

Computers’ Interpretations of Knowledge Representation Using Pre-Conceptual Schemas: An Approach Based on the BERT and Llama 2-Chat Models


Abstract
:1. Introduction
2. Literature Review
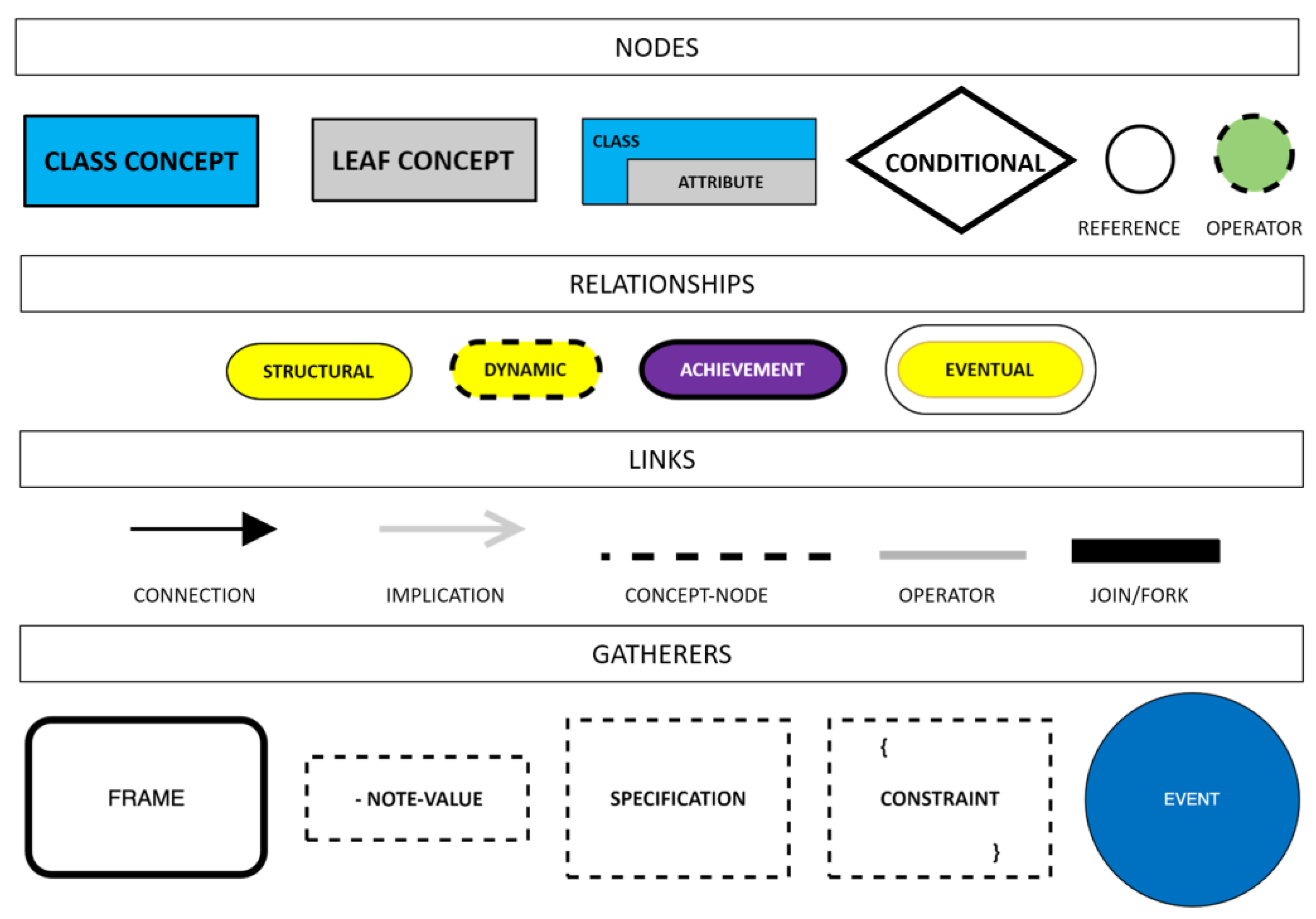
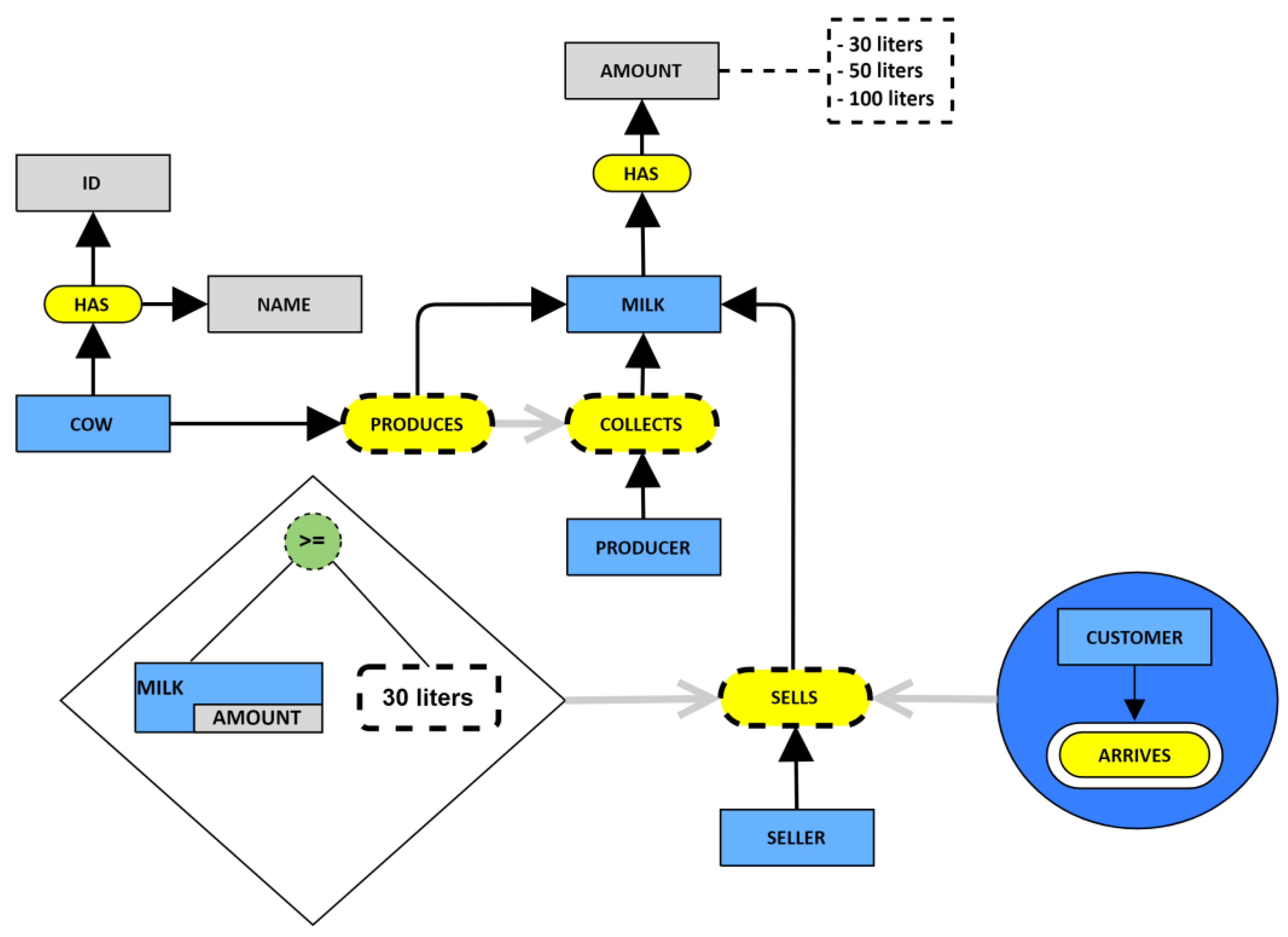
2.1. Pre-Conceptual Schemas
2.2. BERT Model
2.3. Llama 2-Chat Model
3. Materials and Methods
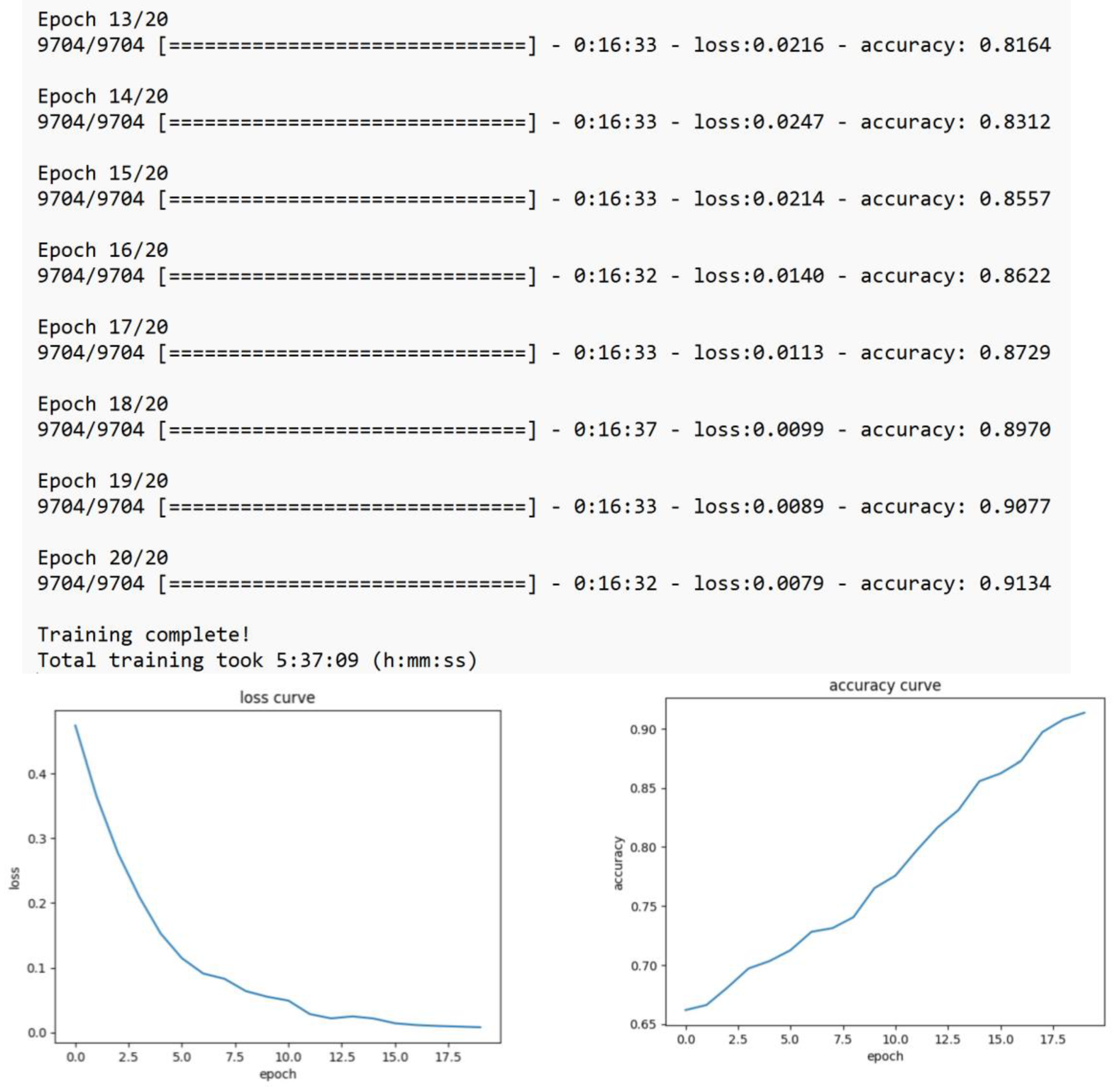
3.1. Retraining the BERT Model
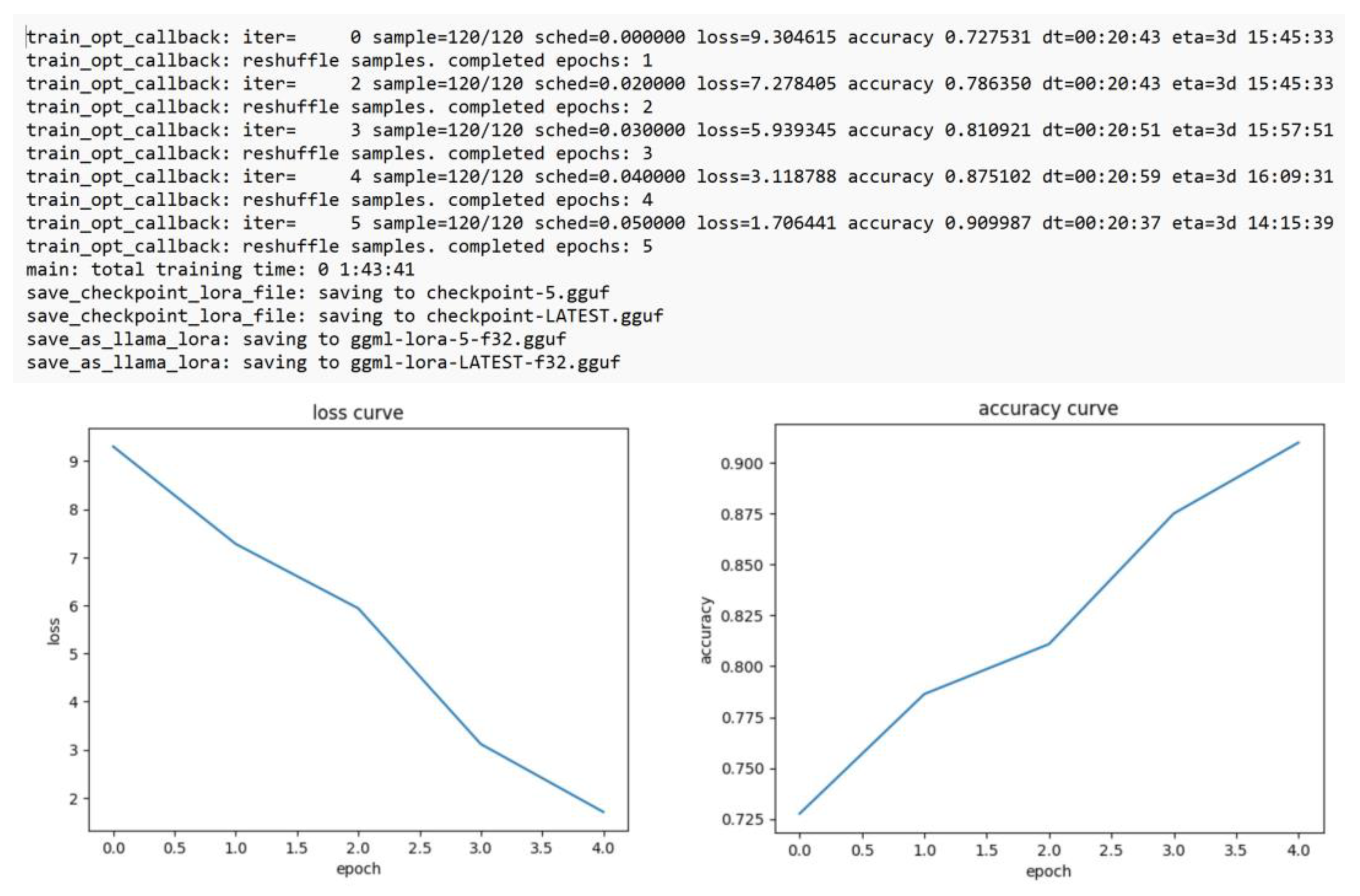
3.2. Fine-Tuning the Llama 2-Chat Model
3.3. Creating a Linguistic Corpus
4. Results
4.1. Building the Computational Solution
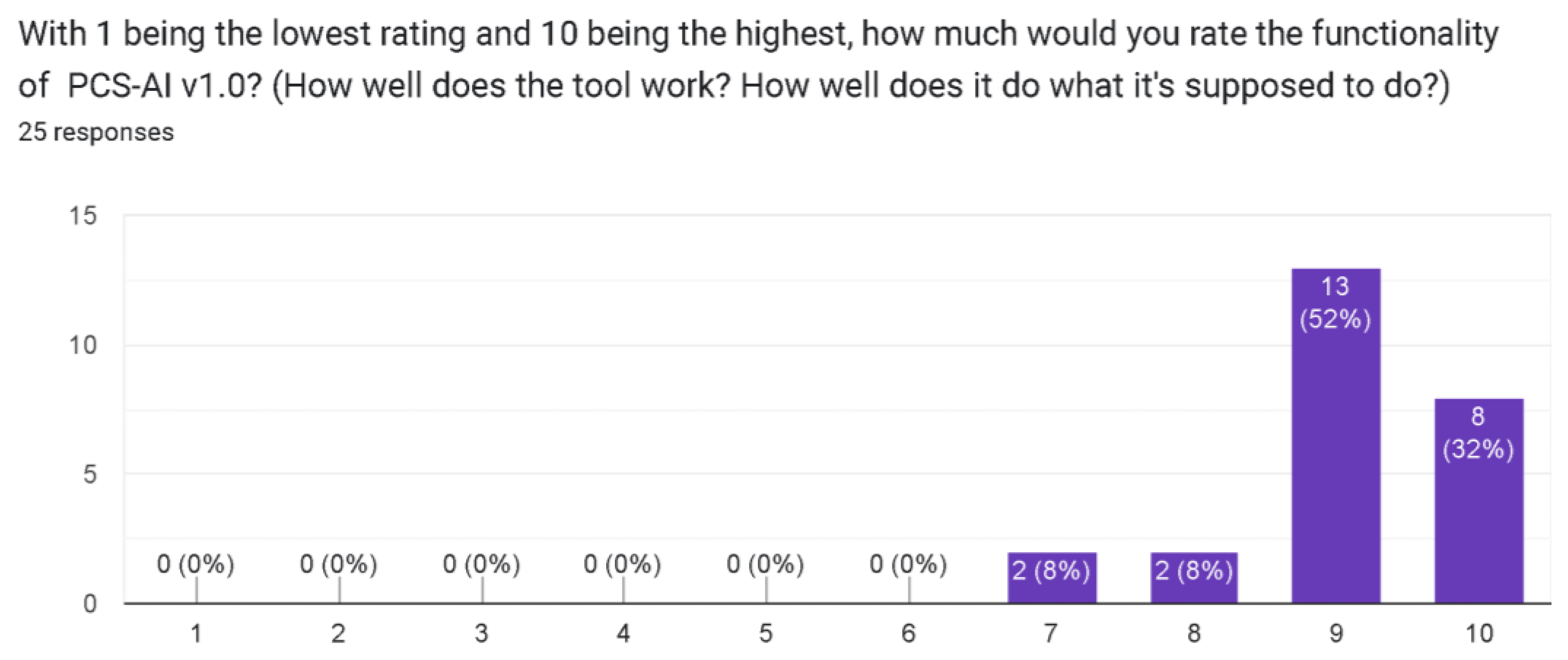
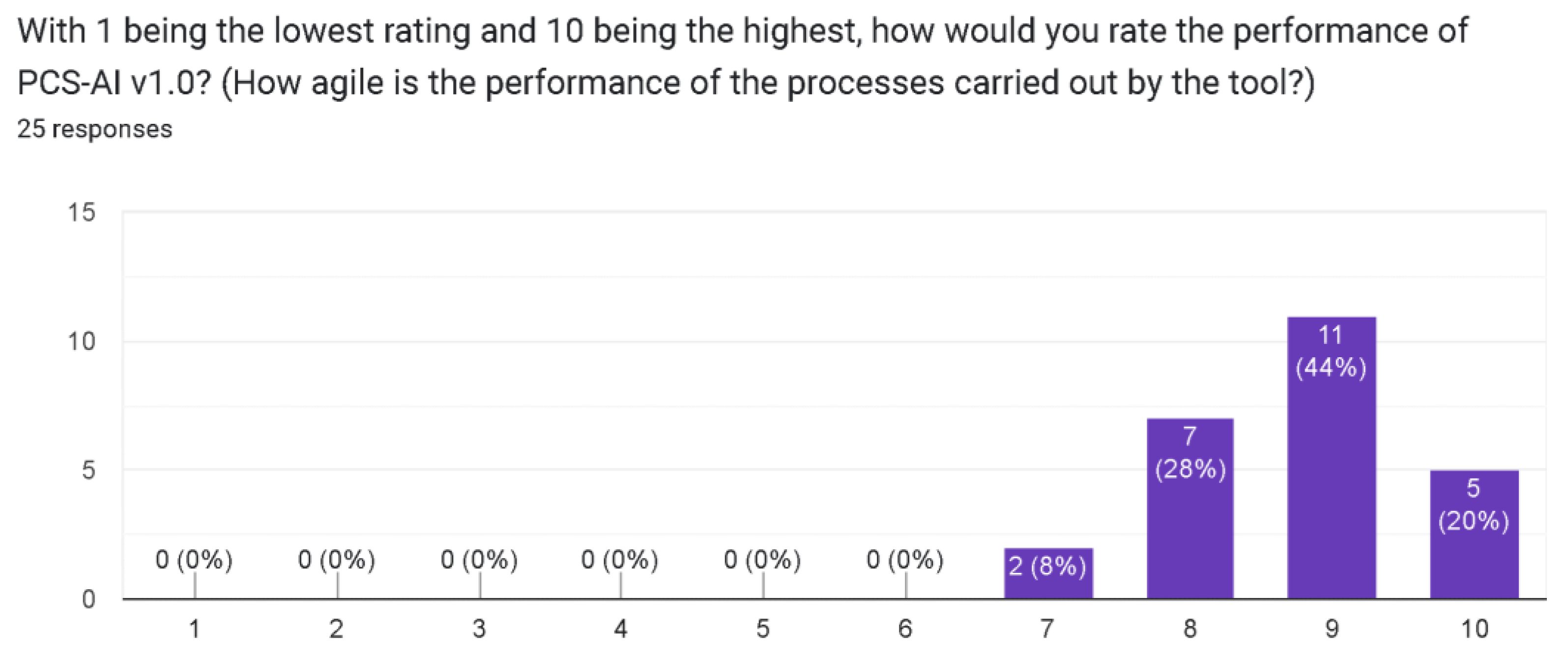
4.2. Validating the Computational Solution in Academic Scenarios
- Functionality rating.
- 0:
- Non-Functional—The features do not work.
- 1:
- Poor—The features have minimal functionality.
- 2:
- Fair—The features work but have significant limitations.
- 3:
- Good—The features are functional with some minor issues.
- 4:
- Very Good—The features provide extensive functionality with minor limitations.
- 5:
- Excellent—The features are fully functional and exceed expectations.
- Quality of the generated responses.
- 0:
- No Understanding—Users have no comprehension of the generated responses.
- 1:
- Minimal Understanding—Users barely understand the generated responses.
- 2:
- Partial Understanding—Users have a basic comprehension of the generated responses.
- 3:
- Good Understanding—Users understand most aspects of the generated responses.
- 4:
- Very Good Understanding—Users have a strong comprehension of nearly all aspects of the generated responses.
- 5:
- Excellent Understanding—Users fully comprehend all aspects of the features.
- Likelihood to recommend the computational solution.
- 0:
- Would Not Recommend at All—Users would strongly advise against using the software.
- 1:
- Unlikely to Recommend—Users are not inclined to recommend the software.
- 2:
- Neutral—Users neither would nor would not recommend the software.
- 3:
- Likely to Recommend—Users are likely to suggest others try the software.
- 4:
- Very Likely to Recommend—Users would strongly recommend the software to others.
- 5:
- Extremely Likely to Recommend—Users would highly advocate for using the software to others.
5. Discussion
6. Conclusions
7. Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zapata, C.; Arango, F.; Gelbukh, A. Pre-conceptual Schema: A UML Isomorphism for Automatically Obtaining UML Conceptual Schemas, Lecture Notes in Computer Science (Artificial Intelligence Bioinformatics). Res. Comput. Sci. 2006, 4293, 27–37. [Google Scholar]
- Torres, D.; Zapata-Jaramillo, C.; Villavicencio, M. Representing Interoperability Between Software Systems by Using Pre-Conceptual Schemas. Int. J. Electr. Eng. Inform. 2022, 14, 101–127. [Google Scholar] [CrossRef]
- Noreña, P.; Zapata, C. Simulating Events in Requirements Engineering by Using Pre-conceptual-Schema-based Components from Scientific Software Domain Representation. Adv. Syst. Sci. Appl. 2022, 21, 1–15. [Google Scholar]
- Zapata-Tamayo, J.; Zapata-Jaramillo, C. Pre-conceptual schemas: Ten Years of Lessons Learned about Software Engineering Teaching. Dev. Bus. Simul. Exp. Learn. 2018, 45, 250–257. [Google Scholar]
- Chaverra, J. Generación Automática de Prototipos Funcionales a Partir de Esquemas Preconceptuales. Master’s Thesis, Universidad Nacional de Colombia, Medellín, Colombia, 2011. [Google Scholar]
- Velasquez, S. Un Modelo Ejecutable para la Simulación Multi-Física de Procesos de Recobro Mejorado en Yacimientos de Petróleo Basado en Esquemas Preconceptuales. Master’s Thesis, Universidad Nacional de Colombia, Medellín, Colombia, 2019. [Google Scholar]
- Villota, C. Modelo de Representación de Buenas Prácticas de Cualquier área de Conocimiento Utilizando Esquemas Preconceptuales. Master’s Thesis, Universidad Nacional de Colombia, Medellín, Colombia, 2019. [Google Scholar]
- Cesar, L.; Manso-Callejo, M.; Cira, C. BERT (Bidirectional Encoder Representations from Transformers) for Missing Data Imputation in Solar Irradiance Time Series. Eng. Proc. 2023, 39, 26. [Google Scholar]
- Shen, J. Ai in Education: Effective Machine Learning. Doctoral Dissertation, The Pennsylvania State University, State College, PA, USA, 2023. [Google Scholar]
- Palani, B.; Elango, S.; Viswanathan, K. CB-Fake: A multimodal deep learning framework for automatic fake news detection using capsule neural network and BERT. Multimed. Tools Appl. 2022, 81, 5587–5620. [Google Scholar] [CrossRef] [PubMed]
- Catelli, R.; Pelosi, S.; Esposito, M. Lexicon-based vs. Bert-based sentiment analysis: A comparative study in Italian. Electronics 2022, 11, 374. [Google Scholar] [CrossRef]
- Doan, A.; Luu, S. Improving sentiment analysis by emotion lexicon approach on Vietnamese texts. In Proceedings of the 2022 International Conference on Asian Language Processing, Singapore, Shenzhen, China, 27–28 October 2022; pp. 39–44. [Google Scholar]
- Zhu, X.; Cheng, D.; Zhang, Z.; Lin, S.; Dai, J. An empirical study of spatial attention mechanisms in deep networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6688–6697. [Google Scholar]
- Zhao, Z. Using Pre-Trained Language Models for Toxic Comment Classification. Doctoral Dissertation, University of Sheffield, Sheffield, UK, 2022. [Google Scholar]
- Trewhela, A.; Figueroa, A. Text-based neural networks for question intent recognition. Eng. Appl. Artif. Intell. 2023, 121, 105–133. [Google Scholar] [CrossRef]
- Choo, J.; Kwon, Y.; Kim, J.; Jae, J.; Hottung, A.; Tierney, K.; Gwon, Y. Simulation-guided beam search for neural combinatorial optimization. Adv. Neural Inf. Process. Syst. 2022, 35, 8760–8772. [Google Scholar]
- Graham, M.; Drobnjak, I.; Zhang, H. A supervised learning approach for diffusion MRI quality control with minimal training data. NeuroImage 2018, 178, 668–676. [Google Scholar] [CrossRef]
- Frisoni, G.; Moro, G.; Carbonaro, A. A survey on event extraction for natural language understanding: Riding the biomedical literature wave. IEEE Access 2021, 9, 160721–160757. [Google Scholar] [CrossRef]
- Beltagi, I.; Lo, K.; Cohan, A. SciBERT: A Pretrained Language Model for Scientific Text. arXiv 2019, arXiv:1903.10676. [Google Scholar]
- Kusakin, I.K.; Fedorets, O.V.; Romanov, A.Y. Classification of Short Scientific Texts. Sci. Tech. Inf. Proc. 2023, 50, 176–183. [Google Scholar] [CrossRef]
- Shen, S.; Liu, J.; Lin, L.; Huang, Y.; Zhang, L.; Liu, C.; Feng, Y.; Wang, D. SsciBERT: A pre-trained language model for social science texts. Scientometrics 2023, 128, 1241–1263. [Google Scholar] [CrossRef]
- Nzungize, L. The Most Popular Huggingface Models. Medium. 2023. Available online: https://medium.com/@nzungize.lambert/the-most-popular-huggingface-models-d67eaaea392c (accessed on 24 February 2023).
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. LLaMA: Open and Efficient Foundation Language Models. Meta AI. arXiv 2023, arXiv:2302.13971. [Google Scholar]
- PR Newswire. ‘IBM Plans to Make Llama 2 Available within Its Watsonx AI and Data Platform’, PR Newswire US, 9 August. 2023. Available online: https://newsroom.ibm.com/2023-08-09-IBM-Plans-to-Make-Llama-2-Available-within-its-Watsonx-AI-and-Data-Platform (accessed on 15 October 2023).
- Xiong, W.; Liu, J.; Molybog, I.; Zhang, H.; Bhargava, P.; Hou, R.; Martin, L.; Rungta, R.; Sankararaman, K.; Oguz, B.; et al. Effective Long-Context Scaling of Foundation Models. arXiv 2023, arXiv:2309.16039. [Google Scholar]
- Touvron, H.; Martin, L.; Stone, K.; Albert, P.; Almahairi, A.; Babaei, Y.; Bashlykov, N.; Batra, S.; Bhargava, P.; Bhosale, S.; et al. Llama 2: Open foundation and fine-tuned chat models. arXiv 2023, arXiv:2307.09288. [Google Scholar]
- Nguyen, T.T.; Wilson, C.; Dalins, J. Fine-tuning llama 2 large language models for detecting online sexual predatory chats and abusive texts. arXiv 2023, arXiv:2308.14683. [Google Scholar]
- Pavlyshenko, B. Financial News Analytics Using Fine-Tuned Llama 2 GPT Model. arXiv 2023, arXiv:2308.13032. [Google Scholar]
- Saghafian, S. Effective Generative AI: The Human-Algorithm Centaur. HKS Working Paper No. RWP23-030. 2023. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4594780 (accessed on 12 January 2023).
- Türkmen, H.; Dikenelli, O.; Eraslan, C.; Çallı, M.C.; Özbek, S. BioBERTurk: Exploring Turkish Biomedical Language Model Development Strategies in Low-Resource Setting. J. Healthc. Inform. Res. 2023, 7, 433–446. [Google Scholar] [CrossRef]
- Shaghaghian, S.; Feng, L.; Jafarpour, B.; Pogrebnyakov, N. Customizing contextualized language models for legal document reviews. In Proceedings of the 2020 IEEE International Conference on Big Data (Big Data), Atlanta, GA, USA, 10–13 December 2020; pp. 2139–2148. [Google Scholar]
- Santy, S.; Srinivasan, A.; Choudhury, M. BERTologiCoMix: How does code-mixing interact with multilingual BERT? In Proceedings of the Second Workshop on Domain Adaptation for NLP, Virtual, 19 April 2021; pp. 111–121. [Google Scholar]
- Sun, C.; Qiu, X.; Xu, Y.; Huang, X. How to fine-tune BERT for text classification? In Proceedings of the Chinese Computational Linguistics: 18th China National Conference, CCL 2019, Kunming, China, 18–20 October 2019; pp. 194–206. [Google Scholar]
- Ajagbe, M.; Zhao, L. Retraining a BERT model for transfer learning in requirements engineering: A preliminary study. In Proceedings of the 2022 IEEE 30th International Requirements Engineering Conference (RE), Melbourne, Australia, 15–19 August 2022; pp. 309–315. [Google Scholar]
- Schwartz, R.; Vassilev, A.; Greene, K.; Perine, L.; Burt, A.; Hall, P. Towards a Standard for Identifying and Managing Bias in Artificial Intelligence; NIST Special Publication 1270; NIST: Gaithersburg, MD, USA, 2022. [CrossRef]
- Li, B.; Qi, P.; Liu, B.; Di, S.; Liu, J.; Pei, J.; Yi, J.; Zhou, B. Trustworthy AI: From principles to practices. ACM Comput. Surv. 2023, 55, 1–46. [Google Scholar] [CrossRef]
- Qiao, Y.; Zhu, X.; Gong, H. BERT-Kcr: Prediction of lysine crotonylation sites by a transfer learning method with pre-trained BERT models. Bioinformatics 2022, 38, 648–654. [Google Scholar] [CrossRef] [PubMed]
- Lawley, C.; Raimondo, S.; Chen, T.; Brin, L.; Zakharov, A.; Kur, D.; Hui, J.; Newton, G.; Burgoyne, S.; Marquis, G. Geoscience language models and their intrinsic evaluation. Appl. Comput. Geosci. 2022, 14, 100–119. [Google Scholar] [CrossRef]
- Chaudhari, D.; Pawar, A.V. Empowering Propaganda Detection in Resource-Restraint Languages: A Transformer-Based Framework for Classifying Hindi News Articles. Big Data Cogn. Comput. 2023, 7, 175. [Google Scholar] [CrossRef]
- Okpala, E.; Cheng, L.; Mbwambo, N.; Luo, F. AAEBERT: Debiasing BERT-based Hate Speech Detection Models via Adversarial Learning. In Proceedings of the 2022 21st IEEE International Conference on Machine Learning and Applications, Nassau, Bahamas, 12–14 December 2022; pp. 1606–1612. [Google Scholar]
- Hunston, S. Systemic functional linguistics, corpus linguistics, and the ideology of science. Text Talk 2013, 33, 617–640. [Google Scholar] [CrossRef]
- Murakami, A.; Thompson, P.; Hunston, S.; Vajn, D. What is this corpus about? using topic modelling to explore a specialised corpus. Corpora 2017, 12, 243–277. [Google Scholar] [CrossRef]
- Hunston, S. Corpora in Applied Linguistics; Cambridge University Press: Cambridge, UK, 2022. [Google Scholar]
- Bonelli, E. Theoretical overview of the evolution of corpus linguistics. In The Routledge Handbook of Corpus Linguistics; Routledge: London, UK, 2010; pp. 14–28. [Google Scholar] [CrossRef]
- Hyland, K. Academic clusters: Text patterning in published and postgraduate writing. Int. J. Appl. Linguist. 2008, 18, 41–62. [Google Scholar] [CrossRef]
- Tseng, H.; Chen, B.; Chang, T.; Sung, Y. Integrating LSA-based hierarchical conceptual space and machine learning methods for leveling the readability of domain-specific texts. Nat. Lang. Eng. 2019, 25, 331–361. [Google Scholar] [CrossRef]
- Venkatesh, V.; Brown, S.; Bala, H. Bridging the Qualitative-Quantitative Divide: Guidelines for Conducting Mixed Methods Research in Information Systems. MIS Q. 2013, 37, 21–54. Available online: http://www.jstor.org/stable/43825936 (accessed on 12 January 2023). [CrossRef]
- Leitan, N.; Chaffey, L. Embodied cognition, and its applications: A brief review. Sensoria A J. Mind Brain Cult. 2014, 10, 3–10. [Google Scholar] [CrossRef]
- Pacho, T. Exploring participants’ experiences using case study. Int. J. Humanit. Soc. Sci. 2015, 5, 44–53. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
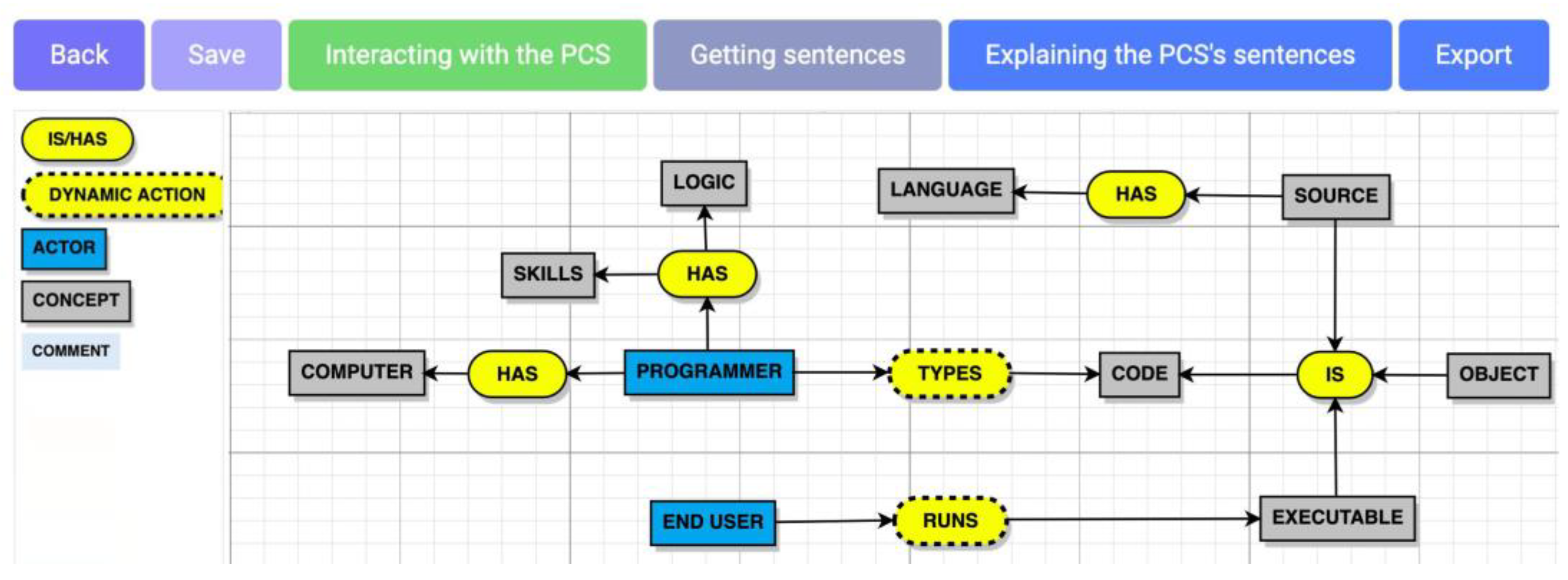{kind=link}
{kind=link}
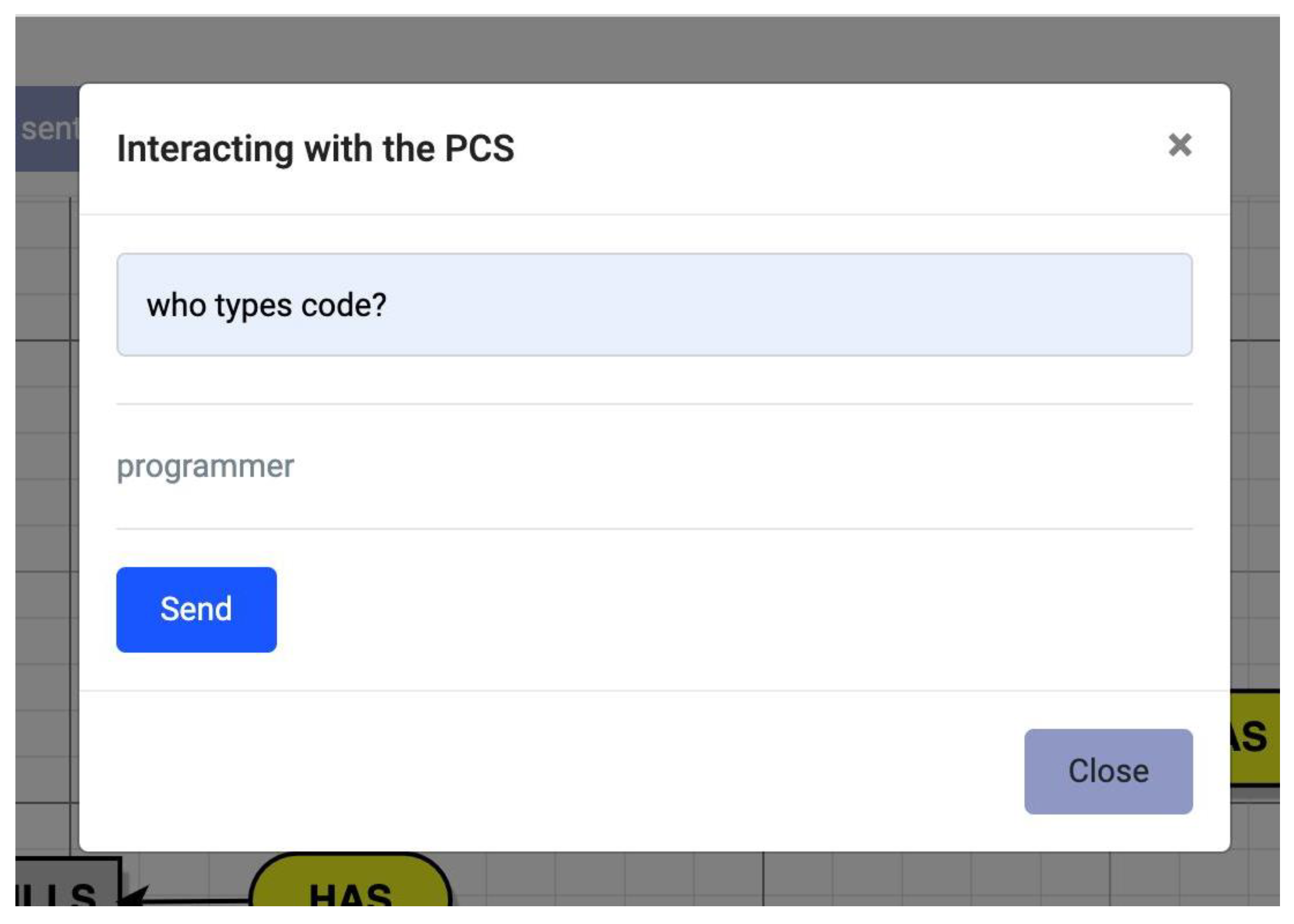{kind=link}
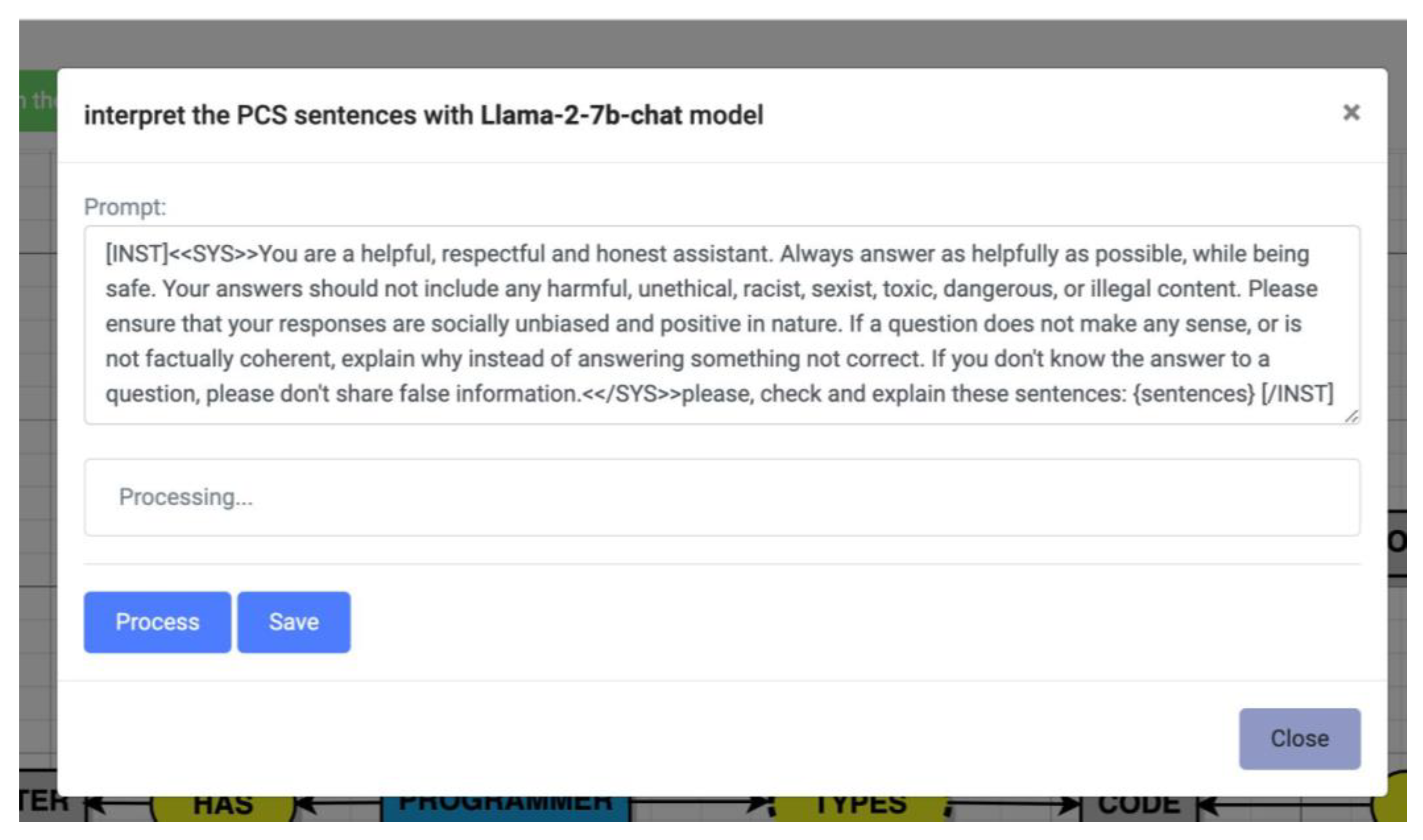{kind=link}
{kind=link}
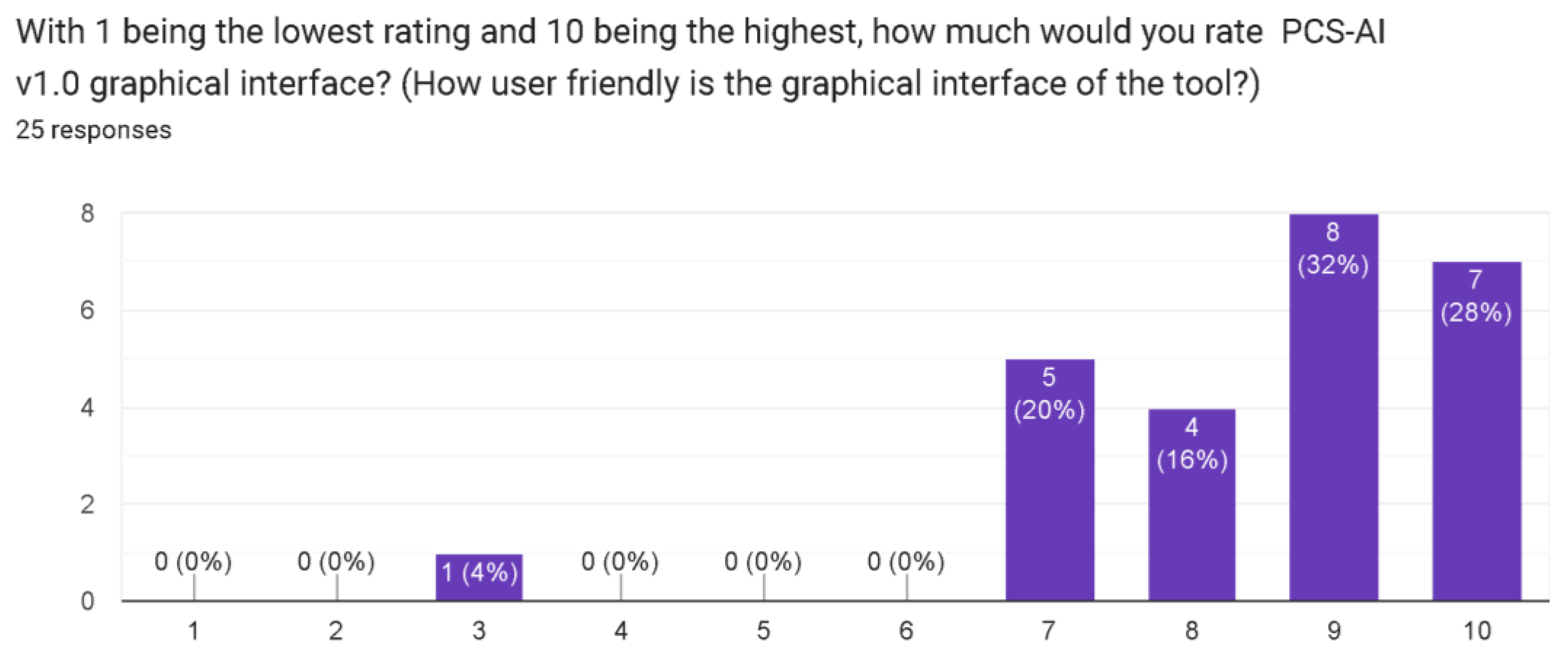{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Year | Main Objective | Key Features | Use Cases |
|---|---|---|---|---|
| BERT | 2018 | Pre-training bidirectional transformers for language understanding | - Uses Transformer architecture - Bidirectional context - Masked Language Model | Text classification, Q&A, NER |
| GPT | 2018 | Improving language understanding with unsupervised learning | - Transformer-based - Unidirectional (left-to-right) context - Generative pre-training | Text generation, fine-tuning tasks |
| T5 | 2019 | Exploring transfer learning with a unified text-to-text framework | - Treats every NLP problem as a text-to-text problem - Unified framework | Translation, summarization, Q&A |
| RoBERTa | 2019 | Optimizing BERT pre-training | - Variations in model size, training data, and training time - Removes NSP, trains with more data and longer | Like BERT’s use-cases |
| DistilBERT | 2019 | Creating a lighter version of BERT | - 40% smaller, retains 95% of BERT’s performance - Knowledge distillation | Where BERT is too large or slow |
| ELECTRA | 2020 | Proposing a new pre-training method | - Replaces masked tokens and tries to detect these replacements - More efficient than MLM-based methods | Text classification, Q&A |
| Llama 2 | 2023 | Advanced Natural Language Understanding | - Size and Scalability - Advanced Algorithms - Free philosophy for research and general use - Multilingual capabilities | Conversational AI, Content generation, Language translation, Information extraction & Analysis, and Educational Tools. |
| Triad | Meaning | Examples | Elicited Triads in the Linguistic Corpus for Training and Fine-Tuning Purposes |
|---|---|---|---|
| <CONCEPT> <IS|HAS> <CONCEPT> | Structural triad | Computer is machine. University has campus. | 5,191,883 |
| <ACTOR> <VERB> <CONCEPT> | Dynamic triad | Professor designs syllabus. Programmer produces software. | 1,297,974 |
| Dataset | Model | Training/Fine-Tuning | Accuracy | Time Spent |
|---|---|---|---|---|
| customPCS | bert-base-multi-lingual-cased 1 | 20 epochs | 91.3% | 5 h, 37 min |
| customPCS | llama-2-7b-chat.ggmlv3.q4_0 2 | 5 epochs | 90.1% | 1 h, 43 min |
| Group | Participant ID | Task Completion Time (min) | Success Rate (%) | Error Frequency |
|---|---|---|---|---|
| 1 | 1 | 15.3 | 90 | 2 |
| 1 | 2 | 16.1 | 85 | 3 |
| 1 | 3 | 14.7 | 92 | 1 |
| 1 | 4 | 15.8 | 88 | 2 |
| 1 | 5 | 16.2 | 86 | 3 |
| 1 | 6 | 15.4 | 89 | 2 |
| 1 | 7 | 15.9 | 87 | 3 |
| 1 | 8 | 15.0 | 91 | 1 |
| 1 | 9 | 16.3 | 85 | 4 |
| 1 | 10 | 15.5 | 88 | 2 |
| 1 | 11 | 14.9 | 90 | 1 |
| 1 | 12 | 16.0 | 86 | 3 |
| 1 | 13 | 15.7 | 87 | 2 |
| 1 | 14 | 15.1 | 89 | 1 |
| 2 | 15 | 16.4 | 84 | 4 |
| 2 | 16 | 15.6 | 88 | 2 |
| 2 | 17 | 15.2 | 89 | 1 |
| 2 | 18 | 16.5 | 83 | 4 |
| 2 | 19 | 15.0 | 90 | 1 |
| 2 | 20 | 15.8 | 87 | 3 |
| 2 | 21 | 14.8 | 91 | 1 |
| 2 | 22 | 16.2 | 85 | 3 |
| 2 | 23 | 15.4 | 88 | 2 |
| 2 | 24 | 15.9 | 86 | 3 |
| 2 | 25 | 15.3 | 89 | 2 |
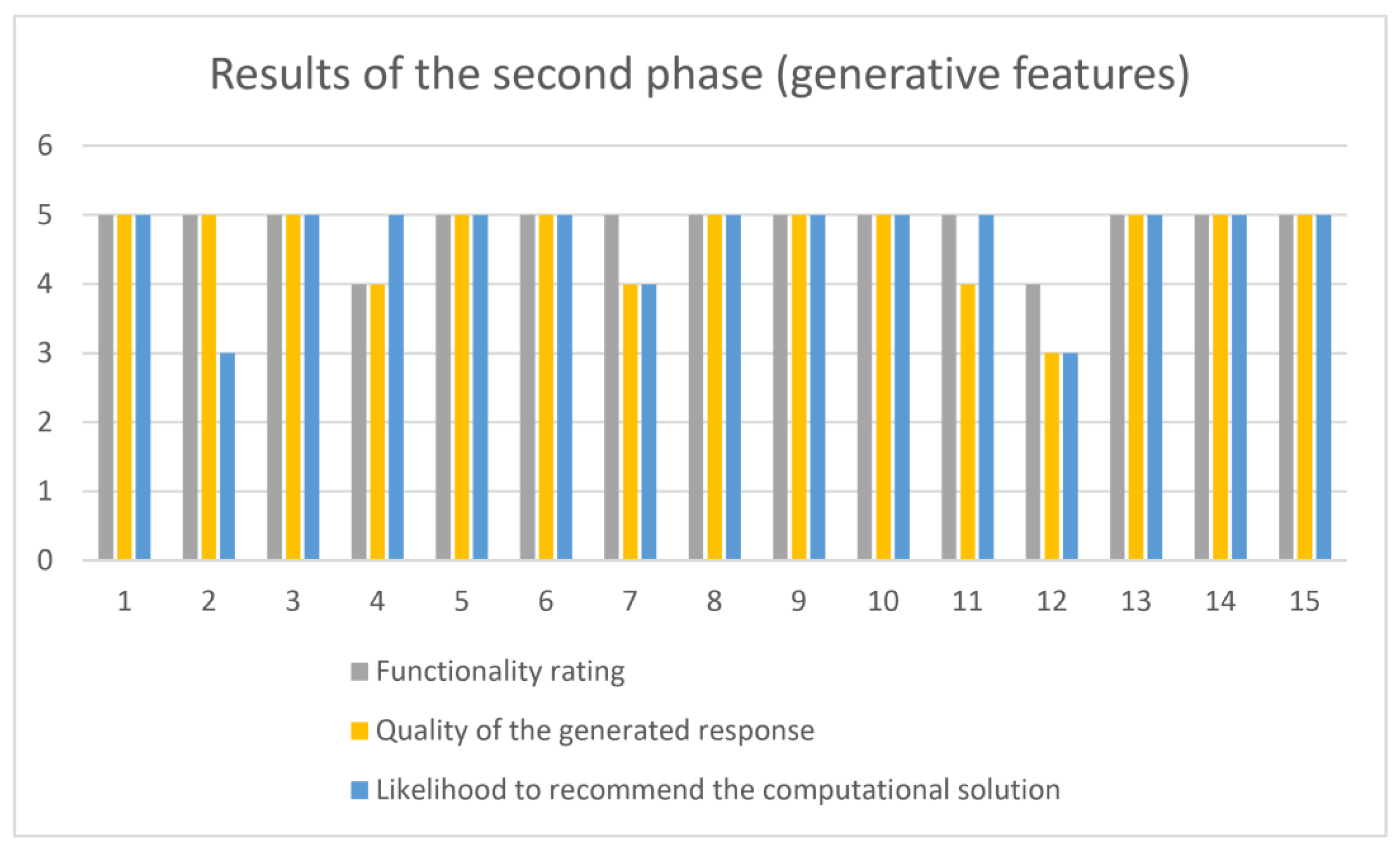
| Group | Participant ID | Functionality Rating | Quality of the Generated Response | Likelihood to Recommend the Computational Solution |
|---|---|---|---|---|
| 1 | 1 | 5 | 5 | 5 |
| 1 | 2 | 5 | 5 | 3 |
| 1 | 3 | 5 | 5 | 5 |
| 1 | 4 | 4 | 4 | 5 |
| 1 | 5 | 5 | 5 | 5 |
| 1 | 6 | 5 | 5 | 5 |
| 1 | 7 | 5 | 4 | 4 |
| 1 | 8 | 5 | 5 | 5 |
| 2 | 9 | 5 | 5 | 5 |
| 2 | 10 | 5 | 5 | 5 |
| 2 | 11 | 5 | 4 | 5 |
| 2 | 12 | 4 | 3 | 3 |
| 2 | 13 | 5 | 5 | 5 |
| 2 | 14 | 5 | 5 | 5 |
| 2 | 15 | 5 | 5 | 5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Insuasti, J.; Roa, F.; Zapata-Jaramillo, C.M. Computers’ Interpretations of Knowledge Representation Using Pre-Conceptual Schemas: An Approach Based on the BERT and Llama 2-Chat Models. Big Data Cogn. Comput. 2023, 7, 182. https://doi.org/10.3390/bdcc7040182
Insuasti J, Roa F, Zapata-Jaramillo CM. Computers’ Interpretations of Knowledge Representation Using Pre-Conceptual Schemas: An Approach Based on the BERT and Llama 2-Chat Models. Big Data and Cognitive Computing. 2023; 7(4):182. https://doi.org/10.3390/bdcc7040182
Chicago/Turabian StyleInsuasti, Jesus, Felipe Roa, and Carlos Mario Zapata-Jaramillo. 2023. "Computers’ Interpretations of Knowledge Representation Using Pre-Conceptual Schemas: An Approach Based on the BERT and Llama 2-Chat Models" Big Data and Cognitive Computing 7, no. 4: 182. https://doi.org/10.3390/bdcc7040182
APA StyleInsuasti, J., Roa, F., & Zapata-Jaramillo, C. M. (2023). Computers’ Interpretations of Knowledge Representation Using Pre-Conceptual Schemas: An Approach Based on the BERT and Llama 2-Chat Models. Big Data and Cognitive Computing, 7(4), 182. https://doi.org/10.3390/bdcc7040182