
Multi-Modal Enhancement Transformer Network for Skeleton-Based Human Interaction Recognition


Abstract
:1. Introduction
- A novel multi-modal enhancement transformer (ME-Former) network is proposed for skeleton-based human interaction recognition, overcoming the challenge of different skeletal modalities not being able to effectively utilize complementary features;
- We propose a simple yet effective two-person skeleton topology and a two-person hypergraph representation, which can model the pairwise and higher-order relations between human joints, and use the TH-SA block to embed the two kinds of structural information into the ME-Former for better recognizing human interaction;
- The extensive experimental results highlight the benefits of our multi-modal enhancement transformer and two-person hypergraph representation. Our proposed ME-Former outperforms state-of-the-art methods on two different skeleton-based action recognition benchmarks.
2. Related Work
2.1. Skeleton-Based Action Recognition
2.2. Human Interaction Recognition
3. Preliminaries
3.1. Attention Mechanism
3.2. Hypergraph Representation
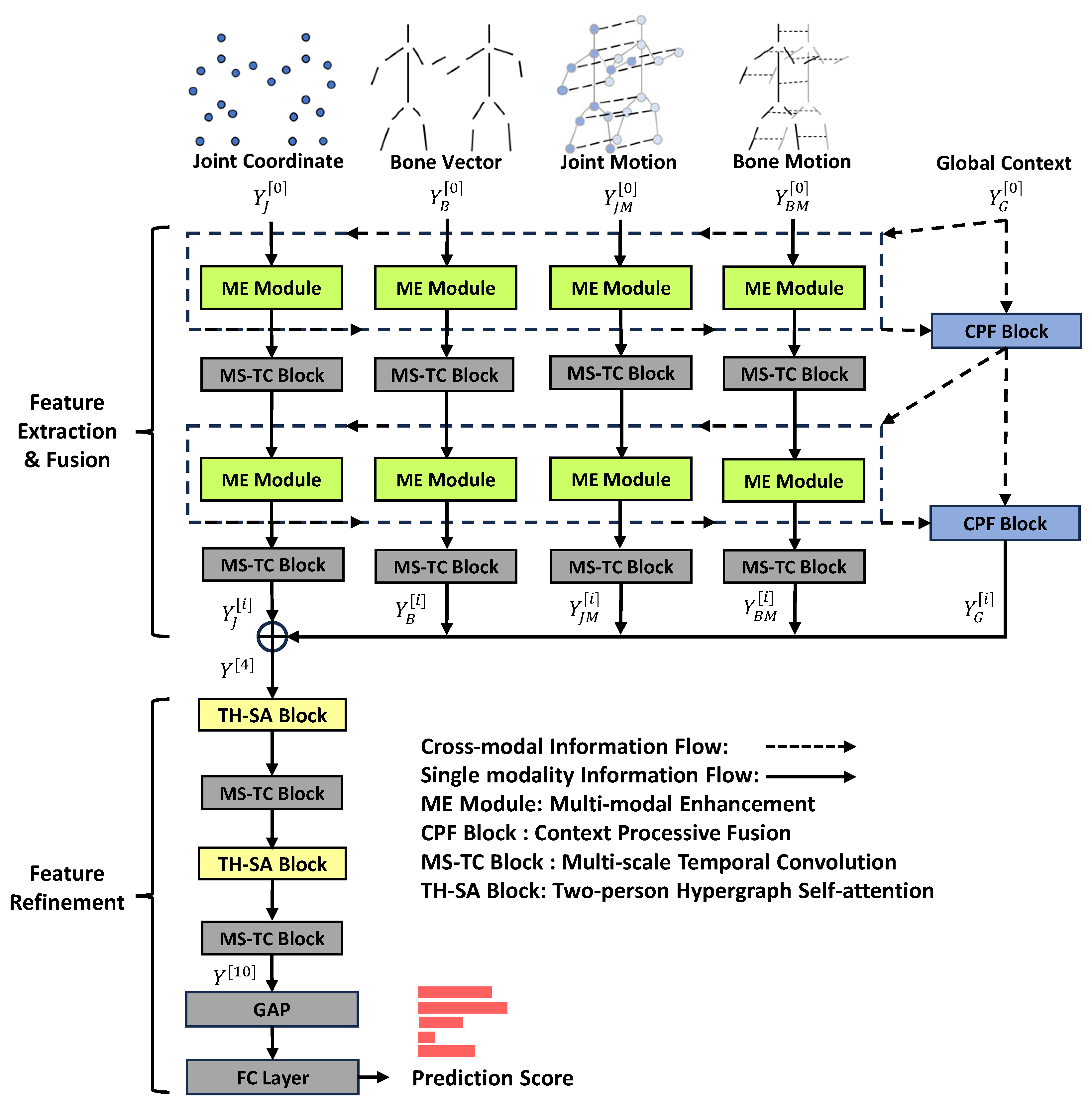
4. The Proposed Method
4.1. Modality Enhancement Module
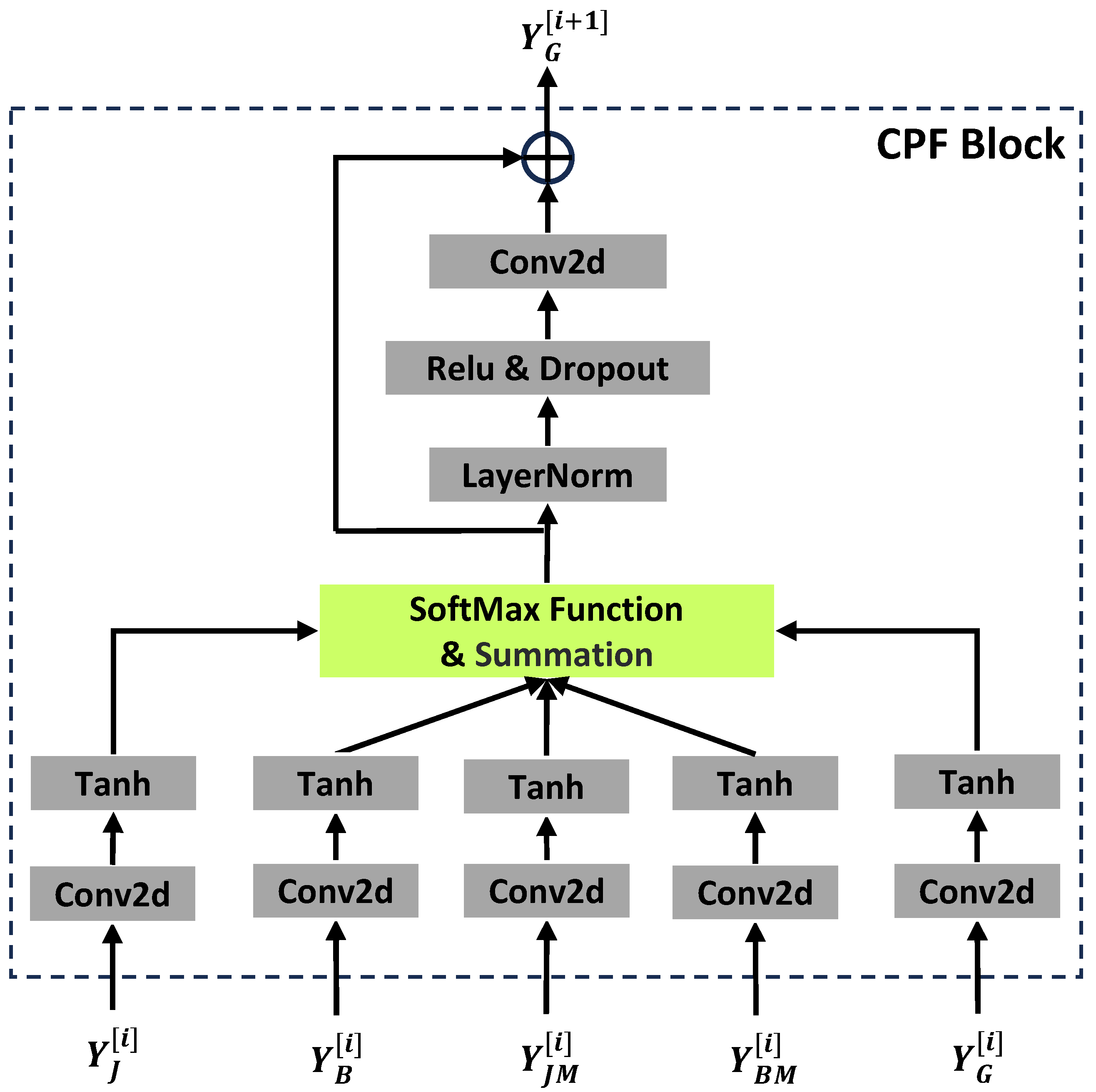
4.2. Context Progressive Fusion Block
4.3. Two-Person Hypergraph Self-Attention Block
4.3.1. Encoding Structural Information about Two-Person Skeleton Topology
4.3.2. Deriving Two-Person Hypergraph Feature
5. Experiment
5.1. Datasets
5.2. Implementation Details
5.3. Comparison with State-of-the-Art Methods
5.4. Ablation Studies
5.4.1. Effectiveness of Multi-Modal Enforcement Transformer
- We first replace the SGC block in the baseline model with four TH-SA blocks to test the effect of the TH-SA block. We can observe that the recognition accuracy is improved by but the number of parameters in the model is also greatly increased. This is because the baseline is a lightweight model with a lot of fine-tuning in the model structure.
- Next, we add MH-CA blocks to each input branch of the feature extraction and fusion stage, so that MH-CA and TH-SA are integrated into the ME modules. The recognition accuracy improves by , which strongly demonstrates the significance of cross-modal information transfer between different input branches. Features of the other skeletal modalities can indeed enhance the skeleton features of each single modality.
- Finally, we add the CPF block to the feature extraction and fusion stage, and the result shows that the accuracy improves by . This proves that using the global context can better aggregate the features among the various skeleton modalities and facilitate the enhancement of each single modality.
5.4.2. Effectiveness of Two-Person Hypergraph Self-Attention Block
- We first compare the effect between single-person skeleton topology embedding and two-person skeleton topology embedding, showing that the performance of the latter is higher than the former. This result proves that additional connections in the two-person skeleton topology facilitate learning interactive information between two persons. Adding two-person skeleton topology embedding improves accuracy by compared to vanilla self-attention (SA).
- Then we add two-person hypergraph embedding to the vanilla SA and the results show that they improve the accuracy by . The effect of two-person hypergraph embedding is slightly better than that of skeleton topology embedding, indicating that the higher-order relationship between joints can better reflect the difference between different actions than the pairwise relationship.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Zhao, S.; Zhao, G.; He, Y.; Diao, Z.; He, Z.; Cui, Y.; Jiang, L.; Shen, Y.; Cheng, C. Biomimetic Adaptive Pure Pursuit Control for Robot Path Tracking Inspired by Natural Motion Constraints. Biomimetics 2024, 9, 41. [Google Scholar] [CrossRef]
- Kwon, J.Y.; Ju, D.Y. Living Lab-Based Service Interaction Design for a Companion Robot for Seniors in South Korea. Biomimetics 2023, 8, 609. [Google Scholar] [CrossRef]
- Song, F.; Li, P. YOLOv5-MS: Real-time multi-surveillance pedestrian target detection model for smart cities. Biomimetics 2023, 8, 480. [Google Scholar] [CrossRef]
- Liu, M.; Meng, F.; Liang, Y. Generalized Pose Decoupled Network for Unsupervised 3d Skeleton Sequence-based Action Representation Learning. Cyborg Bionic Syst. 2022, 2022, 0002. [Google Scholar] [CrossRef]
- Zhang, Y.; Xu, X.; Zhao, Y.; Wen, Y.; Tang, Z.; Liu, M. Facial Prior Guided Micro-Expression Generation. IEEE Trans. Image Process. 2024, 33, 525–540. [Google Scholar] [CrossRef]
- Huang, Z.; Du, C.; Wang, C.; Sun, Q.; Xu, Y.; Shao, L.; Yu, B.; Ma, G.; Kong, X. Bionic Design and Optimization on the Flow Channel of a Legged Robot Joint Hydraulic Drive Unit Based on Additive Manufacturing. Biomimetics 2023, 9, 13. [Google Scholar] [CrossRef]
- Wang, X.; Gao, Y.; Ma, X.; Li, W.; Yang, W. A Bionic Venus Flytrap Soft Microrobot Driven by Multiphysics for Intelligent Transportation. Biomimetics 2023, 8, 429. [Google Scholar] [CrossRef]
- Zhang, Q.; Liu, Q.; Duan, J.; Qin, J. Research on Teleoperated Virtual Reality Human–Robot Five-Dimensional Collaboration System. Biomimetics 2023, 8, 605. [Google Scholar] [CrossRef] [PubMed]
- Bultmann, S.; Memmesheimer, R.; Behnke, S. External Camera-based Mobile Robot Pose Estimation for Collaborative Perception with Smart Edge Sensors. arXiv 2023, arXiv:2303.03797. [Google Scholar]
- Chun, S.; Park, S.; Chang, J.Y. Learnable human mesh triangulation for 3d human pose and shape estimation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–7 January 2023; pp. 2850–2859. [Google Scholar]
- Chun, S.; Park, S.; Chang, J.Y. Representation learning of vertex heatmaps for 3D human mesh reconstruction from multi-view images. In Proceedings of the 2023 IEEE International Conference on Image Processing (ICIP), Kuala Lumpur, Malaysia, 8–11 October 2023; pp. 670–674. [Google Scholar]
- Xue, S.; Gao, S.; Tan, M.; He, Z.; He, L. How does color constancy affect target recognition and instance segmentation? In Proceedings of the 29th ACM International Conference on Multimedia, Virtual, 20–24 October 2021; pp. 5537–5545. [Google Scholar]
- Shi, L.; Zhang, Y.; Cheng, J.; Lu, H. Two-stream adaptive graph convolutional networks for skeleton-based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 12026–12035. [Google Scholar]
- Mehmood, F.; Zhao, H.; Chen, E.; Guo, X.; Albinali, A.A.; Razzaq, A. Extended Multi-Stream Adaptive Graph Convolutional Networks (EMS-AAGCN) for Skeleton-Based Human Action Recognition. Res. Sq. 2022; preprint. [Google Scholar] [CrossRef]
- Trivedi, N.; Sarvadevabhatla, R.K. Psumnet: Unified modality part streams are all you need for efficient pose-based action recognition. In Computer Vision—ECCV 2022 Workshops, Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Cham, Switzerland, 2022; pp. 211–227. [Google Scholar]
- Song, Y.F.; Zhang, Z.; Shan, C.; Wang, L. Constructing stronger and faster baselines for skeleton-based action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 1474–1488. [Google Scholar] [CrossRef]
- Wilms, M.; Eickhoff, S.B.; Hömke, L.; Rottschy, C.; Kujovic, M.; Amunts, K.; Fink, G.R. Comparison of functional and cytoarchitectonic maps of human visual areas V1, V2, V3d, V3v, and V4 (v). Neuroimage 2010, 49, 1171–1179. [Google Scholar] [CrossRef] [PubMed]
- Milošević, N.T.; Ristanović, D. Fractality of dendritic arborization of spinal cord neurons. Neurosci. Lett. 2006, 396, 172–176. [Google Scholar] [CrossRef]
- Ying, C.; Cai, T.; Luo, S.; Zheng, S.; Ke, G.; He, D.; Shen, Y.; Liu, T.Y. Do transformers really perform badly for graph representation? Adv. Neural Inf. Process. Syst. 2021, 34, 28877–28888. [Google Scholar]
- Zhou, Y.; Li, C.; Cheng, Z.Q.; Geng, Y.; Xie, X.; Keuper, M. Hypergraph transformer for skeleton-based action recognition. arXiv 2022, arXiv:2211.09590. [Google Scholar]
- Li, B.; Dai, Y.; Cheng, X.; Chen, H.; Lin, Y.; He, M. Skeleton based action recognition using translation-scale invariant image mapping and multi-scale deep CNN. In Proceedings of the IEEE International Conference on Multimedia & Expo Workshops (ICMEW), Hong Kong, China, 10–14 July 2017; pp. 601–604. [Google Scholar]
- Soo Kim, T.; Reiter, A. Interpretable 3d human action analysis with temporal convolutional networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 20–28. [Google Scholar]
- Li, C.; Zhong, Q.; Xie, D.; Pu, S. Co-occurrence feature learning from skeleton data for action recognition and detection with hierarchical aggregation. arXiv 2018, arXiv:1804.06055. [Google Scholar]
- Tas, Y.; Koniusz, P. Cnn-based action recognition and supervised domain adaptation on 3d body skeletons via kernel feature maps. arXiv 2018, arXiv:1806.09078. [Google Scholar]
- Liu, J.; Shahroudy, A.; Xu, D.; Wang, G. Spatio-temporal lstm with trust gates for 3d human action recognition. In Computer Vision—ECCV 2016, Proceedings of the 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 816–833. [Google Scholar]
- Du, Y.; Wang, W.; Wang, L. Hierarchical recurrent neural network for skeleton based action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1110–1118. [Google Scholar]
- Song, S.; Lan, C.; Xing, J.; Zeng, W.; Liu, J. An end-to-end spatio-temporal attention model for human action recognition from skeleton data. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), San Francisco, CA, USA, 4–9 February 2017; Volume 31. [Google Scholar]
- Zhang, P.; Lan, C.; Xing, J.; Zeng, W.; Xue, J.; Zheng, N. View adaptive recurrent neural networks for high performance human action recognition from skeleton data. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2117–2126. [Google Scholar]
- Liu, J.; Wang, X.; Wang, C.; Gao, Y.; Liu, M. Temporal Decoupling Graph Convolutional Network for Skeleton-based Gesture Recognition. IEEE Trans. Multimed. 2023, 26, 811–823. [Google Scholar] [CrossRef]
- Wang, X.; Zhang, W.; Wang, C.; Gao, Y.; Liu, M. Dynamic Dense Graph Convolutional Network for Skeleton-based Human Motion Prediction. IEEE Trans. Image Process. 2024, 33, 1–15. [Google Scholar] [CrossRef]
- Yan, S.; Xiong, Y.; Lin, D. Spatial temporal graph convolutional networks for skeleton-based action recognition. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Chen, Y.; Zhang, Z.; Yuan, C.; Li, B.; Deng, Y.; Hu, W. Channel-wise topology refinement graph convolution for skeleton-based action recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 13359–13368. [Google Scholar]
- Lee, J.; Lee, M.; Lee, D.; Lee, S. Hierarchically Decomposed Graph Convolutional Networks for Skeleton-Based Action Recognition. arXiv 2022, arXiv:2208.10741. [Google Scholar]
- Wang, Q.; Peng, J.; Shi, S.; Liu, T.; He, J.; Weng, R. Iip-transformer: Intra-inter-part transformer for skeleton-based action recognition. arXiv 2021, arXiv:2110.13385. [Google Scholar]
- Plizzari, C.; Cannici, M.; Matteucci, M. Spatial temporal transformer network for skeleton-based action recognition. In Proceedings of the Pattern Recognition. ICPR International Workshops and Challenges, Virtual, 10–15 January 2021; Springer: Cham, Switzerland, 2021; pp. 694–701. [Google Scholar]
- Zhang, Y.; Wu, B.; Li, W.; Duan, L.; Gan, C. STST: Spatial-temporal specialized transformer for skeleton-based action recognition. In Proceedings of the the 29th ACM International Conference on Multimedia, Virtual, 20–24 October 2021; pp. 3229–3237. [Google Scholar]
- Ji, Y.; Ye, G.; Cheng, H. Interactive body part contrast mining for human interaction recognition. In Proceedings of the IEEE International Conference on Multimedia and Expo Workshops (ICMEW), Chengdu, China, 14–18 July 2014; pp. 1–6. [Google Scholar]
- Yang, C.L.; Setyoko, A.; Tampubolon, H.; Hua, K.L. Pairwise adjacency matrix on spatial temporal graph convolution network for skeleton-based two-person interaction recognition. In Proceedings of the 2020 IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, 25–28 October 2020; pp. 2166–2170. [Google Scholar]
- Li, J.; Xie, X.; Cao, Y.; Pan, Q.; Zhao, Z.; Shi, G. Knowledge embedded gcn for skeleton-based two-person interaction recognition. Neurocomputing 2021, 444, 338–348. [Google Scholar] [CrossRef]
- Zhu, L.; Wan, B.; Li, C.; Tian, G.; Hou, Y.; Yuan, K. Dyadic relational graph convolutional networks for skeleton-based human interaction recognition. Pattern Recognit. 2021, 115, 107920. [Google Scholar] [CrossRef]
- Perez, M.; Liu, J.; Kot, A.C. Interaction relational network for mutual action recognition. IEEE Trans. Multimed. 2021, 24, 366–376. [Google Scholar] [CrossRef]
- Pang, Y.; Ke, Q.; Rahmani, H.; Bailey, J.; Liu, J. IGFormer: Interaction Graph Transformer for Skeleton-based Human Interaction Recognition. In Computer Vision—ECCV 2022, Proceedings of the 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; Springer: Cham, Switzerland, 2022; pp. 605–622. [Google Scholar]
- Gao, F.; Xia, H.; Tang, Z. Attention Interactive Graph Convolutional Network for Skeleton-Based Human Interaction Recognition. In Proceedings of the 2022 IEEE International Conference on Multimedia and Expo (ICME), Taipei, Taiwan, 18–22 July 2022; pp. 1–6. [Google Scholar]
- Li, Z.; Li, Y.; Tang, L.; Zhang, T.; Su, J. Two-person Graph Convolutional Network for Skeleton-based Human Interaction Recognition. IEEE Trans. Circuits Syst. Video Technol. 2022, 33, 3333–3342. [Google Scholar] [CrossRef]
- Liu, Z.; Zhang, H.; Chen, Z.; Wang, Z.; Ouyang, W. Disentangling and unifying graph convolutions for skeleton-based action recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 143–152. [Google Scholar]
- Shahroudy, A.; Liu, J.; Ng, T.T.; Wang, G. Ntu rgb+ d: A large scale dataset for 3d human activity analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1010–1019. [Google Scholar]
- Liu, J.; Shahroudy, A.; Perez, M.; Wang, G.; Duan, L.Y.; Kot, A.C. Ntu rgb+ d 120: A large-scale benchmark for 3d human activity understanding. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 2684–2701. [Google Scholar] [CrossRef]
- Zhang, P.; Lan, C.; Zeng, W.; Xing, J.; Xue, J.; Zheng, N. Semantics-guided neural networks for efficient skeleton-based human action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 1112–1121. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Liu, J.; Shahroudy, A.; Xu, D.; Kot, A.C.; Wang, G. Skeleton-based action recognition using spatio-temporal LSTM network with trust gates. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 3007–3021. [Google Scholar] [CrossRef]
- Liu, J.; Wang, G.; Hu, P.; Duan, L.Y.; Kot, A.C. Global context-aware attention lstm networks for 3d action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1647–1656. [Google Scholar]
- Liu, J.; Wang, G.; Duan, L.Y.; Abdiyeva, K.; Kot, A.C. Skeleton-based human action recognition with global context-aware attention LSTM networks. IEEE Trans. Image Process. 2017, 27, 1586–1599. [Google Scholar] [CrossRef]
- Liu, J.; Shahroudy, A.; Wang, G.; Duan, L.Y.; Kot, A.C. Skeleton-based online action prediction using scale selection network. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 1453–1467. [Google Scholar] [CrossRef]
- Nguyen, X.S. Geomnet: A neural network based on riemannian geometries of spd matrix space and cholesky space for 3d skeleton-based interaction recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 13379–13389. [Google Scholar]
- Li, M.; Chen, S.; Chen, X.; Zhang, Y.; Wang, Y.; Tian, Q. Actional-structural graph convolutional networks for skeleton-based action recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3595–3603. [Google Scholar]
- Song, Y.F.; Zhang, Z.; Shan, C.; Wang, L. Stronger, faster and more explainable: A graph convolutional baseline for skeleton-based action recognition. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 1625–1633. [Google Scholar]
- Shi, L.; Zhang, Y.; Cheng, J.; Lu, H. Decoupled spatial-temporal attention network for skeleton-based action-gesture recognition. In Computer Vision—ACCV 2020, Proceedings of the 15th Asian Conference on Computer Vision, Kyoto, Japan, 30 November–4 December 2020; Springer: Cham, Switzerland, 2020. [Google Scholar]
- Qiu, H.; Hou, B.; Ren, B.; Zhang, X. Spatio-temporal segments attention for skeleton-based action recognition. Neurocomputing 2023, 518, 30–38. [Google Scholar] [CrossRef]
- Wen, Y.; Tang, Z.; Pang, Y.; Ding, B.; Liu, M. Interactive spatiotemporal token attention network for skeleton-based general interactive action recognition. arXiv 2023, arXiv:2307.07469. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Method | Conf./Jour. | NTU-60* (%) | NTU-120* (%) | ||
|---|---|---|---|---|---|---|
| X-Sub | X-View | X-Sub | X-Set | |||
| RNN | ST-LSTM [50] | TPAMI 2017 | 83.00 | 87.30 | 63.00 | 66.60 |
| GCA-LSTM [51] | CVPR 2017 | 85.90 | 89.00 | 70.60 | 73.70 | |
| 2s-GCA-LSTM [52] | TIP 2017 | 87.20 | 89.90 | 73.00 | 73.30 | |
| FSNET [53] | TPAMI 2019 | 74.01 | 80.50 | 61.22 | 69.70 | |
| GeomNet [54] | ICCV 2021 | 93.62 | 96.32 | 86.49 | 87.58 | |
| LSTM-IRN [41] | TMM 2022 | 90.50 | 93.50 | 77.70 | 79.60 | |
| GCN | ST-GCN [31] | AAAI 2018 | 89.31 | 93.72 | 80.69 | 80.27 |
| AS-GCN [55] | CVPR 2019 | 89.30 | 93.00 | 82.90 | 83.70 | |
| 2s-AGCN [13] | CVPR 2019 | 93.36 | 96.67 | 87.83 | 89.21 | |
| ST-GCN-PAM [13] | ICIP 2020 | - | - | 83.28 | 88.36 | |
| Pa-ResGCN-B19 [56] | ACM MM 2020 | 94.34 | 97.55 | 89.64 | 89.94 | |
| CTR-GCN [32] | ICCV 2021 | 91.60 | 94.30 | 83.20 | 84.40 | |
| DR-GCN [40] | PR 2021 | 93.68 | 94.09 | 85.36 | 84.49 | |
| K-GCN [39] | NC 2021 | 93.70 | 96.80 | - | - | |
| 2S-DRAGCN [40] | PR 2021 | 94.68 | 97.19 | 90.56 | 90.41 | |
| AIGCN [43] | ICME 2022 | 93.89 | 97.22 | 87.80 | 87.96 | |
| EfficientGCN-B1 [16] | TPAMI 2022 | 94.49 | 97.23 | 90.64 | 90.21 | |
| 2s-AIGCN [43] | ICME 2022 | 95.34 | 98.00 | 90.71 | 90.65 | |
| Transformer | DSTA-NET [57] | ACCV 2020 | - | - | 88.92 | 90.10 |
| IGFormer [42] | ECCV 2022 | 93.64 | 96.50 | 85.40 | 86.50 | |
| STSA-Net [58] | NC 2023 | - | - | 90.28 | 91.13 | |
| ISTA-Net [59] | IROS 2023 | - | - | 90.60 | 91.87 | |
| Our ME-Former | - | 95.37 | 97.60 | 90.84 | 91.33 | |
| Model Design | Params. (M) | NTU-60*X-Sub (%) | |
|---|---|---|---|
| Feature Extraction and Fusion Stage | Feature Refinement Stage | ||
| 4 × SGC (Baseline) | SGC | 1.2 | 94.49 |
| 4 × TH-SA | TH-SA | 5.6 | 94.98 |
| 4 × ME | TH-SA | 7.8 | 95.26 |
| 4 × (ME + CPF) | TH-SA | 9.2 | 95.37 |
| Model Design | Params. (M) | NTU-60*X-Sub (%) |
|---|---|---|
| Vanilla SA | 4.4 | 93.37 |
| Vanilla SA + Single-person Skeleton Topology Embedding | 4.8 | 94.34 |
| Vanilla SA + Two-person Skeleton Topology Embedding | 4.8 | 94.55 |
| Vanilla SA + Two-person Hypergraph Embedding | 5.1 | 94.67 |
| Entire TH-SA | 5.6 | 94.98 |
| Partition Strategy | NTU-60*X-Sub (%) |
|---|---|
| Upper and Lower Body | 94.53 |
| Body Parts | 94.64 |
| Two-person Hypergraph | 94.98 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, Q.; Liu, H. Multi-Modal Enhancement Transformer Network for Skeleton-Based Human Interaction Recognition. Biomimetics 2024, 9, 123. https://doi.org/10.3390/biomimetics9030123
Hu Q, Liu H. Multi-Modal Enhancement Transformer Network for Skeleton-Based Human Interaction Recognition. Biomimetics. 2024; 9(3):123. https://doi.org/10.3390/biomimetics9030123
Chicago/Turabian StyleHu, Qianshuo, and Haijun Liu. 2024. "Multi-Modal Enhancement Transformer Network for Skeleton-Based Human Interaction Recognition" Biomimetics 9, no. 3: 123. https://doi.org/10.3390/biomimetics9030123
APA StyleHu, Q., & Liu, H. (2024). Multi-Modal Enhancement Transformer Network for Skeleton-Based Human Interaction Recognition. Biomimetics, 9(3), 123. https://doi.org/10.3390/biomimetics9030123