


Multimodal Few-Shot Target Detection Based on Uncertainty Analysis in Time-Series Images


Abstract
:1. Introduction
- A few-shot learning model based on an uncertainty analysis of feature extraction is proposed with an encoder-decoder structure and squeeze-and-attention module. The proposed model is composed of two components in the encoder block, including the residual representation extraction and the attention layers;
- It proposes a novel approach to extracting inherent and latent representation from multimodal images;
- We conducted several multimodal datasets for different real-world scenarios to investigate the behavior of the proposed few-shot learning method.
2. Materials and Methods
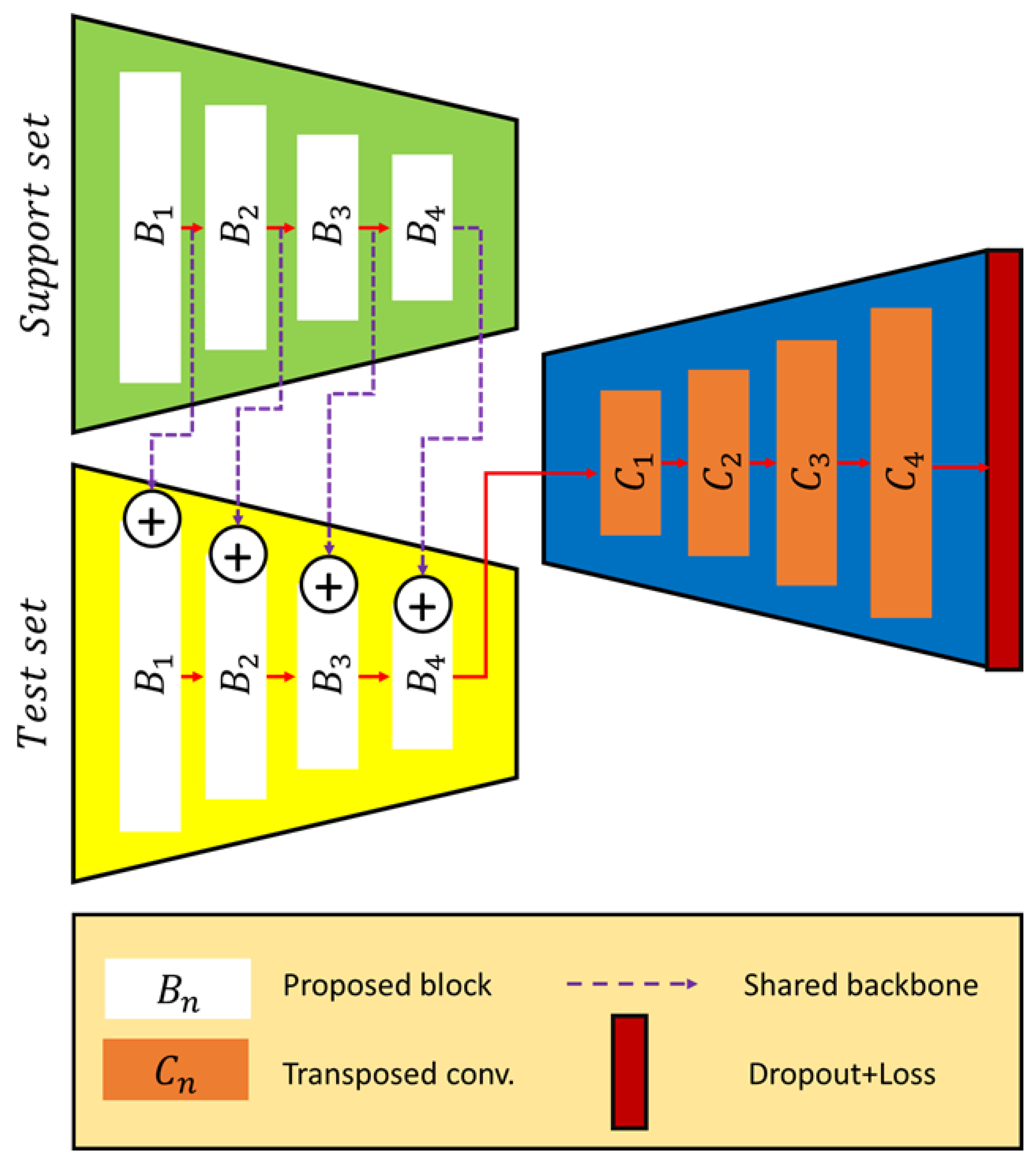
2.1. Definition of the Problem
2.2. Proposed Few-Shot Learning Network
2.3. Datasets
3. Results
3.1. Metrics
3.2. Uncertainty Analysis of Feature Extraction
3.3. Exprimental Results
3.4. Comparative Study of Few-Shot Learning and Classical Methods
4. Discussion
- Our findings indicate that the proposed few-shot learning model offers better generalization performance and outperforms other methods. The proposed few-shot learning model achieved the highest mIoU in comparison to other evaluated methods, such as PFE-Net (as a few-shot learning model), SVM, and RF, for each dataset in multimodal images. Therefore, compared with the state-of-the-art and classical models, the target detection accuracy was improved;
- To our knowledge, we have presented the first multimodal few-shot learning method with a low computational cost for RGB, CIR, and thermal modalities based on uncertainty estimation;
- The proposed method uses unique features of multimodal images during the feature extraction from squeeze-and-attention layers.
4.1. Loss Functions for Training
4.2. Multiple Modalities
4.3. CNN Backbones
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Bi, F.; Sun, X.; Liu, W.; Sun, P.; Wang, H.; Sun, J. Multiscale Anti-Deformation Network for Target Tracking in UAV Aerial Videos. JARS 2022, 16, 022207. [Google Scholar] [CrossRef]
- Lv, J.; Cao, Y.; Wang, X.; Yun, Z. Vehicle Detection Method for Satellite Videos Based on Enhanced Vehicle Features. JARS 2022, 16, 026503. [Google Scholar] [CrossRef]
- Touil, A.; Ghadi, F.; El Makkaoui, K. Intelligent Vehicle Communications Technology for the Development of Smart Cities. In Machine Intelligence and Data Analytics for Sustainable Future Smart Cities; Ghosh, U., Maleh, Y., Alazab, M., Pathan, A.-S.K., Eds.; Studies in Computational Intelligence; Springer International Publishing: Cham, Switzerland, 2021; pp. 65–84. ISBN 978-3-030-72065-0. [Google Scholar]
- Faraj, F.; Braun, A.; Stewart, A.; You, H.; Webster, A.; Macdonald, A.J.; Martin-Boyd, L. Performance of a Modified YOLOv3 Object Detector on Remotely Piloted Aircraft System Acquired Full Motion Video. JARS 2022, 16, 022203. [Google Scholar] [CrossRef]
- Han, G.; Ma, J.; Huang, S.; Chen, L.; Chellappa, R.; Chang, S.-F. Multimodal Few-Shot Object Detection with Meta-Learning Based Cross-Modal Prompting. arXiv 2022, arXiv:2204.07841. [Google Scholar]
- Khoshboresh-Masouleh, M.; Shah-Hosseini, R. 2D Target/Anomaly Detection in Time Series Drone Images Using Deep Few-Shot Learning in Small Training Dataset. In Integrating Meta-Heuristics and Machine Learning for Real-World Optimization Problems; Houssein, E.H., Abd Elaziz, M., Oliva, D., Abualigah, L., Eds.; Studies in Computational Intelligence; Springer International Publishing: Cham, Switzerland, 2022; pp. 257–271. ISBN 978-3-030-99079-4. [Google Scholar]
- Ma, R.; Angryk, R. Distance and Density Clustering for Time Series Data. In Proceedings of the 2017 IEEE International Conference on Data Mining Workshops (ICDMW), New Orleans, LA, USA, 18–21 November 2017; pp. 25–32. [Google Scholar]
- Ma, R.; Ahmadzadeh, A.; Boubrahimi, S.F.; Angryk, R.A. Segmentation of Time Series in Improving Dynamic Time Warping. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; pp. 3756–3761. [Google Scholar]
- Lyu, Y.; Vosselman, G.; Xia, G.-S.; Yilmaz, A.; Yang, M.Y. UAVid: A Semantic Segmentation Dataset for UAV Imagery. ISPRS J. Photogramm. Remote Sens. 2020, 165, 108–119. [Google Scholar] [CrossRef]
- Bayanlou, M.R.; Khoshboresh-Masouleh, M. Multi-Task Learning from Fixed-Wing UAV Images for 2D/3D City Modelling. arXiv 2021, arXiv:2109.00918. [Google Scholar] [CrossRef]
- Gao, Y.; Hou, R.; Gao, Q.; Hou, Y. A Fast and Accurate Few-Shot Detector for Objects with Fewer Pixels in Drone Image. Electronics 2021, 10, 783. [Google Scholar] [CrossRef]
- Karami, A.; Crawford, M.; Delp, E.J. Automatic Plant Counting and Location Based on a Few-Shot Learning Technique. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 5872–5886. [Google Scholar] [CrossRef]
- Kuang, Q.; Jin, X.; Zhao, Q.; Zhou, B. Deep Multimodality Learning for UAV Video Aesthetic Quality Assessment. IEEE Trans. Multimed. 2020, 22, 2623–2634. [Google Scholar] [CrossRef]
- Lu, C.; Koniusz, P. Few-Shot Keypoint Detection with Uncertainty Learning for Unseen Species. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 19394–19404. [Google Scholar]
- Shivakumar, S.S.; Rodrigues, N.; Zhou, A.; Miller, I.D.; Kumar, V.; Taylor, C.J. PST900: RGB-Thermal Calibration, Dataset and Segmentation Network. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 9441–9447. [Google Scholar]
- Unal, G. Visual Target Detection and Tracking Based on Kalman Filter. J. Aeronaut. Space Technol. 2021, 14, 251–259. [Google Scholar]
- Kiyak, E.; Unal, G. Small Aircraft Detection Using Deep Learning. AEAT 2021, 93, 671–681. [Google Scholar] [CrossRef]
- Moon, J.; Le, N.A.; Minaya, N.H.; Choi, S.-I. Multimodal Few-Shot Learning for Gait Recognition. Appl. Sci. 2020, 10, 7619. [Google Scholar] [CrossRef]
- Bodor, R.; Drenner, A.; Fehr, D.; Masoud, O.; Papanikolopoulos, N. View-Independent Human Motion Classification Using Image-Based Reconstruction. Image Vis. Comput. 2009, 27, 1194–1206. [Google Scholar] [CrossRef]
- Hu, Y.; Chen, M.; Saad, W.; Poor, H.V.; Cui, S. Distributed Multi-Agent Meta Learning for Trajectory Design in Wireless Drone Networks. IEEE J. Sel. Areas Commun. 2021, 39, 3177–3192. [Google Scholar] [CrossRef]
- Nishino, Y.; Maekawa, T.; Hara, T. Few-Shot and Weakly Supervised Repetition Counting With Body-Worn Accelerometers. Front. Comput. Sci. 2022, 4, 925108. [Google Scholar] [CrossRef]
- Sugimoto, M.; Shimada, S.; Hashizume, H. RefRec+: Six Degree-of-Freedom Estimation for Smartphone Using Floor Reflecting Light. Front. Comput. Sci. 2022, 4, 856942. [Google Scholar] [CrossRef]
- Zhong, Z.; Lin, Z.Q.; Bidart, R.; Hu, X.; Daya, I.B.; Li, Z.; Zheng, W.-S.; Li, J.; Wong, A. Squeeze-and-Attention Networks for Semantic Segmentation. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 13062–13071. [Google Scholar]
- Li, H.; Wu, L.; Niu, Y.; Wang, C.; Liu, T. Small Sample Meta-Leaming Towards Object Recognition Through UAV Observations. In Proceedings of the 2019 IEEE International Conference on Unmanned Systems (ICUS), Beijing, China, 17–19 October 2019; pp. 860–865. [Google Scholar]
- Tan, S.; Yan, J.; Jiang, Z.; Huang, L. Approach for Improving YOLOv5 Network with Application to Remote Sensing Target Detection. JARS 2021, 15, 036512. [Google Scholar] [CrossRef]
- Khoshboresh-Masouleh, M.; Shah-Hosseini, R. Real-Time Multiple Target Segmentation with Multimodal Few-Shot Learning. Front. Comput. Sci. 2022, 4, 1062792. [Google Scholar] [CrossRef]
- Khoshboresh-Masouleh, M.; Shah-Hosseini, R. Uncertainty Estimation in Deep Meta-Learning for Crop and Weed Detection from Multispectral UAV Images. In Proceedings of the 2022 IEEE Mediterranean and Middle-East Geoscience and Remote Sensing Symposium (M2GARSS), Istanbul, Turkey, 7–9 March 2022; pp. 165–168. [Google Scholar]
- Kendall, A.; Cipolla, R. Modelling Uncertainty in Deep Learning for Camera Relocalization. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 4762–4769. [Google Scholar]
- Kendall, A.; Gal, Y. What Uncertainties Do We Need in Bayesian Deep Learning for Computer Vision? Advances in Neural Information Processing Systems. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Kendall, A.; Badrinarayanan, V.; Cipolla, R. Bayesian SegNet: Model Uncertainty in Deep Convolutional Encoder-Decoder Architectures for Scene Understanding. arXiv 2015, arXiv:1511.02680. [Google Scholar]
- Stow, E.; Kelly, P.H.J. Convolutional Kernel Function Algebra. Front. Comput. Sci. 2022, 4, 921454. [Google Scholar] [CrossRef]
- Zamir, S.W.; Arora, A.; Gupta, A.; Khan, S.; Sun, G.; Khan, F.S.; Zhu, F.; Shao, L.; Xia, G.-S.; Bai, X. ISAID: A Large-Scale Dataset for Instance Segmentation in Aerial Images. arXiv 2019, arXiv:1905.12886. [Google Scholar]
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q. A Comprehensive Survey on Transfer Learning. Proc. IEEE 2021, 109, 43–76. [Google Scholar] [CrossRef]
- Wei, Y.; Zhang, Y.; Huang, J.; Yang, Q. Transfer Learning via Learning to Transfer. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 5085–5094. [Google Scholar]
- Finn, C.; Abbeel, P.; Levine, S. Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 1126–1135. [Google Scholar]
- Gao, K.; Liu, B.; Yu, X.; Zhang, P.; Tan, X.; Sun, Y. Small Sample Classification of Hyperspectral Image Using Model-Agnostic Meta-Learning Algorithm and Convolutional Neural Network. Int. J. Remote Sens. 2021, 42, 3090–3122. [Google Scholar] [CrossRef]
- Khoshboresh-Masouleh, M.; Akhoondzadeh, M. Improving Weed Segmentation in Sugar Beet Fields Using Potentials of Multispectral Unmanned Aerial Vehicle Images and Lightweight Deep Learning. JARS 2021, 15, 034510. [Google Scholar] [CrossRef]
- Khoshboresh-Masouleh, M.; Shah-Hosseini, R. Deep Few-Shot Learning for Bi-Temporal Building Change Detection. arXiv 2021, arXiv:2108.11262. [Google Scholar] [CrossRef]
- Huang, P.-Y.; Hsu, W.-T.; Chiu, C.-Y.; Wu, T.-F.; Sun, M. Efficient Uncertainty Estimation for Semantic Segmentation in Videos; In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany. 2018. pp. 520–535.
- Sa, I.; Popović, M.; Khanna, R.; Chen, Z.; Lottes, P.; Liebisch, F.; Nieto, J.; Stachniss, C.; Walter, A.; Siegwart, R. WeedMap: A Large-Scale Semantic Weed Mapping Framework Using Aerial Multispectral Imaging and Deep Neural Network for Precision Farming. Remote Sens. 2018, 10, 1423. [Google Scholar] [CrossRef] [Green Version]
- Das, S. Image-Segmentation-Using-SVM. Available online: https://github.com/SIdR4g/Semantic-Segmentation-using-SVM (accessed on 11 January 2023).
- Trainable Segmentation Using Local Features and Random Forests—Skimage v0.19.2 Docs. Available online: https://scikit-image.org/docs/stable/auto_examples/segmentation/plot_trainable_segmentation.html (accessed on 11 January 2023).
- Sudre, C.H.; Li, W.; Vercauteren, T.; Ourselin, S.; Cardoso, M.J. Generalised Dice Overlap as a Deep Learning Loss Function for Highly Unbalanced Segmentations. arXiv 2017, arXiv:1707.03237. [Google Scholar] [CrossRef] [Green Version]
- Gaj, S.; Ontaneda, D.; Nakamura, K. Automatic Segmentation of Gadolinium-Enhancing Lesions in Multiple Sclerosis Using Deep Learning from Clinical MRI. PLoS ONE 2021, 16, e0255939. [Google Scholar] [CrossRef]
- Wang, J.; Sun, K.; Cheng, T.; Jiang, B.; Deng, C.; Zhao, Y.; Liu, D.; Mu, Y.; Tan, M.; Wang, X.; et al. Deep High-Resolution Representation Learning for Visual Recognition. arXiv 2020, arXiv:1908.07919. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Encoder | Components | Size | Stride | Result |
|---|---|---|---|---|
| Input | - | - | - | n@CInput × RInput |
| CV1 + Bt + ReL | 64@5 × 5 | 1 | 64@C × R | |
| CV2 + Bt + ReL + B | 64@5 × 5 | 1 | 64@C × R | |
| MP | 2 × 2 | 2 | - | |
| CV3 + Bt + ReL | 128@5 × 5 | 1 | 128@C × R | |
| CV4 + Bt + ReL + B | 128@5 × 5 | 1 | 128@C × R | |
| MP | 2 × 2 | 2 | - | |
| CV5 + Bt + ReL | 256@5 × 5 | 1 | 256@C × R | |
| CV6 + Bt + ReL | 256@5 × 5 | 1 | 256@C × R | |
| CV7 + Bt + ReL + B | 128@5 × 5 | 1 | 256@C × R | |
| MP | 2 × 2 | 2 | - | |
| CV8 + Bt + ReL | 512@5 × 5 | 1 | 512@C × R | |
| CV9 + Bt + ReL | 512@5 × 5 | 1 | 512@C × R | |
| CV10 + Bt + ReL + B | 512@5 × 5 | 1 | 512@C × R | |
| MP | 2 × 2 | 2 | - | |
| Decoder | ||||
| UP | 2 × 2 | 2 | - | |
| DCV1 + Bt + ReL | 1024@5 × 5 | 1 | 1024@C × R | |
| DCV2 + Bt + ReL | 1024@5 × 5 | 1 | 1024@C × R | |
| DCV3 + Bt + ReL | 512@5 × 5 | 1 | 512@C × R | |
| UP | 2 × 2 | 2 | - | |
| DCV4 + Bt + ReL | 512@5 × 5 | 1 | 512@C × R | |
| DCV5 + Bt + ReL | 512@5 × 5 | 1 | 512@C × R | |
| DCV6 + Bt + ReL | 256@5 × 5 | 1 | 256@C × R | |
| UP | 2 × 2 | 2 | - | |
| DCV7 + Bt + ReeL | 256@5 × 5 | 1 | 256@C × R | |
| DCV8 + Bt + RL | 256@5 × 5 | 1 | 256@C × R | |
| DCV9 + Bt + ReL | 128@5 × 5 | 1 | 128@C × R | |
| UP | 2 × 2 128@5 × 5 64@5 × 5 | 2 | - | |
| DCV10 + Bt + ReL | 1 | 128@C × R | ||
| DCV11 + Bt + ReL | 1 | 64@C × R | ||
| Output | UP | 2 × 2 | 2 | - |
| DCV12 + Bt + ReL | 64@5 × 5 | 1 | 64@C × R | |
| DCV13 + Bt + ReL | 2@5 × 5 | 1 | 2@C × R | |
| Loss | - | - | - |
| Dataset | Modality | Patch Size (Pixels) | Samples | ||
|---|---|---|---|---|---|
| Train | Support | Test | |||
| UAVid | RGB | 3840 × 2160 | 500 | 55 | 45 |
| WeedMap | CIR | 480 × 360 | 320 | 100 | 60 |
| PST900 | Thermal | 1280 × 720 | 190 | 100 | 60 |
| Dataset | Type | View | Data Source | Target Class |
|---|---|---|---|---|
| UAVid | Video | Oblique | Drone | Vehicle |
| WeedMap | Orthophoto | Vertical | Drone | Weed |
| PST900 | Video | Oblique | Quadruped robot | Human |
| Data | Target | Samples | Backbone | J (%) | E | T (ms) 1 |
|---|---|---|---|---|---|---|
| UAVid | Vehicle detection | Set-1, n = 15 | SA-Net | 83.4 | 0.41 | 80 |
| Set-2, n = 15 | 89.3 | 0.32 | 76 | |||
| Set-3, n = 15 | 94.6 | 0.21 | 78 | |||
| WeedMap | Weed and crop mapping | Set-1, n = 20 | DMF-Net | 89.6 | 0.28 | 59 |
| Set-2, n = 20 | 96.9 | 0.19 | 62 | |||
| Set-3, n = 20 | 92.0 | 0.26 | 49 | |||
| PS500 | Human detection | Set-1, n = 20 | MF-Net | 83.2 | 0.37 | 43 |
| Set-2, n = 20 | 87.7 | 0.36 | 48 | |||
| Set-3, n = 20 | 85.3 | 0.29 | 39 |
| IoU | C | E | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Methods | Scenario | Backbone | Samples | 1 shot | 10 shot | 1 shot | 10 shot | 1 shot | 10 shot |
| Ours | Vehicle | SA-Net | 45 | 46.7 | 77.2 | 83.7 | 93.1 | 26.4 | 17.3 |
| PFE-Net | 47.2 | 73.1 | 80.1 | 86.4 | 34.1 | 24.8 | |||
| Ours | Weed | DMF-Net | 60 | 51.5 | 89.4 | 73.2 | 91.2 | 29.1 | 18.3 |
| PFE-Net | 51.9 | 84.2 | 72.1 | 83.5 | 36.3 | 27.1 | |||
| Ours | Human | MF-Net | 60 | 63.4 | 91.5 | 79.4 | 93.1 | 24.1 | 17.4 |
| PFE-Net | 57.3 | 87.3 | 74.3 | 83.4 | 34.8 | 29.6 | |||
| Feature Extractor | Backbone | Loss | Modalities | IoU | C | E |
|---|---|---|---|---|---|---|
| Proposed layer | ResNet-101 | Dice | RGB (Vehicle) | 64.2 | 84.2 | 23.4 |
| HRNet.v2 | 63.1 | 81.3 | 24.6 | |||
| ResNet-101 | WBC | 70.2 | 84.3 | 21.6 | ||
| HRNet.v2 | 69.1 | 82.1 | 22.7 | |||
| ResNet-101 | WeC | 73.5 | 85.4 | 19.8 | ||
| HRNet.v2 | 76.1 | 87.4 | 18.2 | |||
| ResNet-101 | Dice | CIR (Weed) | 79.3 | 84.1 | 21.4 | |
| HRNet.v2 | 82.5 | 84.9 | 20.7 | |||
| ResNet-101 | WBC | 83.4 | 85.2 | 19.8 | ||
| HRNet.v2 | 84.1 | 86.6 | 18.9 | |||
| ResNet-101 | WeC | 86.2 | 89.3 | 18.7 | ||
| HRNet.v2 | 87.1 | 90.2 | 18.5 | |||
| ResNet-101 | Dice | Red + Green + Red edge + Near-infrared (Weed) | 82.4 | 87.2 | 19.6 | |
| HRNet.v2 | 85.5 | 88.3 | 18.5 | |||
| ResNet-101 | WBC | 84.2 | 88.7 | 18.3 | ||
| HRNet.v2 | 86.8 | 88.5 | 18.2 | |||
| ResNet-101 | WeC | 87.8 | 90.7 | 18.6 | ||
| HRNet.v2 | 88.0 | 91.0 | 17.9 | |||
| ResNet-101 | Dice | Thermal | 71.3 | 84.2 | 26.1 | |
| HRNet.v2 | 74.2 | 85.5 | 20.3 | |||
| ResNet-101 | WBC | 70.3 | 83.1 | 27.3 | ||
| HRNet.v2 | 72.9 | 85.3 | 24.7 | |||
| ResNet-101 | WeC | 83.4 | 89.4 | 18.3 | ||
| HRNet.v2 | 86.7 | 90.6 | 17.6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khoshboresh-Masouleh, M.; Shah-Hosseini, R. Multimodal Few-Shot Target Detection Based on Uncertainty Analysis in Time-Series Images. Drones 2023, 7, 66. https://doi.org/10.3390/drones7020066
Khoshboresh-Masouleh M, Shah-Hosseini R. Multimodal Few-Shot Target Detection Based on Uncertainty Analysis in Time-Series Images. Drones. 2023; 7(2):66. https://doi.org/10.3390/drones7020066
Chicago/Turabian StyleKhoshboresh-Masouleh, Mehdi, and Reza Shah-Hosseini. 2023. "Multimodal Few-Shot Target Detection Based on Uncertainty Analysis in Time-Series Images" Drones 7, no. 2: 66. https://doi.org/10.3390/drones7020066
APA StyleKhoshboresh-Masouleh, M., & Shah-Hosseini, R. (2023). Multimodal Few-Shot Target Detection Based on Uncertainty Analysis in Time-Series Images. Drones, 7(2), 66. https://doi.org/10.3390/drones7020066