
SIFT-CNN: When Convolutional Neural Networks Meet Dense SIFT Descriptors for Image and Sequence Classification

 ,
,
Abstract
:1. Introduction
2. Related Work
3. Proposed Method
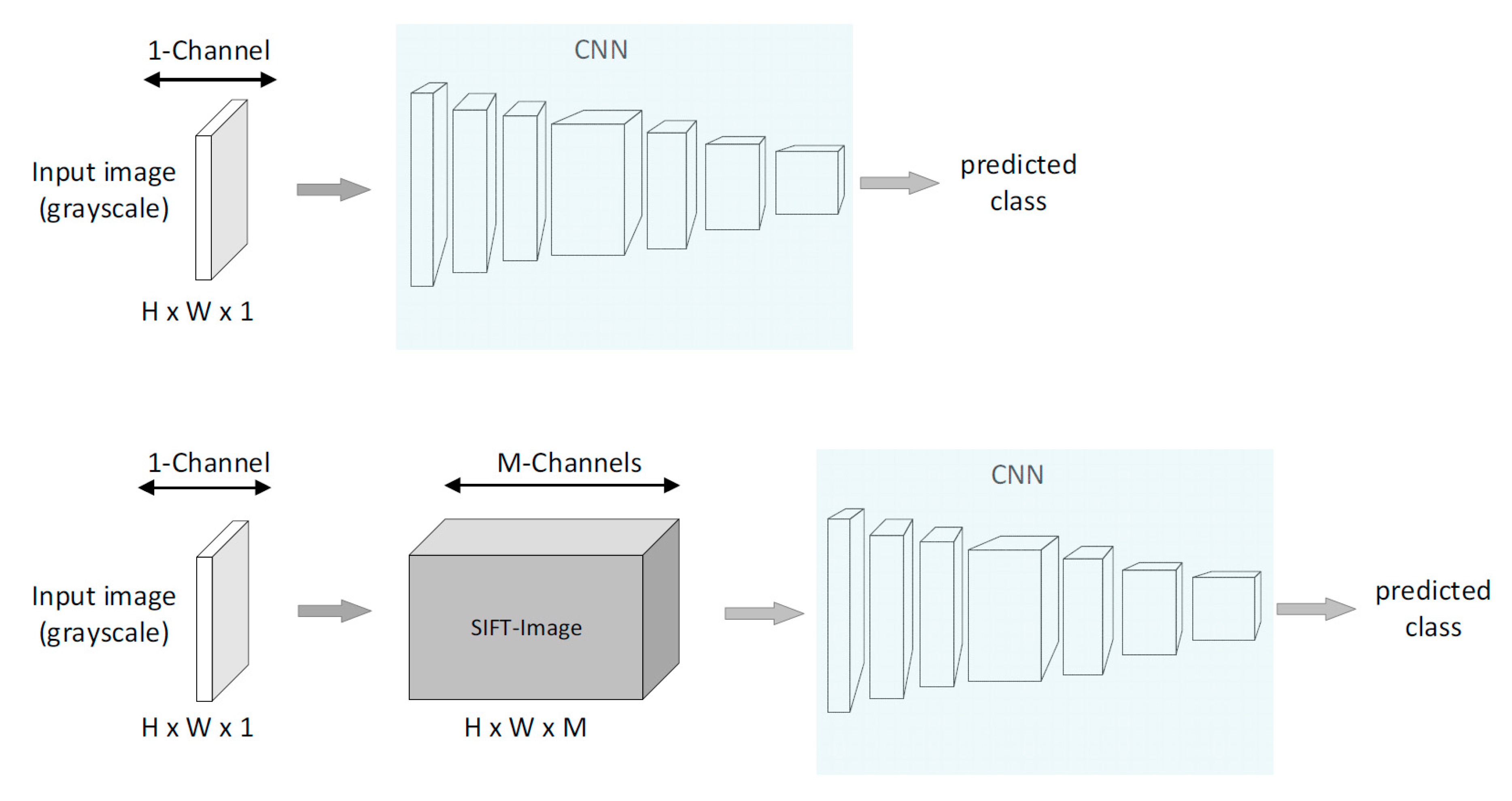
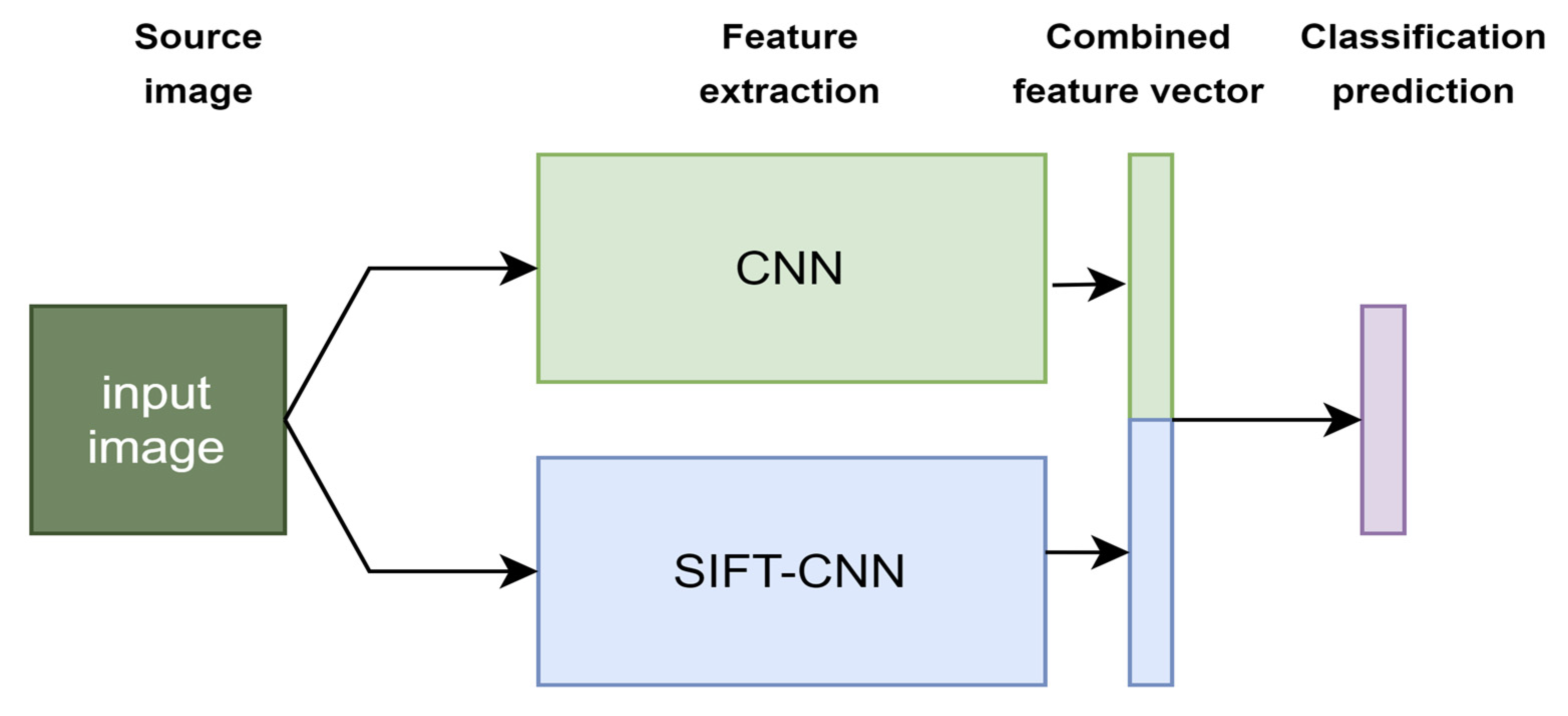
3.1. The SIFT-CNN Framework
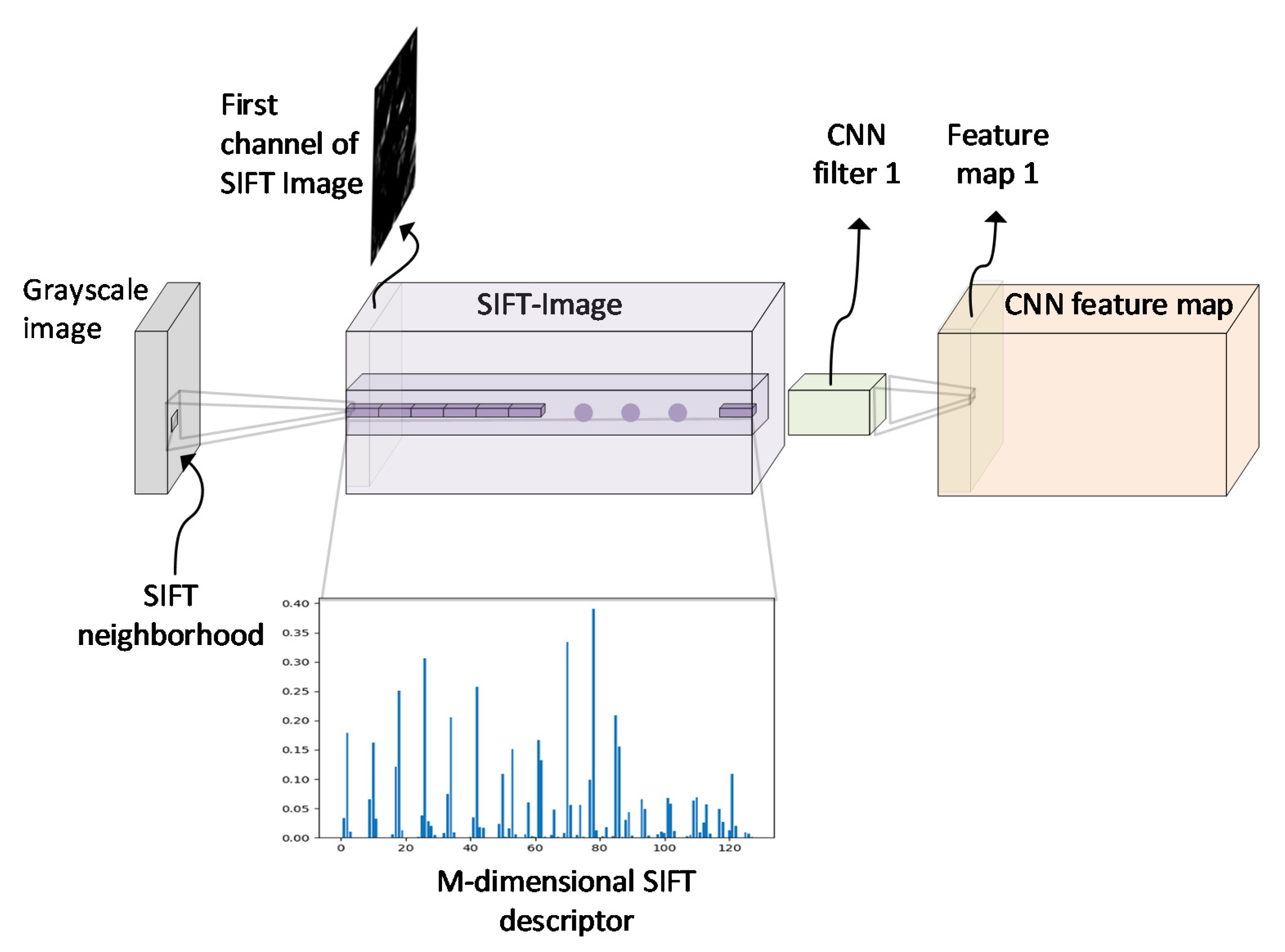
3.2. Mapping Pixels to SIFT Descriptors
4. Experimental Results
4.1. Materials and Methods
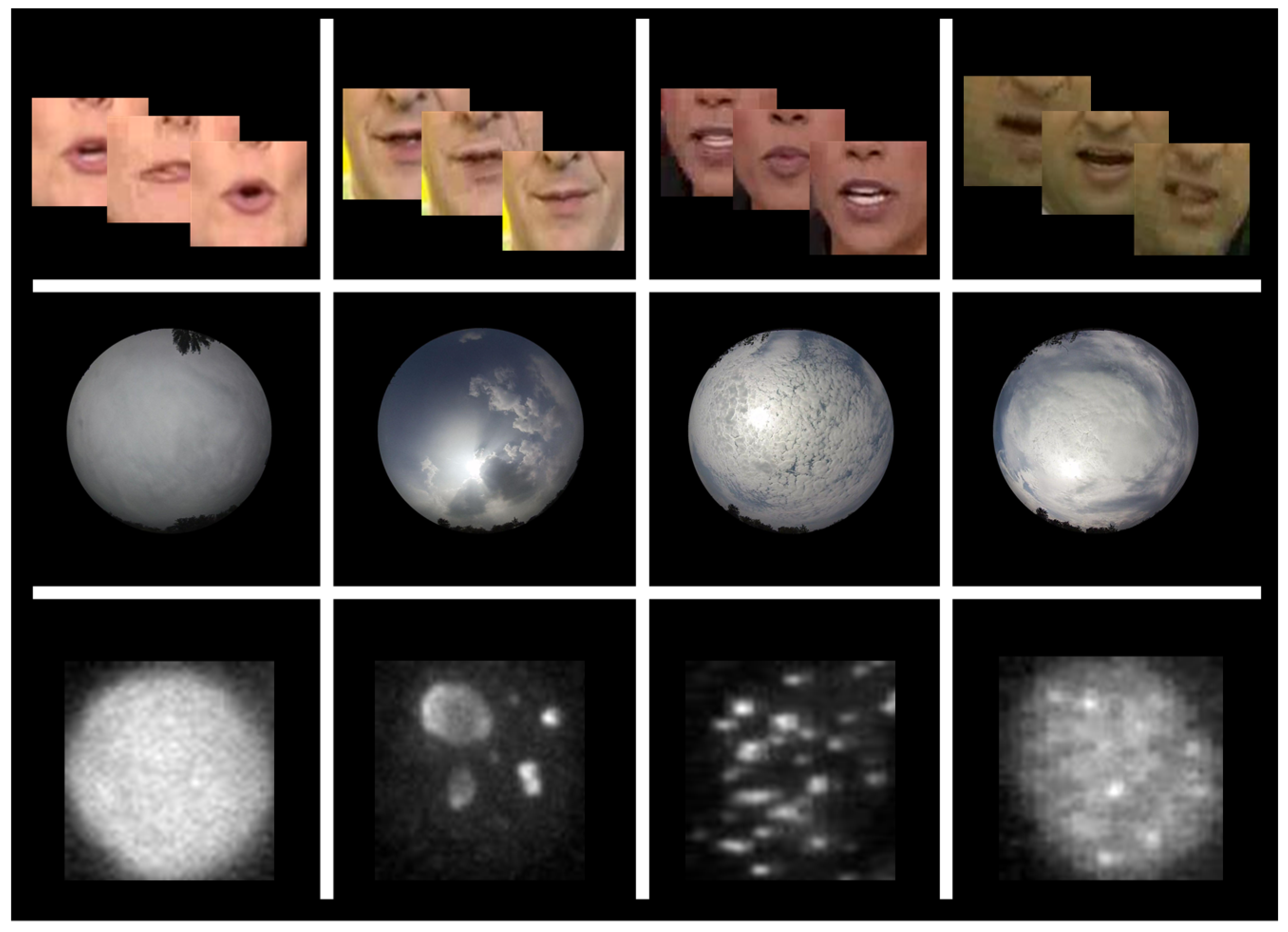
4.2. Datasets
4.3. Classification Results on ICPR 2012 and ICIP 2013 HEp-2 Cell Image Datasets
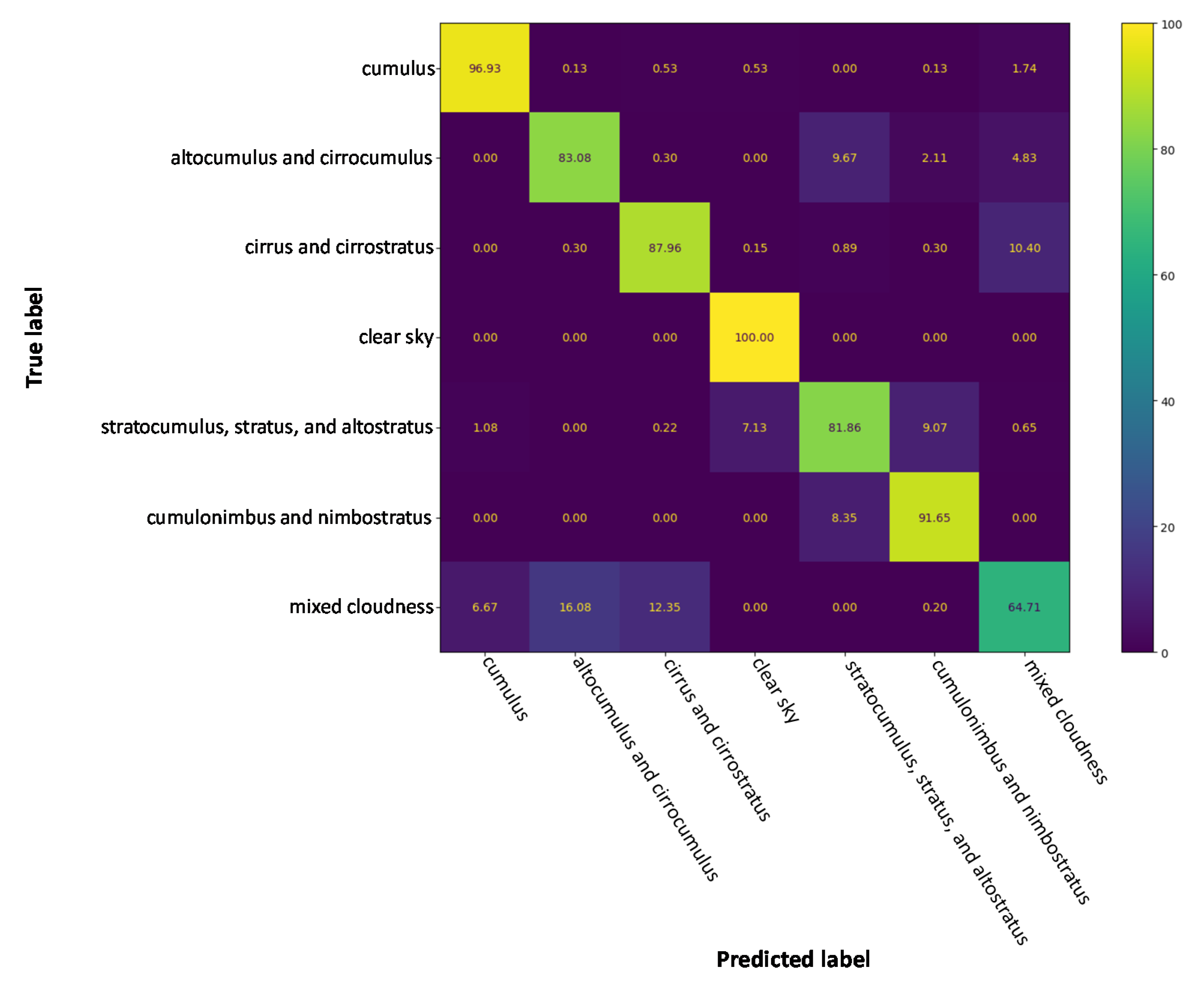
4.4. Classification Results on Cloud Type GRSCD Dataset
4.5. Classification Results on Lip-Reading LRW Dataset
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bay, H.; Tuytelaars, T.; Van Gool, L. SURF: Speeded Up Robust Features. In Computer Vision—ECCV 2006; Leonardis, A., Bischof, H., Pinz, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2006; Volume 3951, pp. 404–417. ISBN 978-3-540-33832-1. [Google Scholar]
- Hutchison, D.; Kanade, T.; Kittler, J.; Kleinberg, J.M.; Mattern, F.; Mitchell, J.C.; Naor, M.; Nierstrasz, O.; Pandu Rangan, C.; Steffen, B.; et al. BRIEF: Binary Robust Independent Elementary Features. In Computer Vision—ECCV 2010; Daniilidis, K., Maragos, P., Paragios, N., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; Volume 6314, pp. 778–792. ISBN 978-3-642-15560-4. [Google Scholar]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; IEEE: Piscataway, NJ, USA, 2005; Volume 1, pp. 886–893. [Google Scholar]
- Arandjelovic, R.; Zisserman, A. All About VLAD. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 1578–1585. [Google Scholar]
- Sivic, J.; Zisserman, A. Efficient Visual Search of Videos Cast as Text Retrieval. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 591–606. [Google Scholar] [CrossRef] [PubMed]
- Kastaniotis, D.; Fotopoulou, F.; Theodorakopoulos, I.; Economou, G.; Fotopoulos, S. HEp-2 cell classification with Vector of Hierarchically Aggregated Residuals. Pattern Recognit. 2017, 65, 47–57. [Google Scholar] [CrossRef]
- Jegou, H.; Douze, M.; Schmid, C.; Perez, P. Aggregating Local Descriptors into a Compact Image Representation; IEEE: Piscataway, NJ, USA, 2010; pp. 3304–3311. [Google Scholar]
- Jegou, H.; Perronnin, F.; Douze, M.; Sanchez, J.; Perez, P.; Schmid, C. Aggregating Local Image Descriptors into Compact Codes. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 1704–1716. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems—Volume 1, Granada, Spain, 12–15 December 2011; Curran Associates Inc.: Red Hook, NY, USA, 2012; pp. 1097–1105. Available online: http://dl.acm.org/citation.cfm?id=2999134.2999257 (accessed on 19 August 2022).
- Gong, Y.; Wang, L.; Guo, R.; Lazebnik, S. Multi-scale orderless pooling of deep convolutional activation features. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2014; pp. 392–407. [Google Scholar]
- Liu, C.; Yuen, J.; Torralba, A. SIFT Flow: Dense Correspondence across Scenes and Its Applications. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 978–994. [Google Scholar] [CrossRef] [PubMed]
- Liu, C.; Yuen, J.; Torralba, A. Nonparametric scene parsing: Label transfer via dense scene alignment. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 1972–1979. [Google Scholar]
- Foggia, P.; Percannella, G.; Saggese, A.; Vento, M. Pattern recognition in stained HEp-2 cells: Where are we now? Pattern Recognit. 2014, 47, 2305–2314. [Google Scholar] [CrossRef]
- Liu, S.; Li, M.; Zhang, Z.; Xiao, B.; Durrani, T.S. Multi-Evidence and Multi-Modal Fusion Network for Ground-Based Cloud Recognition. Remote Sens. 2020, 12, 464. [Google Scholar] [CrossRef]
- Chung, J.S.; Zisserman, A. Lip reading in the wild. In Proceedings of the Asian Conference on Computer Vision, Taipei, Taiwan, 20–24 November 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 87–103. [Google Scholar]
- Zheng, L.; Yang, Y.; Tian, Q. SIFT Meets CNN: A Decade Survey of Instance Retrieval. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 1224–1244. [Google Scholar] [CrossRef]
- Wang, H.; Hou, S. Facial Expression Recognition based on The Fusion of CNN and SIFT Features. In Proceedings of the 2020 IEEE 10th International Conference on Electronics Information and Emergency Communication (ICEIEC), Beijing, China, 17–19 July 2020; pp. 190–194. [Google Scholar]
- Lin, W.; Hasenstab, K.; Moura Cunha, G.; Schwartzman, A. Comparison of handcrafted features and convolutional neural networks for liver MR image adequacy assessment. Sci. Rep. 2020, 10, 20336. [Google Scholar] [CrossRef]
- Tripathi, A.; Kumar, T.V.A.; Dhansetty, T.K.; Kumar, J.S. Real Time Object Detection using CNN. Int. J. Eng. Technol. 2018, 7, 33–36. [Google Scholar] [CrossRef] [Green Version]
- Dudhal, A.; Mathkar, H.; Jain, A.; Kadam, O.; Shirole, M. Hybrid SIFT Feature Extraction Approach for Indian Sign Language Recognition System Based on CNN. In Proceedings of the Proceedings of the International Conference on ISMAC in Computational Vision and Bio-Engineering 2018 (ISMAC-CVB), Palladam, India, 16–17 May 2018; Springer International Publishing: Cham, Switzerland, 2019; pp. 727–738. [Google Scholar]
- Connie, T.; Al-Shabi, M.; Cheah, W.P.; Goh, M. Facial Expression Recognition Using a Hybrid CNN–SIFT Aggregator. In Multi-disciplinary Trends in Artificial Intelligence; Springer International Publishing: Cham, Switzerland, 2017; pp. 139–149. [Google Scholar]
- Kumar, A.; Jain, N.; Singh, C.; Tripathi, S. Exploiting SIFT Descriptor for Rotation Invariant Convolutional Neural Network. In Proceedings of the 2018 15th IEEE India Council International Conference (INDICON), Coimbatore, India, 6–18 December 2018; pp. 1–5. [Google Scholar]
- Weiyue, C.; Geng, J.; Lin, K. Facial Expression Recognition with Small Samples under Convolutional Neural Network. In Lecture Notes of the Institute for Computer Sciences, Social Informatics and Telecommunications Engineering. In Proceedings of the International Conference on 5G for Future Wireless Networks, Huizhou, China, 30–31 October 2021; Springer International Publishing: Cham, Switzerland, 2022; pp. 383–396. [Google Scholar]
- Vidhyalakshmi, M.K.; Poovammal, E.; Bhaskar, V.; Sathyanarayanan, J. Novel Similarity Metric Learning Using Deep Learning and Root SIFT for Person Re-identification. Wirel. Pers. Commun. 2021, 117, 1835–1851. [Google Scholar] [CrossRef]
- Zhao, Q.; Zhang, B.; Lyu, S.; Zhang, H.; Sun, D.; Li, G.; Feng, W. A CNN-SIFT Hybrid Pedestrian Navigation Method Based on First-Person Vision. Remote Sens. 2018, 10, 1229. [Google Scholar] [CrossRef]
- Park, S.K.; Chung, J.H.; Kang, T.K.; Lim, M.T. Binary dense sift flow based two stream CNN for human action recognition. Multimed. Tools Appl. 2021, 80, 35697–35720. [Google Scholar] [CrossRef]
- Varga, D. No-Reference Quality Assessment of Authentically Distorted Images Based on Local and Global Features. J. Imaging 2022, 8, 173. [Google Scholar] [CrossRef] [PubMed]
- Yelampalli, P.K.R.; Nayak, J.; Gaidhane, V.H. Daubechies wavelet-based local feature descriptor for multimodal medical image registration. IET Image Process. 2018, 12, 1692–1702. [Google Scholar] [CrossRef]
- Oyallon, E.; Belilovsky, E.; Zagoruyko, S. Scaling the Scattering Transform: Deep Hybrid Networks. arXiv 2017, arXiv:1703.08961. [Google Scholar]
- Luan, S.; Zhang, B.; Chen, C.; Cao, X.; Han, J.; Liu, J. Gabor Convolutional Networks. arXiv 2017, arXiv:1705.01450. [Google Scholar]
- Zhou, Y.; Ye, Q.; Qiu, Q.; Jiao, J. Oriented Response Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2017; pp. 519–528. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Zisserman, A. Spatial Transformer Networks. In Advances in Neural Information Processing Systems 28; Curran Associates, Inc.: Red Hook, NY, USA, 2015. [Google Scholar]
- Xie, G.-S.; Zhang, X.-Y.; Yan, S.; Liu, C.-L. Hybrid CNN and Dictionary-Based Models for Scene Recognition and Domain Adaptation. IEEE Trans. Circuits Syst. Video Technol. 2017, 27, 1263–1274. [Google Scholar] [CrossRef]
- Perronnin, F.; Larlus, D. Fisher vectors meet Neural Networks: A hybrid classification architecture. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 8–10 June 2015; pp. 3743–3752. [Google Scholar]
- Xi, M.; Chen, L.; Polajnar, D.; Tong, W. Local binary pattern network: A deep learning approach for face recognition. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3224–3228. [Google Scholar]
- Guc, F.; Chen, Y. Sensor Fault Diagnostics Using Physics-Informed Transfer Learning Framework. Sensors 2022, 22, 2913. [Google Scholar] [CrossRef]
- Karniadakis, G.E.; Kevrekidis, I.G.; Lu, L.; Perdikaris, P.; Wang, S.; Yang, L. Physics-informed machine learning. Nat. Rev. Phys. 2021, 3, 422–440. [Google Scholar] [CrossRef]
- Lazebnik, S.; Schmid, C.; Ponce, J. Beyond Bags of Features: Spatial Pyramid Matching for Recognizing Natural Scene Categories. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; Volume 2, pp. 2169–2178. [Google Scholar]
- Theodorakopoulos, I.; Kastaniotis, D.; Economou, G.; Fotopoulos, S. HEp-2 cells classification via sparse representation of textural features fused into dissimilarity space. Pattern Recognit. 2014, 47, 2367–2378. [Google Scholar] [CrossRef]
- Kornblith, S.; Shlens, J.; Le, Q.V. Do Better ImageNet Models Transfer Better? arXiv 2018, arXiv:1805.08974. [Google Scholar]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic differentiation in PyTorch. In Proceedings of the NIPS 2017 Workshop Autodiff Submission, Long Beach, CA, USA, 9 December 2017. [Google Scholar]
- Nigam, I.; Agrawal, S.; Singh, R.; Vatsa, M. Revisiting HEp-2 Cell Image Classification. IEEE Access 2015, 3, 3102–3113. [Google Scholar] [CrossRef]
- Agrawal, P.; Vatsa, M.; Singh, R. HEp-2 Cell Image Classification: A Comparative Analysis. In International Workshop on Machine Learning in Medical Imaging; Springer: Cham, Switzerland, 2013; pp. 195–202. [Google Scholar]
- Ensafi, S.; Lu, S.; Kassim, A.A.; Tan, C.L. A Bag of Words Based Approach for Classification of HEp-2 Cell Images. In Proceedings of the 2014 1st Workshop on Pattern Recognition Techniques for Indirect Immunofluorescence Images, Stockholm, Sweden, 4 December 2014; pp. 29–32. [Google Scholar]
- Li, M.; Liu, S.; Zhang, Z. Dual Guided Loss for Ground-Based Cloud Classification in Weather Station Networks. IEEE Access 2019, 7, 63081–63088. [Google Scholar] [CrossRef]
- Liu, S.; Duan, L.; Zhang, Z.; Cao, X. Hierarchical Multimodal Fusion for Ground-Based Cloud Classification in Weather Station Networks. IEEE Access 2019, 7, 85688–85695. [Google Scholar] [CrossRef]
- Shi, C.; Wang, C.; Wang, Y.; Xiao, B. Deep Convolutional Activations-Based Features for Ground-Based Cloud Classification. IEEE Geosci. Remote Sens. Lett. 2017, 14, 816–820. [Google Scholar] [CrossRef]
- Csurka, G.; Dance, C.; Fan, L.; Willamowski, J.; Bray, C. Visual categorization with bags of keypoints. In Workshop on Statistical Learning in Computer Vision; ECCV: Prague, Czech Republic, 2004; Volume 1, No. 1–22; pp. 1–2. [Google Scholar]
- Ojala, T.; Pietikainen, M.; Maenpaa, T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 971–987. [Google Scholar] [CrossRef]
- Guo, Z.; Zhang, L.; Zhang, D. A Completed Modeling of Local Binary Pattern Operator for Texture Classification. IEEE Trans. Image Process. 2010, 19, 1657–1663. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Zhang, J.; Liu, P.; Zhang, F.; Song, Q. CloudNet: Ground-Based Cloud Classification with Deep Convolutional Neural Network. Geophys. Res. Lett. 2018, 45, 8665–8672. [Google Scholar] [CrossRef]
- Agrawal, S.; Omprakash, V.R. Ranvijay Lip reading techniques: A survey. In Proceedings of the 2016 2nd International Conference on Applied and Theoretical Computing and Communication Technology (iCATccT), Bengaluru, India, 21–23 July 2016; pp. 753–757. [Google Scholar]
- Martinez, B.; Ma, P.; Petridis, S.; Pantic, M. Lipreading Using Temporal Convolutional Networks. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 6319–6323. [Google Scholar]
- Kastaniotis, D.; Tsourounis, D.; Fotopoulos, S. Lip Reading modeling with Temporal Convolutional Networks for medical support applications. In Proceedings of the 2020 13th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI), Chengdu, China, 17–19 October 2020. [Google Scholar] [CrossRef]
- Lea, C.; Flynn, M.D.; Vidal, R.; Reiter, A.; Hager, G.D. Temporal Convolutional Networks for Action Segmentation and Detection; 2017; pp. 156–165. Available online: https://openaccess.thecvf.com/content_cvpr_2017/html/Lea_Temporal_Convolutional_Networks_CVPR_2017_paper.html (accessed on 14 September 2020).
- Jining, Y.; Lin, M.; Wang, L.; Rajiv, R.; Zomaya, A.Y. Temporal Convolutional Networks for the Advance Prediction of ENSO. Sci. Rep. 2020, 10, 8055. [Google Scholar]
- Chung, J.S.; Senior, A.; Vinyals, O.; Zisserman, A. Lip Reading Sentences in the Wild. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 17–21 June 2017; pp. 3444–3453. [Google Scholar]
- Petridis, S.; Stafylakis, T.; Ma, P.; Cai, F.; Tzimiropoulos, G.; Pantic, M. End-to-End Audiovisual Speech Recognition. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 6548–6552. [Google Scholar]
- Stafylakis, T.; Tzimiropoulos, G. Combining Residual Networks with LSTMs for Lipreading. In Interspeech; ISCA: Singapore, 2017; pp. 3652–3656. [Google Scholar]
- Cheng, S.; Ma, P.; Tzimiropoulos, G.; Petridis, S.; Bulat, A.; Shen, J.; Pantic, M. Towards Pose-Invariant Lip-Reading. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 4357–4361. [Google Scholar]
- Wang, C. Multi-Grained Spatio-temporal Modeling for Lip-reading. In Proceedings of the 30th British Machine Vision Conference 2019, BMVC 2019, Cardiff, UK, 9–12 September 2019; p. 276. Available online: https://bmvc2019.org/wp-content/uploads/papers/1211-paper.pdf (accessed on 19 August 2022).
- Courtney, L.; Sreenivas, R. Learning from Videos with Deep Convolutional LSTM Networks. arXiv 2019, arXiv:1904.04817. [Google Scholar]
- Luo, M.; Yang, S.; Shan, S.; Chen, X. Pseudo-Convolutional Policy Gradient for Sequence-to-Sequence Lip-Reading. In Proceedings of the 2020 15th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2020), Buenos Aires, Argentina, 16–20 November 2020. [Google Scholar] [CrossRef]
- Weng, X.; Kitani, K. Learning Spatio-Temporal Features with Two-Stream Deep 3D CNNs for Lipreading. In Proceedings of the 30th British Machine Vision Conference 2019, BMVC 2019, Cardiff, UK, 9–12 September 2019; p. 269. Available online: https://bmvc2019.org/wp-content/uploads/papers/0016-paper.pdf (accessed on 19 August 2022).
- Xiao, J.; Yang, S.; Zhang, Y.-H.; Shan, S.; Chen, X. Deformation Flow Based Two-Stream Network for Lip Reading. In Proceedings of the 2020 15th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2020), Buenos Aires, Argentina, 16–20 November 2020. [Google Scholar] [CrossRef]
- Zhao, X.; Yang, S.; Shan, S.; Chen, X. Mutual Information Maximization for Effective Lip Reading. In Proceedings of the 2020 15th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2020), Buenos Aires, Argentina, 16–20 November 2020. [Google Scholar] [CrossRef]
- Zhang, Y.-H.; Yang, S.; Xiao, J.; Shan, S.; Chen, X. Can We Read Speech Beyond the Lips? Rethinking RoI Selection for Deep Visual Speech Recognition. In Proceedings of the 2020 15th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2020), Buenos Aires, Argentina, 16–20 November 2020. [Google Scholar] [CrossRef]
- Feng, D.; Yang, S.; Shan, S.; Chen, X. Learn an Effective Lip Reading Model without Pains. arXiv 2020, arXiv:2011.07557. [Google Scholar]
- Pan, X.; Chen, P.; Gong, Y.; Zhou, H.; Wang, X.; Lin, Z. Leveraging Unimodal Self-Supervised Learning for Multimodal Audio-Visual Speech Recognition. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Virtual, 22–27 May 2022; pp. 4491–4503. [Google Scholar]
- Kim, M.; Hong, J.; Park, S.J.; Ro, Y.M. Multi-Modality Associative Bridging Through Memory: Speech Sound Recollected from Face Video, 2021; pp. 296–306. Available online: https://openaccess.thecvf.com/content/ICCV2021/html/Kim_Multi-Modality_Associative_Bridging_Through_Memory_Speech_Sound_Recollected_From_Face_ICCV_2021_paper.html (accessed on 2 September 2022).
- Tsourounis, D.; Kastaniotis, D.; Fotopoulos, S. Lip Reading by Alternating between Spatiotemporal and Spatial Convolutions. J. Imaging 2021, 7, 91. [Google Scholar] [CrossRef] [PubMed]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A Simple Framework for Contrastive Learning of Visual Representations. In Proceedings of the International Conference on Machine Learning, Virtual, 13–18 July 2020; Available online: https://proceedings.icml.cc/paper/2020/hash/36452e720502e4da486d2f9f6b48a7bb (accessed on 8 October 2020).
- Grill, J.-B.; Strub, F.; Altché, F.; Tallec, C.; Richemond, P.; Buchatskaya, E.; Doersch, C.; Avila Pires, B.; Guo, Z.; Gheshlaghi Azar, M.; et al. Bootstrap Your Own Latent—A New Approach to Self-Supervised Learning. In Proceedings of the Advances in Neural Information Processing Systems, Virtual, 6–12 December 2020; Volume 33, pp. 21271–21284. [Google Scholar]
- Zbontar, J.; Jing, L.; Misra, I.; LeCun, Y.; Deny, S. Barlow Twins: Self-Supervised Learning via Redundancy Reduction. In Proceedings of the Proceedings of the 38th International Conference on Machine Learning PMLR 2021, Virtual, 18–24 July 2021; pp. 12310–12320. Available online: https://proceedings.mlr.press/v139/zbontar21a.html (accessed on 22 March 2022).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hep-2 Cell Image Classification Systems | Classification Accuracy (%) | |
|---|---|---|
| Method | ICPR 2012 | ICIP 2013 |
| SIFT + VHAR [7] | 73.4 | - |
| SIFT-SURF + BoW [45] | 75.0 | - |
| Pixel-CNN(ResNet-18) without transfer learning | 66.3 | 84.47 |
| SIFT-CNN(ResNet-18) without transfer learning | 73.0 | 89.18 |
| Pixel-CNN(ResNet-18) with transfer learning | 68.5 | 86.12 |
| SIFT-CNN(ResNet-18) with transfer learning | 75.0 | 89.21 |
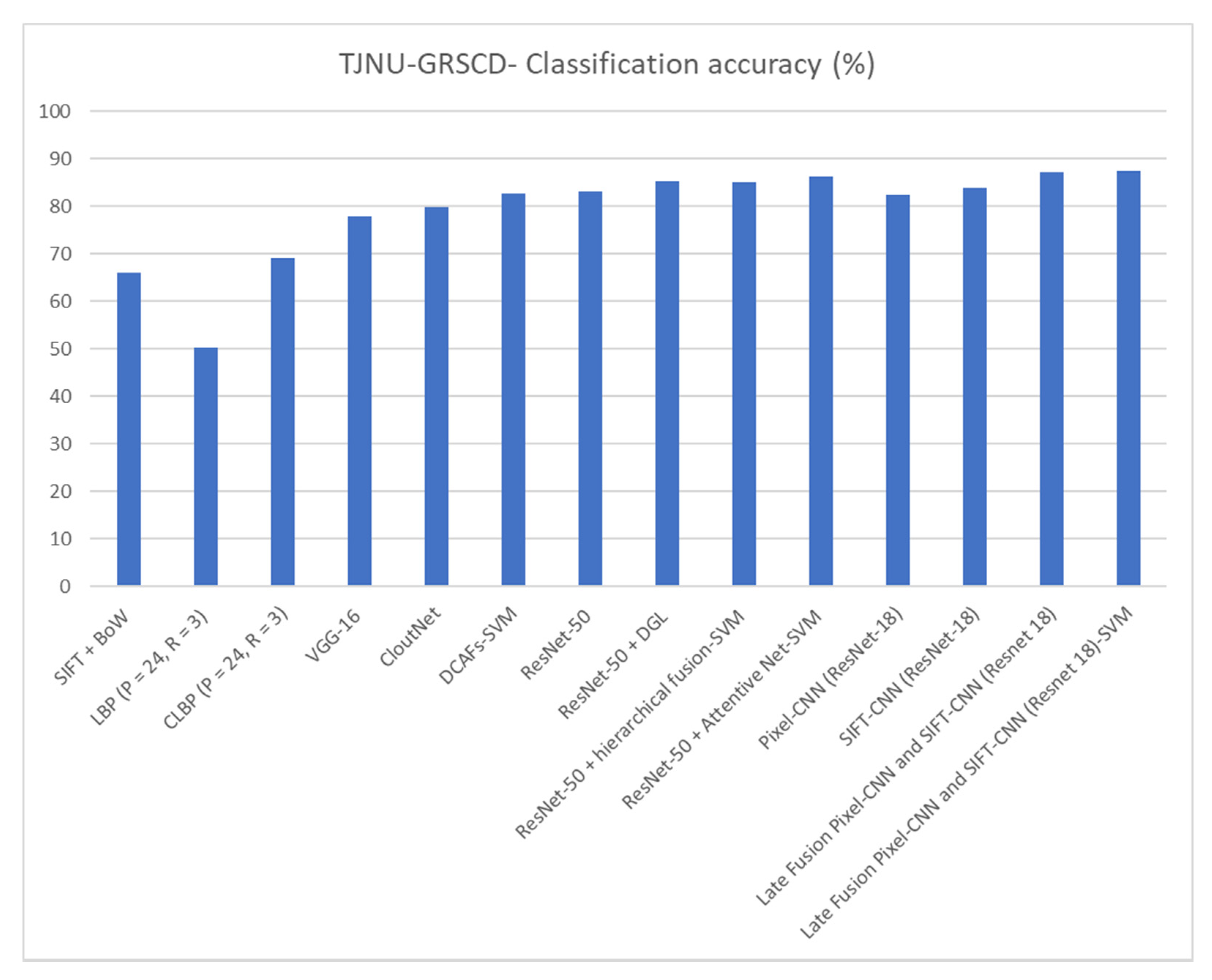
| Different Methods on GRSCD | Classification Accuracy (%) |
|---|---|
| Method | GRSCD |
| SIFT + BoW [15,49] | 66.13 |
| LBP (P = 24, R = 3) [15,50] | 50.20 |
| CLBP (P = 24, R = 3) [15,51] | 69.18 |
| VGG-16 [15,52] | 77.95 |
| CloutNet [15,53] | 79.92 |
| DCAFs-SVM [15,49] | 82.67 |
| ResNet-50 [46] | 83.15 |
| ResNet-50 + DGL [46] | 85.28 |
| ResNet-50 + hierarchical fusion-SVM [47] | 85.12 |
| ResNet-50 + Attentive Net-SVM [15] | 86.25 |
| Pixel-CNN (ResNet-18) | 82.52 |
| SIFT-CNN (ResNet-18) | 83.90 |
| Late Fusion Pixel-CNN and SIFT-CNN (Resnet 18) | 87.22 |
| Late Fusion Pixel-CNN and SIFT-CNN (Resnet 18)-SVM | 87.55 |
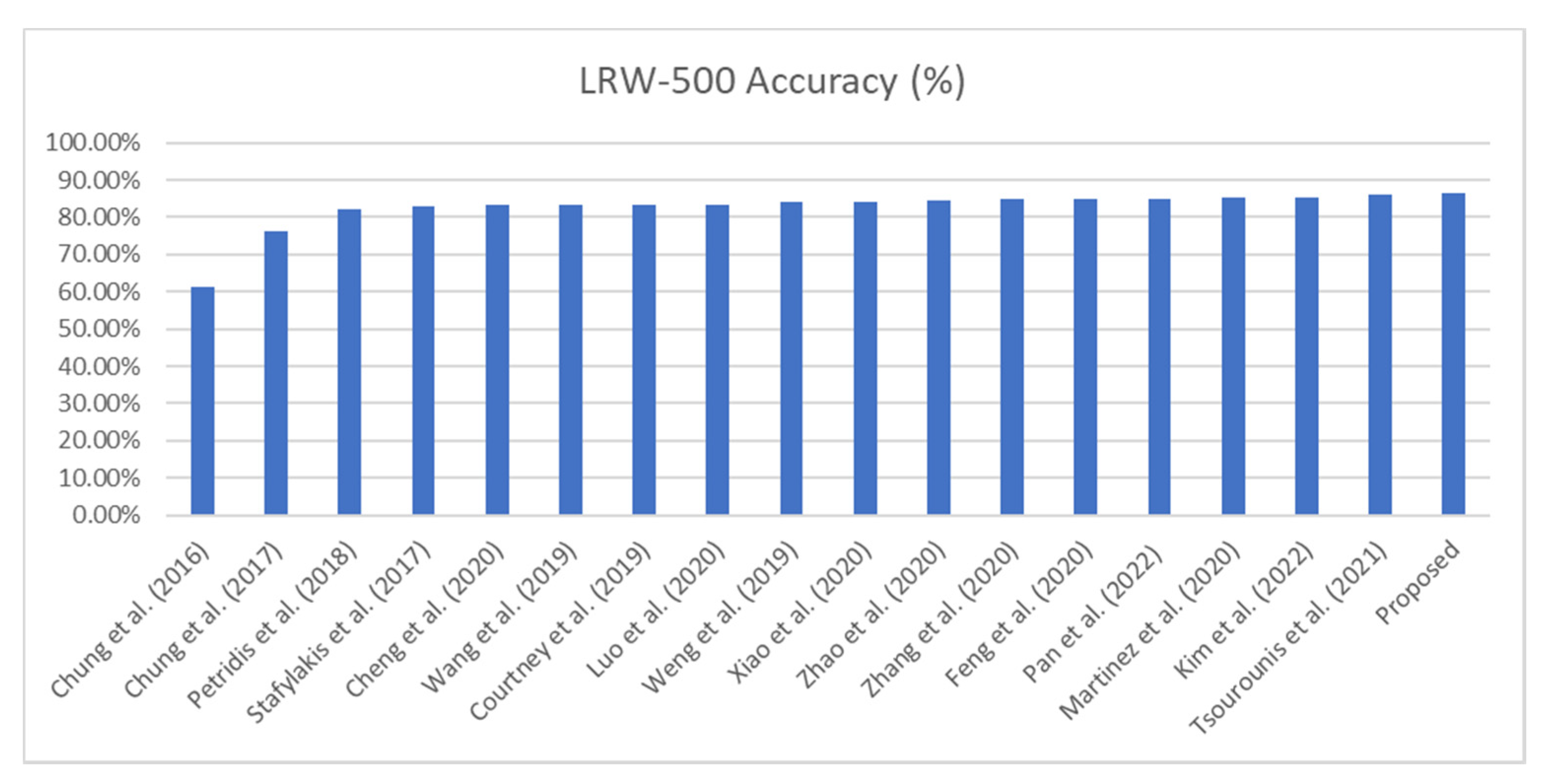
| Method | Data | LRW | |||
|---|---|---|---|---|---|
| Authors’ Name (Year) | Frontend | Backend | Input Image Size | Input and Data Managing Policy | Classification Accuracy WRR (%) |
| Chung et al. (2016) [16] | 3D &VGG M | - | 112 × 112 | Mouth | 61.10% |
| Chung et al. (2017) [59] | 3D & VGG M version | LSTM & Attention | 120 × 120 | Mouth | 76.20% |
| Petridis et al. (2018) [60] | 3D & ResNet-34 | Bi-GRU | 96 × 96 | Mouth | 82.00% |
| Stafylakis et al. (2017) [61] | 3D & ResNet-34 | Bi-LSTM | 112 × 112 | Mouth | 83.00% |
| Cheng et al. (2020) [62] | 3D & ResNet-18 | Bi-GRU | 88 × 88 | Mouth & 3D augmentations | 83.20% |
| Wang et al. (2019) [63] | 2-Stream ResNet-34 & DenseNet3D-52 | Bi-LSTM | 88 × 88 | Mouth | 83.34% |
| Courtney et al. (2019) [64] | alternating ResidualNet Bi-LSTM | alternating ResidualNet Bi-LSTM | 48 × 48, 56 × 56, 64 × 64 | Mouth (& pretraining) | 83.40% (85.20%) |
| Luo et al. (2020) [65] | 3D & 2-Stream ResNet-18 | Bi-GRU | 88 × 88 | Mouth and gradient policy | 83.50% |
| Weng et al. (2019) [66] | deep 3D & 2-Stream ResNet-18 | Bi-LSTM | 112 × 112 | Mouth & optical flow | 84.07% |
| Xiao et al. (2020) [67] | 3D & 2-Stream ResNet-18 | Bi-GRU | 88 × 88 | Mouth & deformation flow | 84.13% |
| Zhao et al. (2020) [68] | 3D & ResNet-18 | Bi-GRU | 88 × 88 | Mouth and mutual information | 84.41% |
| Zhang et al. (2020) [69] | 3D & ResNet-18 | Bi-GRU | 112 × 112 | Mouth (Aligned) | 85.02% |
| Feng et al. (2020) [70] | 3D & SE ResNet-18 | Bi-GRU | 88 × 88 | Mouth (Aligned) & augmentations | 85.00% |
| Pan et al. (2022) [71] | 3D & MoCo | Transformer | 112 × 112 | Mouth (& pretraining) | 85.00% |
| Martinez et al. (2020) [55] | 3D & ResNet-18 | MS-TCN | 88 × 88 | Mouth (Aligned) | 85.30% |
| Kim et al. (2022) [72] | 3D & ResNet-18 | Bi-GRU | 112 × 112 | Mouth (& pretraining) | 85.40% |
| Tsourounis et al. (2021) [73] | alternating ALSOS & ResNet-18 layers | MS-TCN | 88 × 88 | Mouth (Aligned) | 85.96% |
| Proposed | SIFT- 3D & CNN(ResNet-18) | MS-TCN | 88 × 88 | Mouth (Aligned) | 86.46% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tsourounis, D.; Kastaniotis, D.; Theoharatos, C.; Kazantzidis, A.; Economou, G. SIFT-CNN: When Convolutional Neural Networks Meet Dense SIFT Descriptors for Image and Sequence Classification. J. Imaging 2022, 8, 256. https://doi.org/10.3390/jimaging8100256
Tsourounis D, Kastaniotis D, Theoharatos C, Kazantzidis A, Economou G. SIFT-CNN: When Convolutional Neural Networks Meet Dense SIFT Descriptors for Image and Sequence Classification. Journal of Imaging. 2022; 8(10):256. https://doi.org/10.3390/jimaging8100256
Chicago/Turabian StyleTsourounis, Dimitrios, Dimitris Kastaniotis, Christos Theoharatos, Andreas Kazantzidis, and George Economou. 2022. "SIFT-CNN: When Convolutional Neural Networks Meet Dense SIFT Descriptors for Image and Sequence Classification" Journal of Imaging 8, no. 10: 256. https://doi.org/10.3390/jimaging8100256
APA StyleTsourounis, D., Kastaniotis, D., Theoharatos, C., Kazantzidis, A., & Economou, G. (2022). SIFT-CNN: When Convolutional Neural Networks Meet Dense SIFT Descriptors for Image and Sequence Classification. Journal of Imaging, 8(10), 256. https://doi.org/10.3390/jimaging8100256