This section covers the multiple object-tracking stage methodologies. It will involve the challenges of MOT and how these challenges are being solved in state-of-the-art solutions. Next, design decisions and considerations are detailed. Lastly, a thorough explanation of the chosen solution of the MOT stage is presented.
4.1. Brief Review of MOT
MOT is another fundamental computer vision problem. Like other computer vision challenges, MOT has become a research hotspot with the rapid development of deep neural network (DNN). According to [
25], the task of MOT is predominantly partitioned into locating multiple objects, maintaining their identities, and yielding their trajectories. The rapid development in DNN has significantly improved the accuracy of object detection. As a result, the framework tracking-by-detection has become the most popular framework to solve the challenge of MOT.
The tracking-by-detection framework works by decoupling the task of the detector and the tracker. The task of the detector is to detect all objects in each frame. These detected objects are then fed to the tracker. The tracker performs data association on the detected objects across frames to obtain their trajectories. Therefore, the data association problem is a key step to overcome in a tracking-by-detection framework. As the tracking algorithm relies on detections from the detector to locate objects in each frame, the tracker’s performance largely depends on the quality of the detector. On
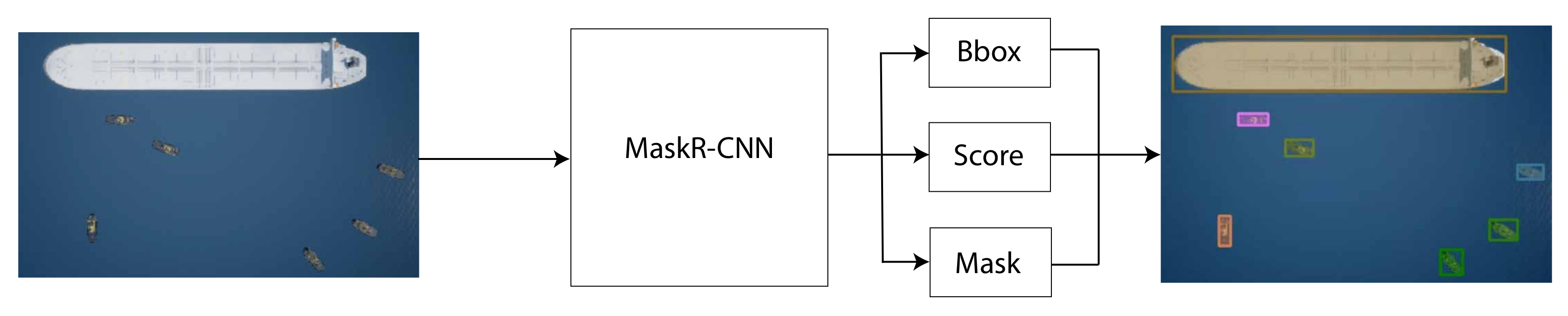
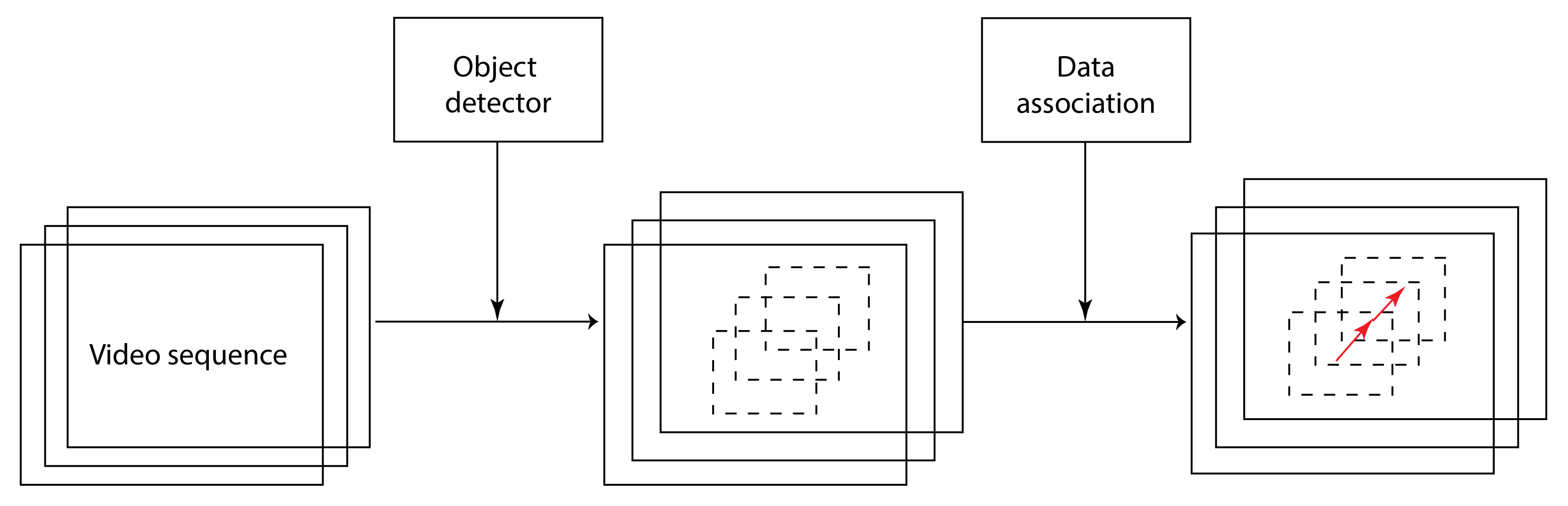
Figure 12 is a high-level illustration of the tracking-by-detection framework.
Data association is the process of associating uncertain detections to known tracks. The typical data association procedure is first to make a new detection, then from the predicted tracks yield a space where the detection is expected. This space is also called a validation gate. Lastly, there is a match if the new measurement lies within the validation gate space.
The problem of data association has been solved in numerous ways. One of the simplest ways is used in [
26], in which the authors propose to solve the data association problem by associating detections across frames using their spatial overlap as validation gate. Because of the aforementioned significant increase in object detectors’ quality, straightforward tracking algorithms such as the IoU tracker can achieve good results. Furthermore, because they are simple, data association can be done at a high frame rate. However, if challenging scenarios such as camera motion, occlusion of objects, or crowded scenes occur, simple data association methods fall through, and more complex algorithms are needed.
Hungarian method, also known as Kuhn–Munkers algorithm [
27] is another used method to perform data association in the MOT problem. The algorithm was first introduced to solve the assignment problem in polynomial time. When the algorithm is applied to the MOT problem, it is explained as finding the optimal matching solution for several targets. This makes it possible to pair new detections to tracks based on a predefined score. Examples of scores are the overlap of bounding boxes across frames or the cosine distance between feature vectors generated by a convolutional neural network (CNN). An assignment cost matrix is then computed based on the score, and matching is done by solving the assignment problem optimally with the Hungarian algorithm.
MOT algorithms can be divided into two different categories: Offline methods and online methods. Offline methods, also called batch tracking algorithms have access to future information (i.e., future frames) when associating detections across frames. Often no inference time requirements restrict these methods allowing for more complex solutions yielding better overall performance. Online tracking algorithms, on the contrary, only have access to current and past information to make predictions in the current frame. Another important reason online tracking algorithms perform worse is that they cannot fix past errors by looking into future frames. Even though online tracking algorithms only use past and present information, they do not necessarily run in real time. Often, they are too slow to run on real-time equipment. Therefore, online real-time tracking algorithms are required to be simple and avoid complex computations to achieve real-time inference requirements [
28].
4.2. Design Decisions and Considerations
This section provides an overview of the considerations and design decisions for the MOT stage. Different solutions will be discussed and compared, leading to a final solution for implementation.
The input to the MOT stage is the axis-aligned bounding boxes outputted by the object detection stage. The output of the MOT stage is a velocity vector of each tracked object. This is the black box representation of inputs and outputs of the tracking stage.
Two main tasks can be derived for the MOT stage to complete:
Task 1 of the MOT stage is to overcome the data association problem described in the previous section. This system is aimed to run on a UAV with limited computational power in real time. Consequently, the tracking algorithm must compute and run the tracking online, with low inference time. The camera is attached to the underside of the UAV making the tracking problem less complex as it can be assumed objects in the image cannot occlude each other. This is a crucial assumption because 3D scenes require a more complex tracking network to solve the task of MOT.
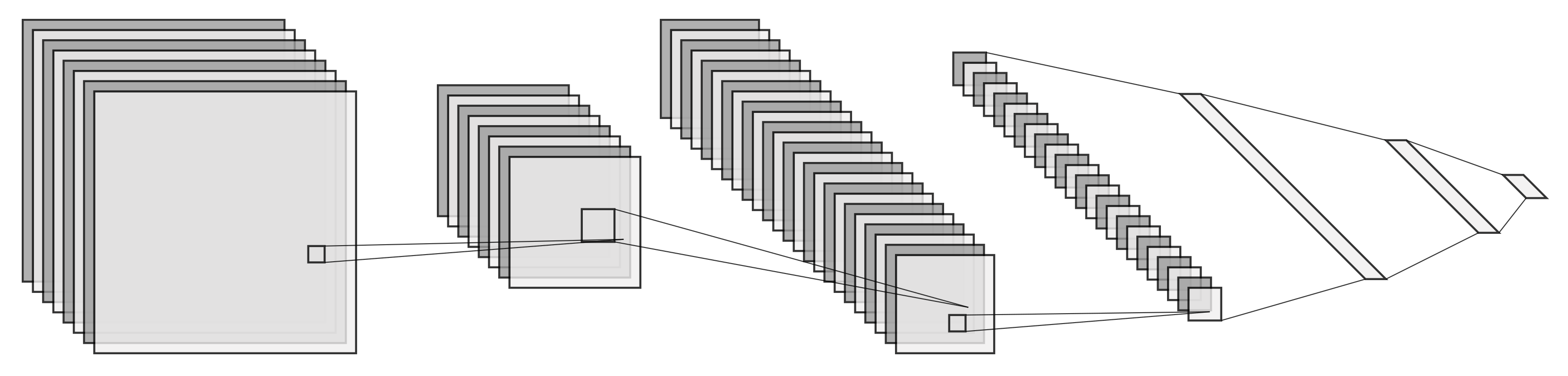
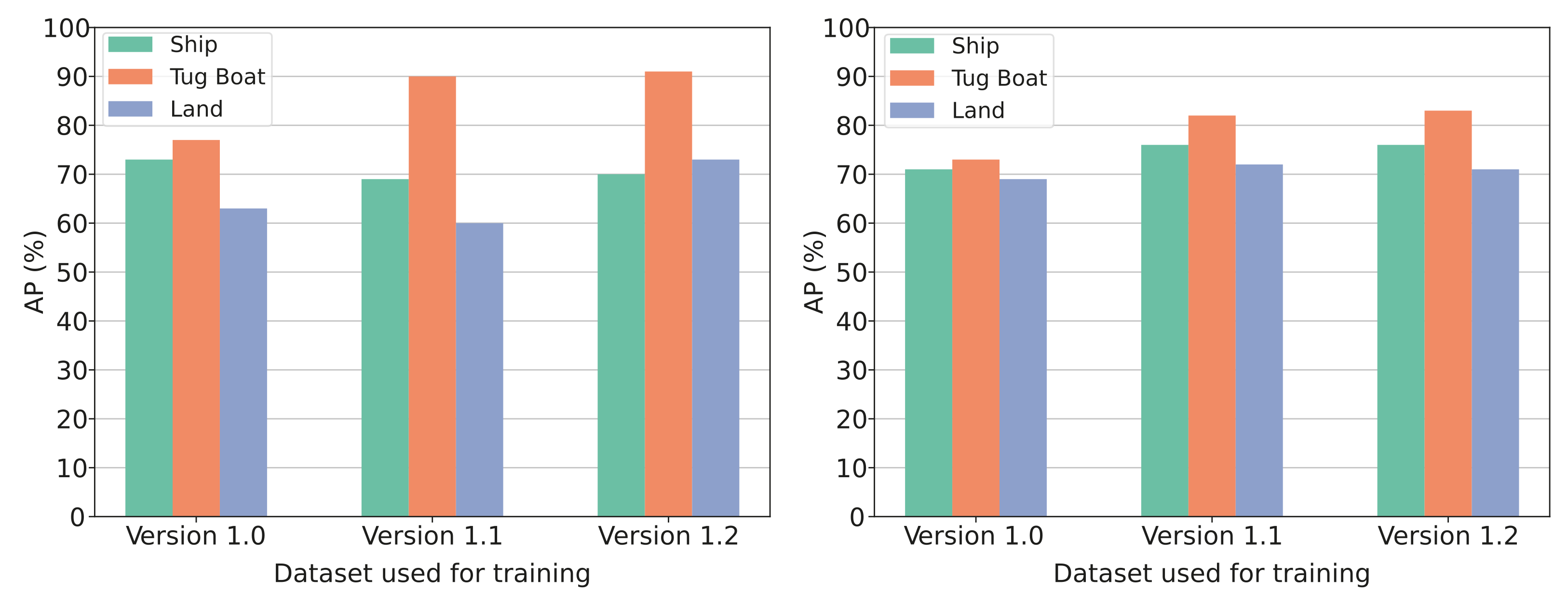
The increasing research attention on MOT has lately boosted the number of MOT algorithms that follow the tracking-by-detection framework, making it impossible to investigate and evaluate all tracking algorithms. Therefore, has a small number of algorithms been chosen for comparison in the following. For this work, TrackR-CNN [
16], SORT [
15], Deep SORT [
29] and Flow-Tracker [
30] have been considered, each with their own pros and cons. All these four contenders are tracking algorithms by the tracking-by-detection framework and can work in continuation of the object detection stage.
As mentioned in the
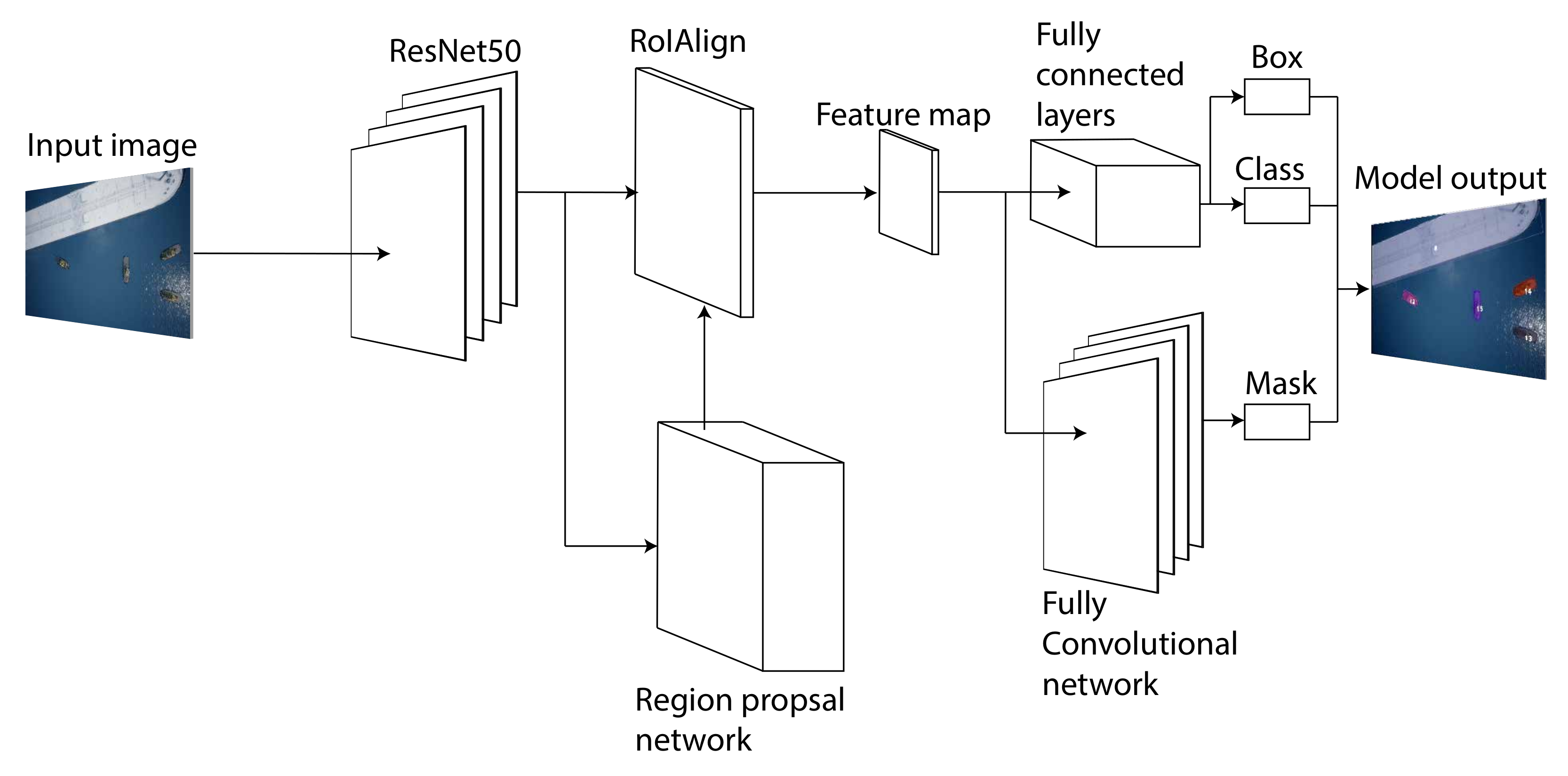
Section 3.2 were the TrackR-CNN considered to be a network for handling both instance-based semantic segmentation and object tracking as an extension of Mask R-CNN using 3D convolutions. This network was discarded because of the unnecessary complexity introduced by 3D-convolution layers. In [
16] the authors presented a high inference time resulting in 2 frames per second (FPS) on a Titan X (Pascal), with an extensive need for memory as three images are fed in at once. This makes the TrackR-CNN unsuited for real-time tracking.
Both SORT [
15] and Deep SORT [
29] were considered to solve the MOT problem. Deep SORT is an extension of SORT, and the architecture of the two algorithms is much alike. Both algorithms are based on Kalman filter and the Hungarian algorithm to solve the data association problem. SORT is the simpler one and uses the IoU distance between each detection and all predicted bounding boxes from existing targets as an assignment problem solved by the Hungarian algorithm. Deep SORT instead uses a small CNN to extract feature vectors from each detection and calculate the smallest cosine distance fused with the Mahalanobis distance between predicted Kalman states and detections as an assignment problem solved by the Hungarian algorithm. This difference makes the Deep SORT better at handling occlusions and objects leaving and re-entering the scene without ID switches, but it comes with a computational cost. The authors ran both tracking algorithms on a GTX 1050 mobile GPU and achieved 60 fps for SORT and 40 fps for Deep SORT, with a significant decrease in ID switches for Deep SORT. With both tracking algorithms well suited for online real-time tracking and Deep SORT achieving better tracking accuracy, Deep SORT is a better contender for a tracking algorithm in this work. Another advantage of using a tracking algorithm based on the Kalman filter is the state estimation. A velocity vector of the tracked objects can be derived from the Kalman filter, to achieve task 2 listed above.
The Flow-Tracker proposed in [
30] is another MOT tracker following the tracking-by-detection scheme. The Flow-Tacker uses an IoU Tracker as a baseline because of its simplicity and high efficiency. The simplicity and high efficiency come at a cost as camera motion leads to many errors and ID switches. The authors accommodate for this by eliminating the effect of camera motion by estimating the motion between two adjacent frames. The method also uses a small CNN to extract feature vectors of bounding boxes to minimize the number of ID switches. Flow-Tracker was tested on a GTX1080Ti GPU and scored a speed of 5 fps. Even though this tracker scores high on average accuracy and precision compared to Deep SORT, the tracker’s inference time is too high to be considered a real-time tracker and therefore discarded. Deep SORT is chosen in this work, for its accuracy and real-time capabilities. Furthermore, Deep SORT uses a Kalman filter which enables easy extraction of each object’s velocity vector.
4.3. Chosen Solution in Detail
To perform MOT the deep learning-based tracking algorithm, Deep SORT [
29] is used. Deep SORT is based on a frame-by-frame data association method and Kalman filtering. This method is aimed at tracking scenarios where the camera is not calibrated, and no ego-motion of the camera is available.
On
Figure 13 is a simplified pipeline of how the Deep SORT algorithm is integrated into the proposed solution. The detector feeds axis-aligned bounding boxes corresponding to new detections to the tracker. This step is illustrated on the first box of
Figure 13.
Deep SORT uses the Hungarian algorithm, to solve the data association problem. The first step within Deep SORT is to compute the association metric, which is a fusion of motion and appearance information.
The motion information is measured as the Mahalanobis distance between the predicted Kalman states and the newly measured states. Camera motion or occlusion of the camera’s viewpoint can introduce rapid and unpredictable changes in the placement of objects from frame to frame, making the Mahalanobis distance metric uninformed for tracking. Therefore, an additional metric is introduced to the assignment problem solved by the Hungarian method. For each bounding box, an appearance descriptor is computed by a pre-trained CNN. This CNN consists of two convolution layers, one max-pooling layer, six residual block layers, and at last, a dense, fully connected layer resulting in a feature vector of size 128. The second metric is calculated as the smallest cosine distance between the tacked and the newly generated feature vectors obtained from new detections. The CNN has been trained on 40 instances of each class. These two metrics are fused into one by a weighted sum
where
is the weighted sum metric of
i-th track and
j-th bounding box,
is a hyper parameter,
and
is the motion metric and appearance metric. This metric is used to solve the association problem with the Hungarian method (the second block within Deep SORT in
Figure 13).
The output of the Hungarian algorithm is either a match between a track and a new bounding box, an unmatched track, or an unmatched bounding box. If it is a match between a track and a new bounding box, the track will be updated with new information, and the age of the track be reset to 0. If it is an unmatched track, the age of the track is incremented by one. If it is an unmatched detection, a new track is made. The age of a track makes sure it is not deleted if the track is not matched with a new detection for a couple of frames. This can happen if an object is occluded or leaves the viewpoint of the camera.
Track handling and the Kalman filtering framework are an integral part of Deep SORT. How Deep SORT defines the tracking scenario and performs track state updates is explained in detail. Bounding boxes fed to the Deep SORT algorithm has the format , where is the center coordinate of the bounding box, is the aspect ratio, and h is the height of the bounding box.
Deep SORT describes the tracking scenario as an eight-dimensional state space . is the velocity in x, y direction and velocity in aspect ratio and height. Deep SORT uses a standard Kalman filter with constant velocity and take bounding-box coordinates as direct observations for the object state.
The Kalman filter updates a track’s state if a match between a new detection and a track is made. This is done using the estimated state of the track from the previous time step and the measured state of the detection at the current time step to estimate the current state of the track. This makes the Kalman filter a recursive estimator. The Kalman filter equations can be written in a single equation, but it is usually explained in two distinct phases: the predict and the update phase. The predict phase produces an estimate of the current state of an object using the state estimate of the object at the previous time step. In this context, the predict phase will estimate the current state of a track using the estimated state of the track at the previous frame. Equations (
4) and (
5) are two equations to explain the predict phase of the Kalman filter.
where
is the estimated state of the track at frame k,
is the state transformation at frame k describing how the track propagates through time,
is the estimated state of the track at frame
k−1.
is the estimated covariance at frame k and explains the uncertainty of state parameters. State parameter are
.
are used as the predicted state when calculating the Mahalanobis distance between the predicted state of a track and the measured state of new detection.
The update phase calculates the residual difference in the current prediction state of the track with the current measured state of the track. On Equations (
6)–(
10) are the equations to explain the update phase listed.
is the measurement pre-fit residual. It calculates the mean error between the observed position of the track and the estimated position of the track.
is the track position at the current frame k.
is called a measurement matrix and are ones on the diagonal where the observations are located.
is the pre-fit residual covariance,
is a noise matrix of the track. It is a 4 × 4 diagonal matrix with the noise of the center point
, width, and height as values, according to:
is the Kalman gain. The Kalman gain is a fusion of the uncertainty in the state parameters
and the uncertainty in the observations
.
is the enhanced estimation of the estimated state at the current frame k using the Kalman gain
together with the measurement pre-fit residual
and add it to the estimated
This is the final step of the update phase. is the updated covariance matrix at the current frame k. It is calculated by Kalman gain and the estimate covariance
After all states of the newly matched tracks have been updated, state parameters and that describes the velocity of a tracked object in x and y direction are derived and used as the output of the MOT stage.
We note that for the sake of simplicity, in the current proposed solution only the vessels’ motion is modeled, and self-motion unconsidered. However, self-motion could be easily introduced by accounting for inertial and absolute measurement sensors placed on the UAV (e.g., GPS, IMU, altimeter).


 ,
, 
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}