
A New Ontology-Based Method for Arabic Sentiment Analysis



Abstract
:1. Introduction
- Building a semantic orientation approach using ontology for mining the different opinions to decrease the effort needed by ordinary users or organizations to make more accurate sentiments classification. The approach is working at the level of semantic features, which are extracted and weighted using the domain ontology.
- Using the domain features’ levels to determine the polarity of the overall review. Also, the important domain features from the users’ point of view are used to efficiently calculate the overall semantic polarity of a subjective text. This approach is different from the previous ontology-based approaches in using a weighting method with two factors to identify the different weights of importance for each semantic domain feature.
- Evaluating the proposed approach with an Arabic dataset from the hotels’ domain, which was selected to build the domain ontology.
2. Related Work
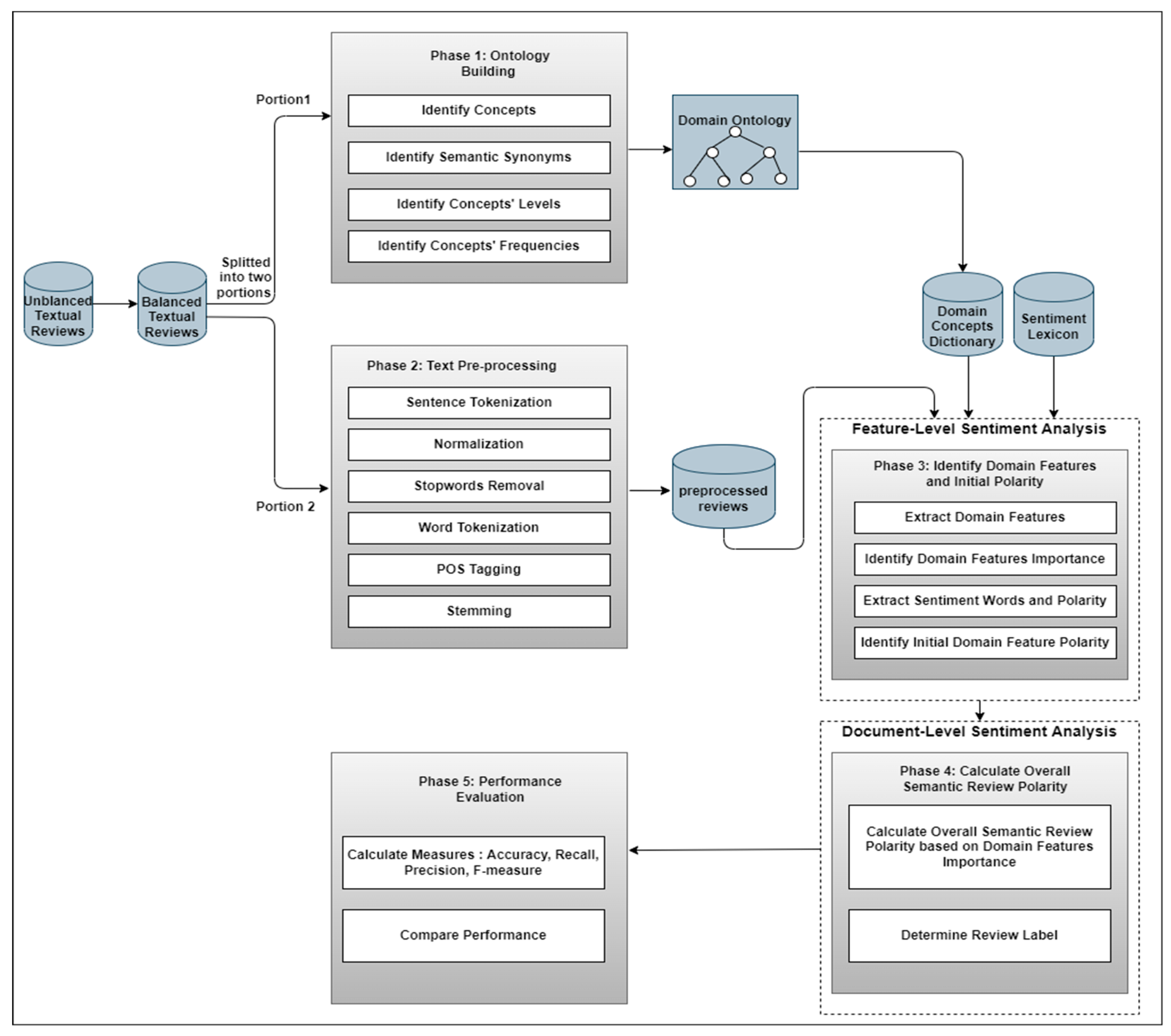
3. Method
3.1. Overall Approach Design
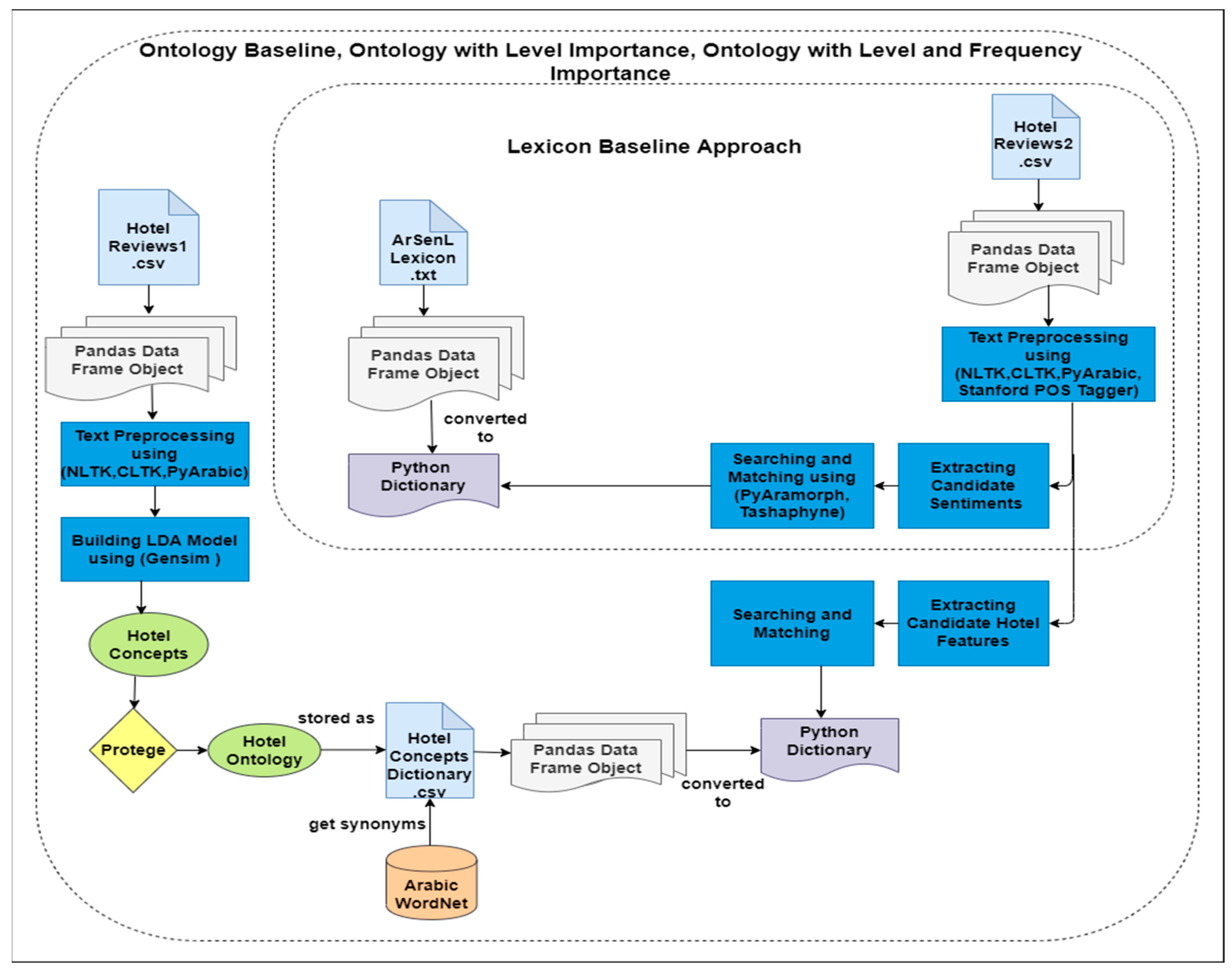
3.2. Description of the Arabic Resources
3.3. Main Phases of the Approach
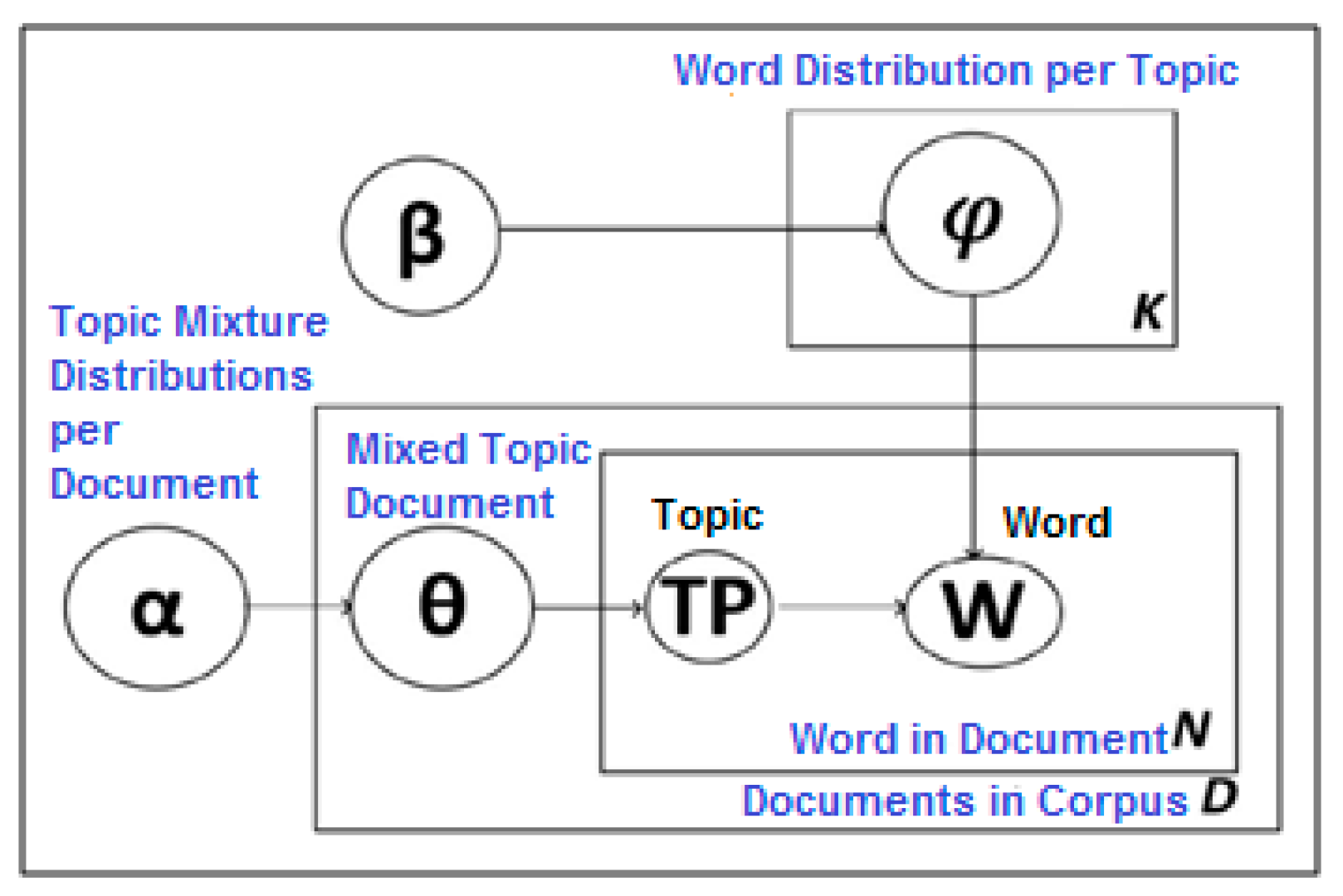
3.3.1. Ontology Building
| Algorithm 1 Building the LDA topic model |
| Input: Hotel Reviews Dataset Output: Topics with Keywords
Tokenization. Stopword Removal.
|
3.3.2. Text Preprocessing
3.3.3. Domain Features and Initial Polarity Identification
3.3.4. Overall Semantic Review Polarity Calculation
3.3.5. Performance Evaluation
- TP (True Positive): represents the number of reviews that are classified as positive in both original classifications and predicted classifications.
- TN (True Negative): represents the number of reviews that are classified as negative in both original classifications and predicted classifications.
- FP (False Positive): represents the number of reviews that are classified as positive in the predicted classifications, while classified as negative in the original classifications.
- FN (False Negative): represents the number of reviews that are classified as negative in the predicted classifications, while classified as positive in the original classifications.
4. Results and Discussion
4.1. Dataset Balancing
4.2. Lexicon Baseline Evaluation
4.3. Ontology Baseline Evaluation
4.4. Ontology with Level Importance Evaluation
4.5. Ontology with Level and Frequency Importance Evaluation
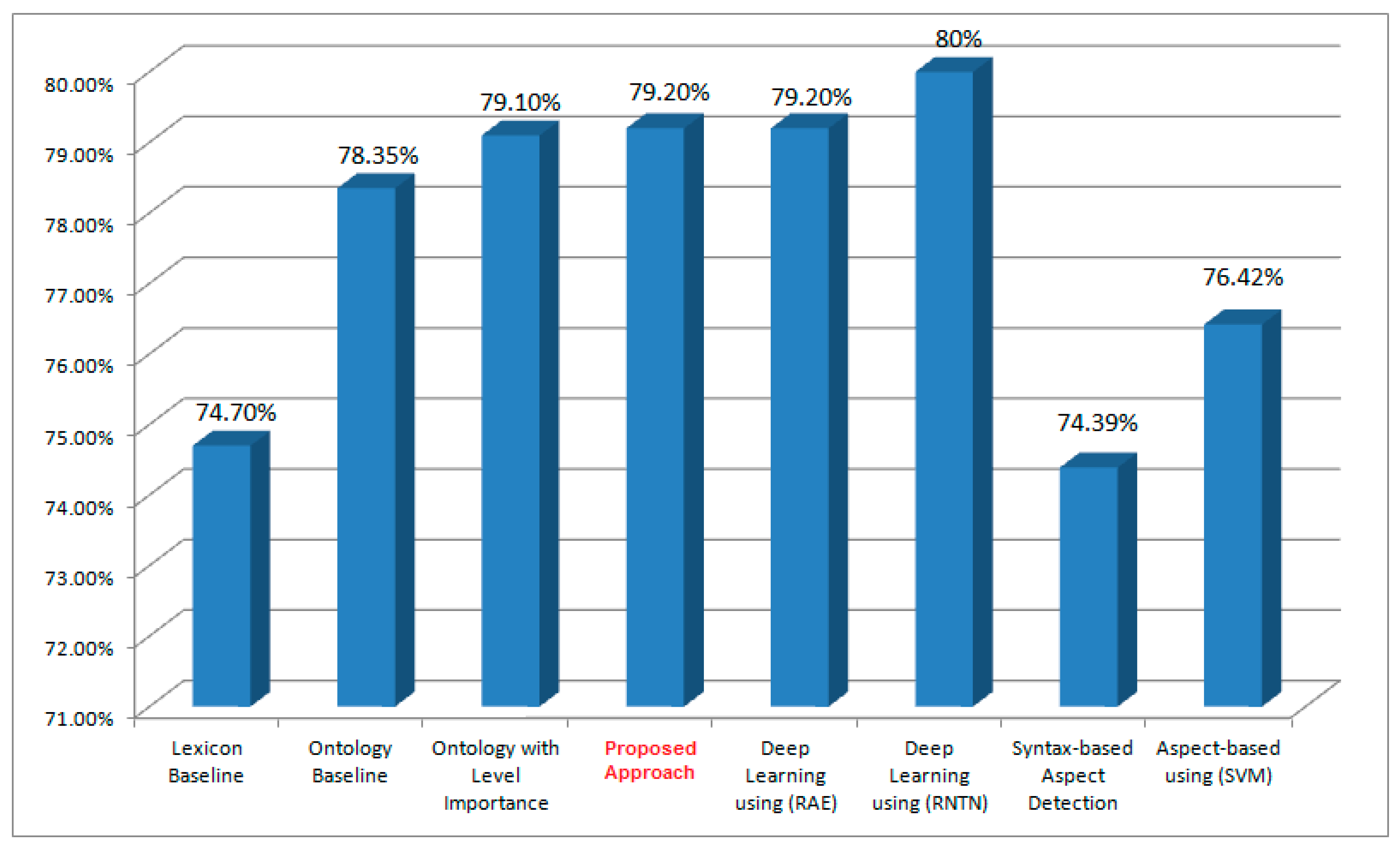
4.6. Results Summary and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Farha, I.A.; Magdy, W. From Arabic sentiment analysis to sarcasm detection: The arsarcasm dataset. In Proceedings of the 4th Workshop on Open-Source Arabic Corpora and Processing Tools, with a Shared Task on Offensive Language Detection, Marseille, France, 12 May 2020; pp. 32–39. [Google Scholar]
- Alrumaih, A.; Al-Sabbagh, A.; Alsabah, R.; Kharrufa, H.; Baldwin, J. Sentiment analysis of comments in social media. Int. J. Electr. Comput. Eng. (IJECE) 2020, 10, 5917–5922. [Google Scholar] [CrossRef]
- Al-Radaideh, Q.A.; Al-Abrat, M.A. An Arabic text categorization approach using term weighting and multiple reducts. Soft Comput. 2019, 23, 5849–5863. [Google Scholar] [CrossRef]
- Manguri, K.H.; Ramadhan, R.N.; Amin, P.R.M. Twitter Sentiment Analysis on Worldwide COVID-19 Outbreaks. Kurdistan J. Appl. Res. 2020, 2020, 54–65. [Google Scholar] [CrossRef]
- Boudad, N.; Faii, R.; Thami, R.; Chiheb, R. Sentiment analysis in Arabic: A review of the literature. Ain Shams Eng. J. 2017, 9, 2479–2490. [Google Scholar] [CrossRef]
- Ghallab, A.; Mohsen, A.; Ali, Y. Arabic sentiment analysis: A systematic literature review. Appl. Comput. Intell. Soft Comput. 2020, 2020, 1–21. [Google Scholar] [CrossRef] [Green Version]
- Nassr, Z.; Sael, N.; Benabbou, F. A comparative study of sentiment analysis approaches. In Proceedings of the 4th International Conference on Smart City Applications, Casablanca, Morocco, 2–4 October 2019; pp. 1–8. [Google Scholar] [CrossRef]
- Atoum, J.O.; Nouman, M. Sentiment analysis of Arabic Jordanian dialect tweets. Int. J. Adv. Comput. Sci. Appl. 2019, 10, 256–262. [Google Scholar] [CrossRef] [Green Version]
- Zahidi, Y.; El Younoussi, Y.; Azroumahli, C. Comparative Study of the Most Useful Arabic-supporting Natural Language Processing and Deep Learning Libraries. In Proceedings of the 2019 5th International Conference on Optimization and Applications (ICOA), Kenitra, Morocco, 25–26 April 2019; pp. 1–10. [Google Scholar] [CrossRef]
- Mäntylä, M.V.; Graziotin, D.; Kuutila, M. The Evolution of Sentiment Analysis—A Review of Research Topics, Venues, and Top Cited Papers. Comput. Sci. Rev. 2018, 27, 16–32. [Google Scholar] [CrossRef] [Green Version]
- Zahidi, Y.; El Younoussi, Y.; Al-Amrani, Y. Different valuable tools for Arabic sentiment analysis: A comparative evaluation. Int. J. Electr. Comput. Eng. 2021, 11, 753–762. [Google Scholar] [CrossRef]
- Alharbi, A.; Taileb, M.; Kalkatawi, M. Deep learning in Arabic sentiment analysis: An overview. J. Inf. Sci. 2021, 47, 129–140. [Google Scholar] [CrossRef]
- Hitzler, P.; Harmelen, S. A Reasonable Semantic Web. Semantic Web. Interoperability Usability Appl. IOS Press J. 2010, 1, 39–44. [Google Scholar] [CrossRef]
- Gontier, E.M. Web Semantic and Ontology. Adv. Internet Things 2015, 5, 15. [Google Scholar] [CrossRef] [Green Version]
- Lakshmi, S.M.; Uma, G.V. Semantic Web based e-Learning System for Sports Domain. Int. J. Comput. Appl. 2010, 8, 21–25. [Google Scholar] [CrossRef]
- Man, D. Ontologies in Computer Science. Didact. Math. 2013, 31, 43–46. [Google Scholar]
- Al Zamil, M.G.; Al-Radaideh, Q. Automatic extraction of ontological relations from Arabic text. J. King Saud Univ.-Comput. Inf. Sci. 2014, 26, 462–472. [Google Scholar] [CrossRef] [Green Version]
- Wu, C.W.; Liu, C.L. Ontology-based Text Summarization for Business News Articles. Comput. Appl. 2003, 2003, 389–392. [Google Scholar]
- Thakor, P.; Sasi, S. Ontology-based sentiment analysis process for social media content. Procedia Comput. Sci. 2015, 53, 199–207. [Google Scholar] [CrossRef] [Green Version]
- Alkadri, A.M.; ElKorany, A.M. Semantic feature based Arabic opinion mining using ontology. Int. J. Adv. Comput. Sci. Appl. 2016, 7, 577–583. [Google Scholar]
- Santosh, D.T.; Vardhan, B.V.; Ramesh, D. Extracting product features from reviews using Feature Ontology Tree applied on LDA topic clusters. In Proceedings of the 6th International Conference on Advanced Computing (IACC), Bhimavaram, India, 27–28 February 2016; pp. 163–168. [Google Scholar] [CrossRef]
- Alfonso, M.M.; Sardinha, M.R. Ontology Based Aspect Level Opinion Mining. Int. J. Eng. Sci. Res. Technol. (IJESRT) 2016, 5, 797–804. [Google Scholar]
- Zehra, S.; Wasi, S.; Jami, S.I.; Nazir, A.; Khan, A.; Waheed, N. Ontology-based Sentiment Analysis Model for Recommendation Systems. In Proceedings of the 9th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management (KEOD 2017), Funchal, Portugal, 1–3 November 2017; pp. 155–160. [Google Scholar] [CrossRef]
- Salas-Zárate, M.D.P.; Medina-Moreira, J.; Lagos-Ortiz, K.; Luna-Aveiga, H.; Rodriguez-Garcia, M.A.; Valencia-García, R. Sentiment analysis on tweets about diabetes: An aspect-level approach. Comput. Math. Methods Med. 2017, 2017, 1–9. [Google Scholar] [CrossRef]
- El-Halees, A.; Al-Asmar, A. Ontology based Arabic opinion mining. J. Inf. Knowl. Manag. 2017, 16, 1750028. [Google Scholar] [CrossRef]
- Ali, F.; Kwak, D.; Khan, P.; El-Sappagh, S.; Ali, A.; Ullah, S.; Kwak, K.S. Transportation sentiment analysis using word embedding and ontology-based topic modeling. Knowl.-Based Syst. 2019, 174, 27–42. [Google Scholar] [CrossRef]
- Ravi, K.; Ravi, V. A survey on opinion mining and sentiment analysis: Tasks, approaches and applications. Knowl.-Based Syst. 2015, 89, 14–46. [Google Scholar] [CrossRef]
- Amjad, A.; Qamar, U. UAMSA: Unified approach for multilingual sentiment analysis using GATE. In Proceedings of the 6th Conference on the Engineering of Computer Based Systems, Bucharest, Romania, 2–3 September 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Tartir, S.; Abdul-Nabi, I. Semantic sentiment analysis in Arabic social media. J. King Saud Univ.-Comput. Inf. Sci. 2017, 29, 229–233. [Google Scholar] [CrossRef]
- Poria, S.; Gelbukh, A.; Hussain, A.; Howard, N.; Das, D.; Bandyopadhyay, S. Enhanced SenticNet with affective labels for concept-based opinion mining. IEEE Intell. Syst. 2013, 28, 31–38. [Google Scholar] [CrossRef]
- Siddiqui, S.; Rehman, M.A.; Daudpota, S.M.; Waqas, A. Ontology Driven Feature Engineering for Opinion Mining. IEEE Access 2019, 7, 67392–67401. [Google Scholar] [CrossRef]
- Oussous, A.; Benjelloun, F.Z.; Lahcen, A.A.; Belfkih, S. ASA: A framework for Arabic sentiment analysis. J. Inf. Sci. 2020, 46, 544–559. [Google Scholar] [CrossRef]
- Al-Radaideh, Q. Applications of mining arabic text: A review. Recent Trends in Computational Intelligence. In Recent Trends in Computational Intelligence; IntechOpen: Lonon, UK, 2020; pp. 91–109. [Google Scholar] [CrossRef] [Green Version]
- Mulki, H.; Haddad, H.; Babaoglu, I. Modern trends in Arabic sentiment analysis: A survey. Rev. TAL 2018, 58, 15–39. [Google Scholar]
- Ihnaini, B.; Mahmuddin, M. Lexicon-Based Sentiment Analysis of Arabic Tweets: A Survey. J. Eng. Appl. Sci. 2018, 13, 7313–7322. [Google Scholar]
- Nithish, R.; Sabarish, S.; Kishen, M.N.; Abirami, A.M.; Askarunisa, A. An Ontology based Sentiment Analysis for mobile products using tweets. In Proceedings of the 5th International Conference on Advanced Computing (ICoAC), Chennai, India, 18–20 December 2013; pp. 342–347. [Google Scholar]
- Lazhar, F.; Yamina, T.G. Identification of opinions in Arabic texts using ontologies. In Proceedings of the Workshop on Ubiquitous Data Mining, Montpellier, France, 27 August 2012; pp. 61–64. Available online: https://www.lirmm.fr/ecai2012/images/stories/ecai_doc/pdf/workshop/W3_procUDMECAI2012.pdf#page=67 (accessed on 24 February 2019).
- Mahyoub, F.H.; Siddiqui, M.A.; Dahab, M.Y. Building an Arabic Sentiment Lexicon Using Semi-Supervised Learning. J. King Saud Univ.—Comput. Inf. Sci. 2014, 26, 417–424. [Google Scholar] [CrossRef] [Green Version]
- Soliman, T.H.; Elmasry, M.A.; Hedar, A.; Doss, M.M. Sentiment analysis of Arabic slang comments on Facebook. Int. J. Comput. Technol. 2014, 12, 3470–3478. [Google Scholar] [CrossRef]
- Elgeldawi, E.; Sayed, A.; Galal, A.R.; Zaki, A.M. Hyperparameter Tuning for Machine Learning Algorithms Used for Arabic Sentiment Analysis. Informatics 2021, 8, 79. [Google Scholar] [CrossRef]
- Saberi, B.; Saad, S. Sentiment analysis or opinion mining: A review. Int. J. Adv. Sci. Eng. Inf. Technol. 2017, 7, 1660–1666. [Google Scholar]
- Sayed, A.A.; Elgeldawi, E.; Zaki, A.M.; Galal, A.R. Sentiment Analysis for Arabic Reviews using Machine Learning Classification Algorithms. In Proceedings of the 2020 International Conference on Innovative Trends in Communication and Computer Engineering (ITCE), Aswan, Egypt, 8–9 February 2020; pp. 56–63. [Google Scholar]
- Abdullah, M.; Hadzikadicy, M.; Shaikhz, S. SEDAT: Sentiment and Emotion Detection in Arabic Text Using CNN-LSTM Deep Learning. In Proceedings of the 17th IEEE International Conference on Machine Learning and Applications (ICMLA), Orlando, FL, USA, 17–20 December 2018; pp. 835–840. [Google Scholar]
- Mohammed, A.; Kora, R. Deep learning approaches for Arabic sentiment analysis. Soc. Netw. Anal. Min. 2019, 9, 1–12. [Google Scholar] [CrossRef]
- Zahidi, Y.; El Younoussi, Y.; Al-Amrani, Y. A powerful comparison of deep learning frameworks for Arabic sentiment analysis. Int. J. Electr. Comput. Eng. 2021, 11, 745–752. [Google Scholar] [CrossRef]
- El-Affendi, M.A.; Alrajhi, K.; Hussain, A. A novel deep learning-based multilevel parallel attention neural (MPAN) model for multidomain arabic sentiment analysis. IEEE Access 2021, 9, 7508–7518. [Google Scholar] [CrossRef]
- Khasawneh, R.T.; Wahsheh, H.A.; Alsmadi, I.M.; AI-Kabi, M.N. Arabic sentiment polarity identification using a hybrid approach. In Proceedings of the 6th International Conference on Information and Communication Systems (ICICS), Amman, Jordan, 7–9 April 2015; pp. 148–153. [Google Scholar] [CrossRef]
- Altawaier, M.M.; Tiun, S. Comparison of machine learning approaches on arabic twitter sentiment analysis. Int. J. Adv. Sci. Eng. Inf. Technol. 2016, 6, 1067–1073. [Google Scholar] [CrossRef]
- Al-Rubaiee, H.; Qiu, R.; Li, D. Identifying Mubasher software products through sentiment analysis of Arabic tweets. In Proceedings of the International Conference on Industrial Informatics and Computer Systems (CIICS), Sharjah, United Arab Emirates, 13–15 March 2016; pp. 1–6. [Google Scholar]
- Alomari, K.M.; ElSherif, H.M.; Shaalan, K. Arabic tweets sentimental analysis using machine learning. In Proceedings of the International Conference on Industrial, Engineering and Other Applications of Applied Intelligent Systems, Arras, France, 27–30 June 2017; pp. 602–610. [Google Scholar] [CrossRef]
- Alayba, A.M.; Palade, V.; England, M.; Iqbal, R. Arabic language sentiment analysis on health services. In Proceedings of the 1st International Workshop on Arabic Script Analysis and Recognition (ASAR), Nancy, France, 3–5 April 2017; pp. 114–118. [Google Scholar]
- Alowaidi, S.; Saleh, M.; Abulnaja, M. Semantic Sentiment Analysis of Arabic Texts. Int. J. Adv. Comput. Sci. Appl. 2017, 8, 256–262. [Google Scholar] [CrossRef] [Green Version]
- Al-Radaideh, Q.A.; Al-Qudah, G.Y. Application of rough set-based feature selection for Arabic sentiment analysis. Cogn. Comput. 2017, 9, 436–445. [Google Scholar] [CrossRef]
- Tripathy, A.; Agrawal, A.; Rath, S.K. Classification of sentiment reviews using n-gram machine learning approach. Expert Syst. Appl. 2016, 57, 117–126. [Google Scholar] [CrossRef]
- Jagdale, R.S.; Shirsat, V.S.; Deshmukh, S.N. Sentiment analysis on product reviews using machine learning techniques. Cogn. Inform. Soft Comput. 2019, 768, 639–647. [Google Scholar] [CrossRef]
- Wang, H.; Liu, L.; Song, W.; Lu, J. Feature-based sentiment analysis approach for product reviews. J. Softw. 2014, 9, 274–279. [Google Scholar] [CrossRef]
- Catal, C.; Nangir, M. A sentiment classification model based on multiple classifiers. Appl. Soft Comput. 2017, 50, 135–141. [Google Scholar] [CrossRef]
- Štrimaitis, R.; Stefanoviˇc, P.; Ramanauskait˙ e, S.; Slotkien˙ e, A. Financial Context News Sentiment Analysis for the Lithuanian Language. Appl. Sci. 2021, 11, 4443. [Google Scholar] [CrossRef]
- El-Masri, M.; Altrabsheh, N.; Mansour, H.; Ramsay, A. A web-based tool for Arabic sentiment analysis. Procedia Comput. Sci. 2017, 117, 38–45. [Google Scholar] [CrossRef]
- Lalji, T.; Deshmukh, S. Twitter sentiment analysis using hybrid approach. Int. Res. J. Eng. Technol. 2016, 3, 2887–2890. [Google Scholar]
- El-Halees, A.M. Arabic opinion mining using combined classification approach. In Proceedings of the International Arab Conference on Information Technology ACIT, Cairo, Egypt, 8–10 December 2011; pp. 264–271. Available online: https://www.researchgate.net/publication/228467530_ARABIC_OPINION_MINING_USING_COMBINED_CLASSIFICATION_APPROACH (accessed on 1 February 2019).
- Aldayel, H.K.; Azmi, A.M. Arabic tweets sentiment analysis–a hybrid scheme. J. Inf. Sci. 2016, 42, 782–797. [Google Scholar] [CrossRef]
- Elshakankery, K.; Ahmed, M.F. HILATSA: A hybrid Incremental learning approach for Arabic tweets sentiment analysis. Egypt. Inform. J. 2019, 20, 163–171. [Google Scholar] [CrossRef]
- Mustafa, H.H.; Mohamed, A.; Elzanfaly, D.S. An Enhanced Approach for Arabic Sentiment Analysis. Int. J. Artif. Intell. Appl. (IJAIA) 2017, 8, 1–14. [Google Scholar] [CrossRef]
- Gautam, G.; Yadav, D. Sentiment analysis of twitter data using machine learning approaches and semantic analysis. In Proceedings of the Seventh International Conference on Contemporary Computing (IC3), Noida, India, 7–9 August 2014; pp. 437–442. [Google Scholar] [CrossRef]
- ElSahar, H.; El-Beltagy, S.R. Building large Arabic multi-domain resources for sentiment analysis. In Proceedings of the International Conference on Intelligent Text Processing and Computational Linguistics, Cairo, Egypt, 14–20 April 2015; Springer: Cham, Switzerland, 2015; Volume 9042, pp. 23–34. [Google Scholar] [CrossRef]
- Badaro, G.; Baly, R.; Hajj, H.; Habash, N.; El-Hajj, W. A large scale Arabic sentiment lexicon for Arabic opinion mining. In Proceedings of the EMNLP 2014 Workshop on Arabic Natural Language Processing (ANLP), Doha, Qatar, 25 October 2014; pp. 165–173. [Google Scholar]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent Dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Zhang, Q.; Liu, S.; Gong, D.; Tu, Q. A Latent-Dirichlet-Allocation Based Extension for Domain Ontology of Enterprise’s Technological Innovation. International Journal of Computers. Commun. Control 2019, 14, 107–123. [Google Scholar]
- Knublauch, H.; Fergerson, R.W.; Noy, N.F.; Musen, M.A. The Protégé OWL plugin: An open development environment for semantic web applications. In Proceedings of the International Semantic Web Conference; Springer: Berlin/Heidelberg, Germany, 2014; pp. 229–243. [Google Scholar]
- Noy, N.F.; McGuinness, D.L. Ontology Development 101: A Guide to Creating Your First Ontology. 2001. 1–25. Available online: https://protege.stanford.edu/publications/ontology_development/ontology101.pdf (accessed on 5 May 2019).
- Green, S.; Manning, C.D. Better Arabic parsing: Baselines, evaluations, and analysis. In Proceedings of the 23rd International Conference on Computational Linguistics, Beijing, China, 23–27 August 2010; pp. 394–402. [Google Scholar]
- Zerrouki, T. Tashaphyne Arabic Light Stemmer and Segmentor. Available online: https://pypi.python.org/pypi/Tashaphyne/0.2 (accessed on 27 March 2019).
- Pandas.PyPI. Available online: https://pypi.org/project/pandas/ (accessed on 14 February 2019).
- Lutz, M. Learning Python: Powerful Object-Oriented Programming; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2013. [Google Scholar]
- Pang, B.; Lee, L. A sentimental education: Sentiment analysis using subjectivity summarization based on minimum cuts. In Proceedings of the 42nd Annual Meeting on Association for Computational Linguistics, Association for Computational Linguistics, Barcelona, Spain, 21–26 July 2004; pp. 271–278. [Google Scholar]
- Poolsawad, N.; Kambhampati, C.; Cleland, J.G.F. Balancing class for performance of classification with a clinical dataset. In Proceedings of the World Congress on Engineering, London, UK, 2–4 July 2014; Volume 1, pp. 1–6. [Google Scholar]
- Kotsiantis, S.; Kanellopoulos, D.; Pintelas, P. Handling imbalanced datasets: A review. GESTS Int. Trans. Comput. Sci. Eng. 2006, 30, 25–36. [Google Scholar]
- Al-Sallab, A.; Baly, R.; Hajj, H.; Shaban, K.B.; El-Hajj, W.; Badaro, G. Aroma: A recursive deep learning model for opinion mining in arabic as a low resource language. ACM Trans. Asian Low-Resour. Lang. Inf. Processing (TALLIP) 2017, 16, 1–20. [Google Scholar] [CrossRef]
- Baly, R.; Hajj, H.; Habash, N.; Shaban, K.B.; El-Hajj, W. A sentiment treebank and morphologically enriched recursive deep models for effective sentiment analysis in arabic. ACM Trans. Asian Low-Resour. Lang. Inf. Processing (TALLIP) 2017, 16, 1–21. [Google Scholar] [CrossRef]
- Mataoui, M.H.; Hacine, T.E.B.; Tellache, I.; Bakhtouchi, A.; Zelmati, O. A new syntax-based aspect detection approach for sentiment analysis in Arabic reviews. In Proceedings of the 2018 2nd International Conference on Natural Language and Speech Processing (ICNLSP), Algiers, Algeria, 25–26 April 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–6. [Google Scholar]
- Mataoui, M.H.; Zelmati, O.; Boumechache, M. A proposed lexicon-based sentiment analysis approach for the vernacular Algerian Arabic. Res. Comput. Sci. 2016, 110, 55–70. [Google Scholar] [CrossRef]
- Mohammad, A.S.; Qwasmeh, O.; Talafha, B.; Al-Ayyoub, M.; Jararweh, Y.; Benkhelifa, E. An enhanced framework for aspect-based sentiment analysis of Hotels’ reviews: Arabic reviews case study. In Proceedings of the 2016 11th International Conference for Internet Technology and Secured Transactions (ICITST), Barcelona, Spain, 5–7 December 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 98–103. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Total Positive Reviews | Total Negative Reviews | Total Neutral Reviews |
|---|---|---|
| 10,775 | 2647 | 2150 |
| # | Review Text | Polarity |
|---|---|---|
| 1 | . ممتاز- رائع-انصح الجميع به في شهر اكتوبر 2013 نزلت 3 يوم في الفندق-كان اكثر من رائع-اسعار مناسبة-خدمة ممتازة-الغرف نظيفة جدا والحمامات رائعة-ادارة الفندق والموظفين اكثر من ممتازة-حراس الامن ممتازة-المطعم والبار والملهي رائعة حقا-لم ارى افضل من ذلك الفندق في اديس ابابا. | 1 (Positive) |
| Translation: Excellent-wonderful-I recommend it to everyone. In October 2013 I stayed 3 days in the hotel-it was more than wonderful-suitable prices-excellent service-rooms are very clean and bathrooms are wonderful-hotel management and staff are more than excellent-security guards are excellent-the restaurant, bar and nightclub are wonderful Really-I’ve never seen a better hotel than that in Addis Ababa. |
| Arabic Form | Meaning | Aramorph Lemma | POS | Positive Sentiment Score | Negative Sentiment Score |
|---|---|---|---|---|---|
| فرح | Happyness | faraH_1 | Noun | 0.5 | 0.125 |
| حزن | Felt sad | Hazin-a_1 | Verb | 0 | 0.5 |
| شريف | Honorable | $ariyf_2 | Adjective | 1 | 0 |
| Topics | Keywords |
|---|---|
| Topic 1 | مطعم ,جيد ,رائع ,موظف ,طاقم ,يمكن ,توجد ,لطيف ,افطار ,استقبال ,قذر ,افضل ,…… Restaurant, good, wonderful, employee, staff, can, there, nice, breakfast, reception, dirty, better, …… |
| Topic 2 | ممتاز ,طعام ,جميل ,شاطئ ,مريح ,سرير ,حمام ,كبير ,نظيف ,موقع ,يتوفر ,اسوء, …… Excellent, food, beautiful, beach, comfortable, bed, bathroom, large, clean, location, available, worst, …… |
| No | Concept | Meaning | Semantic Synonyms | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 1 | فندق | Hotel | نزل | خان | اوتيل | هوتيل | بنسيون | ||
| 2 | طاقم | Staff | كادر | فريق | ستاف | تيم | |||
| 3 | غطاء | Blanket | لحاف | بطانية | دثار | ملاءة | ملاية | حرام | شرشف |
| Number of Distinct Concepts | Number of Ontology Levels |
|---|---|
| 203 | 6 |

| Original Review | Input |
| موقع رائع في مركز المدينة الا انني شعرت بالإستياء لإهمالهم بسبب وجود سجادة قذرة | |
| Step | Output |
| Extract Domain Features with Importance | (موقع, NN):(levelImportance= 5, freqImportance= 1) (سجادة, NN):(levelImportance= 2, freqImportance= 0.25) |
| Extract Around Sentiments | (موقع)[‘رائع’, ‘مركز’, ‘المدينة’, ‘شعرت’] (سجادة)[‘قذرة’, ‘شعرت’, ‘بالإستياء’, ‘لإهمالهم’, ‘وجود’] |
| Initial Domain Feature Polarity Identification | Positive Score (موقع) = 0.4282/Negative Score (موقع) = 0.09063 - Initial Polarity(موقع) = 0.33757 = 0.09063 − 0.4282 Positive Score (سجادة) = 0.20594/Negative Score (سجادة) = 0.7226 - Initial Polarity(سجادة) = 0.51666 − = 0.7226 − 0.20594 |
| Extracted Domain Features and Identified Importance | Input |
| -Initial Polarity (موقع) = 0.33757 (levelImportance = 5, freqImportance = 1) -Initial Polarity (سجادة) = −0.51666 (levelImportance = 2, freqImportance = 0.25) | |
| Step | Output |
| Calculating Overall Semantic Polarity for the Review based on Domain Features Importance | (موقع) = Initial Polarity * (L + F) = 0.33757 *(5 + 1) = 2.02542 (سجادة) = Initial Polarity * (L + F) = −0.51666 *(2 + 0.25) = −1.162485 Overall Semantic Review Polarity = 2.02542 + (−1.162485) = 0.862935 |
| Determine Review Label | Positive (+1) |
| Total Positive Reviews | Total Negative Reviews | Total Reviews | |
|---|---|---|---|
| Unbalanced Reviews | 10,775 | 2647 | 13,422 |
| Balanced Reviews | 2647 | 2647 | 5294 |
| Portion1: Used for Ontology Extraction | 1647 | 1647 | 3294 |
| Portion2: Used for Sentiment Analysis Experiments | 1000 | 1000 | 2000 |
| Predicted | |||
|---|---|---|---|
| Positive | Negative | ||
| Original | Positive | 898 | 102 |
| Negative | 404 | 596 | |
| Precision | Recall | F1-Measure | |
|---|---|---|---|
| Positive | 68.97% | 89.80% | 78.01% |
| Negative | 85.38% | 59.60% | 70.19% |
| Average | 77.17% | 74.70% | 74.10% |
| Predicted | |||
|---|---|---|---|
| Positive | Negative | ||
| Original | Positive | 929 | 71 |
| Negative | 362 | 638 | |
| Precision | Recall | F1-Measure | |
|---|---|---|---|
| Positive | 71.95% | 92.90% | 81.09% |
| Negative | 89.98% | 63.80% | 74.66% |
| Average | 80.96% | 78.35% | 77.87% |
| Predicted | |||
|---|---|---|---|
| Positive | Negative | ||
| Original | Positive | 938 | 62 |
| Negative | 356 | 644 | |
| Precision | Recall | F1-Measure | |
|---|---|---|---|
| Positive | 72.48% | 93.80% | 81.77% |
| Negative | 91.21% | 64.40% | 75.49% |
| Average | 81.84% | 79.10% | 78.63% |
| Predicted | |||
|---|---|---|---|
| Positive | Negative | ||
| Original | Positive | 937 | 63 |
| Negative | 353 | 647 | |
| Precision | Recall | F1-Measure | |
|---|---|---|---|
| Positive | 72.63% | 93.70% | 81.83% |
| Negative | 91.12% | 64.70% | 75.67% |
| Average | 81.87% | 79.20% | 78.75% |
| Reference | Method | Sentiment Lexicon | Dataset | Accuracy |
|---|---|---|---|---|
| Al-Sallab et al. [79] | Deep Learning using Recursive Auto Encoder (RAE). | ArSenL | ATB, QALB, Tweets | 86.5%, 79.2%, 76.9% |
| Baly et al. [80] | Deep Learning using Recursive Neural Tensor Networks (RNTN). | ArSenL, ArSenTB | QALB | 80% |
| Mataoui et al. [81] | Syntax-based Aspect Detection. | Mataoui et al. [82] | Hotels, Products | 74.39%, 72.28% |
| Mohammad et al. [83] | Aspect-based using Support Vector Machine (SVM). | ------ | Hotels | 76.42e% |
| Proposed approach | Ontology-based for Domain Features Extraction and Weighting. | ArSenL | Hotels | 79.20% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khabour, S.M.; Al-Radaideh, Q.A.; Mustafa, D. A New Ontology-Based Method for Arabic Sentiment Analysis. Big Data Cogn. Comput. 2022, 6, 48. https://doi.org/10.3390/bdcc6020048
Khabour SM, Al-Radaideh QA, Mustafa D. A New Ontology-Based Method for Arabic Sentiment Analysis. Big Data and Cognitive Computing. 2022; 6(2):48. https://doi.org/10.3390/bdcc6020048
Chicago/Turabian StyleKhabour, Safaa M., Qasem A. Al-Radaideh, and Dheya Mustafa. 2022. "A New Ontology-Based Method for Arabic Sentiment Analysis" Big Data and Cognitive Computing 6, no. 2: 48. https://doi.org/10.3390/bdcc6020048
APA StyleKhabour, S. M., Al-Radaideh, Q. A., & Mustafa, D. (2022). A New Ontology-Based Method for Arabic Sentiment Analysis. Big Data and Cognitive Computing, 6(2), 48. https://doi.org/10.3390/bdcc6020048