1. Introduction
Nowadays, fact verification models have been developed and implemented using machine learning [
1,
2,
3,
4,
5]. These developments have improved the research aimed at detecting fake news in recent years [
6,
7,
8,
9,
10]. Generally, a bidirectional encoder-based model has been developed to detect fake news to verify a fact. For example, the Bidirectional Encoder Representations from Transformers (BERT) [
11] model has been successfully implemented to detect fake news [
12,
13] and fact verification [
14,
15]. Another model developed from BERT to detect fake news, called RoBERTa [
16], has been successfully implemented [
17,
18]. RoBERTa has been implemented to verify a fact [
19]. Some researchers found a new challenge in machine learning models to optimize and improve the performance of better methods, including applying ensemble models [
20]. An ensemble is a classifier mechanism running concurrently that combines the predicted results of the components. Several cases of ensemble research carried out homogeneously have increased accuracy values in a model [
21,
22].
Ensemble deployments are becoming popular due to the advantages of using a single model across multiple datasets and machine learning tasks. In a simple case, by using an ensemble, a network is trained using a large dataset to check the result of the accuracy, loss, etc., in the validation set [
23]. It is conducted to improve accuracy as a parameter to measure the success of the ensemble application for a model development [
20]. Good fact verification requires the most optimal and has the best evaluation model. The goal is to make the news readers trust the reliable and accurate verification results.
One study [
24] stated that RoBERTa has a higher accuracy value than the other models in verifying facts. Based on several previous studies, it has been proven that the homogeneous ensemble (HE) can improve model performance. This paper combined HE with the RoBERTa model to claim a fact. We evaluated the application of the HE on RoBERTa to prove that the application of an ensemble can be used to improve the accuracy of a model. To obtain optimal results, we modified the algorithm structure of RoBERTa in the training and testing stages. Modifications made in the training phase can be used to set three samples on RoBERTa to improve model performance. Improved model performance using three samples has been proven [
25]. Afterwards, the evaluation results of each model were summed.
Model accuracy and F1-Score were used to measure the performance of the method. In the experimental process, we combined three models of RoBERTa. We found no research related to fact verification by combining ensembles with the model, and we were interested in contributing to this topic to improve model performance in fact verification. Therefore, the results of the fact verification were expected to have better verification.
In summary, our contributions in this paper are as follows:
Improving a RoBERTa model by implementing the HE from three best parameters settings in RoBERTa, we call it RoBERTaEns.
Implementing one of the HE methods, i.e., bagging ensemble to RoBERTa, the kind of bagging ensemble used was called Sum.
Testing and comparing the performance of BERT, RoBERTa, XL-Net, and XLM models with RoBERTaEns to obtain the best model performance.
2. Related Works
The impact of fake news that is widespread in society becomes a challenge in the world of journalism when one must label a fact from the results of claims of whether news or information is true or false based on evidence. Nowadays, fact verification has become a very challenging task in the realm of Natural Language Processing (NLP) [
26,
27], and the research community has paid much attention to research issues related to fact verification [
28,
29,
30,
31]. There are three types of labelling a fact [
32]: (1) If there is an evidence supporting a claim, the facts are labelled with SUPPORTS; (2) If there is an evidence refuting a claim, the facts are labelled with REFUTES; (3) If there is no evidence to support or refute the claim, the facts are labelled with NOT ENOUGH INFO.
There have been many studies related to fact verification for making a model and dataset [
31,
33] to test various types of models [
34] for fact verification [
35]. Many studies have tested various datasets to verify facts. For example, a study comparing two datasets [
36], i.e., the Fake News Challenge (FNC) dataset and the FEVER dataset using the Recognizing Textual Entailment (RTE) model. One of the results of the research has been reviewed by using the FEVER dataset on the train and evaluation domains, and the accuracy of the FEVER dataset was better than the FNC. The FEVER dataset had an accuracy of 83.43% on the test results. Other studies have also implemented the FEVER dataset for fact verification [
15,
34]. The FEVER dataset has the subtasks of document retrieval, sentence retrieval, and claim verification [
37].
In addition to comparing datasets, a comparison of models to obtain the best accuracy in verifying facts has been carried out by several researchers [
14] who compared three models, such as (1) BERT [
11]; (2) Enhanced LSTM (ESIM) [
38]; and (3) the Neural Semantic Matching Network (NSMN) [
39]. The research results prove that BERT has the best results, with an accuracy of 61%, for fact verification. Furthermore, a different study [
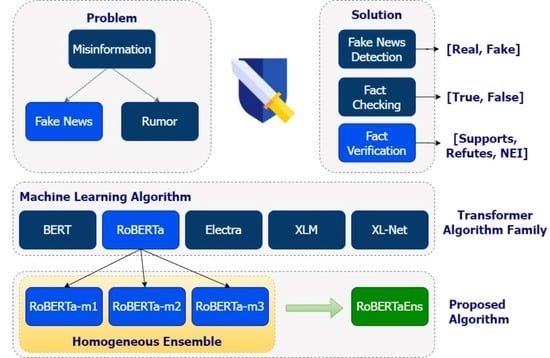
16] developed the BERT model by changing the BERT training structure, resulting in a new model called RoBERTa.
The results of the research were conducted by comparing three models, such as (1) BERT; (2) Generalized Autoregressive Pretraining for Language Understanding (XL-Net) [
40]; and (3) RoBERTa. This study shows that the result of RoBERTa has a higher accuracy than BERT, with an accuracy of 92.5%. These results attracted researchers to develop the RoBERTa model in order to produce novel or better classifications, one of which is a study implementing Natural Language Inference on the RoBERTa model [
41]. The model architecture that has been developed is given in
Figure 1.
The application of HE in several studies proves an improvement in model performance [
25,
42]. HE has a model architecture built with multiple base learners and is generated from a single learning algorithm, in contrast to a heterogeneous ensemble that is built with different algorithms. Many researchers in their research more commonly use HE compared to the heterogeneous one [
43]. For example, recently, several studies have proven HE models to improve model performance. The study applied a tree-based HE model with feature selection to predict diabetic retinopathy. The results showed that HE was established to enhance the performance of the Support Vector Machine (SVM) model [
42]. Another study [
25] also developed a model by applying the HE to improve the evaluation performance of the Decision Trees, Logistics Model Tree, and Bagged Multi-layer Perceptron algorithms. As a result, an effective HE gave satisfactory results, with an average accuracy of 98.1%. The existence of various evidence of improving model performance by applying the HE makes us interested in examining the application of the HE on the RoBERTa model. The bagging ensemble method used in this study was Sum [
44].
Many researchers have carried out the implementation of RoBERTa by combining datasets with the aim of verifying facts. A study concerning fact verification by combining the FEVER dataset and RoBERTa as a model for fact verification has been carried out [
45]. This combination obtained an accuracy of 95.1% by using the F1-Score calculation. F1-Score is the average harmonic value obtained from the precision model. The majority of F1-Scores are used to evaluate the machine learning [
46,
47,
48] model, especially for NLP [
49]. With the application of the HE, the model applied for fact verification is expected to improve the performance of the RoBERTa model. One of the interesting results of the related works that we studied refers to the RoBERTa model and has an updated RoBERTa model explicitly by applying the HE. Our HE application is called RoBERTaEns. The application of HE in the transformer family has been applied [
50,
51] to detect hate speech. Meanwhile, the HE applied in our research focused on fact verification.
RoBERTaEns is formed from three RoBERTa-based models with different epoch settings and batch sizes. RoBERTa-m1 with epoch 5 and batch size 32, RoBERTa-m2 with epoch 30 and batch size 20, and RoBERTa-m3 with epoch 50 and batch size 32. The best epoch and batch size settings are from the research conducted in [
52,
53,
54]. We chose RoBERTa because it has a better accuracy results based on several previous studies. We need the highest accuracy of the claim results to verify the facts to impact the news readers’ trust in the news.
5. Conclusions
Our research focuses on developing a new model based on three types of RoBERTa models for fact verification. We applied the Homogeneous Ensemble (HE) or a system based on a single classification approach for fact verification on the RoBERTa models with a FEVER dataset of 10,000 data. Our method is called RoBERTaEns. In this study, we found that the application of the HE on RoBERTa resulted in better accuracy and a higher F1-Score than RoBERTa-m1, RoBERTa-m2, RoBERTa-m3, BERT, XL-NET, and XLM. The experimental results showed that RoBERTaEns improves model accuracy by 1.1% compared to RoBERTa-m1, 2% compared to RoBERTa-m2, and 1.6% compared to RoBERTa-m3. The F1-Score results on RoBERTaEns also showed an increased percentage of 1.1% compared to RoBERTa-m1, 1.5% compared to RoBERTa-m2, and 1.3% compared to RoBERTa-m3. Regarding the stability of prediction accuracy, the ensemble application has a better fact verification than the other models. In addition, RoBERTaEns has a smaller margin of error compared to the other models, and it proves that RoBERTaEns produces more robust values in dealing with different types of fact input in each fold.
In future research, we suggest applying another ensemble method to the RoBERTa model, i.e., the heterogeneous ensemble, and comparing it with the HE. This exploration could be carried out on different datasets in future studies.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}