Concept Discovery for The Interpretation of Landscape Scenicness

Abstract
:1. Introduction
2. Methodology
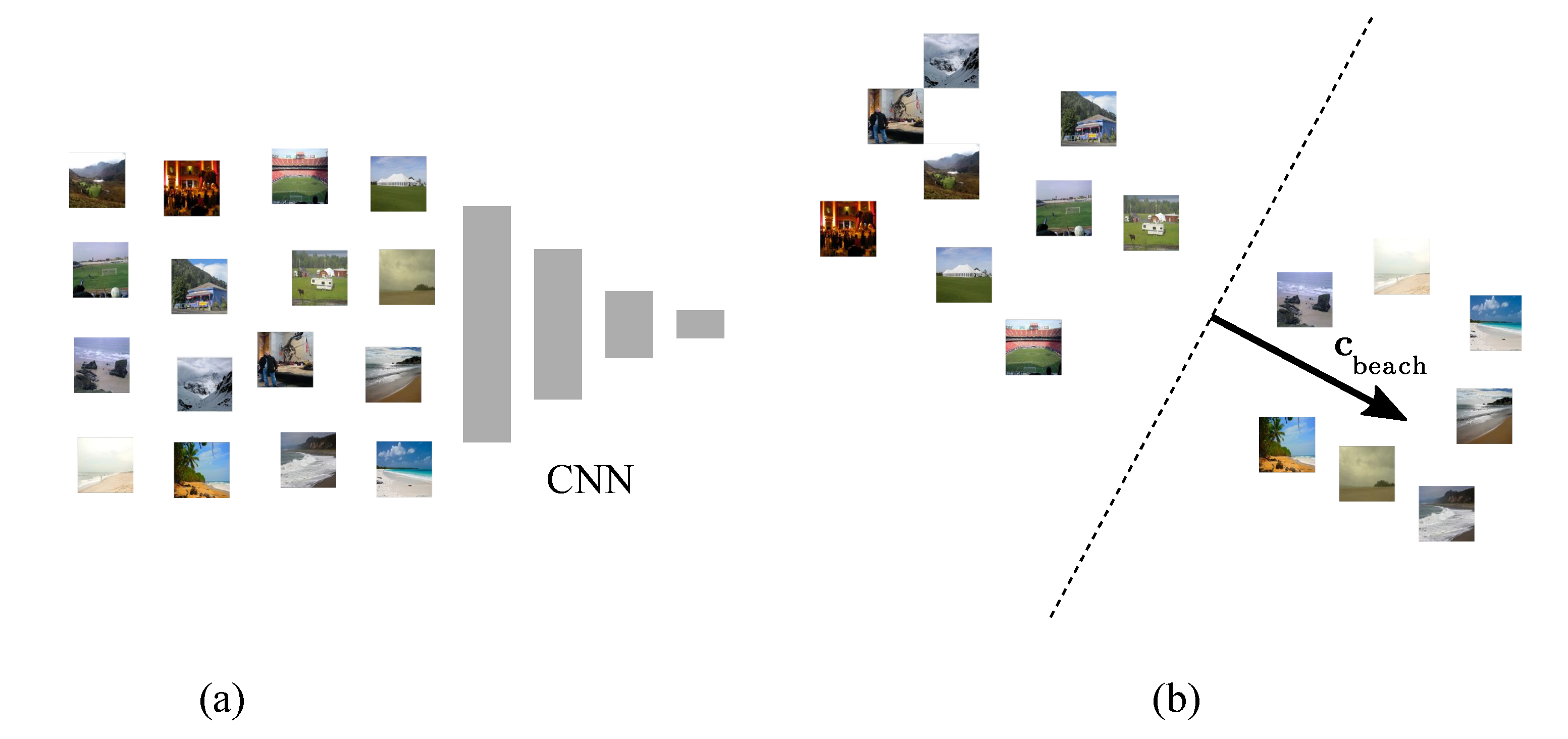
2.1. Concept Activation Vectors
2.2. Linking CAVs to Scenicness
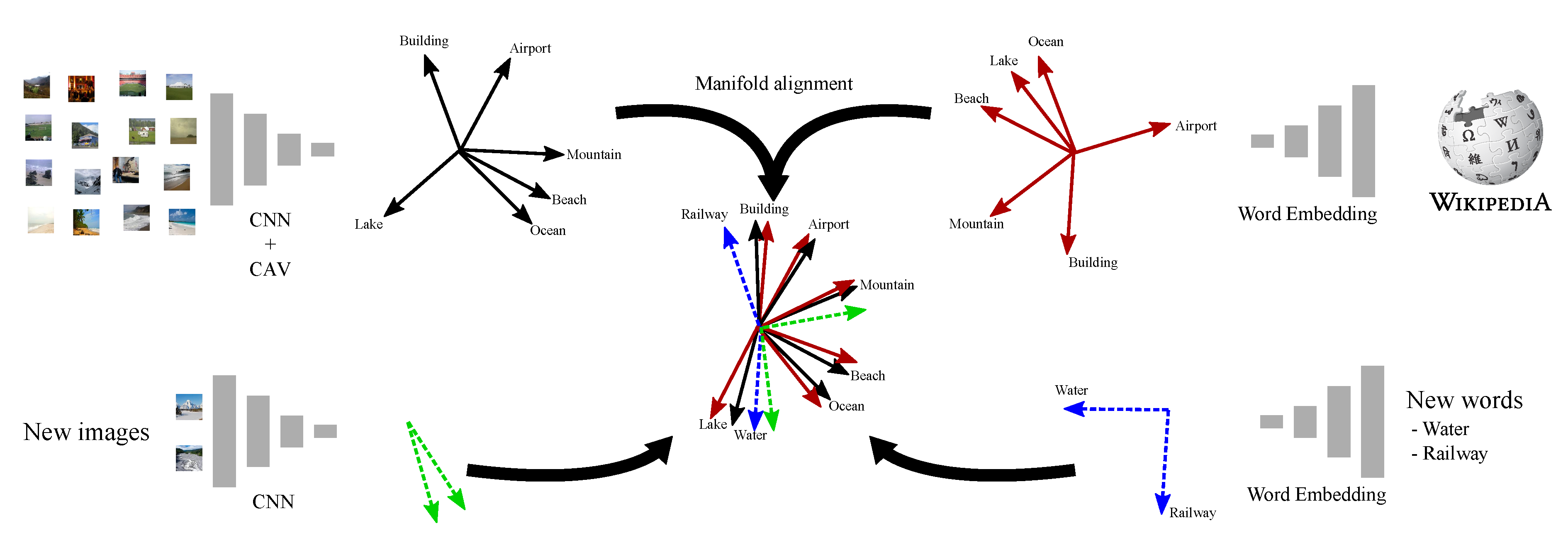
2.3. Exploring New Concepts with Manifold Alignment
3. Datasets
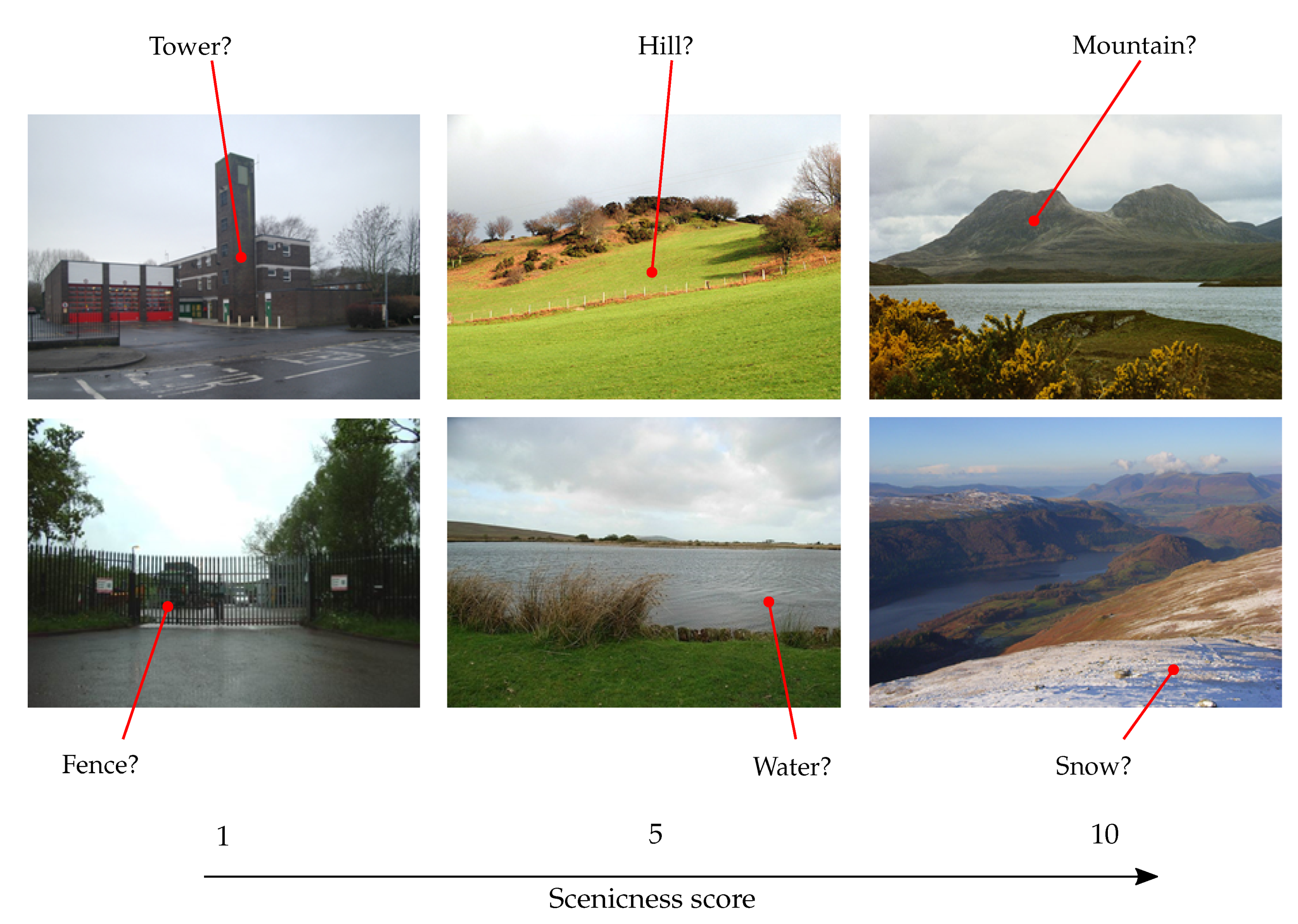
3.1. Landscape Scenicness
3.2. Semantic Concepts
3.3. Word Embeddings
4. Results and Discussion
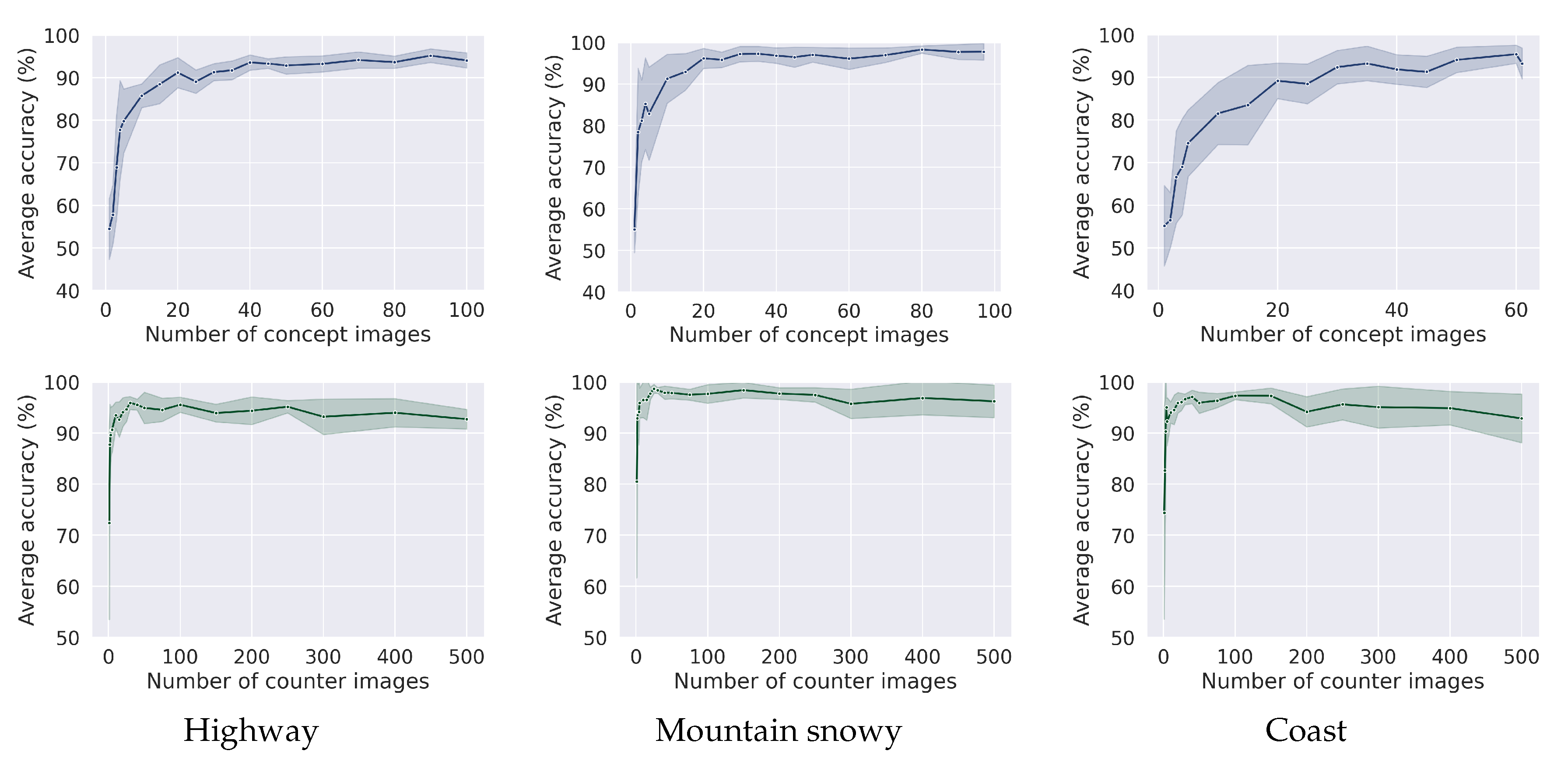
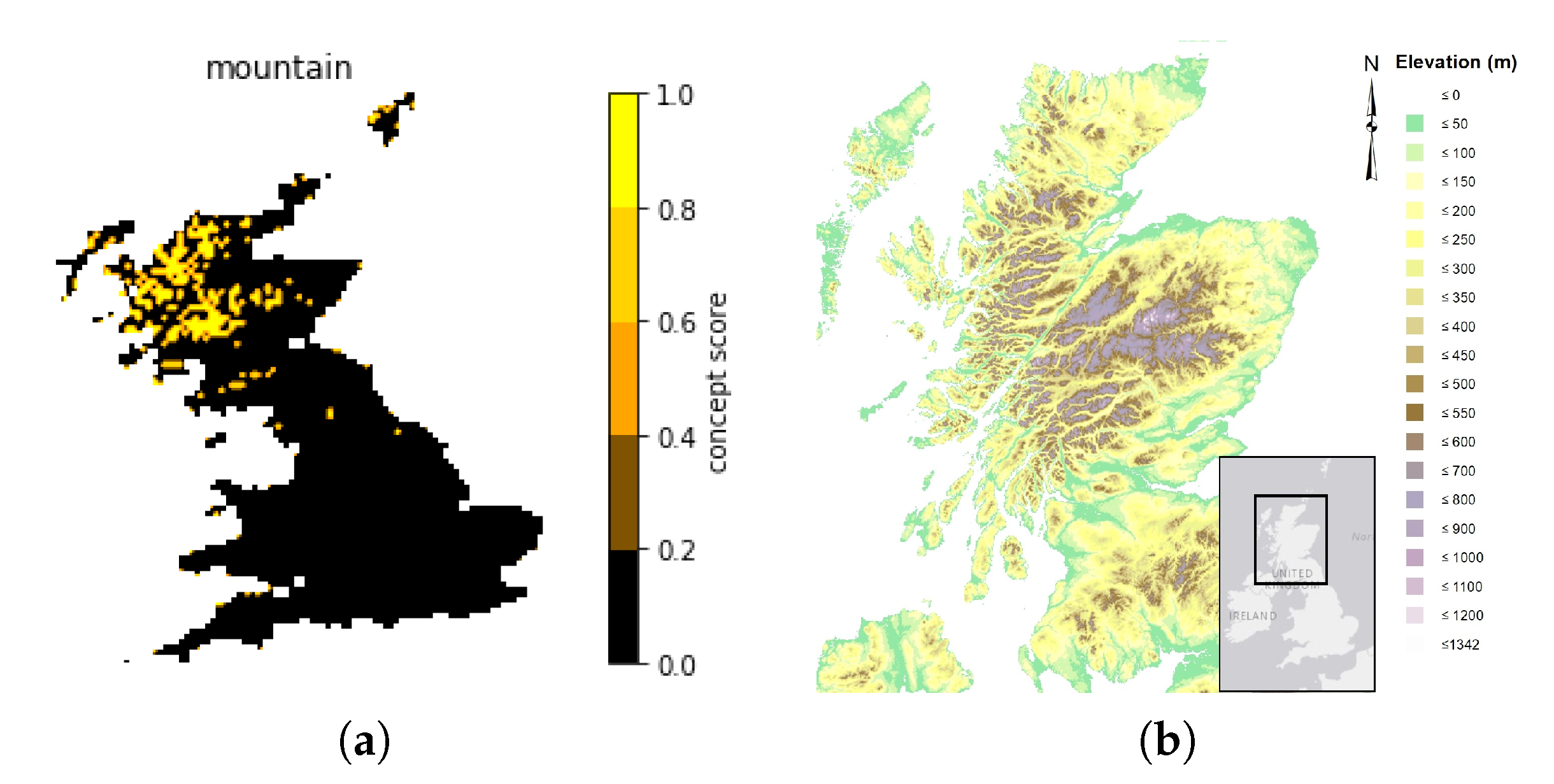
4.1. Deriving CAVs from Broden
4.2. Linking CAV Concepts to Scenicness
4.3. Discovering New Concepts with Word Embeddings
- In the CAV domain, both the non-corresponding CAVs and a random sample of SoN image vector representations were used, resulting in 5052 unmatched samples.
- In the GloVe domain, the ten nearest neighbours for each of the corresponding concepts were added, resulting in a total of 2548 samples.
4.4. Main Limitations of the Approach
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- ScenicOrNot. Available online: http://scenicornot.datasciencelab.co.uk/ (accessed on 14 September 2020).
- Workman, S.; Souvenir, R.; Jacobs, N. Understanding and Mapping Natural Beauty. In Proceedings of the IEEE International Conference on Computer, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Seresinhe, C.I.; Preis, T.; Moat, H.S. Using deep learning to quantify the beauty of outdoor places. R. Soc. Open Sci. 2017, 4, 170170. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Marcos, D.; Lobry, S.; Tuia, D. Semantically Interpretable Activation Maps: What-where-how explanations within CNNs. In Proceedings of the International Conference on Computer Vision Workshops (ICCVw), Seoul, Korea, 27–28 October 2019. [Google Scholar]
- Collins, E.; Achanta, R.; Susstrunk, S. Deep feature factorization for concept discovery. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 336–352. [Google Scholar]
- Wigness, M.; Draper, B.A.; Beveridge, J.R. Selectively guiding visual concept discovery. In Proceedings of the Winter Conference on Applications of Computer Vision, Steamboat Springs, CO, USA, 24–26 March 2014. [Google Scholar]
- Sun, C.; Gan, C.; Nevatia, R. Automatic concept discovery from parallel text and visual corpora. In Proceedings of the International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Wang, C.; Krafft, P.; Mahadevan, S. Manifold alignment. In Manifold Learning: Theory and Applications; Ma, Y., Fu, Y., Eds.; CRC Press: Boca Raton, FL, USA, 2011. [Google Scholar]
- Kim, B.; Wattenberg, M.; Gilmer, J.; Cai, C.; Wexler, J.; Viegas, F.; Sayres, R. Interpretability beyond feature attribution: Quantitative Testing with Concept Activation Vectors. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; p. 6. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Kendall, M.G. A new measure of rank correlation. Biometrika 1938, 30, 81–93. [Google Scholar] [CrossRef]
- Wang, C.; Mahadevan, S. Heterogeneous domain adaptation using manifold alignment. In Proceedings of the International Joint Conference on Artificial Intelligence, Barcelona, Spain, 16–22 July 2011; pp. 1541–1546. [Google Scholar]
- Tuia, D.; Camps-Valls, G. Kernel Manifold Alignment for Domain Adaptation. PLoS ONE 2016, 11, e0148655. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tuia, D.; Volpi, M.; Trolliet, M.; Camps-Valls, G. Semisupervised Manifold Alignment of Multimodal Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2014, 52, 7708–7720. [Google Scholar] [CrossRef]
- Geograph Britain and Ireland. Available online: http://www.geograph.org.uk (accessed on 14 September 2020).
- Bau, D.; Zhou, B.; Khosla, A.; Oliva, A.; Torralba, A. Network dissection: Quantifying interpretability of deep visual representations. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Zhou, B.; Zhao, H.; Puig, X.; Fidler, S.; Barriuso, A.; Torralba, A. Scene Parsing through ADE20K Dataset. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Bell, S.; Bala, K.; Snavely, N. Intrinsic Images in the Wild. ACM Trans. Graph. 2014, 33, 1–12. [Google Scholar] [CrossRef]
- Mottaghi, R.; Chen, X.; Liu, X.; Cho, N.G.; Lee, S.W.; Fidler, S.; Urtasun, R.; Yuille, A. The role of context for object detection and semantic segmentation in the wild. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Chen, X.; Mottaghi, R.; Liu, X.; Fidler, S.; Urtasun, R.; Yuille, A. Detect what you can: Detecting and representing objects using holistic models and body parts. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Cimpoi, M.; Maji, S.; Kokkinos, I.; Mohamed, S.; Vedaldi, A. Describing Textures in the Wild. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. GloVe: Global Vectors for Word Representation. In Proceedings of the Empirical Methods in Natural Language Processing, Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Rank | Concept | Correlation | Rank | Concept | Correlation |
|---|---|---|---|---|---|
| 1 | Canyon | 0.47 | 1 | Building | −0.39 |
| 2 | Cliff | 0.43 | 2 | Street | −0.37 |
| 3 | Island | 0.41 | 3 | Sidewalk | −0.37 |
| 4 | Valley (scene) | 0.41 | 4 | Crosswalk | −0.36 |
| 5 | Ocean | 0.40 | 5 | Parking lot | −0.35 |
| 6 | Wave | 0.40 | 6 | Windows | −0.33 |
| 7 | Mountain | 0.40 | 7 | Parking garage indoor | −0.32 |
| 8 | Valley | 0.40 | 8 | Bleachers outdoor | −0.31 |
| 9 | Smeared | 0.39 | 9 | Platform | −0.30 |
| 10 | Waterfall-block | 0.39 | 10 | Road | −0.30 |
| Rank | Concept | Training | Correlation | Rank | Concept | Training | Correlation |
|---|---|---|---|---|---|---|---|
| Neighbor | |||||||
| 1 | outcrop | islet | 0.54 | 1 | refrigerated | refrigerator | −0.52 |
| 2 | archipelago | island | 0.54 | 2 | expressway | highway | −0.51 |
| 3 | uninhabited | islet | 0.53 | 3 | supported | bush | −0.51 |
| 4 | wilderness | forest | 0.52 | 4 | brakes | wheel | −0.50 |
| 5 | rocky | mountain | 0.52 | 5 | concourse | mezzanine | −0.50 |
| 6 | foothills | mountain | 0.52 | 6 | closed | shed | −0.49 |
| 7 | arctic | ocean | 0.51 | 7 | profits | net | −0.48 |
| 8 | bass | guitar | 0.50 | 8 | undies | bedclothes | −0.48 |
| 9 | rugged | mountain | 0.50 | 9 | console | dashboard | −0.48 |
| 10 | unpopulated | islet | 0.50 | 10 | plastered | poster | −0.48 |
| Bush | Net | Rock | Coach |
|---|---|---|---|
| gore | profit | band | coached |
| w. | quarter | punk | coaches |
| administration | profits | pop | coaching |
| republicans | earnings | bands | team |
| aides | income | album | football |
| democrats | revenue | rocks | basketball |
| dole | revenues | music | assistant |
| president | drop | singer | manager |
| presidential | billion | albums | players |
| republican | pretax | songs | teammates |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Arendsen, P.; Marcos, D.; Tuia, D. Concept Discovery for The Interpretation of Landscape Scenicness. Mach. Learn. Knowl. Extr. 2020, 2, 397-413. https://doi.org/10.3390/make2040022
Arendsen P, Marcos D, Tuia D. Concept Discovery for The Interpretation of Landscape Scenicness. Machine Learning and Knowledge Extraction. 2020; 2(4):397-413. https://doi.org/10.3390/make2040022
Chicago/Turabian StyleArendsen, Pim, Diego Marcos, and Devis Tuia. 2020. "Concept Discovery for The Interpretation of Landscape Scenicness" Machine Learning and Knowledge Extraction 2, no. 4: 397-413. https://doi.org/10.3390/make2040022
APA StyleArendsen, P., Marcos, D., & Tuia, D. (2020). Concept Discovery for The Interpretation of Landscape Scenicness. Machine Learning and Knowledge Extraction, 2(4), 397-413. https://doi.org/10.3390/make2040022