

Learning Template-Constraint Real-Time Siamese Tracker for Drone AI Devices via Concatenation

Abstract
:1. Introduction
- We transfer and improve a learnable feature matching module, which performs the feature matching task more discriminatively than the non-parametric cross-correlation method.
- We propose a simple and effective template-constraint branch for dynamically capturing feature changes of a target and set up a filtering strategy to prevent invalid features from contaminating the tracking template.
- We design a lightweight tracker, ConcatTrk, with an end-to-end and cost-effective structure that performs a balance between tracking speed and accuracy on three benchmarks.
- We deploy and evaluate ConcatTrk on a drone platform under real-world conditions, showing strong tracking capabilities in challenging scenarios as well as low power consumption.
2. Related Work
2.1. Siamese Tracking
2.2. Temporal Information Exploitation
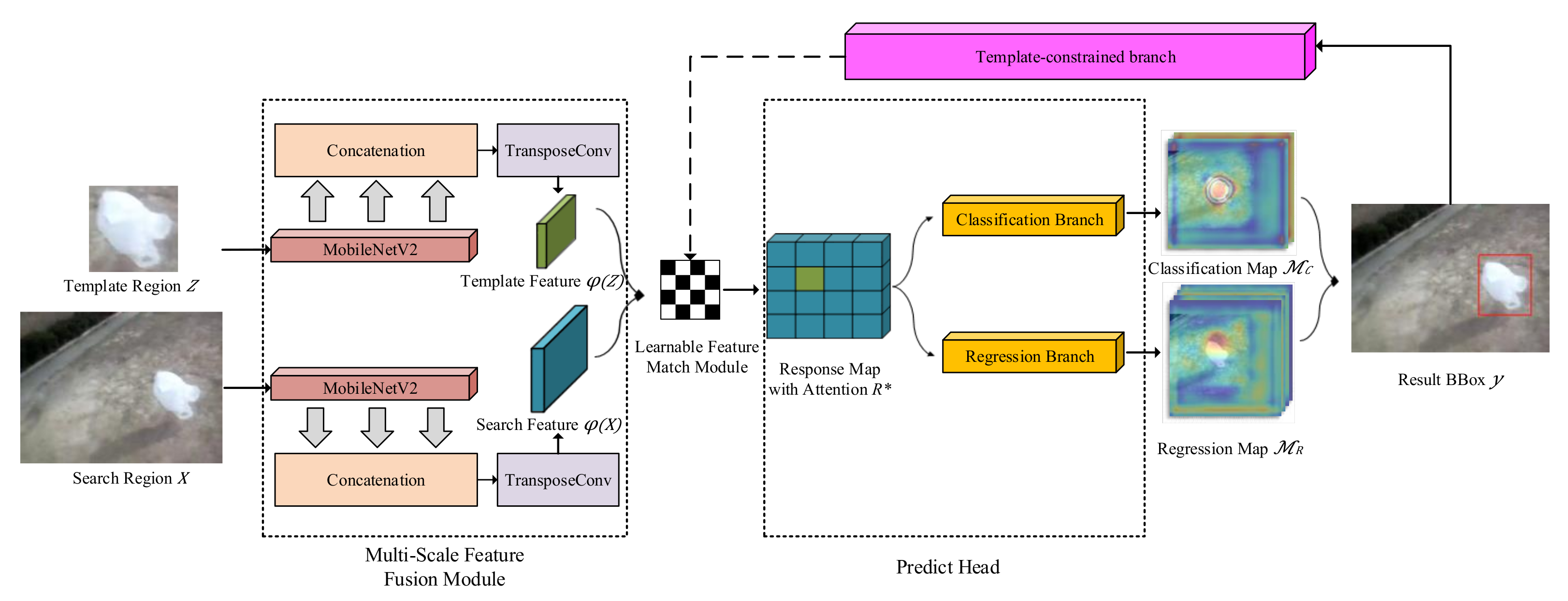
3. Proposed Methods
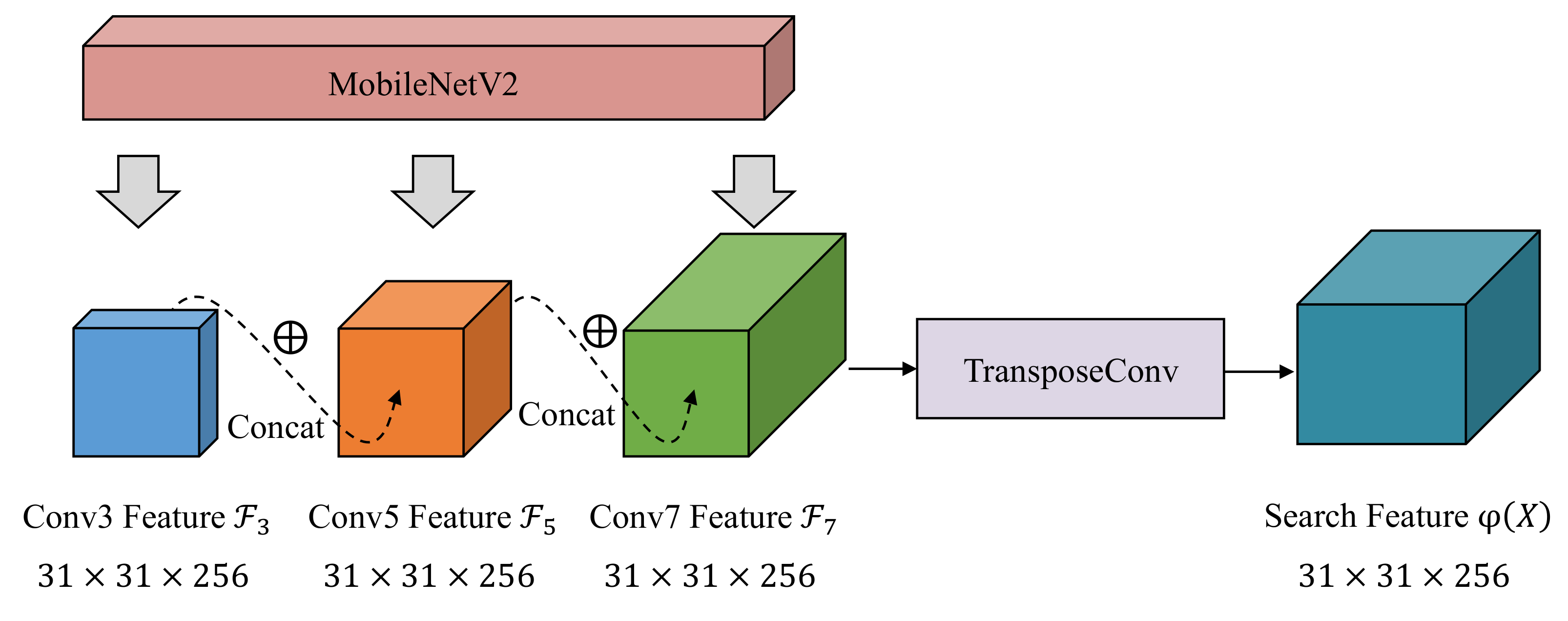
3.1. Multi-Scale Feature Fusion Module
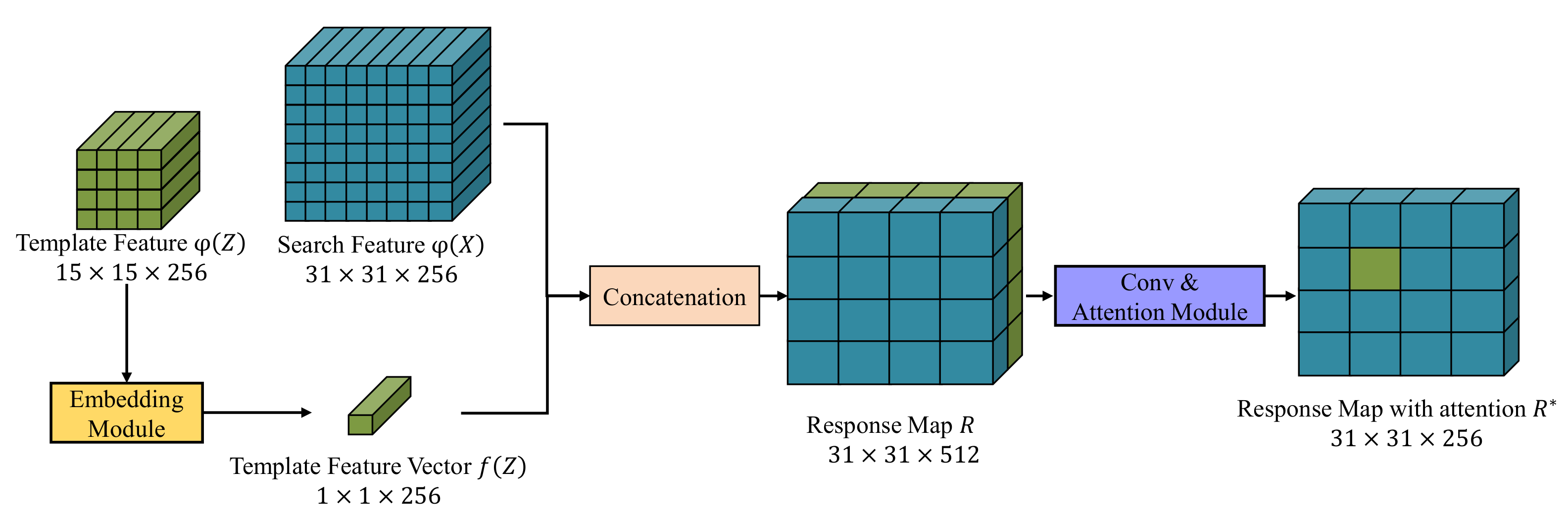
3.2. Learnable Feature Matching Module
3.3. Predict Head
3.4. Template-Constraint Branch
4. Results and Comparison
4.1. Implementation and Training Details
4.2. Results and Comparison
4.2.1. Evaluation Metrics
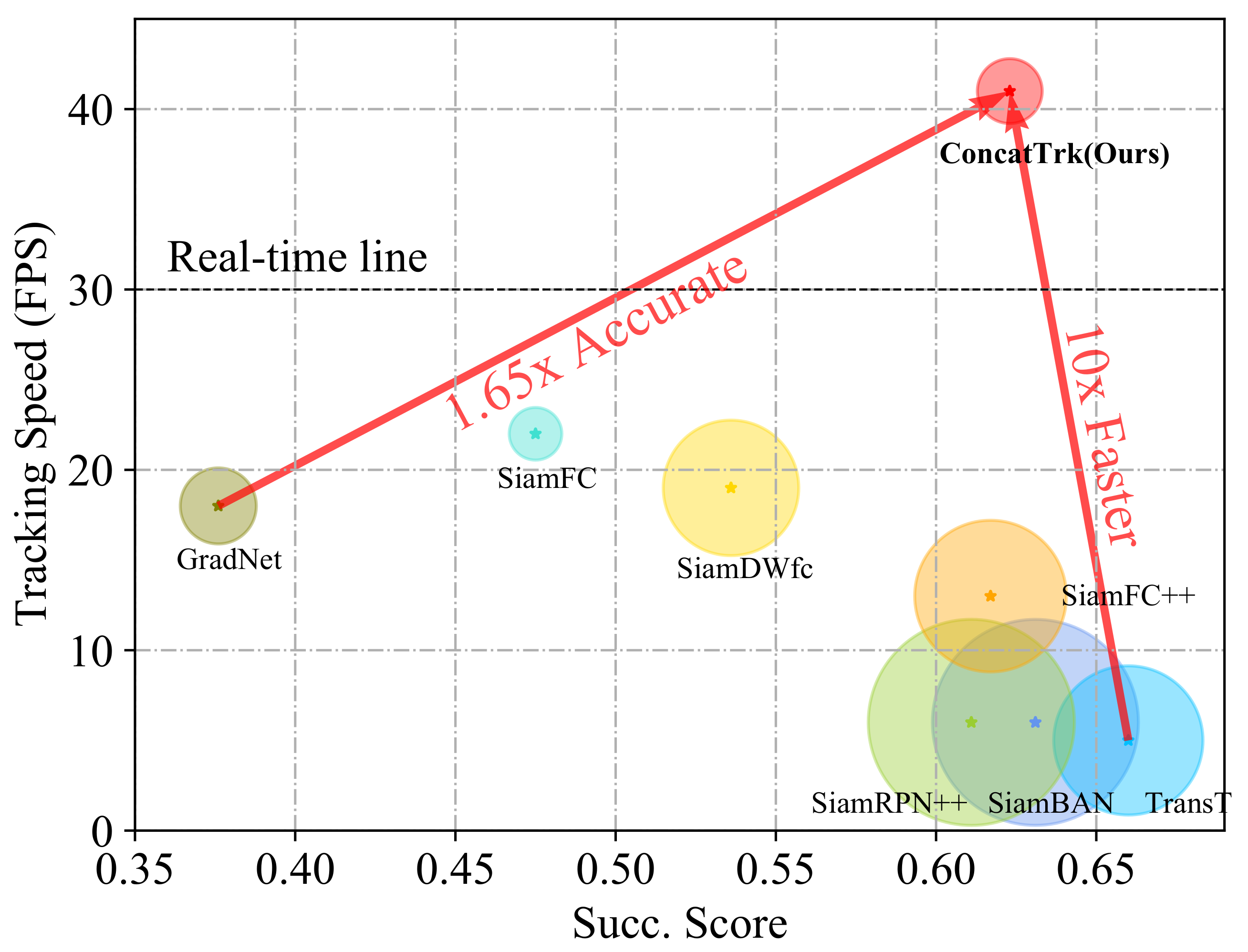
4.2.2. Results of Tracking Speed
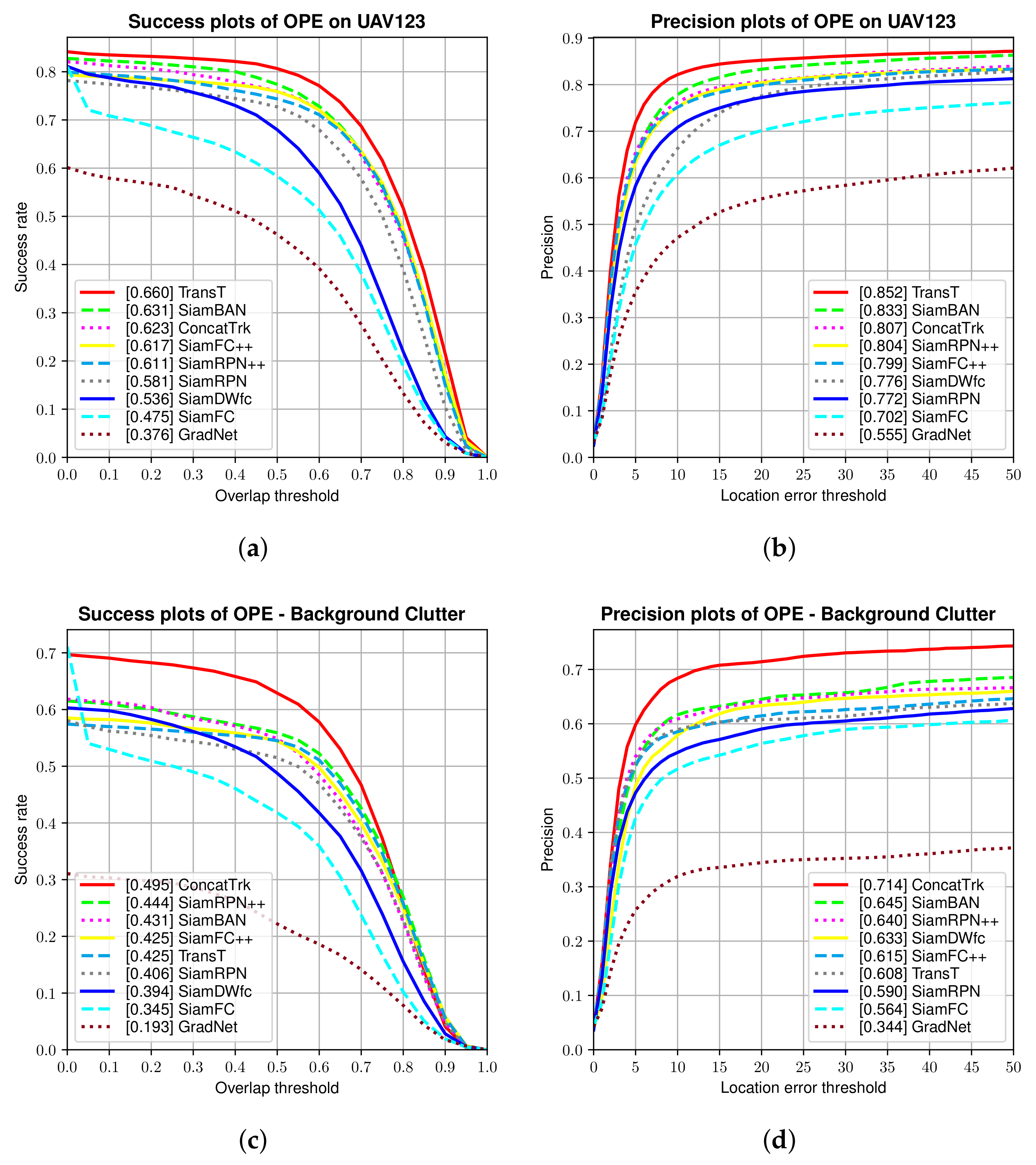
4.2.3. Results from UAV123
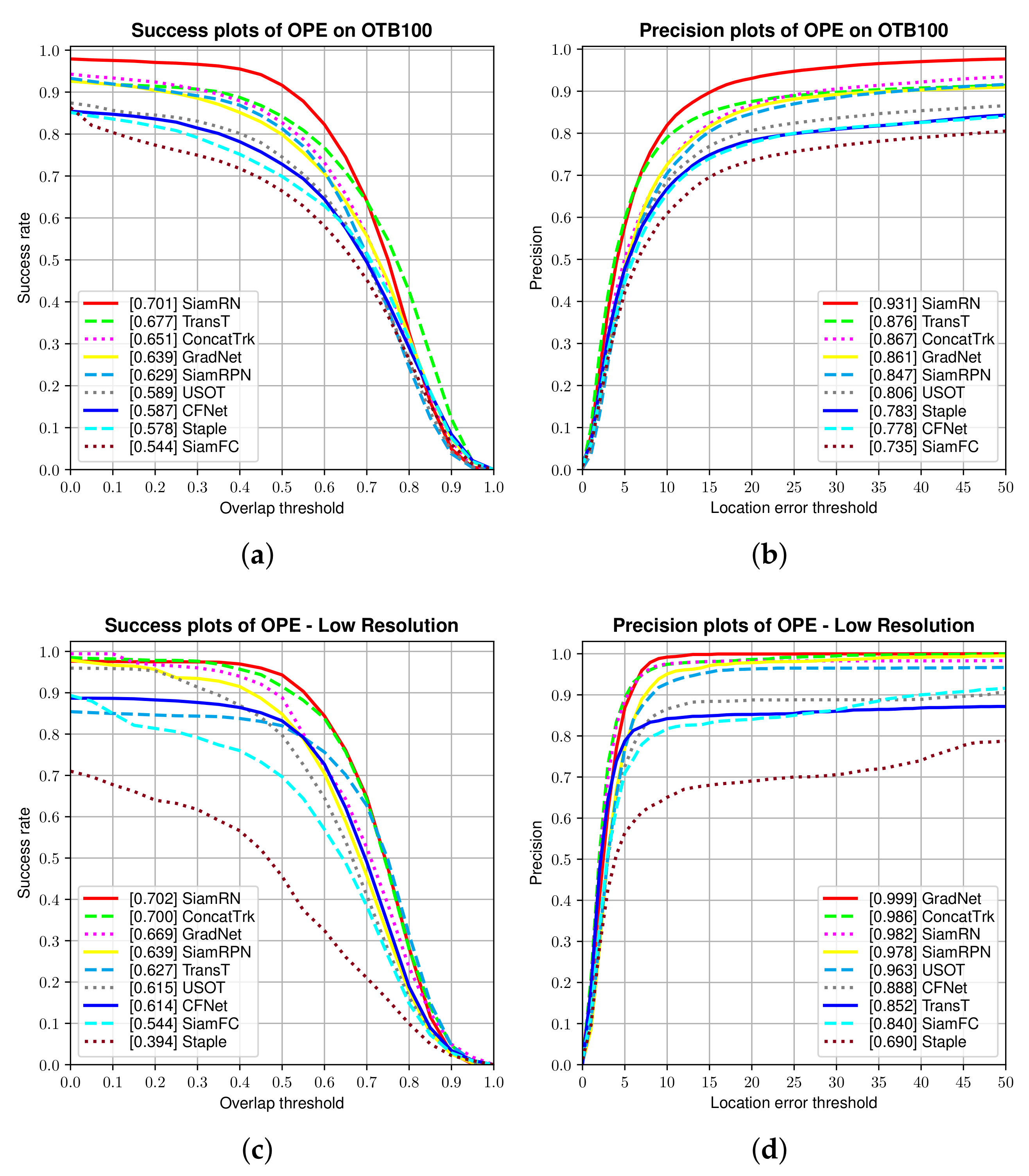
4.2.4. Results from OTB100
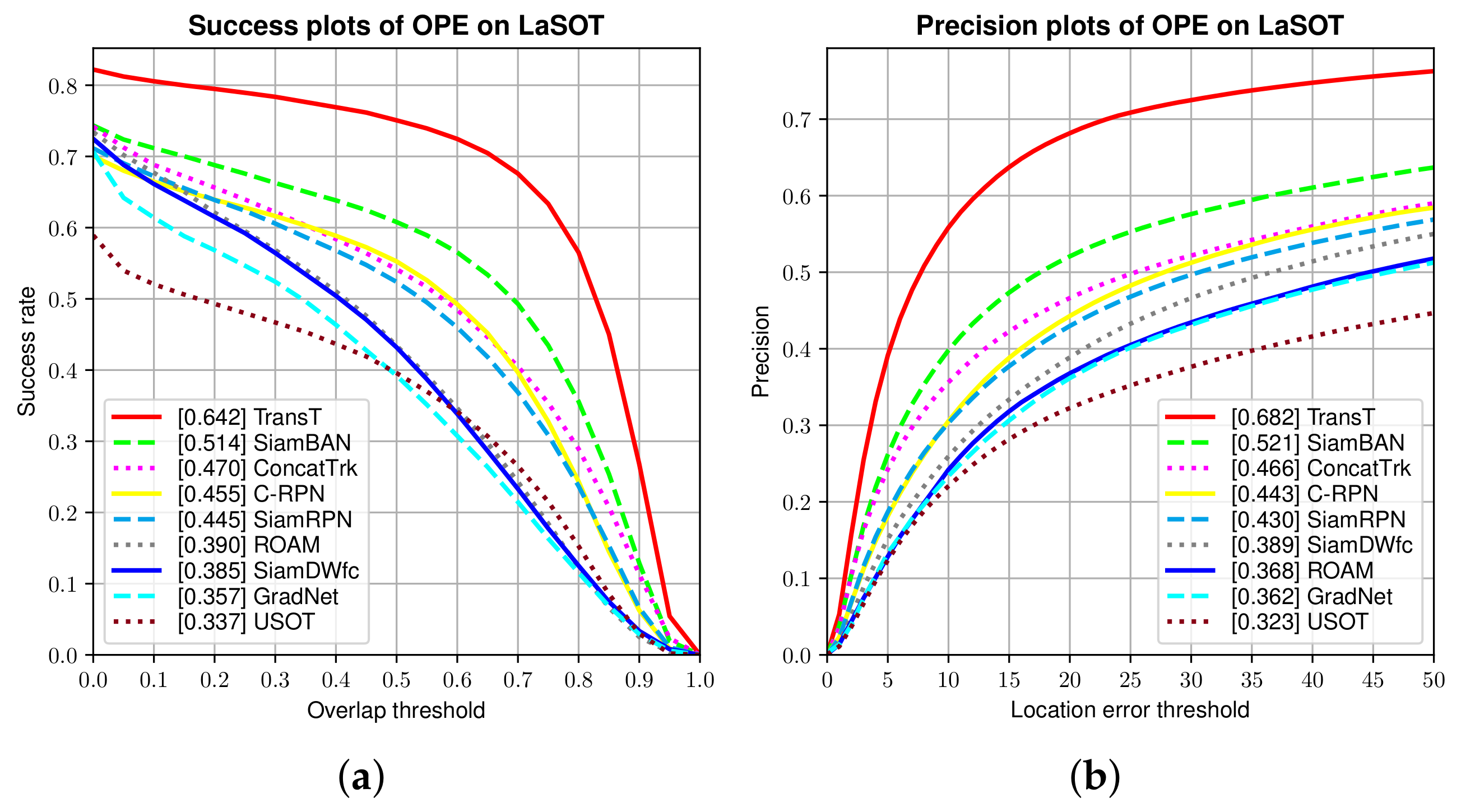
4.2.5. Results from LaSOT
4.3. Ablation Experiment
4.3.1. Impact of Learnable Feature Matching Module
4.3.2. Impact of Template-Constraint Branch
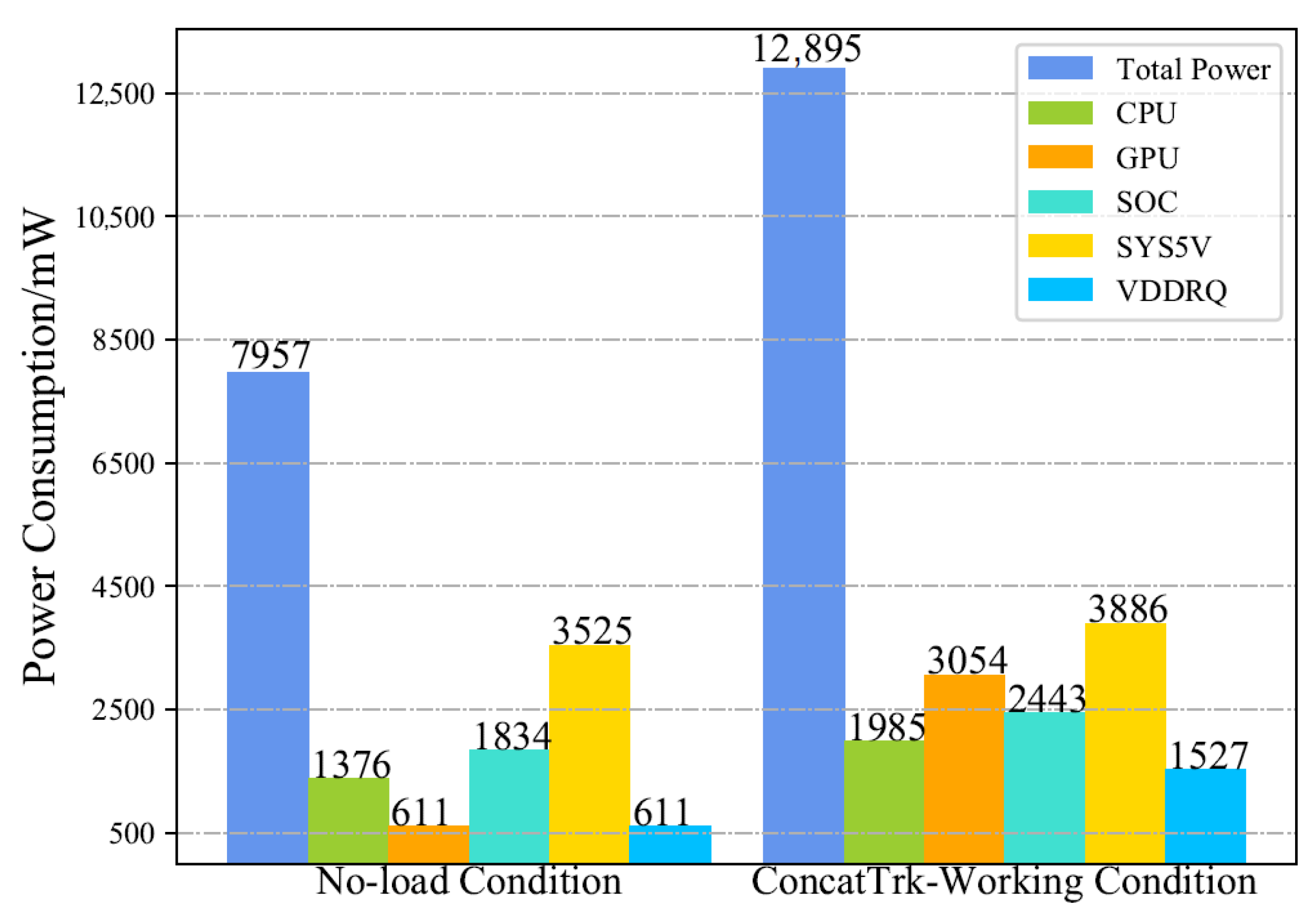
4.4. Real-World Test
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wu, H.; Nie, J.; He, Z.; Zhu, Z.; Gao, M. One-shot multiple object tracking in UAV videos using task-specific fine-grained features. Remote Sens. 2022, 14, 3853. [Google Scholar] [CrossRef]
- Heidari, A.; Jafari Navimipour, N.; Unal, M.; Zhang, G. Machine Learning Applications in Internet-of-Drones: Systematic Review, Recent Deployments, and Open Issues. ACM Comput. Surv. 2023, 55, 247. [Google Scholar] [CrossRef]
- Li, B.; Li, Q.; Zeng, Y.; Rong, Y.; Zhang, R. 3D Trajectory Optimization for Energy-Efficient UAV Communication: A Control Design Perspective. IEEE Trans. Wirel. Commun. 2022, 21, 4579–4593. [Google Scholar] [CrossRef]
- Wang, B.; Zhu, D.; Han, L.; Gao, H.; Gao, Z.; Zhang, Y. Adaptive Fault-Tolerant Control of a Hybrid Canard Rotor/Wing UAV Under Transition Flight Subject to Actuator Faults and Model Uncertainties. IEEE Trans. Aerosp. Electron. Syst. 2023, 59, 4559–4574. [Google Scholar] [CrossRef]
- Wang, B.; Zhang, Y.; Zhang, W. A composite adaptive fault-tolerant attitude control for a quadrotor UAV with multiple uncertainties. J. Syst. Sci. Complex. 2022, 35, 81–104. [Google Scholar] [CrossRef]
- Dai, X.; Xiao, Z.; Jiang, H.; Lui, J.C. UAV-Assisted Task Offloading in Vehicular Edge Computing Networks. IEEE Trans. Mobile Comput. 2023, 1–15. [Google Scholar] [CrossRef]
- Cao, B.; Li, M.; Liu, X.; Zhao, J.; Cao, W.; Lv, Z. Many-Objective Deployment Optimization for a Drone-Assisted Camera Network. IEEE Trans. Netw. Sci. Eng. 2021, 8, 2756–2764. [Google Scholar] [CrossRef]
- Zhao, J.; Gao, F.; Jia, W.; Yuan, W.; Jin, W. Integrated Sensing and Communications for UAV Communications with Jittering Effect. IEEE Trans. Netw. Sci. Eng. 2023, 12, 758–762. [Google Scholar] [CrossRef]
- Sandoval, L.A.C. Low Cost Object Tracking by Computer Vision Using 8 Bits Communication with a Viper Robot. In Proceedings of the 2023 8th International Conference on Control and Robotics Engineering (ICCRE), Niigata, Japan, 21–23 April 2023; pp. 232–237. [Google Scholar] [CrossRef]
- Lee, M.F.R.; Chen, Y.C. Artificial Intelligence Based Object Detection and Tracking for a Small Underwater Robot. Processes 2023, 11, 312. [Google Scholar] [CrossRef]
- Nebeluk, R.; Zarzycki, K.; Seredyński, D.; Chaber, P.; Figat, M.; Domański, P.D.; Zieliński, C. Predictive tracking of an object by a pan–tilt camera of a robot. Nonlinear Dyn. 2023, 111, 8383–8395. [Google Scholar] [CrossRef]
- Gragnaniello, D.; Greco, A.; Saggese, A.; Vento, M.; Vicinanza, A. Benchmarking 2D Multi-Object Detection and Tracking Algorithms in Autonomous Vehicle Driving Scenarios. Sensors 2023, 23, 4024. [Google Scholar] [CrossRef] [PubMed]
- Nie, C.; Ju, Z.; Sun, Z.; Zhang, H. 3D Object Detection and Tracking Based on Lidar-Camera Fusion and IMM-UKF Algorithm Towards Highway Driving. IEEE Trans. Emerg. Top. Comput. Intell. 2023, 7, 1242–1252. [Google Scholar] [CrossRef]
- Bertinetto, L.; Valmadre, J.; Henriques, J.F.; Vedaldi, A.; Torr, P.H. Fully-convolutional siamese networks for object tracking. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 850–865. [Google Scholar]
- Li, B.; Yan, J.; Wu, W.; Zhu, Z.; Hu, X. High Performance Visual Tracking with Siamese Region Proposal Network. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8971–8980. [Google Scholar] [CrossRef]
- Li, B.; Wu, W.; Wang, Q.; Zhang, F.; Xing, J.; Yan, J. SiamRPN++: Evolution of Siamese Visual Tracking with Very Deep Networks. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 4277–4286. [Google Scholar] [CrossRef]
- Wang, Q.; Zhang, L.; Bertinetto, L.; Hu, W.; Torr, P.H. Fast online object tracking and segmentation: A unifying approach. In Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 1328–1338. [Google Scholar]
- Chen, Z.; Zhong, B.; Li, G.; Zhang, S.; Ji, R. Siamese box adaptive network for visual tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–20 June 2020; pp. 6668–6677. [Google Scholar]
- Wang, N.; Zhou, W.; Wang, J.; Li, H. Transformer meets tracker: Exploiting temporal context for robust visual tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Online, 19–25 June 2021; pp. 1571–1580. [Google Scholar]
- Chen, X.; Yan, B.; Zhu, J.; Wang, D.; Yang, X.; Lu, H. Transformer Tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Online, 19–25 June 2021; pp. 8126–8135. [Google Scholar]
- Fan, H.; Ling, H. Siamese cascaded region proposal networks for real-time visual tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 7952–7961. [Google Scholar]
- Yan, B.; Peng, H.; Fu, J.; Wang, D.; Lu, H. Learning spatio-temporal transformer for visual tracking. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Online, 19–25 June 2021; pp. 10448–10457. [Google Scholar]
- Yan, B.; Zhang, X.; Wang, D.; Lu, H.; Yang, X. Alpha-refine: Boosting tracking performance by precise bounding box estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Online, 19–25 June 2021; pp. 5289–5298. [Google Scholar]
- Zhang, L.; Gonzalez-Garcia, A.; Weijer, J.v.d.; Danelljan, M.; Khan, F.S. Learning the model update for siamese trackers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Long Beach, CA, USA, 16–20 June 2019; pp. 4010–4019. [Google Scholar]
- Li, P.; Chen, B.; Ouyang, W.; Wang, D.; Yang, X.; Lu, H. Gradnet: Gradient-guided network for visual object tracking. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Long Beach, CA, USA, 16–20 June 2019; pp. 6162–6171. [Google Scholar]
- Gao, J.; Zhang, T.; Xu, C. Graph convolutional tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 4649–4659. [Google Scholar]
- Mueller, M.; Smith, N.; Ghanem, B. A benchmark and simulator for uav tracking. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 445–461. [Google Scholar]
- Wu, Y.; Lim, J.; Yang, M. Object Tracking Benchmark. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1834–1848. [Google Scholar] [CrossRef] [PubMed]
- Fan, H.; Lin, L.; Yang, F.; Chu, P.; Deng, G.; Yu, S.; Bai, H.; Xu, Y.; Liao, C.; Ling, H. Lasot: A high-quality benchmark for large-scale single object tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 5374–5383. [Google Scholar]
- Guo, D.; Wang, J.; Cui, Y.; Wang, Z.; Chen, S. SiamCAR: Siamese fully convolutional classification and regression for visual tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–20 June 2020; pp. 6269–6277. [Google Scholar]
- Liao, B.; Wang, C.; Wang, Y.; Wang, Y.; Yin, J. Pg-net: Pixel to global matching network for visual tracking. In Proceedings of the European Conference on Computer Vision, Seattle, WA, USA, 16–20 June 2020; pp. 429–444. [Google Scholar]
- Nam, H.; Baek, M.; Han, B. Modeling and Propagating CNNs in a Tree Structure for Visual Tracking. arXiv 2016, arXiv:1608.07242. [Google Scholar]
- Zhou, Z.; Pei, W.; Li, X.; Wang, H.; Zheng, F.; He, Z. Saliency-associated object tracking. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Online, 19–25 June 2021; pp. 9866–9875. [Google Scholar]
- Zhang, Z.; Peng, H.; Fu, J.; Li, B.; Hu, W. Ocean: Object-aware anchor-free tracking. In Proceedings of the European Conference on Computer Vision, Seattle, WA, USA, 16–20 June 2020; pp. 771–787. [Google Scholar]
- Cao, Z.; Fu, C.; Ye, J.; Li, B.; Li, Y. HiFT: Hierarchical feature transformer for aerial tracking. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Online, 19–25 June 2021; pp. 15457–15466. [Google Scholar]
- Danelljan, M.; Bhat, G.; Khan, F.S.; Felsberg, M. ATOM: Accurate Tracking by Overlap Maximization. arXiv 2019, arXiv:1811.07628. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep high-resolution representation learning for human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 5693–5703. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- Zhang, Z.; Liu, Y.; Wang, X.; Li, B.; Hu, W. Learn to match: Automatic matching network design for visual tracking. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Online, 19–25 June 2021; pp. 13339–13348. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7794–7803. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Cheng, S.; Zhong, B.; Li, G.; Liu, X.; Tang, Z.; Li, X.; Wang, J. Learning to filter: Siamese relation network for robust tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Online, 19–25 June 2021; pp. 4421–4431. [Google Scholar]
- Xu, Y.; Wang, Z.; Li, Z.; Yuan, Y.; Yu, G. Siamfc++: Towards robust and accurate visual tracking with target estimation guidelines. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12549–12556. [Google Scholar]
- Zheng, J.; Ma, C.; Peng, H.; Yang, X. Learning to track objects from unlabeled videos. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Online, 19–25 June 2021; pp. 13546–13555. [Google Scholar]
- Yang, T.; Xu, P.; Hu, R.; Chai, H.; Chan, A.B. ROAM: Recurrently optimizing tracking model. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–20 June 2020; pp. 6717–6726. [Google Scholar]
- Zhang, Z.; Peng, H. Deeper and wider siamese networks for real-time visual tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 4591–4600. [Google Scholar]
- Quigley, M.; Conley, K.; Gerkey, B.; Faust, J.; Foote, T.; Leibs, J.; Wheeler, R.; Ng, A.Y. ROS: An open-source Robot Operating System. In Proceedings of the ICRA Workshop on Open Source Software, Kobe, Japan, 12–17 May 2009; Volume 3, p. 5. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tracker | Succ. Score | Pre. Score | Avg. FPS | FLOPs |
|---|---|---|---|---|
| TransT | 0.660 | 0.852 | 5 | 16.7 G |
| SiamBAN | 0.631 | 0.833 | 6 | 48.8 G |
| ConcatTrk(Ours) | 0.623 | 0.807 | 41 | 3.4 G |
| SiamFC++ | 0.617 | 0.799 | 13 | 17.5 G |
| SiamRPN++ | 0.611 | 0.804 | 6 | 48.9 G |
| SiamDWfc | 0.536 | 0.776 | 19 | 12.9 G |
| SiamFC | 0.475 | 0.702 | 22 | 2.7 G |
| GradNet | 0.376 | 0.555 | 18 | 4.2 G |
| Attributes | ALL | Low-Resolution | Out-of-View | Scale-Variation | ||||
|---|---|---|---|---|---|---|---|---|
| Succ. Score | Pre. Score | Succ. Score | Pre. Score | Succ. Score | Pre. Score | Succ. Score | Pre. Score | |
| Depth-wise XCorr [16] | 0.586 | 0.798 | 0.597 | 0.826 | 0.454 | 0.654 | 0.575 | 0.775 |
| Pixel-wise XCorr [23] | 0.610 | 0.801 | 0.553 | 0.761 | 0.487 | 0.660 | 0.589 | 0.787 |
| LFM(Ours) | 0.613 | 0.808 | 0.698 | 0.988 | 0.537 | 0.683 | 0.622 | 0.816 |
| (%) | +0.491 | +0.874 | +17.01 | +19.61 | +10.267 | +3.484 | +5.603 | +3.685 |
| Succ. Score | Pre. Score | FPS | |
|---|---|---|---|
| ConcatTrk | 0.651 | 0.871 | 140 |
| ConcatTrk-noTCB | 0.626 | 0.828 | 145 |
| (%) | +3.99 | +4.71 | −3.5% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, Z.; Liu, Q.; Zhou, S.; Qiu, S.; Zhang, Z.; Zeng, Y. Learning Template-Constraint Real-Time Siamese Tracker for Drone AI Devices via Concatenation. Drones 2023, 7, 592. https://doi.org/10.3390/drones7090592
Wu Z, Liu Q, Zhou S, Qiu S, Zhang Z, Zeng Y. Learning Template-Constraint Real-Time Siamese Tracker for Drone AI Devices via Concatenation. Drones. 2023; 7(9):592. https://doi.org/10.3390/drones7090592
Chicago/Turabian StyleWu, Zhewei, Qihe Liu, Shijie Zhou, Shilin Qiu, Zhun Zhang, and Yi Zeng. 2023. "Learning Template-Constraint Real-Time Siamese Tracker for Drone AI Devices via Concatenation" Drones 7, no. 9: 592. https://doi.org/10.3390/drones7090592
APA StyleWu, Z., Liu, Q., Zhou, S., Qiu, S., Zhang, Z., & Zeng, Y. (2023). Learning Template-Constraint Real-Time Siamese Tracker for Drone AI Devices via Concatenation. Drones, 7(9), 592. https://doi.org/10.3390/drones7090592