


Intelligent Multi-Lingual Cyber-Hate Detection in Online Social Networks: Taxonomy, Approaches, Datasets, and Open Challenges



Abstract
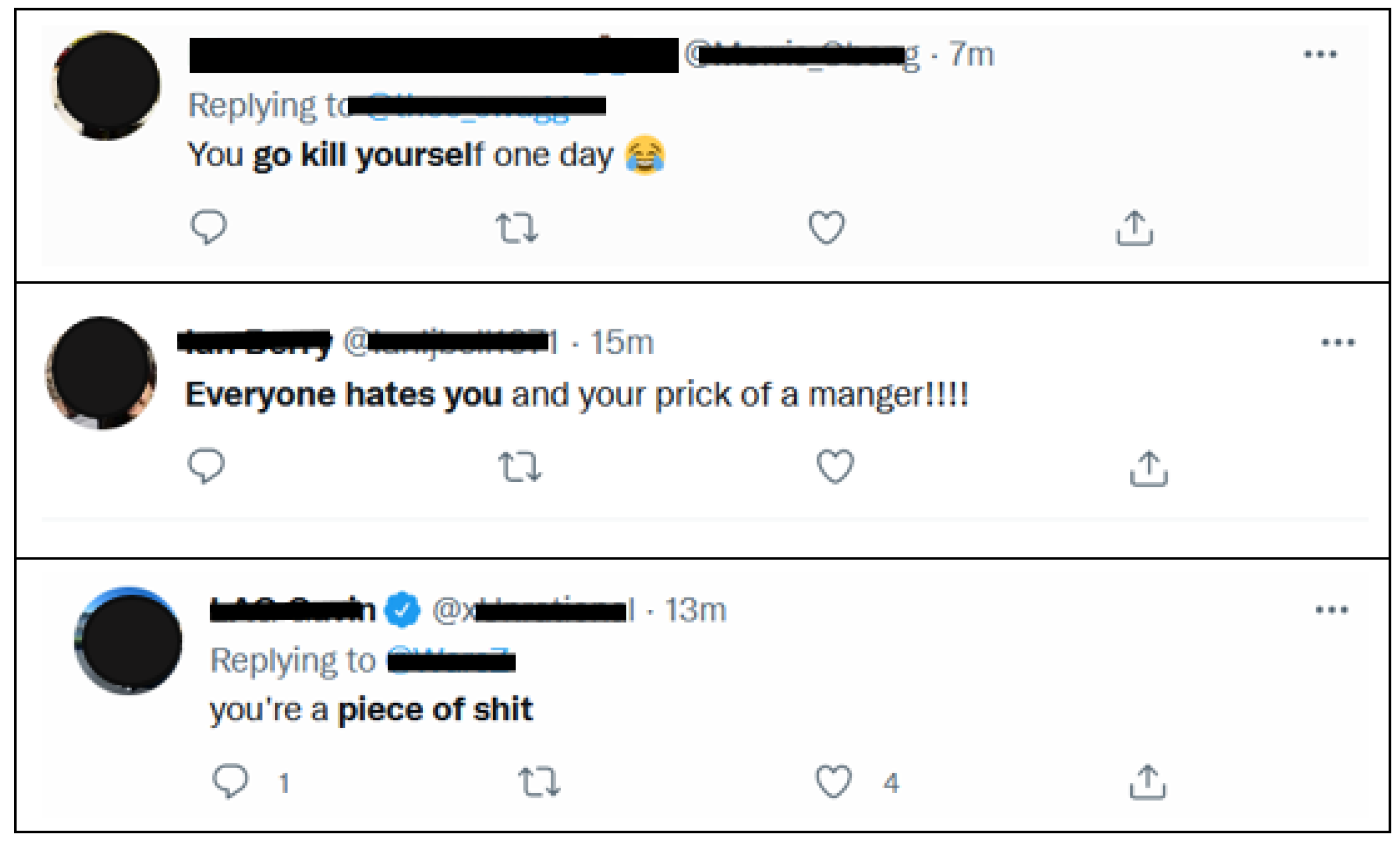
:1. Introduction
- Sending derogatory messages about them.
- Sharing humiliating images or videos of them.
- Spreading slanderous web rumors against them.
- Making fake accounts in their name.
- Making the public believe they are someone else.
2. Cyber-Hate Speech Properties
2.1. Definition
- Posting threats such as physical harm, brutality, or violence.
- Any discussion intended to offend an individual’s feelings, including routinely inappropriately teasing, prodding, or making somebody the brunt of pranks, tricks, or practical jokes.
- Any textual content meant to destroy the social standing or reputation of any individual on online social networks or offline communities.
- Circulating inappropriate, humiliating, or embarrassing images or videos on social networks.
- Persistent, grievous, or egregious utilization of abusive, annoying, insulting, hostile, or offensive language.
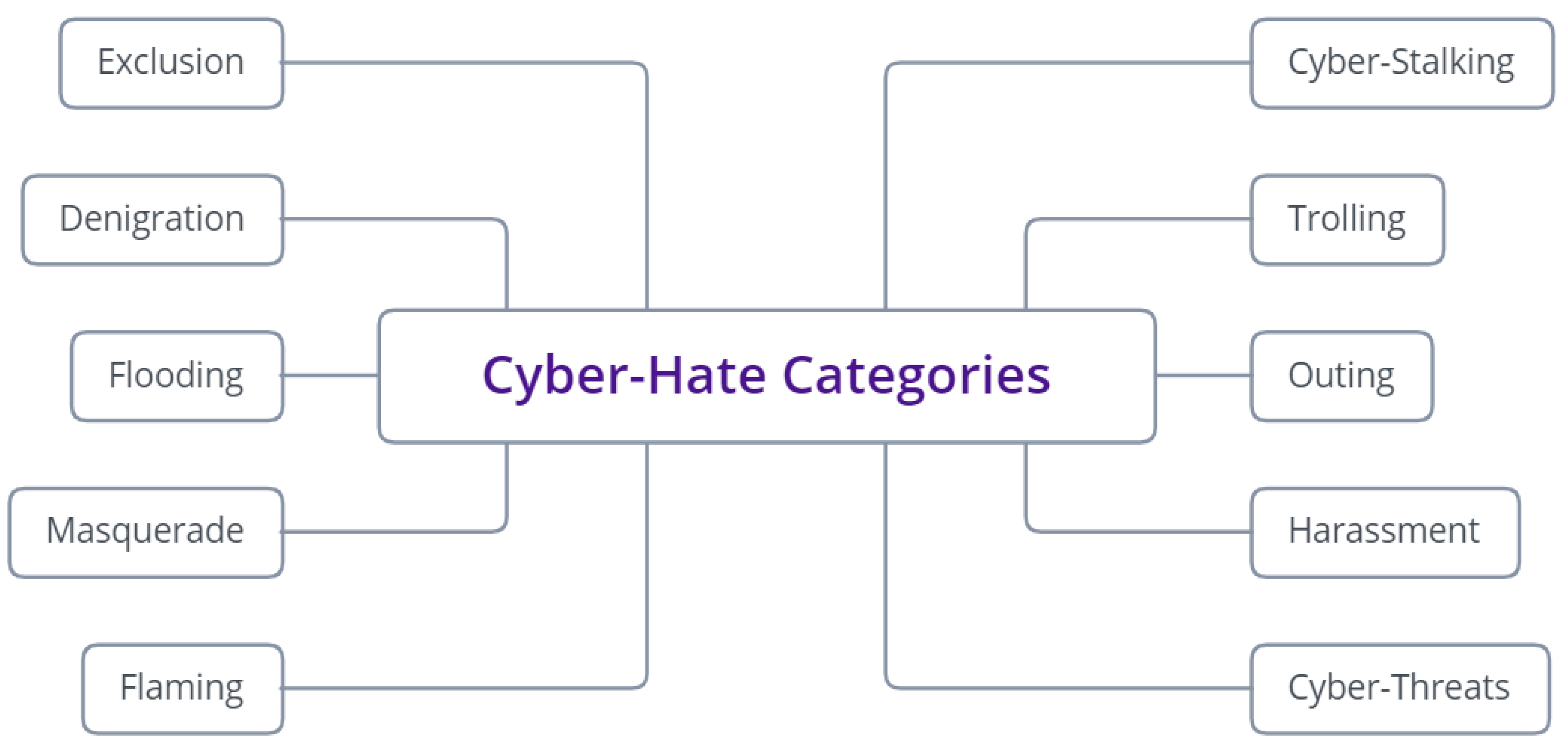
2.2. Taxonomy
- Exclusion is defined as ignoring or neglecting the victim in a conversation [10]. Cyber-Exclusion is an intentional and deliberate action to make it clear to people that they do not belong to the group and that their involvement is not needed. On social networking sites, individuals can defriend or block others, which implies their inability to view their profiles, write comments, and so forth.
- Denigration involves the practice of demeaning, gossiping, dissing, or disrespecting another individual on social networks [11]. Writing rude, vulgar, mean, hurtful, or untrue messages or rumors about someone to another person or posting them in a public community or chat room falls under denigration. The purpose is to hurt the victim in the eyes of his or her community, as the insults are seen not only by the victim but also others.
- Flooding is the posting of a countless number of online social networking messages so the victim cannot post a message [12]. It consists of the bully or harasser repeatedly writing the same comment, posting nonsense comments, or holding down the enter key to not allow the victim to contribute to the chat or conversation.
- Masquerade is defined as the process of impersonating another person to send messages that seem to be originated by that person and cause damage or harm [13]. One of the ways to do this is by, for example, hacking into a victim’s e-mail account and instantly sending these messages. Moreover, friends sharing passwords can also regularly accomplish this type of access; however, the sophisticated hacker may discover other ways, for example, by systematically testing probable passwords. This strategy is inherently hard and difficult to be recognized or detected.
- Flaming, blazing, or bashing involves at least two users attacking and assaulting each other on a personal level. In this category of cyber-hate, flaming refers to a conversation full of hostile, unfriendly, irate, angry, and insulting communications and interactions that are regularly unkind personal attacks [14]. Flaming can occur in a diversity of environments, such as online social networking and discussion boards, group chat rooms, e-mails, and Twitter. Anger is frequently expressed by utilizing capital letters, such as ‘U R AN IDIOT & I HATE U!’. Many flaming texts are vicious, horrible, and cruel and are without fact or reason.
- Cyberstalking is the utilization of social networks to stalk, hassle, or harass any individual, group, or organization [15]. It might contain false incriminations, accusations, criticism, defamation, maligning, slander, and libel. Cases of cyberstalking can often begin as seemingly harmless interactions. Sometimes, particularly at the beginning, a few strange or maybe distasteful messages may even amuse. Nevertheless, if they turn out to be systematic, it becomes irritating, annoying, and even frightening.
- Trolling, also called baiting, attempts to provoke a fight by intentionally writing comments that disagree with other posts in the topic or thread [16]. The poster plans to excite emotions and rouse an argument, while the comments themselves inevitably turn personal, vulgar, enthusiastic, or emotional.
- Outing is similar to denigration but requires the bully and the victim to have a close personal relationship, either on social networks or in-person. It includes writing and sharing personal, private, embarrassing, or humiliating information publicly [17]. This information can incorporate stories heard or received from the victim or any personal information such as personal numbers, passwords, or addresses.
- Harassment using social networks is equivalent to harassment utilizing more conventional and traditional means [18]. Harassment refers to threatening actions dependent on an individual’s age, gender, race, sexual orientation, and so forth.
- Cyber threats include sending short messages that involve threats of harm, are scary, intimidating, are very aggressive, or incorporate extortion [19]. The dividing line where harassment becomes cyberstalking is obscured; however, one indicator may be when the victim starts to fear for his or her well-being or safety, then the act has to be considered cyberstalking.
3. Cyber-Hate Speech Datasets

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Category | Number of Classes | Classes | Social Network Platform | Language | Size | Availability | Year |
|---|---|---|---|---|---|---|---|---|
| Mangaonkar et al. [21] | Trolling and Harassment | 2 | Bullying | English | 1340 | N/A | 2015 | |
| Non-Bullying | ||||||||
| Van Hee et al. [22] | Cyber Threats and Harassment | 2 | Bullying | Ask.fm | Dutch | 85,485 | N/A | 2015 |
| Non-Bullying | ||||||||
| Waseem and Hovy [23] | Cyber Threats and Harassment | 3 | Racism | English | 16 K | [59] | 2016 | |
| Sexism | ||||||||
| None | ||||||||
| Zhao et al. [24] | Trolling and Harassment | 2 | Bullying | English | 1762 | N/A | 2016 | |
| Non-Bullying | ||||||||
| Singh et al. [25] | Trolling and Harassment | 2 | Bullying | English | 4865 | N/A | 2016 | |
| Non-Bullying | ||||||||
| Al-garadi et al. [27] | Trolling and Harassment | 2 | Bullying | English | 10,007 | N/A | 2016 | |
| Non-Bullying | ||||||||
| Hosseinmardi et al. [28] | Flaming and Stalking and Harassment | 2 | Bullying | English | 1954 | N/A | 2016 | |
| Non-Bullying | ||||||||
| Zhang et al. [29] | Trolling and Harassment | 2 | Bullying | Formspring | English | 13 K | N/A | 2016 |
| Non-Bullying | ||||||||
| Wulczyn et al. [30] | Denigration and Masquerade and Harassment | 2 | Attacking | Wikipedia | English | 100 K | [60] | 2017 |
| Non-Attacking | ||||||||
| Batoul et al. [31] | Trolling and Harassment | 2 | Bullying | Arabic | 35,273 | N/A | 2017 | |
| Non-Bullying | ||||||||
| Davidson et al. | Trolling and Harassment | 3 | Bullying | English | 33,458 | [61] | 2017 | |
| Non-Bullying | ||||||||
| Neither | ||||||||
| Sprugnoli et al. [33] | Flaming and Stalking and Harassment and Trolling | 10 | Defense | Italian | 14,600 | [62] | 2018 | |
| General Insult | ||||||||
| Curse or Exclusion | ||||||||
| Threat or Blackmail | ||||||||
| Encouragement to the Harassment | ||||||||
| Body Shame | ||||||||
| Discrimination-Sexism | ||||||||
| Attacking relatives | ||||||||
| Other | ||||||||
| Defamation | ||||||||
| Founta et al. [35] | Cyber Threats and Harassment | 7 | Offensive | English | 100 K | [63] | 2018 | |
| Abusive | ||||||||
| Hateful | ||||||||
| Aggressive | ||||||||
| Cyberbullying | ||||||||
| Spam | ||||||||
| Normal | ||||||||
| De Gibert et al. [36] | Trolling and Harassment | 2 | Hateful | Stormfront | English | 10,568 | [64] | 2018 |
| Non-Hateful | ||||||||
| Nurrahmi and Nurjanah [37] | Trolling and Harassment | 2 | Bullying | Indonesian | 700 | N/A | 2018 | |
| Non-Bullying | ||||||||
| Albadi et al. [38] | Trolling and Harassment | 2 | Hateful | Arabic | 6 K | [65] | 2018 | |
| Non-Hateful | ||||||||
| Bosco et al. [39] | Trolling and Harassment | 2 | Bullying | Italian | 4 K | 2018 | ||
| Non-Bullying | ||||||||
| Corazza et al. [40] | Trolling and Harassment | 2 | Bullying | German | 5009 | 2018 | ||
| Non-Bullying | ||||||||
| Mulki et al. [41] | Trolling and Harassment | 3 | Normal | Arabic | 6 K | [66] | 2019 | |
| Abusive | ||||||||
| Hate | ||||||||
| Ptaszynski et al. [42] | Trolling and Harassment | 3 | Non-harmful | Polish | 11,041 | [67] | 2019 | |
| Cyberbullying | ||||||||
| Hate-speech and other harmful contents | ||||||||
| Ibrohim and Budi [43] | Trolling and Harassment | 2 | Hateful | Indonesian | 11,292 | [68] | 2019 | |
| Non-Hateful | ||||||||
| Basile et al. [44] | Trolling and Harassment | 2 | Hateful | English | 13,000 | [69] | 2019 | |
| Non-Hateful | Spanish | 6600 | ||||||
| Banerjee et al. [45] | Trolling and Harassment | 2 | Bullying | English | 69,874 | N/A | 2019 | |
| Non-Bullying | ||||||||
| Lu et al. [46] | Cyber Threats and Harassment | 3 | Sexism | Sina Weibo | Chinese | 16,914 | [70] | 2020 |
| Racism | ||||||||
| Neither | ||||||||
| Moon et al. [47] | Trolling and Harassment | 3 | Hateful | Online News Platform | Korean | 9.4 K | [71] | 2020 |
| Offensive | ||||||||
| None | ||||||||
| Romim et al. [48] | Trolling and Harassment | 2 | Hateful | Facebook and YouTube | Bengali | 30 K | [72] | 2021 |
| Non-Hateful | ||||||||
| Karim et al. [49] | Trolling and Harassment | 2 | Hateful | Facebook, YouTube comments, and newspapers | Bengali | 8087 | [73] | 2021 |
| Non-Hateful | ||||||||
| Luu et al. [50] | Trolling and Harassment | 3 | Hate | Facebook and YouTube | Vietnamese | 33,400 | [74] | 2021 |
| Offensive | ||||||||
| Clean | ||||||||
| Sadiq et al. [51] | Trolling and Harassment | 2 | Bullying | English | 20,001 | [75] | 2021 | |
| Non-Bullying | ||||||||
| Beyhan et al. [52] | Trolling and Harassment | 2 | Hateful | Turkish | 2311 | [76] | 2022 | |
| Non-Hateful | ||||||||
| Ollagnier et al. [53] | Flaming, Stalking, Harassment and Trolling | 2 | Hateful | French | 1210 | [77] | 2022 | |
| Non-Hateful | ||||||||
| ALBayari and Abdallah [54] | Flaming, Stalking, Harassment and Trolling | 2 | Bullying | Arabic | 46,898 | [78] | 2022 | |
| Non-Bullying | ||||||||
| Patil et al. [55] | Trolling and Harassment | 4 | Hate | Marathi | 25 K | [79] | 2022 | |
| Offensive | ||||||||
| Profane | ||||||||
| None | ||||||||
| Kumar and Sachdeva [56] | Trolling and Harassment | 2 | Bullying | Formspring | English | 13,158 | N/A | 2022 |
| Non-Bullying | MySpace | 1753 | ||||||
| Atoum [57] | Trolling and Harassment | 2 | Bullying | Twitter Dataset 1 | English | 6463 | N/A | 2023 |
| Non-Bullying | Twitter Dataset 2 | 3721 | ||||||
| Nabiilaha et al. [58] | Trolling, Harassment and Flaming | 2 | Bullying | Instagram, Twitter and Kaskus | Indonesian | 7773 | N/A | 2023 |
| Non-Bullying |
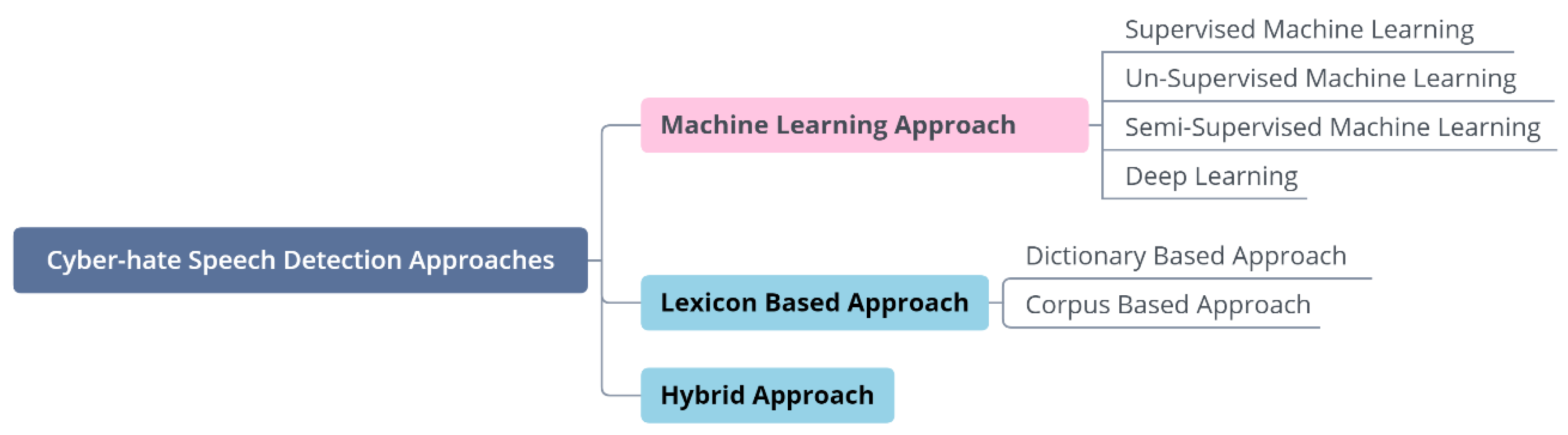
4. Cyber-Hate Speech Detection Approaches
5. Cyber-Hate Detecting Techniques
5.1. Binary Cyber-Hate Classification
5.2. Multi-Class Cyber-Hate Classification
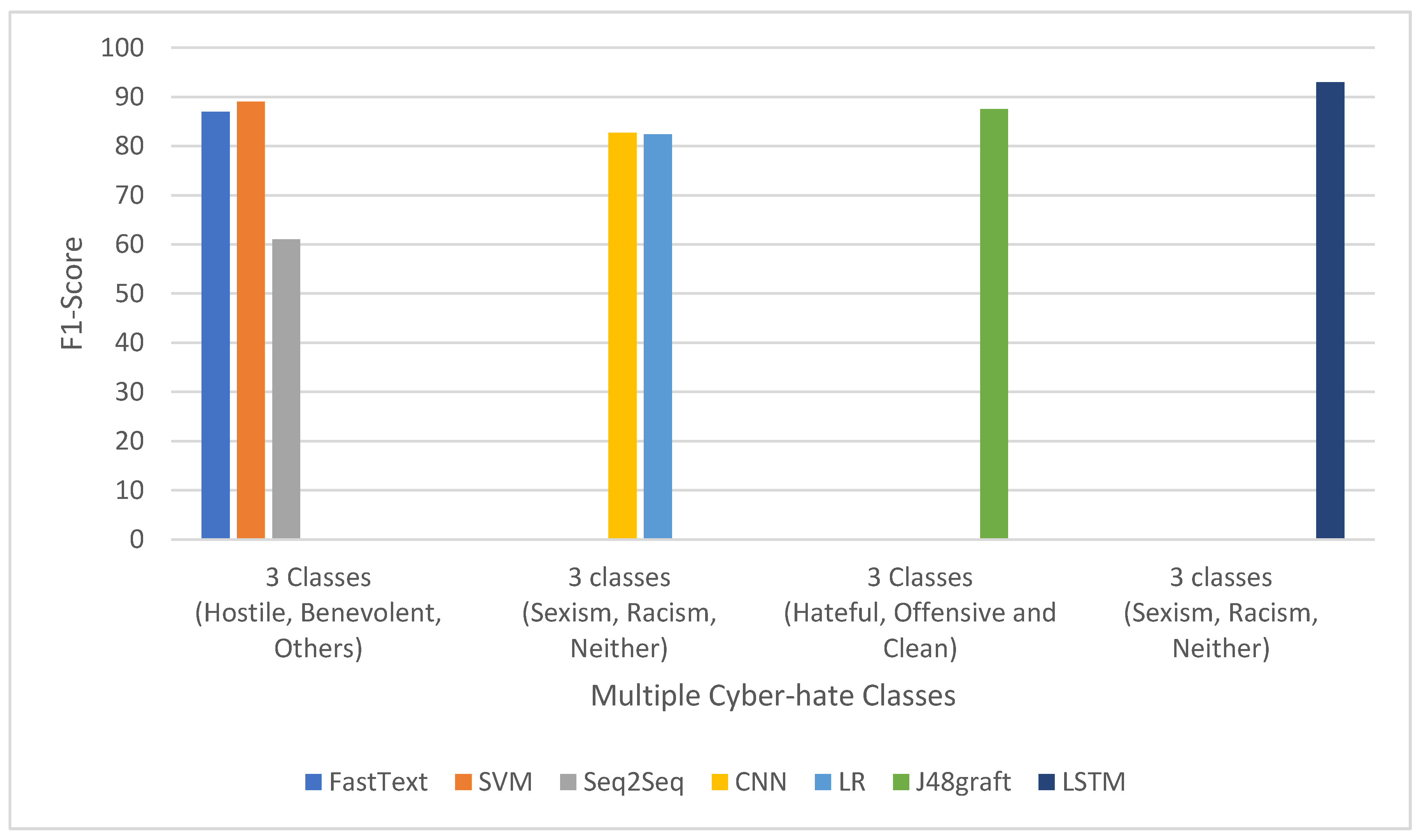
5.3. Analysis of the Literature Review
6. Cyber-Hate Challenges
- Data scarcity.
- The ambiguity of the context.
- The complexity of the Arabic language.
- Availability and accessibility to data on social networks.
- Manual Data Labelling.
- The degree of cyberbullying severity.
7. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Alsayat, A.; Elmitwally, N. A Comprehensive Study for Arabic Sentiment Analysis (Challenges and Applications). Egypt. Inform. J. 2020, 21, 7–12. [Google Scholar] [CrossRef]
- Available online: https://www.Statista.Com/Statistics/278414/Number-of-Worldwide-Social-Network-Users/ (accessed on 3 July 2020).
- Available online: https://www.Oberlo.Com/Statistics/How-Many-People-Use-Social-Media (accessed on 3 July 2020).
- Corazza, M.; Menini, S.; Cabrio, E.; Tonelli, S.; Villata, S. A Multilingual Evaluation for Online Hate Speech Detection. ACM Trans. Internet Technol. 2020, 20, 1–22. [Google Scholar] [CrossRef] [Green Version]
- StopBullying.Gov. Available online: https://www.stopbullying.gov (accessed on 3 July 2020).
- Bisht, A.; Singh, A.; Bhadauria, H.S.; Virmani, J. Detection of Hate Speech and Offensive Language in Twitter Data Using LSTM Model. Recent Trends Image Signal Process. Comput. Vis. 2020, 1124, 243–264. [Google Scholar]
- Miro-Llinares, F.; Rodriguez-Sala, J.J. Cyber Hate Speech on Twitter: Analyzing Disruptive Events from Social Media to Build a Violent Communication and Hate Speech Taxonomy. Des. Nat. Ecodynamics 2016, 11, 406–415. [Google Scholar] [CrossRef] [Green Version]
- Blaya, C. Cyberhate: A Review and Content Analysis of Intervention Strategies. Aggress. Violent Behav. 2018, 45, 163–172. [Google Scholar] [CrossRef]
- Namdeo, P.; Pateriya, R.K.; Shrivastava, S. A Review of Cyber Bullying Detection in Social Networking. In Proceedings of the Inventive Communication and Computational Technologies, Coimbatore, India, 10–11 March 2017; pp. 162–170. [Google Scholar]
- Hang, O.C.; Dahlan, H.M. Cyberbullying Lexicon for Social Media. In Proceedings of the Research and Innovation in Information Systems (ICRIIS), Johor Bahru, Malaysia, 2–3 December 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–6. [Google Scholar]
- Sangwan, S.R.; Bhatia, M.P.S. Denigration Bullying Resolution Using Wolf Search Optimized Online Reputation Rumour Detection. Procedia Comput. Sci. 2020, 173, 305–314. [Google Scholar] [CrossRef]
- Colton, D.; Hofmann, M. Sampling Techniques to Overcome Class Imbalance in a Cyberbullying Context. Comput. Linguist. Res. 2019, 3, 21–40. [Google Scholar] [CrossRef] [Green Version]
- Qodir, A.; Diponegoro, A.M.; Safaria, T. Cyberbullying, Happiness, and Style of Humor among Perpetrators: Is There a Relationship? Humanit. Soc. Sci. Rev. 2019, 7, 200–206. [Google Scholar] [CrossRef]
- Peled, Y. Cyberbullying and Its Influence on Academic, Social, and Emotional Development of Undergraduate Students. Heliyon 2019, 5, e01393. [Google Scholar] [CrossRef] [Green Version]
- Dhillon, G.; Smith, K.J. Defining Objectives for Preventing Cyberstalking. Bus. Ethics 2019, 157, 137–158. [Google Scholar] [CrossRef]
- la Vega, D.; Mojica, L.G.; Ng, V. Modeling Trolling in Social Media Conversations. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC), Miyazaki, Japan, 7–12 May 2018; pp. 3701–3706. [Google Scholar]
- Hassan, S.; Yacob, M.I.; Nguyen, T.; Zambri, S. Social Media Influencer and Cyberbullying: A Lesson Learned from Preliminary Findings. In Proceedings of the 9th Knowledge Management International Conference (KMICe), Miri, Sarawak, Malaysia, 25–27 July 2018; pp. 200–205. [Google Scholar]
- Raisi, E.; Huang, B. Weakly Supervised Cyberbullying Detection Using Co-Trained Ensembles of Embedding Models. In Proceedings of the Advances in Social Networks Analysis and Mining (ASONAM), Barcelona, Spain, 28–31 August 2018; pp. 479–486. [Google Scholar]
- Willard, N.E. Cyberbullying and Cyberthreats: Responding to the Challenge of Online Social Aggression, Threats, and Distress; Research Press: Champaign, IL, USA, 2007. [Google Scholar]
- Available online: https://www.Pewresearch.Org/Internet/2021/01/13/Personal-Experiences-with-Online-Harassment/ (accessed on 3 July 2020).
- Mangaonkar, A.; Hayrapetian, A.; Raje, R. Collaborative Detection of Cyberbullying Behavior in Twitter Data. In Proceedings of the Electro/Information technology (EIT), Dekalb, IL, USA, 21–23 May 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 611–616. [Google Scholar]
- Van Hee, C.; Lefever, E.; Verhoeven, B.; Mennes, J.; Desmet, B.; De Pauw, G.; Daelemans, W.; Hoste, V. Detection and Fine-Grained Classification of Cyberbullying Events. In Proceedings of the Recent Advances in Natural Language Processing (RANLP), Hissar, Bulgaria, 1–8 September 2015; pp. 672–680. [Google Scholar]
- Waseem, Z.; Hovy, D. Hateful Symbols or Hateful People? Predictive Features for Hate Speech Detection on Twitter. In Proceedings of the NAACL Student Research Workshop, San Diego, CA, USA, 1 June 2016; pp. 88–93. [Google Scholar]
- Zhao, R.; Zhou, A.; Mao, K. Automatic Detection of Cyberbullying on Social Networks Based on Bullying Features. In Proceedings of the 17th International Conference on Distributed Computing and Networking, New York, NY, USA, 4 January 2016; pp. 1–6. [Google Scholar]
- Singh, V.K.; Huang, Q.; Atrey, P.K. Cyberbullying Detection Using Probabilistic Socio-Textual Information Fusion. In Proceedings of the Advances in Social Networks Analysis and Mining (ASONAM), San Francisco, CA, USA, 18–21 August 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 884–887. [Google Scholar]
- Available online: https://www.Ra.Ethz.Ch/Cdstore/Www2009/Caw2.Barcelonamedia.Org/Index.Html (accessed on 3 July 2020).
- Al-garadi, M.A.; Varathan, K.D.; Ravana, S.D. Cybercrime Detection in Online Communications: The Experimental Case of Cyberbullying Detection in the Twitter Network. Comput. Hum. Behav. 2016, 63, 433–443. [Google Scholar] [CrossRef]
- Hosseinmardi, H.; Rafiq, R.I.; Han, R.; Lv, Q.; Mishra, S. Prediction of Cyberbullying Incidents in a Media-Based Social Network. In Proceedings of the Advances in Social Networks Analysis and Mining (ASONAM), San Francisco, CA, USA, 18–21 August 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 186–192. [Google Scholar]
- Zhang, X.; Tong, J.; Vishwamitra, N.; Whittaker, E.; Mazer, J.P.; Kowalski, R.; Hu, H.; Luo, F.; Macbeth, J.; Dillon, E. Cyberbullying Detection with a Pronunciation Based Convolutional Neural Network. In Proceedings of the 15th IEEE International Conference on Machine Learning and Applications (ICMLA), Anaheim, CA, USA, 18–20 December 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 740–745. [Google Scholar]
- Wulczyn, E.; Thain, N.; Dixon, L. Ex Machina: Personal Attacks Seen at Scale. In Proceedings of the 26th International Conference on World Wide Web, Perth, Australia, 3 April 2017; pp. 1391–1399. [Google Scholar]
- Haidar, B.; Chamoun, M.; Serhrouchni, A. Multilingual Cyberbullying Detection System: Detecting Cyberbullying in Arabic Content. In Proceedings of the 1st Cyber Security in Networking Conference (CSNet), Rio de Janeiro, Brazil, 18–20 October 2017; pp. 1–8. [Google Scholar]
- Davidson, T.; Warmsley, D.; Macy, M.; Weber, I. Automated Hate Speech Detection and the Problem of Offensive Language. Int. AAAI Conf. Web Soc. Media 2017, 11, 512–515. [Google Scholar] [CrossRef]
- Sprugnoli, R.; Menini, S.; Tonelli, S.; Oncini, F.; Piras, E. Creating a Whatsapp Dataset to Study Pre-Teen Cyberbullying. In Proceedings of the 2nd Workshop on Abusive Language Online (ALW2), Brussels, Belgium, 31 October 2018; pp. 51–59. [Google Scholar]
- Bartalesi Lenzi, V.; Moretti, G.; Sprugnoli, R. Cat: The Celct Annotation Tool. In Proceedings of the Eight International Conference on Language Resources and Evaluation (LREC’12), Istanbul, Turkey, 21–27 May 2012; pp. 333–338. [Google Scholar]
- Founta, A.-M.; Djouvas, C.; Chatzakou, D.; Leontiadis, I.; Blackburn, J.; Stringhini, G.; Vakali, A.; Sirivianos, M.; Kourtellis, N. Large Scale Crowdsourcing and Characterization of Twitter Abusive Behavior. In Proceedings of the Weblogs and Social Media (ICWSM), Palo Alto, CA, USA, 25–28 June 2018; pp. 491–500. [Google Scholar]
- de Gibert, O.; Perez, N.; García-Pablos, A.; Cuadros, M. Hate Speech Dataset from a White Supremacy Forum. In Proceedings of the 2nd Workshop on Abusive Language Online (ALW2), Brussels, Belgium, 31 October 2018; pp. 11–20. [Google Scholar]
- Nurrahmi, H.; Nurjanah, D. Indonesian Twitter Cyberbullying Detection Using Text Classification and User Credibility. In Proceedings of the Information and Communications Technology (ICOIACT), Yogyakarta, Indonesia, 6–7 March 2018; pp. 543–548. [Google Scholar]
- Albadi, N.; Kurdi, M.; Mishra, S. Are They Our Brothers? Analysis and Detection of Religious Hate Speech in the Arabic Twittersphere. In Proceedings of the IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM), Barcelona, Spain, 28–31 August 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 69–76. [Google Scholar]
- Bosco, C.; Felice, D.; Poletto, F.; Sanguinetti, M.; Maurizio, T. Overview of the Evalita 2018 Hate Speech Detection Task. Ceur Workshop Proc. 2018, 2263, 1–9. [Google Scholar]
- Michele, C.; Menini, S.; Pinar, A.; Sprugnoli, R.; Elena, C.; Tonelli, S.; Serena, V. Inriafbk at Germeval 2018: Identifying Offensive Tweets Using Recurrent Neural Networks. In Proceedings of the Germ Eval Workshop, Vienna, Austria, 21 September 2018; pp. 80–84. [Google Scholar]
- Mulki, H.; Haddad, H.; Ali, C.B.; Alshabani, H. L-HSAB: A Levantine Twitter Dataset for Hate Speech and Abusive Language. In Proceedings of the Third Workshop on Abusive Language Online, Florence, Italy, 1–2August 2019; pp. 111–118. [Google Scholar]
- Ptaszynski, M.; Pieciukiewicz, A.; Dybała, P. Results of the PolEval 2019 Shared Task 6: First Dataset and Open Shared Task for Automatic Cyberbullying Detection in Polish Twitter. In Proceedings of the Pol Eval 2019 Workshop, Warsaw, Poland, 31 May 2019; pp. 89–110. [Google Scholar]
- Ibrohim, M.O.; Budi, I. Multi-Label Hate Speech and Abusive Language Detection in Indonesian Twitter. In Proceedings of the Third Workshop on Abusive Language Online, Florence, Italy, 1–2 August 2019; pp. 46–57. [Google Scholar]
- Basile, V.; Bosco, C.; Fersini, E.; Nozza, D.; Patti, V.; Pardo, F.M.R.; Rosso, P.; Sanguinetti, M. Semeval-2019 Task 5: Multilingual Detection of Hate Speech against Immigrants and Women in Twitter. In Proceedings of the 13th International Workshop on Semantic Evaluation, Minneapolis, MN, USA, 6–7 June 2019; pp. 54–63. [Google Scholar]
- Banerjee, V.; Telavane, J.; Gaikwad, P.; Vartak, P. Detection of Cyberbullying Using Deep Neural Network. In Proceedings of the 5th International Conference on Advanced Computing & Communication Systems (ICACCS), Piscataway, NJ, USA, 15 March 2019; pp. 604–607. [Google Scholar]
- Lu, N.; Wu, G.; Zhang, Z.; Zheng, Y.; Ren, Y.; Choo, K.R. Cyberbullying Detection in Social Media Text Based on Character-level Convolutional Neural Network with Shortcuts. Concurr. Comput. Pract. Exp. 2020, 32, 1–11. [Google Scholar] [CrossRef]
- Moon, J.; Cho, W.I.; Lee, J. BEEP! Korean Corpus of Online News Comments for Toxic Speech Detection. In Proceedings of the Eighth International Workshop on Natural Language Processing for Social Media, Online, 10 July 2020; pp. 25–31. [Google Scholar]
- Romim, N.; Ahmed, M.; Talukder, H.; Islam, S. Hate Speech Detection in the Bengali Language: A Dataset and Its Baseline Evaluation. In Proceedings of the International Joint Conference on Advances in Computational Intelligence, Singapore, 23–24 October 2021; pp. 457–468. [Google Scholar]
- Karim, M.R.; Dey, S.K.; Islam, T.; Sarker, S.; Menon, M.H.; Hossain, K.; Hossain, M.A.; Decker, S. Deephateexplainer: Explainable Hate Speech Detection in under-Resourced Bengali Language. In Proceedings of the 2021 IEEE 8th International Conference on Data Science and Advanced Analytics (DSAA), Porto, Portugal, 6–9 October 2021; pp. 1–10. [Google Scholar]
- Luu, S.T.; Van Nguyen, K.; Nguyen, N.L.-T. A Large-Scale Dataset for Hate Speech Detection on Vietnamese Social Media Texts. In Proceedings of the International Conference on Industrial, Engineering and Other Applications of Applied Intelligent Systems, Kitakyushu, Japan, 19–22 July 2021; pp. 415–426. [Google Scholar]
- Sadiq, S.; Mehmood, A.; Ullah, S.; Ahmad, M.; Choi, G.S.; On, B.-W. Aggression Detection through Deep Neural Model on Twitter. Futur. Gener. Comput. Syst. 2021, 114, 120–129. [Google Scholar] [CrossRef]
- Beyhan, F.; Çarık, B.; İnanç, A.; Terzioğlu, A.; Yanikoglu, B.; Yeniterzi, R. A Turkish Hate Speech Dataset and Detection System. In Proceedings of the Thirteenth Language Resources and Evaluation Conference, Marseille, France, 20–25 June 2022; pp. 4177–4185. [Google Scholar]
- Ollagnier, A.; Cabrio, E.; Villata, S.; Blaya, C. CyberAgressionAdo-v1: A Dataset of Annotated Online Aggressions in French Collected through a Role-Playing Game. In Proceedings of the Thirteenth Language Resources and Evaluation Conference, Marseille, France, 20–25 June 2022; pp. 867–875. [Google Scholar]
- ALBayari, R.; Abdallah, S. Instagram-Based Benchmark Dataset for Cyberbullying Detection in Arabic Text. Data 2022, 7, 83. [Google Scholar] [CrossRef]
- Patil, H.; Velankar, A.; Joshi, R. L3cube-Mahahate: A Tweet-Based Marathi Hate Speech Detection Dataset and Bert Models. In Proceedings of the Third Workshop on Threat, Aggression and Cyberbullying (TRAC 2022), Gyeongju, Republic of Korea, 17 October 2022; pp. 1–9. [Google Scholar]
- Kumar, A.; Sachdeva, N. A Bi-GRU with Attention and CapsNet Hybrid Model for Cyberbullying Detection on Social Media. World Wide Web 2022, 25, 1537–1550. [Google Scholar] [CrossRef]
- Atoum, J.O. Detecting Cyberbullying from Tweets Through Machine Learning Techniques with Sentiment Analysis. In Advances in Information and Communication; Arai, K., Ed.; Springer Nature: Cham, Switzerland, 2023; pp. 25–38. [Google Scholar]
- Nabiilah, G.Z.; Prasetyo, S.Y.; Izdihar, Z.N.; Girsang, A.S. BERT Base Model for Toxic Comment Analysis on Indonesian Social Media. Procedia Comput. Sci. 2023, 216, 714–721. [Google Scholar] [CrossRef]
- Hate Speech Twitter Annotations. Available online: https://github.com/ZeerakW/hatespeech (accessed on 9 August 2020).
- Wikipedia Detox. Available online: https://github.com/ewulczyn/wiki-detox (accessed on 20 August 2020).
- Used a Crowd-Sourced Hate Speech Lexicon to Collect Tweets Containing Hate Speech Keywords. We Use Crowd-Sourcing to Label a Sample of These Tweets into Three Categories: Those Containing Hate Speech, Only Offensive Language, and Those with Neither. Available online: https://arxiv.org/abs/1703.04009 (accessed on 16 February 2023).
- WhatsApp-Dataset. Available online: https://github.com/dhfbk/WhatsApp-Dataset (accessed on 18 August 2020).
- Hate and Abusive Speech on Twitter. Available online: https://github.com/ENCASEH2020/hatespeech-twitter (accessed on 22 August 2020).
- Hate Speech Dataset from a White Supremacist Forum. Available online: https://github.com/Vicomtech/hate-speech-dataset (accessed on 18 November 2022).
- Available online: https://Github.Com/Nuhaalbadi/Arabic_hatespeech (accessed on 18 November 2022).
- L-HSAB Dataset: Context and Topics. Available online: https://github.com/Hala-Mulki/L-HSAB-First-Arabic-Levantine-HateSpeech-Dataset (accessed on 18 November 2022).
- Dataset for Automatic Cyberbullying Detection in Polish Laguage. Available online: https://github.com/ptaszynski/cyberbullying-Polish (accessed on 15 August 2020).
- Multi-Label Hate Speech and Abusive Language Detection in the Indonesian Twitter. Available online: https://github.com/okkyibrohim/id-multi-label-hate-speech-and-abusive-language-detection (accessed on 6 February 2022).
- HatEval. Available online: http://hatespeech.di.unito.it/hateval.html (accessed on 18 November 2022).
- BullyDataset. Available online: https://github.com/NijiaLu/BullyDataset (accessed on 6 January 2020).
- Korean HateSpeech Dataset. Available online: https://github.com/kocohub/korean-hate-speech (accessed on 10 February 2022).
- Available online: https://www.Kaggle.Com/Datasets/Naurosromim/Bengali-Hate-Speech-Dataset (accessed on 10 February 2022).
- Available online: https://Github.Com/Rezacsedu/DeepHateExplainer (accessed on 10 February 2022).
- Available online: https://Github.Com/Sonlam1102/Vihsd (accessed on 10 February 2022).
- Available online: https://www.Kaggle.Com/Datasets/Dataturks/Dataset-for-Detection-of-Cybertrolls (accessed on 10 February 2022).
- Available online: https://Github.Com/Verimsu/Turkish-HS-Dataset (accessed on 10 February 2022).
- CyberAgressionAdo-v1. Available online: https://Github.Com/Aollagnier/CyberAgressionAdo-V1 (accessed on 10 February 2022).
- Available online: https://Bit.Ly/3Md8mj3 (accessed on 10 February 2022).
- Available online: https://Huggingface.Co/L3cube-Pune/Mahahate-Bert (accessed on 10 February 2022).
- Lingiardi, V.; Carone, N.; Semeraro, G.; Musto, C.; D’amico, M.; Brena, S. Mapping Twitter Hate Speech towards Social and Sexual Minorities: A Lexicon-Based Approach to Semantic Content Analysis. Behav. Inf. Technol. 2019, 39, 711–721. [Google Scholar] [CrossRef]
- Alloghani, M.; Al-Jumeily, D.; Mustafina, J.; Hussain, A.; Aljaaf, A.J. A Systematic Review on Supervised and Unsupervised Machine Learning Algorithms for Data Science; Springer: Cham, Switzerland, 2020. [Google Scholar]
- Alsharif, M.H.; Kelechi, A.H.; Yahya, K.; Chaudhry, S.A. Machine Learning Algorithms for Smart Data Analysis in Internet of Things Environment: Taxonomies and Research Trends. Symmetry 2020, 12, 88. [Google Scholar] [CrossRef] [Green Version]
- Rout, J.K.; Dalmia, A.; Choo, K.-K.R.; Bakshi, S.; Jena, S.K. Revisiting Semi-Supervised Learning for Online Deceptive Review Detection. IEEE Access 2017, 5, 1319–1327. [Google Scholar] [CrossRef]
- Li, Z.; Fan, Y.; Jiang, B.; Lei, T.; Liu, W. A Survey on Sentiment Analysis and Opinion Mining for Social Multimedia. Multimed. Tools Appl. 2019, 78, 6939–6967. [Google Scholar] [CrossRef]
- Ay Karakuş, B.; Talo, M.; Hallaç, İ.R.; Aydin, G. Evaluating Deep Learning Models for Sentiment Classification. Concurr. Comput. Pract. Exp. 2018, 30, 1–14. [Google Scholar] [CrossRef]
- Asghar, M.Z.; Khan, A.; Ahmad, S.; Qasim, M.; Khan, I.A. Lexicon-Enhanced Sentiment Analysis Framework Using Rule-Based Classification Scheme. Peer-Rev. Open Access Sci. J. (PLoS ONE) 2017, 12, e0171649. [Google Scholar] [CrossRef] [PubMed]
- Khan, F.H.; Qamar, U.; Bashir, S. Lexicon Based Semantic Detection of Sentiments Using Expected Likelihood Estimate Smoothed Odds Ratio. Artif. Intell. Rev. 2017, 48, 113–138. [Google Scholar] [CrossRef]
- Ahmed, M.; Chen, Q.; Li, Z. Constructing Domain-Dependent Sentiment Dictionary for Sentiment Analysis. Neural Comput. Appl. 2020, 32, 14719–14732. [Google Scholar] [CrossRef]
- Nandhini, B.S.; Sheeba, J.I. Cyberbullying Detection and Classification Using Information Retrieval Algorithm. In Proceedings of the International Conference on Advanced Research in Computer Science Engineering & Technology (ICARCSET), Tamilnadu, India, 15–16 March 2015; pp. 1–5. [Google Scholar]
- Reynolds, K.; Kontostathis, A.; Edwards, L. Using Machine Learning to Detect Cyberbullying. In Proceedings of the 2011 10th International Conference on Machine Learning and Applications and Workshops, NW Washington, DC, USA, 18–21 December 2011; Volume 2, pp. 241–244. [Google Scholar]
- Badjatiya, P.; Gupta, S.; Gupta, M.; Varma, V. Deep Learning for Hate Speech Detection in Tweets. In Proceedings of the 26th International Conference on World Wide Web Companion, Republic and Canton of Geneva, Switzerland, 3–7 April 2017; pp. 759–760. [Google Scholar]
- Park, J.H.; Fung, P. One-Step and Two-Step Classification for Abusive Language Detection on Twitter. In Proceedings of the First Workshop on Abusive Language Online, Vancouver, BC, Canada, 4 August 2017; pp. 41–45. [Google Scholar]
- Watanabe, H.; Bouazizi, M.; Ohtsuki, T. Hate Speech on Twitter: A Pragmatic Approach to Collect Hateful and Offensive Expressions and Perform Hate Speech Detection. IEEE Access 2018, 6, 13825–13835. [Google Scholar] [CrossRef]
- Wang, W.; Huang, J.-t.; Wu, W.; Zhang, J.; Huang, Y.; Li, S.; He, P.; Lyu, M. MTTM: Metamorphic Testing for Textual Content Moderation Software. In Proceedings of the International Conference on Software Engineering (ICSE), Lisbon, Portugal, 14–20 May 2023; pp. 1–13. [Google Scholar]
- Roy, P.K.; Tripathy, A.K.; Das, T.K.; Gao, X.-Z. A Framework for Hate Speech Detection Using Deep Convolutional Neural Network. IEEE Access 2020, 8, 204951–204962. [Google Scholar] [CrossRef]
- Yadav, A.; Vishwakarma, D.K. Sentiment Analysis Using Deep Learning Architectures: A Review. Artif. Intell. Rev. 2020, 53, 4335–4385. [Google Scholar] [CrossRef]








| Author | Classes | Dataset | Language | Approach | Algorithm | Evaluation Metric | |
|---|---|---|---|---|---|---|---|
| Mangaonkar et al. 2015 [21] | 2 Classes (Cyberbullying, Non-Cyberbullying) | English | MLA | LR (OR parallelism) | Recall | 60% | |
| LR (AND parallelism) | Accuracy | 70% | |||||
| Van Hee et al. 2015 [22] | 2 Classes (Cyberbullying, Non-Cyberbullying) | Ask.fm | Dutch | MLA | SVM | F1-score | 55.39% |
| Recall | 51.46% | ||||||
| Precision | 59.96% | ||||||
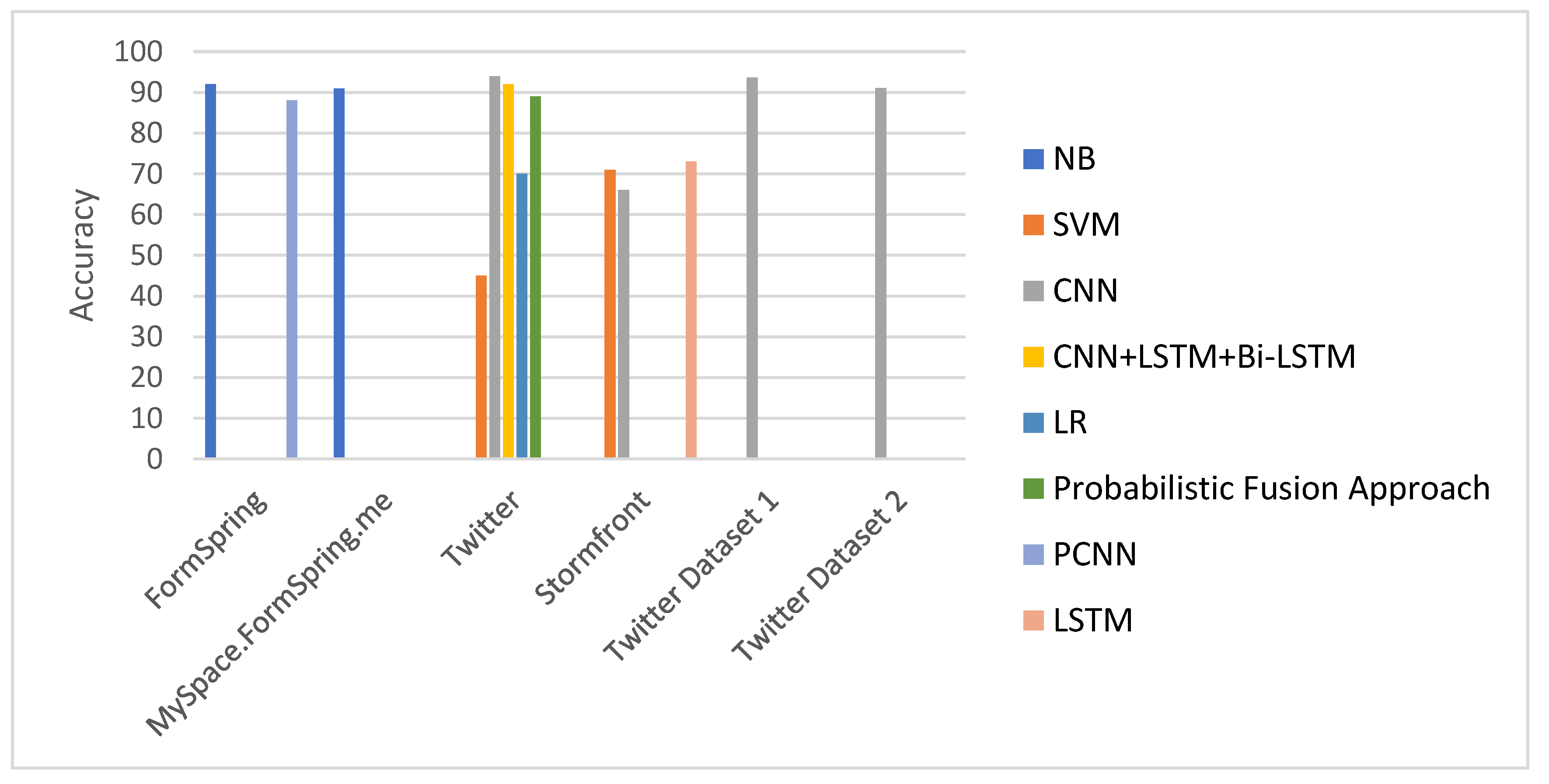
| Nandhini and Sheeba, 2015 [89] | 2 Classes (Cyberbullying–Non-Cyberbullying) | Formspring | English | MLA | NB | Accuracy | 92% |
| MySpace.com | 91% | ||||||
| Waseem and Hovy 2016 [23] | 3 Classes (Sexism, Racism, Neither) | English | MLA | LR | F1-score | 73% | |
| Zhao et al. 2016 [24] | 2 Classes (Cyberbullying, Non-Cyberbullying) | English | MLA | SVM | F1-score | 79.4% | |
| Singh et al. 2016 [25] | 2 Classes (Cyberbullying, Non-Cyberbullying) | English | LBA | Probabilistic Fusion approach | Accuracy | 89% | |
| Al-garadi et al. 2016 [27] | 2 Classes (Cyberbullying, Non-Cyberbullying) | English | MLA | NB | Accuracy | 70.4% | |
| SVM | 50% | ||||||
| RF | 62.9% | ||||||
| KNN | 56.8% | ||||||
| Hosseinmardi et al. 2016 [28] | 2 Classes (Cyberbullying, Non-Cyberbullying) | English | MLA | LR | Recall | 72% | |
| Precision | 78% | ||||||
| Zhang et al. 2016 [29] | 2 Classes (Cyberbullying, Non-Cyberbullying) | Formspring | English | MLA | PCCN | Accuracy | 88.1%. |
| Wulczyn et al. 2017 [30] | 2 Classes (Attacking, Non-Attacking) | Wikipedia | English | MLA | LR | AUROC | 96.18% |
| MLP | 96.59% | ||||||
| Batoul et al. 2017 [31] | 2 Classes (Cyberbullying–Non-Cyberbullying) | Arabic | MLA | NB | Precision | 90.1% | |
| Recall | 90.9% | ||||||
| F1-score | 90.5% | ||||||
| SVM | Precision | 93.4% | |||||
| Recall | 94.1% | ||||||
| F1-score | 92.7% | ||||||
| Badjatiya, Pinkesh et al. 2017 [91] | 3 classes (Sexism, Racism, Neither) | English | MLA | LSTM | F1-score | 93% | |
| Park, Ji Ho et al. 2017 [92] | 3 classes (Sexism, Racism, Neither) | English | MLA | CNN | F1-score | 82.7% | |
| LR | 82.4% | ||||||
| De Gibert et al. 2018 [36] | 2 Classes (Hate, Non-Hate) | Stormfront | English | MLA | SVM | Accuracy | 71% |
| CNN | 66% | ||||||
| LSTM | 73% | ||||||
| Nurrahmi and Nurjanah, 2018 [37] | 2 Classes (Cyberbullying–Non-Cyberbullying) | Indonesian | MLA | SVM | F1-score | 67% | |
| N. Albadi et al. 2018 [38] | 2 Classes (Hate, Non-Hate) | Arabic | MLA | GRU-based RNN | Precision | 76% | |
| Recall | 78% | ||||||
| F1-score | 77% | ||||||
| AUROC | 84% | ||||||
| Watanabe et al. 2018 [93] | 3 Classes (Hateful, Offensive and Clean) | English | MLA | J48graft | Precision | 88% | |
| Recall | 87.4% | ||||||
| F1-score | 87.5% | ||||||
| Mulki et al. 2019 [41] | 3 Classes (Normal, Abusive, Hate) | English | NB | Accuracy | 88.4% | ||
| SVM | 78.6% | ||||||
| Ibrohim and Budi, 2019 [43] | 2 Classes (Hateful, Non-Hateful) | Indonesian | RFDT | Accuracy | 77.36% | ||
| LP | 66.1% | ||||||
| Basile et al. 2019 [39] | 2 Classes (Hate, Non-Hate) | English | SVM | F1-score | 65% | ||
| Spanish | 73% | ||||||
| Banerjee et al. 2019 [45] | 2 Classes (Cyberbullying–Non-Cyberbullying) | English | MLA | CNN | Accuracy | 93.97% | |
| Corazza, Michele et al. 2020 [4] | 2 Classes (Hateful, Non-Hateful) | English | MLA | LSTM | F1-score | 78.5% | |
| German | 71.8% | ||||||
| Italian | 80.1% | ||||||
| Lu et al. 2020 [46] | 3 Classes (Sexism, Racism, and Neither) | Sina Weibo | Chinese | MLA | CNN | Precision | 79% |
| F1-score | 71.6% | ||||||
| Recall | 69.7% | ||||||
| Moon et al. 2020 [47] | 3 Classes (Hate, Offensive, None) | Korean Online News Platform | Korean | MLA | CharCNN | F1-score | 53.5% |
| BiLSTM | 29.1% | ||||||
| BERT | 63.3% | ||||||
| Romim et al. 2021 [48] | 2 Classes (Hateful, Non-Hateful) | Facebook and YouTube | Bengali | MLA | SVM | Accuracy | 87.5% |
| Word2Vec + LSTM | 83.85% | ||||||
| Word2Vec + Bi-LSTM | 81.52% | ||||||
| FastText + LSTM | 84.3% | ||||||
| FastText + Bi-LSTM | 86.55% | ||||||
| BengFastText + LSTM | 81% | ||||||
| BengFastText + Bi-LSTM | 80.44% | ||||||
| Karim et al. 2021 [49] | 2 Classes (Hateful, Non-Hateful) | Facebook, YouTube comments, and newspapers | Bengali | MLA | LR | F1-score | 67% |
| NB | 64% | ||||||
| SVM | 66% | ||||||
| KNN | 66% | ||||||
| RF | 68% | ||||||
| GBT | 68% | ||||||
| CNN | 73% | ||||||
| Bi-LSTM | 75% | ||||||
| Conv-LSTM | 78% | ||||||
| Bangla BERT | 86% | ||||||
| mBERT-cased | 85% | ||||||
| XML-RoBERTA | 87% | ||||||
| mBERT-uncased | 86% | ||||||
| Ensemble * | 88% | ||||||
| Luu et al. 2021 [44] | 3 Classes (Offensive, Hate, None) | Facebook and YouTube | Vietnamese | MLA | BERT | F1-score | 62.69% |
| Sadiq et al. 2021 [51] | 2 Classes (Cyber-aggressive, Non-Cyber-aggressive) | English | MLA | CNN + LSTM + Bi-LSTM | Accuracy | 92% | |
| Beyhan et al. 2022 [52] | 2 Classes (Hateful, Non-Hateful) | Turkish | MLA | BERTurk | Accuracy | 77% | |
| ALBayari and Abdallah 2022 [54] | 2 Classes (Cyberbullying–Non-Cyberbullying) | Arabic | MLA | MNB | F1-score | 66% | |
| RF | 65% | ||||||
| SVM | 69% | ||||||
| LR | 66% | ||||||
| Patil et al. 2022 [55] | 4 Classes (Hate, Offensive, Profane, None) | Marathi | MLA | CNN | Accuracy | 75.1% | |
| LSTM | 75.1% | ||||||
| BiLSTM | 76.1% | ||||||
| BERT | 80.3% | ||||||
| Kumar and Sachdeva 2022 [56] | 2 Classes (Cyberbullying–Non-Cyberbullying) | Formspring | English | HA | Bi-GAC | F1-score | 94.03% |
| MySpace | 93.89% | ||||||
| Wang et al. 2023 [94] | 3 Classes (Cyberbullying–Non-Cyberbullying, Neither) | English | HA | MTTM | Error Finding Rates | 83.9% | |
| Atoum, 2023 [57] | 2 Classes (Cyberbullying–Non-Cyberbullying) | Twitter Dataset 1 | English | MLA | CNN | Accuracy | 93.62% |
| Twitter Dataset 2 | 91.03% | ||||||
| Nabilah et al. 2023 [58] | 2 Classes (Cyberbullying–Non-Cyberbullying) | Instagram and Twitter and Kaskus | Indonesian | MLA | BERT | F1-score | 88.97% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gamal, D.; Alfonse, M.; Jiménez-Zafra, S.M.; Aref, M. Intelligent Multi-Lingual Cyber-Hate Detection in Online Social Networks: Taxonomy, Approaches, Datasets, and Open Challenges. Big Data Cogn. Comput. 2023, 7, 58. https://doi.org/10.3390/bdcc7020058
Gamal D, Alfonse M, Jiménez-Zafra SM, Aref M. Intelligent Multi-Lingual Cyber-Hate Detection in Online Social Networks: Taxonomy, Approaches, Datasets, and Open Challenges. Big Data and Cognitive Computing. 2023; 7(2):58. https://doi.org/10.3390/bdcc7020058
Chicago/Turabian StyleGamal, Donia, Marco Alfonse, Salud María Jiménez-Zafra, and Mostafa Aref. 2023. "Intelligent Multi-Lingual Cyber-Hate Detection in Online Social Networks: Taxonomy, Approaches, Datasets, and Open Challenges" Big Data and Cognitive Computing 7, no. 2: 58. https://doi.org/10.3390/bdcc7020058
APA StyleGamal, D., Alfonse, M., Jiménez-Zafra, S. M., & Aref, M. (2023). Intelligent Multi-Lingual Cyber-Hate Detection in Online Social Networks: Taxonomy, Approaches, Datasets, and Open Challenges. Big Data and Cognitive Computing, 7(2), 58. https://doi.org/10.3390/bdcc7020058