
Sign and Human Action Detection Using Deep Learning




{kind=link}
{kind=link}
{kind=link}
{kind=link}
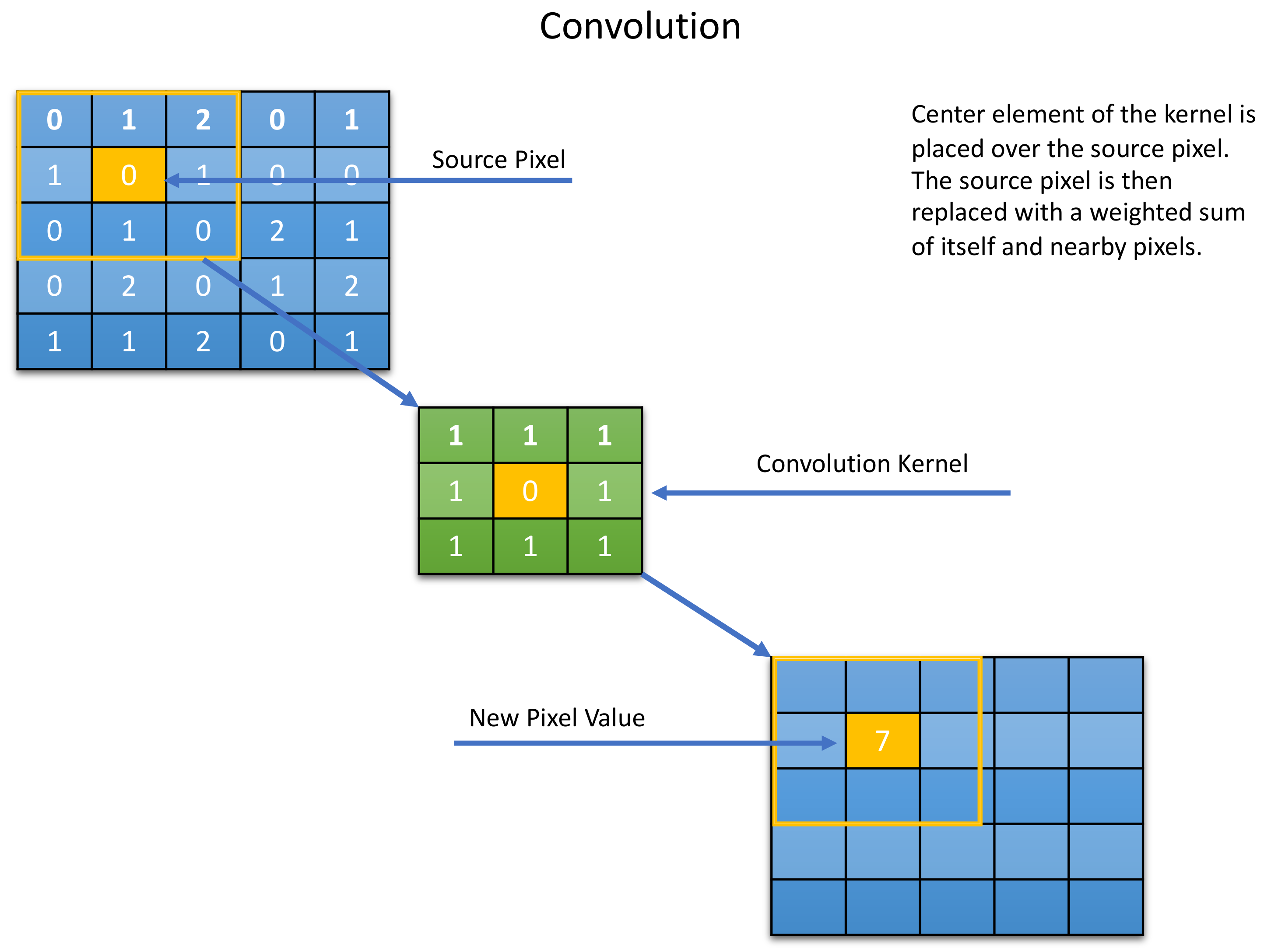{kind=link}
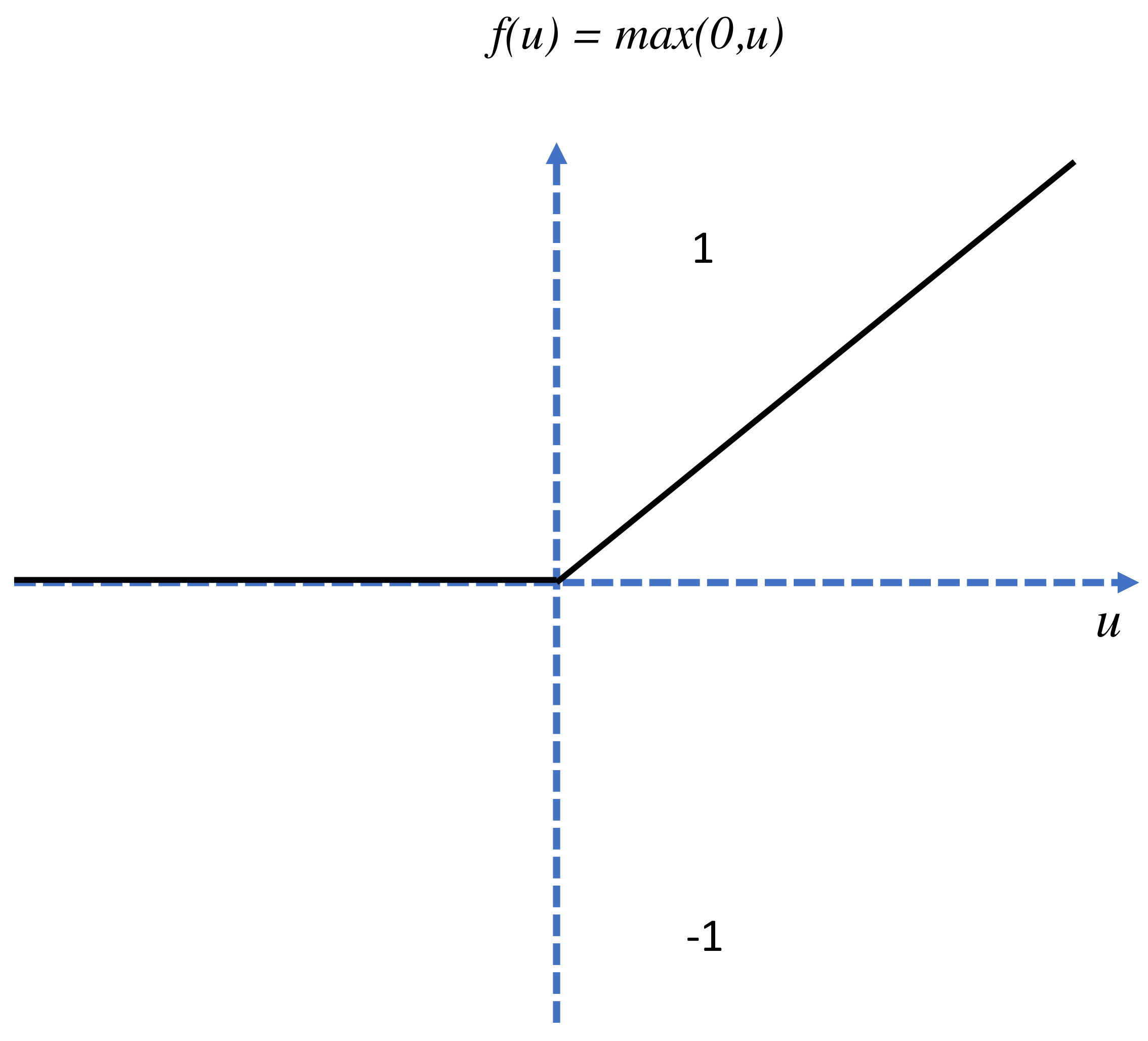{kind=link}
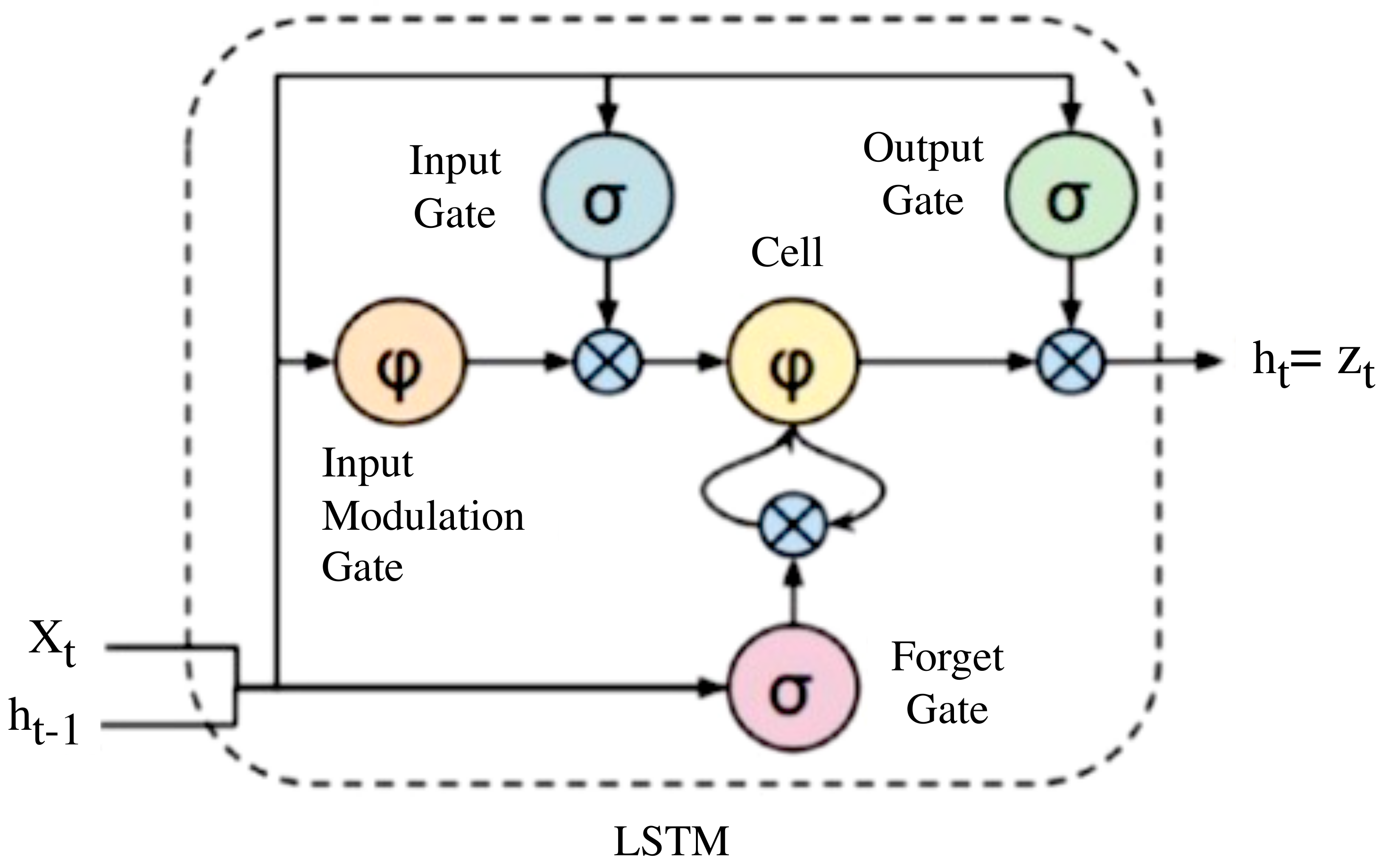{kind=link}
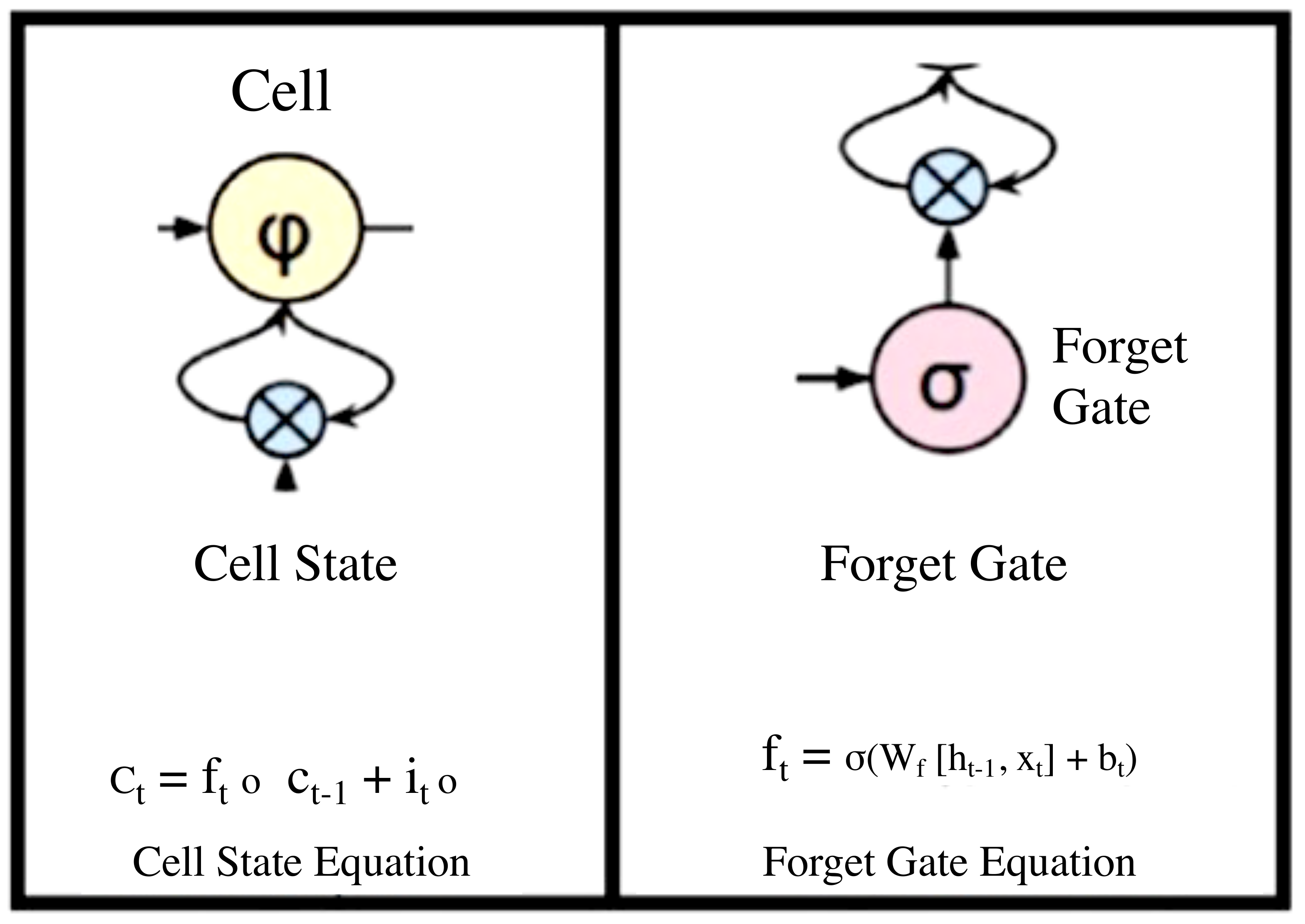{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
1.1. Background
1.2. Problem Statement
1.3. Motivation of the Study
1.4. Scope of the Study
2. Literature Review
2.1. Overview of Sign Language and Human Recognition
2.2. Need for Human Action and Sign Language Recognition
2.3. Related Works
2.4. Research Gap
2.5. Conceptual Framework
2.5.1. Overview of The Approaches
2.5.2. Variables
3. Research Methods and Planning
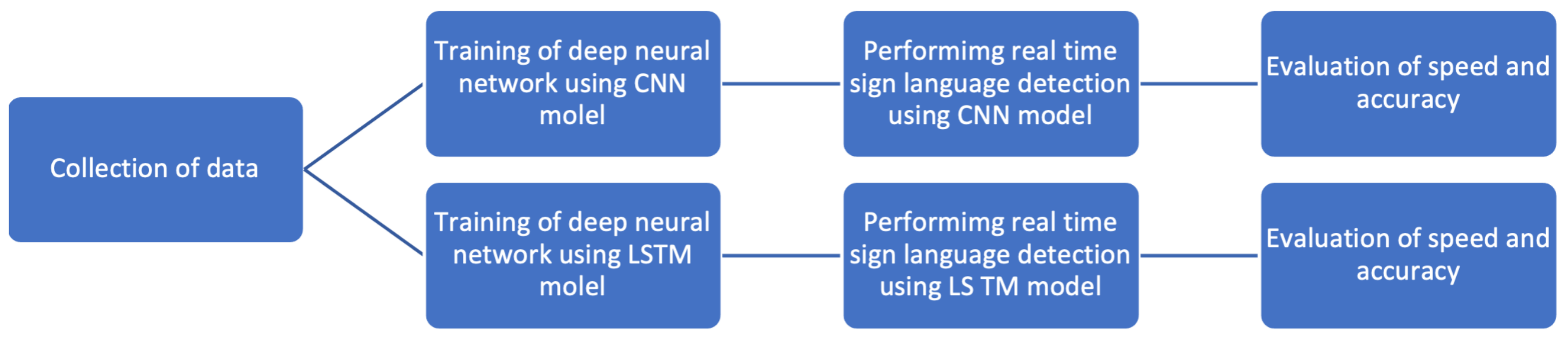
3.1. Methodology
3.2. Architecture of the Proposed Models
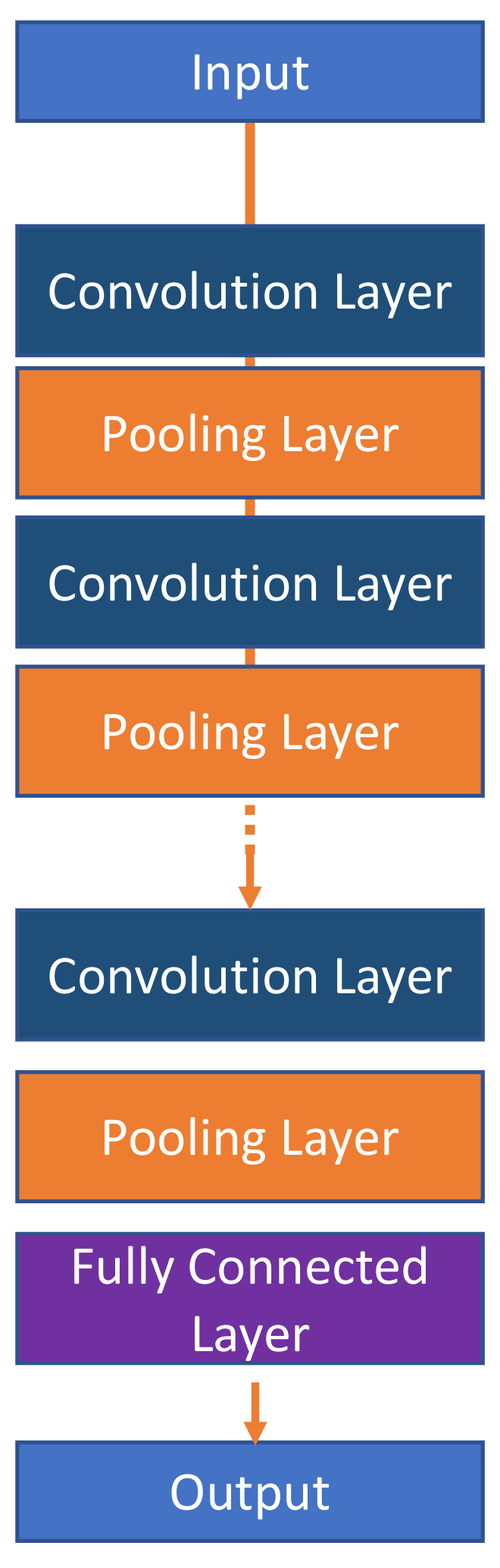
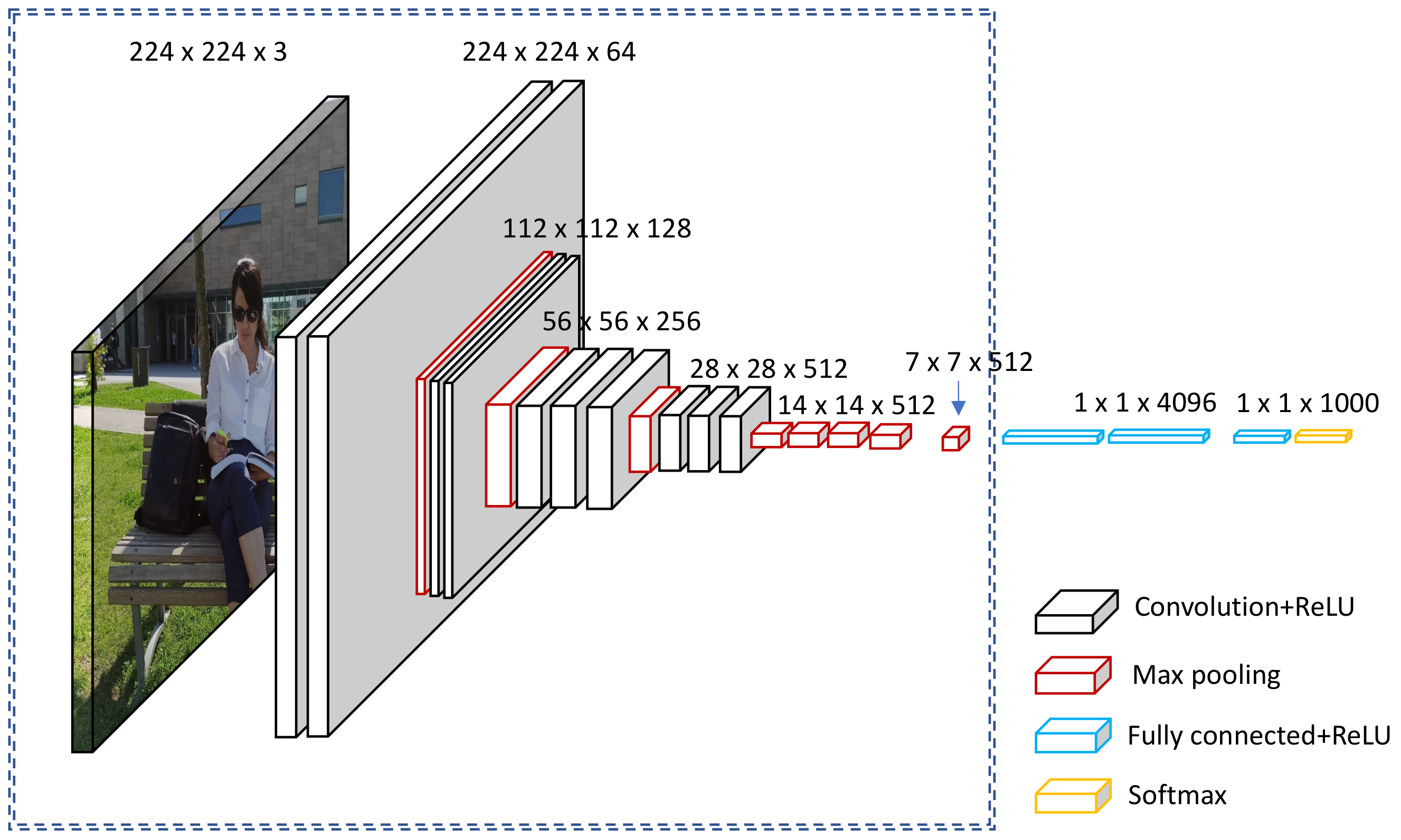
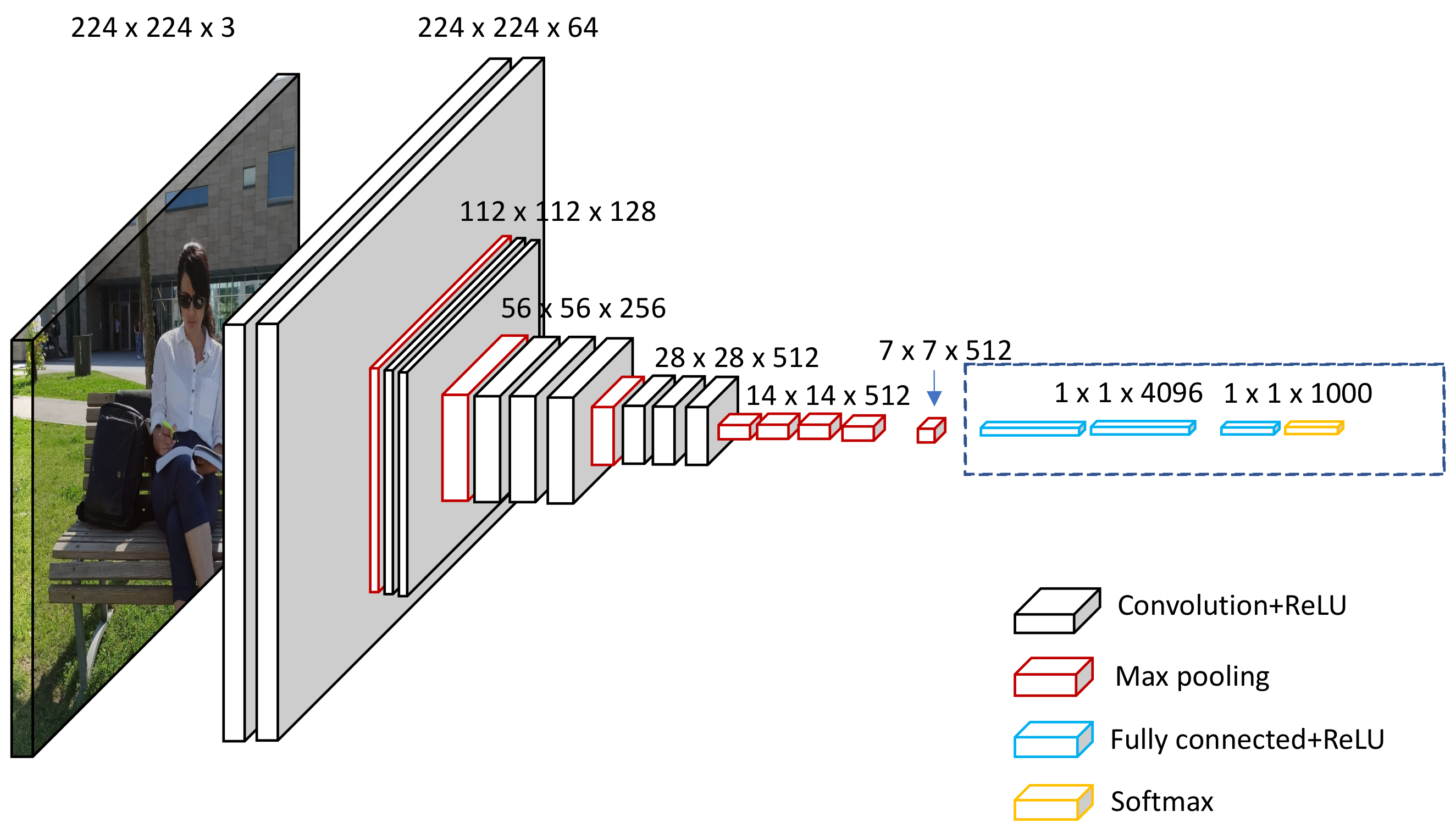
3.2.1. CNN Architecture
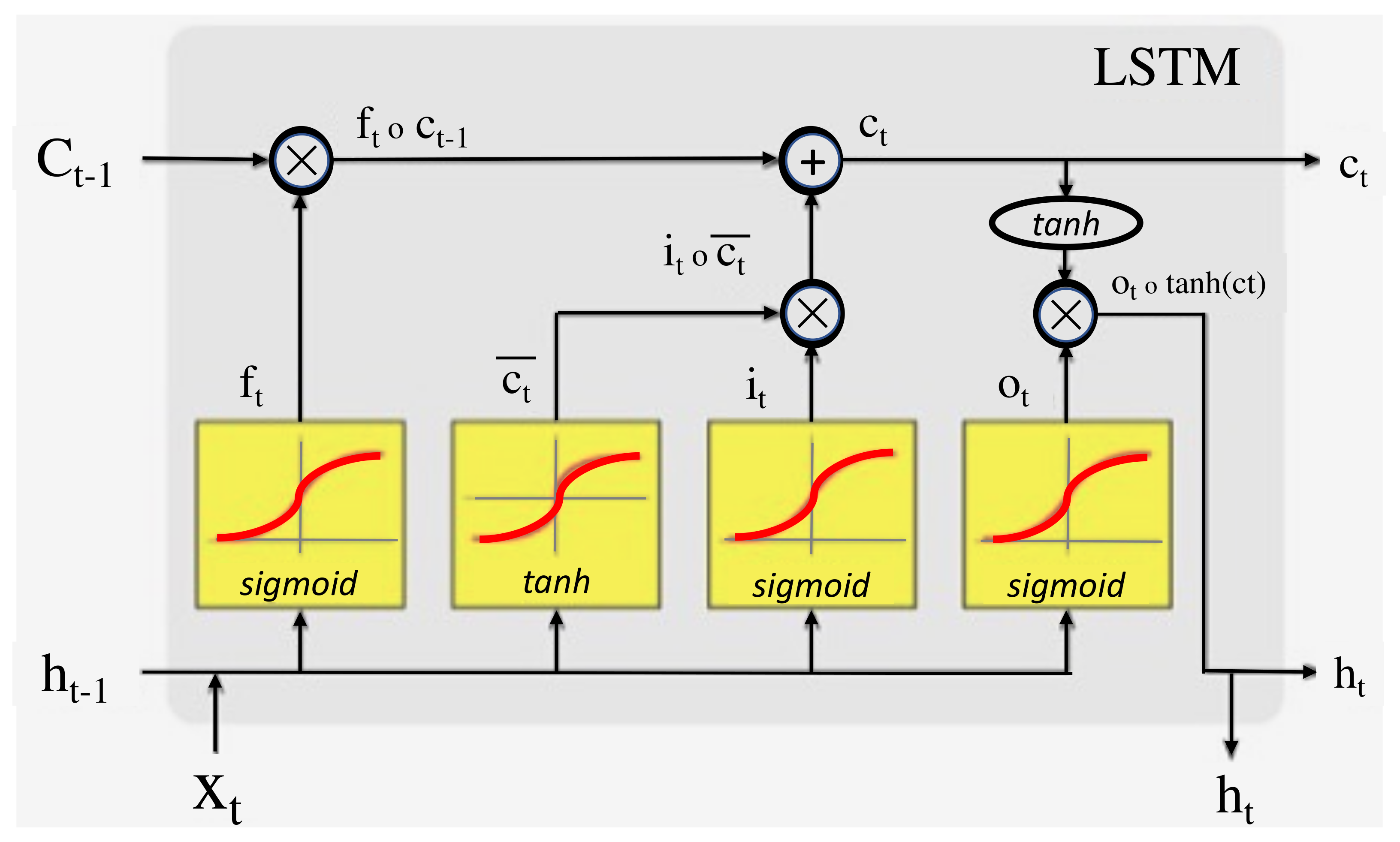
3.2.2. LSTM Architecture
3.3. Experiment Design
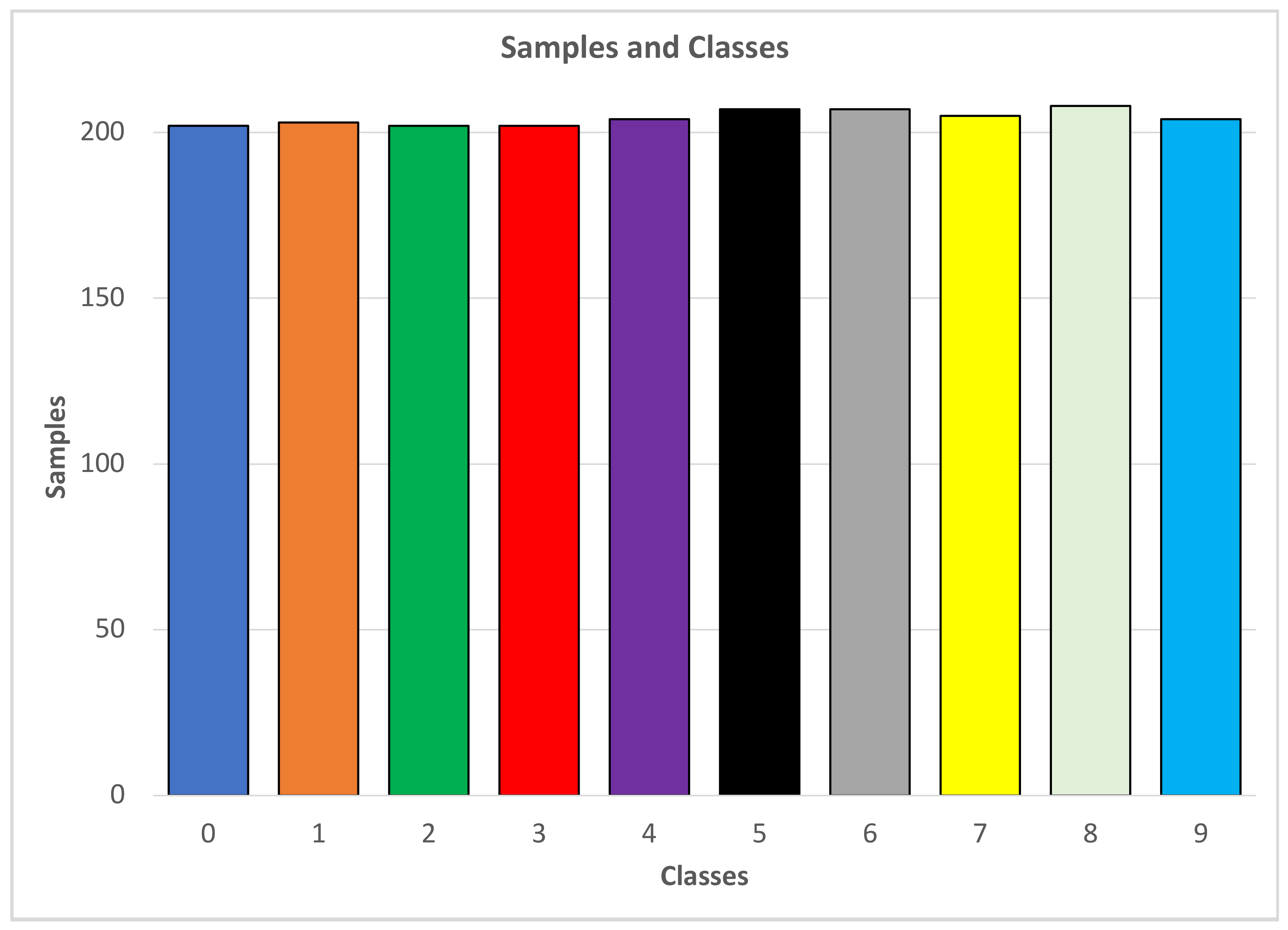
Data Description
3.4. LSTM Model Methodology Design
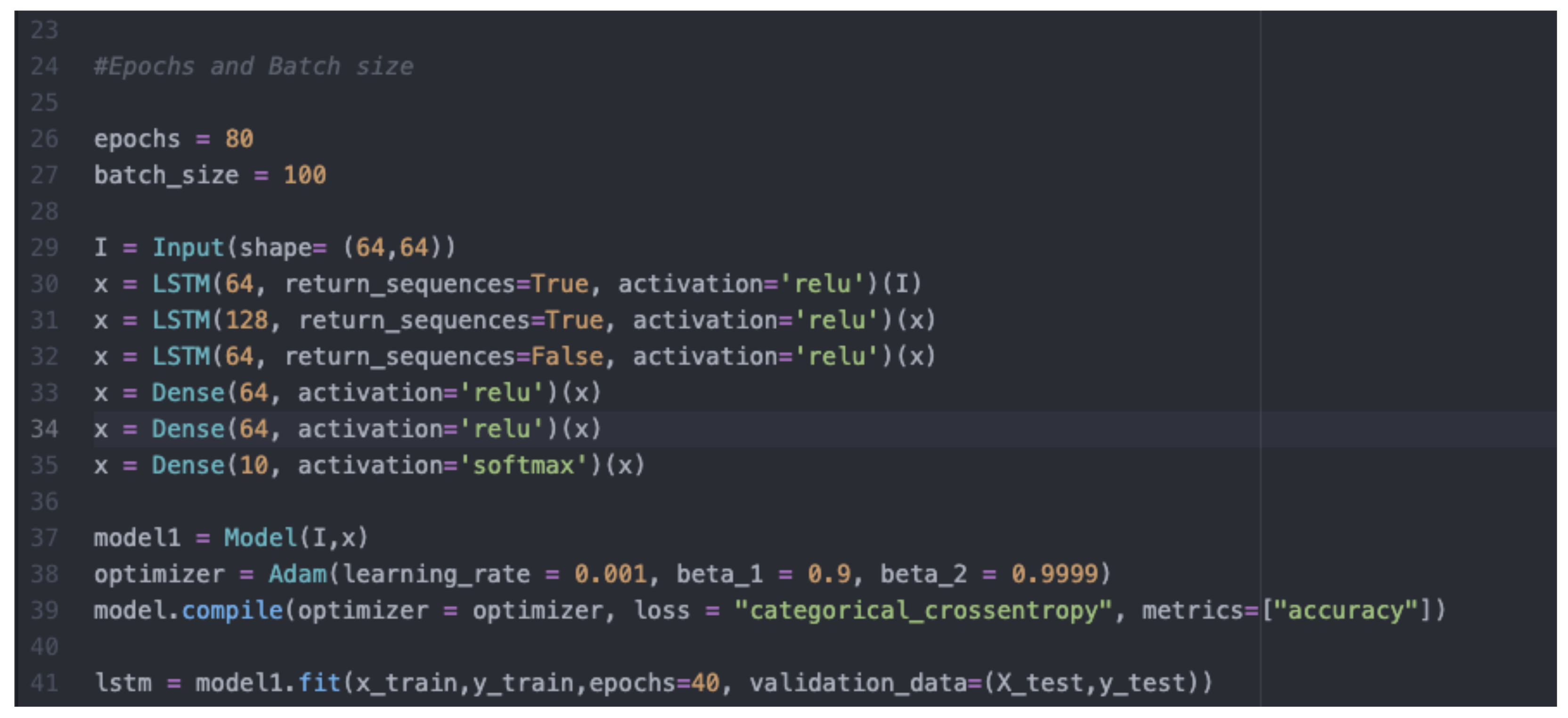
3.4.1. Building and Training of LSTM Neural Networks
3.4.2. Justification for the Used Tools
3.5. CNN Model Methodology Design
3.5.1. Implementation and Training
3.5.2. Justification for the Used Tools
3.6. Evaluation and Comparison
4. Results
4.1. Deep Learning Models for Numeric Sign Language Detection
4.1.1. Building and Training of the CNN Deep Learning Model Using the Pre-Processed Data Set
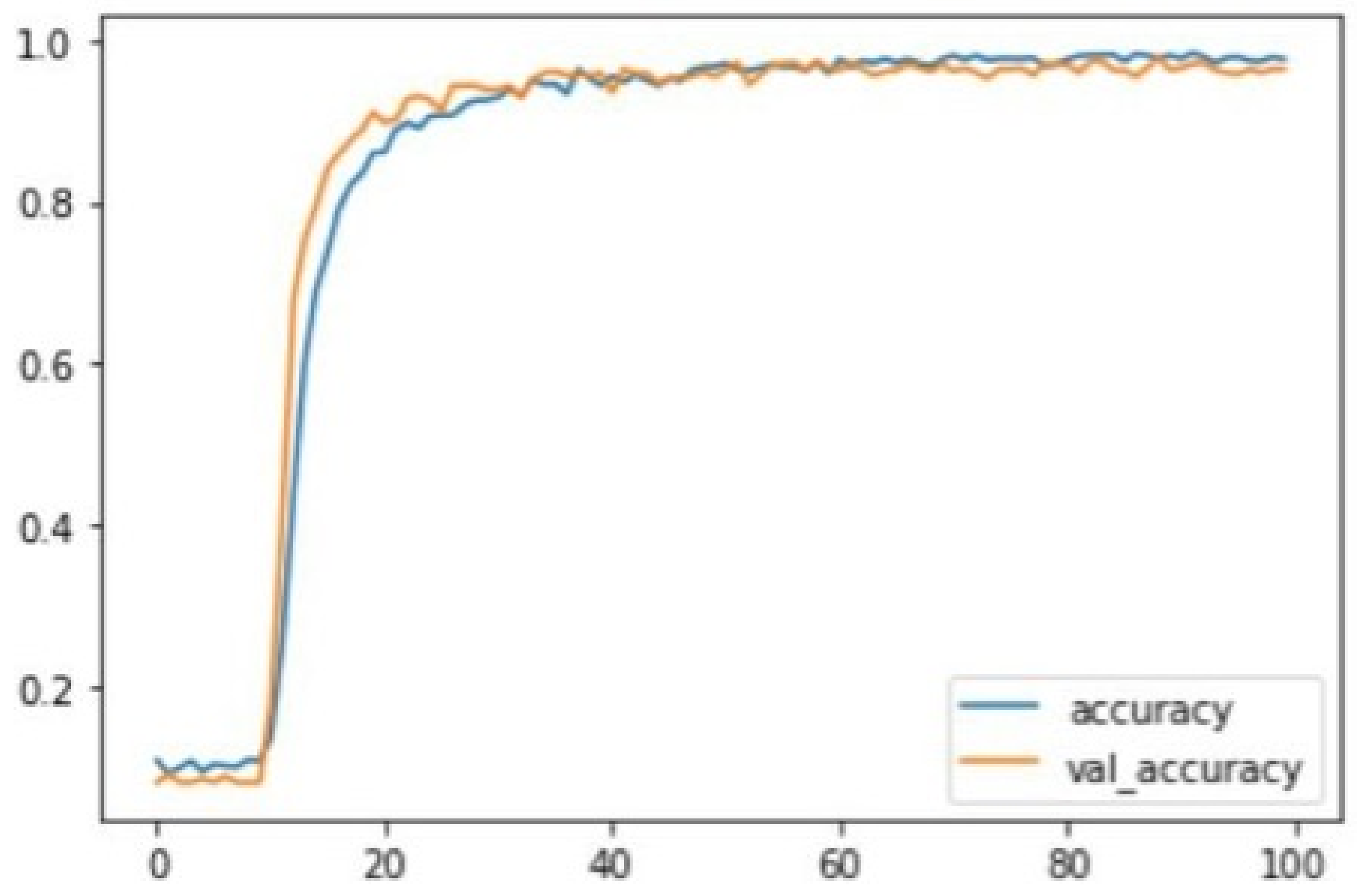
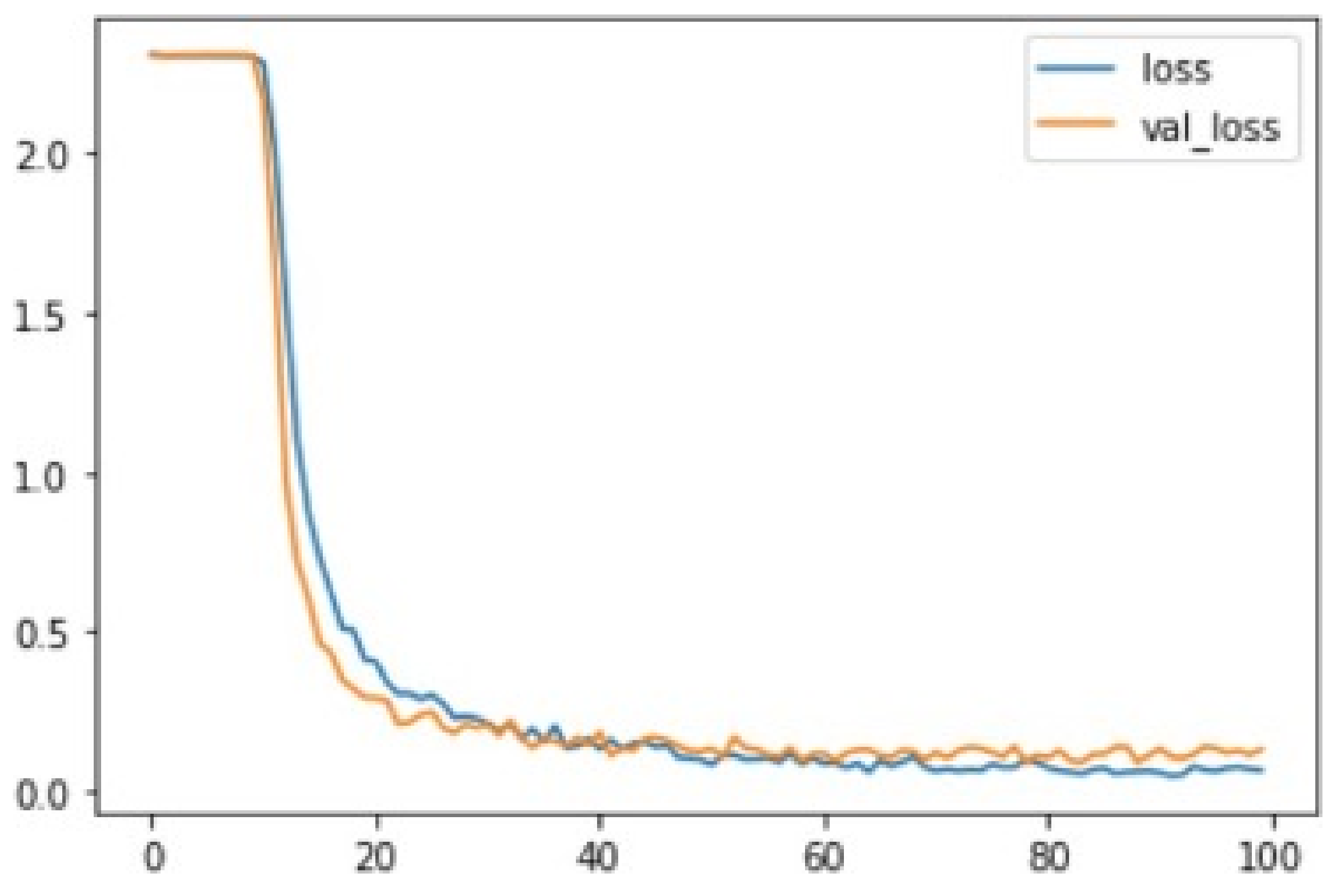
4.1.2. Evaluation of the CNN Model
4.1.3. Building and Training of the LSTM Deep Learning Model Using the Pre-Processed Dataset
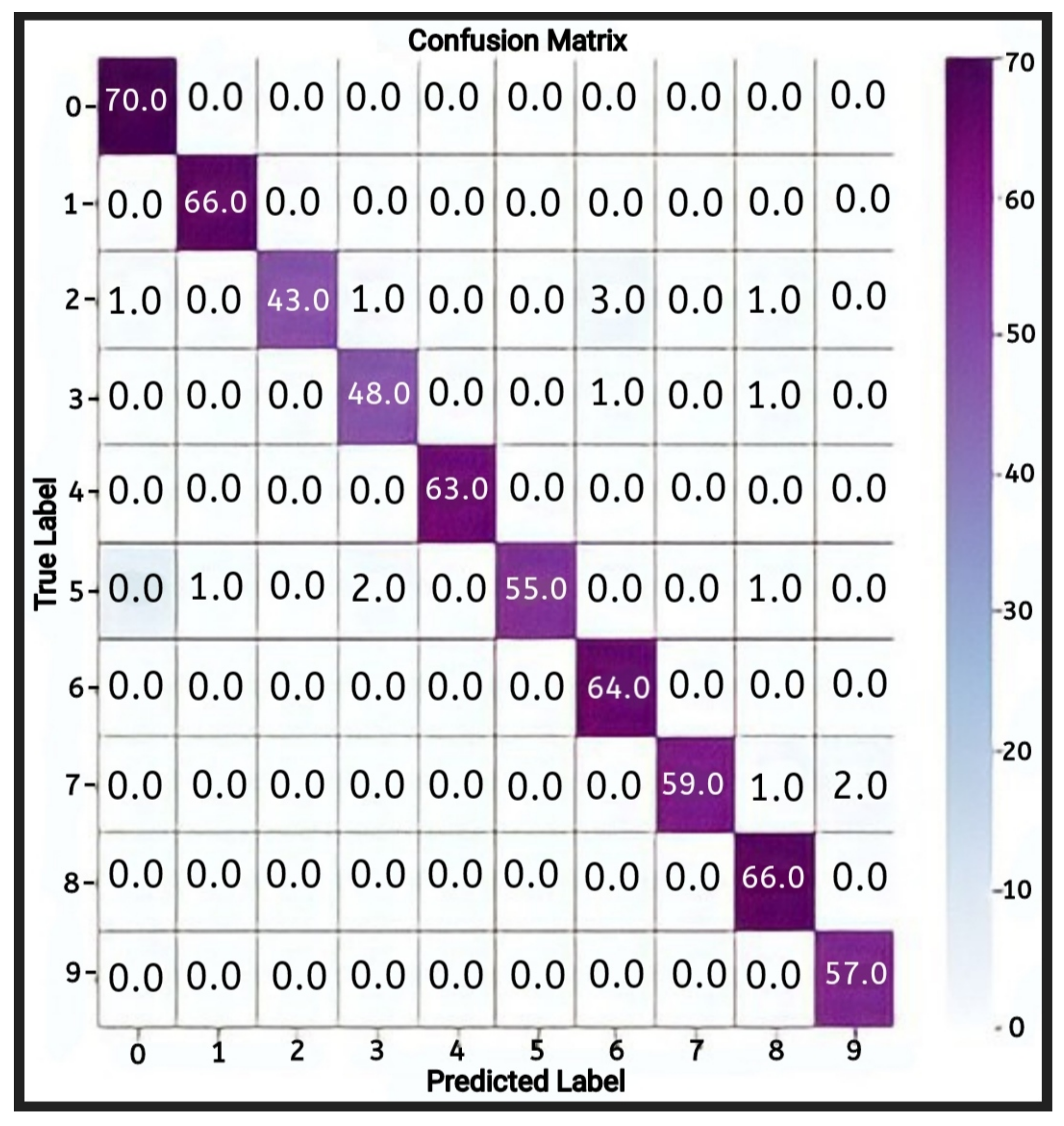
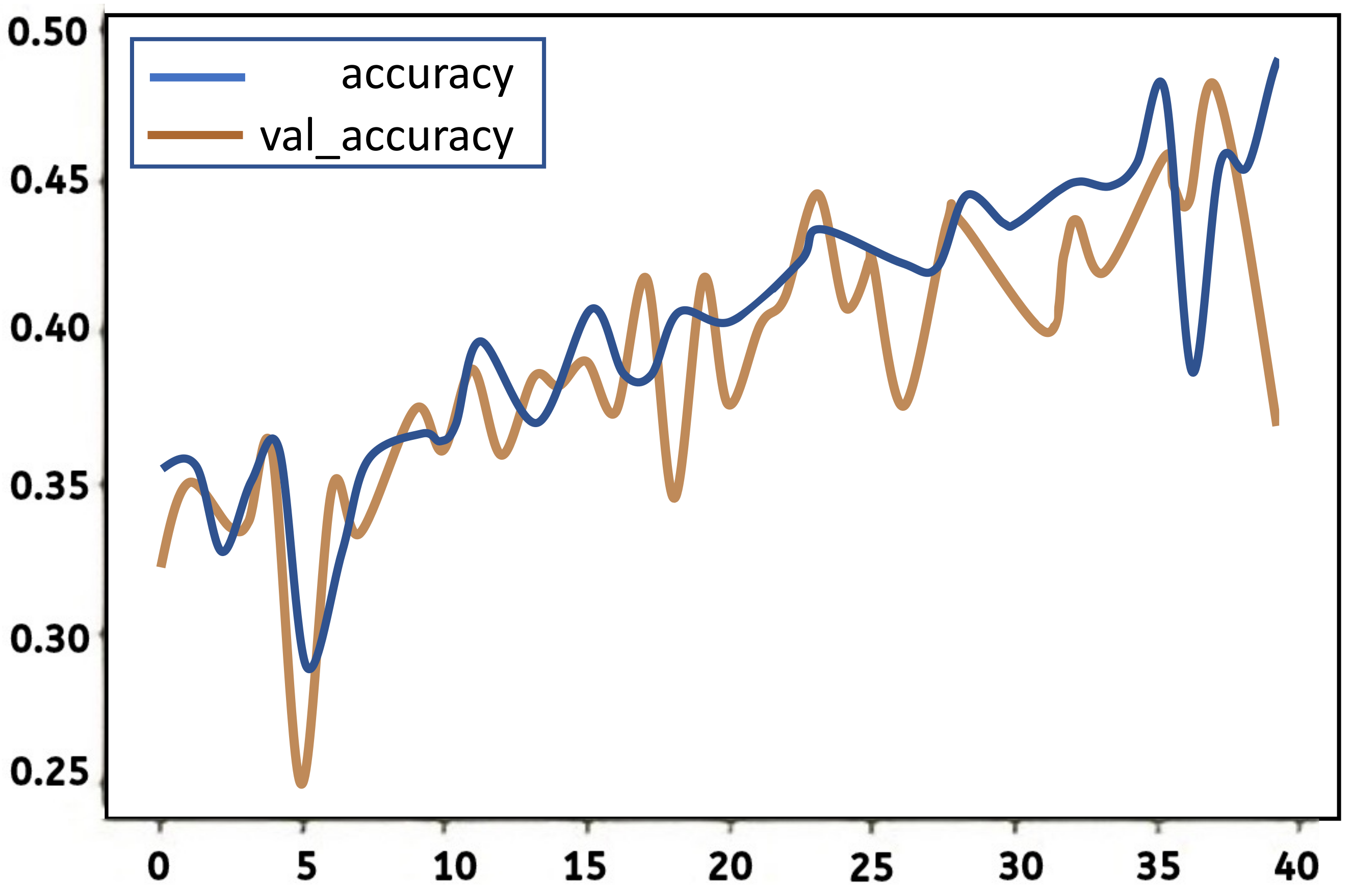
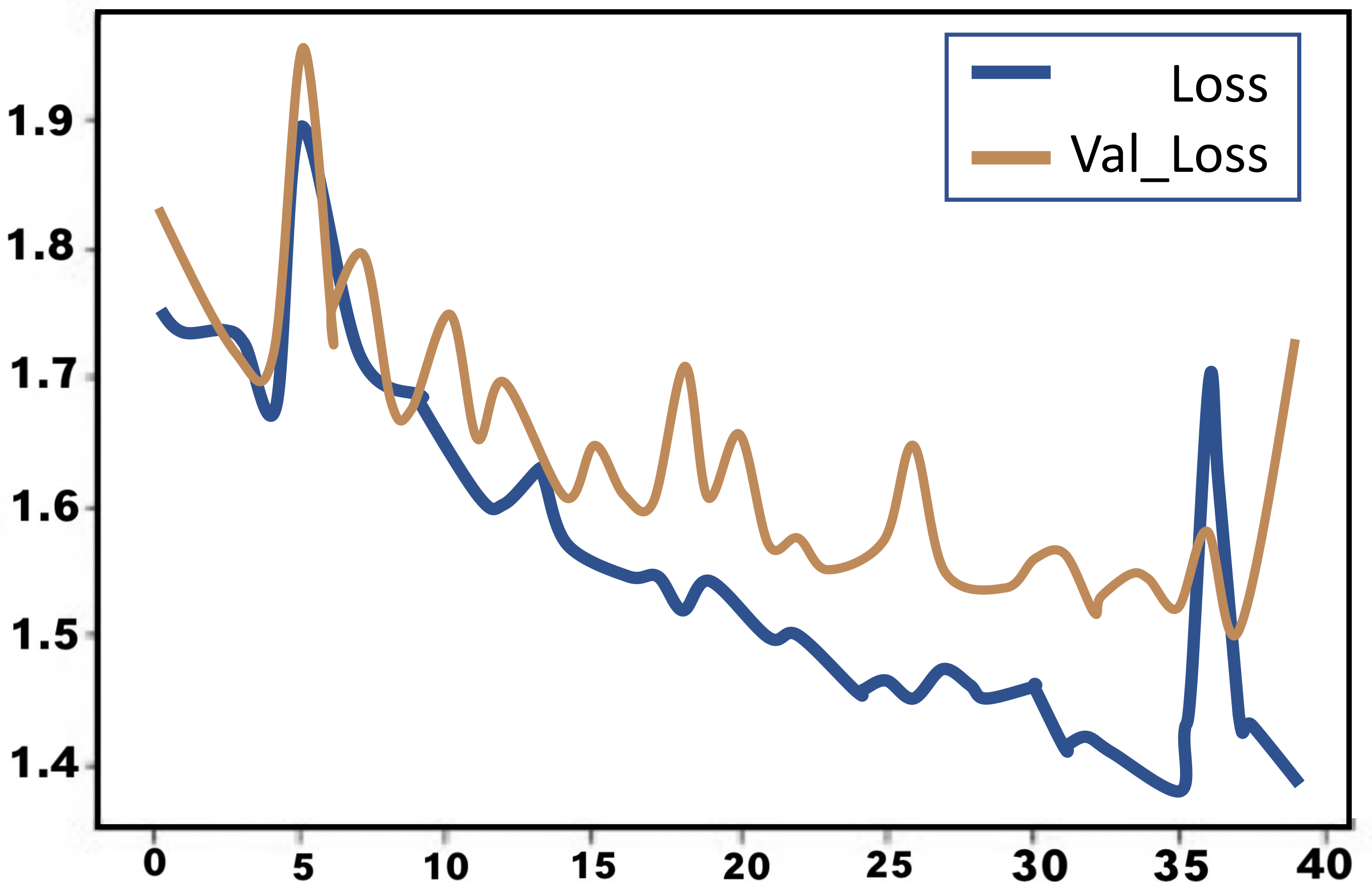
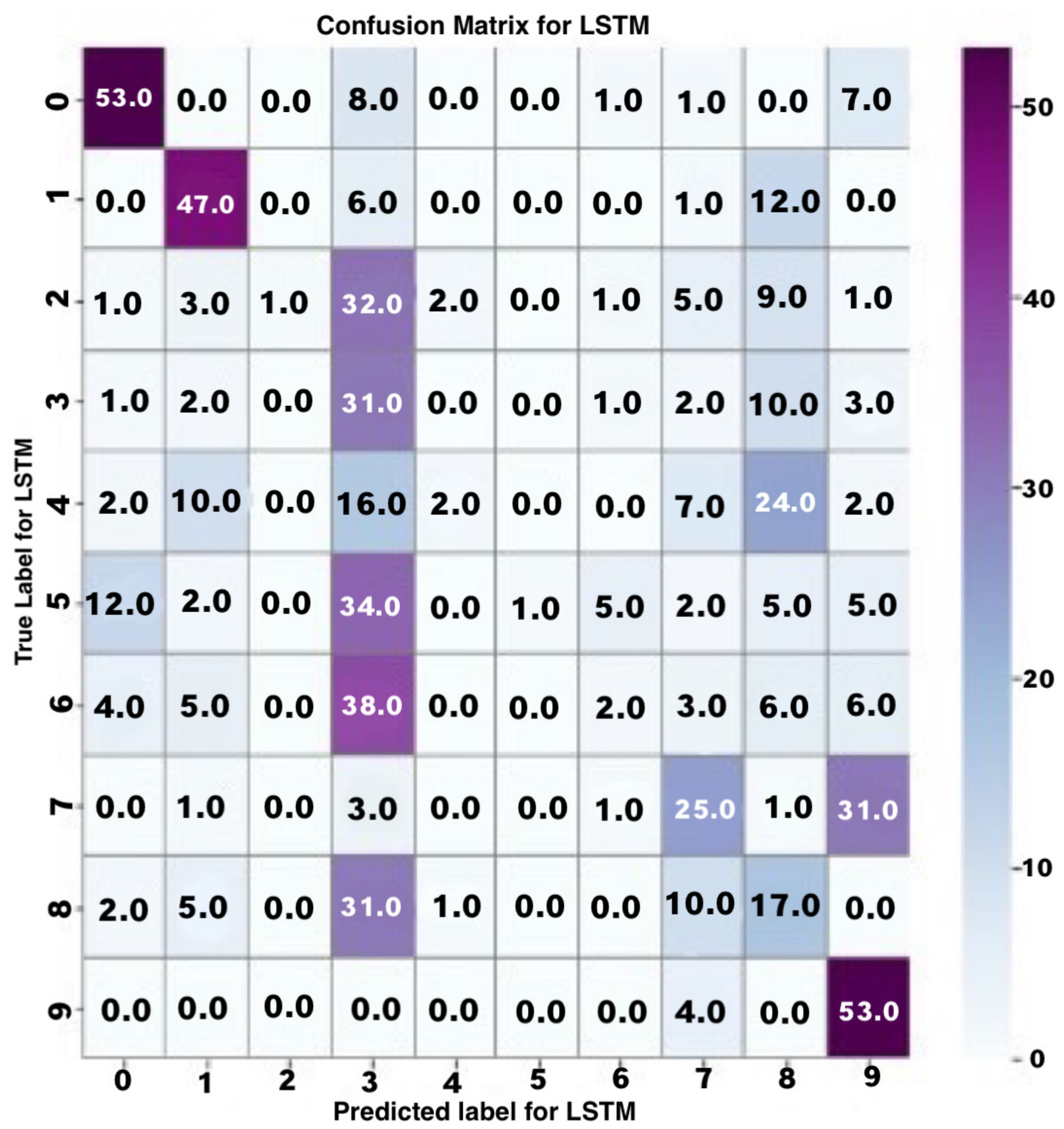
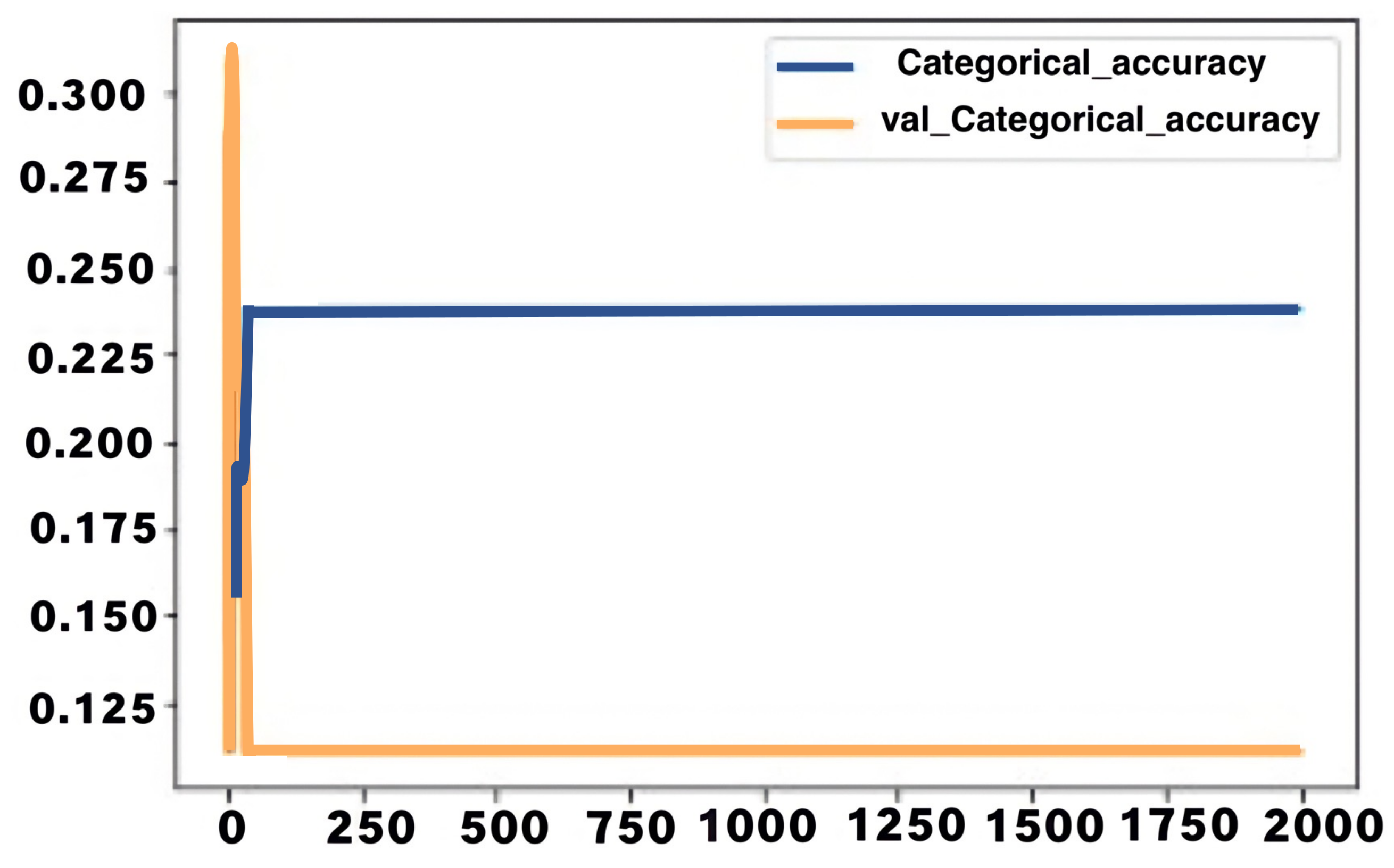
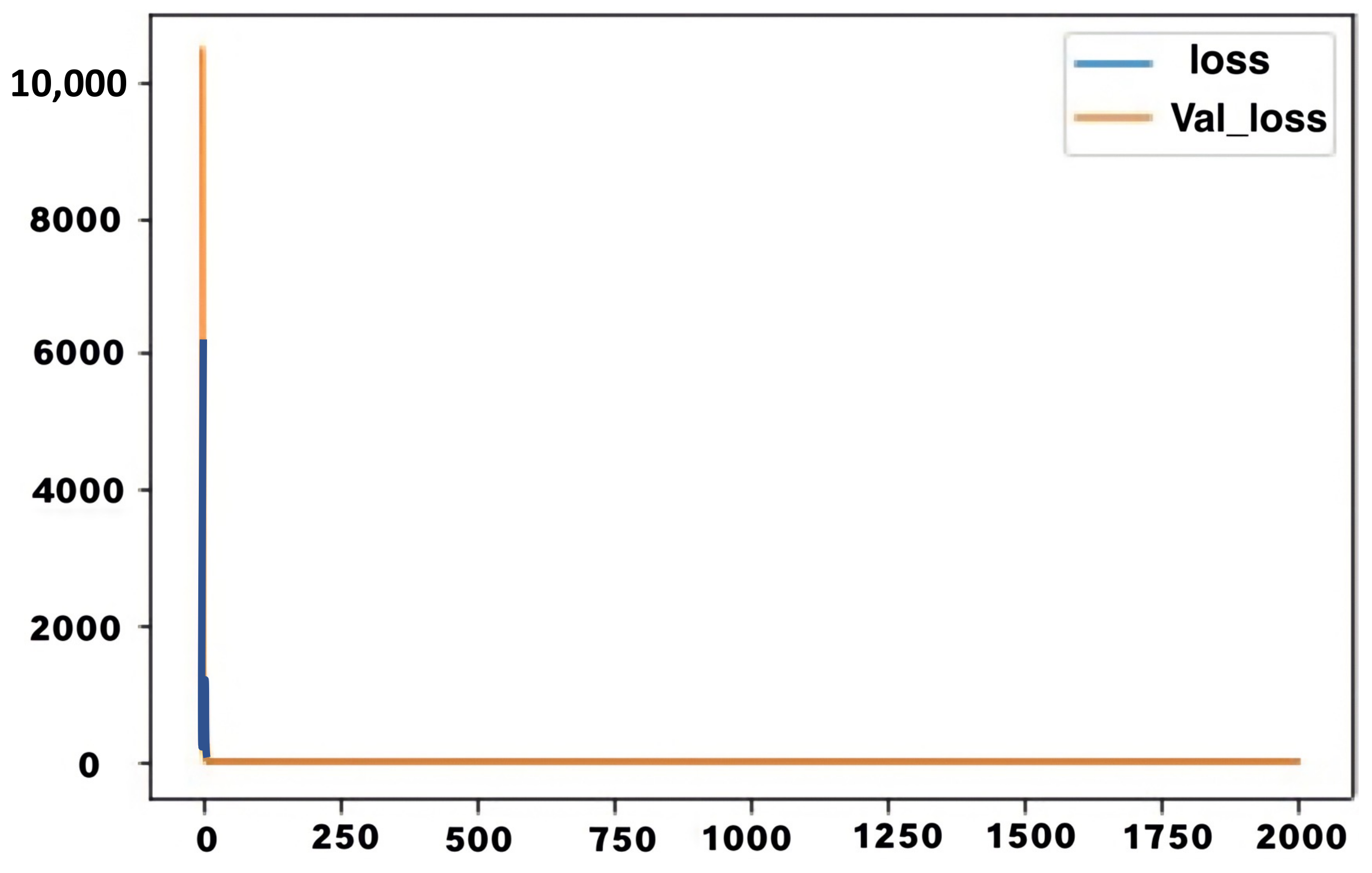
4.1.4. Evaluation of the LSTM Model
4.2. Facial Expressions Combined with Pose Signs
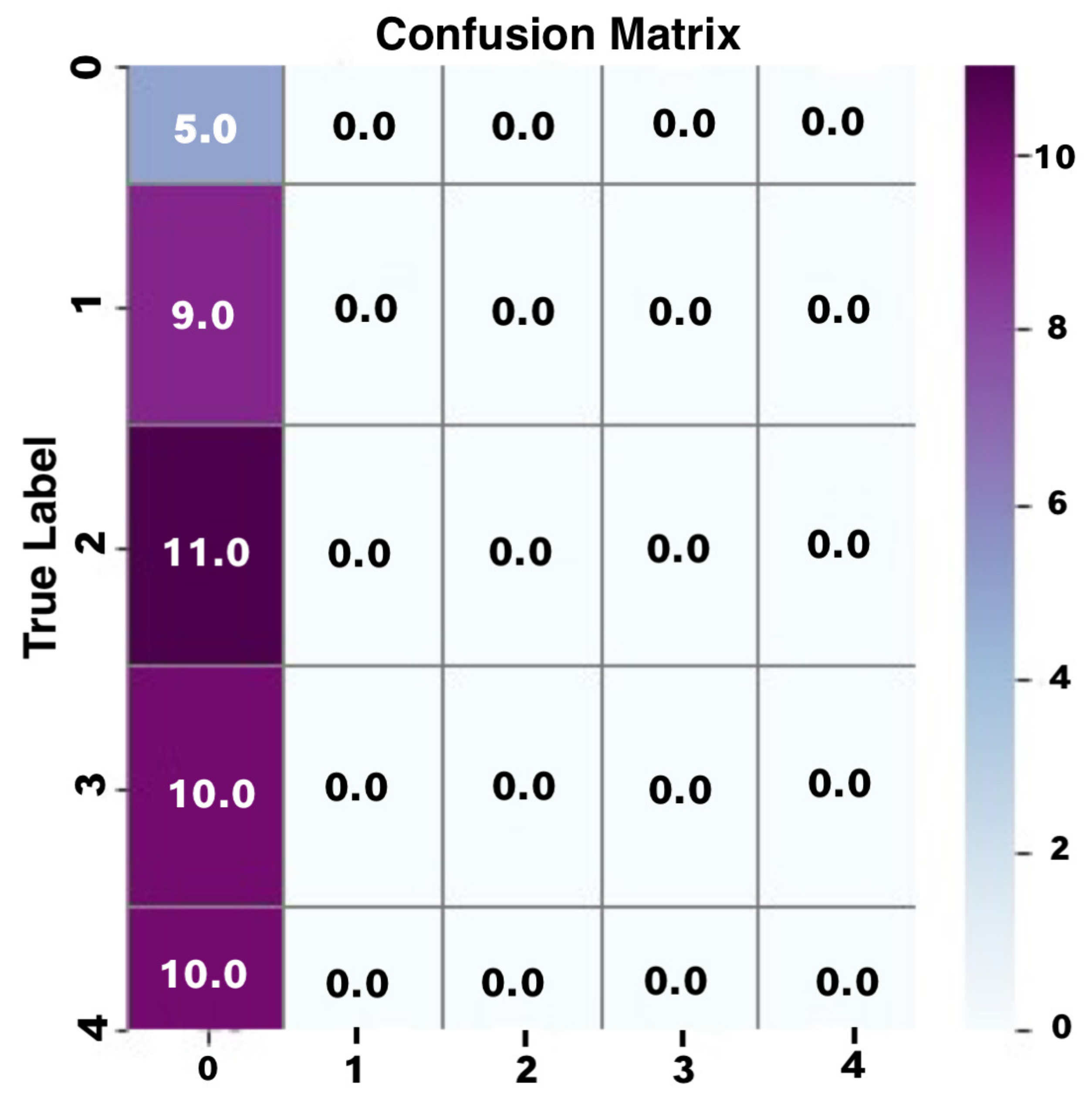
Evaluation of the Second LSTM Model
5. Discussion
5.1. Interpretations of the Results
5.1.1. Summary of the Results
5.1.2. Interpretation of the Results
5.1.3. Interrelation of the Findings and Literature Review
5.2. Implications of the Results
5.3. Acknowledgement of Limitations
6. Conclusions
6.1. Summary and Findings
6.2. Contribution to This Research
6.3. Future Recommendations of This Study
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Chiarelli, B. The Origin of Human Language, Studies in Language Origins; Publisher John Benjamins: Amsterdam, The Netherlands, 1991; 35p. [Google Scholar]
- Thomas, J.; McDonagh, D. Shared language: Towards more effective communication. Australas. Med. J. 2013, 6, 46–54. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Efthimiou, E.; Fotinea, S.E.; Vogler, C.; Hanke, T.; Glauert, J.; Bowden, R.; Braffort, A.; Collet, C.; Maragos, P.; Segouat, J. Sign Language Recognition, Generation, and Modelling: A Research Effort with Applications in Deaf Communication. In UAHCI 2009: Universal Access in Human-Computer Interaction. Addressing Diversity; Lecture Notes in Computer Science; Stephanidis, C., Ed.; Springer: Berlin/Heidelberg, Germany, 2009; Volume 5614. [Google Scholar] [CrossRef]
- Wangchuk, K.; Riyamongkol, P.; Waranusast, R. Real-time Bhutanese Sign Language digits recognition system using Convolutional Neural Network. Science Direct. ICT Express 2021, 7, 215–220. [Google Scholar] [CrossRef]
- İmren, G. (In)accessibility of the deaf to the television contents through sign language interpreting and sdh in turkey. Dokuz EylüL Univ. J. Humanit. 2018, 9, 109–122. Available online: https://dergipark.org.tr/en/pub/deuefad/issue/37120/428164 (accessed on 15 April 2022).
- Haenlein, M.; Kaplan, A. A Brief History of Artificial Intelligence: On the Past, Present, and Future of Artificial Intelligence. Calif. Manag. Rev. 2019, 61, 5–14. [Google Scholar] [CrossRef]
- Ongsulee, P. Artificial intelligence, machine learning and deep learning. In Proceedings of the 2017 15th International Conference on ICT and Knowledge Engineering, Bangkok, Thailand, 22–24 November 2017; pp. 1–6. [Google Scholar]
- Wang, Z.J.; Turko, R.; Shaikh, O.; Park, H.; Das, N.; Hohman, F. CNN Explainer: Learning Convolutional Neural Networks with Interactive Visualization. IEEE Trans. Vis. Comput. Graph. 2021, 27, 1396–1406. [Google Scholar] [CrossRef]
- Bini, S.A. Artificial intelligence, machine learning, deep learning, and cognitive computing: What do these terms mean and how will they impact health care? J. Arthroplast. 2018, 33, 2358–2361. [Google Scholar] [CrossRef]
- Sang-Ki, K.; Chang, J.K.; Hyedong, J.; Cho, C. Neural Sign Language Translation Based on Human Keypoint Estimation. Appl. Sci. 2019, 9, 2683. [Google Scholar] [CrossRef] [Green Version]
- Deng, L. A tutorial survey of architectures, algorithms, and applications for deep learning. APSIPA Trans. Signal Inf. Process. 2014, 3, E2. [Google Scholar] [CrossRef] [Green Version]
- Zhou, T.; Wang, W.; Qi, S.; Ling, H.; Shen, J. Cascaded Human-Object Interaction Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 4263–4272. [Google Scholar]
- Zhou, T.; Wang, W.; Liu, S.; Yang, Y.; Van Gool, L. Differentiable Multi-Granularity Human Representation Learning for Instance-Aware Human Semantic Parsing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 1622–1631. [Google Scholar]
- Farooq, U.; Rahim, M.S.M.; Sabir, N.; Hussain, A.; Abid, A. Advances in machine translation for sign language: Approaches, limitations, and challenges. Neural Comput. Appl. 2021, 33, 14357–14399. [Google Scholar] [CrossRef]
- Venugopalan, A.; Reghunadhan, R. Applying deep neural networks for the automatic recognition of sign language words: A communication aid to deaf agriculturists. Sci. Direct. Expert Syst. Appl. 2021, 185, 115601. [Google Scholar] [CrossRef]
- Abraham, A.; Rohini, V. Real Time Conversion of Sign Language to Speech and Prediction of gestures Using Artificial Neural Network. Procedia Comput. Sci. 2018, 143, 587–594. [Google Scholar] [CrossRef]
- Narayan, S.; Sajjan, V.S. Sign Language Recognition Using Deep Learning. In Proceedings of the 2021 International Conference on Intelligent Technologies (CONIT), Karnataka, India, 25–27 June 2021; pp. 1–5. [Google Scholar] [CrossRef]
- Kang, E. Long Short-Term Memory (LSTM): Concept. 2017. Available online: https://medium.com/@kangeugine/long-short-term-memory-lstm-concept-cb3283934359 (accessed on 10 December 2019).
- Marjusalinah, A.D.; Samsuryadi, S.; Buchari, M.A. Classification of Finger Spelling American Sign Language Using Convolutional Neural Network. Comput. Eng. Appl. J. 2021, 10, 93–103. [Google Scholar]
- Olga, B. A Review of Kaggle As a Data Science Resource—2021 Update. Available online: https://www.pathrise.com/guides/a-review-of-kaggle-as-a-data-science-resource/ (accessed on 24 November 2021).
- Brour, M.; Benabbou, A. ATLASLang NMT: Arabic text language into Arabic sign language neural machine translation. J. King Saud-Univ.-Comput. Inf. Sci. 2021, 33, 1121–1131. [Google Scholar] [CrossRef]
- Albert Florea, G.; Weilid, F. Deep Learning Models for Human Activity Recognition (Dissertation, Malmö Universitet/Teknik och Samhälle). 2019. Available online: http://urn.kb.se/resolve?urn=urn:nbn:se:mau:diva-20201 (accessed on 15 April 2022).
- Ramasamy Ramamurthy, S.; Roy, N. Recent trends in machine learning for human activity recognition—A survey. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2018, 8, e1254. [Google Scholar] [CrossRef]
- Gao, L.; Li, H.; Liu, Z.; Liu, Z. RNN-Transducer based Chinese Sign Language Recognition. Neurocomputing 2021, 434, 45–54. [Google Scholar] [CrossRef]
- Abdul, W.; Alsulaiman, M.; Amin, S.U.; Faisal, M.; Muhammad, G.; Albogamy, F.R.; Ghaleb, H. Intelligent real-time Arabic sign language classification using attention-based inception and BiLSTM. Comput. Electr. Eng. 2021, 95, 107395. [Google Scholar] [CrossRef]
- Farhan, W.; Razmak, J. A comparative study of an assistive e-learning interface among students with and without visual and hearing impairments. Disability and Rehabilitation: Assistive Technology 2020, 17, 431–441. [Google Scholar] [CrossRef]
- Sharma, P.; Anand, R.S. A comprehensive evaluation of deep models and optimizers for Indian sign language recognition. Graph. Vis. Comput. 2021, 5, 200032. [Google Scholar] [CrossRef]
- Sagayam, K.M.; Hemanth, D.J. Hand posture and gesture recognition techniques for virtual reality applications: A survey. Virtual Real. 2017, 21, 91–107. [Google Scholar] [CrossRef]
- Sharma, S.; Singh, S. Vision-based hand gesture recognition using deep learning for the interpretation of sign language. Expert Syst. Appl. 2021, 182, 115657. [Google Scholar] [CrossRef]
- Rajam, P.S.; Balakrishnan, G. Real time Indian Sign Language Recognition System to aid deaf-dumb people. In Proceedings of the 2011 IEEE 13th International Conference on Communication Technology, Jinan, China, 25–28 September 2011; pp. 737–742. [Google Scholar] [CrossRef]
- Liang, R.-H.; Ouhyoung, M.I. A Sign Language Recognition System Using Hidden Markov Model and Context Sensitive Search. In Proceedings of the ACM Symposium on Virtual Reality Software and Technology, Hong Kong, China, 1–4 July 1996. [Google Scholar]
- Pigou, L.; Dieleman, S.; Kindermans, P.J.; Schrauwen, B. Sign Language Recognition Using Convolutional Neural Networks. In ECCV 2014: Computer Vision—ECCV 2014 Workshops; Agapito, L., Bronstein, M., Rother, C., Eds.; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2015; Volume 8925. [Google Scholar] [CrossRef] [Green Version]
- Yeduri, S.R.; Breland, D.S.; Pandey, O.J.; Cenkeramaddi, L.R. Updating thermal imaging dataset of hand gestures with unique labels. Data Brief 2022, 42, 108037. [Google Scholar] [CrossRef] [PubMed]
- Breland, D.S.; Dayal, A.; Jha, A.; Yalavarthy, P.K.; Pandey, O.J.; Cenkeramaddi, L.R. Robust Hand Gestures Recognition Using a Deep CNN and Thermal Images. IEEE Sens. J. 2021, 21, 26602–26614. [Google Scholar] [CrossRef]
- Kamal, S.M.; Chen, Y.; Li, S.; Shi, X.; Zheng, J. Technical approaches to Chinese sign language processing: A review. IEEE Access 2019, 7, 96926–96935. [Google Scholar] [CrossRef]
- Gao, W.; Fang, G.; Zhao, D.; Chen, Y. A Chinese sign language recognition system based on SOFM/SRN/HMM. Pattern Recognit. 2004, 37, 2389–2402. [Google Scholar] [CrossRef]
- Koushik, J. Understanding convolutional neural networks. arXiv 2016, arXiv:1605.09081. [Google Scholar]
- Yoo, H.J. Deep convolution neural networks in computer vision: A review. IEIE Trans. Smart Process. Comput. 2015, 4, 35–43. [Google Scholar] [CrossRef]
- Sharma, N.; Jain, V.; Mishra, A. An analysis of convolutional neural networks for image classification. Procedia Comput. Sci. 2018, 132, 377–384. [Google Scholar] [CrossRef]
- Ghosh, A.; Sufian, A.; Sultana, F.; Chakrabarti, A.; De, D. Fundamental Concepts of Convolutional Neural Network. In Recent Trends and Advances in Artificial Intelligence and Internet of Things; Intelligent Systems Reference Library; Balas, V., Kumar, R., Srivastava, R., Eds.; Springer: Cham, Switzerland, 2020; Volume 172. [Google Scholar] [CrossRef]
- Albawi, S.; Mohammed, T.A.; Al-Zawi, S. Understanding of a convolutional neural network. In Proceedings of the 2017 International Conference on Engineering and Technology (ICET), Antalya, Turkey, 21–23 August 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Viswavarapu, L.K. Real-Time Finger Spelling American Sign Language Recognition Using Deep Convolutional Neural Networks. Master’s Thesis, University of North Texas Libraries, UNT Digital Library, Denton, TX, USA, December 2018. Available online: https://digital.library.unt.edu/ark:/67531/metadc1404616/ (accessed on 15 April 2022).
- Kang, I.; Goy, A.; Barbastathis, G. Dynamical machine learning volumetric reconstruction of objects’ interiors from limited angular views. Light. Sci. Appl. 2021, 10, 74. [Google Scholar] [CrossRef]
- British Sign Language. Available online: https://www.british-sign.co.uk/ (accessed on 15 April 2022).
- Amin, S.U.; Altaheri, H.; Muhammad, G.; Abdul, W.; Alsulaiman, M. Attention-Inception and Long- Short-Term Memory-Based Electroencephalography Classification for Motor Imagery Tasks in Rehabilitation. IEEE Trans. Ind. Inform. 2022, 18, 5412–5421. [Google Scholar] [CrossRef]
- Kaggle 2021. Available online: https://www.kaggle.com/ (accessed on 24 November 2021).
- Luo, W.; Li, Y.; Urtasun, R.; Zemel, R. Understanding the effective receptive field in deep convolutional neural networks. In Proceedings of the 29th Conference on Neural Information Processing System, Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Chandra, B.; Sharma, R.K. On improving recurrent neural network for image classification. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; pp. 1904–1907. [Google Scholar]
- Li, P.; Tang, H.; Yu, J.; Song, W. LSTM and multiple CNNs based event image classification. Multimed. Tools Appl. 2021, 80, 30743–30760. [Google Scholar] [CrossRef]






















Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dhulipala, S.; Adedoyin, F.F.; Bruno, A. Sign and Human Action Detection Using Deep Learning. J. Imaging 2022, 8, 192. https://doi.org/10.3390/jimaging8070192
Dhulipala S, Adedoyin FF, Bruno A. Sign and Human Action Detection Using Deep Learning. Journal of Imaging. 2022; 8(7):192. https://doi.org/10.3390/jimaging8070192
Chicago/Turabian StyleDhulipala, Shivanarayna, Festus Fatai Adedoyin, and Alessandro Bruno. 2022. "Sign and Human Action Detection Using Deep Learning" Journal of Imaging 8, no. 7: 192. https://doi.org/10.3390/jimaging8070192
APA StyleDhulipala, S., Adedoyin, F. F., & Bruno, A. (2022). Sign and Human Action Detection Using Deep Learning. Journal of Imaging, 8(7), 192. https://doi.org/10.3390/jimaging8070192