
Rating Prediction Quality Enhancement in Low-Density Collaborative Filtering Datasets





Abstract
:1. Introduction
2. Related Work
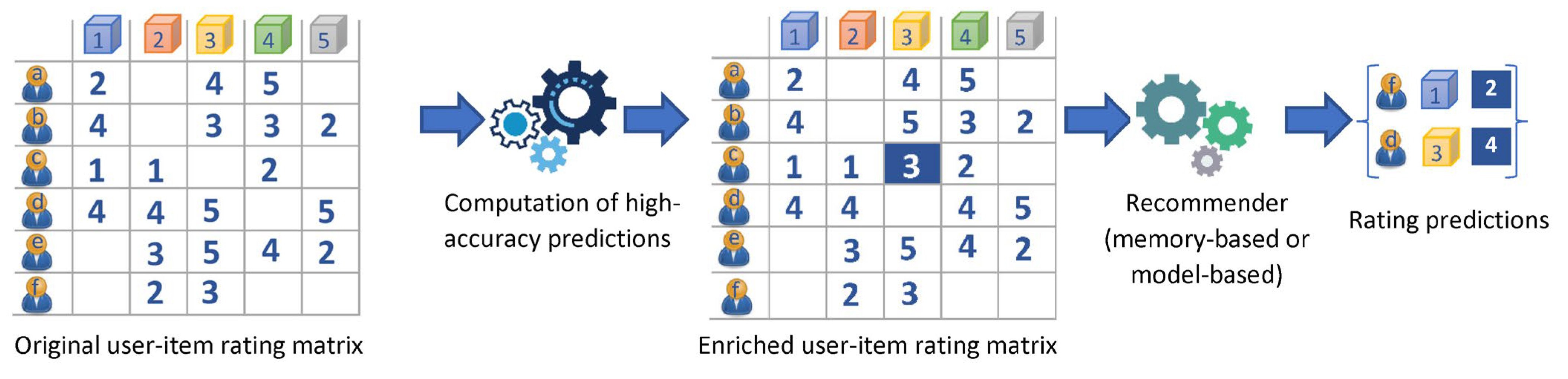
3. The Proposed Algorithm
- (a)
- Compute the similarity between all pairs of users in the dataset, using a similarity metric (such as the Cosine Similarity (CS) and the Pearson Correlation Coefficient (PCC), which are the ones used in the majority of the CF algorithms [38,39]). Once all user-user similarities are computed, the NNs for each user are determined.
- (b)
- For each user, U predict the rating values for the items they have not already rated, based on the rating values their NNs gave to the same items. To this end, a CF rating prediction formula is employed, where a typical formula choice is:where U and i denote the user and the item, respectively, for whom the rating prediction is computed, denotes the average value of U’s ratings, V iterates over the U’s NNs, and sim(U, V) signifies the similarity value between the pair of users U and V (calculated in the first CF step).
- (i)
- The number of NNs considered for the rating prediction formulation is at least four of the user’s NNs have rated the item and have thus contributed to the calculations of Equation (1).
- (ii)
- The active user’s average rating value is close to the lower or the higher end of the rating scale. In more detail, Ref. [16] asserts that for users having average rating values in the lower 10% of the rating scale, or in the higher 10% of the rating scale, rating predictions are considerably more accurate compared to predictions for users having average rating values close to the middle of the rating scale. Consequently, in this paper, we adopt the condition ) for utilizing a prediction to increase the density of the user–item rating matrix, where:and similarly
- (iii)
- The average rating of the prediction item is close to the bounds of the rating scale. Similarly to the case of the user’s average rating, Ref. [16] asserts that for items having average rating values in the lower 10% of the rating scale, or in the higher 10% of the rating scale, rating predictions are considerably more accurate as compared to the rating predictions for items whose average rating values are close to the middle of the rating scale. Therefore, in this research, we adopt the condition ( ) for utilizing a prediction to increase the density of the user–item rating matrix, where:and similarly:
| Algorithm 1: Preprocessing step of the rating prediction enhancement algorithm |
| Input: the original sparse CF dataset D Output: the updated CF dataset containing both the original and the additional ratings, D_enriched 1: function ENRICH_DATASET (CF_Dataset D) 2: credible_predictions ← ∅ 3: for each U ∈ D.users do 4: for each i ∈ D.items do 5: NNs_ratings_on_i = {r ∈ D.ratings: r.user ∈ user_NNs[U] and r.item = i and r.value != NULL} 6: if D.ratings[U,i] = NULL and (avg_user_ratings[U] ≤ user_threshold_min or avg_user_ratings[U] ≥ user_threshold_max) and (avg_item_ratings[i] ≤ item_threshold_min or avg_item_ratings[i] ≥ item_threshold_max) then 7: 8: credible_predictions credible_predictions ∪ (user: U, item: i, value: prediction) 9: end if 10: end for 11: end for 12: D_Enriched.users ← D.users // Formulate and return result 13: D_Enriched.items ←D.items 14: D_Enriched.ratings ← D.ratings ∪ credible_predictions 15: return (D_Enriched) 16: end function |
4. Experimental Evaluation
- Let D be a dataset, train(D) be a subset of D used for training, and test(D) = D − train(D) the subset of D used for testing.
- Let E(train(D)) be the enriched training dataset, formulated by applying the preprocessing step described in Section 3 on train(D).
- Let RP be a rating prediction algorithm.
- We apply RP(train(D)) on test(D), obtaining two sets, namely predictions(RP, train(D), test(D)) and failures(RP, train(D), test(D)), where failures(RP, train(D), test(D)) contains the cases for which a rating prediction could not be formulated (e.g., due to the absence of near neighbors), whereas predictions(RP, train(D), test(D)) contains the predictions that could actually be computed. Using the above, we can compute the rating prediction coverage RPC of algorithm RP on dataset D, which is defined aswhereas the rating prediction error can be quantified using either the MAE or the RMSE error metric, as shown in Equations (7) and (8), respectively:It is important to note here that model-based algorithms typically compute a prediction for every case in the test dataset; when the model is not able to provide specific latent variables for the (user, item) pair for which the prediction is formulated, the prediction value degenerates to a dataset-dependent constant value [51]. Due to this fact, for model-based algorithms, the rating prediction coverage is ignored, and the evaluation is only based on the rating prediction error.
- Correspondingly, we apply RP(train(E(D))) on test(D), i.e., we obtain predictions using the enhanced dataset as input to the rating prediction algorithm, obtaining two sets, namely predictions(RP, train(E(D)), test(D)) and failures(RP, train(E(D)), test(D)), and we compute , and , applying the Equations (1)–(3).
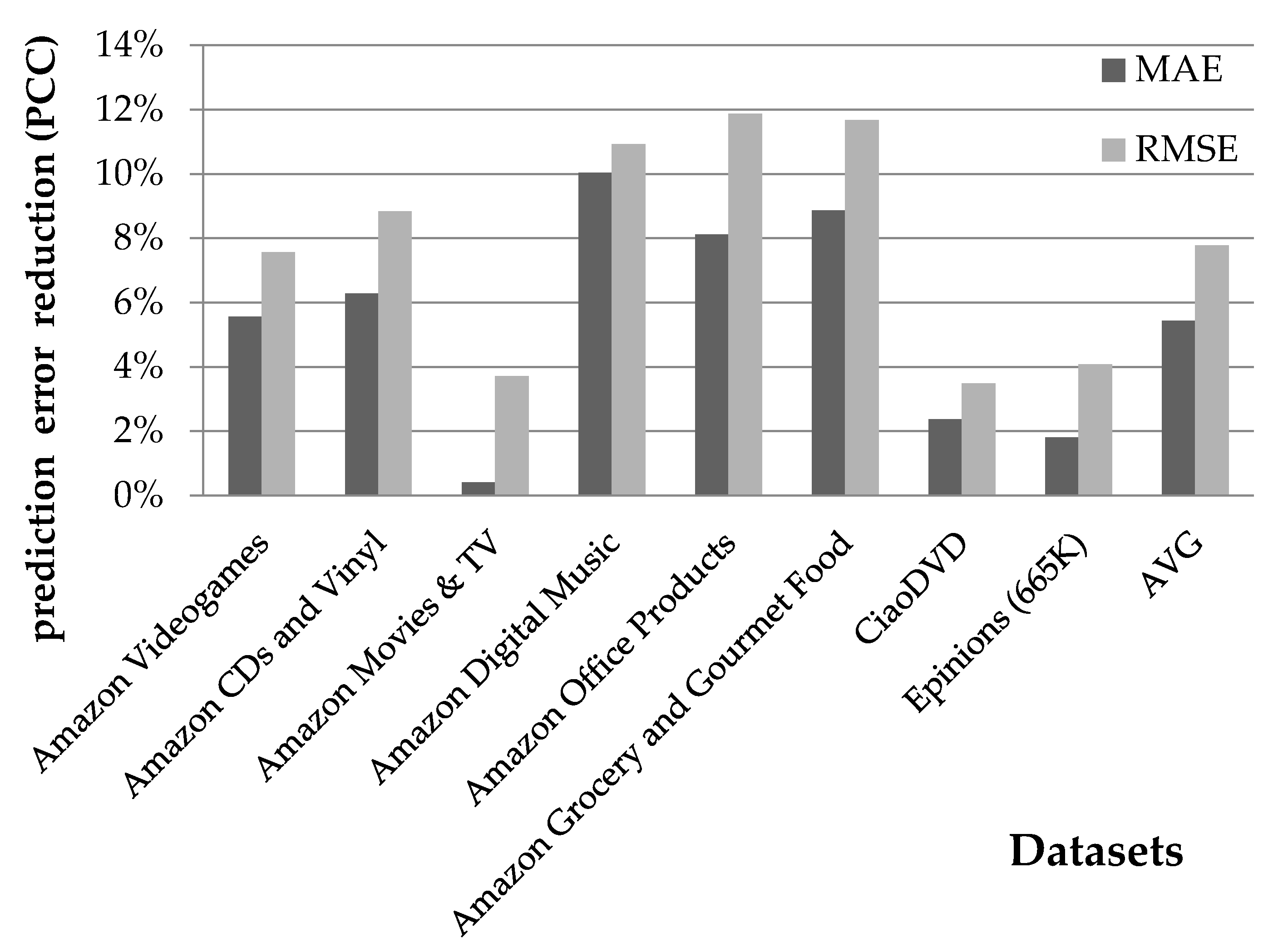
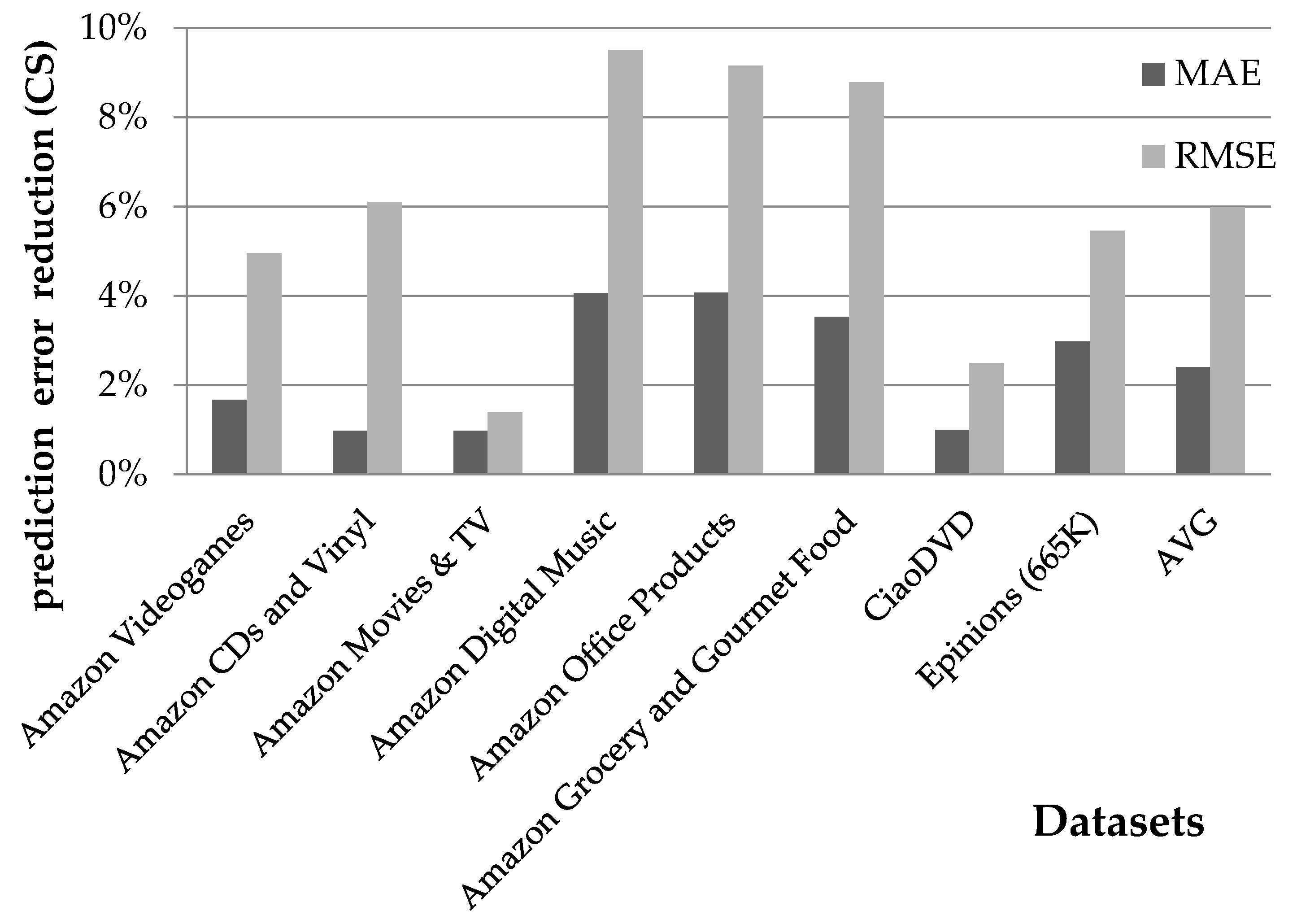
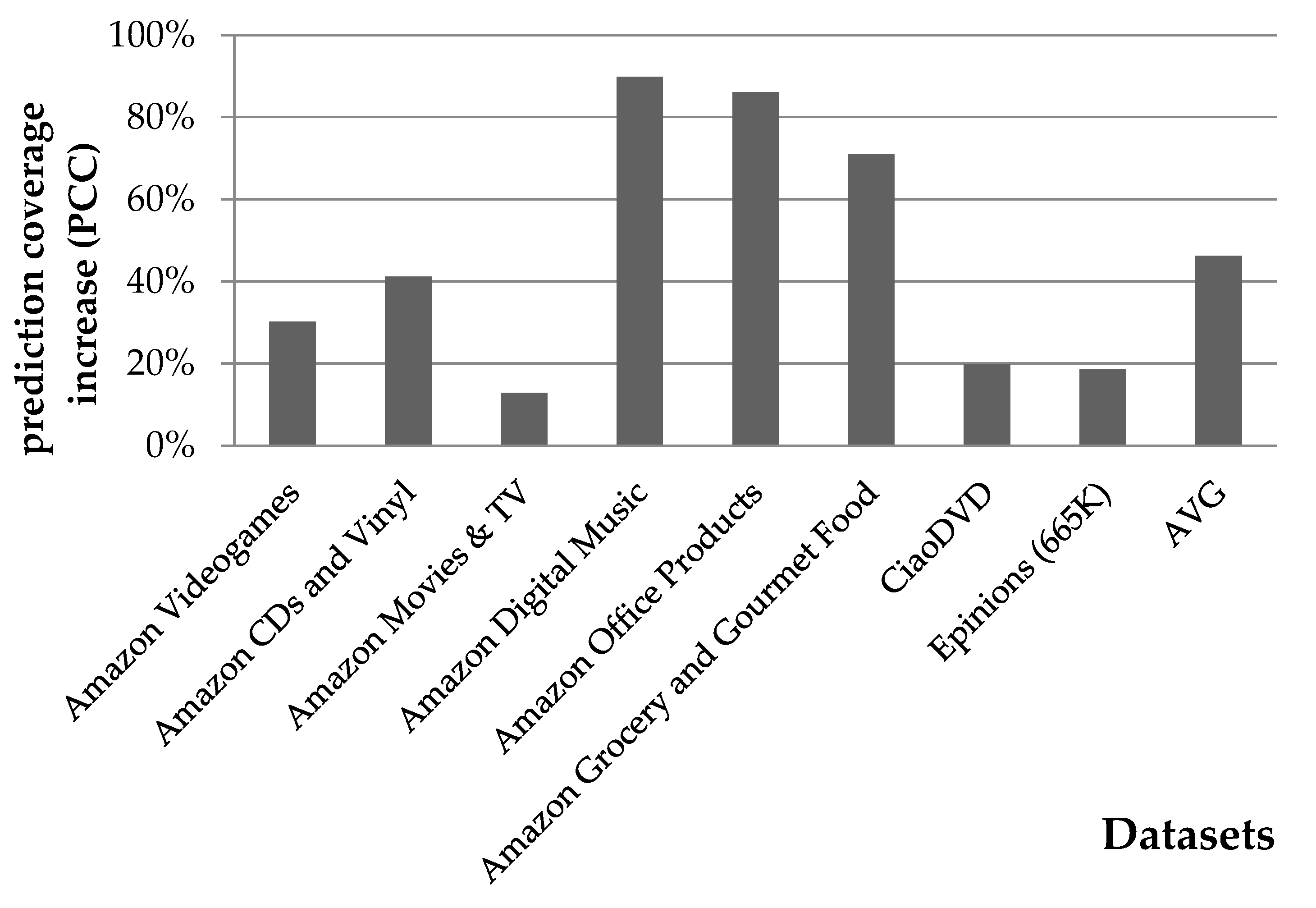
- Then, the rating prediction coverage enhancement (RPCE) for the rating prediction algorithm RP on dataset D is defined aswhereas the rating prediction error reduction (RPER) considering the MAE and RMSE error metrics is computed as shown in Equations (5) and (6), respectively:
4.1. Using the Preprocessing Step with Memory-Based Rating Prediction Algorithms
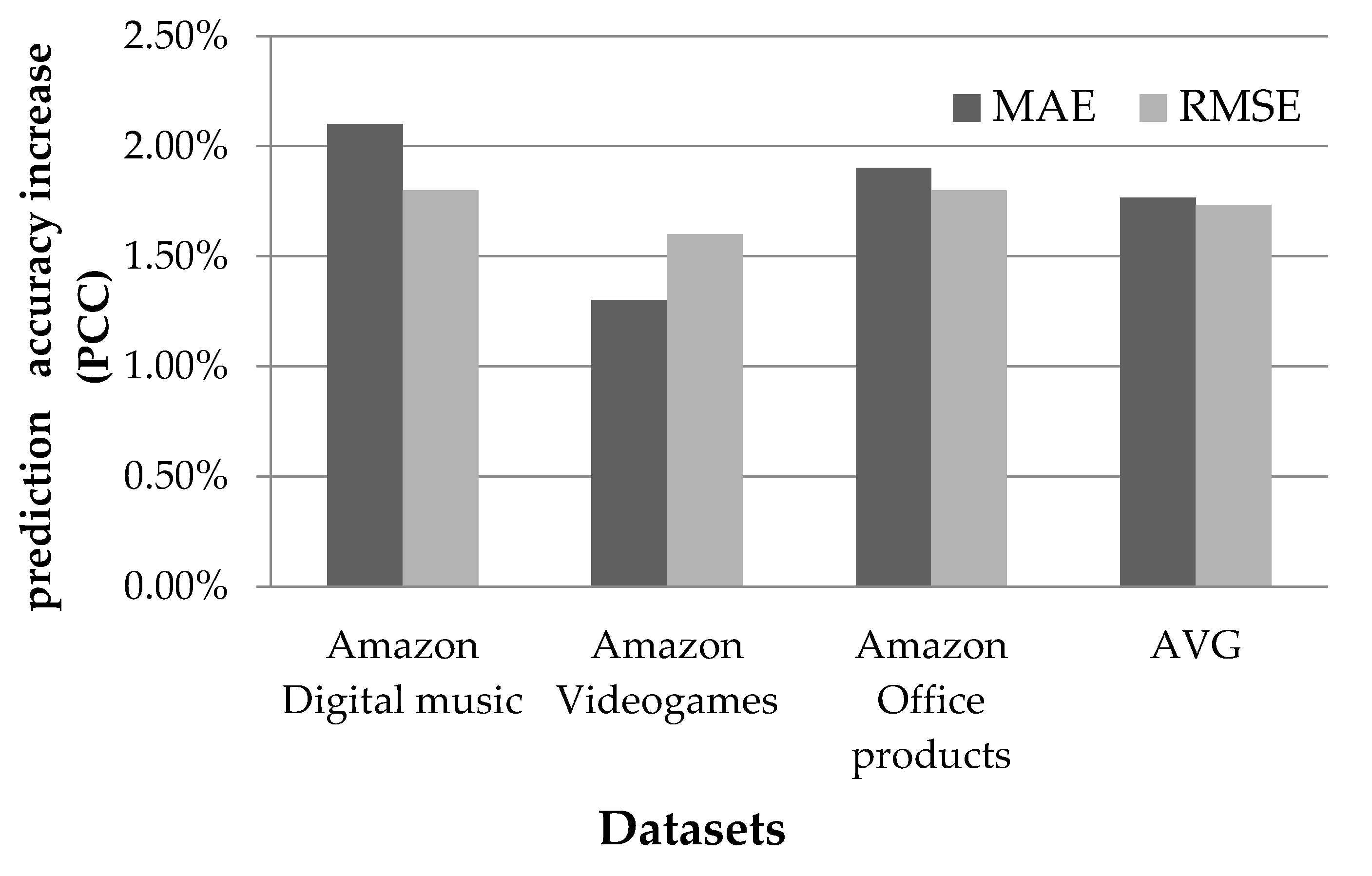
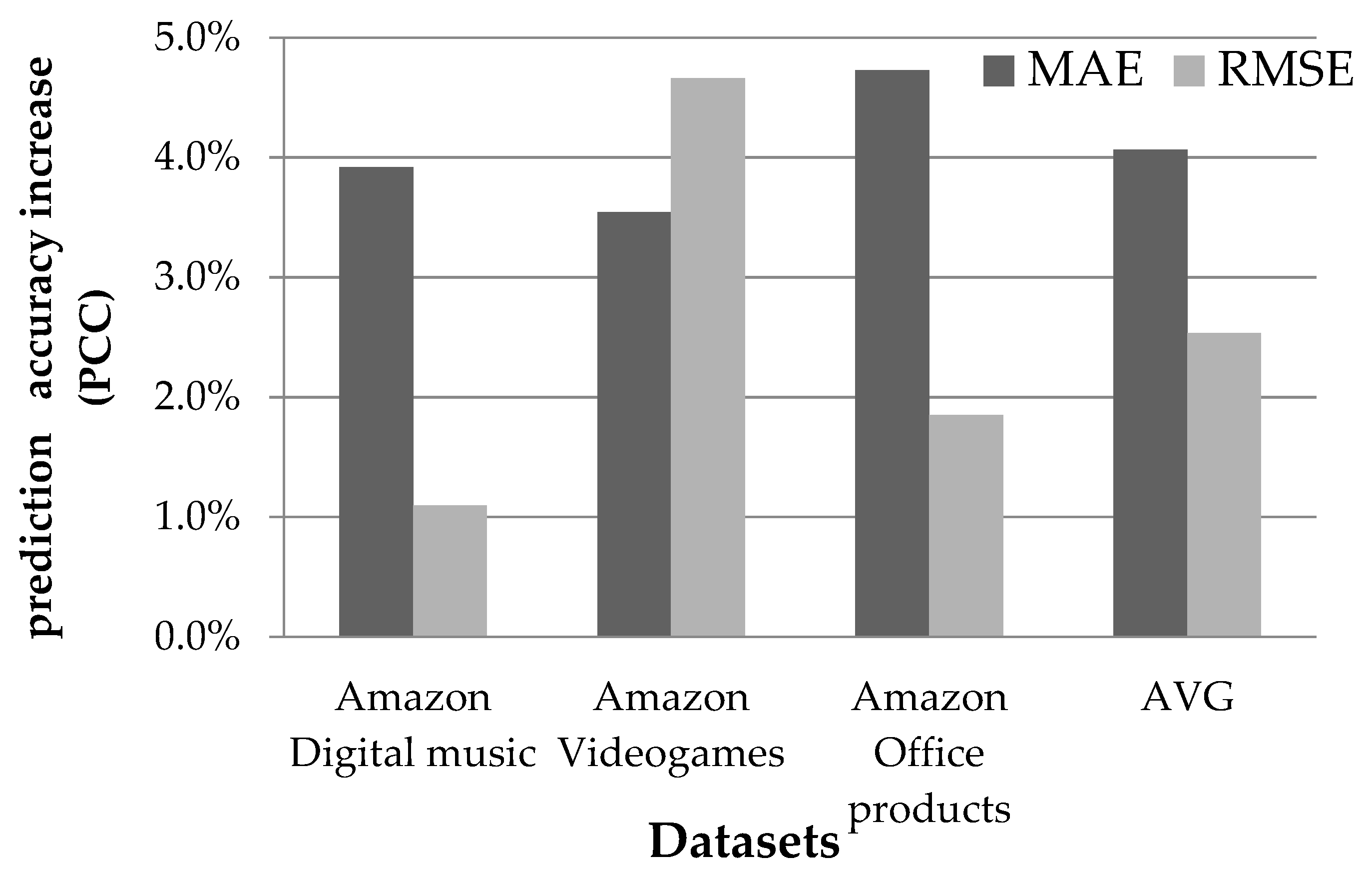
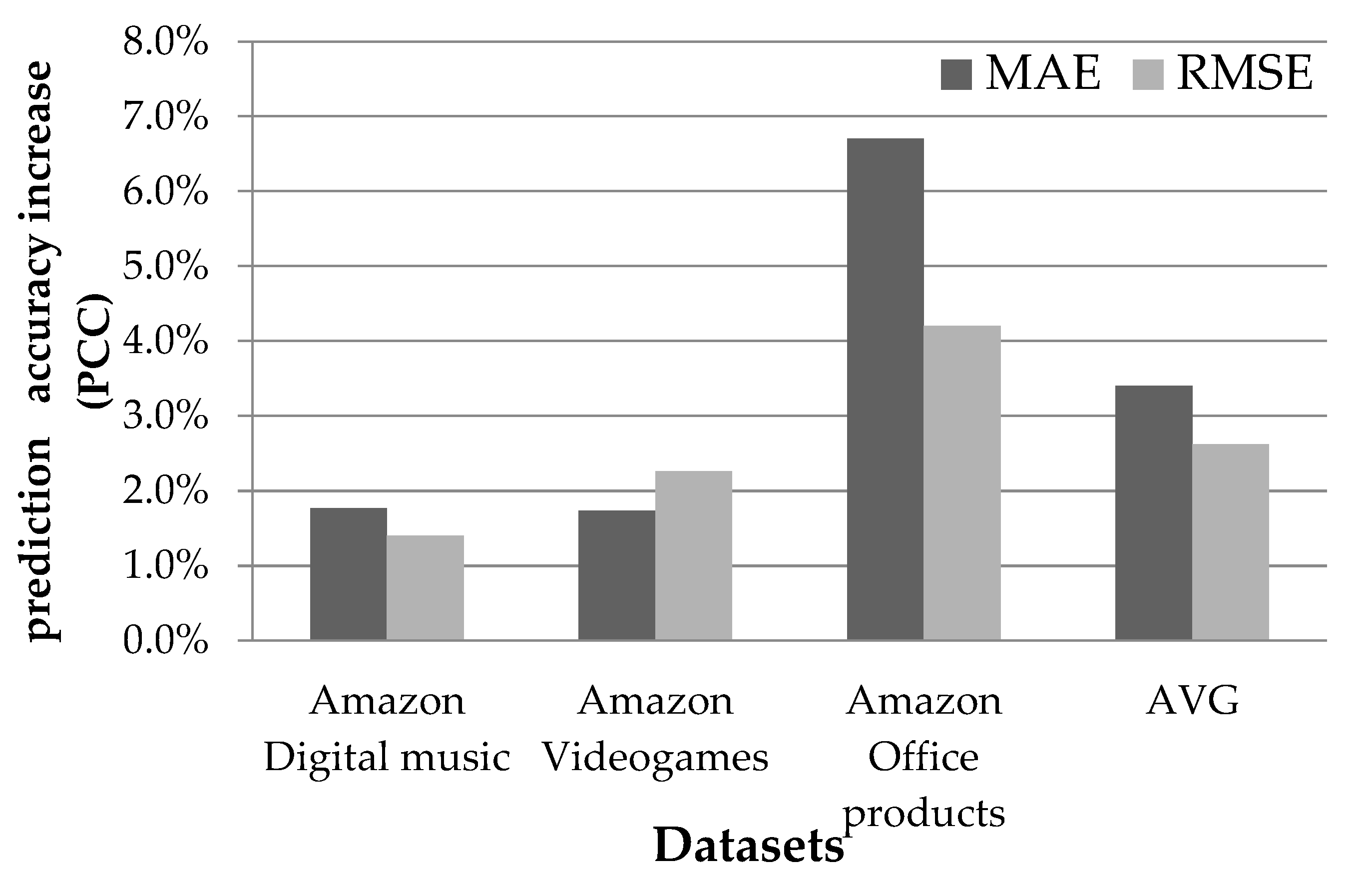
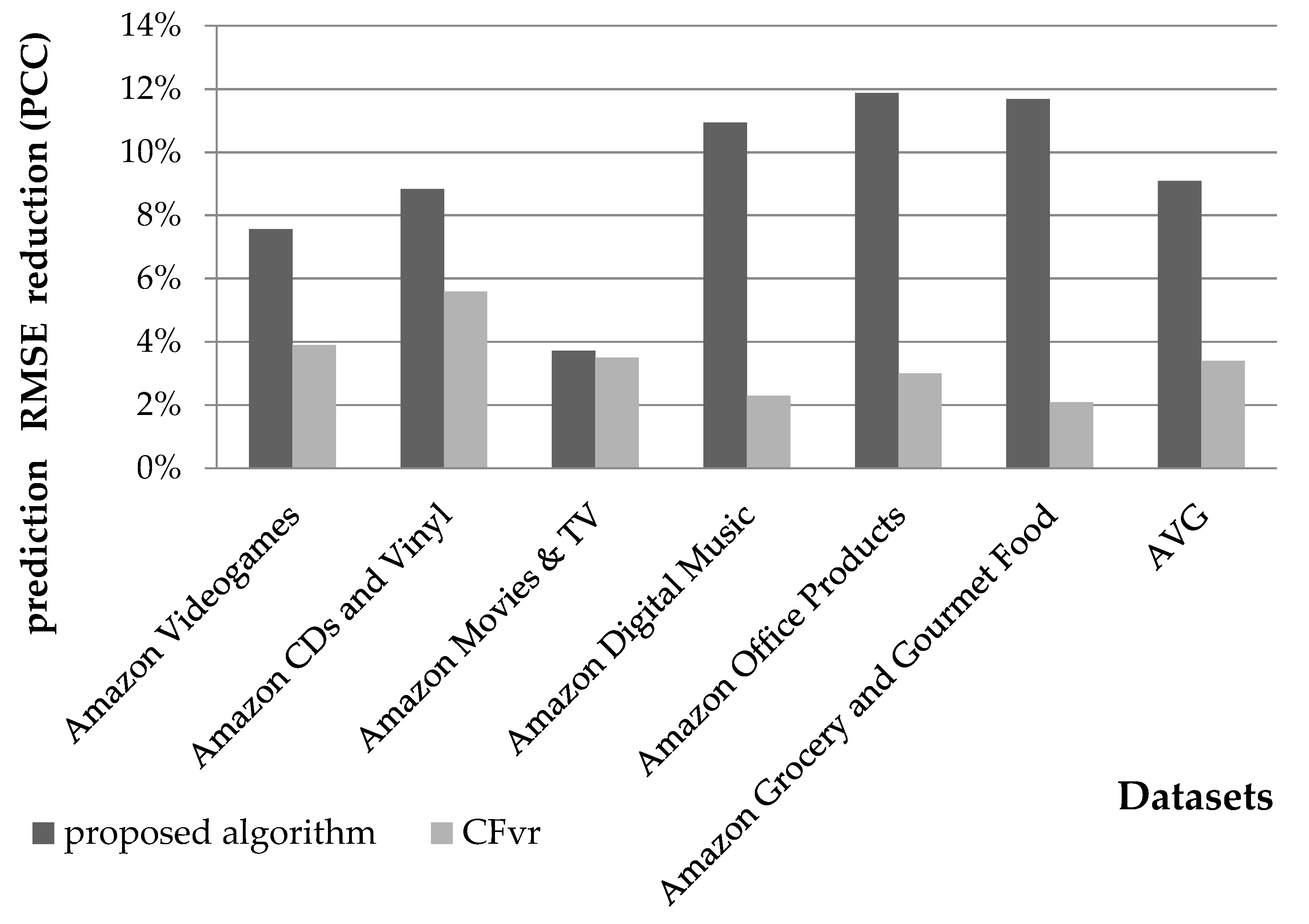
4.1.1. Rating Prediction Accuracy Evaluation
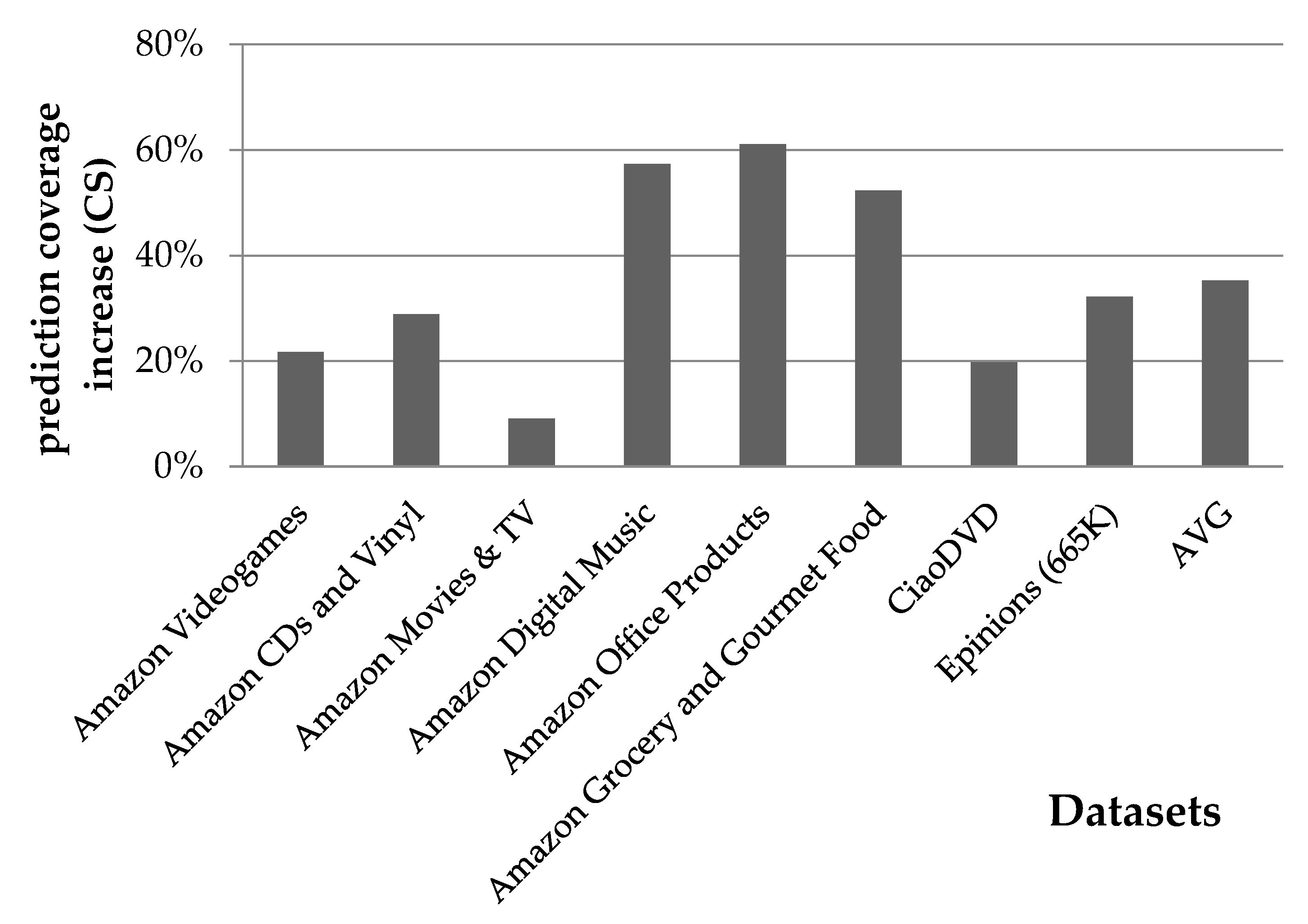
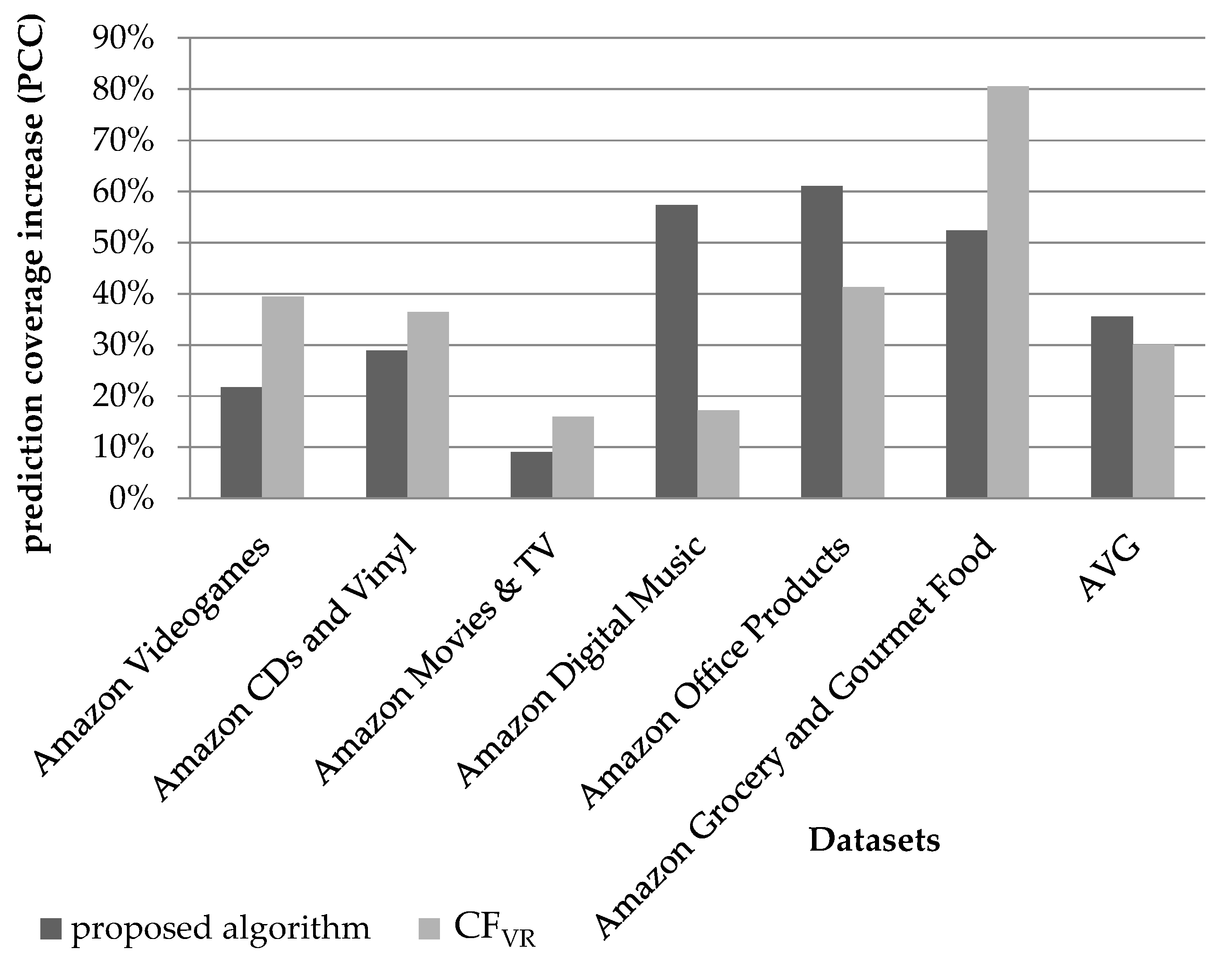
4.1.2. Rating Prediction Coverage Evaluation
4.2. Using the Preprocessing Step with Model-Based Rating Prediction Algorithms
4.3. Using the Preprocessing Step with Implicit Trust Rating Prediction Algorithms
5. Discussion of the Results and Comparison with Previous Work
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Alyari, F.; Navimipour, N.J. Recommender Systems: A Systematic Review of the State of the Art Literature and Suggestions for Future Research. Kybernetes 2018, 47, 985–1017. [Google Scholar] [CrossRef]
- Ricci, F.; Rokach, L.; Shapira, B. Recommender Systems: Introduction and Challenges. In Recommender Systems Handbook; Ricci, F., Rokach, L., Shapira, B., Eds.; Springer: Boston, MA, USA, 2015; pp. 1–34. ISBN 978-1-4899-7636-9. [Google Scholar]
- Shah, K.; Salunke, A.; Dongare, S.; Antala, K. Recommender Systems: An Overview of Different Approaches to Recommendations. In Proceedings of the 2017 International Conference on Innovations in Information, Embedded and Communication Systems (ICIIECS), Coimbatore, India, 17–18 March 2017; pp. 1–4. [Google Scholar]
- Kluver, D.; Ekstrand, M.D.; Konstan, J.A. Rating-Based Collaborative Filtering: Algorithms and Evaluation. In Social Information Access; Brusilovsky, P., He, D., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2018; Volume 10100, pp. 344–390. ISBN 978-3-319-90091-9. [Google Scholar]
- Jalili, M.; Ahmadian, S.; Izadi, M.; Moradi, P.; Salehi, M. Evaluating Collaborative Filtering Recommender Algorithms: A Survey. IEEE Access 2018, 6, 74003–74024. [Google Scholar] [CrossRef]
- Bobadilla, J.; Gutiérrez, A.; Alonso, S.; González-Prieto, Á. Neural Collaborative Filtering Classification Model to Obtain Prediction Reliabilities. IJIMAI 2022, 7, 18. [Google Scholar] [CrossRef]
- Herlocker, J.L.; Konstan, J.A.; Terveen, L.G.; Riedl, J.T. Evaluating Collaborative Filtering Recommender Systems. ACM Trans. Inf. Syst. 2004, 22, 5–53. [Google Scholar] [CrossRef]
- Lathia, N.; Hailes, S.; Capra, L. Trust-Based Collaborative Filtering. In Trust. Management II; Karabulut, Y., Mitchell, J., Herrmann, P., Jensen, C.D., Eds.; IFIP—The International Federation for Information Processing; Springer: Boston, MA, USA, 2008; Volume 263, pp. 119–134. ISBN 978-0-387-09427-4. [Google Scholar]
- Singh, P.K.; Sinha, M.; Das, S.; Choudhury, P. Enhancing Recommendation Accuracy of Item-Based Collaborative Filtering Using Bhattacharyya Coefficient and Most Similar Item. Appl. Intell. 2020, 50, 4708–4731. [Google Scholar] [CrossRef]
- Sánchez-Moreno, D.; López Batista, V.; Vicente, M.D.M.; Sánchez Lázaro, Á.L.; Moreno-García, M.N. Exploiting the User Social Context to Address Neighborhood Bias in Collaborative Filtering Music Recommender Systems. Information 2020, 11, 439. [Google Scholar] [CrossRef]
- Margaris, D.; Spiliotopoulos, D.; Vassilakis, C. Identifying Reliable Recommenders in Users’ Collaborating Filtering and Social Neighbourhoods. In Big Data and Social. Media Analytics; Çakırtaş, M., Ozdemir, M.K., Eds.; Lecture Notes in Social Networks; Springer International Publishing: Cham, Switzerland, 2021; pp. 51–76. ISBN 978-3-030-67043-6. [Google Scholar]
- Ramezani, M.; Akhlaghian Tab, F.; Abdollahpouri, A.; Abdulla Mohammad, M. A New Generalized Collaborative Filtering Approach on Sparse Data by Extracting High Confidence Relations between Users. Inf. Sci. 2021, 570, 323–341. [Google Scholar] [CrossRef]
- Feng, C.; Liang, J.; Song, P.; Wang, Z. A Fusion Collaborative Filtering Method for Sparse Data in Recommender Systems. Inf. Sci. 2020, 521, 365–379. [Google Scholar] [CrossRef]
- Liu, J.; Chen, Y. A Personalized Clustering-Based and Reliable Trust-Aware QoS Prediction Approach for Cloud Service Recommendation in Cloud Manufacturing. Knowl. -Based Syst. 2019, 174, 43–56. [Google Scholar] [CrossRef]
- Chen, R.; Hua, Q.; Chang, Y.-S.; Wang, B.; Zhang, L.; Kong, X. A Survey of Collaborative Filtering-Based Recommender Systems: From Traditional Methods to Hybrid Methods Based on Social Networks. IEEE Access 2018, 6, 64301–64320. [Google Scholar] [CrossRef]
- Margaris, D.; Vassilakis, C.; Spiliotopoulos, D. On Producing Accurate Rating Predictions in Sparse Collaborative Filtering Datasets. Information 2022, 13, 302. [Google Scholar] [CrossRef]
- Chen, L.; Yuan, Y.; Yang, J.; Zahir, A. Improving the Prediction Quality in Memory-Based Collaborative Filtering Using Categorical Features. Electronics 2021, 10, 214. [Google Scholar] [CrossRef]
- Gao, H.; Xu, Y.; Yin, Y.; Zhang, W.; Li, R.; Wang, X. Context-Aware QoS Prediction With Neural Collaborative Filtering for Internet-of-Things Services. IEEE Internet Things J. 2020, 7, 4532–4542. [Google Scholar] [CrossRef]
- Zhang, J.; Lin, Y.; Lin, M.; Liu, J. An Effective Collaborative Filtering Algorithm Based on User Preference Clustering. Appl. Intell. 2016, 45, 230–240. [Google Scholar] [CrossRef]
- Nilashi, M.; Ahani, A.; Esfahani, M.D.; Yadegaridehkordi, E.; Samad, S.; Ibrahim, O.; Sharef, N.M.; Akbari, E. Preference Learning for Eco-Friendly Hotels Recommendation: A Multi-Criteria Collaborative Filtering Approach. J. Clean. Prod. 2019, 215, 767–783. [Google Scholar] [CrossRef]
- Jiang, L.; Shi, L.; Liu, L.; Yao, J.; Ali, M.E. User Interest Community Detection on Social Media Using Collaborative Filtering. Wirel. Netw. 2022, 28, 1169–1175. [Google Scholar] [CrossRef]
- Marin, N.; Makhneva, E.; Lysyuk, M.; Chernyy, V.; Oseledets, I.; Frolov, E. Tensor-Based Collaborative Filtering With Smooth Ratings Scale. arXiv 2022, arXiv:2205.05070. [Google Scholar] [CrossRef]
- Zhang, Y.; Yin, C.; Wu, Q.; He, Q.; Zhu, H. Location-Aware Deep Collaborative Filtering for Service Recommendation. IEEE Trans. Syst. Man. Cybern. Syst. 2021, 51, 3796–3807. [Google Scholar] [CrossRef]
- Yang, B.; Lei, Y.; Liu, J.; Li, W. Social Collaborative Filtering by Trust. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1633–1647. [Google Scholar] [CrossRef]
- Nassar, N.; Jafar, A.; Rahhal, Y. A Novel Deep Multi-Criteria Collaborative Filtering Model for Recommendation System. Knowl. -Based Syst. 2020, 187, 104811. [Google Scholar] [CrossRef]
- Nguyen, L.V.; Hong, M.-S.; Jung, J.J.; Sohn, B.-S. Cognitive Similarity-Based Collaborative Filtering Recommendation System. Appl. Sci. 2020, 10, 4183. [Google Scholar] [CrossRef]
- Ahmed, R.A.E.-D.; Fernández-Veiga, M.; Gawich, M. Neural Collaborative Filtering with Ontologies for Integrated Recommendation Systems. Sensors 2022, 22, 700. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, L.V.; Nguyen, T.; Jung, J.J.; Camacho, D. Extending Collaborative Filtering Recommendation Using Word Embedding: A Hybrid Approach. Concurr. Comput. Pract. Exp. 2021, e6232. [Google Scholar] [CrossRef]
- Margaris, D.; Spiliotopoulos, D.; Vassilakis, C. Augmenting Black Sheep Neighbour Importance for Enhancing Rating Prediction Accuracy in Collaborative Filtering. Appl. Sci. 2021, 11, 8369. [Google Scholar] [CrossRef]
- Aramanda, A.; Md Abdul, S.; Vedala, R. A Comparison Analysis of Collaborative Filtering Techniques for Recommeder Systems. In ICCCE 2020; Kumar, A., Mozar, S., Eds.; Lecture Notes in Electrical Engineering; Springer: Singapore, 2021; Volume 698, pp. 87–95. ISBN 9789811579608. [Google Scholar]
- Valdiviezo-Diaz, P.; Ortega, F.; Cobos, E.; Lara-Cabrera, R. A Collaborative Filtering Approach Based on Naïve Bayes Classifier. IEEE Access 2019, 7, 108581–108592. [Google Scholar] [CrossRef]
- Faculty of Electrical & Computer Engineering, University of Kashan, Kashan, Isfahan, Iran; Neysiani, B.S.; Soltani, N.; Mofidi, R.; Nadimi-Shahraki, M.H. Improve Performance of Association Rule-Based Collaborative Filtering Recommendation Systems Using Genetic Algorithm. Int. J. Inf. Technol. Comput. Sci. 2019, 11, 48–55. [Google Scholar] [CrossRef] [Green Version]
- Cui, Z.; Xu, X.; Xue, F.; Cai, X.; Cao, Y.; Zhang, W.; Chen, J. Personalized Recommendation System Based on Collaborative Filtering for IoT Scenarios. IEEE Trans. Serv. Comput. 2020, 13, 685–695. [Google Scholar] [CrossRef]
- Wang, Y.; Deng, J.; Gao, J.; Zhang, P. A Hybrid User Similarity Model for Collaborative Filtering. Inf. Sci. 2017, 418–419, 102–118. [Google Scholar] [CrossRef]
- Jiang, L.; Cheng, Y.; Yang, L.; Li, J.; Yan, H.; Wang, X. A Trust-Based Collaborative Filtering Algorithm for E-Commerce Recommendation System. J. Ambient. Intell. Hum. Comput. 2019, 10, 3023–3034. [Google Scholar] [CrossRef] [Green Version]
- Margaris, D.; Spiliotopoulos, D.; Karagiorgos, G.; Vassilakis, C.; Vasilopoulos, D. On Addressing the Low Rating Prediction Coverage in Sparse Datasets Using Virtual Ratings. SN Comput. Sci. 2021, 2, 255. [Google Scholar] [CrossRef]
- Spiliotopoulos, D.; Margaris, D.; Vassilakis, C. On Exploiting Rating Prediction Accuracy Features in Dense Collaborative Filtering Datasets. Information 2022, 13, 428. [Google Scholar] [CrossRef]
- Jain, G.; Mahara, T.; Tripathi, K.N. A Survey of Similarity Measures for Collaborative Filtering-Based Recommender System. In Soft Computing: Theories and Applications; Pant, M., Sharma, T.K., Verma, O.P., Singla, R., Sikander, A., Eds.; Advances in Intelligent Systems and Computing; Springer: Singapore, 2020; Volume 1053, pp. 343–352. ISBN 9789811507502. [Google Scholar]
- Khojamli, H.; Razmara, J. Survey of Similarity Functions on Neighborhood-Based Collaborative Filtering. Expert. Syst. Appl. 2021, 185, 115482. [Google Scholar] [CrossRef]
- Chen, V.X.; Tang, T.Y. Incorporating Singular Value Decomposition in User-Based Collaborative Filtering Technique for a Movie Recommendation System: A Comparative Study. In Proceedings of the 2019 the International Conference on Pattern Recognition and Artificial Intelligence—PRAI ’19, Wenzhou, China, 26–28 August 2019; ACM Press: New York, NY, USA, 2019; pp. 12–15. [Google Scholar]
- Mana, S.C.; Sasipraba, T. Research on Cosine Similarity and Pearson Correlation Based Recommendation Models. J. Phys. Conf. Ser. 2021, 1770, 012014. [Google Scholar] [CrossRef]
- Guo, G.; Zhang, J.; Thalmann, D.; Yorke-Smith, N. ETAF: An Extended Trust Antecedents Framework for Trust Prediction. In Proceedings of the 2014 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM 2014), Beijing, China, 17–20 August 2014; pp. 540–547. [Google Scholar]
- Meyffret, S.; Guillot, E.; Médini, L.; Laforest, F. RED: A Rich Epinions Dataset for Recommender Systems. 2012. Available online: https://hal.science/hal-01010246/ (accessed on 2 March 2023).
- Ni, J.; Li, J.; McAuley, J. Justifying Recommendations Using Distantly-Labeled Reviews and Fine-Grained Aspects. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 188–197. [Google Scholar]
- He, R.; McAuley, J. Ups and Downs: Modeling the Visual Evolution of Fashion Trends with One-Class Collaborative Filtering. In Proceedings of the 25th International Conference on World Wide Web, Montréal, QC, Canada, 11–15 April 2016; International World Wide Web Conferences Steering Committee: Geneva, Switzerland; pp. 507–517. [Google Scholar]
- McAuley, J.; Targett, C.; Shi, Q.; van den Hengel, A. Image-Based Recommendations on Styles and Substitutes. In Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval, Santiago, Chile, 9 August 2015; pp. 43–52. [Google Scholar]
- McAuley, J. Amazon Product Data. 2022. Available online: https://snap.stanford.edu/data/amazon/productGraph/ (accessed on 2 March 2023).
- Yazdanfar, N.; Thomo, A. LINK RECOMMENDER: Collaborative-Filtering for Recommending URLs to Twitter Users. Procedia Comput. Sci. 2013, 19, 412–419. [Google Scholar] [CrossRef] [Green Version]
- Yu, K.; Schwaighofer, A.; Tresp, V.; Xu, X.; Kriegel, H. Probabilistic Memory-Based Collaborative Filtering. IEEE Trans. Knowl. Data Eng. 2004, 16, 56–69. [Google Scholar] [CrossRef]
- Le, D.D.; Lauw, H.W. Collaborative Curating for Discovery and Expansion of Visual Clusters. In Proceedings of the Fifteenth ACM International Conference on Web Search and Data Mining, Virtual Event, AZ, USA, 11 February 2022; pp. 544–552. [Google Scholar]
- Margaris, D.; Vassilakis, C. Enhancing User Rating Database Consistency Through Pruning. In Transactions on Large-Scale Data-And Knowledge-Centered Systems XXXIV; Hameurlain, A., Küng, J., Wagner, R., Decker, H., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2017; Volume 10620, pp. 33–64. ISBN 978-3-662-55946-8. [Google Scholar]
- Linden, G.; Smith, B.; York, J. Amazon.Com Recommendations: Item-to-Item Collaborative Filtering. IEEE Internet Comput. 2003, 7, 76–80. [Google Scholar] [CrossRef] [Green Version]
- Pujahari, A.; Sisodia, D.S. Model-Based Collaborative Filtering for Recommender Systems: An Empirical Survey. In Proceedings of the 2020 First International Conference on Power, Control and Computing Technologies (ICPC2T), Raipur, India, 3–5 January 2020; pp. 443–447. [Google Scholar]
- Lian, D.; Xie, X.; Chen, E. Discrete Matrix Factorization and Extension for Fast Item Recommendation. IEEE Trans. Knowl. Data Eng. 2019, 33, 1919–1933. [Google Scholar] [CrossRef]
- Zhang, H.; Ganchev, I.; Nikolov, N.S.; Ji, Z.; O’Droma, M. FeatureMF: An Item Feature Enriched Matrix Factorization Model for Item Recommendation. IEEE Access 2021, 9, 65266–65276. [Google Scholar] [CrossRef]
- Guo, G.; Zhang, J.; Yorke-Smith, N. TrustSVD: Collaborative Filtering with Both the Explicit and Implicit Influence of User Trust and of Item Ratings. In Proceedings of the AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015; Volume 29. [Google Scholar] [CrossRef]
- Margaris, D.; Vasilopoulos, D.; Vassilakis, C.; Spiliotopoulos, D. Improving Collaborative Filtering’s Rating Prediction Coverage in Sparse Datasets through the Introduction of Virtual Near Neighbors. In Proceedings of the 2019 10th International Conference on Information, Intelligence, Systems and Applications (IISA), Patras, Greece, 15–17 July 2019; pp. 1–8. [Google Scholar]
- Toledo, R.Y.; Mota, Y.C.; Martínez, L. Correcting Noisy Ratings in Collaborative Recommender Systems. Knowl. -Based Syst. 2015, 76, 96–108. [Google Scholar] [CrossRef]
- Li, Y.; Liu, J.; Ren, J.; Chang, Y. A Novel Implicit Trust Recommendation Approach for Rating Prediction. IEEE Access 2020, 8, 98305–98315. [Google Scholar] [CrossRef]
- Kim, T.-Y.; Ko, H.; Kim, S.-H.; Kim, H.-D. Modeling of Recommendation System Based on Emotional Information and Collaborative Filtering. Sensors 2021, 21, 1997. [Google Scholar] [CrossRef] [PubMed]
- Polignano, M.; Narducci, F.; de Gemmis, M.; Semeraro, G. Towards Emotion-Aware Recommender Systems: An Affective Coherence Model Based on Emotion-Driven Behaviors. Expert. Syst. Appl. 2021, 170, 114382. [Google Scholar] [CrossRef]
- Anandhan, A.; Shuib, L.; Ismail, M.A.; Mujtaba, G. Social Media Recommender Systems: Review and Open Research Issues. IEEE Access 2018, 6, 15608–15628. [Google Scholar] [CrossRef]
- Kizielewicz, B.; Więckowski, J.; Wątrobski, J. A Study of Different Distance Metrics in the TOPSIS Method. In Intelligent Decision Technologies; Czarnowski, I., Howlett, R.J., Jain, L.C., Eds.; Smart Innovation, Systems and Technologies; Springer: Singapore, 2021; Volume 238, pp. 275–284. ISBN 9789811627644. [Google Scholar]
- Fkih, F. Similarity Measures for Collaborative Filtering-Based Recommender Systems: Review and Experimental Comparison. J. King Saud. Univ. -Comput. Inf. Sci. 2022, 34, 7645–7669. [Google Scholar] [CrossRef]
- Pandove, D.; Malhi, A. A Correlation Based Recommendation System for Large Data Sets. J. Grid Comput. 2021, 19, 42. [Google Scholar] [CrossRef]
- Sinnott, R.O.; Duan, H.; Sun, Y. A Case Study in Big Data Analytics. In Big Data; Elsevier: Amsterdam, The Netherlands, 2016; pp. 357–388. ISBN 978-0-12-805394-2. [Google Scholar]
- Vinh, N.X.; Epps, J.; Bailey, J. Information Theoretic Measures for Clusterings Comparison: Is a Correction for Chance Necessary? In Proceedings of the 26th Annual International Conference on Machine Learning—ICML ’09, Montreal, QC, Canada, 14–18 June 2009; ACM Press: New York, NY, USA, 2009; pp. 1–8. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset # | Dataset Title | Density | #Users (in K) | #Items (in K) | #Ratings (in K) | Avg. Ratings per User |
|---|---|---|---|---|---|---|
| 1 | Amazon Movies & TV | 0.019% | 298 | 60 | 3400 | 11.4 |
| 2 | Amazon CDs and Vinyl | 0.017% | 112 | 74 | 1440 | 12.9 |
| 3 | Amazon Grocery and Gourmet Food | 0.075% | 28 | 11 | 231 | 8.3 |
| 4 | Amazon Videogames | 0.006% | 55 | 17 | 498 | 9.1 |
| 5 | Amazon Office Products | 0.03% | 102 | 28 | 800 | 7.8 |
| 6 | Amazon Digital Music | 0.08% | 17 | 12 | 170 | 10 |
| 7 | CiaoDVD | 0.073% | 30 | 73 | 1600 | 53.3 |
| 8 | Epinions | 0.012% | 40 | 140 | 665 | 16.6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Margaris, D.; Vassilakis, C.; Spiliotopoulos, D.; Ougiaroglou, S. Rating Prediction Quality Enhancement in Low-Density Collaborative Filtering Datasets. Big Data Cogn. Comput. 2023, 7, 59. https://doi.org/10.3390/bdcc7020059
Margaris D, Vassilakis C, Spiliotopoulos D, Ougiaroglou S. Rating Prediction Quality Enhancement in Low-Density Collaborative Filtering Datasets. Big Data and Cognitive Computing. 2023; 7(2):59. https://doi.org/10.3390/bdcc7020059
Chicago/Turabian StyleMargaris, Dionisis, Costas Vassilakis, Dimitris Spiliotopoulos, and Stefanos Ougiaroglou. 2023. "Rating Prediction Quality Enhancement in Low-Density Collaborative Filtering Datasets" Big Data and Cognitive Computing 7, no. 2: 59. https://doi.org/10.3390/bdcc7020059
APA StyleMargaris, D., Vassilakis, C., Spiliotopoulos, D., & Ougiaroglou, S. (2023). Rating Prediction Quality Enhancement in Low-Density Collaborative Filtering Datasets. Big Data and Cognitive Computing, 7(2), 59. https://doi.org/10.3390/bdcc7020059