

MalBERTv2: Code Aware BERT-Based Model for Malware Identification



Abstract
:1. Introduction
- We propose MalBERTv2, an improved version of the MalBERT approach for malware detection representation by creating a full pipeline for a code-aware pre-trained language model for MG detection.
- We propose a pre-tokenization process to present the features.
- We apply extensive experiments and evaluations on a variety of datasets collected from public resources.
2. Related Work
2.1. Deep Learning-Based Methods
2.2. Attention-Based Methods
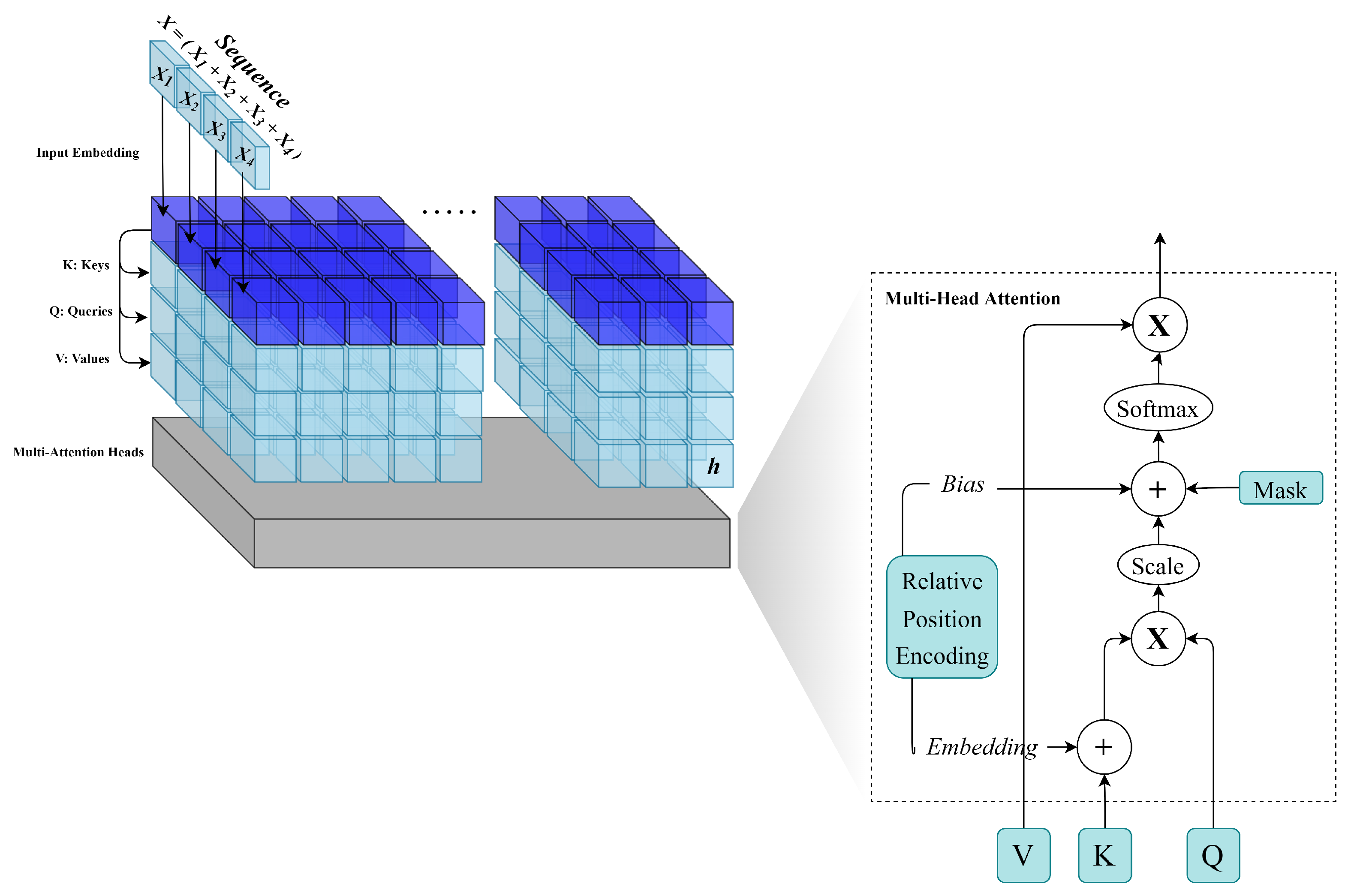
2.3. Transformer-Based Methods
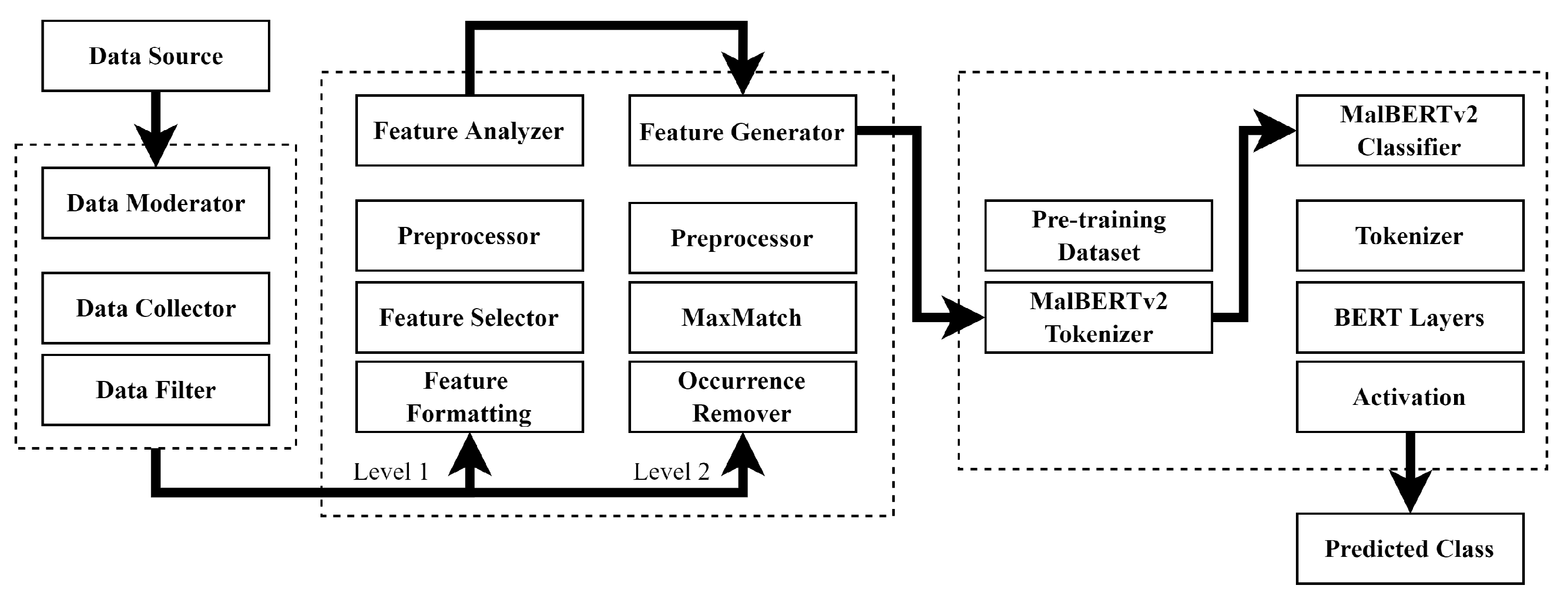
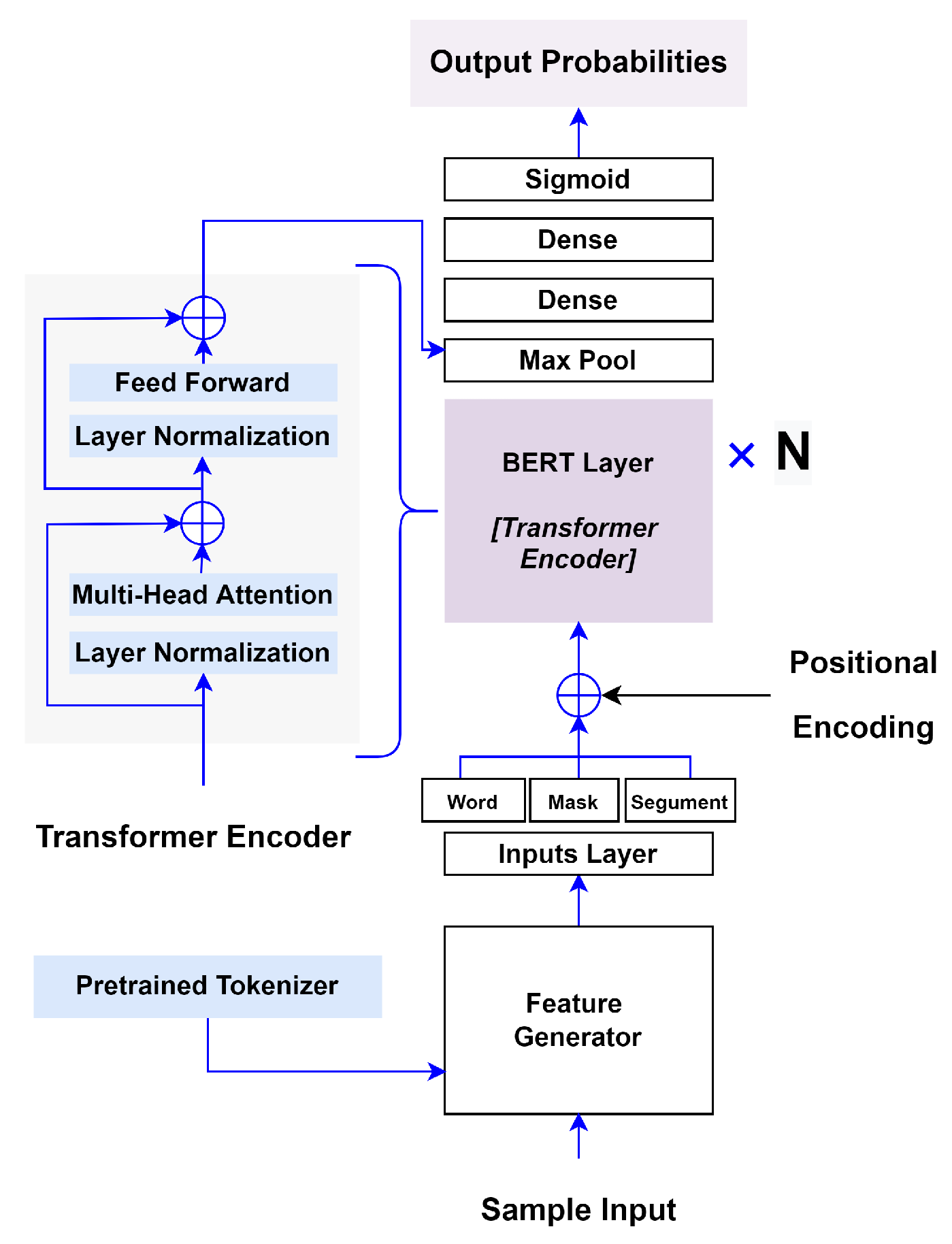
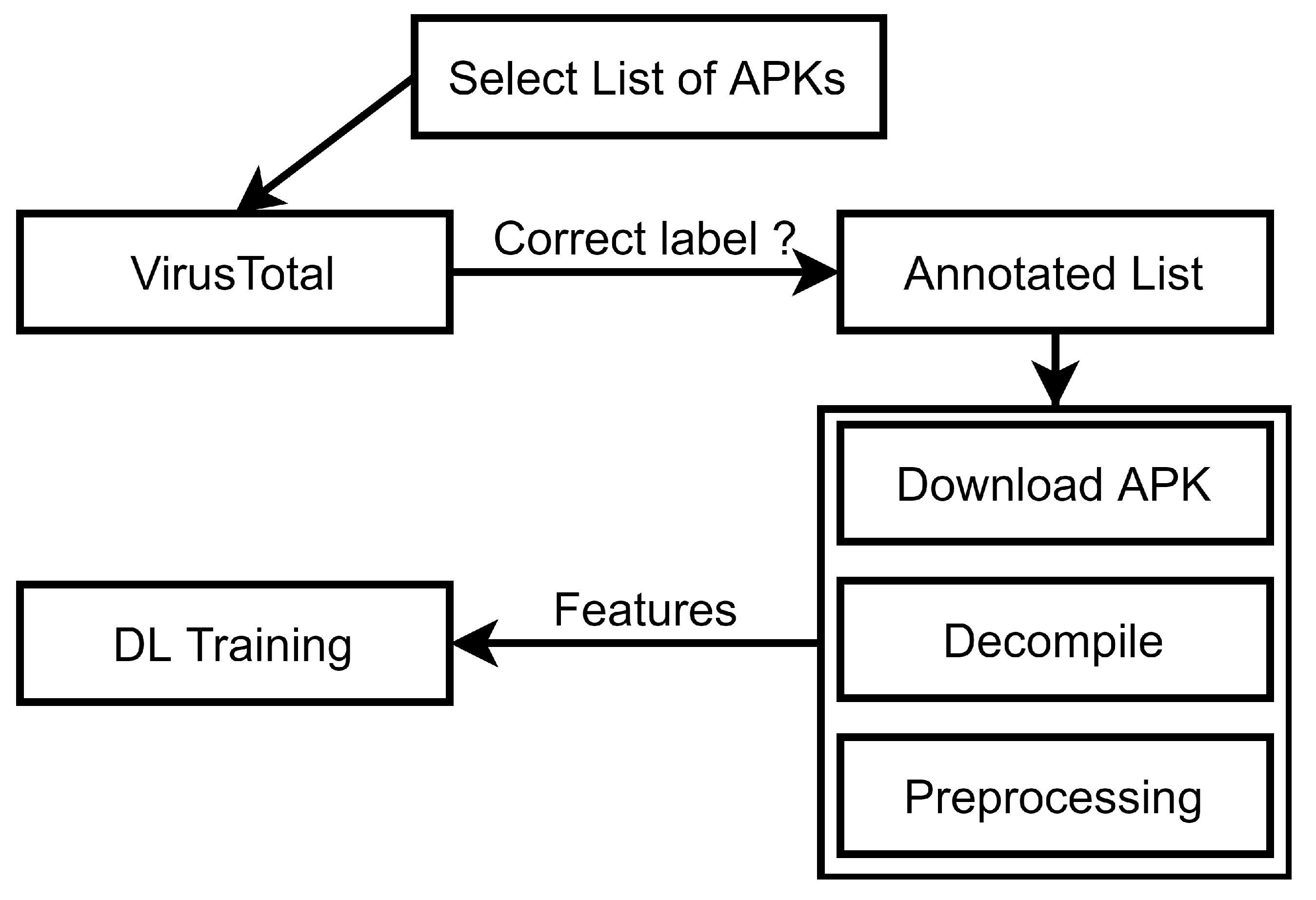
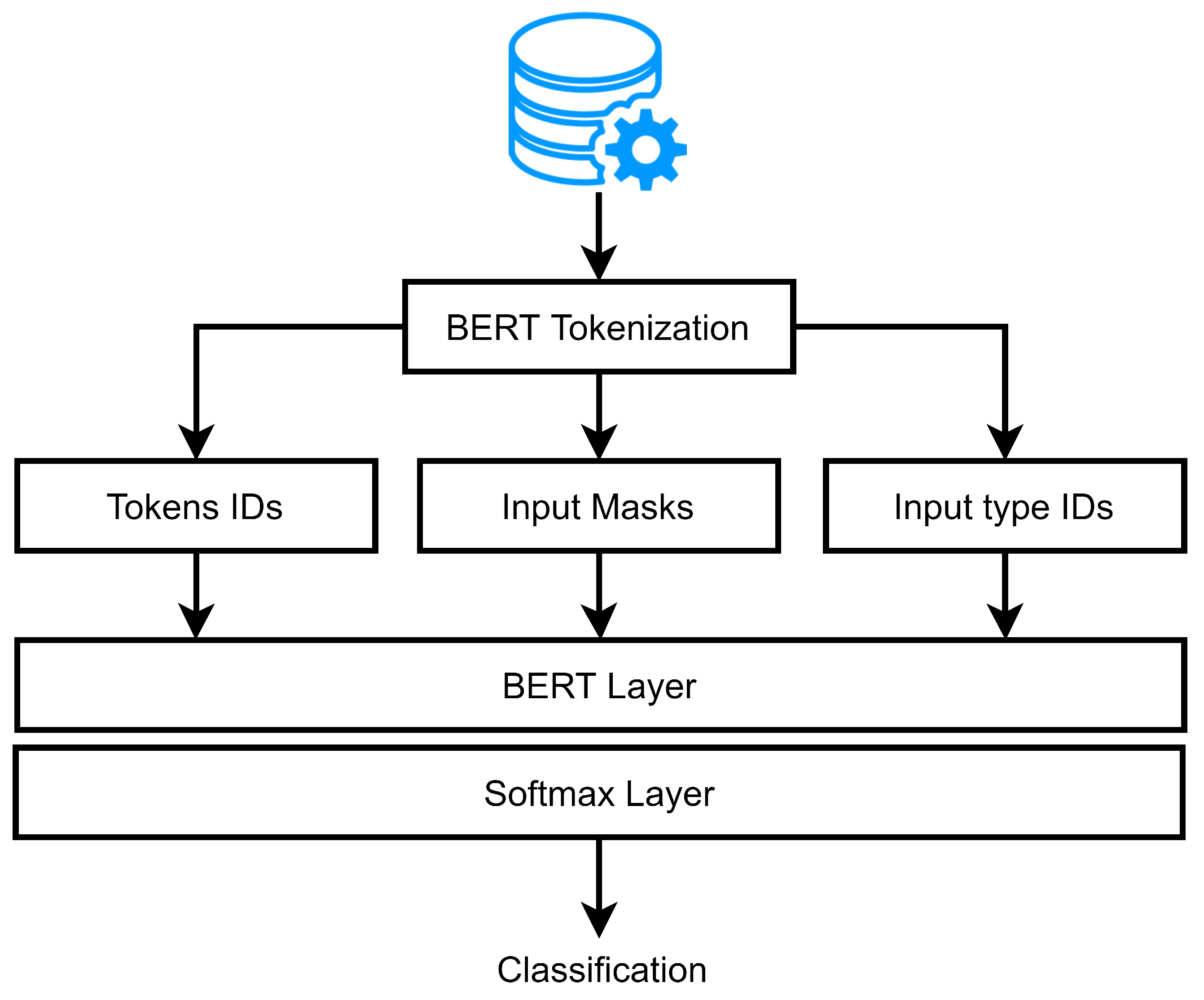
3. Proposed System Architecture
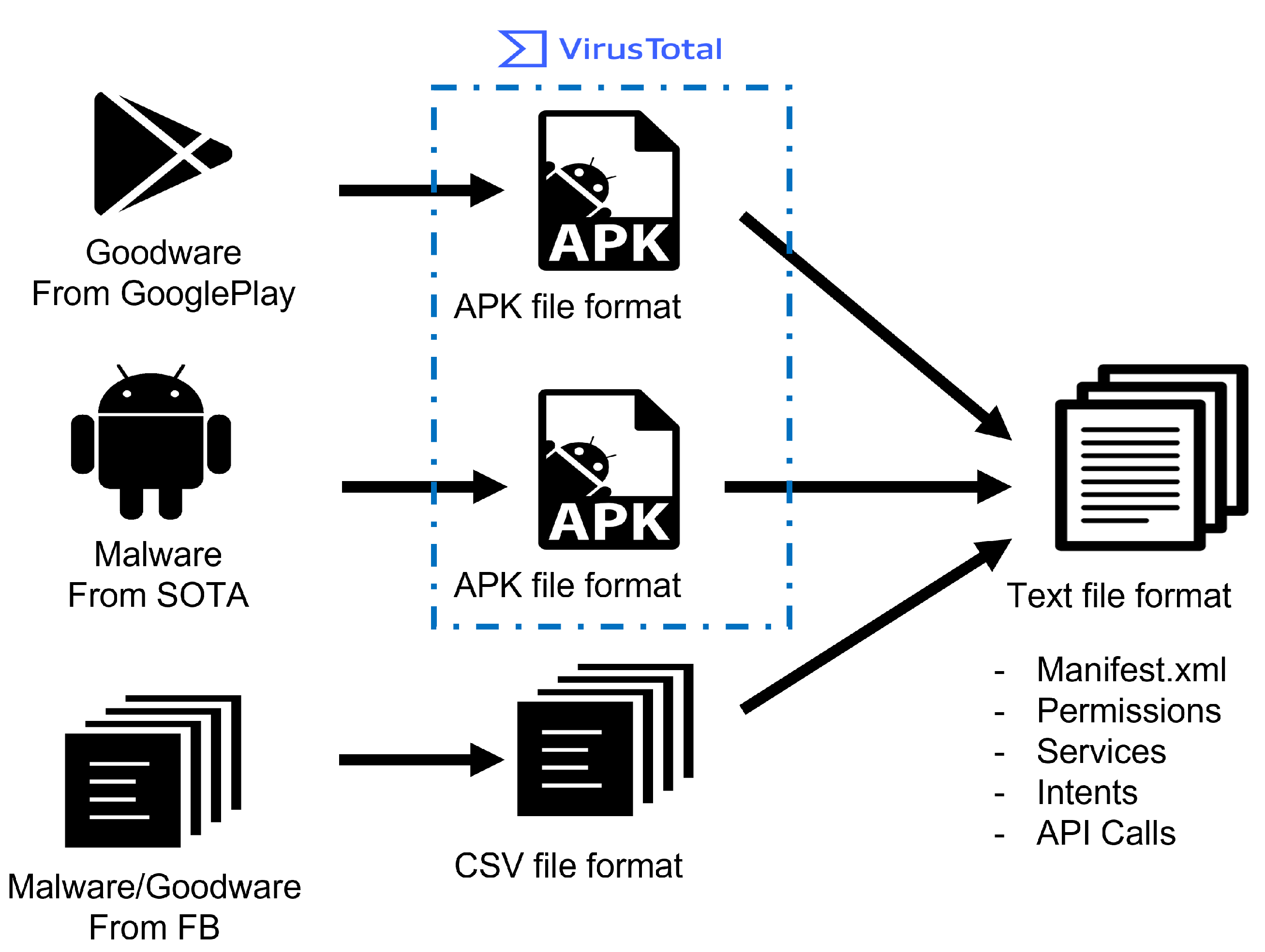
3.1. Data Creation
3.2. Feature Creation Module
- The datasets that the researchers share with the samples in APK format come first, where every sample has a distinct hash identifier that serves as a kind of fingerprint. Malware is typically identified via a technique called hashing. A hashing application is used to run the malicious software, producing a distinct hash that serves as the malware’s identification.
- Second, depending on the extraction method they suggested, the dataset authors share the preprocessed features. These characteristics were primarily displayed as CSV files.
3.2.1. Tokenization
3.2.2. MalBERTv2 Feature Analyzer
| Algorithm 1 Proposed feature generator pre-tokenizer. We used both the MaxMatch [45] algorithm and BPE [42] in the tokenization process. We collected the given dictionary manually after processing the unique words in the collected pretraining datasets. |
1: procedure Segment string C into unique word list W using dictionary D. |
2: |
3: |
4: |
5: |
6: |
7: : |
8: while do |
9: Find longest match w in D from start of C |
10: : |
11: if w is not empty then |
12: . |
13: . |
14: else |
15: Remove first character from C and add to W. |
16: end if |
17: . |
18: end while |
19: return . |
20: end procedure |
3.3. Model Creation
4. Implementation
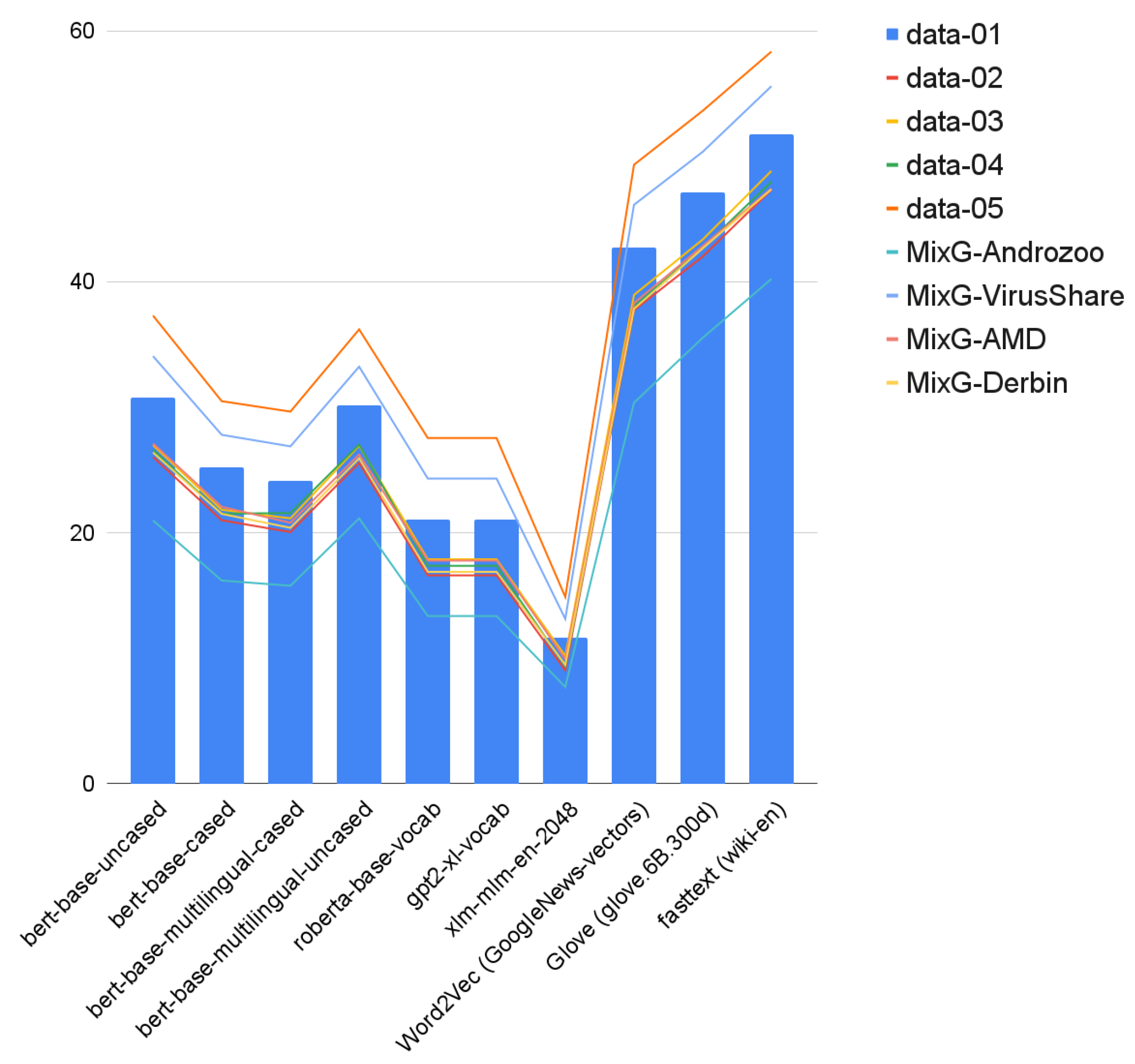
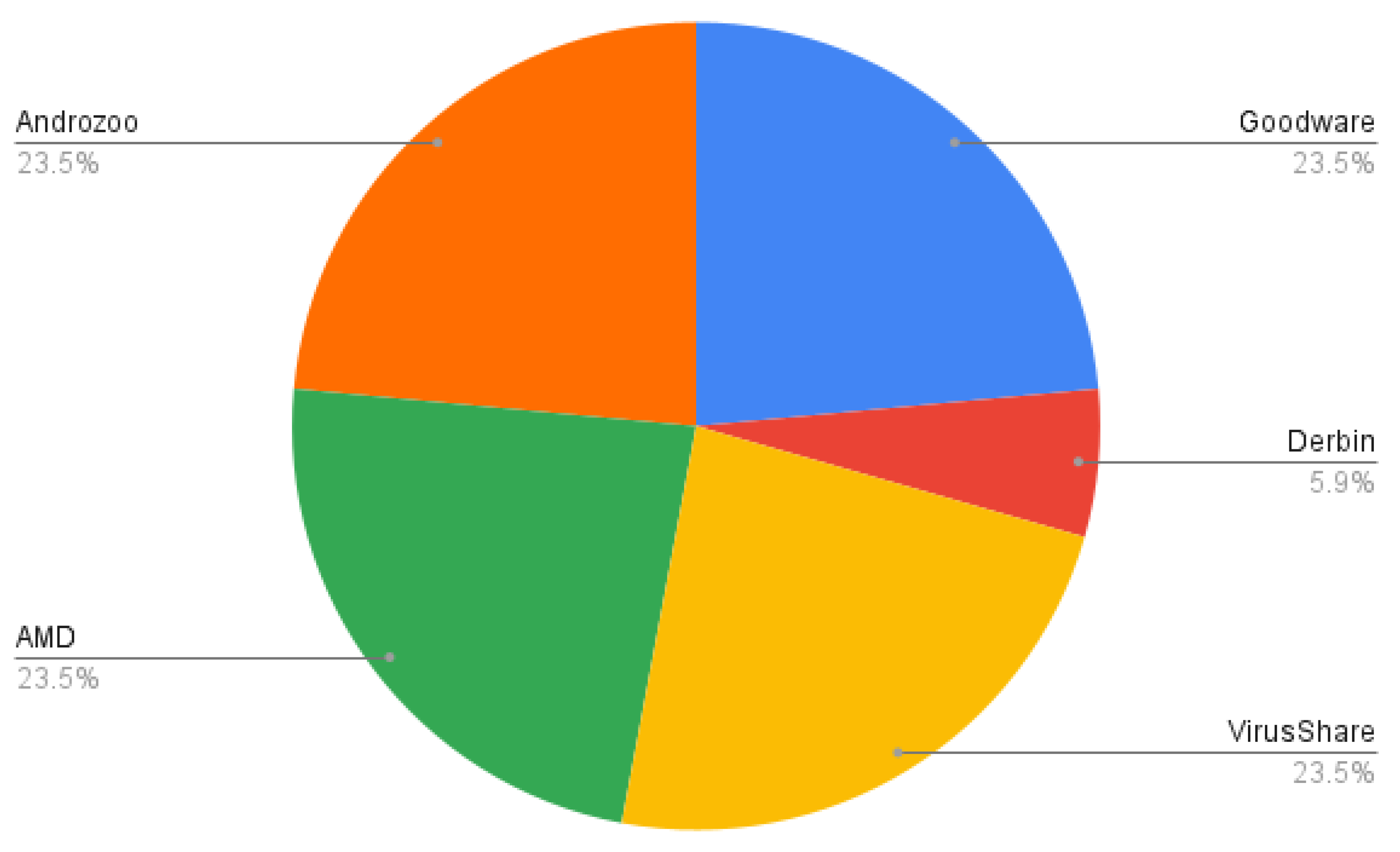
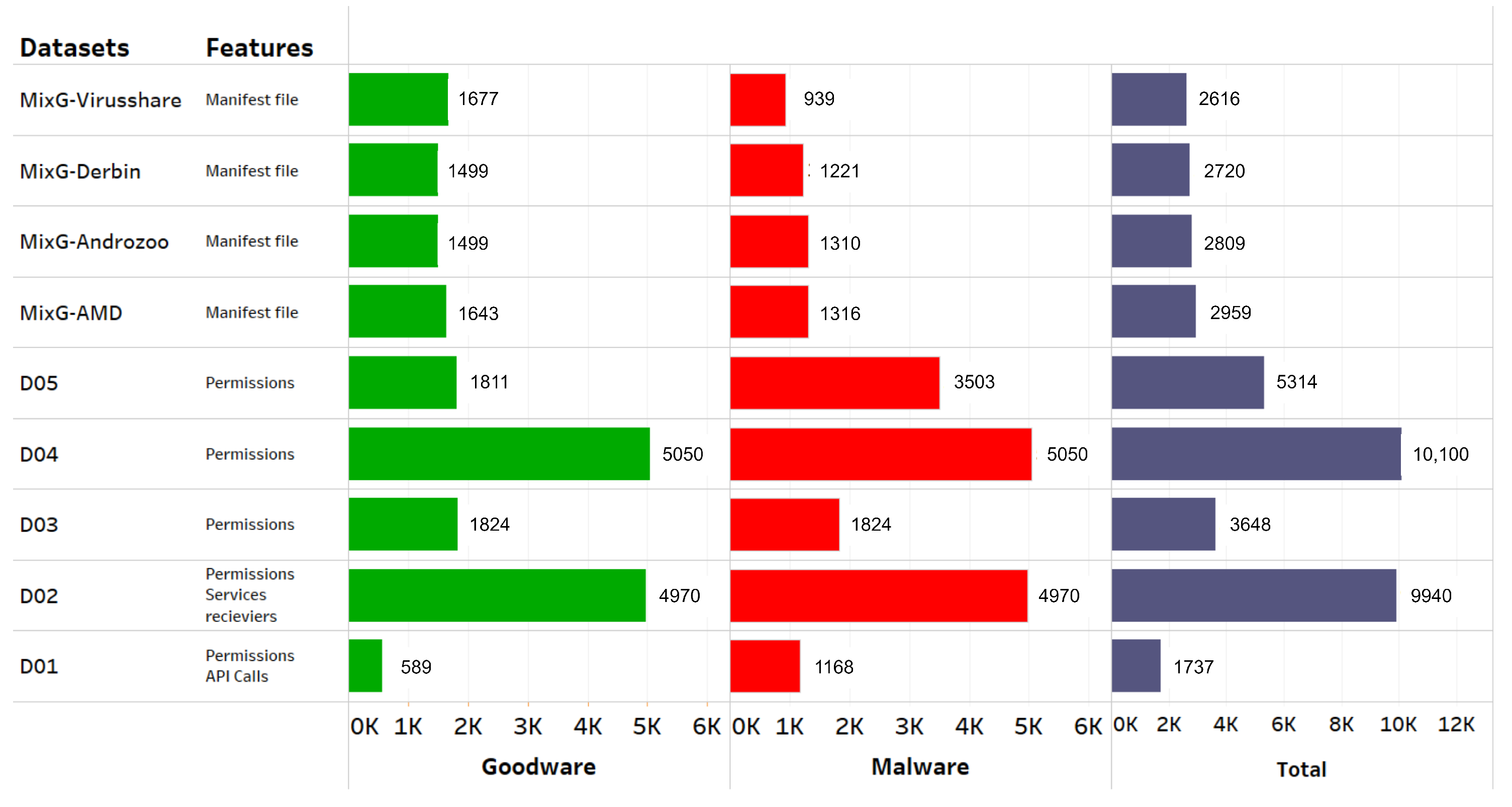
4.1. Datasets
- AMD dataset [47]. It contains 24,553 samples categorized in 135 varieties among 71 malware families ranging from 2010 to 2016. The dataset is publicly shared with the research community.
- Drebin dataset [48]. It contains 5560 applications from 179 different malware families. The samples were collected from August 2010 to October 2012 and were made available by the MobileSandbox project [48]. The authors made the datasets from the project publicly available to foster research on AM and to enable a comparison of different detection approaches.
- Androzoo dataset [51]. It is a growing collection of Android apps gathered from various sources, including the official Google Play app market, with the goal of facilitating Android-related research. It currently contains over 15 million APKs, each of which was or will be analyzed by tens of different anti-virus products to determine which applications are malware. Each app contains more than 20 different types of metadata, such as VirusTotal reports.
- Android permissions and API calls during dynamic analysis [52]. This dataset includes 50,000 Android apps and 10,000 malware apps gathered from various sources. We note this dataset as D01.
- Android malware detection [53]. These data contain APKs from various sources, including malicious and benign applications. They were created after selecting a sufficient number of apps. Using the pyaxmlparser and Androguard [54] framework, we analyze each application in the array. On the set of each feature, we used a binary vector format, and in the last column labeled class, we marked it 1 (Malicious) or 0 (Benign). We note this dataset as D02.
- Android malware dataset for machine learning [55]. These data contain 215 feature vectors extracted from 15,036 applications: 5560 malware apps from the Drebin project and 9476 benign apps. The dataset was used to develop and test the multilevel classifier fusion approach for AM detection. The supporting file contains a more detailed description of the feature vectors or attributes discovered through static code analysis of Android apps. We note this dataset as D03.
- Android malware and normal permissions dataset [56]. These data contain 18,850 normal android application packages and 10,000 malware android packages, which are used to identify the behavior of malware applications on the permission they need at run time. We note this dataset as D04.
- Android permission dataset [57]. These data contain android apps and their permissions. They are classified as 1 (Malicious) or 0 (Benign). We note this dataset as D05.
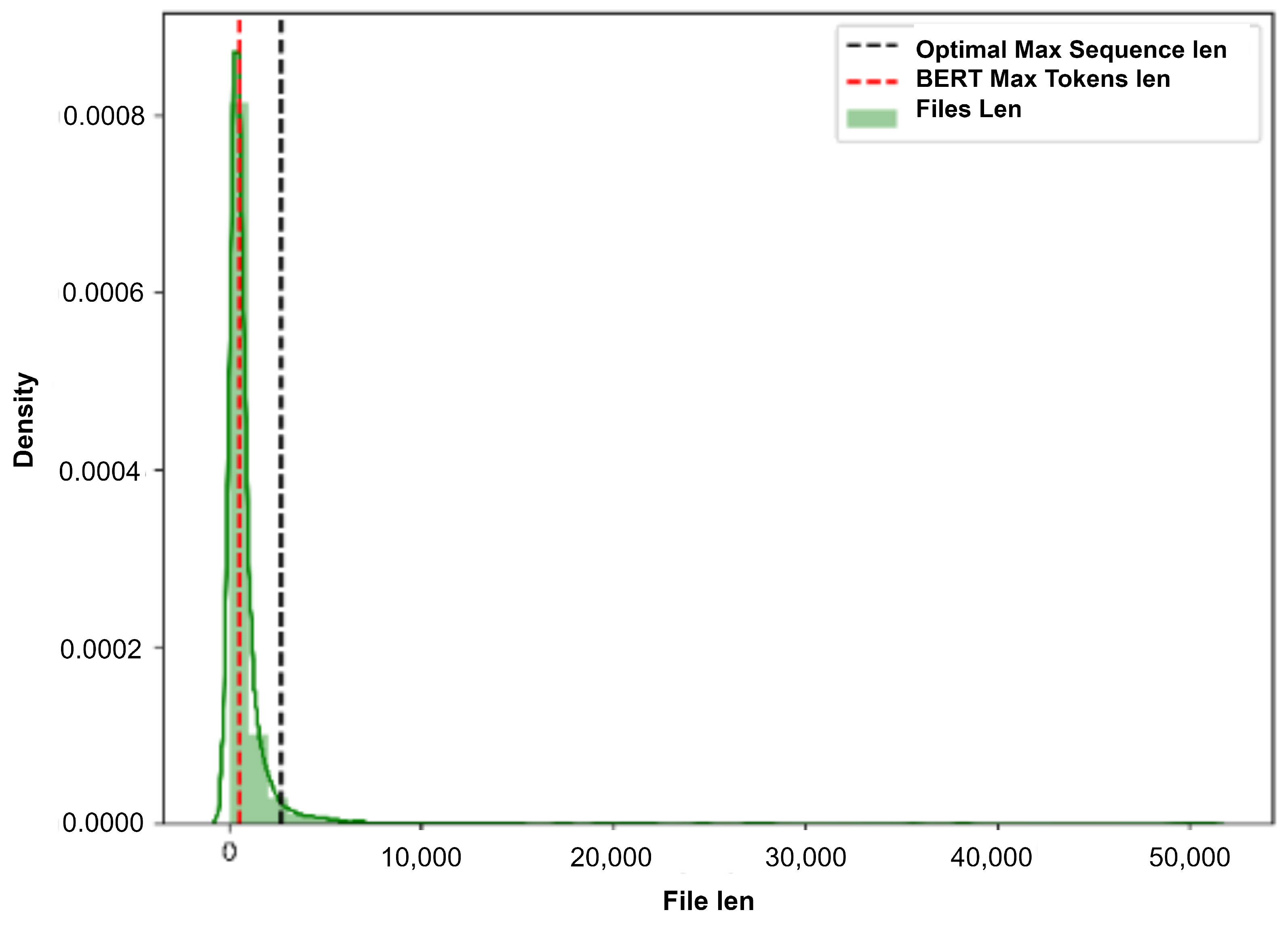
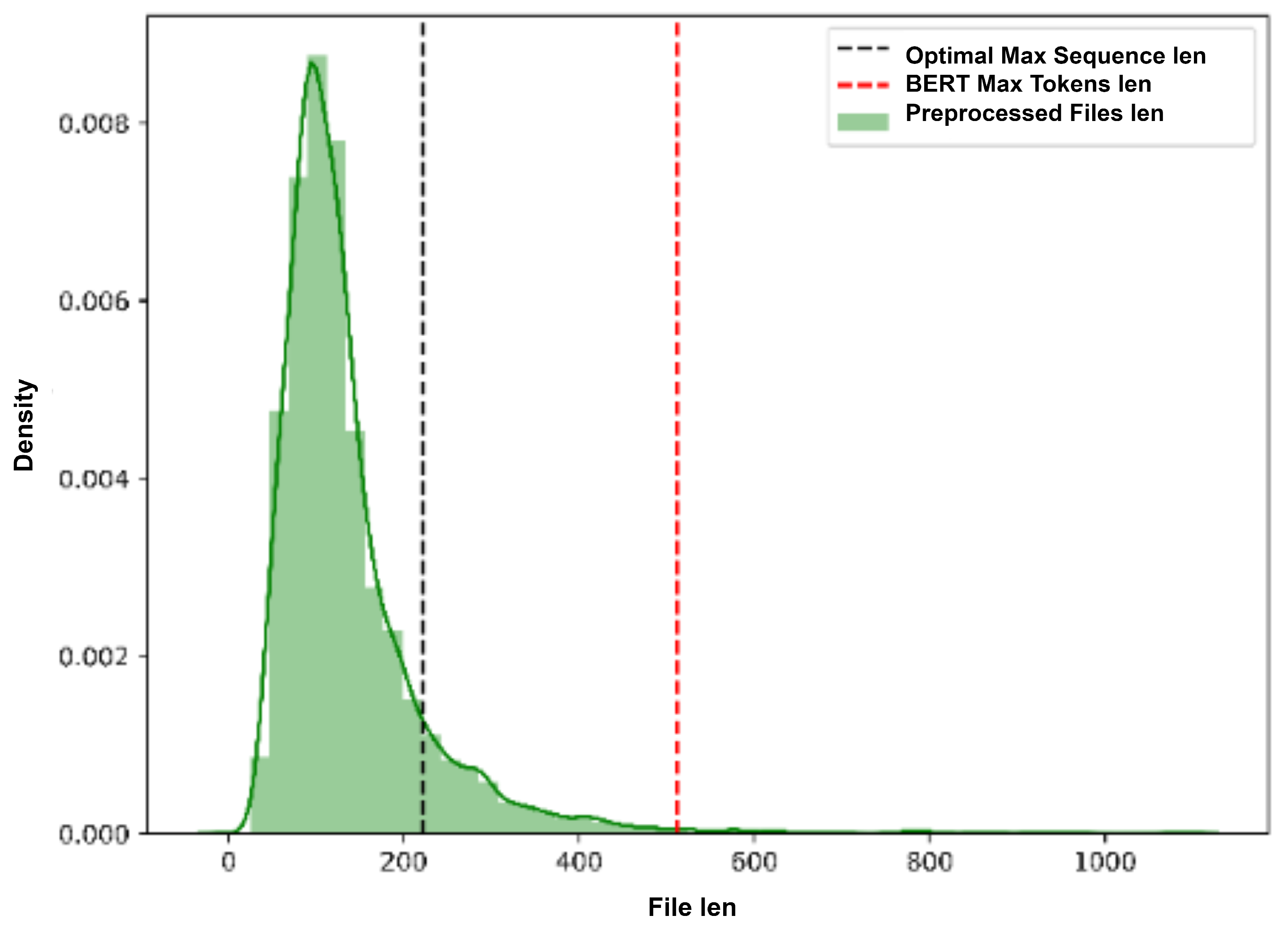
4.2. Preprocessing and Feature Representations
4.3. Occurrences Remover
5. Experimental Results
5.1. Baselines
5.1.1. TFIDF + SVM
5.1.2. Fasttext + CNN
5.1.3. MalBERTv1
5.1.4. TFIDF + Transformer from Scratch
5.2. Training MalBERTv2
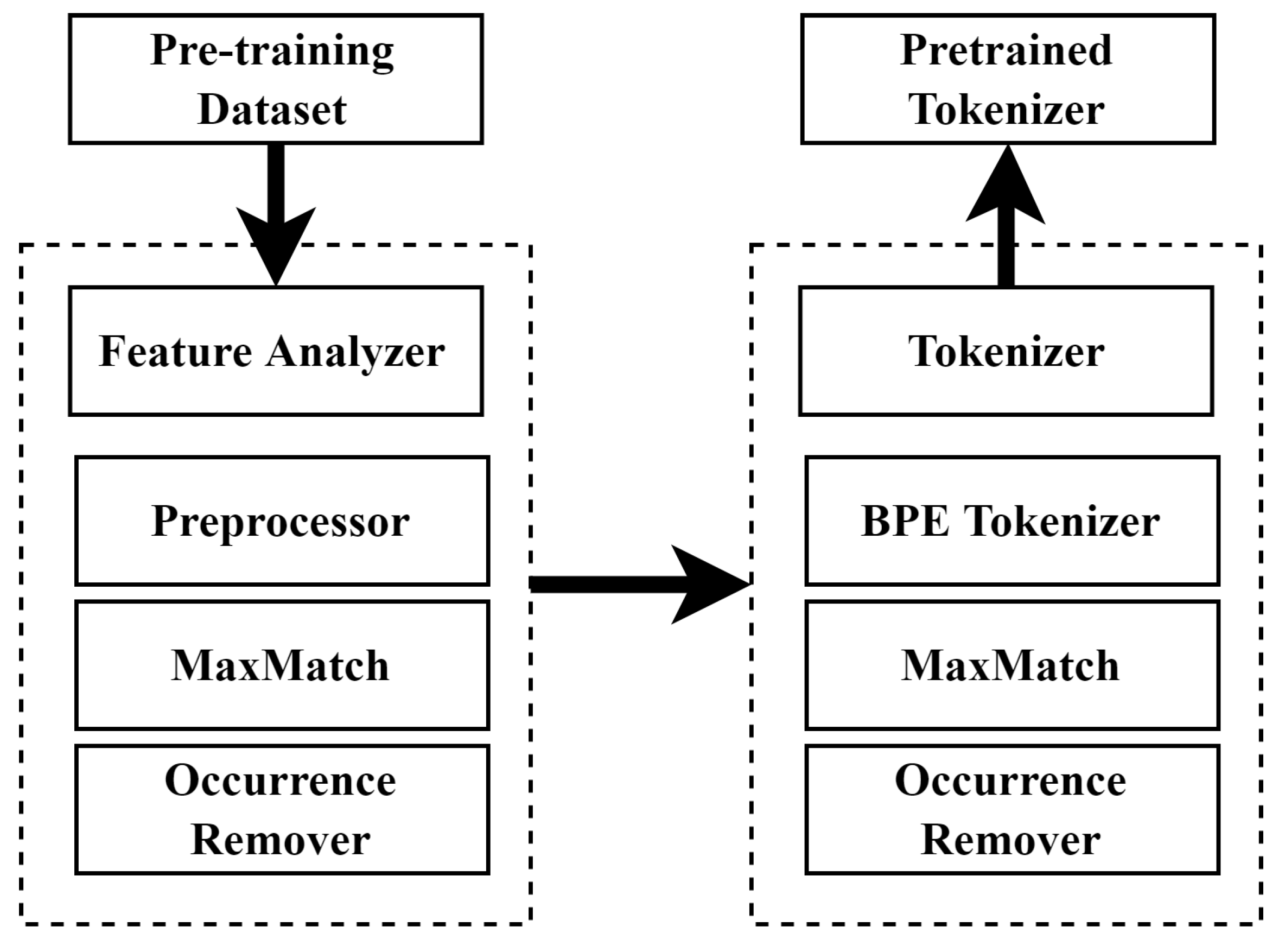
5.2.1. Train MalBERTv2 Tokenizer
- Apply the feature generator on the dataset and use the generated features as input to the tokenizer. The feature generator can be considered as an initial tokenizer since it applies tokenization to the original text to obtain the most relevant and English-related words without losing the most important keywords in the files.
- Create and train a byte-level byte-pair encoding tokenizer with the same special tokens as RoBERTa.
- Train the defined RoBERTa model from scratch using masked language modeling (MLM).
- Save the tokenizer to map the features of the test datasets later to fine-tune the MalBERTv2 classifier.
5.2.2. Train MalBERTv2 Classifier
5.3. Evaluation Metrics
5.4. Experiments Results and Discussion
5.5. MalBERTv2 Performance on Mixed Datasets
5.6. Malbertv2 Performance on Feature-Based Dataset
5.7. Analysis of Time Performance
5.8. Analysis of Baselines Performance
5.9. Qualitative Analysis
5.9.1. Main Factors for Malicious Class
5.9.2. Main Factors for Goodware Class
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| AM | Android Malware |
| API | Application programming interface |
| APK | Android Package File |
| BERT | Bidirectional Encoder Representations from Transformers |
| BiLSTM | Bidirectional Long Short-Term Memory |
| BoW | Bag of Words |
| BPE | Byte Pair Encoding |
| CNN | Convolutional Neural Networks |
| CRF | Conditional Random Field |
| DL | Deep Learning |
| FB | Feature-Based |
| GAN | Graph Attention Network |
| HIN | Heterogeneous Information Network |
| MG | Malware/Goodware |
| ML | Machine Learning |
| NLP | Natural Language Processing |
| RF | Random Forest |
| SVM | Support Vector Machine |
| TB | Transformer Based |
| TDM | Term Document Matrices |
| TFIDF | Term Frequency Inverse Document Frequency |
References
- Damodaran, A.; Di Troia, F.; Visaggio, C.A.; Austin, T.H.; Stamp, M. A comparison of static, dynamic, and hybrid analysis for malware detection. J. Comput. Virol. Hacking Tech. 2017, 13, 1–12. [Google Scholar] [CrossRef]
- Mahdavifar, S.; Ghorbani, A.A. Application of deep learning to cybersecurity: A survey. Neurocomputing 2019, 347, 149–176. [Google Scholar] [CrossRef]
- Karita, S.; Chen, N.; Hayashi, T.; Hori, T.; Inaguma, H.; Jiang, Z.; Someki, M.; Soplin, N.E.Y.; Yamamoto, R.; Wang, X.; et al. A comparative study on transformer vs rnn in speech applications. In Proceedings of the 2019 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Singapore, 14–18 December 2019; pp. 449–456. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. Available online: https://papers.nips.cc/paper/2017/hash/3f5ee243547dee91fbd053c1c4a845aa-Abstract.html (accessed on 13 March 2023).
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Rahali, A.; Akhloufi, M.A. MalBERT: Using transformers for cybersecurity and malicious software detection. arXiv 2021, arXiv:2103.03806. [Google Scholar]
- Rahali, A.; Akhloufi, M.A. MalBERT: Malware Detection using Bidirectional Encoder Representations from Transformers. In Proceedings of the 2021 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Melbourne, VIC, Australia, 17–20 October 2021; pp. 3226–3231. [Google Scholar]
- Swetha, M.; Sarraf, G. Spam email and malware elimination employing various classification techniques. In Proceedings of the 2019 4th International Conference on Recent Trends on Electronics, Information, Communication & Technology (RTEICT), Bengaluru, India, 17–18 May 2019; pp. 140–145. [Google Scholar]
- Mohammad, R.M.A. A lifelong spam emails classification model. Appl. Comput. Inform. 2020; ahead-of-print. [Google Scholar] [CrossRef]
- Zhang, Y.; Jin, R.; Zhou, Z.H. Understanding bag-of-words model: A statistical framework. Int. J. Mach. Learn. Cybern. 2010, 1, 43–52. [Google Scholar] [CrossRef]
- Antonellis, I.; Gallopoulos, E. Exploring term-document matrices from matrix models in text mining. arXiv 2006, arXiv:cs/0602076. [Google Scholar]
- Church, K.W. Word2Vec. Nat. Lang. Eng. 2017, 23, 155–162. [Google Scholar] [CrossRef] [Green Version]
- Mahoney, M.V. Fast Text Compression with Neural Networks. In Proceedings of the FLAIRS Conference, Orlando, FL, USA, 22–24 May 2000; pp. 230–234. [Google Scholar]
- Rudd, E.M.; Abdallah, A. Training Transformers for Information Security Tasks: A Case Study on Malicious URL Prediction. arXiv 2020, arXiv:2011.03040. [Google Scholar]
- Han, L.; Zeng, X.; Song, L. A novel transfer learning based on albert for malicious network traffic classification. Int. J. Innov. Comput. Inf. Control. 2020, 16, 2103–2119. [Google Scholar]
- Li, M.Q.; Fung, B.C.; Charland, P.; Ding, S.H. I-MAD: Interpretable Malware Detector Using Galaxy Transformer. Comput. Secur. 2021, 108, 102371. [Google Scholar] [CrossRef]
- Jusoh, R.; Firdaus, A.; Anwar, S.; Osman, M.Z.; Darmawan, M.F.; Ab Razak, M.F. Malware detection using static analysis in Android: A review of FeCO (features, classification, and obfuscation). PeerJ Comput. Sci. 2021, 7, e522. [Google Scholar] [CrossRef]
- Niveditha, V.; Ananthan, T.; Amudha, S.; Sam, D.; Srinidhi, S. Detect and classify zero day Malware efficiently in big data platform. Int. J. Adv. Sci. Technol. 2020, 29, 1947–1954. [Google Scholar]
- Choi, S.; Bae, J.; Lee, C.; Kim, Y.; Kim, J. Attention-based automated feature extraction for malware analysis. Sensors 2020, 20, 2893. [Google Scholar] [CrossRef]
- Catal, C.; Gunduz, H.; Ozcan, A. Malware Detection Based on Graph Attention Networks for Intelligent Transportation Systems. Electronics 2021, 10, 2534. [Google Scholar] [CrossRef]
- Hei, Y.; Yang, R.; Peng, H.; Wang, L.; Xu, X.; Liu, J.; Liu, H.; Xu, J.; Sun, L. Hawk: Rapid android malware detection through heterogeneous graph attention networks. IEEE Trans. Neural Netw. Learn. Syst. 2021, 1–15. [Google Scholar] [CrossRef]
- Pathak, P. Leveraging Attention-Based Deep Neural Networks for Security Vetting of Android Applications. Ph.D. Thesis, Bowling Green State University, Bowling Green, OH, USA, 2021. Volume 8, Number 29. [Google Scholar] [CrossRef]
- Chen, J.; Guo, S.; Ma, X.; Li, H.; Guo, J.; Chen, M.; Pan, Z. SLAM: A Malware Detection Method Based on Sliding Local Attention Mechanism. Secur. Commun. Netw. 2020, 2020, 6724513. [Google Scholar] [CrossRef]
- Ganesan, S.; Ravi, V.; Krichen, M.; Sowmya, V.; Alroobaea, R.; Soman, K. Robust Malware Detection using Residual Attention Network. In Proceedings of the 2021 IEEE International Conference on Consumer Electronics (ICCE), Las Vegas, NV, USA, 10–12 January 2021; pp. 1–6. [Google Scholar]
- Ren, F.; Jiang, Z.; Wang, X.; Liu, J. A DGA domain names detection modeling method based on integrating an attention mechanism and deep neural network. Cybersecurity 2020, 3, 4. [Google Scholar] [CrossRef]
- Komatwar, R.; Kokare, M. A Survey on Malware Detection and Classification. J. Appl. Secur. Res. 2021, 16, 390–420. [Google Scholar] [CrossRef]
- Singh, J.; Singh, J. A survey on machine learning-based malware detection in executable files. J. Syst. Archit. 2021, 112, 101861. [Google Scholar] [CrossRef]
- Kouliaridis, V.; Kambourakis, G.; Geneiatakis, D.; Potha, N. Two Anatomists Are Better than One—Dual-Level Android Malware Detection. Symmetry 2020, 12, 1128. [Google Scholar] [CrossRef]
- Imtiaz, S.I.; ur Rehman, S.; Javed, A.R.; Jalil, Z.; Liu, X.; Alnumay, W.S. DeepAMD: Detection and identification of Android malware using high-efficient Deep Artificial Neural Network. Future Gener. Comput. Syst. 2021, 115, 844–856. [Google Scholar] [CrossRef]
- Amin, M.; Tanveer, T.A.; Tehseen, M.; Khan, M.; Khan, F.A.; Anwar, S. Static malware detection and attribution in android byte-code through an end-to-end deep system. Future Gener. Comput. Syst. 2020, 102, 112–126. [Google Scholar] [CrossRef]
- Karbab, E.B.; Debbabi, M. PetaDroid: Adaptive Android Malware Detection Using Deep Learning. In Proceedings of the International Conference on Detection of Intrusions and Malware, and Vulnerability Assessment, Online, 14–16 July 2021; pp. 319–340. [Google Scholar]
- Yadav, P.; Menon, N.; Ravi, V.; Vishvanathan, S.; Pham, T.D. EfficientNet convolutional neural networks-based Android malware detection. Comput. Secur. 2022, 115, 102622. [Google Scholar] [CrossRef]
- Yuan, C.; Cai, J.; Tian, D.; Ma, R.; Jia, X.; Liu, W. Towards time evolved malware identification using two-head neural network. J. Inf. Secur. Appl. 2022, 65, 103098. [Google Scholar] [CrossRef]
- Weng Lo, W.; Layeghy, S.; Sarhan, M.; Gallagher, M.; Portmann, M. Graph Neural Network-based Android Malware Classification with Jumping Knowledge. In Proceedings of the 2022 IEEE Conference on Dependable and Secure Computing (DSC), Edinburgh, UK, 22–24 June 2022. [Google Scholar] [CrossRef]
- Roy, K.C.; Chen, Q. Deepran: Attention-based bilstm and crf for ransomware early detection and classification. Inf. Syst. Front. 2021, 23, 299–315. [Google Scholar] [CrossRef]
- Korine, R.; Hendler, D. DAEMON: Dataset/Platform-Agnostic Explainable Malware Classification Using Multi-Stage Feature Mining. IEEE Access 2021, 9, 78382–78399. [Google Scholar] [CrossRef]
- Lu, T.; Du, Y.; Ouyang, L.; Chen, Q.; Wang, X. Android malware detection based on a hybrid deep learning model. Secur. Commun. Netw. 2020, 2020, 8863617. [Google Scholar] [CrossRef]
- Yoo, S.; Kim, S.; Kim, S.; Kang, B.B. AI-HydRa: Advanced hybrid approach using random forest and deep learning for malware classification. Inf. Sci. 2021, 546, 420–435. [Google Scholar] [CrossRef]
- Yousefi-Azar, M.; Varadharajan, V.; Hamey, L.; Tupakula, U. Autoencoder-based feature learning for cyber security applications. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; pp. 3854–3861. [Google Scholar] [CrossRef]
- Viennot, N.; Garcia, E.; Nieh, J. A measurement study of google play. In Proceedings of the 2014 ACM International Conference on Measurement and Modeling of Computer Systems, Austin, TX, USA, 16–20 June 2014; pp. 221–233. [Google Scholar]
- Peng, P.; Yang, L.; Song, L.; Wang, G. Opening the blackbox of virustotal: Analyzing online phishing scan engines. In Proceedings of the Internet Measurement Conference, Amsterdam, The Netherlands, 21–23 October 2019; pp. 478–485. [Google Scholar]
- Shibata, Y.; Kida, T.; Fukamachi, S.; Takeda, M.; Shinohara, A.; Shinohara, T.; Arikawa, S. Byte Pair Encoding: A Text Compression Scheme That Accelerates Pattern Matching. Researchgate. 1999. Available online: https://www.researchgate.net/publication/2310624_Byte_Pair_Encoding_A_Text_Compression_Scheme_That_Accelerates_Pattern_Matching (accessed on 12 March 2023).
- Song, X.; Salcianu, A.; Song, Y.; Dopson, D.; Zhou, D. Fast WordPiece Tokenization. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 7–11 November 2021; pp. 2089–2103. [Google Scholar]
- Kudo, T.; Richardson, J. Sentencepiece: A simple and language independent subword tokenizer and detokenizer for neural text processing. arXiv 2018, arXiv:1808.06226. [Google Scholar]
- Chang, P.C.; Galley, M.; Manning, C.D. Optimizing Chinese word segmentation for machine translation performance. In Proceedings of the Third Workshop on Statistical Machine Translation, Columbus, OH, USA, 19 June 2008; pp. 224–232. [Google Scholar]
- Sennrich, R.; Haddow, B.; Birch, A. Neural machine translation of rare words with subword units. arXiv 2015, arXiv:1508.07909. [Google Scholar]
- Li, Y.; Jang, J.; Hu, X.; Ou, X. Android malware clustering through malicious payload mining. In Proceedings of the International symposium on Research in Attacks, Intrusions, and Defenses, Atlanta, GA, USA, 18–20 September 2017; pp. 192–214. [Google Scholar]
- Arp, D.; Spreitzenbarth, M.; Hubner, M.; Gascon, H.; Rieck, K.; Siemens, C. Drebin: Effective and explainable detection of android malware in your pocket. In Proceedings of the Network and Distributed System Security Symposium (NDSS)’14, San Diego, CA, USA, 23–26 February 2014. [Google Scholar]
- Roberts, J.M. Automatic Analysis of Malware Behaviour using Machine Learning. J. Comput. Secur. 2011, 19, 639–668. [Google Scholar]
- Miranda, T.C.; Gimenez, P.F.; Lalande, J.F.; Tong, V.V.T.; Wilke, P. Debiasing Android Malware Datasets: How Can I Trust Your Results If Your Dataset Is Biased? IEEE Trans. Inf. Forensics Secur. 2022, 17, 2182–2197. [Google Scholar] [CrossRef]
- Li, L.; Gao, J.; Hurier, M.; Kong, P.; Bissyandé, T.F.; Bartel, A.; Klein, J.; Traon, Y.L. Androzoo++: Collecting millions of android apps and their metadata for the research community. arXiv 2017, arXiv:1709.05281. [Google Scholar]
- Arvind, M. Android Permissions and API Calls during Dynamic Analysis. Available online: https://data.mendeley.com/datasets/vng8wg9n65/1 (accessed on 12 March 2023).
- Colaco, C.W.; Bagwe, M.D.; Bose, S.A.; Jain, K. DefenseDroid: A Modern Approach to Android Malware Detection. Strad Res. 2021, 8, 271–282. [Google Scholar] [CrossRef]
- Desnos, A.; Gueguen, G. Androguard-Reverse Engineering, Malware and Goodware Analysis of Android Applications. Available online: https://androguard.readthedocs.io/en/latest/ (accessed on 12 March 2023).
- Yerima, S. Android Malware Dataset for Machine Learning. Figshare. 2018. Available online: https://figshare.com/articles/dataset/Android_malware_dataset_for_machine_learning_2/5854653 (accessed on 12 March 2023).
- Arvind, M. A Android Malware and Normal Permissions Dataset. 2018. Available online: https://data.mendeley.com/datasets/958wvr38gy/5 (accessed on 27 July 2022).
- Arvind, M. Android Permission Dataset. 2018. Available online: https://data.mendeley.com/datasets/8y543xvnsv/1 (accessed on 27 July 2022).
- Concepcion Miranda, T.; Gimenez, P.F.; Lalande, J.F.; Viet Triem Tong, V.; Wilke, P. Dada: Debiased Android Datasets. 2021. Available online: https://ieee-dataport.org/open-access/dada-debiased-android-datasets (accessed on 27 July 2022).
- Hozan, E. Android APK Reverse Engineering: Using JADX. 4 October 2019. Available online: https://www.secplicity.org/2019/10/04/android-apk-reverse-engineering-using-jadx/ (accessed on 30 March 2021).
- Winsniewski, R. Apktool: A Tool for Reverse Engineering Android apk Files. Available online: https://ibotpeaches.github.io/Apktool/ (accessed on 27 July 2022).
- Harrand, N.; Soto-Valero, C.; Monperrus, M.; Baudry, B. Java decompiler diversity and its application to meta-decompilation. J. Syst. Softw. 2020, 168, 110645. [Google Scholar] [CrossRef]
- Bojanowski, P.; Grave, E.; Joulin, A.; Mikolov, T. Enriching Word Vectors with Subword Information. arXiv 2016, arXiv:1607.04606. [Google Scholar] [CrossRef] [Green Version]
- Zhang, B.; Xiao, W.; Xiao, X.; Sangaiah, A.K.; Zhang, W.; Zhang, J. Ransomware classification using patch-based CNN and self-attention network on embedded N-grams of opcodes. Future Gener. Comput. Syst. 2020, 110, 708–720. [Google Scholar] [CrossRef]
- Rahali, A.; Lashkari, A.H.; Kaur, G.; Taheri, L.; GAGNON, F.; Massicotte, F. DIDroid: Android Malware Classification and Characterization Using Deep Image Learning. In Proceedings of the 2020 the 10th International Conference on Communication and Network Security, Tokyo, Japan, 27–29 November 2020; pp. 70–82. [Google Scholar] [CrossRef]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Chicco, D.; Jurman, G. The advantages of the Matthews correlation coefficient (MCC) over F1 score and accuracy in binary classification evaluation. BMC Genom. 2020, 21, 6. [Google Scholar] [CrossRef] [Green Version]
- Narkhede, S. Understanding auc-roc curve. Towards Data Sci. 2018, 26, 220–227. [Google Scholar]
- Jia, Y.; Qi, Y.; Shang, H.; Jiang, R.; Li, A. A practical approach to constructing a knowledge graph for cybersecurity. Engineering 2018, 4, 53–60. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Authors | Description | Methods | Pros | Limitations | Data Type |
|---|---|---|---|---|---|---|
| Spam Detection using NLP | Swetha and Sridevi (2019) [8] | Utilizes natural language processing (NLP) techniques for spam detection in emails. | NLP techniques | Improves accuracy of spam detection compared to traditional methods. | Limited to detecting spam in emails only. | Text |
| NLP for Cybersecurity | Antonellis et al. (2006) [11], Zhang and Zhang (2010) [10] | Explores different text representation methods such as term-document matrix (TDM), bag-of-words (BoW), and term frequency-inverse document frequency (TFIDF) for cybersecurity applications using NLP techniques. | TDM, BoW, TFIDF | Provides an efficient way of detecting malicious content in large volumes of data. | Performance may be affected by the quality of the data used for training. | Text |
| Embeddings for Malware Classification | Church and Huang (2017) [12], Mahoney and Chan (2000) [13] | Uses word2vec and FastText for classifying malware based on the similarity of word meanings and subword information. | Word2vec, FastText | Embedding techniques can handle semantic relations and patterns of the malware code. | Limited to identifying similarities between malware samples, may not be effective in identifying new types of malware. | Text |
| MalBERT for Malware Classification | Rahali et al. (2021) [7] | Utilizes a fine-tuned BERT model, MalBERT, for binary and multi-classification of malware. | BERT | Can detect different types of malware with high accuracy. | Requires a large amount of labeled data for effective training. | Binary, text |
| URL Classifier using Transformer Model | Rudd et al. (2020) [14] | Implements a URL classifier using the Transformer model trained from scratch. | Transformer model | Effective in detecting malicious URLs with high accuracy. | May require large amounts of computational resources for training and testing. | Text |
| ALBERT for Traffic Network Classification | Han et al. (2020) [15] | Proposes two methods for traffic network classification using pre-trained ALBERT model and transfer learning. | ALBERT, transfer learning | Achieves high accuracy in traffic network classification tasks. | May require fine-tuning on new data to achieve optimal performance. | Text |
| I-MAD for Static Malware Detection | Li et al. (2021) [16] | Proposes I-MAD, a deep learning (DL) model for static malware detection using the Galaxy Transformer network. | DL | Achieves high accuracy in static malware detection tasks. | Limited to detecting known malware samples only. | Binary, image |
| Static Analysis for Malware Detection | Jusoh et al. (2021) [17] | Proposes a guide for researchers on detecting malware through static analysis. | Static analysis | Provides a comprehensive guide for researchers to effectively detect malware through static analysis. | May require technical expertise to effectively implement the proposed methods. | Text |
| Hybrid Analytic Approach for Malware Detection | Srinidhi et al. (2020) [18] | Proposes a framework for big data analysis utilizing both static and dynamic malware detection methods. | Static and dynamic analysis | Combines the strengths of both static and dynamic analysis methods for improved accuracy. | May require a large amount of computational resources for analyzing big data. | Binary, text |
| Attention-based Detection Model | Choi et al. (2020) [19] | Proposes a technique for extracting harmful file features based on an attention mechanism using API system calls. | Attention mechanism | Can detect malware based on API system calls. | May not be effective in detecting new types of malware. | Text |
| GAN-based Method for Malware Detection | Cagatay et al. (2021) [20] | Proposes a GAN-based method using API call graphs obtained from malicious and benign Android files. | GAN | Can detect previously unknown types of malware. | May require a large amount of computational resources for training and testing. | Image |
| HAWK for Adaptive Android Apps | Hei et al. (2021) [21] | Proposes HAWK, a malware detection tool for adaptive Android apps using heterogeneous GANs. | GAN | Can detect previously unknown types of malware. | May require a large amount of computational resources for training and testing. | Image |
| Attention-based BiLSTM for Malware Detection | Pathak et al. (2021) [22] | Uses two attention-based BiLSTM models to find the most predictive API calls for malware detection. | Attention mechanism, BiLSTM | Can effectively detect malware based on API calls. | May not be effective in detecting new types of malware. | Text |
| SLAM for Malware Detection | Chen et al. (2020) [23] | Builds a malware detection technique called SLAM on attention methods that use the semantics of API calls. | Attention mechanism | Can detect malware based on semantic analysis of API calls. | May not be effective in detecting new types of malware. | Text |
| Residual Attention-based Method for Malware Detection | Ganesan et al. (2021) [24] | Uses residual attention methods to find malware by focusing on its key features. | Residual attention mechanism | Can effectively detect malware by focusing on key features. | May not be effective in detecting new types of malware. | Text |
| ATT-CNN- BiLSTM for Identifying DGA Attacks | Ren et al. (2020) [25] | Proposes ATT-CNN-BiLSTM, a DL framework for identifying domain generation algorithm (DGA) attacks. | DL, ATT, CNN, BiLSTM | Can effectively identify DGA attacks with high accuracy. | Limited to identifying DGA attacks only. | Text |
| DeepRan for Ransomware Classification | Lao et al. (2021) | Proposes DeepRan, which uses a fully connected layer and an attention-based BiLSTM for the classification of ransomware. | Attention mechanism, fully connected layer, BiLSTM | Achieves high accuracy in ransomware classification tasks. | Limited to classifying ransomware only. | Text |
| System Designs for Malware Classification | Rupali et al. (2020) [26] | Proposes a survey of the category of malware images. | Image processing techniques | Provides a comprehensive survey of the category of malware images. | Limited to analyzing images of malware samples. | Image |
| Executable Files Analysis of Malware Samples | Singh et al. (2021) [27] | Conducts analysis of executable files of malware samples. | Dynamic analysis | Can effectively analyze executable files of malware samples. | May require a large amount of computational resources for analyzing large datasets. | Binary |
| Ensemble Model for Malware Classification | Kouliaridis et al. (2021) [28] | Proposes an ensemble model that combines static and dynamic analysis. | Static and dynamic analysis, ensemble learning | Can effectively detect different types of malware with high accuracy. | May require a large amount of computational resources for training and testing. | Binary |
| DL Model for Malware Detection | Syed et al. (2021) [29] | Proposes DeepAMD, a DL model for malware detection. | DL | Achieves high accuracy in detecting different types of malware. | Requires a large amount of labeled data for effective training. | Binary, image |
| Customized Learning Models for AM Detection | Amin et al. (2020) [30] | Proposes an anti-malware system that uses customized learning models. | Customized learning models | Can effectively detect different types of malware with high accuracy. | May require a large amount of computational resources for training and testing. | Binary, image |
| PetaDroid for AM Detection | Karbab et al. (2021) [31] | Proposes PetaDroid, a static analysis-based method for detecting AM. | Static analysis | Can detect previously unknown types of malware. | May not be effective in detecting new types of malware. | Binary |
| Performance Comparison of Pre-trained CNN Models | Pooja et al. (2022) [32] | Conducts a performance comparison of 26 pre-trained CNN models in AM detection. | Pre-trained CNN models | Provides a comprehensive comparison of different pre-trained CNN models. | May require a large amount of computational resources for training and testing. | Image |
| Anomaly Detection Approach | Chong et al. (2022) [33] | Proposes an anomaly detection approach based on a two-head neural network. | Neural network | Can effectively detect anomalies in malware samples. | May require a large amount of computational resources for training and testing. | Binary, image |
| GNN-based Method for AM Detection | Weng Lo et al. (2022) [34] | Proposes a GNN-based method for AM detection by capturing meaningful intra-procedural call path patterns. | GNN | Can detect previously unknown types of malware. | May require a large amount of computational resources for training and testing. | Binary, image |
| Original File | Preprocessed File |
|---|---|
| <?xml version="1.0" encoding="UTF-8" encoding="utf-8" standalone="no"?> <manifest xmlns:android="http://schemas.android.com/APK/res/android" package="com.lbcsoft.subway"> <uses-permission android:name="android.permission.INTERNET"/> <uses-permission android:name="android.permission.CALL_PHONE"/> <application android:allowBackup="true" android:debuggable="true" android:icon="@drawable/icon_youke_subway" android:label="@string/app_name" android:theme="@android:style/Theme.NoTitleBar"> | xml version encoding utf standalone nomanifest xmlns android http schemas android com APK res android package com lbcsoft subway uses permission android name android permission internet uses permission android name android permission call phone application android allow backup true android debuggable true android icon drawable icon youke subway android label string app name android theme android style theme no title bar |
| Model | Data | Accuracy | f1 (mc) | mcc | Precision (mc) | Recall (mc) | auc |
|---|---|---|---|---|---|---|---|
| TFIDF + SVM | MixG-Androzoo | 0.969589 | 0.969805 | 0.939478 | 0.957895 | 0.982014 | 0.969655 |
| MixG-VirusShare | 0.858803 | 0.857143 | 0.717704 | 0.864964 | 0.849462 | 0.858778 | |
| MixG-AMD | 0.931127 | 0.932751 | 0.863799 | 0.906621 | 0.960432 | 0.931283 | |
| MixG-Derbin | 0.935599 | 0.935018 | 0.871212 | 0.938406 | 0.931655 | 0.935578 | |
| Fasttext + CNN | MixG-Androzoo | 0.953488 | 0.955403 | 0.906829 | 0.958692 | 0.952137 | 0.953554 |
| MixG-VirusShare | 0.801609 | 0.763326 | 0.644415 | 0.962366 | 0.632509 | 0.803596 | |
| MixG-AMD | 0.927549 | 0.933113 | 0.856619 | 0.902556 | 0.965812 | 0.925683 | |
| MixG-Derbin | 0.929338 | 0.930396 | 0.860468 | 0.96 | 0.902564 | 0.930644 | |
| MalBERT | MixG-Androzoo | 0.975689 | 0.976183 | 0.971568 | 0.98651 | 0.966068 | 0.976158 |
| MixG-VirusShare | 0.924039 | 0.924712 | 0.84808 | 0.927176 | 0.922261 | 0.92406 | |
| MixG-AMD | 0.970483 | 0.971478 | 0.941157 | 0.982517 | 0.960684 | 0.970961 | |
| MixG-Derbin | 0.966905 | 0.968076 | 0.933909 | 0.977352 | 0.958974 | 0.967292 | |
| TFIDF + Transformer From Scratch | MixG-Androzoo | 0.9558 | 0.954981 | 0.943421 | 0.952922 | 0.963211 | 0.954092 |
| MixG-VirusShare | 0.9231125 | 0.925467 | 0.884563 | 0.923224 | 0.927892 | 0.92343 | |
| MixG-AMD | 0.9576809 | 0.9540987 | 0.945896 | 0.977345 | 0.973099 | 0.967554 | |
| MixG-Derbin | 0.9567821 | 0.9560983 | 0.958763 | 0.967812 | 0.964398 | 0.968989 | |
| MalBERTv2 = FeatureAnalyzer + MalBERT | MixG-Androzoo | 0.990744 | 0.998341 | 0.991149 | 0.99765 | 0.999033 | 0.998901 |
| MixG-VirusShare | 0.956782 | 0.957819 | 0.945887 | 0.957164 | 0.956292 | 0.944226 | |
| MixG-AMD | 0.988787 | 0.989742 | 0.961892 | 0.999834 | 0.988987 | 0.985977 | |
| MixG-Derbin | 0.988954 | 0.989645 | 0.974889 | 0.998328 | 0.978884 | 0.987329 |
| Model | Data | Accuracy | f1 (mc) | mcc | Precision (mc) | Recall (mc) | auc |
|---|---|---|---|---|---|---|---|
| TFIDF + SVM | D01 | 0.570881 | 0.721393 | 0.188245 | 0.653153 | 0.805556 | 0.427469 |
| D02 | 0.582226 | 0.728216 | 0.122358 | 0.576176 | 0.989259 | 0.520577 | |
| D03 | 0.582226 | 0.728216 | 0.122358 | 0.576176 | 0.989259 | 0.520577 | |
| D04 | 0.814212 | 0.838955 | 0.619591 | 0.832186 | 0.845834 | 0.808882 | |
| D05 | 0.599373 | 0.74552 | 0.123743 | 0.641096 | 0.89058 | 0.463673 | |
| Fasttext + CNN | D01 | 0.617084 | 0.727308 | 0.158007 | 0.627276 | 0.865297 | 0.562497 |
| D02 | 0.886327 | 0.989815 | 0.872379 | 0.876578 | 0.844387 | 0.834099 | |
| D03 | 0.681754 | 0.628078 | 0.59842 | 0.586972 | 0.614239 | 0.607119 | |
| D04 | 0.888516 | 0.889971 | 0.876653 | 0.883587 | 0.896437 | 0.887252 | |
| D05 | 0.664133 | 0.798173 | 0.562563 | 0.664133 | 0.758021 | 0.758021 | |
| MalBERT | D01 | 0.694449 | 0.734708 | 0.656146 | 0.698335 | 0.951598 | 0.615904 |
| D02 | 0.799747 | 0.799775 | 0.799485 | 0.699775 | 0.899775 | 0.899743 | |
| D03 | 0.798821 | 0.79815 | 0.797286 | 0.698766 | 0.897535 | 0.898479 | |
| D04 | 0.899875 | 0.79989 | 0.699745 | 0.79978 | 0.899855 | 0.898855 | |
| D05 | 0.759333 | 0.794697 | 0.659333 | 0.679373 | 0.669332 | 0.568801 | |
| TFIDF + Transformer From Scratch | D01 | 0.623949 | 0.664798 | 0.554896 | 0.688923 | 0.551898 | 0.593549 |
| D02 | 0.783359 | 0.742259 | 0.669237 | 0.682342 | 0.789149 | 0.778833 | |
| D03 | 0.824719 | 0.829188 | 0.779938 | 0.738336 | 0.793799 | 0.812268 | |
| D04 | 0.903338 | 0.894773 | 0.823442 | 0.813492 | 0.813457 | 0.848735 | |
| D05 | 0.775727 | 0.764993 | 0.754489 | 0.749271 | 0.773246 | 0.735923 | |
| MalBERTv2 = FeatureAnalyzer + MalBERT | D01 | 0.824623 | 0.793342 | 0.784459 | 0.824836 | 0.821458 | 0.813454 |
| D02 | 0.883678 | 0.857334 | 0.782653 | 0.773456 | 0.889922 | 0.879653 | |
| D03 | 0.894577 | 0.889882 | 0.848883 | 0.928921 | 0.893939 | 0.881948 | |
| D04 | 0.937643 | 0.894388 | 0.799922 | 0.923562 | 0.973252 | 0.928798 | |
| D05 | 0.834465 | 0.834781 | 0.835549 | 0.872873 | 0.873984 | 0.833654 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rahali, A.; Akhloufi, M.A. MalBERTv2: Code Aware BERT-Based Model for Malware Identification. Big Data Cogn. Comput. 2023, 7, 60. https://doi.org/10.3390/bdcc7020060
Rahali A, Akhloufi MA. MalBERTv2: Code Aware BERT-Based Model for Malware Identification. Big Data and Cognitive Computing. 2023; 7(2):60. https://doi.org/10.3390/bdcc7020060
Chicago/Turabian StyleRahali, Abir, and Moulay A. Akhloufi. 2023. "MalBERTv2: Code Aware BERT-Based Model for Malware Identification" Big Data and Cognitive Computing 7, no. 2: 60. https://doi.org/10.3390/bdcc7020060
APA StyleRahali, A., & Akhloufi, M. A. (2023). MalBERTv2: Code Aware BERT-Based Model for Malware Identification. Big Data and Cognitive Computing, 7(2), 60. https://doi.org/10.3390/bdcc7020060