

Improving Natural Language Person Description Search from Videos with Language Model Fine-Tuning and Approximate Nearest Neighbor


Abstract
:1. Introduction
2. Related Works
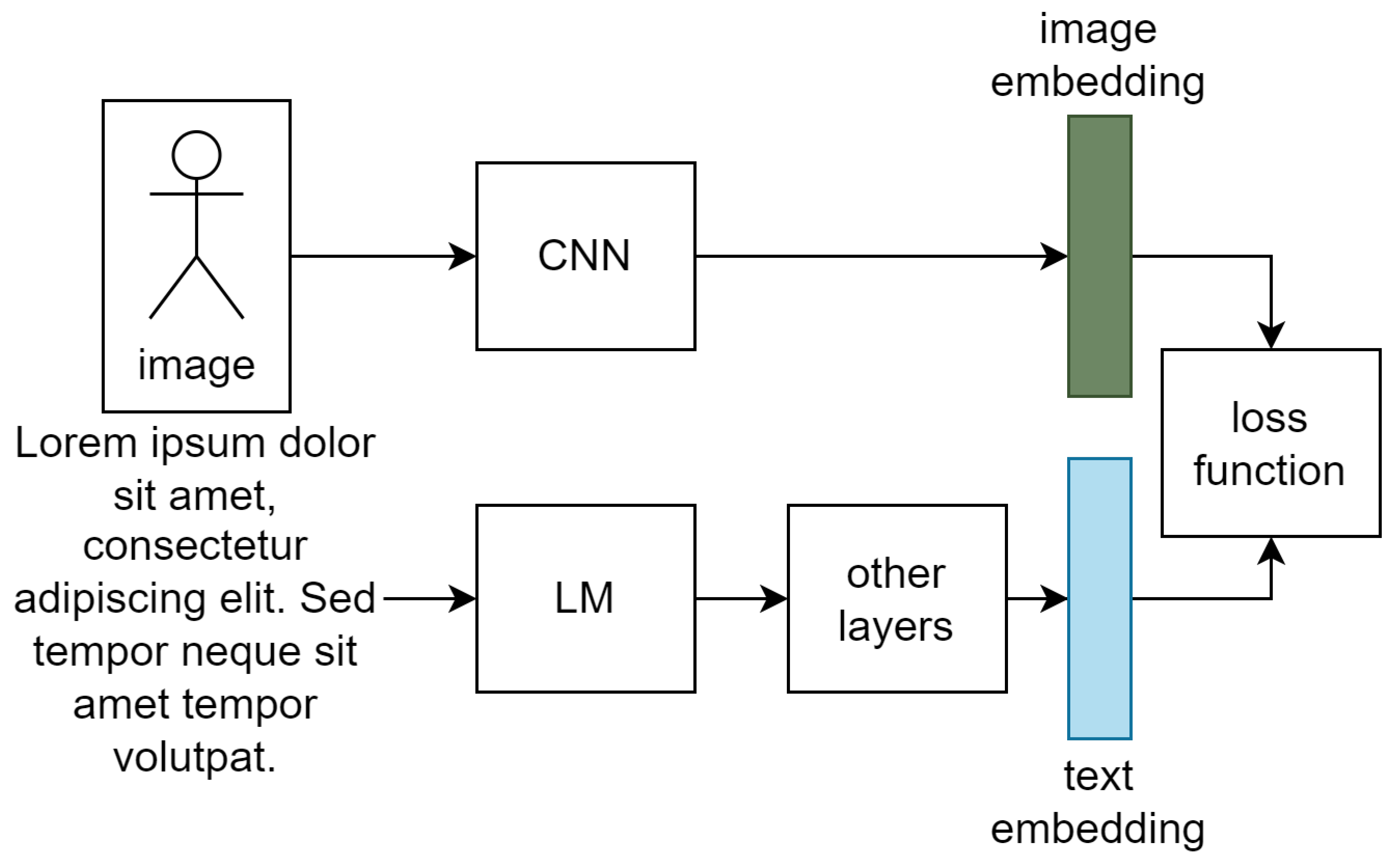
2.1. Joint Image-Text Embedding
2.2. Language Models in Person Description Search
2.3. Loss for Image-Text Matching
2.4. Approximated Nearest Neighbor Search
2.5. Object Detection and Tracking
3. Methods
3.1. Video Indexing Pipeline
| Algorithm 1 Tracking and Bounding Box Filtering |
|
| Algorithm 2 Building ANN Structure for Fast Person Description Search |
|
| Algorithm 3 Searching The ANN Structure |
|
3.2. LM-Finetuning and Model Training
3.3. ANN Construction
4. Results
4.1. The Impact of LM-Finetuning
4.2. System for Person Description Search
4.3. Search Result on Unseen Data
4.4. Comparison of Search Speeds
4.5. Limitations
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Frome, A.; Corrado, G.S.; Shlens, J.; Bengio, S.; Dean, J.; Ranzato, M.; Mikolov, T. Devise: A deep visual-semantic embedding model. Adv. Neural Inf. Process. Syst. 2013, 26, 2121–2129. [Google Scholar]
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation applied to handwritten zip code recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- Rosasco, L.; De Vito, E.; Caponnetto, A.; Piana, M.; Verri, A. Are loss functions all the same? Neural Comput. 2004, 16, 1063–1076. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, S.; Xiao, T.; Li, H.; Zhou, B.; Yue, D.; Wang, X. Person search with natural language description. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1970–1979. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Lu, H. Deep cross-modal projection learning for image-text matching. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 686–701. [Google Scholar]
- Liu, X.; Zhao, H.; Tian, M.; Sheng, L.; Shao, J.; Yi, S.; Yan, J.; Wang, X. Hydraplus-net: Attentive deep features for pedestrian analysis. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 350–359. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Li, S.; Xiao, T.; Li, H.; Yang, W.; Wang, X. Identity-aware textual-visual matching with latent co-attention. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1890–1899. [Google Scholar]
- Sarafianos, N.; Xu, X.; Kakadiaris, I.A. Adversarial representation learning for text-to-image matching. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November; pp. 5814–5824.
- Ge, J.; Gao, G.; Liu, Z. Visual-textual association with hardest and semi-hard negative pairs mining for person search. arXiv 2019, arXiv:1912.03083. [Google Scholar]
- Niu, K.; Huang, Y.; Wang, L. Fusing two directions in cross-domain adaption for real life person search by language. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Korea, 27–28 October 2019. [Google Scholar]
- Jing, Y.; Si, C.; Wang, J.; Wang, W.; Wang, L.; Tan, T. Pose-guided multi-granularity attention network for text-based person search. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 11189–11196. [Google Scholar]
- Niu, K.; Huang, Y.; Ouyang, W.; Wang, L. Improving description-based person re-identification by multi-granularity image-text alignments. IEEE Trans. Image Process. 2020, 29, 5542–5556. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gao, C.; Cai, G.; Jiang, X.; Zheng, F.; Zhang, J.; Gong, Y.; Peng, P.; Guo, X.; Sun, X. Contextual non-local alignment over full-scale representation for text-based person search. arXiv 2021, arXiv:2101.03036. [Google Scholar]
- Wang, Z.; Fang, Z.; Wang, J.; Yang, Y. Vitaa: Visual-textual attributes alignment in person search by natural language. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 402–420. [Google Scholar]
- Zheng, Z.; Zheng, L.; Garrett, M.; Yang, Y.; Xu, M.; Shen, Y.D. Dual-path convolutional image-text embeddings with instance loss. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2020, 16, 1–23. [Google Scholar] [CrossRef]
- Chen, Y.; Zhang, G.; Lu, Y.; Wang, Z.; Zheng, Y. TIPCB: A simple but effective part-based convolutional baseline for text-based person search. Neurocomputing 2022, 494, 171–181. [Google Scholar] [CrossRef]
- Wojke, N.; Bewley, A.; Paulus, D. Simple online and realtime tracking with a deep association metric. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3645–3649. [Google Scholar]
- The Latest in Machine Learning|Papers with Code. Available online: https://paperswithcode.com (accessed on 25 October 2022).
- Xiao, T.; Li, S.; Wang, B.; Lin, L.; Wang, X. End-to-end deep learning for person search. arXiv 2016, arXiv:1604.01850. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 6000–6010. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Zhu, Y.; Kiros, R.; Zemel, R.; Salakhutdinov, R.; Urtasun, R.; Torralba, A.; Fidler, S. Aligning Books and Movies: Towards Story-Like Visual Explanations by Watching Movies and Reading Books. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Chechik, G.; Sharma, V.; Shalit, U.; Bengio, S. Large Scale Online Learning of Image Similarity through Ranking. J. Mach. Learn. Res. 2010, 11, 1109–1135. [Google Scholar]
- Andoni, A.; Indyk, P. Near-optimal hashing algorithms for approximate nearest neighbor in high dimensions. In Proceedings of the 2006 47th Annual IEEE Symposium on Foundations of Computer Science (FOCS’06), Berkeley, CA, USA, 22–24 October 2006; pp. 459–468. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Wieczorek, M.; Rychalska, B.; Dąbrowski, J. On the unreasonable effectiveness of centroids in image retrieval. In Proceedings of the International Conference on Neural Information Processing, Bali, Indonesia, 8–12 December 2021; pp. 212–223. [Google Scholar]
- Bengio, Y.; Courville, A.; Vincent, P. Representation learning: A review and new perspectives. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1798–1828. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Broström, M. Real-Time Multi-Camera Multi-Object Tracker Using YOLOv5 and StrongSORT with OSNet. 2022. Available online: https://github.com/mikel-brostrom/Yolov5_StrongSORT_OSNet (accessed on 9 September 2022).
- Malkov, Y.A.; Yashunin, D.A. Efficient and robust approximate nearest neighbor search using hierarchical navigable small world graphs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 42, 824–836. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Lowphansirikul, L.; Polpanumas, C.; Jantrakulchai, N.; Nutanong, S. Wangchanberta: Pretraining transformer-based thai language models. arXiv 2021, arXiv:2101.09635. [Google Scholar]
- Conneau, A.; Khandelwal, K.; Goyal, N.; Chaudhary, V.; Wenzek, G.; Guzmán, F.; Grave, E.; Ott, M.; Zettlemoyer, L.; Stoyanov, V. Unsupervised cross-lingual representation learning at scale. arXiv 2019, arXiv:1911.02116. [Google Scholar]
- Hugging Face—The AI Community Building the Future. Available online: https://huggingface.co (accessed on 25 October 2022).
- Pytorch Lightning. Available online: https://www.pytorchlightning.ai (accessed on 25 October 2022).
- ONNX Home. Available online: https://onnx.ai (accessed on 25 October 2022).
- nmslib/hnswlib: Header-Only C++/Python Library for Fast Approximate Nearest Neighbors. Available online: https://github.com/nmslib/hnswlib (accessed on 25 October 2022).
- Han, X.; He, S.; Zhang, L.; Xiang, T. Text-based person search with limited data. arXiv 2021, arXiv:2110.10807. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameter | Value |
|---|---|
| batch size | 32 |
| learning rate | |
| MLM mask probability | 5% |
| maximum text length | 64 (subword) tokens |
| weight decay | 0.001 |
| warmup steps | 1400 |
| half precision (FP16) | true |
| train epochs | 100 |
| early stopping patient | 10 epoch |
| optimizer | Adam |
| Hyperparameter | Value |
|---|---|
| batch size | 32 |
| learning rate | |
| Maximum text length (tokens) | 64 |
| Weight decay | |
| Number of epochs | 80 |
| Learning rate reduction epoch | 40 |
| Learning rate reduction factor | 10 |
| Warmup epochs | 10 |
| optimizer | Adam |
| Language | Model | LM-Finetune | Top-1 | Top-5 | Top-10 |
|---|---|---|---|---|---|
| en | BERT-base | n | 0.6314 | 0.8266 | 0.8890 |
| en | BERT-base | y | 0.6424 | 0.8297 | 0.8930 |
| en | BERT-large | n | 0.6399 | 0.8332 | 0.8933 |
| en | BERT-large | y | 0.6354 | 0.8327 | 0.8862 |
| en | RoBERTa-base | n | 0.6324 | 0.8294 | 0.8901 |
| en | RoBERTa-base | y | 0.6451 | 0.8303 | 0.8919 |
| en | RoBERTa-large | n | 0.6319 | 0.8221 | 0.8874 |
| en | RoBERTa-large | y | 0.6429 | 0.8285 | 0.8905 |
| th | WangchanBERTa | n | 0.1690 | 0.2935 | 0.3578 |
| th | WangchanBERTa | y | 0.5737 | 0.7771 | 0.8452 |
| th | xlm-roberta-base | n | 0.5566 | 0.7720 | 0.8470 |
| th | xlm-roberta-base | y | 0.5745 | 0.7794 | 0.8507 |
| th | xlm-roberta-large | n | 0.5564 | 0.7668 | 0.8436 |
| th | xlm-roberta-large | y | 0.5695 | 0.7802 | 0.8468 |
| Video | Number of People | Direct Method | Our Method |
|---|---|---|---|
| 1 | 383 | timeout (>1 min) | <1 s |
| 2 | 103 | 24 s | <1 s |
| 3 | 207 | 47 s | <1 s |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yuenyong, S.; Wongpatikaseree, K. Improving Natural Language Person Description Search from Videos with Language Model Fine-Tuning and Approximate Nearest Neighbor. Big Data Cogn. Comput. 2022, 6, 136. https://doi.org/10.3390/bdcc6040136
Yuenyong S, Wongpatikaseree K. Improving Natural Language Person Description Search from Videos with Language Model Fine-Tuning and Approximate Nearest Neighbor. Big Data and Cognitive Computing. 2022; 6(4):136. https://doi.org/10.3390/bdcc6040136
Chicago/Turabian StyleYuenyong, Sumeth, and Konlakorn Wongpatikaseree. 2022. "Improving Natural Language Person Description Search from Videos with Language Model Fine-Tuning and Approximate Nearest Neighbor" Big Data and Cognitive Computing 6, no. 4: 136. https://doi.org/10.3390/bdcc6040136
APA StyleYuenyong, S., & Wongpatikaseree, K. (2022). Improving Natural Language Person Description Search from Videos with Language Model Fine-Tuning and Approximate Nearest Neighbor. Big Data and Cognitive Computing, 6(4), 136. https://doi.org/10.3390/bdcc6040136