
Context-Aware Explainable Recommendation Based on Domain Knowledge Graph


Abstract
:1. Introduction
- We propose a novel framework for providing context-aware explainable recommendations based on domain KG by utilizing the existing model and embedding framework.
- We carefully design the domain ontology to capture the semantic meaning of entities and relations to make relevant recommendations, in response to user queries.
- We develop a template-based framework to transform users’ natural queries into logical triple segments and extract entity concepts and their relationships using the knowledge base.
2. Related Work
2.1. Knowledge Graph (KG) and Knowledge Graph Embedding (KGE)
2.2. Recommendation
2.3. Semantic Search and Reasoning over KG
2.4. Translating Natural Language Query to Triple
3. Methods
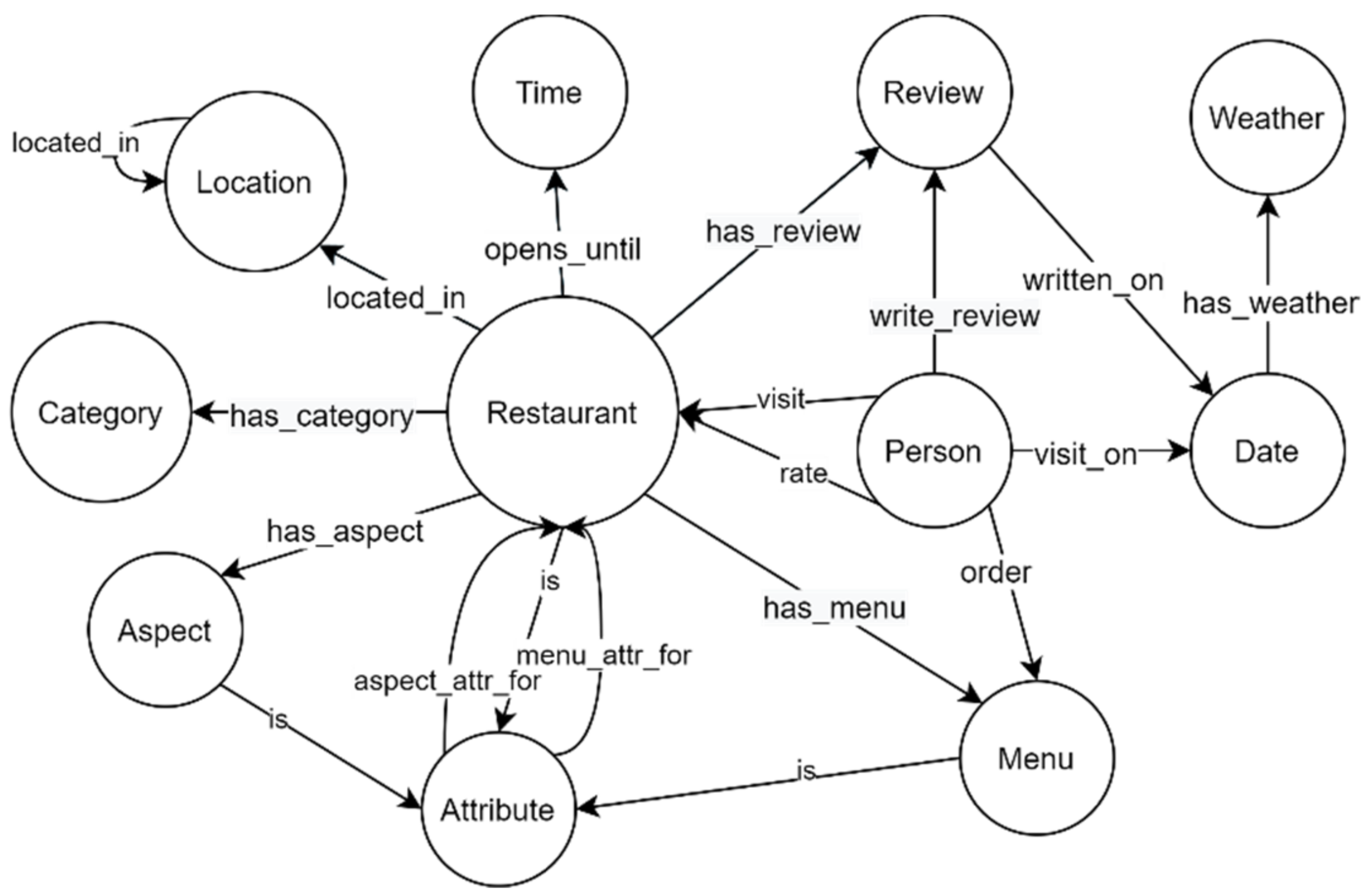
3.1. Ontology Design
3.2. Proposed KG-Based Context-Aware Recommendation
3.2.1. Triple Generation from Natural Language Query
- We eliminate all triples that do not have a direct relation to the target word or triples that do not describes the attribute of the entity concepts given in the user queries. The triple, for instance, (‘Toronto’, ‘LOCATED_IN’, ?), which represents the LOCATED_IN (‘City’, ‘Country’) triple, neither has a direct relationship to the target word nor defines the attribute of any entity concepts given in the user query. Therefore, this triple gets eliminated. On the other hand, the triple (‘?’ LOCATED_IN, ‘Toronto’) represents the LOCATED_IN (‘Restaurant’, ‘City’) triple, which has a direct relation with the restaurant concept. Similarly, the triple (?, ‘ORDER’, ‘Noodles’), which represents ORDER (‘User’, ‘Menu’), gets eliminated.
- The triples that do not belong to the similar concept are eliminated. For example, the ‘Attribute’ entity has two outgoing relationships, i.e., ‘MENU_ATTR_FOR’ and ‘ASPECT_ATTR_FOR’. Therefore, the attribute ‘Spicy’ generates two triples: (‘Spicy’, ‘MENU_ATTR_FOR’, ‘?’) and (‘Spicy’, ‘ASPECT_ATTR_FOR’, ‘?’). However, the former does not fall under the ‘Menu’ concept and, hence, the triple is eliminated.
- The two triples that result in a complete triple fact are considered a true fact and removed from the incomplete triple segments, i.e., [(‘Noodles’, ‘IS’, ‘?’), (‘?’, ‘IS’, ‘Sweet’)] or [(‘Chicken Biryani’, ‘IS’, ‘?’), (‘?’, ‘IS’, ‘Spicy’)] generates (‘Noodles’, ‘IS’, ‘Sweet’) or (‘Chicken Biryani’, ‘IS’, ‘Spicy’).
- The logical operations (∧, ∨) are defined between triple segments.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Extracted Triples | [{‘triple_segment’: [(‘?’, ‘HAS_CATEGORY’, ‘Chinese’)], ‘concept’: ‘Category’, ‘op’: None}, {‘triple_segment ‘: [(‘?’, ‘LOCATED_IN’, ‘Toronto’), (‘Toronto’, ‘LOCATED_IN’, ‘?’)], ‘concept’: ‘City’, ‘op’: None}, {‘triple_segment ‘: [(‘?’, ‘ORDER’, ‘Noodles’), (‘?’, ‘HAS_MENU’, ‘Noodles’), (‘Noodles’, ‘IS’, ‘?’), (‘?’, ‘IS’, ‘Sweet’), (‘Sweet’, ‘MENU_ATTR_FOR’, ‘?’), (‘Sweet’, ‘ASPECT_ATTR_FOR’, ‘?’)], ‘concept’: ‘Menu’, ‘op’: None}, {‘triple_segment ‘: [(‘?’, ‘ORDER’, ‘‘Chicken Biryani ‘), (‘?’, ‘HAS_MENU’, ‘Chicken Biryani’), (‘Chicken Biryani’, ‘IS’, ‘?’), (‘?’, ‘IS’, ‘Spicy’), (‘Spicy’, ‘MENU_ATTR_FOR’, ‘?’), (‘Spicy’, ‘ASPECT_ATTR_FOR’, ‘?’)], ‘concept’: ‘Menu’, ‘op’: ‘AND’}] |
| Filtered Triples | [{‘triple_segment ‘: [(‘?’, ‘HAS_CATEGORY’, ‘Chinese’)], ‘concept’: ‘Category’, ‘op’: None}, {‘triple_segment ‘: [(‘?’, ‘LOCATED_IN’, ‘Toronto’)], ‘concept’: ‘City’, ‘op’: None}, {‘triple_segment ‘: [(‘?’, ‘HAS_MENU’, ‘Noodles’), (‘Sweet’, ‘MENU_ATTR_FOR’, ‘?’)], ‘concept’: ‘Menu’, ‘op’: None}, {‘triple_segment ‘: [(‘?’, ‘HAS_MENU’, ‘Chicken Biryani’), (‘Spicy’, ‘MENU_ATTR_FOR’, ‘?’)], ‘concept’: ‘Menu’, ‘op’: ‘AND’}] |
| Logical Query | q = R?:∃R: Category(R?, Chinese) ∧ Location(R?, Toronto) ∧ (((Menu(R?, Noodles) ∧ MenuAttrFor(Sweet, R?)) ∨ (Menu(R?, Butter Chicken) ∧ MenuAttrFor(Spicy, R?))) |
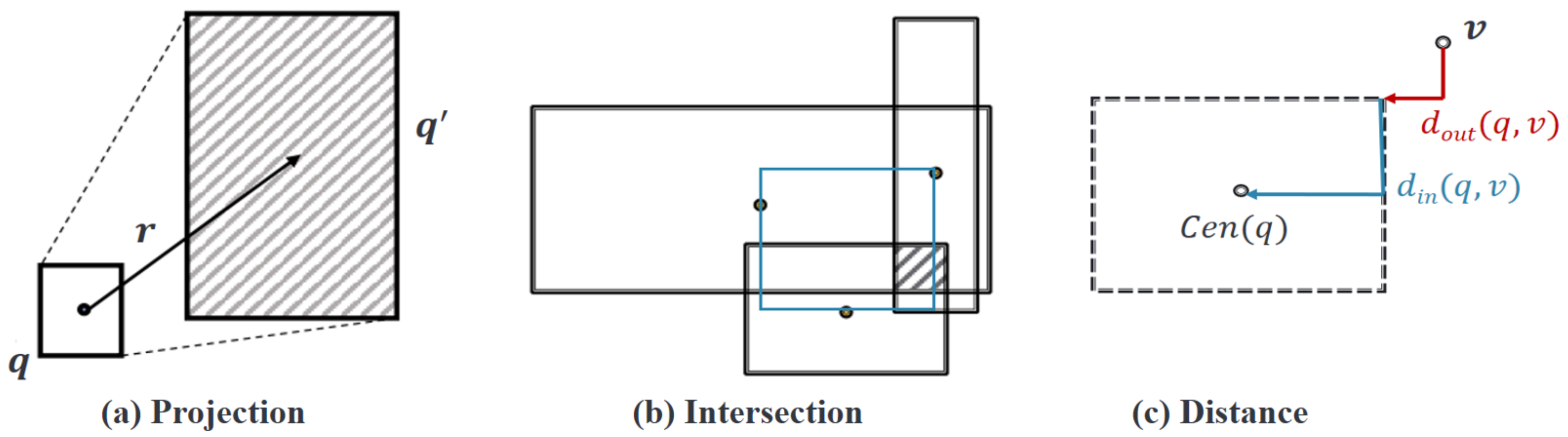
3.2.2. Query2Box (Q2B) Model
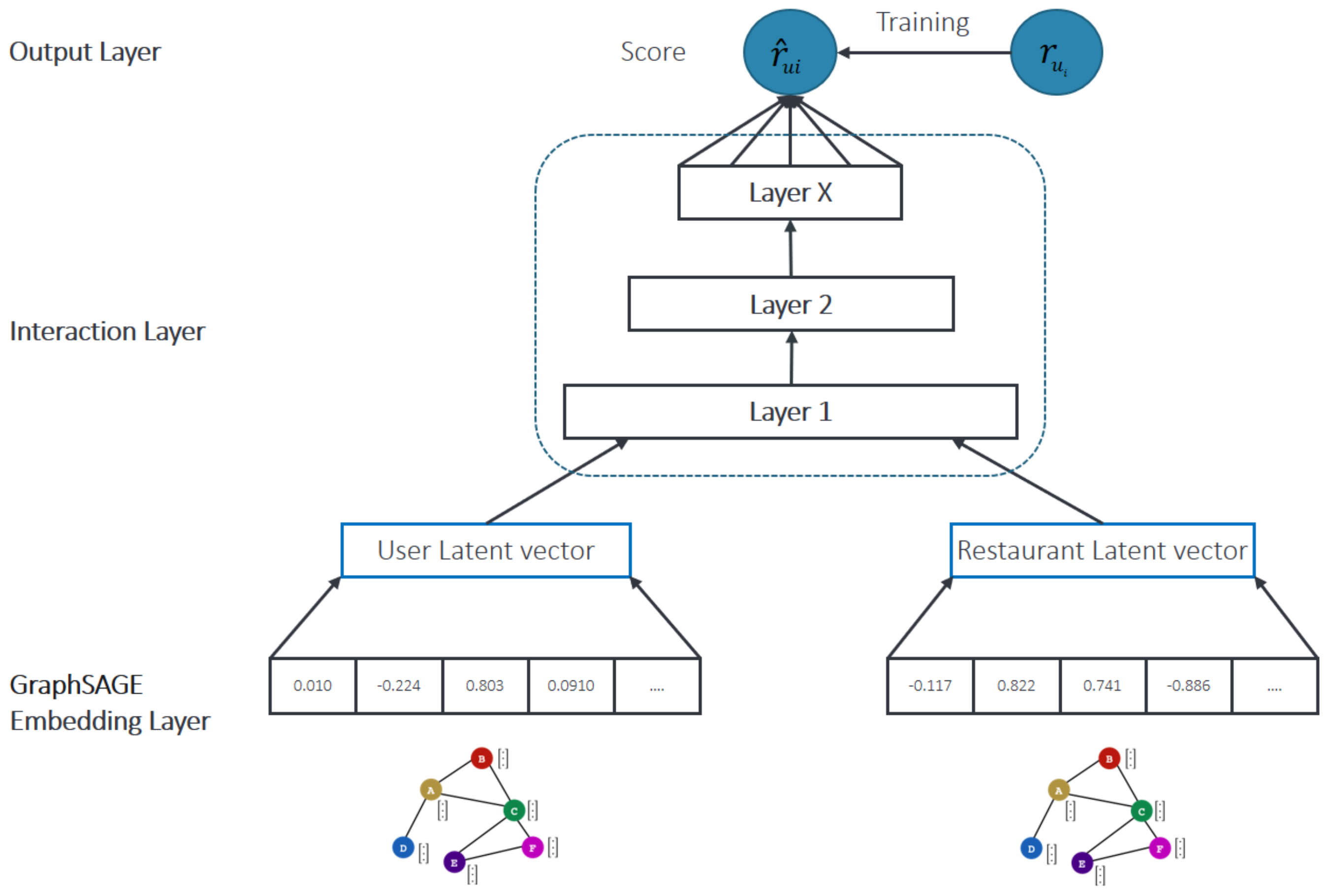
3.2.3. ML-Based NCF Re-Rank Model
4. Evaluation
4.1. Dataset
4.2. Evaluation on Natural Query Conversion
4.3. Evaluation on Query2Box (Q2B) Query and Candidate Generation
“Recommend best Indian restaurant in Toronto which serves sweet Butter Chicken” Query (1)
4.4. Evaluation of Neural Collaborative Filtering (NCF)-based Re-Rank Module
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, H.; Zhang, F.; Wang, J.; Zhao, M.; Li, W.; Xie, X.; Guo, M. RippleNet: Propagating User Preferences on the Knowledge Graph for Recommender Systems. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management, Torino, Italy, 22–26 October 2018; pp. 417–426. [Google Scholar]
- Covington, P.; Adams, J.; Sargin, E. Deep Neural Networks for YouTube Recommendations. In Proceedings of the 10th ACM Conference on Recommender Systems, Boston, MA, USA, 15–19 September 2016; ACM: New York, NY, USA, 2016; pp. 191–198. [Google Scholar]
- Wang, H.; Zhang, F.; Xie, X.; Guo, M. DKN: Deep Knowledge-Aware Network for News Recommendation. In Proceedings of the 2018 World Wide Web Conference (WWW), Lyon, France, 23–27 April 2018; pp. 1835–1844. [Google Scholar]
- Yu, X.; Ren, X.; Sun, Y.; Gu, Q.; Sturt, B.; Khandelwal, U.; Norick, B.; Han, J. Personalized entity recommendation: A heterogeneous information network approach. In Proceedings of the 7th International Conference Web Search and Data Mining (WSDM), New York, NY, USA, 24–28 February 2014; ACM: New York, NY, USA, 2014; pp. 283–292. [Google Scholar]
- Wang, H.; Zhang, F.; Zhao, M.; Li, W.; Xie, X.; Guo, M. Multi-Task Feature Learning for Knowledge Graph Enhanced Recommendation. In Proceedings of the 2019 World Wide Web Conference (WWW), San Francisco, CA, USA, 13–17 May 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 2000–2010. [Google Scholar]
- Wang, X.; He, X.; Cao, Y.; Liu, M.; Chua, T.S. KGAT: Knowledge Graph Attention Network for Recommendation. In Proceedings of the 25th ACM SIGKDD International Conference of Knowledge Discovery & Data Mining (KDD), Anchorage, AK, USA, 4–8 August 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 950–958. [Google Scholar]
- Gao, Y.; Li, Y.F.; Lin, Y.; Gao, H.; Khan, L. Deep learning on knowledge graph for recommender system: A survey. arXiv 2020, arXiv:2004.00387. [Google Scholar]
- Hogan, A.; Blomqvist, E.; Cochez, M.; d’Amato, C.; Melo, G.; Gutierrez, C.; Gayo, J.E.L.; Kirrane, S.; Neumaier, S.; Polleres, A.; et al. Knowledge graphs. ACM Comput. Surv. 2021, 54, 1–37. [Google Scholar] [CrossRef]
- Yelp.com. Available online: https://www.yelp.com/ (accessed on 23 October 2021).
- Ren, H.; Hu, W.; Leskovec, J. Query2box: Reasoning over knowledge graphs in vector space using box embeddings. In Proceedings of the International Conference Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Rendle, S.; Gantner, Z.; Freudenthaler, C.; Thieme, L.S. Fast context-aware recommendations with factorization machines. In Proceedings of the 34th International ACM SIGIR Conference on Research and Development in Information Retrieval, Beijing, China, 24–28 July 2011; pp. 635–644. [Google Scholar]
- He, X.; Liao, L.; Zhang, H.; Nie, L.; Hu, X.; Chua, T.-S. Neural collaborative filtering. In Proceedings of the 26th International Conference on World Wide Web (WWW 2017), Perth, Australia, 3–7 April 2017; pp. 173–182. Available online: https://dblp.org/rec/conf/www/HeLZNHC17 (accessed on 13 November 2021).
- Hamilton, W.; Ying, Z.; Leskovec, J. Inductive representation learning on large graphs. In Proceedings of the NeuralPS, Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 1024–1034. [Google Scholar]
- Hao, X.; Ji, Z.; Li, X.; Yin, L.; Liu, L.; Sun, M.; Liu, Q.; Yang, R. Construction and Application of a Knowledge Graph. Remote Sens. 2021, 13, 2511. [Google Scholar] [CrossRef]
- Zhu, G.; Iglesias, C.A. Sematch: Semantic entity search from knowledge graph. In Proceedings of the SumPre 2015—1st International Workshop Extended Semantic Web Conference (ESWC), Portoroz, Slovenia, 1 June 2015. [Google Scholar]
- Yasunaga, M.; Ren, H.; Bosselut, A.; Liang, P.; Leskovec, J. QA-GNN: Reasoning with Language Models and Knowledge Graphs for Question Answering. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6—11 June 2021; pp. 535–546. Available online: https://aclanthology.org/2021.naacl-main.45/ (accessed on 13 November 2021).
- Papadopoulos, D.; Papadakis, N.; Litke, A. A Methodology for Open Information Extraction and Representation from Large Scientific Corpora: The CORD-19 Data Exploration Use Case. Appl. Sci. 2020, 10, 5630. [Google Scholar] [CrossRef]
- Wang, M.; Qiu, L.; Wang, X. A Survey on Knowledge Graph Embeddings for Link Prediction. Symmetry 2021, 13, 485. [Google Scholar] [CrossRef]
- Bastos, A.; Nadgeri, A.; Singh, K.; Mulang, I.O.; Shekarpour, S.; Hoffart, J.; Kaul, M. RECON: Relation Extraction using Knowledge Graph Context in a Graph Neural Network. In Proceedings of the World Wide Web, Ljubljana, Slovenia, 19–23 April 2021; pp. 1673–1685. [Google Scholar]
- Arakelyan, E.; Daza, D.; Minervini, P.; Cochez, M. Complex Query Answering with Neural Link Predictors. arXiv 2011, arXiv:2011.03459. [Google Scholar]
- Bordes, A.; Usunier, N.; García-Durán, A.; Weston, J.; Yakhnenko, O. Translating embeddings for modeling multi-relational data. In Proceedings of the Advances in Neural Information Processing Systems 26 (NIPS 2013), Stateline, NV, USA, 5—10 December 2013; pp. 2787–2795. Available online: https://papers.nips.cc/paper/2013/hash/1cecc7a77928ca8133fa24680a88d2f9-Abstract.html (accessed on 13 November 2021).
- Choudhary, S.; Luthra, T.; Mittal, A.; Singh, R. A survey of knowledge graph embedding and their applications. arXiv 2021, arXiv:2107.07842. [Google Scholar]
- Wang, Z.; Zhang, J.; Feng, J.; Chen, Z. Knowledge graph embedding by translating on hyperplanes. In Proceedings of the 28th AAAI Conference of Artificial Intelligence, Quebec City, QC, Canada, 27–31 July 2014; pp. 1112–1119. [Google Scholar]
- Lin, Y.; Liu, Z.; Sun, M.; Liu, Y.; Zhu, X. Learning entity and relation embeddings for knowledge graph completion. In Proceedings of the 29th AAAI, Austin, TX, USA, 25–30 January 2015; pp. 2181–2187. [Google Scholar]
- Nickel, M.; Tresp, V.; Kriegel, H.P. A three-way model for collective learning on multi-relational data. In Proceedings of the 28th International Conference on Machine Learning, Bellevue, WA, USA, 28 June –2 July 2011; pp. 809–816. [Google Scholar]
- Yang, B.; Yih, W.T.; He, X.; Gao, J.; Deng, L. Embedding entities and relations for learning and inference in knowledge bases. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015; pp. 1–12. [Google Scholar]
- Dettmers, T.; Minervini, P.; Stenetorp, P.; Riedel, S. Convolutional 2D knowledge graph embeddings. In Proceedings of the AAAI, Quebec City, QC, Canada, 27–31 July 2014; pp. 1811–1818. [Google Scholar]
- Shah, L.; Gaudani, H.; Balani, P. Survey on Recommendation System. Int. J. Comp. Appl. 2016, 137, 43–49. [Google Scholar] [CrossRef]
- Koren, Y.; Bell, R.; Volinsky, C. Matrix factorization techniques for recommender systems. Computer 2009, 42, 30–37. [Google Scholar] [CrossRef]
- Zhang, H.; Ganchev, I.; Nikolov, N.S.; Ji, Z.; O’Droma, M. FeatureMF: An Item Feature Enriched Matrix Factorization Model for Item Recommendation. IEEE Access 2021, 9, 65266–65276. [Google Scholar] [CrossRef]
- He, X.; Chua, T.S. Neural factorization machines for sparse predictive analytics. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval, Tokyo, Japan, 7–11 August 2017; pp. 355–364. [Google Scholar]
- Cheng, H.T.; Koc, L.; Harmsen, J.; Shaked, T.; Chandra, T.; Aradhye, H.; Anderson, G.; Corrado, G.; Chai, W.; Ispir, M. Wide & deep learning for recommender systems. In Proceedings of the 1st Workshop Deep Learning for Recommender Systems, Boston, MA, USA, 15 September 2016; pp. 7–10. [Google Scholar]
- Lian, J.; Zhou, X.; Zhang, F.; Chen, Z.; Xie, X.; Sun, G. XDeepFM: Combining explicit and implicit feature interactions for recommender systems. In Proceedings of the 24th ACM SIGKDD International Conference of Knowledge Discovery and Data Mining, London, UK, 19–23 August 2018; pp. 1754–1763. [Google Scholar]
- Zhang, F.; Yuan, N.J.; Lian, D.; Xie, X.; Ma, W.Y. Collaborative knowledge base embedding for recommender systems. In Proceedings of the 22nd. International Conference of ACM SIGKDD on KDD, San Francisco, CA, USA, 13–17 August 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 353–362. [Google Scholar]
- Guo, Q.; Zhang, F.; Qin, C.; Zhu, H.; Xie, X.; Xiong, H.; He, Q. A survey on knowledge graph-based recommender systems. arXiv 2020, arXiv:2003.00911. [Google Scholar] [CrossRef]
- Liu, C.; Li, L.; Yao, X.; Tang, L. A Survey of Recommendation Algorithms Based on Knowledge Graph Embedding. In Proceedings of the IEEE International Conference on Computer Science and Education informalization (CSEI), Xinxiang, China, 16–19 August 2019; pp. 168–171. [Google Scholar] [CrossRef]
- Zhang, S.; Yao, L.; Sun, A.; Tay, Y. Deep learning based recommender system: A survey and new perspectives. ACM Comput. Surv. 2019, 52, 1–38. [Google Scholar] [CrossRef] [Green Version]
- Sitar-Tăut, D.-A.; Mican, D.; Buchmann, R.A. A knowledge-driven digital nudging approach to recommender systems built on a modified Onicescu method. Expert Syst. Appl. 2021, 181, 115170. [Google Scholar] [CrossRef]
- Zhu, Y.; Gong, Y.; Liu, Q.; Ma, Y.; Ou, W.; Zhu, J.; Wang, B.; Guan, Z.; Cai, D. Query-based interactive recommendation by meta-path and adapted attention-gru. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019; pp. 2585–2593. [Google Scholar]
- Bhattacharya, M.; Barapatre, A. Query as Context for Item-to-Item Recommendation. Comput. J. 2021, 64, 1016–1027. [Google Scholar]
- Ren, H.; Leskovec, J. Beta embeddings for multi-hop logical reasoning in knowledge graphs. In Proceedings of the Advances in Neural Information Processing System, Vancouver, Canada, 6–12 December 2020; Available online: https://papers.nips.cc/paper/2020/hash/e43739bba7cdb577e9e3e4e42447f5a5-Abstract.html (accessed on 13 November 2021).
- Pirro, G. Explaining and suggesting relatedness in knowledge graphs. In ISWC; Springer: Cham, Switzerland, 2015; pp. 622–639. [Google Scholar]
- Feddoul, L. Semantics-driven Keyword Search over Knowledge Graphs. In Proceedings of the DC@ISWC, Vienna, Austria, 3 November 2020; pp. 17–24. [Google Scholar]
- Yan, H.; Wang, Y.; Xu, X. SimG: A Semantic Based Graph Similarity Search Engine. In Proceedings of the 27th International Conference of Advanced Cloud and Big Data, Suzhou, China, 21–22 September 2019; pp. 114–120. [Google Scholar] [CrossRef]
- Hamilton, W.; Bajaj, P.; Zitnik, M.; Jurafsky, D.; Leskovec, J. Embedding logical queries on knowledge graphs. In NeurIPS; Curran Associates Inc.: Red Hook, NY, USA, 2018; pp. 2030–2041. [Google Scholar]
- Ochieng, P. PAROT: Translating natural language to SPARQL. Expert Syst. Appl. X 2020, 5, 100024. [Google Scholar]











| Entity | No. of Nodes | Relationship Types | Attributes | |
|---|---|---|---|---|
| Incoming | Outgoing | |||
| Aspect | 15 | [HAS_ASPECT] | [IS] | aspect_id, name |
| Attr | 241 | [IS] | [ASPECT_ATTR_FOR, MENU_ATTR_FOR] | attr_id, name |
| Category | 56 | [HAS_CATEGORY] | [] | category_id, name |
| City | 31 | [LOCATED_IN] | [LOCATED_IN] | city_id, name |
| Country | 2 | [LOCATED_IN] | [] | country_id, name |
| Menu | 624 | [HAS_MENU] | [IS] | menu_id, name |
| Restaurant | 102 | [ASPECT_ATTR_FOR, MENU_ATTR_FOR, VISIT, RATE] | [LOCATED_IN, HAS_CATEGORY, IS, HAS_ASPECT, HAS_MENU, HAS_REVIEW] | rest_id, name, address, postal_code, rating |
| Review | 3452 | [HAS_REVIEW, WRITE_REVIEW] | [] | review_id, text |
| User | 3227 | [HAS_FRIEND] | [VISIT, ORDER, RATE, WRITE_REVIEW] | user_id, name, gender, age, review_count, avg_star, fans |
| Total No. of Nodes | Total No. of Relations |
|---|---|
| 7750 | 39,158 |
| # | User Query | Query Structure | Logical Query Segments | Result |
|---|---|---|---|---|
| 1 | Recommend best Chinese restaurants | 1p | Category (R?, Chinese) | Correct |
| 2 | What special menus Chinese restaurants serve? | 2p | Category (R?, Chinese) ∧ Menu (R?, M?) | Correct |
| 3 | Recommend best Indian restaurant in Toronto | 2i | Category (R?, Indian) ∧ Location (R?, Toronto) | Correct |
| 4 | Recommend best Indian restaurant in Toronto which serves Butter Chicken. | 3i | Category (R?, Indian) ∧ Location(R?, Toronto) ∧ Menu (R?, Butter Chicken) | Correct |
| 5 | What special menus Indian restaurants serve in Toronto? | ip | Category (R?, Indian) ∧ Location(R?, Toronto) ∧ Menu (R?, M?) | Correct |
| 6 | Who visited Indian restaurant and ordered Butter Chicken? | pi | Category (R?, Indian) ∧Menu (R?, Butter Chicken) | Wrong |
| 7 | Recommend restaurants which serve Butter Chicken or Chicken Biryani | 2u | Menu (R?, Butter Chicken) ∨ Menu (R?, Chicken Biryani) | Correct |
| 8 | Which restaurants in Toronto serves Butter Chicken or Chicken Biryani | up | (Menu (R?, Butter Chicken) ∨ Menu (R?, Chicken Biryani)) ∧ Location (R?, Toronto) | Correct |
| 9 | Recommend best Chinese restaurant in Toronto which serves sweet Noodles or spicy Chicken Biryani | arbitrary | Category (R?, Chinese) ∧ Location (R?, Toronto) ∧ (((Menu (R?, Noodles) ∧ MenuAttrFor (Sweet, R?)) ∨ (Menu (R?, Butter Chicken) ∧ MenuAttrFor (Spicy, R?))) | Correct |
| 10 | Which Chinese restaurants in Toronto have delivery service? | 3i | Category (R?, Chinese) ∧ Location (R?, Toronto) ∧ Aspect (R?, Delivery) ∧ Aspect (R?, Service) | Wrong |
| 11 | Which Chinese restaurants in Toronto have delivery? | 3i | Category (R?, Chinese) ∧ Location (R?, Toronto) ∧ Aspect (R?, Delivery) | Correct |
| Query | Avg | 1p | 2p | 3p | 2i | 3i | ip | pi | 2u | up |
|---|---|---|---|---|---|---|---|---|---|---|
| Yelp (domain-KG) dataset | ||||||||||
| MRR | 0.286 | 0.309 | 0.164 | 0.144 | 0.402 | 0.604 | 0.234 | 0.38 | 0.171 | 0.168 |
| Hits@1 | 0.188 | 0.19 | 0.062 | 0.05 | 0.334 | 0.545 | 0.143 | 0.26 | 0.012 | 0.099 |
| Hits@3 | 0.347 | 0.392 | 0.234 | 0.207 | 0.429 | 0.627 | 0.287 | 0.46 | 0.289 | 0.201 |
| Hit@10 | 0.44 | 0.46 | 0.362 | 0.303 | 0.498 | 0.699 | 0.399 | 0.535 | 0.393 | 0.308 |
| FB15k | ||||||||||
| MRR | 0.41 | 0.654 | 0.373 | 0.274 | 0.488 | 0.602 | 0.194 | 0.339 | 0.468 | 0.301 |
| Hits@3 | 0.484 | 0.786 | 0.413 | 0.303 | 0.593 | 0.712 | 0.211 | 0.397 | 0.608 | 0.33 |
| FB15k-237 | ||||||||||
| MRR | 0.235 | 0.4 | 0.225 | 0.173 | 0.275 | 0.378 | 0.105 | 0.18 | 0.198 | 0.178 |
| Hits@3 | 0.268 | 0.467 | 0.24 | 0.186 | 0.324 | 0.453 | 0.108 | 0.205 | 0.239 | 0.193 |
| NELL995 | ||||||||||
| MRR | 0.254 | 0.413 | 0.227 | 0.208 | 0.288 | 0.414 | 0.125 | 0.193 | 0.266 | 0.155 |
| Hits@3 | 0.306 | 0.555 | 0.266 | 0.233 | 0.343 | 0.48 | 0.132 | 0.212 | 0.369 | 0.163 |
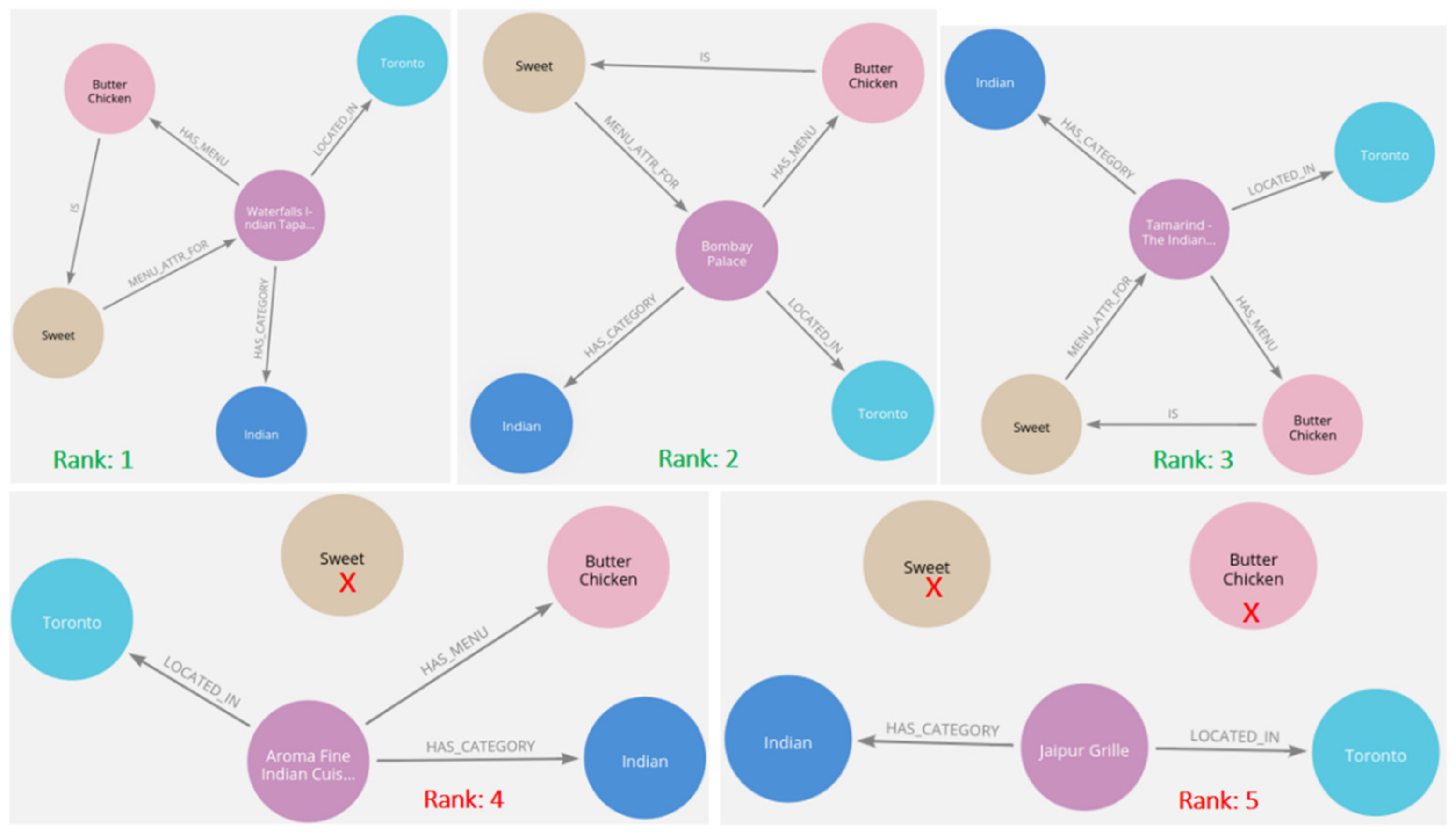
| Rank | RestID | Q2B (z) |
|---|---|---|
| 1 | 4873 | 7.478498 |
| 2 | 4641 | 7.431061 |
| 3 | 3744 | 3.110984 |
| 4 | 3926 | 1.378697 |
| 5 | 5324 | 0.376228 |
| Train | Test |
|---|---|
| 30,000 | 4524 |
| Epochs | MAE | RMSE |
|---|---|---|
| 5000 | 1.0690 | 1.5949 |
| 10,000 | 1.0674 | 1.5925 |
| 20,000 | 1.0673 | 1.5917 |
| Method | MAE | RMSE |
|---|---|---|
| MF | 1.169 | 1.994 |
| NCF Model | 1.0673 | 1.5917 |
| Rank | RestID | Q2B (z) | UserID: 3178 | UserID: 17 | ||||
|---|---|---|---|---|---|---|---|---|
| NCF (r) | Score (s) | Re-Ranking | NCF (r) | Score (s) | Re-Ranking | |||
| 1 | 4873 | 7.478498 | 4.3 | 5.25 | 2 | 4.2 | 5.18 | 2 |
| 2 | 4641 | 7.431061 | 4.7 | 5.52 | 1 | 4.5 | 5.38 | 1 |
| 3 | 3744 | 3.110984 | 4.8 | 4.29 | 3 | 3.9 | 3.66 | 3 |
| 4 | 3926 | 1.378697 | 4.2 | 3.35 | 4 | 4.0 | 3.21 | 4 |
| 5 | 5324 | 0.376228 | 4.1 | 2.98 | 5 | 3.5 | 2.56 | 5 |
| RestID | RestName | Similarity | NCF (r) |
|---|---|---|---|
| 4641 | Bombay Palace | 0.99996 | 4.7 |
| 3744 | Tamarind—The Indian Kitchen | 0.99993 | 4.8 |
| 3926 | OM Restaurant | 0.99988 | 4.2 |
| 4873 | Waterfalls Indian Tapas Bar & Grill | 0.99985 | 4.3 |
| 5324 | Pakwan Indian Bistro | 0.99903 | 4.1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Syed, M.H.; Huy, T.Q.B.; Chung, S.-T. Context-Aware Explainable Recommendation Based on Domain Knowledge Graph. Big Data Cogn. Comput. 2022, 6, 11. https://doi.org/10.3390/bdcc6010011
Syed MH, Huy TQB, Chung S-T. Context-Aware Explainable Recommendation Based on Domain Knowledge Graph. Big Data and Cognitive Computing. 2022; 6(1):11. https://doi.org/10.3390/bdcc6010011
Chicago/Turabian StyleSyed, Muzamil Hussain, Tran Quoc Bao Huy, and Sun-Tae Chung. 2022. "Context-Aware Explainable Recommendation Based on Domain Knowledge Graph" Big Data and Cognitive Computing 6, no. 1: 11. https://doi.org/10.3390/bdcc6010011
APA StyleSyed, M. H., Huy, T. Q. B., & Chung, S.-T. (2022). Context-Aware Explainable Recommendation Based on Domain Knowledge Graph. Big Data and Cognitive Computing, 6(1), 11. https://doi.org/10.3390/bdcc6010011