

An Artificial-Intelligence-Driven Spanish Poetry Classification Framework

Abstract
:1. Introduction
- In response to the problem of the lack of artificial intelligence frameworks for the classification of Spanish poetry, an artificial-intelligence-driven Spanish poetry classification framework is designed in detail, which greatly improves the accuracy and efficiency of classification work, compensating for the shortcomings of traditional manual poetry classification tasks.
- The proposed framework includes multiple selectable algorithms, and it can be very flexible in adding newly designed algorithms. Through model selection, the most suitable method for Spanish poetry classification can be obtained.
- Experiments based on model selection were designed. The results of the experiments showed that the Bagging model exhibited higher accuracy compared to SVMs, AdaBoost, LR, and all the other models. Applying this framework, automatic Spanish poetry style classification work can be more objective and more accurate, facilitating the study of Spanish poetry.
2. Related Works
2.1. Spanish Text Classification
2.2. Classification Methods
2.3. Applications of Natural Language Processing
2.4. Poetry Classification in Other Languages
- English: Saif et al. [17] proposed use of TF_IDF and the rough set theory (RST) algorithm to build a classification model for English poetry. The accuracy reached . Their classification work mainly focused on the topics of poetry. In 2017, Durmus Ozkan Sahin et al. proposed a model to accomplish poet detection tasks. Their results showed that the sequential minimal optimization (SMO) algorithm achieved the best result, which was above .
- Gujarati: In 2017, Bhavin and Bhargav [21] built a Gujarati poetry emotion classification model. They employed NLTK to process the language and the accuracy reached .
- Marathi: Deshmukh et al. [15] proposed the use of SVMs algorithms to automatically classify Marathi poetry. Their accuracy finally reached .
- Ottoman: Ethem et al. [18] proposed the building of an Ottoman poetry classification model. They experimented with two algorithms to attribute the authorship of poetry and to identify each poem’s time period. The algorithms used included SVMs and NB. The results showed that, compared to NB, SVMs was a more accurate algorithm.
- Punjabi: In 2017, Jasleen and Jatinderkumar [20] compared 10 algorithms to classify four different categories of Punjabi poetry. The algorithms that they employed included Adaboost, Bagging, C4.5, Hyperpipes, K-nearest neighbors, NB, PART, SVMs, Voting Feature Interval (VFI), and ZeroR. SVMs reached the highest accuracy of .
- Chinese: Zhu et al. [19] proposed the use of Doc2Vec and XGBoost to build an automatic Chinese poetry style classification model. The accuracy of the algorithms reached above .
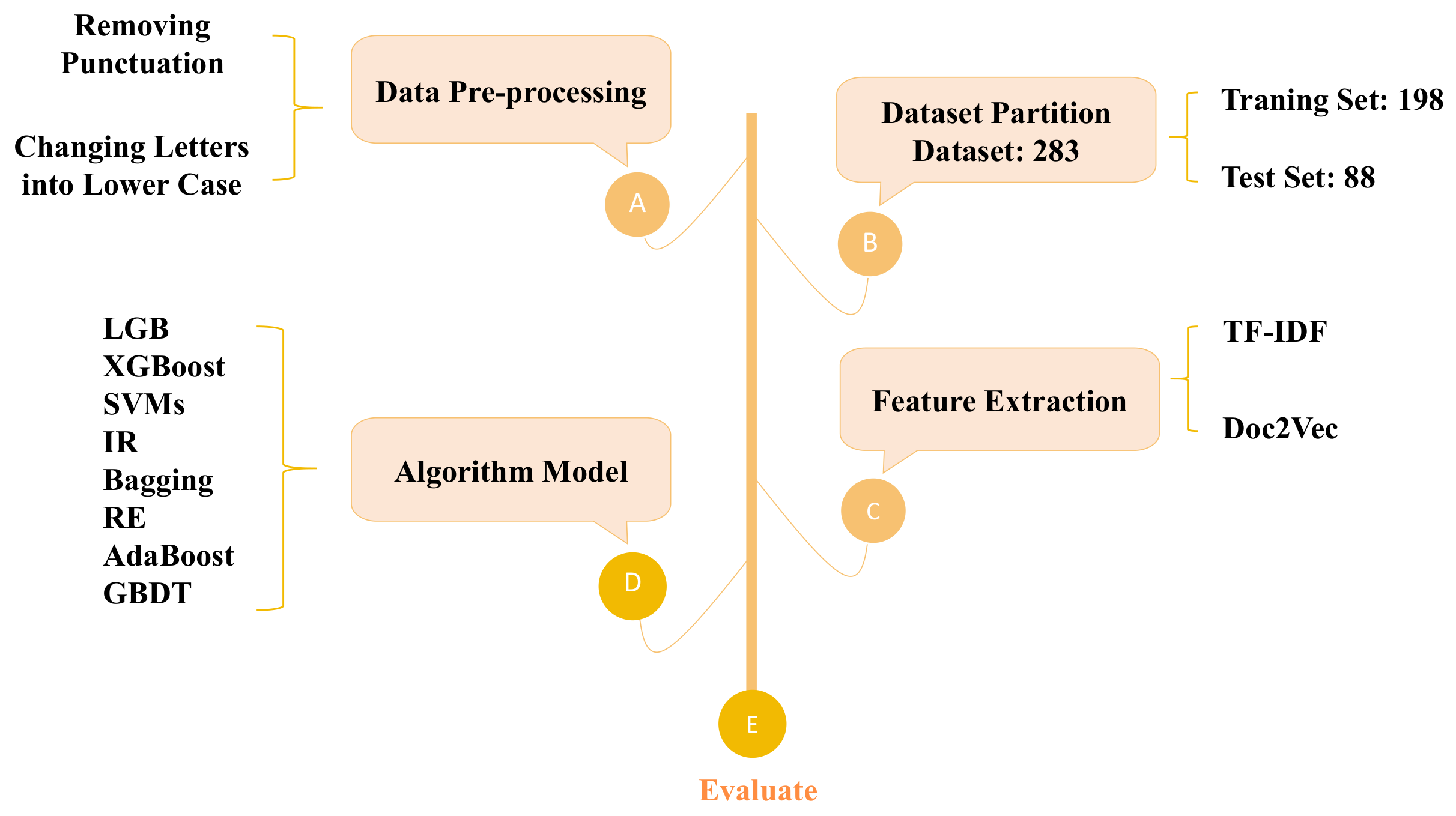
3. Spanish Poetry Classification Framework Driven by Artificial Intelligence
3.1. Data Preprocessing
3.2. Feature Extraction
3.2.1. Term Frequency-Inverse Document Frequency
3.2.2. Document to Vector
3.3. Algorithm Model
4. Experiment
4.1. Datasets
4.2. Evaluation Methods
4.3. Parameters Settings
4.4. Training and Testing of the Framework
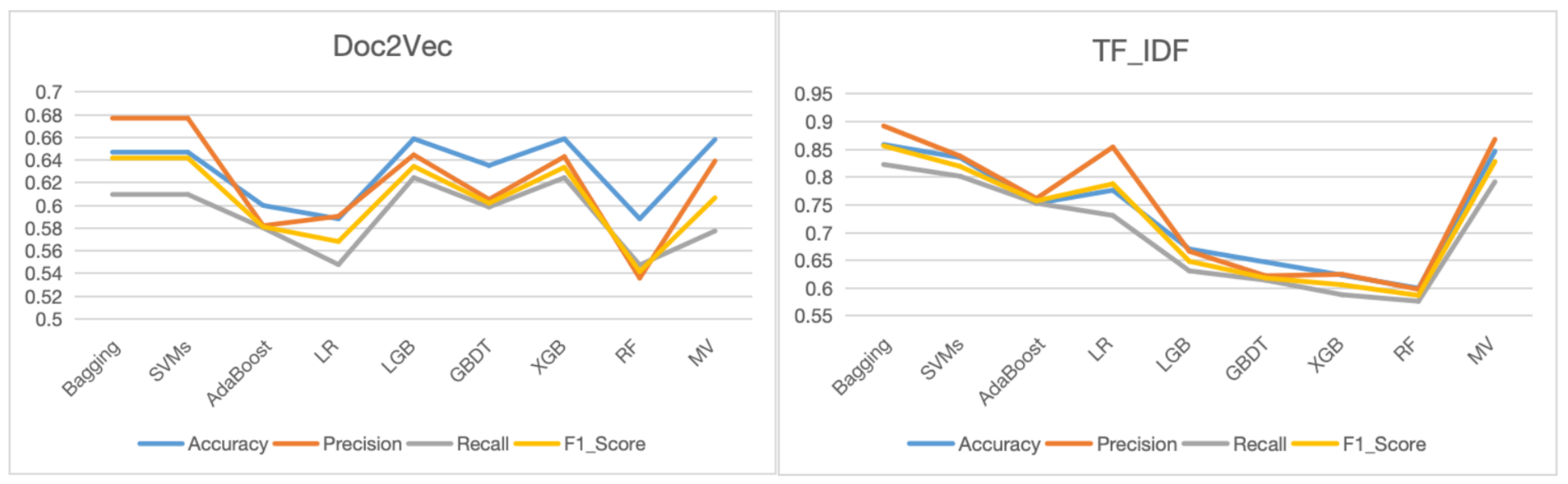
4.5. Results Analysis
5. Conclusions and Prospects
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Cavnar, W.B.; Trenkle, J.M. N-gram-based text categorization. In Proceedings of the SDAIR-94, 3rd Annual Symposium on Document Analysis and Information Retrieval, Las Vegas, NV, USA, 11–13 April 1994; Volume 161175, p. 14. [Google Scholar]
- Lewis, D.D. Feature selection and feature extraction for text categorization. In Proceedings of the Speech and Natural Language: Proceedings of a Workshop Held at Harriman, New York, NY, USA, 23–26 February 1992. [Google Scholar]
- Bijalwan, V.; Kumar, V.; Kumari, P.; Pascual, J. KNN based machine learning approach for text and document mining. Int. J. Database Theory Appl. 2014, 7, 61–70. [Google Scholar] [CrossRef]
- Larkey, L.S.; Croft, W.B. Combining classifiers in text categorization. In Proceedings of the 19th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Zurich, Switzerland, 18–22 August 1996; pp. 289–297. [Google Scholar]
- Damashek, M. Gauging similarity with n-grams: Language-independent categorization of text. Science 1995, 267, 843–848. [Google Scholar] [CrossRef] [PubMed]
- Guzmán-Cabrera, R.; Montes-y Gómez, M.; Rosso, P.; Villasenor-Pineda, L. Using the Web as corpus for self-training text categorization. Inf. Retr. 2009, 12, 400–415. [Google Scholar] [CrossRef]
- Tellez, E.S.; Moctezuma, D.; Miranda-Jimenez, S.; Graff, M. An Automated Text Categorization Framework based on Hyperparameter Optimization. Knowl.-Based Syst. 2017, 149, 110–123. [Google Scholar] [CrossRef]
- Barbado, A.; González, M.D.; Carrera, D. Lexico-semantic and affective modelling of Spanish poetry: A semi-supervised learning approach. arXiv 2021, arXiv:2109.04152. [Google Scholar]
- Pérez Pozo, Á.; Rosa, J.D.L.; Ros, S.; Gonzálezlanco, E.; Hernández, L.; Sisto, M.D. A bridge too far for artificial intelligence?: Automatic classification of stanzas in Spanish poetry. J. Assoc. Inf. Sci. Technol. 2022, 73, 258–267. [Google Scholar] [CrossRef] [PubMed]
- Borja, N.C. On Poetic Topic Modeling: Extracting Themes and Motifs From a Corpus of Spanish Poetry. Front. Digit. Humanit. 2018, 5, 15. [Google Scholar]
- Chiruzzo, L. Emotion Classification in Spanish: Exploring the Hard Classes. Information 2021, 12, 438. [Google Scholar]
- Barros, L.; Rodriguez, P.; Ortigosa, A. Automatic Classification of Literature Pieces by Emotion Detection: A Study on Quevedo’s Poetry. In Proceedings of the 2013 Humaine Association Conference on Affective Computing and Intelligent Interaction, IEEE, Geneva, Switzerland, 2–5 September 2013; pp. 141–146. [Google Scholar]
- Navarro-Colorado, B. A metrical scansion system for fixed-metre Spanish poetry. Digit. Scholarsh. Humanit. 2018, 33, 112–127. [Google Scholar] [CrossRef]
- Torres-Moreno, J.M.; Moreno-Jiménez, L.G. LiSSS: A toy corpus of Spanish Literary Sentences for Emotions detection. arXiv 2020, arXiv:2005.08223. [Google Scholar]
- Deshmukh, R.; Kore, S.; Chavan, N.; Gole, S.; Adarsh, K. Marathi poem classification using machine learning. Int. J. Recent Technol. Eng. 2019, 8, 2723–2727. [Google Scholar] [CrossRef]
- Araújo, P.; Mamede, N. Classificador de Poemas. In Proceedings of the Conferência Científica e Tecnológica em Engenharia. 2002. Available online: https://www.hlt.inesc-id.pt/documents/papers/2002Araujo.pdf (accessed on 14 October 2023).
- Alsaidi, S.A.; Sadeq, A.T.; Abdullah, H.S. English poems categorization using text mining and rough set theory. Bull. Electr. Eng. Inform. 2020, 9, 1701–1710. [Google Scholar] [CrossRef]
- Can, F.; Can, E.; Sahin, P.D.; Kalpakli, M. Automatic categorization of ottoman poems. Glottotheory 2013, 4, 40–57. [Google Scholar] [CrossRef]
- Zhu, M.; Wang, G.; Li, C.; Wang, H.; Zhang, B. Artificial Intelligence Classification Model for Modern Chinese Poetry in Education. Sustainability 2023, 15, 5265. [Google Scholar] [CrossRef]
- Kaur, J.; Saini, J.R. Punjabi poetry classification: The test of 10 machine learning algorithms. In Proceedings of the 9th International Conference on Machine Learning and Computing, Hong Kong, China, 29–31 May 2017; pp. 1–5. [Google Scholar]
- Mehta, B.; Rajyagor, B. Gujarati poetry classification based on emotions using deep learning. Int. J. Eng. Appl. Sci. Technol. 2021, 6, 358–362. [Google Scholar] [CrossRef]
- de la Rosa, J.; Pérez, Á.; Hern, L.; Ros, S.; Gonz, E. PoetryLab as Infrastructure for the Analysis of Spanish Poetry. In Proceedings of the CLARIN Annual Conference, Virtual, 5–7 October 2020; pp. 75–82. [Google Scholar]
- Marco, G.; De La Rosa, J.; Gonzalo, J.; Ros, S.; González-Blanco, E. Automated metric analysis of Spanish poetry: Two complementary approaches. IEEE Access 2021, 9, 51734–51746. [Google Scholar] [CrossRef]
- Zhao, K.; Huang, L.; Song, R.; Shen, Q.; Xu, H. A sequential graph neural network for short text classification. Algorithms 2021, 14, 352. [Google Scholar] [CrossRef]
- Huang, Y.; Song, R.; Giunchiglia, F.; Xu, H. A multitask learning framework for abuse detection and emotion classification. Algorithms 2022, 15, 116. [Google Scholar] [CrossRef]
- Papadia, G.; Pacella, M.; Giliberti, V. Topic Modeling for Automatic Analysis of Natural Language: A Case Study in an Italian Customer Support Center. Algorithms 2022, 15, 204. [Google Scholar] [CrossRef]
- Campos Macias, N.; Düggelin, W.; Ruf, Y.; Hanne, T. Building a technology recommender system using web crawling and natural language processing Technology. Algorithms 2022, 15, 272. [Google Scholar] [CrossRef]
- Neagu, D.C.; Rus, A.B.; Grec, M.; Boroianu, M.A.; Bogdan, N.; Gal, A. Towards Sentiment Analysis for Romanian Twitter Content. Algorithms 2022, 15, 357. [Google Scholar] [CrossRef]
- Tang, H.; Kamei, S.; Morimoto, Y. Data Augmentation Methods for Enhancing Robustness in Text Classification Tasks. Algorithms 2023, 16, 59. [Google Scholar] [CrossRef]
- Zhang, X.; Zhou, H.; Yu, K.; Wu, X.; Yazidi, A. Tsetlin Machine for Sentiment Analysis and Spam Review Detection in Chinese. Algorithms 2023, 16, 93. [Google Scholar] [CrossRef]
- Liu, H.; Ye, Z.; Zhao, H.; Yang, Y. Chinese Text De-Colloquialization Technique Based on Back-Translation Strategy and End-to-End Learning. Appl. Sci. 2023, 13, 10818. [Google Scholar] [CrossRef]
- Torres-Silva, E.A.; Rúa, S.; Giraldo-Forero, A.F.; Durango, M.C.; Flórez-Arango, J.F.; Orozco-Duque, A. Classification of Severe Maternal Morbidity from Electronic Health Records Written in Spanish Using Natural Language Processing. Appl. Sci. 2023, 13, 10725. [Google Scholar] [CrossRef]
- Li, J.; Wu, C. Deep Learning and Text Mining: Classifying and Extracting Key Information from Construction Accident Narratives. Appl. Sci. 2023, 13, 10599. [Google Scholar] [CrossRef]
- Ahn, S. Experimental Study of Morphological Analyzers for Topic Categorization in News Articles. Appl. Sci. 2023, 13, 10572. [Google Scholar] [CrossRef]
- Gu, Y.; Tinn, R.; Cheng, H.; Lucas, M.; Usuyama, N.; Liu, X.; Naumann, T.; Gao, J.; Poon, H. Domain-specific language model pretraining for biomedical natural language processing. ACM Trans. Comput. Healthc. 2021, 3, 1–23. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
| The Case Category | Training Data | Testing Data |
|---|---|---|
| Classical Lyric | 67 | 32 |
| Modernism | 56 | 22 |
| Romantism | 75 | 31 |
| Model/Metrices | Accuracy | Precision | Recall | F1_Score |
|---|---|---|---|---|
| Bagging | 0.8588 | 0.8923 | 0.8229 | 0.8565 |
| SVMs | 0.8353 | 0.8380 | 0.8017 | 0.8195 |
| AdaBoost | 0.7529 | 0.7616 | 0.7532 | 0.7574 |
| LR | 0.7765 | 0.8543 | 0.7311 | 0.7880 |
| LGB | 0.6076 | 0.6667 | 0.6312 | 0.6485 |
| GBDT | 0.6471 | 0.6223 | 0.6145 | 0.6184 |
| XGB | 0.6235 | 0.6250 | 0.5882 | 0.6061 |
| RF | 0.6000 | 0.5980 | 0.5765 | 0.5871 |
| MV | 0.8468 | 0.8682 | 0.7917 | 0.8282 |
| average | 0.7346 | 0.7474 | 0.7012 | 0.7235 |
| Model/Metrices | Accuracy | Precision | Recall | F1_Score |
|---|---|---|---|---|
| Bagging | 0.6471 | 0.6770 | 0.6097 | 0.6419 |
| SVMs | 0.6471 | 0.6770 | 0.6097 | 0.6419 |
| AdaBoost | 0.6000 | 0.5821 | 0.5802 | 0.5812 |
| LR | 0.5882 | 0.5905 | 0.5478 | 0.5682 |
| LGB | 0.6588 | 0.6447 | 0.6245 | 0.6345 |
| GBDT | 0.6353 | 0.6054 | 0.5986 | 0.6020 |
| XGB | 0.6588 | 0.6431 | 0.6245 | 0.6337 |
| RF | 0.5882 | 0.5359 | 0.5475 | 0.5417 |
| MV | 0.6582 | 0.6393 | 0.5775 | 0.6068 |
| average | 0.6313 | 0.6217 | 0.5911 | 0.6059 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Deng, S.; Wang, G.; Wang, H.; Chang, F. An Artificial-Intelligence-Driven Spanish Poetry Classification Framework. Big Data Cogn. Comput. 2023, 7, 183. https://doi.org/10.3390/bdcc7040183
Deng S, Wang G, Wang H, Chang F. An Artificial-Intelligence-Driven Spanish Poetry Classification Framework. Big Data and Cognitive Computing. 2023; 7(4):183. https://doi.org/10.3390/bdcc7040183
Chicago/Turabian StyleDeng, Shutian, Gang Wang, Hongjun Wang, and Fuliang Chang. 2023. "An Artificial-Intelligence-Driven Spanish Poetry Classification Framework" Big Data and Cognitive Computing 7, no. 4: 183. https://doi.org/10.3390/bdcc7040183
APA StyleDeng, S., Wang, G., Wang, H., & Chang, F. (2023). An Artificial-Intelligence-Driven Spanish Poetry Classification Framework. Big Data and Cognitive Computing, 7(4), 183. https://doi.org/10.3390/bdcc7040183