1. Introduction
Sentiment analysis involves analyzing people’s responses, emotions, and opinions in the form of text toward an object, such as a book, service, or video. This type of analysis can be utilized on YouTube comments using machine learning algorithms and techniques to classify them as positive or negative. Classifying a YouTube video based on its comments can save viewers’ time and assist YouTube content creators in gauging the impression of their viewers, leading to improvement in content quality in general on the platform.
The language that holds the fourth spot in terms of popularity on the internet is Arabic [
1]. It takes an essential place within the realm of sentiment analysis and needs more research about it. There are several characteristics of the Arabic language which make it unique compared to other languages. First of all, it has 28 letters with no capitalization format. In addition, words can be written by connecting Arabic letters. For instance, writing a letter alone will be different from writing it in a middle of a word [
2]. Secondly, the Arabic language can be written differently based on its dialects. On the internet, specifically social media, it is common to see the language written using various dialects.
Natural language processing is a part of Artificial Intelligence, and it is a technique used to analyze and process human language by enabling the computer to interpret the intent and sentiment of the writer or the speaker. In addition, it allows the computer to understand the whole meaning of the sentence. The popularity of utilizing Natural Language Processing (NLP) has recently increased noticeably. However, the number of its applications in the Arabic language is incomparable with the English Language. It is clear that English research papers outnumber Arabic ones. When it comes to Arabic YouTube comments, we can capitalize on them to save the time of viewers to know whether it is worth it to watch a specific video or not.
This study uses machine learning and NLP techniques to sentimentally evaluate Arabic YouTube comments. As many research papers have been released for the English language, this study focused on the Arabic language to expand this domain due to insufficient research in Arabic. Our objective is to propose a novel model for sentiment analysis of Arabic comments on YouTube videos, addressing the challenge of evaluating video quality without watching the content. By utilizing NLP techniques and ML algorithms, the model classifies comments as positive or negative. Our study includes the evaluation of the model’s performance on a balanced dataset of manually labeled Arabic comments and compares various classifiers. It provides valuable insights for content creators to improve their content and audience engagement by analyzing viewers’ sentiments.
This paper is divided into the following segments:
Section 2 discusses a Review of Related Literature and Background.
Section 3 discusses the Description of the Methodology.
Section 4 discusses Performance Measurement.
Section 5 illustrates the Experimental Results and Discussion. The final section encompasses the Conclusion and Future Work.
2. Review of Related Literature and Background
This section provides background information on Arabic sentiment analysis and reviews relevant studies.
2.1. Arabic Sentiment Analysis
Numerous languages, including English, have investigated sentiment analysis thoroughly in [
3,
4,
5,
6,
7,
8,
9]. Despite Arabic being the fourth most used language online, there has not been much research on the usage of sentiment analysis in it [
1]. Arabic sentiment analysis is a challenging task due to a variety of challenges with the language. In Arabic, the same word might have a variety of meanings depending on the context. Arabic also has a rich morphology, with verb forms that are difficult to understand and elaborate syntactic patterns. The wide range of dialects spoken in Arabic is a significant barrier to sentiment analysis. In the region of the Middle East and North Africa, Arabic is spoken in a number of dialects, with substantial variations in vocabulary, syntax, and pronunciation. These factors make it challenging to develop accurate sentiment analysis models for Arabic texts. Despite the challenges, there have been successful research studies within the framework of sentiment analysis applied to the Arabic language.
2.2. Related Literature
Al-Tamimi et al. [
10] suggested a classification model of Arabic YouTube comments that was done through the manual collection, annotation of comments, and the use of popular supervised classifiers. The classifiers tested during experiments are SVM-RBF, KNN, and Bernoulli NB classifiers. They demonstrated that a normalized dataset that has two classes (positive and negative), along with the use of SVM-RBF, excelled in comparison to other classification approaches, yielding an f-measure of 88.8%.
Alakrot et al. [
11] presented the findings from predictive modeling for identifying antisocial behavior in Arabic online communication, such as identifying comments that contain offensive or derogatory language. They built a dataset of 15,050 Arabic YouTube comments that was ready for prediction purposes. Three annotators from three distinct Arab nations carried out the labeling process. The reason for selecting different Arab nationalities of annotators is to ensure that dialectal comments can be understood by most Arabs. The comment is labeled offensive if at least two of the annotators agree that they see it offensive. In their experiments, they used the Support Vector Machine classifier for training the dataset. They applied pre-processing techniques and attributes that enable the classifier’s training process that is more accurate—with 90.05% accuracy—than classifiers used in other previous works on Arabic sentiment analysis.
Another study was implemented by Mohaouchane et al. [
12] to detect the offensive language in Arabic YouTube comments using deep learning. This research employed a dataset that was made publicly available and had been gathered and labeled by Alakrot et al. [
11]. Mohaouchane et al. [
12] presented the findings from a comparison of the performance of four various neural network designs. Using a classified dataset of Arabic YouTube comments, these networks were trained and put to the test. The comments were represented by Arabic word embeddings after this dataset had undergone a number of pre-processing steps. They additionally adjusted the hyperparameters of the neural network models using Bayesian optimization approaches. With the use of 5-fold cross-validation, they trained and evaluated each network. The highest Recall was attained with the CNN-LSTM, which was 83.46%. However, CNN attained the highest accuracy, precision, and F1-Score with 87.84%, 86.10%, and 84.05%, respectively.
Mohammed and Kora [
13] conducted a study that made two contributions: they started by presenting a corpus of 40,000 Arabic tweets that had been labeled and covered a range of subjects. Then, for Arabic sentiment analysis, they offered three deep learning models: CNN, LSTM, and RCNN. They verified the performance of the three models on the corpus using word embedding. Their test findings showed that LSTM performed better than CNN and RCNN, indicating an average accuracy score of 81.31% and 88.71% when the corpus was augmented using data augmentation techniques.
In [
14], a pioneering deep-learning model for evaluating sentiment in the Arabic language was presented. To extract local features, the model employs a single layer of CNN architecture while maintaining long-term dependencies. It employs two layers of LSTM. The SVM classifier is used to create the final classification from the feature maps acquired from the CNN and LSTM. Additionally, to support this model, they have used the FastText words embedding model. A training set of 15,100 reviews and a test of 4000 reviews were used with the model. The results show that this model performs outstandingly in terms of classification, with 90.75% accuracy.
In their study, Hadwan et al. [
15] used sentiment analysis and machine learning techniques to analyze Saudi Arabian citizens’ reviews on Google Play and the app store. They conducted their study using a brand-new dataset made up of 8000 user reviews in Arabic that were acquired from social media, Google Play, and the app store. The dataset was subjected to several techniques, and the findings indicate that the k-nearest-neighborhood (KNN) method produced the highest accuracy with 78.46% compared to other employed techniques.
Khabour, Al-Radaideh, and Mustafa [
16] proposed a semantic orientation approach to calculate the overall polarity of Arabic subjective texts. Their methodology involves utilizing a domain ontology and sentiment lexicon to extract and weigh semantic domain features based on ontology levels and dataset frequencies. The authors evaluated their approach using an Arabic dataset from the hotels’ domain, which consists of a total of 15,572 reviews annotated with positive, negative, and neutral classes. The experimental results indicated an overall accuracy of 79.20% and an f-measure of 78.75%.
In their research, Arwa Alqarni and Atta Rahman aimed to analyze the sentiment of Arabic tweets with the consideration of the COVID-19 pandemic in Saudi Arabia. They gathered data across two consecutive time periods from the main Saudi Arabian cities of Riyadh, Dammam, and Jeddah. The tweets were pre-processed and annotated with positive, negative, or neutral sentiments. The total number of those pre-processed tweets was 90,187. For sentiment classification, the authors employed deep learning algorithms, namely Convolutional Neural Networks (CNN) and Bi-directional Long Short-Term Memory (BiLSTM). The experimental results demonstrated that the CNN model achieved an accuracy of 92.80%, while the BiLSTM model achieved 91.99% accuracy.
The key points from the papers reviewed in this section are extracted and presented in
Table 1.
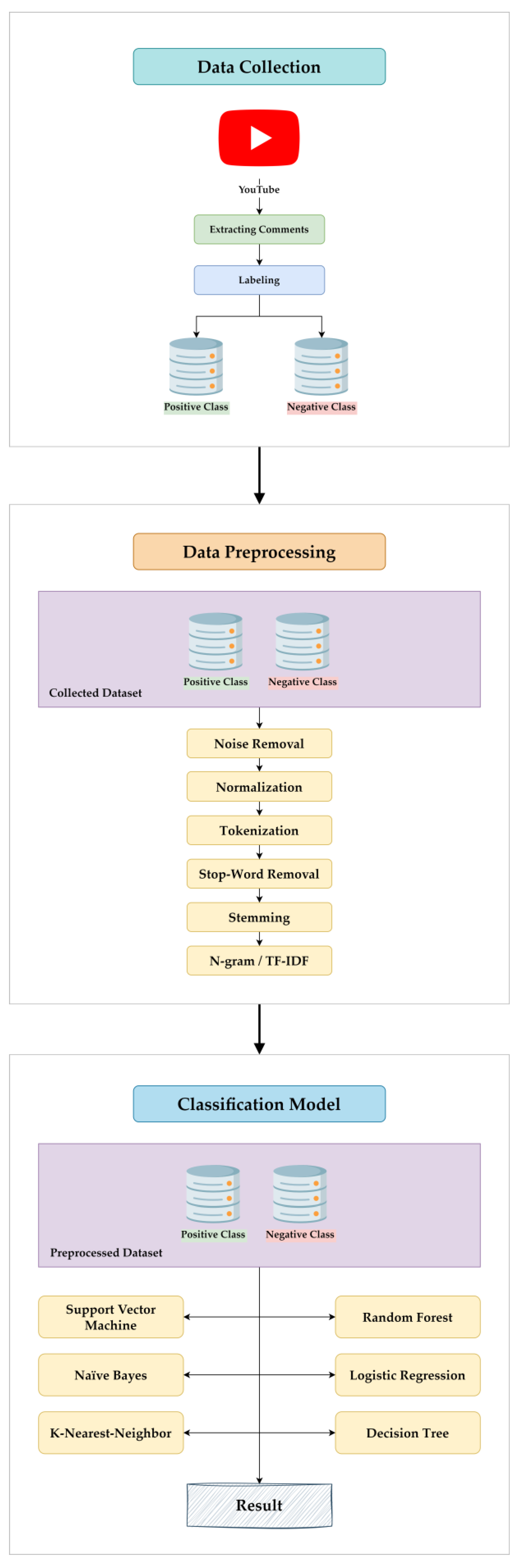
3. Description of Methodology
This section addresses the collection, labeling, description, and preprocessing of the dataset, as well as the subsequent steps of feature extraction and model generation. Representation of data collection, data pre-processing, and classification model are shown in
Figure 1.
3.1. Dataset Collection
Our primary objective was to identify video content that featured favorable and unfavorable comments. Initially, we devised a Python-based instrument to gather our dataset, which was subsequently linked to the YouTube API. Later, we utilized the linked Python script to collect our dataset from the YouTube platform, garnering 4760 comments from diverse categories of videos.
3.2. Dataset Labeling
Our dataset will be stratified into two distinct categories to encompass the entire spectrum of classification. These categories include positive and negative classes. The positive class will comprise comments that are commendatory or appreciative of the YouTube video or its content. On the other hand, the negative class encompasses comments that are derogatory and critical of the YouTube video’s content. Five native Arabic individuals labeled each comment individually in a CSV file that includes the 4760 Arabic YouTube comments. The comment that has been labeled three times or more for a specific class is set as the final label. Following the labeling process, we further investigated the comments to eliminate irrelevant ones, resulting in a total of 4212 comments that are divided equally between 2106 positive and 2106 negative comments.
Evaluation of Inter-Rater Reliability Using Fleiss’ Kappa
The agreement between the five Arabic individuals (raters) who examined 4212 comments was measured using Fleiss’ Kappa. The resulting Kappa value was found to be 0.818, indicating strong agreement among the labels provided by the group of raters. The corresponding z-score of approximately 168 suggests a significant deviation from the null hypothesis of no agreement. These findings highlight the strong inter-rater agreement observed in the dataset, providing valuable insights into the reliability of the ratings provided by the group of individual Arabic raters.
Figure 2 shows dataset analysis obtained by measuring the Fleiss’ Kappa.
3.3. Dataset Pre-Processing
Pre-processing is a vital component of machine learning systems [
18], as it involves cleaning and refining the dataset to facilitate subsequent classifier training. In our dataset, YouTube comments are written in various dialects of Arabic rather than in standard Arabic. To overcome the challenges associated with Arabic language comments, we leveraged NLP techniques incorporating normalization, stemming, and stop-word removal. The previous
Figure 1 demonstrates the main phases of pre-processing that are taken before building the model.
3.3.1. Noise Removal
Removing noise is a useful technique for speeding up analysis while also being essential for accuracy improvement. Noises include objects like hashtags, the URL, and repeatedly used letters. The first step is to remove URLs and HTML tags. This is achieved by searching for the “
https://” followed by any string of characters and the tags <a> and <br> using a special regular expression and then applying the “sub” method provided by the “re” package to perform the removal. The next step is to eliminate symbols, noise, and emojis, as well as frequently used symbols such as “@” and “.”. To accomplish this, a special regular expression is written and applied using the “sub” method provided by the “re” package. Finally, to remove repeated letters, another special regular expression is written and applied using the “sub” method provided by the “re” package.
3.3.2. Normalization
The normalizing process is used to remove noise from the data and correct spelling errors in Arabic. This step showed a noticeable improvement in model accuracy scores for various studies. For instance, in Huq et al. [
19], researchers were able to increase the scores by applying normalization and other preprocessing techniques. The accuracy score increased from 61% to 80% for the SVM classifier model. For the purpose of normalizing some Arabic letters, such as
آ to
ا, we employed the script. First, the script cleans up any leading or trailing whitespace in the given text. After that, Arabic character variants are replaced with their standard versions using regular expressions. For instance, it replaces different representations of the letter “
ا ”(إ, أ, آ, ا, ٱ) with a single “
ا”. It also changes the letter “
ى” (sometimes used as the final form of “
ي”) to “
ي” and it changes the letters “
ؤ” and “
ئ” to “
ء” to normalize their usage. Furthermore, it substitutes “
ة” for the feminine marker “
ه” The output of the function is then the normalized text that was produced. For text processing and analysis activities, these normalization methods can help guarantee that Arabic characters are represented consistently.
Figure 3 demonstrates the script used for applying normalization.
3.3.3. Tokenization
Tokenization is an essential step before analyzing the text since it reduces the variation of typos found in words [
5]. In addition, performing the tokenization phase can help the performance when including a feature extraction such as a bag of words (BOW) [
20]. There are other elements that could affect tokenization, for instance, in N-gram, co-occurrence, and stemming. In tokenization, the spaces, tabs, and newlines are viewed as delimiters. There are also other characters that can be considered delimiters, such as (), ?, and !. Arabic users usually express their opinion in informal Arabic on social media. Thus, the use of a comma can sometimes be wrong, so it is better to consider it as a delimiter as well if it exists between words. One of the usages of tokenization is to tally the frequency of word appearances.
3.3.4. Stop-Word Removal
The sources of stop words are two. The first source is from the “NLTK” library using the “stopwords” class with the “words” method and selecting the Arabic language. The second source is writing the stop words manually in the code. The way of preparing the two sources of stop words. Later, the separation of the words within the comments is performed, and each word will be compared with the stop words from the two previously created sources. If a comparison is true, the word will be considered a stop word and therefore discarded. The loops keep iterating and performing the same comparison until the last word of comments.
3.3.5. Stemming
By eliminating prefixes and suffixes from the word, a process known as stemming allows the word to be restored to its original meaning, which is the root. We used the ISRIStemmer provided by the NLTK library [
21].
3.4. Feature Extraction
The aim of our study was to perform sentiment analysis on Arabic YouTube comments through the implementation of machine learning approaches. Our methodology involved exploring different strategies to identify the most effective features for the model to achieve the highest possible accuracy. We accomplished this by extracting features using various N-gram ranges and TF-IDF methods. To train the dataset, we employed six different supervised machine learning models, specifically SVM, RF, LR, KNN, DT, and NB.
3.4.1. Term Frequency-Inverse Document Frequency (TF-IDF)
Text reorganization and feature extraction are accomplished using the TF-IDF technique. The term frequency signifies how often a word is utilized within a particular document, while the inverse document frequency quantifies how commonly or uncommonly the word occurs across the entire document.
3.4.2. N-Gram
N-gram is a technique that facilitates machine comprehension of word meaning in its context. This method utilizes the words preceding and following the target word to aid the machine in understanding the sentence’s meaning. Spell-checking, next-word prediction, and language identification are all made easier with the use of n-grams. The term “grams” refers to the individual words, whereas the letter “N” signifies the total number of words to be examined. Various types of N-grams exist, such as Unigram N = 1, Bigram N = 2, and Trigram N = 3, among others. The N-gram approach, for instance, can be used to compute the following N-gram versions for the statement “هذا المقطع جميل جدا”:
Unigrams: “هذا”, “المقطع”, “جميل”, “جدا”.
Bigrams: “هذا المقطع”, “المقطع جميل”, “جميل جدا”.
Trigrams: “هذا المقطع جميل”, “المقطع جميل جدا”.
3.5. Generating the Model
Building models using various classifiers, such as Multinomial NB, SVM, DT, Random Forest, Logistic Regression, and KNN, can be achieved by using a number of classes from the Python scikit-learn (sklearn) library, such as GridSearchCV, Confusion Matrix, and Classification Report.
3.5.1. Naïve Bayes (NB)
A supervised classification technique called Naïve Bayes is typically used for statistically based prediction [
19]. It uses statistical and probabilistic principles to categorize tokens into predefined classifications. Nave Bayes is a very scalable method that allows the addition of further parameters (i.e., features or predictor states). In our case, where we seek to categorize a given token sentimentally for a particular class, this approach is frequently employed to ascertain the highest likelihood probability [
22].
3.5.2. Support Vector Machine (SVM)
SVM is a form of supervised learning model that provides a mapping between inputs and classifications by constructing a decision function that takes in an input and outputs a probability indicating the likelihood that the input belongs to a particular class [
4]. The SVM hyperplane is a line that separates the data into two categories. This hyperplane is defined by the value of the weights on the margins that have been optimized. The primary objective of the training is to find a separating hyper-plane that maximizes the distance between the classes of positive and negative examples while at the same time having the smallest possible number of misclassifications. We can describe the hyperplane as:
where
w is the set of weights,
x represents the input vector, and
b denotes the bias. Also, there’s another equation to maximize the margin size, which is:
Figure 4 below demonstrates the concept of SVM with two classes: blue circles represent the positive class, and red circles represent the negative class.
3.5.3. Random Forest (RF)
Random Forest is classified as an ensemble technique that has gained widespread popularity for its flexibility and effectiveness in solving a broad range of problems [
24]. It consists of a group of decision trees, each of which generates a prediction for a given input instance, and the conclusive result generated by the model is based on the majority vote of the individual trees. In
Figure 5, the green circles represent the attributes that are randomly chosen for the split at each node, while the blue circles represent the attributes that are ignored during the construction process. Random Forest has demonstrated success in diverse domains, including image classification, bioinformatics, and NLP.
3.5.4. K-Nearest-Neighbor (KNN)
K-Nearest Neighbors (KNN) is a simple method used in supervised machine learning for regression and classification tasks. KNN runs on the presumption that fresh data is categorized based on its nearest neighbors [
26].
Figure 6 demonstrates three circles belonging to three distinct classes represented by the colors blue, orange, and black. The gray circle represents a data point that needs to be predicted or classified. However, arrows are used to indicate only the closest neighbors, as determined by a K value of seven.
There are several techniques for determining the spatial separation between the points. However, one of the most used methods is Euclidean distance, which uses the following formula to determine the distance between two or more points:
3.5.5. Decision Tree (DT)
A Decision Tree is considered a non-parametric approach in supervised learning used to organize a sequence of roots in a tree structure, as shown in
Figure 7. The decision tree consists of three primary nodes: the root node represents the overall population under consideration, the decision node is created when a sub-node is divided into other sub-nodes, and the leaf node does not split into further nodes [
27]. The decision tree algorithm utilizes entropy to determine the degree of variation in the data, whereby larger entropy has an adverse effect on the selection of the next point.
3.5.6. Logistic Regression (LR)
Logistic regression is a statistical technique that originates from linear regression and is applied to classify or predict values based on specific outcomes. The logistic function is a linear function that produces an S-shaped graph when plotted and is instrumental in developing models for classification and prediction based on given parameters. The function’s output generates a probability value [
28], which can either be greater than 0.50 if the outcome is more likely than not or less than 0.50 if the outcome is improbable. These values generally fall within the interval of 0 to 1, with 0 denoting an impossible outcome and 1 signifying a certain outcome.
4. Performance Measures
Assessing the quality of sentiment analysis involves various metrics and indicators to measure its performance. Several research papers used Precision, Recall, F-score, Accuracy, and Matthews correlation coefficient (MCC) as their performance measures, namely, Novendri et al. [
29], Musleh et al. [
30], Singh and Tiwari [
31], and more. Each of these has a unique formula for calculating the rate of software performance. We evaluated how well classifiers performed by using mathematical formulas. The symbols used in the formulas are as per the following definitions: “TP” signifies instances that are accurately classified as positive, “TN” represents instances that are accurately classified as negative, “FP” denotes instances that are erroneously classified as positive, and “FN” refers to instances that are erroneously classified as negative. The formulas are:
Accuracy is obtained by performing the calculation of true positives and negatives divided by the total comments [
32].
The precision of a classifier was evaluated by computing the number of false positives it produced [
33].
The Recall of a classifier was evaluated by computing the number of false negatives it generated [
33].
The F1-measure or F1-score was determined by finding the weighted harmonic mean of both the recall and precision measurements [
34].
The calculation of the Matthews Correlation Coefficient relies on the information derived from the confusion matrix [
35].
5. Experimental Results and Discussion
This section presents a comprehensive comparative analysis of all used classifiers is undertaken, accompanied by a detailed examination of the impact of enabling the TF-IDF technique in the context of text classification. Performance measure scores, including accuracy, precision, Recall, and F1-measure, for each classifier, are presented in
Table 2. These scores were derived using the optimal parameters determined through grid search. Prior to the classification task, the dataset was collected and preprocessed, followed by a stratified split into 70% for training and 30% for testing, utilizing 5-fold cross-validation to ensure the robustness and reliability of the results.
Through meticulous analysis of the classifiers’ performance, Naïve Bayes emerged as the most proficient classifier, attaining an accuracy of 94.62% and exemplary precision, Recall, and F1-measure scores of 94.64%, 94.64%, and 94.62%, respectively, with TF-IDF disabled. In contrast, the Decision Tree classifier exhibited suboptimal performance, achieving an accuracy score of 84.10% when TF-IDF was deactivated, thereby rendering it the least effective classifier among the evaluated options. The Random Forest classifier exhibited a notable disparity of 9.1% in performance when comparing the use of TF-IDF versus the absence of TF-IDF. Specifically, the classifier achieved an accuracy rate of 91.77% when employing TF-IDF, as opposed to 82.67% without TF-IDF. In the optimal parameter settings of all classifiers, unigram n-grams were consistently included.
Figure 8 below presents a graphical representation of the impact of activating the TF-IDF technique as a feature extraction method on performance measures. The findings illustrated in the graph provide compelling evidence that enabling TF-IDF yields improvements across all performance measures. Notably, it is observed that Naïve Bayes, despite being the top-performing classifier among the others, experienced a slight decline in performance when TF-IDF was activated. These findings shed light on the potential benefits of incorporating TF-IDF as a technique for identifying distinctive features from data in the context of the evaluated performance measures. Regarding evaluating the accuracy score solely, it is observed that all classifiers achieved accuracy scores surpassing 90%, with Naïve Bayes exhibiting the highest accuracy among them. However, the Decision Tree classifier failed to meet the 90% threshold. Furthermore, Random Forest demonstrated the lowest performance among the classifiers surpassing 90% accuracy. This observation suggests that tree-based classifiers, namely Decision Tree and Random Forest, may exhibit relatively lower performance compared to the other classifiers in the context of Arabic sentiment analysis. The best classifier, based on the highest MCC score, is also the Naive Bayes (NB) classifier without using TF-IDF, with a score of 91.46%. On the other hand, the worst classifier, based on the lowest MCC score, is the Decision Tree (DT) classifier without using TF-IDF, with a score of 69.64%. This classifier has the lowest performance in terms of all performance measures among the other five classifiers.
Figure 9 depicts word clouds showcasing the occurrence of lexemes that are indicative of positive affective orientations in the YouTube comments. The size of the font used for each Arabic word in the word clouds corresponds to its frequency of use, with more frequently used words appearing in larger font sizes. Therefore,
Figure 9a highlights the positive Arabic words, such as “
شكرا” meaning “Thanks”, while
Figure 9b presents the same positive words translated into English.
The violin plot presented in
Figure 10 visualizes the distribution of word counts in comments, categorized as “Positive” or “Negative”, with the aim of examining the relationship between comment length and sentiment. The analysis reveals that comments with a prolix nature, containing 100 words or more, tend to convey a negative sentiment from the comment writers, as indicated by the taller portion of the violin plot for the “Negative” category. Furthermore, the graph displays a denser concentration of comments with word counts around 37 on the positive side, suggesting a higher likelihood for positive sentiment.
6. Conclusions
Based on the findings, it is apparent that TF-IDF can improve the performance of most classifiers used in the investigation, with the exception of Naïve Bayes. Naïve Bayes showed satisfactory results when using only n-grams and a count-vectorizer. However, the performance of Naïve Bayes was slightly better without incorporating TF-IDF compared to when TF-IDF was enabled. Specifically, Naïve Bayes achieved an accuracy of 94.62% and an MCC score of 91.46%. In contrast, the Decision Tree exhibited low performance with an accuracy of 84.10% and an MCC score of 69.64% when TF-IDF was not enabled. The study specifically focused on sentiment analysis of YouTube comments from various videos, with the objective of predicting whether the video content was categorized as positive or negative. Manual labeling of comments into “Positive” and “Negative” classes was conducted after preprocessing the dataset. The dataset achieved a Kappa score of 0.818, indicating a substantial level of agreement between the annotators. A total of six distinct supervised ML text classifiers were employed to predict the video recommendation status. Notably, Naïve Bayes exhibited the most optimal performance, attaining an accuracy rate of 94.62% even in the absence of TF-IDF integration.
In the upcoming stages, we aim to enhance the performance of our ML model in various ways, including expanding the dataset by adding more comments to it, testing other types of machine learning classifiers, and even exploring the growing popularity of techniques such as RNNs, transformer-based neural network models, and large language models, which have witnessed significant progress in recent times. Finally, we could also augment the dataset with supplementary features like user engagement metrics such as the number of likes, dislikes, or replies received by a comment. By implementing these improvements, we can aim to make our model even more effective and accurate.
Author Contributions
Conceptualization, methodology, visualization, and writing—original draft: D.A.M., I.A., A.A., M.A., H.A. and F.A.; Writing—review and editing: N.M.-A. and M.M.A. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Tiwari, S.; Trivedi, M.C.; Kolhe, M.L.; Mishra, K.K.; Singh, B.K. Advances in Data and Information Sciences, Proceedings of ICDIS 2021; Springer Nature Singapore Pte Ltd.: Singapore, 2022; ISBN 978-981-16-5688-0. [Google Scholar]
- AlOtaibi, S.; Khan, M.B. Sentiment analysis challenges of informal Arabic language. Int. J. Adv. Comput. Sci. Appl. 2017, 8. [Google Scholar] [CrossRef] [Green Version]
- Rao, L. Sentiment Analysis of English Text with Multilevel Features. Sci. Program. 2022, 2022, 7605125. [Google Scholar] [CrossRef]
- Samsir, S.; Kusmanto, K.; Dalimunthe, A.H.; Aditiya, R.; Watrianthos, R. Implementation Naïve Bayes Classification for Sentiment Analysis on Internet Movie Database. Build. Inform. Technol. Sci. 2022, 4, 1–6. [Google Scholar] [CrossRef]
- Geetha, R.; Padmavathy, T.; Anitha, R. Prediction of the academic performance of slow learners using efficient machine learning algorithm. Adv. Comput. Intell. 2021, 1, 5. [Google Scholar] [CrossRef]
- Umer, M.; Ashraf, I.; Mehmood, A.; Kumari, S.; Ullah, S.; Sang Choi, G. Sentiment analysis of tweets using a unified convolutional neural network-long short-term memory network model. Comput. Intell. 2021, 37, 409–434. [Google Scholar] [CrossRef]
- Murthy, G.S.N.; Allu, S.R.; Andhavarapu, B.; Bagadi, M.; Belusonti, M. Text based Sentiment Analysis using LSTM. Int. J. Eng. Res. 2020, 9. [Google Scholar] [CrossRef]
- Agrawal, S.; Awekar, A. Deep learning for detecting cyberbullying across multiple social media platforms. In Proceedings of the European Conference on Information Retrieval, Grenoble, France, 26–29 March 2018; Springer International Publishing: Cham, Switzerland, 2018; pp. 141–153. [Google Scholar]
- Benkhelifa, R.; Laallam, F.Z. Opinion extraction and classification of real-time youtube cooking recipes comments. In Proceedings of the International Conference on Advanced Machine Learning Technologies and Applications, Cairo, Egypt, 22–24 February 2018; Springer International Publishing: Cham, Switzerland, 2018; pp. 395–404. [Google Scholar]
- Al-Tamimi, A.K.; Shatnawi, A.; Bani-Issa, E. Arabic sentiment analysis of YouTube comments. In Proceedings of the 2017 IEEE Jordan Conference on Applied Electrical Engineering and Computing Technologies, AEECT 2017, Aqaba, Jordan, 11–13 October 2017; pp. 1–6. [Google Scholar]
- Alakrot, A.; Murray, L.; Nikolov, N.S. Towards Accurate Detection of Offensive Language in Online Communication in Arabic. Procedia Comput. Sci. 2018, 142, 315–320. [Google Scholar] [CrossRef]
- Mohaouchane, H.; Mourhir, A.; Nikolov, N.S. Detecting Offensive Language on Arabic Social Media Using Deep Learning. In Proceedings of the 2019 6th International Conference on Social Networks Analysis, Management and Security, SNAMS 2019, Granada, Spain, 22–25 October 2019; pp. 466–471. [Google Scholar]
- Mohammed, A.; Kora, R. Deep learning approaches for Arabic sentiment analysis. Soc. Netw. Anal. Min. 2019, 9, 52. [Google Scholar] [CrossRef]
- Ombabi, A.H.; Ouarda, W.; Alimi, A.M. Deep learning CNN–LSTM framework for Arabic sentiment analysis using textual information shared in social networks. Soc. Netw. Anal. Min. 2020, 10, 53. [Google Scholar] [CrossRef]
- Hadwan, M.; Al-Hagery, M.; Al-Sarem, M.; Saeed, F. Arabic Sentiment Analysis of Users’ Opinions of Governmental Mobile Applications. Comput. Mater. Contin. 2022, 72, 4675–4689. [Google Scholar] [CrossRef]
- Khabour, S.M.; Al-Radaideh, Q.A.; Mustafa, D. A new ontology-based method for Arabic sentiment analysis. Big Data Cogn. Comput. 2022, 6, 48. [Google Scholar] [CrossRef]
- Alqarni, A.; Rahman, A. Arabic Tweets-Based Sentiment Analysis to Investigate the Impact of COVID-19 in KSA: A Deep Learning Approach. Big Data Cogn. Comput. 2023, 7, 16. [Google Scholar] [CrossRef]
- Fischer, T.; Krauss, C. Deep learning with long short-term memory networks for financial market predictions. Eur. J. Oper. Res. 2018, 270, 654–669. [Google Scholar] [CrossRef] [Green Version]
- Huq, M.R.; Ahmad, A.; Rahman, A. Sentiment analysis on Twitter data using KNN and SVM. Int. J. Adv. Comput. Sci. Appl. 2017, 8. [Google Scholar] [CrossRef] [Green Version]
- Hiraoka, T.; Shindo, H.; Matsumoto, Y. Stochastic tokenization with a language model for neural text classification. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 1620–1629. [Google Scholar]
- Deng, L.; Liu, Y. Deep Learning in Natural Language Processing; Springer: Singapore, 2018; ISBN 9789811052095. [Google Scholar]
- Sahni, T.; Chandak, C.; Chedeti, N.R.; Singh, M. Efficient Twitter sentiment classification using subjective distant supervision. In Proceedings of the 2017 9th International Conference on Communication Systems and Networks (COMSNETS), Bengaluru, India, 4–8 January 2017; pp. 548–553. [Google Scholar]
- Liu, G.; Mao, S.; Kim, J.H. A mature-tomato detection algorithm using machine learning and color analysis. Sensors 2019, 19, 2023. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ghallab, A.; Mohsen, A.; Ali, Y. Arabic Sentiment Analysis: A Systematic Literature Review. Appl. Comput. Intell. Soft Comput. 2020, 2020, 7403128. [Google Scholar] [CrossRef] [Green Version]
- Abhishek Sharma Decision Tree, vs. Random Forest—Which Algorithm Should You Use? Available online: https://www.analyticsvidhya.com/blog/2020/05/decision-tree-vs-random-forest-algorithm/ (accessed on 18 October 2022).
- Duwairi, R.M.; Qarqaz, I. Arabic sentiment analysis using supervised classification. In Proceedings of the 2014 International Conference on Future Internet of Things and Cloud, FiCloud 2014, Barcelona, Spain, 27–29 August 2014; pp. 579–583. [Google Scholar]
- Hammad, M.; Al-Awadi, M. Sentiment analysis for Arabic reviews in social networks using machine learning. In Advances in Intelligent Systems and Computing; Springer: Berlin/Heidelberg, Germany, 2016; Volume 448, pp. 131–139. ISBN 9783319324661. [Google Scholar]
- Kleinbaum, D.G.; Dietz, K.; Gail, M.; Klein, M.; Klein, M. Logistic Regression; Springer: Berlin/Heidelberg, Germany, 2002; ISBN 0387953973. [Google Scholar]
- Novendri, R.; Callista, A.S.; Pratama, D.N.; Puspita, C.E. Sentiment analysis of YouTube movie trailer comments using naïve bayes. Bull. Comput. Sci. Electr. Eng. 2020, 1, 26–32. [Google Scholar] [CrossRef]
- Musleh, D.A.; Alkhales, T.A.; Almakki, R.A.; Alnajim, S.E.; Almarshad, S.K.; Alhasaniah, R.S.; Aljameel, S.S.; Almuqhim, A.A. Twitter arabic sentiment analysis to detect depression using machine learning. Comput. Mater. Contin 2022, 71, 3463–3477. [Google Scholar] [CrossRef]
- Singh, R.; Tiwari, A. Youtube comments sentiment analysis. Int. J. Sci. Res. Eng. Manag. 2021, 5. [Google Scholar]
- Aribowo, A.S.; Basiron, H.; Yusof, N.F.A.; Khomsah, S. Cross-domain sentiment analysis model on indonesian youtube comment. Int. J. Adv. Intell. Inform. 2021, 7, 12–25. [Google Scholar] [CrossRef]
- Al-Twairesh, N.; Al-Negheimish, H. Surface and deep features ensemble for sentiment analysis of arabic tweets. IEEE Access 2019, 7, 84122–84131. [Google Scholar] [CrossRef]
- Alsubait, T.; Alfageh, D. Comparison of Machine Learning Techniques for Cyberbullying Detection on YouTube Arabic Comments. Int. J. Comput. Sci. Netw. Secur. 2021, 21, 1–5. [Google Scholar]
- Muaad, A.Y.; Jayappa, H.; Al-antari, M.A.; Lee, S. ArCAR: A novel deep learning computer-aided recognition for character-level Arabic text representation and recognition. Algorithms 2021, 14, 216. [Google Scholar] [CrossRef]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).


 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}