
Single-Core Multiscale Residual Network for the Super Resolution of Liquid Metal Specimen Images


Abstract
:1. Introduction
2. Methods
2.1. Network Structure
2.2. Gross Feature Extraction
2.3. Hierarchical Feature Fusion
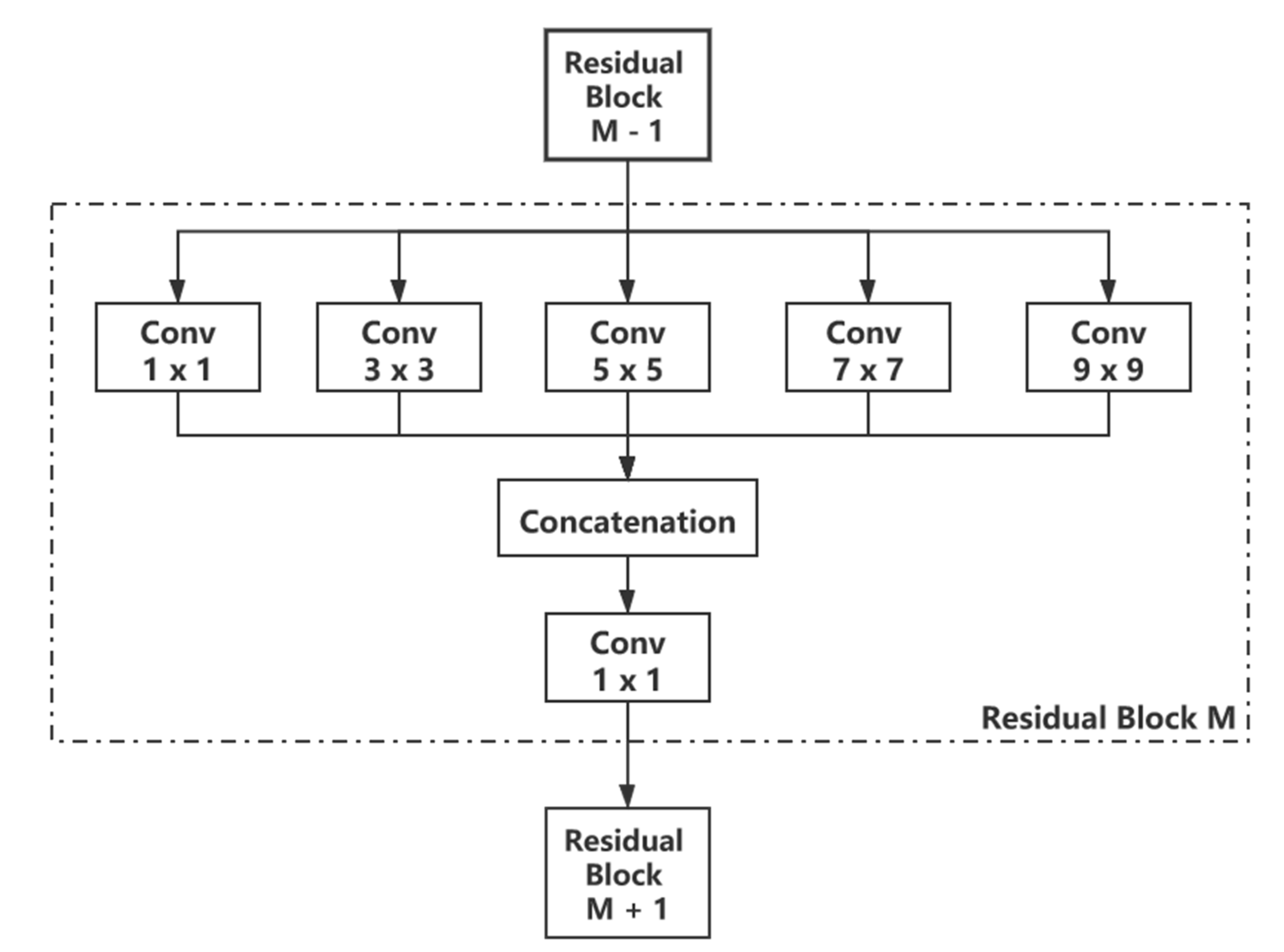
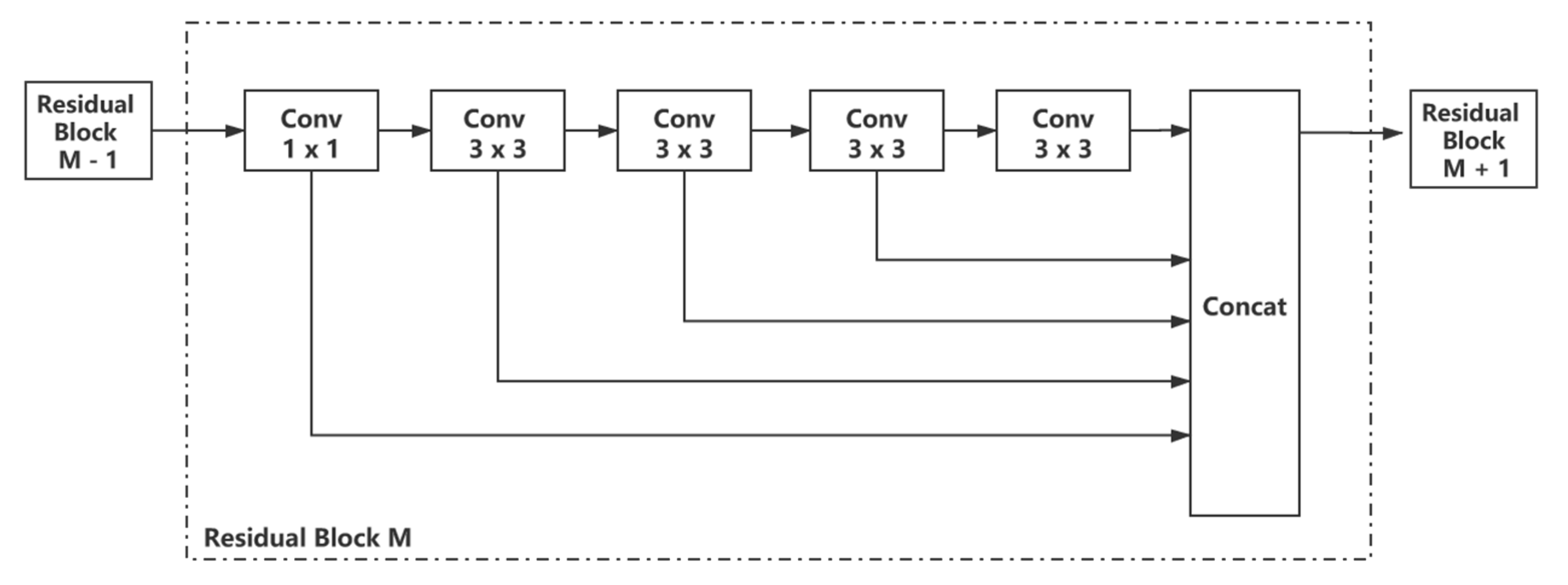
2.4. Single-Core Multiscale Residual Block (SCMSRB)
2.5. Upsampling Construction
2.6. Reconstruction
3. Experimental Process
3.1. Experimental Environment
3.2. Dataset
3.3. Training Details
3.4. Evaluation Criteria
4. Analysis of Results
4.1. Objective Index Analysis
4.2. Visual Effects Analysis
4.3. Model Performance Analysis
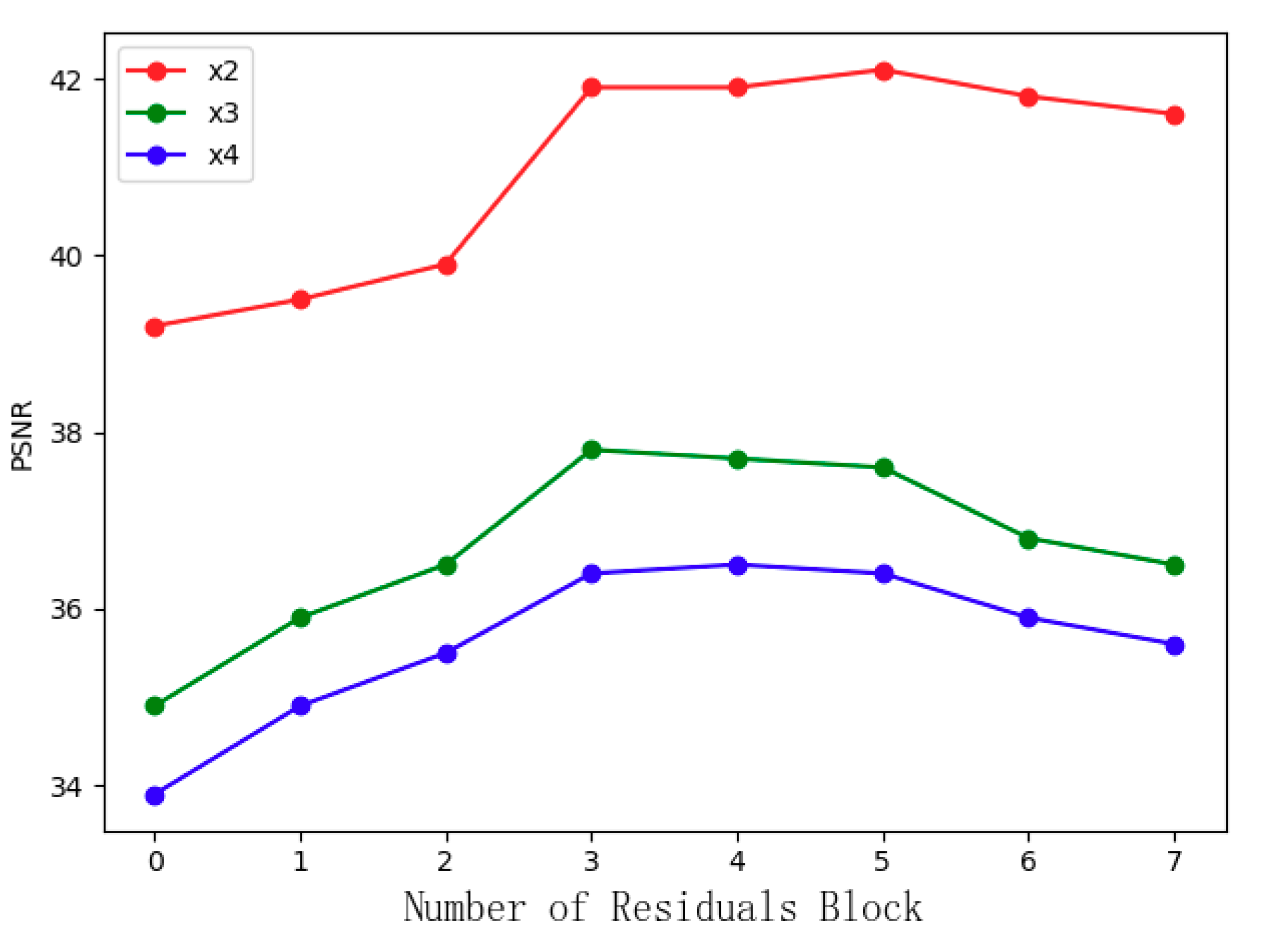
4.3.1. Sub-Module Analysis
4.3.2. Performance Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zou, Z.; Luo, X.; Yu, Q. Droplet Image Super Resolution Based on Sparse Representation and Kernel Regression. Microgravity Sci. Technol. 2018, 30, 321–329. [Google Scholar] [CrossRef]
- Luo, X.H.; Chen, L. Investigation of microgravity effect on solidification of medium-low-melting-point alloy by drop tube experiment. Sci. China Ser. E Technol. Sci. 2008, 51, 1370–1379. [Google Scholar] [CrossRef]
- Dou, R.; Zhou, H.; Liu, L.; Liu, J.; Wu, N. Development of high-speed camera with image quality evaluation. In Proceedings of the 2019 IEEE 8th Joint International Information Technology and Artificial Intelligence Conference (ITAIC), Chongqing, China, 24–26 May 2019; pp. 1404–1408. [Google Scholar] [CrossRef]
- Niu, X. An Overview of Image Super-Resolution Reconstruction Algorithm. In Proceedings of the 2018 11th International Symposium on Computational Intelligence and Design (ISCID), Hangzhou, China, 8–9 December 2018; pp. 16–18. [Google Scholar] [CrossRef]
- Li, K.; Yang, S.; Dong, R.; Wang, X.; Huang, J. Survey of single image super-resolution reconstruction. IET Image Process. 2020, 14, 2273–2290. [Google Scholar] [CrossRef]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image Super-Resolution Using Deep Convolutional Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 295–307. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, P.; Wang, Z.; Huszr, F. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1874–1883. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate Image Super-Resolution Using Very Deep Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Li, J.; Fang, F.; Mei, K.; Zhang, G. Multi-scale Residual Network for Image Super-Resolution. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 517–532. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2818–2826. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7 June–12 June 2015; pp. 1–9. [Google Scholar]
- Viitaniemi, V.; Laaksonen, J. Improving the accuracy of global feature fusion based image categorization. In Proceedings of the International Conference on Semantic and Digital Media Technologies, Genoa, Italy, 5–7 December 2007; Springer: Berlin/Heidelberg, Germany, 2007; pp. 1–14. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Fernando, B.; Fromont, E.; Muselet, D.; Sebban, M. Discriminative feature fusion for image classification. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3434–3441. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Zhao, H.; Gallo, O.; Frosio, I.; Kautz, J. Loss Functions for Neural Networks for Image Processing. arXiv 2015, arXiv:1511.08861. [Google Scholar]
- Köksoy, O. Multiresponse robust design: Mean square error (MSE) criterion. Appl. Math. Comput. 2006, 175, 1716–1729. [Google Scholar] [CrossRef]
- Keys, R.G. Cubic convolution interpolation for digital image processing. IEEE Trans. Acoust. Speech, and Signal Process. 1987, 29, 1153–1160. [Google Scholar] [CrossRef] [Green Version]
- Molchanov, P.; Tyree, S.; Karras, T.; Aila, T.; Kautz, J. Pruning Convolutional Neural Networks for Resource Efficient Transfer Learning. arXiv 2016, arXiv:1611.06440. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Scale | BICUBIC | SRCNN | ESPCN | VDSR | MSRN | MCMSRN | SCMSRN |
|---|---|---|---|---|---|---|---|---|
| Test Datasets | 2 | 36.18 | 37.25 | 38.96 | 39.89 | 40.12 | 40.57 | 42.15 |
| 3 | 34.76 | 35.98 | 37.42 | 36.90 | 37.59 | 37.63 | 37.67 | |
| 4 | 33.39 | 34.56 | 35.87 | 35.69 | 36.27 | 36.28 | 36.48 |
| Datasets | Scale | BICUBIC | SRCNN | ESPCN | VDSR | MSRN | MCMSRN | SCMSRN |
|---|---|---|---|---|---|---|---|---|
| Test Datasets | 2 | 0.8530 | 0.9185 | 0.9392 | 0.9463 | 0.9528 | 0.9623 | 0.9637 |
| 3 | 0.8263 | 0.8482 | 0.8850 | 0.8764 | 0.8885 | 0.8890 | 0.8891 | |
| 4 | 0.8073 | 0.8278 | 0.8431 | 0.8407 | 0.8467 | 0.8512 | 0.8517 |
| Methods | Diameter | Diameter Error | Area | Area Error |
|---|---|---|---|---|
| HR Image | 124.0011 | 0 | 12076.5 | 0 |
| BICUBIC | 123.8572 | 0.1439 | 12049.0 | 27.5 |
| SRCNN | 123.8952 | 0.1059 | 12055.0 | 21.5 |
| ESPCN | 123.9369 | 0.0642 | 12064.0 | 12.5 |
| VDSR | 123.9138 | 0.0873 | 12059.5 | 17 |
| MSRN | 124.0576 | 0.0565 | 12087.5 | 11 |
| MCMSRN | 123.9754 | 0.0257 | 12071.5 | 5 |
| SCMSRN | 124.0114 | 0.0103 | 12078.5 | 2 |
| Methods | Params/k | FLOPs/w | Train Time/min |
|---|---|---|---|
| MCMSRN | 2791.7 | 806.8 | 56 |
| SCMSRN | 694.5 | 200.7 | 38 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ning, K.; Zhang, Z.; Han, K.; Han, S.; Zhang, X. Single-Core Multiscale Residual Network for the Super Resolution of Liquid Metal Specimen Images. Mach. Learn. Knowl. Extr. 2021, 3, 453-466. https://doi.org/10.3390/make3020023
Ning K, Zhang Z, Han K, Han S, Zhang X. Single-Core Multiscale Residual Network for the Super Resolution of Liquid Metal Specimen Images. Machine Learning and Knowledge Extraction. 2021; 3(2):453-466. https://doi.org/10.3390/make3020023
Chicago/Turabian StyleNing, Keqing, Zhihao Zhang, Kai Han, Siyu Han, and Xiqing Zhang. 2021. "Single-Core Multiscale Residual Network for the Super Resolution of Liquid Metal Specimen Images" Machine Learning and Knowledge Extraction 3, no. 2: 453-466. https://doi.org/10.3390/make3020023
APA StyleNing, K., Zhang, Z., Han, K., Han, S., & Zhang, X. (2021). Single-Core Multiscale Residual Network for the Super Resolution of Liquid Metal Specimen Images. Machine Learning and Knowledge Extraction, 3(2), 453-466. https://doi.org/10.3390/make3020023