Rumor Detection Based on SAGNN: Simplified Aggregation Graph Neural Networks


Abstract
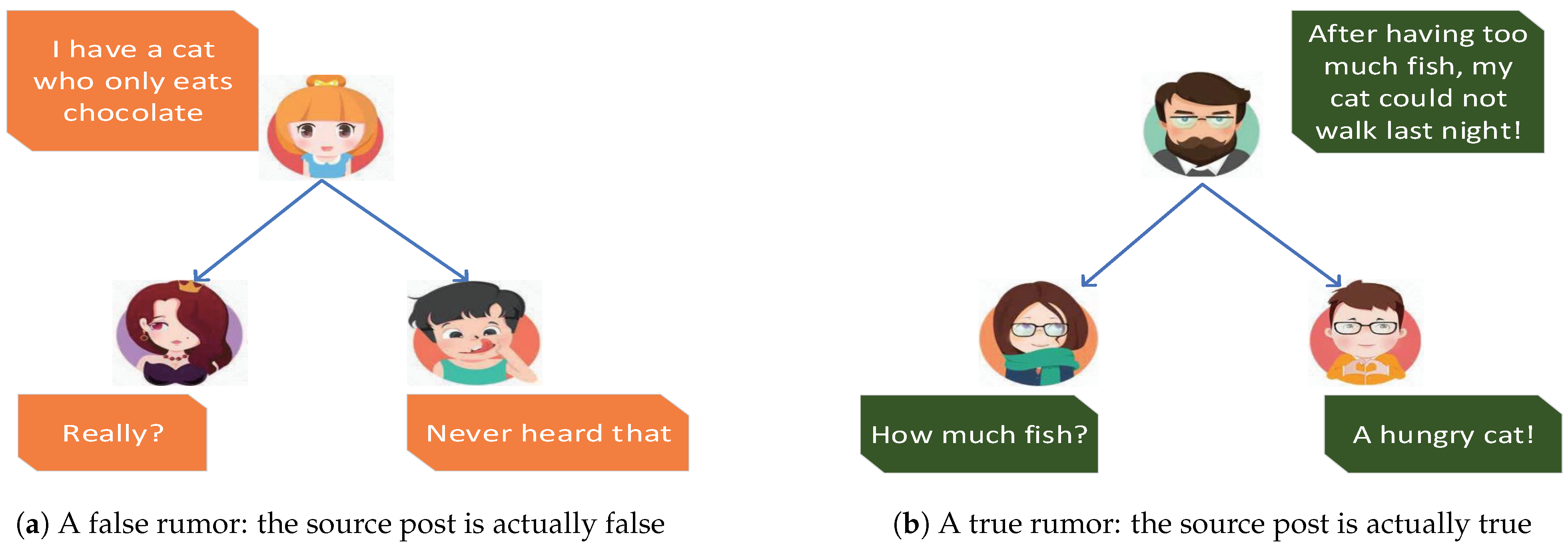
:1. Introduction
2. Related Work
3. SAGNN: Simplified Aggregation Graph Neural Networks
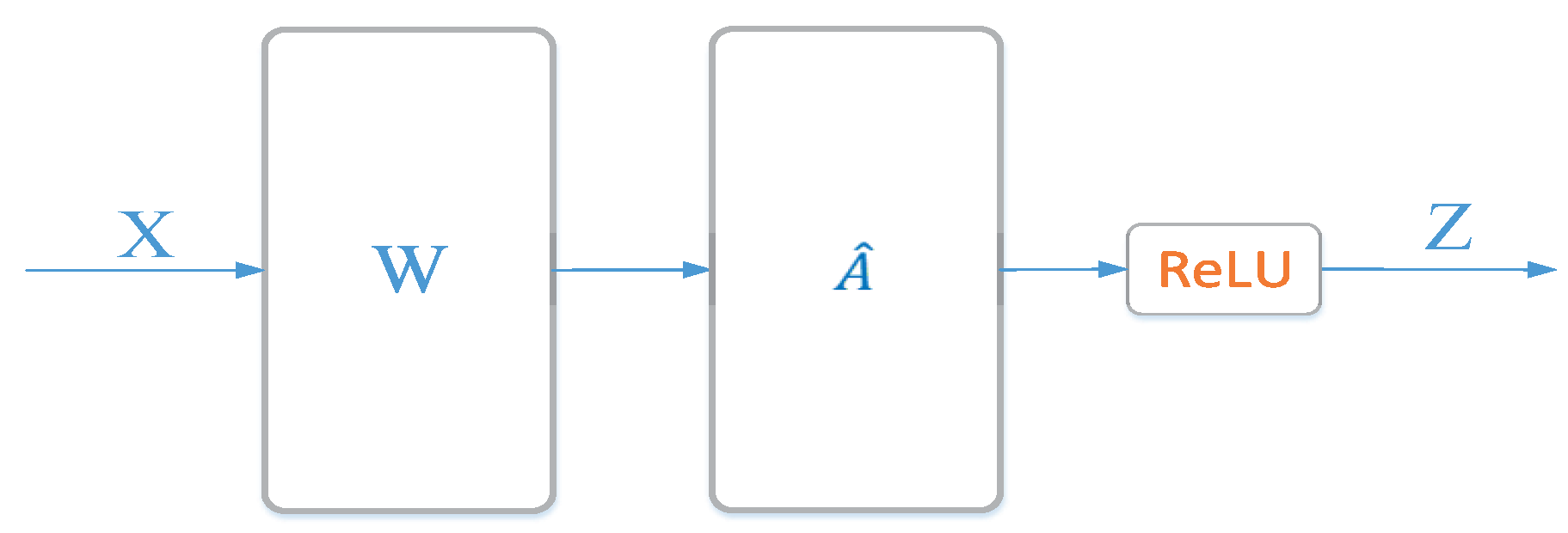
3.1. Preliminary: Graph Convolutional Networks
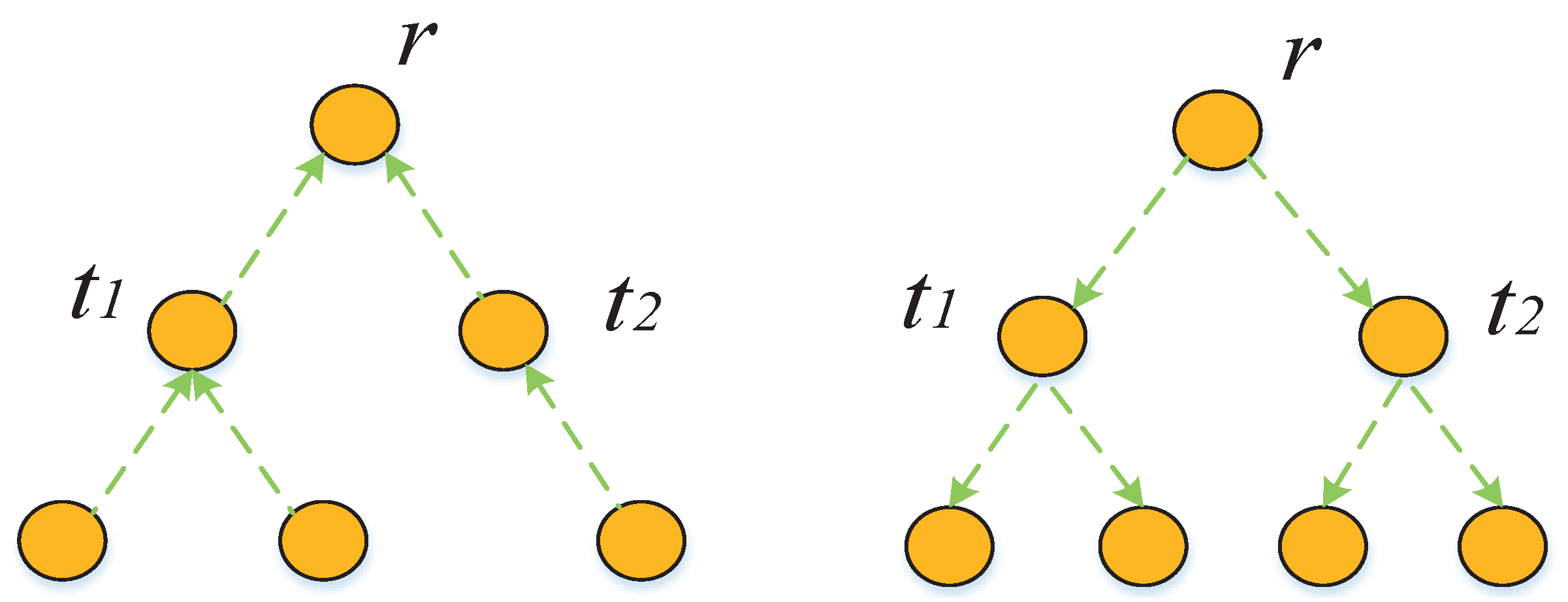
3.2. Motivation for SAGNN
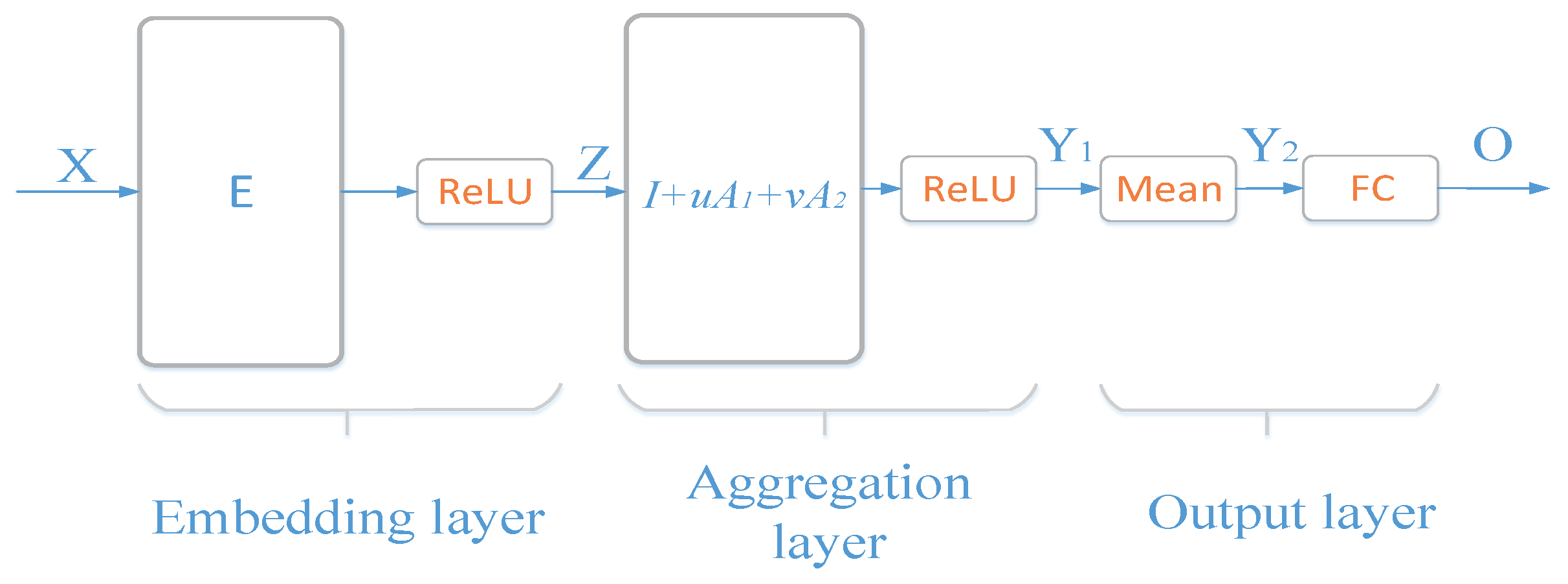
3.3. SAGNN Architecture
3.3.1. Embedding Layer
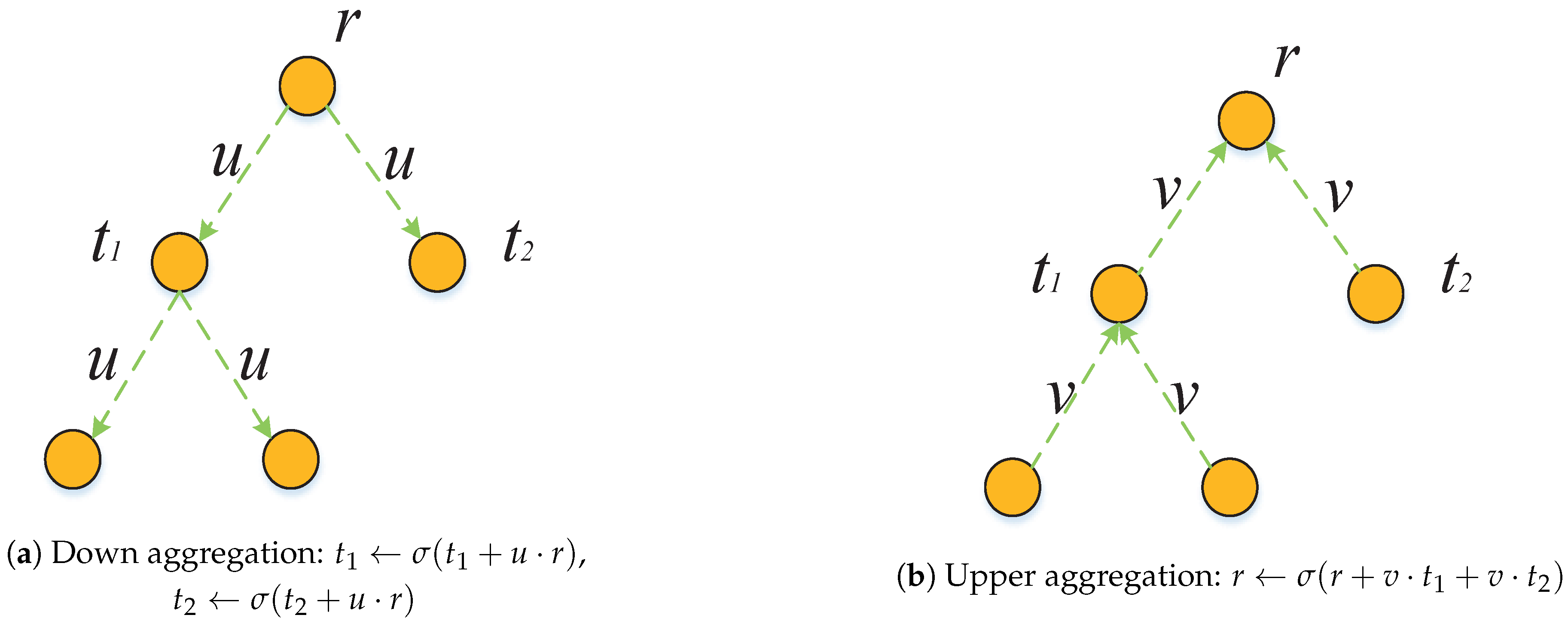
3.3.2. Aggregation Layers
3.3.3. Output Layer
3.4. Learning Algorithm
Cross Entropy Loss Function
4. Experiments
4.1. Datasets
4.2. Network Setup
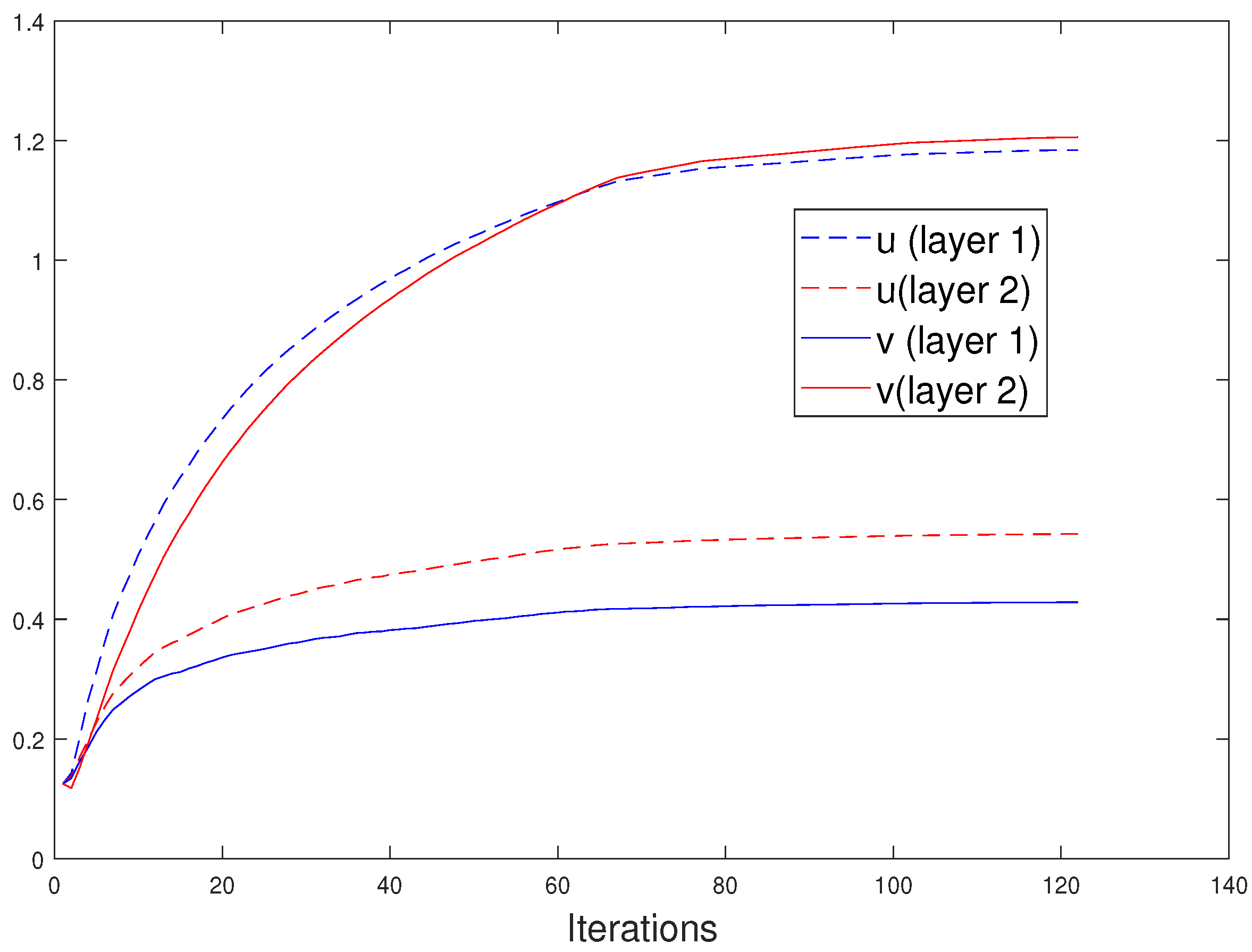
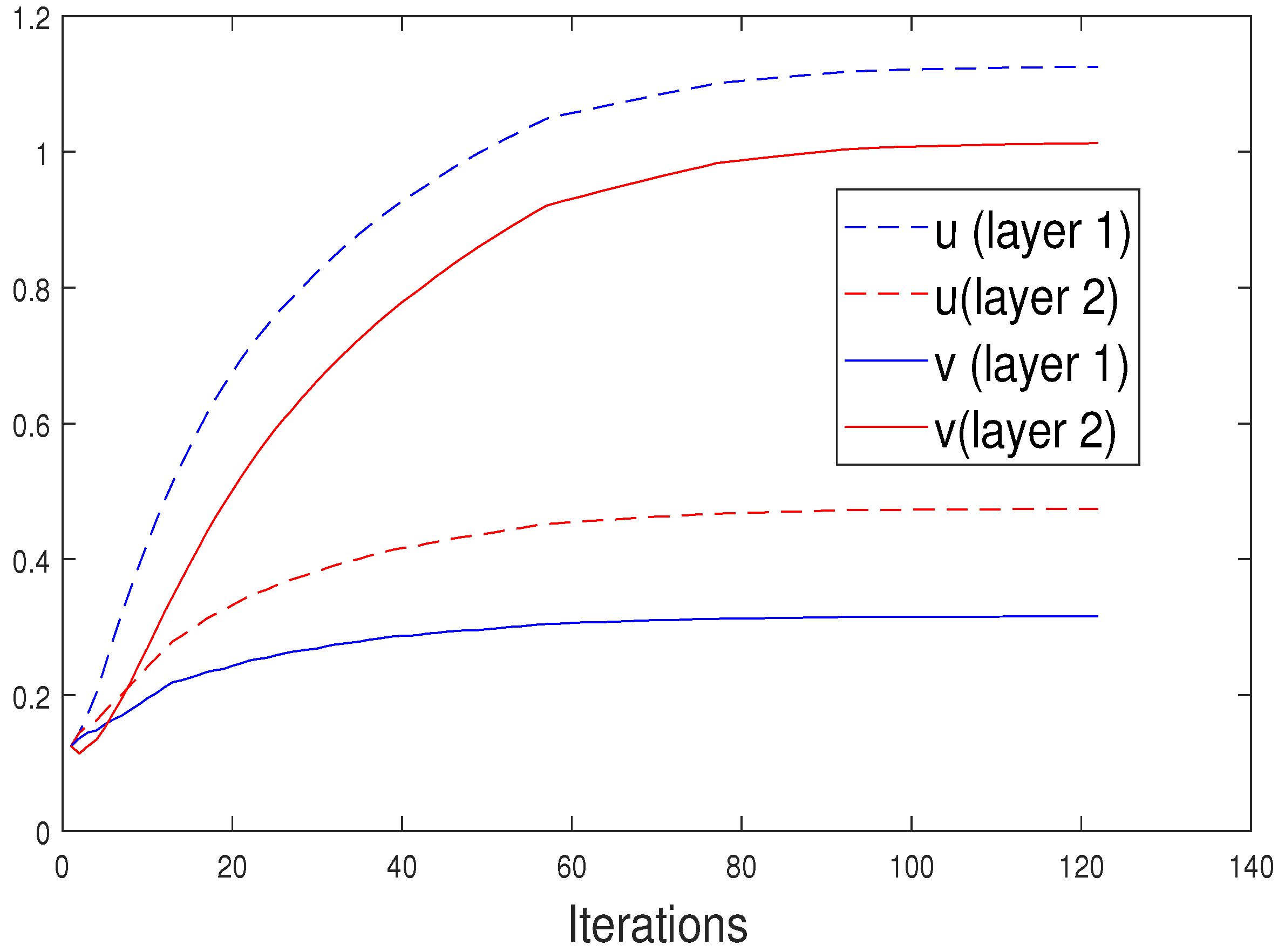
4.3. Results
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Pendleton, S.C. Rumor research revisited and expanded. Lang. Commun. 1998, 18, 69–86. [Google Scholar] [CrossRef]
- Castillo, C.; Mendoza, M.; Poblete, B. Information credibility on twitter. In Proceedings of the 20th International Conference on World Wide Web, Hyderabad, India, 28 March–1 April 2011; pp. 675–684. [Google Scholar]
- Ma, J.; Gao, W.; Wei, Z.; Lu, Y.; Wong, K.F. Detect rumors using time series of social context information on microblogging websites. In Proceedings of the 24th ACM International on Conference on Information and Knowledge Management, Melbourne Australia, 19–23 October 2015; pp. 1751–1754. [Google Scholar]
- Ma, J.; Gao, W.; Wong, K.F. Detect rumors in microblog posts using propagation structure via kernel learning. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; Volume 1, pp. 708–717. [Google Scholar]
- Ma, J.; Gao, W.; Mitra, P.; Kwon, S.; Jansen, B.J.; Wong, K.F.; Cha, M. Detecting rumors from microblogs with recurrent neural networks. In Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence, New York, NY, USA, 9–15 July 2016; pp. 3818–3824. [Google Scholar]
- Qi, H.; Chuan, Z.; Wu, J.; Wang, M.; Wang, B. Deep Structure Learning for Rumor Detection on Twitter. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–8. [Google Scholar] [CrossRef]
- Bian, T.; Xiao, X.; Xu, T.; Zhao, P.; Huang, W.; Rong, Y.; Huang, J. Rumor Detection on Social Media with Bi-Directional Graph Convolutional Networks. In Proceedings of the Thirty-Fourth AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 549–556. [Google Scholar]
- Yuan, C.; Ma, Q.; Zhou, W.; Han, J.; Hu, S. Jointly embedding the local and global relations of heterogeneous graph for rumor detection. In Proceedings of the 19th IEEE International Conference on Data Mining, Beijing, China, 8–11 November 2019. [Google Scholar]
- Ma, J.; Gao, W.; Wong, K.F. Rumor Detection on Twitter with Tree-structured Recursive Neural Networks. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 18–20 July 2018; pp. 1980–1989. [Google Scholar]
- Ma, J.; Gao, W.; Wong, K.F. Detect rumors on twitter by promoting information campaigns with generative adversarial learning. In Proceedings of the World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 3049–3055. [Google Scholar]
- Yu, F.; Liu, Q.; Wu, S.; Wang, L.; Tan, T. A convolutional approach for misinformation identification. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, Melbourne, Australia, 19–25 August 2017; pp. 3901–3907. [Google Scholar]
- Ruchansky, N.; Seo, S.; Liu, Y. Csi: A hybrid deep model for fake news detection. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, Singapore, 6–10 November 2017; pp. 797–806. [Google Scholar]
- Liu, Y.; Wu, Y.F.B. Early detection of fake news on social media through propagation path classification with recurrent and convolutional networks. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 354–361. [Google Scholar]
- Providel, E.; Mendoza, M. Using Deep Learning to Detect Rumors in Twitter. In Social Computing and Social Media. Design, Ethics, User Behavior, and Social Network Analysis. HCII 2020. Lecture Notes in Computer Science; Meiselwitz, G., Ed.; Springer: Cham, Switzerland, 2020; Volume 12194, pp. 3–28. [Google Scholar]
- Tarnpradab, S.; Hua, K.A. Attention Based Neural Architecture for Rumor Detection with Author Context Awareness. In Proceedings of the 2018 Thirteenth International Conference on Digital Information Management (ICDIM), Berlin, Germany, 24–26 September 2018; pp. 82–87. [Google Scholar] [CrossRef] [Green Version]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. In Proceedings of the International Conference on Learning Representations, ICLR, Toulon, France, 24–26 April 2017. [Google Scholar]
- Perozzi, B.; Al-Rfou, R.; Skiena, S. Deepwalk: Online learning of social representations. In Proceedings of the 20th ACM SIGKDD international conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27August 2014; pp. 701–710. [Google Scholar]
- Yang, C.; Liu, Z.; Zhao, D.; Sun, M.; Chang, E.Y. Network Representation Learning with Rich Text Information. In Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015; pp. 2111–2117. [Google Scholar]
- Zhang, D.; Yin, J.; Zhu, X.; Zhang, C. Network Representation Learning: A Survey. IEEE Trans. Big Data 2020, 6, 3–28. [Google Scholar] [CrossRef] [Green Version]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning; Springer: New York, NY, USA, 2009. [Google Scholar]
- Ming Chen, Z.W.; Zengfeng Huang, B.D.; Li, Y. Simple and Deep Graph Convolutional Networks. In Proceedings of the 37th International Conference on Machine Learning, Vienna, Austria, 12–18 July 2020. [Google Scholar]
- Fey, M.; Lenssen, J.E. Fast Graph Representation Learning with PyTorch Geometric. In Proceedings of the ICLR Workshop on Representation Learning on Graphs and Manifolds, New Orleans, LA, USA, 6 May 2019. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Method | Acc | F1 | |||
|---|---|---|---|---|---|---|
| NR | FR | TR | UR | |||
| T150 | SAGNN | 0.857 | 0.851 | 0.892 | 0.867 | 0.826 |
| GCNII | 0.823 | 0.796 | 0.85 | 0.864 | 0.786 | |
| T151 | SAGNN | 0.845 | 0.844 | 0.857 | 0.895 | 0.784 |
| GCNII | 0.813 | 0.810 | 0.829 | 0.896 | 0.725 | |
| T152 | SAGNN | 0.796 | 0.846 | 0.817 | 0.810 | 0.706 |
| GCNII | 0.773 | 0.775 | 0.790 | 0.834 | 0.698 | |
| T153 | SAGNN | 0.792 | 0.75 | 0.790 | 0.907 | 0.718 |
| GCNII | 0.768 | 0.703 | 0.763 | 0.884 | 0.723 | |
| T154 | SAGNN | 0.802 | 0.8 | 0.771 | 0.824 | 0.813 |
| GCNII | 0.769 | 0.761 | 0.719 | 0.861 | 0.742 | |
| Dataset | Method | Acc | F1 | |||
|---|---|---|---|---|---|---|
| NR | FR | TR | UR | |||
| T160 | SAGNN | 0.764 | 0.526 | 0.783 | 0.877 | 0.791 |
| GCNII | 0.802 | 0.718 | 0.849 | 0.873 | 0.731 | |
| T161 | SAGNN | 0.869 | 0.769 | 0.881 | 0.974 | 0.846 |
| GCNII | 0.841 | 0.732 | 0.875 | 0.974 | 0.778 | |
| T162 | SAGNN | 0.816 | 0.817 | 0.836 | 0.919 | 0.698 |
| GCNII | 0.847 | 0.824 | 0.853 | 0.947 | 0.769 | |
| T163 | SAGNN | 0.726 | 0.636 | 0.737 | 0.867 | 0.7 |
| GCNII | 0.790 | 0.776 | 0.794 | 0.879 | 0.762 | |
| T164 | SAGNN | 0.802 | 0.769 | 0.771 | 0.9 | 0.8 |
| GCNII | 0.753 | 0.625 | 0.788 | 0.872 | 0.735 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, L.; Li, J.; Zhou, B.; Jia, Y. Rumor Detection Based on SAGNN: Simplified Aggregation Graph Neural Networks. Mach. Learn. Knowl. Extr. 2021, 3, 84-94. https://doi.org/10.3390/make3010005
Zhang L, Li J, Zhou B, Jia Y. Rumor Detection Based on SAGNN: Simplified Aggregation Graph Neural Networks. Machine Learning and Knowledge Extraction. 2021; 3(1):84-94. https://doi.org/10.3390/make3010005
Chicago/Turabian StyleZhang, Liang, Jingqun Li, Bin Zhou, and Yan Jia. 2021. "Rumor Detection Based on SAGNN: Simplified Aggregation Graph Neural Networks" Machine Learning and Knowledge Extraction 3, no. 1: 84-94. https://doi.org/10.3390/make3010005
APA StyleZhang, L., Li, J., Zhou, B., & Jia, Y. (2021). Rumor Detection Based on SAGNN: Simplified Aggregation Graph Neural Networks. Machine Learning and Knowledge Extraction, 3(1), 84-94. https://doi.org/10.3390/make3010005