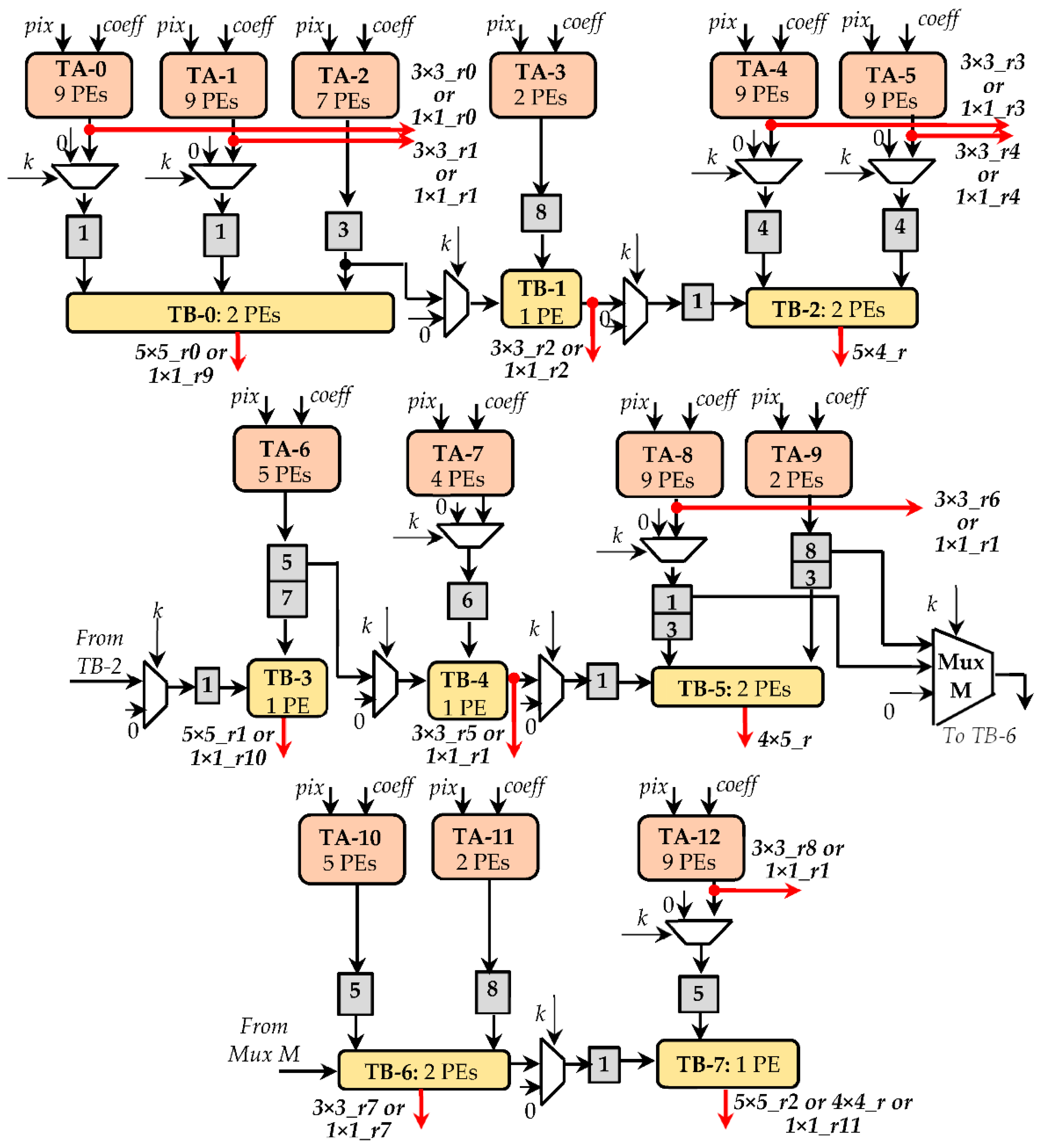
- Twelve 1 × 1 CONVs, whose results are 1 × 1_ru, with u = 0, …,11;
- Nine 3 × 3 CONVs, with the furnished results being 3 × 3_rx, with x = 0,…,8;
- Three 5 × 5 CONVs, whose results are 5 × 5_ry, with y = 0,…,2;
- One 7 × 7 CONV; in this case the results 5 × 5_r0 and the 5 × 5_r1 are added by the external module ATs for CONVs;
- One 9 × 9 CONV; in such a case the results 5 × 5_r0, the 5 × 4_r, 4 × 5_r, and 4 × 4_r are summed up by the external module ATs for CONVs.
5. Experimental Results and Comparisons
- -
- The amount of occupied look-up tables (LUTs), flip-flops (FFs), blocks of random access memory (BRAMs), and digital signal processing slices (DSPs);
- -
- The power consumption, estimated through the switching activity values file (SAIF) that, referring to several benchmark images, taking into account the real activities of all nodes within the analyzed circuit;
- -
- The speed performance, evaluated in terms of the maximum running frequency and the giga operations per second (GOPS), which is the ratio between the overall computational complexity of the referred model and the inference time;
- -
- The energy efficiency (GOPS/W), which is defined as the ratio between the GOPS and the power consumption.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

References
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wei, Y.; Xia, W.; Lin, M.; Huang, J.; Ni, B.; Dong, J.; Zhao, Y.; Yan, S. HCP: A Flexible CNN Framework for Multi-Label Image Classification. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 1901–1907. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dolz, J.; Gopinath, K.; Yuan, J.; Lombaert, H.; Desrosiers, C.; Ben Ayed, I. HyperDense-Net: A Hyper-Densely Connected CNN for Multi-Modal Image Segmentation. IEEE Trans. Medic. Imaging 2019, 38, 1116–1126. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Wu, R.; Guo, X.; Du, J.; Li, J. Accelerating Neural Network Inference on FPGA-Based Platforms—A Survey. Electronics 2021, 10, 1025. [Google Scholar] [CrossRef]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image Super-Resolution Using Deep Convolutional Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 295–307. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chang, H.; Yeung, D.Y.; Xiong, Y. Super-resolution through neighbor embedding. In Proceedings of the 2004 IEEE Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 27 June–2 July 2004. [Google Scholar]
- Yang, J.; Wright, J.; Huang, T.S.; Ma, Y. “Image super-resolution via sparse representation. IEEE Trans. Image Process. 2010, 19, 2861–2873. [Google Scholar] [CrossRef] [PubMed]
- Dong, C.; Loy, C.C.; Tang, X. Accelerating the super-resolution convolutional neural network. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016. [Google Scholar]
- Chang, J.-W.; Kang, K.-W.; Kang, S.-J. An Energy-Efficient FPGA-Based Deconvolutional Neural Networks Accelerator for Single Image Super-Resolution. IEEE Trans. Circ. Syst. Video Tech. 2020, 30, 281–295. [Google Scholar] [CrossRef] [Green Version]
- Perri, S.; Sestito, C.; Spagnolo, F.; Corsonello, P. Efficient Deconvolution Architecture for Heterogeneous Systems-on-Chip. J. Imaging 2020, 6, 85. [Google Scholar] [CrossRef] [PubMed]
- Mao, W.; Lin, J.; Wang, Z. F-DNA: Fast Convolution Architecture for Deconvolutional Neural Network Acceleration. IEEE Trans. VLSI 2020, 28, 1867–1880. [Google Scholar] [CrossRef]
- Tang, Z.; Luo, G.; Jiang, M. FTConv: FPGA Acceleration for Transposed Convolution Layers in Deep Neural Networks. In Proceedings of the 2019 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Seaside, CA, USA, 24–26 February 2019. [Google Scholar]
- Shi, B.; Tang, Z.; Luo, G.; Jiang, M. Winograd-based Real-Time Super-Resolution System on FPGA. In Proceedings of the 2019 International Conference on Field-Programmable Technology, Tianjin, China, 9–13 December 2019. [Google Scholar]
- Kim, Y.; Choi, J.-S.; Kim, M. A Real-Time Convolutional Neural Network for Super-Resolution on FPGA with Applications to 4k UHD 60 fps Video Services. IEEE Trans. Circ. Syst. Video Tech. 2019, 29, 2521–2534. [Google Scholar] [CrossRef]
- Lee, S.; Joo, S.; Ahn, H.K.; Jung, S.-O. CNN Acceleration with Hardware-Efficient Dataflow for Super-Resolution. IEEE Access 2020, 8, 187754–187765. [Google Scholar] [CrossRef]
- Dumoulin, V.; Visin, F. A Guide to convolution arithmetic for deep learning. arXiv 2021, arXiv:1603.07285. [Google Scholar]
- Yu, Y.; Zhao, T.; Wang, M.; Wang, K.; He, L. Uni-OPU: An FPGA-Based Uniform Accelerator for Convolutional and Transposed Convolutional Networks. IEEE Trans. VLSI 2020, 28, 1545–1556. [Google Scholar] [CrossRef]
- Sestito, C.; Spagnolo, F.; Corsonello, P.; Perri, S. Run-Time Adaptive Hardware Accelerator for Convolutional Neural Networks. In Proceedings of the 16th Conference on PhD Research in Microelectronics and Electronics, online, 19–22 July 2021. [Google Scholar]
- Yazdanbakhsh, A.; Brzozowki, M.; Khaleghu, B.; Ghodrati, S.; Samadi, K.; Kim, N.S.; Esmeilzadeh, H. FlexiGAN: An End-to-End Solution for FPGA Acceleration of Generative Adversarial Networks. In Proceedings of the 2018 IEEE 26th Annual Symposium on Field-Programmable Custom Computing Machines, Boulder, CO, USA, 29 April–1 May 2018. [Google Scholar]
- Wang, D.; Shen, J.; Wen, M.; Zhang, C. Efficient Implementation of 2D and 3D Sparse Deconvolutional Neural Networks with a Uniform Architecture on FPGAs. Electronics 2019, 8, 803. [Google Scholar] [CrossRef] [Green Version]
- Di, X.; Yang, H.-G.; Jia, Y.; Huang, Z.; Mao, N. Exploring Efficient Acceleration Architecture for Winograd-Transformed Transposed Convolution of GAN on FPGAs. Electronics 2020, 9, 286. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. In Proceedings of the 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015. [Google Scholar]
- ZCU102Evaluation Board User Guide UG1182 (v1.6). Available online: https://www.xilinx.com/content/dam/xilinx/support/documentation/boards_and_kits/zcu102/ug1182-zcu102-eval-bd.pdf (accessed on 24 September 2021).
- Shi, W.; Caballero, J.; Huszar, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In Proceedings of the the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Processing 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bevilacqua, M.; Roumy, A.; Guillemot, C.; Morel, M.L.A. Low-complexity single-image super-resolution based on nonnegative neighbor embedding. In Proceedings of the British Machine Vision Conference, Surrey, UK, 7–10 September 2020; pp. 1–10. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Op Mode | M | N | k | SD | TM | TN | PN |
|---|---|---|---|---|---|---|---|---|
| 1 | CONV | 1 | 56 | 5 | 1 | 1 | 3 × R | 1 |
| 2 | CONV | 56 | 12 | 1 | 1 | 56 | R | 1 |
| 3 | CONV | 12 | 12 | 3 | 1 | 9 | R | 1 |
| 4 | CONV | 12 | 12 | 3 | 1 | 9 | R | 1 |
| 5 | CONV | 12 | 12 | 3 | 1 | 9 | R | 1 |
| 6 | CONV | 12 | 12 | 3 | 1 | 9 | R | 1 |
| 7 | CONV | 12 | 56 | 1 | 1 | 12 | 3 × R | 1 |
| 8 | TCONV | 56 | 1 | 9 | 2, 3, or 4 | R | 1 | 4, 9, or 16 |
| Accelerator | Proposed | Proposed | [11] | [13] | [15] | [17] | |
|---|---|---|---|---|---|---|---|
| FPGA Device | XCK410T | XCZU9EG | XCK410T | XCVU095 | XCZU9EG | XCVU9P | |
| Model FSRCNN(x,y,z,w) | (56, 12, 4, 9) | (56, 12, 4, 9) | (25, 5, 1, 7) | (56, 12, 4, 8) | (32, 5, 1, 9) | (32, 5, 1, -) 2 | |
| Variable k | Yes, No | Yes, No | No, Yes | Yes, 1 Yes | No, No | No, No | |
| Supported SD | 2, 3, 4 | 2, 3, 4 | 2, 3, 4 | 2, 3, 4 | 2 | 2 | |
| #bits (activations, filters) | (16, 10) | (16, 10) | (13, 13) | (16, 8) | (16, 16) | (14, 10) | |
| Max frequency [MHz] | 227 | 250 | 130 | 200 | 200 | 200 | |
| LUTs | SD = 2 | 63.1 k | 60.6 k | 167 k | 42 k | 168.6 k | 94 k |
| SD = 3 | 56.9 k | 54.6 k | - | - | |||
| SD = 4 | 77.2 k | 74.4 k | - | - | |||
| FFs | SD = 2 | 101.2 k | 101.2 k | 158 k | 20 k | NA | 19 k |
| SD = 3 | 85.5 k | 85.5 k | - | - | |||
| SD = 4 | 122.8 k | 122.8 k | - | - | |||
| BRAMs [Mb] | SD = 2 | 14.3 | 12 | 7.2 | 4.85 | 10.9 | 0.4 |
| SD = 3 | 14.3 | 12 | - | - | |||
| SD = 4 | 18.6 | 15.5 | - | - | |||
| DSPs | SD = 2 | 1212 | 1212 | 1512 | 576 | 746 | 2146 |
| SD = 3 | 1140 | 1140 | - | - | |||
| SD = 4 | 1296 | 1296 | - | - | |||
| Power [W] | SD = 2 | 3.6 | 3.8 | 5.4 | 3.71 | NA | 6.9 |
| SD = 3 | 3.5 | 3.85 | - | - | - | - | |
| SD = 4 | 3.9 | 4 | - | - | - | - | |
| GOPS | SD = 2 | 654.3 | 720.6 | 780 | 605.6 | 795.2 3 | 541.4 4 |
| SD = 3 | 1223.5 | 1347.5 | 1576.3 | 1086.1 | - | - | |
| SD = 4 | 2022.2 | 2227 | 2691 | 1868.8 | - | - | |
| GOPS/W | SD = 2 | 181.8 | 189.6 | 144.9 | 163.7 | NA | 78.5 |
| SD = 3 | 349.6 | 350 | 293 | 293.5 | - | - | |
| SD = 4 | 518.5 | 556.8 | 500.2 | 505.1 | - | - | |
| Proposed | [11] | [13] | [17] | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Dataset | SD | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM |
| Set-5 | 2 | 35.68 | 0.9459 | 36.40 | 0.9527 | 35.85 | NA | 36.42 | 0.9529 |
| Set-14 | 2 | 31.34 | 0.8650 | 32.21 | 0.9047 | NA | NA | 32.27 | 0.9045 |
| B100 | 2 | 30.28 | 0.8765 | 31.15 | 0.8858 | NA | NA | 31.18 | 0.8859 |
| Set-5 | 3 | 32.52 | 0.8816 | 32.48 | 0.9043 | 32.03 | NA | NA | NA |
| Set-14 | 3 | 29.04 | 0.7975 | 29.03 | 0.8146 | NA | NA | NA | NA |
| B100 | 3 | 28.27 | 0.7854 | 28.25 | 0.7808 | NA | NA | NA | NA |
| Set-5 | 4 | 30.6 | 0.8577 | 30.17 | 0.8532 | 29.48 | NA | NA | NA |
| Set-14 | 4 | 27.52 | 0.7480 | 27.24 | 0.7414 | NA | NA | NA | NA |
| B100 | 4 | 26.90 | 0.7135 | 26.71 | 0.7041 | NA | NA | NA | NA |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sestito, C.; Spagnolo, F.; Perri, S. Design of Flexible Hardware Accelerators for Image Convolutions and Transposed Convolutions. J. Imaging 2021, 7, 210. https://doi.org/10.3390/jimaging7100210
Sestito C, Spagnolo F, Perri S. Design of Flexible Hardware Accelerators for Image Convolutions and Transposed Convolutions. Journal of Imaging. 2021; 7(10):210. https://doi.org/10.3390/jimaging7100210
Chicago/Turabian StyleSestito, Cristian, Fanny Spagnolo, and Stefania Perri. 2021. "Design of Flexible Hardware Accelerators for Image Convolutions and Transposed Convolutions" Journal of Imaging 7, no. 10: 210. https://doi.org/10.3390/jimaging7100210
APA StyleSestito, C., Spagnolo, F., & Perri, S. (2021). Design of Flexible Hardware Accelerators for Image Convolutions and Transposed Convolutions. Journal of Imaging, 7(10), 210. https://doi.org/10.3390/jimaging7100210