1. Introduction
Deep learning classifiers are used in a wide variety of situations, such as vision, speech recognition, financial fraud detection, malware detection, autonomous driving, defense, and more.
The ubiquity of deep learning algorithms in many applications, especially those that are critical such as autonomous driving [
1,
2] or that pertain to security and privacy [
3,
4] makes their attack particularly useful. Indeed, this allows firstly to identify possible flaws in the intelligent model and secondly to set up a defense strategy to improve its reliability.
In this context, adversarial machine learning has appeared as a new branch that aims to thwart intelligent algorithms. Many techniques called adversarial attacks succeeded in fooling well-known architectures of neural networks, sometimes very astonishingly. Examples of these methods include for instance: Fast Gradient Sign Method [
5], Basic Iterative Method [
6], Projected Gradient Descent [
7], JSMA [
8], DeepFool [
9], Universal Adversarial Perturbations [
10] and CW attacks [
11].
More formally, a neural network classifier (NNC) is an algorithm whose goal is to predict through a neural network which class an item x belongs to, among a family of K possible classes. It outputs a vector of probabilities where the label of x is deduced by the rule .
An adversarial example constructed on the item x, is an item specially crafted to be as close as possible to x (with respect to some distance function), and such that it is classified by the NNC as (Non-Targeted (NT) attack), or even such that , with L chosen by the attacker and such that (Targeted attack).
In this paper, we focus on the following class of attacks:
(or sparse) adversarial attacks. They aim at generating adversarial samples while minimising the number of modified components. Sparse perturbations can be found in many real-life situations. As motivated in [
12],
sparse perturbations could correspond to some raindrops that reflect the sun on a“STOP" sign, but that are sufficient to fool an autonomous vehicle; or a crop-field with some sparse colorful flowers that force a UAV to spray pesticide on non affected areas. This reveals very disturbing and astonishing properties of neural networks as it is possible to fool them by modifying few pixels [
12,
13]. Their study is therefore fundamental to mitigate their effects and take a step forward towards robustness of neural networks. The first proposed example of
attacks is JSMA, a targeted attack [
8]. In a computer vision application, JSMA achieved 97% adversarial success rate by modifying on average 4.02% input features per sample. [
8] relates this result to the human capacity of visually detecting changes. An important quality of JSMA is that it is easy to understand, set up and it is relatively fast. For instance, relying on its
implementation [
14], JSMA is able to generate 9 adversarial samples on the MNIST handwritten digits dataset [
15] in only 2 s on a laptop with 2 CPU cores. Speed and also the ability to run adversarial attacks with limited resources are important criteria for real-life deployment of neural networks [
16,
17,
18]. JSMA obeys these constraints making its use widespread beyond computer vision applications such as in cybersecurity, anomaly detection and intrusion detection [
19,
20,
21]. Later on, [
11] proposes the second example of targeted
attacks known as CW
. The same paper shows that unlike JSMA, CW
scales well to large datasets by considering the IMAGENET dataset [
22]. CW
is now the state-of-the-art
targeted attack with the lower average
distance. However, it is computationally-expensive, much slower than JSMA on small datasets (a factor of 20 times slower is reported in [
11]) and therefore, despite efficiency, it is less convenient for real-time applications.
Let us now briefly explain how the afore-mentioned attacks concretely work:
JSMA. To fool NNCs, this attack relies on the Jacobian matrix of outputs with respect to inputs. By analysing this matrix, one can deduce how the output probabilities behave given a slight modification of an input feature. Consider a NNC
N as before and call
the outputs of the second-to-last layer of
N (no longer probabilities, but related to the final output by a softmax layer). To generate an adversarial example from
x, JSMA first computes the gradient
. The next step is to build a saliency map and find the most salient component
i that will then be changed:
and
in these maps quantify how much
will increase and
will decrease, given a modification of the input feature
. Counting on the
’s instead of the
’s has been justified in [
8] by the extreme variations induced by the softmax layer. Then the algorithm selects the component:
and increases
by a default value
before clipping to the valid domain. The same process is iterated until the class of
x is changed or a maximum allowed number of iterations is reached. This version of JSMA will be called one-component JSMA. A second, more effective, variant of JSMA recalled later relies on doubly indexed saliency maps.
CW attack. This method is obtained as a solution to the optimisation problem (assuming the domain of inputs is
):
where
is the
distance of the perturbation
r added to
x. The recommended choice of
f is:
. Since the
distance is not convenient for gradient descent, the authors of [
11] solve this problem by making use of their
attack and an algorithm that iteratively eliminates the components without much effect on the output classification. They finally obtain an effective
attack that has a net advantage over JSMA. However, the main drawback of this attack is its high computational cost.
We summarise our main contributions as follows:
- −
For targeted misclassification, we introduce two variants of JSMA called Weighted JSMA (WJSMA) and Taylor JSMA (TJSMA). WJSMA applies a simple weighting to saliency maps by the output probabilities, and TJSMA does the same, while additionally penalising extremal input features. Both attacks are more efficient than JSMA according to several metrics (such as speed and mean
distance). We present qualitative and quantitative results on MNIST and CIFAR-10 [
23] supporting our claims. Moreover, although they are less efficient than CW
, our attacks have a major speed advantage over CW
highlighted by measuring the execution time for each attack.
- −
For non-targeted (NT) misclassification, we improve the known NT variants of JSMA called NT-JSMA and Maximal-JSMA (M-JSMA) [
24]. We do this by introducing NT and M versions of WJSMA and TJSMA. Our attacks yield better results than NT-JSMA and M-JSMA. Also, they are as competitive but significantly much faster than NT CW
. These claims are illustrated through applications to attack a deep NNC on the GTSRB dataset [
25] in the white/black-box modes.
- −
We provide a deep comparison between WJSMA and TJSMA which is of independent interest. Our study concludes that in the targeted case, TJSMA is better than WJSMA. However, in the NT case, WJSMA is preferred over TJSMA, mainly due to the simplicity of its implementation.
- −
We provide fast and optimised implementations of the new attacks using TensorFlow and the
library [
14] that might help users working in adversarial machine learning (In all our experiments, we use the original implementation of JSMA available in the
library and the original code of CW publicly available. As for the NT versions of JSMA [
24], whose implementations are not available, we re-implement these attacks using TensorFlow and
. A link to the codes is provided at the end of
Section 5.2)
The rest of the paper is organised as follows. In
Section 2, we discuss our main motivations and then introduce WJSMA and TJSMA as targeted attacks.
Section 3 is focused on NT and Maximal versions of WJSMA and TJSMA.
Section 4 is dedicated to several comparisons between our attacks, JSMA and CW
. We discuss attacking, defending with targeted/non-targeted attacks in both the white/black-box setups.
Section 5 offers a conclusion and a summary of the main results of the paper. Finally,
Appendix A and
Appendix B are appendices dedicated to supplementary results and materials.
3. Non-Targeted Attacks
NT variants of JSMA have been studied in [
24]. In particular, the paper introduces NT-JSMA-F, NT-JSMA-Z based on NT saliency maps whose role is to select the most salient pairs of components to decrease as much as possible the probability of the current class. The notations -F and -Z indicate if the saliency maps either use the
’s or the
’s. Second, [
24] proposes maximal JSMA (M-JSMA) as a more flexible attack allowing both increasing/decreasing features and also combining targeted/non-targeted strategies at the same time.
In what follows, we again leverage the idea of penalising saliency maps to give our proper NT JSMA attacks. For a unified presentation, we use the letter
X to denote either
W (Weighted) or
T (Taylor) and the letter
Y to denote either
Z (logits) or
F (probabilities). We notice that while the first version of JSMA uses the logits, variants that rely on the
’s also demonstrated good performances [
11,
24]. Thus for a more complete study, we give versions with both
Z and
F.
By a NT reasoning, similar to the previous section, we define Weighted and Taylor NT saliency maps as follows:
where, for
,
and, for
,
These maps can be motivated, like in the previous section, by considering the simple one-component case: . For example, the role of the penalisation by in is to reduce the impact of high gradients when the probability is very small (in this case we penalise choosing k as a new target for x).
Relying on saliency maps, Algorithm 3 below presents our improvements of NT-JSMA-Z and NT-JSMA-F. For the sake of simplification, we have employed a unified notation NT-XJSMA-Y. For example, when we use
, the obtained attack is NT-WJSMA-Z. Again, we only write the increasing version.
| Algorithm 3 NT-WJSMA and NT-TJSMA attacks. |
Inputs: x: input to N with label t, maxIter: maximum number of iterations, X , Y Output: : adversarial sample to x.
|
while do Modify by Remove from
end while return
|
We now turn to extensions of M-JSMA [
24]. This attack modifies the pairs of components achieving the best score among NT-JSMA and all possible targeted (including increasing and decreasing) JSMA. It has a greater capacity to craft adversarial samples but is relatively slower than NT-JSMA. Our extensions of M-JSMA, which we call M-WJSMA and M-TJSMA, are described in Algorithm 4.
| Algorithm 4 M-WJSMA and M-TJSMA attack. |
Inputs: x: input to N with label t, maxIter: maximum number of iterations, X , Y Output: : adversarial sample to x.
|
while do - Compute all targeted increasing/decreasing saliency maps scores ( Section 2) and all NT increasing/decreasing saliency maps scores ( 5). - Choose achieving the best score and saturate to or according to the chosen saliency map. - Remove from -
end while return
|
Note that saliency maps for targeted or non-targeted, features-increasing or features-decreasing attacks are exactly the same (one only needs to decide between an argmax or argmin). This is not the case for M-TJSMA since for example has to be changed to when decreasing features. As a consequence of this fact, M-WJSMA is less cumbersome to implement than M-TJSMA. Trying to keep the paper and code as simple as possible, we choose M-WJSMA over M-TJSMA and do not include M-TJSMA in our experiments. M-WJSMA already gives us satisfactory results.
4. Experiments
This section is dedicated to a variety of experiments on the proposed attacks and several comparisons with the state-of-the-art methods. The first part focuses on targeted attacks and provides intensive comparisons between JSMA, WJSMA and TJSMA on deep NNCs on MNIST and CIFAR-10 as well as comparisons with CW . In the second part, we show that our approach is still relevant for non-targeted misclassification in both the white-box and black-box modes. A particular emphasis will be put on the speed of our attacks in comparison with CW .
4.1. Experiments on Targeted Attacks
In the following, we give attack and defense applications illustrating the interest of WJSMA and TJSMA over JSMA. In doing so, we also compare WJSMA and TJSMA and report overall better results for TJSMA despite the fact that for a large part of samples WJSMA outperforms TJSMA. Finally, we provide a comparison with CW attack and comment on all the obtained results.
The datasets used in this section are:
MNIST [15]. This dataset contains 70,000
greyscale images in 10 classes, divided into 60,000 training images and 10,000 test images. The possible classes are digits from 0 to 9.
CIFAR-10 [23]. This dataset contains 60,000
RGB images. There are 50,000 training images and 10,000 test images. These images are divided into 10 different classes (airplane, automobile, bird, cat, deer, dog, frog, horse, ship, truck), with 6000 images per class.
Figure 2 and
Figure 3 display one sample per class, from MNIST and CIFAR-10 respectively.
On each dataset, a deep NNC is trained and then confronted to attacks.
NNC on MNIST. Similarly to [
8], we consider LeNet-5 model on this dataset [
26]. Its full architecture is described in
Appendix A. We implement and train this model using a
model that optimises crafting adversarial examples. The number of epochs is fixed to 20, the batch-size to 128, the learning rate to 0.001 and the Adam optimizer is used. Training results in 99.98% accuracy on the training dataset and 99.49% accuracy on the test dataset.
NNC on CIFAR-10. We consider a more complex NNC, trained to reach a good performance on this dataset. Its architecture is inspired by the All Convolutional model proposed in
and is fully described in
Appendix A. Likewise, this model is implemented and trained using
for 10 epochs, with a batch size of 128, a learning rate of 0.001 and the Adam optimizer. Training results in a 99.96% accuracy on the training dataset and 83.81% accuracy on the test dataset.
Our first objective is to compare the performances between JSMA, WJSMA and TJSMA on the previous two NNCs. To run JSMA, we use its original implementation, available in . We have also adapted the code to WJSMA and TJSMA thus obtaining fast implementations of these two attacks.
For testing, we consider all images in MNIST, the first 10,000 training and 10,000 test images of CIFAR-10. Moreover, we only test on the images which are correctly predicted by the neural networks as this makes more sense. In this way, the attacks are applied to the whole training set and the 9949 well-predicted images of the MNIST test images. Similarly, CIFAR-10 adversarial examples are crafted from the well-predicted 9995 images of the first training 10,000 images and the 8381 well-predicted test images.
To compare the three attacks, we rely on the notion of maximum distortion of adversarial samples defined as the ratio of altered components to the total number of components. Following [
8], we choose a maximum distortion of
on the adversarial samples from MNIST, corresponding to
. On CIFAR-10, we fix
in order to have the same maximum number of iterations for both experiments. This allows a comparison between the attacks in two different settings. Furthermore, for both experiments, we set
(note that
).
We report the metrics:
Success rate: This is the percentage of successful adversarial examples, i.e crafted before reaching the maximal number of iterations ,
Mean distance: This is the average number of altered components of the successful adversarial examples,
Strict dominance of an attack: Percentage of adversarial examples for which this attack does strictly fewer iterations than the two other ones (As additional results, we give in the
Appendix B more statistics on the dominance between any two attacks),
Run-time of an attack on a set of samples targeting every possible class.
Results on the metrics 1 and 2 are shown in
Table 1 for MNIST and
Table 2 for CIFAR-10.
First, we observe that overall, WJSMA and TJSMA significantly outperform JSMA according to metrics 1 and 2. Here are more comments:
On MNIST. Results in terms of success rate are quite remarkable for WJSMA and TJSMA respectively outperforming JSMA with near 9.46, 10.98 percentage points (pp) on the training set and 9.46, 11.34 pp on the test set. The gain in the average number of altered components exceeds 6 components for WJSMA and 9 components for TJSMA in both experiments.
On CIFAR-10. WJSMA and TJSMA outperform JSMA in success rate by near 9.74, 11.23 pp on the training set and more than 10, 12 pp on the test set. For both training and test sets, we report better mean distances exceeding 7 features in all cases and up to features for TJSMA on the training set.
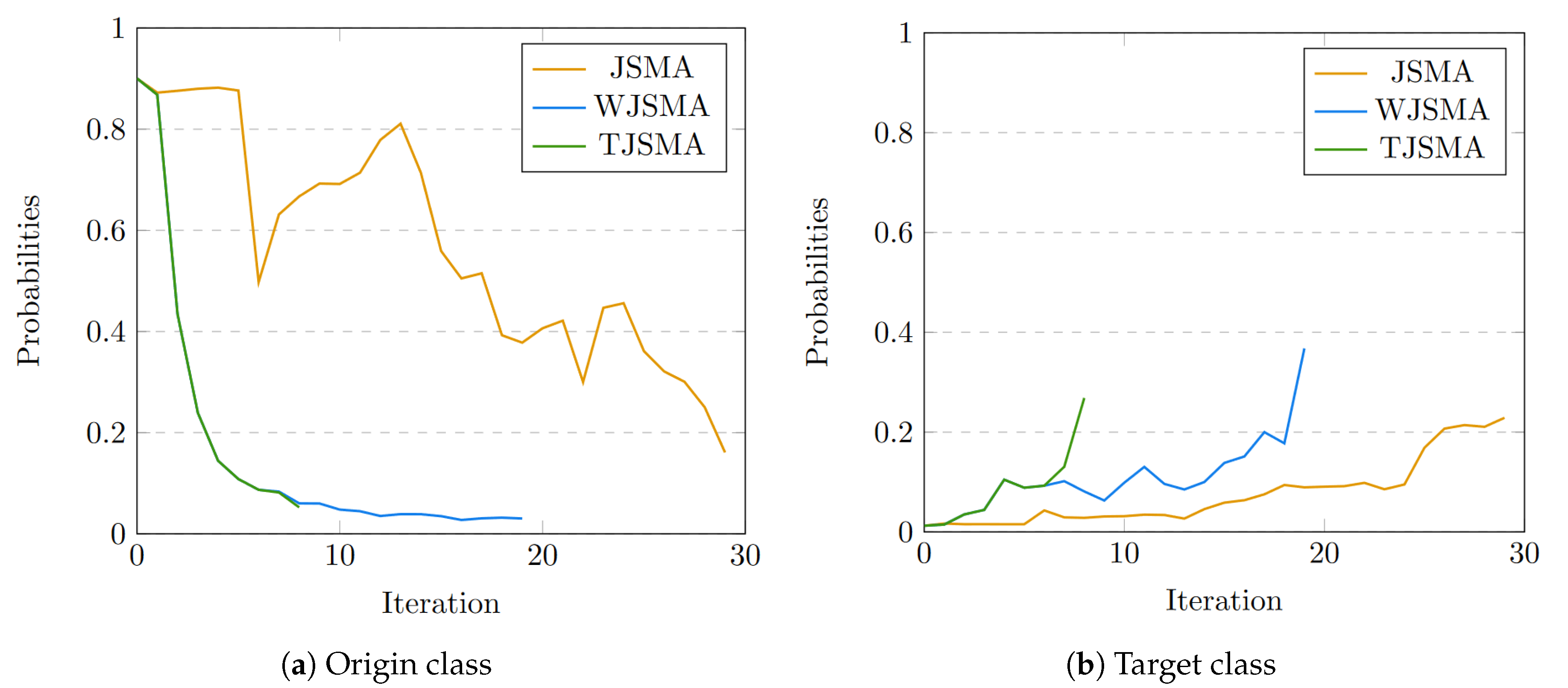
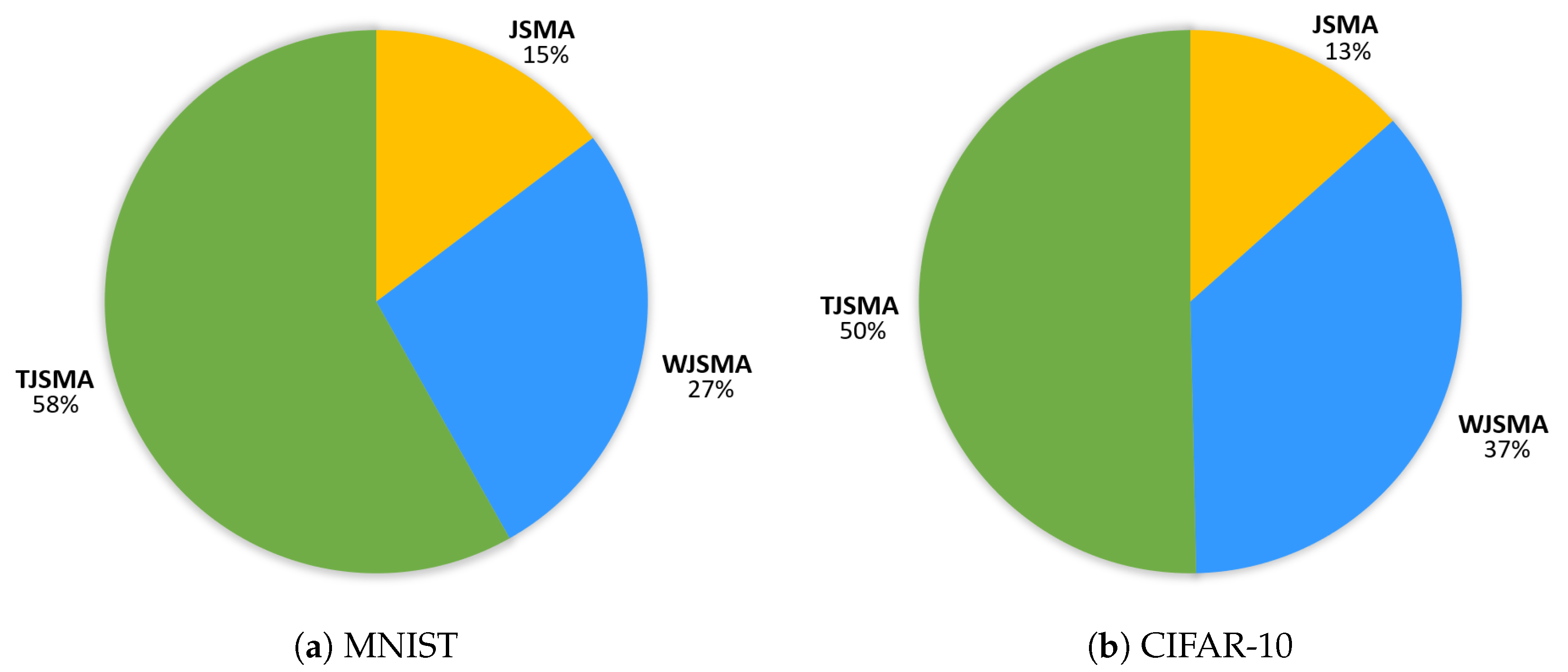
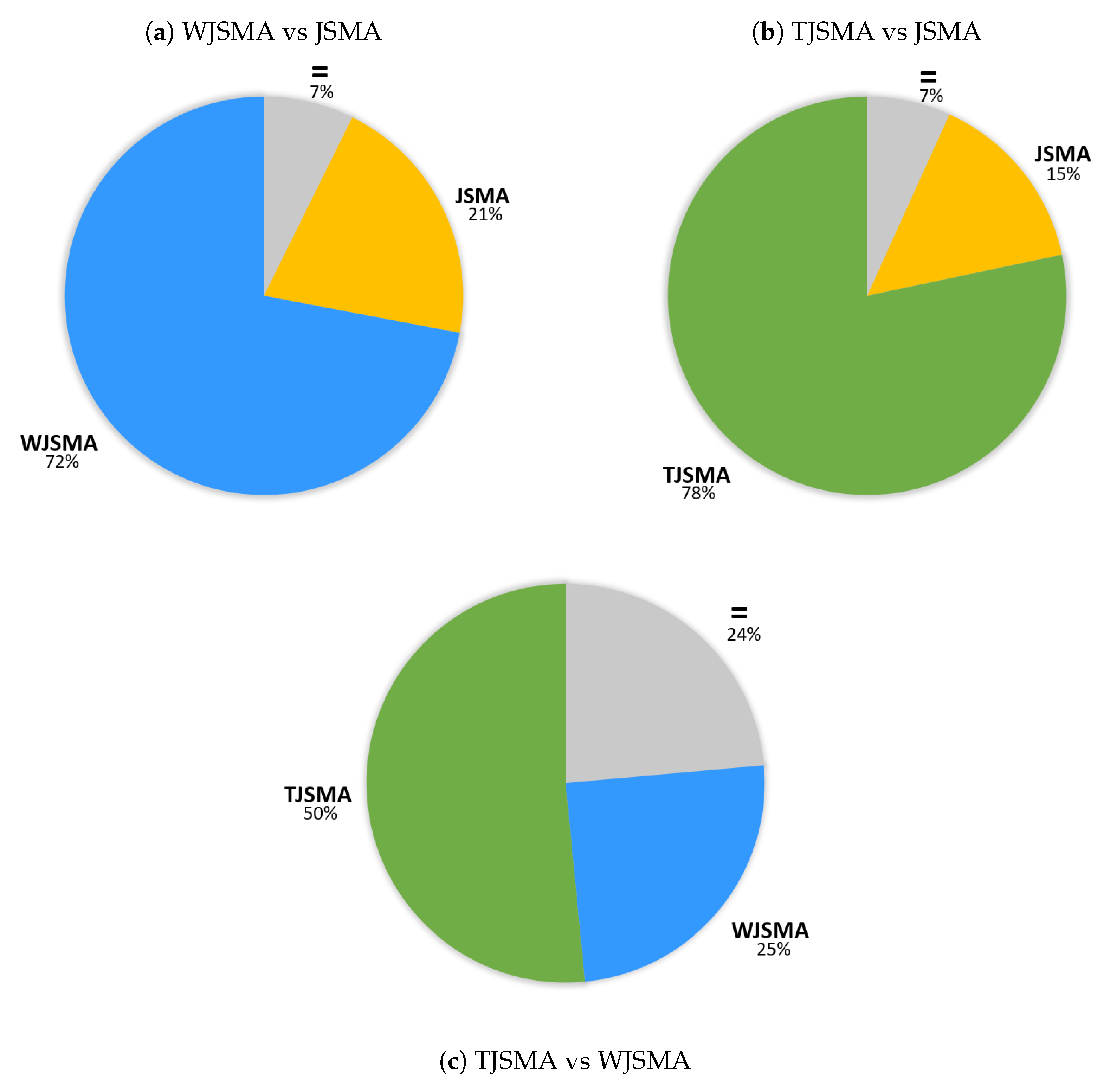
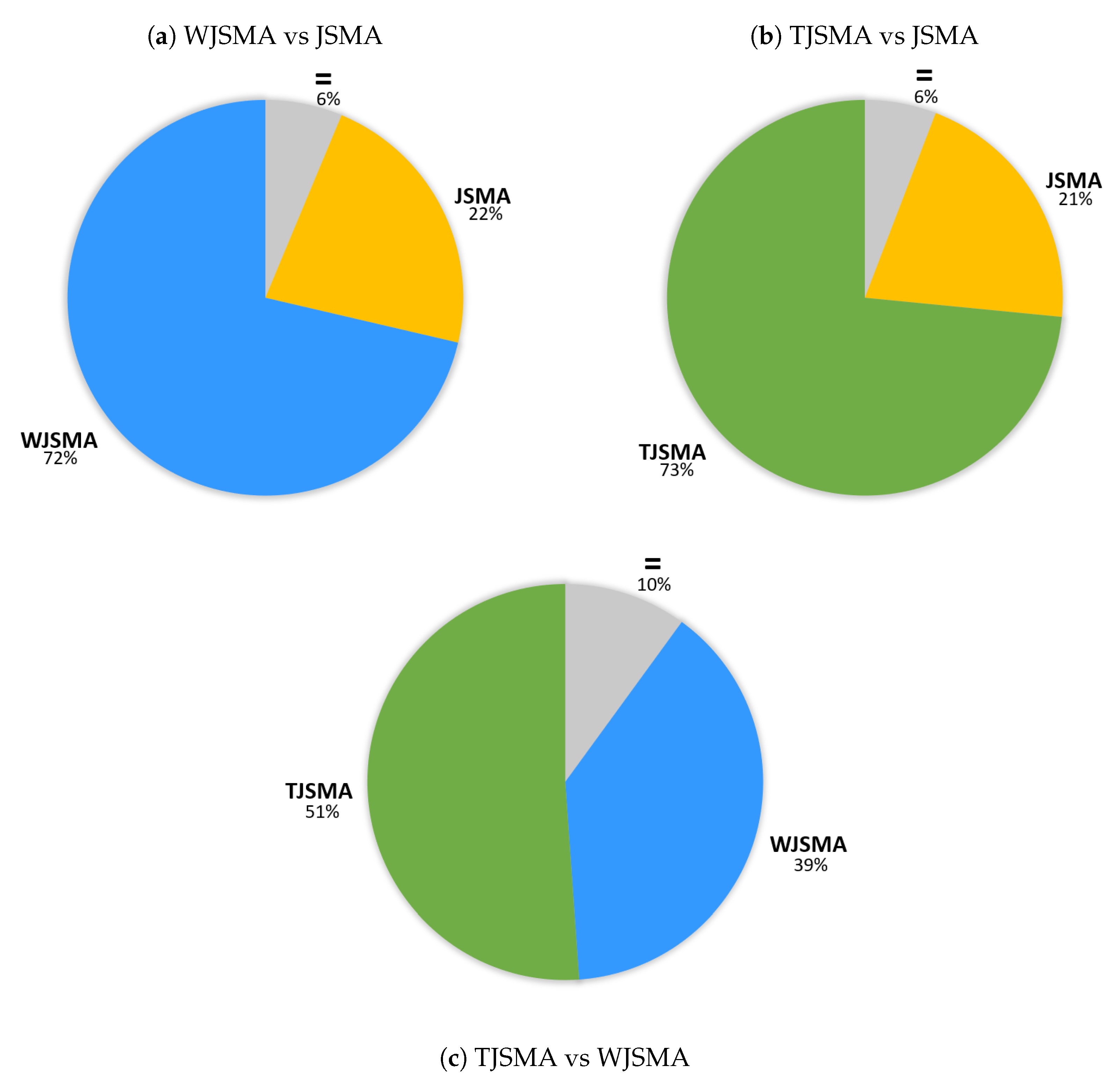
Dominance of the attacks.Figure 4 illustrates the (strict) dominance of the attacks for the two experiments. In these statistics, we do not count the samples for which TJSMA and WJSMA have the same number of iterations and strictly less than JSMA.
For both experiments, TJSMA has a notable advantage over WJSMA and JSMA. The benefit of WJSMA over JSMA is also considerable. This shows that, in most cases, WJSMA and TJSMA craft better adversarial examples than JSMA, while being faster. Our results are indeed better when directly comparing WJSMA or TJSMA with JSMA. As additional results, we give in the appendix the statistics for the pairwise dominance between the attacks. As it might be expected, both WJSMA and TJSMA dominate JSMA, moreover TJSMA dominate WJSMA.
4.1.1. Avoid Confusion
It is important to stress that our results do not contradict [
8] obtaining
success rate on LeNet-5. Indeed, we use a more efficient LeNet-5 model (the one in [
8] has
and
accuracies on the training and test sets). For completeness, we also generated a second model (with
and
accuracies on the training and test sets) and evaluated the three attacks on the first 1000 test MNIST images. We obtain
success rate for JSMA (very similar to [
8]) and more than
for WJSMA and TJSMA. We preferred to work with the more effective model as this makes the paper shorter and moreover, it values more our approach (giving us more advantage with respect to JSMA).
4.1.2. Run-Time Comparison
In order to have a meaningful speed comparison between the three attacks, we computed the time needed for each attack to successfully craft the first 1000 test MNIST images in the targeted mode. Results are shown in
Table 3 and reveal that TJSMA/WJSMA are 1.41/1.28 times faster than JSMA. These performances were measured on a machine equipped with an Intel Xeon 6126 processor and a Nvidia Tesla P100 graphics processor. Note that for WJSMA/TJSMA, the additional computations of one iteration compared to JSMA are negligible (simple multiplications). Thus the difference in speed between the attacks is mainly due to the number of iterations for each attack.
We also notice that in this evaluation, the adversarial samples were crafted one by one. In practice, it is possible to generate samples by batch. In this case, the algorithm stops when all samples are finished. Most of the time, with a batch of large size, the three attacks approximately take the same time to converge. For example, on the same machine as previously and with a batch size equal to 1000, we were able to craft the same amount of samples in about 250 s, for all the attacks.
Defense. The objective now is to train neural networks so that the attacks fail as much as possible. One way of doing this is by adding adversarial samples crafted by JSMA, WJSMA and TJSMA to the training set. This method of training may imply a decrease in the model accuracy but adversarial examples will be more difficult to generate.
We experiment this idea on the MNIST model in every possible configuration. To this end, 2000 adversarial samples per class (20,000 more images in total), with distortion under 14.5%, are added to the original MNIST training set, crafted by either JSMA, WJSMA or TJSMA. Then, three distinct models are trained on these augmented datasets. The models roughly achieve an accuracy of 99.9% on the training set and 99.3% on the test set, showing a slight loss compared to our previous MNIST model. Nevertheless, the obtained neural networks are more robust to the attacks as shown in
Table 4. Note that each experiment is made over the well-predicted samples of the test images. For each model and image, nine adversarial examples are generated by the three attacks.
Overall, the attacks are less efficient on each of these models, compared to
Table 1. The success rates drop by about 8 pp, whereas the number of iterations is increased by approximately 26%. From the defender’s point of view, networks trained against WJSMA and TJSMA give the best performance. The JSMA trained model provides the lowest success rates while the TJSMA trained network is more robust from the
distance point of view. From the attacker’s point of view, TJSMA remains the most efficient attack regardless of the augmented used dataset.
4.1.3. Comparison with CW Attack
Because of the complexity of this attack, comparison on a large number of images as before is very costly. For this reason, we only provide results on the first 100 well-predicted images of CIFAR-10, thus on 1000 adversarial images given in
Table 5.
We report better results of CW in terms of success rate and distance and a remarkable speed advantage of our attacks. Indeed, generating 9 adversarial samples (one by one) from a CIFAR-10 image by CW took on average near one hour and a half on GPU. The same task took 100 s for our attacks (without batching and 25 s when batching). This makes our attacks at least 54 times faster than CW .
4.2. Experiments on Non-Targeted Attacks
In this part, we test the new NT attacks in the white/black-box modes and compare their performances with NT-JSMA and M-JSMA. In the white-box mode, we also compare with NT CW
. For experimentation, we chose the GTSRB dataset [
25] widely used to challenge neural networks, especially in autonomous driving environments [
27]. We recall that GTSRB contains RGB
traffic signs images, 86,989 in the training set, and 12,630 in the test set classified into 43 different possible categories.
Figure 5 displays some images from this dataset.
4.2.1. White-Box Experiments
We consider a simplified NNC, described in
Appendix A, whose architecture is inspired by Alexnet [
28]. After training this model with
, it reaches 99.98% accuracy on the training dataset and 95.83% accuracy on the test set.
We implemented our attacks and those of [
24] again with TensorFlow using
. During the first experiment, we run the attacks given in
Table 6 on the first 1000 test images after taking a maximum distortion
similar to CIFAR-10. The obtained results are shown in the same table.
To analyse these results, it makes more sense to separately compare the NT-versions (faster), the M-versions (the most effective in success rate but slower) and discuss a global comparison with CW . First, we notice a significant advantage of our NT versions over NT-JSMA according to the three metrics. In particular, NT-TJSMA is up to faster than NT-JSMA with nearly less modified pixels on average and more than 5 percentage points in success rate. We also notice that NT-TJSMA is the most effective attack among the three NT versions. Its notable benefit over NT-WJSMA is due to the fact that it converges in much less iterations than NT-WJSMA while both attacks need approximately the same time for an iteration. As for the M-versions, our attack M-WJSMA outperforms M-JSMA according to the three reported metrics. Both attacks are however slower than the NT versions. Finally, we notice that the gap between our attack M-WJSMA and CW is reduced as we obtain a better success rate, achieve less than two pixels in average while being more than 40 times faster.
4.2.2. Black-Box Experiments
Here, we consider that black-box attack means the algorithm can use the targeted model as an oracle: when feeding it an image, the oracle returns a single class label. Moreover, we want to make only a limited amount of queries, which in a realistic setup would mean avoiding any suspicious activity, or at least trying not to depend too much on the oracle. To overcome this restriction, we train a substitute NNC using the Jacobian-based Dataset Augmentation (JBDA) [
27] method. We then perform white-box attacks on the substitute NNC. If it is good enough, the resulting adversarial images should
transfer to the oracle, i.e., effectively fool it even though they were designed to fool the substitute. Details about the substitute NNC architecture can be found in
Appendix A. The JBDA method allows us to make queries to the oracle only during the training of the substitute network. Black-box attacks are thus closer to real-life setups, as one only needs to access for a short period of time the targeted model before being able to durably fool it. A dangerous application of such techniques is against autonomous driving cars and their sign recognition systems. NT black-box attacks are exactly the kind of threat that can be put in practice with relative ease and still disrupt considerably the car’s behaviour. We will illustrate this insecurity through the GTSRB dataset.
Attacks in this paragraph are NT-JSMA and M-JSMA [
24], along with our contributions NT-WJSMA, NT-TJSMA and M-WJSMA. We experiment with different distortion rates. Contrary to white-box attacks, in the context of black-box attacks, the distortion rate is not an upper bound on the percentage of pixels that can be modified, but the exact percentage of pixels we want to perturb. This slight difference accounts for the imperfection of the substitute network: even if it mimics quite well the oracle, stopping as soon as the image switches according to the substitute will often not yield good results, so it is necessary to force the algorithm to push a little bit further. As a consequence, to evaluate the performance of the attacks, we will use two metrics: the success and transferability rates, for each distortion value. The first one measures the percentage of attacks that have been successful on the substitute NNC, while the second one measures the same percentage but for the oracle. The obtained results are given in
Table 7.
We can see in this table that in terms of success rate, the results are compatible with the white-box attack results, meaning that M-WJSMA mostly outperforms NT-TJSMA, which is better than NT-WJSMA which beats NT-JSMA, at least for the F variants. This is somewhat expected, because the attacks as performed on the substitute are merely white-box. However, one can notice that the Z variants of Maximal attacks do not perform well on this substitute network. More interestingly, concerning the transferability of the attacks, one can notice that for the Z attacks, the same hierarchy NT-TJSMA > NT-WJSMA > NT-JSMA is respected, while for the F attacks, NT-WJSMA is overall inferior to all the other attacks, and NT-TJSMA outperforms NT-JSMA, M-JSMA and M-WJSMA.
Overall, NT-TJSMA is the best attack for black-box non-targeted purposes, but the best variant (F or Z) depends on the distortion rate: NT-TJSMA-Z only beats its counterpart NT-TJSMA-F for or 5%. Finally, if one variant were to be chosen, it would be NT-TJSMA-F due to its speed and overall best transferability.
5. Comparisons with Non- Attacks and Conclusion
5.1. Comparison with Non- Attacks
Previously, we only compared with
attacks as it makes more sense to consider methods that optimise the same metric. In this section, we compare our NT-TJSMA with a well-known non-targeted
attack which is the Fast Gradient Sign Method (FGSM) [
5]. We recall that FGSM attempts to minimise the
norm. It is a very fast method; significantly faster than NT-TJSMA. To this end, we run both attacks by dropping the assumption on the number of modified input features for our attack and by experimenting with different values of the
threshold
for FGSM where the results of the best threshold are kept. Then, we computed the mean
and
errors for each attack as alternative comparison metrics.
Table 8 shows the obtained results.
As it can be seen, NT-TJSMA is always successful for each model, while FGSM is far from reaching SR. Moreover, NT-TJSMA obtains better and scores. Thus our attack outperforms FGSM for the SR and the and metrics, while FGSM has only the and speed advantages. Note that for FGSM we considered the best results for different thresholds, while our attack is run one time.
5.2. Conclusions
In this section, we summarise our main findings and also discuss the limitation of our work.
We have introduced WJSMA and TJSMA, new probabilistic adversarial variants of JSMA for targeted and non-targeted misclassification of deep neural network classifiers.
Experiments in the targeted case have demonstrated, after analysing a large amount of images (more than 790,000 images), that our targeted attacks are more efficient and also faster than JSMA. It is important to recall the quite natural derivation of these attacks from a simple and classical log softmax reasoning which has not been noticed before. Our attacks do not beat CW but have an important speed advantage highlighted in the paper (more than 50 times faster on CIFAR-10). Therefore, for targeted misclassification, they offer substantial tools to test neural networks in real-time. This fact is supported by our fast implementation provided with the paper.
As a second contribution, we have introduced NT and M variants of WJSMA/TJSMA and have shown that they outperform the previous NT and M versions of JSMA. Through experiments on GTSRB, we noticed that the gap between our attacks and CW in average is reduced. Moreover, we obtained better success rates, while remaining at least 40 times faster than CW .
In the NT part of the paper, we did not compare our attacks with the one pixel attack [
13]. Indeed, this approach has a high computational cost and we only claim an advantage in speed which is quite evident for us (see also the time evaluation in [
12]). Also, we did not provide a comparison with SparseFool [
12] an effective NT
attack because of the need to reimplement this attack with TensorFlow. On CIFAR-10, [
12] found that crafting an example by SparseFool takes on average 0.34 and 0.69 s on two different neural networks. Our speed performances are very competitive with these values. Indeed, on GTSRB which has many more classes than CIFAR-10, our NT-TJSMA was able to craft an example in near 0.68 s on average (counting only successful images). Thus, regarding SparseFool, we first claim competitive results in speed. Second, our results obtained on LeNet-5 (more than 99.5% on a model similar to [
12], see
Section 4.1.1) are very close to [
12] although we only run the attacks up to a limited maximum number of iterations contrary to [
12].
Overall, our results suggest that for adversarial purposes, TJSMA, M-WJSMA and NT-TJSMA should be preferred over the original variants of JSMA, respectively in the case of white-box targeted attacks, white-box non-targeted attacks, and black-box non-targeted attacks. We recall that despite the fact that TJSMA is a more elaborate version of WJSMA, it is hardly compatible with the “Maximal” approach, which in turn proves to be very efficient for non-targeted purposes. For this reason, as we have demonstrated, M-WJSMA is indeed the right choice for this type of attacks. On the other hand, because the “Maximal” approach has not proved to be very efficient on black-box non-targeted attacks, it is the non-targeted version of TJSMA (NT-TJSMA) that is the best in this case.
Finally, we should mention that despite improving JSMA in different ways, like JSMA, our approach is still not scalable to large datasets. This is because of the high computational cost of saliency maps when the dimension of inputs becomes large. Our approach is therefore intended for “small” datasets such as those considered in the paper. Nevertheless, this kind of datasets is very common in real-life applications. Codes are publicly available through the
Supplementary Materials.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






