Drone-Action: An Outdoor Recorded Drone Video Dataset for Action Recognition




Abstract
:1. Introduction
- The quality of aerial videos is often marred by a lack of image details, perspective distortion, occlusions, and camera movements.
- Many drone applications require online rather than offline processing, but the resource constraints of embedded hardware platforms limit the choice and complexity of action recognition algorithms.
- There are not enough relevant video datasets to help train algorithms for action recognition in the aerial domain. Currently available aerial video datasets are mostly limited to object tracking. While there are some datasets supporting research in aerial action recognition [16], they are limited.
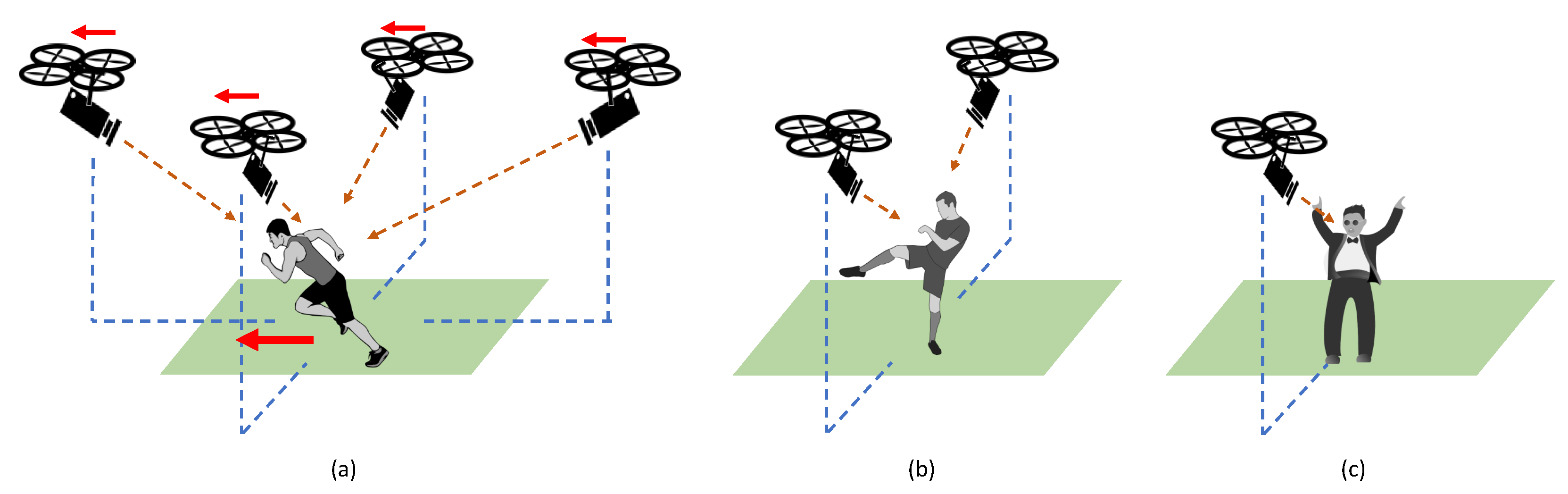
- Avoid flying at overly low altitude, which is hazardous to humans and equipment;
- Avoid flying at overly high altitude, so as to maintain sufficient image resolution;
- Avoid high-speed flying, and therefore, motion blur;
- Hover to acquire more details of interesting scenes;
- Record human subjects from a viewpoint that gives minimum perspective distortion.
2. Related Work
- Object detection and tracking datasets: There has been a surge of interest in aerial object detection and tracking studies. They are mainly focused on vehicle and human detection and tracking. VisDrone [11] is the largest object detection and tracking dataset in this category. This dataset covers various urban and suburban areas with a diverse range of aerial objects (it includes 2.5 million annotated instances). The dataset has been arranged into four tracks for object detection in images/videos and single/multi object tracking. The similar but relatively smaller UAVDT dataset [41] contains 80 thousand annotated instances recorded from low altitude drones. UAV123 dataset [15] has been presented for single object tracking from 123 aerial videos. Videos in these datasets have been annotated for the ground truth object bounding boxes.
- Human action recognition datasets: A large-scale VIRAT dataset [13] contains 550 videos covering a range of realistic and controlled human actions. The dataset has been recorded from both static and moving cameras (called VIRAT ground and aerial datasets). There are 23 outdoor event types with 29 h of videos. A limitation of the VIRAT aerial dataset is its low resolution of 480 × 720 pixels restricts algorithms from retrieving rich activity information from relatively small human subjects. A 4k resolution Okutama-Action [16] video dataset was introduced to detect 12 concurrent actions by multiple subjects. The dataset was recorded in a baseball field using two drones. Abrupt camera movements are present in the dataset making it more challenging for action recognition. However, the 90 degree elevation angle of the camera creates severe self-occlusions and perspective distortions in the videos. Other notable datasets in this category are UCFARG [14], UCF aerial action [43], and Mini-drone [44]. UCF aerial and UCF ARG datasets have been recorded from an R/C-controlled blimp and a helium balloon respectively. Both datasets have similar action classes. UCF ARG is a multi-view dataset with synchronized ground, rooftop, and aerial camera views of the actions. However, UCF aerial action is a single-view dataset. Mini-drone was developed to study various aspects and definitions of privacy in aerial videos. The dataset was captured in a car park covering illicit, suspicious, and normal behaviors.
3. Preparing the Dataset
3.1. Data Collection
3.2. Action Class Selection
3.3. Variations in Data
3.4. Dataset Annotations
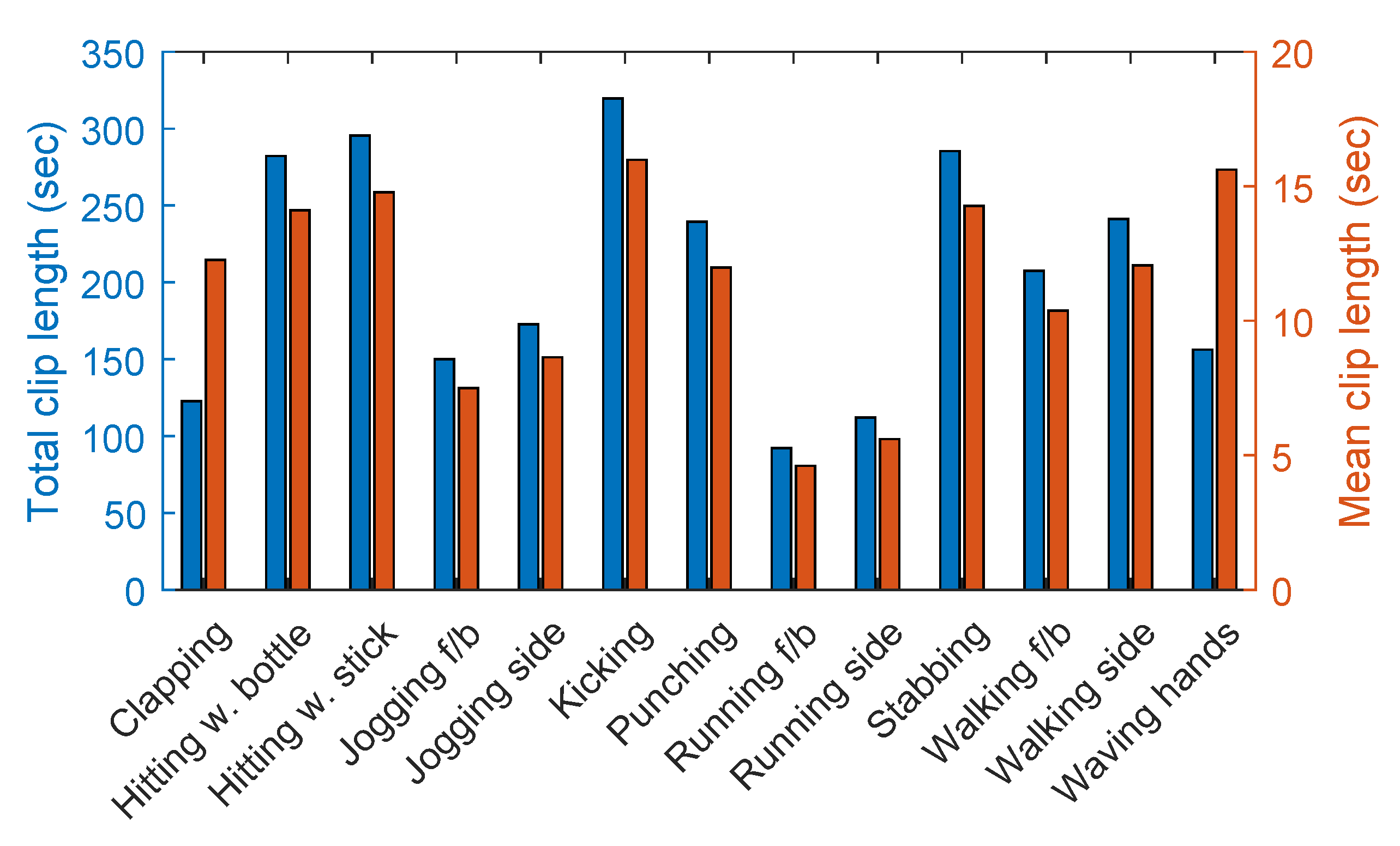
3.5. Dataset Summary
4. Experimental Results
4.1. High-Level Pose Features (HLPF)
- Normalized positions: Each key point was normalized with respect to the belly key point. A total of 30 descriptors were obtained (x and y coordinates of 15 joints).
- Distance relationships: The distance between two key points was calculated for all 15 key points, resulting in 105 descriptors.
- Angular relationships: A total of 1365 angles were calculated. Each angle was that of two vectors connecting a triplet of key points.
- Orientation relationships: 104 angles were calculated between each vector connecting two key points and the vector from neck to abdomen.
- Cartesian trajectory: 30 descriptors were obtained from the translation of 15 key points along x and y axes.
- Radial trajectory: The radial displacement of 15 key points provides 15 descriptors.
- Distance relationship trajectory: 105 descriptors were calculated from the differences between distance relationships.
- Angle relationship trajectory: 1365 descriptors were calculated from the differences between angle relationships.
- Orientation relationship trajectory: 104 descriptors were calculated from the differences between distance relationships.
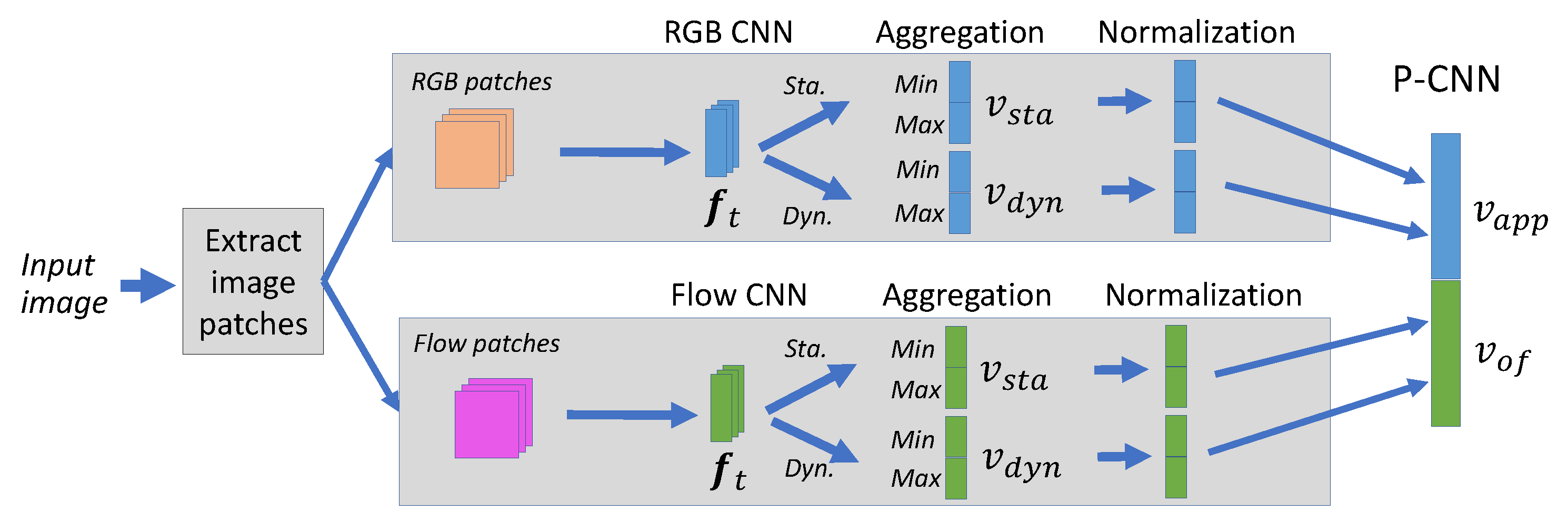
4.2. Pose-Based CNN (P-CNN)
4.2.1. Pose Estimation
4.2.2. Optical Flow Calculation
4.2.3. Extracting Part Patches
4.2.4. CNN Feature Aggregation
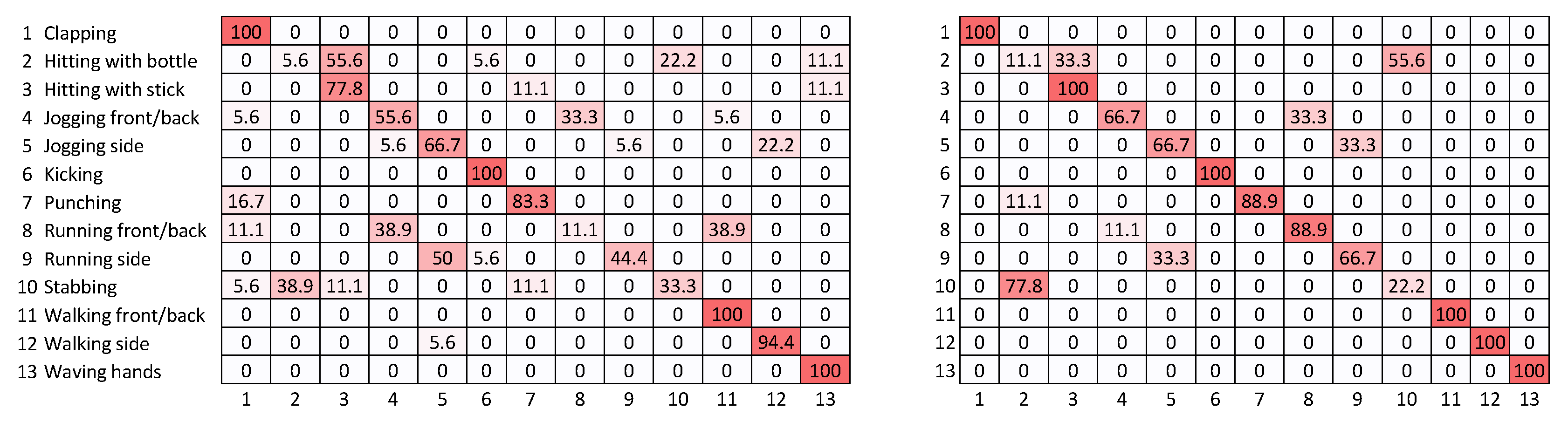
4.3. Performance Evaluation
5. Discussion
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Gonçalves, J.; Henriques, R. UAV photogrammetry for topographic monitoring of coastal areas. ISPRS J. Photogramm. Remote Sens. 2015, 104, 101–111. [Google Scholar] [CrossRef]
- Barbedo, J.G.A. A Review on the Use of Unmanned Aerial Vehicles and Imaging Sensors for Monitoring and Assessing Plant Stresses. Drones 2019, 3, 40. [Google Scholar] [CrossRef]
- Al-Kaff, A.; Moreno, F.M.; José, L.J.S.; García, F.; Martín, D.; de la Escalera, A.; Nieva, A.; Garcéa, J.L.M. VBII-UAV: Vision-Based Infrastructure Inspection-UAV. In Recent Advances in Information Systems and Technologies; Rocha, Á., Correia, A.M., Adeli, H., Reis, L.P., Costanzo, S., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 221–231. [Google Scholar]
- Erdelj, M.; Natalizio, E.; Chowdhury, K.R.; Akyildiz, I.F. Help from the Sky: Leveraging UAVs for Disaster Management. IEEE Pervasive Comput. 2017, 16, 24–32. [Google Scholar] [CrossRef]
- Peschel, J.M.; Murphy, R.R. On the Human–Machine Interaction of Unmanned Aerial System Mission Specialists. IEEE Trans. Hum.-Mach. Syst. 2013, 43, 53–62. [Google Scholar] [CrossRef]
- Chahl, J. Unmanned Aerial Systems (UAS) Research Opportunities. Aerospace 2015, 2, 189–202. [Google Scholar] [CrossRef]
- Xia, G.S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A Large-Scale Dataset for Object Detection in Aerial Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Razakarivony, S.; Jurie, F. Vehicle detection in aerial imagery: A small target detection benchmark. J. Vis. Commun. Image Represent. 2016, 34, 187–203. [Google Scholar] [CrossRef]
- Krajewski, R.; Bock, J.; Kloeker, L.; Eckstein, L. The highD Dataset: A Drone Dataset of Naturalistic Vehicle Trajectories on German Highways for Validation of Highly Automated Driving Systems. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 2118–2125. [Google Scholar] [CrossRef]
- Interstate 80 Freeway Dataset. 2019. Available online: https://www.fhwa.dot.gov/publications/research/operations/06137/index.cfm (accessed on 2 November 2019).
- Zhu, P.; Wen, L.; Bian, X.; Haibin, L.; Hu, Q. Vision Meets Drones: A Challenge. arXiv 2018, arXiv:1804.07437. [Google Scholar]
- Carletti, V.; Greco, A.; Saggese, A.; Vento, M. Multi-Object Tracking by Flying Cameras Based on a Forward-Backward Interaction. IEEE Access 2018, 6, 43905–43919. [Google Scholar] [CrossRef]
- Oh, S.; Hoogs, A.; Perera, A.; Cuntoor, N.; Chen, C.C.; Lee, J.T.; Mukherjee, S.; Aggarwal, J.K.; Lee, H.; Davis, L.; et al. A large-scale benchmark dataset for event recognition in surveillance video. In Proceedings of the CVPR 2011, Providence, RI, USA, 20–25 June 2011; pp. 3153–3160. [Google Scholar] [CrossRef]
- University of Central Florida. UCF-ARG Data Set. 2011. Available online: http://crcv.ucf.edu/data/UCF-ARG.php (accessed on 2 November 2019).
- Mueller, M.; Smith, N.; Ghanem, B. A Benchmark and Simulator for UAV Tracking. In Proceedings of the Computer Vision—ECCV 2016, Amsterdam, The Netherlands, 8–16 October 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 445–461. [Google Scholar]
- Barekatain, M.; Martí, M.; Shih, H.F.; Murray, S.; Nakayama, K.; Matsuo, Y.; Prendinger, H. Okutama-Action: An Aerial View Video Dataset for Concurrent Human Action Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 2153–2160. [Google Scholar] [CrossRef]
- Perera, A.G.; Wei Law, Y.; Chahl, J. UAV-GESTURE: A Dataset for UAV Control and Gesture Recognition. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018; pp. 117–128. [Google Scholar] [CrossRef]
- Natarajan, K.; Nguyen, T.D.; Mete, M. Hand Gesture Controlled Drones: An Open Source Library. In Proceedings of the 2018 1st International Conference on Data Intelligence and Security (ICDIS), South Padre Island, TX, USA, 8–10 April 2018; pp. 168–175. [Google Scholar] [CrossRef]
- Lee, J.; Tan, H.; Crandall, D.; Šabanović, S. Forecasting Hand Gestures for Human-Drone Interaction. In Proceedings of the Companion of the 2018 ACM/IEEE International Conference on Human-Robot Interaction, Chicago, IL, USA, 5–8 March 2018; pp. 167–168. [Google Scholar] [CrossRef]
- Hsu, H.J.; Chen, K.T. DroneFace: An Open Dataset for Drone Research. In Proceedings of the 8th ACM on Multimedia Systems Conference, Taipei, Taiwan, 20–23 June 2017; pp. 187–192. [Google Scholar] [CrossRef]
- Kalra, I.; Singh, M.; Nagpal, S.; Singh, R.; Vatsa, M.; Sujit, P.B. DroneSURF: Benchmark Dataset for Drone-based Face Recognition. In Proceedings of the 2019 14th IEEE International Conference on Automatic Face Gesture Recognition (FG 2019), Lille, France, 14–18 May 2019; pp. 1–7. [Google Scholar] [CrossRef]
- Carletti, V.; Greco, A.; Saggese, A.; Vento, M. An intelligent flying system for automatic detection of faults in photovoltaic plants. J. Ambient Intell. Hum. Comput. 2019. [Google Scholar] [CrossRef]
- Avola, D.; Cinque, L.; Foresti, G.L.; Martinel, N.; Pannone, D.; Piciarelli, C. A UAV Video Dataset for Mosaicking and Change Detection From Low-Altitude Flights. IEEE Trans. Syst. Man Cybern. Syst. 2018. [Google Scholar] [CrossRef]
- Sensefly Mosaic Datasets. 2019. Available online: https://www.sensefiy.com/drones/example-datasets.html (accessed on 2 November 2019).
- Lottes, P.; Khanna, R.; Pfeifer, J.; Siegwart, R.; Stachniss, C. UAV-based crop and weed classification for smart farming. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 3024–3031. [Google Scholar] [CrossRef]
- Monteiro, A.; von Wangenheim, A. Orthomosaic Dataset of RGB Aerial Images for Weed Mapping. 2019. Available online: http://www.lapix.ufsc.br/weed-mapping-sugar-cane (accessed on 2 November 2019).
- Herath, S.; Harandi, M.; Porikli, F. Going deeper into action recognition: A survey. Image Vis. Comput. 2017, 60, 4–21. [Google Scholar] [CrossRef]
- Mabrouk, A.B.; Zagrouba, E. Abnormal behavior recognition for intelligent video surveillance systems: A review. Expert Syst. Appl. 2018, 91, 480–491. [Google Scholar] [CrossRef]
- Cheron, G.; Laptev, I.; Schmid, C. P-CNN: Pose-Based CNN Features for Action Recognition. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Jhuang, H.; Gall, J.; Zuffi, S.; Schmid, C.; Black, M.J. Towards Understanding Action Recognition. In Proceedings of the 2013 IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 3192–3199. [Google Scholar] [CrossRef]
- Schuldt, C.; Laptev, I.; Caputo, B. Recognizing human actions: A local SVM approach. In Proceedings of the 17th International Conference on Pattern Recognition, Cambridge, UK, 26 August 2004; Volume 3, pp. 32–36. [Google Scholar] [CrossRef]
- Blank, M.; Gorelick, L.; Shechtman, E.; Irani, M.; Basri, R. Actions as space-time shapes. In Proceedings of the Tenth IEEE International Conference on Computer Vision (ICCV’05), Beijing, China, 17–21 October 2005; Volume 2, pp. 1395–1402. [Google Scholar] [CrossRef]
- Soomro, K.; Zamir, A.R.; Shah, M. UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild; Technical Report; UCF Center for Research in Computer Vision: Orlando, FL, USA, 2012. [Google Scholar]
- Zhang, W.; Zhu, M.; Derpanis, K.G. From Actemes to Action: A Strongly-Supervised Representation for Detailed Action Understanding. In Proceedings of the 2013 IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 2248–2255. [Google Scholar] [CrossRef]
- Karpathy, A.; Toderici, G.; Shetty, S.; Leung, T.; Sukthankar, R.; Fei-Fei, L. Large-Scale Video Classification with Convolutional Neural Networks. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014; pp. 1725–1732. [Google Scholar] [CrossRef]
- Heilbron, F.C.; Escorcia, V.; Ghanem, B.; Niebles, J.C. ActivityNet: A large-scale video benchmark for human activity understanding. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 961–970. [Google Scholar] [CrossRef]
- Feichtenhofer, C.; Pinz, A.; Zisserman, A. Convolutional Two-Stream Network Fusion for Video Action Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1933–1941. [Google Scholar] [CrossRef]
- Abu-El-Haija, S.; Kothari, N.; Lee, J.; Natsev, A.; Toderici, G.; Varadarajan, B.; Vijayanarasimhan, S. YouTube-8M: A Large-Scale Video Classification Benchmark. arXiv 2016, arXiv:1609.08675. [Google Scholar]
- Kay, W.; Carreira, J.; Simonyan, K.; Zhang, B.; Hillier, C.; Vijayanarasimhan, S.; Viola, F.; Green, T.; Back, T.; Natsev, A.; et al. The Kinetics Human Action Video Dataset. arXiv 2017, arXiv:1705.06950. [Google Scholar]
- Zhao, H.; Yan, Z.; Torresani, L.; Torralba, A. HACS: Human Action Clips and Segments Dataset for Recognition and Temporal Localization. arXiv 2019, arXiv:1712.09374. [Google Scholar]
- Du, D.; Qi, Y.; Yu, H.; Yang, Y.; Duan, K.; Li, G.; Zhang, W.; Huang, Q.; Tian, Q. The Unmanned Aerial Vehicle Benchmark: Object Detection and Tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Song, Y.; Demirdjian, D.; Davis, R. Tracking body and hands for gesture recognition: NATOPS aircraft handling signals database. Face Gesture 2011, 500–506. [Google Scholar] [CrossRef]
- University of Central Florida. UCF Aerial Action Dataset. 2011. Available online: http://crcv.ucf.edu/data/UCF_Aerial_Action.php (accessed on 2 November 2019).
- Bonetto, M.; Korshunov, P.; Ramponi, G.; Ebrahimi, T. Privacy in mini-drone based video surveillance. In Proceedings of the 2015 11th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG), Ljubljana, Slovenia, 4–8 May 2015; Volume 4, pp. 1–6. [Google Scholar] [CrossRef]
- Ovtcharov, K.; Ruwase, O.; Kim, J.Y.; Fowers, J.; Strauss, K.; Chung, E.S. Accelerating deep convolutional neural networks using specialized hardware. Microsoft Res. Whitepaper 2015, 2, 1–4. [Google Scholar]
- Rudol, P.; Doherty, P. Human Body Detection and Geolocalization for UAV Search and Rescue Missions Using Color and Thermal Imagery. In Proceedings of the 2008 IEEE Aerospace Conference, Big Sky, MT, USA, 1–8 March 2008; pp. 1–8. [Google Scholar] [CrossRef]
- Oreifej, O.; Mehran, R.; Shah, M. Human identity recognition in aerial images. In Proceedings of the 2010 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010; pp. 709–716. [Google Scholar] [CrossRef]
- Yeh, M.C.; Chiu, H.K.; Wang, J.S. Fast medium-scale multiperson identification in aerial videos. Multimed. Tools Appl. 2016, 75, 16117–16133. [Google Scholar] [CrossRef]
- Al-Naji, A.; Perera, A.G.; Chahl, J. Remote monitoring of cardiorespiratory signals from a hovering unmanned aerial vehicle. BioMedical Eng. OnLine 2017, 16, 101. [Google Scholar] [CrossRef] [Green Version]
- De Souza, F.D.; Chavez, G.C.; do Valle, E.A., Jr.; Araújo, A.D.A. Violence Detection in Video Using Spatio-Temporal Features. In Proceedings of the 2010 23rd SIBGRAPI Conference on Graphics, Patterns and Images, Gramado, Brazil, 30 August–3 September 2010; pp. 224–230. [Google Scholar] [CrossRef]
- Datta, A.; Shah, M.; Lobo, N.D.V. Person-on-person violence detection in video data. In Proceedings of the Object Recognition Supported by User Interaction for Service Robots, Quebec City, QC, Canada, 11–15 August 2002. [Google Scholar] [CrossRef]
- Cao, Z.; Simon, T.; Wei, S.E.; Sheikh, Y. Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields. In Proceedings of the CVPR, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Ryoo, M.S.; Aggarwal, J.K. Spatio-temporal relationship match: Video structure comparison for recognition of complex human activities. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 1593–1600. [Google Scholar] [CrossRef]
- Robicquet, A.; Sadeghian, A.; Alahi, A.; Savarese, S. Learning Social Etiquette: Human Trajectory Understanding In Crowded Scenes. In Proceedings of the Computer Vision—ECCV, Amsterdam, The Netherlands, 11–14 October 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 549–565. [Google Scholar]
- Simonyan, K.; Zisserman, A. Two-Stream Convolutional Networks for Action Recognition in Videos. In Proceedings of the 27th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 568–576. [Google Scholar]
- Zhao, M.; Li, T.; Alsheikh, M.A.; Tian, Y.; Zhao, H.; Torralba, A.; Katabi, D. Through-Wall Human Pose Estimation Using Radio Signals. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18-22 June 2018; pp. 7356–7365. [Google Scholar] [CrossRef]
- Brox, T.; Bruhn, A.; Papenberg, N.; Weickert, J. High Accuracy Optical Flow Estimation Based on a Theory for Warping. In Proceedings of the Computer Vision—ECCV 2004; Pajdla, T., Matas, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2004; pp. 25–36. [Google Scholar]
- Gkioxari, G.; Malik, J. Finding Action Tubes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Chatfield, K.; Simonyan, K.; Vedaldi, A.; Zisserman, A. Return of the Devil in the Details: Delving Deep into Convolutional Nets. arXiv 2014, arXiv:1405.3531v4. [Google Scholar]
- Cherian, A.; Mairal, J.; Alahari, K.; Schmid, C. Mixing Body-Part Sequences for Human Pose Estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 24–27 June 2014. [Google Scholar]
- Cohen, J. A coefficient of agreement for nominal scales. Educ. Psychol. Meas. 1960, 20, 37–46. [Google Scholar] [CrossRef]
- Landis, J.R.; Koch, G.G. The measurement of observer agreement for categorical data. Biometrics 1977, 33, 159–174. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cardillo, G. Compute the Cohen’s Kappa (Version 2.0.0.0). 2018. Available online: http://www.mathworks.com/matlabcentral/fileexchange/15365 (accessed on 2 November 2019).
- Perera, A.G.; Law, Y.W.; Chahl, J. Human Pose and Path Estimation from Aerial Video Using Dynamic Classifier Selection. Cogn. Comput. 2018, 10, 1019–1041. [Google Scholar] [CrossRef] [Green Version]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature | Value |
|---|---|
| # Actions | 13 |
| # Actors | 10 |
| # Clips | 240 |
| # Clips per class | 10-20 |
| Repetitions per class | 5-10 |
| Mean clip length | 11.15 sec |
| Total duration | 44.6 mins |
| # Frames | 66919 |
| Frame rate | 25 fps |
| Resolution | 1920 × 1080 |
| Camera motion | Yes (hover and follow) |
| Annotation | Bounding box |
| Dataset | Scenario | Purpose | Environment | Frames | Classes | Resolution | Year |
|---|---|---|---|---|---|---|---|
| UT Interaction [53] | Surveillance | Action recognition | Outdoor | 36k | 6 | 360 × 240 | 2010 |
| NATOPS [42] | Aircraft signaling | Gesture recognition | Indoor | N/A | 24 | 320 × 240 | 2011 |
| VIRAT [13] | Drone, surveillance | Event recognition | Outdoor | Many | 23 | Varying | 2011 |
| UCF101 [33] | YouTube | Action recognition | Varying | 558k | 24 | 320 × 240 | 2012 |
| J-HMDB [30] | Movies, YouTube | Action recognition | Varying | 32k | 21 | 320 × 240 | 2013 |
| Mini-drone [44] | Drone | Privacy protection | Outdoor | 23.3k | 3 | 1920 × 1080 | 2015 |
| Campus [54] | Surveillance | Object tracking | Outdoor | 11.2k | 1 | 1414 × 2019 | 2016 |
| Okutama- Action [16] | Drone | Action recognition | Outdoor | 70k | 13 | 3840 × 2160 | 2017 |
| UAV-Gesture [17] | Drone | Gesture recognition | Outdoor | 37.2k | 13 | 1920 × 1080 | 2018 |
| Drone-Action | Drone | Action recognition | Outdoor | 66.9k | 13 | 1920 × 1080 | 2019 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Perera, A.G.; Law, Y.W.; Chahl, J. Drone-Action: An Outdoor Recorded Drone Video Dataset for Action Recognition. Drones 2019, 3, 82. https://doi.org/10.3390/drones3040082
Perera AG, Law YW, Chahl J. Drone-Action: An Outdoor Recorded Drone Video Dataset for Action Recognition. Drones. 2019; 3(4):82. https://doi.org/10.3390/drones3040082
Chicago/Turabian StylePerera, Asanka G., Yee Wei Law, and Javaan Chahl. 2019. "Drone-Action: An Outdoor Recorded Drone Video Dataset for Action Recognition" Drones 3, no. 4: 82. https://doi.org/10.3390/drones3040082
APA StylePerera, A. G., Law, Y. W., & Chahl, J. (2019). Drone-Action: An Outdoor Recorded Drone Video Dataset for Action Recognition. Drones, 3(4), 82. https://doi.org/10.3390/drones3040082