
A Comprehensive Spark-Based Layer for Converting Relational Databases to NoSQL


Abstract
:1. Introduction
- Proposing transformation algorithms from the RDB to document, column, and key–value databases.
- Executing the migration process in a distributed environment using Spark.
- Executing SQL over document, column, and key–value databases in a distributed environment.
- Evaluating the proposed Spark-based layer with different scenarios.
2. Background and Related Work
2.1. NoSQL Background
2.2. Related Works
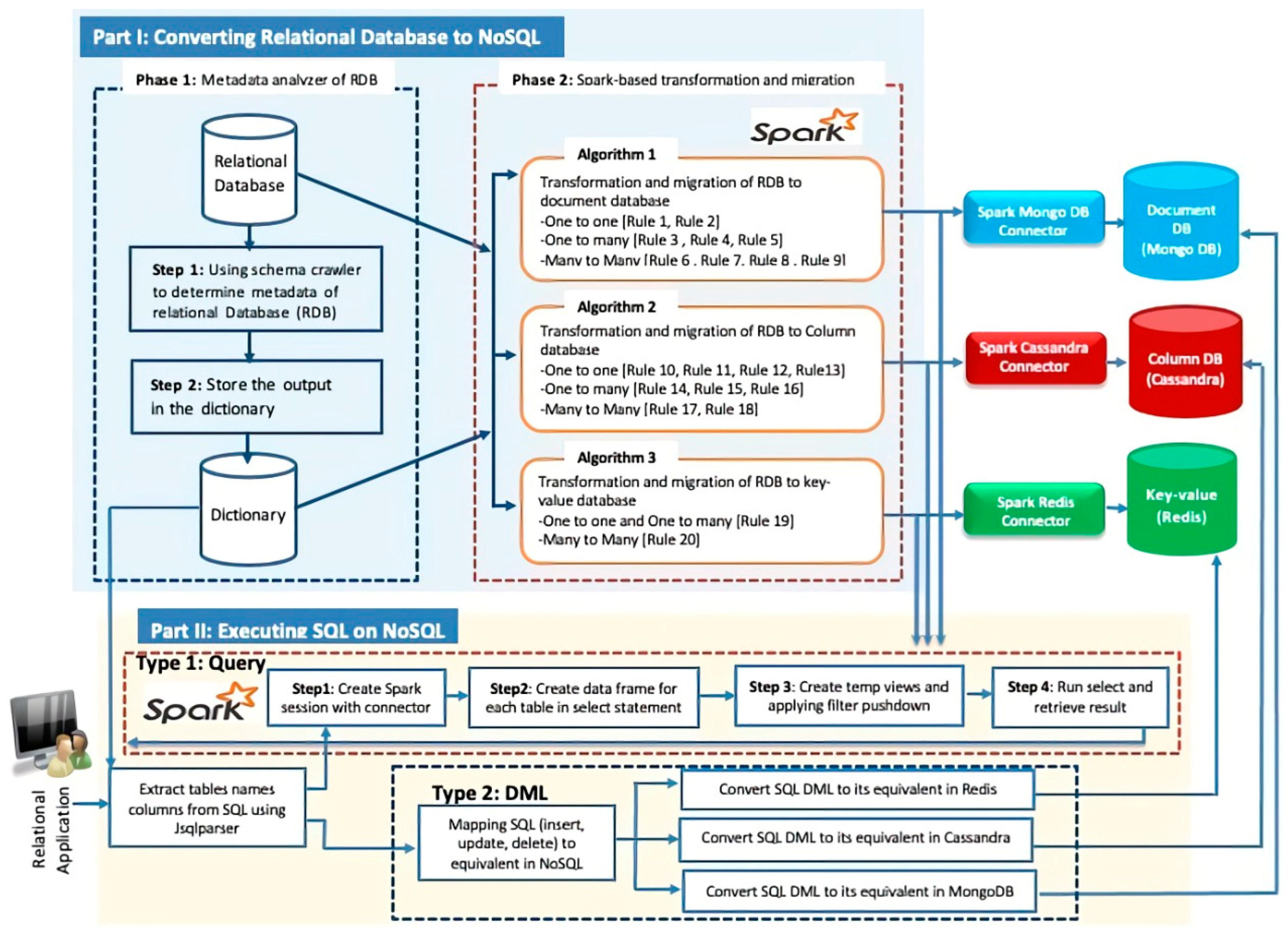
3. The Proposed Architecture of the Spark-Based Layer
3.1. Part I: Converting the Relational Database to NoSQL
3.1.1. Phase 1: Metadata Analyzer of the RDB
3.1.2. Phase 2: Spark-Based Transformation and Migration
- Algorithm 1: Transforms and migrates to a document database.
- Algorithm 2: Transforms and migrates to a column database.
- Algorithm 3: Transforms and migrates to a key–value database.
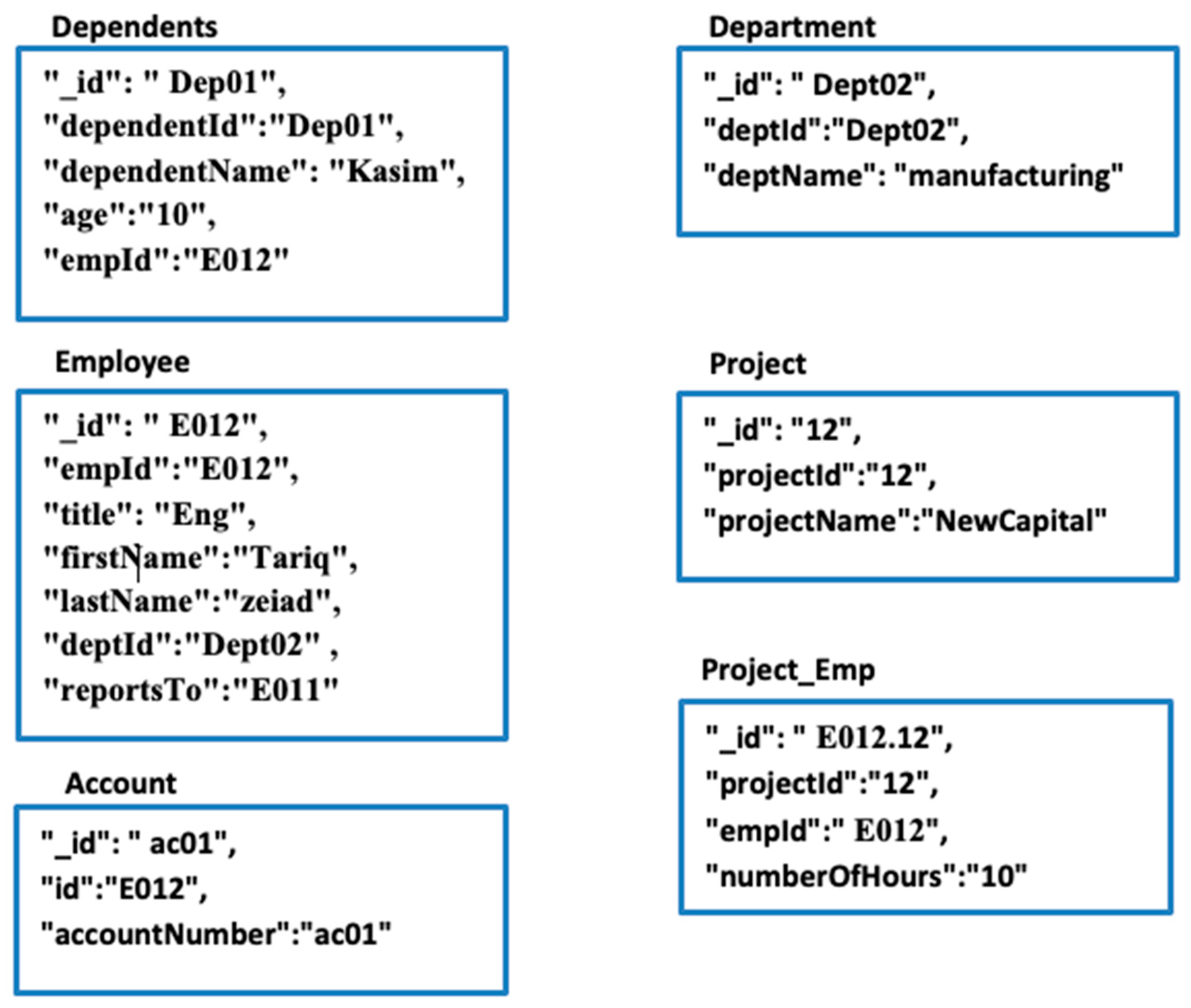
- Rule 1, embedding one-to-one: If the referencing table does not have a relationship with other tables in the RDB, embed referencing objects into the referenced. The primary key of the referenced table is converted as the key of the collection. There is no need to store the field that represents the foreign key because the referencing table and referenced table are migrated to the same collection in the document database.
- Rule 2, referencing one-to-one: If the referencing table has a relationship with other tables in the RDB, add referencing object references to referenced objects (represents foreign key conversion). The primary key of the referenced table is converted as key of the collection and the primary key of the referencing table is converted as key of the collection.
- Rule 3, embedding one-to-many: Embedding the many-side on the one-side if the many-side are not referenced by other tables [33].The primary key of the one-side table is converted as the key of the collection. The many-side is converted as an array inside the one-side, so no need to store the field that represents the foreign key.
- Rule 4, referencing one-to-many, one-side: If the one-side of the one-to-many relationship has relationships with other tables or a small number of the many-side is associated with the one-side, it is transformed by adding into the one-side an array of references of the many-side [33].
- Rule 5, referencing one-to-many, many-side: If the many-side of the one-to-many relationship has relationships with other tables or a large number of the many-side is associated with the one-side, it is transformed by adding a many-side reference to the one-side [10].
- Rule 6, two-way embedding many-to-many N:M: If the size of M is close to N [32].
- Rule 7, one-way embedding many-to-many N:M: If the size of M is significantly greater than N.
| Algorithm 1: TRANSFORMATION AND MIGRATION FROM AN RDB TO A DOCUMENT MODEL | ||
| Input: RDB r, Dictionary, User selected rules | ||
| Output: RDB r transformed and migrated to document database d | ||
| 1 | DocumentDatabase d ← create Document Database | |
| 2 | OneToOne [] ←Extracting One-To-One Relationships From Dictionary of given RDB // OneToOne [] contains referencing table and referenced table of each one-to-one relationship | |
| 3 | OneToMany [] ←Extracting One-To-Many Relationships From Dictionary of given RDB // OneToMany [] contains referencing table and referenced table of each one-to-Many relationship | |
| 4 | ManyToMany [] ←Extracting Many-To-Many Relationships From Dictionary of given RDB /* ManyToMany [] contains metadata of two participating tables that is connected by join table of each M:N relationship and bridge table (join table) */ | |
| 5 | If (automatic selection) // | |
| 6 | Function: ConstructAutomaticSchema (r,d, OneToOne [],OneToMany [], ManyToMany []) | |
| 7 | Else | |
| 8 | Function: ConstructUserSelectedSchema (r,d, OneToOne [],OneToMany [], ManyToMany []) | |
| Function: ConstructUserSelectedSchema (r, d, OneToOne [],OneToMany [], ManyToMany [])) | ||
| 1 | UserSelectedRules [] ←GetUserSelectedRules () // user manually select each rule | |
| 2 | For each rule: UserSelectedRules [] | |
| 3 | If rule {Rule 1, Rule 2} | |
| 4 | TransformAndMigrateOneToOne (rule, OneToOne []) /* TransformAndMigrateOneToOne method takes a user-selected rule of one-to-one relationship and migrates data to document database using Spark */ | |
| 5 | Else If rule {Rule 3, Rule 4, Rule 5} | |
| 6 | TransformAndMigrateOneToMany (rule, OneToMany []) /* TransformAndMigrateOneToMany method takes the user selected rule of one to many relationships and migrates data to document database using Spark */ | |
| 7 | Else | |
| 8 | TransformAndMigrateManyToMany (rule, ManyToMany []) /* TransformAndMigrateManyToMany method takes the user-selected rule (rule 6 or rule 7 or rule 8 or rule) of many-to-many relationships and migrates data to document by using Spark */ | |
| 9 | End for each | |
| Function: ConstructAutomaticSchema (r,d, OneToOne [], OneToMany [], ManyToMany []) | |||
| 1 | For each relationship e: OneToOne [] | ||
| 2 | Table t ←e.getReferencingTable () | ||
| 3 | If (t.getChildTable () = = null) | ||
| 4 | Apply rule 1 Embedding one-to-one | ||
| 5 | Else | ||
| 6 | Apply rule 2 Referencing one-to-one | ||
| 7 | End for each | ||
| 8 | For each relationship e: OneToMany [] | ||
| 9 | Table t1 ←e.getReferencingTable () | ||
| 10 | Table t2 ←e.getReferencedTable () | ||
| 11 | If (t1.getChildTable () = = null) | ||
| 12 | Apply rule 3 Embedding one to many | ||
| 13 | Else If ((t1.getNumberOfRelationships () > t2.getNumberOfRelationships ())) | ||
| 14 | Apply rule 4 referencing one to many one-side | ||
| 15 | Else | ||
| 16 | Apply rule 5 referencing one to many many-side | ||
| 17 | End for each | ||
| 18 | For each relationship e: ManyToMany [] | ||
| 19 | Table t1, t2 ←e.getTables () | ||
| 20 | If frequentjoin (t1, t2) == true // if two participated tables in M:N are frequently join | ||
| 21 | If (t1.size ()—t2.size () <= threshold) // if t1 size is close to t2 size | ||
| 22 | Apply rule 6 two way embedding many to many N:M | ||
| 23 | Else | ||
| 24 | Apply rule 7 one way embedding many to many N:M | ||
| 25 | Else | ||
| 26 | Apply rule 9 referencing M:N | ||
| 27 | End for each | ||
- (1)
- Create one table: this pattern is classified to different strategies
- (2)
- Creating two tables:
- (a)
- Rule 12, creates a column family for each participating table in the RDB, where the row key of the column family is the primary key in the RDB table and the primary key of the one-side becomes a column on the many-side. [38].
- (b)
- Rule 13, creates a column family for each participating table in the RDB, where each column family contains all fields of the two tables [37].
- Rule 14 (creating one table with a single-column family in the column store database): Merge all fields of the two tables in the RDB to a single-column family [37].
- Rule 15 (creating one table with a two-column family): Create a super column family in which each table is stored in a separate column family, where the table on the one-side contains a table on the many-side and the row key is the primary key of the one-side [38].
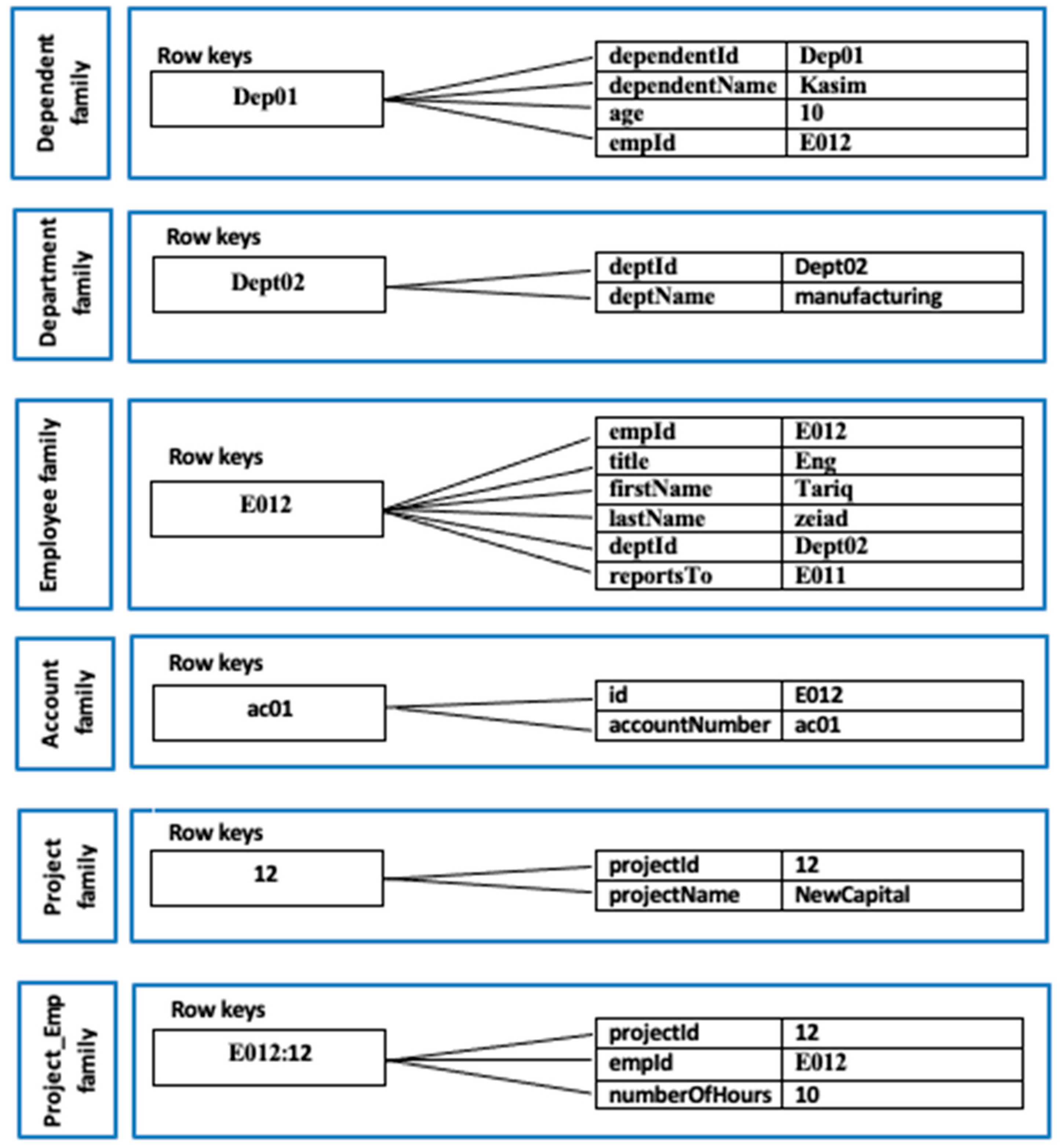
- Rule 16 (creating two tables with one column family per RDB table): Each table in the RDB is represented as a table in the column store, where the table in the column store has a single column family. The row key is the primary key of RDB table, as in this work [7] and the other layers concatenate the RDB table name with the primary key value to generate the row key [15,39].
- Rule 17 (create three tables with one column family per RDB table): Each table in the many-to-many relationship is mapped to a table in a column store, where the row key of the bridge RDB table is a concatenation of the composed primary key [7].
- Rule 18 (create a column family for each table and a super column family): Create a column family for each table in the relationship, where the row key of the column family is the primary key of the RDB table. Create a super column family for the bridge RDB and include all columns of the two RDB tables. The row key of the super family is the concatenation between the relationship name and the primary key of one column that is frequently used in the query [38].
| Algorithm 2: TRANSFORMATION AND MIGRATION FROM AN RDB TO A COLUMN MODEL | ||
| Input: RDB r, user selected rules, dictionary | ||
| Output: RDB r transformed and migrated to column database d | ||
| 1 | Keyspace d ← createKeyspace (r) | |
| 2 | OneToOne [] ←Extracting One-To-One Relationships From Dictionary of given RDB | |
| 3 | OneToMany [] ←Extracting One-To-Many Relationships From Dictionary of given RDB | |
| 4 | ManyToMany [] ←Extracting Many-To-Many Relationships From Dictionary of given RDB /* ManyToMany [] contains metadata of two participating tables that is connected by join table of each M:N relationship and bridge table (join table) */ | |
| 5 | UserSelectedRules [] ←GetUserSelectedRules () | |
| 6 | For each rule: UserSelectedRules [] | |
| 7 | If rule {Rule 10, Rule 11, Rule 12, Rule 13} | |
| 8 | TransformAndMigrateOneToOneCoulmn (rule, OneToOne []) /* TransformAndMigrateOneToOneCoulmn method takes the user-selected rule of a one-to-one relationship and migrates data to the keyspace using Spark */ | |
| 9 | Else If rule {Rule 14, Rule 15, Rule 16} | |
| 10 | TransformAndMigrateOneToManyCoulmn (rule, OneToMany []) /* TransformAndMigrateOneToManyCoulmn method takes a user-selected rule of one to many relationships and migrates data to the keyspace using Spark */ | |
| 11 | Else | |
| 12 | TransformAndMigrateManyToManyCoulmn (rule, ManyToMany []) /* TransformAndMigrateManyToManyCoulmn method takes a user-selected rule of many-to-many (rule 17 or rule 18) relationships and migrates data to the keyspace by using Spark */ | |
| 13 | End for each | |
| Algorithm 3: TRANSFORMATION AND MIGRATION FROM AN RDB TO KEY–VALUE MODEL | |||
| Input: RDB r and dictionary | |||
| Output: RDB r transformed and migrated to key-value database d | |||
| 1 | OneToOne [] ←ExtractingOneToOneRelationshipsFromDictionary of given RDB | ||
| 2 | OneToMany [] ←ExtractingOneToManyRelationshipsFromDictionary of given RDB | ||
| 3 | ManyToMany [] ←ExtractingManyToManyRelationshipsFromDictionary of given RDB // ManyToMany [] contains the bridge table with its columns only | ||
| 4 | For each table t {OneToOne [], OneToMany []} // for each table participating in one-to-one or one-to-many relationship | ||
| 5 | DataFrame df ← ReadRelationalDataUsingSpark (t, r) | ||
| 6 | tableName←t.getName () | ||
| 7 | Pk← t.getPK () // get primary key of table | ||
| 8 | For each element e in df | ||
| 9 | Key ← tableName+ “:“+ pk.getColumnValue ()// construct key by concatenating the table name and the value of primary key column | ||
| 10 | Value← e.getColumnNamesAndValues ()// construct value by generating a set of key-value pairs that represent the fields with their values | ||
| 11 | d←Emits(Key, Value)// store the key and key-value pairs in key-value database | ||
| 12 | End for each | ||
| 13 | End for each | ||
| 14 | For each table t ManyToMany [] // for each bridge table in Many-To-Many | ||
| 15 | DataFrame df ← ReadRelationalDataUsingSpark (t, r) | ||
| 16 | tableName←t.getName () | ||
| 17 | Pks []← t.getPKs () // get columns in the composed primary key | ||
| 18 | For each element e in df | ||
| 19 | Key ← tableName + “: “+ pks.getPKsValueConcatenated () // pks.getPKsValueConcatenated () get the values of the columns in composed primary key // construct key by concatenating the table name and the values of primary key columns | ||
| 20 | Value← e.getColumnNamesAndValues () // construct value by generating a set of key-value pairs that represent the fields with their values | ||
| 21 | d←Emits(Key, Value) // store the key and key-value pairs in key-value database | ||
| 22 | End for each | ||
| 23 | End for each | ||
3.2. Part II: Executing SQL on NoSQL
- Type 1 (Query): Executing SELECT statements (explained in Section 3.2.1)
- Type 2 (DML): Converting INSERT, UPDATE, and DELETE to their equivalents in the NoSQL database (explained in Section 3.2.2)
3.2.1. Type 1: Query
- Step 1: Create a Spark session that connects Spark with NoSQL.
- Step 2: Create data frames for each table in the SELECT statement by using Spark SQL and connectors.
- Step 3: Create temporary views from DataFrames and apply filter pushdown if the query contains filter conditions such as WHERE clause.
- Step 4: Run the SELECT statement on temporary views and retrieve the result as a DataFrame for relational application.
3.2.2. Type 2: DML
Converting SQL DML to MongoDB
Converting SQL DML to Cassandra
Converting SQL DML to Redis
4. Results and Discussion
4.1. Databases
4.2. Experiments and Results
- Number of partitions: maximum number of partitions that can be used for table reading. This property also determines the number of concurrent connections between Spark workers and the relational database because, by default, only one executor in the Spark cluster works.
- Partition column: the name of the column used for partitioning the table.
- Lower bound and upper bound: control the partition stride.
4.2.1. The Proposed Layer vs. Unity in a Single-Node Environment
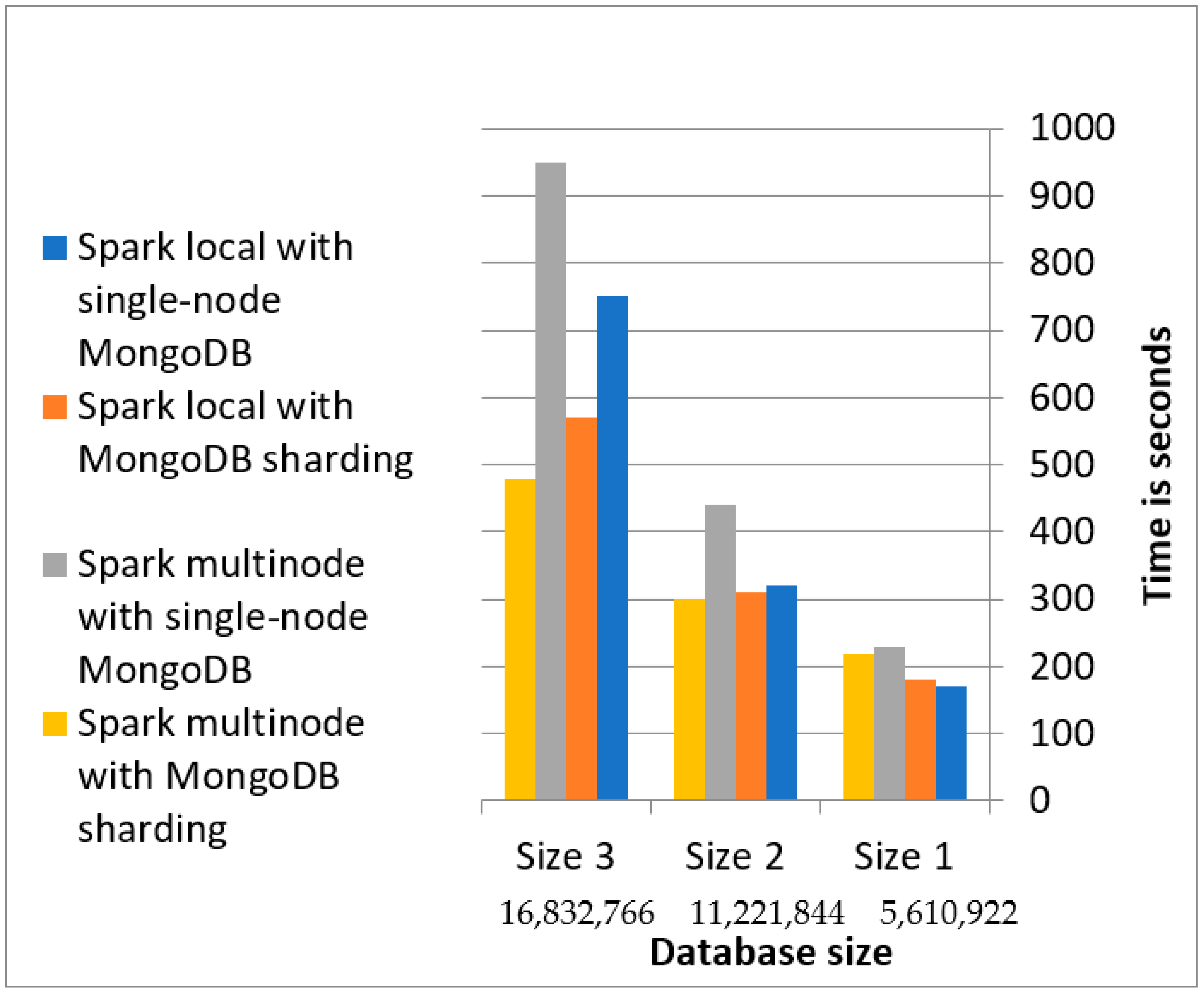
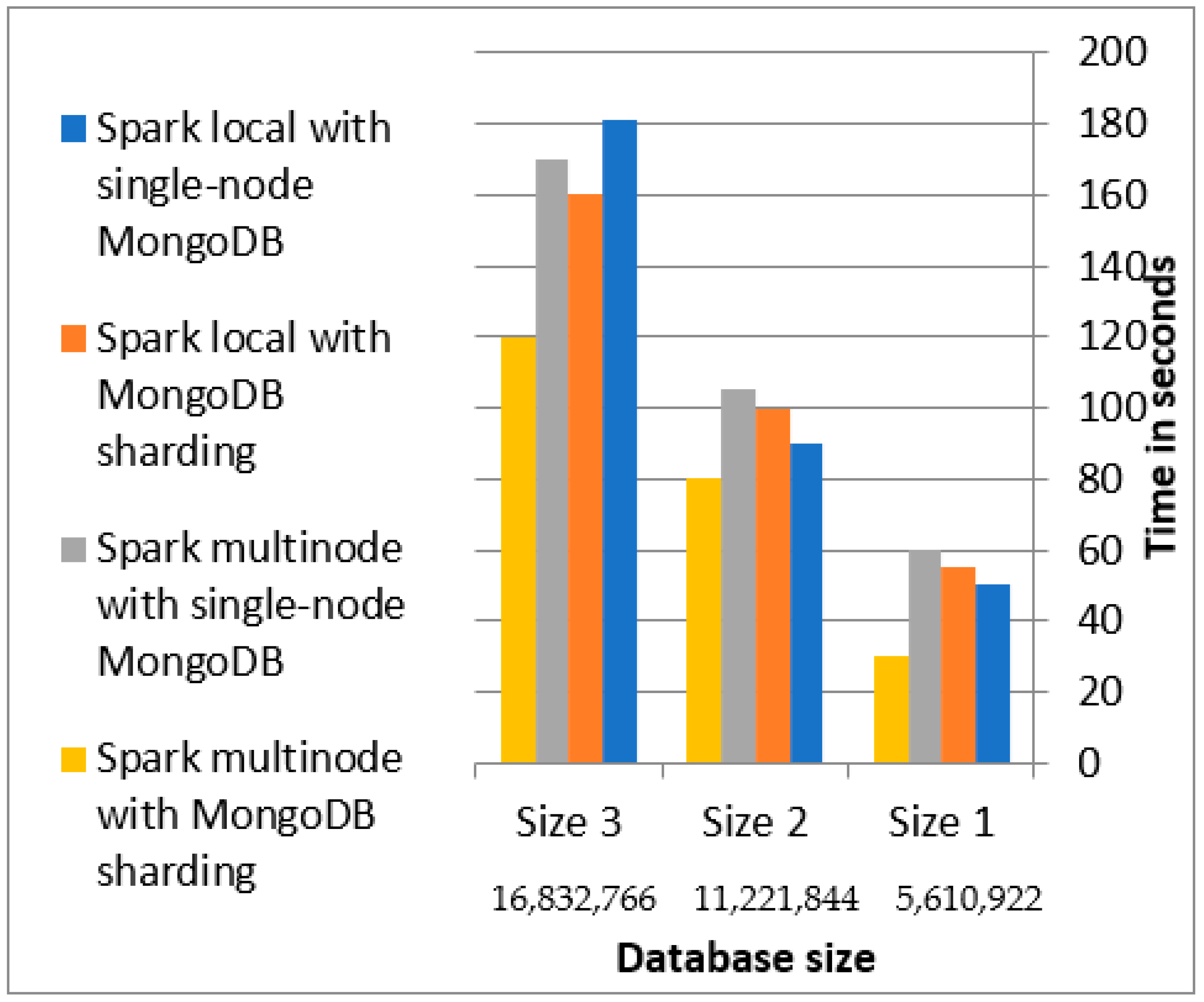
4.2.2. Document Database Evaluation
- Inserting to a sharded collection.
- The indexes are removed at the time of writing data to sharpen the collection and reconstruct the indexes after the end of the writing operation.
- Setting writes concerns only the primary node.
- Ensuring data locality.
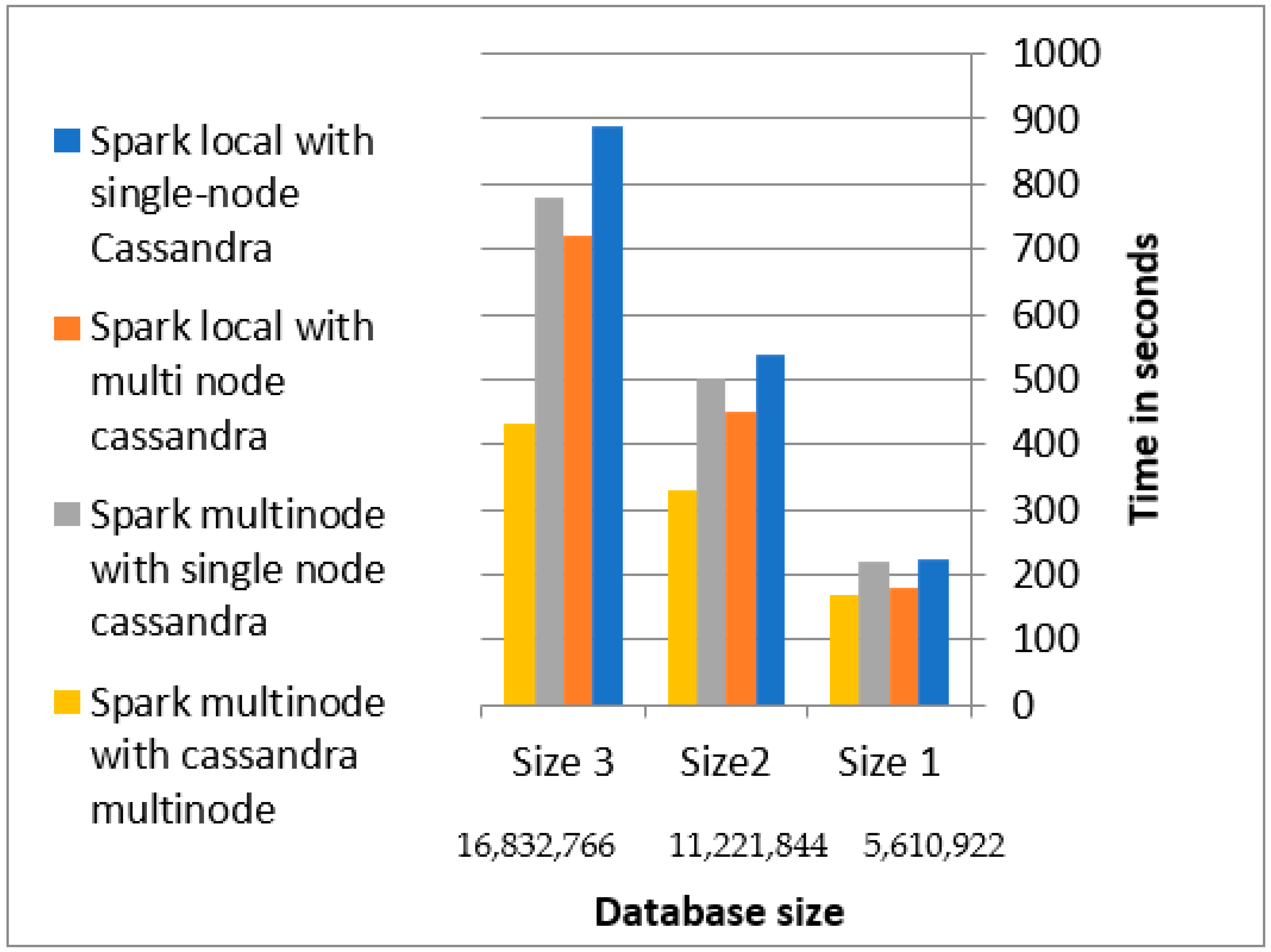
4.2.3. Column Database Evaluation
- Sorting the data before persisting it in the Cassandra database, which reduced the time of migration by 70% than without sorting the data.
- Spark partitions were also tuned using repartition and coalescence methods.
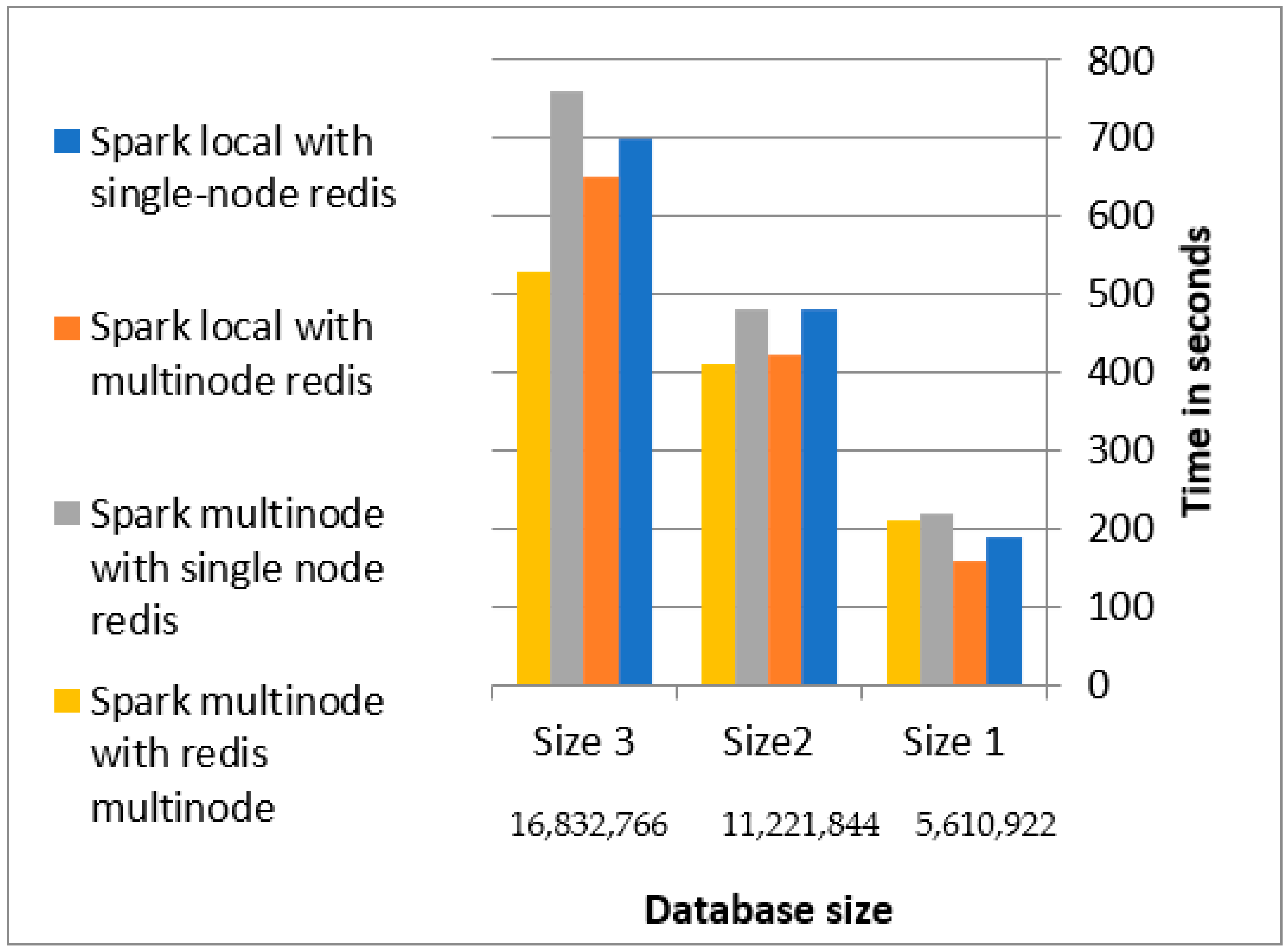
4.2.4. Key–Value Database Evaluation
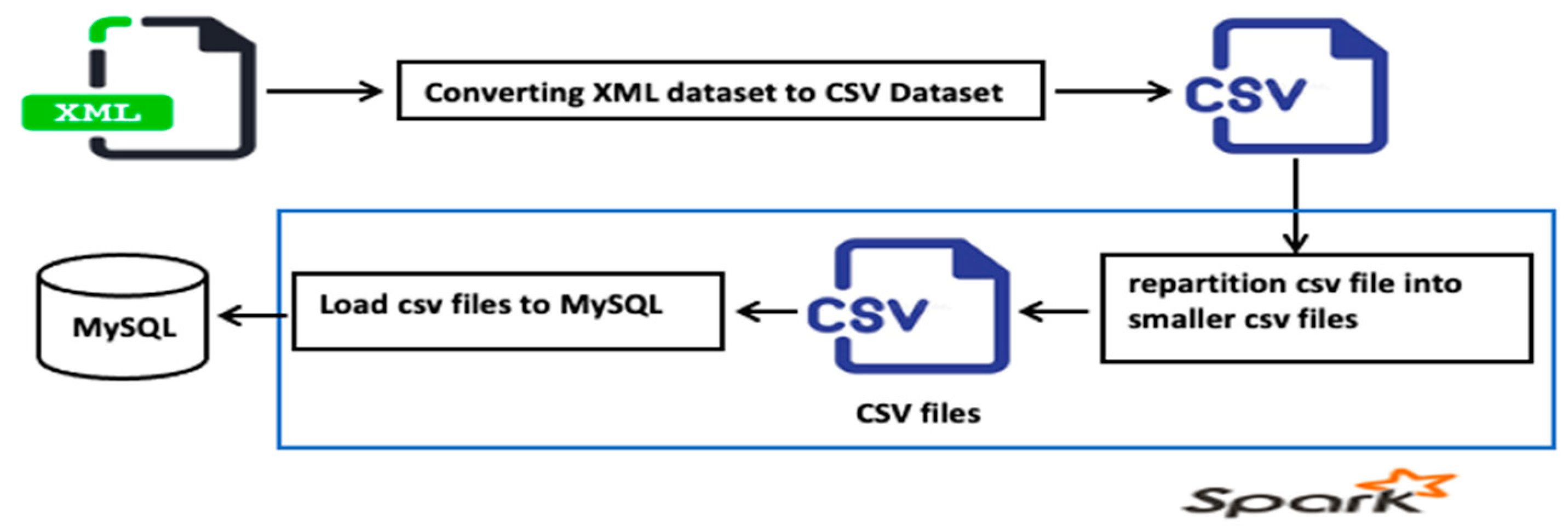
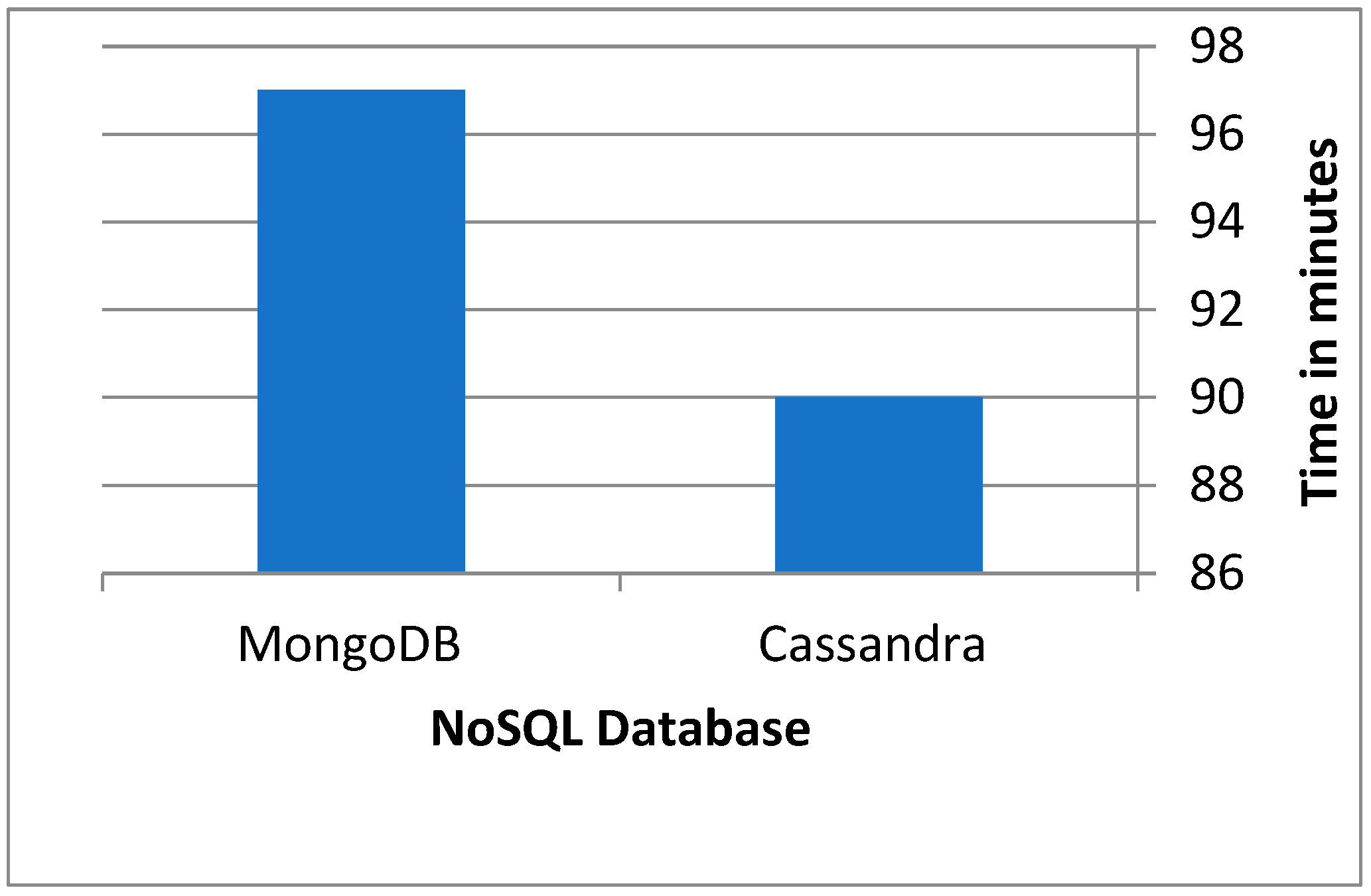
4.2.5. Evaluation for Writing on Stack Exchange Dataset
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Vera-Olivera, H.; Guo, R.; Huacarpuma, R.C.; Da Silva, A.P.B.; Mariano, A.M.; Maristela, H. Data Modeling and NoSQL Databases—A Systematic Mapping Review. ACM Comput. Surv. 2021, 54, 1–26. [Google Scholar] [CrossRef]
- Mostajabi, F.; Safaei, A.A.; Sahafi, A. A Systematic Review of Data Models for the Big Data Problem. IEEE Access 2021, 9, 128889–128904. [Google Scholar] [CrossRef]
- Atzeni, P.; Bugiotti, F.; Cabibbo, L.; Torlone, R. Data Modeling in the NoSQL World. Comput. Stand. Interfaces 2020, 67, 103149. [Google Scholar] [CrossRef]
- Zaharia, M.; Chowdhury, M.; Franklin, M.J.; Shenker, S.; Stoica, I. Spark: Cluster Computing with Working Sets. In Proceedings of the 2nd USENIX Workshop on Hot Topics in Cloud Computing (HotCloud 10), Boston, MA, USA, 1 October 2010. [Google Scholar]
- Armbrust, M.; Xin, R.S.; Lian, C.; Huai, Y.; Liu, D.; Bradley, J.K.; Meng, X.; Kaftan, T.; Franklin, M.J.; Ghodsi, A.; et al. Spark SQL: Relational Data Processing in Spark. In Proceedings of the 2015 ACM SIGMOD International Conference on Management of Data (SIGMOD ’15), Melbourne, Australia, 31 May–4 June 2015; pp. 1383–1394. [Google Scholar]
- Liao, Y.T.; Zhou, J.; Lu, C.H.; Chen, S.C.; Hsu, C.H.; Chen, W.; Jiang, M.F.; Chung, Y.C. Data Adapter for Querying and Transformation between SQL and NoSQL Database. Future Gener. Comput. Syst. 2016, 65, 111–121. [Google Scholar] [CrossRef]
- Schreiner, G.A.; Duarte, D.; dos Santos Mello, R. Bringing SQL Databases to Key-Based NoSQL Databases: A Canonical Approach. Computing 2020, 102, 221–246. [Google Scholar] [CrossRef]
- Ramzan, S.; Bajwa, I.S.; Ramzan, B.; Anwar, W. Intelligent Data Engineering for Migration to NoSQL Based Secure Environments. IEEE Access 2019, 7, 69042–69057. [Google Scholar] [CrossRef]
- Kuszera, E.M.; Peres, L.M.; Didonet, M.; Fabro, D. Toward RDB to NoSQL: Transforming Data with Metamorfose Framework. In Proceedings of the 34th ACM/SIGAPP Symposium on Applied Computing, New York, NY, USA, 8–12 April 2019; pp. 456–463. [Google Scholar]
- Schreiner, G.A.; Duarte, D.; Dos Santos Mello, R. SQLtoKeyNoSQL: A Layer for Relational to Key-Based NoSQL Database Mapping. In Proceedings of the 17th International Conference on Information Integration and Web-Based Applications and Services, iiWAS 2015—Proceedings, Brussels, Belgium, 11–13 December 2015. [Google Scholar]
- MongoDB. Available online: https://www.mongodb.com/ (accessed on 22 January 2018).
- Apache Cassandra. Available online: http://cassandra.apache.org/ (accessed on 22 January 2018).
- Redis. Available online: https://redis.io/ (accessed on 15 January 2022).
- neo4j. Available online: https://neo4j.com/ (accessed on 1 February 2021).
- Chung, W.C.; Lin, H.P.; Chen, S.C.; Jiang, M.F.; Chung, Y.C. JackHare: A Framework for SQL to NoSQL Translation Using MapReduce. Autom. Softw. Eng. 2014, 21, 489–508. [Google Scholar] [CrossRef]
- Li, C.; Gu, J. An Integration Approach of Hybrid Databases Based on SQL in Cloud Computing Environment. Softw. Pract. Exp. 2019, 49, 401–422. [Google Scholar] [CrossRef]
- Lawrence, R. Integration and Virtualization of Relational SQL and NoSQL Systems Including MySQL and MongoDB. In Proceedings of the 2014 International Conference on Computational Science and Computational Intelligence, Las Vegas, NV, USA, 10–13 March 2014; Volume 1, pp. 285–290. [Google Scholar]
- Schreiner, G.A.; Duarte, D.; dos Santos Mello, R. When Relational-Based Applications Go to NoSQL Databases: A Survey. Information 2019, 10, 241. [Google Scholar] [CrossRef] [Green Version]
- Calil, A.; dos Santos Mello, R. SimpleSQL: A Relational Layer for SimpleDB. In Advances in Databases and Information Systems, Proceedings of the 16th East European Conference, ADBIS, Poznan, Poland, 18–21 October 2012; Morzy, T., Härder, T., Wrembel, R., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 99–110. [Google Scholar]
- Jia, T.; Zhao, X.; Wang, Z.; Gong, D.; Ding, G. Model Transformation and Data Migration from Relational Database to MongoDB. In Proceedings of the 2016 IEEE International Congress on Big Data (BigData Congress), Washington, DC, USA, 5–8 December 2016; pp. 60–67. [Google Scholar]
- Rith, J.; Lehmayr, P.S.; Meyer-Wegener, K. Speaking in Tongues: SQL Access to NoSQL Systems. In Proceedings of the ACM Symposium on Applied Computing, Salamanca, Spain, 24–28 March 2014; pp. 855–857. [Google Scholar] [CrossRef]
- Mallek, H.; Ghozzi, F.; Teste, O.; Gargouri, F.; Ghozzi, F. BigDimETL with NoSQL Database. Procedia Comput. Sci. 2018, 126, 798–807. [Google Scholar] [CrossRef]
- Zhao, G.; Lin, Q.; Li, L.; Li, Z. Schema Conversion Model of SQL Database to NoSQL. In Proceedings of the 2014 9th International Conference on P2P, Parallel, Grid, Cloud and Internet Computing, 3PGCIC 2014, Guangdong, China, 8–10 November 2014; pp. 355–362. [Google Scholar]
- Ramzan, S.; Bajwa, I.S.; Kazmi, R. An Intelligent Approach for Handling Complexity by Migrating from Conventional Databases to Big Data. Symmetry 2018, 10, 698. [Google Scholar] [CrossRef] [Green Version]
- Adriana, J.; Holanda, M. NoSQL2: SQL to NoSQL Databases. In Proceedings of the World Conference on Information Systems and Technologies, Naples, Italy, 27–29 March 2018; pp. 938–948. [Google Scholar]
- de la Vega, A.; García-Saiz, D.; Blanco, C.; Zorrilla, M.; Sánchez, P. Mortadelo: Automatic Generation of NoSQL Stores from Platform-Independent Data Models. Future Gener. Comput. Syst. 2020, 105, 455–474. [Google Scholar] [CrossRef]
- Mohamed, W.; Abdel-Fattah, M.A.; Abdelgaber, S. A Comprehensive Approach for Converting Relational to Graph Database Using Spark. J. Theor. Appl. Inf. Technol. 2021, 99, 2972–2990. [Google Scholar]
- Kuszera, E.M.; Peres, L.M.; Del Fabro, M.D. Exploring Data Structure Alternatives in the RDB to NoSQL Document Store Conversion Process. Inf. Syst. 2022, 105, 101941. [Google Scholar] [CrossRef]
- Kim, H.J.; Ko, E.J.; Jeon, Y.H.; Lee, K.H. Techniques and Guidelines for Effective Migration from RDBMS to NoSQL. J. Supercomput. 2020, 76, 7936–7950. [Google Scholar] [CrossRef]
- Vathy-Fogarassy, Á.; Hugyák, T. Uniform Data Access Platform for SQL and NoSQL Database Systems. Inf. Syst. 2017, 69, 93–105. [Google Scholar] [CrossRef]
- Schemacrawler. Available online: https://www.schemacrawler.com/ (accessed on 24 November 2021).
- Imam, A.A.; Basri, S.; Ahmad, R.; Watada, J.; González Aparicio, M.T.; Almomani, M.A. Data Modeling Guidelines for NoSQL Document-Store Databases. Int. J. Adv. Comput. Sci. Appl. 2018, 9, 544–555. [Google Scholar] [CrossRef]
- Liyanaarachchi, G.; Kasun, L.; Nimesha, M.; Lahiru, K.; Karunasena, A. MigDB—Relational to NoSQL Mapper. In Proceedings of the 2016 IEEE International Conference on Information and Automation for Sustainability: Interoperable Sustainable Smart Systems for Next Generation, ICIAfS 2016, Galle, Sri Lanka, 16–19 December 2016. [Google Scholar]
- Imam, A.A.; Basri, S.; Ahmad, R.; Aziz, N.; Gonzålez-Aparicio, M.T. New Cardinality Notations and Styles for Modeling NoSQL Document-Store Databases. In Proceedings of the TENCON 2017–2017 IEEE Region 10 Conference, Penang, Malaysia, 5–8 November 2017; pp. 2765–2770. [Google Scholar]
- Imam, A.A.; Basri, S.; Ahmad, R.; Watada, J.; González-Aparicio, M.T. Automatic Schema Suggestion Model for NoSQL Document-Stores Databases. J. Big Data 2018, 5, 46. [Google Scholar] [CrossRef] [Green Version]
- Mior, M.J.; Salem, K.; Aboulnaga, A.; Liu, R. NoSE: Schema Design for NoSQL Applications. IEEE Trans. Knowl. Data Eng. 2017, 29, 2275–2289. [Google Scholar] [CrossRef]
- Ouanouki, R.; April, A.; Abran, A.; Gomez, A.; Desharnais, J.M. Toward Building RDB to HBase Conversion Rules. J. Big Data 2017, 4, 10. [Google Scholar] [CrossRef]
- Alotaibi, O.; Pardede, E. Transformation of Schema from Relational Database (RDB) to NoSQL Databases. Data 2019, 4, 148. [Google Scholar] [CrossRef] [Green Version]
- Apache Phoenix. Available online: https://phoenix.apache.org/ (accessed on 7 January 2022).
- JSqlParser. Available online: https://github.com/JSQLParser/JSqlParser (accessed on 8 December 2020).
- MongoDB Connector for Spark. Available online: https://docs.mongodb.com/spark-connector/current/ (accessed on 29 October 2021).
- Spark Redis Connector. Available online: https://github.com/RedisLabs/spark-redis (accessed on 1 January 2021).
- Spark Cassandra Connector. Available online: https://github.com/datastax/spark-cassandra-connector (accessed on 13 January 2022).
- IMDb. Internet Movie Database. Available online: www.imdb.com/interfaces (accessed on 20 December 2020).
- Stack Exchange Data. Available online: https://archive.org/details/stackexchange (accessed on 4 January 2022).















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Data Model | Join | Customization Mapping | AutomaticMapping | SQL Support |
|---|---|---|---|---|---|
| JackHare [15] | Column | Supports join with map reduce | No | Yes | DDL + DML subset |
| MSI [16] | Document—key–value | Supports join with nested loop | Yes | No | DML subset |
| Metamorfose [9] | Column—document | - | Yes | No | DML subset |
| Unity [17] | Document | Hash join | No | Yes | DML subset |
| SQLTOKEYNoSQL [7,10,18] | Column—document—key–value | Merge join and hash join | No | Yes | DDL + DML subset |
| SimpleSQL [19] | Document | Supports join by similarity | No | Yes | DDL + DML subset |
| [20] | Document | Support join | Yes | No | DML subset |
| [21] | Document—column | - | No | Yes | DML subset |
| BigDimETL [22] | Column | Supports join by using MapReduce paradigm | No | Yes | DML subset |
| [23] | Document | Supports join | No | Yes | DML subset |
| [8,24] | Key–value | Supports join | No | Yes | DML subset |
| NoSQL2 [25] | Four models | - | Yes | No | Only DDL |
| Moratadelo [26] | Column—document | - | Yes | No | - |
| [27] | Graph database | Supports join | No | Yes | Subset of DML |
| [28] | Document | Supports join | Yes | No | Subset of DML |
| [29] | Column | Supports join | No | Yes | Subset of DML |
| [30] | Document | Supports join | No | Yes | Subset of DML |
| [6] | Column | Supports join | No | Yes | Subset of DML and DDL |
| Entity Relationship Model | Relational Database | Document Database |
|---|---|---|
| Entity | Table | Collection |
| Relationships | Constraint | Reference or embedding or bucketing |
| Attribute | Column | Field |
| Entity instance | Row | Document |
| SQL Statement | MongoDB |
|---|---|
| update actors SET gender= ‘f’, last_name = ‘gamal’ WHERE id <= 3 | db.actors.updateMany({id: {$lte: 3}}, {$set: {gender: ‘f’, last_name: ‘gamal’}}) |
| update actors SET gender= ‘f’, last_name = ‘gamal’ WHERE id = 3 | db.actors.updateMany({id: {$eq: 3}}, {$set: {gender: ‘f’, last_name: ‘gamal’}}) |
| update actors SET gender= ‘f’, last_name = ‘gamal’ WHERE id > 3 | db.actors.updateMany({id: {$gt: 3}}, {$set: {gender: ‘f’, last_name: ‘gamal’}}) |
| Stat. # | SQL Statement | Redis |
|---|---|---|
| St1 | insert into actors (first_name, last_name, gender)values(‘ahmed’, ‘kazim’, ‘m’) | hmset actors:first_name ‘ahmed’ last_name ‘kazim’ gender ‘m’ |
| St2 | update actors SET gender= ‘f’, last_name = ‘gamal’ WHERE id = 845467 | hmset actors:845467 gender ‘f’ last_name ‘gamal’ |
| St3 | delete from actors where id = 3 | DEL actors:3 |
| Databases | Number of Tables | Tuples | Relationships |
|---|---|---|---|
| IMDB | 7 | 5,610,922 | 6 |
| Stack Exchange | 2 | 235,000,000 | 1 |
| Features | Unity | Proposed Layer |
|---|---|---|
| Access document data store | Yes | Yes |
| Access column data store | No | Yes |
| Access key–value data store | No | Yes |
| Supports join operation | Yes | Yes |
| Supports aggregate functions | Yes | Yes |
| Supports subquery | Yes | Yes |
| Transformation and migration using distributed processing engine | No | Yes |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abdel-Fattah, M.A.; Mohamed, W.; Abdelgaber, S. A Comprehensive Spark-Based Layer for Converting Relational Databases to NoSQL. Big Data Cogn. Comput. 2022, 6, 71. https://doi.org/10.3390/bdcc6030071
Abdel-Fattah MA, Mohamed W, Abdelgaber S. A Comprehensive Spark-Based Layer for Converting Relational Databases to NoSQL. Big Data and Cognitive Computing. 2022; 6(3):71. https://doi.org/10.3390/bdcc6030071
Chicago/Turabian StyleAbdel-Fattah, Manal A., Wael Mohamed, and Sayed Abdelgaber. 2022. "A Comprehensive Spark-Based Layer for Converting Relational Databases to NoSQL" Big Data and Cognitive Computing 6, no. 3: 71. https://doi.org/10.3390/bdcc6030071
APA StyleAbdel-Fattah, M. A., Mohamed, W., & Abdelgaber, S. (2022). A Comprehensive Spark-Based Layer for Converting Relational Databases to NoSQL. Big Data and Cognitive Computing, 6(3), 71. https://doi.org/10.3390/bdcc6030071