1. Introduction
In recent years, with the rapid development and wide application of Unmanned Aerial Vehicle (UAV) technology in civil and military fields, there has been a tremendous escalation in the development of applications using UAV swarms. Currently, the main research effort in this context is directed toward developing unmanned aerial systems for UAV cooperation, multi-UAV autonomous navigation, and UAV pursuit-evasion problems [
1].
In modern wars, where UAVs are widely used, the technical requirements for anti-UAV technologies are becoming increasingly significant [
2]. However, existing anti-UAV technologies are not enough to effectively deal with the suppression of UAV swarms [
3]. For a small number of UAVs, countermeasures such as physical capture, navigation deception, seizing control and physical destruction can be used. But it is difficult to cope with a large number of UAVs once they gather together to form a UAV swarm. It is imperative to be able to detect the incoming UAV swarm from a long distance in time and then carry out scale estimation, target tracking, and other operations.
Therefore, the development of UAV swarm target detection and tracking, etc., is the premise and key to achieving comprehensive awareness, scientific decision-making, and active response in battlefield situations. Because anti-UAV swarm systems have high requirements for the accuracy and speed of object location and tracking methods and radar detection, passive location, and other methods experience significant interference from other signal clutter, resulting in false detections or missing detection problems. Therefore, using computer vision technology to detect and track the UAV swarm has significant research value.
This paper focuses on UAV target detection for anti-UAV systems. Specifically, under our proposed method, once the UAV swarm is detected, detectors are rapidly deployed on the ground to obtain video, and quickly and accurately detect the target to facilitate subsequent countermeasures.
Most of the existing object detection algorithms consider the object scale to be of medium size, while a low-flying UAV accounts for a very small proportion of the image, and there is little available texture information. It is difficult to extract useful features, especially against a complex background, and, thus, it is easy to mistakenly detect or miss the UAV target. Therefore, in order to improve the capability of UAV swarm detection in different scales and complex scenes, and meet the application requirements in resource-constrained situations, such as in terms of computing power and storage space, this paper proposes a lightweight UAV swarm detection method that integrates an attention mechanism. Data augmentation technology is applied to expand the dataset to improve the diversity of the training set. In addition, depthwise separable convolution [
4] is used to compress the main structure of the network, with the aim of building a model that meets the accuracy requirements and takes up as little computing resources as possible.
We train and test based on the UAVSwarm dataset [
5], and the experimental results show that the mAP value of the proposed method reaches 82.32%, while the number of parameters is only about 1/10th of that of the YOLOX-S model and the model size is only 3.85 Mb. Under the same experimental conditions, compared with other YOLO series lightweight models, the detection accuracy of the proposed method is 15.59%, 15.41%, 1.78%, 0.58%, and 1.82% higher than MobileNetv3-yolov4, GhostNet-Yolov4, YOLOv4-Tiny, YOLOX-Tiny, and YOLOX-Nano models, respectively. At the same time, the total network parameters and model size are excellent.
The main innovations of this paper are as follows:
(1) The depthwise separable convolution method is used to compress the model, and a nano network is constructed to achieve the lightweight UAV swarm detection network.
(2) A Squeeze-and-Extraction (SE) module [
6] is introduced into the backbone to improve the network′s ability to extract object features. The introduction of a Convolutional Block Attention Module (CBAM) [
7] in the feature fusion network makes the network pay more attention to important features and suppress unnecessary features.
(3) During the training process, Distance-IoU (DIoU) [
8] is used instead of Intersection over Union (IoU) to calculate the regression loss, which is beneficial for model optimization. At the same time, Mosaic [
9] and Mixup [
10] data augmentation technologies are used to expand the dataset to achieve a better detection effect.
3. Materials and Methods
3.1. Overview
The object detection model can generally be abstracted into backbone, neck, and head networks, as shown in
Figure 1. The backbone network performs feature extraction, the neck network performs multi-scale feature fusion on the feature layer obtained by the backbone network, and the head network performs classification and regression analysis.
3.2. Backbone Network
CSPDarkNet [
35] is used as the backbone of our UAV swarm detection model, consisting mainly of convolution layers and a CSP structure, as shown in
Table 2. First, a 640 × 640 RGB three-channel image is input into the network, and the image size and the number of channels are adjusted through Focus. Then, four stacked Resblock body modules are used for feature extraction. In the last Resblock body module, the image is processed through the SPP module; that is, the max pooling operation with different kernel sizes is used for feature extraction to improve the receptive field of the network. The final output of CSPDarkNet is the feature maps of the 2nd, 3rd, and 4th Resblock body modules, with the shapes of 80 × 80 × 256, 40 × 40 × 512, and 20 × 20 × 1024, respectively.
In the Resblock body module, the CSPLayer is similar to the residual structure. The input first passes through convolutional layers with a kernel size of 1×1 and 3×3 for n times, then the result and the original input are concatenated as output, as shown in
Figure 2a. In order to further improve the detection of UAV swarm targets, referring to the MobileNet V3 model [
29], a Squeeze-and-Extraction (SE) module [
6] is introduced into the CSPLayer structure, as shown in
Figure 2b. The UAV detection model uses SiLU as the activation function. SiLU has the characteristics of no upper bound, with a lower bound and smooth and non-monotone functions. It can converge faster during training and its formula is as follows:
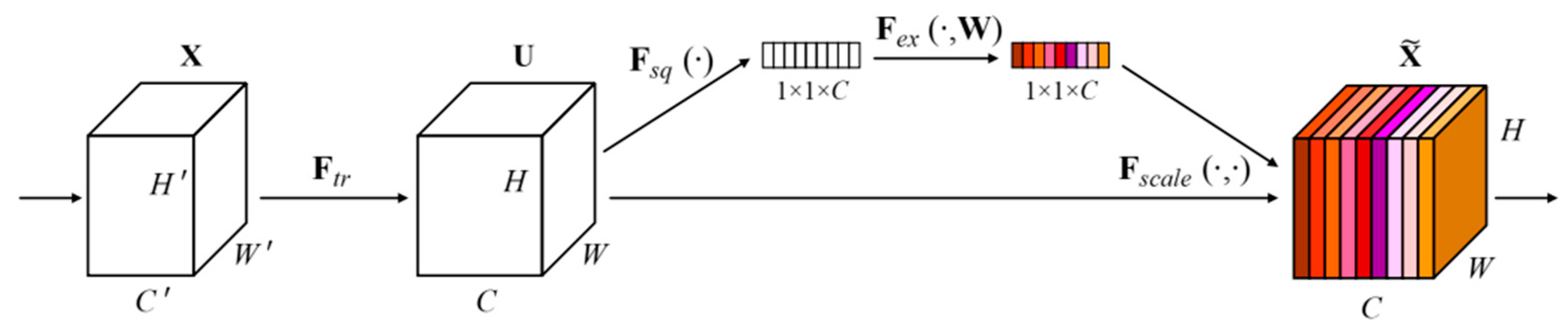
Specifically, the SE module generates different weight coefficients for each channel by using the correlation between feature channels, multiplies them with the previous features, and adds them to the original features to enhance the features. As shown in
Figure 3, the detailed process of the SE attention mechanism is as follows: First, the extracted feature
is mapped to
through the conversion function
. Then, the global information of each channel is represented with a channel characteristic description value through global average pooling
; and then the channel characteristic description value is adaptively calibrated by
to make the weight value more accurate. Finally, the enhanced feature is obtained by multiplying the weight value and the original feature through
.
3.3. Neck Network
The three feature layers obtained by CSPDarkNet are sent to the neck network for enhanced feature extraction and feature fusion. The neck network of the UAV swarm detection model is constructed based on the Path Aggregation Network (PANet) [
36]. The input feature map is resized through a convolution layer and then fused through up- and down-sampling operations. The specific network structure is shown in
Figure 4.
In order to improve the detection performance of the model for UAVs, a Convolutional Block Attention Module (CBAM) [
7] is firstly applied to the three feature maps obtained by the backbone network, and then sent to the neck network for feature fusion. The CBAM is also applied after each up-sampling and down-sampling operation in the PANet. CBAM is a simple and effective attention module for feedforward convolutional neural networks. It combines the two dimensions of channel and spatial features. When the feature map is input, it first goes through the Channel Attention Module (CAM) and then Spatial Attention Module (SAM). The calculation formula is (2):
As shown in
Figure 5, in the CAM, for the input feature map
, first, Global Average Pooling (GAP) and Global Maximum Pooling (GMP) operations are performed based on the width and height of the input feature map, and then they are processed by a shared neural network Multilayer Perceptron (MLP), respectively. The two processed results are added together, and a one-dimensional channel attention vector
is obtained through the Sigmoid function. Finally, the feature map
with channel weights is generated by multiplying the channel attention vector
and the feature map
. In the SAM module, for the feature map
obtained by CAM, a pooling operation is performed, and then the 7 × 7 convolution and Sigmoid function to obtain a two-dimensional spatial attention vector
. Finally,
and
are multiplied to obtain the final feature map
.
3.4. Head Network
After feature fusion and enhanced feature extraction are completed, the head network conducts classification and regression analysis on the three feature layers of different scales, and finally outputs the recognition results. Its network structure is shown in
Figure 6. The head network of the UAV detection model proposed in this paper has two convolution branches [
35], one of which is used to achieve object classification and output object categories. The other branch is used to judge whether the object in the feature point exists and regress the coordinates of the bounding box. Thus, for each feature layer, three prediction results can be obtained:
(1) Reg (h, w, 4): The position information of the target is predicted. The four parameters are x, y, w, and h, where x and y are the coordinates of the center point of the prediction box, and w and h are the width and height.
(2) Obj (h, w, 1): This is used to judge whether the prediction box is a foreground or a background. After being processed by the Sigmoid function, it provides the confidence of the object contained in each prediction box. The closer the confidence is to 1, the greater the probability of the existence of a target.
(3) Cls (h, w, num_classes): Determine what type of object, each object is, give each type of object a score, and obtain the confidence level after the sigmoid function processing.
The above three prediction results are stacked, and the prediction result of each feature layer is (h, w, 4+1+num_classes). The first four parameters of the last dimension are regression parameters of each feature point and the fifth parameter is used to judge whether each feature point contains an object, and the last num_classes parameter is used to judge the category of the object contained in each feature point.
3.5. Lightweight Model
The essence of a lightweight model is to solve the limitations of storage space and energy consumption on the performance of traditional neural networks on equipment with low-performance hardware. Aiming at the problem that the traditional deep convolution neural network consumes a large amount of computing resources, this paper pays more attention to how to reduce the complexity of the model and the amount of computation, while improving the accuracy of object detection. Considering that the depthwise separable convolution method [
4] can effectively compress the model size while retaining the ability of feature extraction, this paper uses it to simplify and optimize the UAV swarm detection network.
A standard convolution both filters and combines inputs into a new set of outputs in one step. Depthwise separable convolution splits this into two layers, for filtering and combining. While minimizing the loss of accuracy, this approach can greatly simplify the network parameters and reduce the amount of calculation. The depth-separable convolution operation divides the traditional convolution operation into two steps: depthwise convolution and pointwise convolution. The depthwise convolution applies a single filter to each input channel. The pointwise convolution then applies a 1 × 1 convolution to combine the outputs of the depthwise convolution. The standard convolution operation and the depthwise separable convolution operation are shown in
Figure 7a,b, respectively. The depthwise separable convolution is used to replace the traditional convolution in the UAV detection network while reducing the network parameters and computation.
The total number of convolution kernel parameters and the total amount of convolution operations are analyzed to determine the amount of internal product operations. If we assume that N groups of convolutions, having the same kernel size,
, are taken to check the input image for convolution and that the required feature map size is
, then the quantity of parameters and operation required by the two methods are shown in
Table 3. The depthwise separable convolution method can compress the network size and reduce the amount of computation. In the process of obtaining a fixed-size feature map using convolution kernels of the same width and height, by expressing convolution as a two-step process of filtering and combining, we get a reduction in necessary computations of
, which is the key to achieving light weight.
3.6. Model Training
In the training process of the UAV swarm detection model, Distance-IoU (DIoU) [
8] is used instead of Intersection over Union (IoU) to calculate regression loss, which is beneficial for model optimization. In addition, Mosaic [
9] and Mixup [
10] data augmentation technologies are used to expand the dataset to achieve better UAV detection.
3.6.1. Data Augmentation
Data augmentation is a means of expanding the dataset in computer vision. The approach enhances the image data to compensate for the problem of insufficient training dataset images and achieve the purpose of expanding the training data. As the UAV swarm dataset UAVSwarm used for the experiment has few training samples and repetitive scenes, the Mosaic and Mixup algorithms are used in the image data preprocessing process in order to increase the diversity of training samples and enrich the background of the target, to avoid, as far as possible, the network falling into overfitting during the training process and improve the recognition accuracy and generalization ability of the network model.
The enhancement effect of the Mosaic algorithm is shown in
Figure 8. First, the four images are randomly cut, scaled, and rotated, and then they are spliced into a new image as the input image for model training. It should be noted that the image during processing contains the coordinate information of the bounding box of the target, so the new image obtained also contains the coordinate information of the bounding box of the UAV. The advantage of this is that, on the one hand, the size of the object in the picture is reduced to meet the requirements for small object detection accuracy, and, on the other hand, the complexity of the background is increased, so that the UAV swarm detection model has better robustness toward complex backgrounds.
The Mixup algorithm was originally used for image classification tasks. The core idea is to randomly select two images from each batch and mix them up to generate new images in a certain proportion. The Mixup algorithm is more lightweight than Mosaic, requiring only minimal computational overhead, and can significantly improve the operation speed of the model. Its mathematical expression is as follows:
where
and
are two randomly selected samples and their corresponding labels,
are the newly generated samples and their corresponding labels that will be used to train the neural network model, and
is a fusion coefficient. It can be seen from Formula (3) that Mixup essentially fuses two samples through a fusion coefficient. The enhancement effect of the Mixup algorithm is shown in
Figure 9.
3.6.2. Loss Function
The goal of network training is to reduce the loss function and make the prediction box close to the ground truth box to obtain a more robust model. The loss function of object detection needs to indicate the proximity between the prediction box and the ground truth, whether the prediction box contains the target to be detected, and whether the object category in the prediction box is true. As predicted by the head network, the loss function consists of three parts, which are given by Formula (4):
(1) Regression loss (
) is the loss of position error between the prediction box and the ground truth. The x, y, w, and h parameters predicted by the model can locate the position of the prediction box, and the loss is calculated based on the DIoU of the ground truth and the prediction box.
Figure 10 shows the principle for DIoU to calculate regression loss, and the corresponding calculation Formula is (5):
where
represents the parameter of the center coordinate of the prediction box and
represents the parameter of the center coordinate of the ground truth;
is the distance between the center point of the prediction box and the ground truth; and
represents the diagonal length of the maximum bounding rectangle of the union of the prediction box and ground truth. IoU measures the intersection ratio between the prediction box and the ground truth. However, if there is no intersection between them, the result of IoU will always be 0. When one of the two boxes is inside the other, if the size of the box remains unchanged, the calculated IoU value will not change, which will make the model difficult to optimize. If DIoU is used to calculate regression loss, this problem can be effectively solved and a good measurement effect can be obtained.
(2) Object loss () is to determine whether there is an object in the predicted box, which is a binary classification problem. According to the result predicted by the head network, whether the target is included can be known, while the feature points corresponding to all ground truths are positive samples, and the remaining feature points are negative samples. The Binary Cross-Entropy loss is calculated according to the prediction results of whether the positive and negative samples include the target.
(3) Classification loss () is applied to reflect the error in object classification. According to the feature points predicted by the model, the predicted category results of the feature points are extracted, and then the Binary Cross-Entropy loss is calculated according to the category of the ground truth and prediction results.
4. Experimental Results and Analysis
The proposed UAV swarm target detection model is constructed based on the deep learning framework Pytorch. The size of the input images needs to be adjusted to 640×640, and the number of input images in each batch is set to 12 during the training process; a total of 100 epochs are trained without using a pre-training weight. Furthermore, the Mosaic and Mixup data augment algorithms are used for the first 70 epochs and canceled for the last 30 epochs. The gradient descent optimization strategy adopts the SGD optimizer, and the initial learning rate is set to 0.01. In this experiment, the mean Average Precision (mAP), the number of parameters, model size, latency, and Frame Per Second (FPS) are used as measurement metrics of the experimental results. We train and test on a computer equipped with dual Intel Xeon E5 2.40GHz CPUs, a single NVIDIA GTX 1080TI GPU, and 32 GB RAM.
4.1. UAVSwarm Dataset
Wang C. et al. [
5] collected 72 UAV image sequences and manually annotated them, creating a new UAV swarm dataset named UAVSwarm for UAV multi-object detection and tracking. This dataset contains 12,598 images in total, of which 23 are included in the images with the largest number of UAVs, 36 image sequences (6844 images) are included in the training set, and the remaining 36 sequences (5754 images) are included in the test set. The dataset we used largely excludes all objects (flocks of birds, etc.) except UAVs but some scenes are complex, leading to the UAVs being blocked.
Figure 11 shows some images and annotation information of the dataset.
4.2. Ablation Experiment
Firstly, the structure of YOLOX is simplified and optimized by depthwise separable convolution to build a nano network. In order to verify the effectiveness of the lightweight module, this paper uses the same training strategy to train three lightweight YOLOX models, namely, YOLOX-S, YOLOX-Tiny, and YOLOX-Nano, and tests them on the same test set to analyze their performance differences. It can be seen from
Table 4 that the UAV detection accuracy of the three differently scaled YOLOX models toward the test set is more than 80%. As far as the network accuracy and scale of YOLOX of the same series are concerned, the results of this experiment are consistent with the general law of the object detection network—that is, the more layers and parameters of the convolutional neural network, the stronger its feature extraction and generalization ability, and the higher its recognition accuracy. When the DIoU threshold score is set to 0.5, the mAP scores of the three networks are largely the same, but the size of the model and the total number of parameters greatly differ Among them, the model size and the total number of parameters of nano network are about 1/10th of those of the version S network. This shows that under the same hardware conditions, the lightweight nano model can process more input images and reduce the equipment cost on the premise of meeting the accuracy requirement. Therefore, YOLOX-Nano is selected as the baseline model for research in this paper.
Table 5 shows that the mAP score of the proposed model on the UAVSwarm test set is 82.32%, which is about 2% higher than that of the baseline model, while the total number of parameters and model size are only about 40 Kb higher. It can also be found that the introduction of the SE and CBAM modules and the improvement of the loss functions have brought about an increase in mAP compared with the baseline model, which proves the effectiveness of the above three modules.
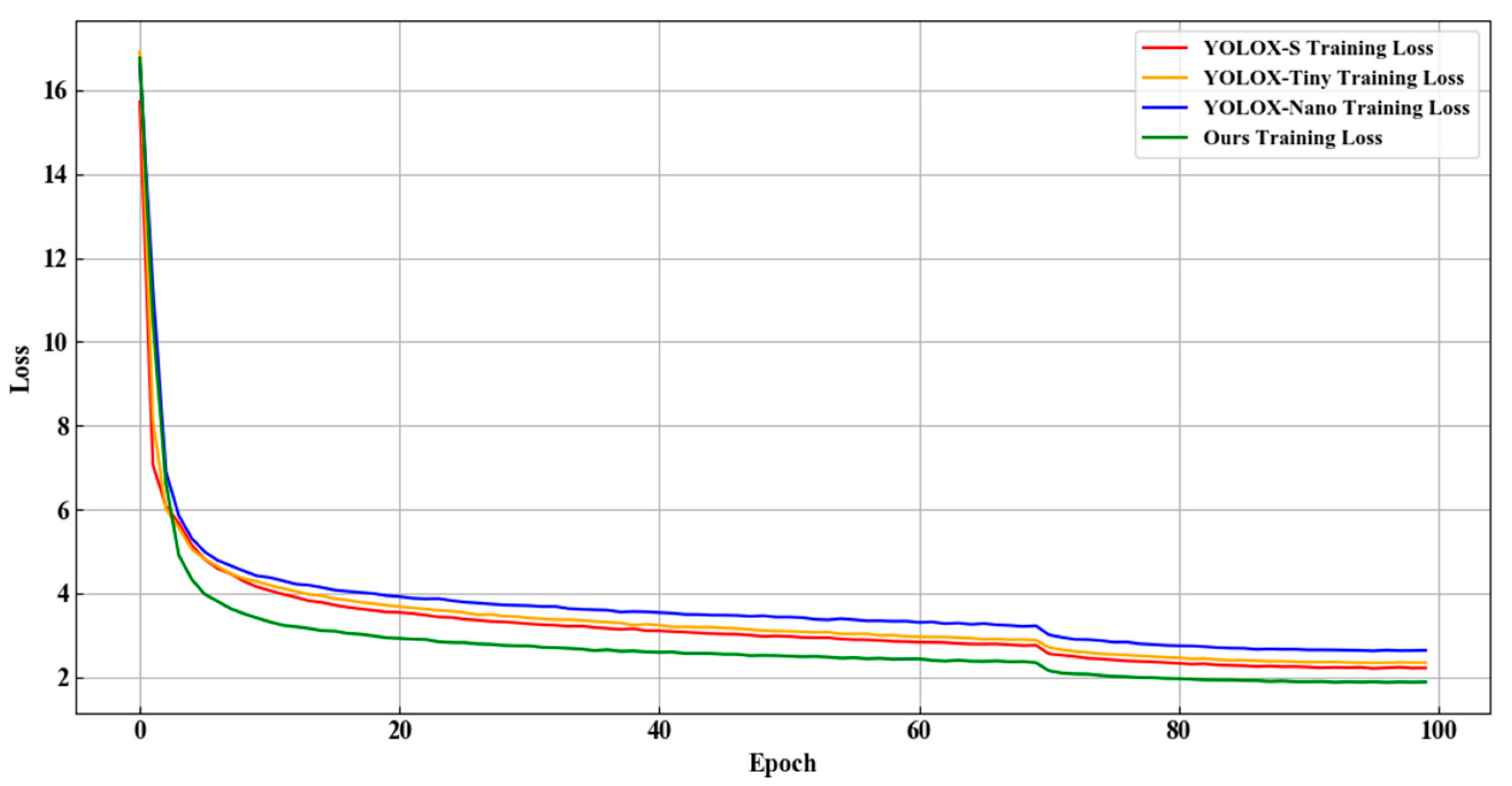
The Loss curves of the different network models during the training process are shown in
Figure 12. The abscissa and ordinate are the Epoch and Loss values, respectively. It can be seen that in the training process, the convergence of different models of the YOLOX series is similar. The loss of the training set decreases rapidly in the early stage. With the increase in epoch, the loss value gradually decreases and tends to be stable. Finally, the loss value of the proposed network model is the lowest, which proves that the training strategy and parameter settings are reasonable and effective for improving the model detection accuracy.
For the UAVSwarm dataset, as a typical small object, the network model proposed in this paper has improved the Precision and Recall indicators of the baseline model by 0.63% and 1.84%, respectively, when the threshold scores are both 0.5, as shown in
Figure 13. The improvement of Recall shows that the optimization strategy we used can effectively increase the learning effect of the model on the target of positive foreground samples.
4.3. Comparison Experiment
In order to objectively reflect the performance of the UAV swarm object detection network proposed in this paper, this study also uses the same settings to train other lightweight YOLO models and conducts a comparative analysis. The comparison results are shown in
Table 6. It can be seen that under the same test set, the mAP value of the proposed UAV detection model has reached 82.32%, which is 15.59%, 15.41%, 1.78%, 0.58%, and 1.82% higher than MobileNetv3-yolov4, GhostNet-YOLOv4, YOLOv4-Tiny, YOLOX-Tiny, and YOLOX-Nano, respectively. At the same time, the total network parameters and model size are optimal.
The experimental results that are obtained on the computational time are tabulated in
Table 6. It should be said that, due to limitations in the hardware platform, our experiment did not achieve the effect in the original paper, but we believe that the proposed method will have lower latency and higher processing speed under the condition of higher computing power.
Table 6 illustrates that, compared with the baseline model YOLOX-Nano, the proposed model achieves higher recognition accuracy under approximately the same inference time. Thus, our model can also meet the requirements of being real-time and is suitable for applications that require low latency. However, the YOLOX-Tiny and YOLOv4-Tiny networks are quicker than the proposed model, as they run 18 FPS and 22 FPS, respectively. Even though the proposed architecture is slower than these two models, significantly, it provides higher detection accuracy. Therefore, the proposed model is a lightweight model with high detection accuracy and suitable for various edge computing devices.
In order to verify the detection effect of the UAV detection model proposed in this paper in actual scenes, some images in the dataset are selected for detection, and the comparison diagram of the detection effect is shown in
Figure 14. As shown in
Figure 14a, in an environment with a simple background, most models can successfully identify UAVs. The proposed method can detect more small and distant objects than the baseline model YOLOX-Nano. As shown in
Figure 14b, when the background is complex or UAVs are densely distributed, there are many undetected phenomena with the other models. The algorithm in this paper shows better detection performance and can accurately detect UAVs when occlusion occurs among objects. As shown in
Figure 14c, when the image resolution is low, the algorithm in this paper can still accurately detect UAVs with complex backgrounds and provide higher confidence scores. Through comparison, it can be demonstrated that our method has improved detection accuracy and confidence, which shows that it can satisfy the requirements of being lightweight and providing higher accuracy, meeting the requirements of industrial applications.
In addition to the construction of an anti-UAV system, the algorithm proposed in this paper can also be applied as a swarm intelligence algorithm to achieve UAV swarm formation, multi-UAV cooperation, etc. By deploying lightweight object detection methods, UAVs in the swarm can quickly and accurately obtain the position and status of other partners, so that they can adjust themselves in time according to the swarm intelligence algorithm. Swarms of UAVs may have enhanced performance during performing some missions where having coordination among multiple UAVs may enable broader mission coverage and provide more efficient operating performance. Moreover, the proposed method will greatly help to improve the performance of UAV swarm systems including total energy, average end-to-end delay, packets delivery ratio, and throughput. According to the analysis, the application of the lightweight model provided by this paper may reduce the total energy demand and average end-to-end delay of the UAV swarm system, while increasing the packets delivery ratio and throughput of the system. This means that the UAV swarm system may be able to achieve higher data transmission efficiency at a lower cost, thus, better performing tasks.
5. Conclusions
This paper proposes a lightweight UAV swarm detection model integrating an attention mechanism. First, the structure of the network is simplified and optimized by using the depthwise separable convolution method, which greatly reduces the total number of parameters of the network. Then, a SE module is introduced into the backbone network to improve the model′s ability to extract object features; the introduction of a CBAM in the feature fusion network makes the network pay more attention to important features and suppress unnecessary features. Finally, in the training process, a loss function based on DIoU can better describe the overlapping information and make the regression faster and more accurate. In addition, two data augmentation technologies are used to expand the UAVSwarm dataset to achieve better UAV detection. The proposed model is a lightweight model with high detection accuracy and only 3.85 MB in size, which is suitable for embedded devices and mobile terminals. In conclusion, the real-time performance and accuracy of the UAV swarm detection model proposed in this paper meet the requirements of rapid detection of UAVs in real environments, which has practical significance for the construction of anti-UAV systems. In our future work, we will continue to study and optimize the improvement strategy, so that it can achieve better recognition accuracy and real-time performance under the premise of minimizing the complexity of the model.


 ,
, 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}













