
The Extraction Method of Navigation Line for Cuttage and Film Covering Multi-Functional Machine for Low Tunnels


Abstract
:1. Introduction
2. Materials and Methods
2.1. Image Acquisition
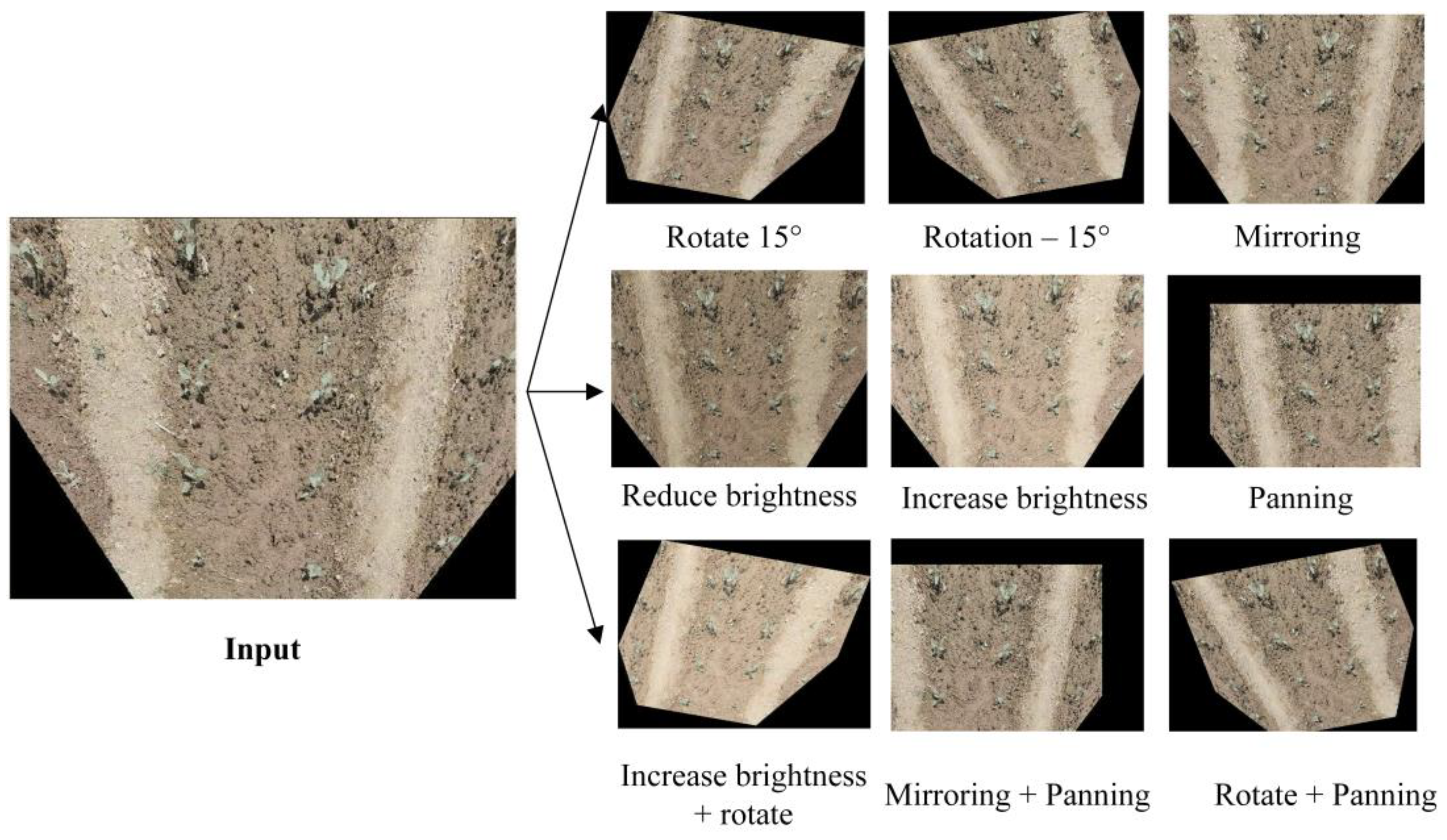
2.2. Image Pre-Processing
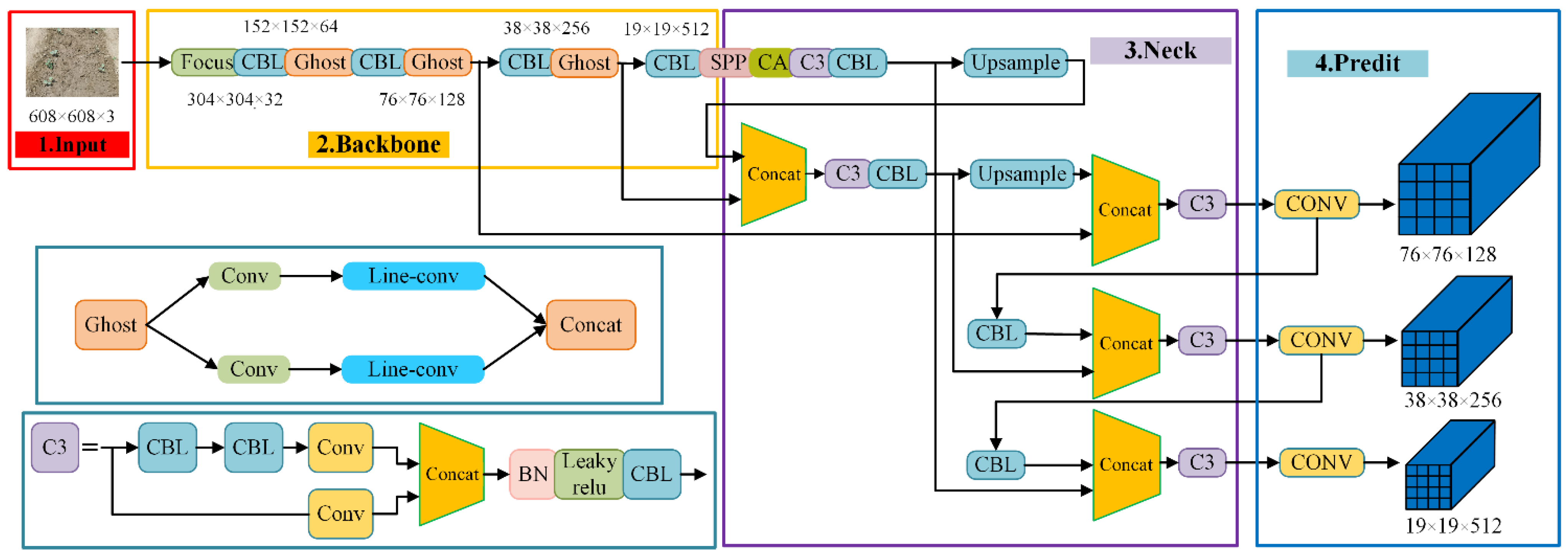
2.3. Improved YOLOv5s Model
- (1)
- To solve the problem of false or missed detection of field targets in images due to scale changes and different shapes, the Coordinate Attention (CA) mechanism is introduced into the YOLOv5s architecture to improve the detection accuracy of field targets by learning target features while suppressing non-target features.
- (2)
- The backbone network of the YOLOv5s architecture is improved by using the Ghost module to reduce the number of parameters and computation while eliminating invalid and duplicate feature maps to achieve an effective increase in detection speed while taking into account the detection accuracy.
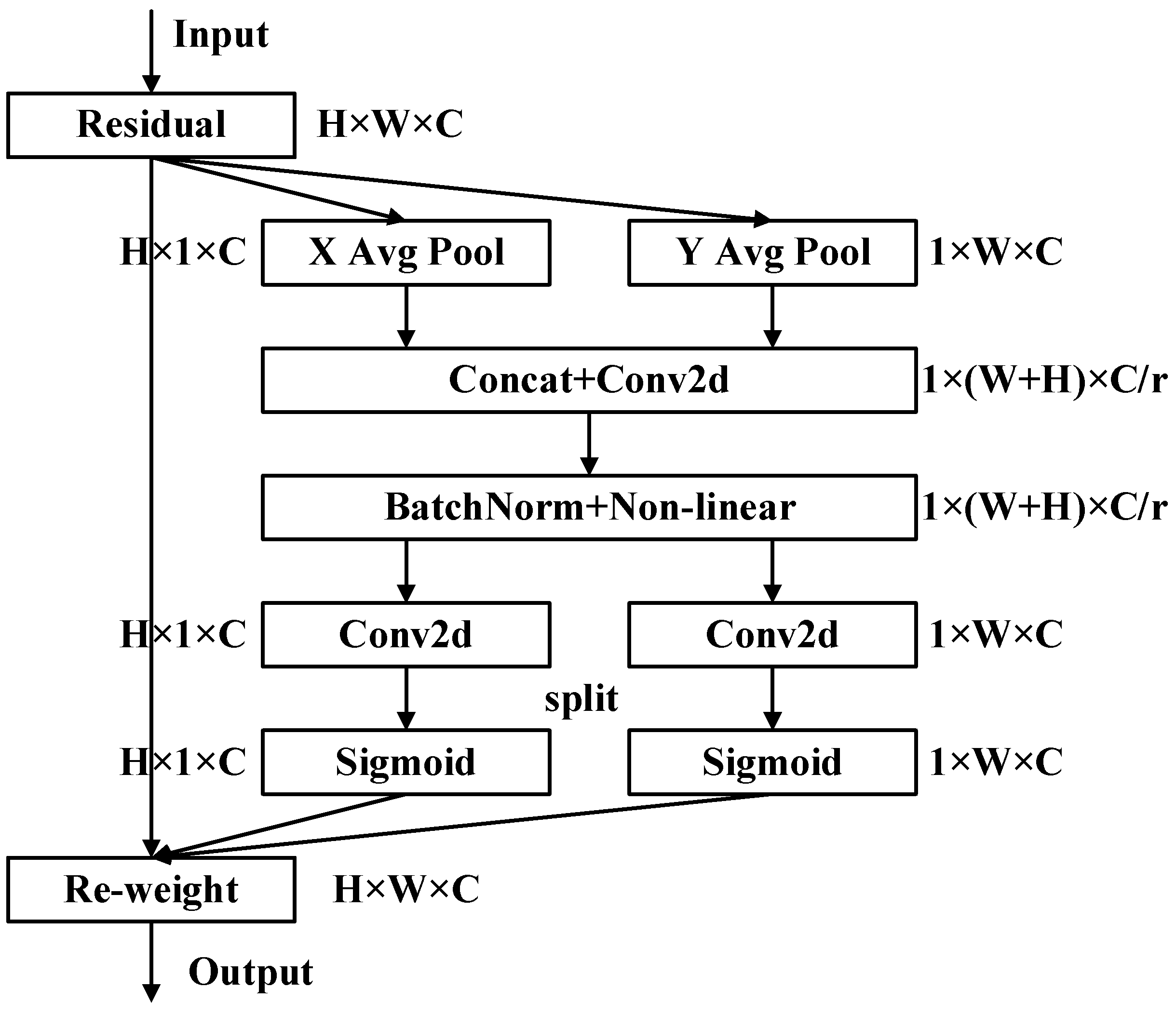
2.3.1. Attention Mechanism
2.3.2. Backbone Network Optimization
2.3.3. Network Training Hyperparameters
2.4. Navigation Line Fitting Method
3. Results
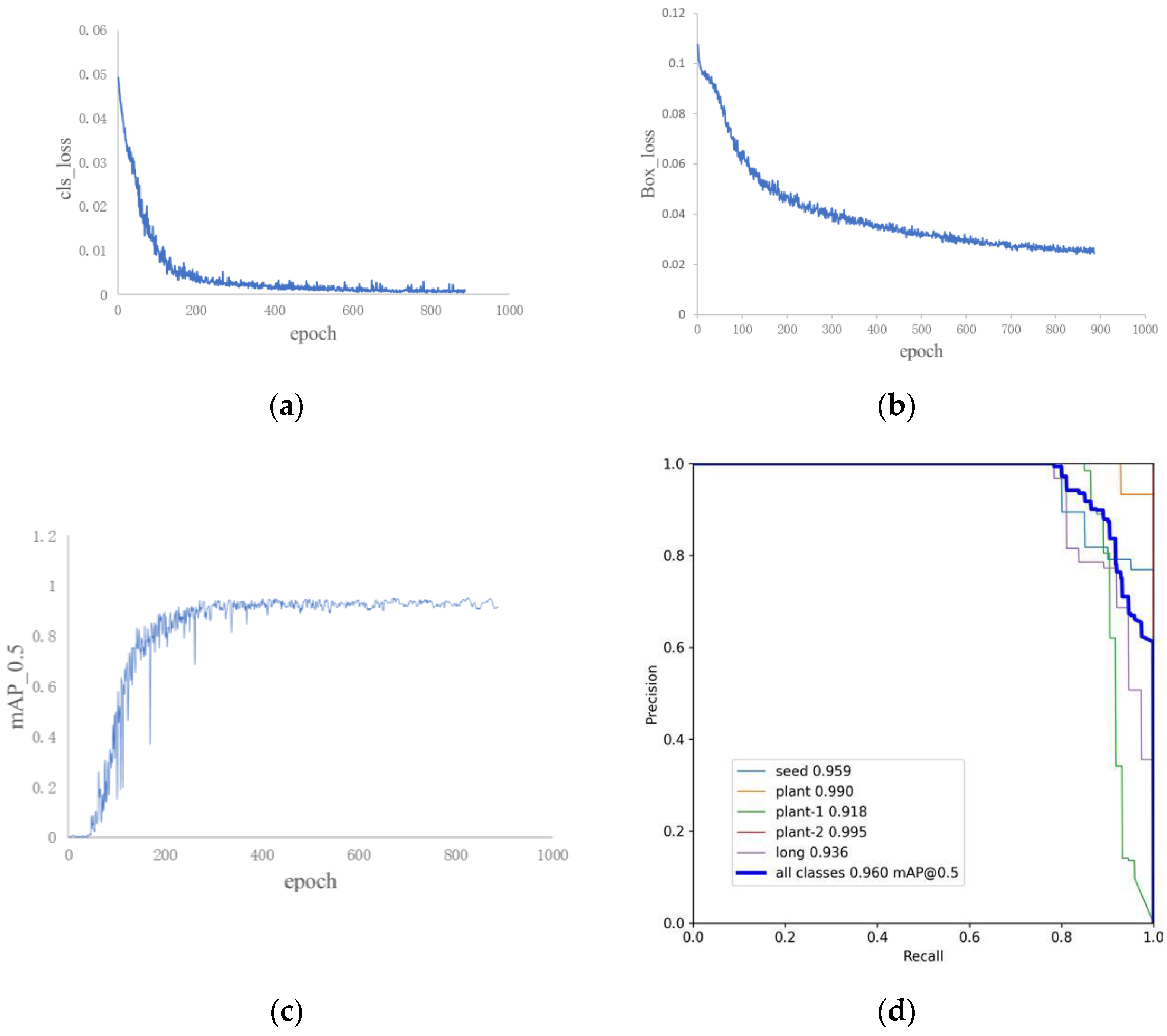
3.1. Improved YOLOv5s Model Training Results
3.2. Ablation Experiments
3.3. Comparison Experiments with Different Networks
3.4. Test Results of Navigation Line Extraction Method
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Mousazadeh, H. A technical review on navigation systems of agricultural autonomous off-road vehicles. J. Terramech. 2013, 50, 211–232. [Google Scholar] [CrossRef]
- Han, S.; He, Y.; Fang, H. Recent development in automatic guidance and autonomous vehicle for agriculture: A Review. J. Zhejiang Univ. Agric. Life Sci. Ed. 2018, 44, 11. [Google Scholar] [CrossRef]
- Ji, C.; Zhou, J. Current Situation of Navigation Technologies for Agricultural Machinery. J. Agric. Mach. 2014, 45, 44–54. [Google Scholar] [CrossRef]
- Lu, W.; Zeng, M.; Wang, L.; Luo, H.; Mukherjee, S.; Huang, X.; Deng, Y. Navigation algorithm based on the boundary line of tillage soil combined with guided filtering and improved anti-noise morphology. Sensors 2019, 19, 3918. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yang, W.; Li, T.; Jia, H. Simulation and experiment of machine vision guidance of agriculture vehicles. J. Agric. Eng. 2004, 1, 160–165. [Google Scholar] [CrossRef]
- Liu, Y.; Gao, G. Research Development of Vision-Based Guidance Directrix Recognition for Agriculture Vehicles. Agric. Mech. Res. 2015, 37, 7–13. [Google Scholar] [CrossRef]
- Burgos-Artizzu, X.P.; Ribeiro, A.; Guijarro, M.; Pajares, G. Real-time image processing for crop/weed discrimination in maize fields. Comput. Electron. Agric. 2011, 75, 337–346. [Google Scholar] [CrossRef] [Green Version]
- Wang, T.; Bin, C.; Zhang, Z.; Li, H.; Zhang, M. Applications of machine vision in agricultural robot navigation: A review. Comput. Electron. Agric. 2022, 198, 107085. [Google Scholar] [CrossRef]
- Neeru, S.; Redhu; Zoozeal, T.; Shikha, Y.; Poonam, M. Chapter 37-Artificial intelligence: A way forward for agricultural sciences. In Bioinformatics in Agriculture; Elsevier: Amsterdam, The Netherlands, 2022; pp. 641–668. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.; Liao, H. YOLOv4: Opstimal speed and accuracy of object detection. arXiv 2004, arXiv:2004.10934. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, K.; Gkioxari, G.; Dollr, R.; Girshick, R. Mask R-CNN. International Conference on Computer Vision. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Volume 9351. [Google Scholar] [CrossRef]
- Peng, M.; Xia, J.; Peng, F. Efficient recognition of cotton and weed in field based on Faster R-CNN by integrating FPN. J. Agric. Eng. 2019, 35, 202–209. [Google Scholar] [CrossRef]
- Zhang, S.; Xu, X.; Qi, G.; Shao, Y. Detecting the pest disease of field crops using deformable VGG-16 model. J. Agric. Eng. 2021, 37, 188–194. [Google Scholar] [CrossRef]
- Long, J.; Zhao, C.; Lin, S.; Guo, W.; Wen, C.; Zhang, Y. Segmentation method of the tomato fruits with different maturities under greenhouse environment based on improved Mask R-CNN. J. Agric. Eng. 2021, 37, 100–108. [Google Scholar] [CrossRef]
- Gao, Z. Method for Kiwi Trunk Detection and Navigation Line Fitting Based on Deep Learning; Northwest Agriculture and Forestry University of Science and Technology: Xianyang, China, 2020. [Google Scholar] [CrossRef]
- Bell, J.; MacDonald, B.A.; Ahn, H.S. Row following in pergola structured orchards. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Korea, 9–14 October 2016; pp. 640–645. [Google Scholar] [CrossRef]
- André, S.; Filipe, B.; Luís, C.; Vitor, M.; Armando, J. Vineyard trunk detection using deep learning—An experimental device benchmark. Comput. Electron. Agric. 2020, 175, 105535. [Google Scholar] [CrossRef]
- Tan, C.; Li, C.; He, D.; Song, H. Towards real-time tracking and counting of seedlings with a one-stage detector and optical flow. Comput. Electron. Agric. 2022, 193, 106683. [Google Scholar] [CrossRef]
- Lac, L.; Da, C.J.; Donias, M.; Keresztes, B.; Bardet, A. Crop stem detection and tracking for precision hoeing using deep learning. Comput. Electron. Agric. 2022, 192, 106606. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CA Module | Ghost Module | Inverse Perspective Transformation | mAP/% | Average Detection Time/ms |
|---|---|---|---|---|
| 91.2 | 21 | |||
| √ | 95.9 | 25 | ||
| √ | 89.4 | 15 | ||
| √ | 92.3 | 17 | ||
| √ | √ | √ | 96.2 | 18 |
| Object Detection Network | Map/% | Average Detection Time/ms |
|---|---|---|
| Faster-RCNN | 82.7 | 43 |
| YOLOv5s | 91.2 | 21 |
| YOLOv3 | 87.9 | 36 |
| YOLOX-s | 88.6 | 32 |
| YOLOv7 | 94.6 | 26 |
| Improved YOLOv5s | 96.2 | 18 |
| Image Type | Accuracy/% | Average Processing Time/ms |
|---|---|---|
| direct seeding strip sowing method | 96 | 86 |
| direct seeding hole sowing method | 97 | 47 |
| seedling transplanting method without weeds | 99 | 31 |
| seedling transplanting method with weeds | 99 | 39 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Zhu, Y.; Li, S.; Liu, P. The Extraction Method of Navigation Line for Cuttage and Film Covering Multi-Functional Machine for Low Tunnels. Inventions 2022, 7, 113. https://doi.org/10.3390/inventions7040113
Li Y, Zhu Y, Li S, Liu P. The Extraction Method of Navigation Line for Cuttage and Film Covering Multi-Functional Machine for Low Tunnels. Inventions. 2022; 7(4):113. https://doi.org/10.3390/inventions7040113
Chicago/Turabian StyleLi, Yumeng, Yanjun Zhu, Shuangshuang Li, and Ping Liu. 2022. "The Extraction Method of Navigation Line for Cuttage and Film Covering Multi-Functional Machine for Low Tunnels" Inventions 7, no. 4: 113. https://doi.org/10.3390/inventions7040113
APA StyleLi, Y., Zhu, Y., Li, S., & Liu, P. (2022). The Extraction Method of Navigation Line for Cuttage and Film Covering Multi-Functional Machine for Low Tunnels. Inventions, 7(4), 113. https://doi.org/10.3390/inventions7040113