
Breast and Lung Anticancer Peptides Classification Using N-Grams and Ensemble Learning Techniques



Abstract
:1. Introduction
2. Related Work
3. Datasets
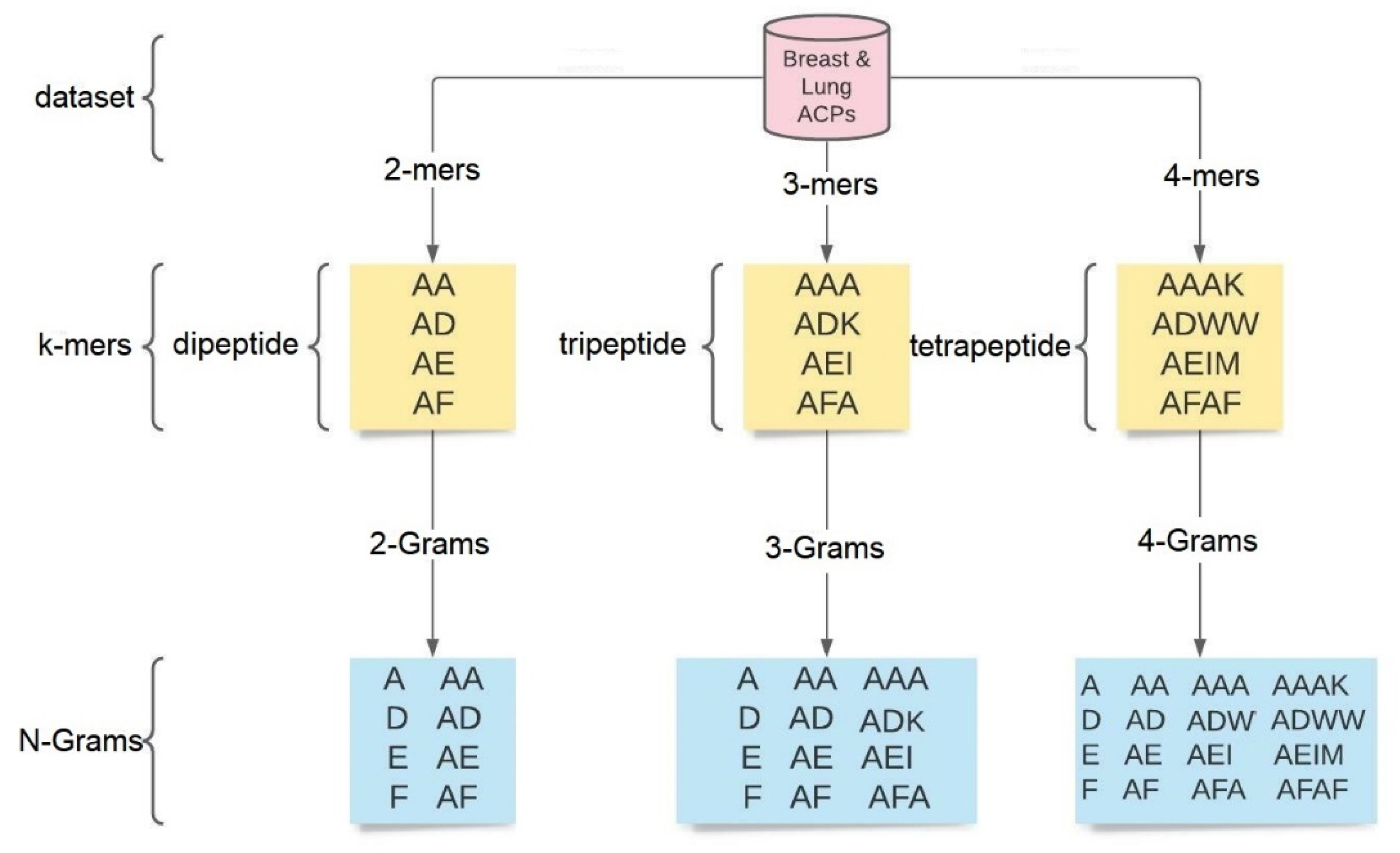
4. Features Extraction for Peptides
- A monopeptide has a single amino acid (k = 1).
- A dipeptide has two amino acids (k = 2).
- A tripeptide has three amino acids (k = 3).
- A tetrapeptide has four amino acids (k = 4).
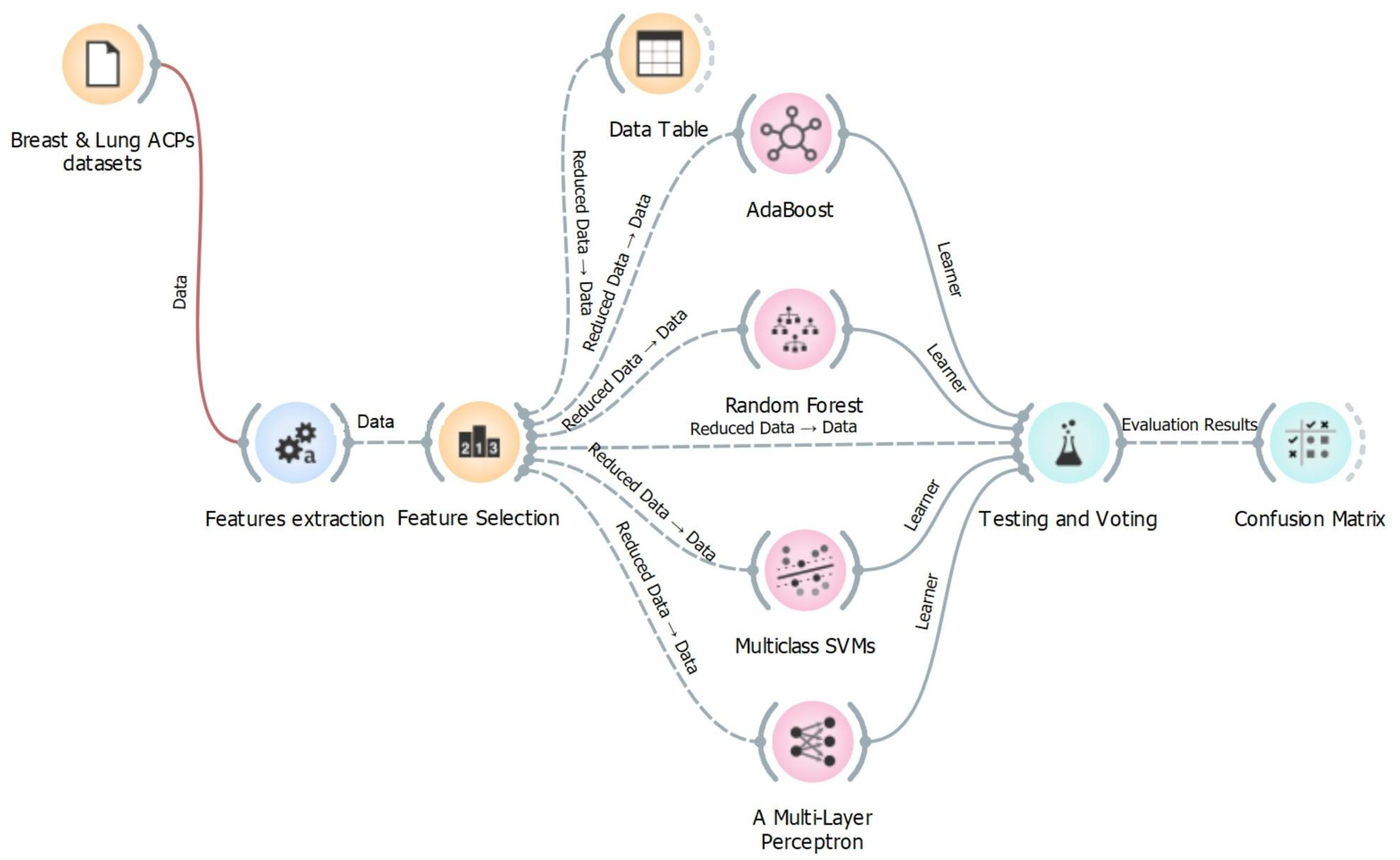
5. Proposed Feature Selection Methods
6. Classifiers
7. Results and Discussion
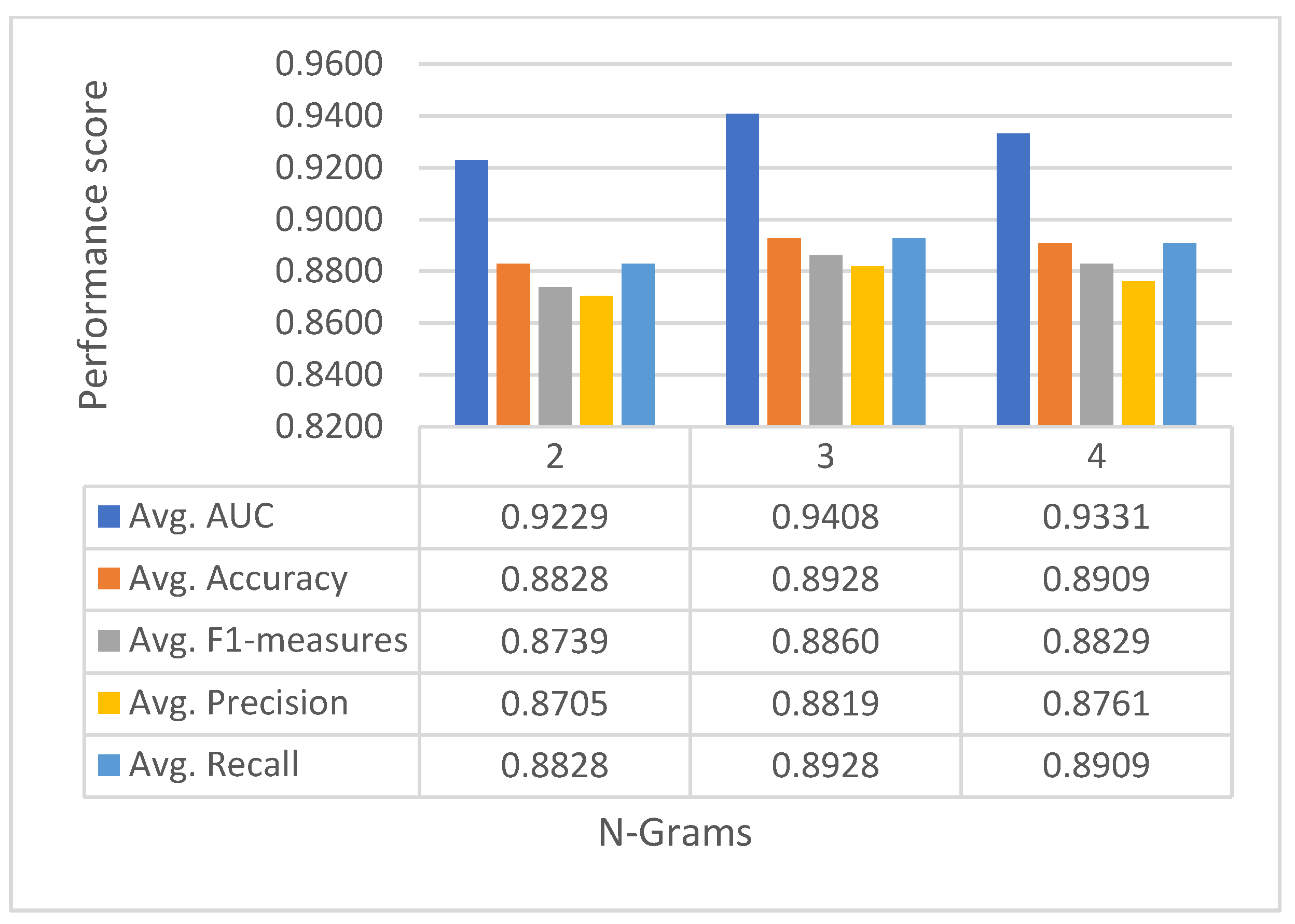
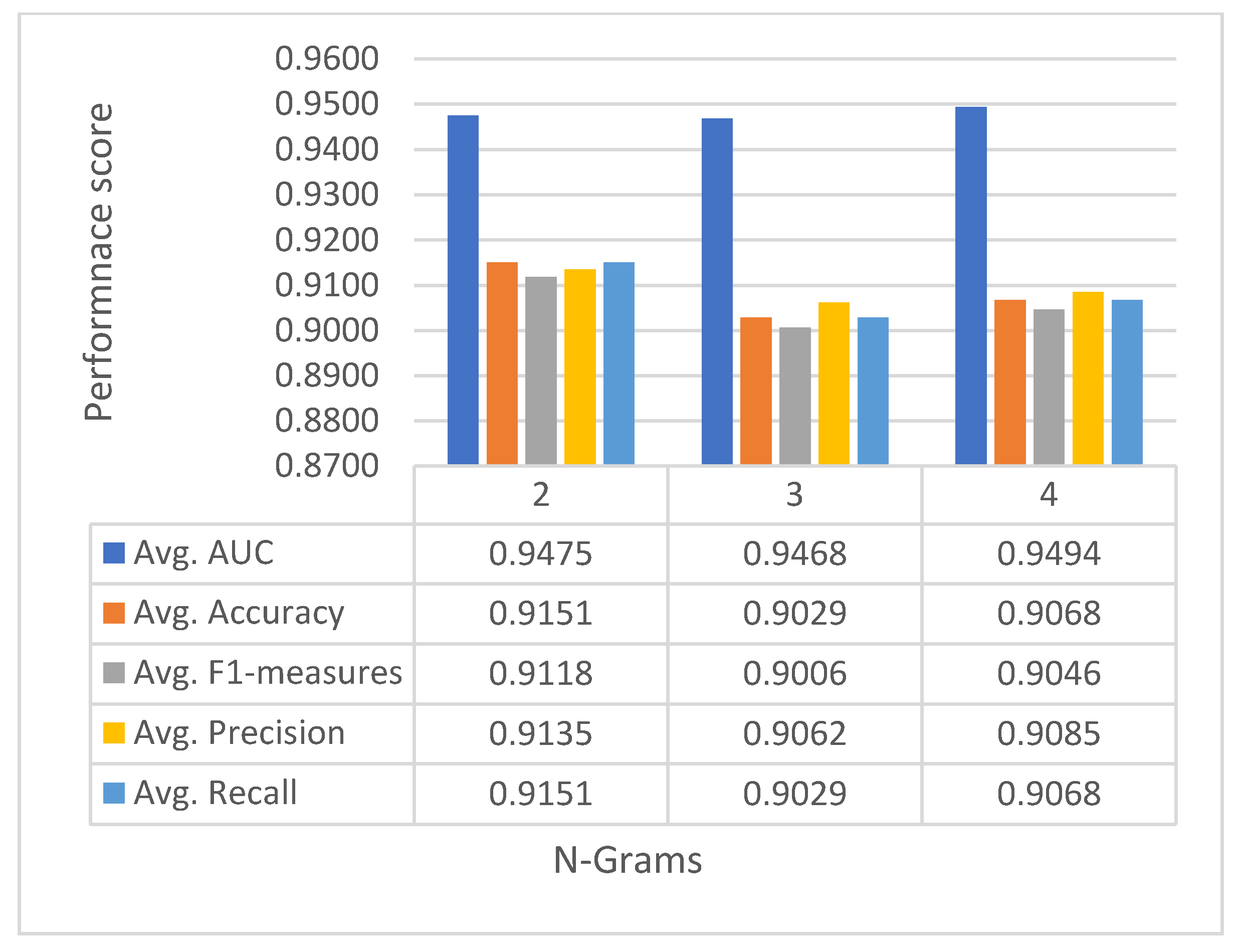
7.1. Performance Comparison with Different Amino Acid Profiles
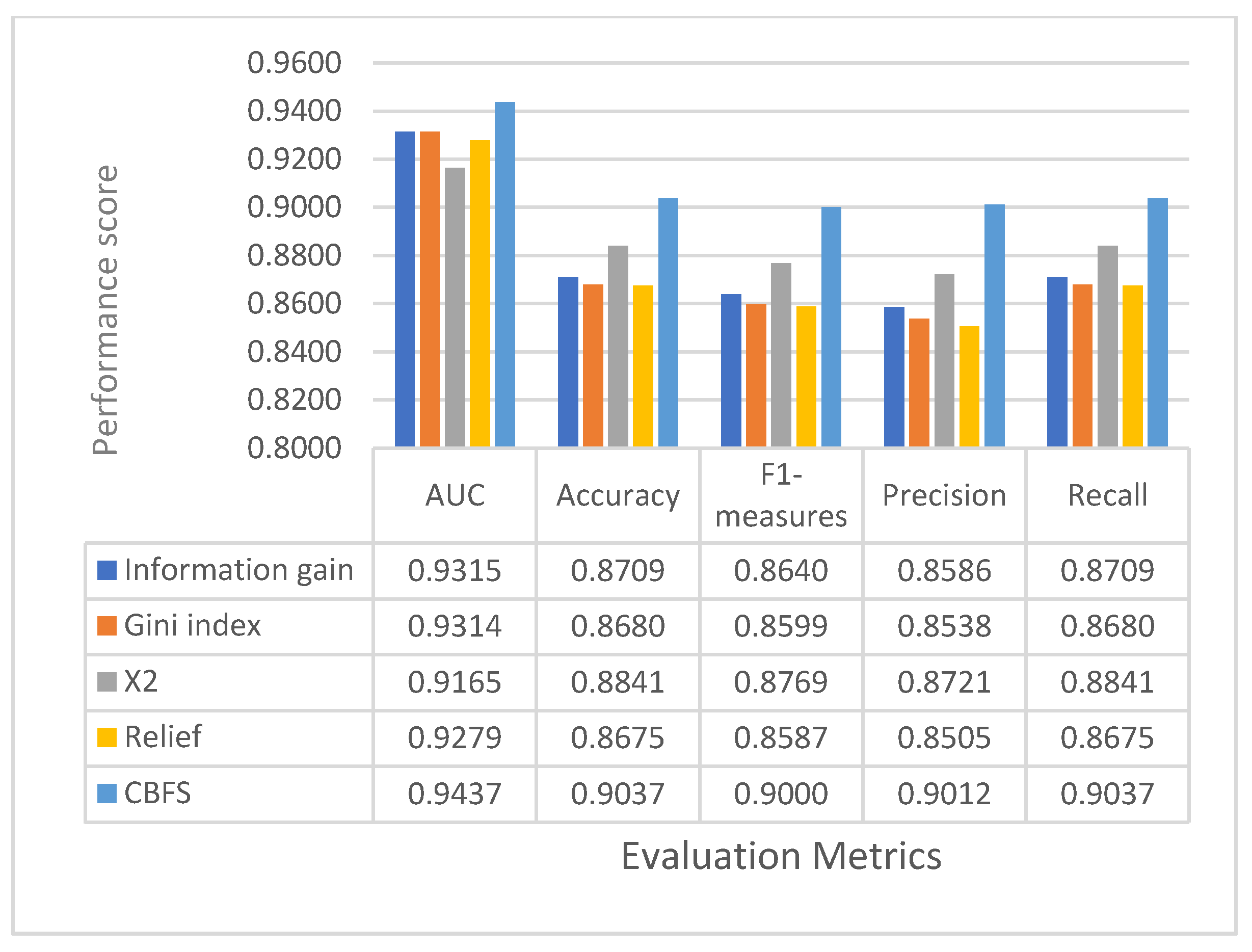
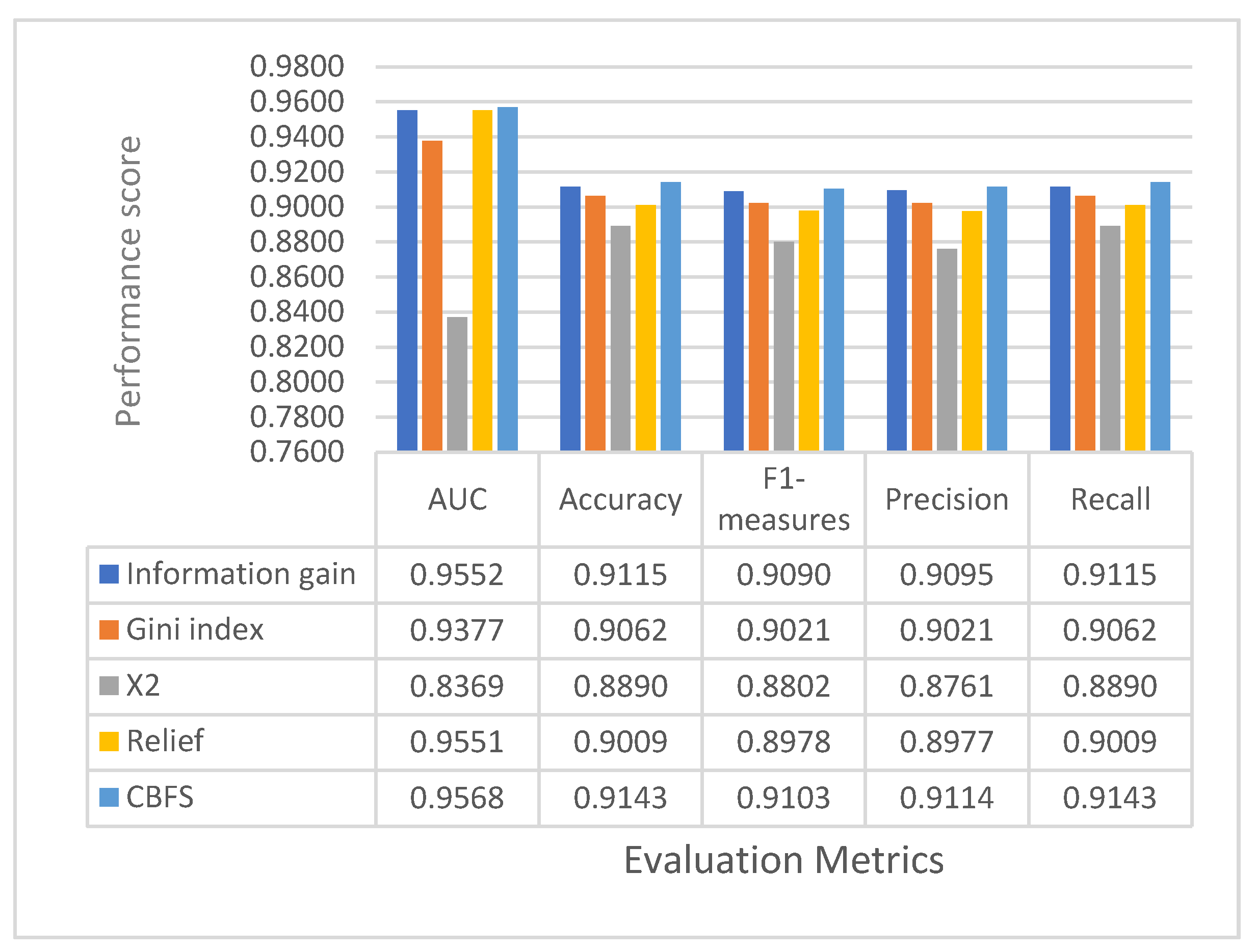
7.2. Performance Comparison with Different Features Selection Methods References
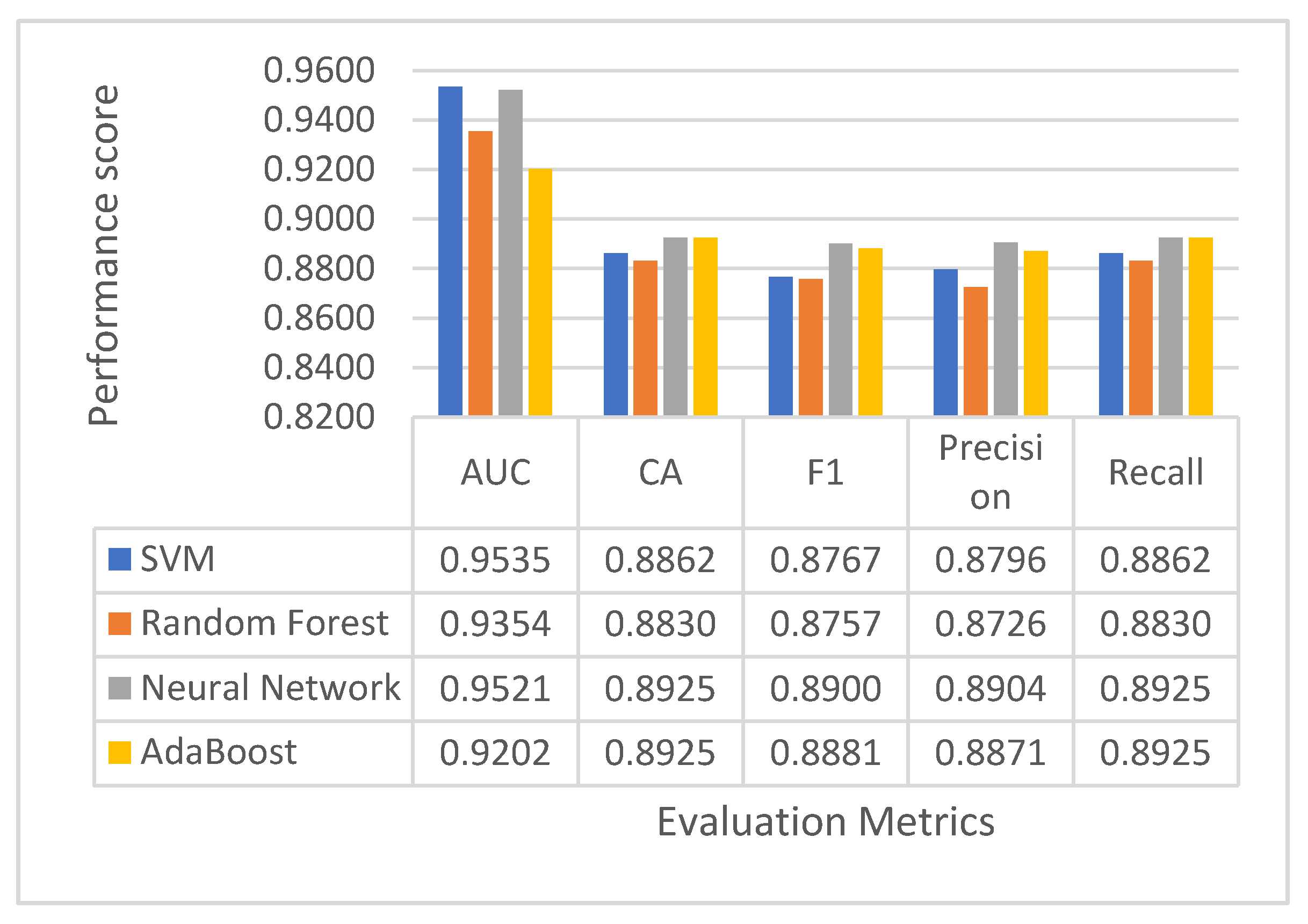
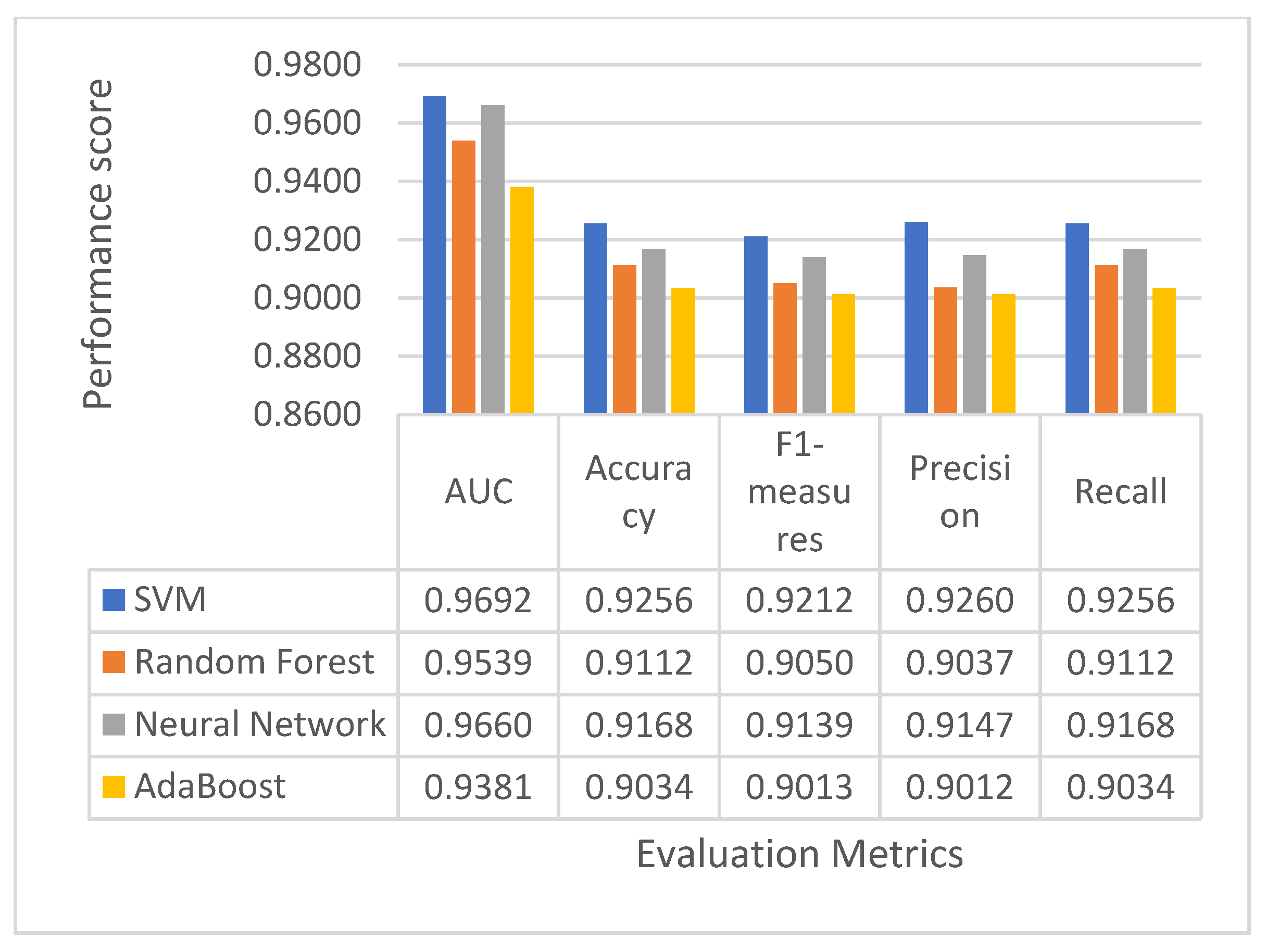
7.3. Performance Comparison with Multiple Classifiers
7.4. Performance Comparison with State of the Art
- The proposed breast ACPs method outperformed all the mentioned methods, except for cACP-2LFS, because a minimal dataset was used (150 non-ACP 150 ACP) with 20 features only.
- The proposed lung ACPs method outperformed all mentioned methods.
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sung, H.; Ferlay, J.; Siegel, R.L.; Laversanne, M.; Soerjomataram, I.; Jemal, A.; Bray, F. Global cancer statistics 2020: GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries. CA Cancer J. Clin. 2021, 71, 209–249. [Google Scholar] [CrossRef] [PubMed]
- Torre, L.A.; Bray, F.; Siegel, R.; Ferlay, J.; Lortet-Tieulent, J.; Jemal, A. Global cancer statistics, 2012. CA Cancer J. Clin. 2015, 65, 87–108. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gaspar, D.; Veiga, A.S.; Castanho, M.A.R.B. From antimicrobial to anticancer peptides. A review. Front. Microbiol. 2013, 4, 294. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chiangjong, W.; Chutipongtanate, S.; Hongeng, S. Anticancer peptide: Physicochemical property, functional aspect and trend in clinical application. Int. J. Oncol. 2020, 57, 678–696. [Google Scholar] [CrossRef] [PubMed]
- Jakubczyk, A.; Karaś, M.; Rybczyńska-Tkaczyk, K.; Zielińska, E.; Zieliński, D. Current trends of bioactive peptides—New sources and therapeutic effect. Foods 2020, 9, 864. [Google Scholar] [CrossRef]
- Harris, F.; Dennison, S.R.; Singh, J.; Phoenix, D.A. On the selectivity and efficacy of defense peptides with respect to cancer cells. Med. Res. Rev. 2013, 33, 190–234. [Google Scholar] [CrossRef]
- Basith, S.; Manavalan, B.; Shin, T.H.; Lee, D.Y.; Lee, G. Evolution of machine learning algorithms in the prediction and design of anticancer peptides. Curr. Protein Pept. Sci. 2020, 21, 1242–1250. [Google Scholar] [CrossRef]
- Wei, L.; Zhou, C.; Chen, H.; Song, J.; Su, R. ACPred-FL: A sequence-based predictor using effective feature representation to improve the prediction of anticancer peptides. Bioinformatics 2018, 34, 4007–4016. [Google Scholar] [CrossRef]
- Pande, A.; Patiyal, S.; Lathwal, A.; Arora, C.; Kaur, D.; Dhall, A.; Mishra, G.; Kaur, H.; Sharma, N.; Jain, S. Computing wide range of protein/peptide features from their sequence and structure. BioRxiv 2019, 599126. [Google Scholar] [CrossRef]
- Chen, W.; Ding, H.; Feng, P.; Lin, H.; Chou, K.-C. iACP: A sequence-based tool for identifying anticancer peptides. Oncotarget 2016, 7, 16895–16909. [Google Scholar] [CrossRef] [Green Version]
- Manavalan, B.; Basith, S.; Shin, T.H.; Choi, S.; Kim, M.O.; Lee, G. MLACP: Machine-learning-based prediction of anticancer peptides. Oncotarget 2017, 8, 77121. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xu, L.; Liang, G.; Wang, L.; Liao, C. A novel hybrid sequence-based model for identifying anticancer peptides. Genes 2018, 9, 158. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Boopathi, V.; Subramaniyam, S.; Malik, A.; Lee, G.; Manavalan, B.; Yang, D.-C. mACPpred: A support vector machine-based meta-predictor for identification of anticancer peptides. Int. J. Mol. Sci. 2019, 20, 1964. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, Q.; Zhou, W.; Wang, D.; Wang, S.; Li, Q. Prediction of anticancer peptides using a low-dimensional feature model. Front. Bioeng. Biotechnol. 2020, 8, 892. [Google Scholar] [CrossRef]
- Akbar, S.; Hayat, M.; Tahir, M.; Chong, K.T. cACP-2LFS: Classification of anticancer peptides using sequential discriminative model of KSAAP and two-level feature selection approach. IEEE Access 2020, 8, 131939–131948. [Google Scholar] [CrossRef]
- Agrawal, P.; Bhagat, D.; Mahalwal, M.; Sharma, N.; Raghava, G.P.S. AntiCP 2.0: An updated model for predicting anticancer peptides. Brief. Bioinform. 2021, 22, bbaa153. [Google Scholar] [CrossRef] [PubMed]
- He, W.; Wang, Y.; Cui, L.; Su, R.; Wei, L. Learning embedding features based on multisense-scaled attention architecture to improve the predictive performance of anticancer peptides. Bioinformatics 2021, 37, 4684–4693. [Google Scholar] [CrossRef]
- Yi, H.-C.; You, Z.-H.; Zhou, X.; Cheng, L.; Li, X.; Jiang, T.-H.; Chen, Z.-H. ACP-DL: A deep learning long short-term memory model to predict anticancer peptides using high-efficiency feature representation. Mol. Ther.-Nucleic Acids 2019, 17, 1–9. [Google Scholar] [CrossRef] [Green Version]
- Chen, J.; Cheong, H.H.; Siu, S.W.I. xDeep-AcPEP: Deep Learning Method for Anticancer Peptide Activity Prediction Based on Convolutional Neural Network and Multitask Learning. J. Chem. Inf. Model. 2021, 61, 3789–3803. [Google Scholar] [CrossRef]
- Ahmed, S.; Muhammod, R.; Adilina, S.; Khan, Z.H.; Shatabda, S.; Dehzangi, A. ACP-MHCNN: An Accurate Multi-Headed Deep-Convolutional Neural Network to Predict Anticancer peptides. BioRxiv 2020, 11, 23676. [Google Scholar] [CrossRef]
- Cao, R.; Wang, M.; Bin, Y.; Zheng, C. DLFF-ACP: Prediction of ACPs based on deep learning and multi-view features fusion. PeerJ 2021, 9, 11906. [Google Scholar] [CrossRef] [PubMed]
- Sun, M.; Yang, S.; Hu, X.; Zhou, Y. ACPNet: A Deep Learning Network to Identify Anticancer Peptides by Hybrid Sequence Information. Molecules 2022, 27, 1544. [Google Scholar] [CrossRef] [PubMed]
- Tyagi, A.; Tuknait, A.; Anand, P.; Gupta, S.; Sharma, M.; Mathur, D.; Joshi, A.; Singh, S.; Gautam, A.; Raghava, G.P.S. CancerPPD: A database of anticancer peptides and proteins. Nucleic Acids Res. 2015, 43, D837–D843. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Grisoni, F.; Neuhaus, C.S.; Hishinuma, M.; Gabernet, G.; Hiss, J.A.; Kotera, M.; Schneider, G. De novo design of anticancer peptides by ensemble artificial neural networks. J. Mol. Model. 2019, 25, 112. [Google Scholar] [CrossRef]
- Luo, H.; Nijveen, H. Understanding and identifying amino acid repeats. Brief. Bioinform. 2014, 15, 582–591. [Google Scholar] [CrossRef] [Green Version]
- Zhang, J.; Guo, J.; Yu, X.; Yu, X.; Guo, W.; Zeng, T.; Chen, L. Mining k-mers of various lengths in biological sequences. In Bioinformatics Research and Applications, Proceedings of the 13th International Symposium, ISBRA 2017, Honolulu, HI, USA, 29 May–2 June 2017; Cai, Z., Daescu, O., Li, M., Eds.; Springer International Publishing: Berlin/Heidelberg, Germany, 2017. [Google Scholar]
- Azhagusundari, B.; Thanamani, A.S. Feature selection based on information gain. Int. J. Innov. Technol. Explor. Eng. 2013, 2, 18–21. [Google Scholar]
- Liu, H.; Zhou, M.; Lu, X.S.; Yao, C. Weighted Gini index feature selection method for imbalanced data. In Proceedings of the 2018 IEEE 15th International Conference on Networking, Sensing and Control (ICNSC), Zhuhai, China, 27–29 March 2018. [Google Scholar]
- Zhai, Y.; Song, W.; Liu, X.; Liu, L.; Zhao, X. A chi-square statistics based feature selection method in text classification. In Proceedings of the 2018 IEEE 9th International Conference on Software Engineering and Service Science (ICSESS), Beijing, China, 23–25 November 2018. [Google Scholar]
- Rosario, S.F.; Thangadurai, K. RELIEF: Feature selection approach. Int. J. Innov. Res. Dev. 2015, 4, 218–224. [Google Scholar]
- Hall, M.A. Correlation-based feature selection of discrete and numeric class machine learning. In Proceedings of the Seventeenth International Conference on Machine Learning, Stanford, CA, USA, 29 June–2 July 2000; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 2000. [Google Scholar]
- An, T.K.; Kim, M.H. A new diverse AdaBoost classifier. In Proceedings of the 2010 International Conference on Artificial Intelligence and Computational Intelligence, Sanya, China, 23–24 October 2010. [Google Scholar]
- Liaw, A.; Wiener, M. Classification and regression by random Forest. R News 2002, 2, 18–22. [Google Scholar]
- Chamasemani, F.F.; Singh, Y.P. Multi-class support vector machine (SVM) classifiers—An application in hypothyroid detection and classification. In Proceedings of the 2011 Sixth International Conference on Bio-Inspired Computing: Theories and Applications, Penang, Malaysia, 27–29 September 2011. [Google Scholar]
- Taud, H.; Mas, J.F. Multilayer perceptron (MLP). In Geomatic Approaches for Modeling Land Change Scenarios, 1st ed.; Camacho Olmedo, M.T., Paege, M., Mas, J.F., Escobar, F., Eds.; Springer: Cham, Switzerland, 2018; pp. 451–455. [Google Scholar]
- Demšar, J.; Curk, T.; Erjavec, A.; Gorup, Č.; Hočevar, T.; Milutinovič, M.; Možina, M.; Polajnar, M.; Toplak, M.; Starič, A.; et al. Orange: Data Mining Toolbox in Python. J. Mach. Learn. Res. 2013, 14, 2349–2353. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| References No. | Method | Dataset | No. of Non-ACP vs. ACP | Classifier |
|---|---|---|---|---|
| [10] | iACP | Hajisharifi | 206 non-ACP 138 ACP | SVM |
| [11] | MLACP | CancerPPD | 206 non-ACP 138 ACP | SVM and RFT |
| [12] | SAP | Hajisharifi | 206 non-ACP 138 ACP | SVM |
| [13] | mACPpred | Independent dataset | 157 non-ACP 157 ACP | SVM |
| [14] | Li, Qingwen, et al. | Hajisharifi | 206 non-ACP 138 ACP | SVM, RFT, and LibD3C |
| [15] | cACP-2LFS | CancerPPD | 150 non-ACP 150 ACP | FKNN, SVM and RFT |
| [16] | AntiCP 2.0 | Main dataset | 861 non-ACP 861 ACP | Extra Tree |
| [18] | ACP-DL | ACP740 and ACP240 | 364/111 non-ACP 376/129 ACP | LSTM |
| [19] | xDeep-AcPEP | CancerPPD | 65 non-ACP 85 ACP | CNN |
| [20] | ACP-MHCNN | Independent dataset | 364/111 non-ACP 376/129 ACP | CNN |
| [21] | DLFF-ACP | CancerPPD | 65 non-ACP 85 ACP | CNN |
| [22] | ACPNet | Independent dataset | 364/111 non-ACP 376/129 ACP | RNN |
| Cancer Types | Class | EC50, IC50, or LC50 | No. of Peptides |
|---|---|---|---|
| breast cancer | virtual inactive | >50 μM | 750 |
| breast cancer | experimental inactive | >50 μM | 83 |
| breast cancer | moderately active | up to 50 μM | 98 |
| breast cancer | very active | ≤5 μM | 18 |
| lung cancer | virtual inactive | >50 μM | 750 |
| lung cancer | experimental inactive | >50 μM | 52 |
| lung cancer | moderately active | up to 50 μM | 75 |
| lung cancer | very active | ≤5 μM | 24 |
| Classifier | Key Parameters |
|---|---|
| AdaBoost | Base estimator: Tree Number of estimators: 50 Learning rate: 1 Classification algorithm: SAMME.R Regression loss function: Linear |
| RFT | Number of trees:10 Number of attributes at each split:5 Limit depth of individual tree: 3 Don’t split subset smaller than: 5 |
| Multi-class SVMs | Cost©: 1 Regression loss epsilon (ɛ): 0.10 Kernel: RBF Numerical tolerance: 0.0010 Iteration limit: 100 |
| Multi-Layer Perceptron | Neurons in hidden layers: 100 Activation function: ReLu Solver: Adam Regularization: 0.0001 Maximum number of iterations: 200 |
| Method | Classifier | No. of Features | Accuracy | Predictions |
|---|---|---|---|---|
| MLACP | SVM and RFT | 20, 400, 5, and 11 | 88.7% | 206 non-ACP 138 ACP |
| cACP-2LFS | FKNN, SVM and RFT | 20 | 93.72% | 150 non-ACP 150 ACP |
| xDeep-AcPEP | CNN | - | 82.42% | 65 non-ACP 85 ACP |
| DLFF-ACP | CNN | - | 82% | 65 non-ACP 85 ACP |
| Proposed breast ACPs | Ensemble learning | 35 | 89.25% | 750 virtual inactive, 83 experimental inactive, 98 moderately active, and 18 very active |
| Proposed lung ACPs | Ensemble learning | 31 | 95.35% | 750 virtual inactive, 52 experimental inactive, 75 moderately active, and 24 very active |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abbas, A.R.; Mahdi, B.S.; Fadhil, O.Y. Breast and Lung Anticancer Peptides Classification Using N-Grams and Ensemble Learning Techniques. Big Data Cogn. Comput. 2022, 6, 40. https://doi.org/10.3390/bdcc6020040
Abbas AR, Mahdi BS, Fadhil OY. Breast and Lung Anticancer Peptides Classification Using N-Grams and Ensemble Learning Techniques. Big Data and Cognitive Computing. 2022; 6(2):40. https://doi.org/10.3390/bdcc6020040
Chicago/Turabian StyleAbbas, Ayad Rodhan, Bashar Saadoon Mahdi, and Osamah Younus Fadhil. 2022. "Breast and Lung Anticancer Peptides Classification Using N-Grams and Ensemble Learning Techniques" Big Data and Cognitive Computing 6, no. 2: 40. https://doi.org/10.3390/bdcc6020040
APA StyleAbbas, A. R., Mahdi, B. S., & Fadhil, O. Y. (2022). Breast and Lung Anticancer Peptides Classification Using N-Grams and Ensemble Learning Techniques. Big Data and Cognitive Computing, 6(2), 40. https://doi.org/10.3390/bdcc6020040