
Startups and Consumer Purchase Behavior: Application of Support Vector Machine Algorithm


 ,
,  and
and 
Abstract
:1. Introduction
2. Background of the Study
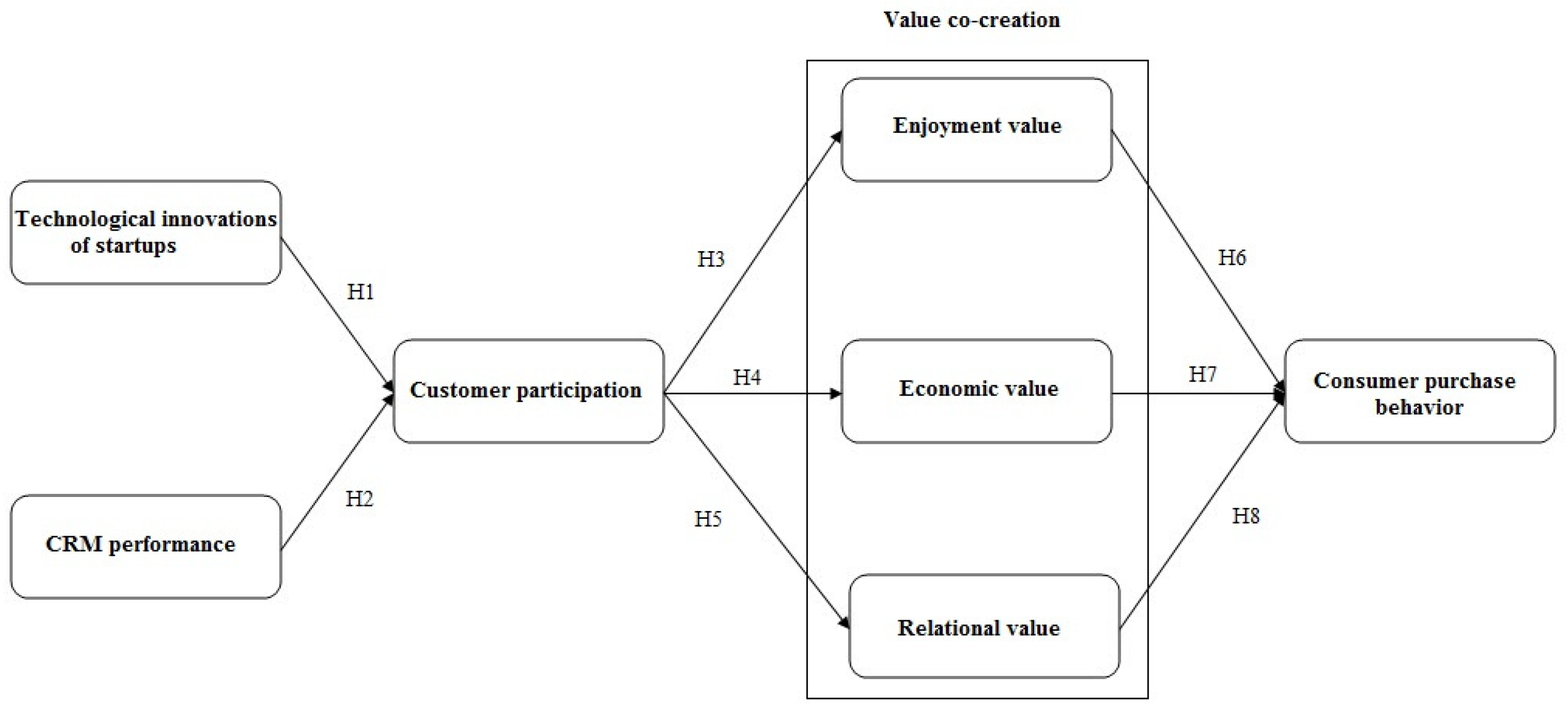
3. Literature Review and Hypotheses Development
3.1. Technological Innovations of Startups and Customer Participation
3.2. CRM Performance and Customer Participation
3.3. Customer Participation and Value Co-Creation
3.4. Value Co-Creation and Consumer Purchase Behavior
3.5. Application of Machine Learning in Business
4. Research Method
4.1. Measures and Data Collection
4.2. Unsupervised Machine Learning Algorithms
4.3. Supervised Machine Learning Algorithms
5. Results
5.1. Evaluation of Measurement Models
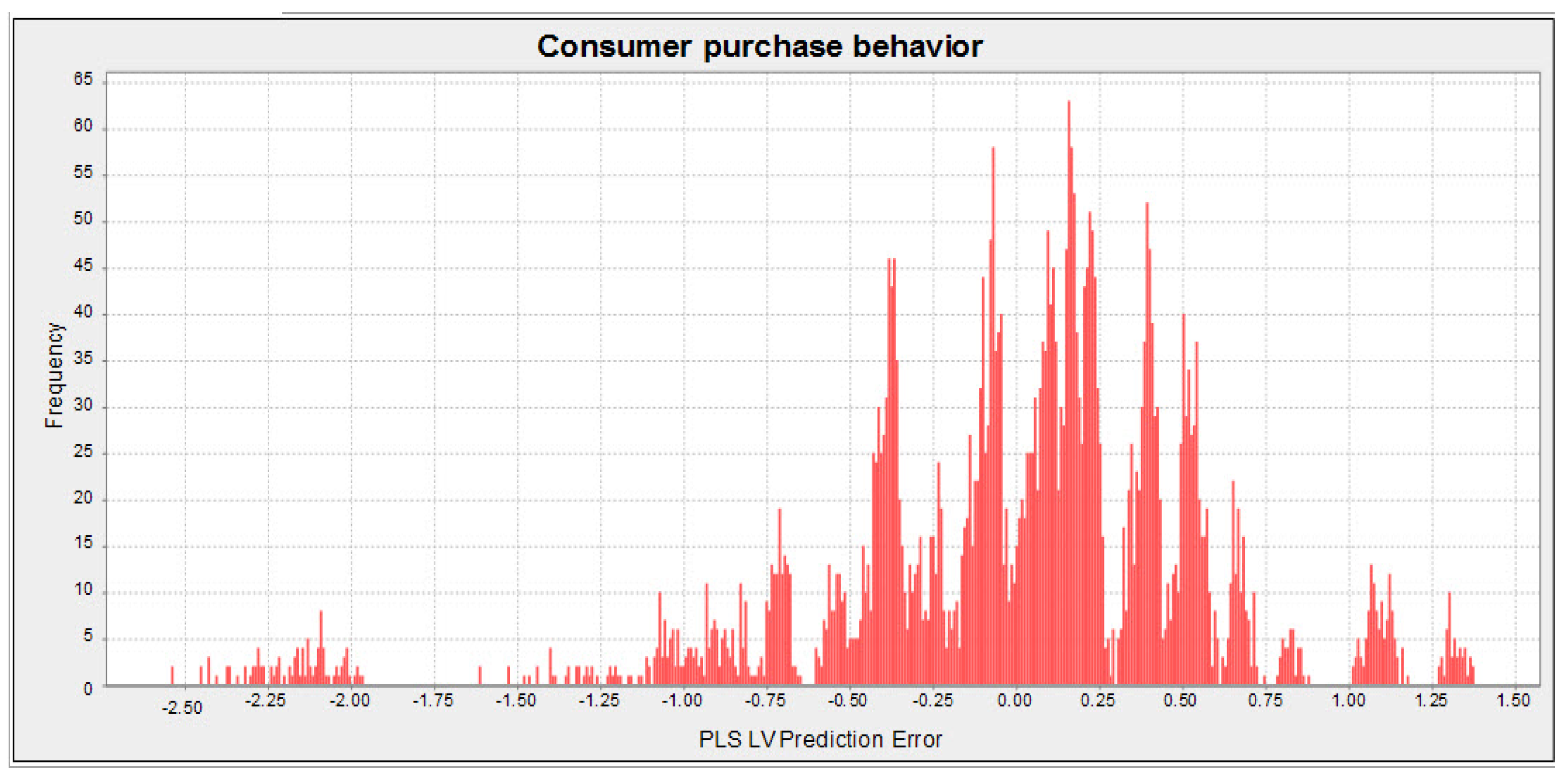
5.2. Structural Model Evaluation
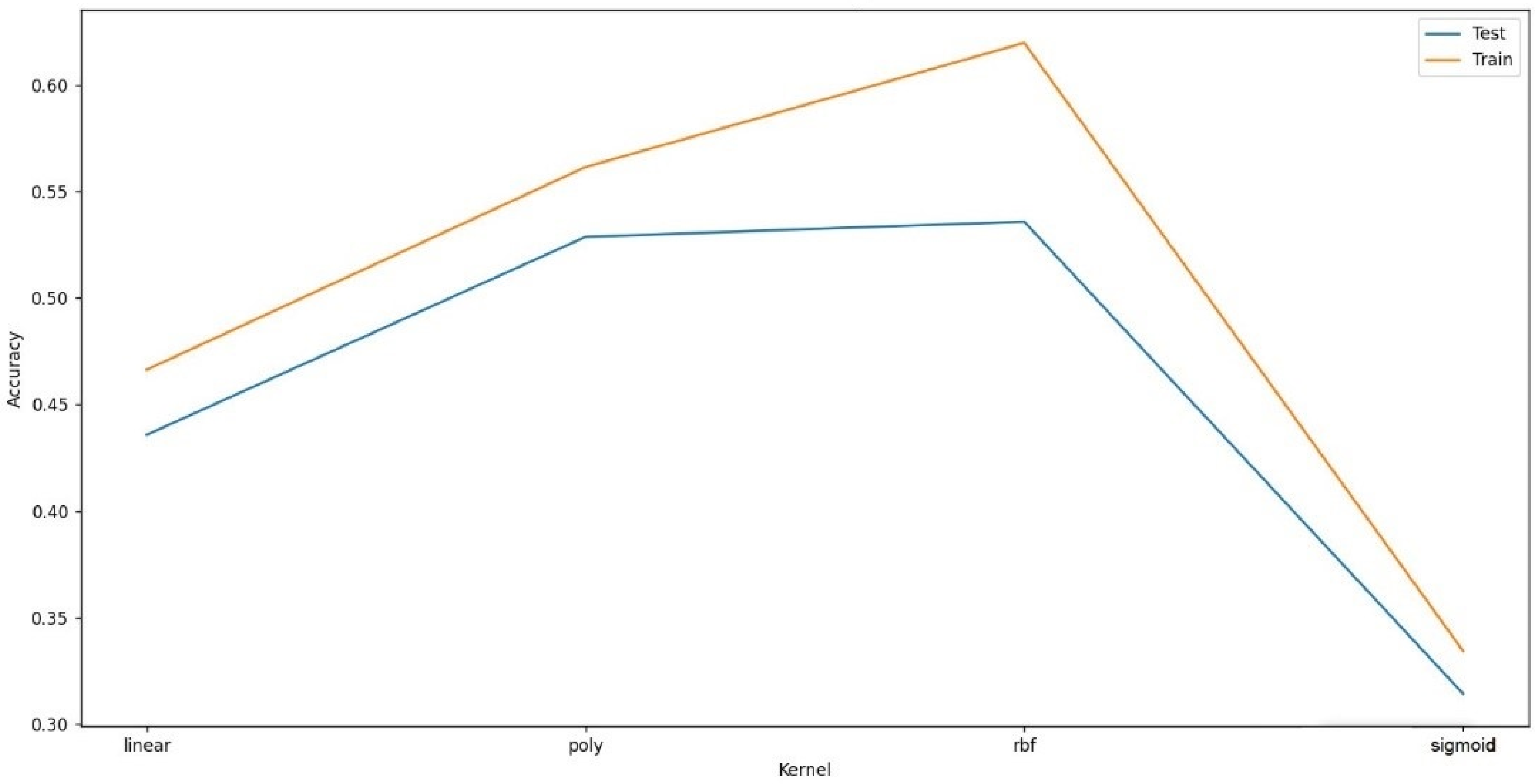
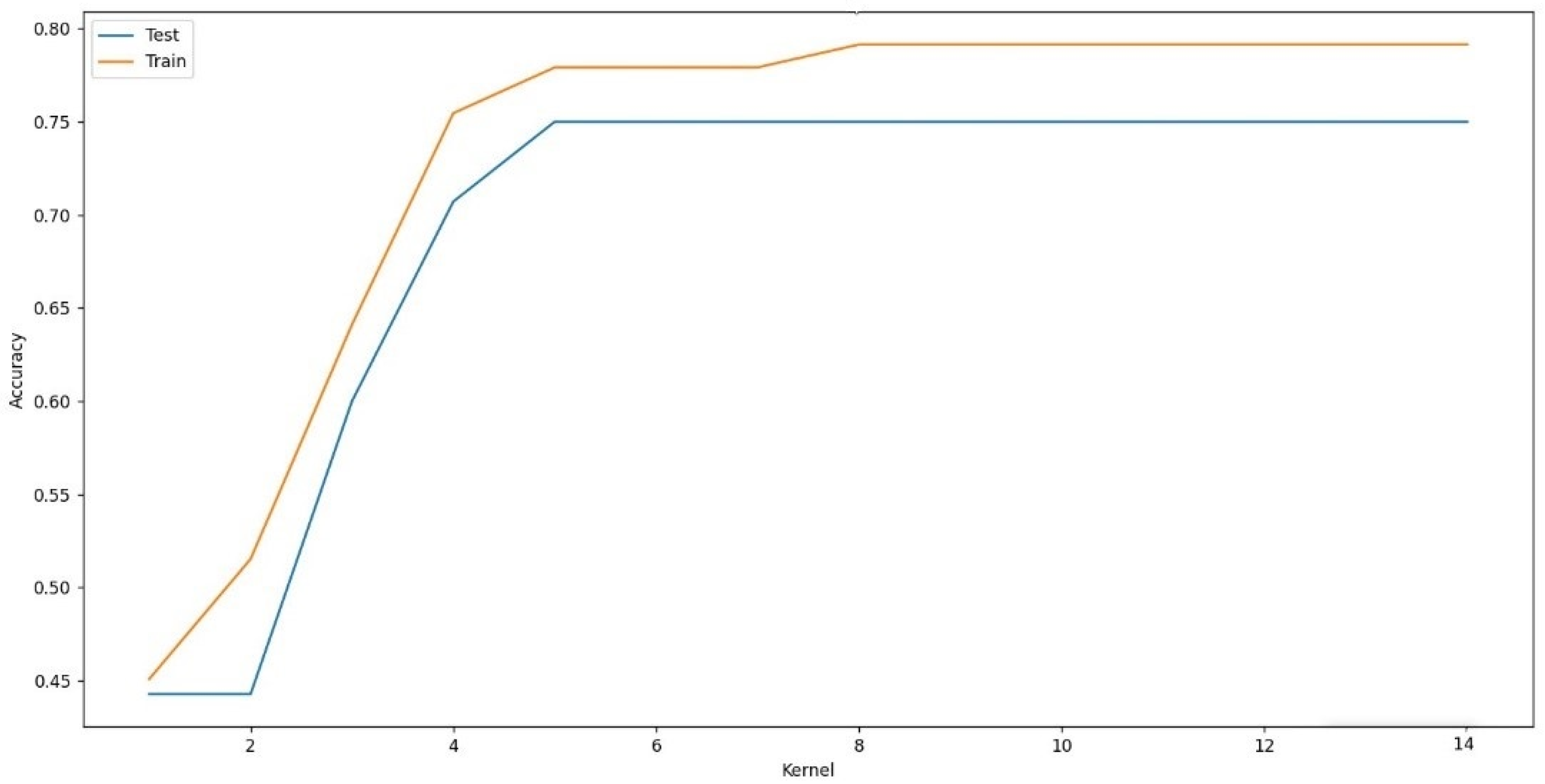
5.3. Support Vector Machine Algorithm (SVM)
6. Discussion
7. Conclusions
7.1. Managerial Implications
7.2. Limitations and Suggestions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Path Coefficients Model

Appendix B
| Algorithms A1: Code 1: Exploratory Data Analysis and plots |
| # import libraries import pandas as pd import matplotlib.pyplot as plt import seaborn as sb sb.set_theme(color_codes=True) # import data data = pd.read_excel(“data.xlsx”) x = data.drop(columns=[“CPB”]) y = data[“CPB”] sb.set_theme(color_codes=True) sb.regplot(x=“independent variables”, y=“CPB”, data=data) plt.show() # visualization: Exploratory Data Analysis (EDA) pd.plotting.scatter_matrix(data, c=y, figsize=[10, 10], s=150) plt.show() |
Appendix C

Appendix D
| Algorithms A2: Code 2: SVM algorithm |
| # import libraries import pandas as pd import matplotlib.pyplot as plt from sklearn.svm import SVC # Support vector Classifier from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score # import data data = pd.read_excel(“data”) x = data.drop(columns=[“Media”]) y = data[“Media”] # Train and Test x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3) print(x_train.shape) print(x_test.shape) # Model fit, model accuracy and score test_accuracy = [] train_accuracy = [] Kernel = [] for i in [“linear”, “poly”, “rbf”, “sigmoid”]: model = SVC(kernel=i, degree=2) model.fit(x_train, y_train) y_predict = model.predict(x_test) # print (model.score(x_test, y_test)) score = accuracy_score(y_test, y_predict) test_accuracy.append(model.score(x_test, y_test)) train_accuracy.append(model.score(x_train, y_train)) Kernel.append(i) # print(f”test accuracy is: {test_accuracy}, train accuracy is: {train_accuracy}, final accuracy is: {score}”) # plots plt.plot(test_accuracy, label=“Test”) plt.plot(train_accuracy, label=“Train”) plt.xticks([0, 1, 2, 3], Kernel) plt.xlabel(“Kernel”) plt.ylabel(“Accuracy”) plt.legend() plt.show() |
Appendix E
| Algorithms A3: Code 3: Polynomial degree |
| for i in range(1, 15): model = SVC(kernel=“poly”, degree=i) model.fit(x_train, y_train) y_predict = model.predict(x_test) # print (model.score(x_test, y_test)) score = accuracy_score(y_test, y_predict) test_accuracy.append(model.score(x_test, y_test)) train_accuracy.append(model.score(x_train, y_train)) Degree.append(i) |
References
- WHO. Director-General’s Opening Remarks at the Media Briefing on COVID-19. 2020. Available online: https://www.who.int/director-general/speeches/detail/who-director-general-s-opening-remarks-at-the-media-briefing-on-covid-19---11-march-2020 (accessed on 11 December 2021).
- Fernandes, N. Economic effects of coronavirus outbreak (COVID-19) on the world economy. IESE Bus. Sch. Work. Pap. 2020, WP-1240-E. [Google Scholar] [CrossRef]
- Salamzadeh, A.; Dana, L.P. The coronavirus (COVID-19) pandemic: Challenges among Iranian startups. J. Small Bus. Entrep. 2021, 33, 489–512. [Google Scholar] [CrossRef]
- Rodrigues, C.D.; de Noronha, M.E.S. What companies can learn from unicorn startups to overcome the COVID-19 crisis. Innov. Manag. Rev. 2021; ahead-of-print. [Google Scholar] [CrossRef]
- Brown, R.; Rocha, A. Entrepreneurial uncertainty during the COVID-19 crisis: Mapping the temporal dynamics of entrepreneurial finance. J. Bus. Ventur. Insights 2020, 14, e00174. [Google Scholar] [CrossRef]
- Kalogiannidis, S.; Chatzitheodoridis, F.; Kontsas, S. An Eclectic Discussion of the Effects of COVID-19 Pandemic on the World Economy During the First Stage of the Spread. Int. J. Financ. Res. 2020, 11, 137. [Google Scholar] [CrossRef]
- Kuckertz, A.; Brändle, L.; Gaudig, A.; Hinderer, S.; Reyes, C.A.M.; Prochotta, A.; Steinbrink, K.M.; Berger, E.S. Startups in times of crisis–A rapid response to the COVID-19 pandemic. J. Bus. Ventur. Insights 2020, 13, e00169. [Google Scholar] [CrossRef]
- Kursan Milaković, I. Purchase experience during the COVID-19 pandemic and social cognitive theory: The relevance of consumer vulnerability, resilience, and adaptability for purchase satisfaction and repurchase. Int. J. Consum. Stud. 2021, 45, 1425–1442. [Google Scholar] [CrossRef]
- Eger, L.; Komárková, L.; Egerová, D.; Mičík, M. The effect of COVID-19 on consumer shopping behaviour: Generational cohort perspective. J. Retail. Consum. Serv. 2021, 61, 102542. [Google Scholar] [CrossRef]
- Skala, A. The startup as a result of innovative entrepreneurship. In Digital Startups in Transition Economies; Springer: Cham, Switzerland, 2019; pp. 1–40. [Google Scholar]
- Voramontri, D.; Klieb, L. Impact of social media on consumer behaviour. Int. J. Inf. Decis. Sci. 2019, 11, 209–233. [Google Scholar]
- Sterk, V.; Sedlacek, P.; Benedetti-Fasil, C. EU Start-Up Calculator: Impact of COVID-19 on Aggregate Employment: Scenario Analysis for Austria, Belgium, Germany, Hungary, Italy and Spain; JRC121715; Publications Office of the European Union: Brussels, Belgium, 2020.
- Pereira, J.; Aldina Correia, V.B.; Salamzadeh, A. Unboxing organisational complexity: How does it affect business performance during the COVID-19 pandemic? J. Entrep. Public Policy 2021, 10, 424–444. [Google Scholar] [CrossRef]
- Sedlacek, P.; Sterk, V. Startups and employment following the COVID-19 pandemic: A calculator. CEPR Discuss. Pap. 2020, 14671. Available online: https://ideas.repec.org/p/cpr/ceprdp/14671.html (accessed on 19 February 2022).
- Roggeveen, A.L.; Sethuraman, R. How the COVID-19 pandemic may change the world of retailing. J. Retail. 2020, 96, 169. [Google Scholar] [CrossRef]
- De Oliveira, P.H.; Terence, A.C.F. Innovation practices in small technology-based companies during incubation and post-incubation periods. Innov. Manag. Rev. 2018, 15, 174–188. [Google Scholar] [CrossRef] [Green Version]
- Zawislak, P.A.; Fracasso, E.M.; Tello-Gamarra, J. Technological intensity and innovation capability in industrial firms. Innov. Manag. Rev. 2018, 15, 189–207. [Google Scholar] [CrossRef]
- Bouzari, P.; Gholampour, A.; Ebrahimi, P. The Interaction between Human and Media in the Future of Banking Industry. In Contemporary Applications of Actor Network Theory; Springer: Cham, Switzerland, 2020; pp. 257–274. [Google Scholar]
- Ebrahimi, P.; Ahmadi, M.; Gholampour, A.; Alipour, H. CRM performance and development of media entrepreneurship in digital, social media and mobile commerce. Int. J. Emerg. Mark. 2019, 16, 25–50. [Google Scholar] [CrossRef]
- Abdallah, A.B.; Phan, A.C.; Matsui, Y. Investigating the effects of managerial and technological innovations on operational performance and customer satisfaction of manufacturing companies. Int. J. Bus. Innov. Res. 2016, 10, 153–183. [Google Scholar] [CrossRef]
- Ngo, L.V.; O’Cass, A. Innovation and business success: The mediating role of customer participation. J. Bus. Res. 2013, 66, 1134–1142. [Google Scholar] [CrossRef]
- Wang, X.; Arnett, D.B.; Hou, L. Using external knowledge to improve organizational innovativeness: Understanding the knowledge leveraging process. J. Bus. Ind. Mark. 2016, 31, 164–173. [Google Scholar] [CrossRef]
- Füller, J.; Matzler, K. Virtual product experience and customer participation—A chance for customer-centred, really new products. Technovation 2007, 27, 378–387. [Google Scholar] [CrossRef]
- Shahin, A.; Nikneshan, P. Integration of CRM and QFD: A novel model for enhancing customer participation in design and delivery. TQM J. 2008, 20, 68–86. [Google Scholar] [CrossRef]
- Khodakarami, F.; Chan, Y.E. Exploring the role of customer relationship management (CRM) systems in customer knowledge creation. Inf. Manag. 2014, 51, 27–42. [Google Scholar] [CrossRef]
- Eisingerich, A.B.; Bell, S.J. Relationship marketing in the financial services industry: The importance of customer education, participation and problem management for customer loyalty. J. Financ. Serv. Mark. 2006, 10, 86–97. [Google Scholar] [CrossRef]
- Ahn, J.; Rho, T. Influence of customer–firm relationships on customer participation in the service industry. Serv. Bus. 2016, 10, 113–133. [Google Scholar] [CrossRef]
- Hau, L.N.; Tram Anh, P.N.; Thuy, P.N. The effects of interaction behaviors of service frontliners on customer participation in the value co-creation: A study of health care service. Serv. Bus. 2017, 11, 253–277. [Google Scholar] [CrossRef]
- Garrido-Moreno, A.; García-Morales, V.; King, S.; Lockett, N. Social Media use and value creation in the digital landscape: A dynamic-capabilities perspective. J. Serv. Manag. 2020, 31, 313–343. [Google Scholar] [CrossRef]
- Dong, B.; Evans, K.R.; Zou, S. The effects of customer participation in co-created service recovery. J. Acad. Mark. Sci. 2008, 36, 123–137. [Google Scholar] [CrossRef]
- Danarahmanto, P.A.; Primiana, I.; Azis, Y.; Kaltum, U. The sustainable performance of the digital start-up company based on customer participation, innovation, and business model. Bus. Theory Pract. 2020, 21, 115–124. [Google Scholar] [CrossRef]
- Fang, E.; Palmatier, R.W.; Evans, K.R. Influence of customer participation on creating and sharing of new product value. J. Acad. Mark. Sci. 2008, 36, 322–336. [Google Scholar] [CrossRef]
- Park, C.; Lee, H.; Jun, J.; Lee, T. Two-sided effects of customer participation: Roles of relationships and social-interaction values in social services. Serv. Bus. 2018, 12, 621–640. [Google Scholar] [CrossRef]
- Mursid, A.; Wu, C.H.-J. Customer participation, value co-creation and customer loyalty: Evidence from Umrah travel agencies in Indonesia. J. Islamic Mark. 2022, 13, 628–648. [Google Scholar] [CrossRef]
- Le Hau, N.; Thuy, P.N. Customer participation to co-create value in human transformative services: A study of higher education and health care services. Serv. Bus. 2016, 10, 603–628. [Google Scholar]
- Chen, C.-F.; Wang, J.-P. Customer participation, value co-creation and customer loyalty–A case of airline online check-in system. Comput. Hum. Behav. 2016, 62, 346–352. [Google Scholar] [CrossRef]
- Khajeheian, D.; Ebrahimi, P. Media branding and value co-creation: Effect of user participation in social media of newsmedia on attitudinal and behavioural loyalty. Eur. J. Int. Manag. 2021, 16, 499–528. [Google Scholar] [CrossRef]
- Vega-Vazquez, M.; Revilla-Camacho, M.Á.; Cossío-Silva, F.J. The value co-creation process as a determinant of customer satisfaction. Manag. Decis. 2013, 51, 1945–1953. [Google Scholar] [CrossRef]
- See-To, E.W.; Ho, K.K. Value co-creation and purchase intention in social network sites: The role of electronic Word-of-Mouth and trust–A theoretical analysis. Comput. Hum. Behav. 2014, 31, 182–189. [Google Scholar] [CrossRef]
- Guzel, M.; Sezen, B.; Alniacik, U. Drivers and consequences of customer participation into value co-creation: A field experiment. J. Prod. Brand Manag. 2020, 30, 1047–1061. [Google Scholar] [CrossRef]
- Hsu, L.-C. Investigating community members’ purchase intention on Facebook fan page: From a dualistic perspective of trust relationships. Ind. Manag. Data Syst. 2017, 117, 766–800. [Google Scholar] [CrossRef]
- Blasco-Arcas, L.; Hernandez-Ortega, B.; Jimenez-Martinez, J. The online purchase as a context for co-creating experiences. Drivers of and consequences for customer behavior. Internet Res. 2014, 24, 393–412. [Google Scholar] [CrossRef]
- Kelleher, J.D.; Mac Namee, B.; D’Arcy, A. Fundamentals of Machine Learning for Predictive Data Analytics: Algorithms, Worked Examples, and Case Studies; MIT Press: Cambridge, MA, USA, 2020. [Google Scholar]
- Kitsios, F.; Kamariotou, M. Artificial intelligence and business strategy towards digital transformation: A research agenda. Sustainability 2021, 13, 2025. [Google Scholar] [CrossRef]
- Schmidt, J.; Marques, M.R.; Botti, S.; Marques, M.A. Recent advances and applications of machine learning in solid-state materials science. npj Comput. Mater. 2019, 5, 83. [Google Scholar] [CrossRef]
- Al-Anqoudi, Y.; Al-Hamdani, A.; Al-Badawi, M.; Hedjam, R. Using Machine Learning in Business Process Re-Engineering. Big Data Cogn. Comput. 2021, 5, 61. [Google Scholar] [CrossRef]
- Chen, Q.; Lee, S. A Machine Learning Approach to Predict Customer Usage of a Home Workout Platform. Appl. Sci. 2021, 11, 9927. [Google Scholar] [CrossRef]
- Cioffi, R.; Travaglioni, M.; Piscitelli, G.; Petrillo, A.; De Felice, F. Artificial intelligence and machine learning applications in smart production: Progress, trends, and directions. Sustainability 2020, 12, 492. [Google Scholar] [CrossRef] [Green Version]
- Wuest, T.; Weimer, D.; Irgens, C.; Thoben, K.-D. Machine learning in manufacturing: Advantages, challenges, and applications. Prod. Manuf. Res. 2016, 4, 23–45. [Google Scholar] [CrossRef] [Green Version]
- Duan, Y.; Edwards, J.S.; Dwivedi, Y.K. Artificial intelligence for decision making in the era of Big Data–evolution, challenges and research agenda. Int. J. Inf. Manag. 2019, 48, 63–71. [Google Scholar] [CrossRef]
- Obthong, M.; Tantisantiwong, N.; Jeamwatthanachai, W.; Wills, G.B. A Survey on Machine Learning for Stock Price Prediction: Algorithms and Techniques. In Proceedings of the FEMIB 2020—2nd International Conference on Finance, Economics, Management and IT Business, Prague, Czech Republic, 5–6 May 2020. [Google Scholar]
- Carvalho, T.P.; Soares, F.A.; Vita, R.; Francisco, R.D.P.; Basto, J.P.; Alcalá, S.G. A systematic literature review of machine learning methods applied to predictive maintenance. Comput. Ind. Eng. 2019, 137, 106024. [Google Scholar] [CrossRef]
- Ebrahimi, P.; Salamzadeh, A.; Gholampour, A.; Fekete-Farkas, M. Social networks marketing and Hungarian online consumer purchase behavior: The microeconomics strategic view based on IPMA matrix. Acad. Strateg. Manag. J. 2021, 20, 1–7. [Google Scholar]
- Kim, J.O.; Forsythe, S.; Gu, Q.; Moon, S.J. Cross-cultural consumer values, needs and purchase behavior. J. Consum. Mark. 2002, 19, 481–502. [Google Scholar] [CrossRef]
- Etikan, I.; Musa, S.A.; Alkassim, R.S. Comparison of convenience sampling and purposive sampling. Am. J. Theor. Appl. Stat. 2016, 5, 1–4. [Google Scholar] [CrossRef] [Green Version]
- Alshurideh, M.; Al Kurdi, B.; Salloum, S.A.; Arpaci, I.; Al-Emran, M. Predicting the actual use of m-learning systems: A comparative approach using PLS-SEM and machine learning algorithms. Interact. Learn. Environ. 2020, 2020, 1–15. [Google Scholar] [CrossRef]
- Podsakoff, P.M.; MacKenzie, S.B.; Lee, J.-Y.; Podsakoff, N.P. Common method biases in behavioral research: A critical review of the literature and recommended remedies. J. Appl. Psychol. 2003, 88, 879. [Google Scholar] [CrossRef]
- Addagarla, S.K.; Amalanathan, A. Probabilistic unsupervised machine learning approach for a similar image recommender system for E-commerce. Symmetry 2020, 12, 1783. [Google Scholar] [CrossRef]
- Wang, R.; Song, Q.; Liu, Z.; Ma, H.; Gupta, M.K.; Liu, Z. A Novel Unsupervised Machine Learning-Based Method for Chatter Detection in the Milling of Thin-Walled Parts. Sensors 2021, 21, 5779. [Google Scholar] [CrossRef] [PubMed]
- Baldominos, A.; Saez, Y.; Isasi, P. A survey of handwritten character recognition with mnist and emnist. Appl. Sci. 2019, 9, 3169. [Google Scholar] [CrossRef] [Green Version]
- Yuan, C.; Yang, H. Research on K-value selection method of K-means clustering algorithm. J 2019, 2, 226–235. [Google Scholar] [CrossRef] [Green Version]
- Jafarzadegan, M.; Safi-Esfahani, F.; Beheshti, Z. Combining hierarchical clustering approaches using the PCA method. Expert Syst. Appl. 2019, 137, 1–10. [Google Scholar] [CrossRef]
- Melit Devassy, B.; George, S.; Nussbaum, P. Unsupervised clustering of hyperspectral paper data using t-SNE. J. Imaging 2020, 6, 29. [Google Scholar] [CrossRef]
- Severson, K.A.; Molaro, M.C.; Braatz, R.D. Principal component analysis of process datasets with missing values. Processes 2017, 5, 38. [Google Scholar] [CrossRef] [Green Version]
- Li, M.; Kashef, R.; Ibrahim, A. Multi-level clustering-based outlier’s detection (MCOD) using self-organizing maps. Big Data Cogn. Comput. 2020, 4, 24. [Google Scholar] [CrossRef]
- Zhong, M.; Wang, J.; Jiang, T.; Huang, Z.; Chen, X.; Hong, Y. Using the apriori algorithm and Copula function for the bivariate analysis of flash flood risk. Water 2020, 12, 2223. [Google Scholar] [CrossRef]
- Comesaña-Campos, A.; Bouza-Rodríguez, J.B. An application of Hebbian learning in the design process decision-making. J. Intell. Manuf. 2016, 27, 487–506. [Google Scholar] [CrossRef]
- Chen, T.-C.T.; Liu, C.-L.; Lin, H.-D. Advanced artificial neural networks. Algorithms 2018, 11, 102. [Google Scholar] [CrossRef] [Green Version]
- Schaffer, J.D. Initial experiments evolving spiking neural networks with supervised learning capability. Procedia Comput. Sci. 2017, 114, 184–191. [Google Scholar] [CrossRef]
- Lee, J.H.; Shin, J.; Realff, M.J. Machine learning: Overview of the recent progresses and implications for the process systems engineering field. Comput. Chem. Eng. 2018, 114, 111–121. [Google Scholar] [CrossRef]
- Alsharif, M.H.; Kelechi, A.H.; Yahya, K.; Chaudhry, S.A. Machine learning algorithms for smart data analysis in internet of things environment: Taxonomies and research trends. Symmetry 2020, 12, 88. [Google Scholar] [CrossRef] [Green Version]
- Alimi, O.A.; Ouahada, K.; Abu-Mahfouz, A.M.; Rimer, S.; Alimi, K.O.A. A review of research works on supervised learning algorithms for SCADA intrusion detection and classification. Sustainability 2021, 13, 9597. [Google Scholar] [CrossRef]
- Aspuru, J.; Ochoa-Brust, A.; Félix, R.A.; Mata-López, W.; Mena, L.J.; Ostos, R.; Martínez-Peláez, R. Segmentation of the ECG signal by means of a linear regression algorithm. Sensors 2019, 19, 775. [Google Scholar] [CrossRef] [Green Version]
- Wu, X.; Gao, Y.; Jiao, D. Multi-label classification based on random forest algorithm for non-intrusive load monitoring system. Processes 2019, 7, 337. [Google Scholar] [CrossRef] [Green Version]
- Thanh Noi, P.; Kappas, M. Comparison of random forest, k-nearest neighbor, and support vector machine classifiers for land cover classification using Sentinel-2 imagery. Sensors 2018, 18, 18. [Google Scholar] [CrossRef] [Green Version]
- Senekane, M. Differentially private image classification using support vector machine and differential privacy. Mach. Learn. Knowl. Extr. 2019, 1, 483–491. [Google Scholar] [CrossRef] [Green Version]
- He, H.; Li, S.; Hu, L.; Duarte, N.; Manta, O.; Yue, X.-G. Risk factor identification of sustainable guarantee network based on logistic regression algorithm. Sustainability 2019, 11, 3525. [Google Scholar] [CrossRef] [Green Version]
- Rrmoku, K.; Selimi, B.; Ahmedi, L. Application of Trust in Recommender Systems—Utilizing Naive Bayes Classifier. Computation 2022, 10, 6. [Google Scholar] [CrossRef]
- Ma, S.; Yang, P.; Lai, B.; Su, C.; Zhao, W.; Yang, K.; Jin, R.; Cheng, T.; Xu, B. Adaptive gradient estimation stochastic parallel gradient descent algorithm for laser beam cleanup. Photonics 2021, 8, 165. [Google Scholar] [CrossRef]
- Ringle, C.M. Partial Least Squares Structural Equation Modelling (PLS-SEM) Using SmartPLS 3. 2015. Available online: http://www.smartpls.com (accessed on 14 November 2021).
- Hair, J.F., Jr.; Hult, G.T.M.; Ringle, C.M.; Sarstedt, M. A Primer on Partial Least Squares Structural Equation Modeling (PLS-SEM); Sage Publications: Thousand Oaks, CA, USA, 2017. [Google Scholar]
- Hair, J.F.; Risher, J.J.; Sarstedt, M.; Ringle, C.M. When to use and how to report the results of PLS-SEM. Eur. Bus. Rev. 2019, 31, 2–24. [Google Scholar] [CrossRef]
- Ringle, C.M.; Sarstedt, M. Gain more insight from your PLS-SEM results: The importance-performance map analysis. Ind. Manag. Data Syst. 2016, 116, 1865–1886. [Google Scholar] [CrossRef]
- Roshandel-Arbatani, T.; Kawamorita, H.; Ghanbary, S.; Ebrahimi, P. Modelling media entrepreneurship in social media: SEM and MLP-ANN Approach. AD-Minist. 2019, 34, 35–57. [Google Scholar]
- Ebrahimi, P.; Soleimani, M.; Kot, S.; Fekete-Farkas, M.; Alipour, H. COVID-19 crisis and online businesses resilience: A moderated mediation model. Eur. J. Int. Manag. 2021. [Google Scholar] [CrossRef]
- Gholampour, A.; Jamshidi, M.H.M.; Habibi, A.; Motamedi Dehkordi, N.; Ebrahimi, P. The Impact of Hospital Information System on Nurses’ Satisfaction in Iranian Public Hospitals: The Moderating Role of Computer Literacy. J. Inf. Technol. Manag. 2020, 12, 141–159. [Google Scholar]
- Moghadamzadeh, A.; Ebrahimi, P.; Radfard, S.; Salamzadeh, A.; Khajeheian, D. Investigating the role of customer co-creation behavior on social media platforms in rendering innovative services. Sustainability 2020, 12, 6926. [Google Scholar] [CrossRef]
- Janavi, E.; Soleimani, M.; Gholampour, A.; Friedrichsen, M.; Ebrahimi, P. Effect of social media adoption and media needs on online purchase behavior: The moderator roles of media type, gender, age. J. Inf. Technol. Manag. 2021, 13, 1–24. [Google Scholar]
- Rehman Khan, S.A.; Yu, Z. Assessing the eco-environmental performance: An PLS-SEM approach with practice-based view. Int. J. Logist. Res. Appl. 2021, 24, 303–321. [Google Scholar] [CrossRef]
- Liu, Y.; Ting, H.; Ringle, C. Appreciation to and behavior intention regarding upscale ethnic restaurants. J. Hosp. Tour. Res. 2021, 10963480211011544. [Google Scholar] [CrossRef]
- Sarstedt, M.; Hair, J.F., Jr.; Cheah, J.-H.; Becker, J.-M.; Ringle, C.M. How to specify, estimate, and validate higher-order constructs in PLS-SEM. Australas. Mark. J. AMJ 2019, 27, 197–211. [Google Scholar] [CrossRef]
- Fornell, C.; Larcker, D.F. Evaluating structural equation models with unobservable variables and measurement error. J. Mark. Res. 1981, 18, 39–50. [Google Scholar] [CrossRef]
- Manley, S.C.; Hair, J.F.; Williams, R.I.; McDowell, W.C. Essential new PLS-SEM analysis methods for your entrepreneurship analytical toolbox. Int. Entrep. Manag. J. 2021, 17, 1805–1825. [Google Scholar] [CrossRef]
- Kock, N. Common method bias in PLS-SEM: A full collinearity assessment approach. Int. J. E-Collab. IJEC 2015, 11, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Raza, A.; Rather, R.A.; Iqbal, M.K.; Bhutta, U.S. An assessment of corporate social responsibility on customer company identification and loyalty in banking industry: A PLS-SEM analysis. Manag. Res. Rev. 2020, 43, 1337–1370. [Google Scholar] [CrossRef]
- Shmueli, G.; Ray, S.; Estrada, J.M.V.; Chatla, S.B. The elephant in the room: Predictive performance of PLS models. J. Bus. Res. 2016, 69, 4552–4564. [Google Scholar] [CrossRef]
- Shmueli, G.; Sarstedt, M.; Hair, J.F.; Cheah, J.-H.; Ting, H.; Vaithilingam, S.; Ringle, C.M. Predictive model assessment in PLS-SEM: Guidelines for using PLSpredict. Eur. J. Mark. 2019, 53, 2322–2347. [Google Scholar] [CrossRef]
- Henseler, J. Partial least squares path modeling: Quo Vadis? Qual. Quant. 2018, 52, 1–8. [Google Scholar] [CrossRef] [Green Version]
- Ye, K. Key feature recognition algorithm of network intrusion signal based on neural network and support vector machine. Symmetry 2019, 11, 380. [Google Scholar] [CrossRef] [Green Version]
- Zhang, H.; Lu, Y.; Wang, B.; Wu, S. The impacts of technological environments and co-creation experiences on customer participation. Inf. Manag. 2015, 52, 468–482. [Google Scholar] [CrossRef]
- Nambisan, S.; Baron, R.A. Interactions in virtual customer environments: Implications for product support and customer relationship management. J. Interact. Mark. 2007, 21, 42–62. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Respondent Profile | (N = 466) | ||
|---|---|---|---|
| Attributes | Distribution | Frequency | Percent |
| Sex | Male | 269 | 57.7 |
| Female | 197 | 42.3 | |
| Age | 16 to 24 | 128 | 27.5 |
| 25 to 34 | 196 | 42.1 | |
| 35 to 44 | 106 | 22.7 | |
| 45 to 54 | 28 | 6.0 | |
| 55 and up | 8 | 1.7 | |
| Education | Below diploma and diploma | 134 | 28.8 |
| Bachelor degree | 93 | 20.0 | |
| Associate degree | 145 | 31.1 | |
| Master | 85 | 18.2 | |
| PhD | 9 | 1.9 | |
| Variables and Items | Outer Loadings | VIF |
|---|---|---|
| Technological innovations of startups (AVE = 0.791, C. alpha = 0.868, Rho_A = 0.873, CR = 0.919) | ||
| TECH 1: Product innovations introduced by various startups (in Hungary) during the COVID-19 pandemic have been extensive. | 0.914 | 2.650 |
| TECH 2: Service innovations introduced by various startups (in Hungary) during the COVID-19 pandemic have been extensive. | 0.893 | 2.295 |
| TECH 3: Different startups (in Hungary) introduced process innovations during the COVID-19 pandemic have been extensive. | 0.861 | 2.069 |
| CRM performance (AVE = 0.647, C. alpha = 0.818, Rho_A = 0.841, CR = 0.880) | ||
| CRM 1: I have experienced startups gathering information about how often customers buy products/services during the pandemic. | 0.885 | 2.198 |
| CRM 2: I have experienced that startups target different marketing communication to different customer groups during the pandemic. | 0.772 | 1.687 |
| CRM 3: I have experienced startups trying to assess the customer’s profitability during the pandemic. | 0.812 | 1.875 |
| CRM 4: I have experienced that startups try to improve the quality of their products and services during the pandemic. | 0.742 | 1.429 |
| Customer participation (AVE = 0.733, C. alpha = 0.878, Rho_A = 0.881, CR = 0.916) | ||
| CP 1: Reporting further comments (related to products/ services of startups) coverage and public information during the COVID-19 pandemic. | 0.817 | 1.925 |
| CP 2: Commenting on social media accounts of news media contents creates a social dialogue related to different startups. | 0.859 | 2.210 |
| CP 3: Users’ suggestions of related articles and social media accounts about different startups provide value to other users. | 0.880 | 2.858 |
| CP 4: Users of startups read and follow other users’ posts and comments (compare services during the pandemic). | 0.867 | 2.749 |
| Enjoyment value (AVE = 0.675, C. alpha = 0.760, Rho_A = 0.782, CR = 0.861) | ||
| ENJ 1: Users of startups like to read other users’ posts and comments on different social media during the COVID-19 pandemic. | 0.839 | 1.544 |
| ENJ 2: Reading further comments are enjoyable for other startup users during the COVID-19 pandemic. | 0.748 | 1.450 |
| ENJ 3: Reading the recommended articles and posts on social media is enjoyable for other users of startups during the COVID-19 pandemic. | 0.873 | 1.803 |
| Economic value | ||
| (AVE = 0.701, C. alpha = 0.788, Rho_A = 0.799, CR = 0.876) | ||
| ECO 1: Analysis of users’ commentaries on the social media platform offers data leading to economic benefit related to startups during the pandemic. | 0.796 | 1.559 |
| ECO 2: Users’ contribution to social media platforms leads to economic benefit by coupons, tickets, and another price cut related to startups during the pandemic. | 0.856 | 1.760 |
| ECO 3: Contribution of users in social media platforms decreases the cost of finding the relevant articles for other users related to startups during the pandemic. | 0.859 | 1.677 |
| Relational value (AVE = 0.676, C. alpha = 0.761, Rho_A = 0.762, CR = 0.862) | ||
| REL 1: Through startups, users can expand their communications during the COVID-19 pandemic. | 0.820 | 1.617 |
| REL 2: Through startups, new friendships are made during the COVID-19 pandemic. | 0.845 | 1.832 |
| REL 3: Through startups, users find new economic ways of living, and they can adjust costs during the COVID-19 pandemic. | 0.801 | 1.403 |
| Consumer purchase behavior (AVE = 0.741, C. alpha = 0.821, Rho_A = 0.825, CR = 0.895) | ||
| CPB 1: Many users perform online shopping following startups capabilities. | 0.864 | 3.225 |
| CPB 2: I am faithful to some brands based on the startup’s capabilities. | 0.938 | 4.091 |
| CPB 3: If I want to repurchase an item, I prioritize previously purchased brands in different startups. | 0.773 | 1.563 |
| Constructs | CRM | CPB | CP | ECO | ENJ | REL | TECH |
|---|---|---|---|---|---|---|---|
| CRM | 0.805 | ||||||
| CPB | 0.801 | 0.861 | |||||
| CP | 0.782 | 0.730 | 0.856 | ||||
| ECO | 0.743 | 0.708 | 0.734 | 0.837 | |||
| ENJ | 0.763 | 0.736 | 0.733 | 0.718 | 0.822 | ||
| REL | 0.694 | 0.797 | 0.739 | 0.717 | 0.715 | 0.822 | |
| TECH | 0.671 | 0.711 | 0.731 | 0.695 | 0.666 | 0.668 | 0.889 |
| Items | CRM | CPB | CP | ECO | ENJ | REL | TECH |
|---|---|---|---|---|---|---|---|
| CP1 | 0.674 | 0.656 | 0.817 | 0.659 | 0.708 | 0.623 | 0.566 |
| Cp2 | 0.534 | 0.528 | 0.859 | 0.501 | 0.538 | 0.588 | 0.686 |
| Cp3 | 0.674 | 0.579 | 0.880 | 0.589 | 0.541 | 0.545 | 0.566 |
| Cp4 | 0.589 | 0.673 | 0.867 | 0.502 | 0.659 | 0.566 | 0.573 |
| CPB1 | 0.689 | 0.864 | 0.659 | 0.678 | 0.622 | 0.527 | 0.682 |
| CPB2 | 0.562 | 0.938 | 0.747 | 0.531 | 0.510 | 0.560 | 0.667 |
| CPB3 | 0.655 | 0.773 | 0.532 | 0.673 | 0.722 | 0.567 | 0.489 |
| CRM1 | 0.885 | 0.722 | 0.774 | 0.676 | 0.668 | 0.582 | 0.636 |
| CRM2 | 0.772 | 0.580 | 0.515 | 0.519 | 0.579 | 0.485 | 0.403 |
| CRM3 | 0.812 | 0.655 | 0.572 | 0.526 | 0.575 | 0.529 | 0.468 |
| CRM4 | 0.742 | 0.661 | 0.611 | 0.646 | 0.624 | 0.632 | 0.615 |
| ECO1 | 0.509 | 0.606 | 0.582 | 0.796 | 0.638 | 0.508 | 0.512 |
| ECO2 | 0.650 | 0.670 | 0.722 | 0.856 | 0.698 | 0.567 | 0.582 |
| ECO3 | 0.689 | 0.544 | 0.573 | 0.859 | 0.515 | 0.508 | 0.642 |
| ENJ1 | 0.638 | 0.767 | 0.746 | 0.695 | 0.839 | 0.577 | 0.497 |
| ENJ2 | 0.519 | 0.528 | 0.552 | 0.526 | 0.748 | 0.540 | 0.484 |
| ENJ3 | 0.605 | 0.634 | 0.630 | 0.669 | 0.873 | 0.645 | 0.655 |
| REL1 | 0.579 | 0.660 | 0.628 | 0.571 | 0.607 | 0.820 | 0.596 |
| REL2 | 0.527 | 0.596 | 0.525 | 0.570 | 0.528 | 0.845 | 0.478 |
| REL3 | 0.596 | 0.698 | 0.652 | 0.619 | 0.617 | 0.801 | 0.561 |
| TECH1 | 0.605 | 0.643 | 0.679 | 0.652 | 0.622 | 0.614 | 0.914 |
| TECH2 | 0.621 | 0.640 | 0.674 | 0.662 | 0.606 | 0.594 | 0.893 |
| TECH3 | 0.563 | 0.614 | 0.591 | 0.533 | 0.545 | 0.573 | 0.861 |
| Hypotheses | Direct Effect | SD | T-Statistics | p Value | Low CL | High CL | Decision |
|---|---|---|---|---|---|---|---|
| H1 | 0.374 | 0.042 | 8.940 *** | 0.000 | 0.286 | 0.451 | Supported |
| H2 | 0.531 | 0.039 | 13.600 *** | 0.000 | 0.463 | 0.612 | Supported |
| H3 | 0.833 | 0.023 | 35.445 *** | 0.000 | 0.782 | 0.869 | Supported |
| H4 | 0.834 | 0.029 | 28.423 *** | 0.000 | 0.767 | 0.885 | Supported |
| H5 | 0.739 | 0.039 | 18.813 *** | 0.000 | 0.644 | 0.802 | Supported |
| H6 | 0.394 | 0.042 | 9.438 *** | 0.000 | 0.315 | 0.478 | Supported |
| H7 | 0.240 | 0.048 | 4.950 *** | 0.000 | 0.141 | 0.325 | Supported |
| H8 | 0.343 | 0.034 | 10.008 *** | 0.000 | 0.285 | 0.410 | Supported |
| Model fit | R2 | R2 Adjusted | Q2 predicted | ||||
| CPB | 79.7% | 79.6% | 0.670 | ||||
| CP | 68.9% | 68.7% | 0.688 | ||||
| ENJ | 69.4% | 69.3% | 0.611 | ||||
| ECO | 69.6% | 69.5% | 0.610 | ||||
| REL | 54.6% | 54.4% | 0.535 |
| Items | RMSEPLS-SEM | RMSELM | ∆RMSE |
|---|---|---|---|
| CPB1 | 0.478 | 0.516 | −0.038 |
| CPB2 | 0.452 | 0.473 | −0.021 |
| CPB3 | 0.615 | 0.641 | −0.026 |
| Latent Variables | Importance | Performance |
|---|---|---|
| CRM performance | 0.415 | 80.373 |
| Customer participation | 0.782 | 82.353 |
| Economic value | 0.240 | 80.905 |
| Enjoyment value | 0.394 | 78.873 |
| Relational value | 0.343 | 80.352 |
| Technological innovations of startups | 0.292 | 78.087 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ebrahimi, P.; Salamzadeh, A.; Soleimani, M.; Khansari, S.M.; Zarea, H.; Fekete-Farkas, M. Startups and Consumer Purchase Behavior: Application of Support Vector Machine Algorithm. Big Data Cogn. Comput. 2022, 6, 34. https://doi.org/10.3390/bdcc6020034
Ebrahimi P, Salamzadeh A, Soleimani M, Khansari SM, Zarea H, Fekete-Farkas M. Startups and Consumer Purchase Behavior: Application of Support Vector Machine Algorithm. Big Data and Cognitive Computing. 2022; 6(2):34. https://doi.org/10.3390/bdcc6020034
Chicago/Turabian StyleEbrahimi, Pejman, Aidin Salamzadeh, Maryam Soleimani, Seyed Mohammad Khansari, Hadi Zarea, and Maria Fekete-Farkas. 2022. "Startups and Consumer Purchase Behavior: Application of Support Vector Machine Algorithm" Big Data and Cognitive Computing 6, no. 2: 34. https://doi.org/10.3390/bdcc6020034
APA StyleEbrahimi, P., Salamzadeh, A., Soleimani, M., Khansari, S. M., Zarea, H., & Fekete-Farkas, M. (2022). Startups and Consumer Purchase Behavior: Application of Support Vector Machine Algorithm. Big Data and Cognitive Computing, 6(2), 34. https://doi.org/10.3390/bdcc6020034