
Robust 3D Face Reconstruction Using One/Two Facial Images


Abstract
:1. Introduction
2. Related Work
3. Methodology
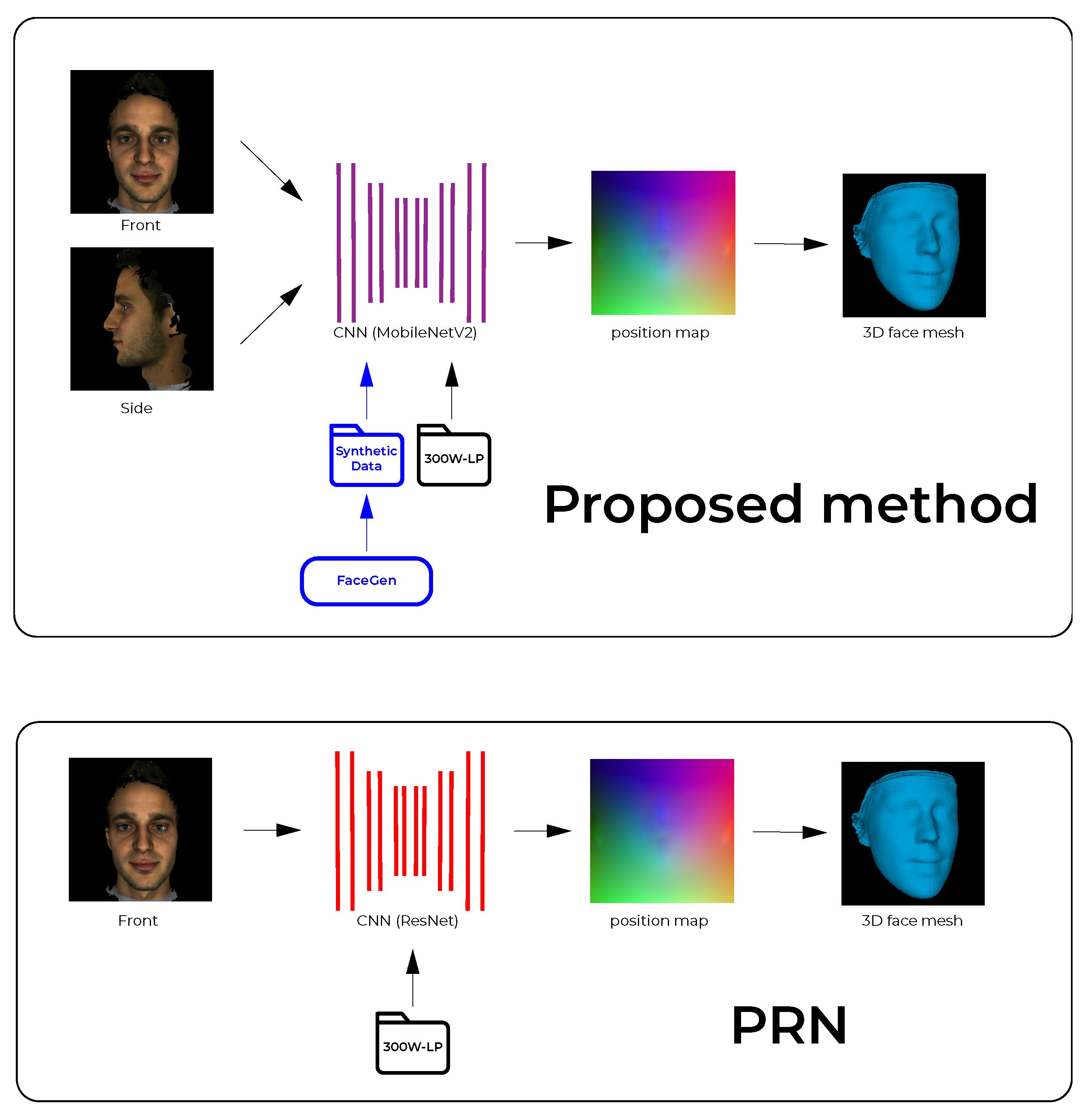
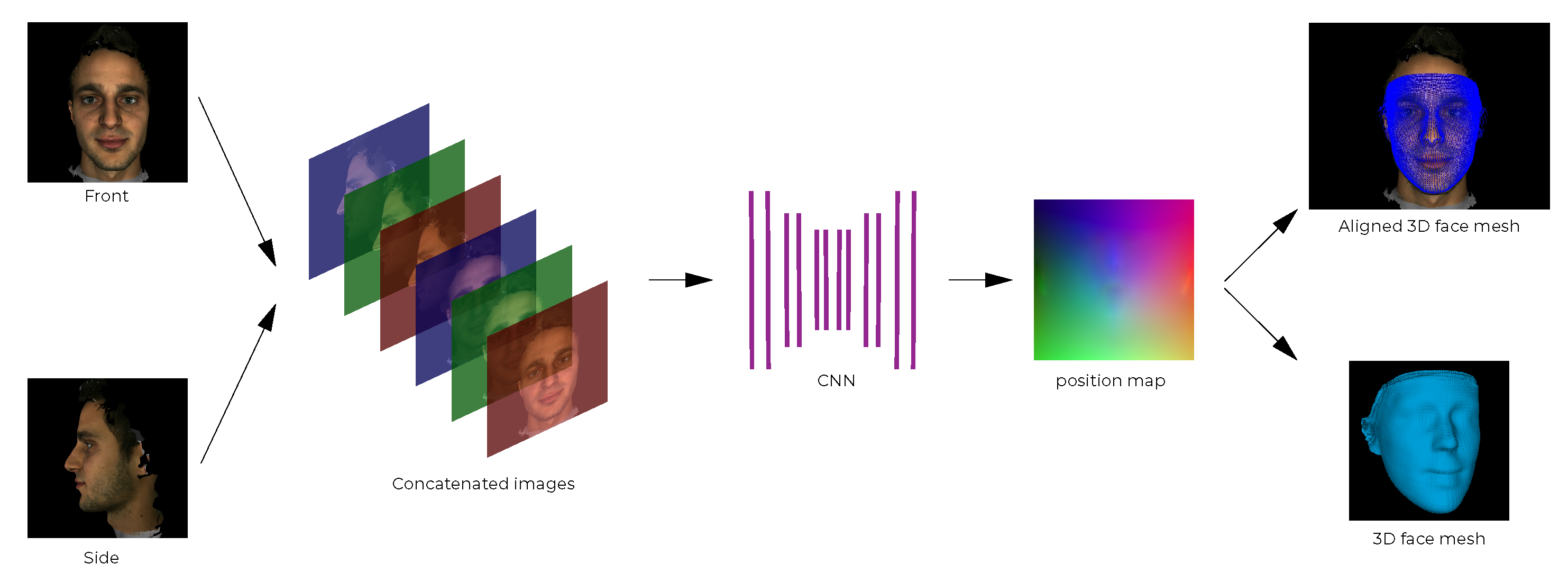
3.1. 3D Face Reconstruction Using Front and Side Facial Images
3.1.1. Proposed Pipeline
3.1.2. Real Training Data
- 300W-LP Dataset
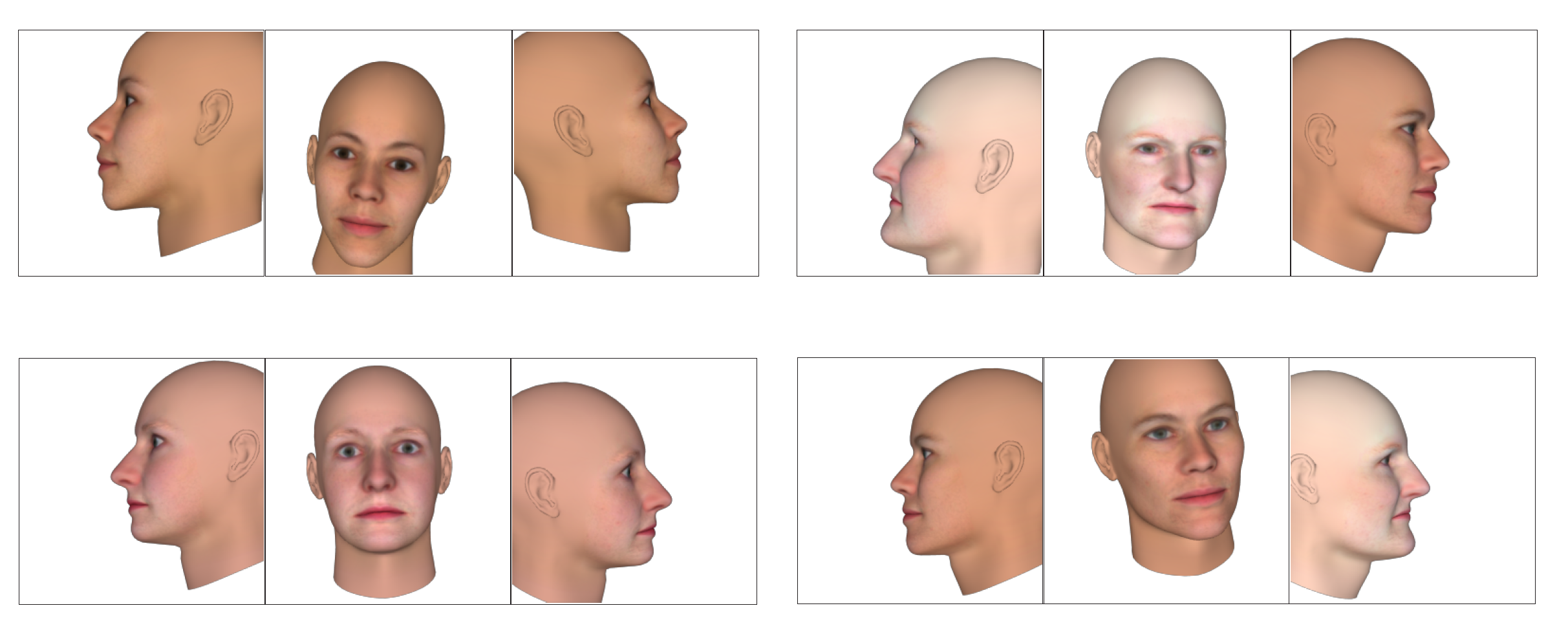
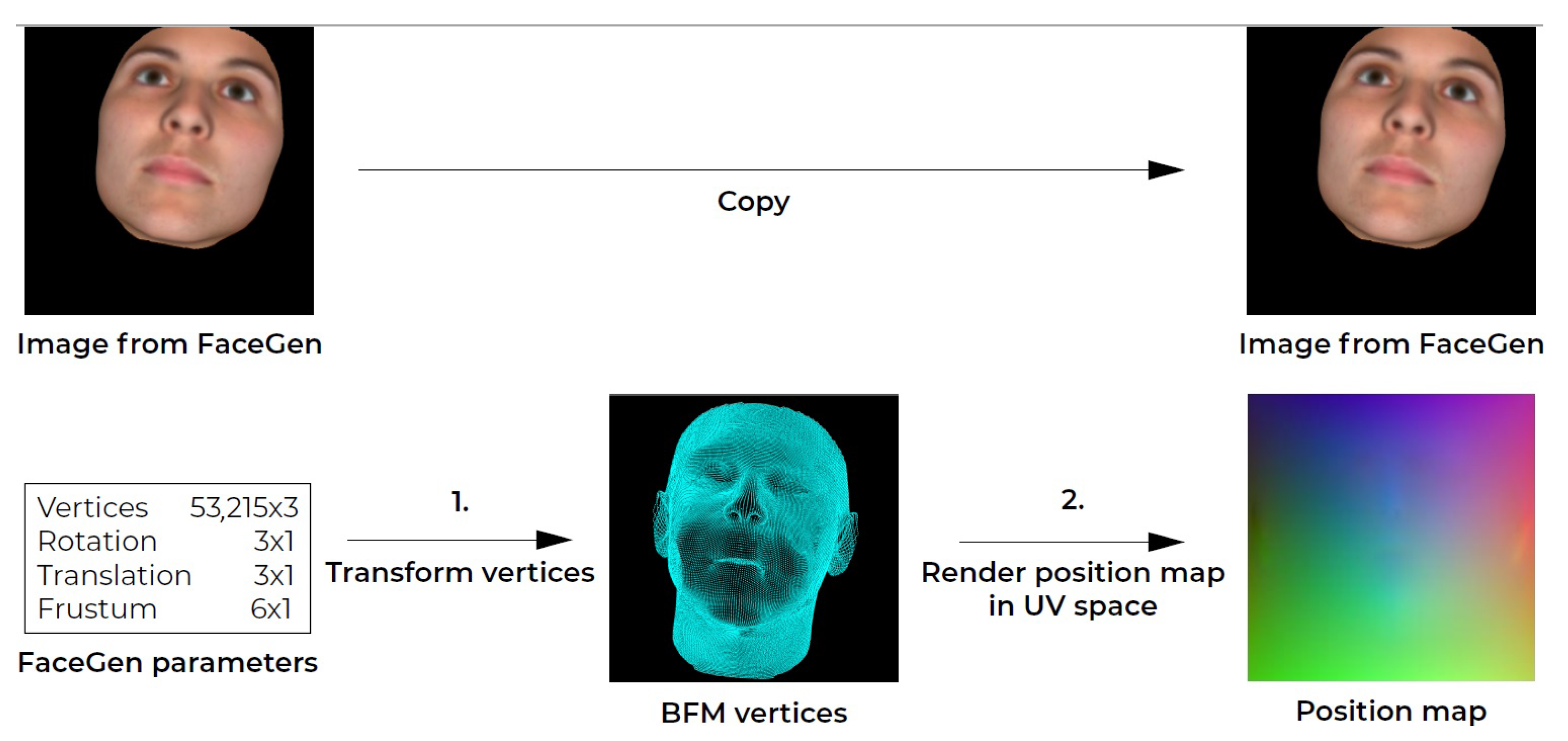
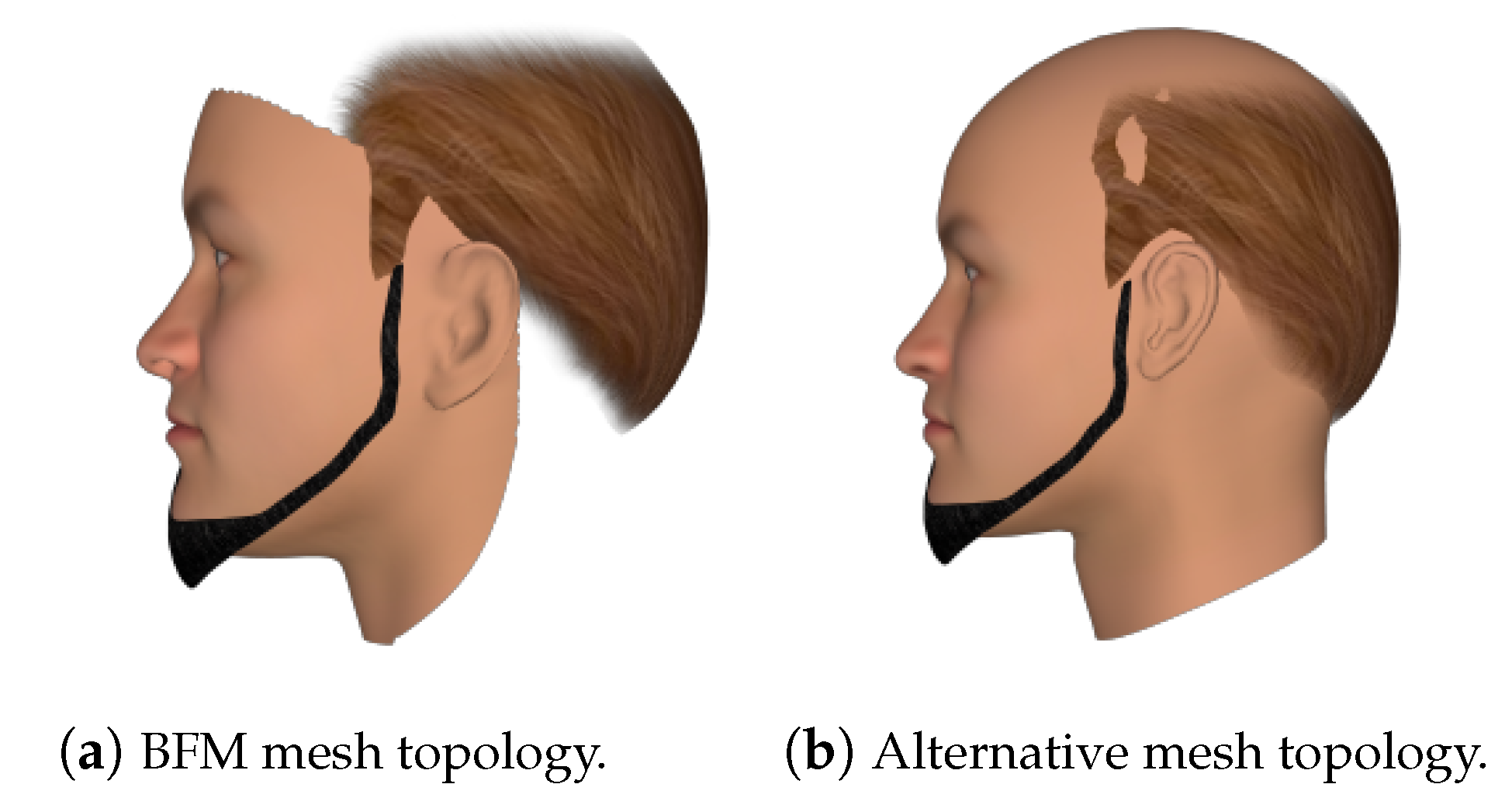
- Synthetic Training Data
- FaceGen Dataset
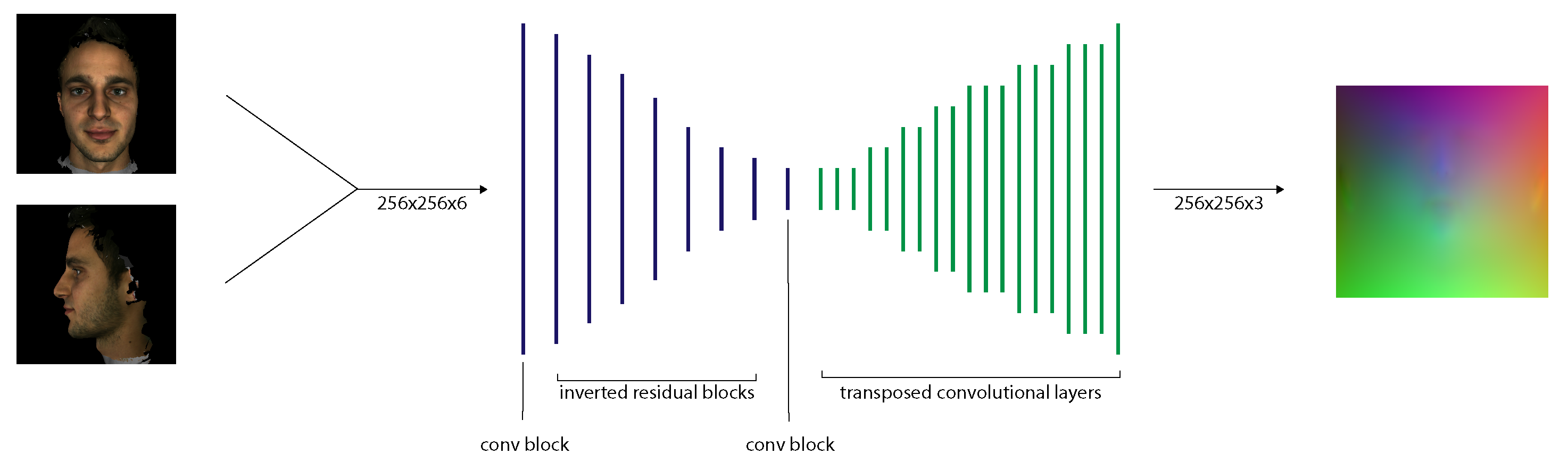
3.1.3. CNN Implementation
- Input and Output
- Network Architecture
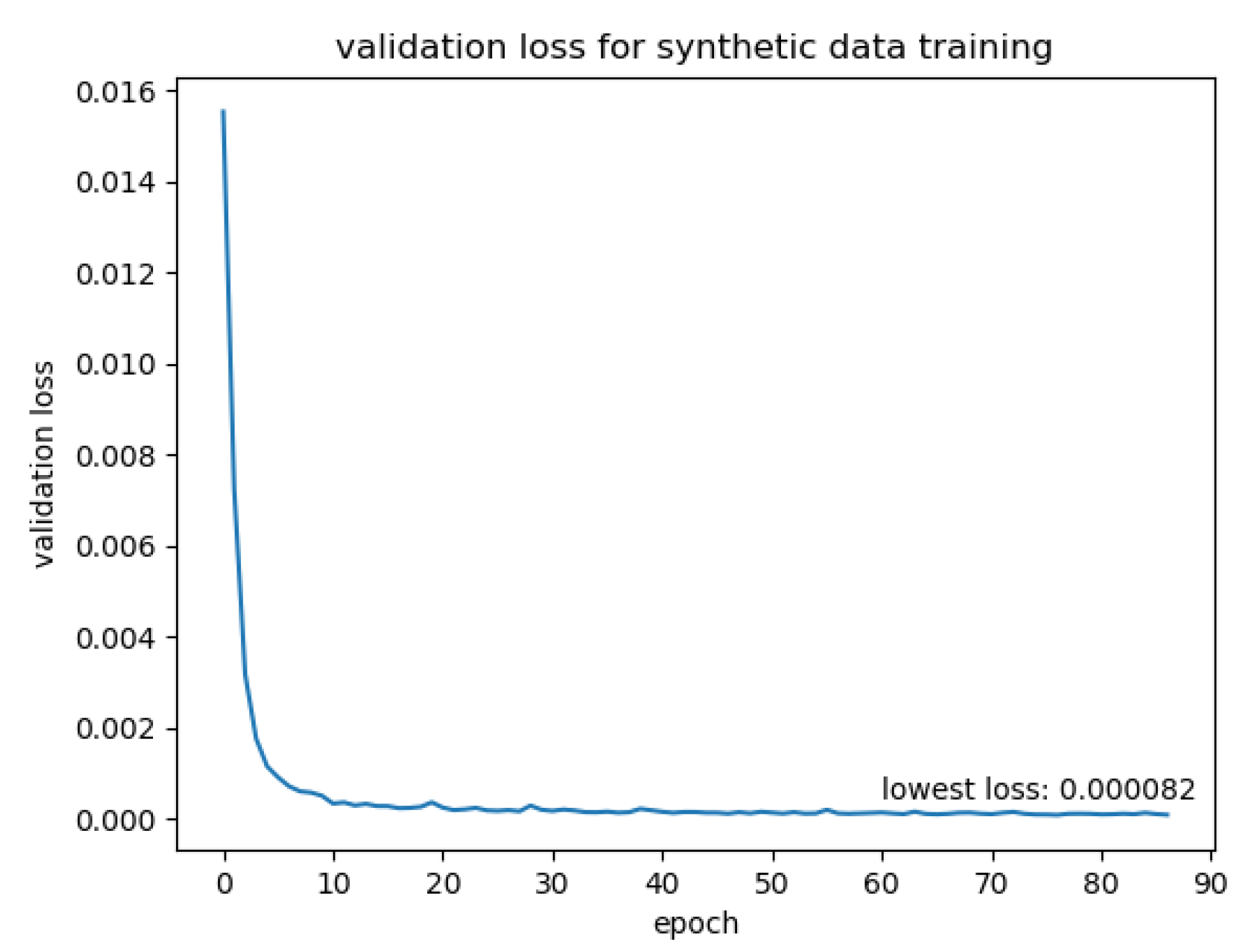
- Training on synthetic data
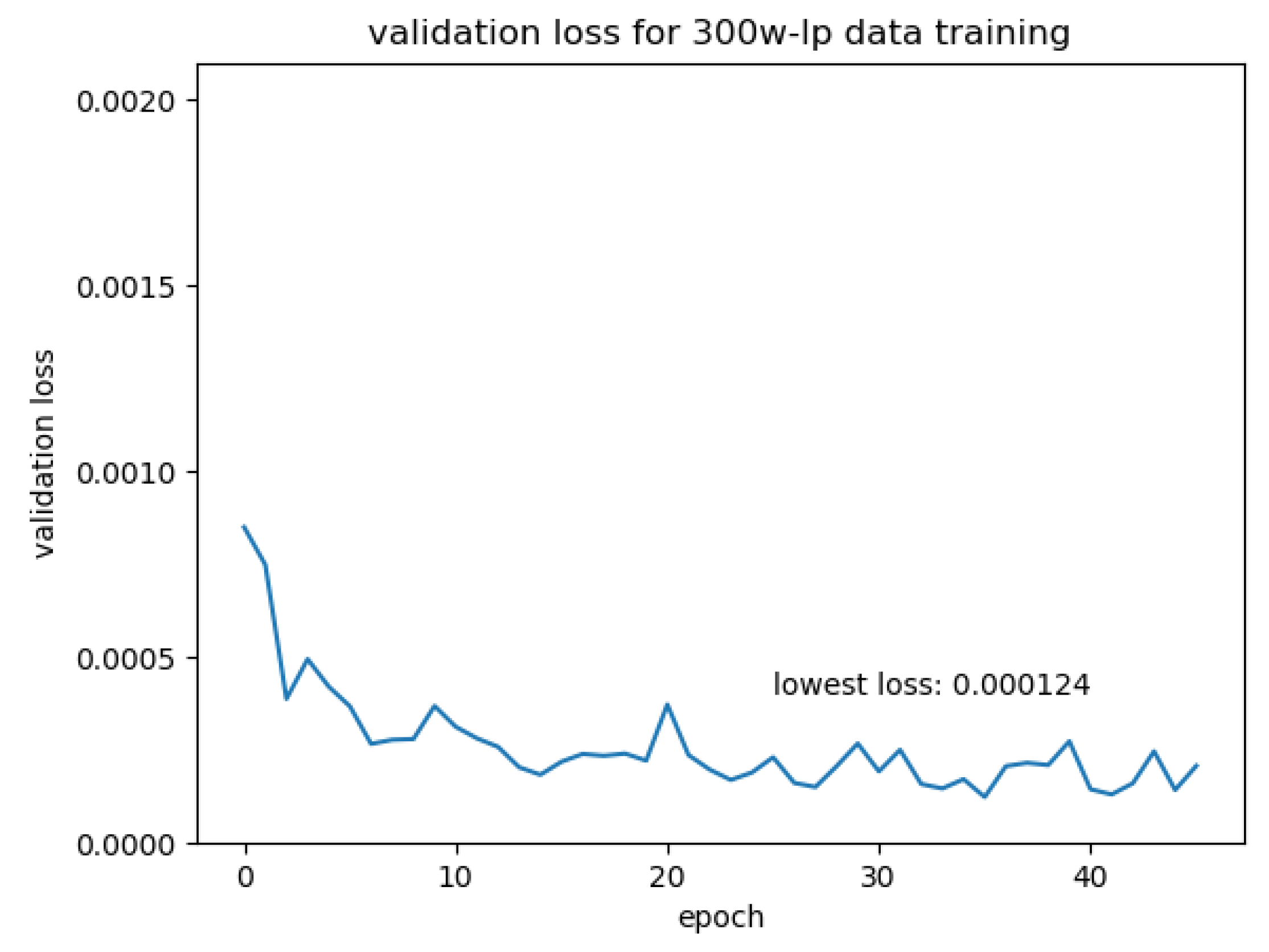
- Transfer Learning with 300W-LP data
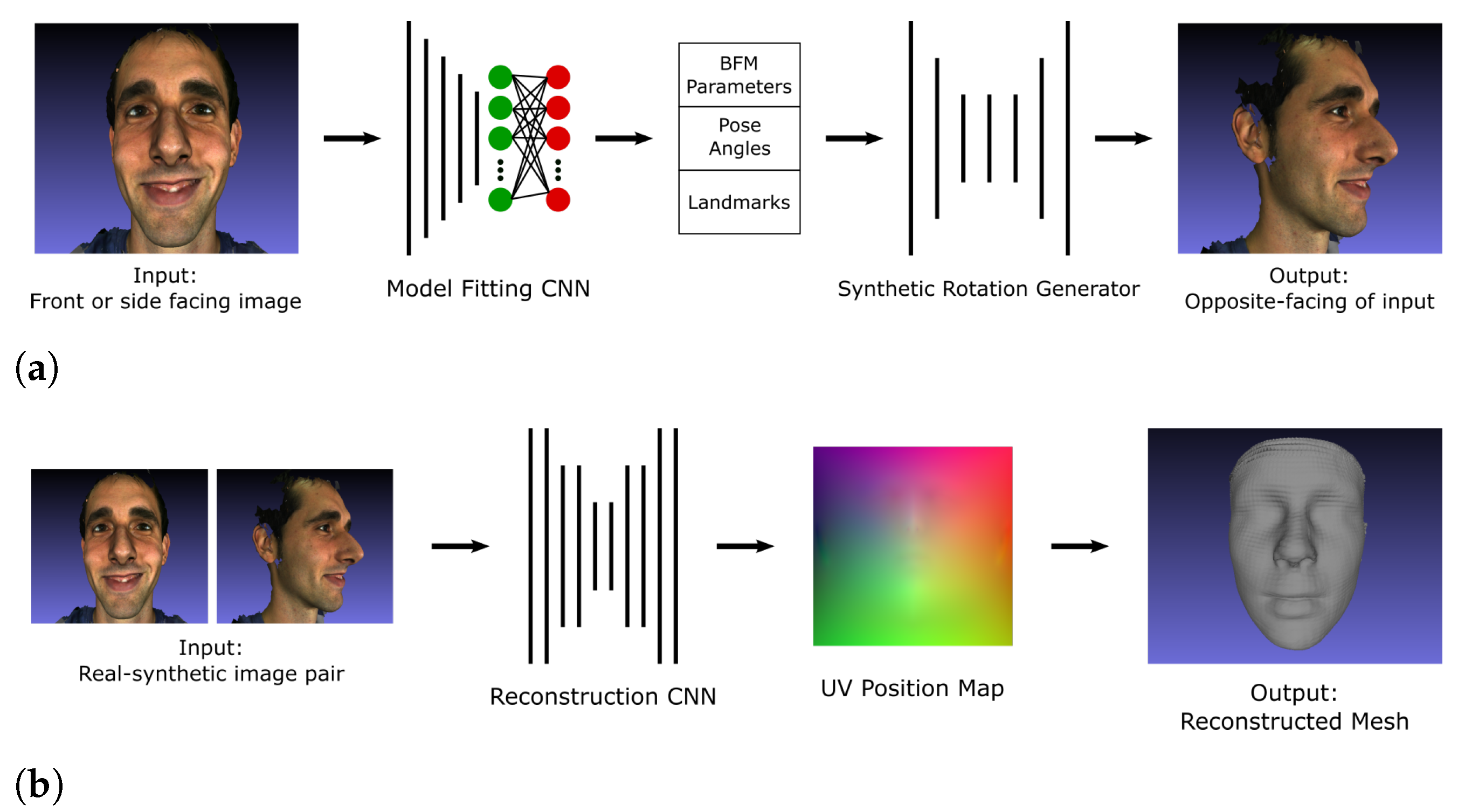
3.2. 3D Face Reconstruction Using a Single Facial Image Input
3.2.1. Proposed Pipeline
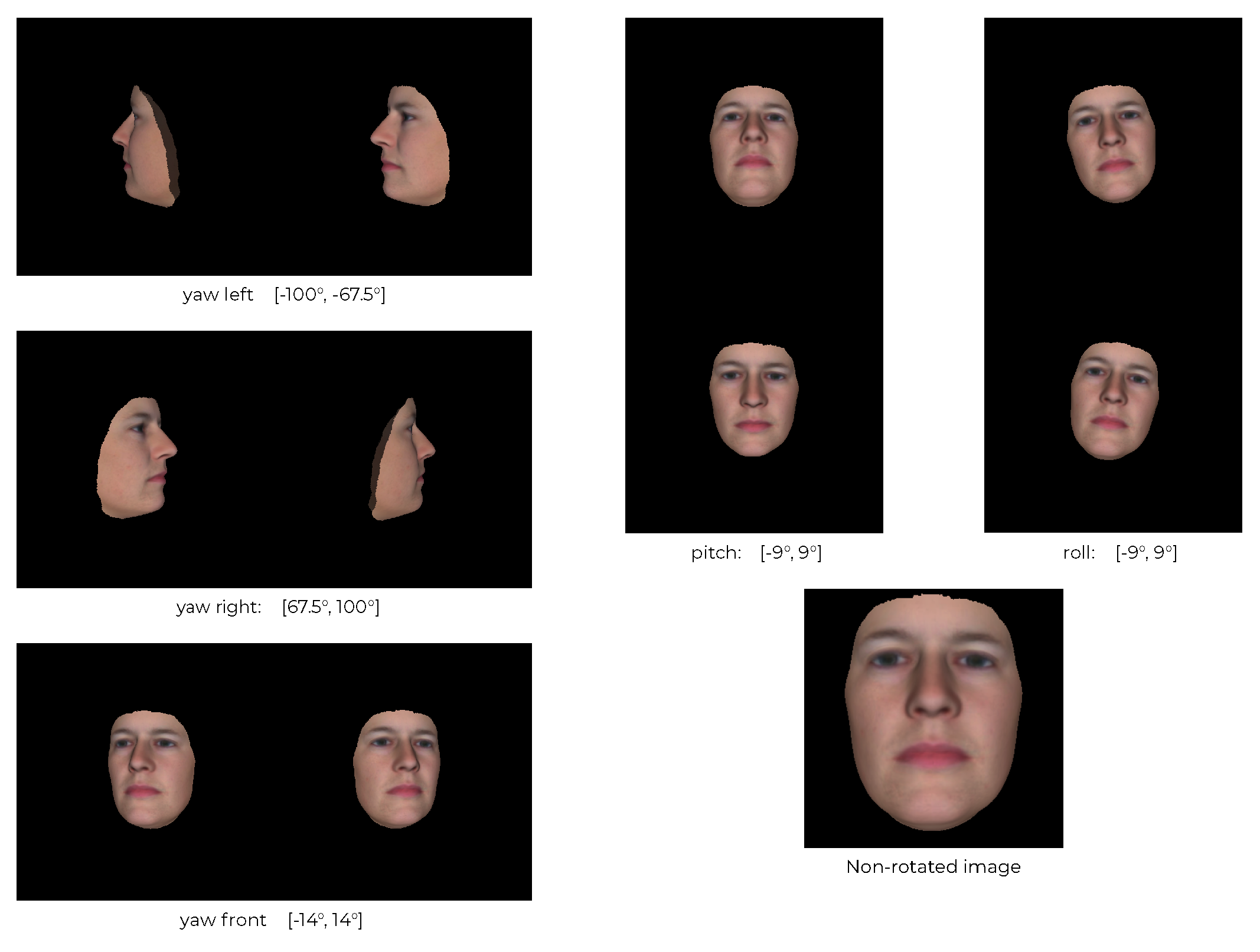
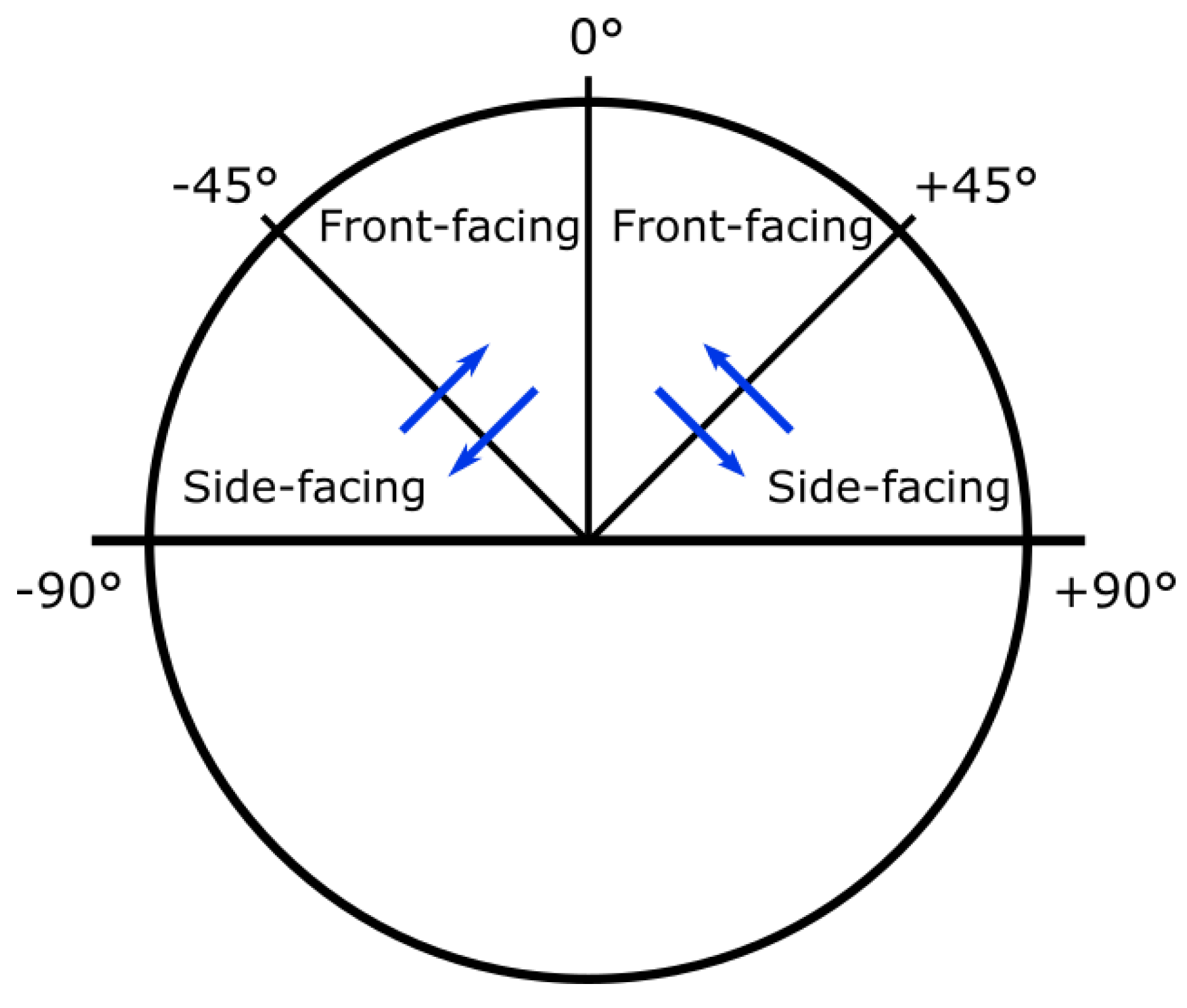
- Synthetic Rotation
3.2.2. Training Data
- Pre-processing
- Data Augmentation
3.2.3. Training Procedure
4. Evaluation
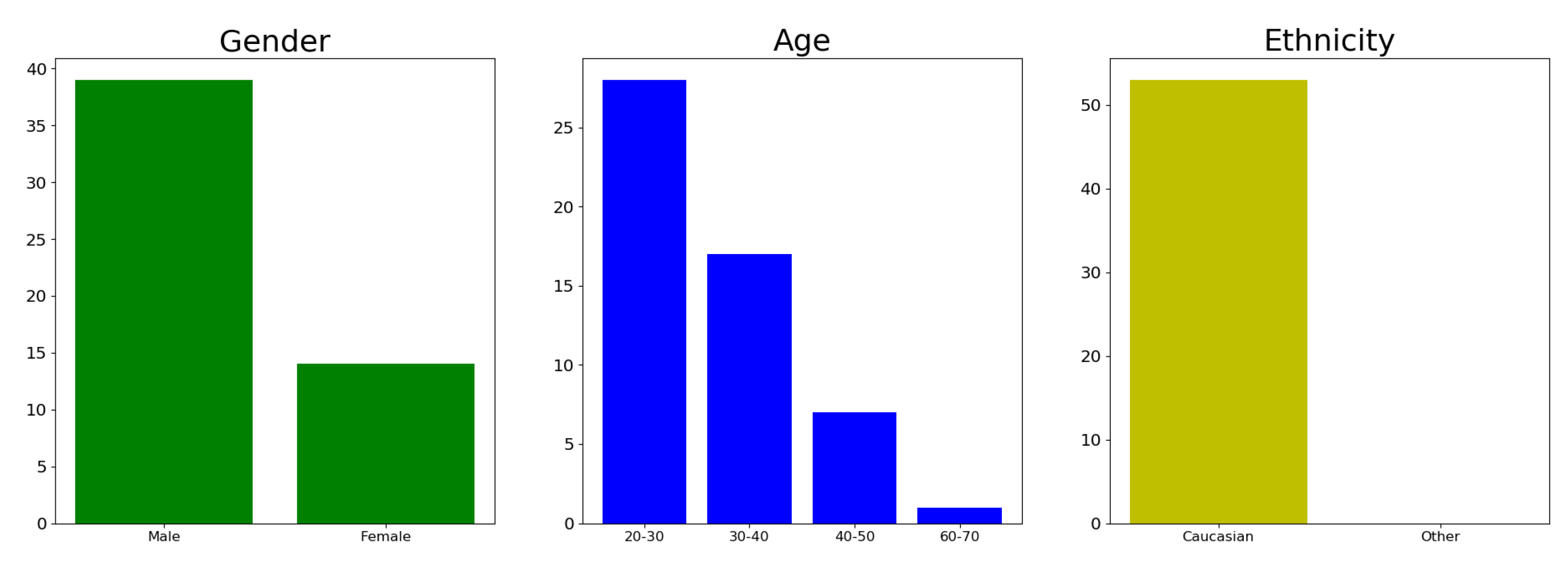
4.1. Evaluation Data: MICC Florence Dataset
4.2. Evaluation Metric
4.3. Evaluation of the Two-Input Pipeline (Front and Side)
4.3.1. Evaluation Procedure
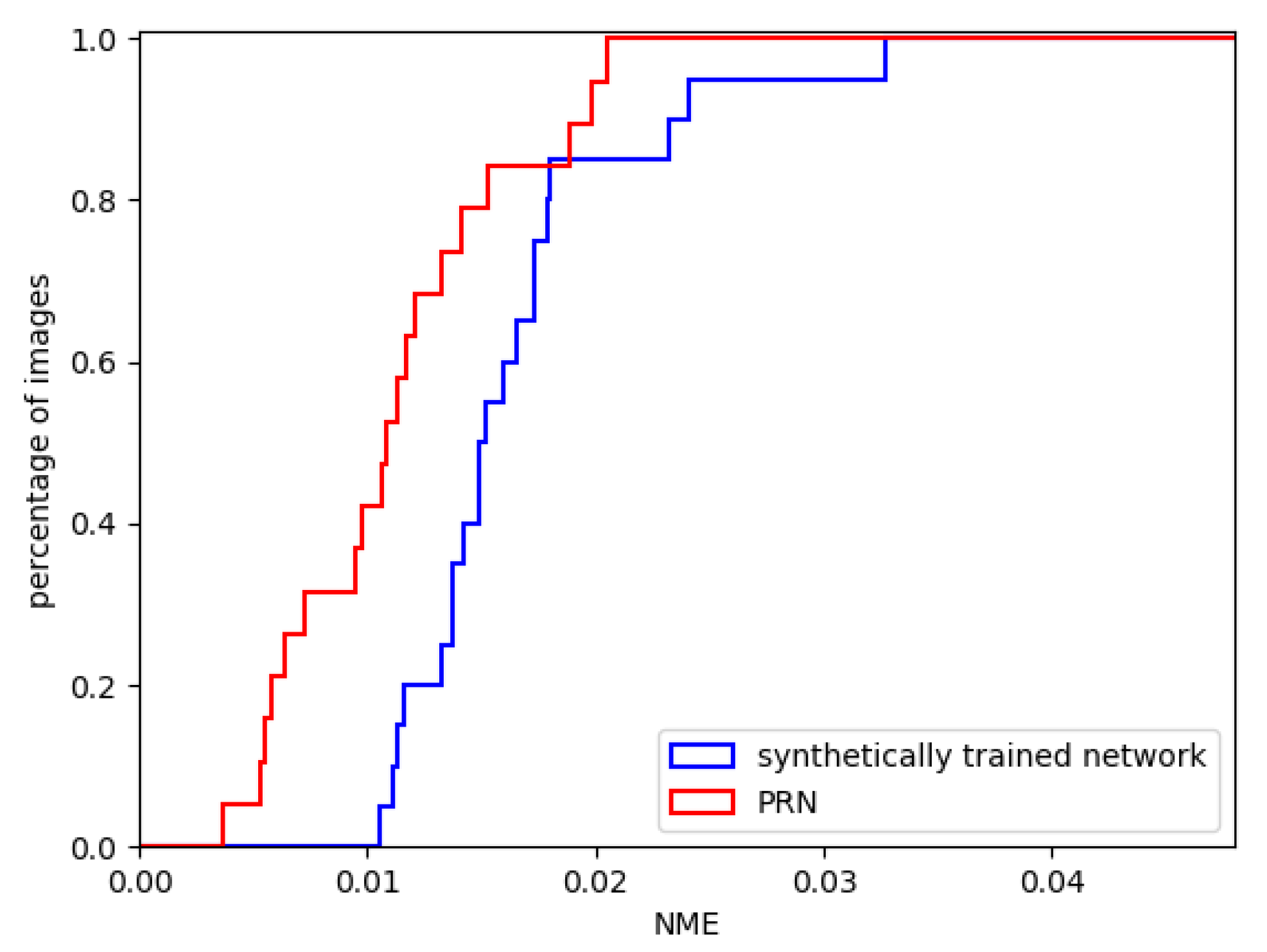
4.3.2. The Performance of the Synthetically Trained Network
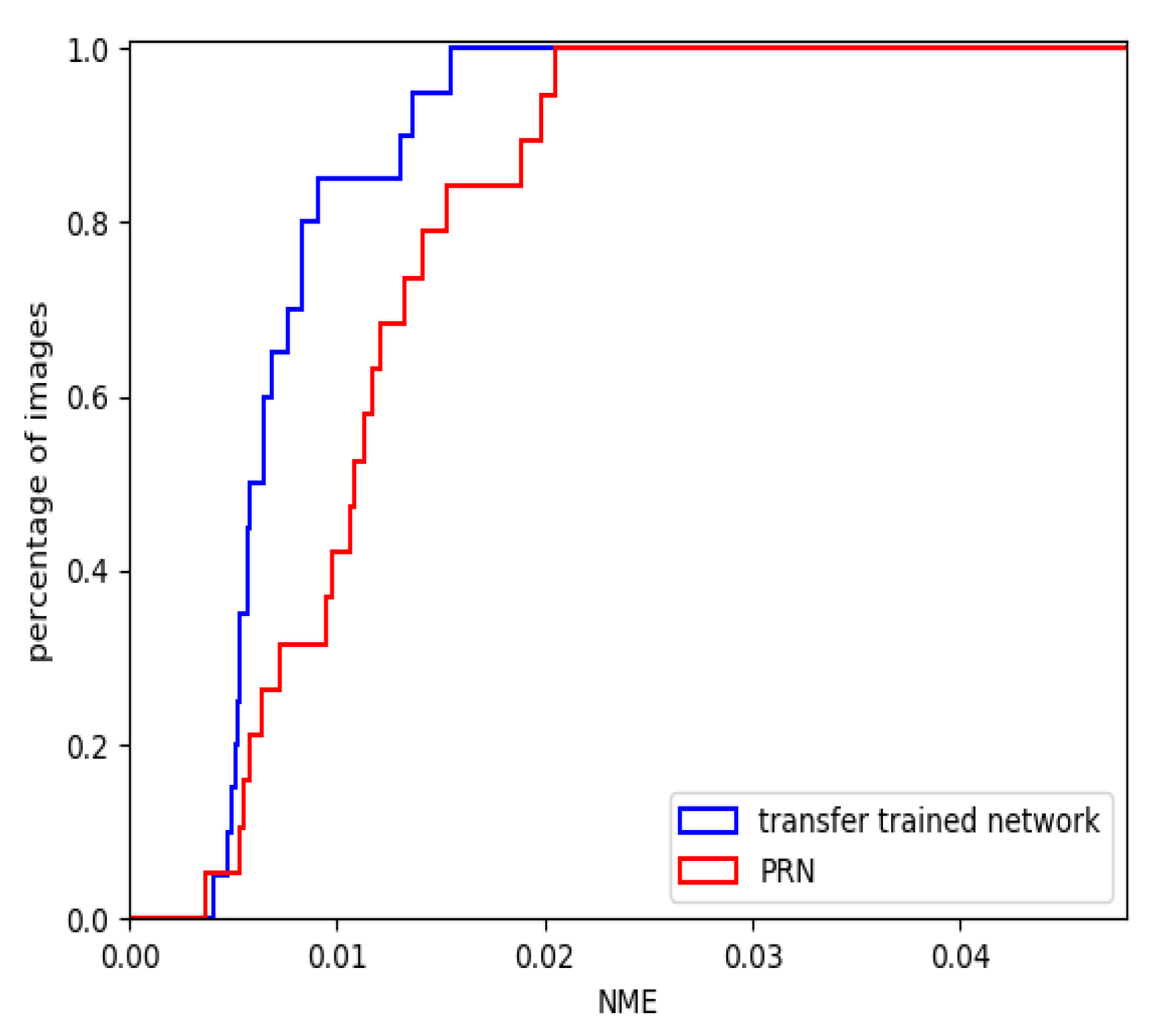
4.3.3. The Performance of the Transfer Trained Network
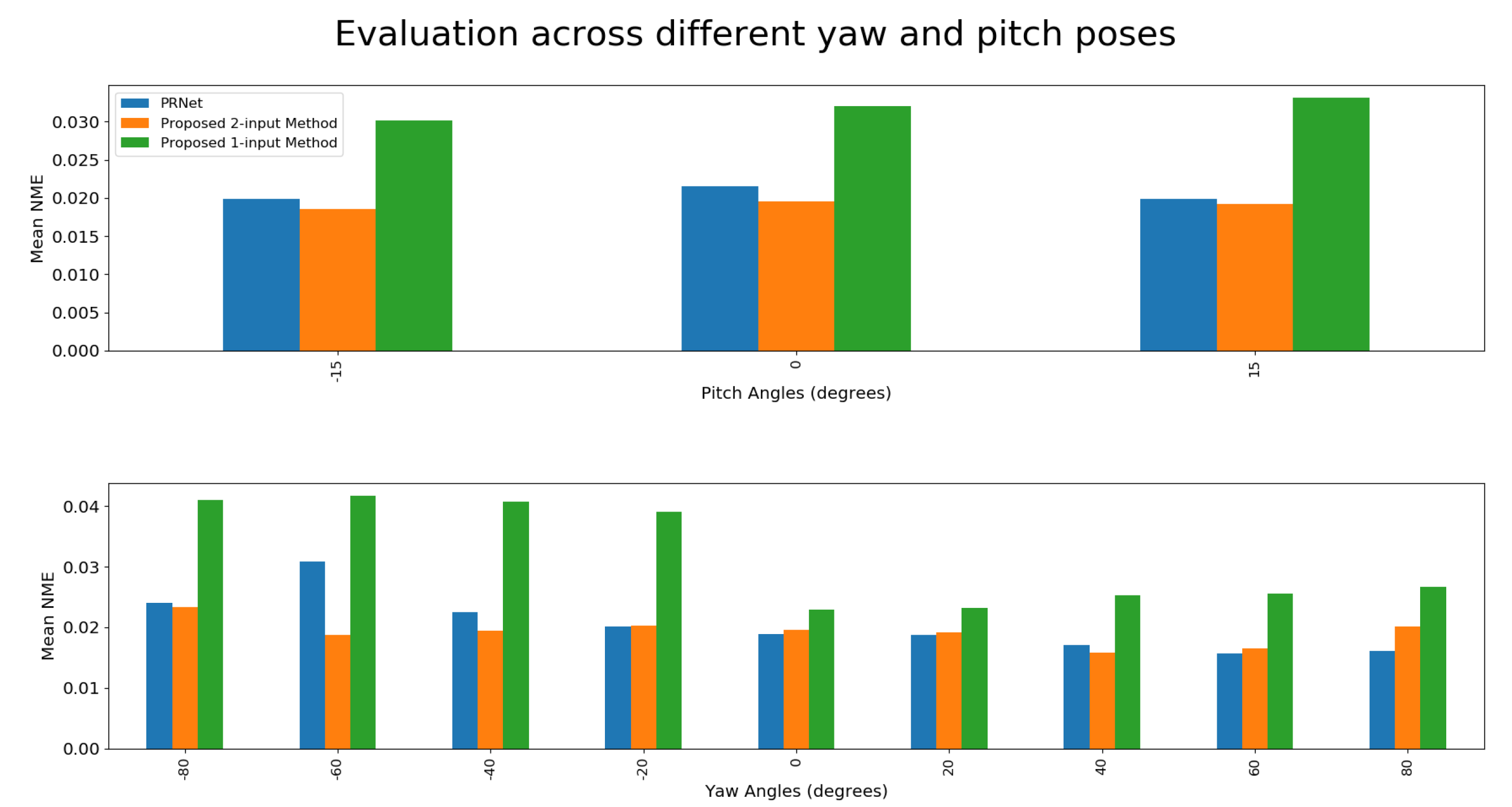
4.4. Evaluation of The One-Input Pipeline
4.5. Potential Sources of Error
4.5.1. MICC Florence Dataset
4.5.2. ICP Alignment
4.6. Qualitative Evaluation of Synthetic Rotation
5. Discussion
6. Conclusions
7. Future Work
Author Contributions
Funding

Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bagdanov, A.D.; Del Bimbo, A.; Masi, I. The Florence 2D/3D hybrid face dataset. In Proceedings of the 2011 Joint ACM Workshop on Human Gesture and Behavior Understanding, Scottsdale, AZ, USA, 1 December 2011; pp. 79–80. [Google Scholar]
- Lattas, A.; Moschoglou, S.; Gecer, B.; Ploumpis, S.; Triantafyllou, V.; Ghosh, A.; Zafeiriou, S. AvatarMe: Realistically Renderable 3D Facial Reconstruction “In-the-Wild”. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 760–769. [Google Scholar]
- Wang, X.; Guo, Y.; Deng, B.; Zhang, J. Lightweight photometric stereo for facial details recovery. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 740–749. [Google Scholar]
- Feng, Y.; Wu, F.; Shao, X.; Wang, Y.; Zhou, X. Joint 3D face reconstruction and dense alignment with position map regression network. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 534–551. [Google Scholar]
- Piao, J.; Qian, C.; Li, H. Semi-supervised monocular 3D face reconstruction with end-to-end shape-preserved domain transfer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 9398–9407. [Google Scholar]
- Zeng, X.; Peng, X.; Qiao, Y. DF2Net: A dense-fine-finer network for detailed 3D face reconstruction. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 2315–2324. [Google Scholar]
- Afzal, H.M.R.; Luo, S.; Afzal, M.K.; Chaudhary, G.; Khari, M.; Kumar, S.A.P. 3D Face Reconstruction From Single 2D Image Using Distinctive Features. IEEE Access 2020, 8, 180681–180689. [Google Scholar] [CrossRef]
- Wu, F.; Bao, L.; Chen, Y.; Ling, Y.; Song, Y.; Li, S.; Ngan, K.N.; Liu, W. Mvf-net: Multi-view 3D face morphable model regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 959–968. [Google Scholar]
- Deng, Y.; Yang, J.; Xu, S.; Chen, D.; Jia, Y.; Tong, X. Accurate 3D face reconstruction with weakly-supervised learning: From single image to image set. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Blanz, V.; Vetter, T. A morphable model for the synthesis of 3D faces. In Proceedings of the 26th Annual Conference on Computer Graphics and Interactive Techniques, Los Angeles, CA, USA, 8–13 August 1999; pp. 187–194. [Google Scholar]
- Jourabloo, A.; Liu, X. Large-pose face alignment via CNN-based dense 3D model fitting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4188–4196. [Google Scholar]
- Richardson, E.; Sela, M.; Kimmel, R. 3D face reconstruction by learning from synthetic data. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 460–469. [Google Scholar]
- Tuan Tran, A.; Hassner, T.; Masi, I.; Medioni, G. Regressing robust and discriminative 3D morphable models with a very deep neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5163–5172. [Google Scholar]
- Booth, J.; Antonakos, E.; Ploumpis, S.; Trigeorgis, G.; Panagakis, Y.; Zafeiriou, S. 3D face morphable models “in-the-wild”. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 48–57. [Google Scholar]
- Genova, K.; Cole, F.; Maschinot, A.; Sarna, A.; Vlasic, D.; Freeman, W.T. Unsupervised training for 3D morphable model regression. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8377–8386. [Google Scholar]
- Jackson, A.S.; Bulat, A.; Argyriou, V.; Tzimiropoulos, G. Large pose 3D face reconstruction from a single image via direct volumetric CNN regression. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1031–1039. [Google Scholar]
- Gecer, B.; Ploumpis, S.; Kotsia, I.; Zafeiriou, S. GanFit: Generative adversarial network fitting for high fidelity 3d face reconstruction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1155–1164. [Google Scholar]
- Zhu, X.; Lei, Z.; Liu, X.; Shi, H.; Li, S.Z. Face alignment across large poses: A 3D solution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 146–155. [Google Scholar]
- Guo, J.; Zhu, X.; Yang, Y.; Yang, F.; Lei, Z.; Li, S.Z. Towards fast, accurate and stable 3D dense face alignment. arXiv 2020, arXiv:2009.09960. [Google Scholar]
- Sandler, M.; Howard, A.G.; Zhu, M.; Zhmoginov, A.; Chen, L. Inverted Residuals and Linear Bottlenecks: Mobile Networks for Classification, Detection and Segmentation. arXiv 2018, arXiv:1801.04381. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Paysan, P.; Knothe, R.; Amberg, B.; Romdhani, S.; Vetter, T. A 3D Face Model for Pose and Illumination Invariant Face Recognition. In Proceedings of the 2009 Sixth IEEE International Conference on Advanced Video and Signal Based Surveillance, Genova, Italy, 2–4 September 2009. [Google Scholar] [CrossRef]
- Sagonas, C.; Antonakos, E.; Tzimiropoulos, G.; Zafeiriou, S.; Pantic, M. 300 Faces In-the-Wild Challenge: Database and results. Image Vision Comput. 2016, 47, 3–18. [Google Scholar] [CrossRef] [Green Version]
- Barbosa, I.B.; Cristani, M.; Caputo, B.; Rognhaugen, A.; Theoharis, T. Looking Beyond Appearances: Synthetic Training Data for Deep CNNs in Re-identification. arXiv 2017, arXiv:1701.03153. [Google Scholar] [CrossRef] [Green Version]
- Kortylewski, A.; Egger, B.; Schneider, A.; Gerig, T.; Morel-Forster, A.; Vetter, T. Analyzing and Reducing the Damage of Dataset Bias to Face Recognition With Synthetic Data. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Theoharis, T.; Papaioannou, G.; Platis, N.; Patrikalakis, N.M. Graphics and Visualization: Principles & Algorithms; CRC Press: Boca Raton, FL, USA, 2008. [Google Scholar]
- Cimpoi, M.; Maji, S.; Kokkinos, I.; Mohamed, S.; Vedaldi, A. Describing Textures in the Wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Zhou, H.; Liu, J.; Liu, Z.; Liu, Y.; Wang, X. Rotate-and-render: Unsupervised photorealistic face rotation from single-view images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5911–5920. [Google Scholar]
- Gross, R.; Matthews, I.; Cohn, J.; Kanade, T.; Baker, S. Multi-pie. Image Vis. Comput. 2010, 28, 807–813. [Google Scholar] [CrossRef]
- Besl, P.J.; McKay, N.D. Method for registration of 3-D shapes. In Proceedings of the Sensor Fusion IV: Control Paradigms and Data Structures, Boston, MA, USA, 14–15 November 1991; International Society for Optics and Photonics: San Diego, CA, USA, 1992; Volume 1611, pp. 586–606. [Google Scholar]




























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input | Layer | Kernel | Stride | Output |
|---|---|---|---|---|
| 256 × 256 × 6 | Convolution | 3 | 2 | 128 × 128 × 32 |
| 128 × 128 × 32 | Inverted Residual | 3 | - | 64 × 64 × 96 |
| 64 × 64 × 96 | Inverted Residual | 3 | - | 32 × 32 × 144 |
| 32 × 32 × 144 | Inverted Residual | 3 | - | 16 × 16 × 192 |
| 16 × 16 × 192 | Inverted Residual | 3 | - | 8 × 8 × 576 |
| 8 × 8 × 576 | Convolution | 3 | 2 | 8 × 8 × 512 |
| 8 × 8 × 512 | Transposed Convolution | 4 | 1 | 8 × 8 × 512 |
| 8 × 8 × 512 | Transposed Convolution | 4 | 2 | 16 × 16 × 256 |
| 16 × 16 × 256 | Transposed Convolution | 4 | 1 | 16 × 16 × 256 |
| 16 × 16 × 256 | Transposed Convolution | 4 | 1 | 16 × 16 × 256 |
| 16 × 16 × 256 | Transposed Convolution | 4 | 2 | 32 × 32 × 128 |
| 32 × 32 × 128 | Transposed Convolution | 4 | 1 | 32 × 32 × 128 |
| 32 × 32 × 128 | Transposed Convolution | 4 | 1 | 32 × 32 × 128 |
| 32 × 32 × 128 | Transposed Convolution | 4 | 2 | 64 × 64 × 64 |
| 64 × 64 × 64 | Transposed Convolution | 4 | 1 | 64 × 64 × 64 |
| 64 × 64 × 64 | Transposed Convolution | 4 | 1 | 64 × 64 × 64 |
| 64 × 64 × 64 | Transposed Convolution | 4 | 2 | 128 × 128 × 32 |
| 128 × 128 × 32 | Transposed Convolution | 4 | 1 | 128 × 128 × 32 |
| 128 × 128 × 32 | Transposed Convolution | 4 | 2 | 256 × 256 × 16 |
| 256 × 256 × 16 | Transposed Convolution | 4 | 1 | 256 × 256 × 16 |
| 256 × 256 × 16 | Transposed Convolution | 4 | 1 | 256 × 256 × 3 |
| 256 × 256 × 3 | Transposed Convolution | 4 | 1 | 256 × 256 × 3 |
| 256 × 256 × 3 | Transposed Convolution | 4 | 1 | 256 × 256 × 3 |
| Methodology | Mean NME |
|---|---|
| 3DDFA_V2 [19] | 0.0127 |
| PRN [4] | 0.0134 |
| Proposed 2-input Method | 0.0164 |
| VRN_Guided [16] | 0.0187 |
| 3DDFA [18] | 0.0227 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lium, O.; Kwon, Y.B.; Danelakis, A.; Theoharis, T. Robust 3D Face Reconstruction Using One/Two Facial Images. J. Imaging 2021, 7, 169. https://doi.org/10.3390/jimaging7090169
Lium O, Kwon YB, Danelakis A, Theoharis T. Robust 3D Face Reconstruction Using One/Two Facial Images. Journal of Imaging. 2021; 7(9):169. https://doi.org/10.3390/jimaging7090169
Chicago/Turabian StyleLium, Ola, Yong Bin Kwon, Antonios Danelakis, and Theoharis Theoharis. 2021. "Robust 3D Face Reconstruction Using One/Two Facial Images" Journal of Imaging 7, no. 9: 169. https://doi.org/10.3390/jimaging7090169
APA StyleLium, O., Kwon, Y. B., Danelakis, A., & Theoharis, T. (2021). Robust 3D Face Reconstruction Using One/Two Facial Images. Journal of Imaging, 7(9), 169. https://doi.org/10.3390/jimaging7090169