
Creating Implicit Measure Stimulus Sets Using a Multi-Step Piloting Method


Abstract
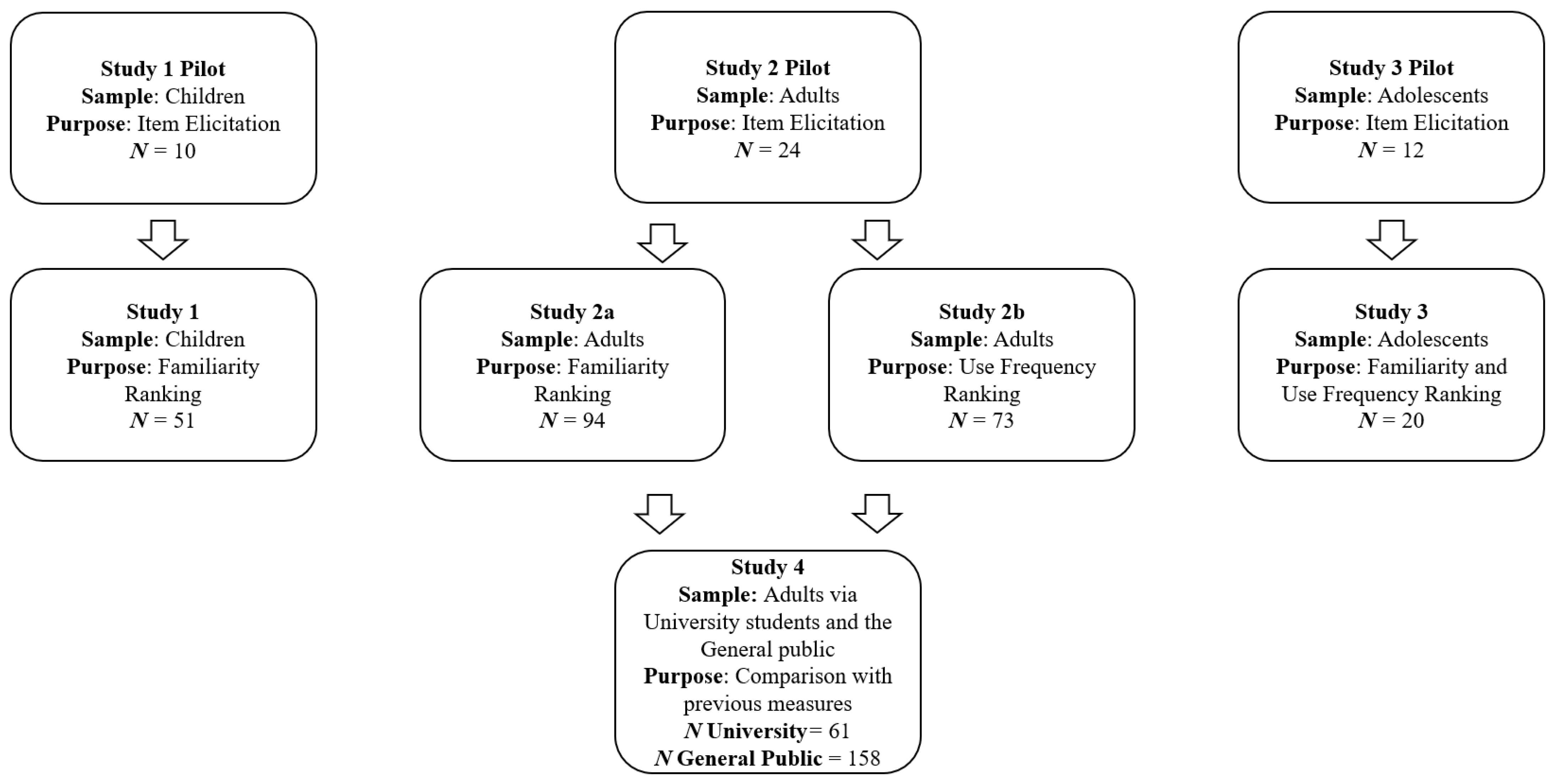
:1. Creating Implicit Measure Stimulus Sets Using a Multi-Step Piloting Method
The Current Study
2. Study 1
2.1. Pilot
2.2. Participants and Procedure
2.3. Results and Discussion
3. Study 2
3.1. Pilot
3.2. Participants and Procedure
3.3. Results and Discussion
4. Study 3
4.1. Pilot
4.2. Participants and Procedure
4.3. Results and Discussion
5. Study 4
5.1. Participants and Procedure
5.2. Measures
5.2.1. Single Target Implicit Association Tests
5.2.2. Behavior
5.3. Results
6. General Discussion
6.1. Strengths, Limitations, and Future Directions
6.2. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Gawronski, B.; Bodenhausen, G.V. Associative and Propositional Processes in Evaluation: An Integrative Review of Implicit and Explicit Attitude Change. Psychol. Bull. 2006, 132, 692. [Google Scholar] [CrossRef]
- Greenwald, A.G.; Poehlman, T.A.; Uhlmann, E.L.; Banaji, M.R. Understanding and Using the Implicit Association Test: III. Meta-Analysis of Predictive Validity. J. Personal. Soc. Psychol. 2009, 97, 17–41. [Google Scholar] [CrossRef]
- Perugini, M. Predictive Models of Implicit and Explicit Attitudes. Br. J. Soc. Psychol. 2005, 44, 29–45. [Google Scholar] [CrossRef]
- Strack, F.; Deutsch, R. Reflective and Impulsive Determinants of Social Behavior. Personal. Soc. Psychol. Rev. 2004, 8, 220–247. [Google Scholar] [CrossRef]
- Gawronski, B.; Houwer, J.D. Implicit Measures in Social and Personality Psychology. In Handbook of Research Methods in Social and Personality Psychology; Reis, H.T., Judd, C.M., Eds.; Cambridge University Press: Cambridge, UK, 2014; Volume 1, pp. 283–310. [Google Scholar]
- Kurdi, B.; Ratliff, K.A.; Cunningham, W.A. Can the Implicit Association Test Serve as a Valid Measure of Automatic Cognition? A Response to Schimmack (2021). Perspect. Psychol. Sci. 2021, 16, 422–434. [Google Scholar] [CrossRef]
- Oswald, F.L.; Mitchell, G.; Blanton, H.; Jaccard, J.; Tetlock, P.E. Using the IAT to Predict Ethnic and Racial Discrimination: Small Effect Sizes of Unknown Societal Significance. J. Personal. Soc. Psychol. 2015, 108, 562–571. [Google Scholar] [CrossRef]
- Schimmack, U. The Implicit Association Test: A Method in Search of a Construct. Perspect. Psychol. Sci. 2021, 16, 396–414. [Google Scholar] [CrossRef]
- Schimmack, U. Invalid Claims About the Validity of Implicit Association Tests by Prisoners of the Implicit Social-Cognition Paradigm. Perspect. Psychol. Sci. 2021, 16, 435–442. [Google Scholar] [CrossRef]
- Gast, A.; Rothermund, K. When Old and Frail Is Not the Same: Dissociating Category and Stimulus Effects in Four Implicit Attitude Measurement Methods. Q. J. Exp. Psychol. 2010, 63, 479–498. [Google Scholar] [CrossRef]
- Nosek, B.A.; Greenwald, A.G.; Banaji, M.R. Understanding and Using the Implicit Association Test: II. Method Variables and Construct Validity. Personal. Soc. Psychol. Bull. 2005, 31, 166–180. [Google Scholar] [CrossRef]
- Nosek, B.A.; Greenwald, A.G.; Banaji, M.R. The Implicit Association Test at Age 7: A Methodological and Conceptual Review. In Social Psychology and the Unconscious: The Automaticity of Higher Mental Processes; Bargh, J.A., Ed.; Psychology Press: London, UK, 2007; pp. 265–292. [Google Scholar]
- Wolsiefer, K.; Westfall, J.; Judd, C.M. Modeling Stimulus Variation in Three Common Implicit Attitude Tasks. Behav. Res. Methods 2017, 49, 1193–1209. [Google Scholar] [CrossRef]
- Greenwald, A.G.; McGhee, D.E.; Schwartz, J.L. Measuring Individual Differences in Implicit Cognition: The Implicit Association Test. J. Personal. Soc. Psychol. 1998, 74, 1464. [Google Scholar] [CrossRef]
- Nosek, B.A.; Banaji, M.R. The Go/No-Go Association Task. Soc. Cogn. 2001, 19, 625–666. [Google Scholar] [CrossRef]
- Payne, K.; Cheng, C.M.; Govorun, O.; Stewart, B.D. An Inkblot for Attitudes: Affect Misattribution as Implicit Measurement. J. Personal. Soc. Psychol. 2005, 89, 277. [Google Scholar] [CrossRef]
- Kurdi, B.; Seitchik, A.E.; Axt, J.R.; Carroll, T.J.; Karapetyan, A.; Kaushik, N.; Tomezsko, D.; Greenwald, A.G.; Banaji, M.R. Relationship between the Implicit Association Test and Intergroup Behavior: A Meta-Analysis. Am. Psychol. 2019, 74, 569. [Google Scholar] [CrossRef]
- Hagger, M.S. Non-Conscious Processes and Dual-Process Theories in Health Psychology. Health Psychol. Rev. 2016, 10, 375–380. [Google Scholar] [CrossRef]
- Sheeran, P.; Bosch, J.A.; Crombez, G.; Hall, P.A.; Harris, J.L.; Papies, E.K.; Wiers, R.W. Implicit Processes in Health Psychology: Diversity and Promise. Health Psychol. 2016, 35, 761–766. [Google Scholar] [CrossRef]
- Hamilton, K.; Phipps, D.J.; Loxton, N.; Modecki, K.L.; Hagger, M.S. Reciprocal Relations between Past Behavior, Implicit Beliefs, and Habits: A Cross-Lagged Panel Design. J. Health Psychol. 2023. [Google Scholar] [CrossRef]
- Phipps, D.J.; Hannan, T.; Hamilton, K. A Cross-Lagged Model of Habits, Implicit Attitudes, Autonomous Motivation, and Physical Activity during COVID-19. Psychol. Health Med. 2022, 1–12. [Google Scholar] [CrossRef]
- Ackermann, C.-L.; Mathieu, J.-P. Implicit Attitudes and Their Measurement: Theoretical Foundations and Use in Consumer Behavior Research. Rech. Appl. En Mark. (Engl. Ed.) 2015, 30, 55–77. [Google Scholar] [CrossRef]
- Mitchell, J.P.; Nosek, B.A.; Banaji, M.R. Contextual Variations in Implicit Evaluation. J. Exp. Psychol. Gen. 2003, 132, 455. [Google Scholar] [CrossRef]
- Carnevale, J.J.; Fujita, K.; Han, H.A.; Amit, E. Immersion versus Transcendence: How Pictures and Words Impact Evaluative Associations Assessed by the Implicit Association Test. Soc. Psychol. Personal. Sci. 2015, 6, 92–100. [Google Scholar] [CrossRef]
- Govan, C.L.; Williams, K.D. Changing the Affective Valence of the Stimulus Items Influences the IAT by Re-Defining the Category Labels. J. Exp. Soc. Psychol. 2004, 40, 357–365. [Google Scholar] [CrossRef]
- Foroni, F.; Bel-Bahar, T. Picture-IAT versus Word-IAT: Level of Stimulus Representation Influences on the IAT. Eur. J. Soc. Psychol. 2010, 40, 321. [Google Scholar] [CrossRef]
- Dasgupta, N.; Greenwald, A.G.; Banaji, M.R. The First Ontological Challenge to the IAT: Attitude or Mere Familiarity? Psychol. Inq. 2003, 14, 238–243. [Google Scholar] [CrossRef]
- Ottaway, S.A.; Hayden, D.C.; Oakes, M.A. Implicit Attitudes and Racism: Effects of Word Familiarity and Frequency on the Implicit Association Test. Soc. Cogn. 2001, 19, 97–144. [Google Scholar] [CrossRef]
- Bluemke, M.; Fiedler, K. Base Rate Effects on the IAT. Conscious. Cogn. 2009, 18, 1029–1038. [Google Scholar] [CrossRef]
- New, B. Reexamining the Word Length Effect in Visual Word Recognition: New Evidence from the English Lexicon Project. Psychon. Bull. Rev. 2006, 13, 45–52. [Google Scholar] [CrossRef]
- Bluemke, M.; Friese, M. On the Validity of Idiographic and Generic Self-concept Implicit Association Tests: A Core-concept Model. Eur. J. Personal. 2012, 26, 515–528. [Google Scholar] [CrossRef]
- Bohner, G.; Siebler, F.; González, R.; Haye, A.; Schmidt, E.A. Situational Flexibility of In-Group-Related Attitudes: A Single Category IAT Study of People with Dual National Identity. Group Process. Intergroup Relat. 2008, 11, 301–317. [Google Scholar] [CrossRef]
- Field, M.; Mogg, K.; Bradley, B.P. Cognitive Bias and Drug Craving in Recreational Cannabis Users. Drug Alcohol Depend. 2004, 74, 105–111. [Google Scholar] [CrossRef]
- Rudman, L.A.; Greenwald, A.G.; Mellott, D.S.; Schwartz, J.L. Measuring the Automatic Components of Prejudice: Flexibility and Generality of the Implicit Association Test. Soc. Cogn. 1999, 17, 437–465. [Google Scholar] [CrossRef]
- Saminaden, A.; Loughnan, S.; Haslam, N. Afterimages of Savages: Implicit Associations between Primitives, Animals and Children. Br. J. Soc. Psychol. 2010, 49, 91–105. [Google Scholar] [CrossRef]
- Stieger, S.; Göritz, A.S.; Burger, C. Personalizing the IAT and the SC-IAT: Impact of Idiographic Stimulus Selection in the Measurement of Implicit Anxiety. Personal. Individ. Differ. 2010, 48, 940–944. [Google Scholar] [CrossRef]
- Chall, J.S.; Jacobs, V.A. The Classic Study on Poor Children’s Fourth-Grade Slump. Am. Educ. 2003, 27, 14–15. [Google Scholar]
- Coch, D. The N400 and the Fourth Grade Shift. Dev. Sci. 2015, 18, 254–269. [Google Scholar] [CrossRef]
- Samuels, S.; LaBerge, D.; Bremer, C.D. Units of Word Recognition: Evidence for Developmental Changes. J. Verbal Learn. Verbal Behav. 1978, 17, 715–720. [Google Scholar] [CrossRef]
- Bayetto, A. The New Oxford Wordlist Research Report; Oxford University Press Australia and New Zealand: Melbourne, Australia, 2017. [Google Scholar]
- Biber, D.; Egbert, J.; Davies, M. Exploring the Composition of the Searchable Web: A Corpus-Based Taxonomy of Web Registers. Corpora 2015, 10, 11–45. [Google Scholar] [CrossRef]
- Greenwald, A.G.; Nosek, B.A.; Banaji, M.R. Understanding and Using the Implicit Association Test: I. An Improved Scoring Algorithm. J. Personal. Soc. Psychol. 2003, 85, 197–216. [Google Scholar] [CrossRef]
- Bluemke, M.; Friese, M. Reliability and Validity of the Single-Target IAT (ST-IAT): Assessing Automatic Affect towards Multiple Attitude Objects. Eur. J. Soc. Psychol. 2008, 38, 977–997. [Google Scholar] [CrossRef]
- Carpenter, T.P.; Pogacar, R.; Pullig, C.; Kouril, M.; Aguilar, S.; LaBouff, J.; Isenberg, N.; Chakroff, A. Survey-Software Implicit Association Tests: A Methodological and Empirical Analysis. Behav. Res. Methods 2019, 51, 2194–2208. [Google Scholar] [CrossRef]
- Craeynest, M.; Crombez, G.; Haerens, L.; De Bourdeaudhuij, I. Do Overweight Youngsters like Food More than Lean Peers? Assessing Their Implicit Attitudes with a Personalized Implicit Association Task. Food Qual. Prefer. 2007, 18, 1077–1084. [Google Scholar] [CrossRef]
- Hagger, M.S.; Trost, N.; Keech, J.J.; Chan, D.K.C.; Hamilton, K. Predicting Sugar Consumption: Application of an Integrated Dual-Process, Dual-Phase Model. Appetite 2017, 116, 147–156. [Google Scholar] [CrossRef]
- Phipps, D.J.; Hagger, M.S.; Hamilton, K. Predicting Limiting “free Sugar” Consumption Using an Integrated Model of Health Behavior. Appetite 2020, 150, 104668. [Google Scholar] [CrossRef]
- Francis, H.; Stevenson, R. Validity and Test–Retest Reliability of a Short Dietary Questionnaire to Assess Intake of Saturated Fat and Free Sugars: A Preliminary Study. J. Hum. Nutr. Diet. 2013, 26, 234–242. [Google Scholar] [CrossRef]
- Shaw, S.; Crozier, S.; Strömmer, S.; Inskip, H.; Barker, M.; Vogel, C. Development of a Short Food Frequency Questionnaire to Assess Diet Quality in UK Adolescents Using the National Diet and Nutrition Survey. Nutr. J. 2021, 20, 5. [Google Scholar] [CrossRef]
- Phipps, D.J.; Hannan, T.E.; Rhodes, R.E.; Hamilton, K. A Dual-Process Model of Affective and Instrumental Attitudes in Predicting Physical Activity. Psychol Sport Exerc 2021, 54, 54. [Google Scholar] [CrossRef]
- Phipps, D.J.; Hagger, M.S.; Hamilton, K. Evidence That Habit Moderates the Implicit Belief-Behavior Relationship in Health Behaviors. Int. J. Behav. Med. 2021, 29, 116–121. [Google Scholar] [CrossRef]
- Phipps, D.J.; Rhodes, R.E.; Jenkins, K.; Hannan, T.E.; Browning, N.; Hamilton, K. A Dual Process Model of Affective and Instrumental Implicit Attitude, Self-Monitoring, and Sedentary Behavior. Psychol. Sport Exerc. 2022, 102222. [Google Scholar] [CrossRef]
- Cummins, J.; Hussey, I.; Spruyt, A. The Role of Attitude Features in the Reliability of IAT Scores. J. Exp. Soc. Psychol. 2022, 101, 104330. [Google Scholar] [CrossRef]
- Chant, K. What NSW Children Eat and Drink; NSW Health: Sydney, Australia, 2017. [Google Scholar]
- Roy Morgan Australia. Roy Morgan Young Australians Survey; Roy Morgan: Melbourne, Australia, 2017. [Google Scholar]
- Australian Bureau of Statistics. Australian Health Survey: Consumption of Added Sugars, 2011-12; Australian Bureau of Statistics: Canberra, Australia, 2016. [Google Scholar]
- National Health and Medical Research Council. Australian Dietary Guidelines: Providing the Scientific Evidence for Healthier Australian Diets; National Health and Medical Research Council: Canberra, Australia, 2013; ISBN 1-86496-574-6. [Google Scholar]
- Lindgren, K.P.; Baldwin, S.A.; Ramirez, J.J.; Olin, C.C.; Peterson, K.P.; Wiers, R.W.; Teachman, B.A.; Norris, J.; Kaysen, D.; Neighbors, C. Self-Control, Implicit Alcohol Associations, and the (Lack of) Prediction of Consumption in an Alcohol Taste Test with College Student Heavy Episodic Drinkers. PLoS ONE 2019, 14, e0209940. [Google Scholar] [CrossRef]
- Richetin, J.; Perugini, M.; Adjali, I.; Hurling, R. The Moderator Role of Intuitive versus Deliberative Decision Making for the Predictive Validity of Implicit and Explicit Measures. Eur. J. Personal. 2007, 21, 529–546. [Google Scholar] [CrossRef]
- Scinta, A.; Gable, S.L. Automatic and Self-Reported Attitudes in Romantic Relationships. Personal. Soc. Psychol. Bull. 2007, 33, 1008–1022. [Google Scholar] [CrossRef]


{kind=link}
| Sample Characteristics | Word Characteristics | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Variables | Minimum | Maximum | Mode | Median | Mean | SD | Syllables | Length | Use Frequency Rank |
| Broccoli | 1 | 5 | 5 | 5 | 4.55 | 0.97 | 3 | 8 | 4957 |
| Fruit | 2 | 5 | 5 | 5 | 4.55 | 0.73 | 1 | 5 | 924 |
| Carrot | 1 | 5 | 5 | 5 | 4.35 | 0.84 | 2 | 6 | 1217 |
| Watermelon | 2 | 5 | 5 | 4 | 4.27 | 0.85 | 4 | 10 | 3345 |
| Apples | 2 | 5 | 5 | 4 | 4.22 | 0.88 | 2 | 6 | 856 |
| Cucumber | 0 | 5 | 5 | 5 | 4.18 | 1.20 | 3 | 8 | 4305 |
| Strawberry | 1 | 5 | 5 | 4 | 4.10 | 0.99 | 3 | 10 | 1715 |
| Grape | 1 | 5 | 5 | 4 | 4.08 | 0.98 | 1 | 5 | 4419 |
| Banana | 1 | 5 | 5 | 4 | 4.04 | 1.13 | 3 | 6 | 958 |
| Tomato | 1 | 5 | 4 | 4 | 3.73 | 1.20 | 3 | 6 | 1262 |
| Avocado | 0 | 5 | 5 | 4 | 3.69 | 1.46 | 4 | 7 | 6202 |
| Beans | 0 | 5 | 5 | 4 | 3.67 | 1.47 | 1 | 5 | 3053 |
| Blueberry | 0 | 5 | 4 | 4 | 3.65 | 1.35 | 3 | 9 | 3385 |
| Mangos | 0 | 5 | 4 | 4 | 3.61 | 1.25 | 2 | 6 | 3525 |
| Rice | 0 | 5 | 3 | 3 | 3.18 | 1.23 | 1 | 4 | 1149 |
| Salmon | 0 | 5 | 3 | 3 | 2.88 | 1.63 | 2 | 6 | 5698 |
| Olive | 0 | 5 | 3 | 3 | 2.31 | 1.62 | 2 | 5 | Unranked |
| Sample Characteristics | Word Characteristics | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Minimum | Maximum | Mode | Median | Mean | SD | Syllables | Letters | Corpus Frequency Rank | |
| Candy | 2 | 5 | 5 | 5.00 | 4.58 | 0.82 | 2 | 5 | 2377 |
| Ice cream | 2 | 5 | 5 | 4.50 | 4.35 | 0.76 | 2 | 8 | 416 |
| Lollipop | 1 | 5 | 5 | 5.00 | 4.33 | 1.08 | 3 | 8 | 1285 |
| Doughnut | 0 | 5 | 5 | 4.00 | 4.00 | 1.26 | 2 | 8 | 1579 |
| Cupcakes | 1 | 5 | 5 | 4.00 | 3.98 | 0.98 | 2 | 8 | 3100 |
| Cookies | 1 | 5 | 5 | 4.00 | 3.77 | 1.08 | 2 | 7 | 1117 |
| Soft Drink | 0 | 5 | 5 | 4.00 | 3.75 | 1.58 | 2 | 9 | Unranked |
| Gummies | 0 | 5 | 5 | 4.00 | 3.52 | 1.60 | 2 | 7 | Unranked |
| Ice Block | 0 | 5 | 4 | 4.00 | 3.50 | 1.34 | 3 | 8 | 5350 |
| Coke | 0 | 5 | 5 | 5.00 | 3.48 | 1.96 | 1 | 4 | 5030 |
| Lemonade | 0 | 5 | 4 | 3.00 | 3.17 | 1.45 | 3 | 8 | 1976 |
| Strawberry Milk | 0 | 5 | 4 | 3.00 | 3.08 | 1.57 | 4 | 14 | Unranked |
| Chocolate Milk | 0 | 5 | 3 | 3.00 | 3.06 | 1.45 | 4 | 13 | Unranked |
| Juice | 1 | 5 | 3 | 3.00 | 2.75 | 1.21 | 1 | 5 | 1306 |
| Liquorice | 0 | 5 | 0 | 1.00 | 2.00 | 1.97 | 3 | 9 | 3928 |
| Gatorade | 0 | 5 | 0 | 0.00 | 1.73 | 2.01 | 3 | 8 | Unranked |
| Familiarity (Sample 1) | Use Frequency (Sample 2) | Word Characteristics | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Mode | Median | Mean | SD | Mode | Median | Mean | SD | Syllables | Letters | Corpus Frequency | |
| Fruit | 5 | 5.00 | 4.62 | 0.81 | 5 | 5.00 | 4.86 | 0.92 | 1 | 5 | 33.59 |
| Vegetables | 5 | 5.00 | 4.60 | 0.98 | 5 | 5.00 | 4.84 | 1.01 | 4 | 10 | 21.95 |
| Broccoli | 5 | 5.00 | 4.45 | 1.01 | 4 | 4.00 | 3.75 | 1.41 | 3 | 8 | 4.57 |
| Lettuce | 5 | 5.00 | 4.45 | 1.04 | 4 | 4.00 | 4.36 | 1.10 | 2 | 7 | 5.15 |
| Bananas | 5 | 5.00 | 4.40 | 0.90 | 4 | 4.00 | 4.01 | 1.45 | 3 | 7 | 4.34 |
| Oranges | 5 | 5.00 | 4.38 | 0.96 | 4 | 4.00 | 3.99 | 1.23 | 3 | 7 | 3.99 |
| Spinach | 5 | 5.00 | 4.38 | 1.12 | 5 | 4.00 | 3.93 | 1.39 | 2 | 7 | 5.17 |
| Salad | 5 | 5.00 | 4.35 | 1.00 | 4 | 4.00 | 4.33 | 1.34 | 2 | 5 | 19.74 |
| Apples | 5 | 5.00 | 4.34 | 0.99 | 4 | 4.00 | 4.15 | 1.11 | 2 | 6 | 11.32 |
| Grapes | 5 | 5.00 | 4.34 | 0.98 | 4 | 4.00 | 3.89 | 1.28 | 2 | 6 | 5.75 |
| Kale | 5 | 5.00 | 4.34 | 1.27 | 1 | 2.00 | 2.81 | 1.58 | 1 | 4 | 2.53 |
| Tomatoes | 5 | 5.00 | 4.26 | 1.08 | 5 | 5.00 | 4.30 | 1.42 | 3 | 8 | 15.02 |
| Avocado | 5 | 5.00 | 4.24 | 1.13 | 5 | 4.00 | 4.11 | 1.33 | 4 | 7 | 2.46 |
| Zucchini | 5 | 5.00 | 4.24 | 1.22 | 4 | 3.00 | 3.42 | 1.52 | 3 | 8 | 2.52 |
| Peas | 5 | 5.00 | 4.23 | 1.11 | 2 | 4.00 | 3.62 | 1.52 | 1 | 4 | 6.06 |
| Lentils | 5 | 5.00 | 4.22 | 1.21 | 1 | 2.00 | 2.75 | 1.54 | 2 | 7 | 1.28 |
| Strawberries | 5 | 4.00 | 4.22 | 0.92 | 5 | 5.00 | 4.37 | 1.26 | 3 | 12 | 3.68 |
| Fish | 5 | 5.00 | 4.19 | 1.15 | 4 | 4.00 | 3.77 | 1.55 | 1 | 4 | 83.08 |
| Legumes | 5 | 5.00 | 4.18 | 1.26 | 2 | 2.00 | 2.62 | 1.48 | 3 | 7 | 1.06 |
| Cabbage | 5 | 5.00 | 4.16 | 1.20 | 2 | 3.00 | 3.04 | 1.37 | 2 | 7 | 4.50 |
| Beans | 5 | 5.00 | 4.15 | 1.19 | 4 | 4.00 | 3.66 | 1.48 | 1 | 5 | 18.82 |
| Corn | 5 | 4.50 | 4.14 | 1.10 | 4 | 4.00 | 3.60 | 1.34 | 1 | 4 | 26.62 |
| Blueberries | 5 | 5.00 | 4.13 | 1.14 | 4 | 4.00 | 3.77 | 1.43 | 3 | 11 | 2.00 |
| Chickpeas | 5 | 5.00 | 4.10 | 1.24 | 2 | 3.00 | 3.04 | 1.67 | 2 | 9 | 0.83 |
| Nuts | 5 | 4.00 | 4.05 | 1.09 | 4 | 4.00 | 3.64 | 1.37 | 1 | 4 | 21.31 |
| Chia | 5 | 5.00 | 4.04 | 1.26 | 2 | 2.00 | 2.81 | 1.54 | 1 | 4 | 0.50 |
| Quinoa | 5 | 4.50 | 4.03 | 1.27 | 1 | 2.00 | 2.51 | 1.50 | 2 | 6 | 1.00 |
| Almonds | 5 | 4.00 | 4.00 | 1.21 | 4 | 3.00 | 3.27 | 1.45 | 2 | 7 | 2.89 |
| Eggs | 5 | 4.00 | 4.00 | 1.14 | 6 | 4.00 | 4.29 | 1.53 | 1 | 4 | 32.53 |
| Whole Grains | 5 | 4.00 | 3.98 | 1.15 | 4 | 4.00 | 3.30 | 1.48 | 3 | 11 | 0.43 |
| Grains | 5 | 4.00 | 3.97 | 1.11 | 4 | 4.00 | 3.52 | 1.42 | 1 | 6 | 6.72 |
| Oats | 4 | 4.00 | 3.97 | 1.09 | 3 | 4.00 | 3.77 | 1.45 | 1 | 4 | 2.31 |
| Chicken | 4 | 4.00 | 3.84 | 1.14 | 5 | 5.00 | 4.55 | 1.41 | 2 | 7 | 47.47 |
| Olives | 5 | 4.00 | 3.80 | 1.28 | 2 | 3.00 | 3.07 | 1.58 | 3 | 6 | 3.64 |
| Tofu | 5 | 4.00 | 3.77 | 1.26 | 1 | 2.00 | 2.99 | 1.74 | 2 | 4 | 3.18 |
| Meat | 5 | 4.00 | 3.68 | 1.26 | 5 | 5.00 | 4.48 | 1.41 | 1 | 4 | 43.24 |
| Wheat | 5 | 4.00 | 3.60 | 1.19 | 4 | 4.00 | 3.32 | 1.46 | 1 | 5 | 11.97 |
| Red Meat | 4 | 4.00 | 3.57 | 1.27 | 5 | 4.00 | 3.99 | 1.51 | 2 | 7 | 1.62 |
| Yogurt | 3 | 3.00 | 3.47 | 1.15 | 4 | 4.00 | 3.81 | 1.40 | 2 | 6 | 6.57 |
| Trail mix | 3 | 3.50 | 3.46 | 1.16 | 2 | 2.00 | 2.33 | 1.30 | 2 | 8 | 0.21 |
| Juice | 3 | 3.00 | 3.20 | 1.06 | 2 | 4.00 | 3.58 | 1.42 | 1 | 5 | 26.55 |
| Bread | 3 | 3.00 | 3.16 | 1.23 | 5 | 5.00 | 4.58 | 1.09 | 1 | 5 | 33.49 |
| Pasta | 3 | 3.00 | 3.14 | 1.09 | 5 | 5.00 | 4.47 | 1.21 | 2 | 5 | 10.32 |
| Cheese | 2 | 3.00 | 2.93 | 1.23 | 5 | 5.00 | 4.34 | 1.31 | 1 | 6 | 36.26 |
| Association (Sample 1) | Use Frequency (Sample 2) | Word Characteristics (Data) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Mode | Median | Mean | SD | Mode | Median | Mean | SD | Syllables | Letters | Corpus Frequency | |
| Soft Drink | 5 | 5.00 | 4.57 | 0.91 | 3 | 3.00 | 2.51 | 1.34 | 2 | 9 | 6.89 |
| Lollies | 5 | 5.00 | 4.56 | 0.91 | 2 | 2.00 | 2.25 | 1.23 | 2 | 7 | 0.58 |
| Coke | 5 | 5.00 | 4.48 | 1.13 | 3 | 3.00 | 2.48 | 1.47 | 1 | 4 | 37.51 |
| Candy | 5 | 5.00 | 4.46 | 1.04 | 1 | 1.00 | 1.59 | 1.34 | 2 | 5 | 11.45 |
| Energy Drinks | 5 | 5.00 | 4.43 | 1.16 | 1 | 1.00 | 1.53 | 1.43 | 4 | 12 | 0.36 |
| Sunkist | 5 | 5.00 | 4.27 | 1.18 | 1 | 1.00 | 1.38 | 1.25 | 2 | 7 | 0.02 |
| Cordial | 5 | 5.00 | 4.26 | 1.24 | 1 | 1.00 | 1.33 | 1.25 | 2 | 7 | 1.32 |
| Sweets | 5 | 5.00 | 4.26 | 1.01 | 1 | 2.00 | 1.97 | 1.30 | 1 | 6 | 3.70 |
| Chocolate | 5 | 4.00 | 4.21 | 0.83 | 4 | 3.00 | 3.07 | 1.08 | 3 | 9 | 27.13 |
| Lemonade | 5 | 5.00 | 4.21 | 1.17 | 2 | 2.00 | 1.96 | 1.15 | 3 | 8 | 2.60 |
| Jellybeans | 5 | 5.00 | 4.13 | 1.20 | 1 | 1.00 | 1.18 | 1.11 | 3 | 10 | 0.08 |
| Cake | 5 | 4.00 | 4.11 | 1.04 | 2 | 2.00 | 2.07 | 1.11 | 1 | 4 | 26.02 |
| Maple Syrup | 5 | 4.00 | 4.06 | 1.12 | 1 | 1.00 | 1.47 | 1.12 | 4 | 11 | 0.77 |
| Ice Cream | 5 | 4.00 | 4.05 | 1.03 | 3 | 3.00 | 2.70 | 1.04 | 3 | 9 | 10.17 |
| Doughnuts | 5 | 4.00 | 4.03 | 1.16 | 1 | 2.00 | 2.08 | 1.23 | 2 | 9 | 1.32 |
| Fast Food | 5 | 4.00 | 4.01 | 1.06 | 1 | 3.00 | 2.59 | 1.37 | 2 | 9 | 4.57 |
| McDonalds | 5 | 4.00 | 3.86 | 1.20 | 4 | 3.00 | 2.95 | 1.41 | 2 | 9 | 2.45 |
| Flavoured Milk | 4 | 4.00 | 3.74 | 1.19 | 0 | 1.00 | 1.16 | 1.11 | 4 | 14 | 0.04 |
| Juice | 4 | 4.00 | 3.73 | 0.95 | 3 | 3.00 | 2.60 | 1.29 | 1 | 5 | 16.79 |
| Cookies | 4 | 4.00 | 3.70 | 1.11 | 3 | 3.00 | 2.67 | 1.04 | 2 | 7 | 7.28 |
| Muffins | 4 | 4.00 | 3.59 | 1.19 | 2 | 2.00 | 1.96 | 1.32 | 2 | 7 | 1.64 |
| Pastries | 4 | 4.00 | 3.52 | 1.23 | 1 | 1.00 | 1.63 | 1.12 | 2 | 8 | 1.30 |
| Biscuits | 4 | 4.00 | 3.51 | 1.17 | 2 | 2.00 | 2.30 | 1.16 | 2 | 8 | 4.38 |
| Sugar in Coffee | 3 | 3.00 | 3.45 | 1.21 | 0 | 2.00 | 1.99 | 1.59 | 5 | 15 | 0.08 |
| Muesli Bars | 3 | 3.00 | 3.13 | 1.26 | 1 | 1.00 | 1.63 | 1.37 | 3 | 11 | 0.04 |
| Pie | 3 | 3.00 | 3.09 | 1.22 | 1 | 1.00 | 1.59 | 1.29 | 1 | 3 | 15.43 |
| Associations | Use Frequency | Word Characteristics (Data) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Mode | Median | Mean | SD | Mode | Median | Mean | SD | Syllables | Letters | Corpus Frequency | |
| Vegetables | 5 | 5.00 | 4.50 | 1.00 | 3 | 4.00 | 3.89 | 0.99 | 4 | 10 | 21.95 |
| Carrots | 5 | 5.00 | 4.50 | 0.61 | 3 | 4.00 | 3.74 | 0.81 | 2 | 7 | 6.26 |
| Salad | 5 | 5.00 | 4.50 | 0.69 | 4 | 4.00 | 3.68 | 1.06 | 2 | 5 | 19.74 |
| Broccoli | 5 | 5.00 | 4.35 | 1.23 | 3 | 3.00 | 3.42 | 1.26 | 3 | 8 | 4.57 |
| Apple | 5 | 4.50 | 4.30 | 0.86 | 3 | 3.00 | 3.35 | 0.99 | 2 | 6 | 11.32 |
| Lettuce | 5 | 5.00 | 4.30 | 1.08 | 3 | 3.50 | 3.61 | 0.85 | 2 | 7 | 5.15 |
| Bananas | 5 | 4.50 | 4.25 | 0.85 | 4 | 4.00 | 3.55 | 0.83 | 3 | 7 | 4.34 |
| Fruit | 5 | 4.00 | 4.20 | 0.89 | 4 | 4.00 | 3.80 | 0.95 | 1 | 5 | 33.59 |
| Mango | 4 | 4.00 | 4.20 | 0.83 | 3 | 3.00 | 3.60 | 0.82 | 2 | 5 | 2.62 |
| Avocado | 5 | 5.00 | 4.20 | 1.28 | 3 | 4.00 | 3.74 | 0.99 | 4 | 7 | 2.46 |
| Strawberry | 5 | 4.00 | 4.10 | 1.07 | 3 | 4.00 | 3.74 | 0.93 | 3 | 12 | 3.68 |
| Brussel Sprouts | 5 | 5.00 | 4.10 | 1.29 | 2 | 2.00 | 2.40 | 1.06 | 3 | 14 | 0.08 |
| Oranges | 5 | 4.00 | 4.10 | 1.07 | 3 | 3.00 | 3.32 | 0.82 | 3 | 7 | 3.99 |
| Chicken | 4 | 4.00 | 3.95 | 0.69 | 4 | 4.00 | 4.00 | 0.79 | 2 | 7 | 47.47 |
| Yoghurt | 4 | 4.00 | 3.95 | 0.76 | 4 | 4.00 | 3.65 | 0.88 | 2 | 6 | 6.57 |
| Cauliflower | 5 | 5.00 | 3.95 | 1.43 | 2 | 2.50 | 2.75 | 0.86 | 4 | 11 | 1.74 |
| Spinach | 5 | 5.00 | 3.90 | 1.65 | 3 | 3.00 | 3.31 | 0.95 | 2 | 7 | 5.17 |
| Nuts | 4 | 4.00 | 3.75 | 1.02 | 3 | 3.00 | 3.39 | 1.04 | 1 | 4 | 21.31 |
| Rice | 3 | 3.00 | 3.50 | 0.95 | 3 | 3.00 | 3.53 | 1.07 | 1 | 4 | 27.42 |
| Bread | 3 | 3.00 | 3.35 | 0.99 | 4 | 4.00 | 4.15 | 0.75 | 1 | 5 | 33.49 |
| Weetbix | 2 | 3.00 | 3.35 | 1.14 | 2 | 3.00 | 2.88 | 1.22 | 2 | 7 | 0.09 |
| Smoothies | 3 | 3.00 | 3.25 | 0.97 | 3 | 3.00 | 3.40 | 1.10 | 2 | 9 | 1.09 |
| Associations | Use Frequency | Word Characteristics (Data) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Mode | Median | Mean | SD | Mode | Median | Mean | SD | Syllables | Letters | Corpus Frequency | |
| Coke | 5 | 5.00 | 4.60 | 1.10 | 2 | 3.00 | 2.88 | 1.32 | 1 | 4 | 37.51 |
| Brownies | 5 | 5.00 | 4.50 | 0.95 | 2 | 3.00 | 3.06 | 1.11 | 2 | 8 | 1.32 |
| Soft drink | 5 | 5.00 | 4.45 | 1.10 | 3 | 3.00 | 3.37 | 0.96 | 2 | 9 | 6.89 |
| Lollies | 5 | 5.00 | 4.45 | 1.05 | 3 | 3.00 | 3.45 | 0.94 | 2 | 7 | 0.58 |
| Chocolate | 5 | 5.00 | 4.45 | 0.69 | 4 | 4.00 | 3.75 | 1.07 | 3 | 9 | 27.13 |
| Ice Cream | 5 | 5.00 | 4.40 | 0.82 | 5 | 4.00 | 3.85 | 1.04 | 3 | 9 | 10.17 |
| Cake | 5 | 5.00 | 4.30 | 0.98 | 3 | 3.00 | 3.21 | 0.92 | 1 | 4 | 26.02 |
| Lemonade | 5 | 5.00 | 4.25 | 1.21 | 3 | 3.00 | 3.32 | 0.95 | 3 | 8 | 2.60 |
| Energy Drinks | 5 | 5.00 | 4.25 | 1.07 | 2 | 2.00 | 2.20 | 1.01 | 4 | 12 | 0.36 |
| Slurpees | 5 | 5.00 | 4.15 | 1.46 | 2 | 3.00 | 3.00 | 1.20 | 2 | 8 | 0.34 |
| Jelly | 4 | 4.00 | 3.95 | 1.00 | 2 | 2.00 | 2.47 | 0.90 | 2 | 5 | 5.81 |
| Chips | 4 | 4.00 | 3.65 | 1.35 | 4 | 4.00 | 3.63 | 0.90 | 1 | 5 | 16.00 |
| Cordial | 5 | 3.50 | 3.55 | 1.36 | 2 | 2.00 | 2.44 | 0.96 | 2 | 7 | 1.32 |
| Biscuits | 3 | 3.00 | 3.45 | 0.83 | 3 | 3.00 | 2.89 | 0.81 | 2 | 8 | 4.38 |
| Juice | 4 | 3.50 | 3.40 | 1.19 | 3 | 3.50 | 3.55 | 1.10 | 1 | 5 | 16.79 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Phipps, D.J.; Hamilton, K. Creating Implicit Measure Stimulus Sets Using a Multi-Step Piloting Method. Methods Protoc. 2023, 6, 47. https://doi.org/10.3390/mps6030047
Phipps DJ, Hamilton K. Creating Implicit Measure Stimulus Sets Using a Multi-Step Piloting Method. Methods and Protocols. 2023; 6(3):47. https://doi.org/10.3390/mps6030047
Chicago/Turabian StylePhipps, Daniel J., and Kyra Hamilton. 2023. "Creating Implicit Measure Stimulus Sets Using a Multi-Step Piloting Method" Methods and Protocols 6, no. 3: 47. https://doi.org/10.3390/mps6030047
APA StylePhipps, D. J., & Hamilton, K. (2023). Creating Implicit Measure Stimulus Sets Using a Multi-Step Piloting Method. Methods and Protocols, 6(3), 47. https://doi.org/10.3390/mps6030047