4.2. Determining the Spatial Scope of the Sentiment of a User on a Topic
In this section, we illustrate our approach to determine the spatial scope of the sentiment of a user
on a topic
. In
Section 3.2.1, we have seen that there exist four possible sentiment types. Consequently, it is possible to determine four kinds of scope, one for each sentiment type. In this section, we examine all of them starting with the scope associated with a strongly positive sentiment.
First, let us specify how the spatial scope of
on
can be represented. A first possibility consists of a set
of pairs, as shown in Equation (
6):
Each pair , , belongs to and consists of a user , directly or indirectly connected to , and the corresponding positive sentiment degree on .
A second representation consists of a subgraph of . A node belongs to if the corresponding user is present in . Furthermore, belongs to . An arc belongs to if an arc also exists in . We call origin of the node corresponding to the user .
At this point we can define our approach for computing the spatial scope associated with a strongly positive sentiment (hereafter referred to as
strongly positive spatial scope) of
on
. We represent this approach by defining a function
shown in Equation (
7). It receives
,
and the initially empty set
as parameters. It basically performs a depth-first search on
, starting from
and selecting a node only if certain constraints are satisfied for it. It can be formalized as shown in Equation (
7):
In other words, the function , when applied on and , first checks whether has a strongly positive sentiment on . If this is true and the pair is not already present in , then adds this pair to . Afterwards, it recursively calls itself by passing as input each node directly connected to in . In contrast, if has not a strongly positive sentiment on or the pair is already present in , then simply returns ∅ and the recursion stops.
The
strongly negative spatial scope can be defined in a similar way (see Equation (
8)). Again, we can introduce a function
that receives
,
and the initially empty set
. It has an identical behavior to the function
, except that
is replaced by
and the function
is replaced by the function
, defined in
Section 3.2.1. Its formalization is shown in Equation (
8):
The
weakly positive (resp.,
negative)
spatial scope is defined similarly to the strongly positive (resp., negative) spatial scope. In this case, we introduce a function
(resp.,
) that receives
,
and an initially empty set
(resp.,
). Its behavior is identical to the one of the function
(resp.,
) except that the function
(resp.,
) is replaced by the function
(resp.,
). The formalization of
and
is shown in Equations (
9) and (
10):
At this point, we have defined the functions for computing the strongly positive (resp., negative) spatial scope
(resp.,
) and the weakly positive (resp., negative) spatial scope
(resp.,
)). We have also previously seen that it is possible to provide a graph-based representation of such a scope. In the following, in order not to burden the notation, we will use the symbol
(resp.,
,
,
) to denote the graph-based representation corresponding to
(resp.,
,
,
). Its formalization is reported in Equation (
11):
By studying some properties of these graphs, it is possible to define a variety of information regarding the scope of the sentiment of on .
In what follows we will perform all our analyses with regard to the graph , although everything we will see can be straightforwardly extended to the other three graphs.
The first two properties of the scope of the sentiment of on that we consider are its breadth and its depth. Regarding the breadth, it is immediate to think that it can be obtained by considering the size of , that is, the number of its nodes. As far as the depth is concerned, we recall that derives from a depth-first search performed on starting from the node , which we have also called the origin of . Therefore, the depth of the scope can be determined by computing the diameter of , that is, the maximum length of the minimum paths from to any other node of .
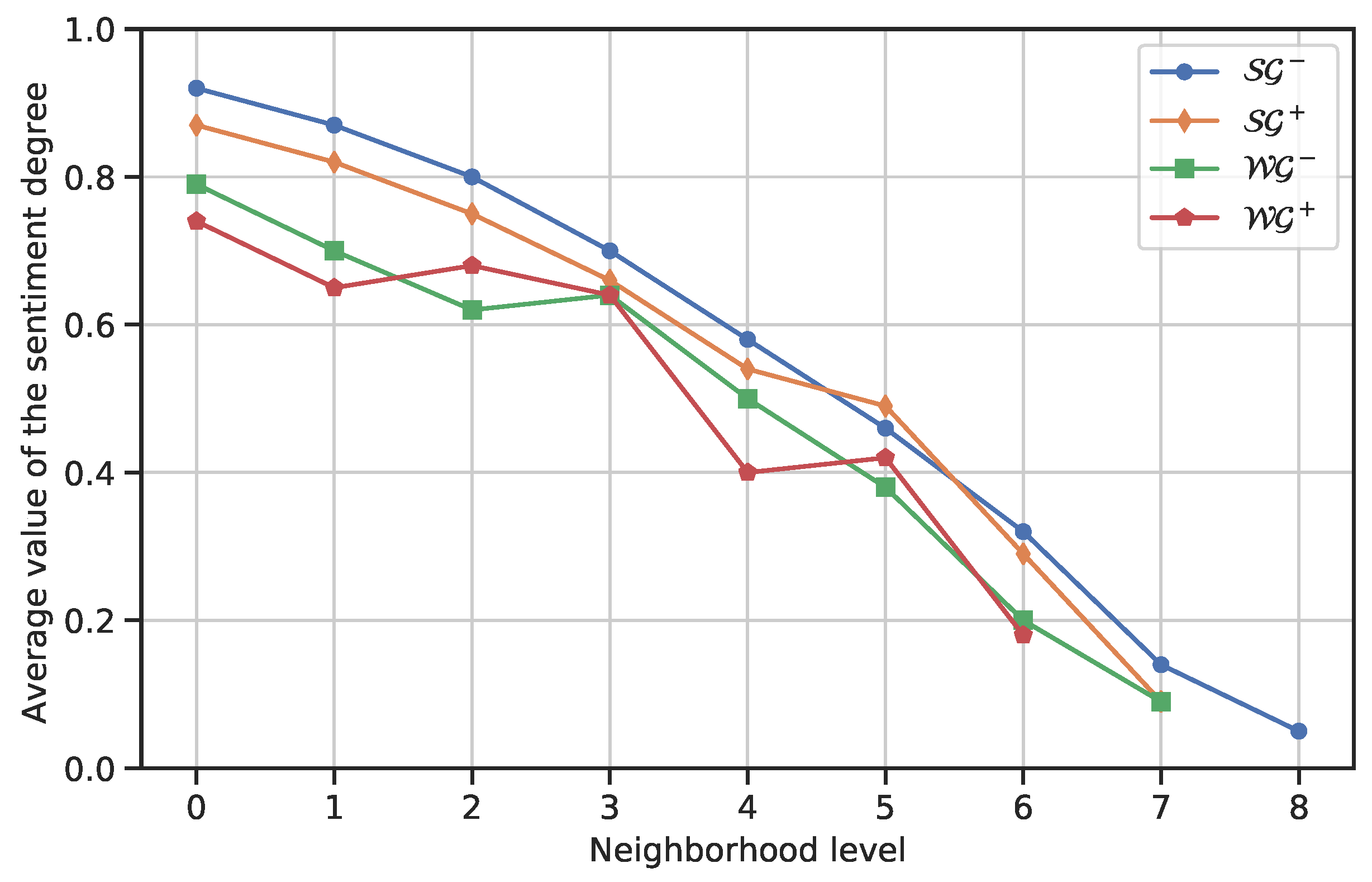
An important investigation consists in determining how the strongly positive sentiment degree varies as we move away from in . To do this, we can consider the neighborhood of level , , obtained by applying the function on , and . For each neighborhood, it is then possible to compute the average strongly positive sentiment degree of the nodes belonging to it. Generally, if there were no interference, as we move away from , the average strongly positive sentiment degree of a neighborhood should decrease because the influence that exerts on nodes tends to decrease. However, it could be the case that, once we move away from , there is another node different from it that exerts an influence on the nodes of the neighborhood of . If the new “influencer” has a discordant sentiment with , we might see a steep decrease in the average strongly positive sentiment degree, or even a reversal of sentiment polarity. By contrast, if the new “influencer” has a concordant sentiment with , we may see a slowdown in the decline of the average strongly positive sentiment degree, or even a new growth of it. The correlation that can arise between two scopes is a challenging topic that is, however, beyond the objective of this paper. Here, we simply provide a tool for computing the variation in the average strongly positive sentiment degree as we move away from .
Let
be the neighborhood of level
,
of
in
. The average positive sentiment degree
of
is defined in Equation (
12):
In other words, it is obtained by computing the average strongly positive sentiment degree of all the nodes belonging to . ranges in the real interval ; the higher its value, the higher the strength of the average positive sentiment.
At this point, we have at our disposal a succession of values such that , , , . The examination of that succession can give us some interesting insights into how the average strongly positive sentiment degree evolves as we move away from . It takes into account the decreasing influence of as we move away from it, as well as the possible presence of any interference from other “influencers”.
By plotting the values of , we get a “spectrum” of the trend of the strongly positive sentiment degree in the spatial scope of . In fact, several interesting pieces of information can be derived from that spectrum. These include:
The variation in the average strongly positive sentiment degree in the
hth section of the spectrum, defined in Equation (
13):
The relative variation in the average strongly positive sentiment degree in the
hth section of the spectrum, defined in Equation (
14):
The mean variation in the average strongly positive sentiment degree in the
hth section of the spectrum, defined in Equation (
15):
The maximum variation in the average strongly positive sentiment degree in the
hth section of the spectrum, defined in Equation (
16):
The minimum variation in the average strongly positive sentiment degree in the
hth section of the spectrum, defined in Equation (
17):
Finally, we can analyze the monotonicity of the succession . In particular, we are interested in whether it is monotonically non-increasing. This occurs when . In fact, if such a condition is not satisfied, we can say that, as we move away from , there is at least one further “influencer” with a sentiment concordant with the one of that is acting on the nodes of the neighborhoods of . Otherwise, it could be that there is no other “influencer” interfering with or that such an “influencer” is present but with a discordant sentiment with the one of .
What we have seen now are just some of the analyses we can perform on spatial scope. They allow us to give an idea of the potential of this concept. Many other analyses could be thought of simply by applying concepts from mathematical analysis to the succession or concepts from graph theory to the graph .
Finally, it is worth emphasizing again that all the analyses we have previously done on could be straightforwardly extended to , and .
4.3. Determining the Temporal Scope of the Sentiment of a User on a Topic
In this section, we illustrate our approach to determine the temporal scope of the sentiment of the user
on a topic
. In
Section 3.2.1, we introduced two concepts on sentiment scope, namely
sentiment type and
sentiment degree of
on
. These two concepts play a key role in the analysis of temporal scope. Recall that the sentiment type of
on
can be strongly positive (
), weakly positive (
), weakly negative (
), and strongly negative (
). Instead, the sentiment degree of
on
is given by the value of the parameter
, in case the sentiment type is
or
, or the value of the parameter
, in case it is
or
.
The temporal scope of
on
in the time interval
can be represented by an ordered list of pairs, as shown in Equations (
18)–(
20).
Recall that
(resp.,
,
,
) represents the projection of
(resp.,
,
,
) in the time slice
(see
Section 3.2.1). Analogously
(resp.,
) denotes the value returned by the function
(resp.,
) when projected in the time slice
(see, again,
Section 3.2.1).
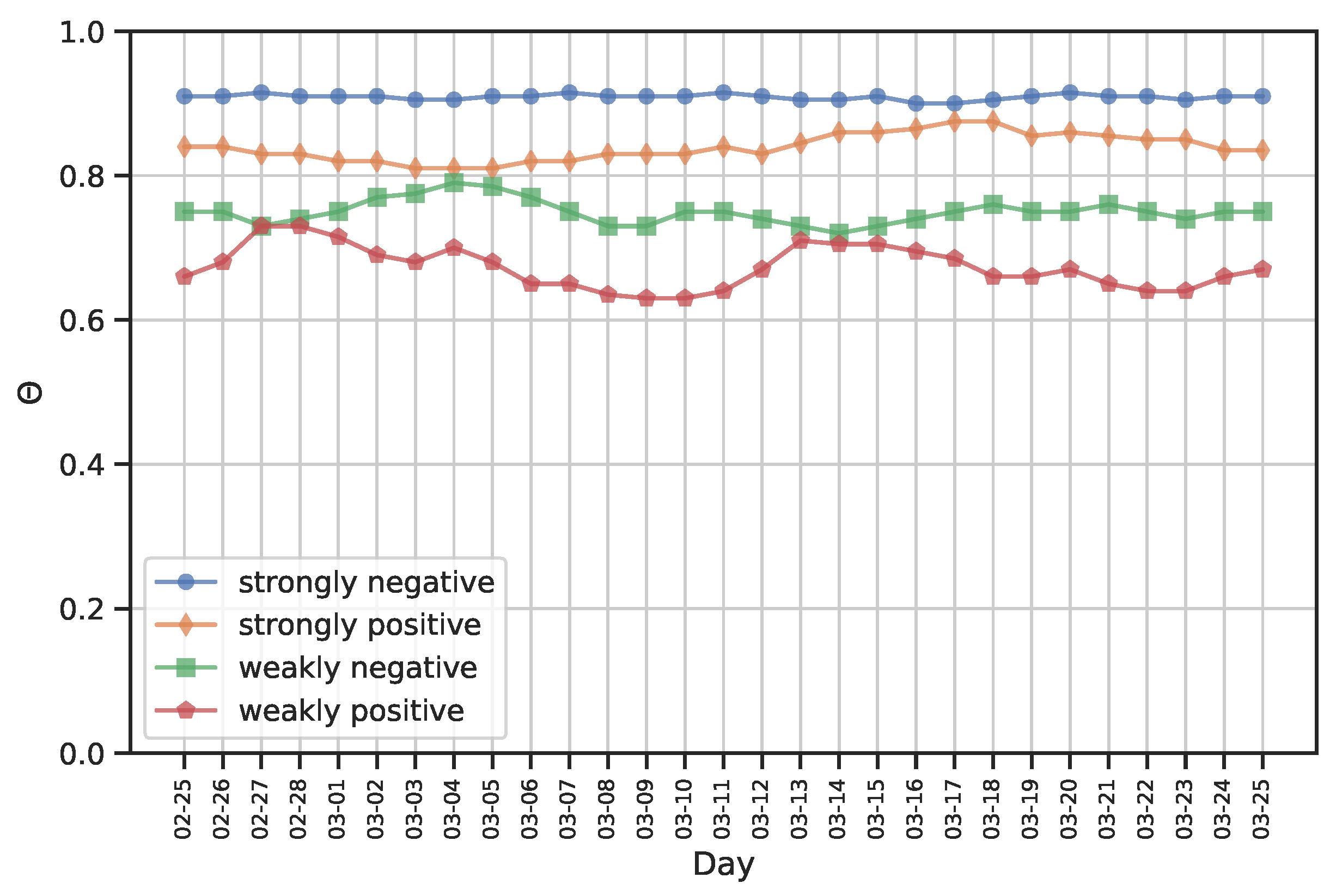
Clearly, by moving from a time instant to a time instant the value of can remain unvaried or change and the value of can increase, decrease, or remain constant. Each combination of the trend of these two parameters at the transition from to gives us interesting information about the time trend of the sentiment degree of on . For example:
If both and are equal to :
- –
if , it means that the sentiment degree is strengthening;
- –
if , it means that the sentiment degree is static;
- –
if , it means that, although a strongly positive sentiment still characterizes , it is weakening.
If and , it means that the posts and comments on published by in which she shows a neutral sentiment, are increasing. This increase is such that they exceed the ones in which shows a positive sentiment. The number of posts/comments with a positive sentiment continues to be greater than the number of posts/comments with a negative sentiment. However, at the time slice we are seeing a weakening of the positivity of the sentiment of on , compared to the time slice .
If and , it means that is changing her sentiment on . This change is not yet radical, since there is a prevalence of neutral posts/comments over negative ones.
If and , it means that has completely changed her sentiment on . The greater the gap between and and the greater the change occurred.
Similarly, suitable information can be extracted in case , or, finally, .
Analogously to what we have seen for spatial scope, several measures can also be defined for temporal scope. They allow us to get a quantitative view of the changes in the sentiment degree of
on
over a time interval. Some of these measures are the following (in defining these measures, we will refer to the time slices
and
, instead of the time slices
and
, to bring their definition in line with that of the metrics for spatial scope, explained in
Section 4.2.):
The variation in the sentiment degree between the time slices
and
. It can be defined in Equation (
21):
The relative variation in the sentiment degree between the time slices
and
. It can be defined in Equation (
22):
The mean variation in the sentiment degree in the time interval
. It is defined in Equation (
23):
The maximum variation in the sentiment degree in the time interval
. It is defined in Equation (
24):
The minimum variation in the sentiment degree in the time interval
. It is defined in Equation (
25):
In addition to defining appropriate metrics to measure the change in the sentiment of on , we can check whether the succession of the values of the sentiment degree in the interval is monotonic or not. This information must be closely coupled with that related to sentiment type. In particular, if the succession of values , , ⋯, is monotonically non-increasing, it means that, in the time interval , the sentiment of on is not strengthening and, rather, it is presumably decreasing. Such a decrease could cause the sentiment type to go from strongly positive to weakly positive, weakly negative, or even strongly negative. On the other hand, if the previous succession of values is monotonically non-decreasing, it means that, in the time interval , the sentiment of on is not weakening, and, rather, it is presumably strengthening. In this case, we might see reverse transitions from the previous case, e.g., from strongly negative to weakly negative, weakly positive, and strongly positive.
The previous succession may also not be monotonic. In this case, the measures on changes in sentiment degree defined above could be extremely useful. It might also be useful to determine how often the change from one type of sentiment to another occurs, or how often the change from an increasing to a decreasing trend occurs, or vice versa.
Analogously to the spatial scope, those seen above are just some of the analyses that can be performed on the temporal scope. Many other analyses could be performed by applying the concepts of mathematical analysis or time series analysis to the succession of values , , ⋯, .




 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}