


Using an Evidence-Based Approach for Policy-Making Based on Big Data Analysis and Applying Detection Techniques on Twitter

 , ,
, , 

Abstract
:1. Introduction
2. Background
3. Literature Review
3.1. Evidence-Based Policy
3.2. What Is the Evidence?
3.2.1. Challenges of Using Evidence in Policy-Making
3.2.2. Evidence from Public Engagement
3.3. Social Media Data as Evidence in the Policy-Making Process
4. Methods
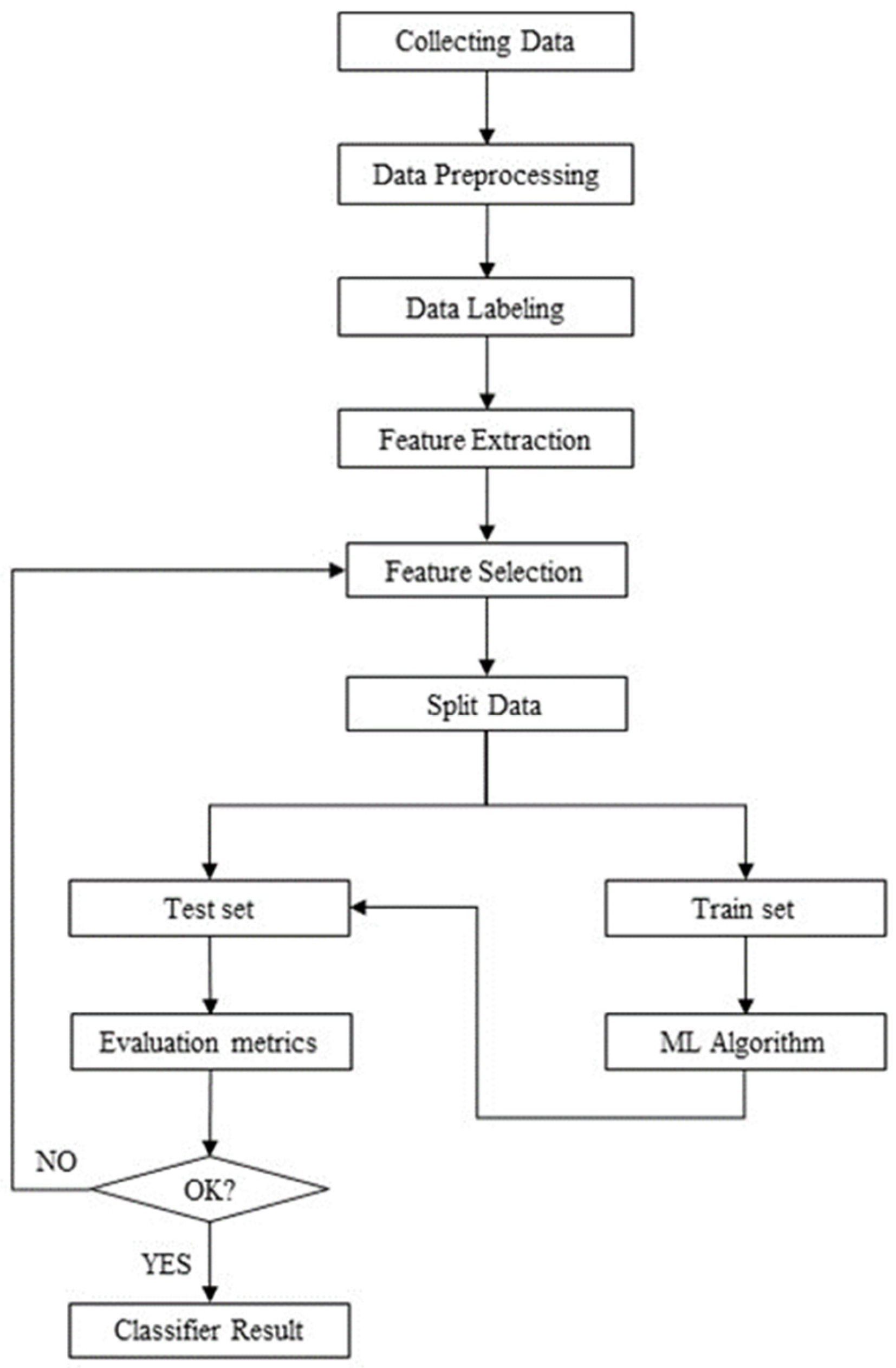
4.1. Proposed Model for Evidence Detection
4.2. Data Set and Feature Engineering
4.2.1. Data Collection
4.2.2. Feature Extraction
4.2.3. Feature Selection
4.3. Proposed Classification Approach
4.4. Evaluation Metrics
- True positive (TP): tweets that belong to class Evidence (E) and are correctly predicted as class E.
- False positive (FP): tweets that do not belong to class E and are incorrectly predicted as class E.
- True negative (TN): tweets that do not belong to class E and are correctly predicted as class non-E.
- False negative (FN): tweets that belong to class E and are incorrectly predicted as class non-E.
5. Experiments and Results
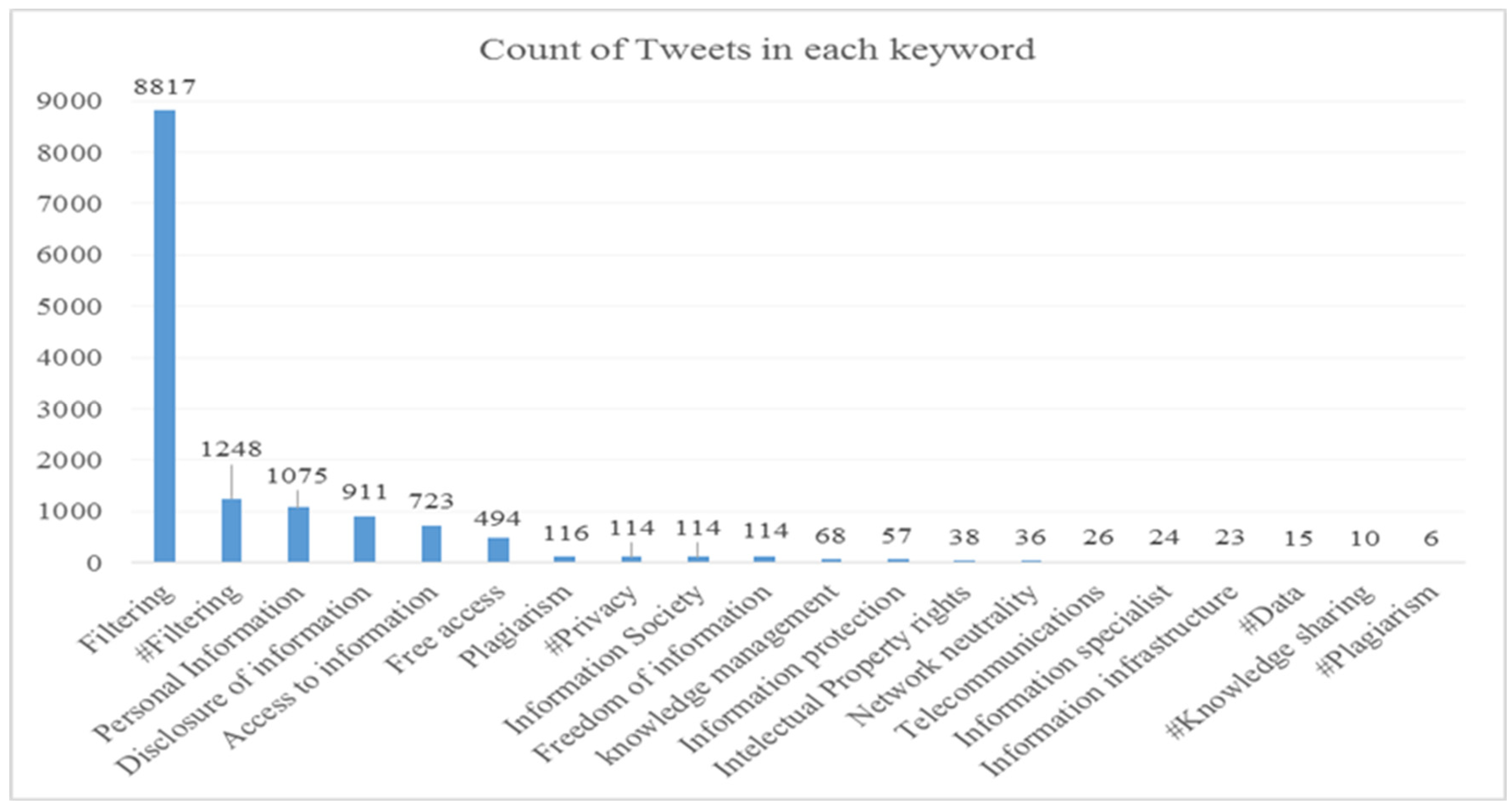
5.1. Statistical Report
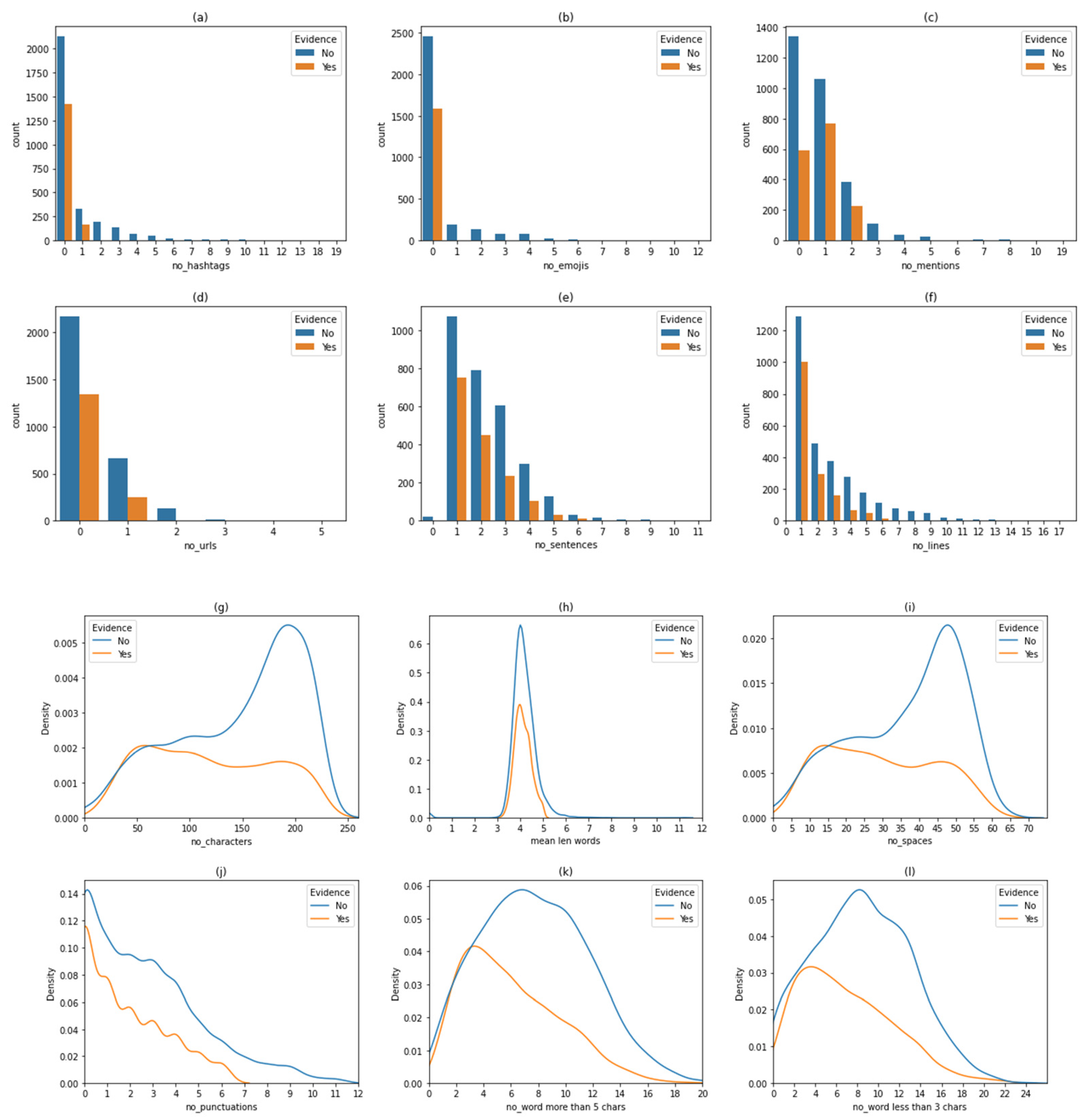
5.2. Analyzing the Behavior of the Users Posting Evidence Tweets
5.3. Evaluating Proposed Model
6. Discussion
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kaplan, A.M.; Haenlein, M. Users of the world, unite! The challenges and opportunities of social media. Bus. Horiz. 2010, 53, 59–68. [Google Scholar] [CrossRef]
- Nooren, P.; Van Gorp, N.; Van Eijk, N.; Fathaigh, R. Should We Regulate Digital Platforms? A New Framework for Evaluating Policy Options. Policy Internet 2018, 10, 264–301. [Google Scholar] [CrossRef]
- Chan-Olmsted, S.M.; Wolter, L. Perceptions and practices of media engagement: A global perspective. Int. J. Media Manag. 2018, 20, 1–24. [Google Scholar] [CrossRef]
- Fuchs, C. Social Media: A Critical Introduction; SAGE: Thousand Oaks, CA, USA, 2017. [Google Scholar]
- Edom, S.J.; Hwang, H.; Kim, J.H. Can social media increase government responsiveness? A case study of Seoul, Korea. Gov. Inf. Q. 2018, 35, 109–122. [Google Scholar]
- Evens, T.; Donders, K. Platform Power and Policy in Transforming Television Markets; Springer: Berlin/Heidelberg, Germany, 2018. [Google Scholar]
- Janssen, M.; Helbig, N. Innovating and changing the policy cycle: Policy-makers be prepared! Gov. Inf. Q. 2016, 12, 120–132. [Google Scholar] [CrossRef]
- Fernando, S.; Díaz López, J.A.; Şerban, O.; Gómez-Romero, J.; Molina-Solana, M.; Guo, Y. Towards a large-scale twitter observatory for political events. Future Gener. Comput. Syst. 2019, 14, 976–983. [Google Scholar] [CrossRef]
- Suzor, N.; Dragiewicz, M.; Harris, B.; Gillett, R.; Burgess, J.; Van Geelen, T. Human Rights by Design: The Responsibilities of Social Media Platforms to Address Gender-Based Violence Online. Policy Internet 2019, 11, 84–103. [Google Scholar] [CrossRef] [Green Version]
- Dekker, R.; van den Brink, P.; Meijer, A. Social media adoption in the police: Barriers and strategies. Gov. Inf. Q. 2020, 37, 101441. [Google Scholar] [CrossRef]
- DePaula, N.; Dincelli, E.; Harrison, M. Toward a typology of government social media communication: Democratic goals, symbolic acts, and self-presentation. Gov. Inf. Q. 2018, 35, 98–108. [Google Scholar] [CrossRef]
- Driss, O.B.; Mellouli, S.; Trabelsi, Z. From citizens to government policy-makers: Social media data analysis. Gov. Inf. Q. 2019, 36, 560–570. [Google Scholar] [CrossRef]
- Panayiotopoulos, P.; Bowen, F.; Brooker, P. The value of social media data: Integrating crowd capabilities in evidence-based policy. Gov. Inf. Q. 2017, 34, 601–612. [Google Scholar] [CrossRef]
- Chen, C.; Wang, Y.; Zhang, J.; Xiang, Y.; Zhou, W.; Min, G. Statistical features-based real-time detection of drifted twitter spam. IEEE Trans. Inf. Forensics Secur. 2016, 12, 914–925. [Google Scholar] [CrossRef] [Green Version]
- Matheus, R.; Janssen, M.; Maheshwari, D. Data science empowering the public: Data-driven dashboards for transparent and accountable decision-making in smart cities. Gov. Inf. Q. 2020, 37, 101284. [Google Scholar] [CrossRef]
- Simonofski, A.; Fink, J.; Burnay, C. Supporting policy-making with social media and e-participation platforms data: A policy analytics framework. Gov. Inf. Q. 2021, 38, 101590. [Google Scholar] [CrossRef]
- Sun, T.Q.; Medaglia, R. Mapping the Challenges of Artificial Intelligence in the Public Sector: Evidence from Public Healthcare. Gov. Inf. Q. 2019, 36, 368–383. [Google Scholar] [CrossRef]
- Clarke, A.; Margetts, H. Governments and citizens getting to know each other? Open, closed, and big data in public management reform. Policy Internet 2014, 6, 393–417. [Google Scholar] [CrossRef]
- Enroth, H. Governance: The art of governing after governmentality. Eur. J. Soc. Theory 2014, 17, 60–76. [Google Scholar] [CrossRef]
- Davies, H.; Nutley, S.; Smith, P. What Works? Evidence-Based Policy and Practice in Public Services; Policy Press: Bristol, UK, 2001. [Google Scholar]
- Nutley, S.M.; Walter, I.; Davies, H.T. Using Evidence: How Research Can Inform Public Services; Policy Press: Bristol, UK, 2007. [Google Scholar]
- Picazo-Vela, S.; Gutiérrez-Martínez, I.; Luna-Reyes, L.F. Understanding risks, benefits, and strategic alternatives of social media applications in the public sector. Gov. Inf. Q. 2012, 29, 504–511. [Google Scholar] [CrossRef]
- Prpić, J.; Taeihagh, A.; Melton, J. The fundamentals of policy crowdsourcing. Policy Internet 2015, 7, 340–361. [Google Scholar] [CrossRef] [Green Version]
- Park, C.S.; Kaye, B.K. The tweet goes on: Interconnection of Twitter opinion leadership, network size, and civic engagement. Comput. Hum. Behav. 2017, 69, 174–180. [Google Scholar] [CrossRef]
- Stamatelatos, G.; Gyftopoulos, S.; Drosatos, G.; Efraimidis, P.S. Revealing the political affinity of online entities through their Twitter followers. Inf. Process. Manag. 2020, 57, 102–172. [Google Scholar] [CrossRef]
- Parkhurst, J. The Politics of Evidence; from Evidence-Based Policy to the Good Governance of Evidence; Routledge: London, UK, 2017. [Google Scholar]
- Bucher, T.; Helmond, A. The affordances of social media platforms. In The SAGE Handbook of Social Media; Burgess, J., Marwick, A., Poell, T., Eds.; SAGE Publications Ltd.: London, UK, 2017; pp. 233–253. [Google Scholar]
- Styles, K. Twitter is 10 and It’s Still Not a Social Network. 2016. Available online: http://thenextweb.com/opinion/2016/03/21/twitter-10-still-not-social-network/ (accessed on 24 June 2020).
- Lee, E.J.; Lee, H.Y.; Choi, S. Is the message the medium? How politicians’ Twitter blunders affect perceived authenticity of Twitter communication. Comput. Hum. Behav. 2020, 104, 106–188. [Google Scholar] [CrossRef]
- Beta Research Center. Report on Social Media Networks in Iran. Available online: http://betaco.ir/%da%af%d8%b2%d8%a7%d8%b1%d8%b4%d8%b4%d8%a8%da%a9%d9%87%d9%87%d8%a7%db%8c-%d8%a7%d8%ac%d8%aa%d9%85%d8%a7%d8%b9%db%8c%db%b1%db%b4%db%b0%db%b0-%d9%85%d8%b1%da%a9%d8%b2%d8%a8%d8%aa%d8%a7/ (accessed on 13 April 2022).
- Mahdavi, S. Twitter, power and activism in the public sphere. Q. Mod. Media Stud. 2019, 4, 147–188. [Google Scholar]
- Lee, J.; Xu, W. The more attacks, the more retweets: Trump’s and Clinton’s agenda setting on Twitter. Public Relat. Rev. 2018, 44, 201–213. [Google Scholar] [CrossRef]
- Howlett, M. Policy analytical capacity and evidence-based policy-making: Lessons from Canada. Can. Public Adm. 2009, 52, 153–175. [Google Scholar] [CrossRef]
- Sanderson, I. Evaluation, policy learning and evidence-based policy-making. Public Adm. 2002, 80, 1–22. [Google Scholar] [CrossRef]
- Parsons, W. From muddling through to muddling up—Evidence-based policy-making and the modernization of British government. Public Policy Adm. 2002, 17, 43–60. [Google Scholar]
- Cairney, P. The Politics of Evidence-Based Policy-Making; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Head, B. Reconsidering evidence-based policy: Key issues and challenges. Policy Soc. 2010, 29, 77–94. [Google Scholar] [CrossRef]
- Shaxson, L. Is your evidence robust enough? Questions for policy-makers and practitioners. Evid. Policy A J. Res. Debate Pract. 2005, 1, 101–112. [Google Scholar] [CrossRef]
- Cartwright, N.; Hardie, J. Evidence-Based Policy: A Practical Guide to Doing It Better; Oxford University Press: Oxford, UK, 2012. [Google Scholar]
- Young, K.; Ashby, D.; Boaz, A.; Grayson, L. Social Science and the Evidence-based Policy Movement. Soc. Policy Soc. 2002, 1, 215–224. [Google Scholar] [CrossRef] [Green Version]
- Lodge, M.; Wegrich, K. Crowdsourcing and regulatory reviews: A new way of challenging red tape in British government? Regul. Gov. 2014, 9, 30–46. [Google Scholar] [CrossRef]
- Misuraca, G.; Codagnone, C.; Rossel, P. From practice to theory and back to practice: Reflexivity in measurement and evaluation for evidence-based policy making in the information society. Gov. Inf. Q. 2013, 30, S68–S82. [Google Scholar] [CrossRef]
- Koziarski, J.; Lee, J.R. Connecting evidence-based policing and cybercrime. Polic. Int. J. 2020, 43, 198–211. [Google Scholar] [CrossRef]
- Yang, Q. A New Approach to Evidence-Based Practice Evaluation of Mental Health in Psychological Platform under the Background of Internet + Technology. In Proceedings of the 2019 International Conference on Electronic Engineering and Informatics (EEI), Nanjing, China, 8–10 November 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 321–323. [Google Scholar]
- Shiroishi, Y.; Uchiyama, K.; Suzuki, N. Better actions for society 5.0: Using AI for evidence-based policy-making that keeps humans in the loop. Computer 2019, 52, 73–78. [Google Scholar] [CrossRef]
- Setiadarma, E.G. Understanding the Evidence-Based Policy Making (EBPM) Discourse in the Making of the Master Plan of National Research (RIRN) Indonesia 2017-2045. STI Policy Rev. 2018, 9, 30–54. [Google Scholar]
- Newman, J.; Cherney, A.; Head, B.W. Policy capacity and evidence-based policy in the public service. Public Manag. Rev. 2017, 19, 157–174. [Google Scholar] [CrossRef]
- Head, B.W. Three lenses of evidence-based policy. Aust. J. Public Adm. 2008, 67, 1–11. [Google Scholar] [CrossRef]
- Freedman, D. The Politics of Media Policy; Polity: Cambridge, UK, 2008. [Google Scholar]
- Cairney, P.; Oliver, K. Evidence-based policy-making is not like evidence-based medicine, so how far should you go to bridge the divide between evidence and policy? Health Res. Policy Syst. 2017, 15, 1–11. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pang, M.S.; Lee, G.; DeLone, W.H. IT resources, organizational capabilities, and value creation in public-sector organizations: A public-value management perspective. J. Inf. Technol. 2014, 29, 187–205. [Google Scholar] [CrossRef]
- Castelló, I.; Morsing, M.; Schultz, F. Communicative dynamics and the polyphony of corporate social responsibility in the network society. J. Bus. Ethics 2013, 118, 683–694. [Google Scholar] [CrossRef] [Green Version]
- Kasabov, E. The challenge of devising public policy for high-tech, science-based, and knowledge-based communities: Evidence from a life science and biotechnology community. Environ. Plan. C Gov. Policy 2008, 26, 210–228. [Google Scholar] [CrossRef]
- Zahra, S.A.; George, G. Absorptive capacity: A review, reconceptualization, and extension. Acad. Manag. Rev. 2002, 27, 185–203. [Google Scholar] [CrossRef]
- McCay-Peet, L.; Quan-Haase, A. A model of social media engagement: User profiles, gratifications, and experiences. In Why Engagement Matters: Cross-Disciplinary Perspectives and Innovations on User Engagement with Digital Media; O’Brien, H., Lalmas, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Abayomi-Alli, O.; Misra, S.; Abayomi-Alli, A.; Odusami, M. A review of soft techniques for SMS spam classification: Methods, approaches, and applications. Eng. Appl. Artif. Intell. 2019, 86, 197–212. [Google Scholar] [CrossRef]
- Yan, Z. Big Data and Government Governance. In Proceedings of the International Conference on Information Management and Processing, London, UK, 12–14 January USA; IEEE: Piscataway, NJ, USA; 2018; pp. 110–114. [Google Scholar]
- Lundberg, J.; Laitinen, M. Twitter trolls: A linguistic profile of anti-democratic discourse. Lang. Sci. 2020, 8, 101268. [Google Scholar] [CrossRef]
- Bekkers, V.; Edwards, A.; de Kool, D. Social media monitoring: Responsive governance in the shadow of surveillance? Gov. Inf. Q. 2013, 30, 335–342. [Google Scholar] [CrossRef] [Green Version]
- Panagiotopoulos, P.; Shan, L.C.; Barnett, J.; Regan, Á.; McConnon, Á. A framework of social media engagement: Case studies with food and consumer organisations in the UK and Ireland. Int. J. Inf. Manag. 2015, 35, 394–402. [Google Scholar] [CrossRef] [Green Version]
- Williams, M.L.; Edwards, A.; Housley, W.; Burnap, P.; Rana, O.; Avis, N.; Morgan, J.; Sloan, L. Policing cyber neighbourhoods: Tension monitoring and social media networks. Polic. Soc. 2013, 23, 461–481. [Google Scholar] [CrossRef]
- Fernandez, M.; Wandhoefer, T.; Allen, B.; Cano Basave, A.; Alani, H. Using social media to inform policy-making: To whom are we listening? In Proceedings of the European Conference on Social Media (ECSM 2014), Brighton, UK, 10–11 July 2014.
- Gintova, M. Understanding government social media users: An analysis of interactions on Immigration, Refugees and Citizenship Canada Twitter and Facebook. Gov. Inf. Q. 2019, 36, 101388. [Google Scholar] [CrossRef]
- Napoli, P.M. User data as public resource: Implications for social media regulation. Policy Internet 2019, 11, 439–459. [Google Scholar] [CrossRef]
- Benthaus, J.; Risius, M.; Beck, R. Social media management strategies for organizational impression management and their effect on public perception. J. Strateg. Inf. Syst. 2016, 25, 127–139. [Google Scholar] [CrossRef]
- Fan, W.; Gordon, M.D. The power of social media analytics. Commun. ACM 2014, 57, 74–81. [Google Scholar] [CrossRef]
- Hoffman, D.L.; Fodor, M. Can you measure the ROI of your social media marketing? Sloan Manag. Rev. 2010, 52, 41–49. [Google Scholar]
- Zhang, C.; Liu, C.; Zhang, X.; Almpanidis, G. An up-to-date comparison of state-of-the-art classification algorithms. Expert Syst. Appl. 2017, 82, 128–150. [Google Scholar] [CrossRef]
- Schniederjans, D.; Cao, E.S.; Schniederjans, M. Enhancing financial performance with social media: An impression management perspective. Decis. Support Syst. 2013, 55, 911–918. [Google Scholar] [CrossRef]
- Boyd, D.; Crawford, K. Critical questions for big data. Inf. Commun. Soc. 2012, 15, 662–679. [Google Scholar] [CrossRef]
- Schintler, L.A.; Kulkarni, R. Big data for policy analysis: The good, the bad, and the ugly. Rev. Policy Res. 2014, 31, 343–348. [Google Scholar] [CrossRef]
- Ghanei Raad, M.; Mohammadi, A.; Beigdeloo, N. Reviewing interactive patterns of institutions collaborating with science and technology supreme councils of policy. Rahyaft 2011, 49, 5–17. [Google Scholar]
- Ahmadian, M.; Aqajani, H.; Shirkhodaei, M. Tehranchian A. Designing science & technology policy model based on economic complexity approach. Public Policy 2018, 4, 27–29. [Google Scholar]
- Kalantari, E.; Montazer, G.; Qazinoori, S. Drafting passe scenarios of enhanced science and technology policy structure in Iran. Strateg. Manag. Res. 2019, 74, 75–102. [Google Scholar]
- Sedhai, S.; Sun, A. Semi-supervised spam detection in the Twitter stream. IEEE Trans. Comput. Soc. Syst. 2017, 5, 169–175. [Google Scholar] [CrossRef] [Green Version]
- Mostafa, S.A.; Mustapha, A.; Mohammed, M.A.; Hamed, R.I.; Arunkumar, N.; Abd Ghani, M.K.; Jaber, M.M.; Khaleefah, S.H. Examining multiple feature evaluation and classification methods for improving the diagnosis of Parkinson’s disease. Cogn. Syst. Res. 2019, 54, 90–99. [Google Scholar] [CrossRef]
- Ghasemaghaei, M. Are firms ready to use big data analytics to create value? The role of structural and psychological readiness. Enterp. Inf. Syst. 2019, 13, 650–674. [Google Scholar] [CrossRef]
- De Paula, N.O.B.; de Araújo Costa, I.P.; Drumond, P.; Moreira, M.Â.L.; Gomes, C.F.S.; Dos Santos, M.; do Nascimento Maêda, S.M. Strategic support for the distribution of vaccines against Covid-19 to Brazilian remote areas: A multicriteria approach in the light of the ELECTRE-MOr method. Procedia Comput. Sci. 2022, 199, 40–47. [Google Scholar] [CrossRef] [PubMed]
- Moreira, M.Â.L.; Gomes, C.F.S.; Dos Santos, M.; da Silva Júnior, A.C.; de Araújo Costa, I.P. Sensitivity Analysis by the PROMETHEE-GAIA method: Algorithms evaluation for COVID-19 prediction. Procedia Comput. Sci. 2022, 199, 431–438. [Google Scholar] [CrossRef] [PubMed]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No | Evaluation Criteria |
|---|---|
| 1 | Relevance to technology policies |
| 2 | Distinguish individual comments from retweets |
| 3 | Contain a specific need relevant to technology |
| 4 | Contain statistics relevant to technology |
| 5 | Relevance to modern technologies |
| 6 | Provide political knowledge relevant to technology |
| 7 | Provide practical and professional experience relevant to technology |
| 8 | Posted by a technology expert or someone with relevant experience |
| 9 | Contain a critical issue |
| 10 | Indicative of social values in technology |
| 11 | Capable of creating a network effect |
| 12 | The topic has political priorities for the policy-maker |
| 13 | The urgency of the topic mentioned in a tweet |
| 14 | Reveal corruption in technology |
| 15 | Provide analytic and technical knowledge relevant to technology |
| No | Feature Name | Description |
|---|---|---|
| 1 | Swear Word | The tweet contains swear words |
| 2 | Tweet Time | The time a tweet was sent |
| 3 | No_Sentences | The number of sentences in a tweet |
| 4 | No_Lines | The number of lines that a tweet has |
| 5 | No_Mentions | The number of mentions included in a tweet |
| 6 | No_Urls | The number of URLs included in a tweet |
| 7 | No_Hashtags | The number of hashtags included in a tweet |
| 8 | No_Digits | The total number of digits in a tweet |
| 9 | No_Emojis | The number of emojis included in a tweet |
| 10 | No_Spaces | The number of spaces included in a tweet |
| 11 | Length of Tweet | The length of a tweet |
| 12 | Max Length of Words | The maximum length of words that a tweet has |
| 13 | Mean Length of Words | The mean length of words that a tweet has |
| 14 | No_Exclamation Marks | The number of exclamation marks included in a tweet |
| 15 | No_Question Marks | The number of question marks included in a tweet |
| 16 | No_Punctuations | The number of punctuations marks included in a tweet, except for question and exclamation marks |
| 17 | No_Words | Total number of words that a tweet has |
| 18 | No_Characters | The total number of characters that have been used in a tweet |
| 19 | Digits To Chars Ratio | The number of digits to the number of characters ratio in a tweet |
| 20 | Lines To Sentences Ratio | The number of lines to the number of sentences ratio in a tweet |
| 21 | Words To Sentences Ratio | The number of words to the number of sentences ratio in a tweet |
| 22 | Hashtags More Than 2 | The tweet has more than 2 hashtags |
| 23 | No_Words Less Than 3 Chars | Total number of words with less than 3 characters that a tweet has |
| 24 | No_Words More Than 5 Chars | Total number of words with more than 5 characters that a tweet has |
| 25 | Video | The tweet contains a video |
| 26 | Image | The tweet contains an image |
| No | Feature Name | Description |
|---|---|---|
| 1 | No. of_Followers | The number of followers of this Twitter user |
| 2 | No. of_Following | The number of accounts this Twitter user follows |
| 3 | FF_Ratio | The number of followers to the number of followings ratio |
| 4 | Description | Contains a description in the profile |
| 5 | No. of_Likes | The number of user favorites by this Twitter user |
| 6 | URL In Description | Contains a URL in the description of the Twitter user |
| 7 | No. of Lists | The number of lists that this Twitter user added |
| 8 | No. of_Tweets | The number of tweets this Twitter user sent |
| 9 | Profile Image | Contains a profile image in the Twitter profile account |
| 10 | Background Image | Contains a background image in the Twitter profile account |
| 11 | Profile Background Image | Contains a profile background image in the Twitter profile account |
| No | Feature Name | IG | No | Feature Name | IG |
|---|---|---|---|---|---|
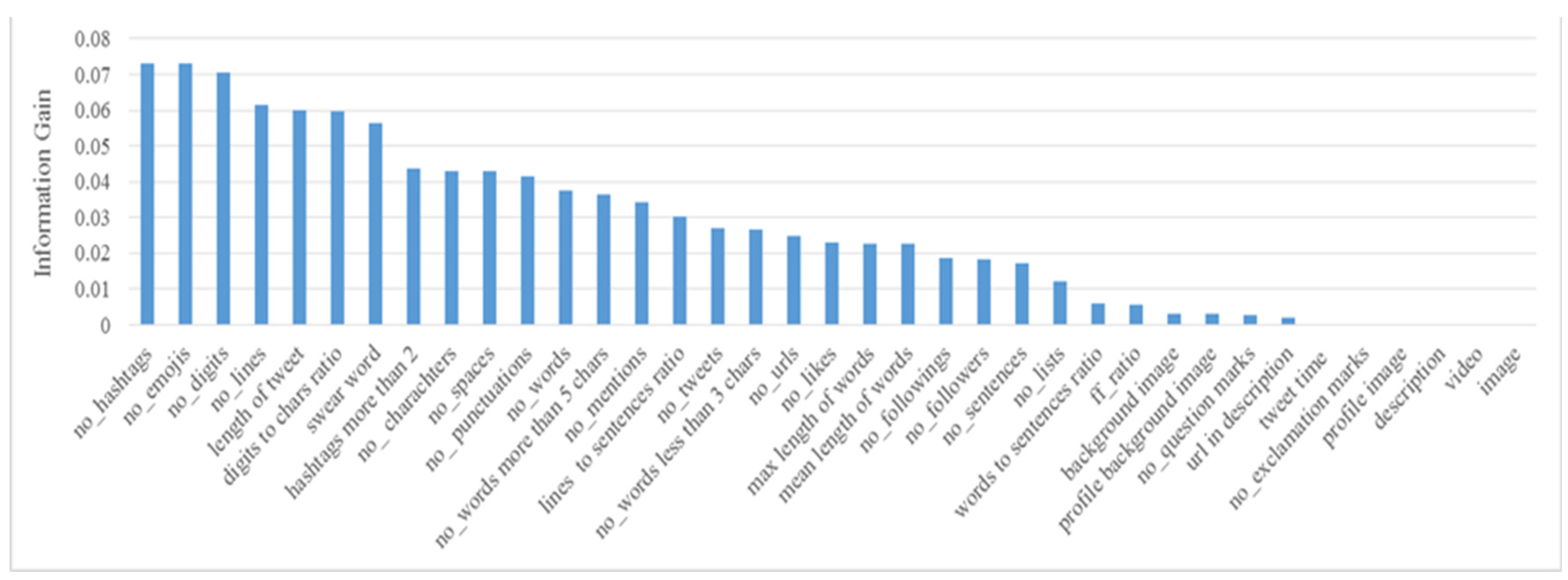
| 1 | No_Hashtags | 0.07309 | 20 | Max Length of Words | 0.02279 |
| 2 | No_Emojis | 0.07305 | 21 | Mean Length of Words | 0.02258 |
| 3 | No_Digits | 0.07054 | 22 | No_Followings | 0.01878 |
| 4 | No_Lines | 0.06164 | 23 | No_Followers | 0.01825 |
| 5 | Length of Tweet | 0.06003 | 24 | No_Sentences | 0.01737 |
| 6 | Digits to Chars Ratio | 0.05954 | 25 | No_Lists | 0.01227 |
| 7 | Swear Words | 0.05654 | 26 | Words to Sentences Ratio | 0.00597 |
| 8 | Hashtags More Than 2 | 0.04358 | 27 | Ff_Ratio | 0.00544 |
| 9 | No_ Characters | 0.04293 | 28 | Background Image | 0.00313 |
| 10 | No_Spaces | 0.04287 | 29 | Profile Background Image | 0.00313 |
| 11 | No_ Punctuations | 0.04163 | 30 | No_Question Marks | 0.00258 |
| 12 | No_Words | 0.03741 | 31 | URL In Description | 0.00199 |
| 13 | No_Word More Than 5 Chars | 0.03626 | 32 | Tweet Time | 0 |
| 14 | No_Mentions | 0.03428 | 33 | No_Exclamation Marks | 0 |
| 15 | Lines To Sentences Ratio | 0.03036 | 34 | Profile Image | 0 |
| 16 | No_Tweets | 0.02697 | 35 | Description | 0 |
| 17 | No_Words Less Than 3 Chars | 0.02653 | 36 | Video | 0 |
| 18 | No_Urls | 0.02469 | 37 | Image | 0 |
| 19 | No_Likes | 0.02287 |
| Prediction | |||
|---|---|---|---|
| Evidence | Non-Evidence | ||
| Label | Evidence | True-positive (TP) | False-negative (FN) |
| Non-evidence | False-positive (FP) | True-negative (TN) | |
| Algorithm | Precision | Recall | F_Measure |
|---|---|---|---|
| Decision tree (DT) | 79.13 | 90.1 | 84.26 |
| XGBoost | 80 | 83.17 | 81.55 |
| K-nearest neighbor (KNN) | 75.54 | 68.81 | 72.02 |
| Logistic regression (LR) | 72.96 | 70.79 | 71.86 |
| Linear discriminant analysis (LDA) | 73.85 | 47.52 | 57.83 |
| Support vector machine (SVM) | 62.8 | 50.99 | 56.28 |
| Algorithm | Accuracy (%) |
|---|---|
| Decision tree (DT) | 85.09 |
| XGBoost | 83.33 |
| K-nearest neighbor (KNN) | 76.32 |
| Logistic regression (LR) | 75.44 |
| Linear discriminate analysis (LDA) | 69.3 |
| Support vector machine (SVM) | 64.91 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Labafi, S.; Ebrahimzadeh, S.; Kavousi, M.M.; Abdolhossein Maregani, H.; Sepasgozar, S. Using an Evidence-Based Approach for Policy-Making Based on Big Data Analysis and Applying Detection Techniques on Twitter. Big Data Cogn. Comput. 2022, 6, 160. https://doi.org/10.3390/bdcc6040160
Labafi S, Ebrahimzadeh S, Kavousi MM, Abdolhossein Maregani H, Sepasgozar S. Using an Evidence-Based Approach for Policy-Making Based on Big Data Analysis and Applying Detection Techniques on Twitter. Big Data and Cognitive Computing. 2022; 6(4):160. https://doi.org/10.3390/bdcc6040160
Chicago/Turabian StyleLabafi, Somayeh, Sanee Ebrahimzadeh, Mohamad Mahdi Kavousi, Habib Abdolhossein Maregani, and Samad Sepasgozar. 2022. "Using an Evidence-Based Approach for Policy-Making Based on Big Data Analysis and Applying Detection Techniques on Twitter" Big Data and Cognitive Computing 6, no. 4: 160. https://doi.org/10.3390/bdcc6040160
APA StyleLabafi, S., Ebrahimzadeh, S., Kavousi, M. M., Abdolhossein Maregani, H., & Sepasgozar, S. (2022). Using an Evidence-Based Approach for Policy-Making Based on Big Data Analysis and Applying Detection Techniques on Twitter. Big Data and Cognitive Computing, 6(4), 160. https://doi.org/10.3390/bdcc6040160