
A Comparative Study of MongoDB and Document-Based MySQL for Big Data Application Data Management




Abstract
:1. Introduction
2. Overview of MongoDB and the Document-Based MySQL
3. Related Work
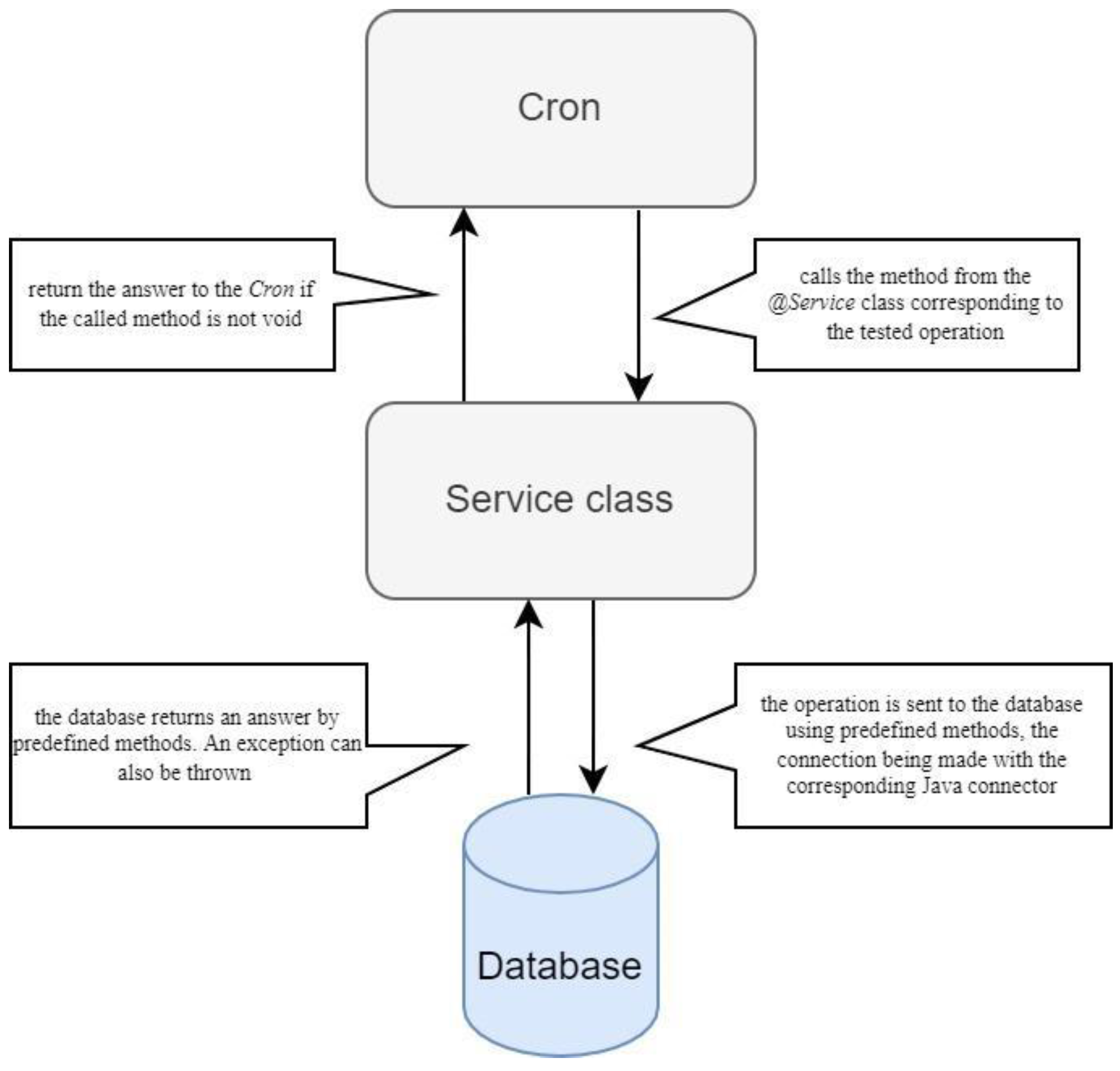
4. Method and Testing Architecture
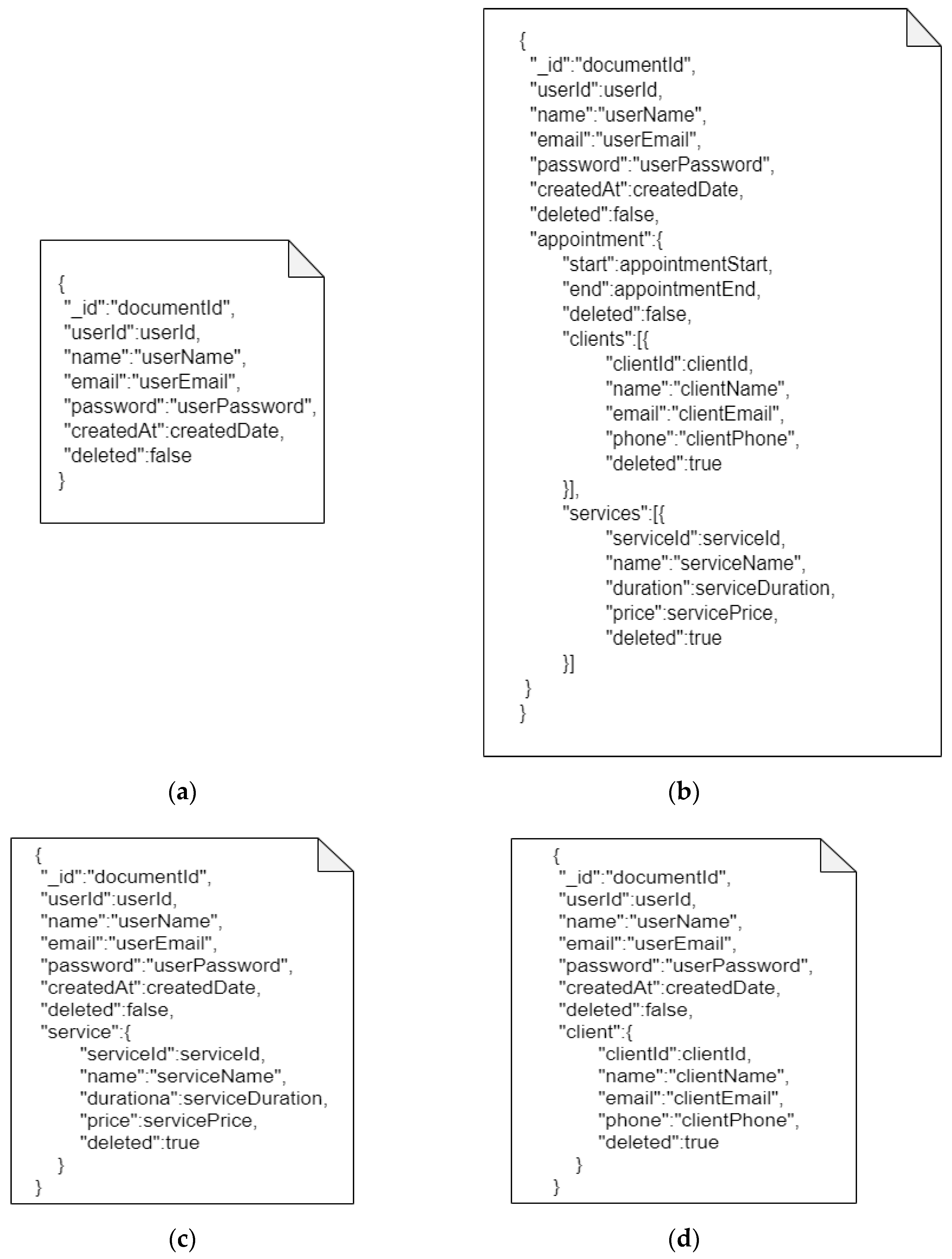
- User document—stores user information, as can be seen in Figure 2a. Since the user is the main entity in the application, both the services and the clients are linked to this entity. With each service being associated with a user, the document contains data about the user that is also present in the user document and the fields of the service entity as an embedded object (and the same for the client). These fields that define the user entity are the same everywhere, in order to provide independence. In this way, these documents can be used independently. Each document type has its own collection, corresponding to a table in relational MySQL; therefore, they are stored in different collections and the difference in terms of structure involves whether the embedded object is either a service or a client with the corresponding fields.
- Appointment document—stores information about the main object, i.e., the user, with the scheduling details being embedded in an object in the user, as can be seen in Figure 2b. This embedded object, the appointment, in turn contains two objects in addition to the other details, a list of customers and a list of services with all their information.
- Service document—as each document is independent, the service document must contain all of the information about the user because it is the main entity, and the service entity appears as an embedded document that contains all the necessary fields, as shown in Figure 2c.
- Customer type document—as shown is Figure 2d, customer information (client) appears as an object that is embedded in the user object, because the user is the main entity and each document must contain this information to be independent.
5. Performance Tests
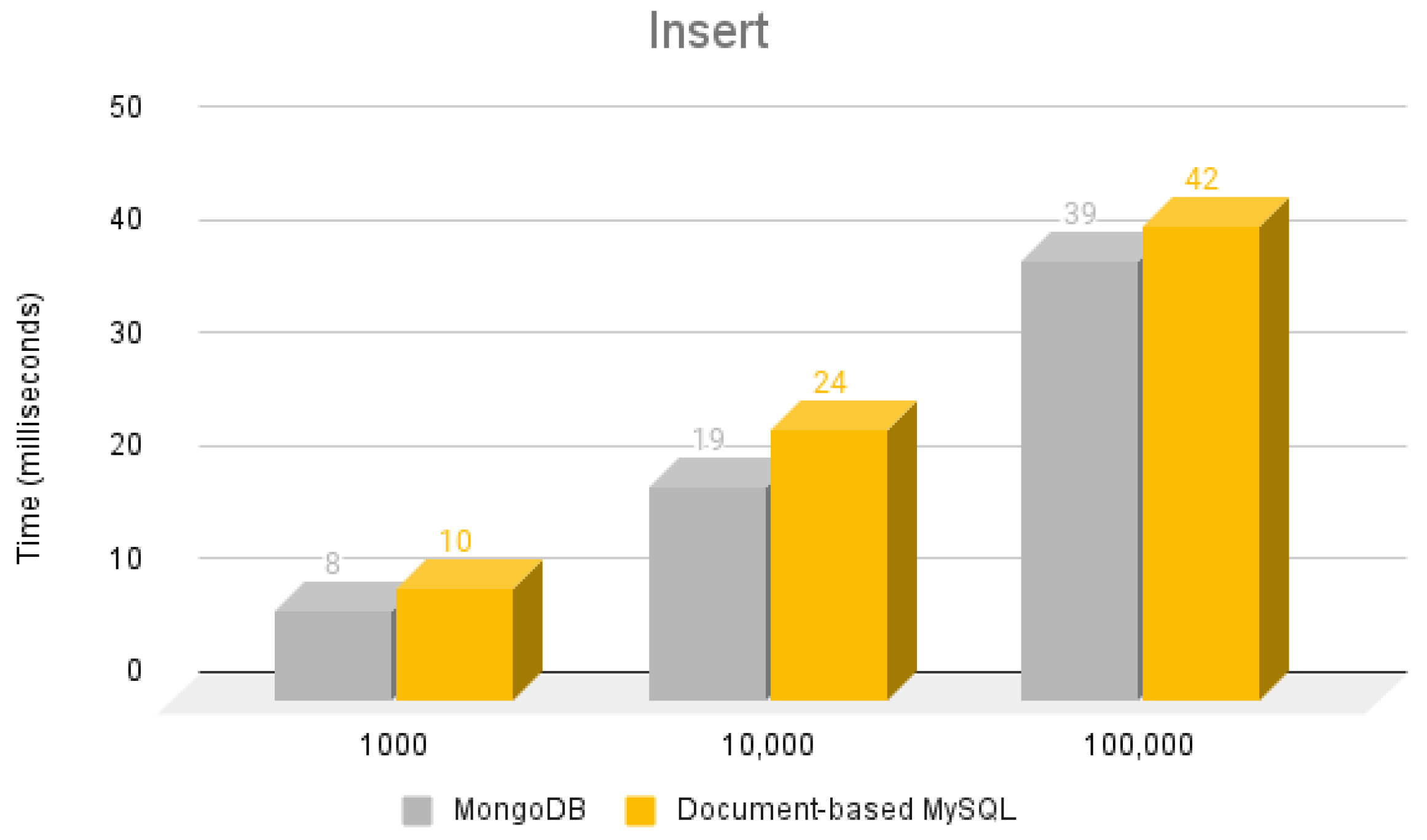
5.1. Insert Operation
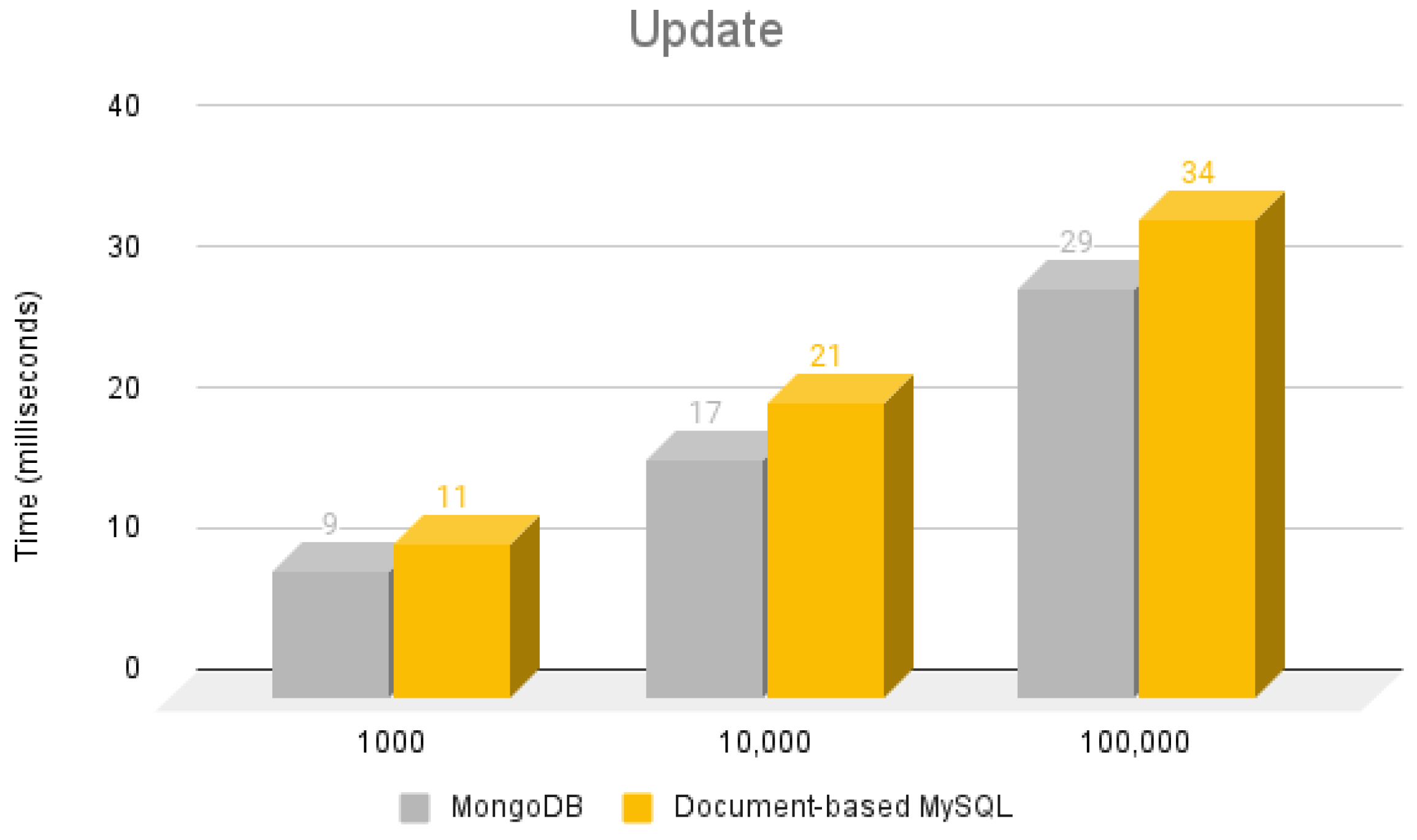
5.2. Update Operation
5.3. Select Operation
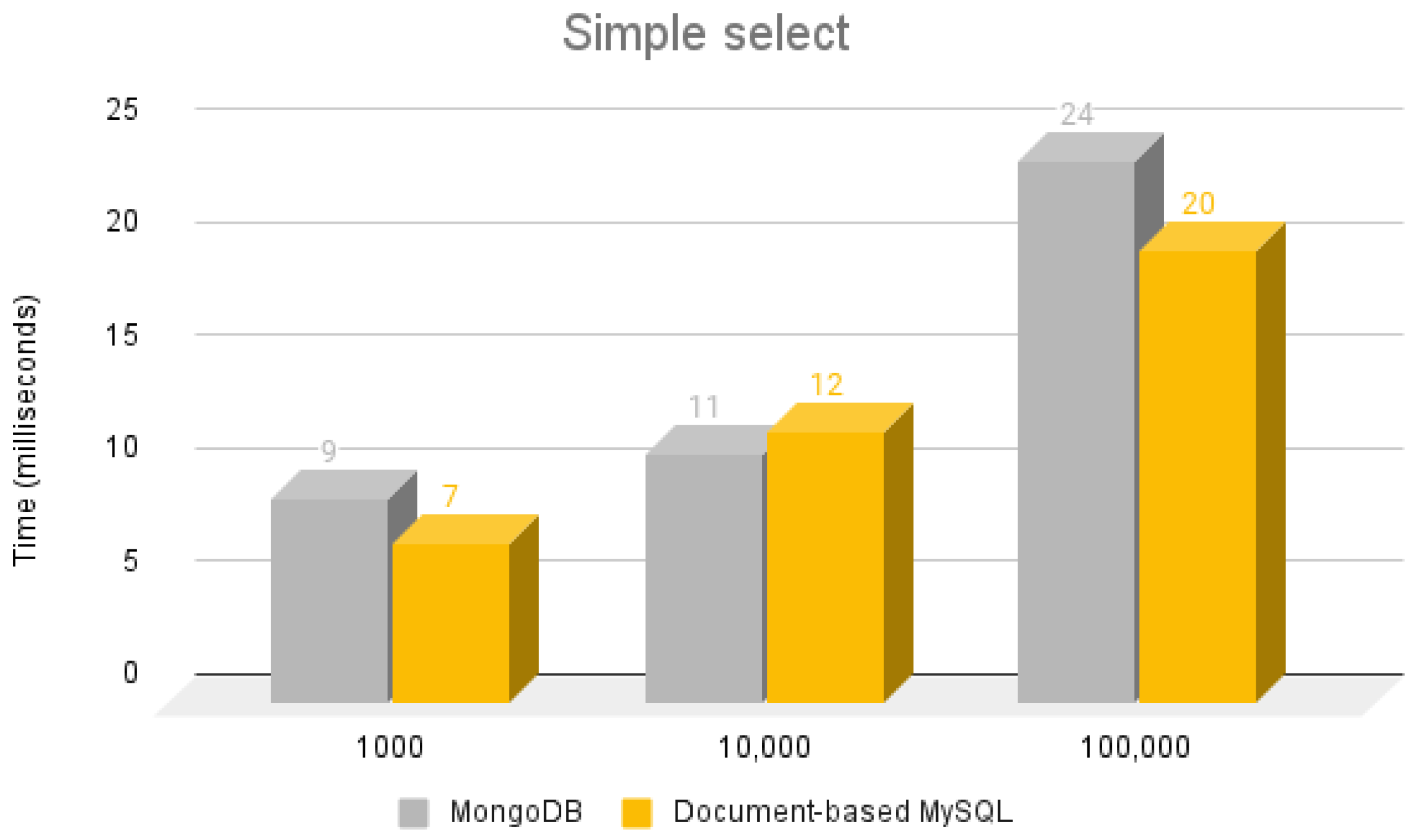
5.3.1. Simple Select Operation
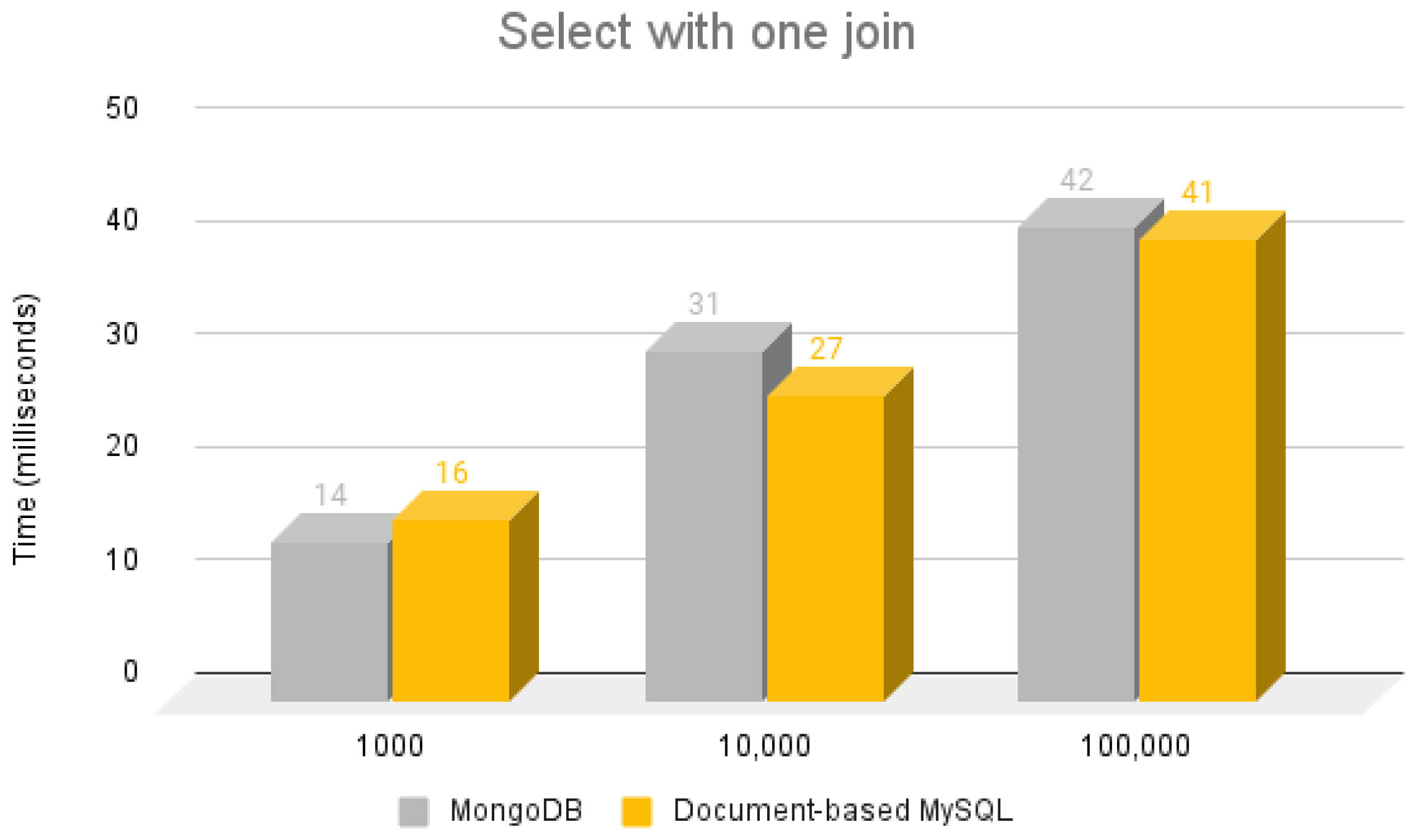
5.3.2. Select Using a Single Join Operation
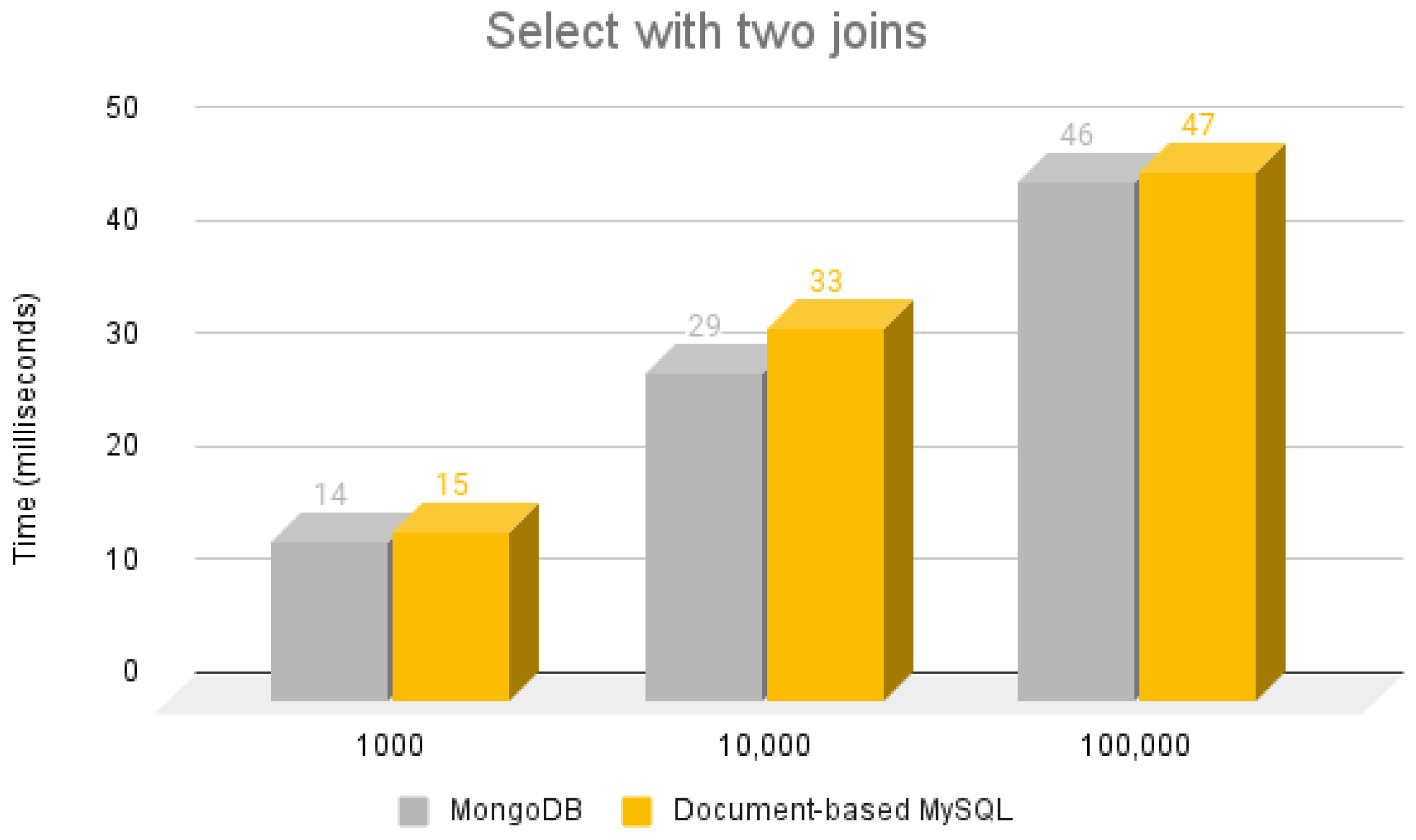
5.3.3. Select Using Two Joins Operations
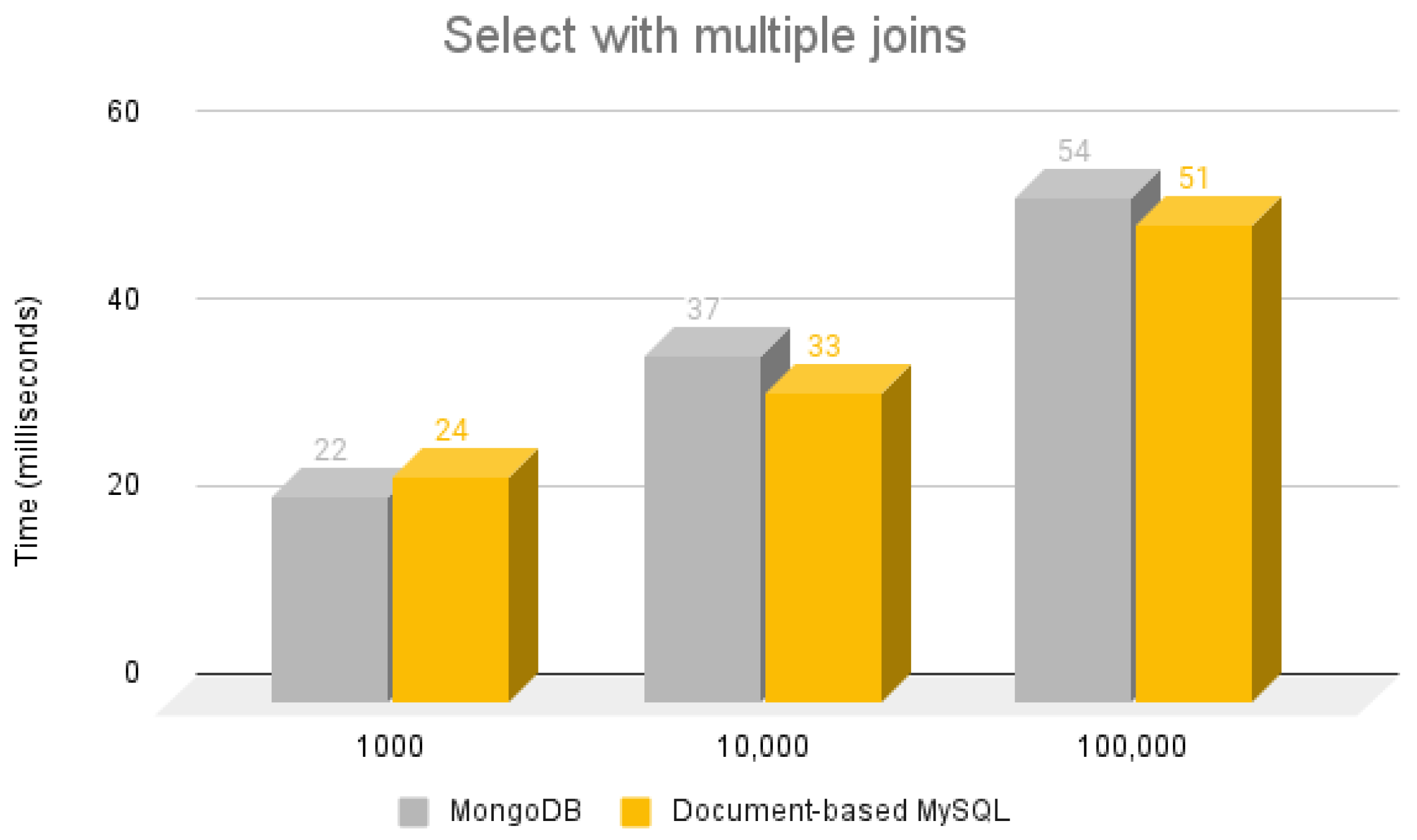
5.3.4. Select with Multiple Joins
5.4. Delete Operation
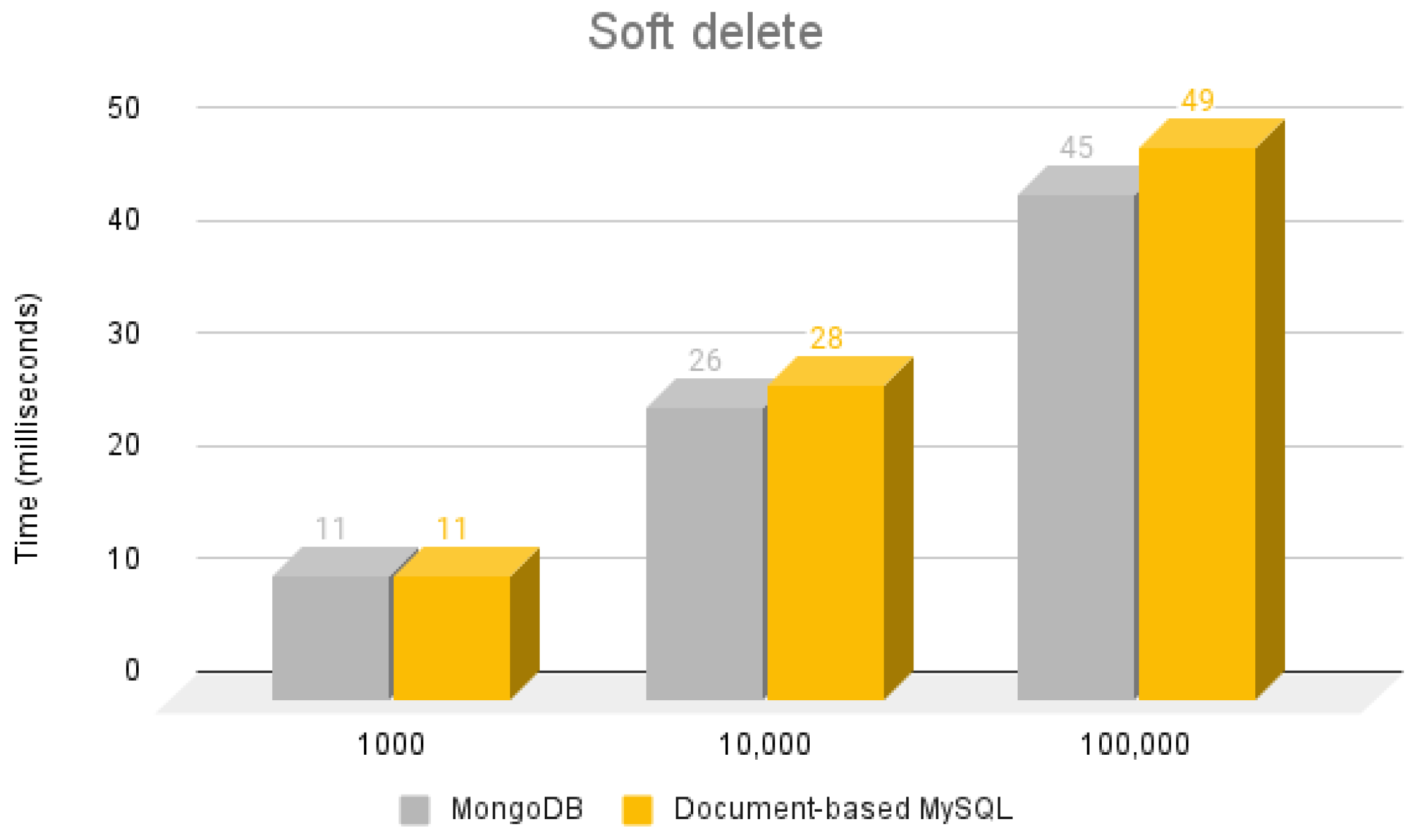
5.4.1. Soft Delete
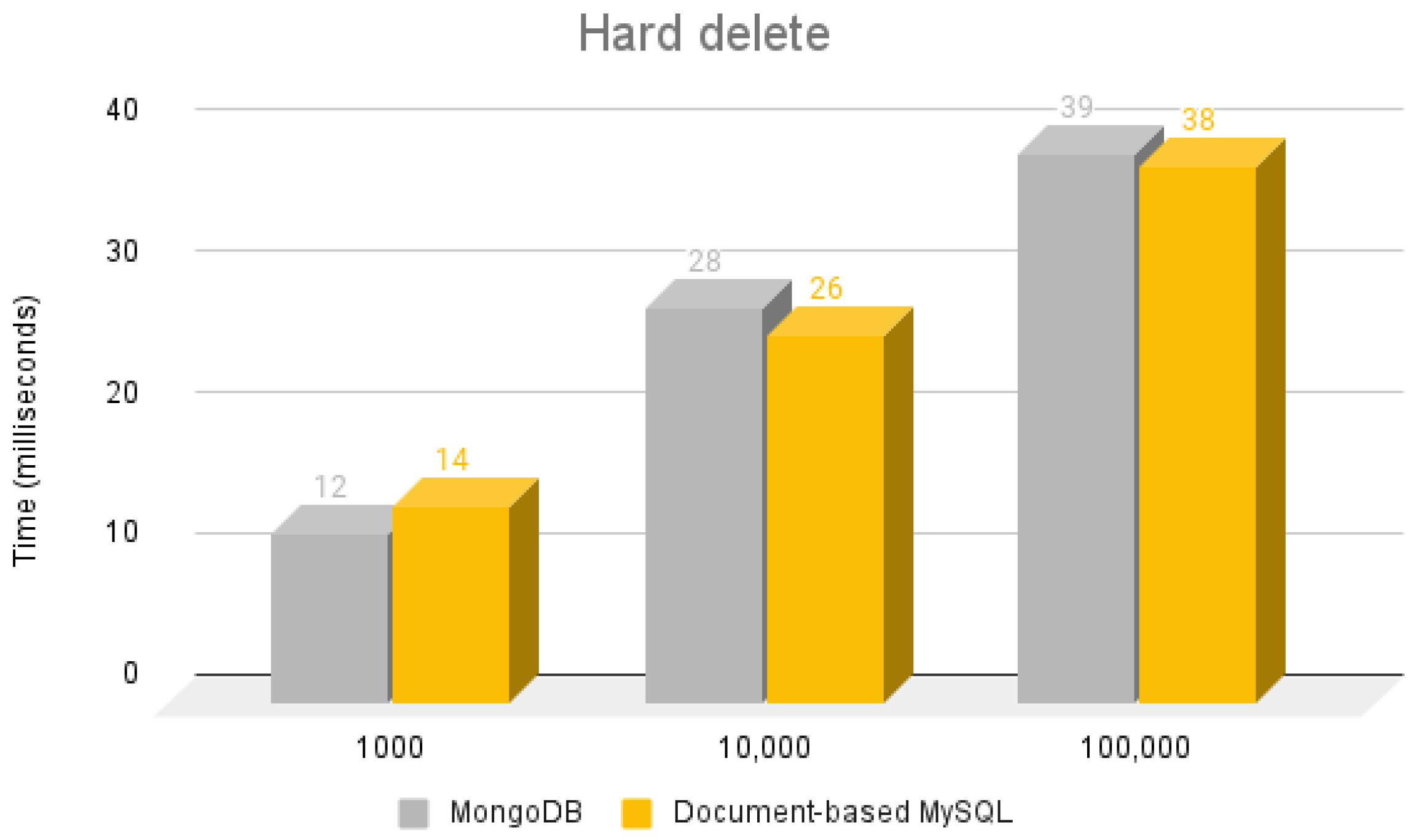
5.4.2. Hard Delete
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hoy, M.B. The “Internet of Things”: What it is and what it means for libraries. Med. Ref. Serv. Q. 2015, 34, 353–358. [Google Scholar] [CrossRef]
- Thakur, N.; Han, K.Y. An Ambient Intelligence-Based Human Behavior Monitoring Framework for Ubiquitous Environments. Information 2021, 12, 81. [Google Scholar] [CrossRef]
- Assunçãoa, M.D.; Calheiros, R.N.; Bianchi, S.; Netto, M.A.S.; Buyya, R. Big Data computing and clouds: Trends and future directions. J. Parallel Distrib. Comput. 2015, 79–80, 3–15. [Google Scholar] [CrossRef] [Green Version]
- Chen, M.; Mao, S.; Liu, Y. Big data: A survey. Mob. Netw. Appl. 2014, 19, 171–209. [Google Scholar] [CrossRef]
- Jatana, N.; Puri, S.; Ahuja, M.; Kathuria, I.; Gosain, D. A survey and comparison of relational and non-relational databases. Int. J. Eng. Res. Technol. 2012, 1, 1–5. [Google Scholar]
- Celesti, A.; Fazio, M.; Villari, M. A study on join operations in MongoDB preserving collections data models for future internet applications. Future Internet 2019, 11, 83. [Google Scholar] [CrossRef] [Green Version]
- Fahd, K.; Venkatraman, S.; Hammeed, F.K. A Comparative Study of NOSQL System Vulnerabilities with Big Data. Int. J. Manag. Inf. Technol. 2019, 11, 1–19. [Google Scholar] [CrossRef]
- Tauro, C.J.M.; Patil, B.R.; Prashanth, K.R. A comparative analysis of different nosql databases on data model, query model and replication model. In Proceedings of the International Conference on ERCICA, Yelahanka, Bangalore, India, 2–3 August 2013. [Google Scholar]
- Győrödi, C.A.; Dumşe-Burescu, D.V.; Győrödi, R.Ş.; Zmaranda, D.R.; Bandici, L.; Popescu, D.E. Performance Impact of Optimization Methods on MySQL Document-Based and Relational Databases. Appl. Sci. 2021, 11, 6794. [Google Scholar] [CrossRef]
- Feuerstein, S.; Pribyl, B. Oracle PL/SQL Programming, 6th ed.; O’Reilly Media: Sebastopol, CA, USA, 2016; p. 1340. [Google Scholar]
- Atzeni, P.; Bugiotti, F.; Rossi, L. Uniform access to NoSQL systems. Inf. Syst. 2014, 43, 117–133. [Google Scholar] [CrossRef]
- Damodaran, B.D.; Salim, S.; Vargese, S.M. Performance evaluation of MySQL and MongoDB databases. Int. J. Cybern. Inform. 2016, 5, 387–394. [Google Scholar] [CrossRef]
- Document-Based MySQL Library. Available online: https://www.mysql.com/products/enterprise/document_store.html (accessed on 10 January 2022).
- Bell, C. Introducing the MySQL 8 Document Store, 1st ed.; Apress: New York City, NY, USA, 2018; p. 555. [Google Scholar]
- MapReduce—MongoDB. Available online: https://docs.mongodb.org/manual/core/map-reduce (accessed on 15 January 2022).
- MongoDB 5.0 Documentation. Available online: https://docs.mongodb.com/manual/replication/ (accessed on 25 January 2022).
- Gyorödi, C.; Gyorödi, R.; Andrada, I.; Bandici, L. A Comparative Study Between the Capabilities of MySQL vs. MongoDB as a Back-End for an Online Platform. Int. J. Adv. Comput. Sci. Appl. 2016, 7, 73–78. [Google Scholar] [CrossRef] [Green Version]
- Gupta, G.S. Correlation and comparison of nosql specimen with relational data store. Int. J. Res. Eng. Technol. 2015, 4, 1–5. [Google Scholar]
- Celesti, A.; Fazio, M.; Romano, A.; Villari, M. A hospital cloud-based archival information system for the efficient management of HL7 big data. In Proceedings of the 39th International Convention on Information and Communication Technology, Electronics and Microelectronics, Opatija, Croatia, 30 May–3 June 2016; pp. 406–411. [Google Scholar]
- Celesti, A.; Fazio, M.; Romano, A.; Bramanti, A.; Bramanti, P.; Villari, M. An OAIS-Based Hospital Information System on the Cloud: Analysis of a NoSQL Column-Oriented Approach. IEEE J. Biomed Health Inform. 2018, 22, 912–918. [Google Scholar] [CrossRef] [PubMed]
- Hiriyannaiah, S.; Siddesh, G.M.; Anoop, P.; Srinivasa, K.G. Semi-structured data analysis and visualisation using NoSQL. Int. J. Big Data Intell. 2018, 5, 133–142. [Google Scholar] [CrossRef]
- Martins, P.; Abbasi, M.; Sá, F. A Study over NoSQL Performance. New Knowledge in Information Systems and Technologies. In WorldCIST’19 2019. Advances in Intelligent Systems and Computing; Rocha, Á., Adeli, H., Reis, L., Costanzo, S., Eds.; Springer: Cham, Switzerland, 2019; Volume 930, pp. 603–611. [Google Scholar]
- Martins, P.; Tomé, P.; Wanzeller, C.; Sá, F.; Abbasi, M. NoSQL Comparative Performance Study. In Proceedings of the World Conference on Information Systems and Technologies, Terceira Island, Portugal, 30 March–2 April 2021; Springer: Cham, Switzerland, 2021; pp. 428–438. [Google Scholar]
- Seghier, N.B.; Kazar, O. Performance Benchmarking and Comparison of NoSQL Databases: Redis vs. MongoDB vs. Cassandra Using YCSB Tool. In Proceedings of the 2021 International Conference on Recent Advances in Mathematics and Informatics (ICRAMI), Tebessa, Algeria, 21–22 September 2021; IEEE: New York City, NY, USA, 2021; pp. 1–6. [Google Scholar]
- Gaikwad, R.; Goje, A.C. A Study of YCSB—Tool for measuring a performance of NOSQL databases. Int. J. Eng. Technol. Comput. Res. IJETCR 2015, 3, 37–40. [Google Scholar]
- Daskevics, A.; Nikiforova, A. IoTSE-based open database vulnerability inspection in three Baltic countries: ShoBEVODSDT sees you. In Proceedings of the 8th International Conference on Internet of Things: Systems, Management and Security (IOTSMS), Gandia, Spain, 6–9 December 2021; pp. 1–8. [Google Scholar] [CrossRef]
- Patel, S.; Kumar, S.; Katiyar, S.; Shanmugam, R.; Chaudhary, R. MongoDB Versus MySQL: A Comparative Study of Two Python Login Systems Based on Data Fetching Time. In Research in Intelligent and Computing in Engineering; Springer: Singapore, 2021; pp. 57–64. [Google Scholar]
- Jose, B.; Abraham, S. Performance analysis of NoSQL and relational databases with MongoDB and MySQL. Mater. Today Proc. 2020, 24, 2036–2043. [Google Scholar] [CrossRef]
- Palanisamy, S.; SuvithaVani, P. A survey on RDBMS and NoSQL Databases MySQL vs. MongoDB. In Proceedings of the 2020 International Conference on Computer Communication and Informatics (ICCCI), Coimbatore, India, 22–24 January 2020; IEEE: New York City, NY, USA, 2020; pp. 1–7. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| MongoDB | Document-Based MySQL | |
|---|---|---|
| Data model | BSON objects [8]—key–value documents, each document identified via a unique identifier, offer predefined methods for all relational MySQL commands. | BSON objects [8]—key–value documents, each document identified via a unique identifier, does not require defining a fixed structure during document creation [13,14]. |
| Query model | Queries are expressed as JSON objects and are sent by the database driver using the “find” method [15]; more complex queries could be expressed using a Map Reduce operation for batch processing of data and aggregation operations [8]. The user specifies the map and reduces functions in JavaScript, and they are executed on the server side [15]. The results of the operation are possible to store in a temporary collection that is automatically removed after the client receives the results, or they can be stored in a permanent collection, so that they are always available. MongoDB has introduced the $lookup operator in version 3.2. that performs Left Outer Join (called left join) operations with two or more collections [9]. | Document-based MySQL allows developers, through the X Dev API, to work with relational tables and JSON document collections [13]. The X DEV API provides an easy-to-use API for performing CRUD operations, being optimized and extensible for performing these operations. In the case of more complex operations, knowledge of relational MySQL is very helpful for writing queries in document-based MySQL, because certain search or edit methods take as a parameter part of the query from relational MySQL; more precisely, the conditions, the part after the “where” clause. |
| Replication model | Provides Master–Slave replication and replica sets, where data is asynchronously replicated between servers [8]. A replica set contains several data-bearing nodes and optionally, one arbiter node. Of the data-bearing nodes, one and only one member is deemed the primary node, while the other nodes are deemed secondary nodes [15]. Replica sets provide a high performance for replication with automated failure handling, while sharded clusters make it possible to divide large data sets over different machines that are transparent to the users [13]. MongoDB users combine replica sets and sharded clusters to provide high levels of redundancy in data sets that are transparent for applications [8]. | Provides multi-document transaction support and full ACID compliance for schema-less JSON documents having a high availability by using all the advantages of MySQL Group Replication and the InnoDB Cluster to scale-out applications [13,14]. Documents are replicated across all members of the high-availability group, and transactions are committed in sync across masters. Any source server can take over from another source server if one fails, without downtime [13]. |
| Operations for Creating the Connections | |
|---|---|
| MongoDB | MongoClient mongoClient = new MongoClient(“localhost”, 27017); MongoDatabase database = mongoClient.getDatabase(“application”); database.createCollection(“user”); database.createCollection(“client”); database.createCollection(“service”); database.createCollection(“appointment”); |
| Document-based MySQL | SessionFactory sFact = new SessionFactory (); Session session = sFact.getSession (“mysqlx://name:password@localhost:33060”); Schema schema = session.createSchema (“application”, true); Collection userCollection = schema.createCollection(“user”, true); Collection clientCollection = schema.createCollection(“client”, true); Collection serviceCollection = schema.createCollection(“service”, true); Collection appointmentCollection = schema.createCollection(“appointment”, true); |
| MongoDB Insert Operation |
| public void insert(MongoCollection<Document> collection) { Document document = new Document(); Service service = new Service(1, false, “Makeup”, 100, 60); document.put(“userId”, 1); document.put(“name”, “Ioana”); document.put(“createdAt”, new Date()); document.put(“email”, “[email protected]”); document.put(“password”, “password”); document.put(“deleted”, false); document.put(“service”, service); collection.insertOne(document); } // and from cron it is called serviceEntityService.insert(serviceCollection); |
| Document-based MySQL Insert operation |
| public void insert(Collection collection) { Service service = new Service(1, false, “Makeup”, 100, 60); User user = new User(1, false, new Date(), “Ioana”, “[email protected]”, “password”, service); try {collection.add(new ObjectMapper().writeValueAsString(user)).execute();} catch (JsonProcessingException e) { System.out.println(“Failed to insert service with id “ + service.getServiceId()); } } |
| MongoDB Update Operation |
| public void updateEmailByUserId(MongoCollection<Document> collection, int userId) { collection.updateMany(new BasicDBObject(“userId”, userId), new BasicDBObject(“client.email”, ““)); } // and from cron it is called clientService.updateEmailByUserId(clientCollection, 100); |
| Document-based MySQL Update operation |
| public void updateEmailByUserId(Collection collection, int userId) { collection.modify(“userId = “ + userId).set(“client.email”, ““).execute(); } // and from cron it is called clientService.updateEmailByUserId(clientCollection, 100); |
| MongoDB Simple Select Operation |
| public FindIterable<Document> getByEmail(MongoCollection<Document> collection, String email) { return collection.find(new BasicDBObject(“email”, email)); } // and from cron it is called userService.getByEmail(userCollection, “[email protected]”); |
| Document-based MySQL Simple Select operation |
| public DbDoc getByEmail(Collection collection, String email) { return collection.find(“email = ‘“ + email + “‘“).execute().fetchOne(); } // and from cron it is called userService.getByEmail(userCollection, “[email protected]”); |
| MongoDB Select Using a Single Join Operation |
| public MongoCursor<Document> getAppointmentsForEachUser (MongoCollection<Document> collection) { Bson matchCondition = match(and(eq(“deleted”, false), eq(“appointment.deleted”, false))); Bson groupCondition = group(“userId”, first(“userId”, “$userId”)); Bson projection = project(fields(include(“userId”), fields(include(“email”), count(“appointment.start”), excludeId())); return collection.aggregate(asList(matchCondition, groupCondition, projection)).iterator(); } // and from cron it is called appointmentService.getAppointmentsForEachUser(appointmentCollection); |
| Document-based MySQL Select using a single join operation |
| public DocResult getAppointmentsForEachUser(Collection collection) { return collection.find(“deleted = false and appointment.deleted = false”) .fields(“userId as userId”, “email as userEmail”, “count(appointment.start) as appointments”).groupBy(“userId”).execute(); } // and from cron it is called appointmentService.getAppointmentsForEachUser(appointmentCollection); |
| MongoDB SELECT Using Two Joins Operation |
| public FindIterable<Document> getClientsForAppointmentsNewerThan(MongoCollection<Document> collection, Date minCreatedAt, Date minAppointmentStart) { Bson matchCondition = match(and(gt(“createdAt”, minCreatedAt), gt(“appointment.start”, minAppointmentStart))); Bson fields= project(fields(include(“clients”), excludeId())); return collection.find(matchCondition).projection(fields); } // and from cron it is called clientService.getClientsForAppointmentsNewerThan(appointmentCollection, new Date(1620468000000L), new Date(1621072800000L)); |
| Document-based MySQL SELECT using two joins operation |
| public List<JsonValue> getClientsForAppointmentsNewerThan (Collection collection, Date minCreatedAt, Date minAppointmentStart) { return collection.find(“createdAt > “ + minCreatedAt + “and appointment.start > “ + minAppointmentStart).execute().fetchAll().stream() .map(dbDoc -> dbDoc.get(“clients”)).collect(Collectors.toList()); } // and from cron it is called clientService.getClientsForAppointmentsNewerThan(appointmentCollection, new Date(1620468000000L), new Date(1621072800000L)); |
| MongoDB SELECT Using Multiple Joins Operation |
| public MongoCursor<Document> getDetailsAboutAppointmentsNewerThan (MongoCollection<Document> collection, Date minCreatedAt) { Bson matchCondition = match(and(eq(“deleted”, false), eq(“appointment.deleted”, false), gt(“createdAt”, minCreatedAt))); Bson projection = project(fields(include(“userId”, “appointment.services.name”, “appointment.clients.name”), excludeId())); return collection.aggregate(asList(matchCondition, projection)).iterator(); } // and from cron it is called appointmentService.getDetailsAboutAppointmentsNewerThan (appointmentCollection, new Date(1620468000000L)); |
| Document-based MySQL SELECT using multiple joins operation |
| public DocResult getDetailsAboutAppointmentsNewerThan (Collection collection, Date minCreatedAt) { return collection.find(“deleted = false and appointment.deleted = false and createdAt >“ + minCreatedAt).fields(“email”, “appointment.services.name”, “appointment.client.name”).execute(); } // and from cron it is called appointmentService.getDetailsAboutAppointmentsNewerThan (appointmentCollection, new Date(1620468000000L)); |
| MongoDB Soft Delete Operation |
| public void markAsSoftDeletedClientsForDeletedUsers (MongoCollection<Document> collection) { collection.updateMany(new BasicDBObject(“deleted”, true), new BasicDBObject(“client.deleted”, true)); } // and from cron it is called clientService.markAsSoftDeletedClientsForDeletedUsers(appointmentCollection); |
| Document-based MySQL Soft delete operation |
| public void markAsSoftDeletedClientsForDeletedUsers(Collection collection) { collection.modify(“deleted = true”).set(“client.deleted”, “true”).execute(); } // and from cron it is called clientService.markAsSoftDeletedClientsForDeletedUsers(appointmentCollection); |
| MongoDB Hard Delete Operation |
| public void deleteServicesOlderThan(MongoCollection<Document> collection) { Bson match1 = match(and(lt(“createdAt”, 1620378000000L), eq(“service.deleted”, true))); collection.deleteMany(match1); } // and from cron it is called serviceEntityService.deleteServicesOlderThan(appointmentCollection); |
| Document-based MySQL Hard delete operation |
| public void deleteServicesOlderThan(Collection collection) { collection.remove(“createdAt < 1620378000000 and service.deleted = true”).execute(); } // and from cron it is called serviceEntityService.deleteServicesOlderThan(appointmentCollection); |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Győrödi, C.A.; Dumşe-Burescu, D.V.; Zmaranda, D.R.; Győrödi, R.Ş. A Comparative Study of MongoDB and Document-Based MySQL for Big Data Application Data Management. Big Data Cogn. Comput. 2022, 6, 49. https://doi.org/10.3390/bdcc6020049
Győrödi CA, Dumşe-Burescu DV, Zmaranda DR, Győrödi RŞ. A Comparative Study of MongoDB and Document-Based MySQL for Big Data Application Data Management. Big Data and Cognitive Computing. 2022; 6(2):49. https://doi.org/10.3390/bdcc6020049
Chicago/Turabian StyleGyőrödi, Cornelia A., Diana V. Dumşe-Burescu, Doina R. Zmaranda, and Robert Ş. Győrödi. 2022. "A Comparative Study of MongoDB and Document-Based MySQL for Big Data Application Data Management" Big Data and Cognitive Computing 6, no. 2: 49. https://doi.org/10.3390/bdcc6020049
APA StyleGyőrödi, C. A., Dumşe-Burescu, D. V., Zmaranda, D. R., & Győrödi, R. Ş. (2022). A Comparative Study of MongoDB and Document-Based MySQL for Big Data Application Data Management. Big Data and Cognitive Computing, 6(2), 49. https://doi.org/10.3390/bdcc6020049