
Fusion of Moment Invariant Method and Deep Learning Algorithm for COVID-19 Classification

 , ,
, ,
Abstract
:1. Introduction
- A fusion of DL-based features and MI-based features is employed into a neural network-based framework for a more reliable and faster screening of COVID-19 patients using CT scans.
- An extensive experimental analysis is presented to validate the effectiveness and efficiency of the MI-based COVID-19 detection algorithm. By incorporating the MI method in the feature extraction, the proposed framework can attain the best accuracy of 93% with high sensitivity (90%) and specificity (96%).
2. Related Works
2.1. Deep Learning Approaches for COVID-19 Detection
2.2. Application of Moment Invariant in Image-Based Classification
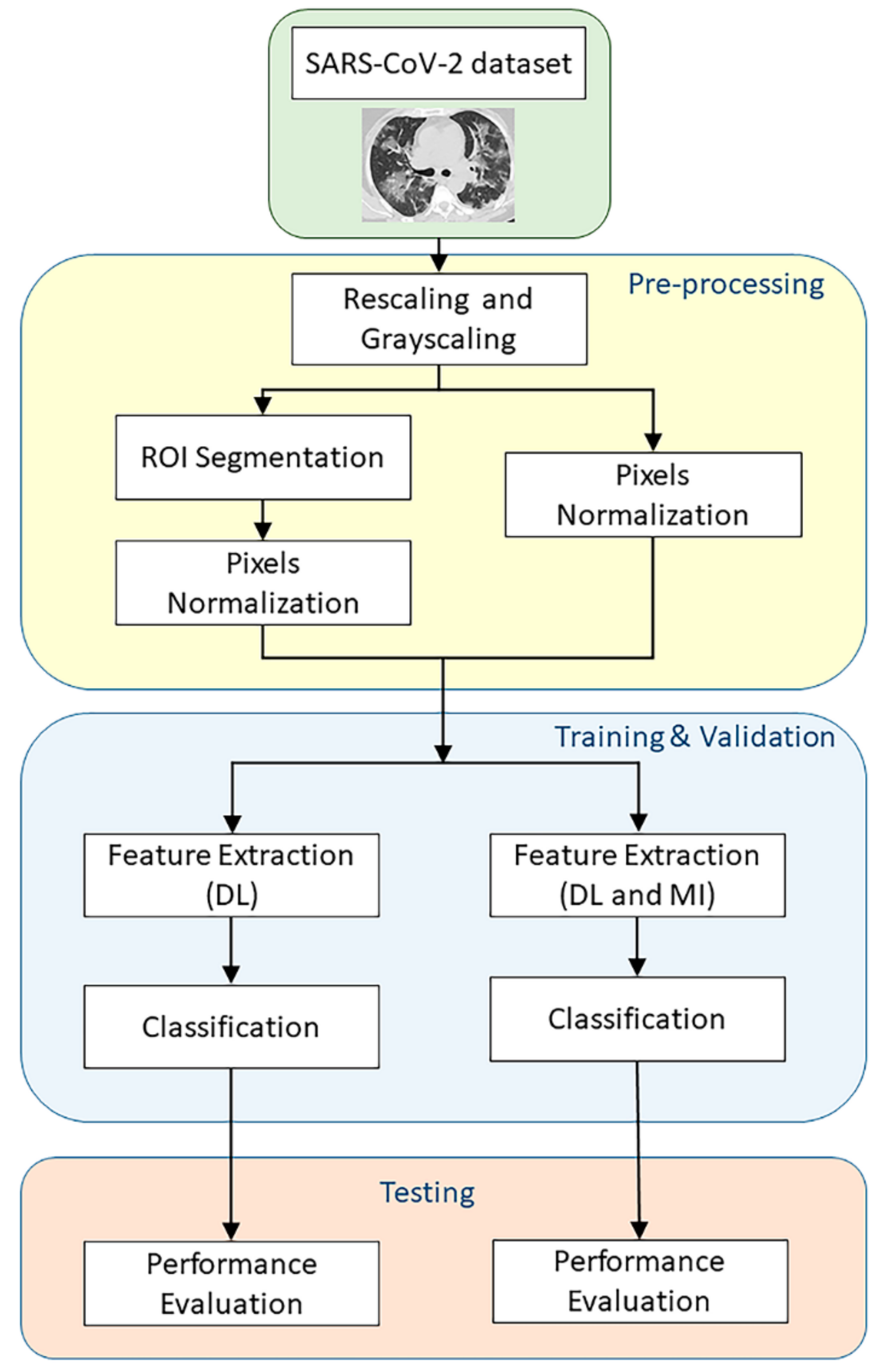
3. Proposed Method
3.1. DL Features Extraction
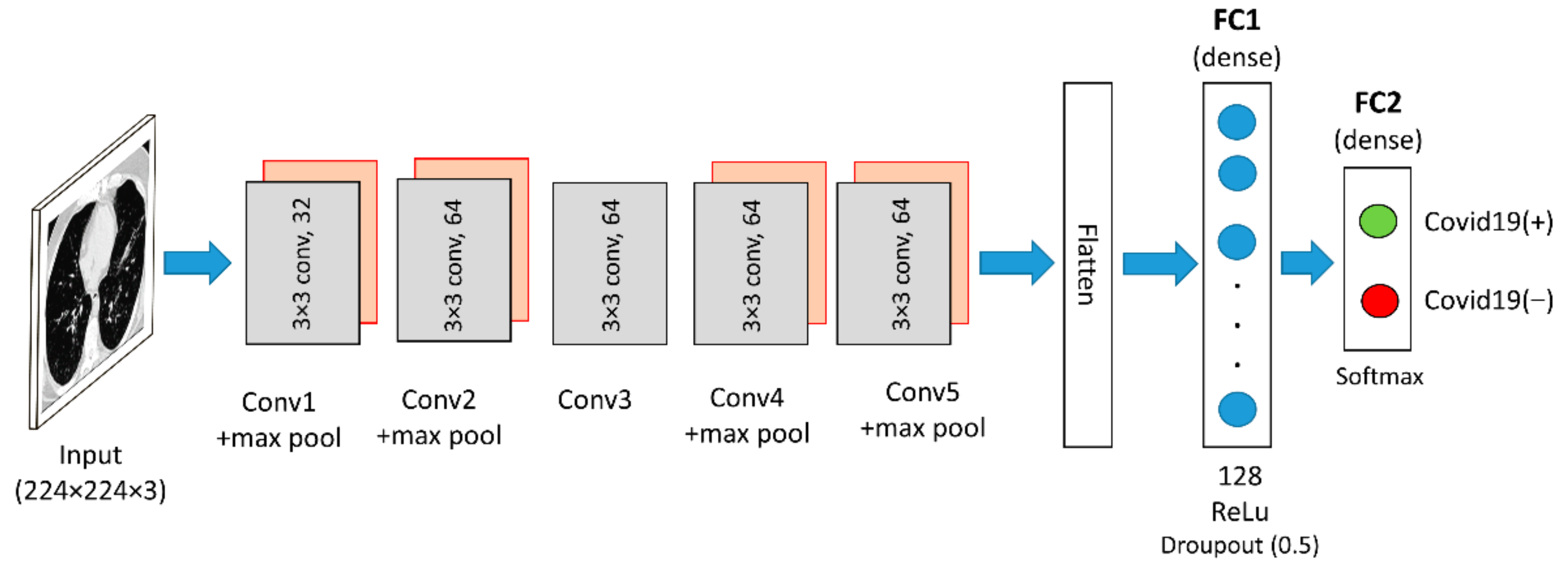
3.1.1. Pre-Trained Model (VGG16)
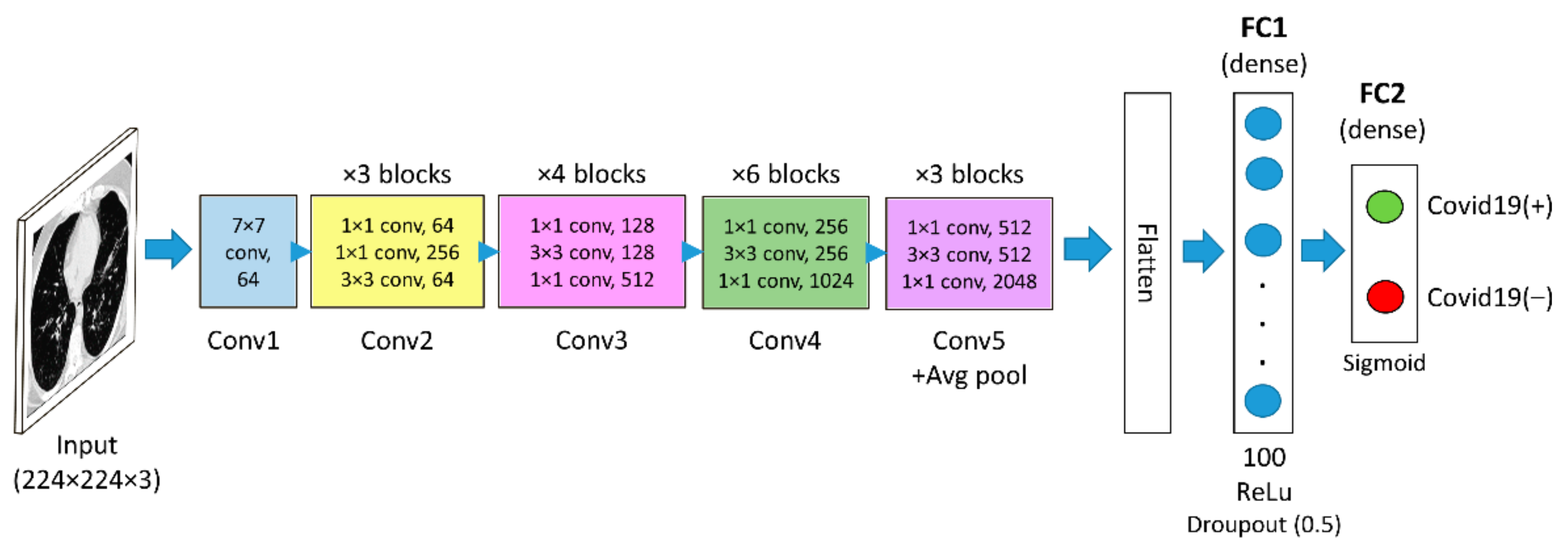
3.1.2. Pre-Trained Model (ResNet50)
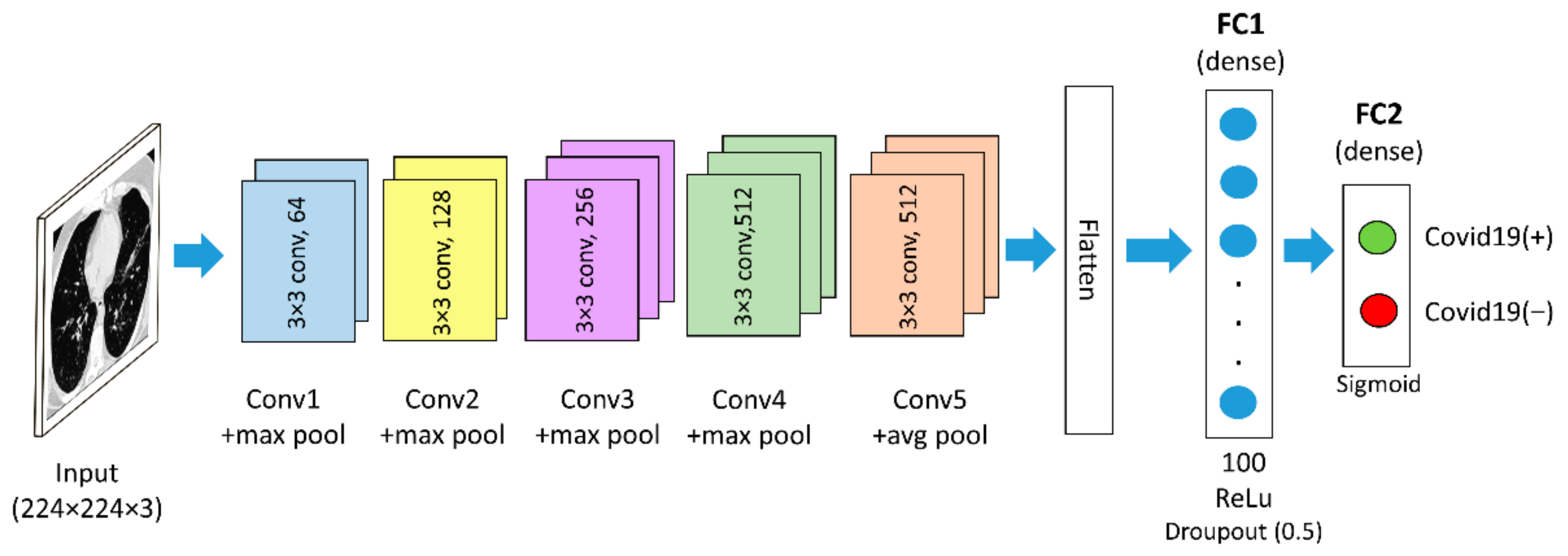
3.1.3. Custom CNN
3.2. Hu Invariant Moment
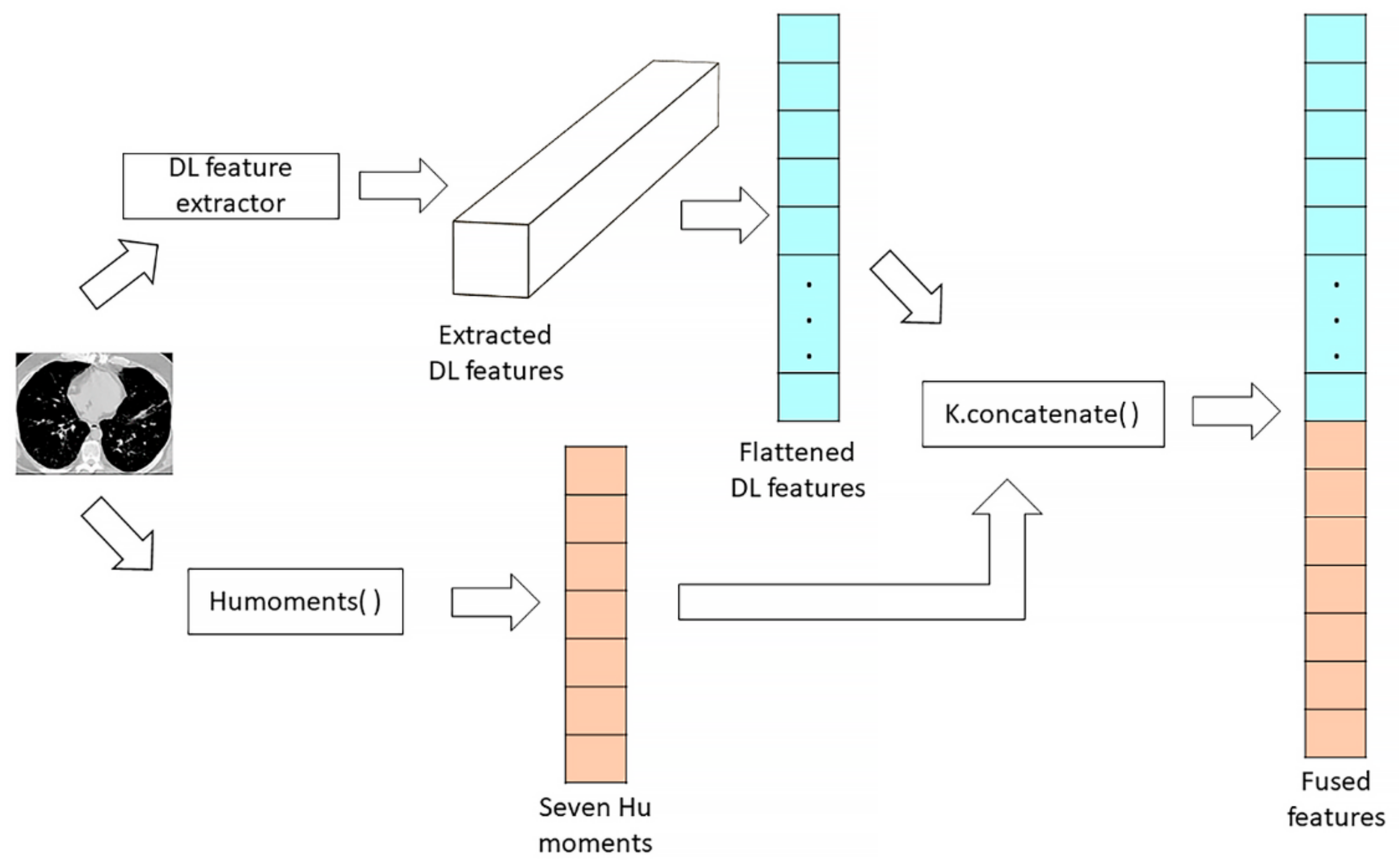
3.3. Features Concatenation
3.4. Classification Phase
4. Dataset
5. Experiments
6. Results and Discussion
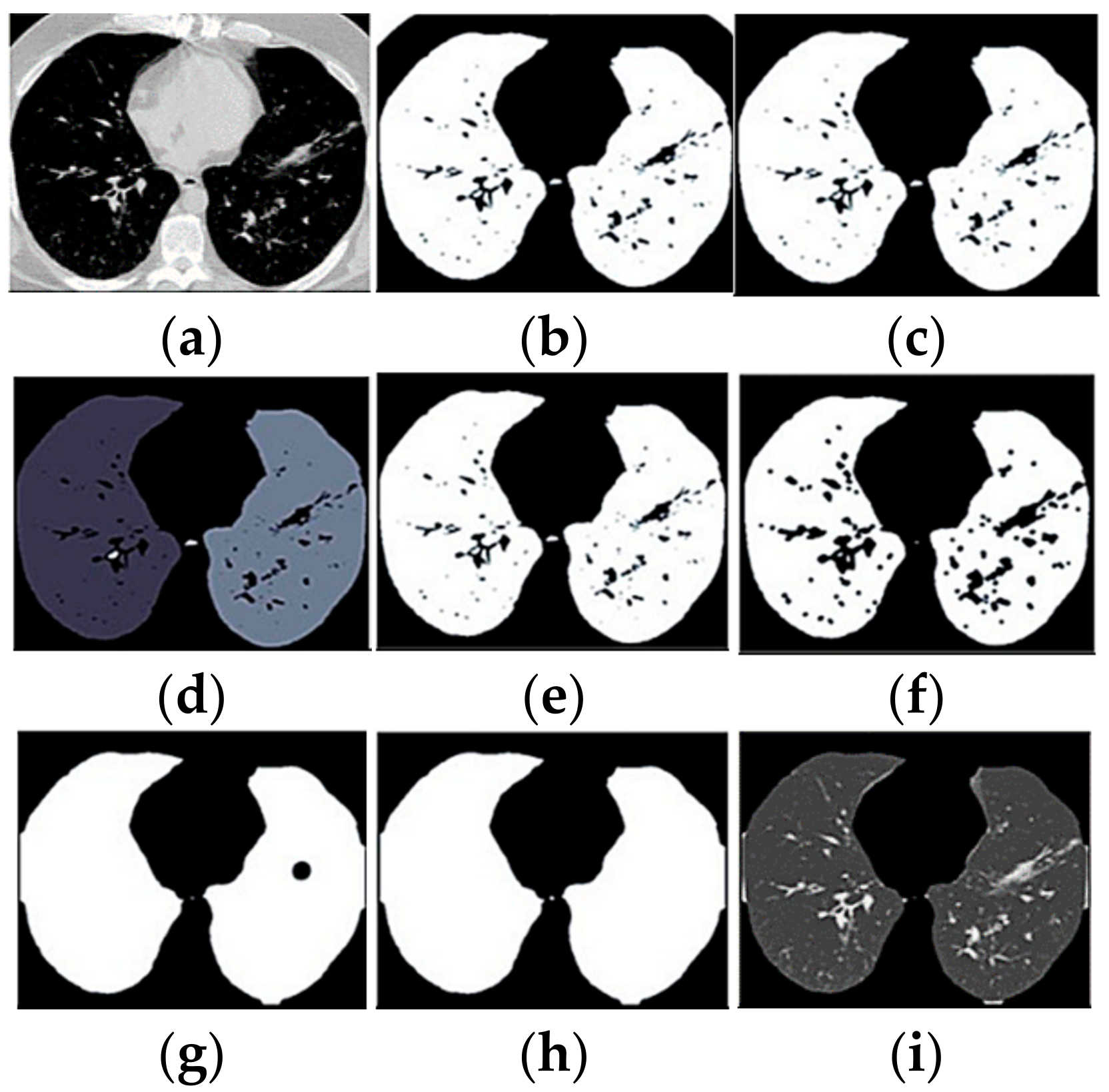
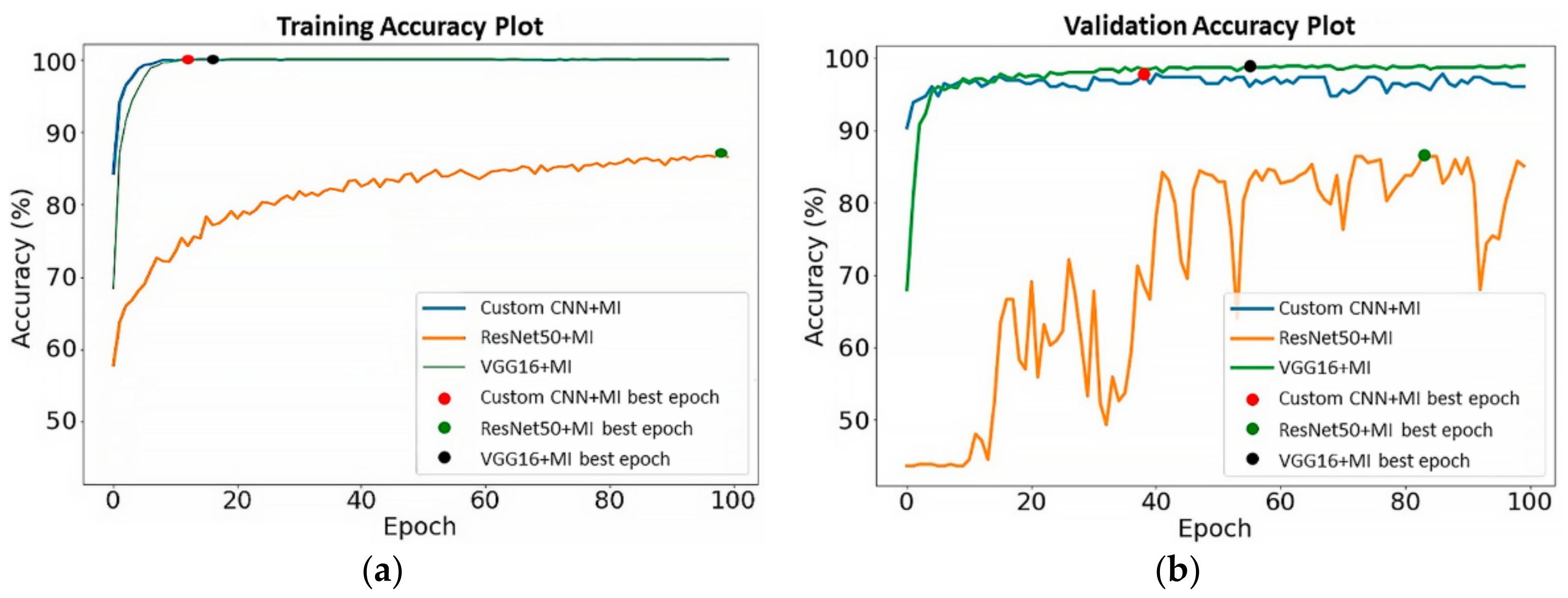
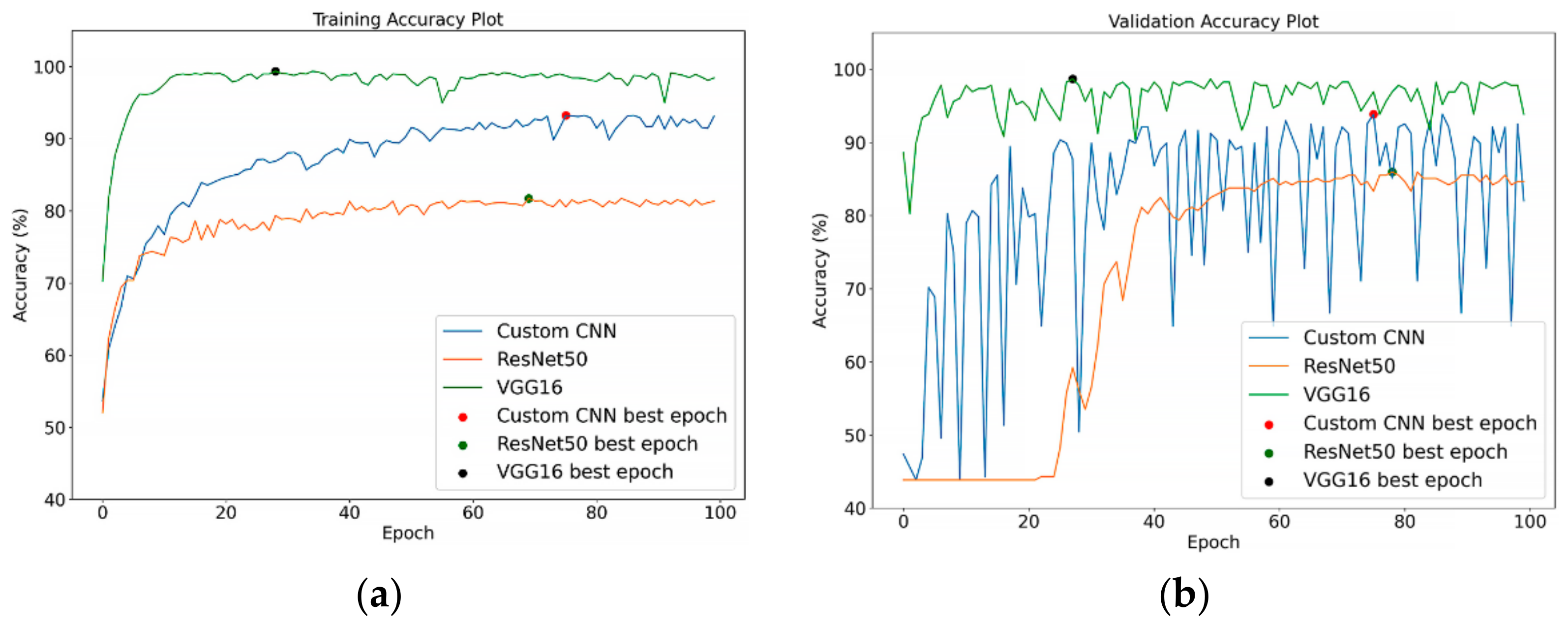
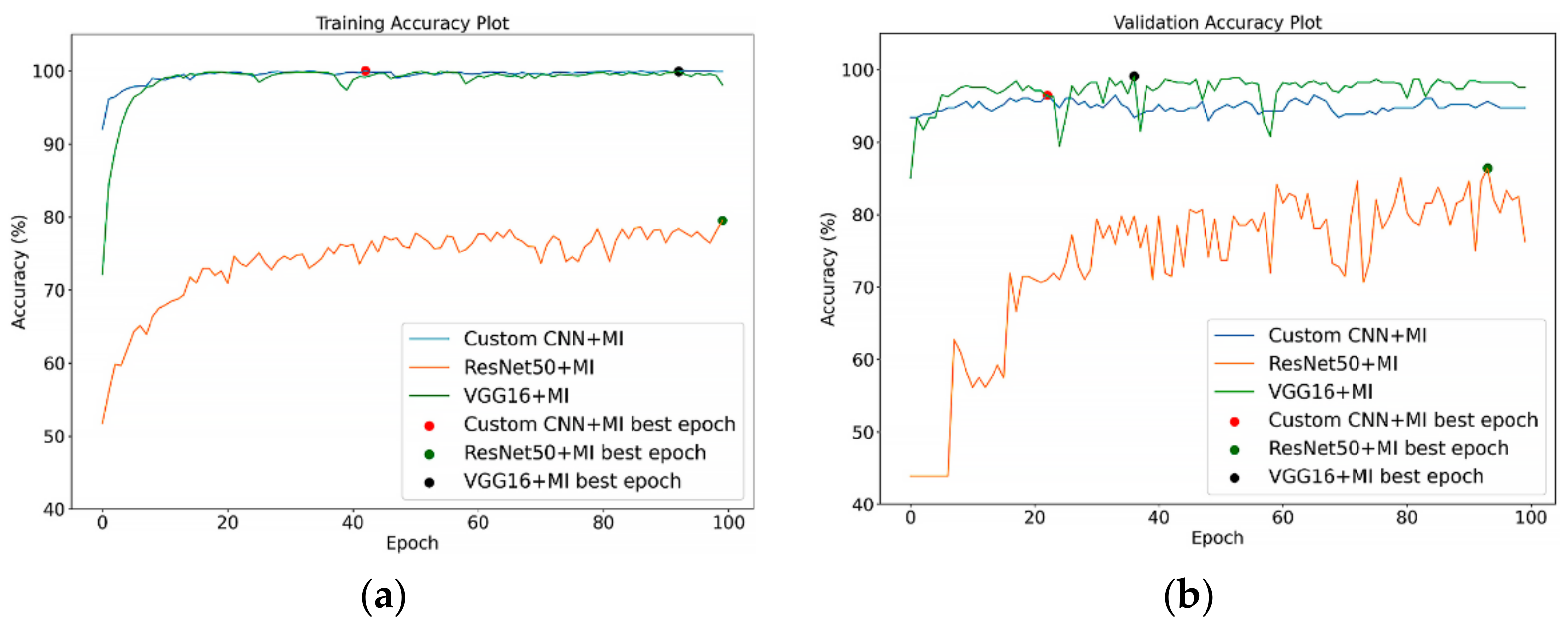
6.1. Models’ Performance on Unsegmented CT Images
6.2. Models’ Performance on Segmented CT Images
6.3. Models’ Performance Report with Confidence Intervals
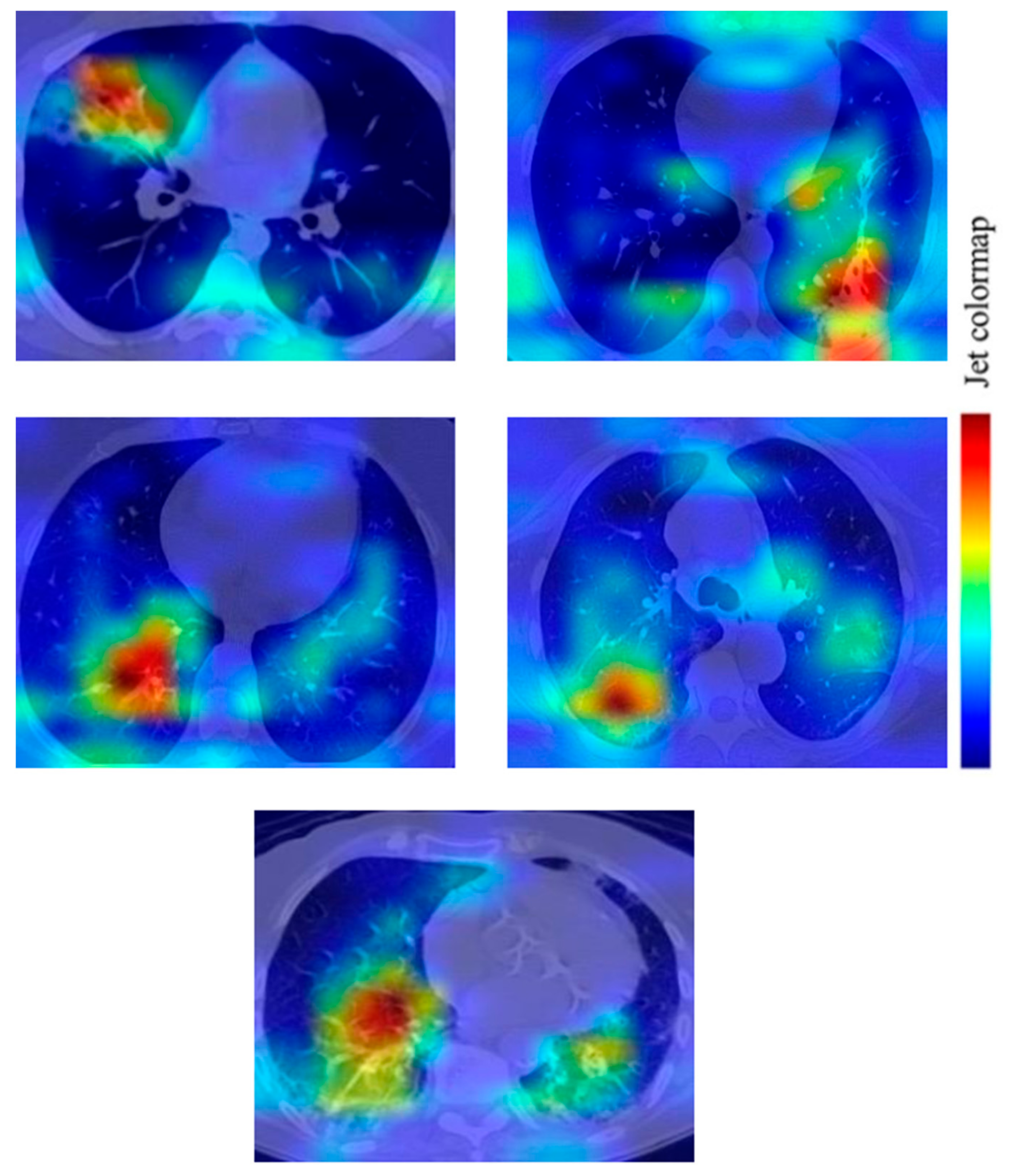
6.4. Gradient-Weight Class Activation Mapping (Grad-CAM)
6.5. Comparison with Other Works
7. Conclusions
8. Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wu, F.; Zhao, S.; Yu, B.; Chen, Y.-M.; Wang, W.; Song, Z.-G.; Hu, Y.; Tao, Z.-W.; Tian, J.-H.; Pei, Y.-Y.; et al. A new coronavirus associated with human respiratory disease in China. Nature 2020, 579, 265–269. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Guan, W.-J.; Ni, Z.-Y.; Hu, Y.; Liang, W.-H.; Ou, C.-Q.; He, J.-X.; Liu, L.; Shan, H.; Lei, C.-L.; Hui, D.S.C.; et al. China Medical Treatment Expert Group for COVID-19. Clinical Characteristics of Coronavirus Disease 2019 in China. N. Engl. J. Med. 2020, 382, 1708–1720. [Google Scholar] [CrossRef] [PubMed]
- Xie, X.; Zhong, Z.; Zhao, W.; Zheng, C.; Wang, F.; Liu, J. Chest CT for Typical Coronavirus Disease 2019 (COVID-19) Pneumonia: Relationship to Negative RT-PCR Testing. Radiology 2020, 296, E41–E45. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Huang, C.; Wang, Y.; Li, X.; Ren, L.; Zhao, J.; Hu, Y.; Zhang, L.; Fan, G.; Xu, J.; Gu, X.; et al. Clinical features of patients infected with 2019 novel coronavirus in Wuhan, China. Lancet 2020, 395, 497–506. [Google Scholar] [CrossRef] [Green Version]
- Fiala, M.J. Ultrasound in COVID-19: A time of ultrasound findings in relation to CT. Elsevier Public Health Emerg. Collect. 2020, 75, 553–554. [Google Scholar] [CrossRef]
- Adebowale, M.A.; Lwin, K.T.; Hossain, M.A. Intelligent phishing detection scheme using deep learning algorithms. J. Enterp. Inf. Manag. 2020. [Google Scholar] [CrossRef]
- Yahya, F. Machine Learning in Dam Water Research: An Overview of Applications and Approaches. Int. J. Adv. Trends Comput. Sci. Eng. 2020, 9, 1268–1274. [Google Scholar] [CrossRef]
- Moung, E.G. Face Recognition State-of-the-art, Enablers, Challenges and Solutions: A Review. Int. J. Adv. Trends Comput. Sci. Eng. 2020, 9, 96–105. [Google Scholar] [CrossRef]
- Dargham, J.A.; Chekima, A.; Moung, E.G.; Omatu, S. The Effect of Training Data Selection on Face Recognition in Surveillance Application. Adv. Intell. Syst. Comput. 2015, 373, 227–234. [Google Scholar] [CrossRef]
- Razali, M.N.; Moung, E.G.; Yahya, F.; Hou, C.J.; Hanapi, R.; Mohamed, R.; Hashem, I.A.T. Indigenous Food Recognition Model Based on Various Convolutional Neural Network Architectures for Gastronomic Tourism Business Analytics. Information 2021, 12, 322. [Google Scholar] [CrossRef]
- Jaiswal, A.; Gianchandani, N.; Singh, D.; Kumar, V.; Kaur, M. Classification of the COVID-19 infected patients using DenseNet201 based deep transfer learning. J. Biomol. Struct. Dyn. 2021, 39, 5682–5689. [Google Scholar] [CrossRef]
- Yu, Z.; Li, X.; Sun, H.; Wang, J.; Zhao, T.; Chen, H.; Ma, Y.; Zhu, S.; Xie, Z. Rapid identification of COVID-19 severity in CT scans through classification of deep features. Biomed. Eng. Online 2020, 19, 63. [Google Scholar] [CrossRef]
- Butt, C.; Gill, J.; Chun, D.; Babu, B.A. RETRACTED ARTICLE: Deep learning system to screen coronavirus disease 2019 pneumonia. Appl. Intell. 2020. [Google Scholar] [CrossRef]
- Ardakani, A.A.; Kanafi, A.R.; Acharya, U.R.; Khadem, N.; Mohammadi, A. Application of deep learning technique to manage COVID-19 in routine clinical practice using CT images: Results of 10 convolutional neural networks. Comput. Biol. Med. 2020, 121, 103795. [Google Scholar] [CrossRef]
- Yang, Y.; Newsam, S. Comparing SIFT descriptors and gabor texture features for classification of remote sensed imagery. In Proceedings of the 2008 15th IEEE International Conference on Image Processing, San Diego, CA, USA, 12–15 October 2008; pp. 1852–1855. [Google Scholar]
- Elaziz, M.A.; Hosny, K.M.; Selim, I.M. Galaxies image classification using artificial bee colony based on orthogonal Gegenbauer moments. Soft Comput. 2018, 23, 9573–9583. [Google Scholar] [CrossRef]
- Suykens, J.A.K.; Vandewalle, J. Least Squares Support Vector Machine Classifiers. Neural Process. Lett. 1999, 9, 293–300. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Hosny, K.M.; Hamza, H.M.; Lashin, N.A. Copy-for-duplication forgery detection in colour images using QPCETMs and sub-image approach. IET Image Process. 2019, 13, 1437–1446. [Google Scholar] [CrossRef]
- Eltoukhy, M.M.; Elhoseny, M.; Hosny, K.; Singh, A.K. Computer aided detection of mammographic mass using exact Gaussian–Hermite moments. J. Ambient. Intell. Humaniz. Comput. 2018. [Google Scholar] [CrossRef]
- Hosny, K.; Elaziz, M.; Selim, I.; Darwish, M. Classification of galaxy color images using quaternion polar complex exponential transform and binary Stochastic Fractal Search. Astron. Comput. 2020, 31, 100383. [Google Scholar] [CrossRef]
- Antun, V.; Renna, F.; Poon, C.; Adcock, B.; Hansen, A.C. On instabilities of deep learning in image reconstruction and the potential costs of AI. Proc. Natl. Acad. Sci. USA 2020, 117, 30088–30095. [Google Scholar] [CrossRef] [PubMed]
- Mohammed, Y.K. A deep learning framework to detect COVID-19 disease via chest X-ray and CT scan images. Int. J. Electr. Comput. Eng. 2020, 11, 844–850. [Google Scholar]
- Panwar, H.; Gupta, P.; Siddiqui, M.K.; Morales-Menendez, R.; Bhardwaj, P.; Singh, V. A deep learning and grad-CAM based color visualization approach for fast detection of COVID-19 cases using chest X-ray and CT-Scan images. Chaos Solitons Fractals 2020, 140, 110190. [Google Scholar] [CrossRef]
- Xiao, L.-S.; Li, P.; Sun, F.; Zhang, Y.; Xu, C.; Zhu, H.; Cai, F.-Q.; He, Y.-L.; Zhang, W.-F.; Ma, S.-C.; et al. Development and Validation of a Deep Learning-Based Model Using Computed Tomography Imaging for Predicting Disease Severity of Coronavirus Disease 2019. Front. Bioeng. Biotechnol. 2020, 8, 898. [Google Scholar] [CrossRef] [PubMed]
- Ahuja, S.; Panigrahi, B.K.; Dey, N.; Rajinikanth, V.; Gandhi, T.K. Deep transfer learning-based automated detection of COVID-19 from lung CT scan slices. Appl. Intell. 2021, 51, 571–585. [Google Scholar] [CrossRef] [PubMed]
- Belkasim, S.; Shridhar, M.; Ahmadi, M. Pattern recognition with moment invariants: A comparative study and new results. Pattern Recognit. 1991, 24, 1117–1138. [Google Scholar] [CrossRef]
- Ruggeri, A.; Pajaro, S. Automatic recognition of cell layers in corneal confocal microscopy images. Comput. Methods Programs Biomed. 2002, 68, 25–35. [Google Scholar] [CrossRef]
- Wang, J.-L.; Wang, B.-H. An invariant approach for image registration in digital subtraction angiography. Zhongguo Yi Liao Qi Xie Za Zhi Chin. J. Med. Instrum. 2006, 30, 15. [Google Scholar]
- Hung, C.-M.; Huang, Y.-M.; Chang, M.-S. Alignment using genetic programming with causal trees for identification of protein functions. Nonlinear Anal. Theory, Methods Appl. 2005, 65, 1070–1093. [Google Scholar] [CrossRef]
- Mangin, J.-F.; Poupon, F.; Duchesnay, E.; Riviere, D.; Cachia, A.; Collins, D.L. rain morphometry using 3D moment invariants. Med. Image Anal. 2004, 8, 187–196. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F.F. Imagenet: A Large-Scale Hierarchical Image Database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Perumal, V.; Theivanithy, K. A Transfer Learning Model for COVID-19 Detection with Computed Tomography and Sonogram Images. In Proceedings of the 2021 Sixth International Conference on Wireless Communications, Signal Processing and Networking (WiSPNET), Chennai, India, 25–27 March 2021; pp. 80–83. [Google Scholar]
- Mahesh, V.G.V.; Raj, A.N.J.; Fan, Z. Invariant moments based convolutional neural networks for image analysis. Int. J. Comput. Intell. Syst. 2017, 10, 936. [Google Scholar] [CrossRef] [Green Version]
- Li, D. Analysis of Moment Invariants on Image Scaling and Rotation. Innov. Comput. Sci. Softw. Eng. 2010, 415–419. [Google Scholar] [CrossRef]
- Hu, M.-K. Visual pattern recognition by moment invariants. IEEE Trans. Inf. Theory 1962, 8, 179–187. [Google Scholar] [CrossRef] [Green Version]
- Ren, Y.; Yang, J.; Zhang, Q.; Guo, Z. Ship recognition based on Hu invariant moments and convolutional neural network for video surveillance. Multimedia Tools Appl. 2021, 80, 1343–1373. [Google Scholar] [CrossRef]
- Soares, E.; Angelov, P.; Biaso, S.; Froes, M.H.; Abe, K. SARS-CoV-2 CT-scan dataset: A large dataset of real patients CT scans for SARS-CoV-2 identification. MedRxiv 2020. [Google Scholar] [CrossRef]
- Uçar, M.K.; Nour, M.; Sindi, H.; Polat, K. The Effect of Training and Testing Process on Machine Learning in Biomedical Datasets. Math. Probl. Eng. 2020, 2020, 2836236. [Google Scholar] [CrossRef]
- Afify, H.M.; Darwish, A.; Mohammed, K.K.; Hassanien, A.E. Ingénierie des Systèmes d’ Information an Automated CAD System of CT Chest Images for COVID-19 Based on Genetic Algorithm and K-Nearest Neighbor Classifier. Ingénierie Systèmes Inf. 2020, 25, 589–594. [Google Scholar] [CrossRef]
- Sun, S.; Zhang, R. Region of Interest Extraction of Medical Image based on Improved Region Growing Algorithm. In Proceedings of the 2017 International Conference on Material Science, Energy and Environmental Engineering (MSEEE 2017), Xi’an, China, 26–27 August 2017. [Google Scholar]
- Satapathy, S.C.; Hemanth, D.J.; Kadry, S.; Manogaran, G.; Hannon, N. Segmentation and Evaluation of COVID-19 Lesion from CT scan Slices—A Study with Kapur/Otsu Function and Cuckoo Search Algorithm. Res. Sq. 2020. [Google Scholar] [CrossRef]
- Meeker, W.Q.; Hahn, G.J.; Escobar, L.A. Statistical Intervals: A Guide for Practitioners and Researchers, Second; John Wiley&Sons, Inc.: Hoboken, NJ, USA, 2017. [Google Scholar]
- Papoulis, A. Probability, Random Variables, and Stochastic Processes, 2nd ed.; McGraw-Hill: New York, NY, USA, 1984. [Google Scholar]
- Witten, I.H.; Frank, E.; Hall, M.A. Data Mining: Practical Machine Learning Tools and Techniques, 3rd ed.; Elsevier Morgan Kaufmann: San Francisco, CA, USA, 2011. [Google Scholar] [CrossRef] [Green Version]
- Jangam, E.; Barreto, A.A.D.; Annavarapu, C.S.R. Automatic detection of COVID-19 from chest CT scan and chest X-Rays images using deep learning, transfer learning and stacking. Appl. Intell. 2021, 1–17. [Google Scholar] [CrossRef]
- Wang, Z.; Liu, Q.; Dou, Q. Contrastive Cross-Site Learning with Redesigned Net for COVID-19 CT Classification. IEEE J. Biomed. Health Inform. 2020, 24, 2806–2813. [Google Scholar] [CrossRef]
- Hasan, N.; Bao, Y.; Shawon, A.; Huang, Y. DenseNet Convolutional Neural Networks Application for Predicting COVID-19 Using CT Image. SN Comput. Sci. 2021, 2, 389. [Google Scholar] [CrossRef] [PubMed]
- Li, C.; Dong, D.; Li, L.; Gong, W.; Li, X.; Bai, Y.; Wang, M.; Hu, Z.; Zha, Y.; Tian, J. Classification of Severe and Critical COVID-19 Using Deep Learning and Radiomics. IEEE J. Biomed. Health Inform. 2020, 24, 3585–3594. [Google Scholar] [CrossRef] [PubMed]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | COVID-19 Positive | COVID-19 Negative | Total | Percentage |
|---|---|---|---|---|
| Training | 1022 | 1032 | 2054 | 82.8% |
| Validation | 107 | 121 | 228 | 9.1% |
| Testing | 100 | 100 | 200 | 8.1% |
| Total | 1252 | 1230 | 2482 | 100% |
| Model | TP | TN | FP | FN | AUC | Sensitivity (%) | Specificity (%) | Accuracy (%) |
|---|---|---|---|---|---|---|---|---|
| Custom CNN | 90 | 90 | 10 | 10 | 0.956 | 90 | 90 | 90 |
| ResNet50 | 84 | 69 | 31 | 16 | 0.856 | 84 | 69 | 76.5 |
| VGG16 | 88 | 97 | 3 | 12 | 0.975 | 88 | 97 | 92.5 |
| Custom CNN + MI | 85 | 96 | 4 | 15 | 0.968 | 85 | 96 | 90.5 |
| ResNet50 + MI | 75 | 72 | 28 | 25 | 0.825 | 75 | 72 | 73.5 |
| VGG16 + MI | 90 | 96 | 4 | 10 | 0.969 | 90 | 96 | 93.0 |
| Model | With Segmentation | Without Segmentation | ||||
|---|---|---|---|---|---|---|
| Sensitivity (%) | Specificity (%) | Accuracy (%) | Sensitivity (%) | Specificity (%) | Accuracy (%) | |
| Custom CNN | 80 | 88 | 84.6 | 90 | 90 | 90 |
| ResNet50 | 77 | 82 | 79.5 | 84 | 69 | 76.5 |
| VGG16 | 82 | 93 | 87.5 | 88 | 97 | 92.5 |
| Custom CNN + MI | 81 | 84 | 82.5 | 85 | 96 | 90.5 |
| ResNet50 + MI | 76 | 79 | 77.5 | 75 | 72 | 73.5 |
| VGG16 + MI | 86 | 90 | 88 | 90 | 96 | 93 |
| Model | |||
|---|---|---|---|
| Custom CNN | 90 ± 4.16 | 90 ± 4.16 | 90 ± 4.16 |
| ResNet50 | 84 ± 5.08 | 69 ± 6.41 | 76.5 ± 5.88 |
| VGG16 | 88 ± 4.5 | 97 ± 2.36 | 92.5 ± 3.65 |
| Custom CNN + MI | 85 ± 4.95 | 96 ± 2.72 | 90.5 ± 4.06 |
| ResNet50 + MI | 75 ± 6.0 | 72 ± 6.22 | 73.5 ± 6.12 |
| VGG16 + MI | 90 ± 4.16 | 96 ± 2.72 | 93.0 ± 3.54 |
| Model | |||
|---|---|---|---|
| Custom CNN | 80 ± 5.54 | 88 ± 4.5 | 84.6 ± 5.0 |
| ResNet50 | 77 ± 5.83 | 82 ± 5.32 | 79.5 ± 5.6 |
| VGG16 | 82 ± 5.32 | 93 ± 3.54 | 87.5 ± 4.58 |
| Custom CNN + MI | 81 ± 5.44 | 84 ± 5.08 | 82.5 ± 5.27 |
| ResNet50 + MI | 76 ± 5.92 | 79 ± 5.65 | 77.5 ± 5.79 |
| VGG16 + MI | 86 ± 4.81 | 90 ± 4.16 | 88 ± 4.5 |
| Author and DL Model | Accuracy | Sensitivity | Data Augmentation |
|---|---|---|---|
| Panwar et al. [24], VGG19 + Grad-CAM | 95% | 94.04% | ✔ |
| Jangam et al. [46], VGG19 + DenseNet169 | 91.5% | 90% | ✖ |
| Wang et al. [47], Redesigned COVID-Net | 90.83% | 85.89% | ✖ |
| Hasan et al. [48], DenseNet121 | 92% | 92% | ✖ |
| Out best model, VGG16 + MI | 93% | 90% | ✖ |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Moung, E.G.; Hou, C.J.; Sufian, M.M.; Hijazi, M.H.A.; Dargham, J.A.; Omatu, S. Fusion of Moment Invariant Method and Deep Learning Algorithm for COVID-19 Classification. Big Data Cogn. Comput. 2021, 5, 74. https://doi.org/10.3390/bdcc5040074
Moung EG, Hou CJ, Sufian MM, Hijazi MHA, Dargham JA, Omatu S. Fusion of Moment Invariant Method and Deep Learning Algorithm for COVID-19 Classification. Big Data and Cognitive Computing. 2021; 5(4):74. https://doi.org/10.3390/bdcc5040074
Chicago/Turabian StyleMoung, Ervin Gubin, Chong Joon Hou, Maisarah Mohd Sufian, Mohd Hanafi Ahmad Hijazi, Jamal Ahmad Dargham, and Sigeru Omatu. 2021. "Fusion of Moment Invariant Method and Deep Learning Algorithm for COVID-19 Classification" Big Data and Cognitive Computing 5, no. 4: 74. https://doi.org/10.3390/bdcc5040074
APA StyleMoung, E. G., Hou, C. J., Sufian, M. M., Hijazi, M. H. A., Dargham, J. A., & Omatu, S. (2021). Fusion of Moment Invariant Method and Deep Learning Algorithm for COVID-19 Classification. Big Data and Cognitive Computing, 5(4), 74. https://doi.org/10.3390/bdcc5040074