Principal Component Neural Networks for Modeling, Prediction, and Optimization of Hot Mix Asphalt Dynamics Modulus


Abstract
:
1. Introduction
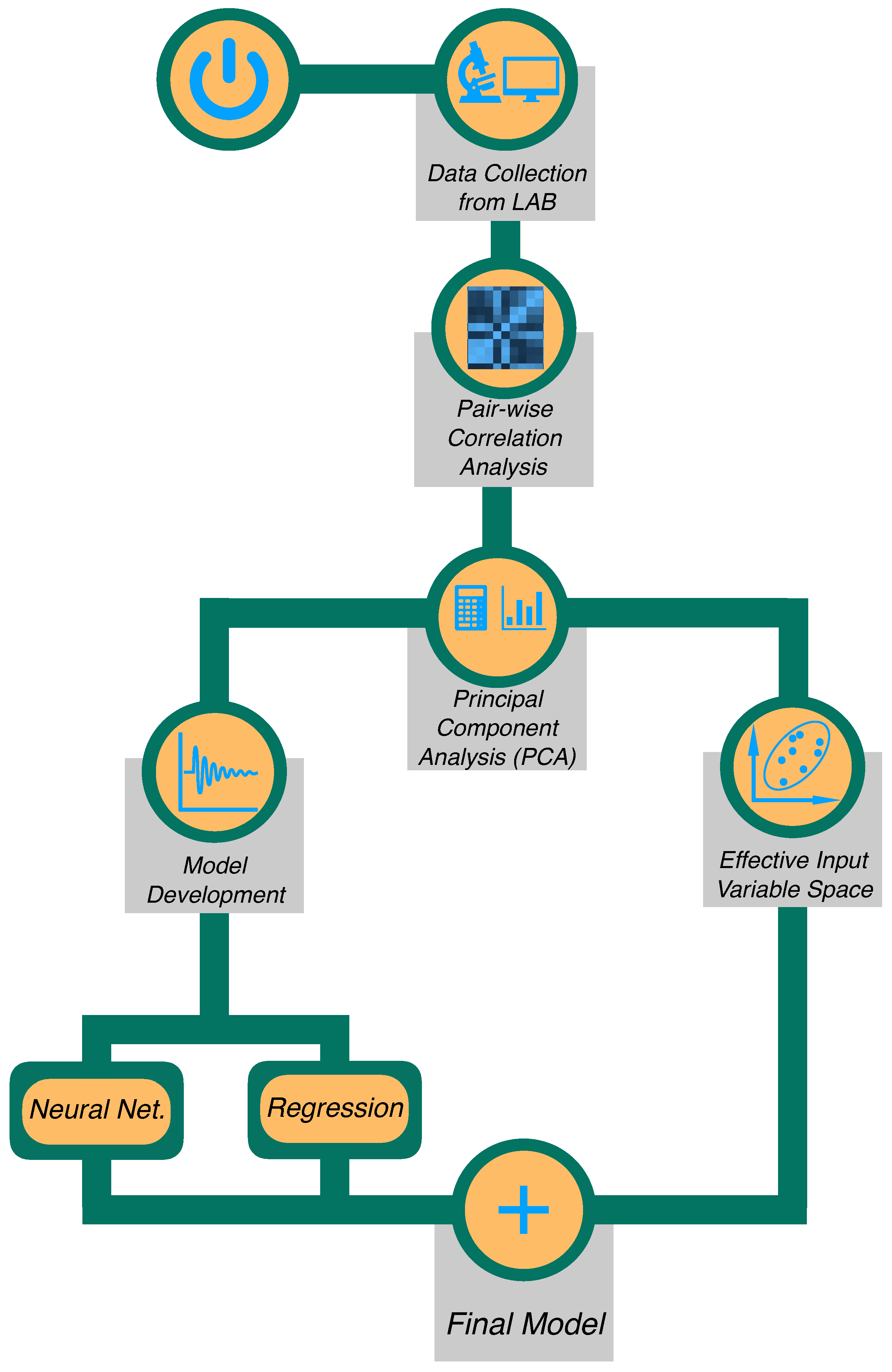
2. Material and Methodology
2.1. Preliminary Processing Step: Input Variable Selection
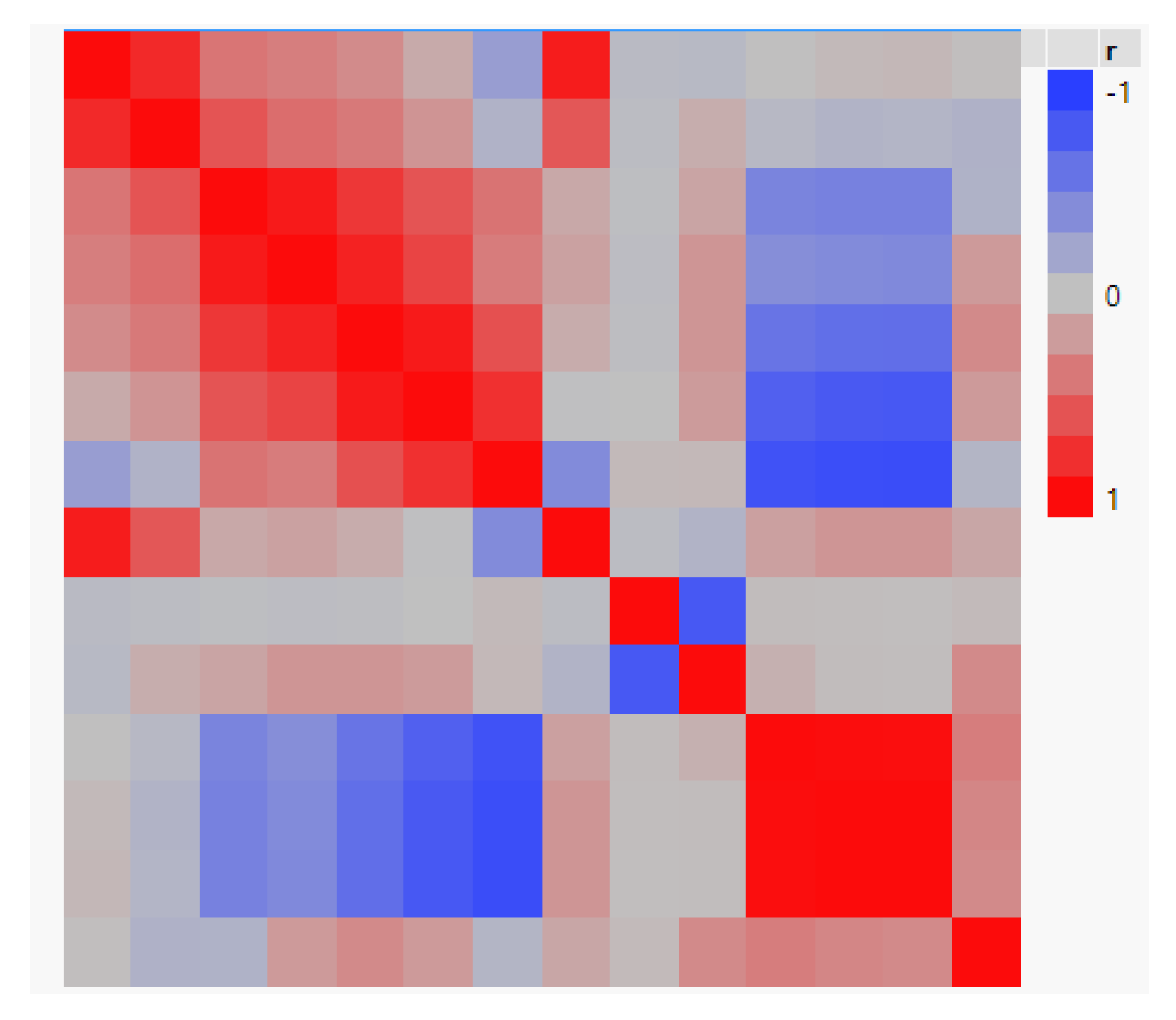
2.2. Orthogonal Transformation Using PCA
2.3. Holdout Cross Validation
2.4. Principal Component Regression (PCR)
2.5. Principal Component Neural Network (PCNN)
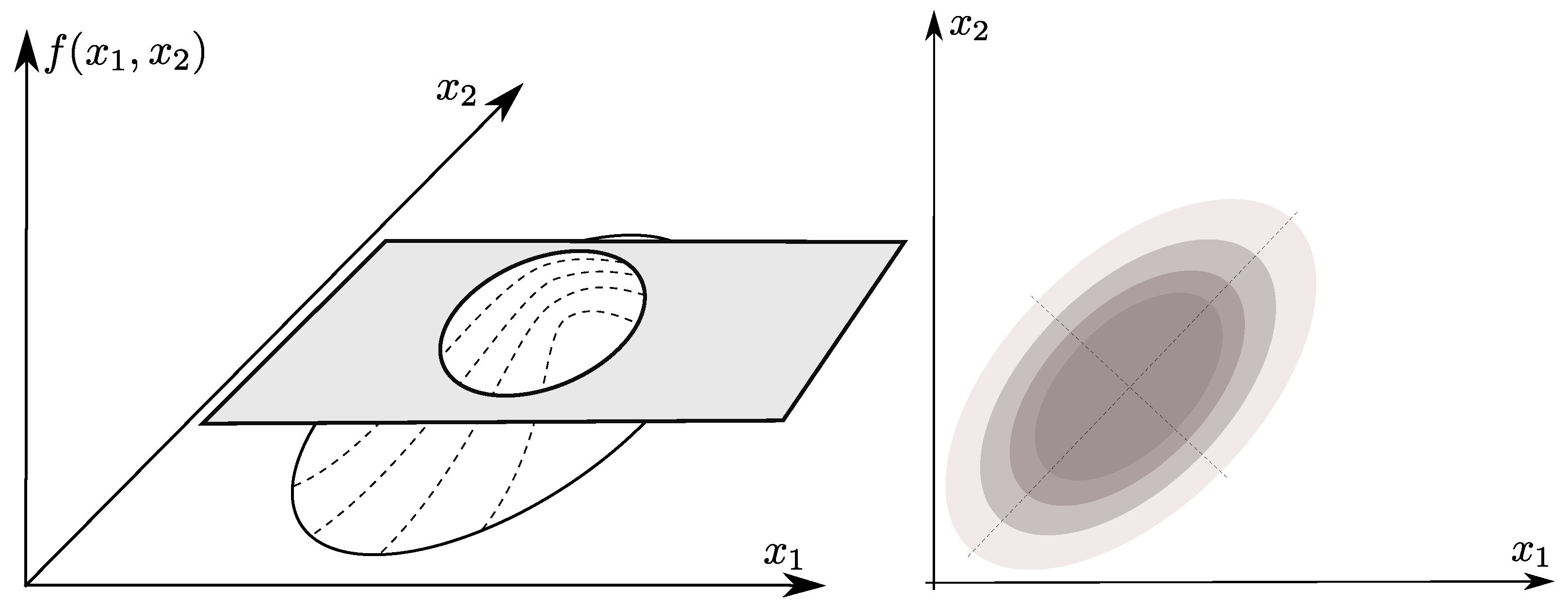
2.6. Effective Variable Space
2.7. Guideline for Implementation
3. Developed Model Results, Performance, and Validation
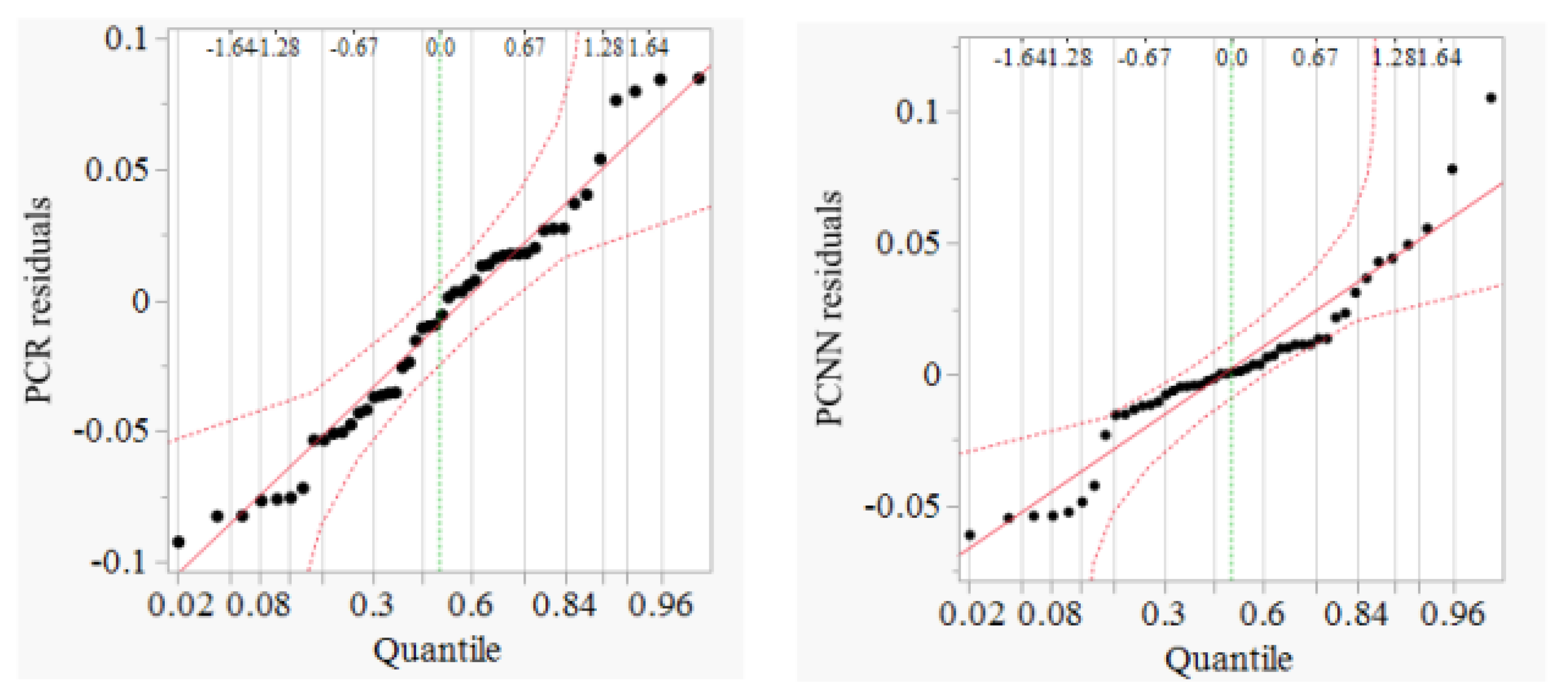
3.1. Model Performance
3.2. Receiver Operating Characteristic Analysis (ROC)
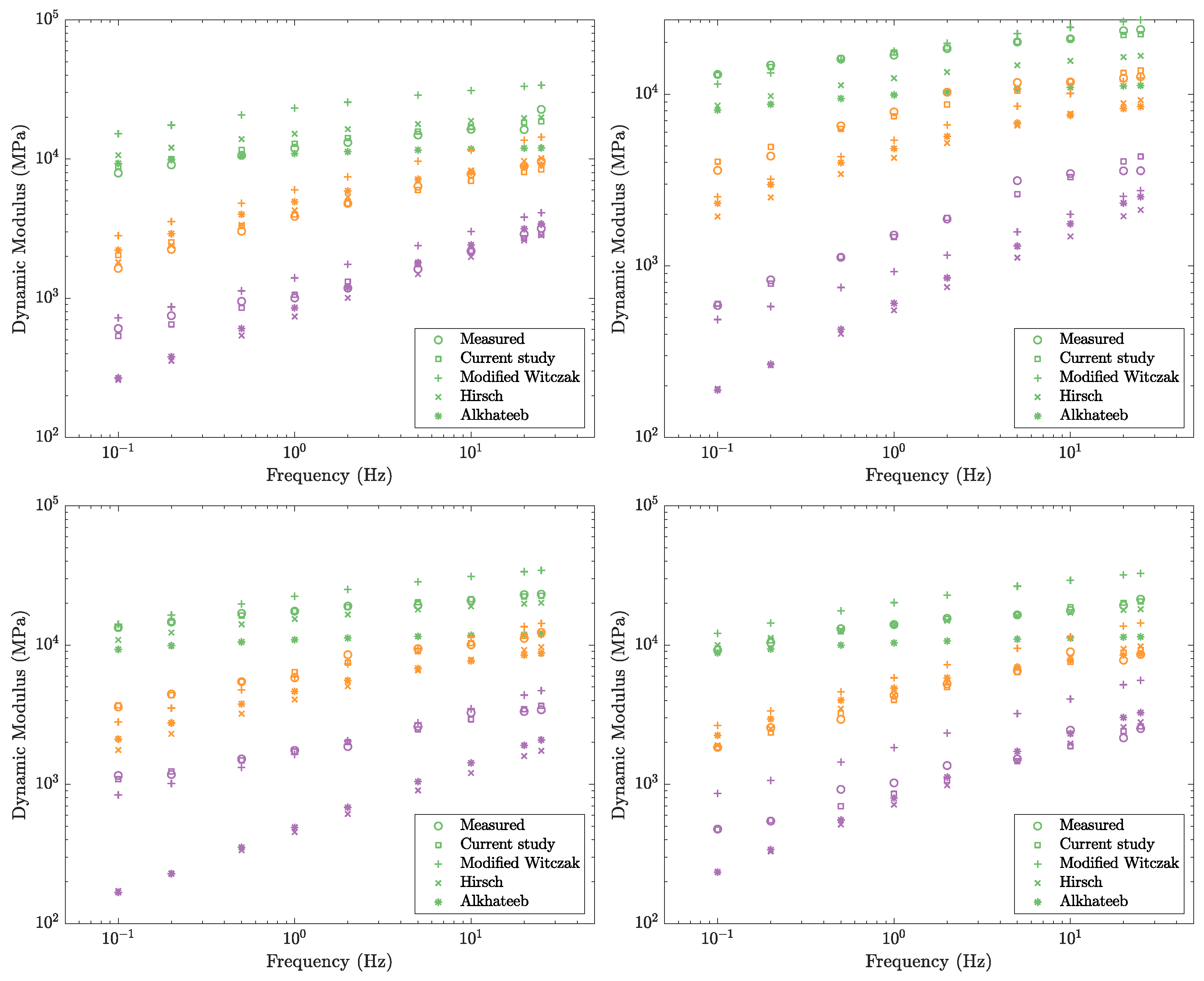
3.3. Model Validation
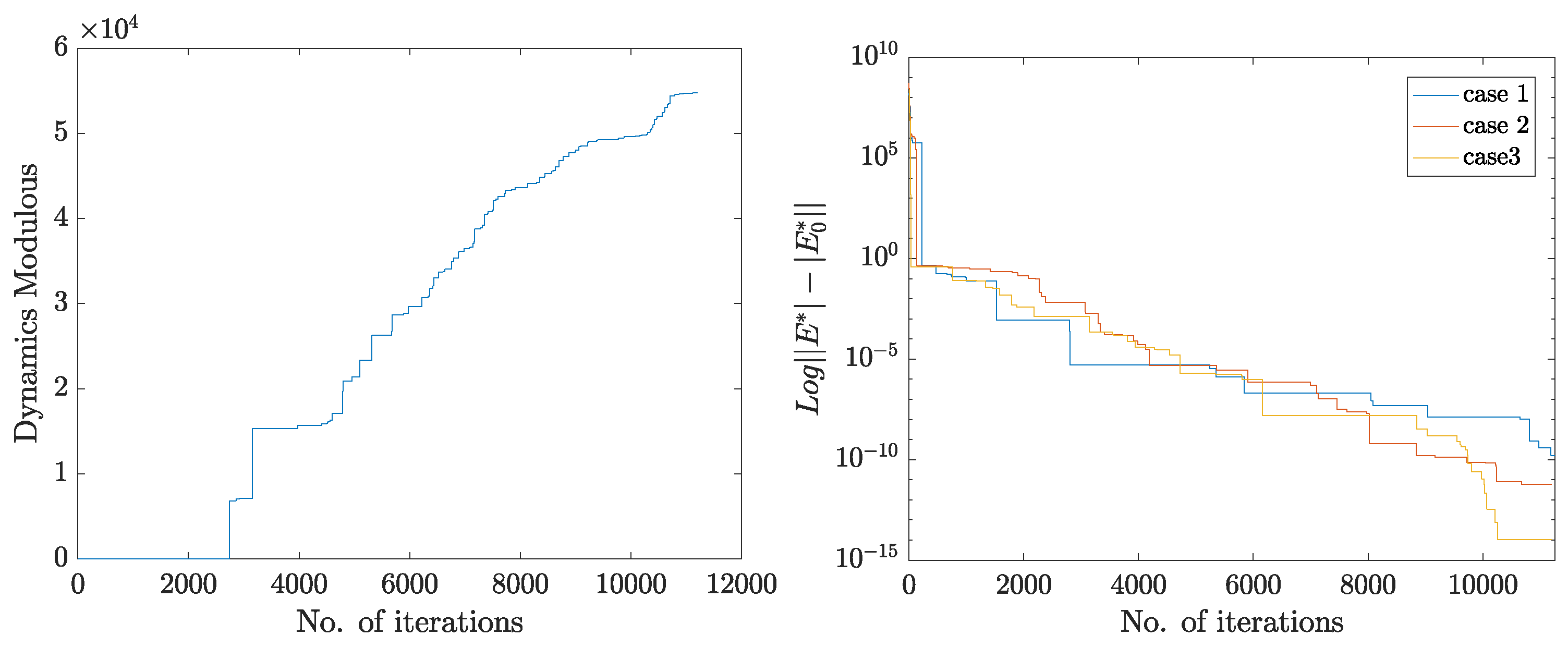
4. Application of the Framework: Flexible Pavement Design and Optimization
- what design parameters result in the maximum ?
- what design parameters result in a pre-specified ?
- traffic loading < 0.3 → 70 < VFA < 80
- 0.3 < traffic loading < 3.0 → 65 < VFA < 78
- traffic loading > 3.0 → 65 < VFA < 75
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Ghasemi, P. Performance Evaluation of Coarse-Graded Field Mixtures Using Dynamic Modulus Results Gained from Testing in Indirect Tension Mode of Testing. Graduate Theses and Dissertations 16717. Available online: https://lib.dr.iastate.edu/etd/16717 (accessed on 1 August 2019).
- Birgisson, B.; Roque, R.; Kim, J.; Pham, L.V. The Use of Complex Modulus to Characterize the Performance of Asphalt Mixtures and Pavements in Florida; Technical Report; Florida Department of Transportation: Tallahassee, FL, USA, 2004.
- Arabali, P.; Sakhaeifar, M.S.; Freeman, T.J.; Wilson, B.T.; Borowiec, J.D. Decision-making guideline for preservation of flexible pavements in general aviation airport management. J. Transp. Eng. Part B Pavements 2017, 143, 04017006. [Google Scholar] [CrossRef]
- Bozorgzad, A.; Lee, H.D. Consistent distribution of air voids and asphalt and random orientation of aggregates by flipping specimens during gyratory compaction process. Constr. Build. Mater. 2017, 132, 376–382. [Google Scholar] [CrossRef]
- Guide, N.D. Guide 1-37A, Guide for Mechanistic-Empirical Design of New and Rehabilitated Pavement Structures, National Cooperative Highway Research Program; Transportation Research Board, National Research Council: Washington, DC, USA, 2004. [Google Scholar]
- AASHTO, A. Mechanistic-Empirical Pavement Design Guide: A Manual of Practice; AAoSHaT Officials (American Association of State Highway and Transportation Officials): Washington, DC, USA, 2008. [Google Scholar]
- Nobakht, M.; Sakhaeifar, M.S. Dynamic modulus and phase angle prediction of laboratory aged asphalt mixtures. Constr. Build. Mater. 2018, 190, 740–751. [Google Scholar] [CrossRef]
- Peng, C.; Feng, J.; Feiting, S.; Changjun, Z.; Decheng, F. Modified two-phase micromechanical model and generalized self-consistent model for predicting dynamic modulus of asphalt concrete. Constr. Build. Mater. 2019, 201, 33–41. [Google Scholar] [CrossRef]
- Shu, X.; Huang, B. Dynamic modulus prediction of HMA mixtures based on the viscoelastic micromechanical model. J. Mater. Civ. Eng. 2008, 20, 530–538. [Google Scholar] [CrossRef]
- Devore, J.L. Probability and Statistics for Engineering and the Sciences; Cengage Learning: Boston, MA, USA, 2011. [Google Scholar]
- El-Badawy, S.; Abd El-Hakim, R.; Awed, A. Comparing Artificial Neural Networks with Regression Models for Hot-Mix Asphalt Dynamic Modulus Prediction. J. Mater. Civ. Eng. 2018, 30, 04018128. [Google Scholar] [CrossRef]
- Andrei, D.; Witczak, M.; Mirza, M. Development of a revised predictive model for the dynamic (complex) modulus of asphalt mixtures. In Development of the 2002 Guide for the Design of New and Rehabilitated Pavement 451 Structures; NCHRP: Washington, DC, USA, 1999. [Google Scholar]
- Bari, J.; Witczak, M. New predictive models for viscosity and complex shear modulus of asphalt binders: For use with mechanistic-empirical pavement design guide. Transp. Res. Rec. J. Transp. Res. Board 2007, 2001, 9–19. [Google Scholar] [CrossRef]
- Christensen, D., Jr.; Pellinen, T.; Bonaquist, R. Hirsch model for estimating the modulus of asphalt concrete. J. Assoc. Asph. Paving Technol. 2003, 72, 97–121. [Google Scholar]
- Jamrah, A.; Kutay, M.E.; Ozturk, H.I. Characterization of Asphalt Materials Common to Michigan in Support of the Implementation of the Mechanistic-Empirical Pavement Design Guide; Technical Report; Transportation Research Board: Washington, DC, USA, 2014.
- Al-Khateeb, G.; Shenoy, A.; Gibson, N.; Harman, T. A new simplistic model for dynamic modulus predictions of asphalt paving mixtures. J. Assoc. Asph. Paving Technol. 2006, 75, 1254–1293. [Google Scholar]
- Sakhaeifar, M.S.; Richard Kim, Y.; Garcia Montano, B.E. Individual temperature based models for nondestructive evaluation of complex moduli in asphalt concrete. Constr. Build. Mater. 2017, 137, 117–127. [Google Scholar] [CrossRef]
- Ghasemi, P.; Aslani, M.; Rollins, D.K.; Williams, R.C.; Schaefer, V.R. Modeling rutting susceptibility of asphalt pavement using principal component pseudo inputs in regression and neural networks. Int. J. Pavement Res. Technol. 2018. [Google Scholar] [CrossRef]
- Ren, R.; Han, K.; Zhao, P.; Shi, J.; Zhao, L.; Gao, D.; Zhang, Z.; Yang, Z. Identification of asphalt fingerprints based on ATR-FTIR spectroscopy and principal component-linear discriminant analysis. Constr. Build. Mater. 2019, 198, 662–668. [Google Scholar] [CrossRef]
- Fodor, I.K. A Survey of Dimension Reduction Techniques; Technical Report; U.S. Department of Energy: Washington, DC, USA, 2002.
- Johnson, R.A.; Wichern, D.W. Applied Multivariate Statistical Analysis; Prentice-Hall: Upper Saddle River, NJ, USA, 2014; Volume 4. [Google Scholar]
- Ghasemi, P.; Aslani, M.; Rollins, D.K.; Williams, R. Principal component analysis-based predictive modeling and optimization of permanent deformation in asphalt pavement: Elimination of correlated inputs and extrapolation in modeling. Struct. Multidiscip. Optim. 2018, 59, 1335–1353. [Google Scholar] [CrossRef]
- Kim, Y.R.; Underwood, B.; Far, M.S.; Jackson, N.; Puccinelli, J. LTPP Computed Parameter: Dynamic Modulus; Technical Report; Federal Highway Administration Research and Technology: Washington, DC, USA, 2011.
- Sakhaeifar, M.S.; Richard Kim, Y.; Kabir, P. New predictive models for the dynamic modulus of hot mix asphalt. Constr. Build. Mater. 2015, 76, 221–231. [Google Scholar] [CrossRef]
- Rollins, D.K.; Zhai, D.; Joe, A.L.; Guidarelli, J.W.; Murarka, A.; Gonzalez, R. A novel data mining method to identify assay-specific signatures in functional genomic studies. BMC Bioinf. 2006, 7, 377. [Google Scholar] [CrossRef]
- Jolliffe, I.T. Principal Component Analysis, Second Edition. Encycl. Stat. Behav. Sci. 2002, 30, 487. [Google Scholar]
- Kuźniar, K.; Waszczyszyn, Z. Neural networks and principal component analysis for identification of building natural periods. J. Comput. Civ. Eng. 2006, 20, 431–436. [Google Scholar] [CrossRef]
- Hua, X.; Ni, Y.; Ko, J.; Wong, K. Modeling of temperature–frequency correlation using combined principal component analysis and support vector regression technique. J. Comput. Civ. Eng. 2007, 21, 122–135. [Google Scholar] [CrossRef]
- Kartam, N. Neural Netwroks in Civil Engineering: Systems and Application. J. Comput. Civ. Eng. 1994, 8, 149–162. [Google Scholar]
- Sanabria, N.; Valentin, V.; Bogus, S.; Zhang, G.; Kalhor, E. Comparing Neural Networks and Ordered Probit Models for Forecasting Pavement Condition in New Mexico; Technical Report; Transportation Research Board: Washington, DC, USA, 2017. [Google Scholar]
- Gong, H.; Sun, Y.; Mei, Z.; Huang, B. Improving accuracy of rutting prediction for mechanistic-empirical pavement design guide with deep neural networks. Constr. Build. Mater. 2018, 190, 710–718. [Google Scholar] [CrossRef]
- Cheng, B.; Titterington, D. Neural networks: A review from a statistical perspective. Stat. Sci. 1994, 9, 2–30. [Google Scholar] [CrossRef]
- Kutner, M.H.; Nachtsheim, C.; Neter, J. Applied Linear Regression Models; McGraw-Hill/Irwin: Chicago, IL, USA, 2004. [Google Scholar]
- Todd, M.J.; Yıldırım, E.A. On Khachiyan’s algorithm for the computation of minimum-volume enclosing ellipsoids. Discret. Appl. Math. 2007, 155, 1731–1744. [Google Scholar] [CrossRef]
- Fawcett, T. An introduction to ROC analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Bi, J.; Bennett, K.P. Regression error characteristic curves. In Proceedings of the 20th International Conference on Machine Learning (ICML-03), Washington, DC, USA, 21–24 August 2003; pp. 43–50. [Google Scholar]
- Marti-Vargas, J.R.; Ferri, F.J.; Yepes, V. Prediction of the transfer length of prestressing strands with neural networks. Comput. Concr. 2013, 12, 187–209. [Google Scholar] [CrossRef]
- Rahami, H.; Kaveh, A.; Aslani, M.; Asl, R.N. A hybrid modified genetic-nelder mead simplex algorithm for large-scale truss optimization. Int. J. Optim. Civ. Eng. 2011, 1, 29–46. [Google Scholar]
- He, J.; Yao, X. From an individual to a population: An analysis of the first hitting time of population-based evolutionary algorithms. IEEE Trans. Evol. Comput. 2002, 6, 495–511. [Google Scholar]
- Cai, Z.; Cai, Z.; Wang, Y. A Multiobjective Optimization-Based Evolutionary Algorithm for Constrained Optimization. IEEE Trans. Evol. Comput. 2006, 10, 658–675. [Google Scholar] [CrossRef]
- Rueda, J.L.; Erlich, I. Testing MVMO on learning-based real-parameter single objective benchmark optimization problems. In Proceedings of the 2015 IEEE Congress on Evolutionary Computation (CEC), Sendai, Japan, 25–28 May 2015; pp. 1025–1032. [Google Scholar]
- Erlich, I.; Venayagamoorthy, G.K.; Worawat, N. A mean-variance optimization algorithm. In Proceedings of the IEEE Congress on Evolutionary Computation, Barcelona, Spain, 18–23 July 2010; pp. 1–6. [Google Scholar]
- Aslani, M.; Ghasemi, P.; Gandomi, A.H. Constrained mean-variance mapping optimization for truss optimization problems. Struct. Des. Tall Spec. Build. 2018, 27, e1449. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Mix 1 | Mix 2 | Mix 3 | Mix 4 | Mix 5 | Mix 6 | Mix 7 | Mix 8 | Mix 9 | |
|---|---|---|---|---|---|---|---|---|---|
| Binder performance grade | 58–28 | 58–28 | 58–28 | 58–34 | 58–34 | 58–34 | 64–28 | 64–34 | 64–28 |
| % V | 4.20 | 4.10 | 4.10 | 3.90 | 3.50 | 4.30 | 4.20 | 4.00 | 4.60 |
| %VMA | 13.50 | 13.50 | 13.60 | 13.10 | 12.50 | 13.90 | 13.70 | 13.40 | 14.40 |
| % VFA | 70.30 | 70.40 | 70.60 | 69.60 | 68.10 | 71.20 | 70.80 | 70.20 | 72.30 |
| 2.32 | 2.31 | 2.31 | 2.32 | 2.31 | 2.32 | 2.31 | 2.32 | 2.31 | |
| 2.41 | 2.46 | 2.51 | 2.48 | 2.64 | 2.46 | 2.48 | 2.51 | 2.44 | |
| % | 4.01 | 3.99 | 3.99 | 3.98 | 3.98 | 4.03 | 4 | 3.99 | 3.98 |
| % passing 3/4 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 |
| % passing 1/2 | 93.90 | 96.40 | 87.20 | 93.50 | 95.10 | 96.40 | 94.10 | 94.40 | 94.20 |
| % passing 3/8 | 77.50 | 84.60 | 73.70 | 76.40 | 83.10 | 87.30 | 83.40 | 82.00 | 80.90 |
| % passing #4 | 49.80 | 53.10 | 48.40 | 52.20 | 52.20 | 60.90 | 63.80 | 48.20 | 58.60 |
| % passing #8 | 34.40 | 38.40 | 35.10 | 43.60 | 38.80 | 46.90 | 47.10 | 34.90 | 46.00 |
| % passing #30 | 16.70 | 18.70 | 17.90 | 20.90 | 18.80 | 23.40 | 21.70 | 19.20 | 25.90 |
| % passing #50 | 10.30 | 10.80 | 10.90 | 11.40 | 9.90 | 12.40 | 11.90 | 11.80 | 13.80 |
| % passing #100 | 6.10 | 5.90 | 6.40 | 5.80 | 5.40 | 6.10 | 6.60 | 6.10 | 7.20 |
| % passing #200 | 3.60 | 3.30 | 6.20 | 3.30 | 3.50 | 3.40 | 4.00 | 3.10 | 4.00 |
| Variable | Identity | Min. | Max. | Ave. | Std. Dev. |
|---|---|---|---|---|---|
| y | 2.62 | 4.37 | 3.76 | 0.46 | |
| Cum. % retained on 3/4 | 3.60 | 13.00 | 6.11 | 2.63 | |
| Cum. % retained on 3/8 | 12.68 | 26.29 | 19.01 | 4.11 | |
| Cum. % retained on #4 | 36.20 | 51.76 | 45.86 | 5.319 | |
| Cum. % retained on #8 | 52.87 | 65.70 | 59.42 | 5.06 | |
| Cum. % retained on #30 | 74.06 | 83.30 | 79.63 | 2.76 | |
| Cum. % retained on #50 | 86.22 | 90.12 | 88.57 | 1.15 | |
| Cum. % retained on #100 | 92.81 | 94.59 | 93.83 | 0.48 | |
| % Passing from #200 | 3.07 | 6.18 | 3.81 | 0.89 | |
| −2.29 | 3.03 | 0.50 | 1.26 | ||
| Phase angle (degree) | 28.15 | 79.17 | 52.86 | 11.54 | |
| % | 3.50 | 4.60 | 4.10 | 0.29 | |
| %VMA | 12.50 | 14.40 | 13.51 | 0.49 | |
| %VFA | 68.10 | 72.30 | 70.40 | 1.08 | |
| % | 3.98 | 4.01 | 3.99 | 0.01 |
| 1 | 0.832 | 0.412 | 0.366 | 0.294 | 0.119 | −0.269 | 0.905 | −0.044 | −0.058 | 0.003 | 0.04 | 0.049 | 0.013 | |
| 0.832 | 1 | 0.597 | 0.458 | 0.391 | 0.246 | −0.109 | >0.583 | −0.035 | 0.106 | −0.061 | −0.099 | −0.089 | −0.115 | |
| 0.412 | 0.597 | 1 | 0.918 | 0.756 | 0.596 | 0.425 | 0.133 | −0.019 | 0.154 | −0.465 | −0.485 | −0.49 | −0.111 | |
| 0.366 | 0.458 | 0.918 | 1 | 0.87 | 0.687 | 0.375 | 0.169 | −0.028 | 0.237 | −0.388 | −0.412 | −0.424 | 0.212 | |
| 0.294 | 0.391 | 0.756 | 0.87 | 1 | 0.919 | 0.618 | 0.112 | −0.021 | 0.235 | −0.585 | −0.631 | −0.633 | 0.3 | |
| 0.119 | 0.246 | 0.596 | 0.687 | 0.919 | 1 | 0.794 | −0.009 | 0.003 | 0.203 | −0.741 | −0.796 | −0.806 | 0.209 | |
| −0.269 | −0.109 | 0.425 | 0.375 | 0.618 | 0.794 | 1 | −0.414 | 0.036 | 0.047 | −0.854 | −0.886 | −0.892 | −0.087 | |
| 0.905 | 0.583 | 0.133 | 0.169 | 0.112 | −0.009 | −0.414 | 1 | −0.032 | −0.102 | 0.179 | 0.238 | 0.238 | 0.142 | |
| −0.044 | −0.035 | −0.019 | −0.028 | −0.021 | −0.003 | 0.036 | −0.032 | 1 | −0.808 | 0.021 | 0.016 | 0.013 | 0.034 | |
| −0.058 | 0.106 | 0.154 | 0.237 | 0.235 | 0.203 | 0.047 | −0.102 | −0.808 | 1 | 0.09 | 0.024 | 0.014 | 0.3 | |
| 0.003 | −0.061 | −0.465 | −0.388 | −0.585 | −0.741 | −0.854 | 0.179 | 0.021 | 0.09 | 1 | 0.988 | 0.985 | 0.372 | |
| 0.04 | −0.099 | −0.485 | −0.412 | −0.631 | −0.796 | −0.886 | 0.238 | 0.016 | 0.024 | 0.988 | 1 | 0.998 | 0.321 | |
| 0.049 | −0.089 | −0.49 | −0.424 | −0.633 | −0.806 | −0.892 | 0.238 | 0.013 | 0.014 | 0.985 | 0.998 | 1 | 0.301 | |
| 0.013 | −0.115 | −0.111 | 0.212 | 0.3 | 0.209 | −0.087 | 0.142 | 0.034 | 0.3 | 0.372 | 0.321 | 0.301 | 1 |
| Number | Eigenvalue | Percent Variation | Cumulative Percent Variation |
|---|---|---|---|
| 1 | 6.0225 | 43.018 | 43.018 |
| 2 | 3.2193 | 22.995 | 66.013 |
| 3 | 1.9746 | 14.104 | 80.118 |
| 4 | 1.4174 | 10.124 | 90.242 |
| 5 | 0.7850 | 5.607 | 95.848 |
| 6 | 0.3176 | 2.269 | 98.117 |
| 7 | 0.1091 | 0.779 | 98.896 |
| 8 | 0.0778 | 0.556 | 99.452 |
| 9 | 0.0549 | 0.392 | 99.844 |
| 10 | 0.0218 | 0.156 | 100 |
| Statistical Component | Formula | Definition |
|---|---|---|
| Average difference (AD) | An estimate of systematic model bias | |
| Average absolute difference (AAD) | Average closeness of the fitted and measured values of response | |
| Correlation of the measured and fitted values of response | ||
| Coefficient of determination () | Portion of the response variation elucidated by regressors in the fitted model in linear models |
| Average Difference (MPa) | Average Absolute Difference (MPa) | ||||
|---|---|---|---|---|---|
| PCR | Training | 3.9 | 575.3 | 0.996 | 0.99 |
| Testing | −162.3 | 718.9 | 0.995 | na | |
| PCNN | Training | 13.2 | 380.7 | 0.997 | na |
| Testing | 9.7 | 337.5 | 0.997 | na | |
| Modified Witczak | −2460 | 3152.1 | 0.93 | 0.88 | |
| Hirsch | 1241.6 | 1785.7 | 0.95 | 0.91 | |
| Alkhateeb | 2844.5 | 2984.5 | 0.95 | 0.90 | |
| Identity | Optimal Design 1 | Optimal Design 2 | Design 1 | Design 2 | Design 3 | Design Specification | |||
|---|---|---|---|---|---|---|---|---|---|
| Control Points | Restricted Zone | ||||||||
| Lower | Upper | Lower | Upper | ||||||
| %Passing from 3/4 | 100 | 100 | 100 | 100 | 100 | - | 100 | - | - |
| %Passing from 1/2 | 93.38 | 94.03 | 92.25 | 91.88 | 91.80 | 90 | 100 | - | - |
| %Passing from 3/8 | 81.74 | 81.72 | 79.57 | 79.92 | 80.70 | - | 90 | - | - |
| %Passing from #4 | 53.00 | 53.90 | 55.36 | 55.23 | 54.39 | - | - | - | - |
| %Passing from #8 | 39.56 | 40.51 | 41.37 | 41.08 | 40.92 | 28 | 58 | 39.1 | 39.1 |
| %Passing from #30 | 20.75 | 20.68 | 21.02 | 20.87 | 20.83 | - | - | 19.1 | 23.1 |
| %Passing from #50 | 11.66 | 11.60 | 12.08 | 11.81 | 12.02 | - | - | 15.5 | 15.5 |
| %Passing from #100 | 6.22 | 6.21 | 6.52 | 6.38 | 6.40 | - | - | - | - |
| %Passing from #200 | 4.10 | 3.85 | 4.38 | 4.58 | 4.56 | 2 | 10 | - | - |
| G* (Mpa) | 103.13 | 7.81 | 133.51 | 30.20 | 11.82 | - | - | - | - |
| Phase angle (degree) | 35.71 | 39.60 | 47.69 | 47.27 | 44.77 | 2 | 8 | - | - |
| Vbeff% | 4.11 | 4.18 | 4.02 | 4.06 | 4.05 | - | - | - | - |
| VMA | 13.47 | 13.56 | 13.41 | 13.45 | 13.44 | - | - | - | - |
| VFA | 70.29 | 70.50 | 70.11 | 70.24 | 70.24 | - | - | - | - |
| Va% | 4.00 | 4.00 | 3.99 | 4.00 | 4.01 | 4 | - | - | |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ghasemi, P.; Aslani, M.; Rollins, D.K.; Williams, R.C. Principal Component Neural Networks for Modeling, Prediction, and Optimization of Hot Mix Asphalt Dynamics Modulus. Infrastructures 2019, 4, 53. https://doi.org/10.3390/infrastructures4030053
Ghasemi P, Aslani M, Rollins DK, Williams RC. Principal Component Neural Networks for Modeling, Prediction, and Optimization of Hot Mix Asphalt Dynamics Modulus. Infrastructures. 2019; 4(3):53. https://doi.org/10.3390/infrastructures4030053
Chicago/Turabian StyleGhasemi, Parnian, Mohamad Aslani, Derrick K. Rollins, and R. Christopher Williams. 2019. "Principal Component Neural Networks for Modeling, Prediction, and Optimization of Hot Mix Asphalt Dynamics Modulus" Infrastructures 4, no. 3: 53. https://doi.org/10.3390/infrastructures4030053
APA StyleGhasemi, P., Aslani, M., Rollins, D. K., & Williams, R. C. (2019). Principal Component Neural Networks for Modeling, Prediction, and Optimization of Hot Mix Asphalt Dynamics Modulus. Infrastructures, 4(3), 53. https://doi.org/10.3390/infrastructures4030053