

DECCo-A Dynamic Task Scheduling Framework for Heterogeneous Drone Edge Cluster

Abstract
:1. Introduction
- Due to the different types and quantities of IoE services provided by UAV nodes, they show heterogeneity in terms of hardware resources (including CPU and memory, etc.) and network resources (including communication latency and data transmission latency, etc.). At the same time, UAV task scheduling also faces the limitations of MEC computing resources and the dynamic changes in different task requests. Some customized distributed edge computing frameworks (e.g., KubeEdge [9]) fail to match such dynamic, heterogeneous DEC scenarios;
- The DEC collaborative task scheduling in the UAV scenario needs to comprehensively consider multiple indicators such as resource load balancing among UAVs, resource overload, and communication latency. The conventional edge computing frameworks usually only schedule for a single indicator, which makes them unable to completely describe the global state of DECs and local states of UAVs.
- We propose a distributed framework for DEC task scheduling, named DECCo. It can schedule dynamically changing task requests for heterogeneous DECs while ensuring high response rates and low communication latency. Tailored for real-world requirements, the architecture provides two complementary solutions for UAV collaborative scheduling, switching based on real-time scheduling performance;
- We designed a targeted and scalable cost function for the collaborative scheduling of DEC, which includes aspects of resource load balancing, resource overload penalty, and communication latency optimization. Some custom objectives, such as priority and geographic distribution, can also be added to the cost function, so DECCo can adjust and generate required scheduling operations based on specific preferences related to the natural DEC environment;
- We designed a UAV coordination scheduling algorithm mA2C based on Advantage Actor–Critic, which uses DRL to evaluate the global status of DEC and optimizes the UAV collaborative scheduling policy based on the policy gradient algorithm. mA2C uses target networks and experience replay to enhance the stability of scheduling policy learning, and avoids interference from local downtime on policy learning through action space masking.
2. Related Work
2.1. Classical Solutions
2.2. Reinforcement Learning Solutions
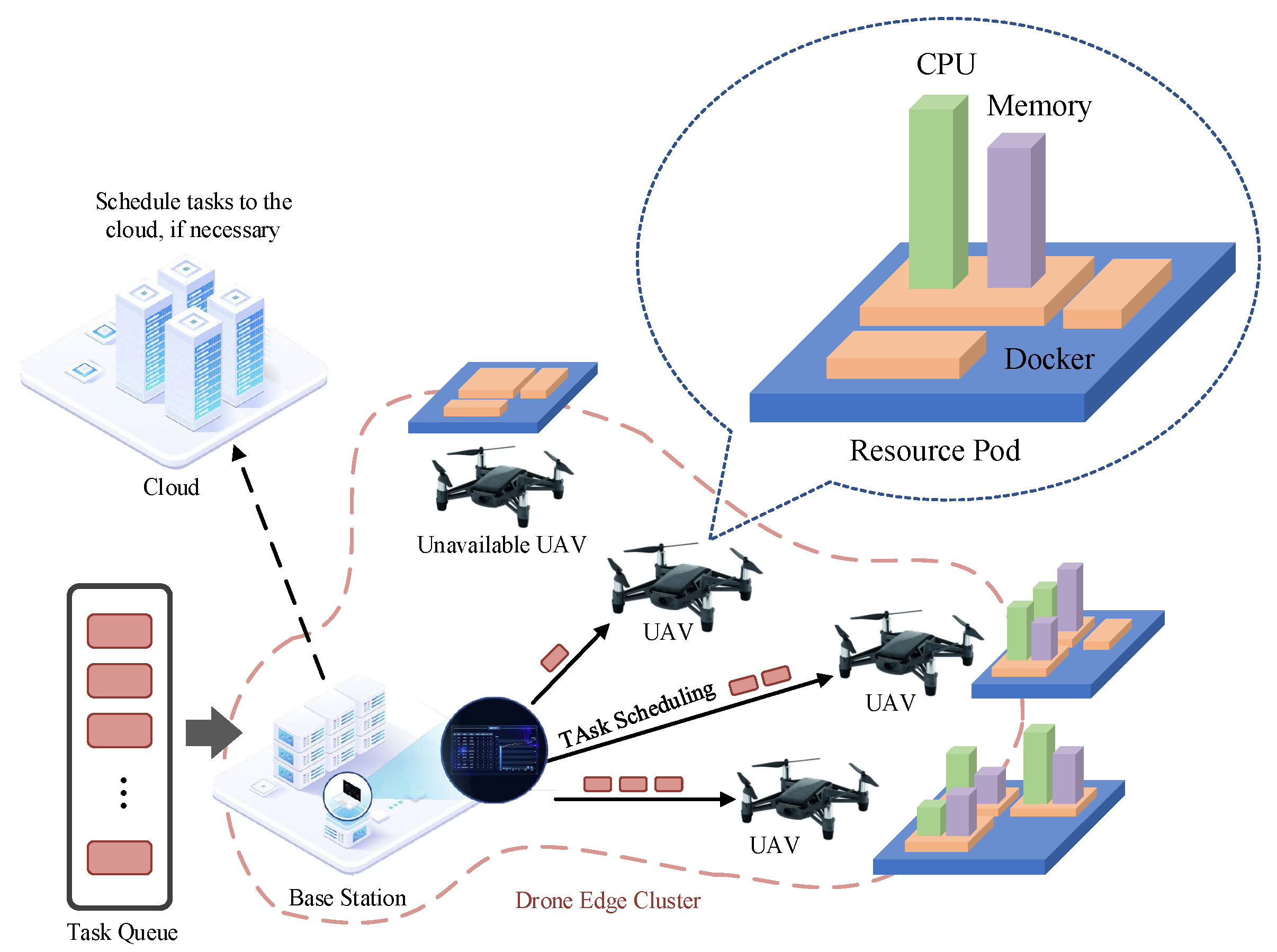
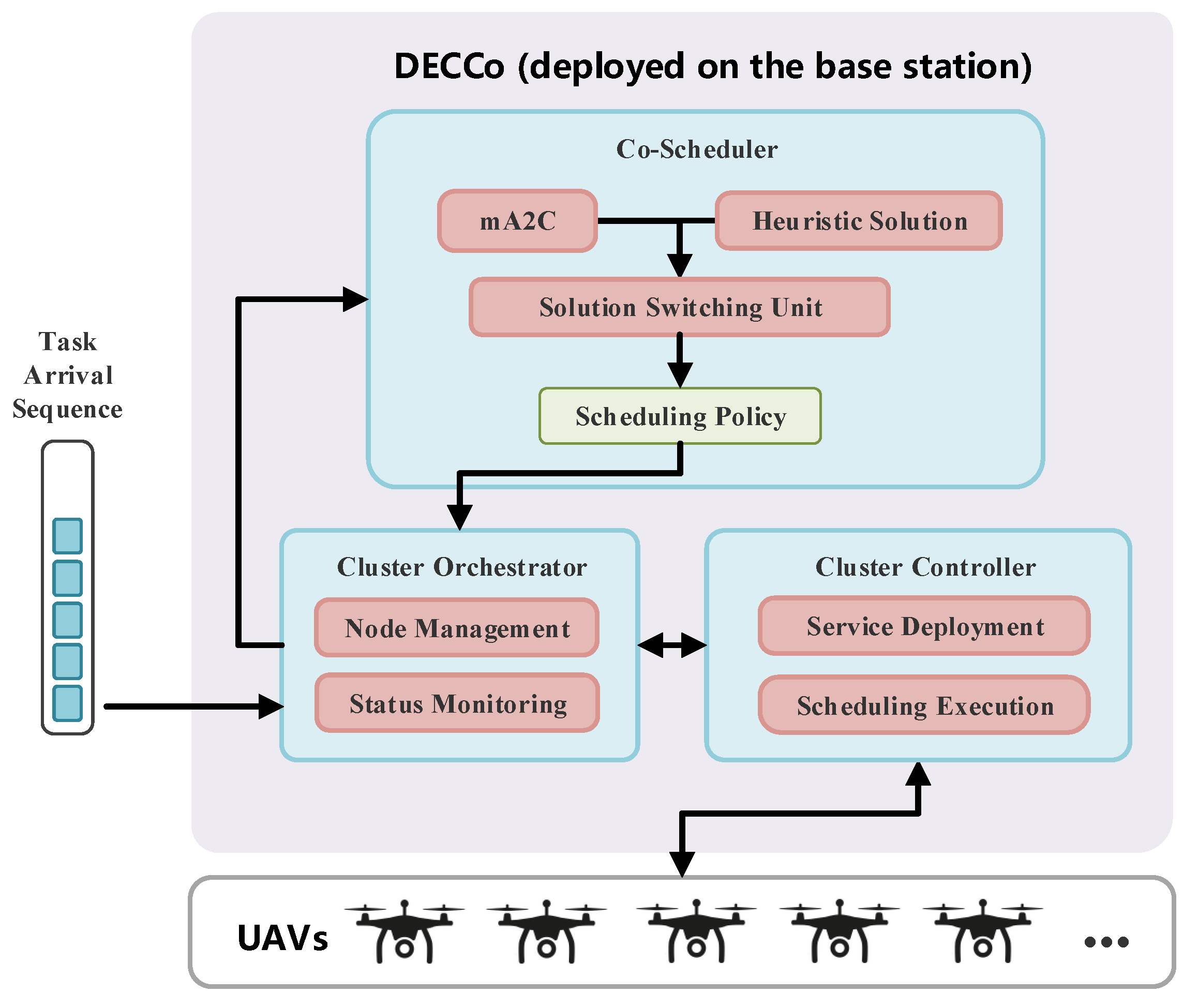
3. DECCo Framework Design
3.1. Cluster Orchestrator
3.2. Co-Scheduler
3.2.1. mA2C
3.2.2. Heuristic Solution
3.2.3. Solution Switching Unit
3.3. Cluster Controller
4. Problem Formulation and System Model
4.1. Background
- Base Stations and UAVs: The UAVs are represented by the set , which refers to UAV nodes connected to and managed by the base station. Upon the arrival of a task request at the base station, it is either dispatched to the cloud or allocated to its supervised UAVs for processing. To facilitate the processing of task requests, each UAV should contain corresponding service entities;
- Cloud: Unlike the UAVs within DEC, the cloud possesses abundant computational and storage resources. It is connected to the base station via a wide area network (WAN). When the UAVs cannot fulfill the tasks allocated by the base station, the cloud shoulders these tasks.
4.2. Scheduling Problem Formulation
4.2.1. MDP Formulation for DECCo
- State Space. denotes the state space. For each time slot t, we construct a state for the base station, which includes (i) the resource request of the current task , where and represent the CPU and memory requirements of the task, respectively; (ii) the task request queue information awaiting scheduling at the base station; (iii) the available resources and the hardware resources of UAV u. It is worth noting that UAV u ’s hardware resources do not necessarily reflect the resources available for tasks, as there is a boundary , i.e., cannot fall below . System administrators set this boundary to reserve expansion space for other applications in the event of system overload; and (iv) communication latency between the base station and each UAV, with denoting the communication latency between the base station and the cloud.
- Action Space. denotes that the current task request is assigned for execution on UAV i. We permit the base station to schedule only one task request for all UAVs it manages in a time slot t. All actions of the scheduling policy are deterministic, meaning that if , then the base station will schedule the current request to the UAV with id u in time slot .
- Cost Function. DECCo uses the cost function to calculate the cost of task scheduling action . In Section 4.2.2, we discuss the three objectives that make up the cost function: load balancing, resource overload penalty, and communication latency.
- Probability Transition. We denote as the probability of the base station transitioning from state to given a deterministic action . In this paper, the probability of the base station issuing the scheduling action is represented as .
- Discount Factor. is a decimal number in the range , usually close to 1. ’s primary use is to expedite convergence by discounting the reward for the next state.
4.2.2. Cost Function
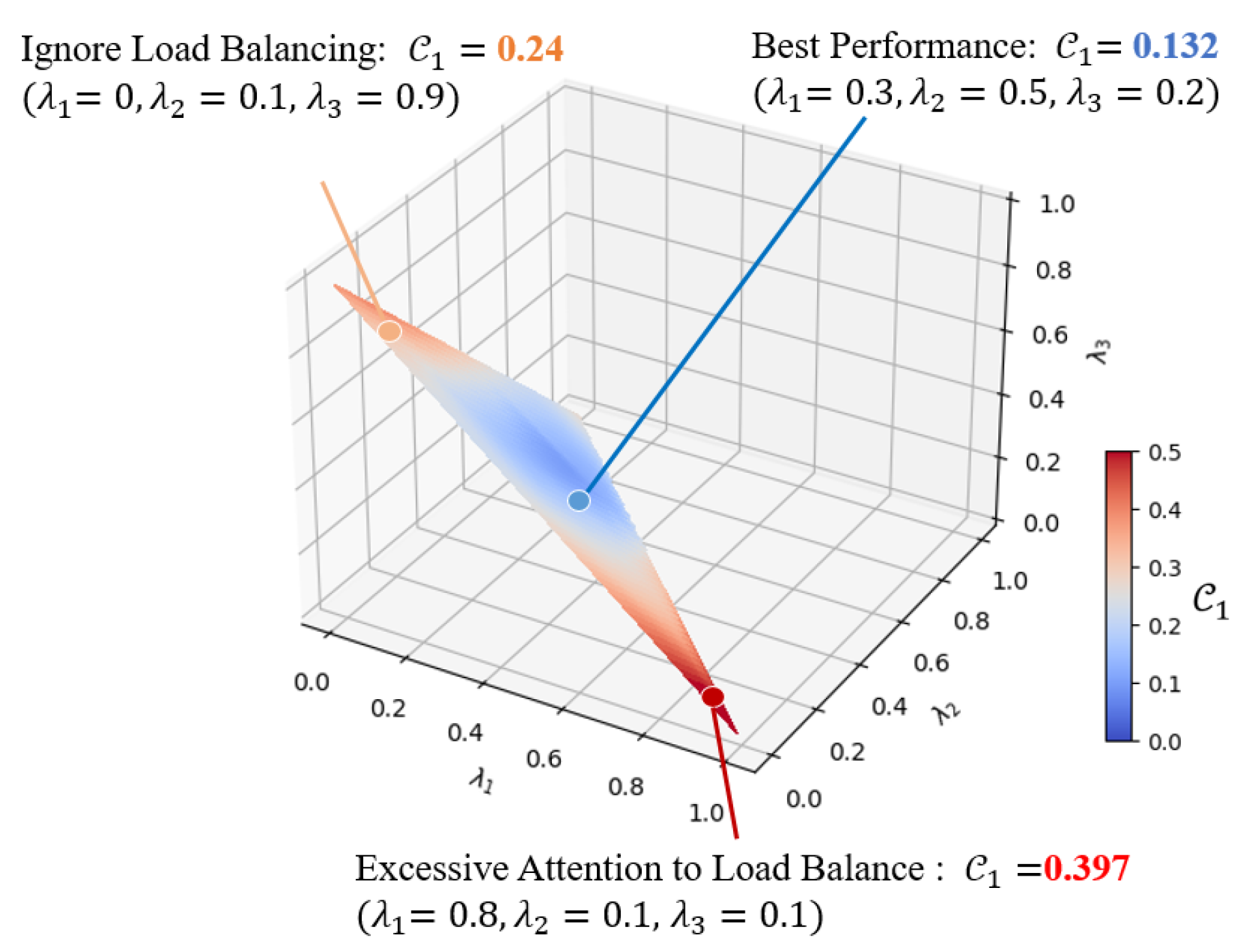
- Load Balancing : Balancing CPU and memory resources across all UAVs ensures efficient utilization of resources and promotes system stability. This objective function aims to keep the load on the CPU and memory resources of UAVs as balanced as possible after execution of the schedule, that is, at time slot . The standard deviation of the CPU resources load of all UAVs at time t is given by Equation (1):where and represent the available CPU resources of the current UAV u and the CPU resources required to execute the current task, respectively. indicates the CPU size of UAV u. In the above cost function, we only consider the available resource of UAVs whose CPU and memory resources are not overloaded after task scheduling, that is, . For actions that cause resource overload on UAV u, we set the standard deviation of CPU and memory resources on u to 0 and punish the action in the resource overload cost function.The above computation refers to the cost function for CPU load balancing, and the process of calculating the load balancing cost for memory is identical. Finally, .
- Resource Overload Penalty : In this objective function, the base station is penalized for causing the resource requirements of the task request to exceed the available resources of the UAV. We represent this objective’s cost as and , which calculates the resource overload cost of the CPU and memory on each UAV after performing the task scheduling action . The calculation process of the CPU resource overload cost is represented by Equations (3) and (4):If the scheduling action overestimates the available resources of UAV u, the base station will return the proportion of overloaded resources for this; otherwise, the resource overload cost is 0, which means the base station will not be penalized for this action. We sum and multiply the possible resource overloads on each UAV by to achieve a stricter overload penalty, which is crucial for preventing node downtime, similar to , .
- Communication Latency : Unlike most models with the same functionality, some custom cost items can be added to the cost function of DECCo. DECCo can leverage and adjust these custom targets based on specific preferences related to the actual DEC environment to perform smarter scheduling operations more closely aligned with actual needs. One of the potential objectives to be considered in this study is the minimization of communication latency between the base station and the selected UAVs. Upon obtaining the communication latency for each UAV and the base station at time t, the communication latency cost can be represented as . Given the co-existence of minimizing communication latency and balancing load, DECCo can consider hardware resources (i.e., load balancing) and network resources (i.e., communication latency cost) in the DEC during policy learning. Therefore, the weights of and in the total cost function will depend on the importance of maintaining the two types of cluster resources.
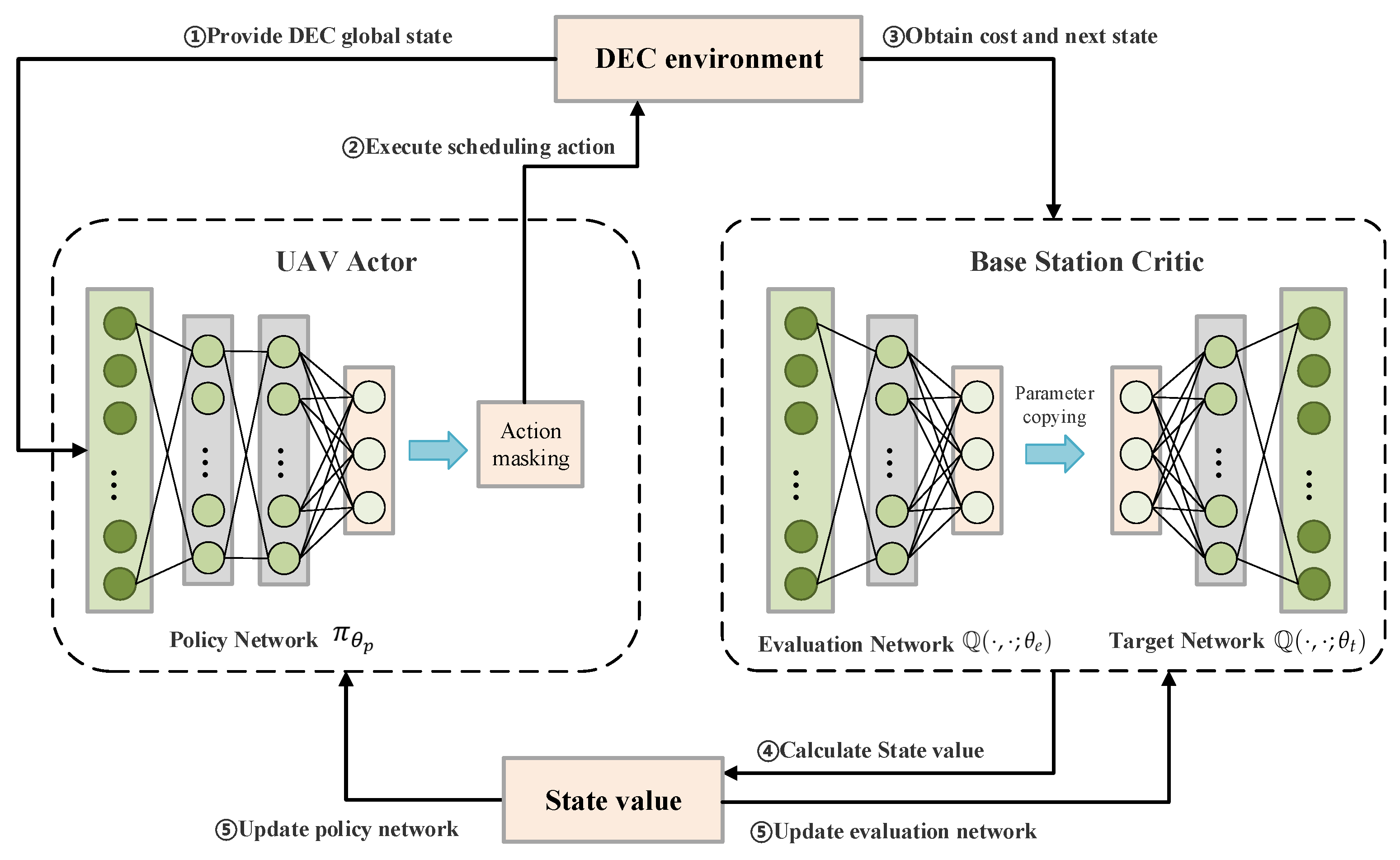
4.3. mA2C
| Algorithm 1 Training mA2C |
| Input: DEC environment Output: Task scheduling policy
|
4.3.1. Base Station Critic
4.3.2. UAV Actor
4.3.3. Heuristic Solution
5. Experiments and Evaluations
5.1. Experiment Setup
5.1.1. Task Requests
5.1.2. Cluster Construction
5.1.3. Architecture Implementation
5.2. Experimental Evaluation
- Kubernetes scheduler [27]: This carries out scheduling operations based on system metrics monitored in real time. In this paper, we employ a purely greedy strategy, scheduling each request to the UAV node that minimizes load balancing and communication latency;
- Heuristic solution: We directly demonstrate the independent decision making of the heuristic solution in DECCo, i.e., the evolutionary algorithm with cross-mutation;
- LyDROO [15] and DRLRM [40]: These are both UAV scheduling algorithms based on Lyapunov optimization and DRL. The actor modules in them use DNNs and action quantizers to balance exploration and exploitation. The critic utilizes model-based optimization instead of deep neural networks. In this regard, LyDROO and DRLRM also combine intelligent and heuristic solutions. Due to different scheduling scenarios, we set the Critic to a downright greedy strategy based on load balancing and communication latency minimization when using LyDROO and DRLRM as baselines. The Actor’s network parameters are the same as mA2C.
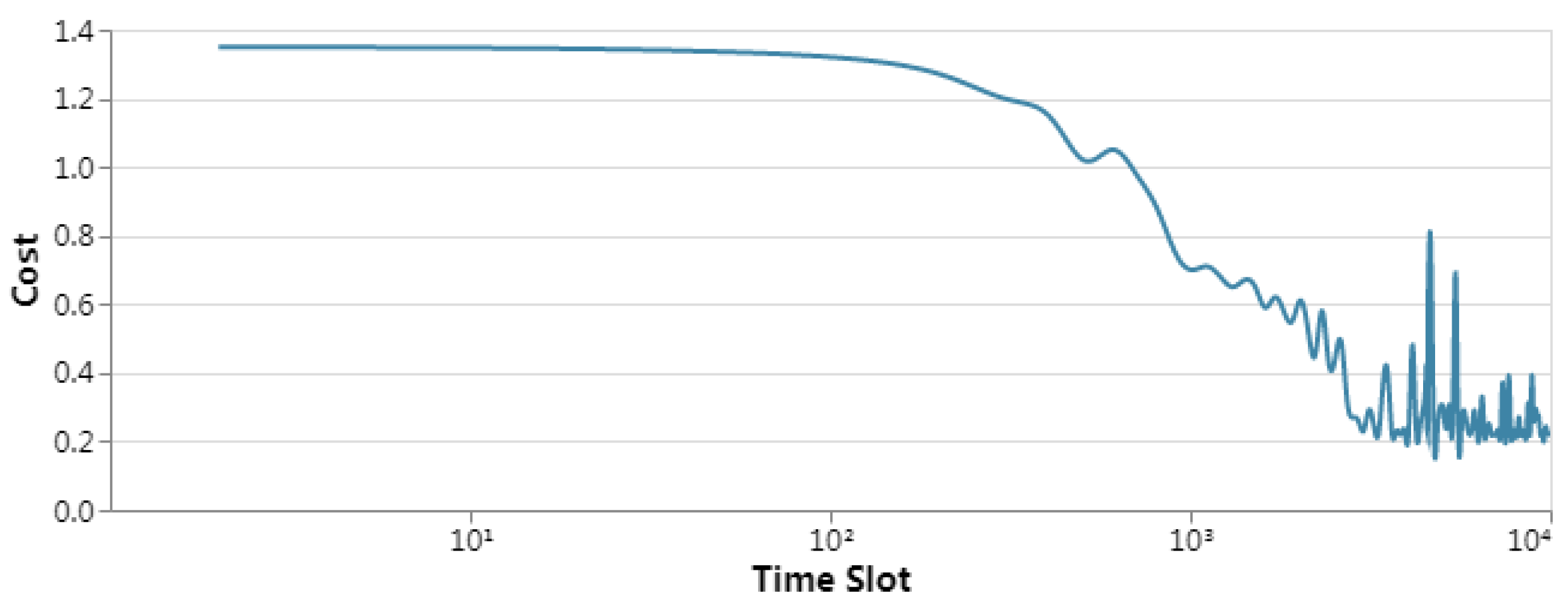
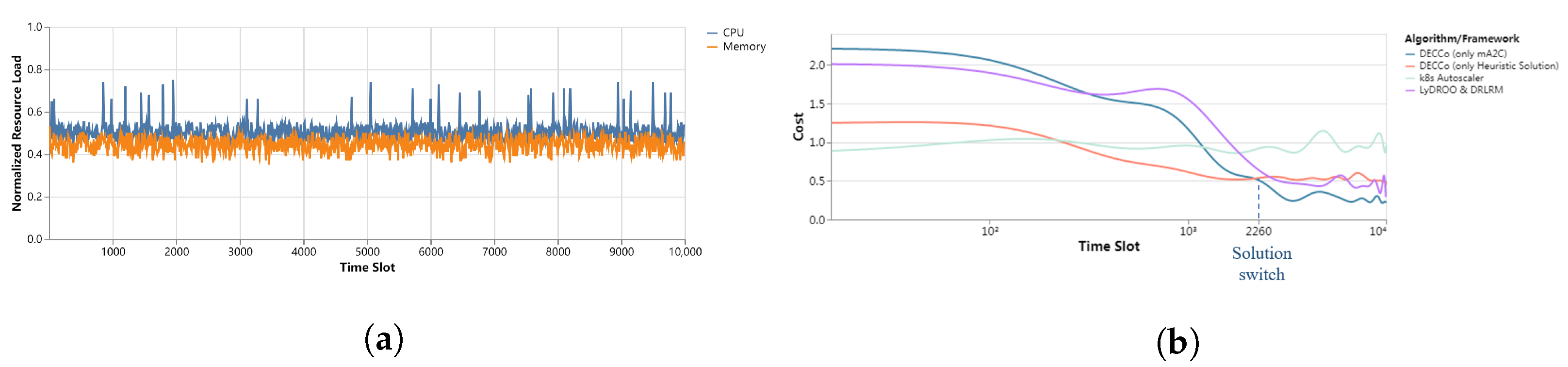
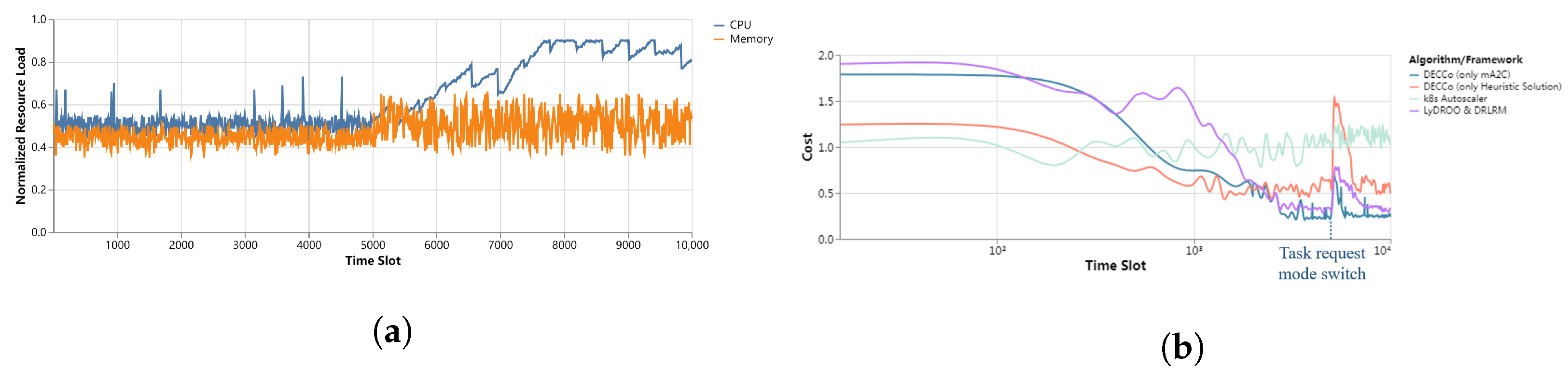
5.2.1. Practicability of DECCo
5.2.2. Load Balancing
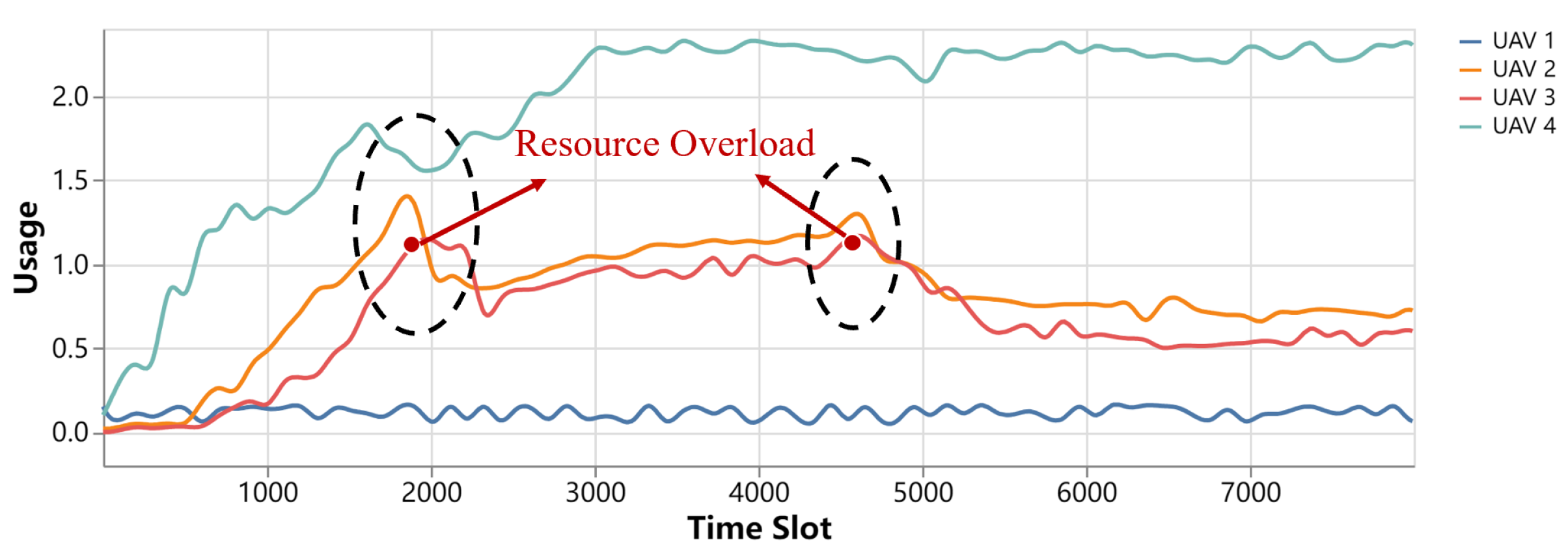
5.2.3. Resource Overload
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Explanation |
|---|---|
| UAV nodes set | |
| Tasks scheduled by DEC at time slot t | |
| The resource request of the current task | |
| The available resources of UAV u at time slot t | |
| The hardware resources of UAV u | |
| Communication latency between the base station and each UAV at time slot t | |
| The state of the DEC at time slot t | |
| The scheduling action performed by DEC at time slot t | |
| Cost Function | |
| Discount factor | |
| Parameters of evaluation network, target network, policy network | |
| The state value function of DEC at time slot t | |
| The task scheduling policy | |
| Vector to record available UAV nodes | |
| The size of the experience pool | |
| N | Target network update period |
References
- Giordani, M.; Polese, M.; Mezzavilla, M.; Rangan, S.; Zorzi, M. Toward 6G Networks: Use Cases and Technologies. IEEE Commun. Mag. 2020, 58, 55–61. [Google Scholar] [CrossRef]
- Alameddine, H.A.; Sharafeddine, S.; Sebbah, S.; Ayoubi, S.; Assi, C. Dynamic Task Offloading and Scheduling for Low-Latency IoT Services in Multi-Access Edge Computing. IEEE J. Sel. Areas Commun. 2019, 37, 668–682. [Google Scholar] [CrossRef]
- Nath, S.; Wu, J. Deep Reinforcement Learning for Dynamic Computation Offloading and Resource Allocation in Cache-Assisted Mobile Edge Computing Systems. Intell. Converg. Netw. 2020, 1, 181–198. [Google Scholar]
- Yang, T.; Hu, Y.; Gursoy, M.C.; Schmeink, A.; Mathar, R. Deep Reinforcement Learning Based Resource Allocation in Low Latency Edge Computing Networks. In Proceedings of the 2018 15th International Symposium on Wireless Communication Systems (ISWCS), Lisbon, Portugal, 28–31 August 2018; pp. 1–5. [Google Scholar]
- Yang, L.; Yao, H.; Wang, J.; Jiang, C.; Benslimane, A.; Liu, Y. Multi-UAV-Enabled Load-Balance Mobile-Edge Computing for IoT Networks. IEEE Internet Things J. 2020, 7, 6898–6908. [Google Scholar] [CrossRef]
- Tuli, S.; Ilager, S.; Ramamohanarao, K.; Buyya, R. Dynamic Scheduling for Stochastic Edge-Cloud Computing Environments Using A3C Learning and Residual Recurrent Neural Networks. IEEE Trans. Mob. Comput. 2020, 21, 940–954. [Google Scholar] [CrossRef]
- Burns, B.; Grant, B.; Oppenheimer, D.; Brewer, E.; Wilkes, J. Borg, Omega, and Kubernetes. Commun. ACM 2016, 59, 50–57. [Google Scholar]
- Wang, X.; Han, Y.; Leung, V.C.; Niyato, D.; Yan, X.; Chen, X. Convergence of Edge Computing and Deep Learning: A Comprehensive Survey. IEEE Commun. Surv. Tutorials 2020, 22, 869–904. [Google Scholar] [CrossRef] [Green Version]
- Xiong, Y.; Sun, Y.; Xing, L.; Huang, Y. Extend Cloud to Edge with KubeEdge. In Proceedings of the 2018 IEEE/ACM Symposium on Edge Computing (SEC), Bellevue, WA, USA, 25–27 October 2018; pp. 373–377. [Google Scholar]
- Pham, Q.V.; Mirjalili, S.; Kumar, N.; Alazab, M.; Hwang, W.J. Whale Optimization Algorithm with Applications to Resource Allocation in Wireless Networks. IEEE Trans. Veh. Technol. 2020, 69, 4285–4297. [Google Scholar]
- Tran, T.X.; Pompili, D. Joint Task Offloading and Resource Allocation for Multi-Server Mobile-Edge Computing Networks. IEEE Trans. Veh. Technol. 2018, 68, 856–868. [Google Scholar] [CrossRef] [Green Version]
- Li, B.; Fei, Z.; Zhang, Y. UAV Communications for 5G and Beyond: Recent Advances and Future Trends. IEEE Internet Things J. 2018, 6, 2241–2263. [Google Scholar] [CrossRef] [Green Version]
- Huang, L.; Bi, S.; Zhang, Y.J.A. Deep Reinforcement Learning for Online Computation Offloading in Wireless Powered Mobile-Edge Computing Networks. IEEE Trans. Mob. Comput. 2019, 19, 2581–2593. [Google Scholar] [CrossRef] [Green Version]
- He, Y.; Zhang, Z.; Yu, F.R.; Zhao, N.; Yin, H.; Leung, V.C.; Zhang, Y. Deep-Reinforcement-Learning-Based Optimization for Cache-Enabled Opportunistic Interference Alignment Wireless Networks. IEEE Trans. Veh. Technol. 2017, 66, 10433–10445. [Google Scholar] [CrossRef]
- Bi, S.; Huang, L.; Wang, H.; Zhang, Y.J.A. Lyapunov-Guided Deep Reinforcement Learning for Stable Online Computation Offloading in Mobile-Edge Computing Networks. IEEE Trans. Wirel. Commun. 2021, 20, 7519–7537. [Google Scholar] [CrossRef]
- Farhadi, V.; Mehmeti, F.; He, T.; La Porta, T.F.; Khamfroush, H.; Wang, S.; Poularakis, K. Service Placement and Request Scheduling for Data-Intensive Applications in Edge Clouds. IEEE/ACM Trans. Netw. 2021, 29, 779–792. [Google Scholar] [CrossRef]
- Mao, H.; Alizadeh, M.; Menache, I.; Kandula, S. Resource Management with Deep Reinforcement Learning. In Proceedings of the 15th ACM Workshop on Hot Topics in Networks, Atlanta, GA, USA, 9–10 November 2016; pp. 50–56. [Google Scholar]
- Ma, X.; Zhou, A.; Zhang, S.; Wang, S. Cooperative Service Caching and Workload Scheduling in Mobile Edge Computing. In Proceedings of the IEEE INFOCOM 2020—IEEE Conference on Computer Communications, Toronto, ON, Canada, 6–9 July 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 2076–2085. [Google Scholar]
- Jeong, S.; Simeone, O.; Kang, J. Mobile Edge Computing via a UAV-Mounted Cloudlet: Optimization of Bit Allocation and Path Planning. IEEE Trans. Veh. Technol. 2017, 67, 2049–2063. [Google Scholar] [CrossRef] [Green Version]
- Zhang, T.; Xu, Y.; Loo, J.; Shen, X.S.; Wang, J.; Liang, Y.; Wang, X. Joint Computation and Communication Design for UAV-Assisted Mobile Edge Computing in IoT. IEEE Trans. Ind. Inform. 2019, 16, 5505–5516. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Xiong, K.; Ni, Q.; Fan, P.; Letaief, K.B. UAV-Assisted Wireless Powered Cooperative Mobile Edge Computing: Joint Offloading, CPU Control, and Trajectory Optimization. IEEE Internet Things J. 2019, 7, 2777–2790. [Google Scholar] [CrossRef]
- Li, C.; Sun, H.; Chen, Y.; Luo, Y. Edge Cloud Resource Expansion and Shrinkage Based on Workload for Minimizing the Cost. Future Gener. Comput. Syst. 2019, 101, 327–340. [Google Scholar] [CrossRef]
- Chai, X.; Zheng, Z.; Xiao, J.; Yan, L.; Qu, B.; Wen, P.; Wang, H.; Zhou, Y.; Sun, H. Multi-Strategy Fusion Differential Evolution Algorithm for UAV Path Planning in Complex Environment. Aerosp. Sci. Technol. 2022, 121, 107287. [Google Scholar] [CrossRef]
- Google Kubernetes Engine (GKE). Available online: https://cloud.google.com/kubernetes-engine (accessed on 1 August 2023).
- Azure Kubernetes Service (AKS). Available online: https://azure.microsoft.com/en-us/services/kubernetes-service (accessed on 1 August 2023).
- Amazon Elastic Kubernetes Service (EKS). Available online: https://aws.amazon.com/eks (accessed on 1 August 2023).
- Google Cloud Platform (GCP). Available online: https://console.cloud.google.com (accessed on 1 August 2023).
- Li, M.; Gao, J.; Zhao, L.; Shen, X. Deep Reinforcement Learning for Collaborative Edge Computing in Vehicular Networks. IEEE Trans. Cogn. Commun. Netw. 2020, 6, 1122–1135. [Google Scholar] [CrossRef]
- Luong, N.C.; Hoang, D.T.; Gong, S.; Niyato, D.; Wang, P.; Liang, Y.C.; Kim, D.I. Applications of Deep Reinforcement Learning in Communications and Networking: A Survey. IEEE Commun. Surv. Tutor. 2019, 21, 3133–3174. [Google Scholar] [CrossRef] [Green Version]
- Yang, C.; Liu, B.; Li, H.; Li, B.; Xie, K.; Xie, S. Learning Based Channel Allocation and Task Offloading in Temporary UAV-Assisted Vehicular Edge Computing Networks. IEEE Trans. Veh. Technol. 2022, 71, 9884–9895. [Google Scholar] [CrossRef]
- Liu, Q.; Shi, L.; Sun, L.; Li, J.; Ding, M.; Shu, F. Path Planning for UAV-Mounted Mobile Edge Computing with Deep Reinforcement Learning. IEEE Trans. Veh. Technol. 2020, 69, 5723–5728. [Google Scholar] [CrossRef] [Green Version]
- Hoang, L.T.; Nguyen, C.T.; Pham, A.T. Deep Reinforcement Learning-Based Online Resource Management for UAV-Assisted Edge Computing with Dual Connectivity. IEEE/ACM Trans. Netw. 2023. [Google Scholar] [CrossRef]
- Grondman, I.; Busoniu, L.; Lopes, G.A.; Babuska, R. A Survey of Actor-Critic Reinforcement Learning: Standard and Natural Policy Gradients. IEEE Trans. Syst. Man Cybern. C Appl. Rev. 2012, 42, 1291–1307. [Google Scholar] [CrossRef] [Green Version]
- Sutton, R.S.; McAllester, D.; Singh, S.; Mansour, Y. Policy Gradient Methods for Reinforcement Learning with Function Approximation. Adv. Neural Inf. Process. Syst. 1999, 12. [Google Scholar]
- Haja, D.; Szalay, M.; Sonkoly, B.; Pongracz, G.; Toka, L. Sharpening Kubernetes for the Edge. In Proceedings of the ACM SIGCOMM 2019 Conference Posters and Demos, Beijing, China, 19–23 August 2019; pp. 136–137. [Google Scholar]
- Rossi, F.; Cardellini, V.; Presti, F.L.; Nardelli, M. Geo-Distributed Efficient Deployment of Containers with Kubernetes. Comput. Commun. 2020, 159, 161–174. [Google Scholar] [CrossRef]
- Kumar, J.; Singh, A.K.; Buyya, R. Self Directed Learning Based Workload Forecasting Model for Cloud Resource Management. Inf. Sci. 2021, 543, 345–366. [Google Scholar] [CrossRef]
- Kim, I.K.; Wang, W.; Qi, Y.; Humphrey, M. Forecasting Cloud Application Workloads with Cloudinsight for Predictive Resource Management. IEEE Trans. Cloud Comput. 2020, 10, 1848–1863. [Google Scholar] [CrossRef]
- Verma, A.; Pedrosa, L.; Korupolu, M.; Oppenheimer, D.; Tune, E.; Wilkes, J. Large-Scale Cluster Management at Google with Borg. In Proceedings of the Tenth European Conference on Computer Systems, Bordeaux, France, 21–24 April 2015; pp. 1–17. [Google Scholar]
- Zhu, X.; Luo, Y.; Liu, A.; Xiong, N.N.; Dong, M.; Zhang, S. A Deep Reinforcement Learning-Based Resource Management Game in Vehicular Edge Computing. IEEE Trans. Intell. Transp. Syst. 2021, 23, 2422–2433. [Google Scholar] [CrossRef]








Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Z.; Wu, D.; Zhang, F.; Wang, R. DECCo-A Dynamic Task Scheduling Framework for Heterogeneous Drone Edge Cluster. Drones 2023, 7, 513. https://doi.org/10.3390/drones7080513
Zhang Z, Wu D, Zhang F, Wang R. DECCo-A Dynamic Task Scheduling Framework for Heterogeneous Drone Edge Cluster. Drones. 2023; 7(8):513. https://doi.org/10.3390/drones7080513
Chicago/Turabian StyleZhang, Zhiyang, Die Wu, Fengli Zhang, and Ruijin Wang. 2023. "DECCo-A Dynamic Task Scheduling Framework for Heterogeneous Drone Edge Cluster" Drones 7, no. 8: 513. https://doi.org/10.3390/drones7080513
APA StyleZhang, Z., Wu, D., Zhang, F., & Wang, R. (2023). DECCo-A Dynamic Task Scheduling Framework for Heterogeneous Drone Edge Cluster. Drones, 7(8), 513. https://doi.org/10.3390/drones7080513