Large-Scale, Language-Agnostic Discourse Classification of Tweets During COVID-19


Abstract
:1. Introduction
2. Relevant Work
2.1. COVID-19 Twitter
2.2. Representing Tweets
3. Methods
3.1. Data
3.2. Tweet Embeddings
3.3. Intent Classification
3.4. Bayesian Hyperparameter Optimization
3.5. Evaluation
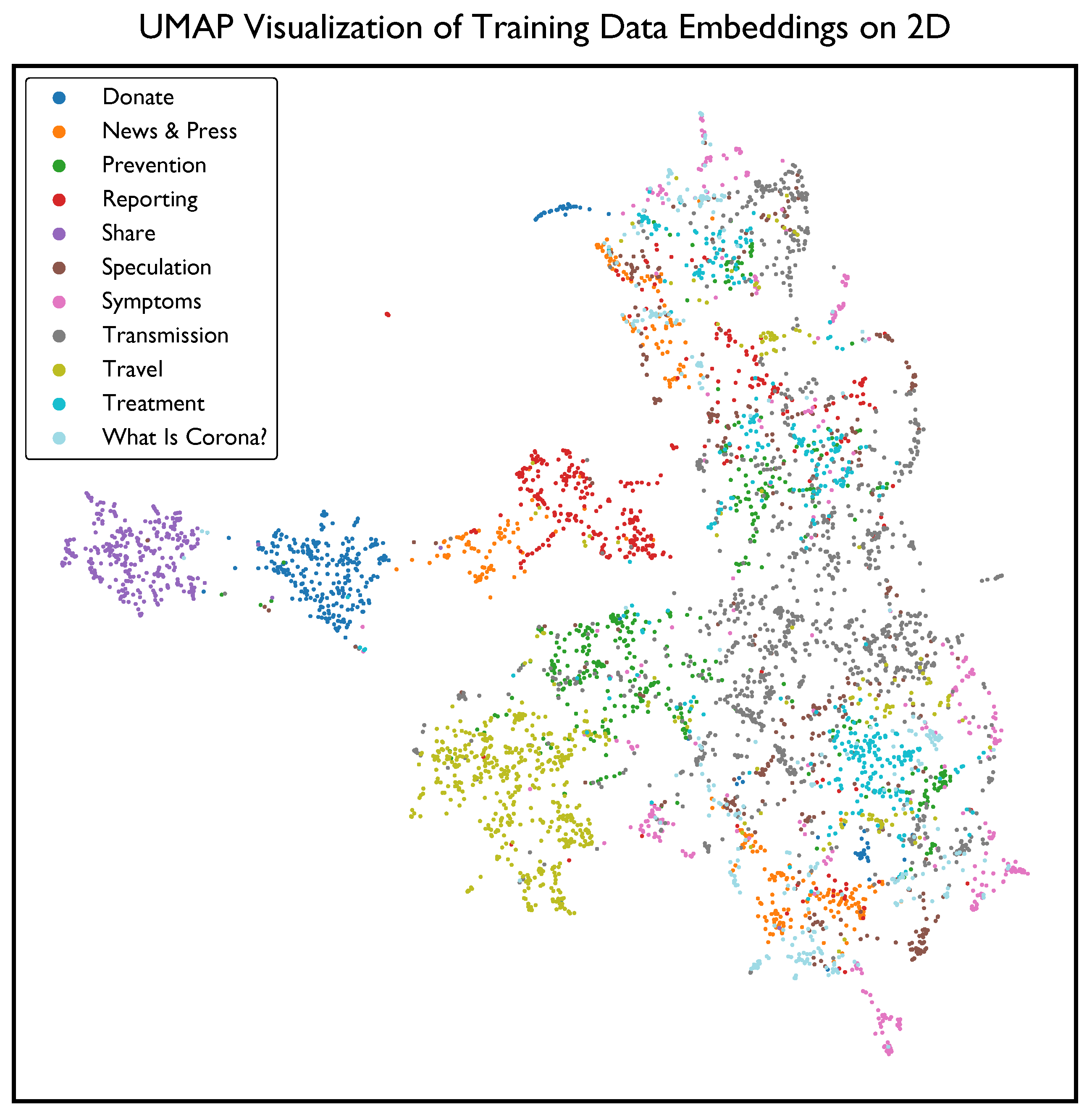
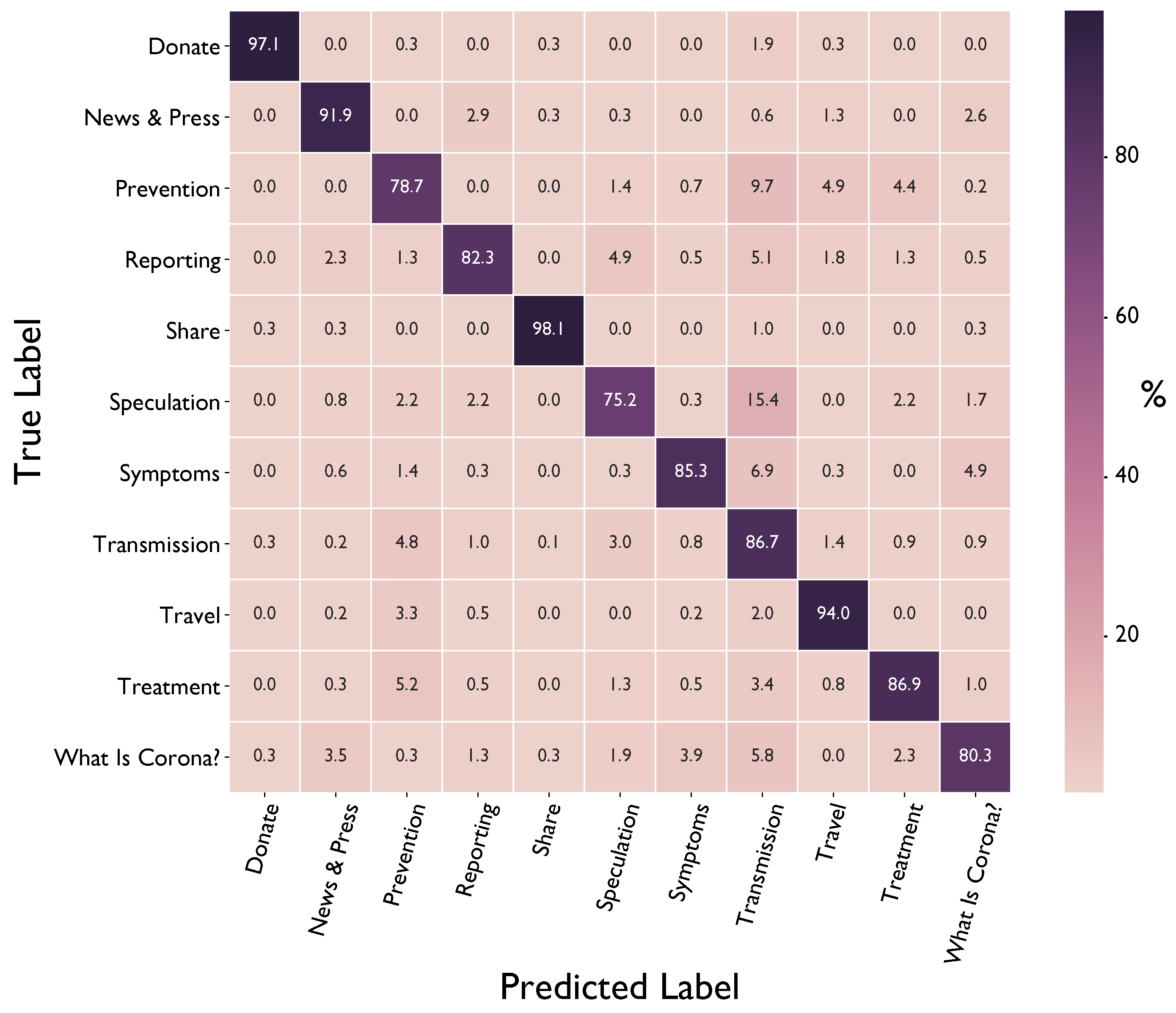
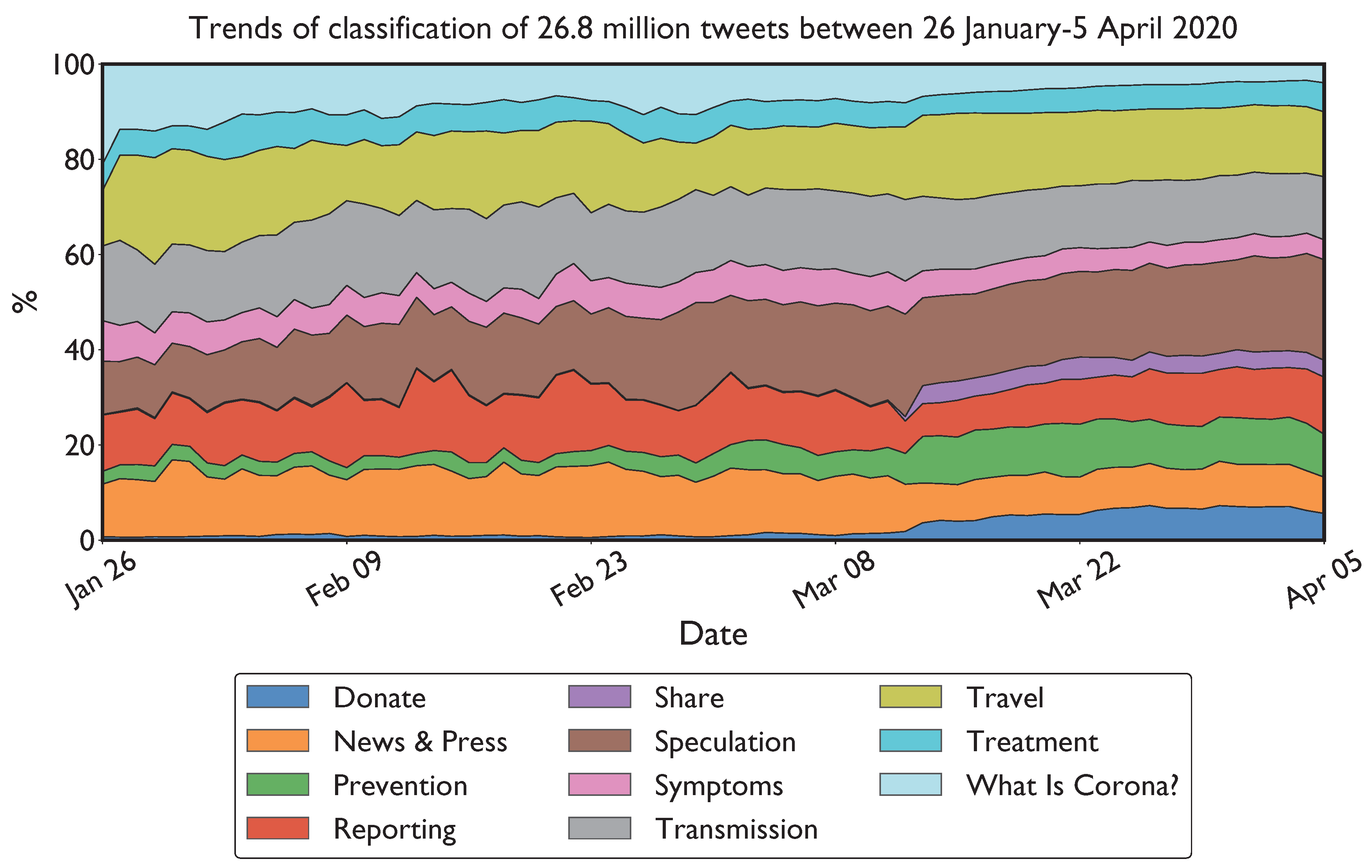
4. Results
5. Discussion
6. Conclusions
Funding
Conflicts of Interest
Abbreviations
| BERT | Bidirectional Encoder Representations from Transformers |
| CDC | Center for Disease Control |
| COVID-19 | Coronavirus disease 2019 |
| FAQ | Frequently Asked Questions |
| kNN | k-nearest neighbor (kNN) |
| LaBSE | Language-agnostic BERT Sentence Embeddings |
| LDA | Latent Dirichlet Allocation |
| LR | Logistic regression |
| SVM | Support vector machine |
| UMAP | Uniform Manifold Approximation and Projection |
References
- Cucinotta, D.; Vanelli, M. WHO declares COVID-19 a pandemic. Acta-Bio-Med. Atenei Parm. 2020, 91, 157–160. [Google Scholar] [CrossRef]
- Dong, E.; Du, H.; Gardner, L. An interactive web-based dashboard to track COVID-19 in real time. Lancet Infect. Dis. 2020, 20, 533–534. [Google Scholar] [CrossRef]
- Mahase, E. Coronavirus: COVID-19 has killed more people than SARS and MERS combined, despite lower case fatality rate. BMJ 2020. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jurgens, M.; Helsloot, I. The effect of social media on the dynamics of (self) resilience during disasters: A literature review. J. Conting. Crisis Manag. 2018, 26, 79–88. [Google Scholar] [CrossRef] [Green Version]
- Van Bavel, J.J.; Baicker, K.; Boggio, P.S.; Capraro, V.; Cichocka, A.; Cikara, M.; Crockett, M.J.; Crum, A.J.; Douglas, K.M.; Druckman, J.N.; et al. Using social and behavioural science to support COVID-19 pandemic response. Nat. Hum. Behav. 2020, 4, 460–471. [Google Scholar] [CrossRef]
- Zhong, B.L.; Luo, W.; Li, H.M.; Zhang, Q.Q.; Liu, X.G.; Li, W.T.; Li, Y. Knowledge, attitudes, and practices towards COVID-19 among Chinese residents during the rapid rise period of the COVID-19 outbreak: A quick online cross-sectional survey. Int. J. Biol. Sci. 2020, 16, 1745. [Google Scholar] [CrossRef]
- Signorini, A.; Segre, A.M.; Polgreen, P.M. The use of Twitter to track levels of disease activity and public concern in the US during the influenza A H1N1 pandemic. PLoS ONE 2011, 6, e0019467. [Google Scholar] [CrossRef] [Green Version]
- Ji, X.; Chun, S.A.; Geller, J. Monitoring public health concerns using twitter sentiment classifications. In Proceedings of the 2013 IEEE International Conference on Healthcare Informatics, Philadelphia, PA, USA, 9–11 September 2013; pp. 335–344. [Google Scholar] [CrossRef]
- Ji, X.; Chun, S.A.; Wei, Z.; Geller, J. Twitter sentiment classification for measuring public health concerns. Soc. Netw. Anal. Min. 2015, 5, 13. [Google Scholar] [CrossRef]
- Weeg, C.; Schwartz, H.A.; Hill, S.; Merchant, R.M.; Arango, C.; Ungar, L. Using Twitter to measure public discussion of diseases: A case study. JMIR Public Health Surveill. 2015, 1, e6. [Google Scholar] [CrossRef]
- Mollema, L.; Harmsen, I.A.; Broekhuizen, E.; Clijnk, R.; De Melker, H.; Paulussen, T.; Kok, G.; Ruiter, R.; Das, E. Disease detection or public opinion reflection? Content analysis of tweets, other social media, and online newspapers during the measles outbreak in The Netherlands in 2013. J. Med. Internet Res. 2015, 17, e128. [Google Scholar] [CrossRef]
- Jordan, S.E.; Hovet, S.E.; Fung, I.C.H.; Liang, H.; Fu, K.W.; Tse, Z.T.H. Using Twitter for public health surveillance from monitoring and prediction to public response. Data 2019, 4, 6. [Google Scholar] [CrossRef] [Green Version]
- Rosenberg, H.; Syed, S.; Rezaie, S. The Twitter pandemic: The critical role of Twitter in the dissemination of medical information and misinformation during the COVID-19 pandemic. Can. J. Emerg. Med. 2020, 22, 418–421. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, E.; Lerman, K.; Ferrara, E. COVID-19: The first public coronavirus Twitter dataset. arXiv 2020, arXiv:2003.07372. [Google Scholar]
- Gao, Z.; Yada, S.; Wakamiya, S.; Aramaki, E. NAIST COVID: Multilingual COVID-19 Twitter and Weibo Dataset. arXiv 2020, arXiv:2004.08145. [Google Scholar]
- Lamsal, R. Corona Virus (COVID-19) Tweets Dataset. Sch. Comput. Syst. Sci. 2020. [Google Scholar] [CrossRef]
- Aguilar-Gallegos, N.; Romero-García, L.E.; Martínez-González, E.G.; García-Sánchez, E.I.; Aguilar-Ávila, J. Dataset on dynamics of Coronavirus on Twitter. Data Brief. 2020, 30, 105684. [Google Scholar] [CrossRef]
- Chen, E.; Lerman, K.; Ferrara, E. Tracking Social Media Discourse About the COVID-19 Pandemic: Development of a Public Coronavirus Twitter Data Set. JMIR Public Health Surveill. 2020, 6, e19273. [Google Scholar] [CrossRef]
- Abd-Alrazaq, A.; Alhuwail, D.; Househ, M.; Hamdi, M.; Shah, Z. Top concerns of tweeters during the COVID-19 pandemic: Infoveillance study. J. Med. Internet Res. 2020, 22. [Google Scholar] [CrossRef] [Green Version]
- Rao, H.R.; Vemprala, N.; Akello, P.; Valecha, R. Retweets of officials’ alarming vs reassuring messages during the COVID-19 pandemic: Implications for crisis management. Int. J. Inf. Manag. 2020, 55, 102187. [Google Scholar] [CrossRef]
- Park, H.W.; Park, S.; Chong, M. Conversations and medical news frames on twitter: Infodemiological study on covid-19 in south korea. J. Med. Internet Res. 2020, 22, e18897. [Google Scholar] [CrossRef]
- Feng, F.; Yang, Y.; Cer, D.; Arivazhagan, N.; Wang, W. Language-agnostic BERT Sentence Embedding. arXiv 2020, arXiv:2007.01852. [Google Scholar]
- Dewhurst, D.R.; Alshaabi, T.; Arnold, M.V.; Minot, J.R.; Danforth, C.M.; Dodds, P.S. Divergent modes of online collective attention to the COVID-19 pandemic are associated with future caseload variance. arXiv 2020, arXiv:2004.03516. [Google Scholar]
- Thelwall, M.; Thelwall, S. Retweeting for COVID-19: Consensus building, information sharing, dissent, and lockdown life. arXiv 2020, arXiv:2004.02793. [Google Scholar]
- Alshaabi, T.; Minot, J.R.; Arnold, M.V.; Adams, J.L.; Dewhurst, D.R.; Reagan, A.J.; Muhamad, R.; Danforth, C.M.; Dodds, P.S. How the world’s collective attention is being paid to a pandemic: COVID-19 related 1-gram time series for 24 languages on Twitter. arXiv 2020, arXiv:2003.12614. [Google Scholar]
- Hamamsy, T.C.; Bonneau, R. Twitter activity about treatments during the COVID-19 pandemic: Case studies of remdesivir, hydroxychloroquine, and convalescent plasma. medRxiv 2020. [Google Scholar] [CrossRef]
- Singh, L.; Bansal, S.; Bode, L.; Budak, C.; Chi, G.; Kawintiranon, K.; Padden, C.; Vanarsdall, R.; Vraga, E.; Wang, Y. A first look at COVID-19 information and misinformation sharing on Twitter. arXiv 2020, arXiv:2003.13907. [Google Scholar]
- Lopez, C.E.; Vasu, M.; Gallemore, C. Understanding the perception of COVID-19 policies by mining a multilanguage Twitter dataset. arXiv 2020, arXiv:2003.10359. [Google Scholar]
- Kouzy, R.; Abi Jaoude, J.; Kraitem, A.; El Alam, M.B.; Karam, B.; Adib, E.; Zarka, J.; Traboulsi, C.; Akl, E.W.; Baddour, K. Coronavirus Goes Viral: Quantifying the COVID-19 Misinformation Epidemic on Twitter. Cureus 2020, 12. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wicke, P.; Bolognesi, M.M. Framing COVID-19: How we conceptualize and discuss the pandemic on Twitter. PLoS ONE 2020, 15, e0240010. [Google Scholar] [CrossRef]
- Jarynowski, A.; Wójta-Kempa, M.; Belik, V. Trends in Perception of COVID-19 in Polish Internet. medRxiv 2020. [Google Scholar] [CrossRef]
- Ordun, C.; Purushotham, S.; Raff, E. Exploratory analysis of covid-19 tweets using topic modeling, umap, and digraphs. arXiv 2020, arXiv:2005.03082. [Google Scholar]
- Medford, R.J.; Saleh, S.N.; Sumarsono, A.; Perl, T.M.; Lehmann, C.U. An “Infodemic”: Leveraging High-Volume Twitter Data to Understand Early Public Sentiment for the Coronavirus Disease 2019 Outbreak. Open Forum Infect. Dis. 2020, 7. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.; Lyu, H.; Yang, T.; Wang, Y.; Luo, J. In the eyes of the beholder: Sentiment and topic analyses on social media use of neutral and controversial terms for COVID-19. arXiv 2020, arXiv:2004.10225. [Google Scholar]
- Cinelli, M.; Quattrociocchi, W.; Galeazzi, A.; Valensise, C.M.; Brugnoli, E.; Schmidt, A.L.; Zola, P.; Zollo, F.; Scala, A. The COVID-19 Social Media Infodemic. Sci. Rep. 2020, 10, 16598. [Google Scholar] [CrossRef] [PubMed]
- Hosseini, P.; Hosseini, P.; Broniatowski, D.A. Content analysis of Persian/Farsi Tweets during COVID-19 pandemic in Iran using NLP. arXiv 2020, arXiv:2005.08400. [Google Scholar]
- Jang, H.; Rempel, E.; Carenini, G.; Janjua, N. Exploratory Analysis of COVID-19 Related Tweets in North America to Inform Public Health Institutes. arXiv 2020, arXiv:2007.02452. [Google Scholar]
- Saad, M.; Hassan, M.; Zaffar, F. Towards Characterizing the COVID-19 Awareness on Twitter. arXiv 2020, arXiv:2005.08379. [Google Scholar]
- Odlum, M.; Cho, H.; Broadwell, P.; Davis, N.; Patrao, M.; Schauer, D.; Bales, M.E.; Alcantara, C.; Yoon, S. Application of Topic Modeling to Tweets as the Foundation for Health Disparity Research for COVID-19. Stud. Health Technol. Inform. 2020, 272, 24–27. [Google Scholar] [CrossRef]
- Park, S.; Han, S.; Kim, J.; Molaie, M.M.; Vu, H.D.; Singh, K.; Han, J.; Lee, W.; Cha, M. Risk Communication in Asian Countries: COVID-19 Discourse on Twitter. JMIR 2020. [Google Scholar] [CrossRef]
- Xue, J.; Chen, J.; Hu, R.; Chen, C.; Zheng, C.; Zhu, T. Twitter discussions and concerns about COVID-19 pandemic: Twitter data analysis using a machine learning approach. JMIR 2020. [Google Scholar] [CrossRef]
- Gupta, R.K.; Vishwanath, A.; Yang, Y. COVID-19 Twitter Dataset with Latent Topics, Sentiments and Emotions Attributes. arXiv 2020, arXiv:2007.06954. [Google Scholar]
- Wang, X.; Zou, C.; Xie, Z.; Li, D. Public Opinions towards COVID-19 in California and New York on Twitter. medRxiv 2020. [Google Scholar] [CrossRef]
- Feng, Y.; Zhou, W. Is Working From Home The New Norm? An Observational Study Based on a Large Geo-tagged COVID-19 Twitter Dataset. arXiv 2020, arXiv:2006.08581. [Google Scholar]
- Yin, H.; Yang, S.; Li, J. Detecting Topic and Sentiment Dynamics Due to COVID-19 Pandemic Using Social Media. arXiv 2020, arXiv:2007.02304. [Google Scholar]
- McQuillan, L.; McAweeney, E.; Bargar, A.; Ruch, A. Cultural Convergence: Insights into the behavior of misinformation networks on Twitter. arXiv 2020, arXiv:2007.03443. [Google Scholar]
- Omoya, Y.; Kaigo, M. Suspicion Begets Idle Fears—An Analysis of COVID-19 Related Topics in Japanese Media and Twitter. SSRN 2020. [Google Scholar] [CrossRef]
- Sharma, K.; Seo, S.; Meng, C.; Rambhatla, S.; Dua, A.; Liu, Y. Coronavirus on Social Media: Analyzing Misinformation in Twitter Conversations. arXiv 2020, arXiv:2003.12309. [Google Scholar]
- Kabir, M.; Madria, S. CoronaVis: A Real-time COVID-19 Tweets Analyzer. arXiv 2020, arXiv:2004.13932. [Google Scholar]
- Rosa, K.D.; Shah, R.; Lin, B.; Gershman, A.; Frederking, R. Topical clustering of tweets. SWSM 2011, 63. Available online: http://www.cs.cmu.edu/~encore/sigir_swsm2011.pdf (accessed on 30 July 2020).
- Kaleel, S.B.; Abhari, A. Cluster-discovery of Twitter messages for event detection and trending. J. Comput. Sci. 2015, 6, 47–57. [Google Scholar] [CrossRef]
- Lo, S.L.; Chiong, R.; Cornforth, D. An unsupervised multilingual approach for online social media topic identification. Expert Syst. Appl. 2017, 81, 282–298. [Google Scholar] [CrossRef]
- Le, Q.; Mikolov, T. Distributed representations of sentences and documents. In Proceedings of the 31st International Conference on Machine Learning, Beijing, China, 21–26 June 2014. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar] [CrossRef]
- Vosoughi, S.; Vijayaraghavan, P.; Roy, D. Tweet2vec: Learning tweet embeddings using character-level cnn-lstm encoder-decoder. In Proceedings of the 39th International ACM SIGIR Conference on Research and Development in Information Retrieval, Pisa, Italy, 17–21 July 2016; pp. 1041–1044. [Google Scholar] [CrossRef] [Green Version]
- Dhingra, B.; Zhou, Z.; Fitzpatrick, D.; Muehl, M.; Cohen, W. Tweet2Vec: Character-Based Distributed Representations for Social Media. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2016; pp. 269–274. [Google Scholar] [CrossRef]
- Liu, J.; He, Z.; Huang, Y. Hashtag2Vec: Learning hashtag representation with relational hierarchical embedding model. In Proceedings of the 27th International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; pp. 3456–3462. [Google Scholar] [CrossRef]
- Peters, M.E.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep contextualized word representations. arXiv 2018, arXiv:1802.05365. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 1–6 June 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Gencoglu, O. Deep Representation Learning for Clustering of Health Tweets. arXiv 2018, arXiv:1901.00439. [Google Scholar]
- Zhu, J.; Tian, Z.; Kübler, S. UM-IU@LING at SemEval-2019 Task 6: Identifying Offensive Tweets Using BERT and SVMs. In Proceedings of the 13th International Workshop on Semantic Evaluation, Minneapolis, MN, USA, 6–7 June 2019; pp. 788–795. [Google Scholar] [CrossRef] [Green Version]
- Ray Chowdhury, J.; Caragea, C.; Caragea, D. Keyphrase extraction from disaster-related tweets. In Proceedings of the World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 1555–1566. [Google Scholar] [CrossRef] [Green Version]
- Chowdhury, J.R.; Caragea, C.; Caragea, D. On Identifying Hashtags in Disaster Twitter Data. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 498–506. [Google Scholar] [CrossRef]
- Roitero, K.; Cristian, B.; Mea, V.D.; Mizzaro, S.; Serra, G. Twitter Goes to the Doctor: Detecting Medical Tweets Using Machine Learning and BERT. In Proceedings of the International Workshop on Semantic Indexing and Information Retrieval for Health from Heterogeneous Content Types and Languages, Lisbon, Portugal, 14–17 April 2020; Volume 2619. [Google Scholar]
- Mazoyer, B.; Cagé, J.; Hervé, N.; Hudelot, C. A french corpus for event detection on twitter. In Proceedings of the 12th Language Resources and Evaluation Conference, Marseille, France, 11–16 May 2020; pp. 6220–6227. [Google Scholar]
- Nguyen, D.Q.; Vu, T.; Nguyen, A.T. BERTweet: A pre-trained language model for English Tweets. arXiv 2020, arXiv:2005.10200. [Google Scholar]
- Müller, M.; Salathé, M.; Kummervold, P.E. COVID-Twitter-BERT: A Natural Language Processing Model to Analyse COVID-19 Content on Twitter. arXiv 2020, arXiv:2005.07503. [Google Scholar]
- Reimers, N.; Gurevych, I. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 3982–3992. [Google Scholar] [CrossRef] [Green Version]
- Gencoglu, O.; Gruber, M. Causal Modeling of Twitter Activity during COVID-19. Computation 2020, 8, 85. [Google Scholar] [CrossRef]
- Baly, R.; Karadzhov, G.; An, J.; Kwak, H.; Dinkov, Y.; Ali, A.; Glass, J.; Nakov, P. What Was Written vs. Who Read It: News Media Profiling Using Text Analysis and Social Media Context. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Seattle, WA, USA, 5–10 July 2020. [Google Scholar] [CrossRef]
- Kim, H.; Walker, D. Leveraging volunteer fact checking to identify misinformation about COVID-19 in social media. Harv. Kennedy Sch. Misinf. Rev. 2020, 1. [Google Scholar] [CrossRef]
- Gencoglu, O. Cyberbullying Detection with Fairness Constraints. IEEE Internet Comput. 2020. [Google Scholar] [CrossRef]
- Banda, J.M.; Tekumalla, R.; Wang, G.; Yu, J.; Liu, T.; Ding, Y.; Chowell, G. A Twitter Dataset of 150+ million tweets related to COVID-19 for open research. Zenodo 2020. [Google Scholar] [CrossRef]
- Covid-19 Twitter Chatter Dataset for Scientific Use. Available online: http://www.panacealab.org/covid19/ (accessed on 30 July 2020).
- Arora, A.; Shrivastava, A.; Mohit, M.; Lecanda, L.S.M.; Aly, A. Cross-Lingual Transfer Learning for Intent Detection of Covid-19 Utterances. 2020. Available online: https://openreview.net/pdf?id=vP-CQG-ap-R (accessed on 29 November 2020).
- Wei, J.; Huang, C.; Vosoughi, S.; Wei, J. What Are People Asking About COVID-19? A Question Classification Dataset. In Proceedings of the 1st Workshop on NLP for COVID-19 at ACL 2020, Seattle, WA, USA, 19 July 2020. [Google Scholar]
- Rasmussen, C.E. Gaussian Processes in Machine Learning. In Summer School on Machine Learning; Springer: Berlin/Heidelberg, Germany, 2003; pp. 63–71. [Google Scholar] [CrossRef] [Green Version]
- Močkus, J. On Bayesian methods for seeking the extremum. Optimization Techniques IFIP Technical Conference; Springer: Berlin/Heidelberg, Germany, 1975; pp. 400–404. [Google Scholar] [CrossRef] [Green Version]
- McInnes, L.; Healy, J.; Saul, N.; Großberger, L. UMAP: Uniform Manifold Approximation and Projection. J. Open Source Softw. 2018, 3, 861. [Google Scholar] [CrossRef]
- Lacoste, A.; Luccioni, A.; Schmidt, V.; Dandres, T. Quantifying the Carbon Emissions of Machine Learning. arXiv 2019, arXiv:1910.09700. [Google Scholar]
- Sandman, P.M. Responding to Community Outrage: Strategies for Effective Risk Communication; AIHA: Fairfax County, VA, USA, 1993. [Google Scholar]
- Bento, A.I.; Nguyen, T.; Wing, C.; Lozano-Rojas, F.; Ahn, Y.Y.; Simon, K. Evidence from internet search data shows information-seeking responses to news of local COVID-19 cases. Proc. Natl. Acad. Sci. USA 2020, 117, 11220–11222. [Google Scholar] [CrossRef] [PubMed]
- Wong, C.M.L.; Jensen, O. The paradox of trust: Perceived risk and public compliance during the COVID-19 pandemic in Singapore. J. Risk Res. 2020. [Google Scholar] [CrossRef]
- COVID-19 Solidarity Response Fund. Available online: https://www.who.int/emergencies/diseases/novel-coronavirus-2019/donate (accessed on 30 July 2020).
- Wang, C.; Pan, R.; Wan, X.; Tan, Y.; Xu, L.; Ho, C.S.; Ho, R.C. Immediate psychological responses and associated factors during the initial stage of the 2019 coronavirus disease (COVID-19) epidemic among the general population in China. Int. J. Environ. Res. Public Health 2020, 17, 1729. [Google Scholar] [CrossRef] [Green Version]
- Cullen, W.; Gulati, G.; Kelly, B. Mental health in the Covid-19 pandemic. QJM Int. J. Med. 2020, 113, 311–312. [Google Scholar] [CrossRef]
- Brooks, S.K.; Webster, R.K.; Smith, L.E.; Woodland, L.; Wessely, S.; Greenberg, N.; Rubin, G.J. The psychological impact of quarantine and how to reduce it: Rapid review of the evidence. Lancet 2020, 395, 912–920. [Google Scholar] [CrossRef] [Green Version]
- Merchant, R.M.; Lurie, N. Social Media and Emergency Preparedness in Response to Novel Coronavirus. J. Am. Med. Assoc. 2020, 323. [Google Scholar] [CrossRef] [Green Version]
- Forman, G. Counting Positives Accurately Despite Inaccurate Classification. In European Conference on Machine Learning; Springer: Berlin/Heidelberg, Germany, 2005; pp. 564–575. [Google Scholar] [CrossRef] [Green Version]
- Forman, G. Quantifying Counts and Costs via Classification. Data Min. Knowl. Discov. 2008, 17, 164–206. [Google Scholar] [CrossRef]
- Bella, A.; Ferri, C.; Hernández-Orallo, J.; Ramirez-Quintana, M.J. Quantification via Probability Estimators. In Proceedings of the IEEE International Conference on Data Mining, Sydney, Australia, 13–17 December 2010; pp. 737–742. [Google Scholar] [CrossRef] [Green Version]
- González, P.; Díez, J.; Chawla, N.; del Coz, J.J. Why Is Quantification an Interesting Learning Problem? Prog. Artif. Intell. 2017, 6, 53–58. [Google Scholar] [CrossRef] [Green Version]
- Chan, J.L.; Purohit, H. Challenges to transforming unconventional social media data into actionable knowledge for public health systems during disasters. Disaster Med. Public Health Prep. 2019. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Language | Samples |
|---|---|
| English | 2119 |
| French | 1400 |
| Spanish | 1400 |
| Total | 4919 |
| Category | Samples |
|---|---|
| Donate | 310 |
| News & Press | 310 |
| Prevention | 431 |
| Reporting | 389 |
| Share | 310 |
| Speculation | 363 |
| Symptoms | 348 |
| Transmission | 1152 |
| Travel | 615 |
| Treatment | 381 |
| What Is Corona? | 310 |
| Total | 4919 |
| Model | BERT | LaBSE | ||||
|---|---|---|---|---|---|---|
| Accuracy (%) | F1 (Micro) | F1 (Macro) | Accuracy (%) | F1 (Micro) | F1 (Macro) | |
| kNN | 72.54 | 0.725 | 0.725 | 82.76 | 0.828 | 0.827 |
| LR | 76.62 | 0.766 | 0.771 | 86.05 | 0.844 | 0.846 |
| SVM | 81.81 | 0.818 | 0.820 | 86.92 | 0.876 | 0.881 |
| Tweet | Predicted Class |
|---|---|
| China Providing Assistance To Pakistani Students Trapped in Wuhan: Ambassador—#Pakistan | Donate |
| Results are in. State health officials say three suspected cases of Coronavirus have tested NEGATIVE. There is a forth possible case from Washtenaw County being sent to the CDC. | News & Press |
| what are good steps to protect ourselves from the Coronavirus? | Prevention |
| The first coronavirus case has been confirmed in the U.S. #virus | Reporting |
| Share this and save lives #coronavirus #SSOT | Share |
| #coronavirus Don’t let these ignorant people make you believe that this corona virus is any different than SARS IN 2003 which was contained after a few months. They want you to panic as they have ulterior motives such as shorting the stock market etc. | Speculation |
| I have a rushing sound in my ears. It doesn’t seem to match the symptoms for the #coronavirus so perhaps it is the sound of the #EU leaving my body... | Symptoms |
| what animals can carry Wuhan coronavirus? | Transmission |
| can we ban flights from wuhan pls?!? | Travel |
| ¿Qué medicamento nos colará en está ocasión la industria farmacéutica para combatir al coronavirus? | Treatment |
| Oque é coronavirus? | What Is Corona? |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gencoglu, O. Large-Scale, Language-Agnostic Discourse Classification of Tweets During COVID-19. Mach. Learn. Knowl. Extr. 2020, 2, 603-616. https://doi.org/10.3390/make2040032
Gencoglu O. Large-Scale, Language-Agnostic Discourse Classification of Tweets During COVID-19. Machine Learning and Knowledge Extraction. 2020; 2(4):603-616. https://doi.org/10.3390/make2040032
Chicago/Turabian StyleGencoglu, Oguzhan. 2020. "Large-Scale, Language-Agnostic Discourse Classification of Tweets During COVID-19" Machine Learning and Knowledge Extraction 2, no. 4: 603-616. https://doi.org/10.3390/make2040032
APA StyleGencoglu, O. (2020). Large-Scale, Language-Agnostic Discourse Classification of Tweets During COVID-19. Machine Learning and Knowledge Extraction, 2(4), 603-616. https://doi.org/10.3390/make2040032