A Character Validation Proposal for High-Speed Visual Monitoring of Expiration Codes on Beverage Cans †


Abstract
:1. Introduction
- Selection of the best frame and area of interest, obtained in the transit of the can for code validation (see Figure 2). The area of interest is the region at the bottom of the can where the expiration code is printed.
- Character segmentation.
2. Acquired Shapes and Expected Code
3. Validation and Recognition
- Recognize the text.
- Compare the recognized text with the expected text.
- Give a decision from the comparison.
- Compare the extracted shapes with the expected shapes.
- Give a decision from the comparison.
4. Morphologies, Morphological Families, and the Morphological Family Base
4.1. Morphologies
- If the shapes are legible and recognizable, the associated morphologies will retain those qualities.
- Industrial printing standardizes. It is expected that printed characters will be similar between cans and can be associated with the same morphology.
4.2. Distance between Two Morphologies
- Ink Coincidences (IC): Counts ink coincidences between A and B.
- No-Ink Coincidences (NIC): Count background coincidences between A and B.
- Absent Ink (AI): Counts non-coincidences due to absent ink in B that is present in A.
- Unexpected Ink (UI): Counts non-coincidences due to ink present in B that is not present in A.
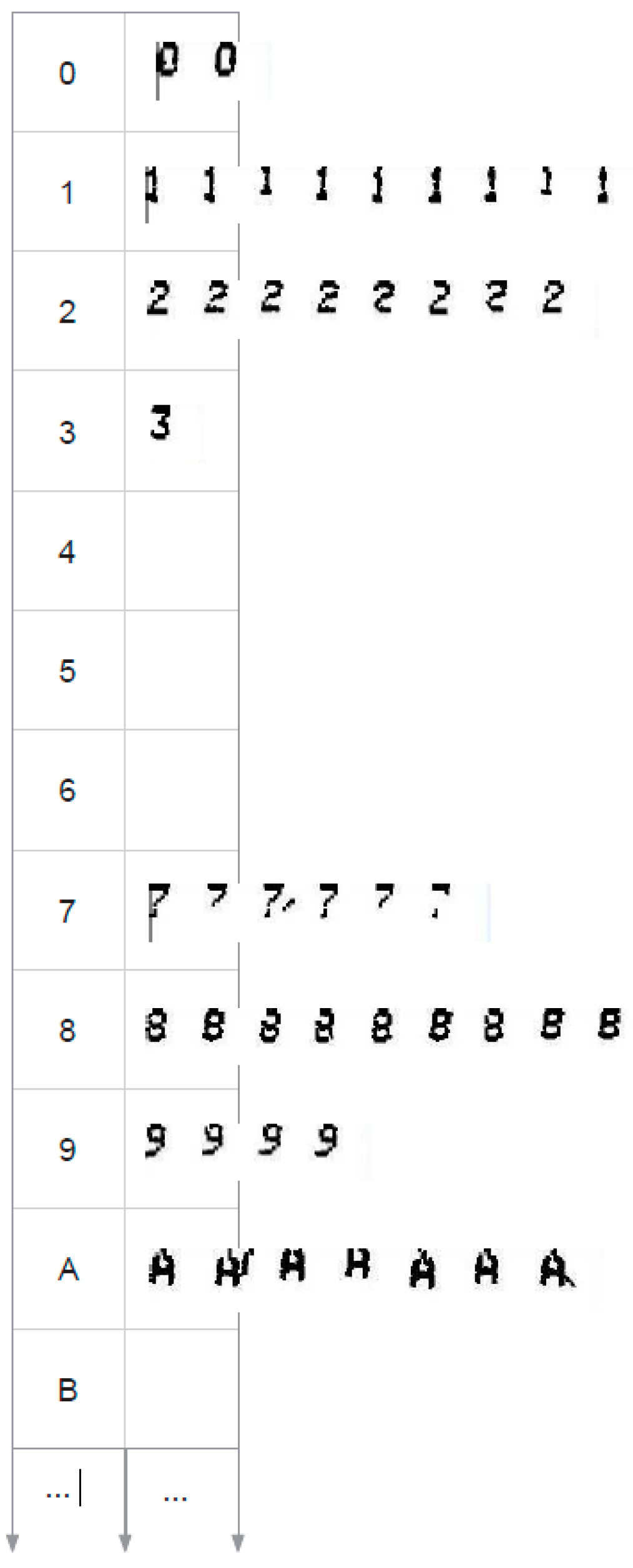
4.3. Morphological Families
- No repetition: There are never two identical morphologies within a morphological family.
- Relationship: All the morphologies have more similarity with any of the morphologies of its own family than with any other morphology belonging to another family (see Section 4.2).
4.4. Morphological Family Base (MFB)
5. Code Validation
5.1. Selection of Comparison Pair
- The searched characters are in the can.
- The next expected character is not examined until the current one has been found.
- If the acquired character does not correspond to the expected one, it will be assumed that the acquired character is noise and the system will advance to the next acquired character (but the expected character remains fixed).
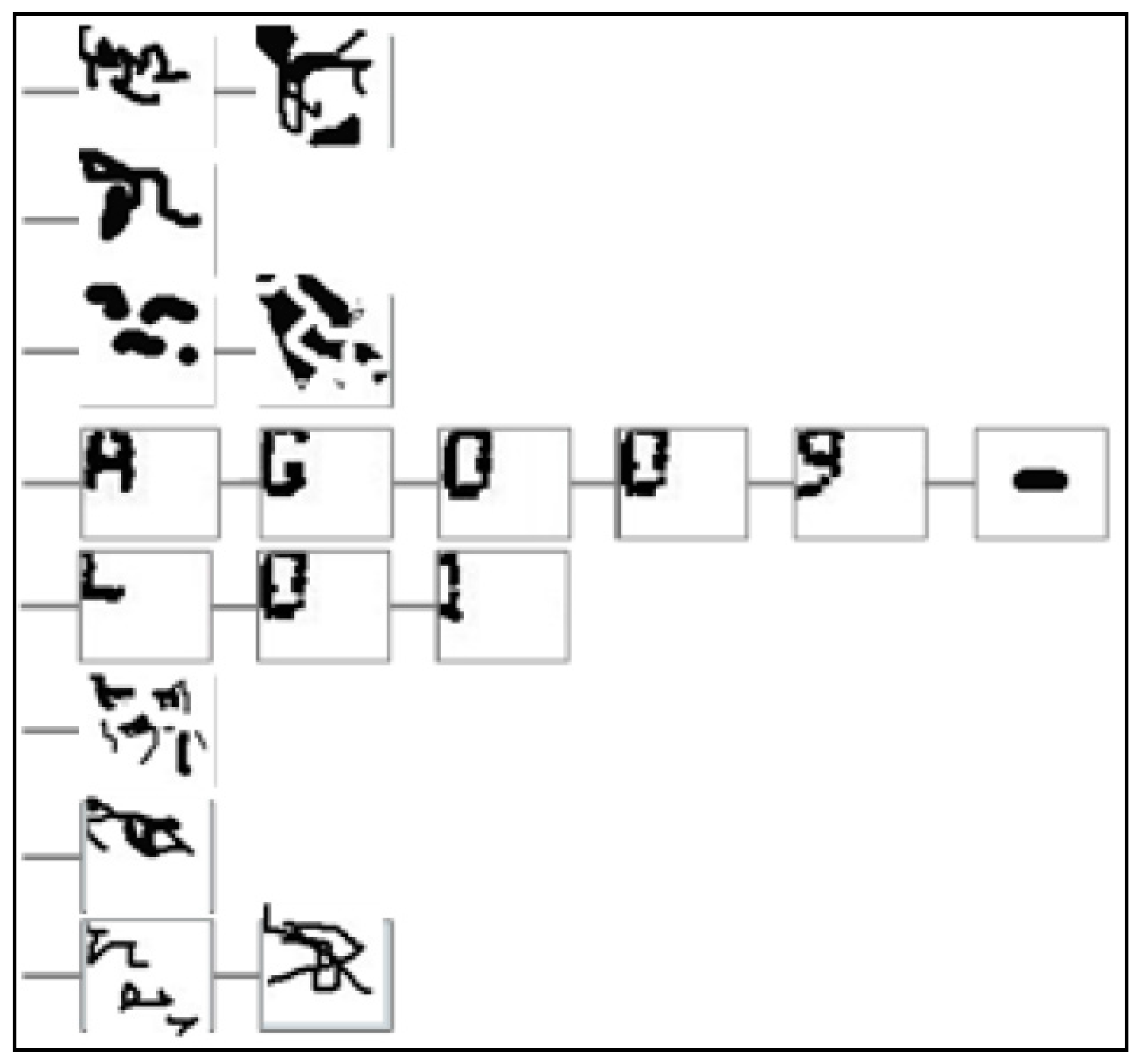
- When reading from left to right, we have useful information to refine clusters of ink fragments, and we always leave complete characters behind. So, if the current grouping does not correspond to a character, the only alternative is to consider possible mergers with the grouping to the right.
- In the expiration codes, it seems that the importance of the characters decreases from left to right and from top to bottom; that is, within a line, a character is more likely to have equal or greater importance than the immediate character to its right. If the code is going to be negatively validated, it is better to know it as soon as possible, and giving priority to the important characters makes us advance in that purpose. This rule is fulfilled in all the studied codes.
- It is more likely that a line has greater or equal importance than that which is immediately lower. In all the studied codes (two lines), this rule is met.
- The first line of the expected code not yet processed is selected in the order from top to bottom. If there are no expected lines to be processed, we go to the stage described in Section 5.3.
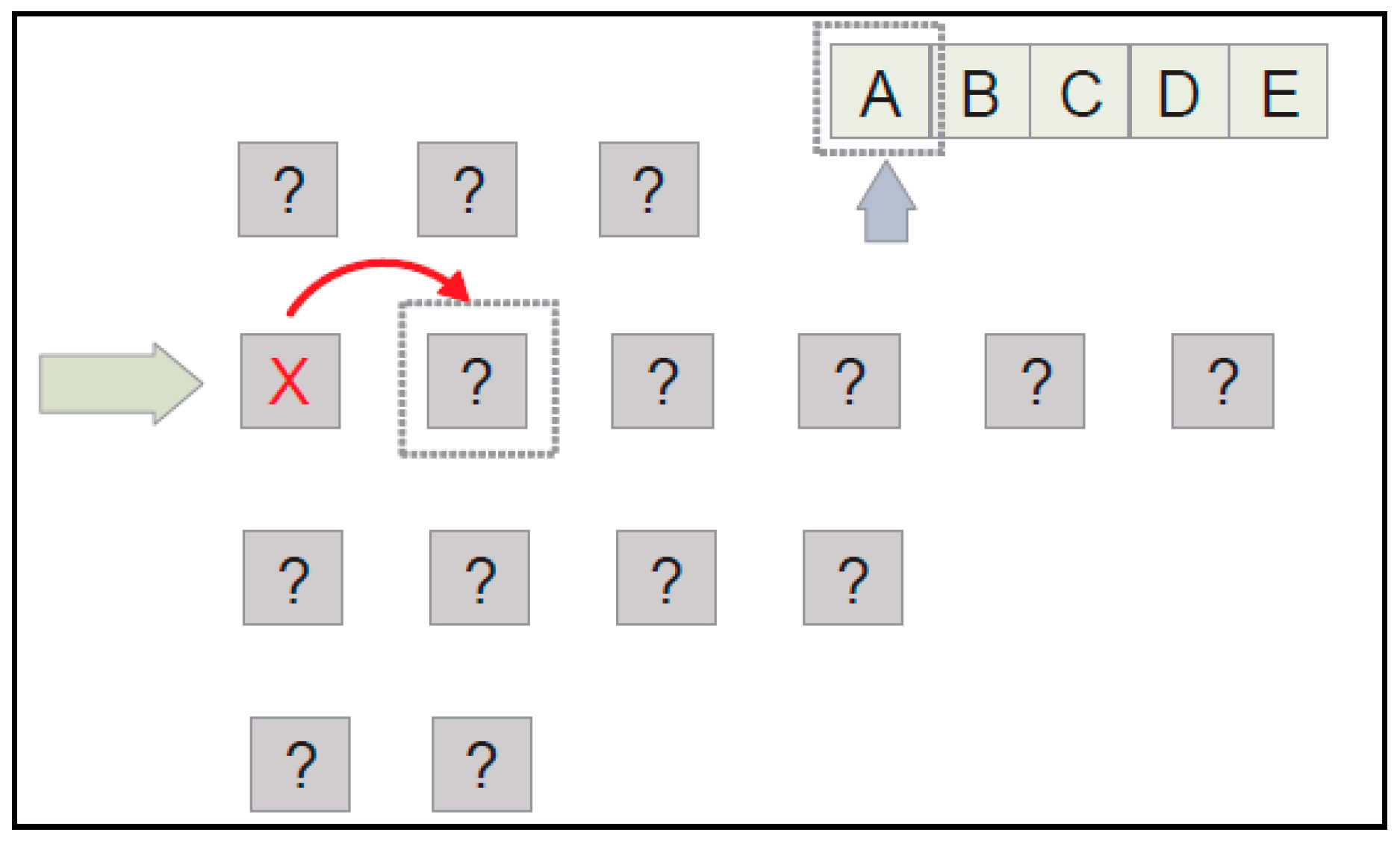
- We choose, within the bands of acquired shapes, the one that may contain the expected line selected in step 1. It will be done from top to bottom starting from the next band after the last band successfully verified. The rule to be fulfilled is that the selected band has the same or greater number of shapes than the number of characters of the expected code line (see Figure 9).
- Within the selected expected line, we select the first expected character not yet verified from the expected code following the order from left to right. If all the characters have already been validated, then the expected line has already been completely processed, and therefore, we return to step 1.
- Within the band of acquired shapes, we select the first acquired shape not yet treated. If there are no acquired shapes, it is necessary to select another band, so all the expected characters verified in this line become unverified, and we return to step 2.
- Verification is made between the morphological family of the expected character and the acquired shape (see Section 5.2).
- The verification is negative: The current acquired shape is merged with the immediately following one and the verification between the morphological family of the expected character and the new shape, as the result of the described merging process, is repeated (see Figure 10 and Section 5.2),
- Verification is positive: We consider the current and the next acquired shape as treated. The expected character is marked as verified. Go back to step 3.
- The verification is negative. We consider the current acquired shape as noise. We mark it as treated (see Figure 11). Go back to step 4.
- The verification is positive: The acquired shape is marked as treated. The expected character is marked as verified (see Figure 12). Go back to step 3.
5.2. Matching
- The morphological family corresponding to the expected character is recovered from the MFB. The family must exist, and there must be morphologies within that family. Otherwise, we will face a critical failure in the validation, which should be notified to the operator immediately.
- The morphologies of the morphological family are recovered one by one. Each morphology is compared with the acquired shape. This comparison includes two tests:
- Comparison of the amount of ink present. It is a previous filtering. The ink difference between the morphology and the acquired character is compared. A difference above a permissible maximum ink difference threshold makes it unnecessary to carry out a template matching. If it passes the ink covered area test, the second test is applied. Otherwise, it is stated that they are different. The similarity value in that case is 0.
- Templates matching. A comparison of templates is made using the distance between morphologies described in Section 4.2 to evaluate the similarity between the morphology and the acquired character. The similarity value (distance) obtained is stored.
- Finally, the maximum similarity value obtained in the previous phase is chosen when facing all the morphologies of the morphological family with the acquired character. If it exceeds a certain threshold, the verification has been positive. Otherwise, it is negative. This result feeds the code validation resolution.
5.3. Validation Resolution
- Which expected characters have been verified positively (in position and line) in the acquired can image. The procedure described in the previous sections provides this information.
- Which characters are important. The user has previously provided the system with this information through a configuration file.
6. Results
7. Conclusions and Future Works
Acknowledgments
References
- Rodríguez-Rodríguez, J.C.; Quesada-Arencibia, A.; Moreno-Díaz, R., Jr.; García, C.R. A Character Segmentation Proposal for High-Speed Visual Monitoring of Expiration Codes on Beverage Cans. Sensors 2016, 16, 527. [Google Scholar] [CrossRef] [PubMed]
- Cheriet, M.; Kharma, N.; Liu, C.-L.; Suen, C.Y. Character Recognition Systems: A Guide for Students and Practitioners, 1st ed.; Wiley-Interscience: New York, NY, USA, 2007; pp. 5–128. [Google Scholar]
- Rodriguez-Rodriguez, J.C.; Quesada-Arencibia, A.; Moreno-Diaz, R., Jr. Industrial Vision Systems, Real Time, and Demanding Environment: A Working-Case for Quality Control. In Vision Systems. Applications; Obinata, G., Dutta, A., Eds.; I-Tech Education and Publishing: Vienna, Austria, 2007; pp. 407–422. [Google Scholar]
- Rodriguez-Rodriguez, J.C. MONICOD: Supervisión Visual a Muy Alta Velocidad de Codificación Impresa Industrial (Visual Monitoring for Ultra High Speed Printed Industrial Coding). Ph.D. Thesis, Universidad de Las Palmas de Gran Canaria, Las Palmas de Gran Canaria, Spain, 2013. [Google Scholar]
- Saradhadevi, D.V.V. A survey on digital image enhancement techniques. Int. J. Comput. Inf. Sci. 2010, 8, 173–178. [Google Scholar]
- Zhu, H.; Chan, F.H.Y.; Lam, F.K. Image contrast enhancement by constrained local histogram equalization. Comput. Vis. Image Und. 1999, 73, 281–290. [Google Scholar] [CrossRef]
- Sezgin, M.; Sankur, B. Survey over image thresholding techniques and quantitative performance evaluation. J. Electron. Imaging 2004, 13, 146–165. [Google Scholar]
- Otsu, N. A threshold selection method from gray-scale histogram. IEEE Trans. Syst. Man Cybern. 1979, 9, 62–66. [Google Scholar] [CrossRef]
- Kittler, J.; Illingworth, J. Minimum error thresholding. Pattern Recogn. 1986, 19, 41–47. [Google Scholar] [CrossRef]
- Haralick, R.M.; Shapiro, L.G. Image segmentation techniques. Comput. Gr. Image Process. 1985, 29, 100–132. [Google Scholar] [CrossRef]
- Spiliotis, I.M.; Mertzios, B.G. Real-time computation of two-dimensional moments on binary images using image block representation. IEEE Trans. Image Process. 1998, 7, 1609–1615. [Google Scholar] [CrossRef] [PubMed]
- Papakostas, G.A.; Karakasis, E.G.; Koulouriotis, D.E. Efficient and accurate computation of geometric moments on gray-scale images. Pattern Recogn. 2008, 41, 1895–1904. [Google Scholar] [CrossRef]
- Kotoulas, L.; Andreadis, I. Accurate Calculation of Image Moments. IEEE T. Image Process. 2007, 16, 2028–2037. [Google Scholar] [CrossRef] [PubMed]
- Yap, P.-T.; Paramesran, R.; Ong, S.-H. Image analysis using Hahn moments. IEEE T. Pattern Anal. 2007, 29, 2057–2062. [Google Scholar] [CrossRef] [PubMed]
- Kotoulas, L.; Andreadis, I. Image analysis using moments. In Proceedings of the 5th Int. Conf. on Technology and Automation, Thessaloniki, Greece, 15–16 October 2005; pp. 360–364. [Google Scholar]
- Abdul-Hameed, M.S. High order multi-dimensional moment generating algorithm and the efficient computation of Zernike moments. In Proceedings of the 1997 IEEE International Conference on Acoustics, Speech, and Signal Processing, Munich, Germany, 21–24 April 1997; pp. 3061–3064. [Google Scholar]
- Hatamian, M. A real-time two-dimensional moment generating algorithm and its single chip implementation. IEEE Trans. Acoust. Speech 1986, 34, 546–553. [Google Scholar] [CrossRef]
- Dalhoum, A.L.A. A comparative survey on the fast computation of geometric moments. Eur. J. Sci. Res. 2008, 24, 104–111. [Google Scholar]
- Di Ruberto, C.; Morgera, A. A comparison of 2-d moment-based description techniques. In Proceedings of the 13th International Conference on Image Analysis and Processing ICIAP 2005, Cagliari, Italy, 6–8 September 2005; Roli, F., Vitulano, S., Eds.; Springer-Verlag: Berlin/Heidelberg, Germany, 2005; pp. 212–219. [Google Scholar]
- Arya, S.; Mount, D.M.; Netanyahu, N.S.; Silverman, R.; Wu, A.Y. An optimal algorithm for approximate nearest neighbor searching fixed dimensions. J. ACM 1998, 45, 891–923. [Google Scholar] [CrossRef]
- Haykin, S. Neural Networks and Learning Machines, 3rd ed.; Pearson Education: Upper Saddle River, NJ, USA, 2009; pp. 122–268. [Google Scholar]
- Burges, C.J.C. A tutorial on support vector machines for pattern recognition. Data Min. Knowl. Disc. 1998, 2, 121–167. [Google Scholar] [CrossRef]
- Cristianini, N.; Shawe-Taylor, J. An Introduction to Support Vector Machines and Other Kernel-Based Learning Methods, 1st ed.; Cambridge University Press: Cambridge, UK, 2000; pp. 93–124. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Total Validations | Successful Validations | Failures |
|---|---|---|
| 465 | 438 | 27 |
| Number of Failures | Percentage | |
|---|---|---|
| Failure in the selection of the best can | 13 | 50.0% |
| Band division failure | 11 | 42.3% |
| Grouping failure | 1 | 3.8% |
| Failure in character validation | 1 | 3.8% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rodríguez-Rodríguez, J.C.; Blasio, G.S.d.; García, C.R.; Quesada-Arencibia, A. A Character Validation Proposal for High-Speed Visual Monitoring of Expiration Codes on Beverage Cans. Proceedings 2019, 31, 56. https://doi.org/10.3390/proceedings2019031056
Rodríguez-Rodríguez JC, Blasio GSd, García CR, Quesada-Arencibia A. A Character Validation Proposal for High-Speed Visual Monitoring of Expiration Codes on Beverage Cans. Proceedings. 2019; 31(1):56. https://doi.org/10.3390/proceedings2019031056
Chicago/Turabian StyleRodríguez-Rodríguez, José Carlos, Gabriele Salvatore de Blasio, Carmelo R. García, and Alexis Quesada-Arencibia. 2019. "A Character Validation Proposal for High-Speed Visual Monitoring of Expiration Codes on Beverage Cans" Proceedings 31, no. 1: 56. https://doi.org/10.3390/proceedings2019031056
APA StyleRodríguez-Rodríguez, J. C., Blasio, G. S. d., García, C. R., & Quesada-Arencibia, A. (2019). A Character Validation Proposal for High-Speed Visual Monitoring of Expiration Codes on Beverage Cans. Proceedings, 31(1), 56. https://doi.org/10.3390/proceedings2019031056