


The “Unreasonable” Effectiveness of the Wasserstein Distance in Analyzing Key Performance Indicators of a Network of Stores

Abstract
:1. Introduction
1.1. Motivations
1.2. Related Works
1.3. Contributions
2. Key Performance Indicators and the Formulation of the Problem
- Overall: Measures the overall sentiment of the customer for the whole process.
- Store Building: Features of the store, such as parking spaces and cleanliness.
- Customer Relationship: Measures sentiment about the vendors.
- Commercial Relationship: Aggregates scores given by customers in the customer relation before conversion.
- Selection: Aggregates scores from features such as the availability of products and clarity of presentation.
- Affordability: Aggregates scores from customers related to prices and discounts.
- Payment: Aggregates scores such as the length of the queue and easy payment.
3. Space of Data and Distributional Representation
3.1. Distributional Representation
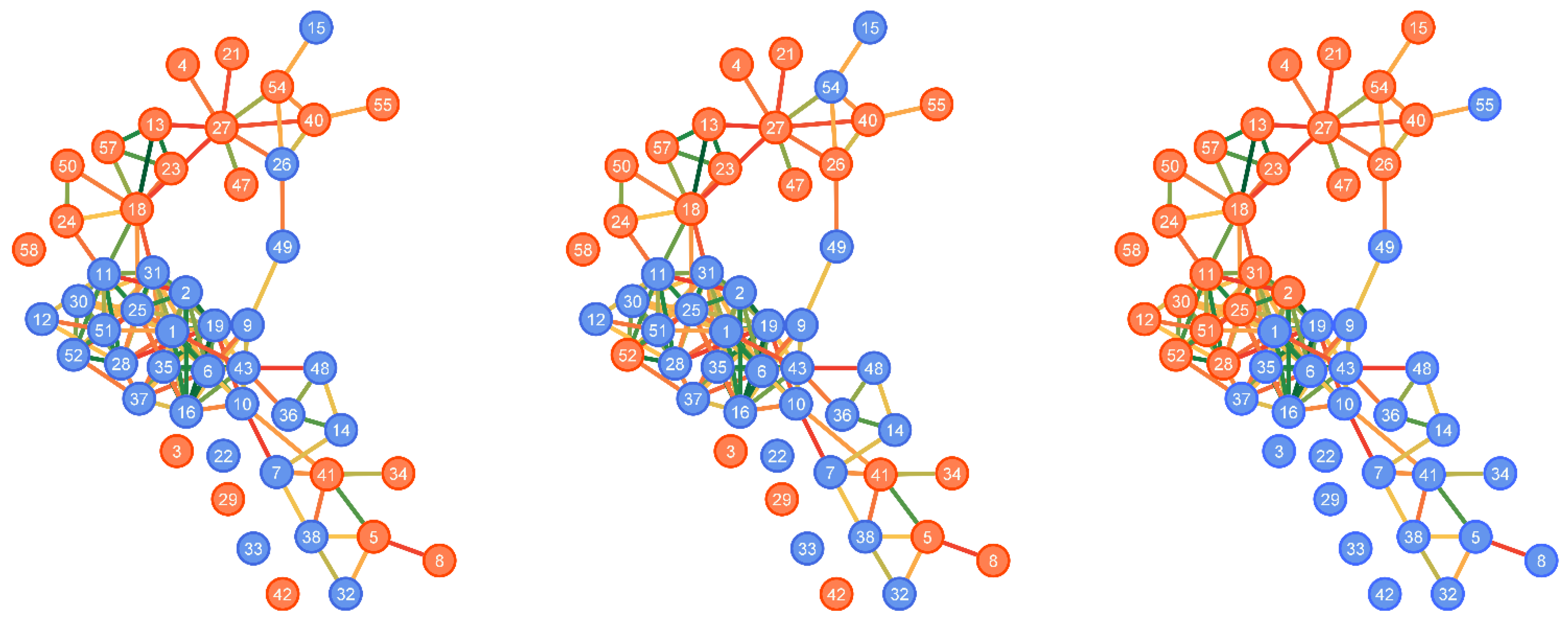
3.2. Graph Representation
4. Wasserstein Distance
4.1. Basic Definitions
4.2. Barycenter and Clustering
5. Results
5.1. Feature Selection
5.2. Wasserstein Analysis
5.3. Clustering Analysis
5.4. Nonlinear Structures in Data
6. Conclusions, Limitations and Perspectives
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Reichheld, F.F. The One Number You Need to Grow. Harv. Bus. Rev. 2003, 81, 46–55. [Google Scholar]
- Fisher, N.I. Analytics for Leaders. A Performance Measurement System for Business Success, 1st ed.; Cambridge University Press: Cambridge, UK, 2013. [Google Scholar]
- Fisher, N.I. A Comprehensive Approach to Problems of Performance Measurement. J. R. Stat. Soc. Ser. A Stat. Soc. 2019, 182, 755–803. [Google Scholar] [CrossRef]
- Baehre, S.; O’Dwyer, M.; O’Malley, L.; Lee, N. The Use of Net Promoter Score (NPS) to Predict Sales Growth: Insights from an Empirical Investigation. J. Acad. Mark. Sci. 2022, 50, 67–84. [Google Scholar] [CrossRef]
- Markoulidakis, I.; Rallis, I.; Georgoulas, I.; Kopsiaftis, G.; Doulamis, A.; Doulamis, N. A Machine Learning Based Classification Method for Customer Experience Survey Analysis. Technologies 2020, 8, 76. [Google Scholar] [CrossRef]
- Markoulidakis, I.; Rallis, I.; Georgoulas, I.; Kopsiaftis, G.; Doulamis, A.; Doulamis, N. Multiclass Confusion Matrix Reduction Method and Its Application on Net Promoter Score Classification Problem. Technologies 2021, 9, 81. [Google Scholar] [CrossRef]
- Monge, G. Mémoire Sur La Théorie Des Déblais et Des Remblais. In Histoire de l’Académie Royale des Sciences de Paris; Nabu Press: Charleston, NC, USA, 1781; pp. 666–704. [Google Scholar]
- Kantorovitch, L. On the Translocation of Masses. Manag. Sci. 1958, 5, 1–4. [Google Scholar] [CrossRef]
- Bonneel, N.; Peyré, G.; Cuturi, M. Wasserstein Barycentric Coordinates: Histogram Regression Using Optimal Transport. ACM Trans. Graph. 2016, 35, 71-1. [Google Scholar] [CrossRef] [Green Version]
- Huang, G.; Quo, C.; Kusner, M.J.; Sun, Y.; Weinberger, K.Q.; Sha, F. Supervised Word Mover’s Distance. In Proceedings of the 30th International Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 4869–4877. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein Generative Adversarial Networks. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 214–223. [Google Scholar]
- Villani, C. Optimal Transport: Old and New; Springer: Berlin, Germany, 2008. [Google Scholar]
- Peyré, G.; Cuturi, M. Computational Optimal Transport. Found. Trends Mach. Learn. 2019, 11, 355–607. [Google Scholar] [CrossRef]
- Panaretos, V.M.; Zemel, Y. An Invitation to Statistics in Wasserstein Space; Springer: Berlin, Germany, 2020. [Google Scholar]
- Bigot, J. Statistical Data Analysis in the Wasserstein Space. ESAIM Proc. Surv. 2020, 68, 1–19. [Google Scholar] [CrossRef]
- Cohen, S.; Arbel, M.; Deisenroth, M.P. Estimating Barycenters of Measures in High Dimensions. arXiv 2020, arXiv:2007.07105. [Google Scholar]
- Verdinelli, I.; Wasserman, L. Hybrid Wasserstein Distance and Fast Distribution Clustering. Electron. J. Stat. 2019, 13, 5088–5119. [Google Scholar] [CrossRef]
- Galichon, A. Optimal Transport Methods in Economics; Princeton University Press: Princeton, NJ, USA, 2018. [Google Scholar]
- Galichon, A. The Unreasonable Effectiveness of Optimal Transport in Economics. arXiv 2021, arXiv:2107.04700. [Google Scholar]
- Kiesel, R.; Rühlicke, R.; Stahl, G.; Zheng, J. The Wasserstein Metric and Robustness in Risk Management. Risks 2016, 4, 32. [Google Scholar] [CrossRef]
- Backhoff-Veraguas, J.; Bartl, D.; Beiglböck, M.; Eder, M. Adapted Wasserstein Distances and Stability in Mathematical Finance. Financ. Stoch. 2020, 24, 601–632. [Google Scholar] [CrossRef]
- Horvath, B.; Issa, Z.; Muguruza, A. Clustering Market Regimes Using the Wasserstein Distance. arXiv 2021, arXiv:2110.11848. [Google Scholar] [CrossRef]
- Kuhn, D.; Esfahani, P.M.; Nguyen, V.A.; Shafieezadeh-Abadeh, S. Wasserstein Distributionally Robust Optimization: Theory and Applications in Machine Learning. arXiv 2019, arXiv:1908.08729. [Google Scholar] [CrossRef]
- Mohajerin Esfahani, P.; Kuhn, D. Data-Driven Distributionally Robust Optimization Using the Wasserstein Metric: Performance Guarantees and Tractable Reformulations. Math. Program. 2018, 171, 115–166. [Google Scholar] [CrossRef] [Green Version]
- Lau, T.T.-K.; Liu, H. Wasserstein Distributionally Robust Optimization via Wasserstein Barycenters. arXiv 2022, arXiv:2203.12136. [Google Scholar]
- Chen, Z.; Kuhn, D.; Wiesemann, W. Data-Driven Chance Constrained Programs over Wasserstein Balls. Oper. Res. 2022. [Google Scholar] [CrossRef]
- Xie, W. Tractable Reformulations of Distributionally Robust Two-Stage Stochastic Programs With∞- Wasserstein Distance. arXiv 2019, arXiv:1908.08454. [Google Scholar]
- Ma, C.; Ma, L.; Zhang, Y.; Tang, R.; Liu, X.; Coates, M. Probabilistic Metric Learning with Adaptive Margin for Top-K Recommendation. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual Event, 6–10 July 2020; pp. 1036–1044. [Google Scholar]
- Rakotomamonjy, A.; Traoré, A.; Berar, M.; Flamary, R.; Courty, N. Distance Measure Machines. arXiv 2018, arXiv:1803.00250. [Google Scholar]
- Le, T.; Cuturi, M. Adaptive Euclidean Maps for Histograms: Generalized Aitchison Embeddings. Mach. Learn. 2015, 99, 169–187. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| … | ||||
|---|---|---|---|---|
| Distance | Order | |||
|---|---|---|---|---|
| Manhattan | 1 | 2.000 | 1.000 | 1.000 |
| Euclidean | 2 | 0.894 | 0.510 | 0.490 |
| Wasserstein | 1 | 0.583 | 0.250 | 0.333 |
| 2 | 0.677 | 0.324 | 0.374 |
| KPI | Information Gain |
|---|---|
| Selection | 0.37 |
| Customer Relationship | 0.34 |
| Commercial Relationship | 0.33 |
| Store Building | 0.32 |
| Affordability | 0.30 |
| Overall | 0.29 |
| Payment | 0.26 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ponti, A.; Giordani, I.; Mistri, M.; Candelieri, A.; Archetti, F. The “Unreasonable” Effectiveness of the Wasserstein Distance in Analyzing Key Performance Indicators of a Network of Stores. Big Data Cogn. Comput. 2022, 6, 138. https://doi.org/10.3390/bdcc6040138
Ponti A, Giordani I, Mistri M, Candelieri A, Archetti F. The “Unreasonable” Effectiveness of the Wasserstein Distance in Analyzing Key Performance Indicators of a Network of Stores. Big Data and Cognitive Computing. 2022; 6(4):138. https://doi.org/10.3390/bdcc6040138
Chicago/Turabian StylePonti, Andrea, Ilaria Giordani, Matteo Mistri, Antonio Candelieri, and Francesco Archetti. 2022. "The “Unreasonable” Effectiveness of the Wasserstein Distance in Analyzing Key Performance Indicators of a Network of Stores" Big Data and Cognitive Computing 6, no. 4: 138. https://doi.org/10.3390/bdcc6040138
APA StylePonti, A., Giordani, I., Mistri, M., Candelieri, A., & Archetti, F. (2022). The “Unreasonable” Effectiveness of the Wasserstein Distance in Analyzing Key Performance Indicators of a Network of Stores. Big Data and Cognitive Computing, 6(4), 138. https://doi.org/10.3390/bdcc6040138