
Detecting Multi-Density Urban Hotspots in a Smart City: Approaches, Challenges and Applications



Abstract
:1. Introduction
2. Related Works
3. Algorithms to Detect Urban Hotspots
3.1. DBSCAN
3.2. OPTICS-xi
3.3. HDBSCAN
3.4. City Hotspot Detector
4. Experimental Evaluation and Results
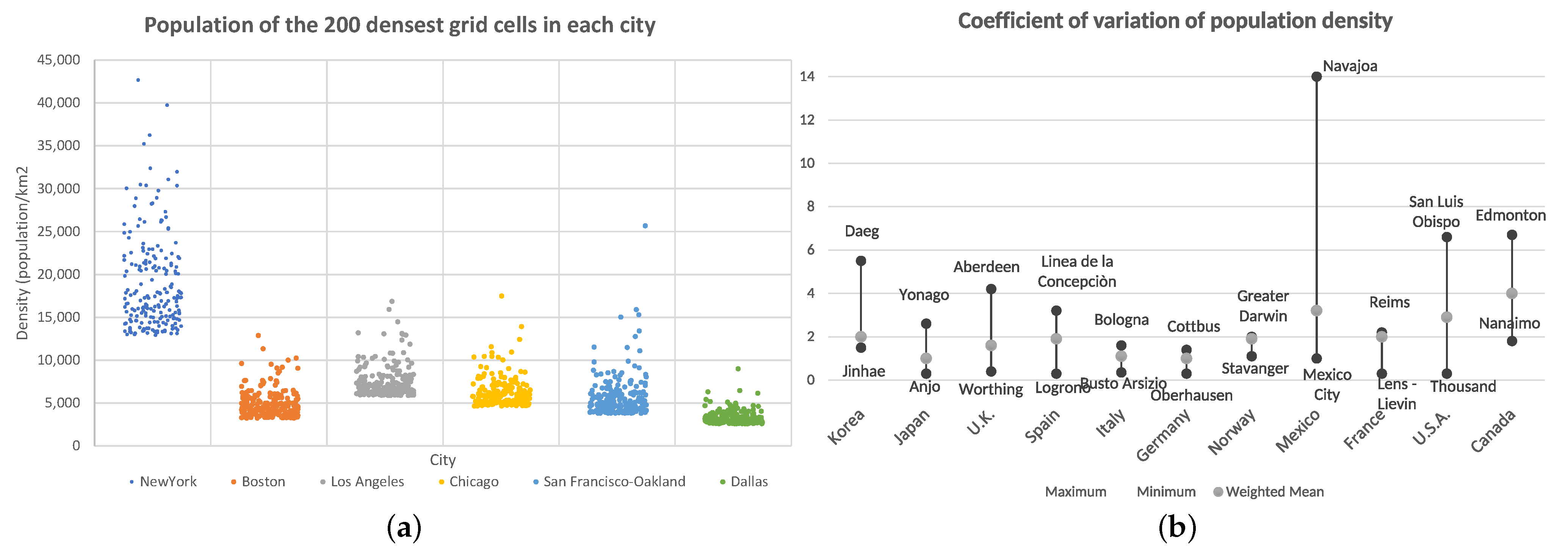
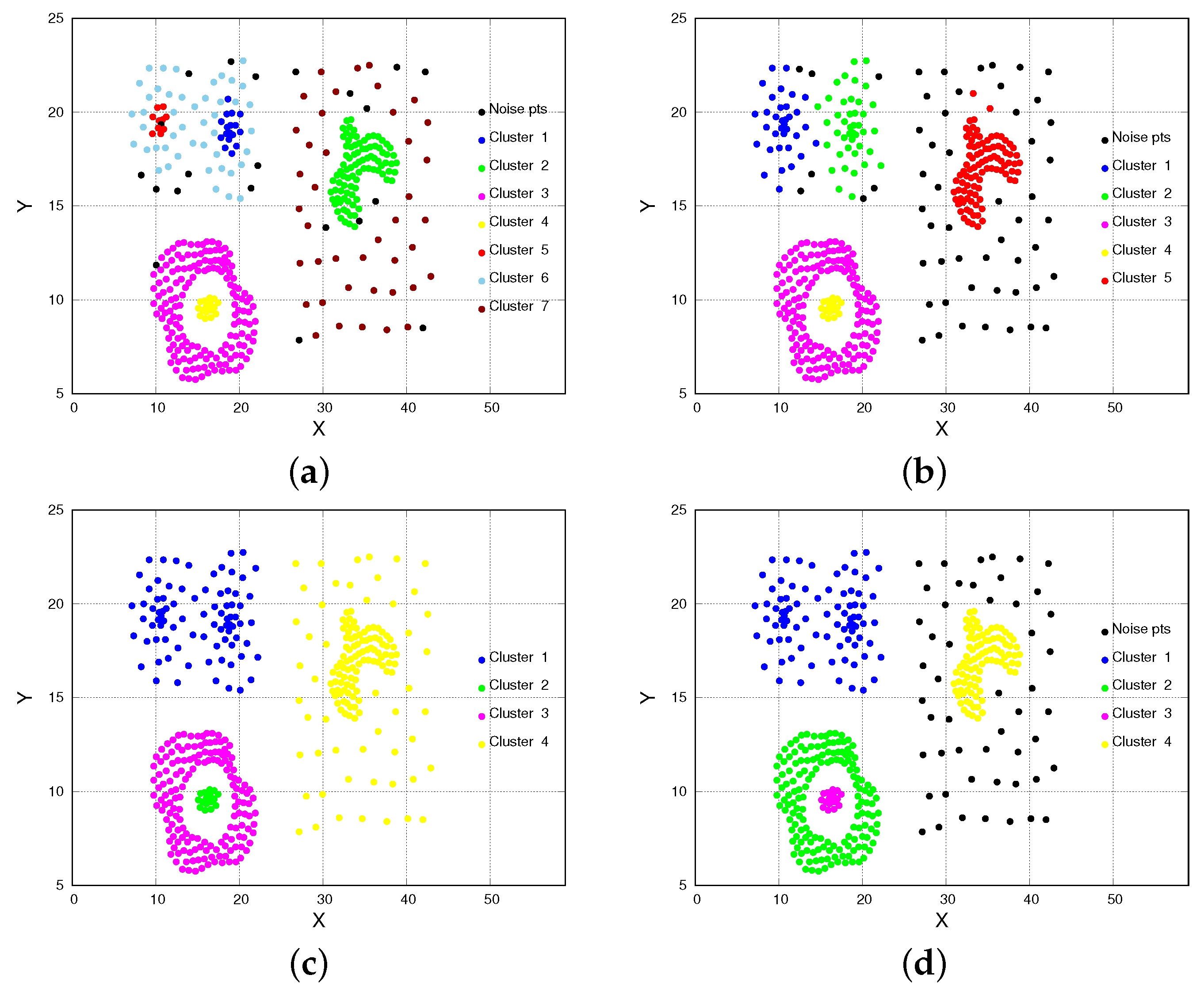
4.1. Data Description
- -
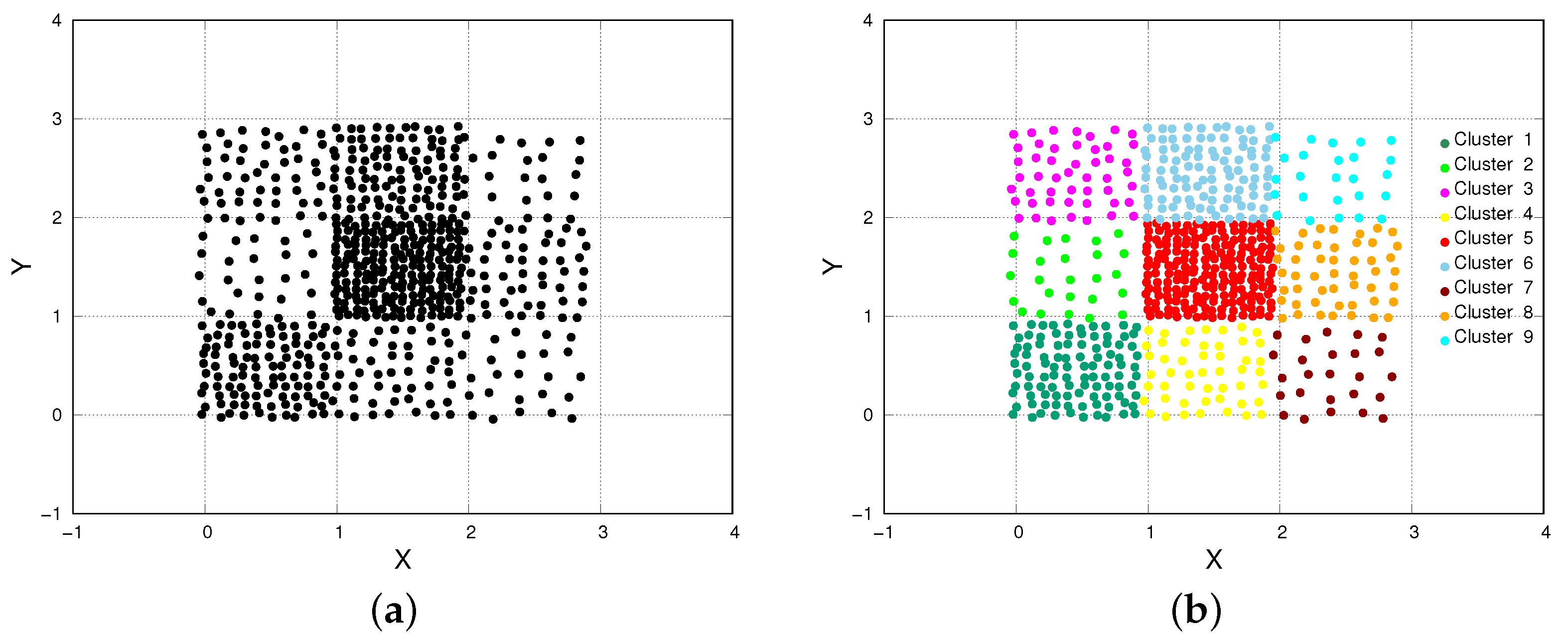
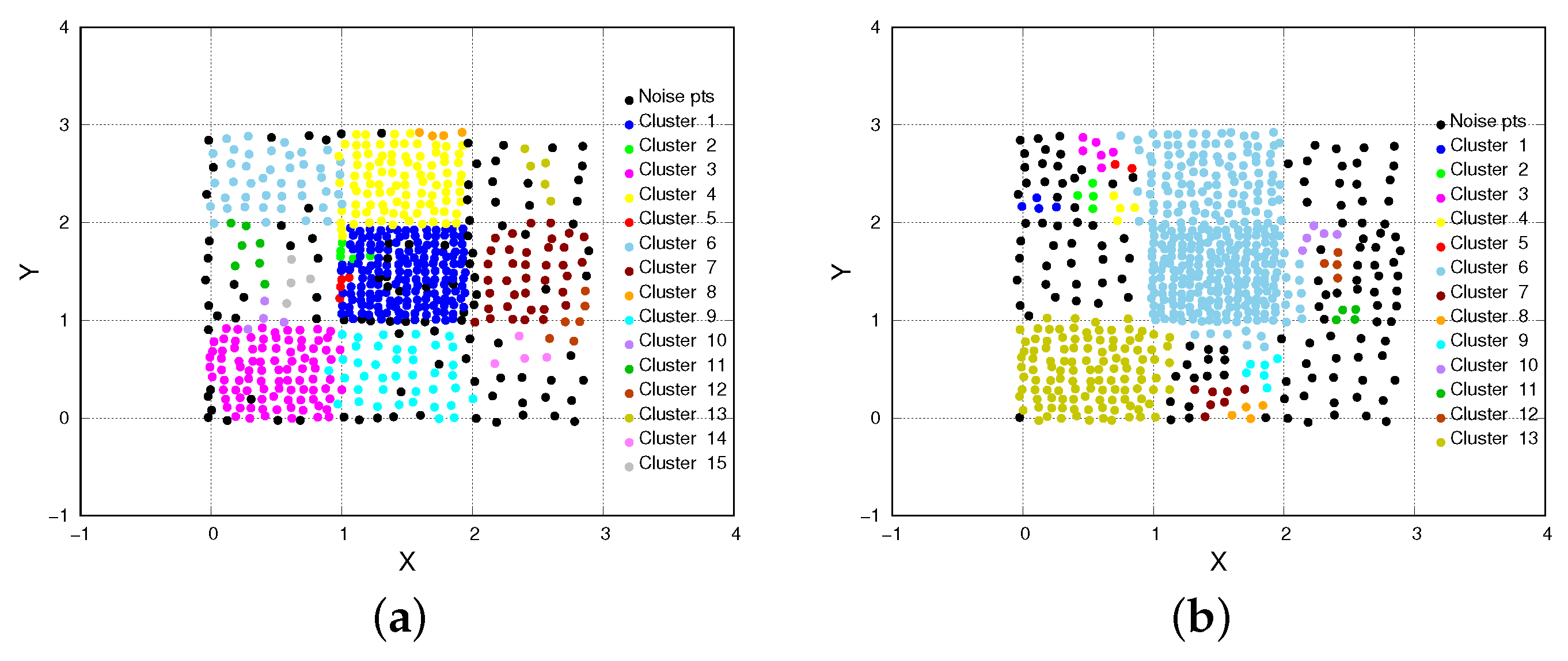
- The chess dataset is composed of 618 instances and partitioned in nine target clusters. Each instance is described by X and Y features (Figure 2). Clusters are very contiguous, and they have regular block shapes, different densities and sizes. In particular, the highest density cluster has a density (cluster n. 5, n. of points = 196, area = 0.92), while the lowest density one has a density (cluster n. 7, n. of points = 25, area = 0.79).
- -
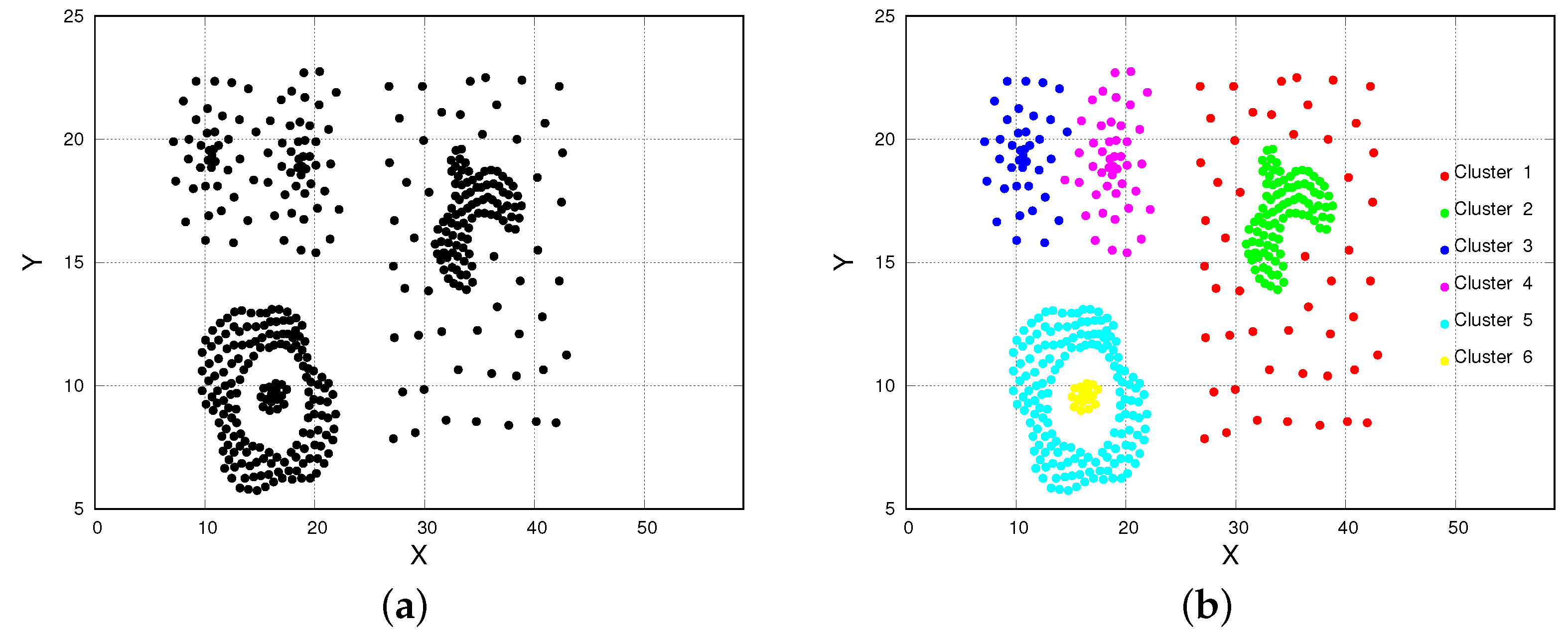
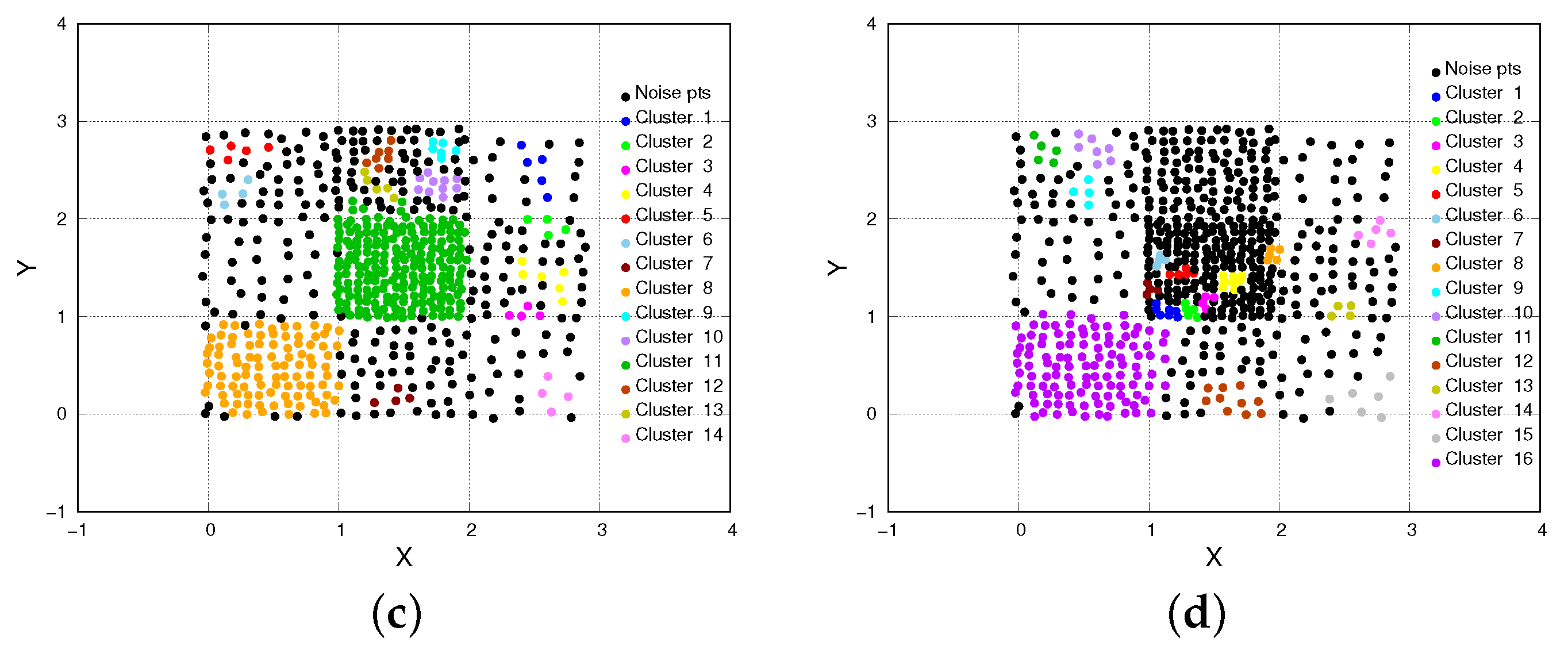
- The compound dataset is composed of 399 instances, described by X and Y features, and partitioned in six target clusters (Figure 3). Clusters are well separated, and they have irregular multi-geometric shapes (different from the previous dataset), different densities and sizes. In this dataset, the highest density cluster has a density (cluster n. 6, n. of points = 16, area = 2.58), while the lowest density cluster has a density (cluster n. 1, n. of points = 50, area = 236.60).
4.2. Results on State-of-the-Art Data
- -
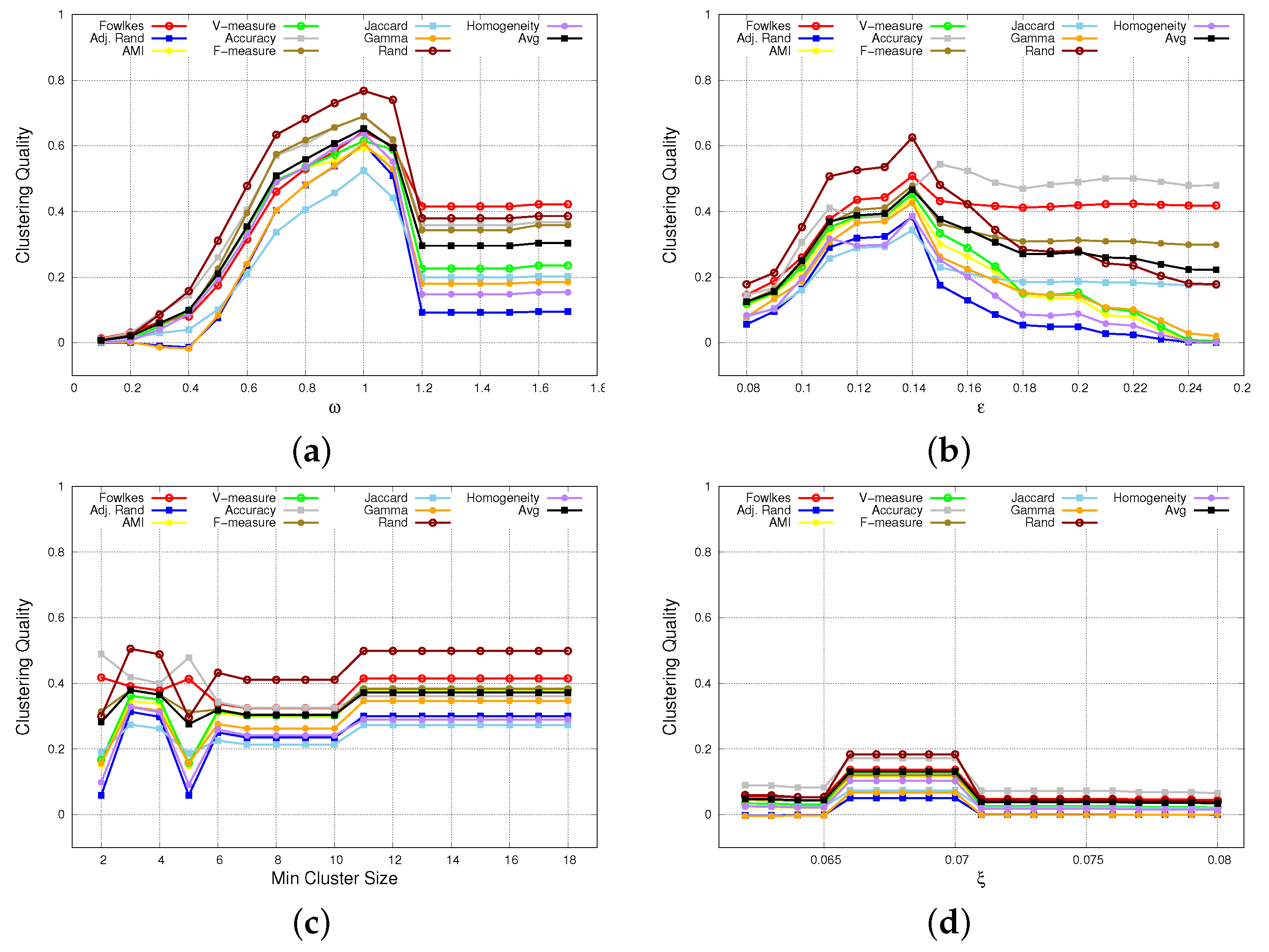
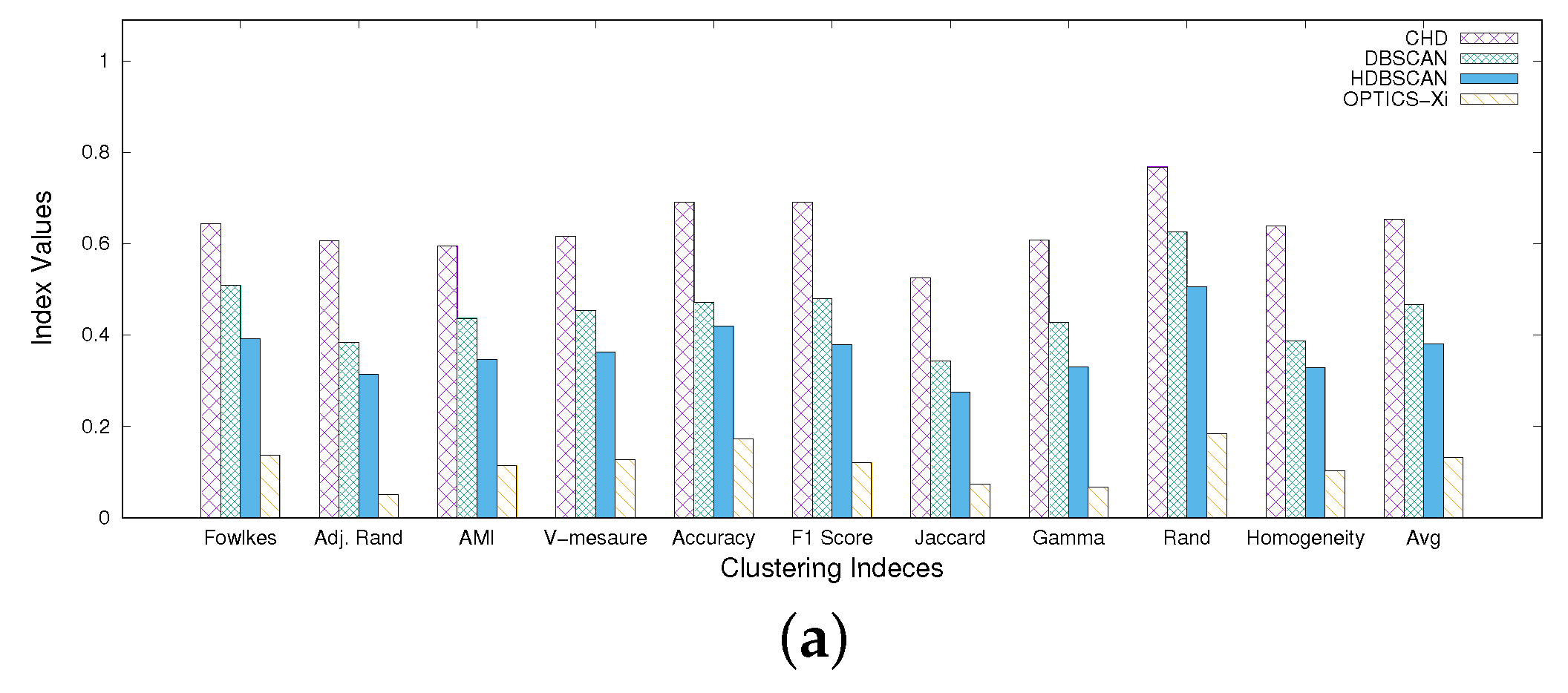
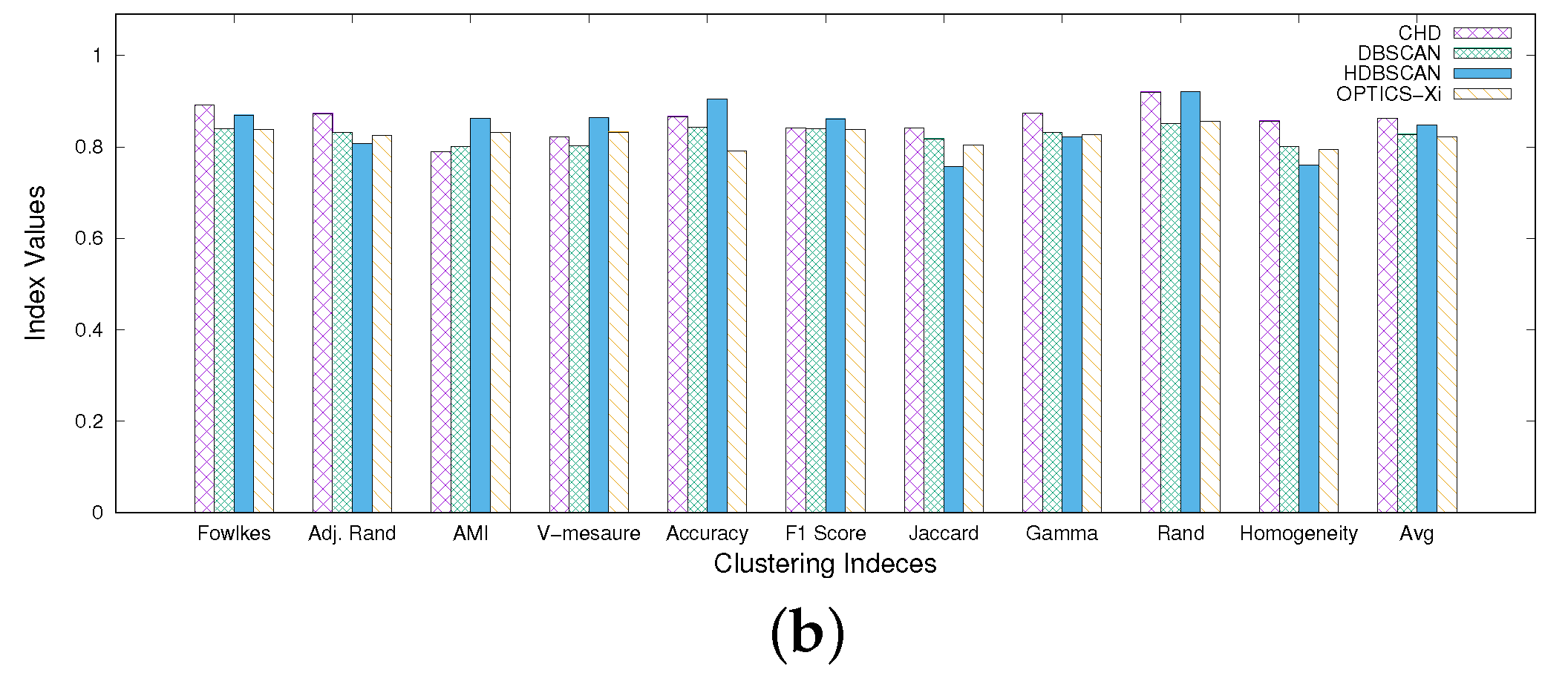
- CHD detects higher quality clusters than DBSCAN, HDBSCAN and OPTICS-Xi. For both datasets, in fact, Figure 6 shows that CHD achieves better performance than the other three algorithms, for all indices. Specifically, on chess, considering the best parameter setting case for each algorithm, CHD achieves an average clustering quality (computed over all indices) equal to 0.65, while DBSCAN, HDBSCAN, and OPTICS-Xi achieve 0.47, 0.38 and 0.13, respectively. Similarly, on compound, CHD slightly outperforms the other three algorithms, assessing on an average clustering quality equal to 0.86, while DBSCAN, HDBSCAN, and OPTICS-Xi achieve 0.83, 0.84, and 0.82, respectively. This is an interesting result since it shows that a multi-density approach, applied over such datasets, overtakes the other algorithms in terms of accuracy, compactness, and separability. In addition, the higher the closeness among clusters (chess dataset), the more evident the clustering quality improvement.
- -
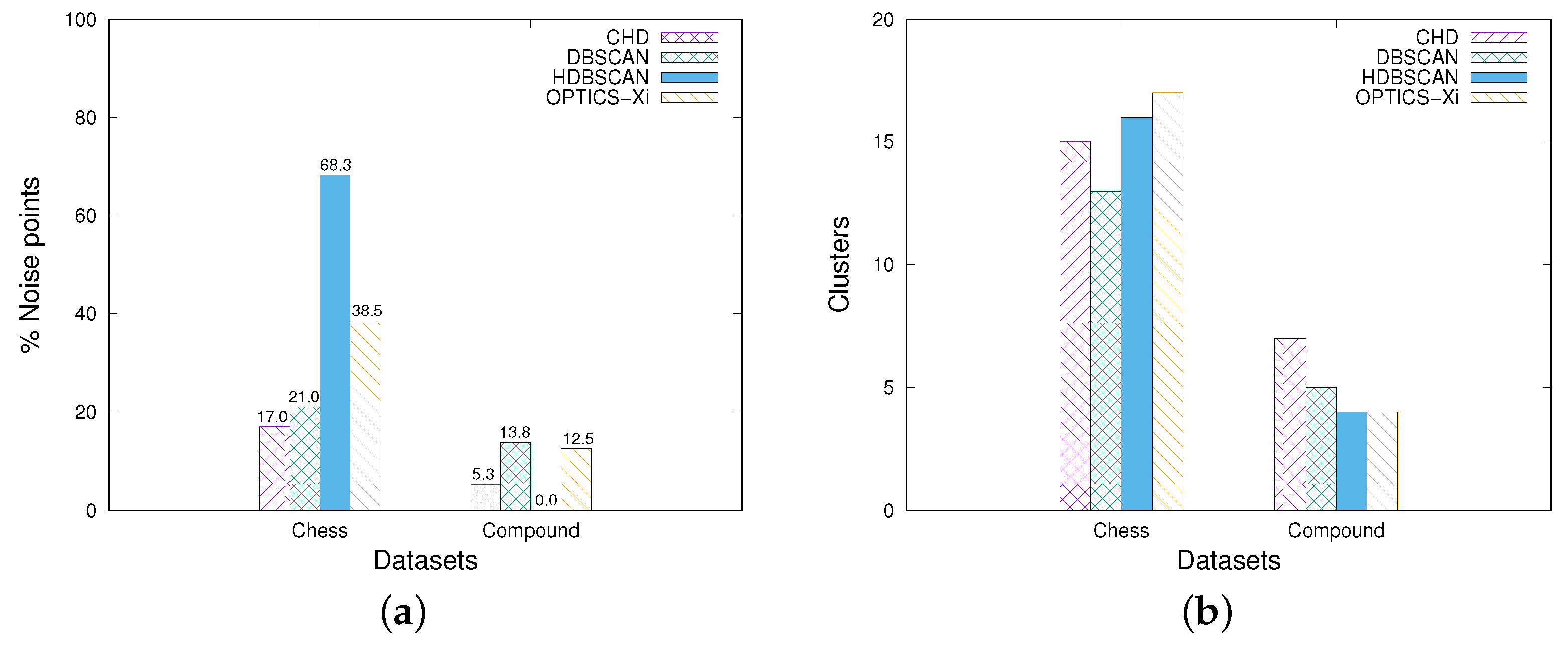
- CHD and HDBSCAN detect a lower number of noise points than DBSCAN, and OPTICS-Xi. Figure 7 shows the number of noise points and the number of clusters detected by the two algorithms. Specifically, Figure 7a shows that CHD, on the Chess dataset, is the algorithm detecting the lowest number of noise points (17%). On the compound dataset, HDBSCAN detects no noise points, while CHD detects the 5.3% of the total number of instances, which is a very low number as well. The other two algorithms detect a higher number of noise points.
- -
- CHD largely outperforms the other algorithms when detecting not-well-separated clusters. Observing Figure 2 and Figure 3, we can observe that the chess dataset shows clusters that are very contiguous and not-well-separated, while in the compound dataset, the separation among clusters is more evident. Generally, the low separation between clusters is a crucial issue for density-based algorithms to detect proper clusters. Considering the results of our tests performed on both datasets, it is worth noting that, in particular on the chess dataset, CHD outperforms the other three algorithms, for all indices (see Figure 6). This means that its application results in being more effective than the other approaches when clusters are very close, which is a classic urban case scenario. On the compound dataset (see Figure 6), characterized by well-separated clusters, all four algorithms achieve good results, and the difference in their performance is less evident than in the first dataset.
5. A Real-Case Study: Detecting Multi-Density Crime Hotspots in Chicago
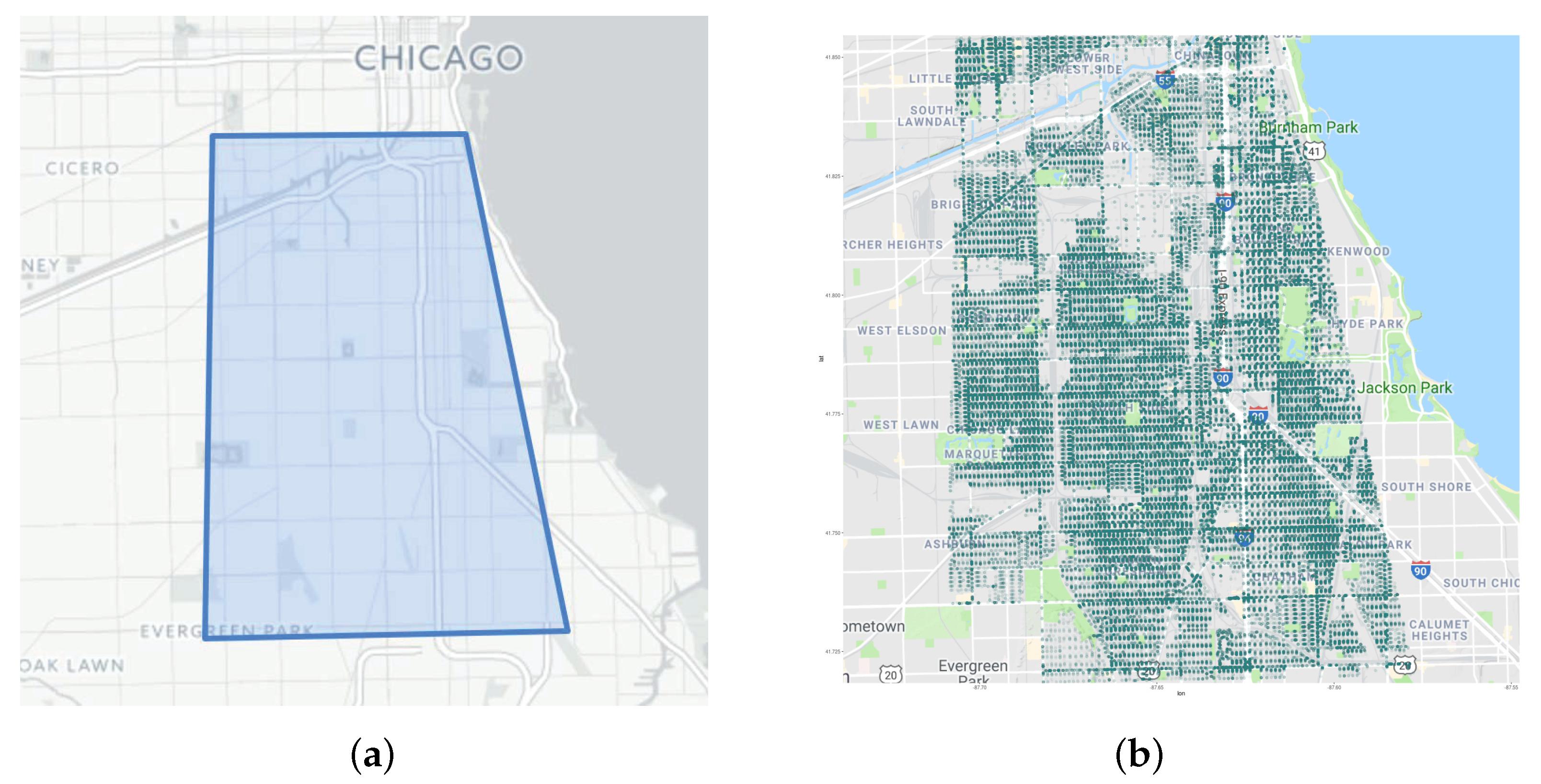
5.1. Data Description
5.2. Results
- -
- CHD detects a higher number of significant hotspots than DBSCAN, HDBSCAN and OPTICS-Xi. After a preliminary split in several density level sets, CHD partitions each one by exploiting specific values (as described in Section 3), finally detecting 181 hotspots; on the other side, DBSCAN and HDBSCAN detect a lower number of clusters, i.e., 78 and 61 hotspots, respectively. Finally, OPTICS-Xi detects 279 (very small) hotspots, which are not very significant.
- -
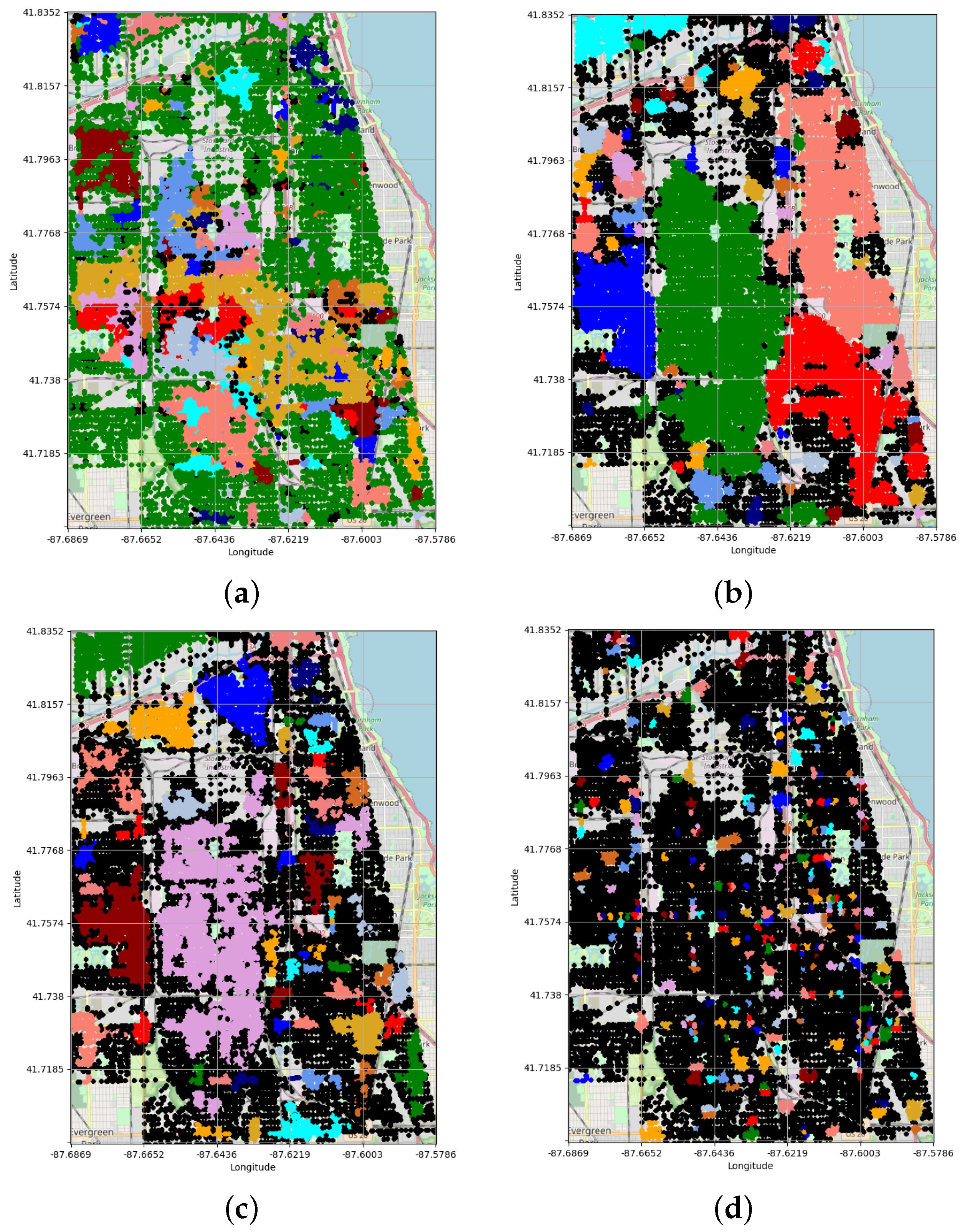
- CHD performs higher separation among the hotspots than DBSCAN, HDBSCAN and OPTICS-Xi. The results depicted in Figure 11 highlight that CHD is able to achieve a more refined spatial partitioning than DBSCAN and HDBSCAN, splitting some areas of the city. Contrariwise, OPTICS-Xi detected a large number of noise points and a lot of very small hotspots. In particular, CHD detects several hotspots in the central area (colored in red, orange, violet, and blue in Figure 11a, whereas DBSCAN and HDBSCAN labeled such points as only a single hotspot (the large green area in Figure 11b and the large violet area in Figure 11c). Similarly, CHD detects different hotspots in the left-middle part of the analyzed area, while DBSCAN and HDBSCAN label those as only one hotspot (colored in blue and red). OPTICS-Xi fails in a reasonable clustering of points, by detecting only some small hotspots sparsely distributed in the whole area. This shows that CHD is able to perform higher separation than the other algorithms among the city hotspots, by creating clusters having different densities.
- -
- CHD labels a lower number of noise points than DBSCAN, HDBSCAN, and OPTICS-Xi. The noise points, which are those points that could not be assigned to a hotspot since they do not satisfy the density requirements of a given algorithm, are colored in black in Figure 11. Table 2 reports that CHD, DBSCAN, and HDBSCAN classify 5.7%, 12.6%, and 34.6% of data instances as noise points, respectively. On the other side, OPTICS-Xi labels almost 72% of total points as noise, showing de facto low-quality results. Considering the first three algorithms, it seems that CHD, in several cases, is able to better detect hotspots characterized by distinct densities, labeling a low percentage of instances as noise points. This is clearly evident by comparing Figure 11a–c. In particular, we can notice that large regions located in the top part and bottom part of the analyzed area are labeled as noise by DBSCAN and HDBSCAN (black-colored blows in Figure 11b,c), while CHD is able to detect several clusters from it (several hotspots colored in green and blue in Figure 11a). Finally, the presence of noise points in Figure 11d is pervasive and diffused, showing low-quality results achieved by OPTICS-Xi.
- -
- HDBSCAN and CHD achieve higher clustering quality than DBSCAN and OPTICS-Xi. Table 2 shows that HDBSCAN and CHD assess on silhouette values equal to and , respectively. Indeed, they achieve better results than DBSCAN and OPTICS-xi, whose clustering quality assess on and . Such results show that multi-density clustering (i.e., HDBASCN and CHD) is able to distinguish several density regions and identify proper hotspots in urban environments better than DBSCAN and OPTICS-xi.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Li, L.; Jiang, R.; He, Z.; Chen, X.; Zhou, X. Trajectory data-based traffic flow studies: A revisit. Transp. Res. Part C Emerg. Technol. 2021, 114, 225–240. [Google Scholar]
- Cesario, E.; Comito, C.; Talia, D. An approach for the discovery and validation of urban mobility patterns. Pervasive Mob. Comput. 2017, 42, 77–92. [Google Scholar]
- Ali, M.E.; Hasan, M.F.; Siddiqa, S.; Molla, M.M.; Nasrin Akhter, M. FVM-RANS Modeling of Air Pollutants Dispersion and Traffic Emission in Dhaka City on a Suburb Scale. Sustainability 2022, 15, 673. [Google Scholar] [CrossRef]
- Wang, Q.; Jin, G.; Zhao, X.; Feng, Y.; Huang, J. CSAN: A neural network benchmark model for crime forecasting in spatio-temporal scale. Knowl.-Based Syst. 2020, 189, 105–120. [Google Scholar] [CrossRef]
- Catlett, C.; Cesario, E.; Talia, D.; Vinci, A. Spatio-temporal crime predictions in smart cities: A data-driven approach and experiments. Pervasive Mob. Comput. 2019, 53, 62–74. [Google Scholar]
- Chintalapudi, N.; Battineni, G.; Amenta, F. COVID-19 virus outbreak forecasting of registered and recovered cases after sixty day lockdown in Italy: A data driven model approach. J. Microbiol. Immunol. Infect. 2020, 53, 396–403. [Google Scholar] [PubMed]
- Ghosh, S.; Bhattacharya, S. A data-driven understanding of COVID-19 dynamics using sequential genetic algorithm based probabilistic cellular automata. Appl. Soft Comput. 2020, 96, 106692. [Google Scholar] [CrossRef] [PubMed]
- Hu, S.; Xiong, C.; Yang, M.; Younes, H.; Luo, W.; Zhang, L. A big-data driven approach to analyzing and modeling human mobility trend under non-pharmaceutical interventions during COVID-19 pandemic. Transp. Res. Part C Emerg. Technol. 2021, 124, 102955. [Google Scholar] [CrossRef] [PubMed]
- Cicirelli, F.; Guerrieri, A.; Mastroianni, C.; Spezzano, G.; Vinci, A. The Internet of Things for Smart Urban Ecosystems; Springer: Cham, Switzerland, 2019. [Google Scholar]
- Liu, P.; Zhou, D.; Wu, N. VDBSCAN: Varied density based spatial clustering of applications with noise. In Proceedings of the 2007 International Conference on Service Systems and Service Management, Chengdu, China, 9–11 June 2007; pp. 1–4. [Google Scholar]
- Mitra, S.; Nandy, J. KDDclus: A simple method for multi-density clustering. In Proceedings of the International Workshop on Soft Computing Applications and Knowledge Discovery (SCAKD 2011), Moscow, Russia, 24 June 2011; pp. 72–76. [Google Scholar]
- Cesario, E. Big Data Analysis for Smart City Applications. In Encyclopedia of Big Data Technologies; Sakr, S., Zomaya, A.Y., Eds.; Springer: Cham, Switzerland, 2019. [Google Scholar] [CrossRef]
- Canino, M.P.; Cesario, E.; Vinci, A.; Zarin, S. Epidemic forecasting based on mobility patterns: An approach and experimental evaluation on COVID-19 Data. Soc. Networks Anal. Min. 2022, 12, 116. [Google Scholar]
- Mastroianni, C.; Cesario, E.; Giordano, A. Efficient and scalable execution of smart city parallel applications. Concurr. Comput. Pract. Exp. 2018, 30, e4258. [Google Scholar] [CrossRef]
- Garrett Dash Nelson. What Micro-Mapping a City’s Density Reveals. 9 May 2021. Available online: https://www.bloomberg.com/news/articles/2019-07-09/what-micro-mapping-a-city-s-density-reveals (accessed on 18 December 2022).
- Organisation for Economic Cooperation and Development (OECD). Rethinking Urban Sprawl; OECD: Paris, France, 2018; p. 168. [Google Scholar] [CrossRef]
- Center for International Earth Science Information Network—CIESIN—Columbia University. Gridded Population of the World, Version 4 (GPWv4): Population Count, Revision 11, NASA Socioeconomic Data and Applications Center (SEDAC). 2021. Available online: https://sedac.ciesin.columbia.edu/data/set/gpw-v4-population-count-rev11 (accessed on 18 December 2022). [CrossRef]
- Deng, T.; Manders, A.; Jin, J.; Lin, H.X. Clustering-based spatial transfer learning for short-term ozone forecasting. J. Hazard. Mater. Adv. 2022, 8, 100168. [Google Scholar]
- Krupnova, T.G.; Rakova, O.V.; Bondarenko, K.A.; Tretyakova, V.D. Environmental Justice and the Use of Artificial Intelligence in Urban Air Pollution Monitoring. Big Data Cogn. Comput. 2022, 6, 75. [Google Scholar] [CrossRef]
- Khan, A.N.; Iqbal, N.; Rizwan, A.; Ahmad, R.; Kim, D.H. An Ensemble Energy Consumption Forecasting Model Based on Spatial-Temporal Clustering Analysis in Residential Buildings. Energies 2021, 14, 3020. [Google Scholar] [CrossRef]
- Kolevatova, A.; Riegler, M.A.; Cherubini, F.; Hu, X.; Hammer, H.L. Unraveling the Impact of Land Cover Changes on Climate Using Machine Learning and Explainable Artificial Intelligence. Big Data Cogn. Comput. 2021, 5, 55. [Google Scholar] [CrossRef]
- Cesario, E.; Marozzo, F.; Talia, D.; Trunfio, P. SMA4TD: A social media analysis methodology for trajectory discovery in large-scale events. Online Soc. Netw. Media 2017, 3–4, 49–62. [Google Scholar]
- Tayebi, M.; Ester, M.; Glasser, U.; Brantingham, P. CRIMETRACER: Activity space based crime location prediction. In Proceedings of the Advances in Social Networks Analysis and Mining (ASONAM), 2014 IEEE/ACM International Conference, Beijing, China, 17–20 August 2014; pp. 472–480. [Google Scholar]
- Kianmehr, K.; Alhajj, R. Crime Hot-Spots Prediction Using Support Vector Machine. In Proceedings of the Computer Systems and Applications, IEEE International Conference, Dubai, United Arab Emirates, 8 March 2006; pp. 952–959. [Google Scholar]
- Zhuang, Y.; Almeida, M.; Morabito, M.; Ding, W. Crime Hot Spot Forecasting: A Recurrent Model with Spatial and Temporal Information. In Proceedings of the 2017 IEEE International Conference on Big Knowledge (ICBK), Hefei, China, 9–10 August 2017. [Google Scholar]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A density-based algorithm for discovering clusters in large spatial databases with noise. In Proceedings of the Second International Conference on Knowledge Discovery and Data Mining, Portland, OR, USA, 2–4 August 1996; Volume 96, pp. 226–231. [Google Scholar]
- Ankerst, M.; Breunig, M.M.; Kriegel, H.P.; Sander, J. OPTICS: Ordering points to identify the clustering structure. In Proceedings of the ACM Sigmod Record, Philadelphia, PA, USA, 1–3 June 1999; Volume 28, pp. 49–60. [Google Scholar]
- Campello, R.J.; Moulavi, D.; Zimek, A.; Sander, J. Hierarchical density estimates for data clustering, visualization, and outlier detection. ACM Trans. Knowl. Discov. Data (TKDD) 2015, 10, 1–51. [Google Scholar] [CrossRef]
- Müller, D.W.; Sawitzki, G. Excess mass estimates and tests for multimodality. J. Am. Stat. Assoc. 1991, 86, 738–746. [Google Scholar]
- Cesario, E.; Uchubilo, P.I.; Vinci, A.; Zhu, X. Multi-density urban hotspots detection in smart cities: A data-driven approach and experiments. Pervasive Mob. Comput. 2022, 86, 101687. [Google Scholar] [CrossRef]
- Fränti, P.; Sieranoja, S. K-Means Properties on Six Clustering Benchmark Datasets. 2018. Available online: http://cs.uef.fi/sipu/datasets/ (accessed on 18 December 2022).
- Zahn, C. Graph-theoretical methods for detecting and describing gestalt clusters. IEEE Trans. Comput. 1971, 100, 68–86. [Google Scholar]
- Jain, A.; Dubes, R. Algorithms for Clustering Data; Prentice-Hall: Hoboken, NJ, USA, 1988. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
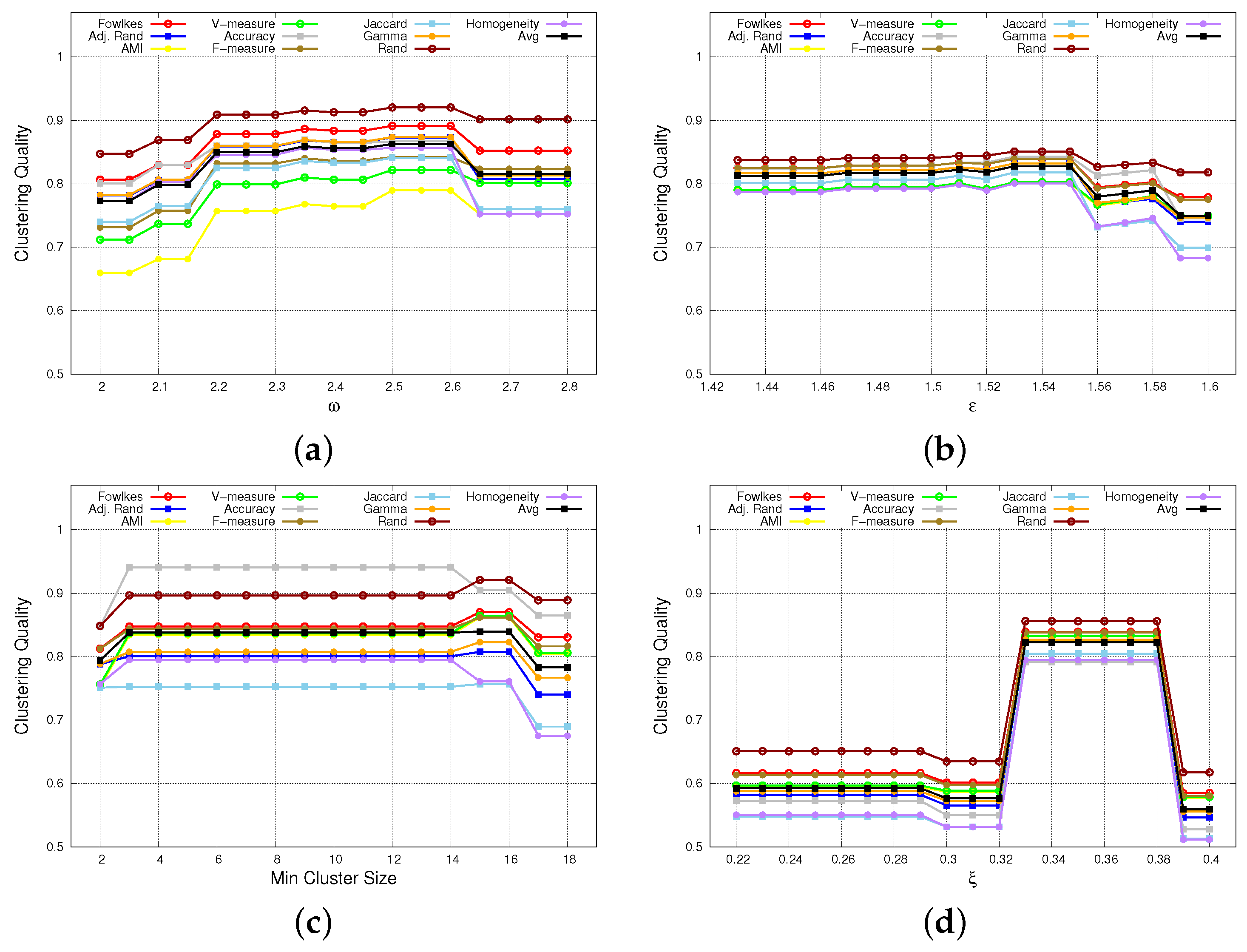
| Dataset | Algorithm | Fixed Parameter | Swept Parameter | Begin | End | Best Average Performance | Best Swept Parameter Value |
|---|---|---|---|---|---|---|---|
| Chess | CHD | 0.1 | 1.7 | 0.65 | = 1 | ||
| DBSCAN | 0.08 | 0.25 | 0.47 | = 0.14 | |||
| HDBSCAN | 2 | 18 | 0.38 | = 3 | |||
| OPTICS-Xi | 0.06 | 0.08 | 0.13 | = 0.066 | |||
| Compound | CHD | 2.0 | 2.8 | 0.86 | = 2.5 | ||
| DBSCAN | 1.43 | 1.6 | 0.83 | = 1.53 | |||
| HDBSCAN | 2 | 18 | 0.84 | = 15 | |||
| OPTICS-Xi | 0.2 | 0.4 | 0.82 | = 0.33 |
| Input Parameters | # Hotspots | # Noise Points | Silhouette Index | |
|---|---|---|---|---|
| CHD | , , | 181 | 5.7% | −0.23 |
| DBSCAN | , | 78 | 12.6% | −0.28 |
| HDBSCAN | , | 61 | 34.6% | −0.19 |
| OPTICS-Xi | 0.05, | 279 | 71.9% | −0.46 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cesario, E.; Lindia, P.; Vinci, A. Detecting Multi-Density Urban Hotspots in a Smart City: Approaches, Challenges and Applications. Big Data Cogn. Comput. 2023, 7, 29. https://doi.org/10.3390/bdcc7010029
Cesario E, Lindia P, Vinci A. Detecting Multi-Density Urban Hotspots in a Smart City: Approaches, Challenges and Applications. Big Data and Cognitive Computing. 2023; 7(1):29. https://doi.org/10.3390/bdcc7010029
Chicago/Turabian StyleCesario, Eugenio, Paolo Lindia, and Andrea Vinci. 2023. "Detecting Multi-Density Urban Hotspots in a Smart City: Approaches, Challenges and Applications" Big Data and Cognitive Computing 7, no. 1: 29. https://doi.org/10.3390/bdcc7010029
APA StyleCesario, E., Lindia, P., & Vinci, A. (2023). Detecting Multi-Density Urban Hotspots in a Smart City: Approaches, Challenges and Applications. Big Data and Cognitive Computing, 7(1), 29. https://doi.org/10.3390/bdcc7010029