Automatic Electronic Invoice Classification Using Machine Learning Models



Abstract
:1. Introduction
2. Literature Review
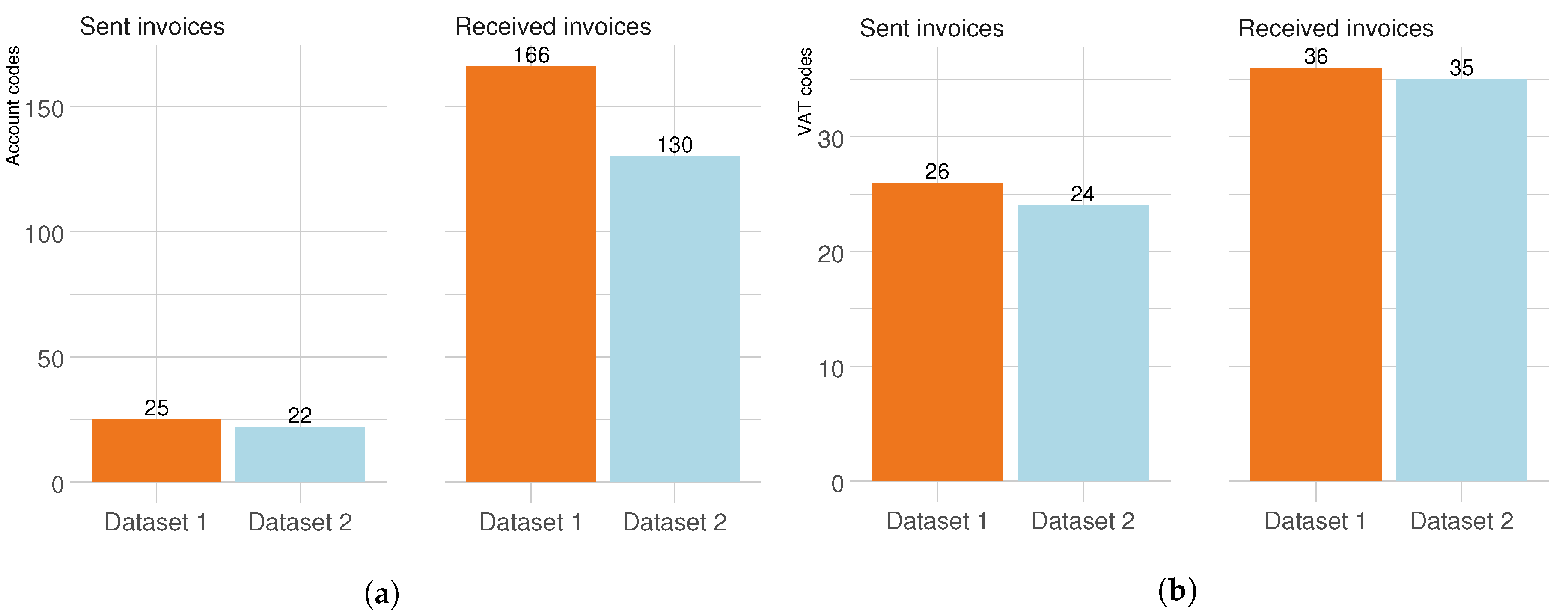
3. Dataset Description
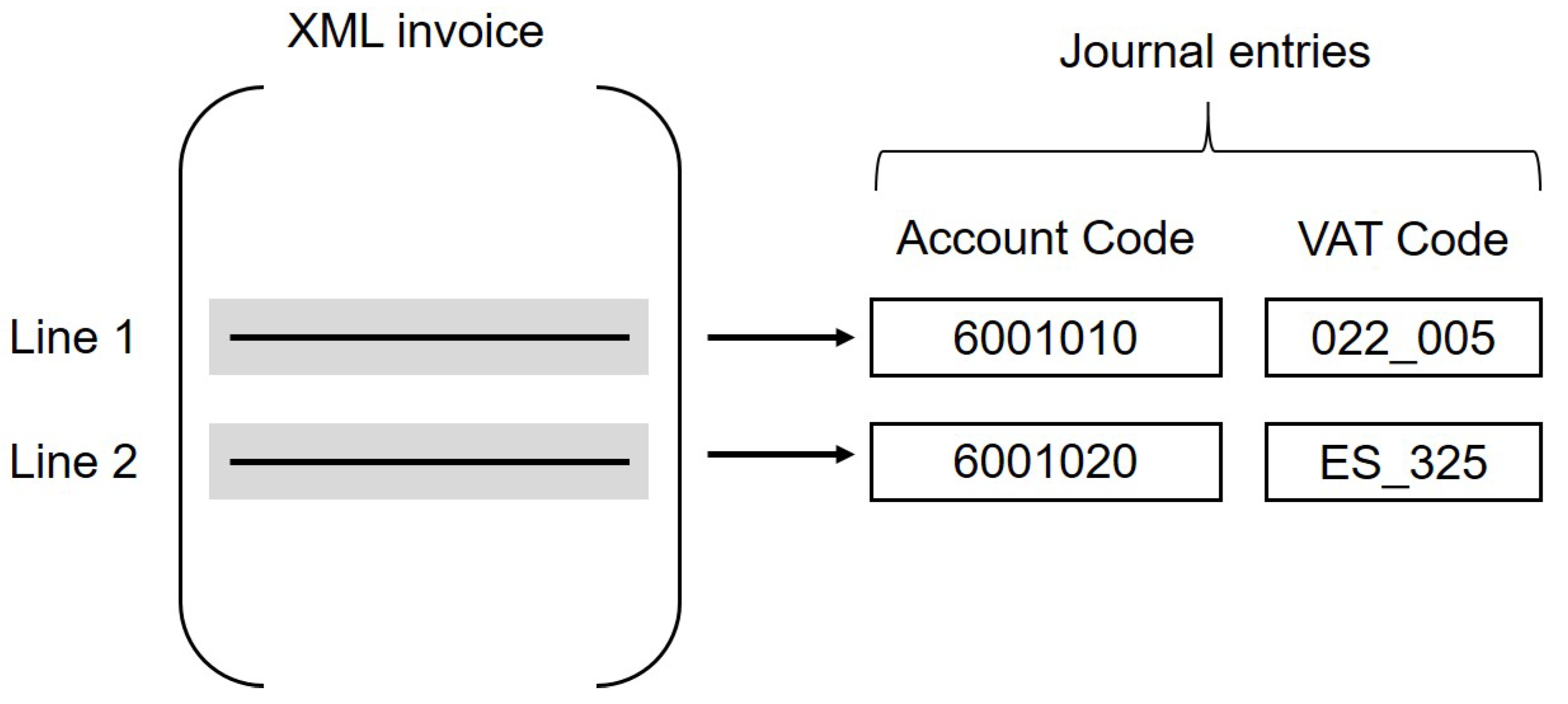
- , , are categorical observations which represent the account codes associated to the ith line of the invoice. The account codes belong to the Chart of Accounts which has a particular structure: codes are organized in a hierarchical structure and only the accounts, which are the leaves of the tree, are used as tag in the journal entry. In our problem, we consider only the accounts in the leaves of the hierarchical tree.
- , represent the VAT codes to predict associated to the ith line of the invoice. This target variable is composed of two different sub-codes: one related to the tax rate applied to the line of the invoice, and the other one related to tax rule. In our problem, this two codes are considered as a unique variable to predict.
- is the vector of predictors related to the content of the invoice and the characteristics of companies involved in the transactions.
- Customers and suppliers xml invoices of different companies
- Accounting journal entries related to the recording process of xml invoices (this data source contains account codes and VAT codes)
- textual description of the line of the invoice;
- codes associated to the line (e.g., tax rate); and
- information about activities performed by companies:
- –
- ATECO code (classification of economic Italian activities) provided by ISTAT (the Italian Statistics Agency);
- –
- ISA categories based on the level of fiscal reliability;
- –
- type of supplier, namely person, Italian firm, European company, or extra-European company;
- –
- type of accounting used by the company: ordinary or simplified; and
- –
- tax regime.
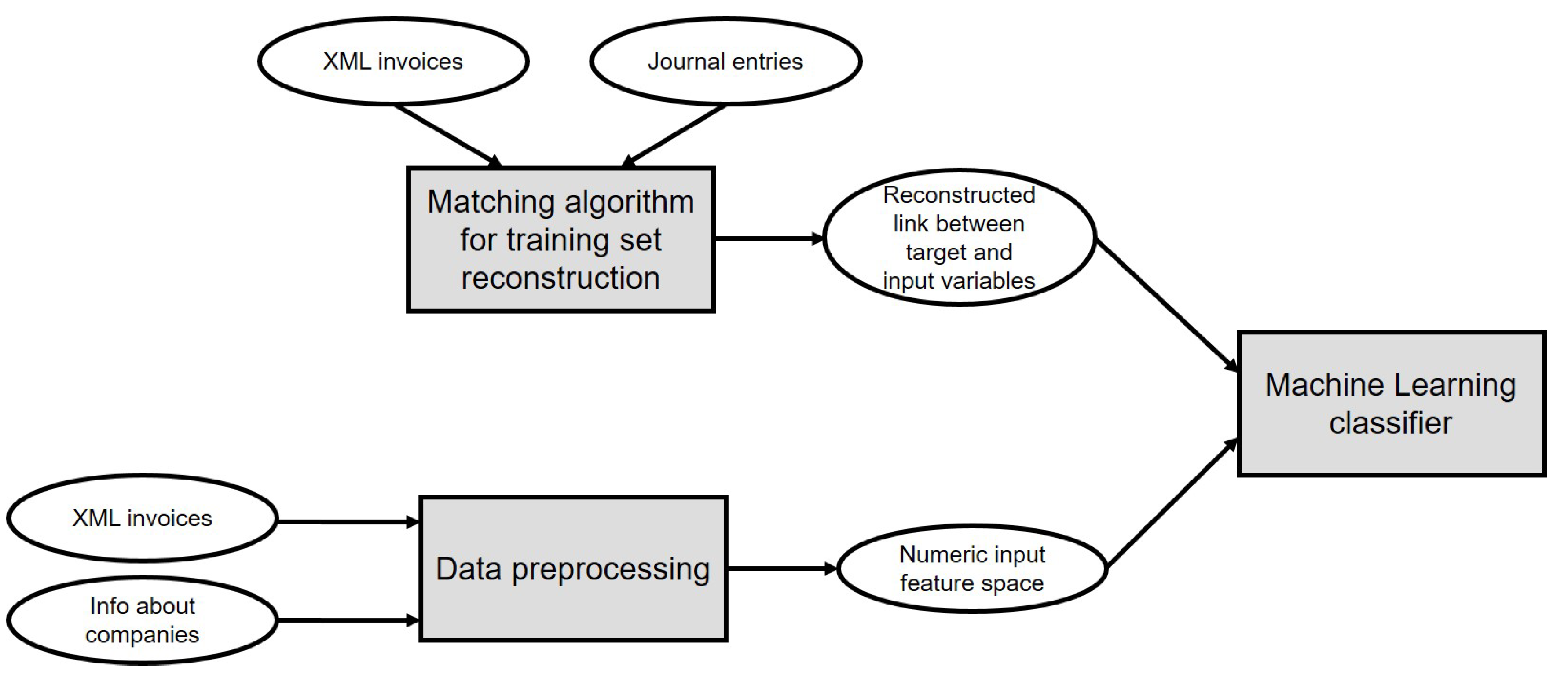
4. Methodological Proposal
4.1. Knapsack Problem
4.2. Data Pre-Processing
- Bag of Words (BoW) approach [18] is a simple way to encode the array of words into a binary vector. The main drawback is that the length of the feature space grows linearly with the number of distinct words, leading to infeasible dimensions of the feature space. Different methods can be adopted for the dimensionality reduction [19]; in our case, we included in the vocabulary words with a frequency higher than 0.1% in the collection of documents.
- Word2Vec (W2V) algorithm [20] is a language modeling technique which maps similar sentences into similar numeric vectors of fixed size. Since Continuous Bag of Words (CBoW) model is faster with respect to Skipgram model and shows better performances in case of high sample size [20], we preferred to apply CBoW to our dataset fixing the dimension of the output vector to 100 and the window of words to consider for the prediction equal to 5. All words with total frequency lower than 10 were ignored.
4.3. Classification Algorithm
- the account codes related to the economic nature of the transaction; and
- the VAT codes related to the tax rates coupled with tax regulations applied to the invoices.
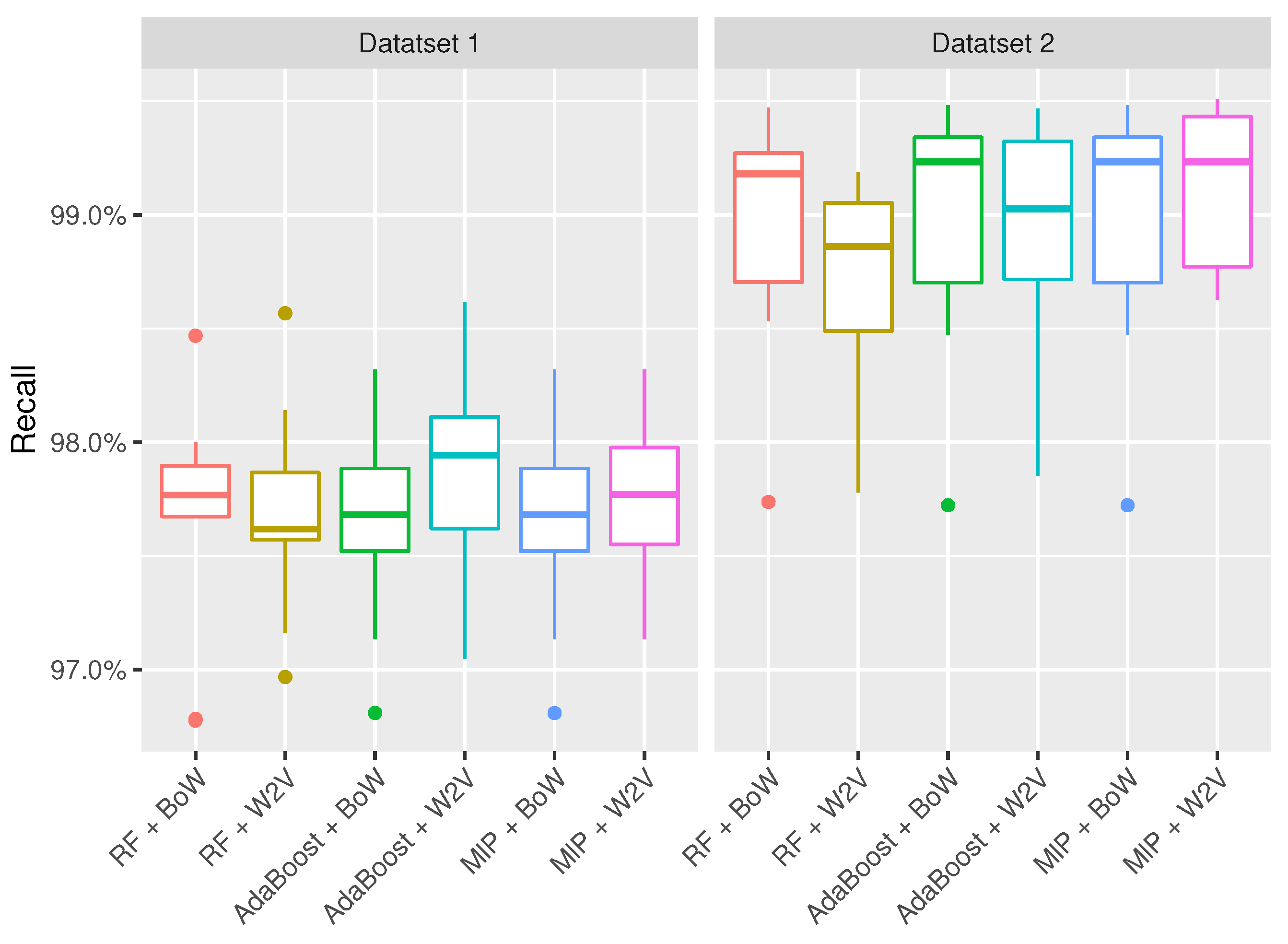
5. Empirical Analysis
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Frey, C.B.; Osborne, M.A. The future of employment: How susceptible are jobs to computerisation? Technol. Forecast. Soc. Chang. 2017, 114, 254–280. [Google Scholar] [CrossRef]
- Tekbas, I.; Nonwoven, K. The Profession of the digital age: Accounting Engineering. In IFAC Proceedings Volumes, Project: The Theory of Accounting, Enginnering; Elsevier: Amsterdam, The Netherlands, 2018. [Google Scholar]
- Gulin, D.; Hladika, M.; Valenta, I. Digitalization and the Challenges for the Accounting Profession. In Proceedings of the 2019 ENTRENOVA Conference, Rovinj, Croatia, 12–14 September 2019. [Google Scholar]
- ICAEW. Artificial Intelligence and the Future of Accountancy. Technical Report. Available online: https://www.icaew.com/technical/technology/artificial-intelligence/artificial-intelligence-the-future-of-accountancy (accessed on 29 November 2020).
- Tang, Y.Y.; Suen, C.Y.; De Yan, C.; Cheriet, M. Financial document processing based on staff line and description language. IEEE Trans. Syst. Man Cybern. 1995, 25, 738–754. [Google Scholar] [CrossRef]
- Cesarini, F.; Gori, M.; Marinai, S.; Soda, G. INFORMys: A flexible invoice-like form-reader system. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 730–745. [Google Scholar] [CrossRef]
- Holt, X.; Chisholm, A. Extracting structured data from invoices. In Proceedings of the Australasian Language Technology Association Workshop 2018, Dunedin, New Zealand, 10–12 December 2018; pp. 53–59. [Google Scholar]
- Wang, Y.; Gui, G.; Zhao, N.; Yin, Y.; Huang, H.; Li, Y.; Wang, J.; Yang, J.; Zhang, H. Deep learning for optical character recognition and its application to VAT invoice recognition. In Proceedings of the International Conference in Communications, Signal Processing, and Systems, Dalian, China, 14–16 July 2018; Springer: Berlin, Germany, 2018; pp. 87–95. [Google Scholar]
- Palm, R.B.; Winther, O.; Laws, F. Cloudscan-a configuration-free invoice analysis system using recurrent neural networks. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; IEEE: New York, NY, USA, 2017; Volume 1, pp. 406–413. [Google Scholar]
- Schreyer, M.; Sattarov, T.; Borth, D.; Dengel, A.; Reimer, B. Detection of anomalies in large scale accounting data using deep autoencoder networks. arXiv 2017, arXiv:1709.05254. [Google Scholar]
- Zupan, M.; Letinic, S.; Budimir, V. Accounting Journal Reconstruction with Variational Autoencoders and Long Short-term Memory Architecture. 2020. Available online: http://ceur-ws.org/Vol-2646/05-paper.pdf (accessed on 29 November 2020).
- Schultz, M.; Tropmann-Frick, M. Autoencoder Neural Networks versus External Auditors: Detecting Unusual Journal Entries in Financial Statement Audits. In Proceedings of the 53rd Hawaii International Conference on System Sciences, Maui, HI, USA, 7–10 January 2020. [Google Scholar]
- Bengtsson, H.; Jansson, J. Using Classification Algorithms for Smart Suggestions in Accounting Systems. Master’s Thesis, Chalmers University of Technology, Gothenburg, Sweden, 2015. [Google Scholar]
- Bergdorf, J. Machine Learning and Rule Induction in Invoice Processing: Comparing Machine Learning Methods in Their Ability to Assign Account Codes in the Bookkeeping Process. 2018. Available online: http://www.diva-portal.se/smash/get/diva2:1254853/FULLTEXT01.pdf (accessed on 29 November 2020).
- Kozanidis, G.; Melachrinoudis, E.; Solomon, M.M. The linear multiple choice knapsack problem with equity constraints. Int. J. Oper. Res. 2005, 1, 52–73. [Google Scholar] [CrossRef]
- Pyle, D. Data Preparation for Data Mining; Morgan Kaufmann: Burlington, MA, USA, 1999. [Google Scholar]
- Khan, A.; Baharudin, B.; Lee, L.H.; Khan, K. A review of machine learning algorithms for text-documents classification. J. Adv. Inf. Technol. 2010, 1, 4–20. [Google Scholar]
- Joachims, T. Learning to Classify Text Using Support Vector Machines; Springer Science & Business Media: Berlin, Germany, 2002; Volume 668. [Google Scholar]
- Sebastiani, F. Machine learning in automated text categorization. ACM Comput. Surv. (CSUR) 2002, 34, 1–47. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Kowsari, K.; Jafari Meimandi, K.; Heidarysafa, M.; Mendu, S.; Barnes, L.; Brown, D. Text classification algorithms: A survey. Information 2019, 10, 150. [Google Scholar] [CrossRef] [Green Version]
- Kim, S.B.; Han, K.S.; Rim, H.C.; Myaeng, S.H. Some effective techniques for naive bayes text classification. IEEE Trans. Knowl. Data Eng. 2006, 18, 1457–1466. [Google Scholar]
- Wang, Z.; He, Y.; Jiang, M. A comparison among three neural networks for text classification. In Proceedings of the 2006 8th International Conference on Signal Processing, Beijing, China, 16–20 November 2006; IEEE: New York, NY, USA, 2006; Volume 3. [Google Scholar]
- Wang, Z.Q.; Sun, X.; Zhang, D.X.; Li, X. An optimal SVM-based text classification algorithm. In Proceedings of the 2006 International Conference on Machine Learning and Cybernetics, Dalian, China, 13–16 August 2006; IEEE: New York, NY, USA, 2006; pp. 1378–1381. [Google Scholar]
- Kanakaraj, M.; Guddeti, R.M.R. Performance analysis of Ensemble methods on Twitter sentiment analysis using NLP techniques. In Proceedings of the 2015 IEEE 9th International Conference on Semantic Computing (IEEE ICSC 2015), Anaheim, CA, USA, 7–9 February 2015; IEEE: New York, NY, USA, 2015; pp. 169–170. [Google Scholar]
- Colas, F.; Brazdil, P. Comparison of SVM and some older classification algorithms in text classification tasks. In Proceedings of the IFIP International Conference on Artificial Intelligence in Theory and Practice, Santiago, Chile, 21–24 August 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 169–178. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Hastie, T.; Rosset, S.; Zhu, J.; Zou, H. Multi-class adaboost. Stat. Its Interface 2009, 2, 349–360. [Google Scholar] [CrossRef] [Green Version]
- Delashmit, W.H.; Manry, M.T. Recent developments in multilayer perceptron neural networks. In Proceedings of the Seventh Annual Memphis Area Engineering and Science Conference, MAESC, Memphis, TN, USA, 11 May 2005. [Google Scholar]
- Silla, C.N.; Freitas, A.A. A survey of hierarchical classification across different application domains. Data Min. Knowl. Discov. 2011, 22, 31–72. [Google Scholar] [CrossRef]
- Cesa-Bianchi, N.; Gentile, C.; Zaniboni, L. Incremental algorithms for hierarchical classification. J. Mach. Learn. Res. 2006, 7, 31–54. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset 1 | Dataset 2 | |||
|---|---|---|---|---|
| Precision | F1-score | Precision | F1-score | |
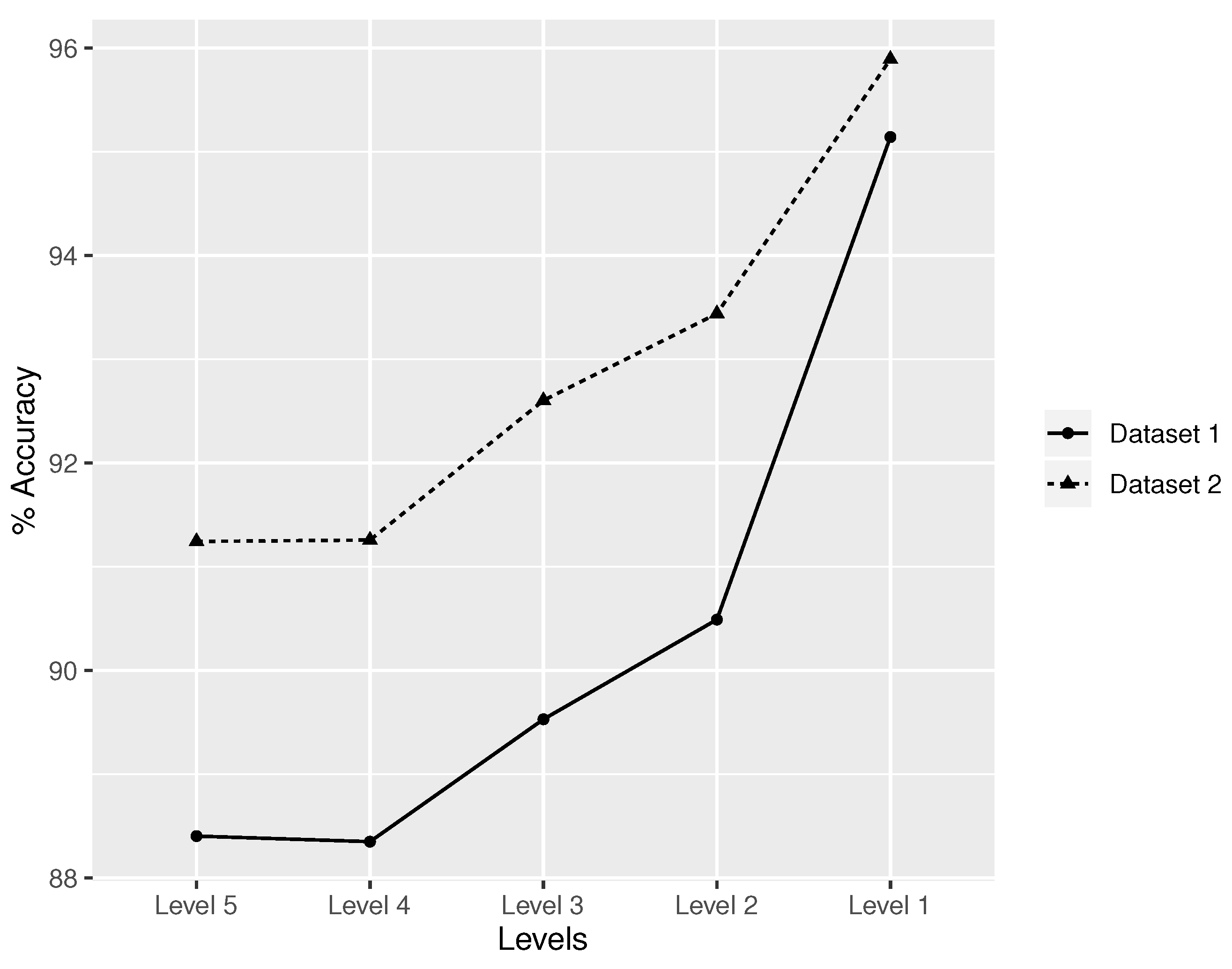
| RF + BoW | 97.7% (±0.5%) | 97.6% (±0.5%) | 98.9% (±0.6%) | 98.8% (±0.7%) |
| RF + W2V | 97.8% (±0.4%) | 97.6% (±0.5%) | 98.7% (±0.5%) | 98.6% (±0.6%) |
| AdaBoost + BoW | 97.7% (±0.4%) | 97.6% (±0.4%) | 98.9% (±0.6%) | 98.9% (±0.7%) |
| AdaBoost + W2V | 98.0% (±0.4%) | 97.8% (±0.5%) | 98.9% (±0.5%) | 98.8% (±0.6%) |
| MlP + BoW | 97.7% (±0.4%) | 97.6% (±0.4%) | 98.9% (±0.6%) | 98.9% (±0.7%) |
| MlP + W2V | 97.9% (±0.3%) | 97.6% (±0.4%) | 99.0% (±0.5%) | 98.9% (±0.7%) |
| Dataset 1 | Dataset 2 | |||
|---|---|---|---|---|
| Precision | F1-score | Precision | F1-score | |
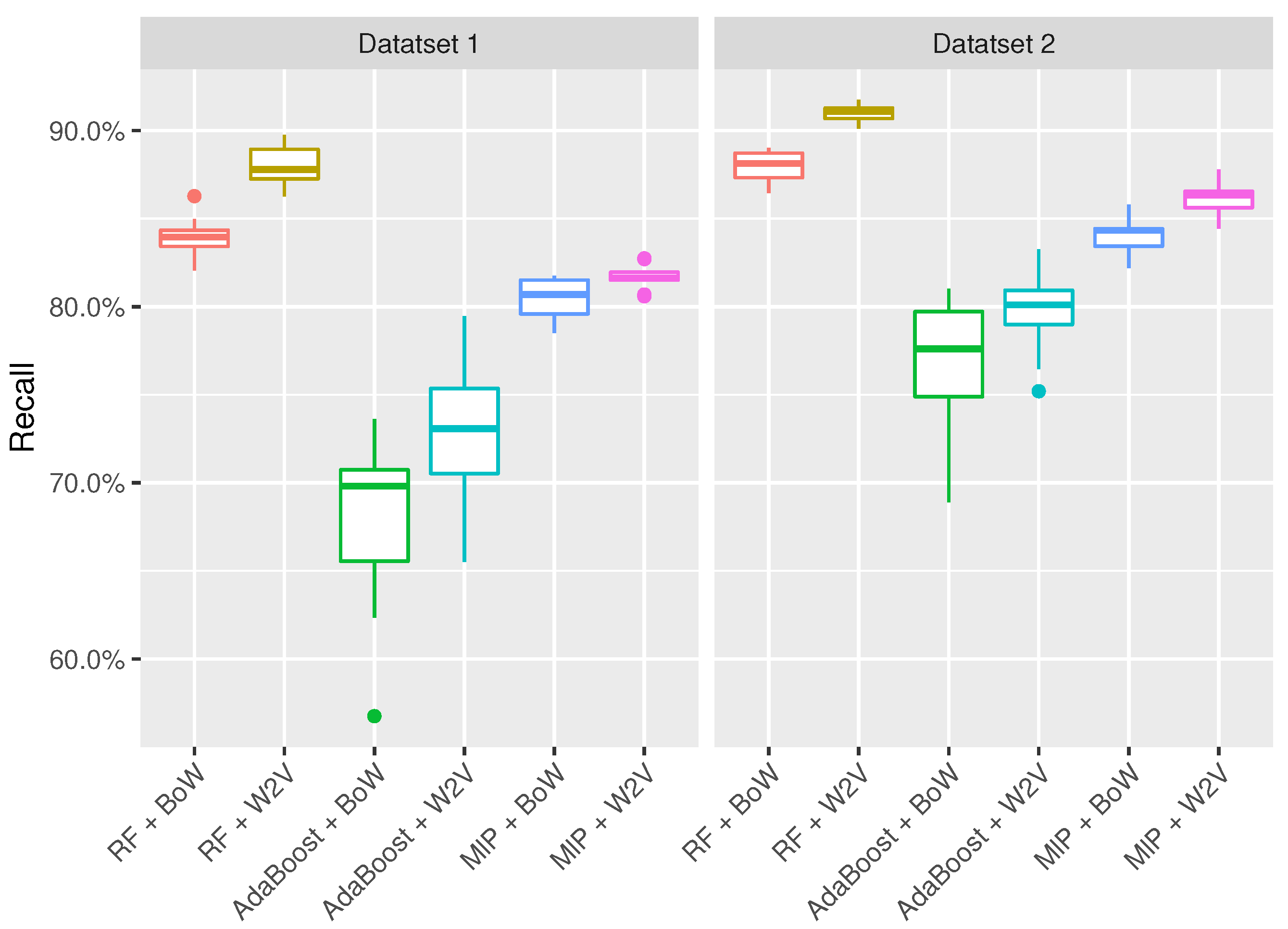
| RF + BoW | 83.2% (±1.5%) | 82.6% (±1.4%) | 86.7% (±0.6%) | 86.4% (±0.8%) |
| RF + Word2Vec | 87.4% (±1.7%) | 86.9% (±1.5%) | 90.0% (±0.5%) | 89.8% (±0.6%) |
| AdaBoost + BoW | 68.6% (±5.0%) | 67.7% (±4.7%) | 76.2% (±4.5%) | 77.0% (±3.6%) |
| AdaBoost + Word2Vec | 73.6% (±4.3%) | 72.8% (±4.3%) | 79.6% (±3%) | 79.5.2% (±2.8%) |
| MlP + BoW | 80.8% (±1.4%) | 81.2% (±1.5%) | 83.2% (±1.6%) | 83.9.1% (±1.4%) |
| MlP + W2V | 79.5% (±1.2%) | 80.0% (±1.0%) | 83.1% (±1.0%) | 84.0% (±1.1%) |
| Dataset 1 | Dataset 2 | |||
|---|---|---|---|---|
| Precision | F1-score | Precision | F1-score | |
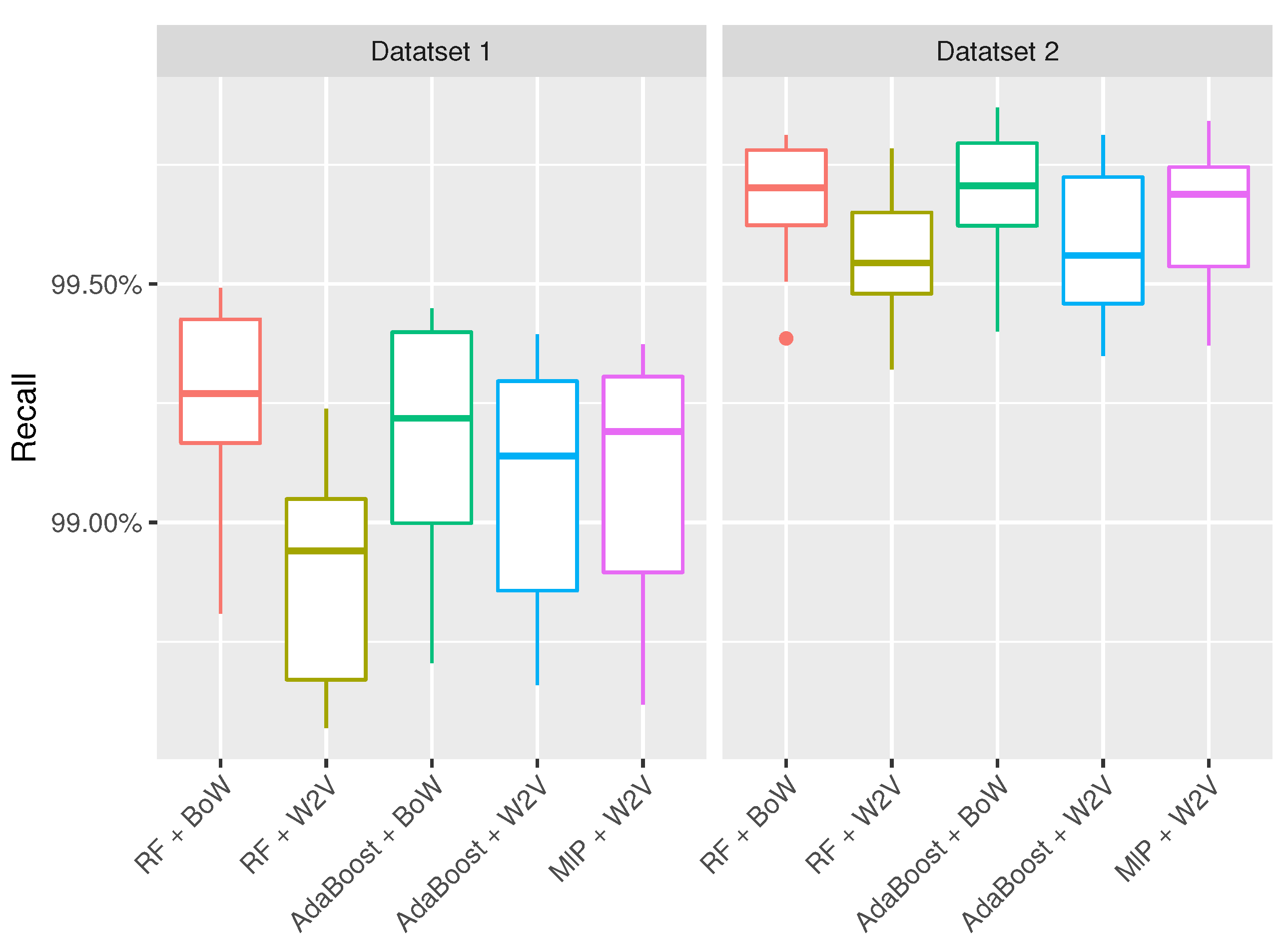
| RF + BoW | 99.2% (±0.2%) | 99.2% (±0.3%) | 99.7% (±0.1%) | 99.6% (±0.2%) |
| RF + Word2Vec | 98.8% (±0.2%) | 98.7% (±0.3%) | 99.5% (±0.1%) | 99.5% (±0.2%) |
| AdaBoost + Bow | 99.2% (±0.3%) | 99.1% (±0.4%) | 99.7% (±0.1%) | 99.6% (±0.2%) |
| AdaBoost + Word2Vec | 99.1% (±0.3%) | 99.0% (±0.4%) | 99.6% (±0.2%) | 99.5% (±0.2%) |
| MlP + BoW | 99.3% (±0.3%) | 99.2% (±0.4%) | 99.7% (±0.2%) | 99.6% (±0.3%) |
| MlP + W2V | 99.1% (±0.3%) | 99.0% (±0.4%) | 99.6% (±0.1%) | 99.6% (±0.2%) |
| Dataset 1 | Dataset 2 | |||
|---|---|---|---|---|
| Precision | F1-score | Precision | F1-score | |
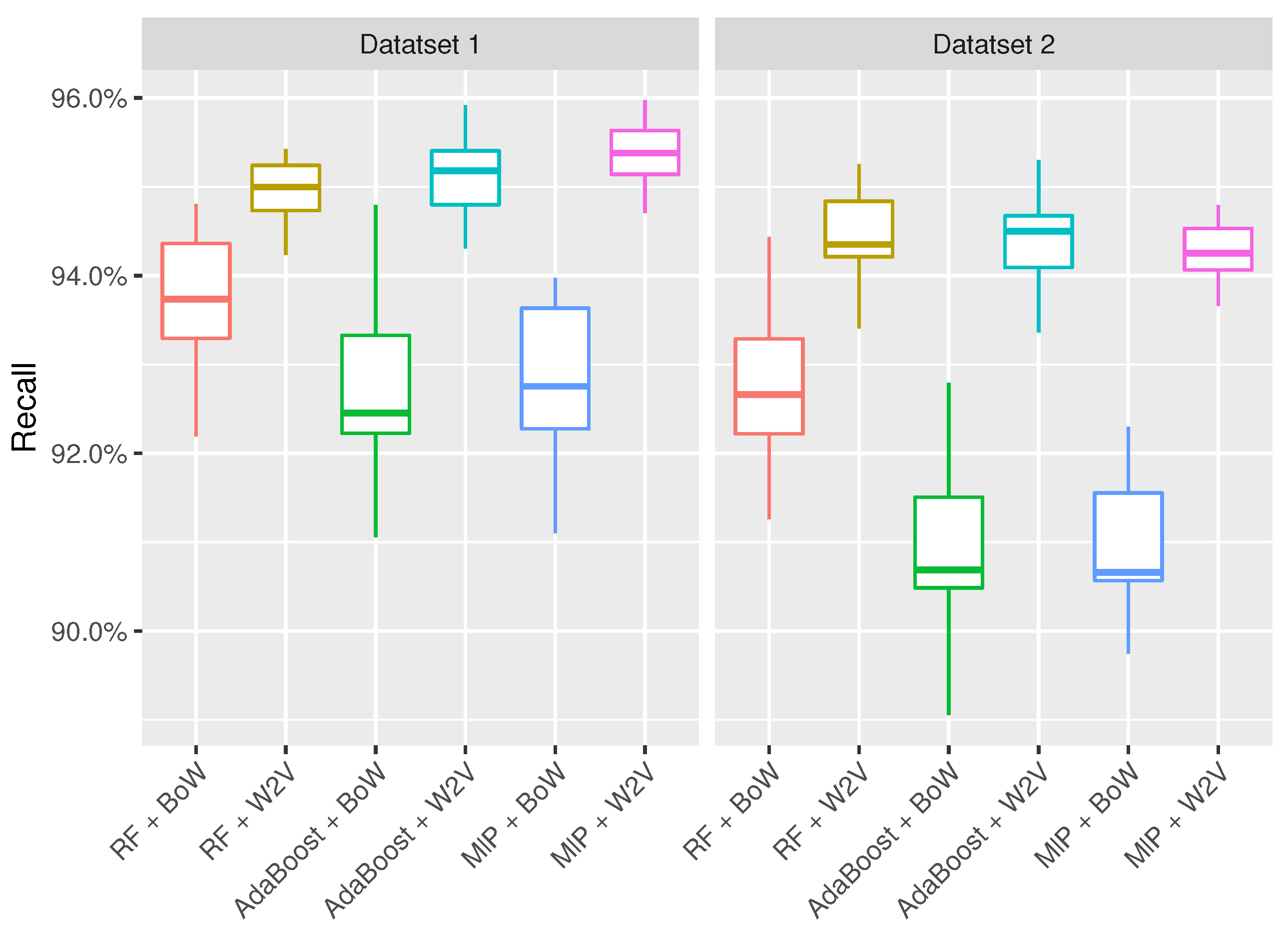
| RF + BoW | 93.4% (±0.8%) | 93.7% (±1.0%) | 92.2% (±0.9%) | 91.8% (±1.1%) |
| RF + Word2Vec | 94.8% (±0.5%) | 94.6% (±0.5%) | 94.3% (±0.6%) | 94.2% (±0.6%) |
| AdaBoost + Bow | 92.6% (±0.6%) | 92.8% (±0.8%) | 89.9% (±1.0%) | 90.5% (±0.8%) |
| AdaBoost + Word2Vec | 94.9% (±0.5%) | 94.9% (±0.6%) | 94.2% (±0.5%) | 94.1% (±0.5%) |
| MlP + BoW | 92.8% (±1.0%) | 97.2% (±0.8%) | 91.4% (±0.6%) | 91.8% (±0.5%) |
| MlP + W2V | 95.4% (±0.3%) | 95.0% (±0.4%) | 94.3% (±0.5%) | 93.8% (±0.6%) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bardelli, C.; Rondinelli, A.; Vecchio, R.; Figini, S. Automatic Electronic Invoice Classification Using Machine Learning Models. Mach. Learn. Knowl. Extr. 2020, 2, 617-629. https://doi.org/10.3390/make2040033
Bardelli C, Rondinelli A, Vecchio R, Figini S. Automatic Electronic Invoice Classification Using Machine Learning Models. Machine Learning and Knowledge Extraction. 2020; 2(4):617-629. https://doi.org/10.3390/make2040033
Chicago/Turabian StyleBardelli, Chiara, Alessandro Rondinelli, Ruggero Vecchio, and Silvia Figini. 2020. "Automatic Electronic Invoice Classification Using Machine Learning Models" Machine Learning and Knowledge Extraction 2, no. 4: 617-629. https://doi.org/10.3390/make2040033
APA StyleBardelli, C., Rondinelli, A., Vecchio, R., & Figini, S. (2020). Automatic Electronic Invoice Classification Using Machine Learning Models. Machine Learning and Knowledge Extraction, 2(4), 617-629. https://doi.org/10.3390/make2040033