Challenges of Machine Learning Applied to Safety-Critical Cyber-Physical Systems



{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Related Work
3. Safety and Machine Learning
3.1. Safety
3.2. Machine Learning and Notations
3.3. Safety in Machine Learning
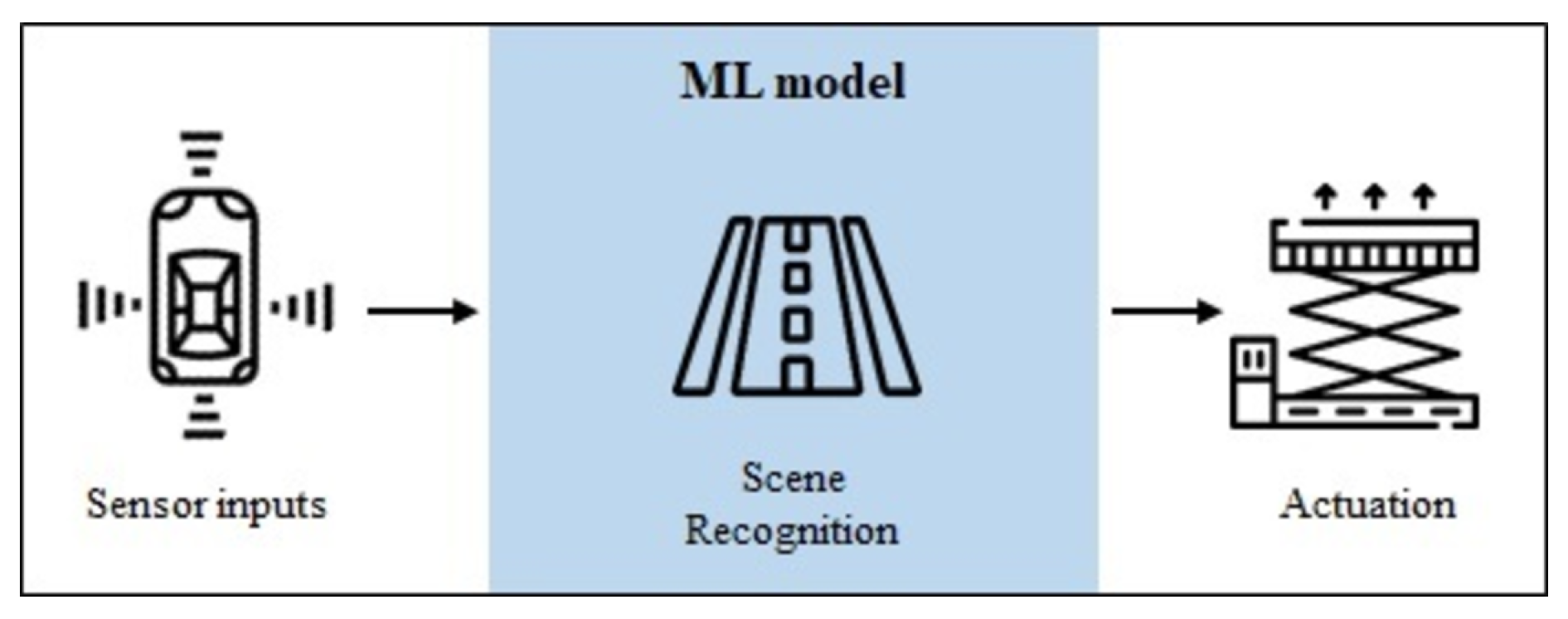
3.4. Example Application
4. Machine Learning Lifecycle
4.1. Requirements
4.1.1. Activities
- Data Management: Requirements focused on defining the desired dataset according to the use case. Identification of all possibly relevant sources of data that may help the ML system to provide accurate and robust results. The definition of the data will impact the dataset distribution and the ML model effectiveness to generalize.
- Model Development: Requirements focused on the objective/loss function and performance measures definition. Definition and discussion of the performance measures and expectations by which the ML system shall be assessed. As mentioned by Vogelsang et al. [48], performance measures such as accuracy, precision, or recall are not well understood by customers. On the other hand, the adequacy of the measures depends on the problem domain. Therefore, requirements should consider the demands of the stakeholders by translating them to the appropriate measures.
- Model Testing and Verification: Definition of testing and verification requirements related with performance metrics, fault tolerance, and scenario coverage. Here it is important to clarify which scenarios should be tested, which performance metrics should be achieved, and which faults the systems should tolerate.
- Model Deployment: Specifications of conditions for data anomalies that may potentially lead to unreasonable or non-safe behavior of the ML system during runtime. The specification should also contain statements about the expected predictive power: performance on the training data can be specified as expected performance that can immediately be checked after the training process, whereas the performance at runtime (i.e., during operations) can only be expressed as desired performance that must be assessed during operation.
4.1.2. Hazard Identification
- Incomplete definition of data. When defining the operation mode of an ML-based system it is important to have a complete definition of all data examples in order to avoid future problems on the dataset distribution, which will surface during the Data Management phase. This assumes that humans can correctly identify all varying conditions at requirement specification time, which is a difficult mark to achieve.
- Incorrect objective function definition. One of the requirements that needs to be defined is the objective function, that is, the loss function that needs to be minimized. The definition of this function could cause different problems in case the wrong objective function is defined, or that some undesirable behavior occurs during the learning process. The incorrect definition of the objective function could potentially harm any ML-based system, since its maximization leads to harmful results, even in the limit of perfect learning and infinite data. This could happen when the designer/requirements engineer specifies an objective function that focuses on accomplishing some specific task in the potentially very large environment, but ignores other aspects of it. By doing that, it implicitly expresses indifference over environmental variables that might actually be harmful to change, resulting in negative side effects specifically if human safety is not correctly accounted for.
- Inadequate performance measure. The definition of the performance measures happens during this phase and it will have a direct impact on model training during the Model Development phase and ultimately on the delivered model. Although there exist several measures that can be used for evaluating the performance of ML algorithms, most of these measures focus mainly on some properties of interest in the domains where they were developed. According to a specific system, different predictions can be of great importance in safety-critical systems, and deciding which measure we want to optimize will influence the system behavior.
- Incompleteness on testing/verification. The definition of the entire necessary testing and verification scenarios may not be complete, and/or values to be achievable for different metrics may not be correctly defined. For both cases, incompleteness in the quantity and quality (i.e., threshold values for metrics) could lead to safety hazards (e.g., error rate, execution time).
- Inadequate safe operating values. During the Model Deployment phase, the monitoring of outputs requires the definition of some kind of “measure of confidence” and/or a “comparison to reasonable values” in order to detect incorrect outputs. The inadequate definition and/or implementation of this requirement could potentially provoke a safety hazard.
4.2. Data Management
4.2.1. Activities
4.2.2. Hazard Identification
- Inadequate distribution. Real-world data are usually imbalanced and it is one of the main causes for the decrease of generalization in ML algorithms [60]. As already mentioned in the Requirements phase, distribution problems may occur when the definition of the requirements for the dataset are not complete. Several other aspects of the distributions can contribute to a safety hazard. First, if the distribution of the training examples does not adequately represent the probability distribution of (e.g., due to lost or corrupted data), the learned hypothesis H may be susceptible to failure [11]. Additionally, the distribution of input variables can also be different between training and the operating environment. This issue is called covariate/distribution shift, which is one form of epistemic uncertainty [21]. ML algorithms assume that training and operating data are drawn from the same distribution, making algorithms sensitive even to small distribution drifts. Moreover, datasets are not complete when rare examples are absent or under-represented due to their small probability density (they were probably not anticipated when acquiring data), which could yield a substantial mishap risk [11,20]. Here, rare examples could be divided into corner cases (i.e., infrequent combinations) and edge cases (i.e., combinations that behave unexpectedly, so the system does not perform as required/expected) [61]. For these cases, the learned function h will be completely dependent on an inductive bias encoded through H rather than the uncertain true distribution, which could introduce a safety hazard. Additionally, edge cases also incorporate adversarial attacks, where deliberated actions are taken by an adversary, which manages to modify input data in order to provoke incorrect outputs and harm the system and the surroundings [62]. Despite adversarial attacks happening only during the Model Deployment phase, not considering adversarial inputs as part of the dataset could potentially cause some harm later on in the lifecycle. For that reason, this hazard is being presented here, since the dataset acquired should account for input examples of possible adversarial attacks in order to prevent a future safety hazard. Furthermore, other sources that affect distribution rely on datasets that were obtained synthetically, which could impact distribution by not accounting for real-world scenarios, or by introducing some bias if they generate inputs with frequent features (e.g., all generated examples containing the same background color or noise). All the hazards presented above are mostly connected with data collection activity. Other possible hazards affecting distribution are introduced during data preprocessing, for the case where the partition of the dataset into train, validation, and test set is not done correctly and affects distribution.
- Insufficient dataset size. First, as ML is used in new applications, it is common that there is not enough training data. Traditional applications, like machine translation or object detection, have massive amounts of training data that have been accumulated over decades. On the other hand, more recent applications have little or no training data. It takes a lot of data for most ML algorithms to work properly and generalize well on unseen data. Even for very simple problems, thousands of examples could be needed, and for complex problems such as image or speech recognition, millions of examples may be required [36]. Size is connected with distribution, since having a small dataset directly influences the distribution and total coverage of all possible cases. The dataset has to have a minimum size in order to be representative and adequately distributed. ML models can overfit if the dataset is too small (i.e., the case of high variance, where variance is defined as the difference in performance on the training set vs. the test set). Even if a dataset is adequately distributed if it is too small, the model has only a small number of cases to learn from, which will affect its general performance and potentially cause a safety hazard.
- Bias. There are different types of bias that could be introduced when data are collected to train and test a model. Considering the dataset distribution mentioned above, when examples are missing in a dataset, we are introducing sample bias. Here, the variety and amount of samples collected will introduce bias on the model if the samples are not representative. Data examples could also come from different sources, so we should also keep in mind that if all the samples of training and/or testing sets come from the same source, we could be introducing measurement bias. Other types of bias connected with distribution is confirmation bias [63]. This type of bias happens when we focus on information that confirms already held perceptions. That is, samples might have some features that appear together on the collected data but their connection has no meaning in the real-world. This way, ML models could learn incorrect features to make a prediction because they seem to be correlated for some random reason (i.e., they keep showing up together on samples). Additionally, during data prepossessing, some important samples and features could be removed, which contributes to exclusion bias.
- Irrelevance. The data acquired contains extraneous and irrelevant information, ML algorithms may produce less accurate and understandable results, or may fail to discover anything of use at all. Relevance here considers the intersection between the dataset and the desired behavior in the intended operational domain [16].
- Quality deficiencies. Each activity of the Data Management phase affects data quality. First, during data collection, all kinds of data collected (based on sensors but also on human input) are limited in their accuracy and can be potentially affected by various types of quality issues. This property can also be defined as accuracy, since it considers how measurement (and measurement-like) issues can affect the way that samples reflect the intended operational domain, covering sensor accuracy [16]. Next, during data annotation, quality could be compromised due to the incorporation of incorrect labels or incorrectly annotated area, since it is a task mainly performed by humans. During preprocessing, different techniques such as rescaling, filtering, and normalization contribute to a delta between the quality of the cleaned data and the data on which the model is currently being applied, which contributes to uncertainty [22]. Lastly, during data augmentation, the inclusion of non-realistic examples could affect dataset quality by using augmentation techniques, which generate data that do not make sense and change the complete meaning in a sample.
4.3. Model Development
4.3.1. Activities
4.3.2. Hazards Identification
- Model mismatch. During the model selection activity, the selected ML model or the model architecture does not fit the use case application, not fully covering the requirements defined. The choice of a particular model depends on the size of the training data, number of relevant features, linearity (if classes can be separated by a straight line), the goal for an interpretable or accurate model (trade-off between accuracy and interpretability), and the time and resources for training [68]. Additionally, model selection could also be affected by the computational power required to train a model. To reduce computational costs, the complexity of the models selected is restricted, which commonly leads to a decrease in model performance. Therefore, in some cases a trade-off may be required when the computational power is limited to some extent [16], which is related to the model mismatch hazard.
- Bias. The bias introduced in this phase is called algorithm bias, and it comes from the model selection activity. This bias is a mathematical property of an algorithm.
- (Hyper) Parameters mismatch. The methodology for selection and initialization of the model parameters or the training hyperparameters has a high impact on model performance. This happens because the same training process can produce different training results, since there are several techniques for model weights initialization and hyperparameter tuning.
- Performance measure mismatch. The selection of the adequate performance measures happens during the Requirements phase, as mentioned in Section 4.1; however, the impact of its definition takes effect during the Model Development phase, specifically during model training. If there is a mismatch between the selected performance measure(s) and the requirements, the ML model could be inadequately optimized during training.
- Error rate. Although an estimate of the true error rate is an output of the ML development process, there is only a statistical guarantee about the reliability of this estimate. Even if the estimation of the true error rate was accurate, it may not reflect the error rate that the system actually experiences while in operation after a finite set of inputs, since the true error is based on an infinite set of samples [23]. Additionally, the probability of failing is intrinsic to an ML model. The system is not able to ensure the complete correctness of an ML module output in the user environment where unexpected input occurs sporadically. Furthermore, wrong predictions could happen; however, there is not an impact in the system behavior (model “silently” fails) compromising the definition of safety-critical scenarios, which could later become a problem.
- Lack of interpretability. The process of integrating machines and algorithms into peoples daily lives requires inseparability to increase social acceptance [69]. Interpretability in ML supports assurance [16] since it provides evidence for: (1) justifying results (i.e., explanation of a decision for a specific outcome, particularly when unexpected decisions are made. and also justifications in order to be compliant with legislation); (2) preventing things from going wrong and identifying and correcting errors (i.e., the understanding about the system behavior provides greater visibility over unknown vulnerabilities and flaws); (3) assisting model improvement (i.e., a model that can be explained and understood is one model that can be more easily improved); and (4) supporting the understanding of the operational domain (i.e., a helpful tool to learn new facts, gather information, and thus to gain knowledge) [69]. ML and DL models can have millions or billions of parameters, and the most successful constructs are very complex and difficult to understand or explain [70]. Interpretability does not ensure safety by itself, but can help to understand where models are failing. Therefore, non-interpretable models may not constitute a hazard, we consider that it is important to mention its influence at this phase.
4.4. Model Testing and Verification
4.4.1. Activities
4.4.2. Hazards Identification
- Incompleteness. The definition of testing/verification requirements can be inadequate and/or not sufficient. As mentioned before, this step is performed during the Requirements but it impacts the Model Testing and Verification phase. Other important aspects related to incompleteness is the case of limited test scenarios. Due to the large input space, it is difficult to test or approximate all possible inputs (the unknown is never tested). This way, the ML model only encounters a finite number of test samples and the actual operational risk is an empirical quantity of the test set. Thus, the operational risk may be much larger than the identifiable actual risk for the test set, not being representative of the real-world operation performance [21].
- Non-representative distribution. Keeping the goal of achieving a certain performance, the test set should also be adequately distributed, in order to cover a balanced number of all the possible scenarios (the ones we can think of). This hazard distinguishes itself from the previous, since it assumes that the amount of test scenarios is enough, and it is mainly concerned with its distribution (the need to make accurate predictions in a representative/well distributed set).
4.5. Model Deployment
4.5.1. Activities
4.5.2. Hazards Identification
- Differences in computation platforms. Deploying a model into a device can result in computation limitations and compatibility issues across platforms. For example, for a neural network, which is mostly developed and trained on servers or computers with Graphic Processing Unit (GPU) support, when it needs to be deployed on a mobile device or edge device with limited computation power, the software must be adjusted for computation/energy efficiency, which could lead to computation differences affecting system behavior (e.g., time performance).
- Operational environment. Differences between the operational environment and data used for model development and testing, can lead to different/new inputs that affect the output produced. This could happen due to several reasons: (1) failure on one of the subsystems that provide inputs to the deployed ML model, (2) deliberate actions of an adversary; and (3) changes in the underlying processes to which the data are related (changes on the environment or on the way people or other systems behave) [16].
- Non detection of potentially incorrect outputs. An ML model may produce an incorrect output when it is used outside the intended operational domain, which could be detected during monitoring. For that purpose, ML-based systems calculate a “measure of confidence” (mentioned in the Requirements phase as the inadequate safe operating values hazard). If this value is incorrectly defined and/or implemented, its consequences are felt during the Model Deployment phase, where there is a non-safe confidence in the model and potentially incorrect outputs may not be detected.
- New data/Continuous learning. This hazard only considers the case of online learning (i.e., systems that continue to learn parameters and train the model during operation). Despite the fact that the incorporation of new data from the real operation domain suggests improving the model performance, since new data are added to the model training, the dataset distribution could be biased and it is no longer supervised, susceptible to result in lower model performance in scenarios that are no longer as frequent on the new data (e.g., a self-driving vehicle that was trained before operation on an adequate distributed dataset is now operating only at dark scenarios; for this case, the model could start to be optimized for dark conditions and to behave less accurate in the remaining day time scenarios).
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Dreossi, T.; Donzé, A.; Seshia, S.A. Compositional falsification of cyber-physical systems with machine learning components. J. Autom. Reason. 2019, 63, 1031–1053. [Google Scholar] [CrossRef] [Green Version]
- Shi, J.; Wan, J.; Yan, H.; Suo, H. A survey of cyber-physical systems. In Proceedings of the 2011 International Conference on Wireless Communications and Signal Processing (WCSP), Nanjing, China, 9–11 November 2011; pp. 1–6. [Google Scholar]
- Lu, Y. Cyber physical system (CPS)-based industry 4.0: A survey. J. Ind. Integr. Manag. 2017, 2, 1750014. [Google Scholar] [CrossRef]
- Zheng, P.; Sang, Z.; Zhong, R.Y.; Liu, Y.; Liu, C.; Mubarok, K.; Yu, S.; Xu, X.; Wang, H. Smart manufacturing systems for Industry 4.0: Conceptual framework, scenarios, and future perspectives. Front. Mech. Eng. 2018, 13, 137–150. [Google Scholar] [CrossRef]
- Thoben, K.D.; Wiesner, S.; Wuest, T. “Industrie 4.0” and smart manufacturing-a review of research issues and application examples. Int. J. Autom. Technol. 2017, 11, 4–16. [Google Scholar] [CrossRef] [Green Version]
- Heng, S. Industry 4.0: Upgrading of Germany’s Industrial Capabilities on the Horizon. 2014. Available online: https://ssrn.com/abstract=2656608 (accessed on 14 November 2020).
- Robla-Gómez, S.; Becerra, V.M.; Llata, J.R.; Gonzalez-Sarabia, E.; Torre-Ferrero, C.; Perez-Oria, J. Working together: A review on safe human-robot collaboration in industrial environments. IEEE Access 2017, 5, 26754–26773. [Google Scholar] [CrossRef]
- Oyekan, J.O.; Hutabarat, W.; Tiwari, A.; Grech, R.; Aung, M.H.; Mariani, M.P.; López-Dávalos, L.; Ricaud, T.; Singh, S.; Dupuis, C. The effectiveness of virtual environments in developing collaborative strategies between industrial robots and humans. Robot. Comput. Integr. Manuf. 2019, 55, 41–54. [Google Scholar] [CrossRef]
- Evjemo, L.D.; Gjerstad, T.; Grøtli, E.I.; Sziebig, G. Trends in Smart Manufacturing: Role of Humans and Industrial Robots in Smart Factories. Curr. Robot. Rep. 2020, 1, 35–41. [Google Scholar] [CrossRef] [Green Version]
- Gharib, M.; Lollini, P.; Botta, M.; Amparore, E.; Donatelli, S.; Bondavalli, A. On the Safety of Automotive Systems Incorporating Machine Learning Based Components: A Position Paper. In Proceedings of the 48th Annual IEEE/IFIP International Conference on Dependable Systems and Networks Workshops (DSN-W), Luxembourg, 25–28 June 2018; pp. 271–274. [Google Scholar]
- Faria, J.M. Machine learning safety: An overview. In Proceedings of the 26th Safety-Critical Systems Symposium, York, UK, 6–8 February 2018. [Google Scholar]
- Amodei, D.; Olah, C.; Steinhardt, J.; Christiano, P.; Schulman, J.; Mané, D. Concrete problems in AI safety. arXiv 2016, arXiv:1606.06565. [Google Scholar]
- Serban, A.C. Designing Safety Critical Software Systems to Manage Inherent Uncertainty. In Proceedings of the 2019 IEEE International Conference on Software Architecture Companion (ICSA-C), Hamburg, Germany, 25–29 March 2019; pp. 246–249. [Google Scholar]
- Hains, G.J.; Jakobsson, A.; Khmelevsky, Y. Formal methods and software engineering for DL. Security, safety and productivity for DL systems development. arXiv 2019, arXiv:1901.11334. [Google Scholar]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: New York, NY, USA, 2006. [Google Scholar]
- Ashmore, R.; Calinescu, R.; Paterson, C. Assuring the machine learning lifecycle: Desiderata, methods, and challenges. arXiv 2019, arXiv:1905.04223. [Google Scholar]
- Kumeno, F. Sofware engneering challenges for machine learning applications: A literature review. Intell. Decis. Technol. 2020, 13, 463–476. [Google Scholar] [CrossRef] [Green Version]
- Jenn, E.; Albore, A.; Mamalet, F.; Flandin, G.; Gabreau, C.; Delseny, H.; Gauffriau, A.; Bonnin, H.; Alecu, L.; Pirard, J.; et al. Identifying Challenges to the Certification of Machine Learning for Safety Critical Systems. In Proceedings of the 10th European Congress on Embedded Real Time Systems (ERTS), Toulouse, France, 29–31 January 2020. [Google Scholar]
- G-34, Artificial Intelligence in Aviation. Available online: https://www.sae.org/works/committeeHome.do?comtID=TEAG34 (accessed on 22 October 2020).
- Varshney, K.R. Engineering safety in machine learning. In Proceedings of the 2016 Information Theory and Applications Workshop (ITA), La Jolla, CA, USA, 31 January–5 February 2016; pp. 1–5. [Google Scholar]
- Varshney, K.R.; Alemzadeh, H. On the safety of machine learning: Cyber-physical systems, decision sciences, and data products. Big Data 2017, 5, 246–255. [Google Scholar] [CrossRef] [PubMed]
- Kläs, M.; Vollmer, A.M. Uncertainty in machine learning applications: A practice-driven classification of uncertainty. In International Conference on Computer Safety, Reliability, and Security; Springer: Västerås, Sweden, 2018; pp. 431–438. [Google Scholar]
- Salay, R.; Queiroz, R.; Czarnecki, K. An analysis of ISO 26262: Using machine learning safely in automotive software. arXiv 2017, arXiv:1709.02435. [Google Scholar]
- Borg, M.; Englund, C.; Wnuk, K.; Duran, B.; Levandowski, C.; Gao, S.; Tan, Y.; Kaijser, H.; Lönn, H.; Törnqvist, J. Safely entering the deep: A review of verification and validation for machine learning and a challenge elicitation in the automotive industry. arXiv 2018, arXiv:1812.05389. [Google Scholar] [CrossRef] [Green Version]
- Henriksson, J.; Borg, M.; Englund, C. Automotive Safety and Machine Learning: Initial Results from a Study on How to Adapt the ISO 26262 Safety Standard. In Proceedings of the 2018 IEEE/ACM 1st International Workshop on Software Engineering for AI in Autonomous Systems (SEFAIAS), Gothenburg, Sweden, 28 May 2018; pp. 47–49. [Google Scholar]
- Koopman, P.; Fratrik, F. How many operational design domains, objects, and events? In Proceedings of the SafeAI@ AAAI, Honolulu, HI, USA, 27 January 2019. [Google Scholar]
- Schwalbe, G.; Schels, M. A Survey on Methods for the Safety Assurance of Machine Learning Based Systems. In Proceedings of the 10th European Congress on Embedded Real Time Software and Systems (ERTS 2020), Toulouse, France, 29–31 January 2020. [Google Scholar]
- Ma, L.; Juefei-Xu, F.; Xue, M.; Hu, Q.; Chen, S.; Li, B.; Liu, Y.; Zhao, J.; Yin, J.; See, S. Secure deep learning engineering: A software quality assurance perspective. arXiv 2018, arXiv:1810.04538. [Google Scholar]
- Aravantinos, V.; Diehl, F. Traceability of deep neural networks. arXiv 2018, arXiv:1812.06744. [Google Scholar]
- Avizienis, A.; Laprie, J.; Randell, B.; Landwehr, C. Basic concepts and taxonomy of dependable and secure computing. IEEE Trans. Dependable Secur. Comput. 2004, 1, 11–33. [Google Scholar] [CrossRef] [Green Version]
- Smith, D.; Simpson, K. Functional Safety; Routledge: London, UK, 2004. [Google Scholar]
- Möller, N.; Hansson, S.O. Principles of engineering safety: Risk and uncertainty reduction. Reliab. Eng. Syst. Saf. 2008, 93, 798–805. [Google Scholar] [CrossRef]
- Möller, N. The concepts of risk and safety. In Handbook of Risk Theory: Epistemology, Decision Theory, Ethics, and Social Implications of Risk; Springer: Dordrecht, The Netherlands, 2012; Volume 1. [Google Scholar]
- Leveson, N.G. Engineering a Safer World: Systems Thinking Applied to Safety; The MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Kelly, T. Arguing Safety—A Systematic Approach to Safety Case Management. Ph.D. Thesis, Department of Computer Science, University of York, York, UK, 1998. [Google Scholar]
- Géron, A. Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems; O’Reilly Media: Newton, MA, USA, 2019. [Google Scholar]
- Witten, I.H.; Frank, E. Data mining: Practical machine learning tools and techniques with Java implementations. ACM Sigmod Rec. 2002, 31, 76–77. [Google Scholar] [CrossRef]
- Dey, A. Machine learning algorithms: A review. Int. J. Comput. Sci. Inf. Technol. 2016, 7, 1174–1179. [Google Scholar]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. An Introduction to Statistical Learning; Springer: Berlin/Heidelberg, Germany, 2013; Volume 112, ISBN 978-1-4614-7138-7. [Google Scholar]
- Patterson, J.; Gibson, A. Deep Learning: A Practitioner’s Approach; O’Reilly Media, Inc.: Newton, MA, USA, 2017. [Google Scholar]
- International Standards Organization. ISO 26262:2018-12: Road Vehicles—Functional Safety; International Standards Organization: Geneva, Switzerland, 2018. [Google Scholar]
- The International Electrotechnical Commission. IEC 61508:2010: Functional Safety of Electrical/Electronic/ Programmable Electronic Safety-Related Systems; The International Electrotechnical Commission: Geneva, Switzerland, 2010. [Google Scholar]
- SAE International. ARP4754A:2010: Guidelines for Development of Civil Aircraft and Systems; SAE International: Warrendale, PA, USA, 2010. [Google Scholar]
- Küpper, D.; Lorenz, M.; Kuhlmann, K.; Bouffault, O.; Heng, L.Y.; Van Wyck, J.; Köcher, S.; Schlagete, J. AI in the Factory of the Future. The Ghost in the Machine; The Boston Consulting Group: Boston, MA, USA, 2018. [Google Scholar]
- Ansari, F.; Erol, S.; Sihn, W. Rethinking Human-Machine Learning in Industry 4.0: How Does the Paradigm Shift Treat the Role of Human Learning? Procedia Manuf. 2018, 23, 117–122. [Google Scholar] [CrossRef]
- Kato, S.; Takeuchi, E.; Ishiguro, Y.; Ninomiya, Y.; Takeda, K.; Hamada, T. An Open Approach to Autonomous Vehicles. IEEE Micro 2015, 35, 60–68. [Google Scholar] [CrossRef]
- Zaharia, M.; Chen, A.; Davidson, A.; Ghodsi, A.; Hong, S.; Konwinski, A.; Murching, S.; Nykodym, T.; Ogilvie, P.; Parkhe, M.; et al. Accelerating the Machine Learning Lifecycle with MLflow. IEEE Data Eng. Bull. 2018, 41, 39–45. [Google Scholar]
- Vogelsang, A.; Borg, M. Requirements Engineering for Machine Learning: Perspectives from Data Scientists. In Proceedings of the 2019 IEEE 27th International Requirements Engineering Conference Workshops (REW), Jeju Island, Korea, 23–27 September 2019; pp. 245–251. [Google Scholar]
- Ishikawa, F.; Yoshioka, N. How Do Engineers Perceive Difficulties in Engineering of Machine-Learning Systems?—Questionnaire Survey. In Proceedings of the 2019 IEEE/ACM Joint 7th International Workshop on Conducting Empirical Studies in Industry (CESI) and 6th International Workshop on Software Engineering Research and Industrial Practice (SER IP), Montreal, QC, Canada, 28 May 2019; pp. 2–9. [Google Scholar]
- Davis, A.M. Software Requirements: Objects, Functions, and States; Prentice-Hall, Inc.: Upper Saddle River, NJ, USA, 1993. [Google Scholar]
- Ellims, M.; Barbier, E.; Botham, J. Safety Analysis Process for Machine Learning in Automated Vehicle Software. In Proceedings of the 26th ITS World Congress, Singapore, 21–25 October 2019. [Google Scholar]
- Gharib, M.; Bondavalli, A. On the Evaluation Measures for Machine Learning Algorithms for Safety-Critical Systems. In Proceedings of the 2019 15th European Dependable Computing Conference (EDCC), Naples, Italy, 17–20 September 2019; pp. 141–144. [Google Scholar]
- Reschka, A. Safety concept for autonomous vehicles. In Autonomous Driving; Springer: Berlin/Heidelberg, Germany, 2016; pp. 473–496. [Google Scholar]
- Roh, Y.; Heo, G.; Whang, S.E. A Survey on Data Collection for Machine Learning: A Big Data—AI Integration Perspective. IEEE Trans. Knowl. Data Eng. 2019. [Google Scholar] [CrossRef] [Green Version]
- Xiao, H.; Rasul, K.; Vollgraf, R. Fashion-mnist: A novel image dataset for benchmarking machine learning algorithms. arXiv 2017, arXiv:1708.07747. [Google Scholar]
- Chen, X.; Fang, H.; Lin, T.Y.; Vedantam, R.; Gupta, S.; Dollár, P.; Zitnick, C.L. Microsoft coco captions: Data collection and evaluation server. arXiv 2015, arXiv:1504.00325. [Google Scholar]
- Patki, N.; Wedge, R.; Veeramachaneni, K. The Synthetic Data Vault. In Proceedings of the 2016 IEEE International Conference on Data Science and Advanced Analytics (DSAA), Montreal, QC, Canada, 17–19 October 2016; pp. 399–410. [Google Scholar]
- Zhang, S.; Zhang, C.; Yang, Q. Data preparation for data mining. Appl. Artif. Intell. 2003, 17, 375–381. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft Coco: Common Objects in Context; European Conference on Computer Vision; Springer: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Japkowicz, N.; Stephen, S. The class imbalance problem: A systematic study. Intell. Data Anal. 2002, 6, 429–449. [Google Scholar] [CrossRef]
- Koopman, P.; Wagner, M. Autonomous Vehicle Safety: An Interdisciplinary Challenge. IEEE Intell. Transp. Syst. Mag. 2017, 9, 90–96. [Google Scholar] [CrossRef]
- Goodfellow, I.; McDaniel, P.; Papernot, N. Making Machine Learning Robust against Adversarial Inputs; Communications of the ACM: New York, NY, USA, 2018; pp. 56–66. [Google Scholar]
- Mitchel, M. Bias in the Vision and Language of Artificial Intelligence. Available online: https://web.stanford.edu/class/archive/cs/cs224n/cs224n.1194/slides/cs224n-2019-lecture19-bias.pdf (accessed on 18 November 2020).
- Gu, X.; Easwaran, A. Towards Safe Machine Learning for CPS: Infer Uncertainty from Training Data. In Proceedings of the 10th ACM/IEEE International Conference on Cyber-Physical Systems (ICCPS’19), Montreal, QC, Canada, 16–18 April 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 249–258. [Google Scholar] [CrossRef] [Green Version]
- Goodfellow, I.; Bengio, Y.; Courville, A.; Bengio, Y. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Roscher, R.; Bohn, B.; Duarte, M.F.; Garcke, J. Explainable machine learning for scientific insights and discoveries. IEEE Access 2020, 8, 42200–42216. [Google Scholar] [CrossRef]
- Miao, H.; Li, A.; Davis, L.S.; Deshpande, A. Towards Unified Data and Lifecycle Management for Deep Learning. In Proceedings of the 2017 IEEE 33rd International Conference on Data Engineering (ICDE), San Diego, CA, USA, 19–22 April 2017; pp. 571–582. [Google Scholar]
- How to Select Algorithms for Azure Machine Learning. Available online: https://docs.microsoft.com/en-us/azure/machine-learning/how-to-select-algorithms (accessed on 24 August 2020).
- Molnar, C. Interpretable Machine Learning; Lulu.com: Morrisville, NC, USA, 2020. [Google Scholar]
- Marcus, G. Deep learning: A critical appraisal. arXiv 2018, arXiv:1801.00631. [Google Scholar]
- Grigorescu, S.; Trasnea, B.; Cocias, T.; Macesanu, G. A survey of deep learning techniques for autonomous driving. J. Field Robot. 2020, 37, 362–386. [Google Scholar] [CrossRef]
- Kim, J.; Canny, J. Interpretable Learning for Self-Driving Cars by Visualizing Causal Attention. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 December 2017. [Google Scholar]
- Zambaldi, V.; Raposo, D.; Santoro, A.; Bapst, V.; Li, Y.; Babuschkin, I.; Tuyls, K.; Reichert, D.; Lillicrap, T.; Lockhart, E.; et al. Relational deep reinforcement learning. arXiv 2018, arXiv:1806.01830. [Google Scholar]
- Brown, A.; Tuor, A.; Hutchinson, B.; Nichols, N. Recurrent neural network attention mechanisms for interpretable system log anomaly detection. In Proceedings of the First Workshop on Machine Learning for Computing Systems, Tempe, AZ, USA, 12 June 2018; pp. 1–8. [Google Scholar]
- Zhang, J.M.; Harman, M.; Ma, L.; Liu, Y. Machine Learning Testing: Survey, Landscapes and Horizons. IEEE Trans. Softw. Eng. 2020. [Google Scholar] [CrossRef] [Green Version]
- Pütz, A.; Zlocki, A.; Bock, J.; Eckstein, L. System validation of highly automated vehicles with a database of relevant traffic scenarios. Situations 2017, 1, 19–22. [Google Scholar]
- ISO. PAS 21448-Road Vehicles-Safety of the Intended Functionality; International Organization for Standardization: Geneva, Switzerland, 2019. [Google Scholar]
- Mariani, R. Challenges in AI/ML for Safety Critical Systems. Available online: http://www.dfts.org/_2019/DFT_2019-Mariani-v3.pdf (accessed on 14 November 2020).
- Sutherland, G.; Hessami, A. Safety Critical Integrity Assurance in Large Datasets. In Proceedings of the 28th Safety-Critical Systems Symposium, York, UK, 11–13 February 2020; p. 308. [Google Scholar]
- Huang, L.; Joseph, A.D.; Nelson, B.; Rubinstein, B.I.; Tygar, J.D. Adversarial Machine Learning. In Proceedings of the 4th ACM Workshop on Security and Artificial Intelligence (AISec ’11), Chicago, IL, USA, 17–21 October 2011; pp. 43–58. [Google Scholar] [CrossRef]


Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pereira, A.; Thomas, C. Challenges of Machine Learning Applied to Safety-Critical Cyber-Physical Systems. Mach. Learn. Knowl. Extr. 2020, 2, 579-602. https://doi.org/10.3390/make2040031
Pereira A, Thomas C. Challenges of Machine Learning Applied to Safety-Critical Cyber-Physical Systems. Machine Learning and Knowledge Extraction. 2020; 2(4):579-602. https://doi.org/10.3390/make2040031
Chicago/Turabian StylePereira, Ana, and Carsten Thomas. 2020. "Challenges of Machine Learning Applied to Safety-Critical Cyber-Physical Systems" Machine Learning and Knowledge Extraction 2, no. 4: 579-602. https://doi.org/10.3390/make2040031
APA StylePereira, A., & Thomas, C. (2020). Challenges of Machine Learning Applied to Safety-Critical Cyber-Physical Systems. Machine Learning and Knowledge Extraction, 2(4), 579-602. https://doi.org/10.3390/make2040031