

PSO-Driven Feature Selection and Hybrid Ensemble for Network Anomaly Detection


Abstract
:1. Introduction
- (a)
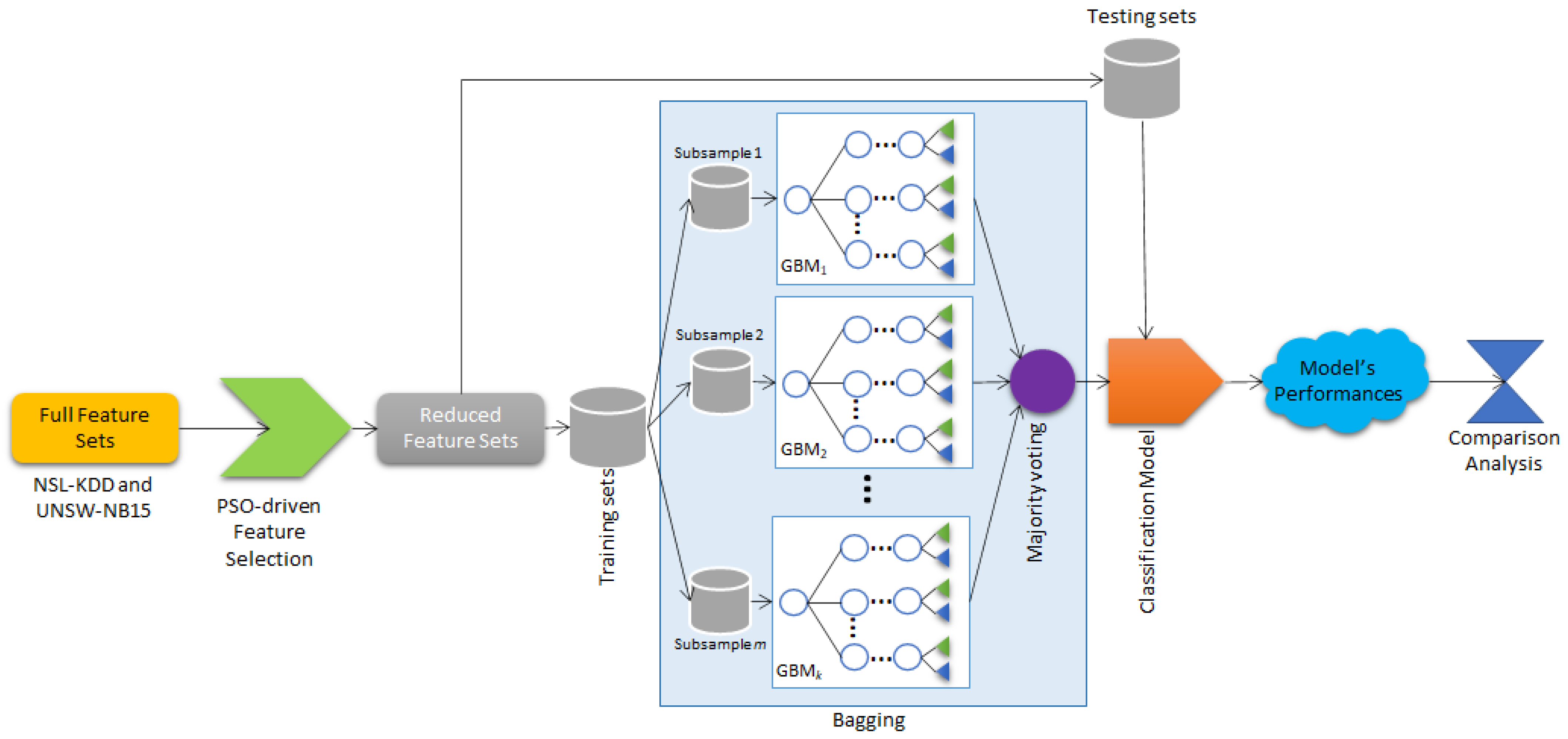
- A simple yet accurate network anomaly detection using hybrid bagging and GBM ensemble is proposed. GBM is not trained independently as a classifier; rather, we use it as the base learning model for bagging in order to increase its detection performance.
- (b)
- A PSO-guided feature selection is applied to choose the most optimal subset of features for the input of the hybrid ensemble model. The full feature set may not give substantial prediction accuracy; thus, we use an optimum feature subset derived from the PSO-based feature selection approach.
- (c)
- Based on our experiment validation, our proposed model is superior compared to existing anomaly-based IDS methods presented in the current literature.
2. Related Work
3. Materials and Methods
3.1. Data Sets
3.2. Methods
3.2.1. PSO-Based Feature Selection
3.2.2. Hybrid Ensemble Based on Bagging-GBM
| Algorithm 1: A procedure to construct bagging–GBM for anomaly-based IDS. |
Building classification model: Require: Training set ; base classifier (e.g., GBM); number of GBMs ; size of subsample . 1. 1 2. repeat 3. replacement-based subsample of instances from D. 4. Construct classifier using GBM on . 5. 6. until Evaluating classification model: Require: An object deserving of a classification . Output: Final class label prediction 1. 2. for to do 3. 4. 5. end for 6. the most prevalent class label chosen by constituents. 7. Return |
3.2.3. Evaluation Criteria
3.3. Metrics
3.4. Validation Procedure
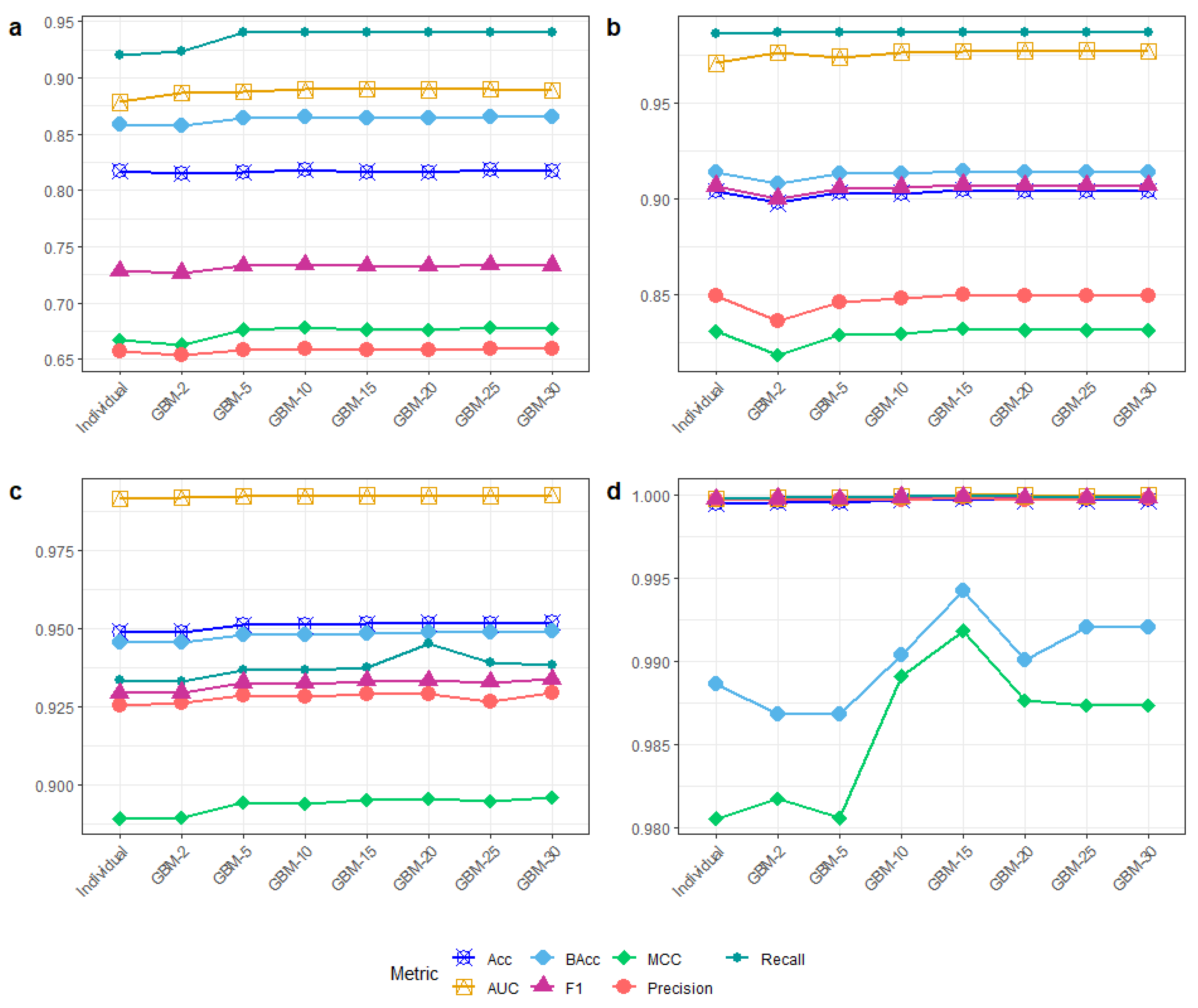
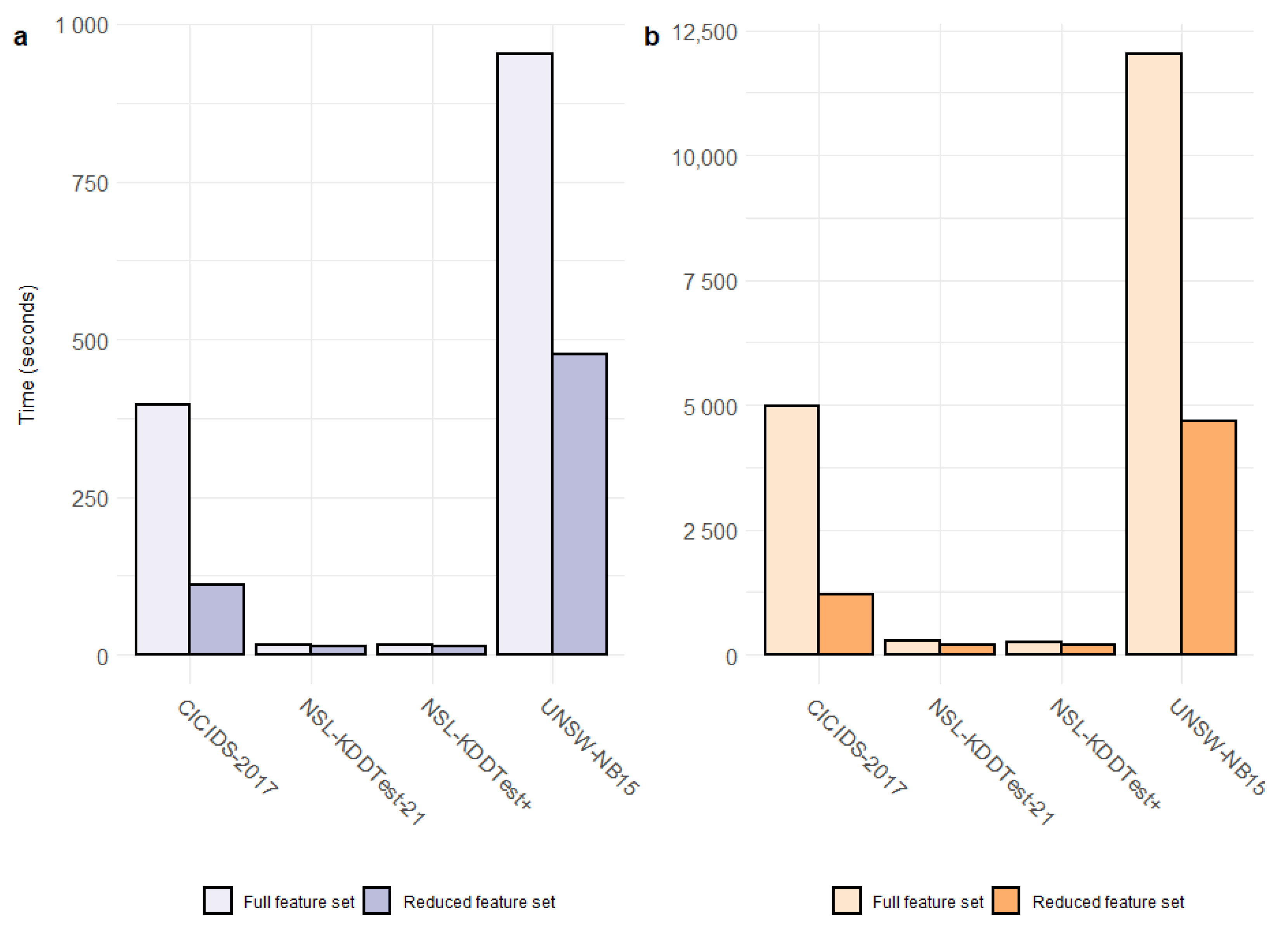
4. Results and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
List of Acronyms
| AB | Adaboost |
| AUC | Area Under ROC Curve |
| BA | Bat Algorithm |
| CFS | Correlation-based Feature Selection |
| CV | Cross Validation |
| DL | Deep Learning |
| DNN | Deep Neural Network |
| DT | Decision Tree |
| FPE | Feature Probability Estimation |
| GA | Genetic Algorithm |
| GR | Gain Ratio |
| HGB | Histogram-based Gradient Boosting |
| IBL | Instance-based Learning |
| IFA | Improved Firefly Algorithm |
| IG | Information Gain |
| LR | Logistic Regression |
| MCC | Matthew Correlation Coefficient |
| MLP | Multilayer Perceptron |
| NB | Naive Bayes |
| NN | Neural Network |
| PC | Pearson Correlation |
| PCA | Principle Component Analysis |
| RF | Random Forest |
| SVM | Support Vector Machine |
References
- Ghorbani, A.A.; Lu, W.; Tavallaee, M. Network Intrusion Detection and Prevention: Concepts and Techniques; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2009; Volume 47. [Google Scholar]
- Bhattacharyya, D.K.; Kalita, J.K. Network Anomaly Detection: A Machine Learning Perspective; CRC Press: Boca Raton, FL, USA, 2013. [Google Scholar]
- Thakkar, A.; Lohiya, R. A review on machine learning and deep learning perspectives of IDS for IoT: Recent updates, security issues, and challenges. Arch. Comput. Methods Eng. 2021, 28, 3211–3243. [Google Scholar] [CrossRef]
- Rokach, L. Pattern Classification Using Ensemble Methods; World Scientific: Singapore, 2010; Volume 75. [Google Scholar]
- Tama, B.A.; Lim, S. Ensemble learning for intrusion detection systems: A systematic mapping study and cross-benchmark evaluation. Comput. Sci. Rev. 2021, 39, 100357. [Google Scholar] [CrossRef]
- Tama, B.A.; Rhee, K.H. HFSTE: Hybrid Feature Selections and Tree-Based Classifiers Ensemble for Intrusion Detection System. IEICE Trans. Inf. Syst. 2017, 100D, 1729–1737. [Google Scholar] [CrossRef] [Green Version]
- Tama, B.A.; Comuzzi, M.; Rhee, K.H. TSE-IDS: A two-stage classifier ensemble for intelligent anomaly-based intrusion detection system. IEEE Access 2019, 7, 94497–94507. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef] [Green Version]
- Khraisat, A.; Gondal, I.; Vamplew, P.; Kamruzzaman, J. Survey of intrusion detection systems: Techniques, datasets and challenges. Cybersecurity 2019, 2, 20. [Google Scholar] [CrossRef] [Green Version]
- Resende, P.A.A.; Drummond, A.C. A Survey of Random Forest Based Methods for Intrusion Detection Systems. ACM Comput. Surv. 2018, 51, 1–36. [Google Scholar] [CrossRef]
- Aburomman, A.A.; Reaz, M.B.I. A survey of intrusion detection systems based on ensemble and hybrid classifiers. Comput. Secur. 2017, 65, 135–152. [Google Scholar] [CrossRef]
- Thakkar, A.; Lohiya, R. A survey on intrusion detection system: Feature selection, model, performance measures, application perspective, challenges, and future research directions. Artif. Intell. Rev. 2022, 55, 453–563. [Google Scholar] [CrossRef]
- Lohiya, R.; Thakkar, A. Application domains, evaluation data sets, and research challenges of IoT: A Systematic Review. IEEE Internet Things J. 2020, 8, 8774–8798. [Google Scholar] [CrossRef]
- Thakkar, A.; Lohiya, R. A review of the advancement in intrusion detection datasets. Procedia Comput. Sci. 2020, 167, 636–645. [Google Scholar] [CrossRef]
- Jafarian, T.; Masdari, M.; Ghaffari, A.; Majidzadeh, K. Security anomaly detection in software-defined networking based on a prediction technique. Int. J. Commun. Syst. 2020, 33, e4524. [Google Scholar] [CrossRef]
- Kaur, G. A comparison of two hybrid ensemble techniques for network anomaly detection in spark distributed environment. J. Inf. Secur. Appl. 2020, 55, 102601. [Google Scholar] [CrossRef]
- Seth, S.; Chahal, K.K.; Singh, G. A novel ensemble framework for an intelligent intrusion detection system. IEEE Access 2021, 9, 138451–138467. [Google Scholar] [CrossRef]
- Halim, Z.; Yousaf, M.N.; Waqas, M.; Sulaiman, M.; Abbas, G.; Hussain, M.; Ahmad, I.; Hanif, M. An effective genetic algorithm-based feature selection method for intrusion detection systems. Comput. Secur. 2021, 110, 102448. [Google Scholar] [CrossRef]
- Nazir, A.; Khan, R.A. A novel combinatorial optimization based feature selection method for network intrusion detection. Comput. Secur. 2021, 102, 102164. [Google Scholar] [CrossRef]
- Jain, M.; Kaur, G. Distributed anomaly detection using concept drift detection based hybrid ensemble techniques in streamed network data. Clust. Comput. 2021, 24, 2099–2114. [Google Scholar] [CrossRef]
- Krishnaveni, S.; Sivamohan, S.; Sridhar, S.; Prabakaran, S. Efficient feature selection and classification through ensemble method for network intrusion detection on cloud computing. Clust. Comput. 2021, 24, 1761–1779. [Google Scholar] [CrossRef]
- Liu, J.; Gao, Y.; Hu, F. A fast network intrusion detection system using adaptive synthetic oversampling and LightGBM. Comput. Secur. 2021, 106, 102289. [Google Scholar] [CrossRef]
- Al, S.; Dener, M. STL-HDL: A new hybrid network intrusion detection system for imbalanced dataset on big data environment. Comput. Secur. 2021, 110, 102435. [Google Scholar] [CrossRef]
- Tian, Q.; Han, D.; Hsieh, M.Y.; Li, K.C.; Castiglione, A. A two-stage intrusion detection approach for software-defined IoT networks. Soft Comput. 2021, 25, 10935–10951. [Google Scholar] [CrossRef]
- Zhang, H.; Li, J.L.; Liu, X.M.; Dong, C. Multi-dimensional feature fusion and stacking ensemble mechanism for network intrusion detection. Future Gener. Comput. Syst. 2021, 122, 130–143. [Google Scholar] [CrossRef]
- Gupta, N.; Jindal, V.; Bedi, P. CSE-IDS: Using cost-sensitive deep learning and ensemble algorithms to handle class imbalance in network-based intrusion detection systems. Comput. Secur. 2022, 112, 102499. [Google Scholar] [CrossRef]
- Krishnaveni, S.; Sivamohan, S.; Sridhar, S.; Prabhakaran, S. Network intrusion detection based on ensemble classification and feature selection method for cloud computing. Concurr. Comput. Pract. Exp. 2022, 34, e6838. [Google Scholar] [CrossRef]
- Rashid, M.; Kamruzzaman, J.; Imam, T.; Wibowo, S.; Gordon, S. A tree-based stacking ensemble technique with feature selection for network intrusion detection. Appl. Intell. 2022, 52, 9768–9781. [Google Scholar] [CrossRef]
- Wang, Z.; Liu, J.; Sun, L. EFS-DNN: An Ensemble Feature Selection-Based Deep Learning Approach to Network Intrusion Detection System. Secur. Commun. Netw. 2022, 2022, 2693948. [Google Scholar] [CrossRef]
- Wolpert, D.H. Stacked generalization. Neural Netw. 1992, 5, 241–259. [Google Scholar] [CrossRef]
- Ting, K.M.; Witten, I.H. Issues in stacked generalization. J. Artif. Intell. Res. 1999, 10, 271–289. [Google Scholar] [CrossRef] [Green Version]
- Schapire, R.E.; Freund, Y. Boosting: Foundations and algorithms. Kybernetes 2013, 42, 164–166. [Google Scholar] [CrossRef]
- Thakkar, A.; Lohiya, R. Fusion of statistical importance for feature selection in Deep Neural Network-based Intrusion Detection System. Inf. Fusion 2022, 90, 353–363. [Google Scholar] [CrossRef]
- Thakkar, A.; Lohiya, R. Attack classification using feature selection techniques: A comparative study. J. Ambient Intell. Humaniz. Comput. 2021, 12, 1249–1266. [Google Scholar] [CrossRef]
- Thakkar, A.; Lohiya, R. Role of swarm and evolutionary algorithms for intrusion detection system: A survey. Swarm Evol. Comput. 2020, 53, 100631. [Google Scholar] [CrossRef]
- Tavallaee, M.; Bagheri, E.; Lu, W.; Ghorbani, A.A. A detailed analysis of the KDD CUP 99 data set. In Proceedings of the 2009 IEEE Symposium on Computational Intelligence for Security and Defense Applications, Ottawa, ON, Canada, 8–10 July 2009; pp. 1–6. [Google Scholar]
- Moustafa, N.; Slay, J. UNSW-NB15: A comprehensive data set for network intrusion detection systems (UNSW-NB15 network data set). In Proceedings of the 2015 Military Communications and Information Systems Conference (MilCIS), Canberra, Australia, 10–12 November 2015; pp. 1–6. [Google Scholar]
- Sharafaldin, I.; Lashkari, A.H.; Ghorbani, A.A. Toward generating a new intrusion detection dataset and intrusion traffic characterization. ICISSp 2018, 1, 108–116. [Google Scholar]
- Hall, M.A. Correlation-Based Feature Selection for Machine Learning. Ph.D. Thesis, The University of Waikato, Hamilton, New Zealand, 1999. [Google Scholar]
- Kennedy, J.; Eberhart, R.C. A discrete binary version of the particle swarm algorithm. In Proceedings of the 1997 IEEE International Conference on Systems, Man, and Cybernetics, Computational Cybernetics and Simulation, Orlando, FL, USA, 12–15 October 1997; Volume 5, pp. 4104–4108. [Google Scholar]
- Brodersen, K.H.; Ong, C.S.; Stephan, K.E.; Buhmann, J.M. The balanced accuracy and its posterior distribution. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 3121–3124. [Google Scholar]
- Chicco, D.; Tötsch, N.; Jurman, G. The Matthews correlation coefficient (MCC) is more reliable than balanced accuracy, bookmaker informedness, and markedness in two-class confusion matrix evaluation. BioData Min. 2021, 14, 13. [Google Scholar] [CrossRef] [PubMed]
- Demšar, J. Statistical comparisons of classifiers over multiple data sets. J. Mach. Learn. Res. 2006, 7, 1–30. [Google Scholar]
- Tama, B.A.; Nkenyereye, L.; Islam, S.R.; Kwak, K.S. An Enhanced Anomaly Detection in Web Traffic Using a Stack of Classifier Ensemble. IEEE Access 2020, 8, 24120–24134. [Google Scholar] [CrossRef]
- Ieracitano, C.; Adeel, A.; Morabito, F.C.; Hussain, A. A novel statistical analysis and autoencoder driven intelligent intrusion detection approach. Neurocomputing 2020, 387, 51–62. [Google Scholar] [CrossRef]
- Zhou, Y.; Cheng, G.; Jiang, S.; Dai, M. Building an efficient intrusion detection system based on feature selection and ensemble classifier. Comput. Netw. 2020, 174, 107247. [Google Scholar] [CrossRef] [Green Version]
- Prasad, M.; Tripathi, S.; Dahal, K. An efficient feature selection based Bayesian and Rough set approach for intrusion detection. Appl. Soft Comput. 2020, 87, 105980. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, Q. On IoT intrusion detection based on data augmentation for enhancing learning on unbalanced samples. Future Gener. Comput. Syst. 2022, 133, 213–227. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author(s) | Ensemble Approach(es) | Base Learner(s) | Feature Selector | Validation Method(s) | Dataset(s) |
|---|---|---|---|---|---|
| [16] | Stacking | NN, NB, DL, SVM | IG | Hold-out | Private |
| [17] | AB, stacking | LR, RF | PCA | CV and hold-out | NSL-KDD, UNSW-NB15 |
| [18] | RF, XGBoost, HGB, LightGBM | - | RF+PCA | CV | CICIDS-2018 |
| [19] | XGBoost | - | GA | CV | CIRA-CIC-DoHBrw-2020, Bot-IoT, UNSW-NB15 |
| [20] | RF | - | Gain ratio, Chi-squared, Pearson correlation | Hold-out | UNSW-NB15 |
| [21] | Stacking | RF, LR | K-means | Hold-out | NSL-KDD, CIDDS-2017, Testbed |
| [22] | Majority voting | SVM, NB, LR, DT | Filter and univariate ensemble | CV | Honeypot, NSL-KDD, Kyoto |
| [23] | LightGBM | - | - | CV | NSL-KDD, UNSW-NB15, CICIDS-2017 |
| [24] | RF | - | - | Hold-out | CIDDS-001, UNSW-NB15 |
| [25] | Weighted voting | C4.5, MLP, IBL | IFA | CV | NSL-KDD, UNSW-NB15 |
| [26] | RF | - | - | CV | NSL-KDD, UNSW-NB15, CICIDS-2017 |
| [27] | XGBoost, RF | - | - | Hold-out | NSL-KDD, CIDDS-001, CICIDS-2017 |
| [28] | Weighted majority voting | SVM, LR, NB, DT | Gain-ratio, Chi-squared, Information gain | Hold-out | Honeypot, NSL-KDD, Kyoto |
| [29] | Stacking | DT, RF, XGBoost | SelectKbest | CV | NSL-KDD, UNSW-NB15 |
| [30] | LightGBM | - | DNN | Hold-out | KDD-99, NSL-KDD, UNSW-NB15 |
| Dataset | #Total Samples | #Samples Labelled Normal | #Samples Labelled Anomaly | #Categorical Features | #Numerical Features |
|---|---|---|---|---|---|
| NSL-KDD | 25,192 | 13,449 | 11,743 | 7 | 34 |
| UNSW-NB15 | 82,332 | 37,000 | 45,332 | 6 | 38 |
| CICIDS-2017 | 136,292 | 134,548 | 1744 | - | 78 |
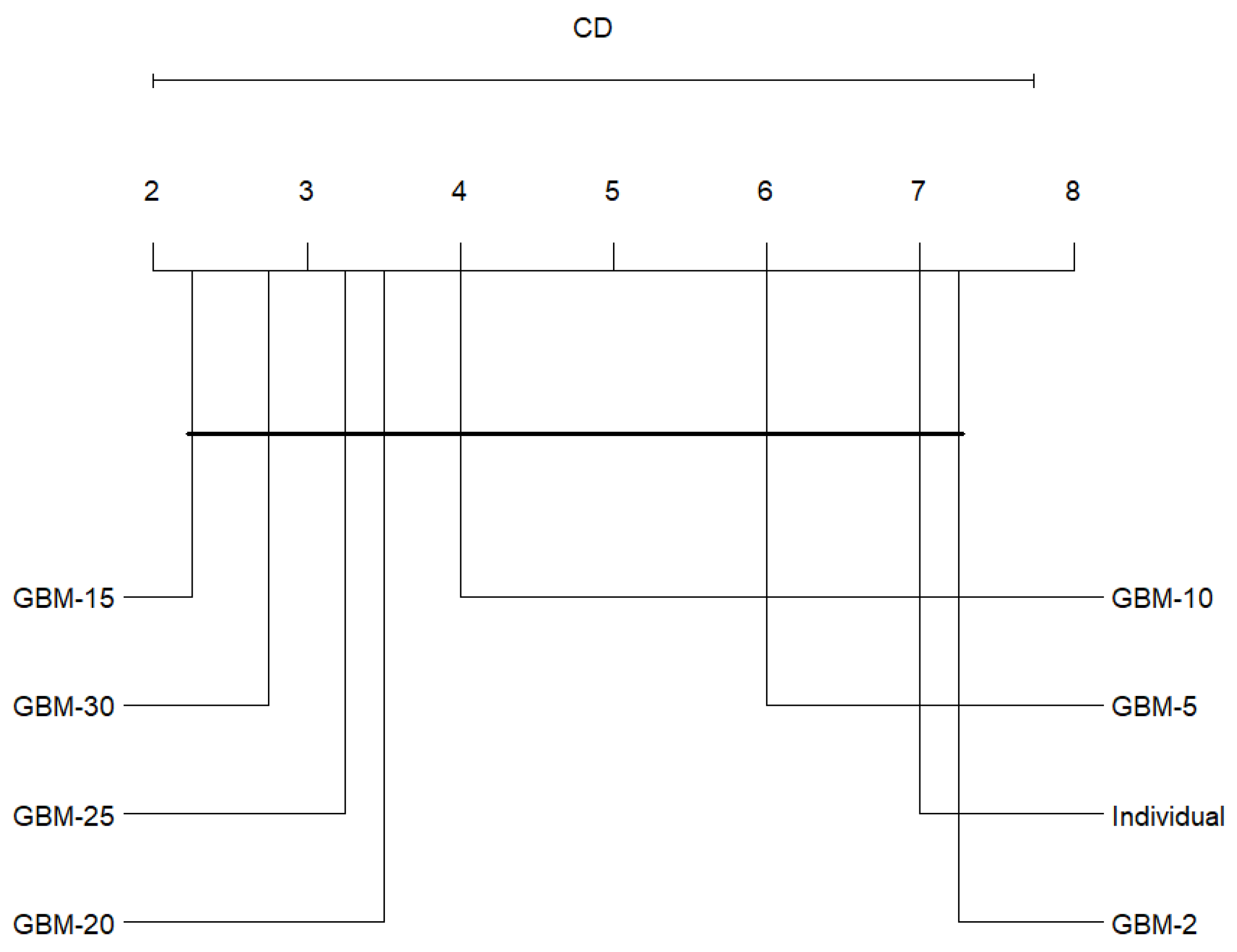
| Dataset | GBM-10 | GBM-15 | GBM-2 | GBM-20 | GBM-25 | GBM-30 | GBM-5 | Individual |
|---|---|---|---|---|---|---|---|---|
| CICIDS-2017 | 2 | 1 | 6 | 3 | 4 | 5 | 7 | 8 |
| KDDTest-21 | 2 | 4 | 8 | 6 | 1 | 3 | 5 | 7 |
| KDDTest+ | 6 | 1 | 8 | 3 | 4 | 2 | 7 | 5 |
| UNSW-NB15-Test | 6 | 3 | 7 | 2 | 4 | 1 | 5 | 8 |
| Average rank | 4.00 | 2.25 | 7.25 | 3.50 | 3.25 | 2.75 | 6.00 | 7.00 |
| p-value | 0.01197 | |||||||
| Ref. | Method | Feature Selection | Acc (%) | FPR (%) | Precision (%) | Recall (%) | AUC | F1 |
|---|---|---|---|---|---|---|---|---|
| KDDTest+ | ||||||||
| [45] | Stacking | - | 92.17 | 2.52 | - | - | - | - |
| [46] | Autoencoder | - | 84.21 | - | - | 87.00 | - | - |
| [23] | LightGBM | - | 89.79 | 9.13 | - | - | - | - |
| [26] | MFFSEM | RF | 84.33 | 24.82 | 74.61 | 97.15 | - | 0.841 |
| [28] | Weighted majority voting | GR, IG, and | 85.23 | 12.8 | 90.3 | - | - | 0.855 |
| This study | Hybrid ensemble | PSO | 90.39 | 1.59 | 84.94 | 98.68 | 0.9767 | 0.907 |
| KDDTest-21 | ||||||||
| [47] | Voting ensemble | CFS-BA | 73.57 | 12.92 | 73.6 | - | - | - |
| This study | Hybrid ensemble | PSO | 81.72 | 2.1 | 65.87 | 94.00 | 0.8886 | 0.7332 |
| UNSW-NB15-Test | ||||||||
| [45] | Stacking | - | 92.45 | 11.3 | - | - | - | - |
| [26] | MFFSEM | RF | 88.85 | 2.27 | - | 80.44 | - | - |
| [20] | RF | GR, , and PC | 83.12 | 3.7 | - | - | - | - |
| [23] | LightGBM | - | 85.89 | 14.79 | - | - | - | - |
| [30] | LightGBM | DNN | 88.34 | 12.46 | - | - | - | 0.881 |
| This study | Hybrid ensemble | PSO | 95.20 | 4.03 | 92.93 | 93.84 | 0.9925 | 0.9338 |
| CICIDS-2017 | ||||||||
| [48] | Rough set theory + Bayes | FPE | 97.95 | - | - | 96.37 | - | 0.9637 |
| [21] | Stacking | K-Means | 98.0 | 0.2 | 97.0 | 98.0 | - | 0.98 |
| [49] | ICVAE-BSM | - | 99.86 | - | 99.68 | 99.68 | - | 0.9968 |
| This study | Hybrid ensemble | PSO | 99.98 | 2.6 | 99.99 | 99.99 | 1.00 | 0.9998 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Louk, M.H.L.; Tama, B.A. PSO-Driven Feature Selection and Hybrid Ensemble for Network Anomaly Detection. Big Data Cogn. Comput. 2022, 6, 137. https://doi.org/10.3390/bdcc6040137
Louk MHL, Tama BA. PSO-Driven Feature Selection and Hybrid Ensemble for Network Anomaly Detection. Big Data and Cognitive Computing. 2022; 6(4):137. https://doi.org/10.3390/bdcc6040137
Chicago/Turabian StyleLouk, Maya Hilda Lestari, and Bayu Adhi Tama. 2022. "PSO-Driven Feature Selection and Hybrid Ensemble for Network Anomaly Detection" Big Data and Cognitive Computing 6, no. 4: 137. https://doi.org/10.3390/bdcc6040137
APA StyleLouk, M. H. L., & Tama, B. A. (2022). PSO-Driven Feature Selection and Hybrid Ensemble for Network Anomaly Detection. Big Data and Cognitive Computing, 6(4), 137. https://doi.org/10.3390/bdcc6040137