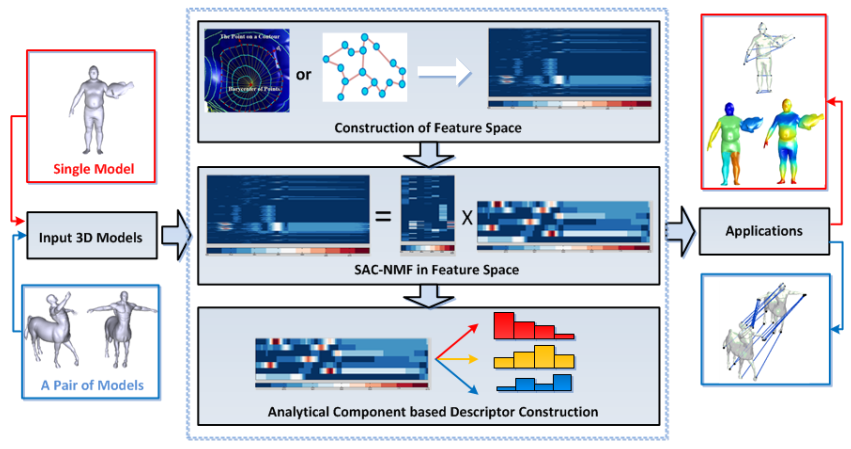
SAC-NMF-Driven Graphical Feature Analysis and Applications

Abstract
:1. Introduction
- We propose a simple, but efficient, framework for conducting feature analysis on 3D models by introducing NMF onto a feature matrix.
- We introduce the SAC-NMF to achieve sparse and part-aware analytical components (bases, encodings, and hidden variables) for feature analysis.
- We adapt analytical components to construct descriptors to empower various applications, including symmetry detection, correspondence, segmentation, and saliency detection.
2. Related Work
3. Construction of NMF-Based Analytical Components
3.1. Standard NMF Model
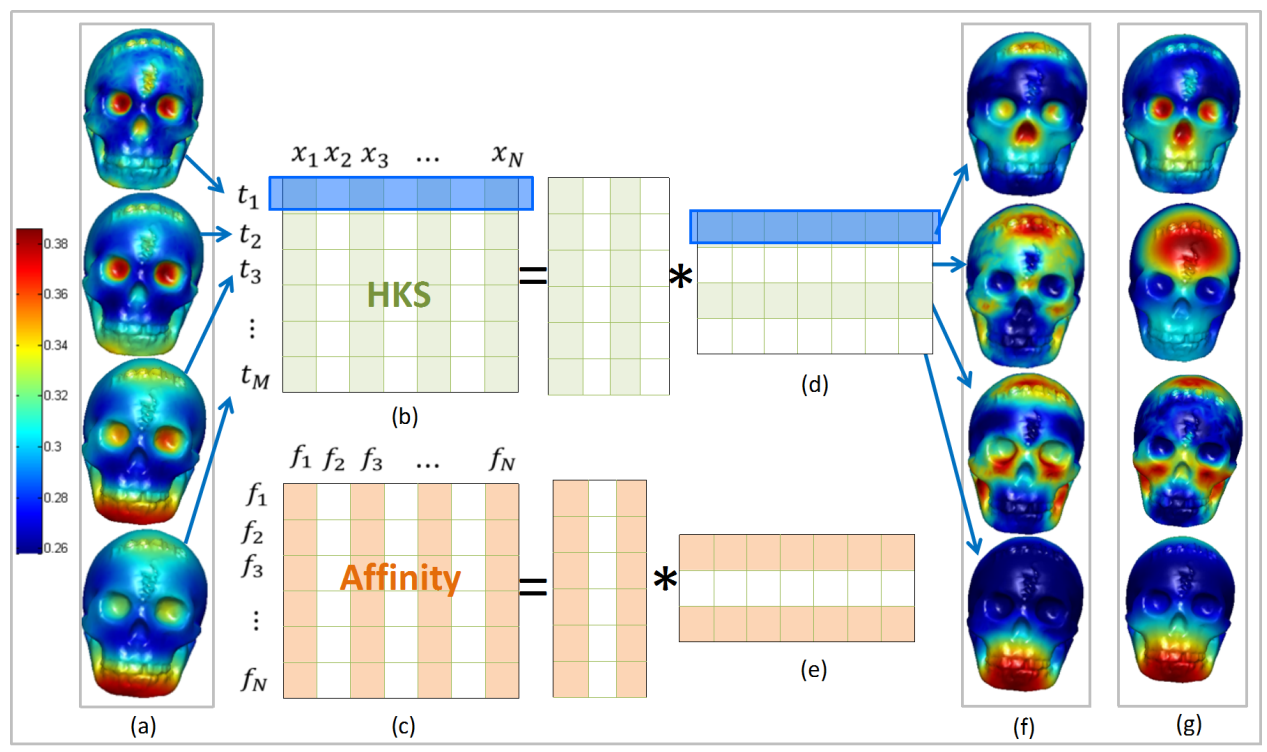
3.2. Analytical Components
4. SAC-NMF on Feature Space
4.1. Construction of Feature Matrix on 3D Model
4.2. SAC-NMF Model
5. SAC-NMF-Driven Graphical Applications
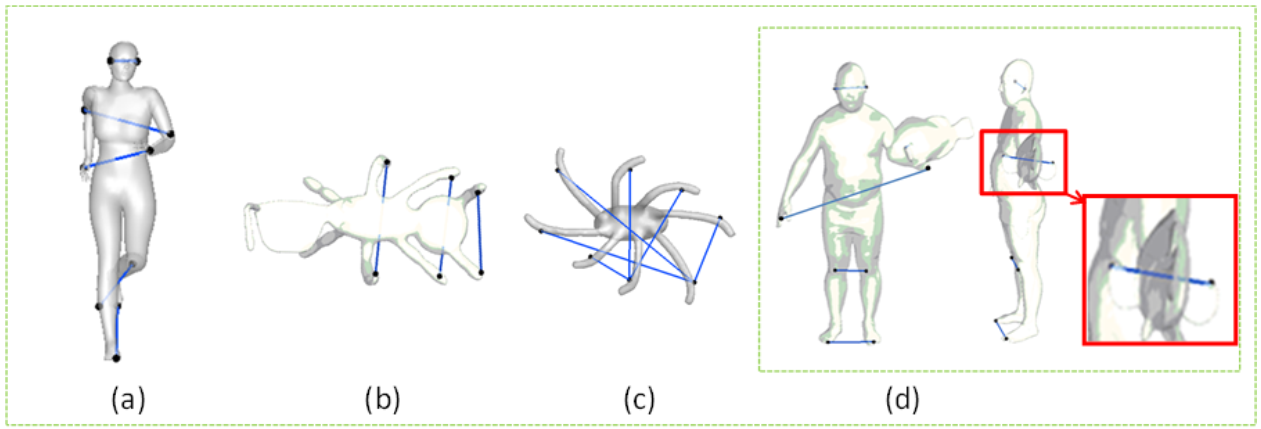
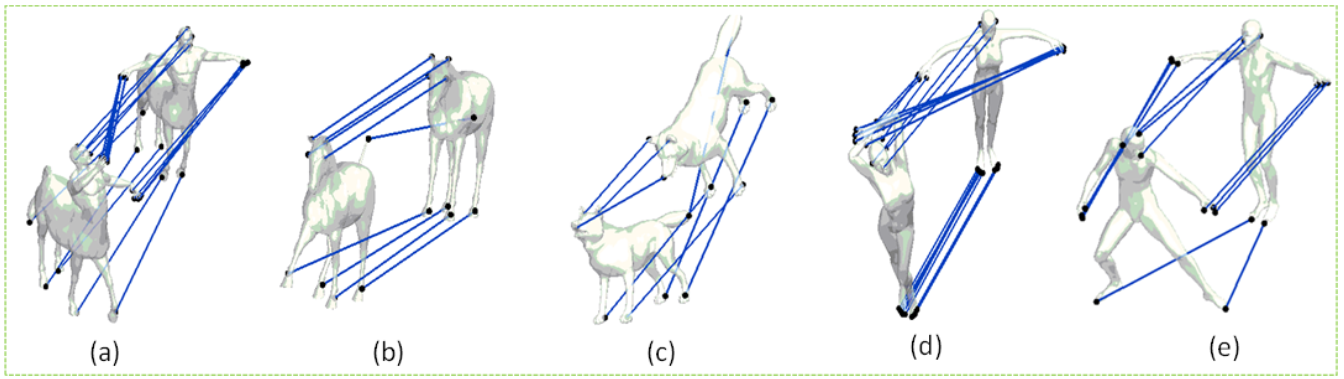
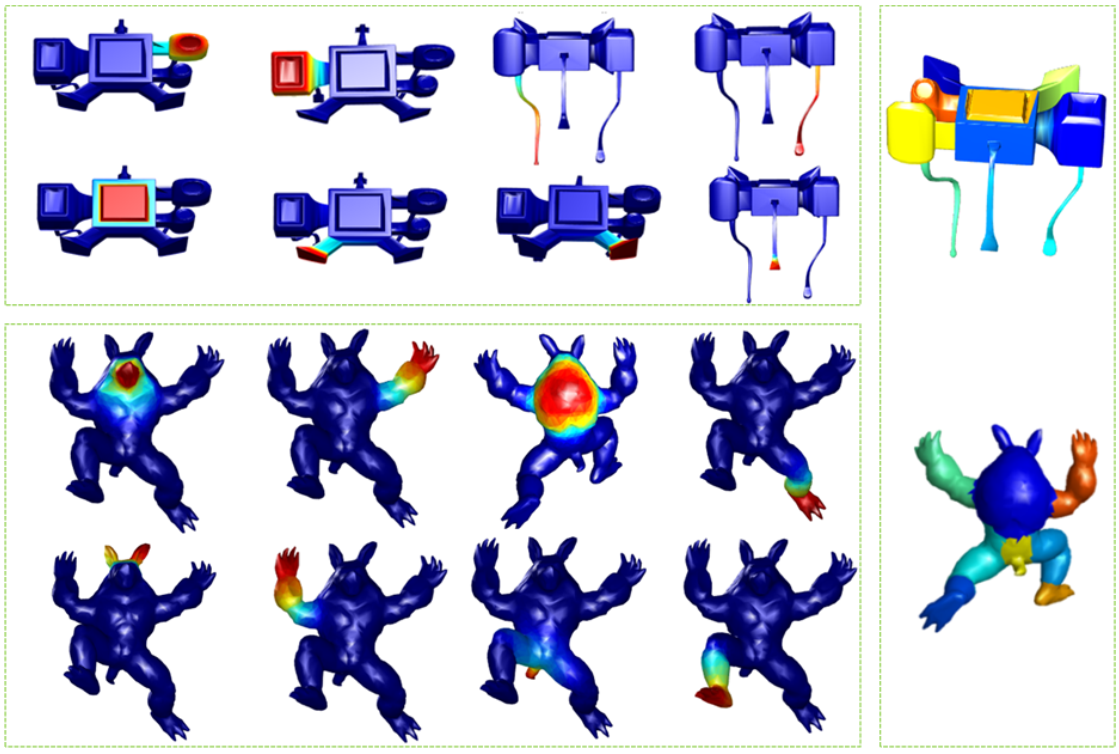
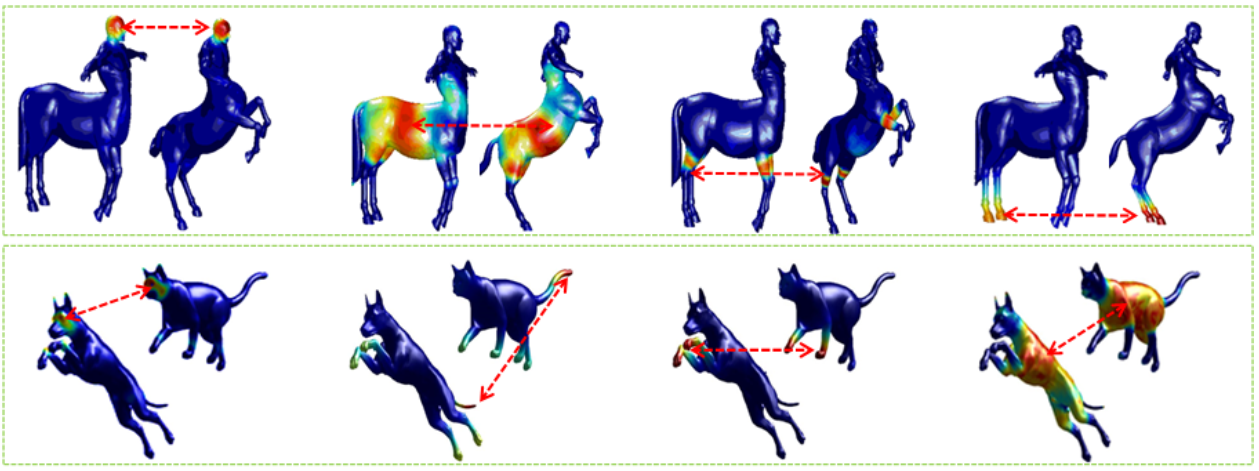
5.1. Symmetry Detection and Correspondence
5.2. Segmentation and Saliency Detection
6. More Experiments and Discussion
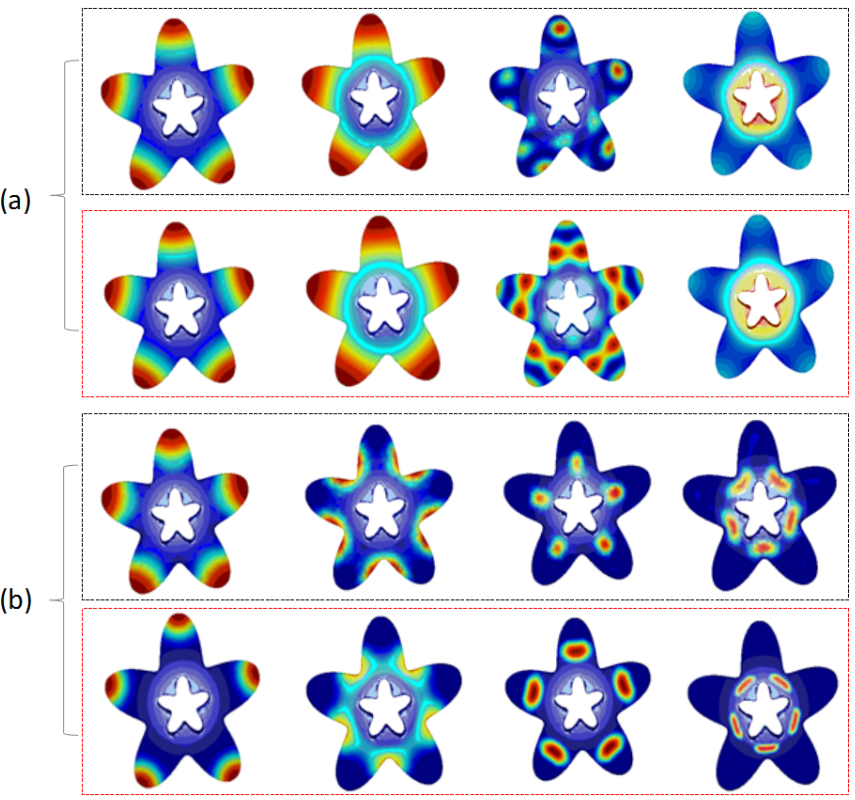
6.1. Parameter Settings
6.2. Properties of Our Framework
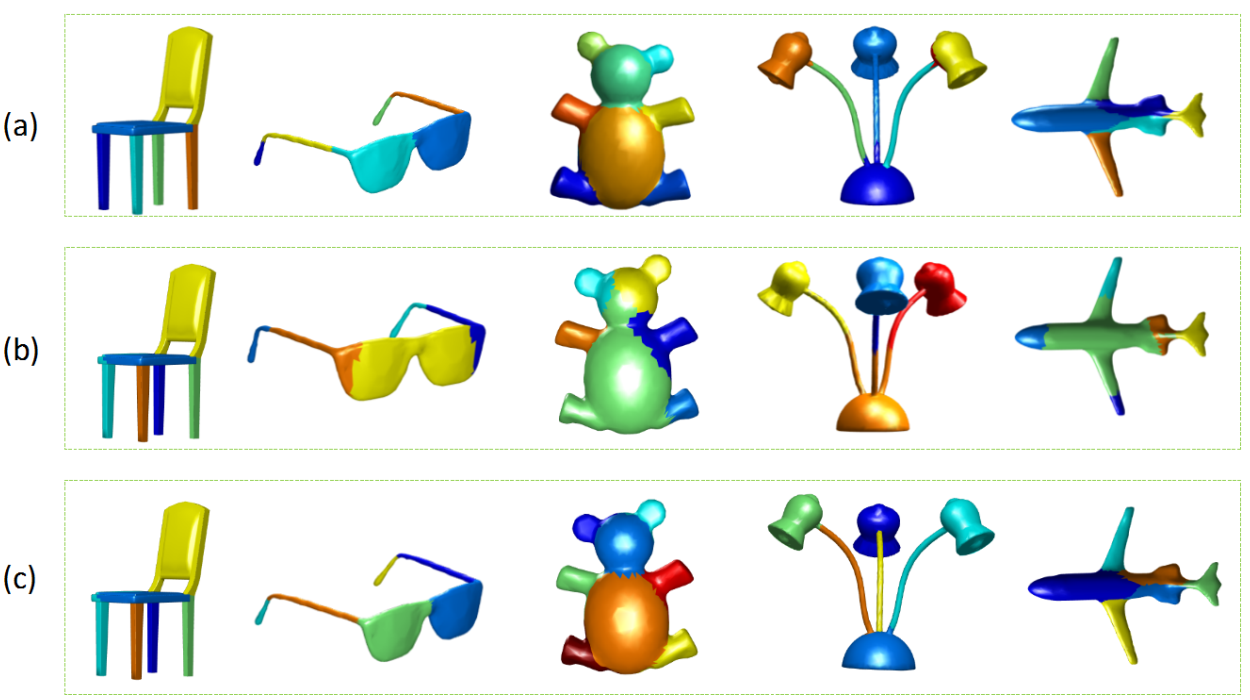
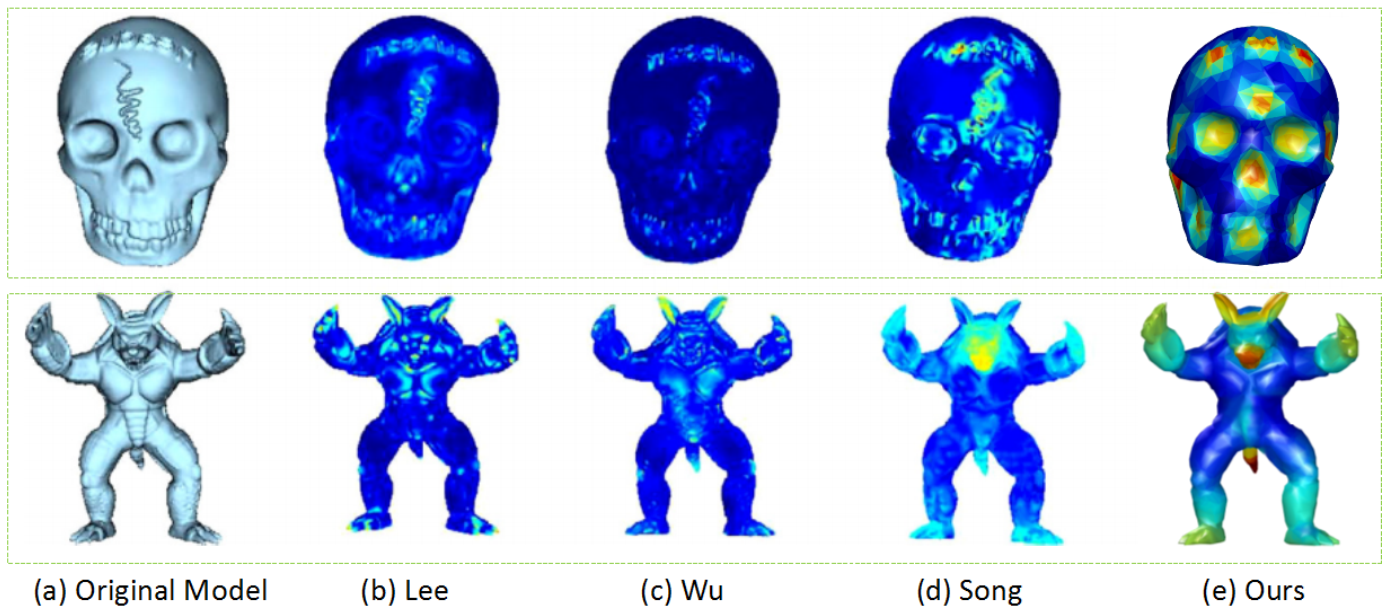
6.3. Comparisons
7. Conclusions and Discussion
Author Contributions
Funding
Conflicts of Interest
References
- Xie, X.; Feng, J. Volumetric shape contexts for mesh co-segmentation. Comput. Aided Geom. Des. 2016, 43, 159–171. [Google Scholar] [CrossRef]
- Kin-Chung Au, O.; Zheng, Y.; Chen, M.; Xu, P.; Tai, C.L. Mesh Segmentation with Concavity-Aware Fields. IEEE Trans. Vis. Comput. Graph. 2012, 18, 1125–1134. [Google Scholar] [CrossRef] [Green Version]
- Song, R.; Liu, Y.; Martin, R.R.; Rosin, P.L. Mesh Saliency via Spectral Processing. ACM Trans. Graph. 2014, 33, 1–17. [Google Scholar] [CrossRef]
- Chen, M.; Zou, Q.; Wang, C.; Liu, L. EdgeNet: Deep metric learning for 3D shapes. Comput. Aided Geom. Des. 2019, 72, 19–33. [Google Scholar] [CrossRef]
- Shu, Z.; Xin, S.; Xu, X.; Liu, L.; Kavan, L. Detecting 3D Points of Interest Using Multiple Features and Stacked Auto-encoder. IEEE Trans. Vis. Comput. Graph. 2019, 25, 2583–2596. [Google Scholar] [CrossRef] [PubMed]
- Abdi, H.; Williams, L.J. Principal Component Analysis. WIREs Comput. Stat. 2010, 2, 433–459. [Google Scholar] [CrossRef]
- Rustamov, R.M. Laplace-Beltrami Eigenfunctions for Deformation Invariant Shape Representation. In Geometry Processing; Belyaev, A., Garland, M., Eds.; The Eurographics Association: Barcelona, Spain, 2007. [Google Scholar] [CrossRef]
- Hyvarinen, J.K.; Oja, E. Independent Component Analysis. Wiley Intersci. 2001, 2, 433–459. [Google Scholar]
- Wang, S.; Li, N.; Li, S.; Luo, Z.; Su, Z.; Qin, H. Multi-scale mesh saliency based on low-rank and sparse analysis in shape feature space. Comput. Aided Geom. Des. 2015, 35–36, 206–214. [Google Scholar] [CrossRef] [Green Version]
- Burton, D.; Shore, J.; Buck, J. A generalization of isolated word recognition using vector quantization. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, Boston, MA, USA, 14–16 April 1983; Volume 8, pp. 1021–1024. [Google Scholar] [CrossRef]
- Liu, Z.; Mitani, J.; Fukui, Y.; Nishihara, S. A 3D Shape Retrieval Method Based on Continuous Spherical Wavelet Transform. In Proceedings of the International Conference on Computer Graphics and Imaging, Innsbruck, Austria, 13–15 February 2007; pp. 21–26. [Google Scholar]
- Zhang, H.; Fiume, E. Shape matching of 3D contours using normalized Fourier descriptors. Proc. SMI Shape Model. Int. 2002, 2002, 261–268. [Google Scholar] [CrossRef]
- Lee, D. Learning the parts of objects with nonnegative matrix factorization. Nature 1999, 401, 788. [Google Scholar] [CrossRef] [PubMed]
- Hoyer, P.O. Non-negative Matrix Factorization with Sparseness Constraints. J. Mach. Learn. Res. 2004, 5, 1457–1469. [Google Scholar]
- Cai, D.; He, X.; Wu, X.; Han, J. Non-negative Matrix Factorization on Manifold. In Proceedings of the Eighth IEEE International Conference on Data Mining, Pisa, Italy, 15–19 December 2008; pp. 63–72. [Google Scholar]
- Li, Y.; Alioune, N. The non-negative matrix factorization toolbox for biological data mining. Source Code Biol. Med. 2013, 8, 10. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mcgraw, T.; Kang, J.; Herring, D. Sparse Non-Negative Matrix Factorization for Mesh Segmentation. Int. J. Image Graph. 2016, 16, 1650004. [Google Scholar] [CrossRef] [Green Version]
- Tenenbaum, J.B.; Silva, V.D.; Langford, J.C. A Global Geometric Framework for Nonlinear Dimensionality Reduction. Science 2000, 290, 2319. [Google Scholar] [CrossRef]
- Belkin, M.; Niyogi, P. Laplacian eigenmaps and spectral techniques for embedding and clustering. Adv. Neural Inf. Process. Syst. 2001, 14, 585–591. [Google Scholar]
- Sheaves, M.; Johnston, R.; Johnson, A.; Baker, R.; Connolly, R.M. Neighborhood preserving Nonnegative Matrix Factorization for spectral mixture analysis. In Proceedings of the Geoscience and Remote Sensing Symposium, Quebec City, QC, Canada, 13–18 July 2014; pp. 2573–2576. [Google Scholar]
- Buchsbaum, G.; Bloch, O. Color categories revealed by non-negative matrix factorization of Munsell color spectra. Vis. Res. 2002, 42, 559–563. [Google Scholar] [CrossRef] [Green Version]
- Guillamet, D.; Bressan, M.; Vitri, J. A Weighted Non-Negative Matrix Factorization for Local Representations. In Proceedings of the 2001 IEEE Computer Society Conference on CVPR 2001, Kauai, HI, USA, 8–14 December 2001; pp. 942–947. [Google Scholar]
- Buciu, I.; Pitas, I. Application of non-Negative and Local non Negative Matrix Factorization to Facial Expression Recognition. In Proceedings of the International Conference on Pattern Recognition, Cambridge, UK, 23–26 August 2004; pp. 288–291. [Google Scholar]
- Li, S.Z.; Hou, X.W.; Zhang, H.J.; Cheng, Q. Learning spatially localized, parts-based representation. In Proceedings of the 2001 IEEE Computer Society Conference on CVPR 2001, Kauai, HI, USA, 8–14 December 2001; Volume 1, pp. 207–212. [Google Scholar]
- Liu, W.; Zheng, N. Non-negative matrix factorization based methods for object recognition. Pattern Recognit. Lett. 2004, 25, 893–897. [Google Scholar] [CrossRef]
- Wild, S.; Curry, J.; Dougherty, A. Improving non-negative matrix factorizations through structured initialization. Pattern Recognit. 2004, 37, 2217–2232. [Google Scholar] [CrossRef]
- Xu, W.; Liu, X.; Gong, Y. Document clustering based on non-negative matrix factorization. Proc. Acm. Sigir. 2003, 267–273. [Google Scholar]
- Cai, D.; He, X.; Wang, X.; Bao, H.; Han, J. Locality preserving nonnegative matrix factorization. In Proceedings of the International Jont Conference on Artifical Intelligence, Pasadena, CA, USA, 11–17 July 2009; pp. 1010–1015. [Google Scholar]
- Yuang, W.; Jia, Y.; Hu, C.; Turk, M. Non-negative Matrix Factorization framework for face recognition. Int. J. Pattern Recognit. Artif. Intell. 2005, 19, 495–511. [Google Scholar]
- Zafeiriou, S.; Tefas, A.; Buciu, I.; Pitas, I. Exploiting discriminant information in nonnegative matrix factorization with application to frontal face verification. IEEE Trans. Neural Netw. 2006, 17, 683–695. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kim, W.H.; Pachauri, D.; Hatt, C.; Chung, M.K.; Johnson, S.; Singh, V. Wavelet based multi-scale shape features on arbitrary surfaces for cortical thickness discrimination. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1241–1249. [Google Scholar]
- Sun, J.; Ovsjanikov, M.; Guibas, L. A Concise and Provably Informative Multi-Scale Signature Based on Heat Diffusion. Comput. Graph. Forum 2009, 28, 1383–1392. [Google Scholar] [CrossRef]
- Li, N.; Wang, S.; Zhong, M.; Su, Z.; Qin, H. Generalized Local-to-global Shape Feature Detection based on Graph Wavelets. IEEE Trans. Vis. Comput. Graph. 2016, 22, 2094–2106. [Google Scholar] [CrossRef] [PubMed]
- Lipman, Y.; Rustamov, R.M.; Funkhouser, T.A. Biharmonic Distance. ACM Trans. Graph. 2010, 29, 1–11. [Google Scholar] [CrossRef]
- Meyer, M.; Desbrun, M.; Schröder, P.; Barr, A. Discrete Differential-Geometry Operators for Triangulated 2-Manifolds. In Visualization and Mathematics III; Springer: Berlin/Heidelberg, Germany, 2003. [Google Scholar]
- Aubry, M.; Schlickewei, U.; Cremers, D. The wave kernel signature: A quantum mechanical approach to shape analysis. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Barcelona, Spain, 6–13 November 2011; pp. 1626–1633. [Google Scholar]
- Wang, S. Primary Correspondences between Intrinsically Symmetrical Shapes. J. Inf. Comput. Sci. 2014, 11, 2975–2982. [Google Scholar] [CrossRef]
- Wang, H.; Simari, P.; Su, Z.; Zhang, H. Spectral global intrinsic symmetry invariant functions. In Graphics Interface 2014; A K Peters/CRC Press: New York, NY, USA, 2014; pp. 209–215. [Google Scholar]
- Liu, R.; Zhang, H. Segmentation of 3D meshes through spectral clustering. In Proceedings of the 12th Pacific Conference on Computer Graphics and Applications, Seoul, Korea, 6–8 October 2004; pp. 298–305. [Google Scholar]
- Lee, C.H.; Varshney, A.; Jacobs, D.W. Mesh saliency. ACM Trans. Graph. 2005, 24, 659–666. [Google Scholar] [CrossRef]
- Wu, J.; Shen, X.; Zhu, W.; Liu, L. Mesh Saliency with Global Rarity. Graph. Models 2013, 75, 255–264. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Vertices | Timing (s) | ||
|---|---|---|---|---|
| Descriptor | Factorization | Symmetry | ||
| Dinosaur | 14 K | 3.42 | 2.40 | 1.22 |
| Dog | 26 K | 4.94 | 3.63 | 1.78 |
| Armadillo | 34 K | 6.28 | 4.87 | 2.56 |
| Santa | 75 K | 8.73 | 6.82 | 3.51 |
| Dragon | 430 K | 16.54 | 17.62 | 5.02 |
| Method | Human | Cup | Glasses | Plane | Ant | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Reduced | Normal | Reduced | Normal | Reduced | Normal | Reduced | Normal | Reduced | Normal | |
| Mcgraw [17] | 17.9 | 12.6 | 15.6 | 13.6 | 14.4 | 10.1 | 18.6 | 11.5 | 4.7 | 3.9 |
| Liu [39] | 22.9 | 17.6 | 35.8 | 23.6 | 20.4 | 14.2 | 25.6 | 18.6 | 6.5 | 4.7 |
| Ours | 11.9 | 12.3 | 9.9 | 9.9 | 10.1 | 9.8 | 9.2 | 9.2 | 2.2 | 1.9 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, N.; Wang, S.; Li, H.; Li, Z. SAC-NMF-Driven Graphical Feature Analysis and Applications. Mach. Learn. Knowl. Extr. 2020, 2, 630-646. https://doi.org/10.3390/make2040034
Li N, Wang S, Li H, Li Z. SAC-NMF-Driven Graphical Feature Analysis and Applications. Machine Learning and Knowledge Extraction. 2020; 2(4):630-646. https://doi.org/10.3390/make2040034
Chicago/Turabian StyleLi, Nannan, Shengfa Wang, Haohao Li, and Zhiyang Li. 2020. "SAC-NMF-Driven Graphical Feature Analysis and Applications" Machine Learning and Knowledge Extraction 2, no. 4: 630-646. https://doi.org/10.3390/make2040034
APA StyleLi, N., Wang, S., Li, H., & Li, Z. (2020). SAC-NMF-Driven Graphical Feature Analysis and Applications. Machine Learning and Knowledge Extraction, 2(4), 630-646. https://doi.org/10.3390/make2040034